use of late-binding technology for workload management...
TRANSCRIPT

Use of Late-Binding Technology for WorkloadManagement System in CMS
Sanjay Padhi, Haifeng Pi, Igor Sfiligoi, Frank WuerthweinUniversity of California, San Diego
Abstract—Condor glidein-based workload management system(glideinWMS) has been developed and integrated with distributedphysics analysis and Monte Carlo (MC) production system atCompact Muon Solenoid (CMS) experiment. The late-bindingbetween the jobs and computing element (CE), and the validationof WorkerNode (WN) environment help significantly reduce thefailure rate of Grid jobs. For CPU-consuming MC data produc-tion, opportunistic grid resources can be effectively explored viathe extended computing pool built on top of various heteroge-neous Grid resources. The Virtual Organization (VO) policy isembedded into the glideinWMS and pilot job configuration. GSIauthentication, authorization and interfacing with gLExec allowsa large user basis to be supported and seamlessly integrated withGrid computing infrastructure. The operation of glideinWMS atCMS shows that it is a highly available and stable system for alarge VO of thousands of users and running tens of thousandsof user jobs simultaneously. The enhanced monitoring allowssystem administrators and users to easily track the system-leveland job-level status.
I. INTRODUCTION
CONDOR glidein can be used to submit and execute theCondor [1] daemons on a Globus [2] resource. During the
period of the daemons running, the remote machine appearsas part of the Condor pool at the submission host. Thecondor glidein technology includes two important features:
• The glideins, as pilot jobs, can be late-binded withuser jobs. Any technical problem occurred at remotemachines can be detected by glideins, which allows thesubmission host to hold user jobs or redirect them toother functioning resources. In addition to detect the Gridfailure at middleware level, pilot jobs can also checkthe configuration of WorkerNodes (WN) and the runningenvironment. Equipped with late-binding, a significantfaction of user job failure can be avoided.
• The host that manages the glideins can build a virtualunified condor pool on top of remote computing machineseven of different sites. Thus the complexity of the Grid re-sources provided by a number of sites is largely reduced.This technology essentially creates a layer of abstractionfor the heterogeneous Grid resources and makes the Gridtransparent to the high level job creation and submissiontools.
Condor glidein technology provides an ideal platform forsome Virtual Organizations (VO) to build an advanced work-load management system to efficiently deal with a largenumber of user jobs, different types of applications and a largegroup of resource providers.
In addition to the advantages mentioned above which aremainly on the submission side, the Grid resource providers willalso get better CPU efficiency due to more prompt discoveryand utilization of opportunistic resources by glideins. Sincethe user jobs are associated with glideins, it is possible forGrid sites to identify and classify the type of user jobs andimplement more delicate scheduling priority for different typesof applications.
The glidein-based workload management system (glidein-WMS) [3] is an implementation of Condor glidein technologyfor the distributed Grid computing at Compact Muon Solenoid(CMS) experiment [4]. This paper describes the integrationstrategy, operation experience and benchmark performance ofglideinWMS at CMS. It should be emphasized that the coreof the system is a general purpose workload managementsystem and can be easily ported to other Virtual Organization’scomputing environment.
II. ARCHITECTURE OF GLIDEINWMSDetails of the glideinWMS architecture and working mech-
anism are described in [3]. Here is a brief review of majorlogical components of the system:
• A condor central manager that runs condor collector andnegotiator.
• One or more condor submission machines that run con-dor schedd. The users send normal condor jobs to theseschedds.
• A glideinWMS collector that mainly serves as a dash-board for message passing between glideins and userjobs.
• One or more VO frontends that regulate the number ofglideins to be submitted according to the number of userjobs waiting in the queue.
• One or more glidein factories that submit glideins to theGrid.
• glideins (pilot condor job) that are submitted by glideinfactories and run at the Grid sites.
The architecture of glideinWMS is shown in Fig. 1. Inthe following, the mechanism of how glideinWMS works arediscussed:
• Submission of glideinsTwo components: glidein factoriy and VO frontend, to-gether decide how glideins are sent and to which Gridsites. These two processes communicate via ClassAdsusing condor collector daemon. The glidein factory pub-lishes the information of Grid sites according to the list of

sites in the configuration. The VO frontend uses the jobsin the submission queue to match to the factory ClassAds.If a match occurs, the VO frontend will instruct theglidein factory about how glideins should be submitted.Once the factory receives the “instruction” (actually theClassAds from VO frontend), it will submit the glideinsto the Grid.Each glidein will run condor startd if it is able to run atthe Grid site. All the condor startd are collected to forma condor pool by the glideinWMS.
• Condor pool and job managementThe glideinWMS condor pool manages the condor execu-tion daemons, condor startd, which are submitted as Gridjobs (glideins). The condor central manager manages thecondor pool by collecting the information from all otherdaemons especially the daemons of user jobs in the queueat submission machines and deamons of running glideinsat the WorkerNode of Grid sites. The condor negotiatorcan match the attributes of user jobs to those of glideins.If a match occurs, the user job can be sent to thatmatched WN via condor shadow daemon and run by thecondor starter at the WN.Condor Connection Broker (CCB) is used to provide one-way connection between glideinWMS and WorkerNode(WN) if there is a firewall between them.
• GSI authentication and authorizationSince the Grid sites treat glideins as normal Grid jobs,one or more valid X509 proxy are used for glideins.The user jobs contains the valid X509 proxy of the userwhich is handled by condor schedd. The authenticationof users can be file system-based or GSI-based. Fora site serving a large group of Grid users, GSI-basedauthentication using GUMS is a scalable and flexibleapproach.
• Security in running glideins and user jobsglideins behave like a Grid user running at the Gridsites and manages the actual user jobs that are submittedto glideinWMS system. The condor execution daemon,condor startd, running at the WN is under the identity ofglidein’s. The most secure mode for glidein to processactual user jobs is to use gLExec, so that the site isable to identify the actual user via its X509 proxy anduse a different user id to run the jobs. But for the WNenvironment at a site, the availability of gLExec and setupof a large group of user accounts for one or more VO(s)with full mapping (X509 proxy to username) may beabsent, so the glidein needs to use its identity to runthe user jobs, which leads to security problem. So it isadvised not to run glideins at the system without thesupport of gLExec.If a fully specified Grid job creation and managementsystem is used by a VO, the execution commands andlibraries for the user jobs are well defined and checkedand leaves little room for unsecured access to Gridresources. But there is still possible potential security holein the system for users to be able to run any code. Webelieve this is largely subject to VO’s policy. A systembuilt on top of glideinWMS needs to be secure, which is
beyond the scope of glideinWMS’s security model.• Configuration of glideins
glidein contains a shell script designed to download andexecute other files. These files are maintained at the webserver by glideinWMS. A VO or service provider thatruns glideinWMS has a lot of flexibility in putting usefulcommands or implementing useful functionalities forglideins, e.g. let the glideins check the Grid middlewarestatus, application software availability, I/O of the site,etc.
Fig. 1. Archiecture of glideinWMS
III. INTEGRATION OF GLIDEINWMS WITH CMSCOMPUTING TOOLS
The implementation of glideinWMS at CMS is to take it alayer of service as shown in Fig. 2, which is interfacing withtwo major CMS Grid job creation and submission systems:
• Production and Data Reprocessing via a tool calledProdAgent [5].This system targets at relatively small amount of privi-leged users that run the data processing for the CMS VO.The Grid jobs are run at Tier-0, Tier-1 and Tier-2 siteswith dedicated resources.The use of glideinWMS aims at better management oflarge scale dedicated CPU resources, short turn aroundtime in handling jobs and very low job failure rate.
• Data analysis via a tool called CRAB [6].This system targets at all Grid users at the CMS VO.The Grid jobs are primarily run at Tier-2 sites and withrelatively small amount for Tier-3 sites, in which thosesites publish the datasets for data analysis. For most oftime, user jobs need to compete on the CPU resources.Multiple destinations can be specified by users if thedata are available at those destination sites. Before usingglideinWMS, a resource broker (RB) can used to selecta site from the white list of the sites defined at user jobs,or the system needs to randomly pick a site to send thejobs.The use of glideinWMS aims at better discovery andscheduling of CPU resources for targeted sites, handlinglarge scale of user jobs, handling large scale of highlydistributed CPU resources, and low job failure rate.

glideinWMS is also used for user-level Monte Carlo produc-tion, which targets at those opportunistic CPU resource acrossthe CMS VO.
Fig. 2. Integration of glideinWMS with CMS job creation and managementtools
The technical details of integration between glideinWMSand CRAB is described in the following and shown in Fig. 3.
• CRAB uses a server/client model to create, submit andmanage user jobs. The jobs are created at the client sideand transfered to server. The server sends the user jobsto the Grid and maintains the job status at the databasewhich can be retrieved by the clients.The implementation of glideinWMS creates a servicelayer that makes user jobs late-bind with the sites, dis-covers the valid CPU resources at the site, and makesa simple unified condor pool for the CRAB server. TheCRAB server will treat the Grid like a large local condorpool and put user jobs on the queue of the pool.
• gLExec and GUMS are used together to map Grid userproxy to local user and send the condor jobs via mappedusername. In this way, the CRAB server can identifyevery single Grid user and use appropriate identity tosend the jobs to the glideinWMS.
• An enhanced monitoring system is accomplished forCRAB server and glideinWMS for both system adminis-trator and Grid users.The status of glideins and general statistics of user jobsrelated to targeted Grid sites can be retrieved from theglideinWMS built-in monitoring web service.The specific job monitoring and debugging can be donevia tools provided by glideinWMS that can directlyaccess the running jobs at the WN via glideins.The job monitoring web service for users is achieved bythe tool described in [7] that is able to provide a logicalview of user jobs in quasi-real time with plenty of detailsincluding logs to evaluate the status of the jobs.
Fig. 3. Integration of glideinWMS with CRAB infrastructure
IV. OPERATION EXPERIENCE OF GLIDEINWMS IN CMSThe development and operation team of University of Cal-
ifornia San Diego (UCSD) and Fermi National AcceleratorLaboratory (FNAL) have accumlated more than 3 years ofexperience in operating the glideinWMS for dedicated data re-processing or more general service for physics data analysis.A detailed description of the experience of operating glidein-WMS at CMS can be found in [8]. Here is a summary ofoperation scalability of the glideinWMS at CMS
• Over 50 CMS Tier-2 and 10 tier-3 sites participate aproduction glidein factory with 16 thousand pledged slotsas of June 2009.
• Sustainable running over 12 thousand user jobs simul-taneously and peaking at 14 thousand, 200 thousandidle jobs in the glideinWMS queue, 22 thousand runningglideins.
• Large scalability in collector over WAN and in con-dor schedds
• High success rate for analysis jobs. Common failure ingrid middleware level is prevented. Pilot jobs are ableto detect setup issues in the running environment andapplication software at the site .
• More than 4 thousand user-level production jobs with lowpriority running at opportunistic resources.
• The operation of glideinWMS is integrated with theoverall management of user analysis and data operation.Various efforts have been taken to analyze and prevent theroot cause of job failure with glideinWMS and externalmonitoring infrastructure.
CMS has conducted several large scale computing exercisesto test the readiness and scalability of the overall computinginfrastructure. The overall status of job running by glidein-WMS and utilization of CPUs for the Scale Testing for theExperimental Program in 2009 (SETP09) [9] are shown inFig. 4 and 5 respectively. The number of jobs runningat various sites using glideinWMS for Common ComputingReadiness Challeneg in 2008 (CCRC08) [10] is shown inFig. 6.
Fig. 4. Number of jobs running at STEP09 which are submitted viaglideinWMS system
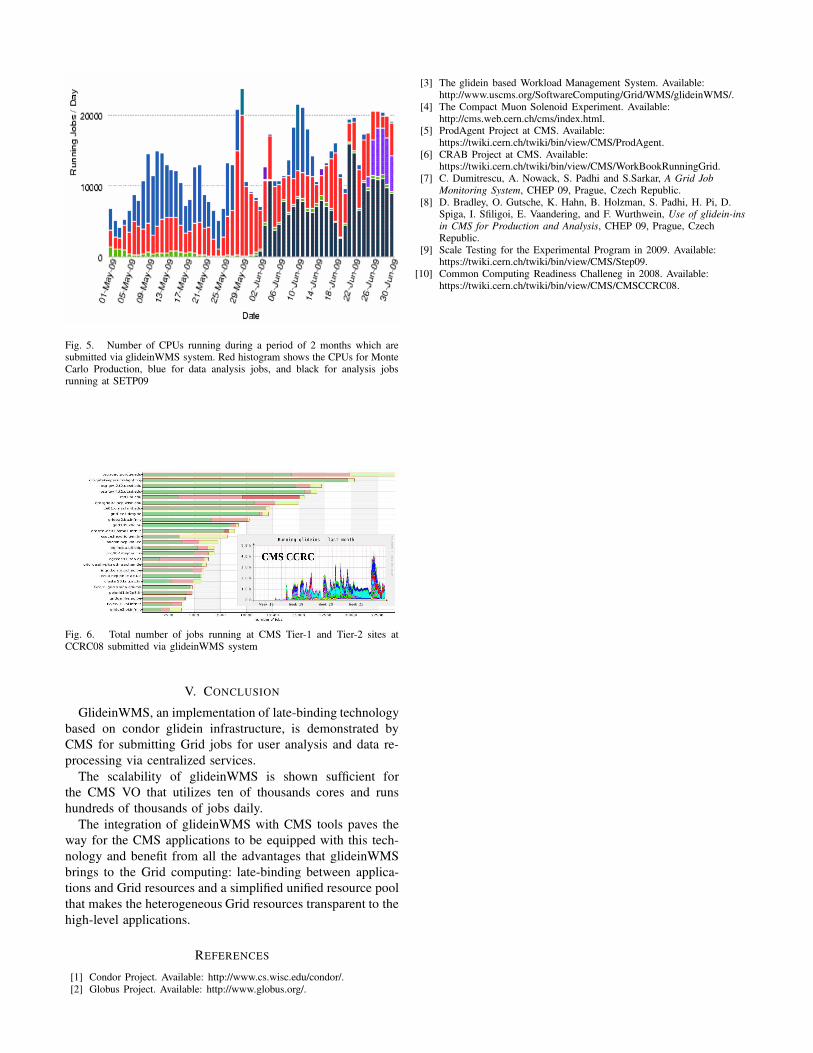
Fig. 5. Number of CPUs running during a period of 2 months which aresubmitted via glideinWMS system. Red histogram shows the CPUs for MonteCarlo Production, blue for data analysis jobs, and black for analysis jobsrunning at SETP09
Fig. 6. Total number of jobs running at CMS Tier-1 and Tier-2 sites atCCRC08 submitted via glideinWMS system
V. CONCLUSION
GlideinWMS, an implementation of late-binding technologybased on condor glidein infrastructure, is demonstrated byCMS for submitting Grid jobs for user analysis and data re-processing via centralized services.
The scalability of glideinWMS is shown sufficient forthe CMS VO that utilizes ten of thousands cores and runshundreds of thousands of jobs daily.
The integration of glideinWMS with CMS tools paves theway for the CMS applications to be equipped with this tech-nology and benefit from all the advantages that glideinWMSbrings to the Grid computing: late-binding between applica-tions and Grid resources and a simplified unified resource poolthat makes the heterogeneous Grid resources transparent to thehigh-level applications.
REFERENCES
[1] Condor Project. Available: http://www.cs.wisc.edu/condor/.[2] Globus Project. Available: http://www.globus.org/.
[3] The glidein based Workload Management System. Available:http://www.uscms.org/SoftwareComputing/Grid/WMS/glideinWMS/.
[4] The Compact Muon Solenoid Experiment. Available:http://cms.web.cern.ch/cms/index.html.
[5] ProdAgent Project at CMS. Available:https://twiki.cern.ch/twiki/bin/view/CMS/ProdAgent.
[6] CRAB Project at CMS. Available:https://twiki.cern.ch/twiki/bin/view/CMS/WorkBookRunningGrid.
[7] C. Dumitrescu, A. Nowack, S. Padhi and S.Sarkar, A Grid JobMonitoring System, CHEP 09, Prague, Czech Republic.
[8] D. Bradley, O. Gutsche, K. Hahn, B. Holzman, S. Padhi, H. Pi, D.Spiga, I. Sfiligoi, E. Vaandering, and F. Wurthwein, Use of glidein-insin CMS for Production and Analysis, CHEP 09, Prague, CzechRepublic.
[9] Scale Testing for the Experimental Program in 2009. Available:https://twiki.cern.ch/twiki/bin/view/CMS/Step09.
[10] Common Computing Readiness Challeneg in 2008. Available:https://twiki.cern.ch/twiki/bin/view/CMS/CMSCCRC08.