use fewer instances of the letter “i”: toward writing style anonymization · 2017-11-29 · of...
TRANSCRIPT

Use Fewer Instances of the Letter “i”:
Toward Writing Style Anonymization
Andrew W.E. McDonald, Sadia Afroz, Aylin Caliskan, Ariel Stolerman, and Rachel Greenstadt
PSAL, Drexel University http://psal.cs.drexel.edu

How do you change your writing style?
2

Well, Why Change Your Writing Style?
3

Well, Why Change Your Writing Style?
• Stylometry: – Authorship-attribution based on linguistic properties found in
text
4

Well, Why Change Your Writing Style?
• Stylometry: – Authorship-attribution based on linguistic properties found in
text – Stylometric methods can achieve high accuracy across a
high number of authors • Writeprints: > 90% accuracy for 100 authors (Abbasi and
Chen, 2008) • Scaling stylometry up to 100,000 authors (Narayanan et
al., 2012)
5

Well, Why Change Your Writing Style?
• Stylometry: – Authorship-attribution based on linguistic properties found in
text – Stylometric methods can achieve high accuracy across a
high number of authors • Writeprints: > 90% accuracy for 100 authors (Abbasi and
Chen, 2008) • Scaling stylometry up to 100,000 authors (Narayanan et
al., 2012) • Accuracy and precision of stylometry
are increasing 6

Well, Why Change Your Writing Style?
• Increasingly easier to determine the author of a text
7

Well, Why Change Your Writing Style?
• Increasingly easier to determine the author of a text
• Harder to express ideas / opinions without taking ownership
8

Well, Why Change Your Writing Style?
• Increasingly easier to determine the author of a text
• Harder to express ideas / opinions without taking ownership
• Can be a threat to security and privacy
9

Stylometry: A Threat to Security and Privacy
• Physical – Restrictive/oppressive regimes
10

Stylometry: A Threat to Security and Privacy
• Physical – Restrictive/oppressive regimes
• Job – Talking against abusive boss
11

Stylometry: A Threat to Security and Privacy
• Physical – Restrictive/oppressive regimes
• Job – Talking against abusive boss
• Generally, your writing style could give you away regardless of other precautions taken – Tor, VPN, changed MAC address, etc…
12

Purely Hypothetical? ‡ • Previous examples are purely hypothetical. What
about a real example? • From Inside WikiLeaks by Daniel Domscheit-Berg:
– “I nudged Julian with my foot. We exchanged glances and started giggling. If someone had run WikiLeaks documents through such a program, he would have discovered that the same two people were behind all the various press releases, document summaries, and correspondence issued by the project. The official number of volunteers we had was also, to put it mildly, grotesquely exaggerated.”
13 ‡Slide taken from Michael Brennan’s 28C3 talk

• Okay, so it’s necessary to change your writing style to stay anonymous…
14
• Okay, so it’s necessary to change your writing style to stay anonymous…
• Why do we need a tool to do this?
15

Why Do We Need a Tool for This?
• Machine translation
16

Why Do We Need a Tool for This?
• Machine translation – Either does too little:
• They passed through the city at noon of the day following.
17

Why Do We Need a Tool for This?
• Machine translation – Either does too little:
• They passed through the city at noon of the day following."
è German è Japanese è
18

Why Do We Need a Tool for This?
• Machine translation – Either does too little:
• They passed through the city at noon of the day following."
è German è Japanese è • They passed the city at noon the following day.
19

Why Do We Need a Tool for This?
• Machine translation – Either does too little:
• They passed through the city at noon of the day following."
è German è Japanese è • They passed the city at noon the following day.
– Or does too much: • Just remember that the things you put into your head are
there forever, he said.
20

Why Do We Need a Tool for This?
• Machine translation – Either does too little:
• They passed through the city at noon of the day following."
è German è Japanese è • They passed the city at noon the following day.
– Or does too much: • Just remember that the things you put into your head are
there forever, he said. "è German è Japanese è
21

Why Do We Need a Tool for This?
• Machine translation – Either does too little:
• They passed through the city at noon of the day following."
è German è Japanese è • They passed the city at noon the following day.
– Or does too much: • Just remember that the things you put into your head are
there forever, he said. "è German è Japanese è • You are dead, that there always is set, please do not
forget what he said." 22

Why Do We Need a Tool for This?
• Machine translation • Imitation of an author
23

Why Do We Need a Tool for This?
• Machine translation • Imitation of an author
– In a small study with 10 participants, not one managed to imitate Cormac McCarthy’s writing well enough to fool our Writeprints feature set (not even 10% change in classification)
24

Why Do We Need a Tool for This?
• Machine translation • Imitation of an author
– In a small study with 10 participants, not one managed to imitate Cormac McCarthy’s writing well enough to fool our Writeprints feature set (not even 10% change in classification)
– Even if this is managed, it is hard to sustain (e.g. “A Gay Girl in Damascus” – Afroz and Greenstadt, 2012)
25

Why Do We Need a Tool for This?
• Machine translation • Imitation of an author • Simply obfuscating your writing
26

Why Do We Need a Tool for This?
• Machine translation • Imitation of an author • Simply obfuscating your writing
– Brennan and Greenstadt (2009) showed that this can be done while writing the text (not for preexisting writing)
27

Why Do We Need a Tool for This?
• Machine translation • Imitation of an author • Simply obfuscating your writing
– Brennan and Greenstadt (2009) showed that this can be done while writing the text (not for preexisting writing)
– However, the quality of the texts produced was far from scholarly
28

Why Do We Need a Tool for This?
• Machine translation • Imitation of an author • Simply obfuscating your writing
– Brennan and Greenstadt (2009) showed that this can be done while writing the text (not for preexisting writing)
– However, the quality of the texts produced was far from scholarly
– No way to “know” if you are doing the right thing 29

Why Do We Need a Tool for This?
• Machine translation • Imitation of an author • Simply obfuscating your writing
30

Anonymouth
• Java based program that uses JStylo and machine learning techniques to a9empt to aid users in severing stylometric :es between themselves and a document they authored
31

The Goals
• An efficient, usable, and effec:ve tool to allow people to express their thoughts anonymously
32

The Goals
• An efficient, usable, and effec:ve tool to allow people to express their thoughts anonymously
• Make clear that stylometry can be fooled, and therefore it cannot be relied upon absolutely
33

The Goals
• An efficient, usable, and effec:ve tool to allow people to express their thoughts anonymously
• Make clear that stylometry can be fooled, and therefore it cannot be relied upon absolutely
• A tool that provides a usable interface between the outcomes from machine learning analy:cs and a user
34

Key Contributions • JStylo-Anonymouth framework
– Authorship attribution – Identifies changes required for document
anonymization relative to a corpus – Assists the user making necessary changes
accordingly
35

Key Contributions • JStylo-Anonymouth framework
– Authorship attribution – Identifies changes required for document
anonymization relative to a corpus – Assists the user making necessary changes
accordingly • User study showed that Anonymouth is
effective in determining what needs to be changed to achieve anonymization – But has trouble telling the user how to make the
changes 36

Problem Statement
37
• Author has a document to anonymize A D

Problem Statement
38
• Author has a document to anonymize – : set of labeled documents written by
A DAP

Problem Statement
39
• Author has a document to anonymize – : set of labeled documents written by – : set of labeled documents written by other
authors (“blend-in” corpus)
A DAN
PO

Problem Statement
40
• Author has a document to anonymize – : set of labeled documents written by – : set of labeled documents written by other
authors (“blend-in” corpus) – : set of linguistic features to extract
A DAN
P
F
O

Problem Statement
41
• Author has a document to anonymize – : set of labeled documents written by – : set of labeled documents written by other
authors (“blend-in” corpus) – : set of linguistic features to extract – : classifier trained on PO
A DAN
P
F
O
C

Problem Statement
42
• Author has a document to anonymize – : set of labeled documents written by – : set of labeled documents written by other
authors (“blend-in” corpus) – : set of linguistic features to extract – : classifier trained on
• Goal: create from where the extracted features from are sufficiently changed such that:
PO!D
A DAN
P
F
O
CD
F
Pr[C( !D ) = A]≤ 1N +1

Framework
• JStylo – authorship attribution
• Anonymouth – authorship anonymization
43

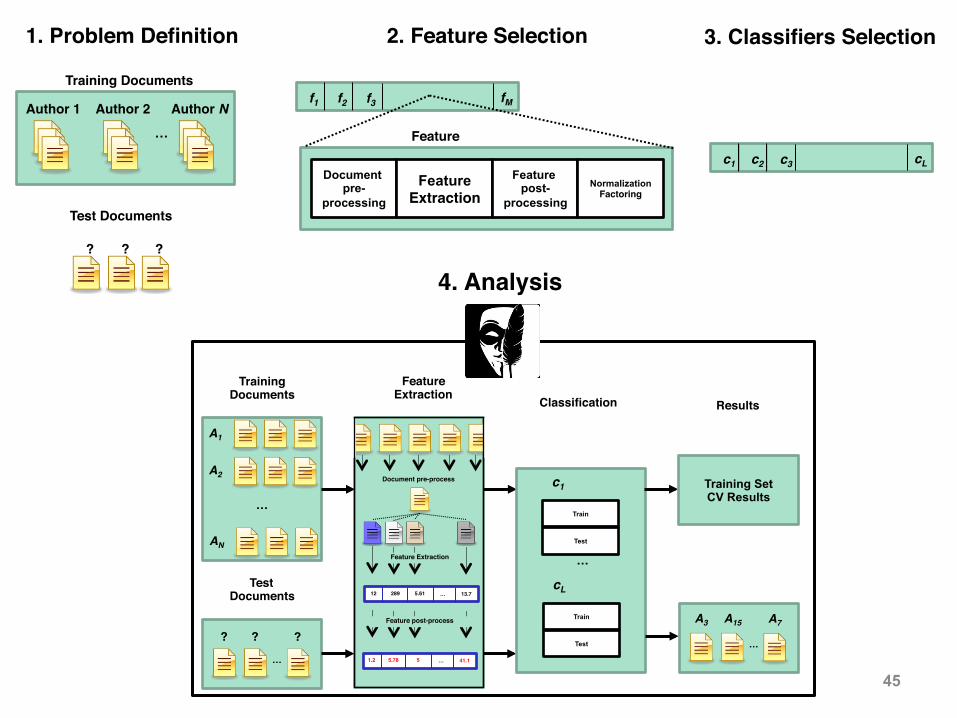
JStylo • Standalone platform for authorship attribution • Underlying feature extraction and authorship attribution engine
of Anonymouth • NLP for feature extraction • Supervised machine learning:
– Trains on documents of known candidate authors – Tests anonymous documents to attribute authorship
• Phases: – Problem set definition – Feature extraction – Classifiers selection – Analysis
• Powered by JGAAP, Weka 44
1. Problem Definition!
Author 1! Author 2! Author N!
…!
Training Documents!
Test Documents!
?! ?! ?!
2. Feature Selection!
Feature Set!
Feature!
fM!f1! f2! f3!
Document pre-
processing!
Feature Extraction!
Feature post-
processing!Normalization
Factoring!
cL!c1! c2! c3!
Training!Documents!
A1!
A2!
AN!
…!
Test!Documents!
Document pre-process!
12! 289! 5.61! 13.7!…!
Feature Extraction!
1.2! 5.78! 5! 41.1!…!
Feature post-process!
Feature!Extraction!
?! ?! ?!
…!
Classification!
Train!
Test!
c1!
Train!
Test!
cL!
…!
A3! A15! A7!
…!
Training Set CV Results
Results!
3. Classifiers Selection!
4. Analysis!
45
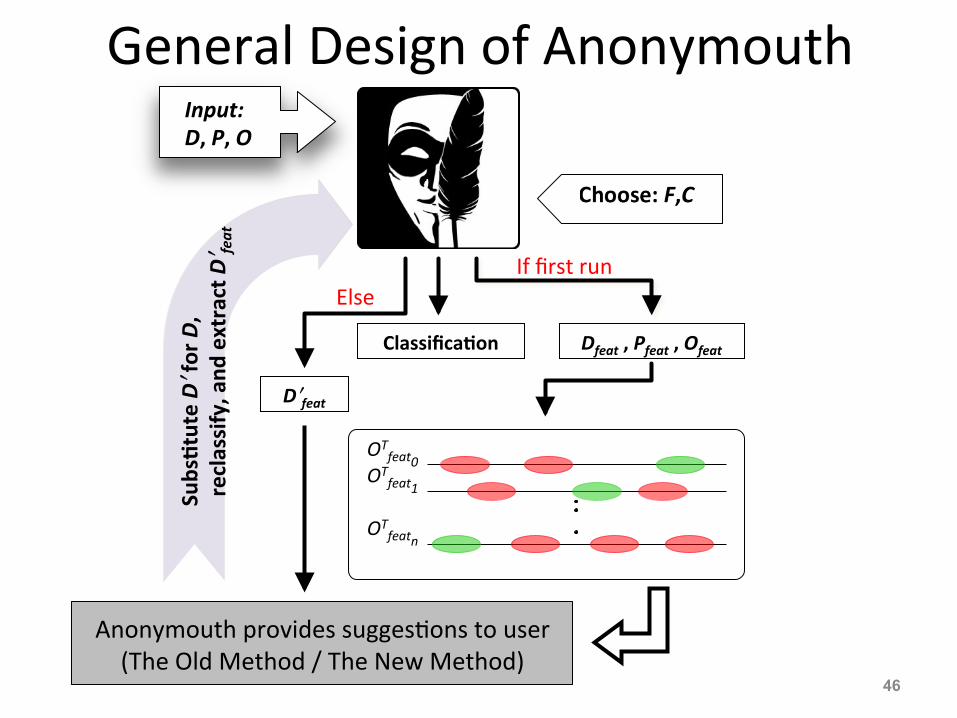
General Design of Anonymouth Input: D, P, O
Classifica)on Dfeat , Pfeat , Ofeat
OTfeat0
OTfeat1
OTfeatn
Anonymouth provides sugges:ons to user (The Old Method / The New Method)
Sub
s)tute Dʹ′ for D,
re
classify, and
extract Dʹ′ fe
at
If first run Else
Dʹ′feat
46

Anonymouth’s Clusters (updated display)
The green circles comprise the target cluster group, T. The red circles are the author’s confidence interval for each feature, and the black dot on each plot is the present
value of that feature in the author’s document to anonymize 47
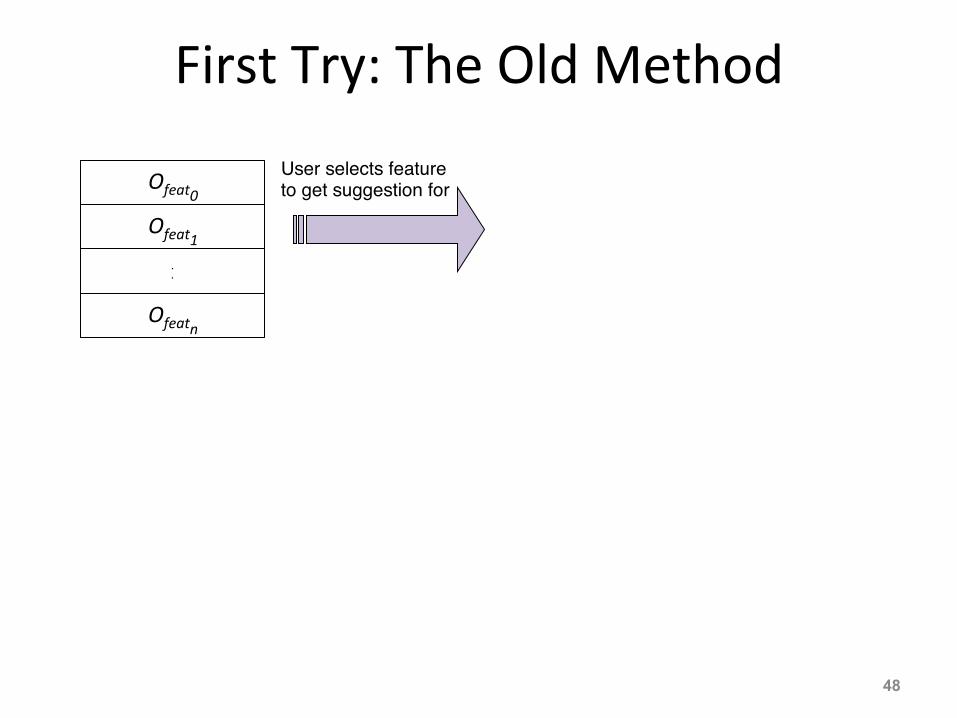
First Try: The Old Method
Ofeat0
Ofeat1
.
.
Ofeatn
User selects feature to get suggestion for"
48

First Try: The Old Method
Ofeat0
Ofeat1
.
.
Ofeatn
User selects feature to get suggestion for"
Anonymouth tells user current value and target value (Ticentroid
) of chosen feature, along with ways to bring current value up/down to target value
"
49
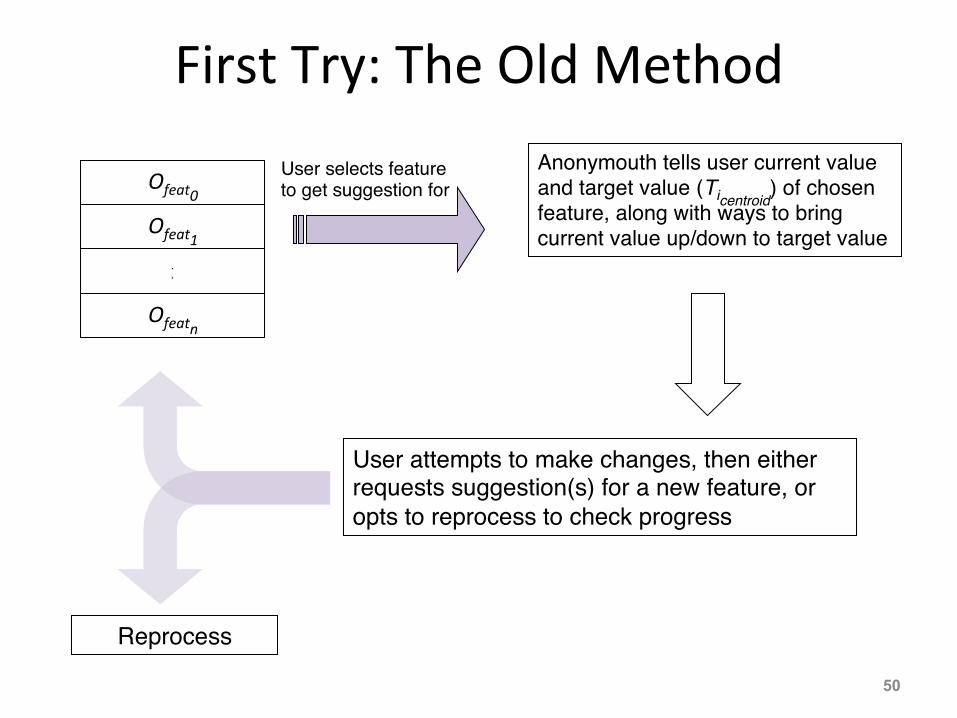
First Try: The Old Method
Ofeat0
Ofeat1
.
.
Ofeatn
User selects feature to get suggestion for"
Anonymouth tells user current value and target value (Ticentroid
) of chosen feature, along with ways to bring current value up/down to target value
"
User attempts to make changes, then either requests suggestion(s) for a new feature, or opts to reprocess to check progress"
Reprocess"
50

Results of User Study Using The Old Method
• When people are able to do what is asked of them, they are able to anonymize their wri:ng
51

Results of User Study Using The Old Method
• When people are able to do what is asked of them, they are able to anonymize their wri:ng
• 8/10 par:cipants were able to anonymize their wri:ng with respect to JStylo’s Basic-‐9 feature set
52

Results of User Study Using The Old Method
• When people are able to do what is asked of them, they are able to anonymize their wri:ng
• 8/10 par:cipants were able to anonymize their wri:ng with respect to JStylo’s Basic-‐9 feature set
• 7/10 were able to achieve a classifica:on less than or equal to random chance
53

Results of User Study Using The Old Method
• When people are able to do what is asked of them, they are able to anonymize their wri:ng
• 8/10 par:cipants were able to anonymize their wri:ng with respect to JStylo’s Basic-‐9 feature set
• 7/10 were able to achieve a classifica:on less than or equal to random chance
• But, no users were able to anonymize their wri:ng using JStylo’s Writeprints feature set
54

Results of User Study Using The Old Method
• However, changing ≈14% (≈100) of the features Anonymouth indicated, 8/10 user’s documents were classified as having been wri9en by a different author with 95% probability (Jstylo’s Writeprints feature set)
55

Results of User Study Using The Old Method
• However, changing ≈14% (≈100) of the features Anonymouth indicated, 8/10 user’s documents were classified as having been wri9en by a different author with 95% probability (Jstylo’s Writeprints feature set)
• Revealed that ini:al approach needed revision
56

Results of User Study Using The Old Method
• However, changing ≈14% (≈100) of the features Anonymouth indicated, 8/10 user’s documents were classified as having been wri9en by a different author with 95% probability (Jstylo’s Writeprints feature set)
• Revealed that ini:al approach needed revision • Conclusion: Anonymouth was unusable, but core methodology sound
• Also, asking users to select cluster groups is problema:c
57

Editor – Basic-‐9 Feature Set
58

Basic-‐9 Feature Set Results
59
0
10
20
30
40
50
60
70
80
90
100
s1 s2 s3 s4 s5 s6 s7 s8 s9 s10
Au
thors
hip
Att
rib
uti
on
Acc
ura
cy
Participants
Anonymization in terms of original background corpus
Original document
Modified document
‐‐Random Chance

Editor – Writeprints Feature Set
60

Next Steps: The New Method • Need to present user with more feasible task • Tweak / change cluster ordering algorithms to eliminate the need for user to select a cluster group
• Present document sentence by sentence, rather than all at once
• Ask to change words rather than specific features • Allow user to shuffle and remove words to gain a different perspec:ve / help user to see each sentence from a different perspec:ve
• Find “best” synonyms for words • (Possibly) analyze point of view (1st, 2nd, 3rd person), tense, and verb conjuga:on habits
61

Extract POS tags using Stanford POS Tagger, wrap each “word” in an object which keeps track of how many features from Ofeat were found in that word.
For each word compute: Where: ai = appearances of feature i in word; T = total features found in word; gi = Informa:on Gain of feature i; and pi = percent change needed of feature i
Negative"Anonymity Index"
Positive"Anonymity Index"
Words to remove" Words to add"
User requests next sentence or opts to reprocess"
Reprocess"
Present sentence to user with lists of words to add and to remove"
User may choose to “shuffle” sentence, with or without stripping “words to remove”, which randomly reorganizes remaining words in sentence edit box"
W
hen user is sa
)sfie
d with
cha
nges to
current se
nten
ce
( ) ( )∑=
××⎟⎟⎠
⎞⎜⎜⎝
⎛n
iii
i pgaT0
=Index Anonymity
62

Going Forward • Clustering is unreliable • Usability:
– What informa:on should be given to the user?
– What is the best way to get the user to make the changes needed to the document?
– Tes:ng our new method
63

Ques:ons? • Contact informa:on:
– Andrew McDonald • [email protected]
– Sadia Afroz • [email protected]
– Aylin Caliskan • [email protected]
– Ariel Stolerman • [email protected]
– Rachel Greenstadt • [email protected]
• Drexel PSAL website (to download JStylo and Anonymouth): – h9ps://psal.cs.drexel.edu/index.php/JStylo-‐Anonymouth 64

How Does it Work? • User inputs three sets of documents
– D, P, and O • He chooses
– A feature set, F, – A classifier, C
• JStylo extracts features from D, P, and O, crea:ng Dfeat , Pfeat , and Ofeat , respec:vely, and delivers a classifica:on of document D among P ∪ O
• Anonymouth individually clusters the values of a single feature for all documents represented by OT
feat
65

How Does it Work? • User inputs three sets of documents
– D, P, and O • He chooses
– A feature set, F, – A classifier, C
• JStylo extracts features from D, P, and O, crea:ng Dfeat , Pfeat , and Ofeat , respec:vely, and delivers a classifica:on of document D among P ∪ O
• Anonymouth individually clusters the values of a single feature for all documents represented by OT
feat
O0 O1 : . On
fo f1 .. . fm
Ofeat
66

How Does it Work? • User inputs three sets of documents
– D, P, and O • He chooses
– A feature set, F, – A classifier, C
• JStylo extracts features from D, P, and O, crea:ng Dfeat , Pfeat , and Ofeat , respec:vely, and delivers a classifica:on of document D among P ∪ O
• Anonymouth individually clusters the values of a single feature for all documents represented by OT
feat
O0 O1 : . On
fo f1 .. . fm
Ofeat fo f1 : .
fm
O0 O1 .. . On
OTfeat
67

How Does it Work? • User inputs three sets of documents
– D, P, and O • He chooses
– A feature set, F, – A classifier, C
• JStylo extracts features from D, P, and O, crea:ng Dfeat , Pfeat , and Ofeat , respec:vely, and delivers a classifica:on of document D among P ∪ O
• Anonymouth individually clusters the values of a single feature for all documents represented by OT
feat
O0 O1 : . On
fo f1 .. . fm
Ofeat fo f1 : .
fm
O0 O1 .. . On
OTfeat
All values of feature fn found in all documents in O are clustered
68

• Primary preference calcula:on orders each feature’s clusters based upon number of elements and distance from user’s average (for that feature)
69
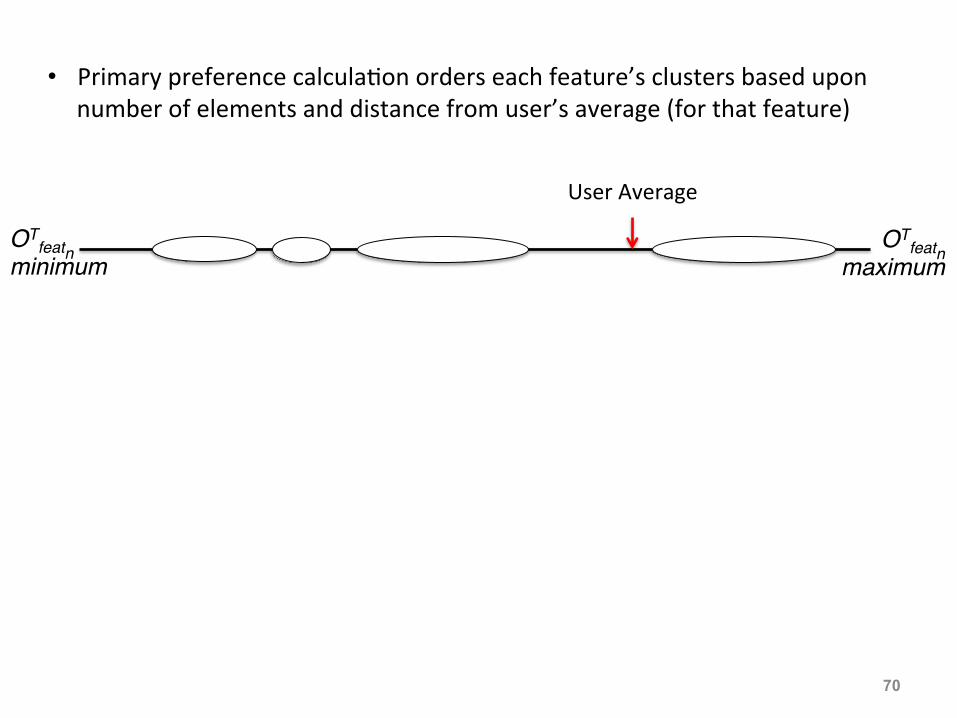
User Average
OTfeatn minimum
!
OTfeatn maximum
!
• Primary preference calcula:on orders each feature’s clusters based upon number of elements and distance from user’s average (for that feature)
70
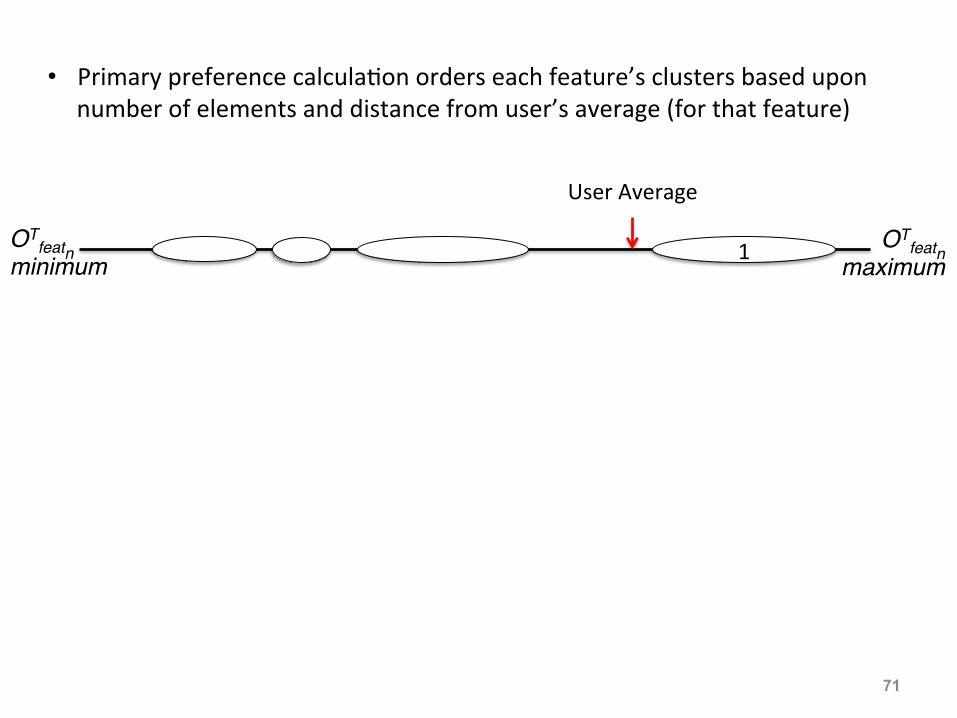
1
User Average
OTfeatn minimum
!
OTfeatn maximum
!
• Primary preference calcula:on orders each feature’s clusters based upon number of elements and distance from user’s average (for that feature)
71

4 1
User Average
OTfeatn minimum
!
OTfeatn maximum
!
• Primary preference calcula:on orders each feature’s clusters based upon number of elements and distance from user’s average (for that feature)
72
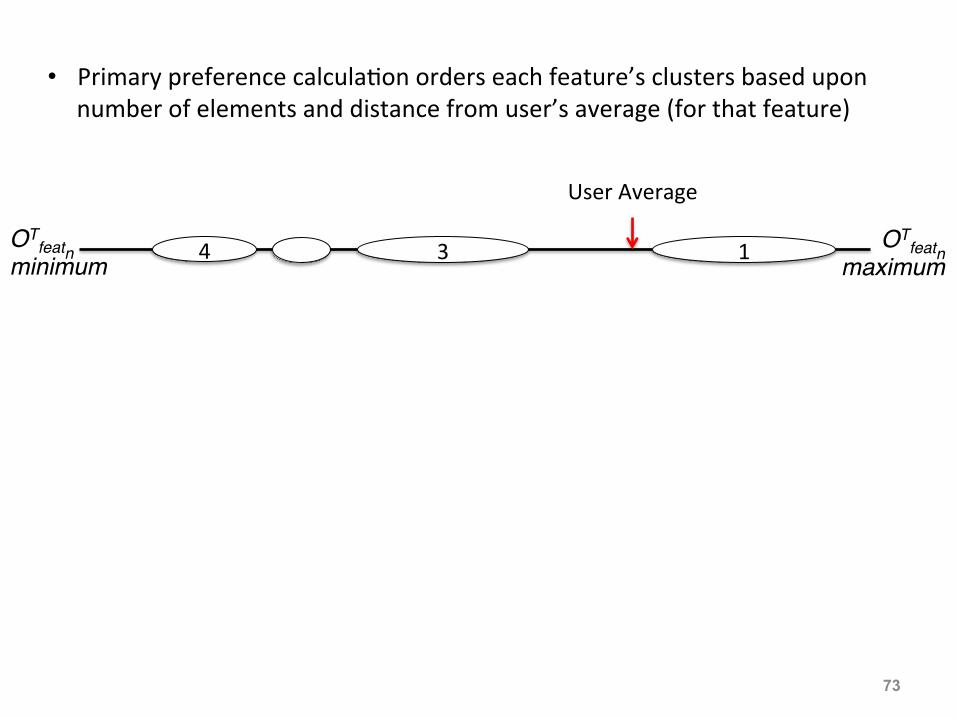
4 3 1
User Average
OTfeatn minimum
!
OTfeatn maximum
!
• Primary preference calcula:on orders each feature’s clusters based upon number of elements and distance from user’s average (for that feature)
73

4 2 3 1
User Average
OTfeatn minimum
!
OTfeatn maximum
!
• Primary preference calcula:on orders each feature’s clusters based upon number of elements and distance from user’s average (for that feature)
74

4 2 3 1
User Average Most Preferable
OTfeatn minimum
!
OTfeatn maximum
!
• Primary preference calcula:on orders each feature’s clusters based upon number of elements and distance from user’s average (for that feature)
75

4 2 3 1
User Average Most Preferable
OTfeatn minimum
!
OTfeatn maximum
!
• Primary preference calcula:on orders each feature’s clusters based upon number of elements and distance from user’s average (for that feature)
• Once all features have been clustered and ordered, cluster groups are assembled – Each cluster group represents at least one document
76
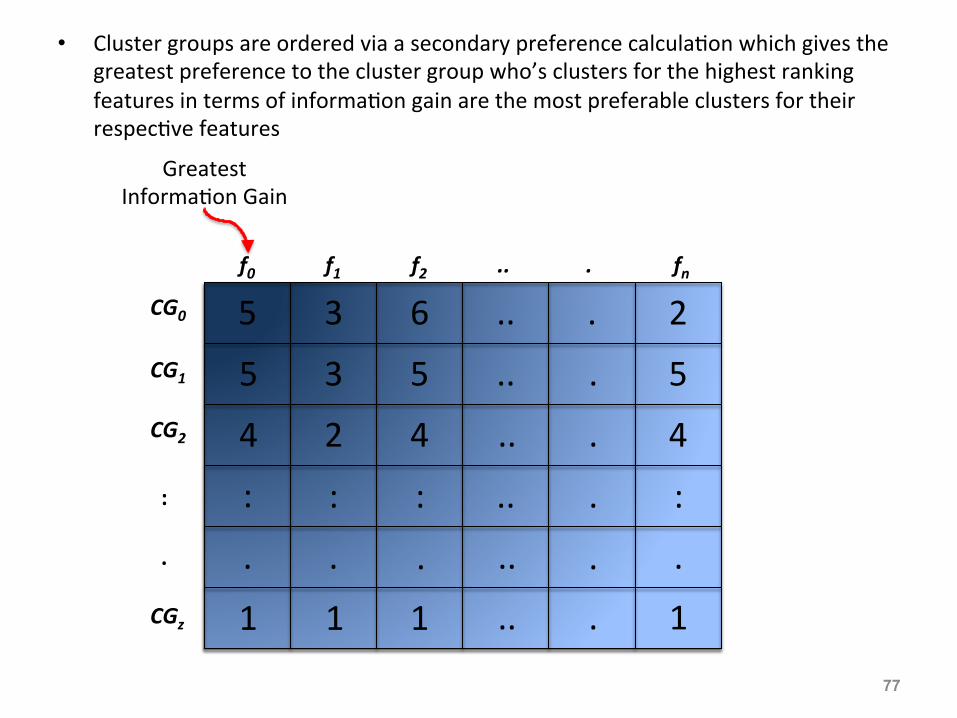
• Cluster groups are ordered via a secondary preference calcula:on which gives the greatest preference to the cluster group who’s clusters for the highest ranking features in terms of informa:on gain are the most preferable clusters for their respec:ve features
f0 f1 f2 .. . fn
Greatest Informa:on Gain
5
5
4
:
.
1
3
3
2
:
.
1
6
5
4
:
.
1
..
..
..
..
..
2
5
4
:
.
1
.. .
.
.
.
.
.
CG0
CG1 CG2
: . CGz
77
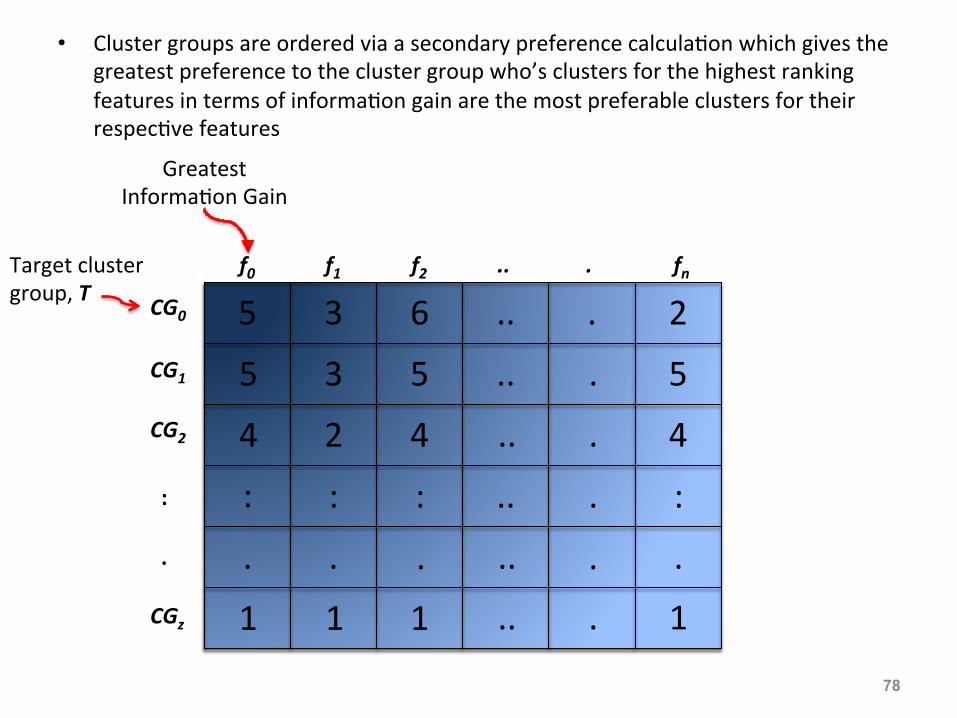
• Cluster groups are ordered via a secondary preference calcula:on which gives the greatest preference to the cluster group who’s clusters for the highest ranking features in terms of informa:on gain are the most preferable clusters for their respec:ve features
f0 f1 f2 .. . fn
Greatest Informa:on Gain
5
5
4
:
.
1
3
3
2
:
.
1
6
5
4
:
.
1
..
..
..
..
..
2
5
4
:
.
1
.. .
.
.
.
.
.
CG0
CG1 CG2
: . CGz
Target cluster group, T
78
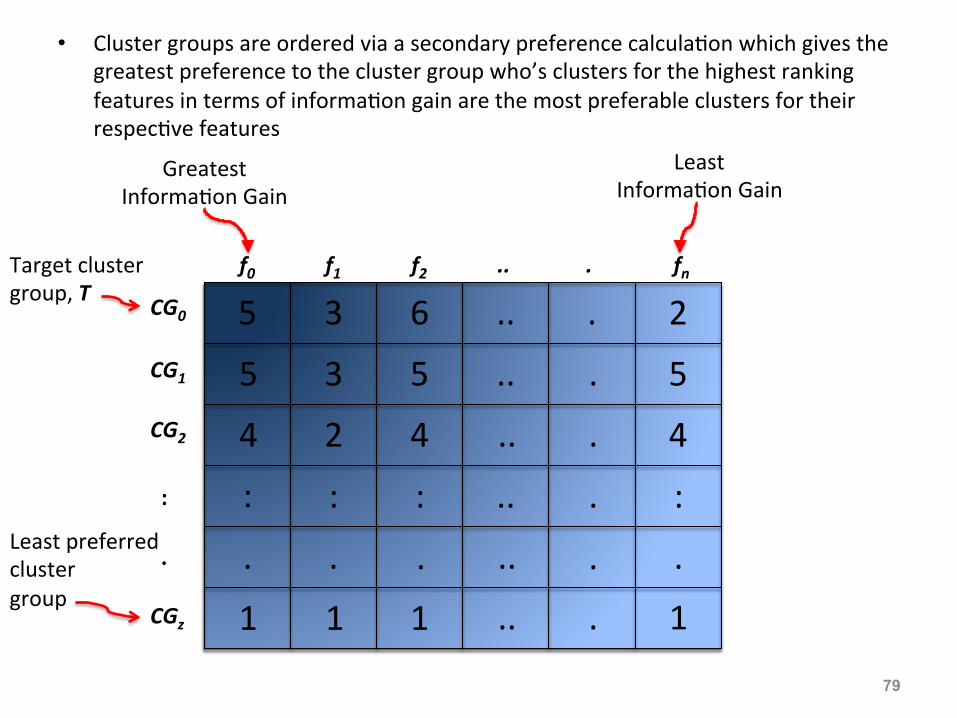
• Cluster groups are ordered via a secondary preference calcula:on which gives the greatest preference to the cluster group who’s clusters for the highest ranking features in terms of informa:on gain are the most preferable clusters for their respec:ve features
f0 f1 f2 .. . fn
Greatest Informa:on Gain
5
5
4
:
.
1
3
3
2
:
.
1
6
5
4
:
.
1
..
..
..
..
..
2
5
4
:
.
1
.. .
.
.
.
.
.
CG0
CG1 CG2
: . CGz
Target cluster group, T
Least Informa:on Gain
Least preferred cluster group
79
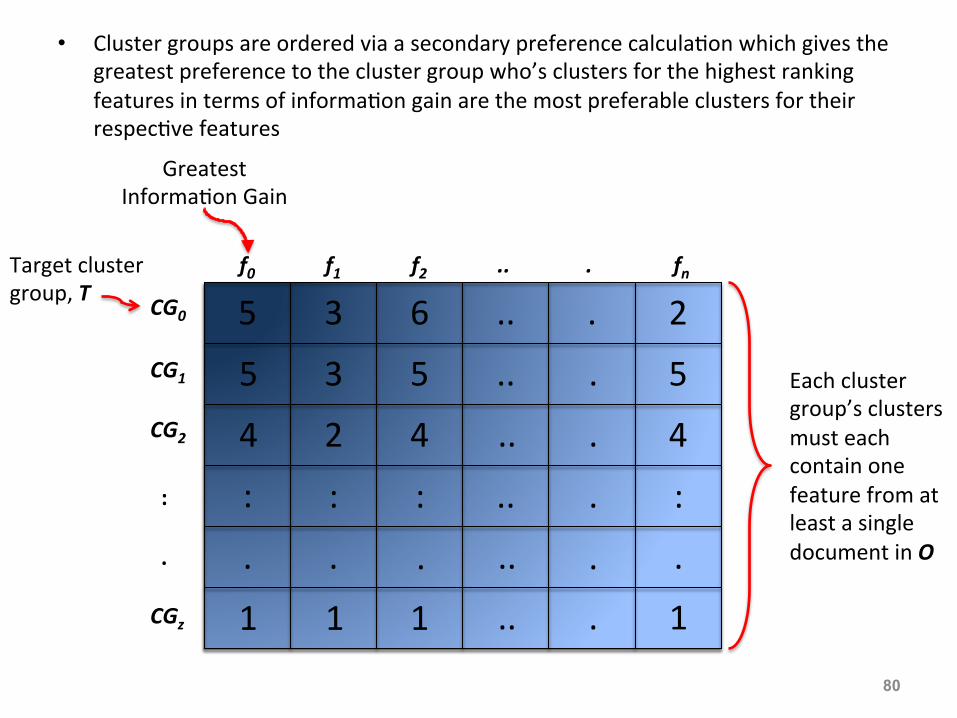
• Cluster groups are ordered via a secondary preference calcula:on which gives the greatest preference to the cluster group who’s clusters for the highest ranking features in terms of informa:on gain are the most preferable clusters for their respec:ve features
f0 f1 f2 .. . fn
Greatest Informa:on Gain
5
5
4
:
.
1
3
3
2
:
.
1
6
5
4
:
.
1
..
..
..
..
..
2
5
4
:
.
1
.. .
.
.
.
.
.
CG0
CG1 CG2
: . CGz
Target cluster group, T
Each cluster group’s clusters must each contain one feature from at least a single document in O
80

• Cluster groups are ordered via a secondary preference calcula:on which gives the greatest preference to the cluster group who’s clusters for the highest ranking features in terms of informa:on gain are the most preferable clusters for their respec:ve features
f0 f1 f2 .. . fn
Greatest Informa:on Gain
5
5
4
:
.
1
3
3
2
:
.
1
6
5
4
:
.
1
..
..
..
..
..
2
5
4
:
.
1
.. .
.
.
.
.
.
CG0
CG1 CG2
: . CGz
Target cluster group, T
T contains the most preferable clusters from the most important features
81
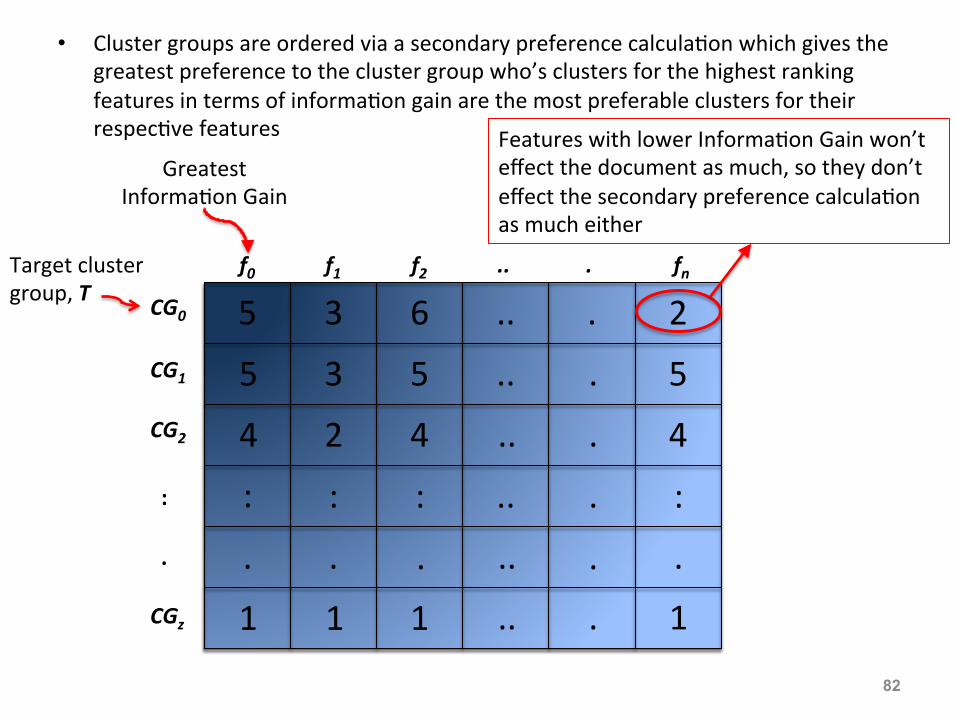
• Cluster groups are ordered via a secondary preference calcula:on which gives the greatest preference to the cluster group who’s clusters for the highest ranking features in terms of informa:on gain are the most preferable clusters for their respec:ve features
f0 f1 f2 .. . fn
Greatest Informa:on Gain
5
5
4
:
.
1
3
3
2
:
.
1
6
5
4
:
.
1
..
..
..
..
..
2
5
4
:
.
1
.. .
.
.
.
.
.
CG0
CG1 CG2
: . CGz
Target cluster group, T
Features with lower Informa:on Gain won’t effect the document as much, so they don’t effect the secondary preference calcula:on as much either
82