usability, user preferences, effectiveness, and user behaviors when searching individual and...
TRANSCRIPT

Usability, User Preferences, Effectiveness, and UserBehaviors When Searching Individual and IntegratedFull-Text Databases: Implications for Digital Libraries
Soyeon ParkSchool of Communication, Information and Library Studies, Rutgers University, 4 Huntington Street,New Brunswick, NJ 08901-1071. E-mail: [email protected]
This article addresses a crucial issue in the digital libraryenvironment: how to support effective interaction of us-ers with heterogeneous and distributed information re-sources. In particular, this study compared usability,user preference, effectiveness, and searching behaviorsin systems that implement interaction with multiple da-tabases through a common interface, and with multipledatabases as if they were one (integrated interaction) inan experiment in the Text REtrieval Conference (TREC)environment. Twenty-eight volunteers were recruitedfrom the graduate students of the School of Communi-cation, Information, & Library Studies at Rutgers Univer-sity. Significantly more subjects preferred the commoninterface to the integrated interface, mainly becausethey could have more control over database selection.Subjects were also more satisfied with the results fromthe common interface, and performed better with thecommon interface than with the integrated interface.Overall, it appears that for this population, interactingwith databases through a common interface, is prefera-ble on all grounds to interacting with databases throughan integrated interface. These results suggest that: (1)the general assumption of the information retrieval (IR)literature that an integrated interaction is best needs tobe revisited; (2) it is important to allow for more usercontrol in the distributed environment; (3) for digital li-brary purposes, it is important to characterize differentdatabases to support user choice for integration; and, (4)certain users prefer control over database selectionwhile still opting for results to be merged.
Introduction
This article addresses a crucial issue in the digital libraryenvironment: how to support effective interaction of userswith heterogeneous and distributed information resources.In a typical digital library context, users are faced withchoosing the “right” database(s) out of many different in-formation resources, and interacting with each different
database. Having interacted with one, they are then facedwith the problem of how to relate that experience to a(different) interaction with the next. Finally, having inter-acted with them all, users are faced with how to integrate theresults of all of the different interactions. Without propersupport of such interaction, the effectiveness of digital li-braries could decline. This is an important issue, becausethere are many different databases of different types thathave varying degrees of relevance to any given problem.
Despite the growing interest in and importance of inter-action in information retrieval (IR), there have been fewstudies of user interaction with large numbers of distributedheterogeneous information resources. Most studies in thedatabase merging and data fusion areas have focused ontechnical issues and system performance issues, but notinteraction issues (Belkin, Kantor, Fox, & Shaw, 1995;Callan, Croft, & Harding, 1995; Fox & Shaw, 1994; Hawk-ing, Thistlewaite, & Bailey, 1997; Lee, 1995; Lu, Callan, &Croft, 1996; Savoy, LeCalve, & Vrajitoru, 1997; Schiette-catte, 1997; Voorhees, Gupta, & Johnson-Laird, 1995; Xu& Callan, 1998). For example, many studies used existingor past queries to test the performance of a database merg-ing technique (compared to single database searching) with-out involving actual users. In Fox and Shaw’s experiment(1994), all of the queries were created from the topic de-scription provided by National Institute of Standards andTechnology (NIST), and the performance of multiple data-base searching and single database searching was comparedbased on the these queries. Similarly, Schiettecatte’s study(1997) took the manually constructed queries from anotherexperiment, ran them across databases, merged the resultsinto a single ranked list, and compared the performance ofthis merged result with a nonmerged result. In her report onthe Text REtrieval Conference (TREC)1 5 database mergingtrack, Voorhees (1997, p. 103) even comments that “users
Received April 6, 1999; revised August 5, 1999; accepted August 5,1999.
© 2000 John Wiley & Sons, Inc.
1 TREC is an information retrieval conference for evaluating andunderstanding advanced information retrieval systems and techniques. Itwill be explained in more detail in the Methodology section.
JOURNAL OF THE AMERICAN SOCIETY FOR INFORMATION SCIENCE. 51(5):456–468, 2000

prefer a mechanism for performing a single, integratedsearch.” The hidden assumption behind these studies is thatcombining multiple information sources can improve infor-mation retrieval system performance; thus, it is furtherassumed that the integrated (merged) interaction with mul-tiple information resources is the appropriate mode to offerusers.
This study tested this general assumption of the IRliterature by directly comparing usability, user preference,effectiveness, and searching behaviors in systems that im-plement interaction with multiple databases through a com-mon interface, and with multiple databases as if they wereone (integrated interaction).2
Comparison of Different Levels of Interaction
In general, there have been three different ways to ad-dress issues corresponding to the three different levels ofinteraction: separate interaction, intermediate interaction(common interaction), and integrated interaction. Eachmethod is assumed to have its own advantages and disad-vantages.
Separate interaction connects users to different systems(therefore, different interfaces), and allows interaction withdifferent sources separately. With this method, users canclearly see where information comes from; further, interac-tive features such as relevance feedback and query refor-mulation can be easily implemented. Also, if one systemprovides special system features or special indexing meth-ods that are unique to particular systems, users might preferseparate interaction. The disadvantages of separate interac-tion are that users have to: learn and use many differentinterfaces or systems; leave one system to go to anothersystem; and integrate and compare separate search results.Any system that provides a single interface over a singledatabase can be considered as a separate interface. TheScientific & Technical Information Network (STN) Chem-ical Abstracts Online, Internet PubMed, and Grateful Medare examples of separate interaction. Internet search enginessuch as Altavista, Yahoo, and Excite are also examples ofthis method.
The second method, common interaction, allows search-ing different resources within the same interface. With thismethod, users do not have to switch among different inter-faces and, therefore, do not have the problem of learninghow to interact with many different systems. However,users still have to repeat their interaction when they movefrom one information source to another information source.They still have to integrate and compare separate searchresults. Furthermore, it may not be possible to support all ofthe features of each different resource in a common inter-face. This method does, however, have the advantages ofclarity, consistency, and ease of implementation of rele-
vance feedback, query reformulation, and related tech-niques. With this method, users are able to see and selectparticular database(s) to search. Single database searchingin most commercial database systems such as Dialog, Lexis/Nexis, and Ovid can be considered as a common interactionwith some aspects of separate interaction. Because thesesystems provide the same interface for their databases, usersdo not have to switch among different databases when theymove from one database to another database. However,users could make use of special indexing methods for eachdatabase, because these systems maintain special features orspecial indexing methods that are unique to particular da-tabases.
Finally, the integrated interface searches multiple data-bases all together, integrates results from different sources,and allows users to interact with integrated results. Advan-tages of this method lie in its efficiency (saving time, cost,and effort) and ease of learning, and that users do not haveto identify, or select among, large numbers of databases. Aproblem of this method lies in the difficulty of mergingresults and implementing interactive system features likequery reformulation, database browsing, and relevancefeedback. Another problem of the integrated system is re-duced functionalities: the system cannot support specialsystem features or special ways of indexing that are uniqueto a particular system. This method (integrated interaction)is related to the problems of data fusion and, in particular,database merging. Internet meta-search engines such asMetaCrawler, Profusion, SavvySearch, and Inference Find!are examples of integrated interaction. Multiple databasesearching in commercial database systems like Dialog couldbe considered as integrated interaction with some aspects ofcommon interaction. With these systems, multiple databasescan be searched at the same time. However, the results arelisted by either chronological order or database order, butnot integrated according to their rankings.
Related Work
Previous research in the fields of database merging anddata fusion has paid little attention to the issue of howindividuals interact with multiple heterogeneous informa-tion resources and how they would like to interact withmultiple information resources. Most studies in this prob-lem area have focused on technical issues and performanceissues but not interaction issues (Belkin et al., 1995; Callanet al., 1995; Fox & Shaw 1994; Hawking et al., 1997; Lee,1995; Lu et al., 1996; Savoy et al., 1997; Schiettecatte,1997; Voorhees et al., 1995; Xu & Callan, 1998). There isone study by Payette and Rieger (1997) that comparedusers’ perspectives about multiple database searching and acommon user interface. The researchers conducted inter-views and focus group studies with a select group of facultyand students. The subjects were asked about their percep-tions of a database-specific interface (called a “separateinterface” in this study), a common interface, and a multipledatabase search option (“integrated interface” in this study).
2 The data for this article came from a recently completed doctoraldissertation (Park, 1999).
JOURNAL OF THE AMERICAN SOCIETY FOR INFORMATION SCIENCE—March 15, 2000 457

Most users identified a common interface as preferable to aseparate interface because the common interface could al-low users to search in a more uniform, simple, and consis-tent way. They commented that the value of the commoninterface would outweigh the potential loss of database-specific features. Although the users studied by Payette andRieger (1997) perceived both efficiency and increased ac-cess as major benefits to multidatabase searching and re-trieving, they were concerned about problems such as in-formation overload and irrelevant information. The resultsof that study suggest that in order to satisfy user require-ments for the presentation of results from a multidatabasesearch, a system will have to support merged results sets,elimination of duplicates, and cross-database relevanceranking.
Payette and Rieger’s (1997) study is interesting in that itcompares individuals’ perceptions of three different levelsof interaction that have been identified earlier. However,they did not study actual uses of the different systems. Also,their perception of multiple database searching is relativelysimple (e.g., they consider presentation of results by chro-nological order and author name as multiple databasesearching). In most research studies, database merging usu-ally involves ranking documents and merging retrieveddocuments from different databases according to theirscores or rankings.
Methodology
General Design, Task, Databases, Topics
An experiment was conducted to compare a “commoninterface” system with an “integrated interface” system us-ing a within-subjects design so that each individual couldsearch and compare the two systems. Twenty-eight subjectswere asked to conduct three different searches on eachsystem. Table 1 shows the general experimental design ofthis study.
This experiment was conducted using the resources ofthe Text REtrieval Conference (TREC) (Voorhees & Har-man, 1997). TREC is a major IR conference for evaluatingand understanding advanced information retrieval systemsand techniques. Various groups from industry, academia,and government have participated in TREC. An importantgoal of TREC is to “encourage research in text retrieval
based on large test collections” (Voorhees & Harman, 1997,p. 1). Another important goal of TREC is “to provide acommon task evaluation that allows cross-system compar-isons” (Voorhees & Harman, 1997, p. 3). The main char-acteristics of TREC are its use of large-scale full textcollections4 and the availability of thousands of relevancejudgments for each of 500 different information problems.
Starting in TREC-4 (1995), a set of “tracks” that focus onparticular subproblems of text retrieval were introduced,each having its own guidelines and evaluation measures.The TREC interactive track was designed to investigate andevaluate interactive information retrieval and to investigatesearching as an interactive task by examining the process aswell as the outcome (Voorhees & Harman, 1997). InTREC-5 (1996), the interactive track specified a new IRtask, the so called “aspectual” task, and began developing astandard methodology for evaluating that task (Over, 1997).This task is to identify as many different aspects as possiblefor a given topic and save documents that, taken together,cover all distinct aspects of that topic. The study reportedhere used a slight modification of the fifth Text RetrievalConference (TREC-5) interactive task (see Appendix for asample topic).5 This task was chosen because it requiressignificant interaction between users and the system, be-cause it seems relevant for the distributed information en-vironment where there are heterogeneous multiple data-bases, and also because the performance criteria for this taskwere established for TREC.
Aspectual recall, a performance measure designed for theinteractive track, was used as the performance measure forthis study, because the TREC-5’s interactive task was usedin this study along with TREC-5 collections and informa-tion problems. It was also used because other performancemeasures based on relevance judgments were not as appro-priate for this task. Aspectual recall began with TREC-5
3 Two different experimental designs have been considered for thisstudy: (1) a Latin-square design where topics are randomized and rotatedcompletely; (2) a design that creates blocks of topics and rotates theseblocks instead of rotating individual topics. Given the advantages anddisadvantages of each method, the second method (rotating blocks of topic)was chosen over the first method, because possible order effects have beenoutweighed by the necessity to control the variable (i.e., varying the topicorder). To create topic blocks, the six selected topics were matchedpair-wise according to the topic distribution characteristic, with one fromeach pair assigned to one of two “topic blocks.” Initially, topics wererandomly ordered within each block; this order was then fixed, and theorder of the topic blocks was rotated.
4 The capacity of TREC-7 adhoc collections is about 2.3 GB.
5 The task was structured in the following way to encourage queryreformulation: You have been asked to write a background paper thatsurveys (overviews) the different points of view or different developmentson_topic. You have 20 minutes to find and save some articles that will beuseful for this purpose. Please save at least one document that identifieseach different aspect.
TABLE 1. Experimental design (repeated for every four subjects).
Subject First system Topic block3 Second system Topic block
S1 A271,286,255 B 299,292,274
S2 B271,286,255 A 299,292,274
S3 A299,292,274 B 271,286,255
S4 B299,292,274 A 271,286,255
A: common interface (HERMES); B: integrated interface (HERA).
458 JOURNAL OF THE AMERICAN SOCIETY FOR INFORMATION SCIENCE—March 15, 2000

(1996)6 and it is computed by comparing the list of aspectsidentified for each search with “the list of document-aspecttuples identified by the assessors” (Belkin et al., 1997). Inother words, it is the ratio between the number of uniqueaspects identified within each search session and the totalnumber of aspects identified by the TREC assessors. Forexample, if TREC assessors identified 10 aspects for aparticular topic and a searcher identified seven unique as-pects, the aspectual recall is 0.7. The value of aspectualrecall varies from 0 to 1. If the saved documents did notcover any of the aspects identified by TREC assessors, theaspectual recall is 0, whereas if the saved documents cov-ered all the aspects identified by the judges, the aspectualrecall is 1.
The databases used for this study were the full texts of:Congressional Record of the 103rd Congress (27,922 doc-uments); Federal Register (55,630 documents); FinancialTimes 1991–1994 (210,158 documents); and Wall StreetJournal 1990–1992 (74,520 documents). The rationale forthis selection of databases is that they cover overlappingtime periods; that they are different from one another intopic, coverage, length, structure, writing style, vocabulary,and/or genre; and, that there are topics for which all of thesedatabases have relevant documents, and others for whichthey have none (or very few). In this study, these fourdatabases were separated into different collections insteadof a single collection, and were indexed separately. Sixtopics were selected from TREC-5 ad hoc7 and interactivetopics, considering the following characteristics: (a) distri-bution of relevant documents across databases; (b) hardnessof topic (measured by mean precision); and (c) subject oftopic.
The distribution of relevant documents across the fourdatabases could influence individuals’ preference for a par-ticular system. For example, if relevant documents areevenly scattered across the databases, subjects might preferthe integrated interface. On the other hand, if all relevantdocuments are found in one database, they might prefer the
common interface system so that they could only focus onthat database. The six selected topics had three differentdistributions of relevant documents: two with roughly evendistributions; two biased so that (almost) all relevant docu-ments are in one database; and, two biased so that onedatabase has (almost) no relevant documents while relevantdocuments are distributed almost evenly across the otherthree databases.
Second, an attempt was made to control for topic diffi-culty. The average precision (for each topic) of all theparticipating systems in TREC, the “hardness” measure inTREC-5, was used. All six topics selected have similarlevels of difficulty, and represent middle rather than extremevalues.
Finally, topics were selected which would be accessiblewithin general knowledge, nontechnical subject areas to thegreatest extent possible, varying subject content as neces-sary to avoid bias between topics.
Based upon these criteria, the following six topics werechosen for this study, and these are listed in Table 2.
The six selected topics were matched pair-wise accord-ing to the topic distribution characteristic, with one fromeach pair assigned to one of two “topic blocks.” Topics wererandomly ordered within each block, this order was thenfixed, and the order of the topic blocks was rotated (as isshown in Table 1).
Systems
INQUERY 3.2, developed at the Center for IntelligentInformation Retrieval (CIIR), University of Massachusetts,was used as the underlying system for the two experimentalsystems. INQUERY is a probabilistic inference network-based system, based upon the idea of combining multiplesources of evidence to plausibly infer the relevance of adocument to a query (Callan, Croft, & Harding, 1992). Theinterfaces for two systems were implemented by SCILSdoctoral student, Shin-jeng Lin, in Tk/Tcl (Ousterhout,1994; Welch, 1995). The salient features of this version ofINQUERY are automatic relevance feedback, documentranking, and manual query modification. These systemsaccepted only unstructured query input, and they did notsupport typical Boolean search commands. Searchers were
6 The name has been changed to “instance recall” from TREC-6(1997).
7 The adhoc task investigates the performance of systems that search anexisting set of documents using new ad hoc topics.
TABLE 2. Topic distribution across databases.
TopicFederal
Register 94Wall Street
Journal 90–92Financial
Times 91–94Congressional
Record 93
Approximately even distribution271 Solar power 13 20 33 9299 Military downsizing 13 8 6 23
Biased to one database286 Paper cost 0 20 111 0292 World-wide welfare 0 7 42 2
Biased against one database255 Environmental protection 2 32 48 15274 Electric automobiles 20 34 59 5
JOURNAL OF THE AMERICAN SOCIETY FOR INFORMATION SCIENCE—March 15, 2000 459

able to mark retrieved documents as relevant for use inautomatic relevance feedback, and also to save them,whether they were marked relevant or not. They were alsoable to retrieve the full text of retrieved documents, and toscroll through the full text to identify the location of high-lighted keywords in the documents. Searchers were able tosave and reload queries if they wished.
HERMES (common interface)
The system labeled HERMES allowed users to interactseparately with the four different resources (databases)through a common interface. This method allowed for auser-directed choice of database. That is, if users knewenough about the characteristics of different databases, theycould select and interact only with the databases they pre-ferred, and did not have to deal with the results fromirrelevant databases. To support user choice of a database,meta-information about each database such as content,genre, and size was presented to users during the tutorial.With this method, when users moved from one resource toanother resource, they still had to repeat their interaction.Also, users had to compare and integrate the results bythemselves. Figure 1 is a sample screen display of thecommon interface system, HERMES.
HERA (integrated interface system)
The system referred to as HERA combined results fromdifferent sources and let users interact with these integratedresults. Users submitted a query, and the databases wereranked with respect to that query. Then each database was
searched by the system, and the results of searches weremerged according to the document scores and weighted bycollection scores. Like the common interface, the four da-tabases were indexed separately. The merging and rankingalgorithm for this system was developed at the University ofMassachusetts (Callan et al., 1995; Xu & Callan, 1998), andis based on weighted similarity scores. With this interface,users did not have to switch among different informationinterfaces, and they did not have to leave one source to goto another source. The result was that they only needed tointeract with integrated results. All the functionalities of thecommon interface system were also implemented for theintegrated interface system, and they looked similar to us-ers. The only difference between these two interfaces wasthat the common interface provided buttons for each data-base so that a user could select the particular database(s)that he or she wanted to search. Figure 2 is a sample screendisplay of the integrated interface system, HERA.
Experimental Procedure
Twenty-eight volunteers were recruited from the gradu-ate students of the School of Communication, Information,& Library Studies at Rutgers University to participate assearchers in this study. The two systems used in this studywere new to all the participants. Each volunteer searchercame to the experiment site for a 3-hour search session.Each session consisted of the following procedures: consentform; tutorial for the first system (up to 20 minutes); search-ing three topics (up to 20 minutes for each search); post-search questionnaire after each search; postsystem question-naire; a break and then the same procedure for the secondsystem; a demographic questionnaire; an exit questionnaire
FIG. 2. Screen dump of HERA (integrated interface system).
FIG. 1. Screen dump of HERMES (common interface system).
460 JOURNAL OF THE AMERICAN SOCIETY FOR INFORMATION SCIENCE—March 15, 2000
comparing the two systems; and an exit interview at thevery end of the session. After completing the first tutorial,subjects were given a general task description. For thesystem HERMES (common interface), a separate introduc-tion was given as follows:
When you conduct searches on HERMES, you can searchon as many as all the databases, or as few as one database.Remember, before you start your search at HERMES, youshould choose the database that you want to search on.
Then they began the individual topic searches. Afterconducting each search, subjects answered questions abouttheir familiarity with the search topic, experiences with thesearching task, and their satisfaction with the results. Aftercompleting three searches for the first system, subjectsanswered several questions about the system in general.After a short break, the subjects were given a tutorial for thesecond system, searched another three topics, completed thepostsearch questionnaire for each topic, and the postsystemquestionnaire. Subjects were instructed tothink aloud asthey searched, verbalizing their thoughts, especially thereasons for their actions and problems associated with spe-cific information interactions. Each search was videotaped,and computer logged.
At the end of this entire session, subjects completed aquestionnaire that elicited demographic characteristics andtheir searching experiences with a variety of IR systems.Subjects were also asked to compare the two systems, andcomment on their understanding and use of interactivefeatures and different interaction support mechanisms. Tohave a better understanding of subjects’ overall searchingexperience, a brief semistructured exit interview was con-ducted at the very end of the session.
Twenty of the subjects in the study were female (71.4%)and eight were male (28.6%). All but two participants werecurrent graduate students. Twenty-one (75%) were libraryand information science majors and 7 (25%) were commu-nication majors. The mean and median ages were 36.18 and35, respectively. Although the subjects did not have anyexperience with the two systems used in this study, they hada variety of searching experiences in the use of differenttypes of IR systems. Table 3 shows the level and types ofsearching experience among the subjects.
Results
This section compares HERA (integrated interface) andHERMES (common interface) in terms of user preference,usability, effectiveness, and searching characteristics.
User Preference
Of the questions that were posed in the exit questionnaireand interview, this section discusses the responses to thosepertaining to user preferences. To compare user preferencesfor the two systems, the following questions were askedduring the exit questionnaire and exit interview:
● Which system did you like better? System HERA orsystem HERMES? Why? Or did you like them equally?
● Which system did you find more useful? System HERAor system HERMES? Why? Or did you find them equallyuseful?
● Which system did you find easier to use? System HERAor system HERMES? Why? Or were they equally difficultto use?
● Which system did you find easier to learn to use? SystemHERA or system HERMES? Why? Or were they equallydifficult to learn to use?
Table 4 summarizes the individuals’ responses to thesequestions.
For the question “which system did you like better,” 29%of the subjects (n 5 8) answered that they preferred HERA(integrated interface), and 64% of the subjects (n 5 18)preferred HERMES (common interface), and the rest, 7% (n5 2), liked them equally. For the question about usefulness,14% of the subjects (n 5 4) found HERA more useful, 57%of the subjects (n 5 16) found HERMES more useful, andthe rest, 21% (n 5 6), found them equally useful. Therewere two missing values for this question. For the questionof ease of learning to use, 28% of the subjects (n 5 8)answered that they found HERA (integrated interface) eas-ier to learn to use, 21% of the subjects (n 5 6) foundHERMES (common interface) easier to learn to use, andhalf of the subjects (n 5 14) found them equally easy tolearn to use. For the question of ease of use, about 21% ofthe individuals (n 5 6) said that HERA is easier to use,39% of them (n 5 11) found HERMES easier to use, andanother 39% (n 5 11) found them of equal ease of use.
Overall, subjects liked the common interface system(HERMES) better than the integrated interface system
TABLE 4. Searchers’ response to exit questionnaire,n 5 28.
HERA (%)(integrated interface)
HERMES (%)(common interface) Equally (%)
Like better 8 (28.6%) 18 (64.3%) 2 (7.1%)More useful 4 (14.3%) 16 (57.1%) 6 (21.4%)Easier to use 6 (21.4%) 11 (39.3%) 11 (39.3%)Easier to learn
to use8 (28.6%) 6 (21.4%) 14 (50%)
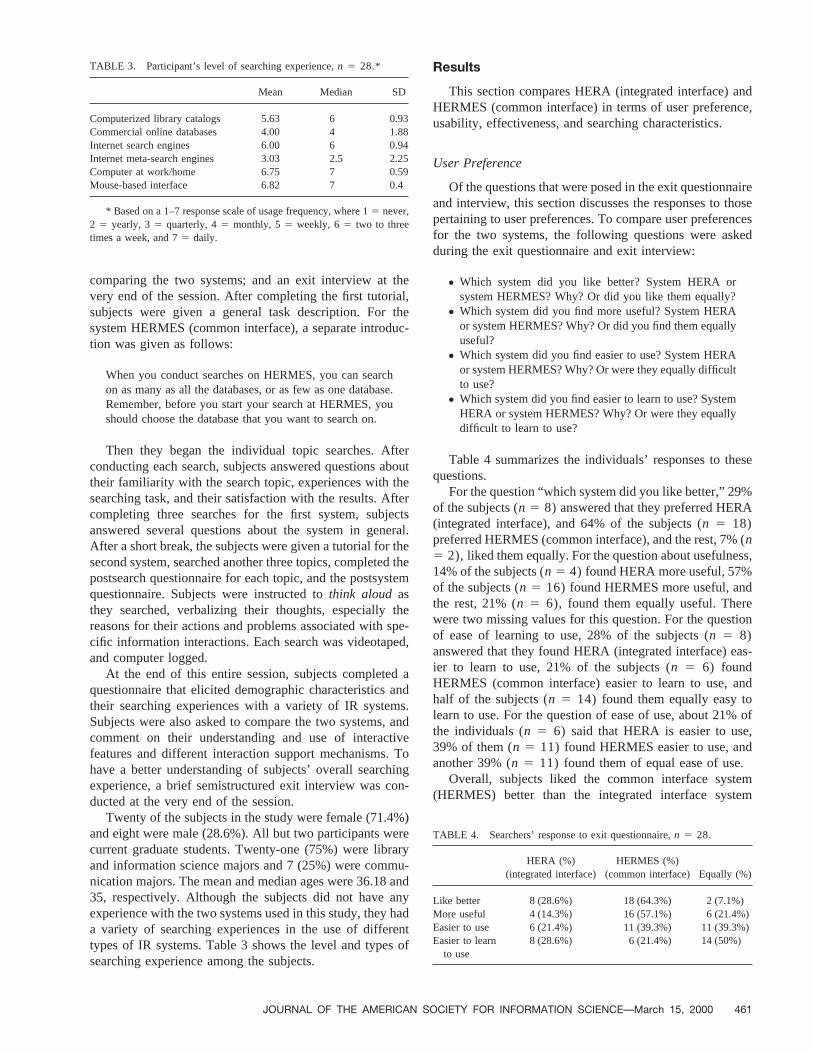
TABLE 3. Participant’s level of searching experience,n 5 28.*
Mean Median SD
Computerized library catalogs 5.63 6 0.93Commercial online databases 4.00 4 1.88Internet search engines 6.00 6 0.94Internet meta-search engines 3.03 2.5 2.25Computer at work/home 6.75 7 0.59Mouse-based interface 6.82 7 0.4
* Based on a 1–7 response scale of usage frequency, where 15 never,2 5 yearly, 35 quarterly, 45 monthly, 55 weekly, 65 two to threetimes a week, and 75 daily.
JOURNAL OF THE AMERICAN SOCIETY FOR INFORMATION SCIENCE—March 15, 2000 461

(HERA), and found HERMES more useful than HERA.However, because the two systems shared most systemfeatures, there was no clear distinction between the systemsin terms of ease of use, and ease of learning to use.
Because this study was interested in the frequency dis-tribution of a categorical variable, a one-way chi-square testwas conducted for these questions. Under the assumptionthat individuals have a preference for either system, theresponse “equally” has been treated as a missing value.
Hypothesis 1:There is a statistically significant differ-ence in individuals’ preference for system HERA andHERMES.8
There was a statistically significant difference in individ-uals’ preference for two systems,x2(1, 26) 5 3.846, p# 0.05. Searchers significantly preferred HERMES (com-mon interface) over HERA (integrated interface).
Hypothesis 2:There is a statistically significant differ-ence in individuals’ perception of the usefulness for thesystem HERA and HERMES.
Although there were fewer than five cases in one group(four subjects in HERA), a one-way chi-square test wasconducted to see whether a consistent pattern exists in thefrequency distribution for the two systems. Again, there wassignificant difference in individuals’ perception of useful-ness for two system,x2(1, 20) 5 7.2, p # 0.007, withsearchers preferring HERMES (common interface). It issuggested that a larger sample size be used to confirm thisfinding.
Hypothesis 3:There is a statistically significant differ-ence in ease of use for the system HERA and HERMES.
Hypothesis 4:There is a statistically significant differ-ence in ease of learning to use for system HERA andHERMES.
There were no statistically significant differences in easeof use or ease of learning to use the two systems. This couldbe explained by the fact that two systems shared commonsystem features except for the feature of database selection.Nevertheless, subjects did show a clear distinction in theareas of “system preference” and “usefulness,” with the
common interface preferred to the integrated one. Thesefindings are contrary to assumptions held in IR research.
To further explore the reasons for such preferences,content analysis was done on the subjects’ responses toquestions in the exit interview. The following question wasasked during the exit interview:
Today you experienced two different information retrievalsystems. With system HERMES, you were able to see andselect different databases, but you had to compare andintegrate search results from different databases by yourself.On the other hand, system HERA searches different data-bases all together and integrates results for you, but youwere not able to select particular database(s) to search.Given these characteristics, which system did you like bet-ter? System HERA or system HERMES? Why? Or did youlike them equally?
Table 5 summarizes subjects’ responses to the two dif-ferent systems and, in particular, the reasons associated withthese preferences.
Individuals liked HERA (integrated interface) for vari-ous reasons. First of all, they found it more convenient andefficient than HERMES (common interface), because thesearch results are integrated for users. They felt that it takesless time and less effort to use HERA than HERMES.
Subject 014 said that he found HERA (integrated inter-face) more convenient in that it was already integrated.Subject 001 commented that he liked to have all databasesin one file without having to switch databases. Subject 015found it repetitive and time consuming to select and switchdatabases with HERMES. Subject 025 mentioned HERArequires much less time in doing the search.
Because HERA requires much less time in doing the search,because it would retrieve the relevant articles for you fromall four databases. And you could skip through yourself.Whereas, with HERMES, I had to put the query to eachdatabase, four times on my own, to get the relevant articles.So, with HERA, I retrieved relevant articles much faster.And another reason is, I wouldn’t have to save my querywith HERA as much because it was already in the screen, Ijust modify it so to, you know, use other words. With8 Preference is defined by which system the users liked better.
TABLE 5. Searcher response to HERA (integrated) and HERMES (common) interfaces.
System Advantages Disadvantages
HERA (integrated interface) ● Convenient, efficient: takes less time and less(physical/behavioral) effort
● Lack of control
● Easier: fewer decisions to make, and less effort ● Distracting to have irrelevant databases● Provides more comprehensive and general
overview of search results● Related to searching habit: start with general
search and narrow it downHERMES (common interface) ● More control over the database selection ● Inconvenient and inefficient
● Could concentrate on the database of their choice ● Time consuming● Could eliminate or exclude the irrelevant and
useless database(s)
462 JOURNAL OF THE AMERICAN SOCIETY FOR INFORMATION SCIENCE—March 15, 2000

HERMES, each time I want to switch the database, I had tosave the query, . . . (Subject 025)
Similarly, some subjects found HERA (integrated inter-face) easier because they did not have to worry aboutselecting the right database(s), and it involved making fewerdecisions than with HERMES. Subject 005, for example,mentioned specifically that she liked HERA better becausethere are fewer decisions to be made. Subject 001 found itdistracting to make a choice between databases, whereasHERA made the decisions for him. Subject 005 liked HERAbetter because she did not have to go through the trouble offinding the different databases and did not have to worryabout having to test each database.
Well, I think it was mainly because of the integration of thedatabases because I found it distracting to a certain degree,especially when I switched to . . . . I had tofigure out whatthose databases included when I had to make a choicebetween them whereas I didn’t have to necessarily knowabout the databases in the first group, HERA, because it sortof made the decisions for me. (Subject 001)
Another reason for preferring HERA (integrated inter-face) was that it provides more comprehensive and generalsearch results. Subject 022 said that since HERA “forced”him to use all the databases, he felt his searching was morecomplete using HERA than HERMES. He found it morehelpful to look at the results from all the databases to guardagainst selecting an inappropriate database. Subject 028also found it useful to have them all together, because eventhough one does not necessarily read them all, one could usekeywords for later searches. Finally, one subject likedHERA better because of his search habits. He usually startsfrom a general search and narrows it down if necessary.Therefore, HERA was more relevant for his approach tosearching.
Despite these comments about HERA, about 64% (n5 18) of the subjects liked HERMES (common interface)better than HERA (integrated interface). They preferredHERMES, mainly because they had more control over thedatabase selection. Subject 003 said that he liked to havemore control over choosing his database environment. Sub-ject 024 also mentioned that she felt like she had morecontrol with HERMES.
I liked it (HERMES) better only because I felt like I hadmore control over choosing where it is that I wanted to look.I felt a little frustrated when I was using the first one(HERA), because there were times when I was searching, Iwas getting all like Congressional Record or the FederalRegister, and it was frustrating because I wanted to look inthe newspaper, because I thought that would be more rele-vant and, should have more of what I’m actually interestedin looking at. But they were like very down in the list. Andeven so, I felt like it didn’t really bring up what I wanted,what I was looking for. So, I felt that with the HERMES,that at least, then I could choose the databases that I wanted
to be in, that I could decide if they’re relevant or not on myown. (Subject 003)
In particular, subjects wanted to be able to concentrate onthe databases they liked and eliminate or exclude the onesthat they did not like. Subject 010 commented that he likedto be able to exercise control over the databases selected,because there were sources that he wished to exclude orsources that he wished to concentrate on. Similarly, subject011 commented that with HERMES (common interface), itwas easier to target the response that she wanted. Subject017 also mentioned that it was easier to continue searchingin more depth without being distracted by documents fromirrelevant databases.
Most subjects in this study found the CongressionalRecord and Federal Register useless from the beginning(despite there being relevant documents in each for sometopics), and did not want to deal with these databases in thelater searches. Therefore, they liked the feature of HERMES(the common interface), which allows users to turn offparticular database(s) that they do not want to deal with.Subject 013 commented that the documents from irrelevantdatabases hindered her from finding relevant informationand found HERMES more efficient. In this sense, HERMESacted to filter out extraneous noise. Unlike those who pre-ferred HERA (the integrated interface), they did not find itinconvenient or cumbersome to switch databases, becausefor them, more control over HERMES outweighed the con-venience of HERA, and also because they could repeat thesame interaction by using “save query” and “load query”features. In other words, the common interface HERMESmight have required more behavioral effort, but not neces-sarily cognitive effort. Subject 013 mentioned that withHERMES it was quick and easy to repeat queries using the“save query” feature.
I liked it (HERMES) better because I knew some of thedatabases wouldn’t really be relevant for, to my search. Infact they just hindered me from finding relevant informationbecause I had to weed through things like, you know, thequestion that required answer, the questions that requireinternational places or different countries, you know, some-thing like the Congressional Record just really wasn’t help-ful. And there was no way to turn that off or anything withHERA. With HERMES, it’s just quicker for me, there’s thatfeature to save, save your query. You know, it’s just quick.Just flip back and forth . . . (Subject 013).
Both quantitative data (questionnaire) and qualitativedata (interview) suggest that for this group of users, inter-acting with databases through a common interface is pref-erable to interacting with databases through an integratedinterface.
Although more subjects liked HERMES (common inter-face) better than HERA (integrated interface), several sub-jects commented that they would like to have a combinationof both systems. That is, they would like to have controlover database choice, but once they choose the right data-
JOURNAL OF THE AMERICAN SOCIETY FOR INFORMATION SCIENCE—March 15, 2000 463

base(s), they prefer searching them altogether rather thanseparately. Subject 010 explicitly commented that he wouldlike to combine the features from both systems, so that “hecould select anywhere from one to all sources,” and when hechooses more than one source, merge the search results.
010: Now, these seemed to be arbitrarily painful, dichoto-mous systems. There are times when it’s very nice, as inHERA, to have fusion but it’s also nice to be able to turn itoff once you’ve done some queries to identify other sourcesyou do or don’t want. I would actually like a combination ofthe two systems.I: Could you be more specific, like how would you com-bine?010: How would I combine the two? I would basicallyprovide the features of both. So that if I choose, if I chooseto, I could select anywhere from 1 to all sources. But if Ichoose more than one source, it would do the fusion for me.
Subject 020 also made the same point. She wished for asystem that allows a user to choose either one, or two, orthree or all the databases, then search them together. Subject008 mentioned that it would be ideal to combine two sys-tems. Subject 016 mentioned that she would like to have theintegrated system at the beginning to learn about the char-acteristics of different databases, then filter the databasesthat she does not like.
I liked the features in the HERMES where you could onlylook at one database. But I found myself at the beginning ofthe search, checking each of the databases to find out whichone of them looked like it would be most useful. But HERAis such that it looks at all the databases, you can look atsample articles you can see which of the databases is themost useful. But then unfortunately, you have to filterthrough all the ones you decided weren’t useful. So, itwould be nice to have a combination of the two, wherehaving looked at it integrated, then you could eliminate thedatabases that you don’t want to consider. (Subject 016)
An interesting finding from the exit interview data is thatseveral subjects suggested that if the databases were similar(i.e., in content and coverage), they would prefer mergingthem together. However the Federal Register and the Con-gressional Record are so different from the newspaper da-tabases that subjects found it distracting to have them alltogether. Subject 013 commented that if databases weresimilar in content, then, it might be nice to integrate theresults together. Similarly subject 018 mentioned that if thedatabases were very different, she would rather keep themseparate, but if they were alike, she would prefer the mergedresults.
Usability and User Satisfaction
In general, usability of the system refers to the ease ofuse, ease of learning, and user assessment of specific fea-tures. A postsearch questionnaire, a postsystem question-
naire, an exit questionnaire, and an exit interview were usedto investigate the issues of usability and user satisfaction.Thinking aloud data were also collected to address theseissues.
To assess the subjects’ satisfaction with search processand results, the following questions were asked after eachsearch:
● How easy was it to do the search on this topic?● How satisfied are you with your search results?● Did you have enough time to do an effective search?
A seven-point scale was used for these questions, where1 indicates not at all, 4 somewhat, and 7 very much.
Although subjects were new to the systems, overall, theyfound it somewhat easy to do the search (mean5 4.05), hadsomewhat enough time to do the search (mean5 4.58), andwere somewhat satisfied with the search results (mean5 4.04).
Table 6 compares the two systems in terms of subjects’responses to the questions about ease of searching, satisfac-tion with the search results, and assessment of time (enoughtime to do an effective search) in the postsearch question-naires.
Hypothesis 5:There is a statistically significant differ-ence in ease of searching between HERA and HERMES.
Hypothesis 6:There is a statistically significant differ-ence in assessments of time to search between HERA andHERMES.
Hypothesis 7:There is a statistically significant differ-ence in individuals’ satisfaction with HERA and HERMES.
Because the mean differences of the two systems werecompared within the same individual, a dependent-samplest-test (pairedt-test) was conducted for these hypotheses.The mean for ease to search HERMES (common interface)(mean5 4.31, SD5 0.97) was higher than the mean forease to search HERA (integrated interface) (mean5 3.8,SD 5 1.22), but this difference was not statistically signif-icant. Individuals’ assessment of time was similar between
TABLE 6. Comparison of HERA and HERMES (usability),n 5 28.*
Mean SD t p #
Satisfaction with search resultsHERA (integrated interface) 3.7143 1.2692 2.117* 0.04HERMES (commoninterface) 4.3690 1.2968
Easy to do the searchHERA (integrated interface) 3.7976 1.2217 1.752 0.09HERMES (commoninterface) 4.3095 .9726
Assessments of time to searchHERA (integrated interface) 4.5238 1.4891 0.477 0.637HERMES (commoninterface) 4.6429 1.5501
* 1 indicates not at all, 4 somewhat, and 7 very much.* p # 0.05, **p # 0.01, *** p # 0.001.
464 JOURNAL OF THE AMERICAN SOCIETY FOR INFORMATION SCIENCE—March 15, 2000
HERA (mean5 4.52, SD5 1.49) and HERMES (mean5 4.64, SD5 1.55). The mean for searchers’ satisfactionwith HERMES (mean5 4.37, SD5 1.29) was significantlyhigher than the mean for searchers’ satisfaction with HERA(mean5 3.71, SD5 1.27).
Consistent with the exit questionnaire results where moreindividuals liked HERMES (common interface) than HERA(integrated interface), there was a statistically significantdifference in individuals’ satisfaction with search results,t(27) 5 2.117, with p # 0.05. Individuals were moresatisfied with the results from HERMES than HERA. How-ever, there were no statistically significant differences be-tween the ease to search HERA and the ease to searchHERMES, nor with assessments of time to search betweenHERA and HERMES. Again, this might be explained by thefact that common system features were implemented forboth systems.
Effectiveness
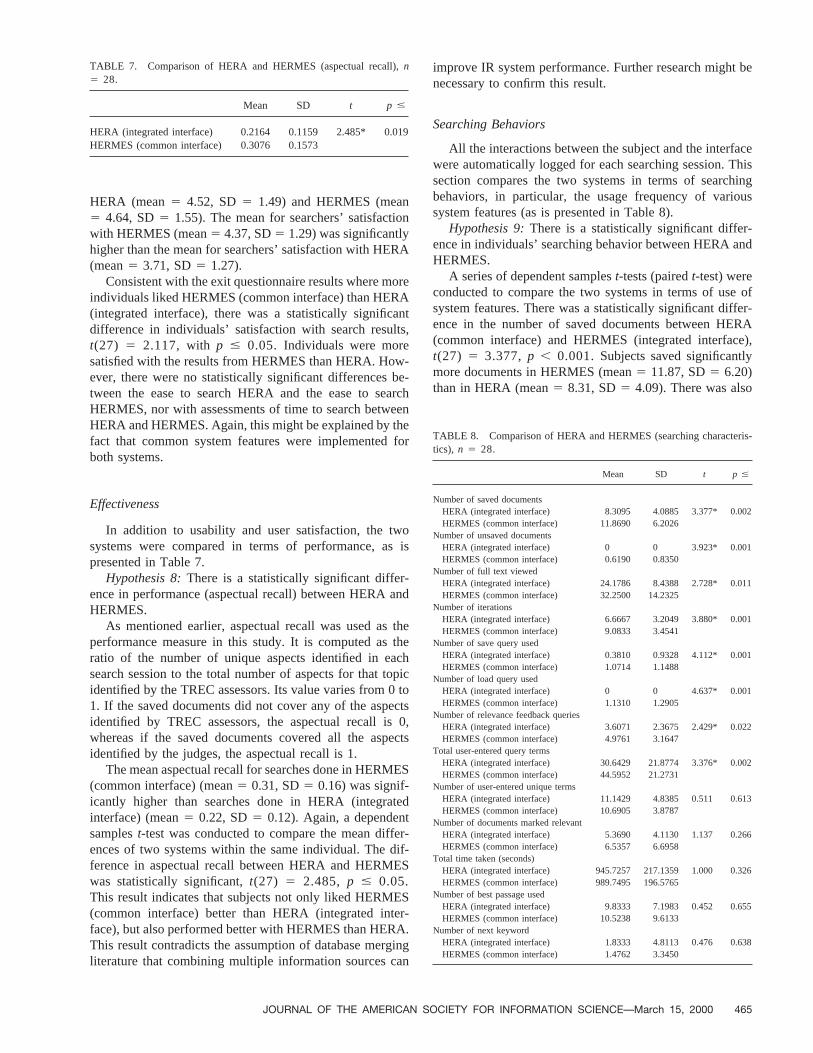
In addition to usability and user satisfaction, the twosystems were compared in terms of performance, as ispresented in Table 7.
Hypothesis 8:There is a statistically significant differ-ence in performance (aspectual recall) between HERA andHERMES.
As mentioned earlier, aspectual recall was used as theperformance measure in this study. It is computed as theratio of the number of unique aspects identified in eachsearch session to the total number of aspects for that topicidentified by the TREC assessors. Its value varies from 0 to1. If the saved documents did not cover any of the aspectsidentified by TREC assessors, the aspectual recall is 0,whereas if the saved documents covered all the aspectsidentified by the judges, the aspectual recall is 1.
The mean aspectual recall for searches done in HERMES(common interface) (mean5 0.31, SD5 0.16) was signif-icantly higher than searches done in HERA (integratedinterface) (mean5 0.22, SD5 0.12). Again, a dependentsamplest-test was conducted to compare the mean differ-ences of two systems within the same individual. The dif-ference in aspectual recall between HERA and HERMESwas statistically significant,t(27) 5 2.485, p # 0.05.This result indicates that subjects not only liked HERMES(common interface) better than HERA (integrated inter-face), but also performed better with HERMES than HERA.This result contradicts the assumption of database mergingliterature that combining multiple information sources can
improve IR system performance. Further research might benecessary to confirm this result.
Searching Behaviors
All the interactions between the subject and the interfacewere automatically logged for each searching session. Thissection compares the two systems in terms of searchingbehaviors, in particular, the usage frequency of varioussystem features (as is presented in Table 8).
Hypothesis 9:There is a statistically significant differ-ence in individuals’ searching behavior between HERA andHERMES.
A series of dependent samplest-tests (pairedt-test) wereconducted to compare the two systems in terms of use ofsystem features. There was a statistically significant differ-ence in the number of saved documents between HERA(common interface) and HERMES (integrated interface),t(27) 5 3.377, p , 0.001. Subjects saved significantlymore documents in HERMES (mean5 11.87, SD5 6.20)than in HERA (mean5 8.31, SD5 4.09). There was also
TABLE 8. Comparison of HERA and HERMES (searching characteris-tics), n 5 28.
Mean SD t p #
Number of saved documentsHERA (integrated interface) 8.3095 4.0885 3.377* 0.002HERMES (common interface) 11.8690 6.2026
Number of unsaved documentsHERA (integrated interface) 0 0 3.923* 0.001HERMES (common interface) 0.6190 0.8350
Number of full text viewedHERA (integrated interface) 24.1786 8.4388 2.728* 0.011HERMES (common interface) 32.2500 14.2325
Number of iterationsHERA (integrated interface) 6.6667 3.2049 3.880* 0.001HERMES (common interface) 9.0833 3.4541
Number of save query usedHERA (integrated interface) 0.3810 0.9328 4.112* 0.001HERMES (common interface) 1.0714 1.1488
Number of load query usedHERA (integrated interface) 0 0 4.637* 0.001HERMES (common interface) 1.1310 1.2905
Number of relevance feedback queriesHERA (integrated interface) 3.6071 2.3675 2.429* 0.022HERMES (common interface) 4.9761 3.1647
Total user-entered query termsHERA (integrated interface) 30.6429 21.8774 3.376* 0.002HERMES (common interface) 44.5952 21.2731
Number of user-entered unique termsHERA (integrated interface) 11.1429 4.8385 0.511 0.613HERMES (common interface) 10.6905 3.8787
Number of documents marked relevantHERA (integrated interface) 5.3690 4.1130 1.137 0.266HERMES (common interface) 6.5357 6.6958
Total time taken (seconds)HERA (integrated interface) 945.7257 217.1359 1.000 0.326HERMES (common interface) 989.7495 196.5765
Number of best passage usedHERA (integrated interface) 9.8333 7.1983 0.452 0.655HERMES (common interface) 10.5238 9.6133
Number of next keywordHERA (integrated interface) 1.8333 4.8113 0.476 0.638HERMES (common interface) 1.4762 3.3450
TABLE 7. Comparison of HERA and HERMES (aspectual recall),n5 28.
Mean SD t p #
HERA (integrated interface) 0.2164 0.1159 2.485* 0.019HERMES (common interface) 0.3076 0.1573
JOURNAL OF THE AMERICAN SOCIETY FOR INFORMATION SCIENCE—March 15, 2000 465

a statistically significant difference in the number of un-saved documents between HERA and HERMES,t(27)5 3.923, p , 0.001. Subjects never used the “unsavedocument” feature in the integrated interface system,whereas they used this feature an average of 0.62 times inthe common interface system (mean5 0.62, SD5 0.84).Subjects viewed significantly more full texts in HERMES(common interface) (mean5 32.25, SD5 14.23) than inHERA (integrated interface) (mean5 24.18, SD5 8.44),and this difference was statistically significant,t(27)5 2.728,p # 0.02. Individuals conducted an average ofnine queries (iterations) in HERMES (mean5 9.08, SD5 3.45), whereas they conducted an average of 6.67 queriesin HERA (mean5 6.67, SD5 3.20). The difference in thenumber of “run queries” between two systems was statisti-cally significant,t(27) 5 3.880,p # 0.001.
Of the total 1,323 queries, searchers had the opportunityto use or not use relevance feedback in 1,195 queries. Thatis, after the first query, searchers could use relevance feed-back. Subjects used more relevance feedback queries in thecommon interface system (mean5 4.98, SD5 3.1647) thanin the integrated interface system (mean5 3.61, SD5 2.37). The difference in the number of “relevance feed-back queries” between two systems was statistically signif-icant, t(27) 5 2.429, p # 0.05.
There was also a statistically significant difference in thenumber of the “save query” feature used between HERA(integrated interface) and HERMES (common interface),t(27) 5 4.112,p # 0.001. The“save query” feature wasused more often in HERMES (mean5 1.07, SD5 1.15)than HERA (mean5 0.38, SD5 0.93). Similarly, the “loadquery” feature was used more often in HERMES (mean5 1.13, SD5 1.29) than in HERA (mean5 0), with t(27)5 4.637, p # 0.001. It is interesting to note that “loadquery” feature was never used in the integrated interface.Finally, there was statistically significant difference in thetotal query terms used between HERMES (mean5 44.60,SD 5 21.27) and HERA (mean5 30.64, SD5 21.88),t(27) 5 3.376, p , 0.01.
Although it takes a little longer to search the commoninterface (mean5 989.75, SD5 196.58) than the integratedinterface (mean5 945.73, SD5 217.14), this differencewas not statistically significant. Also, there was no statisti-cally significant difference in the number of “best passage”feature used, “next keyword” used, the number of uniqueterms used, and the number of documents marked as rele-vant between the two systems.
In the common interface HERMES, subjects tried torepeat the same interaction when they moved to a differentdatabase. In the exit interview, many subjects commentedthat they repeated the same queries with different databases.There was a statistically significant difference in the use of“save query” and “load query” features between HERA andHERMES; “save query” and “load query” features wereused more frequently in HERMES than in HERA.
Although subjects tried to repeat the same queries acrossthe databases by either retyping the query or using “save
queries” and “load queries” functions, the common inter-face HERMES certainly requires more behavioral effort,interaction, and slightly longer time (time was not statisti-cally significant between two systems) from the user. Sub-jects went through significantly more full text documents inthe common interface, conducted more queries, requestedmore relevance feedback, saved more documents, and un-saved more documents. It is interesting to note that subjectsnever used the “load query” feature in the integrated inter-face, whereas they used that feature more than once onaverage in the common interface. This implies that subjectswere well aware of the characteristics of various systemfeatures as well as the difference between the systems, andtried to use the two different IR systems by utilizing systemfeatures differently for each system.
Conclusions and Future Research
This article addressed a crucial issue in the distributedinformation environment: how to support effective interac-tion of users with heterogeneous and distributed informationresources. Most studies in this problem area have focusedon technical issues and performance issues but not interac-tion issues. The hidden assumption behind such studies isthat combining multiple information resources will be pre-ferred by searchers; therefore, integrated access to multipleand distributed information resources is assumed to be anappropriate mode of interaction. This study tested this gen-eral assumption of IR literature, by comparing usability,user preference, effectiveness, and searching behaviors intwo different levels of interaction (the common interactionand the integrated interaction). The data for this study camefrom a variety of sources: transaction logs, thinking-aloudprotocols, postsearch questionnaires, demographic ques-tionnaires, exit questionnaires, and exit interviews.
What is of most interest is that there was a statisticallysignificant difference in the subjects’ preference for thecommon interaction (HERMES) over the integrated inter-action (HERA), mainly because they could have more con-trol over database selection. For most of the subjects in thisstudy, the greater control in HERMES outweighed the ad-vantages of HERA including such concerns as convenience,efficiency, and ease of use. Similarly, subjects were moresatisfied with the search results from HERMES.
In addition to usability, the effectiveness of the twosystems was compared. Consistent with other results, indi-viduals performed better with the common interfaceHERMES than the integrated interface HERA. This resultcontradicts the expectation of the database merging litera-ture where merged results in the integrated interface wouldbe as effective as (or more effective than) the search resultsin the common interface. Most research that has investi-gated the effectiveness of database merging or data fusiontechniques has been conducted on noninteractive tasks, such
466 JOURNAL OF THE AMERICAN SOCIETY FOR INFORMATION SCIENCE—March 15, 2000

as an ad hoc task or routing task.9 This study suggests thatthe findings from database merging and data fusion litera-ture might not hold for the interactive task.
Also, individuals’ searching behaviors were comparedbetween the integrated interface HERA and the commoninterface HERMES. There were statistically significant dif-ferences in searching behaviors between HERA andHERMES. Subjects engaged in significantly more interac-tions with HERMES than HERA: interactive system fea-tures like relevance feedback, full text, save query, and loadquery were used more frequently in HERMES than HERA.Features such as “load query” and “unsaved documents”were never used in the integrated interface (HERA). Thisimplies that the common interface (HERMES) may requiremore behavioral effort and interaction from the user, andsubjects tried to use the two different IR systems by utiliz-ing system features differently for each system. Most sub-jects did not find it difficult to make more behavioral effort,because for them, more control over HERMES outweighedthe convenience of HERA.
Overall, it appears that for this population, interactingwith different databases through a common interface ispreferable on all grounds to interacting with databasesthrough an integrated interface.
Although more subjects liked HERMES (common inter-face) better than HERA (integrated interface), many of themexplicitly expressed a desire for the combination of twosystems: the combination of control (HERMES) and effi-ciency (HERA). In other words, certain users prefer controlover database selection while still opting for results to bemerged. They would like to have control of database choice,but once they choose the right databases, they want thesearch results and interactions to be integrated. This sug-gests that for digital library purposes, it may be importantnot just to integrate the search results, but also to charac-terize different databases to support user choice for integra-tion, rather than relying on blind system integration. Espe-cially, it could be useful to characterize databases withrespect to the query, so that users could make reasonablechoices of databases, which could then be integrated forsearching.
The subjects in this study wanted more control not justfor database selection but for other system features as well.For example, many subjects commented that they wouldlike to have more control over relevance feedback. Insteadof automatic relevance feedback, they wanted to be able tochoose the relevant terms from a list of terms suggested bythe system. They also wanted to have negative relevancefeedback as well as positive relevance feedback. This resultis similar to findings from other studies (Belkin, Cool,
Koenemann, Ng, & Park, 1996; Koenemann & Belkin,1996). Koenemann’s study (1996) found that increased con-trol of relevance feedback led to more efficient interactionswhile maintaining or increasing effectiveness. These find-ings suggest that it is important to allow for more usercontrol in various ways in the distributed environment,whether it is a control over database selection or controlover relevance feedback.
There are some limitations of this study regarding thenature of the sample. First, due to some practical constraints(i.e., lengthy 3-hour search sessions, and dependence onvolunteers), nonrandom sampling was used. Second, theseresults came from a homogeneous group of subjects. Be-cause most of the subjects were highly educated and hadexperience as searchers, they could easily identify the char-acteristics of different databases and did not find it difficultto switch databases or to repeat the interaction. This couldhave led to the result that control over source selectionoutweighs the ease and convenience of the integrated inter-action. This finding might not be applied to a different userpopulation. For example, novice users who are not familiarwith new systems, and do not know the characteristics ofdifferent databases might prefer the integrated interaction tothe common interaction. This issue needs to be addressed byrandomly sampling different groups of users. Third, thesmall sample size is another limitation of this study. Asample size around 30 was chosen for this study because atthis point, data may begin to fit at-distribution. The samplesize was also a result of the time needed to conduct thesearches by volunteers. Additionally, the sample did allowfor meaningful breakouts of data when comparing prefer-ences of the two systems. But for more sophisticated anal-yses, and to increase the generality of these results, futureresearch with a larger and randomly selected sample isindicated. Finally, the relatively small number of databaseswith which the users could interact may have biased theresults. If users had to interact with (or select from) tens orhundreds of databases, their preferences might be quitedifferent.
Despite these limitations, the results of this study con-tribute to the field of digital libraries by demonstrating thatusers may indeed prefer to interact with databases sepa-rately, rather than in an integrated fashion, and by suggest-ing new system features for digital libraries that incorporatethis result.
Acknowledgments
This research was supported in part by DARPA ContractNumber MDA904-96-C1297, under the TIPSTER Phase 3Program. I would like to thank Professor Nick Belkin for hisguidance and support. Thanks go to Professor Daniel O.O’Connor for his insightful suggestions, challenging ideasand editorial help. Thanks to Margie Connell and ProfessorJamie Callan at University of Massachusetts for generouslyproviding the latest version of INQUERY and their techni-cal expertise. Thanks to Shin-jeng Lin for developing sys-
9 The ad hoc task investigates the performance of systems that searchan existing set of documents using new topics. The task is similar to howa researcher might use a library—the collection is known but the questionlikely to be asked are not known (Voorhees & Harman, 1997, p. 2). On theother hand, the routing task investigates the performance of systems thatsearch a new set of documents using old topics.
JOURNAL OF THE AMERICAN SOCIETY FOR INFORMATION SCIENCE—March 15, 2000 467

tems for this study. Thanks to Kwong Bor Ng for histechnical support. I appreciate anonymous referees’ com-ments and suggestions.
References
Belkin, N.J., Kantor, P., Fox, E.A., & Shaw, J.A. (1995). Combining theevidence of multiple query representations for information retrieval.Information Processing & Management, 31(3), 431–448.
Belkin, N.J., Cool, C., Koenemann, J., Ng, K., & Park, S. (1996). Usingrelevance feedback and ranking in interactive searching. In D. Harman.(Ed.), TREC-4, proceedings of the fourth text retrieval conference (pp.181–210). Washington, DC: Government Printing Office.
Belkin, N.J., Cabezas, A., Cool, C., Lin, S., Park, S., Rieh, S., Savage, P.,Sikora, C., Xie, H., & Allan, J. (1997). Rutgers’ TREC-5 interactivetrack experience. In D. Harman (Ed.), TREC-5 proceedings of the fifthtext retrieval conference (pp. 257–266). Washington, DC: GovernmentPrinting Office.
Callan, J.P., Croft, W.B., & Harding, S.M. (1992). The INQUERY re-trieval system. In DEXA 3: Proceedings of the third international con-ference on database and expert systems applications (pp. 83–87). Berlin:Springer Verlag.
Callan, J.P., Lu, Z., & Croft, W.B. (1995). Searching distributed collectionswith inference networks. In E.A. Fox, P. Ingwersen, & R. Fidel (Eds.),SIGIR ’95: Proceedings of the 18th annual international ACM SIGIRconference on research and development in information retrieval (pp.21–28). New York: ACM.
Fox, E.A., & Shaw, J.A. (1994). Combination of multiple searches. In D.Harman (Ed.), TREC-2, proceedings of the second text retrieval confer-ence (pp. 243–252). Washington, DC: Government Printing Office.
Hawking, D., Thistlewaite, P., & Bailey, B. (1997). ANU/ACSys TREC-5experiments. In D. Harman (Ed.), TREC-5, Proceedings of the fifth textretrieval conference (pp. 359–375). Washington, DC: GovernmentPrinting Office.
Koeneman, J. (1996). Relevance feedback: Usage, usability, utility. Un-published doctoral dissertation. New Brunswick, NJ, Rutgers University.
Koeneman, J., Belkin, N.J. (1996). A case for interaction: A study ofinteractive information retrieval behavior and effectiveness. Conferenceon Human Factors in Computing Systems (CHI) 96: Common ground(pp. 205–212). New York: ACM.
Lee, J. (1995). Combining multiple evidence from different properties ofweighting schemes. In E.A. Fox, P. Ingwersen, & R. Fidel (Eds.), SIGIR’95: Proceedings of the 18th annual international ACM SIGIR confer-ence on research and development in information retrieval (pp. 180–188). New York: ACM.
Lu, Z., Callan, J.P., & Croft, W.B. (1996). Applying inference networks tomultiple collection searching (Umass Technical Report TR96-42). Uni-versity of Massachusetts, MA: Center for Intelligent Information Re-trieval.
Ousterhout, J. (1994). Tcl and the TK toolkit. Reading, PA: Addison–Wesley.
Over, P. (1997). TREC-5 interactive track report. In D. Harman (Ed.),TREC-5, proceedings of the fifth text retrieval conference (pp. 29–56).Washington, DC: Government Printing Office.
Park, S. (1999). Supporting interaction with distributed and heterogeneousinformation resources. Unpublished doctoral dissertation. New Bruns-wick, NJ, Rutgers University.
Payette, S.D., & Rieger, O.Y. (1997). Z39.50: The user’s perspective.D-Lib Magazine, April 1997. Available: http://www.dlib.org/dlib/april97/cornell/04payette.html.
Savoy, J., Le Calve, A., & Vrajitoru, D. (1997). Report on the TREC-5experiment: Data fusion and collection fusion. In D. Harman (Ed.),TREC-5, proceedings of the fifth text retrieval conference (pp. 489–502). Washington, DC: Government Printing Office.
Schiettecatte, F. (1997). Document retrieval using the MPS informationserver (a report on the TREC-5 experiment. In D. Harman (Ed.),TREC-5, proceedings of the fifth text retrieval conference (pp. 391–404). Washington, DC: Government Printing Office.
Voorhees, E.M., Gupta, N.K., & Johnson–Laird, B. (1995). Learningcollection fusion strategies. In E.A. Fox, P. Ingwersen, & R. Fidel (Eds.),SIGIR ’95: Proceedings of the 18th annual international ACM SIGIRconference on research and development in information retrieval (pp.172–179). New York: ACM.
Voorhees, E.M. (1997). The TREC-5 database merging track. In D. Har-man (Ed.), TREC-5, proceedings of the fifth text retrieval conference(pp. 103–104). Washington, DC: Government Printing Office.
Voorhees, E.M., & Harman, D. (1997). Overview of the fifth text retrievalconference (TREC-5). In D. Harman (Ed.), TREC-5, proceedings of thefifth text retrieval conference (pp. 1–28). Washington, DC: GovernmentPrinting Office.
Welch, B. (1995). Practical programming in Tcl and Tk. Englewood Cliffs,NJ: Prentice Hall.
Xu, J., & Callan, J. (1998). Effective retrieval with distributed collections.In A. Moffat, & J. Zobel (Eds.), SIGIR 98: Proceedings of the 21thannual international ACM SIGIR conference on research and develop-ment in information retrieval (pp. 112–120). New York: ACM.
Appendix: Topic 274i, Electric Automobiles
Imagine that you are working for General Motors, andjust started a project on electric automobiles. You have beenasked to write a background paper that surveys differentdevelopments on electric automobiles. You have 20 minutesto find and save some articles that will be useful for thispurpose. Please save at least one document that identifiesEACH DIFFERENT recent developments in the field ofelectric automobiles. If one document discusses severaldevelopments, then you need not save other documents thatrepeat those developments, since your goal is to identify thedifferent ones that have been discussed.
468 JOURNAL OF THE AMERICAN SOCIETY FOR INFORMATION SCIENCE—March 15, 2000