use of a high level language in high performance biomechanics simulations katherine yelick, armando...
Post on 22-Dec-2015
214 views
TRANSCRIPT

Use of a High Level Language in High Performance Biomechanics Simulations
Katherine Yelick, Armando Solar-Lezama, Jimmy Su, Dan Bonachea, Amir Kamil
U.C. Berkeley and LBNL
Collaborators: S. Graham, P. Hilfinger, P. Colella, K. Datta, E. Givelberg, N. Mai, T. Wen, C. Bell, P. Hargrove, J. Duell, C. Iancu, W. Chen, P. Husbands, M. Welcome, R. Nishtala

1
10
100
1000
10000
1978 1980 1982 1984 1986 1988 1990 1992 1994 1996 1998 2000 2002 2004 2006
Un
ipro
cess
or
Sp
ecI
nt P
erf
orm
an
ce (
vs. V
AX
-11
/78
0)
25%/year
52%/year
??%/year
A New World for Computing
• VAX : 25% per year 1978 to 1986• RISC + x86: 52% per year 1986 to 2002• RISC + x86: 18% per year 2002 to present
From Hennessy and Patterson, Computer Architecture: A Quantitative Approach, 4th edition, 2006
Sea change in chip design: multiple “cores” or processors per chip from IBM, Sun,, AMD, Intel today
Slide Source: Dave Patterson

Why Is the Computer Industry Worried?
• For 20 years, hardware designers have taken care of performance
• Now they will produce only parallel processors– Double number of cores every 18-24 months – Uniprocessor performance relatively flat
Performance is a software problem
All software will be parallel
• Programming options: – Libraries: OpenMP (scalabililty?), MPI (usability?)– Languages: parallel C, Fortran, Java, Matlab
Titanium: High Level Language for Scientific Computing
• Titanium is an object-oriented language based on Java
• Additional languages support– Multidimensional arrays– Value classes (Complex type)– Fast memory management– Scalable parallelism model with locality
• Implementation strategy– Titanium compiler translates Titanium to C with
calls to communication library (GASNet), no JVM– Portable across machines with C compilers– Cross language calls to C/F/MPI possible
Joint work with Titanium group
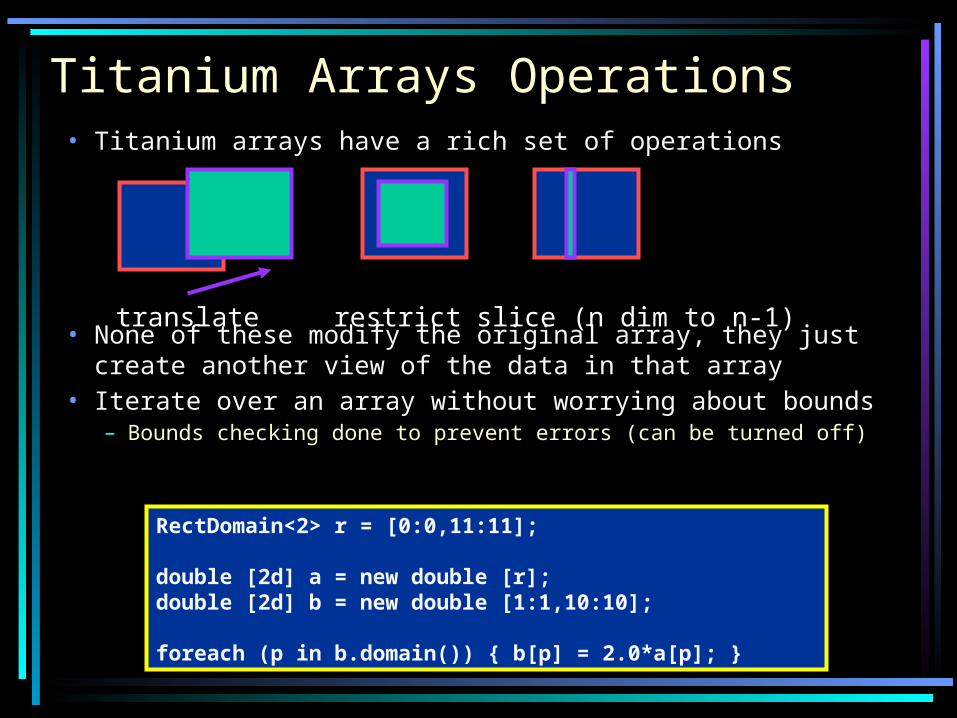
Titanium Arrays Operations• Titanium arrays have a rich set of operations
• None of these modify the original array, they just create another view of the data in that array
• Iterate over an array without worrying about bounds– Bounds checking done to prevent errors (can be turned off)
translate restrict slice (n dim to n-1)
RectDomain<2> r = [0:0,11:11];
double [2d] a = new double [r];double [2d] b = new double [1:1,10:10];
foreach (p in b.domain()) { b[p] = 2.0*a[p]; }
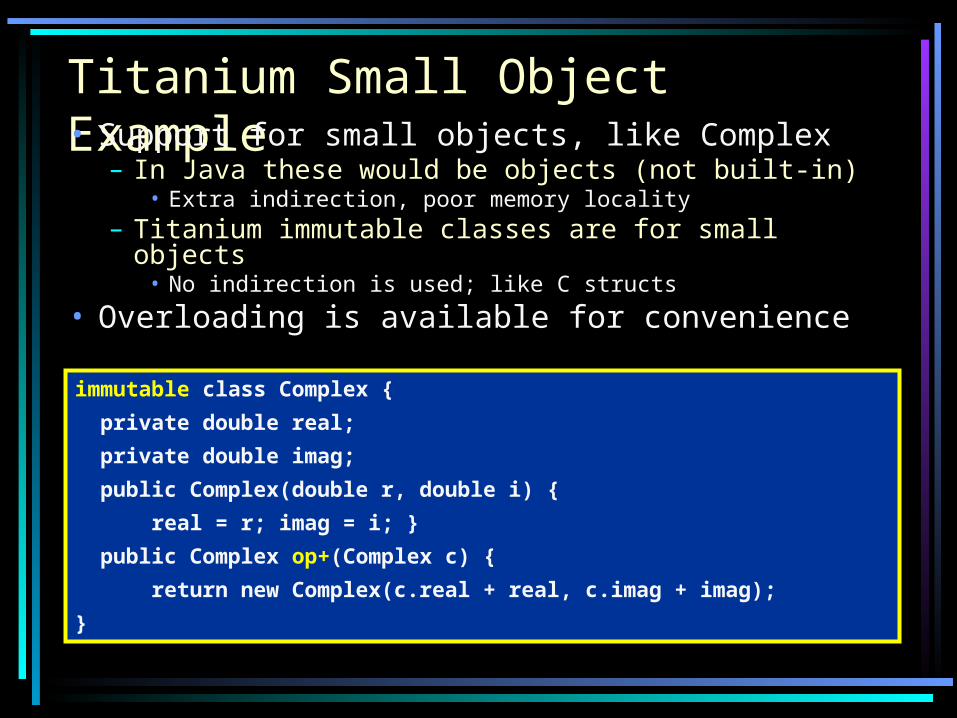
Titanium Small Object Example
immutable class Complex {
private double real;
private double imag;
public Complex(double r, double i) {
real = r; imag = i; }
public Complex op+(Complex c) {
return new Complex(c.real + real, c.imag + imag);
}
• Support for small objects, like Complex– In Java these would be objects (not built-in)
• Extra indirection, poor memory locality– Titanium immutable classes are for small objects
• No indirection is used; like C structs
• Overloading is available for convenience
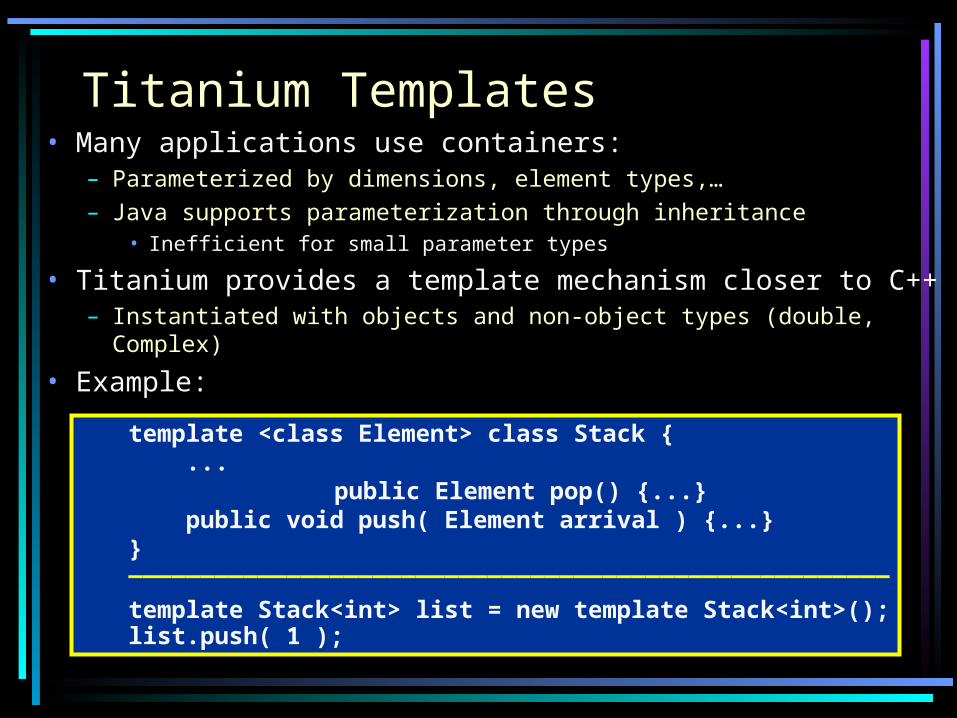
Titanium Templates• Many applications use containers:
– Parameterized by dimensions, element types,…– Java supports parameterization through inheritance
• Inefficient for small parameter types
• Titanium provides a template mechanism closer to C++– Instantiated with objects and non-object types (double, Complex)
• Example:template <class Element> class Stack { ...
public Element pop() {...} public void push( Element arrival ) {...}}_____________________________________________________
template Stack<int> list = new template Stack<int>();list.push( 1 );

Partitioned Global Address Space
• Global address space: any thread/process may directly read/write data allocated by another
• Partitioned: data is designated as local (near) or global (possibly far); programmer controls layout
Glo
bal
ad
dre
ss s
pac
e
x: 1y:
l: l: l:
g: g: g:
x: 5y:
x: 7y: 0
p0 p1 pn
By default: • Object heaps
are shared• Program
stacks are private
• Besides Titanium, Unified Parallel C and Co-Array Fortran use this parallelism model
Joint work with Titanium group

Arrays in a Global Address Space• Key features of Titanium arrays
– Generality: indices may start/end and any point– Domain calculus allow for slicing, subarray, transpose and
other operations without data copies (F90 arrays and more)
• Domain calculus to identify boundaries and iterate: foreach (p in gridA.shrink(1).domain()) ...
• Array copies automatically work on intersection gridB.copy(gridA.shrink(1));
gridA gridB
“restricted” (non-ghost) cells
ghost cells
intersection (copied area)
Joint work with Titanium group
Useful in grid-based computations

Immersed Boundaries in Biomechanics
• Fluid flow within the body is one of the major challenges, e.g., – Blood through the heart– Coagulation of platelets in clots– Effect of sounds waves on the inner ear– Movement of bacteria
• A key problem is modeling an elastic structure immersed in a fluid– Irregular moving boundaries– Wide range of scales– Vary by structure, connectivity, viscosity, external
forced, internally-generated forces, etc.
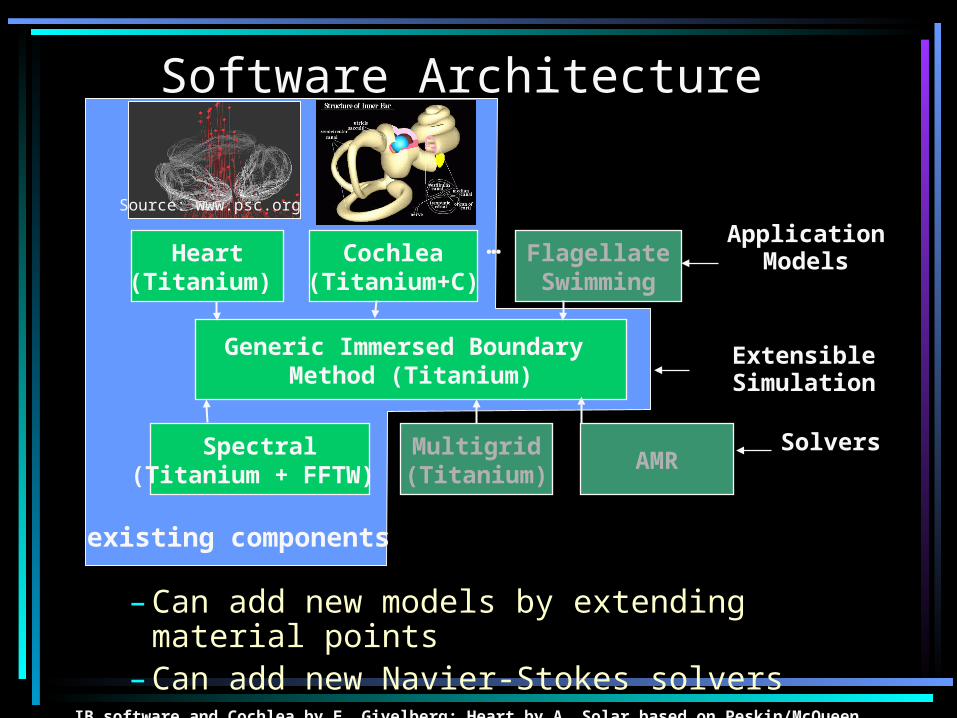
Software Architecture
Application Models
Generic Immersed Boundary Method (Titanium)
Heart(Titanium)
Cochlea(Titanium+C)
FlagellateSwimming
…
Spectral(Titanium + FFTW)
AMR
Extensible Simulation
SolversMultigrid(Titanium)
– Can add new models by extending material points– Can add new Navier-Stokes solvers
IB software and Cochlea by E. Givelberg; Heart by A. Solar based on Peskin/McQueen
existing components
Source: www.psc.org

Immersed Boundary Method
1. Compute the force f the immersed material applies to the fluid.
2. Compute the force applied to the fluid grid:
3. Solve the Navier-Stokes equations:
4. Move the material:

Immersed Boundary Method Structure
4. Interpolate &move material
3. Navier-Stokes Solver
2. SpreadForce
4 steps in each timestep
Material Points
Interaction
Fluid Lattice
2D Dirac Delta Function
1.Material activation &force calculation

Challenges to Parallelization
• Irregular material points need to interact with regular fluid lattice– Efficient “scatter-gather” across processors
• Placement of materials across processors– Locality: store material points with underlying fluid
and with nearby material points– Load balance: distribute points evenly
• Scalable fluid solver– Currently based on 3D FFT– Communication optimized using overlap (not yet in
full IB code)

P1P2
Improving Communication Performance 1: Material Interaction
• Communication within a material can be high– E.g., spring force law in heart fibers to contract– Instead, replicate point; uses linearity in spread
• Use graph partitioning (Metis) on materials– Improve locality in interaction– Nearby points on same proc
• Take advantage of hierarchical machines– Shared memory “nodes” within network
P1P2
communication redundant work
Joint work with A. Solar, J. Su
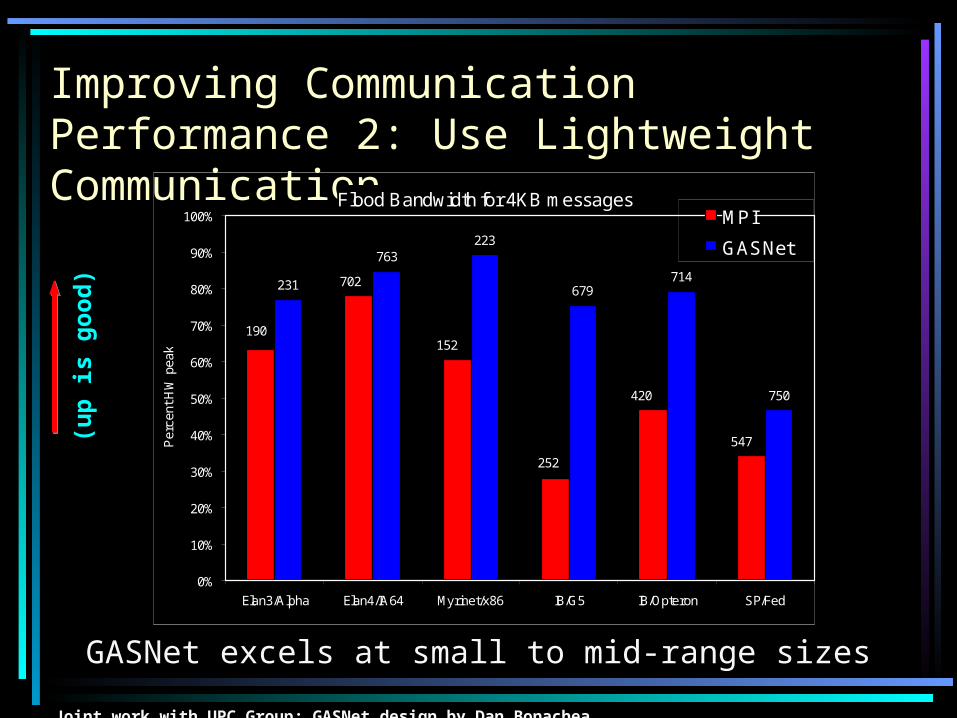
(up
is
go
od
)
GASNet excels at small to mid-range sizes
Improving Communication Performance 2: Use Lightweight Communication
Flood Bandwidth for 4KB messages
252
152
702
190
420
547
679
223763
231714
750
0%
10%
20%
30%
40%
50%
60%
70%
80%
90%
100%
Elan3/Alpha Elan4/IA64 Myrinet/x86 IB/G5 IB/Opteron SP/Fed
Per
cent
HW
pea
k
MPI
GASNet
Joint work with UPC Group; GASNet design by Dan Bonachea

Improving Communication Performance 3: Fast FFTs with overlapped communication
.5 Tflop/s
0
200
400
600
800
1000
1200
C/64 D/256 D/256 D/512 D/256 D/512
Myrinet Infiniband Elan3 Elan3 Elan4 Elan4
MF
lop
s/P
roc
MPI/Fortran without overalpMPI with overlapGASNet with overlap
size/procs
network
• Better performance in GASNet version than MPI• This code is in UPC, not Titanium; not yet in full IB code
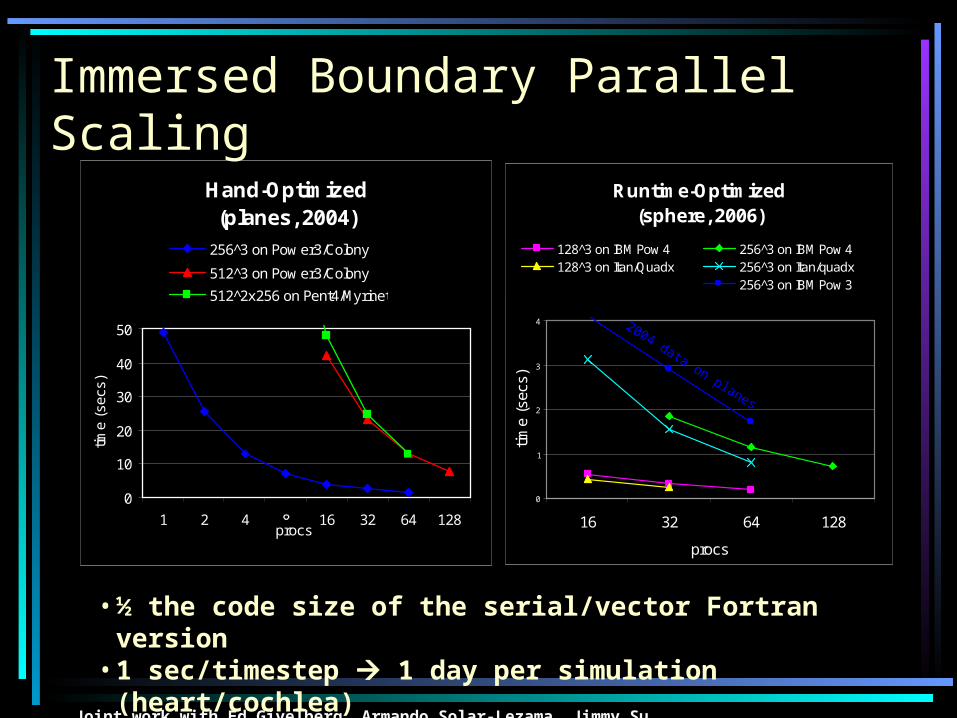
Immersed Boundary Parallel Scaling
Joint work with Ed Givelberg, Armando Solar-Lezama, Jimmy Su
Hand-Optimized (planes, 2004)
0
10
20
30
40
50
1 2 4 8 16 32 64 128procs
time
(sec
s)
256^3 on Pow er3/Colony
512^3 on Pow er3/Colony
512^2x256 on Pent4/Myrinet
• ½ the code size of the serial/vector Fortran version• 1 sec/timestep 1 day per simulation (heart/cochlea)
Runtime-Optimized (sphere, 2006)
0
1
2
3
4
16 32 64 128
procs
time
(sec
s)
128^3 on IBM Pow 4 256^3 on IBM Pow 4128^3 on Itan/Quadx 256^3 on Itan/quadx
256^3 on IBM Pow 3
2004 data on planes

Use of Adaptive Mesh Refinement• Adaptive Mesh
Refinement (AMR)– Improves scalability– Fine mesh only
where needed
• PhD thesis by Boyce Griffith at NYU for use in the heart– Uses of PETSc and
SAMRAI in parallel implementation
• AMR in Titanium– IB code is not yet
adaptive– Separate study on
AMR in Titanium
Image source: B. Griffith, http://www.math.nyu.edu/~griffith/

Adaptive Mesh Refinement in Titanium
C++/Fortran/MPI AMR• Chombo package from LBNL• Bulk-synchronous comm:
– Pack boundary data between procs
Titanium AMR• Entirely in Titanium• Finer-grained communication
– No explicit pack/unpack code– Automated in runtime system
Code Size in Lines
C++/F/MPI Titanium
AMR data Structures 35000 2000
AMR operations 6500 1200
Elliptic PDE solver 4200* 1500 10X reduction in lines of code!
* Somewhat more functionality in PDE part of Chombo code
AMR Work by Tong Wen and Philip Colella
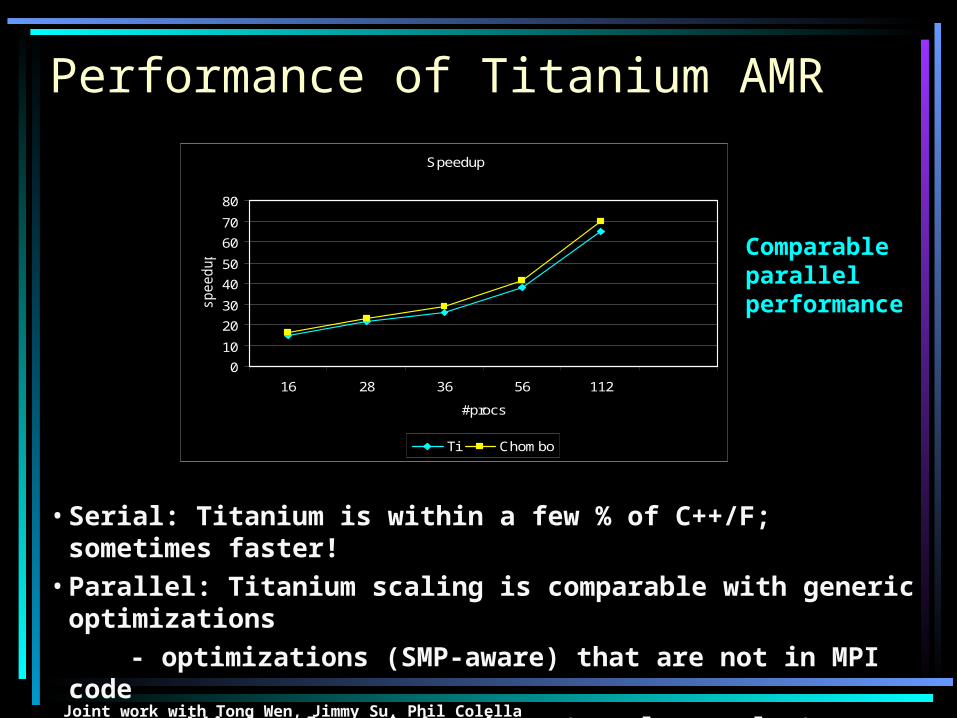
Performance of Titanium AMR
Speedup
0
10
20
30
40
50
60
70
80
16 28 36 56 112
#procs
speedup
Ti Chombo
• Serial: Titanium is within a few % of C++/F; sometimes faster!• Parallel: Titanium scaling is comparable with generic
optimizations
- optimizations (SMP-aware) that are not in MPI code
- additional optimizations (namely overlap) not yet implemented
Comparable parallel performance
Joint work with Tong Wen, Jimmy Su, Phil Colella
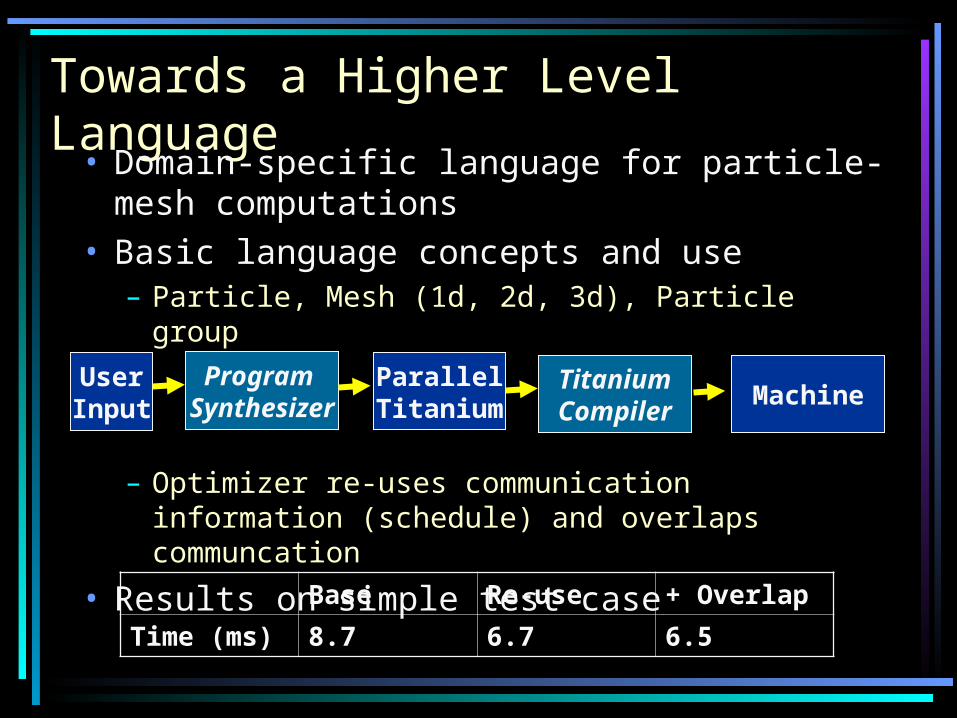
Towards a Higher Level Language
• Domain-specific language for particle-mesh computations
• Basic language concepts and use– Particle, Mesh (1d, 2d, 3d), Particle group
– Optimizer re-uses communication information (schedule) and overlaps communcation
• Results on simple test case
UserInput
Program Synthesizer
ParallelTitanium
TitaniumCompiler
Machine
Base Re-use + Overlap
Time (ms) 8.7 6.7 6.5

Conclusions
• All software will soon be parallel– End of the single processor scaling era
• Titanium is a high level parallel language – Support for scientific computing– High performance and scalable– Highly portable across serial / parallel machines– Download: http://titanium.cs.berkeley.edu
• Immersed boundary method framework– Designed for extensibility– Demonstrations on heart and cochlea simulations– Some optimizations done in compiler / runtime– Contact: {jimmysu,yelick}@cs.berkeley.edu