usage of parallel fuzzy clustering for performance of distributed esa datasets processing lycom...
TRANSCRIPT

Usage of Parallel Fuzzy Clustering for Performance of Distributed ESA
Datasets ProcessingLycom Dmitri1, Trzasala Milena2, Students Gr.1 -8BM23, 2 –AO-1841-Tomsk Polytechnic University, Russia
2-Wroclaw University of Technology, Poland
Scientific advisor: Dr. Sergey Axyonov

Gaia project
Usage of Parallel Fuzzy Clustering for Performance of Distributed ESA Datasets Processing 2
European Space Agency (ESA) mission
Launch Date: 2013Mission End: after 5 years (2018)Launch Vehicle: Soyuz-FregatOrbit: Lissajous-type orbit around L2
OBJECTIVES: Gaia is an ambitious mission to chart a three-dimensional map of our Galaxy, the Milky Way, in the process revealing the composition, formation and evolution of the Galaxy.
MISSION: Produce a stereoscopic and kinematic census of about one billion stars in our Galaxy and throughout the Local Group.
Detection and orbital classification of tens of thousands of extra-solar planetary systems.

Objective & Tasks
3
MotivationPresence of large-scale datasets from the Gaia space projectNeed for fast and accurate analysis of received informationThe technique can be used to process other huge industrial databases
ObjectiveHigh Performance of Vectors Clustering Techniques for Rapid and Reliable ESA Datasets Analysis
TasksDesign a technique that allows to get effective data distribution and supercomputer processing.Create a program implementation of the suggested technique that is capable to be used with computational cluster.Test and estimate the performance of developed software with ESA testing datasets.
Usage of Parallel Fuzzy Clustering for Performance of Distributed ESA Datasets Processing

Datasets & Attributes
4
An
aly
zin
g S
tars
Featu
res
Test
ing
Data
sets
Attribute Name Meaninglog-f1 Log of the first frequencylog-f2 Log of the second frequencylog-af1h1-t Log amplitude, first harmonic, first frequencylog-af1h2-t Log amplitude, second harmonic, first frequencylog-af1h3-t Log amplitude, third harmonic, first frequencylog-af1h4-t Log amplitude, fourth harmonic, first frequencylog-af2h1-t Log amplitude, first harmonic, second frequencylog-af2h2-t Log amplitude, second harmonic, second frequencylog-crf10 Amplitude ratio between harmonics of the first frequencypdf12 Phase difference between harmonics of first frequencyVarrat Variance ratio before and after first frequency
subtractionB-V Colour indexV-I Colour indexDataset # Instances # Attributes Usage
Synth43K 43860 13 Validation of clustering quality and implementation of algorithm
Synth-105 100878 13 Scalability performance testing
Synth-106 1008780 13 Scalability performance testing
Synth-107 10087800 13 Scalability performance testing
Synth-108 100878000 13 Scalability performance testing
Usage of Parallel Fuzzy Clustering for Performance of Distributed ESA Datasets Processing

DBSCAN Clustering technique
5
Allows to get clusters (groups of points) with any shape.
Based on the points density
Usage of Parallel Fuzzy Clustering for Performance of Distributed ESA Datasets Processing
Disadvantage: Performance!!!Heavily Depends on Dataset Sizes

Data Distribution Problem
6
Each process that is connected with a computational node gets just a part of data.
Processes can’t detect clusters because neighboring points are located in different memory space
Our SolutionMessage Passing Interface MPI_Scatter result
Usage of Parallel Fuzzy Clustering for Performance of Distributed ESA Datasets Processing
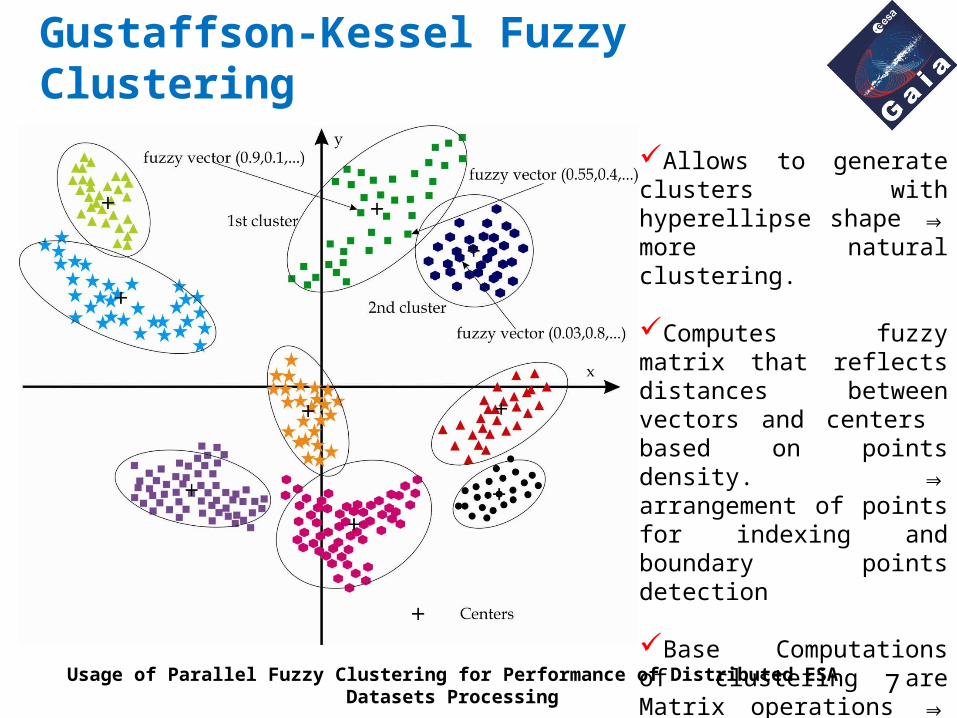
Gustaffson-Kessel Fuzzy Clustering
7
Allows to generate clusters with hyperellipse shape ⇒ more natural clustering.
Computes fuzzy matrix that reflects distances between vectors and centers based on points density. ⇒ arrangement of points for indexing and boundary points detection
Base Computations of clustering are Matrix operations ⇒ easy to parallizeUsage of Parallel Fuzzy Clustering for Performance of Distributed ESA
Datasets Processing

Preclustering
8
Use a part of data to clusterize ⇒ speed up processing.Use some computational nodes with different data ⇒ reliability of analysis.Usage of Parallel Fuzzy Clustering for Performance of Distributed ESA
Datasets Processing
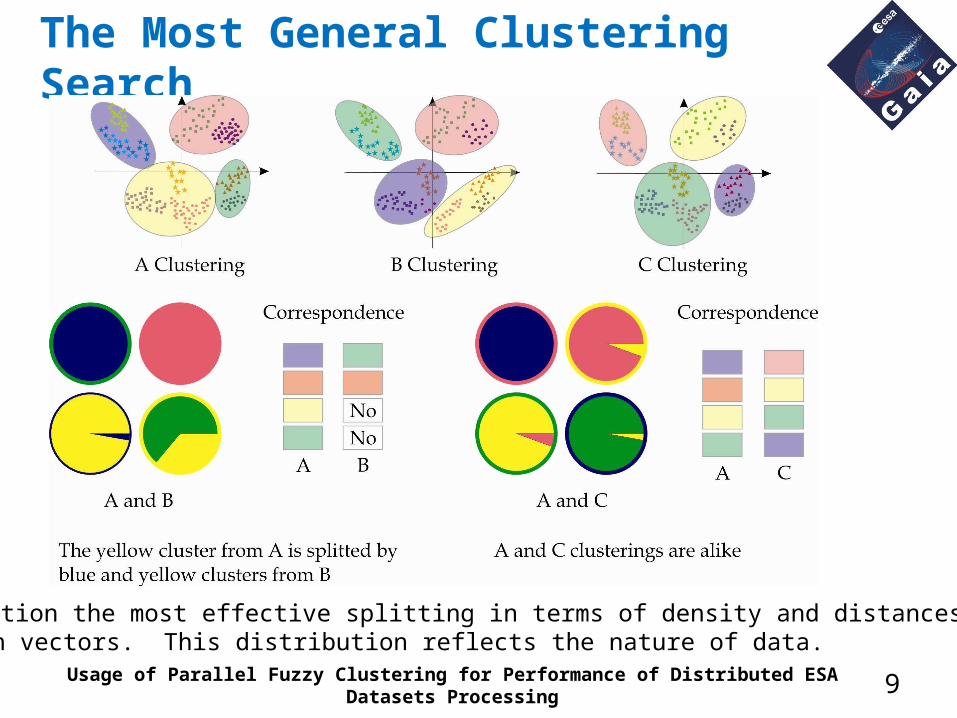
The Most General Clustering Search
9
Detection the most effective splitting in terms of density and distances between vectors. This distribution reflects the nature of data.Usage of Parallel Fuzzy Clustering for Performance of Distributed ESA
Datasets Processing

Clusters join (Output Synchronization)
10
Each point has a fuzzy vector that reflects distances between the point and centers of clusters.
Perform “Join” operation if distances between boundary points in two processes are less the radius of neighborhood.
We need just a very small part of clustered points that are located at the borders between clusters ⇒ speedup.
Usage of Parallel Fuzzy Clustering for Performance of Distributed ESA Datasets Processing

Implementation
11
The program is developed with MS Visual C#(multi-core + multi-node computations were used)
Libraries of Parallel Computing .NET4(Multi-core processing)•Matrix operations in GK clustering•Cluster equivalence (The Most General Clustering search)
Libraries of Distributed Programming MPI.NET(Multi-node processing)•Data Scattering (for Preclustering)•Data Distribution (for DBSCAN Procedure)•Data Broadcasting (The Most General Clustering sending)•Clusters join (Point-to-Point Communication)
The program was tested with SKIF-TPU Computational Cluster (used 20 computational nodes, 80 processors)
Usage of Parallel Fuzzy Clustering for Performance of Distributed ESA Datasets Processing

Performance
12
Performance of the suggested technique to analyze the Synth-105 Dataset in distributed manner. ⇒ The approach really increases the performance of algorithm.
Usage of Parallel Fuzzy Clustering for Performance of Distributed ESA Datasets Processing

Results
13
Designed a new original approach to parallel-distributed large-scale dataset clustering
Created a C# program that implements the suggested model based on MPI.NET and parallel libraries of .NET 4.
The software was tested to estimate the performance of suggested approach with the Gaia test datasets
The suggested technique increases the DBSCAN performance. Parallel-distributed processing is much more effective versus standard DBSCAN method.
Usage of Parallel Fuzzy Clustering for Performance of Distributed ESA Datasets Processing