unterstützung semantischer komposition in mashupscarad/files/radeck (2011) - unterstützung...
TRANSCRIPT

Unterstützung semantischerKomposition in Mashups
DiplomarbeitTechnische Universität Dresden
Februar 2011
vorgelegt von
Carsten Radeckgeboren am 2.7.1985 in Meißen
zur Erlangung des akademischen GradesDiplom-Medieninformatiker
Betreuer: Dipl.-Medieninf. Stefan PietschmannHochschullehrer: Prof. Dr.-Ing. Klaus Meißner
Fakultät InformatikInstitut für Software- und Multimediatechnik
Professur für Multimediatechnik

Semantische Komposition in Mashups
AufgabenstellungDiese Seite wird beim Druck durch die originale Aufgabenstellung ersetzt.
Copyright TU Dresden, Carsten Radeck II

Semantische Komposition in Mashups
ErklärungHiermit erkläre ich, Carsten Radeck, die vorliegende Diplomarbeit zum Thema
Unterstützung semantischer Komposition in Mashups
selbständig und ausschließlich unter Verwendung der im Quellenverzeichnis aufge-führten Literatur- und sonstigen Informationsquellen verfasst zu haben.
Dresden, 28. Februar 2011
Unterschrift
Copyright TU Dresden, Carsten Radeck III

Semantische Komposition in Mashups Inhaltsverzeichnis
Inhaltsverzeichnis
1 Einleitung 11.1 Motivation und Problemstellung . . . . . . . . . . . . . . . . . . . . . 11.2 Zielsetzung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21.3 Aufbau der Arbeit . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
2 Grundlagen und Anforderungsanalyse 42.1 Begriffsdefinitionen . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
2.1.1 Mashups als komposite Webanwendungen . . . . . . . . . . . 42.1.2 Semantic Web . . . . . . . . . . . . . . . . . . . . . . . . . . . 52.1.3 Semantic Web Services . . . . . . . . . . . . . . . . . . . . . . 7
2.2 CRUISe . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 82.2.1 Architektonischer Überblick . . . . . . . . . . . . . . . . . . . 82.2.2 Integration von Mashup-Komponenten . . . . . . . . . . . . . 92.2.3 Vorhandene Defizite . . . . . . . . . . . . . . . . . . . . . . . 14
2.3 Übertragung der Nutzung semantischer Dienstbeschreibungen in SWSauf CRUISe . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
2.4 Referenzszenario . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 202.5 Anforderungsanalyse . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
2.5.1 Anforderungen an die semantische Komponentenbeschreibung 232.5.2 Anforderungen an die Komponenten des Integrationsprozesses 242.5.3 Anforderungen an das Kompositionsmodell . . . . . . . . . . . 25
3 Stand der Forschung und Technik 263.1 Semantische Beschreibung von Web Services und Komponenten . . . 26
3.1.1 Überblick zu zugrundeliegenden formalen Sprachen . . . . . . 263.1.2 Top-Down Ansätze . . . . . . . . . . . . . . . . . . . . . . . . 273.1.3 Bottom-Up Ansätze . . . . . . . . . . . . . . . . . . . . . . . 333.1.4 Beschreibung von Komponenten im Bereich CBSE . . . . . . . 363.1.5 Fazit . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
3.2 Discovery . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 373.2.1 Alternativen für die Art der Anfrage . . . . . . . . . . . . . . 383.2.2 Discovery auf Basis von Beschreibungslogik . . . . . . . . . . . 393.2.3 Nicht-logikbasierte Discovery mit XML-Schema-Matching . . . 413.2.4 Hybride Beschreibungslogik-basierte Discovery . . . . . . . . . 423.2.5 Semantische Rangfolgebildung und Selektion . . . . . . . . . . 44
3.3 Mediation von Daten . . . . . . . . . . . . . . . . . . . . . . . . . . . 463.3.1 Mehrstufige Mediation mit ontologiebasierter Zwischenreprä-
sentation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 463.3.2 Mediation mit automatischer Generierung der Transformati-
onsvorschriften . . . . . . . . . . . . . . . . . . . . . . . . . . 48
Copyright TU Dresden, Carsten Radeck IV

Semantische Komposition in Mashups Inhaltsverzeichnis
3.4 Zusammenfassung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 49
4 Konzeption 514.1 Semantische Komponentenbeschreibung . . . . . . . . . . . . . . . . . 51
4.1.1 SMCDL . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 534.1.2 Komponenten als Ontologieinstanzen . . . . . . . . . . . . . . 614.1.3 Repräsentation von Komponenten und Vorlagen im Komposi-
tionsmodell . . . . . . . . . . . . . . . . . . . . . . . . . . . . 624.2 Architektonischer Überblick . . . . . . . . . . . . . . . . . . . . . . . 65
4.2.1 Vorbetrachtungen . . . . . . . . . . . . . . . . . . . . . . . . . 654.2.2 Konzipierte Architektur . . . . . . . . . . . . . . . . . . . . . 68
4.3 Integrationsprozess von Komponenten . . . . . . . . . . . . . . . . . . 704.3.1 Modellinterpretation . . . . . . . . . . . . . . . . . . . . . . . 714.3.2 Semantische Discovery . . . . . . . . . . . . . . . . . . . . . . 734.3.3 Ranking . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 794.3.4 Unterstützung von Mediation auf Datenebene . . . . . . . . . 81
4.4 Austausch von Komponenten . . . . . . . . . . . . . . . . . . . . . . 864.5 Zusammenfassung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 87
5 Implementation 895.1 Verwendete Technologien . . . . . . . . . . . . . . . . . . . . . . . . . 895.2 Erweiterung vorhandener Implementierungen . . . . . . . . . . . . . . 91
5.2.1 Testfälle und -system zur Performanzanalyse . . . . . . . . . . 915.2.2 Runtime . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 915.2.3 Component Repository samt Integration Service . . . . . . . . 965.2.4 Type Repository . . . . . . . . . . . . . . . . . . . . . . . . . 101
5.3 Beispielanwendung . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1025.4 Zusammenfassung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 104
6 Zusammenfassung und Ausblick 1056.1 Ergebnisse . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1056.2 Ausblick . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 107
A Anhang iA.1 Matching-Algorithmus . . . . . . . . . . . . . . . . . . . . . . . . . . iA.2 Ontologien der Beispielanwendung . . . . . . . . . . . . . . . . . . . . iiA.3 Schemata . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . ivA.4 Klassendiagramm . . . . . . . . . . . . . . . . . . . . . . . . . . . . . iv
Literaturverzeichnis vi
Copyright TU Dresden, Carsten Radeck V

Semantische Komposition in Mashups Abbildungsverzeichnis
Abbildungsverzeichnis
2.1 Kompositionsprozess in der CRUISe-Architektur . . . . . . . . . . . . 82.2 Architektonischer Überblick der CRUISe Runtime . . . . . . . . . . . 112.3 Struktur des Integration Service . . . . . . . . . . . . . . . . . . . . . 122.4 SWS Usage Process . . . . . . . . . . . . . . . . . . . . . . . . . . . . 152.5 Screenshot des Mashups zur Reiseplanung . . . . . . . . . . . . . . . 21
3.1 Hauptkonzepte von OWL-S (in Version 1.2) . . . . . . . . . . . . . . 283.2 Annotationen in WSMO-Lite (nach [KVF09a]) . . . . . . . . . . . . . 353.3 Vorschlag zum Matchmaking von [JRGL+05] . . . . . . . . . . . . . . 403.4 Aggregation der Einzelergebnisse in SAWSDL-MX . . . . . . . . . . . 443.5 Mediation inkompatibler XML-Daten in SAWSDL mit gemeinsamer
Ontologie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 47
4.1 Mengendarstellung der verschiedenen Varianten zur semantischen Kom-ponentenbeschreibung bzw. -repräsentation . . . . . . . . . . . . . . . 52
4.2 Oberste Ebene des XML-Schemas der SMCDL . . . . . . . . . . . . . 534.3 Überblick der semantischen Annotation der SMCDL . . . . . . . . . . 544.4 Aufbau von Transformationen in das vorgegebene Schema . . . . . . 554.5 Beispiel eines abhängigen Ereignisses . . . . . . . . . . . . . . . . . . 584.6 Klassenhierarchie der nicht-funktionalen Eigenschaften . . . . . . . . 604.7 Ausschnitt des aktualisierten Kompositionsmetamodells . . . . . . . . 634.8 Grundlegende Aufgaben . . . . . . . . . . . . . . . . . . . . . . . . . 654.9 Alternative Verteilungsstrategien . . . . . . . . . . . . . . . . . . . . 674.10 Übersicht der Architektur . . . . . . . . . . . . . . . . . . . . . . . . 694.11 Aktivitäten bei der Integration von Komponenten . . . . . . . . . . . 714.12 Schnittstelle für die Integration einer Komponente per Vorlage . . . . 724.13 Schematischer Aufbau eines Matching Results . . . . . . . . . . . . . 724.14 Schnittstelle für die Integration einer Komponente per ID . . . . . . . 734.15 Einfluss der Contravariance auf das Matching . . . . . . . . . . . . . 754.16 Bestimmung der Übereinstimmung der Properties für zwei Kandidaten 784.17 Matching von Operationen zwischen Vorlage und Kandidat . . . . . . 784.18 Grundlegende Aufgaben bei der Mediation von Daten . . . . . . . . . 824.19 Aufgaben des Wrappers und resultierende Beziehungen zur Laufzeit . 844.20 Beispielhafte Situation der Mediation zur Laufzeit . . . . . . . . . . . 85
5.1 Sequenzdiagramm des Ablaufs der Integration per Vorlage . . . . . . 925.2 Sequenzdiagramm des Ablaufs bei der Suche anhand einer Vorlage . . 975.3 Vergleich der durchschnittlichen Laufzeiten zweier Regeln . . . . . . . 1005.4 Beispiel einer SMCDL und der annotierten Ontologiekonzepte . . . . 1025.5 Screenshot der Beispielanwendung . . . . . . . . . . . . . . . . . . . . 103
Copyright TU Dresden, Carsten Radeck VI

Semantische Komposition in Mashups Abbildungsverzeichnis
A.1 Ontologie von Aufgaben in der Domäne der Beispielanwendung [Bli11] iiA.2 Ontologie von Ereignissen in der Domäne der Beispielanwendung (nach
[Bli11]) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . iiA.3 Ausschnitt der Ontologie zur Beschreibung der Domäne der Beispielan-
wendung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . iiiA.4 XML-Schema für Integration Requests . . . . . . . . . . . . . . . . . ivA.5 Klassendiagramm des erweiterten Component Repository . . . . . . . v
Copyright TU Dresden, Carsten Radeck VII

Semantische Komposition in Mashups Tabellenverzeichnis
Tabellenverzeichnis
2.1 Anfrage und verfügbare Komponenten des Szenarios . . . . . . . . . . 22
3.1 Pragmatische Annahmen für SAWSDL-MX [KK08] . . . . . . . . . . 43
4.1 Beispiel der Aggregation elementarer Matches von vier funktionalenModellreferenzen auf Ebene der gesamten Komponente . . . . . . . . 77
4.2 Beispiel der Berechnung des Gesamtergebnisses von Komponente 1 . . 79
Copyright TU Dresden, Carsten Radeck VIII

Semantische Komposition in Mashups Listingverzeichnis
Listingverzeichnis
3.1 Ausschnitt einer Beschreibung eines Web Service in OWL-S (Profile)(nach http://www.ai.sri.com/daml/services/owl-s/1.2/CongoProfile.owl) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29
3.2 Ausschnitt einer Beschreibung eines Web Service in WSML (nachhttp://www.wsmo.org/TR/d16/d16.1/v0.21/) . . . . . . . . . . . . . . 31
3.3 Ausschnitt einer Beschreibung eines Web Service SAWSDL (nach [FL07]) 343.4 YASA Erweiterung von SAWSDL (nach [CTO10]) . . . . . . . . . . . 343.5 Goal mit Angabe einer nicht-funktionalen Eigenschaft (nach [FKZ08,
S.200]) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 443.6 Definition einer nicht-funktionalen Eigenschaft in WSML (nach [FKZ08,
S.199f]) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 45
4.1 Import von Ontologien in SMCDL . . . . . . . . . . . . . . . . . . . . 544.2 Semantische Typisierung einer Property . . . . . . . . . . . . . . . . 554.3 Funktionale Annotation von Operationen und Ereignissen . . . . . . . 574.4 Beispielhafte Metadaten einer SMCDL-Instanz . . . . . . . . . . . . . 594.5 Angabe von kompatiblen CRUISe Runtimes im Binding . . . . . . . . 604.6 Beispiel einer Jena Rule zur dynamischen Berechnung des Preises . . 624.7 Grober Aufbau der Antwort mit einer Kandidatenliste in XML . . . . 72
5.1 Zu konvertierendes Instanzdokument . . . . . . . . . . . . . . . . . . 935.2 Lifting der Klasse EventLocation . . . . . . . . . . . . . . . . . . . . 945.3 SPARQL-Anfrage des Lowerings . . . . . . . . . . . . . . . . . . . . . 945.4 Ergebnis der SPARQL-Abfrage des Lowerings . . . . . . . . . . . . . 945.5 Ergebnis der Konvertierung . . . . . . . . . . . . . . . . . . . . . . . 955.6 Beispiel der Ein- und Ausgabe des BestAssignmentSolvers . . . . . . 985.7 Beispiel einer Occurance Rule mit Platzhalter . . . . . . . . . . . . . 995.8 Beispiel einer Occurance Rule ohne Platzhalter . . . . . . . . . . . . . 1005.9 Beispiel einer Normalize Rule . . . . . . . . . . . . . . . . . . . . . . 1005.10 Beispiel einer Mapping Rule . . . . . . . . . . . . . . . . . . . . . . . 1005.11 Java-Interface des Query Service . . . . . . . . . . . . . . . . . . . . . 101
Copyright TU Dresden, Carsten Radeck IX

Semantische Komposition in Mashups Abkürzungsverzeichnis
Abkürzungsverzeichnis
JSON JavaScript Object Notation
MCDL Mashup Component Description LanguageMOF Meta Object Facility
OCL Object Constraint LanguageOWL Web Ontology LanguageOWL-S Web Ontology Language for Web Services
QoS Quality of Service
RDF Resource Description Framework
SA-REST Semantic Annotations for RESTSAWSDL Semantic Annotations for WSDLSMCDL Semantic Mashup Component Description LanguageSPARQL SPARQL Protocol and RDF Query LanguageSWRL Semantic Web Rule LanguageSWS Semantik Web Services
UML Unified Modelling LanguageURI Uniform Resource IdentifierURL Unified Resource Locator
W3C World Wide Web ConsortiumWSDL Web Service Description LanguageWSML Web Service Modeling LanguageWSMO Web Service Modeling Ontology
XML Extensible Markup LanguageXSD XML Schema DefinitionXSLT XSL Transformation
Copyright TU Dresden, Carsten Radeck X

Semantische Komposition in Mashups Kapitel 1 Einleitung
1Einleitung
1.1 Motivation und ProblemstellungDas World Wide Web stellt zunehmend eine Plattform für Anbieter von unter-schiedlichsten Diensten dar. Web Services ermöglichen die dynamische und verteilteBerechnung im Web und stehen über implementierungsunabhängige Schnittstellenbereit. Aktuelle Standards zur Beschreibung vonWeb Services, insbesondere die WebService Description Language (WSDL) [CCMW01], sind überwiegend auf syntakti-sche Aspekte der Schnittstelle beschränkt [PLL06]. Aufgrund der Uneindeutigkeitder Syntax ist oftmals ein menschliches Eingreifen, z. B. bei der Auswahl passen-der Web Services, notwendig. Auftretende Probleme sind u. a. Diskrepanzen derStruktur, Typen, Granularität und dem Inhalt von Daten sowie in der erwartetenSequenz von Operationsaufrufen. Aber auch zwei Dienste mit gleicher syntaktischerBeschreibung können eine komplett verschiedene Funktionalität bereitstellen, wasfür eine Software als Dienstnutzer nicht erkennbar ist. Dies erschwert die automati-sierte Verwendung von Web Services. Um den an letztere geknüpften Erwartungen,wie verbesserte Wiederverwendbarkeit, Interoperabilität und Komponierbarkeit, ge-recht zu werden, ist daher zusätzlich die maschinell interpretierbare Beschreibungder Semantik, d. h. der Bedeutung, einer Schnittstelle nötig (vgl. [FKZ08]).Die Zusammenführung der Ideen und Technologien des »Semantischen Webs«
[BLHL01] und Web Services führt zu Semantic Web Services [MSZ01]. Diese sindseit einigen Jahren von hohem Interesse für die Forschung, da vielversprechen-de Vorteile und Anwendungsgebiete erwartet und bereits erzielt werden, wie beider dynamischen Suche, Komposition und dem Aufruf von Web Services [FKZ08,MSZ01, PLL06]. Das Ziel ist die Bereitstellung konzeptioneller Modelle und (for-maler) Sprachen zur semantischen Beschreibung von Web Services. Dadurch ver-spricht der Ansatz einen höheren Grad der Automatisierung [PLL06]. Mehrere Vor-schläge zur semantischen Beschreibung von Web Services wurden unterbreitet, z. B.OWL-S [MBM+07] und SAWSDL [FL07], und unterliegen teilweise bereits Stan-dardisierungsbemühungen seitens des W3C. Solche Modelle und Sprachen sind je-doch nur ein Schritt dahin Semantic Web Services zu realisieren, denn geeigneteKompositions-Infrastrukturen sind zu schaffen, welche die semantischen Informatio-nen tatsächlich verwenden. Auch hierfür wurden Forschungsansätze vorgestellt undbisherige Ergebnisse zeigen, dass die Automatisierung z. B. der Suche und Kompo-sition von Web Services anhand deren semantischen Beschreibungen möglich ist.
Copyright TU Dresden, Carsten Radeck 1

Semantische Komposition in Mashups Kapitel 1 Einleitung
Eine weitere aktuelle Entwicklung ist das Konzept sogenannter Mashups. Dabeihandelt es sich um ein Modell zur Konstruktion von Webanwendungen, die Datenund/oder Funktionalität existierender Dienste, v. a. Web Services, integrieren undkomponieren. Angesichts der Ähnlichkeit zur Komposition von Web Services ist dieUntersuchung der Übertragbarkeit der Erkenntnisse aus dem Bereich der SemanticWeb Services lohnenswert, um genannte Probleme zu umgehen und sich die Vorteilezu Nutze zu machen, z. B. durch Mediation bei der Integration syntaktisch ver-schiedener Daten. Benslimane et al. sehen in einer solchen Weiterentwicklung vonMashup-Ansätzen eine wesentliche Herausforderung für die Forschung [BDS08].Das Forschungsprojekt CRUISe stellt eine Referenzarchitektur für komponenten-
basierte Mashups bereit. Auf Basis eines universellen Komponentenmodells wird dieIdee der serviceorientierten Komposition einheitlich auf allen Ebenen des Mashups(Daten, Logik und Präsentation) unterstützt. Die dabei zum Einsatz kommendeBeschreibungssprache MCDL ist angelehnt an die WSDL und bietet Mittel zur De-finition der funktionalen Schnittstelle und Metadaten von Komponenten. CRUISeist bisher auf syntaktische Aspekte im Rahmen der Dienstauswahl und -kompositionbegrenzt, z. B. basiert die Suche auf einer Klassifikation der Komponenten, jedochnicht auf der Semantik der angebotenen Operationen. Der angesprochene Nutzen derAnreicherung mit Semantik wird somit derzeit nicht ausgeschöpft. Beispielsweise istes nicht möglich, zwei Komponenten mit gleicher Funktionalität, aber verschiedenenNamen von Operationen und Parametern auszutauschen. Deshalb ist die wesentlicheFragestellung, von welchen Aspekten der Verwendung semantischer Informationendie Architektur profitieren kann und welche Anpassungen dies impliziert.
1.2 ZielsetzungDas Ziel der vorliegenden Arbeit ist es, ein Konzept zur Verwendung semantischerKomponentenbeschreibungen in CRUISe zu entwickeln. Die an der Integration vonKomponenten beteiligten Infrastrukturkomponenten von CRUISe sind im Rahmendessen zu erweitern, um das bestehende Klassenkonzept abzulösen.Dazu ist es zunächst erforderlich, den aktuellen Stand der Forschung und Tech-
nik hinsichtlich semantischer Beschreibungssprachen und Komposition im Bereichkomponenten- und serviceorientierter Systeme zu analysieren und bezüglich aufzu-stellender bzw. abgeleiteter Anforderungen zu bewerten. Dabei sind die Erfordernisseund Gegebenheiten von CRUISe zu beachten. Zudem muss die Anwendung der se-mantischen Komponentenbeschreibung im Rahmen von CRUISe bei der Integrationund dem Austausch von Komponenten diskutiert werden. Weiterhin ist zu untersu-chen, ob vorhandene Beschreibungsmittel der MCDL den Anforderungen genügenoder ob eine Erweiterung um semantische Informationen, z. B. nach dem Vorbildexistierender Lösungen, angebracht ist. Dies schließt die Ableitung und Formalisie-rung semantischer Konzepte ein. Davon ausgehend soll das zu entwickelnde Konzeptdie Verwaltung der Komponentenbeschreibungen, die Selektion und Integration derKomponenten zur Laufzeit auf die Verwendung der semantischen Beschreibung um-stellen. Zum Beispiel soll eine Komponente gegen eine andere ausgetauscht werdenkönnen, deren Operationen und Ereignisse die gleiche Semantik ihrer Datentypenund Funktionalität aufweisen. Letztlich soll eine prototypische Implementierung dasKonzept validieren und somit dessen Umsetzbarkeit nachweisen.
Copyright TU Dresden, Carsten Radeck 2

Semantische Komposition in Mashups Kapitel 1 Einleitung
1.3 Aufbau der ArbeitDie vorliegende Arbeit gliedert sich wie folgt. Zu Beginn von Kapitel 2 bildet die Klä-rung von grundlegenden Begrifflichkeiten den Schwerpunkt. Weiterhin wird auf dieRahmenbedingungen und Probleme der CRUISe-Architektur eingegangen. Auf Basisumfassender Recherchen gewährt das Kapitel einen Überblick über die Anwendungs-gebiete semantischer Komponentenbeschreibungen im Umfeld von serviceorientierterSoftware. Die Diskussion der Übertragbarkeit dieser Erkenntnisse auf CRUISe de-finiert den Fokus der Arbeit und somit wesentliche zu lösende Herausforderungen.Zur Veranschaulichung dieser dient ein beispielhaftes Szenario. Darauf aufsetzenderfolgt die Ableitung von Anforderungen an das zu entwickelnde Konzept.Unter Betrachtung der Erkenntnisse aus Kapitel 2 ist der wesentliche Beitrag
von Kapitel 3 die kompakte Darstellung des Standes von Forschung und Technikfür wesentliche Herausforderungen und dessen Bewertung für die Verwendung inCRUISe. Dies betrifft die semantische Beschreibung, das Auffinden und die Bildungeiner Rangfolge von Komponenten und Web Services. Zusätzlich werden Ansätzezur Auflösung von Heterogenität auszutauschender Daten analysiert.Die Konzeption der semantischen Komponentenbeschreibung und deren Nutzung
bei der Integration und dem Austausch von Komponenten in CRUISe schließt sichin Kapitel 4 an. Dabei erfolgt die Auseinandersetzung mit den zuvor aufgestelltenAnforderungen und Herausforderungen und ein neues Konzept zur Suche, Rangfol-gebildung und Auflösung von Unterschieden der Datentypen und Schnittstellen wirdspezifiziert und architektonisch eingeordnet.Eine prototypische Umsetzung des entwickelten Konzepts ist das Thema von Ka-
pitel 5. Dabei werden verwendete Technologien beschrieben und schwerpunktmäßigDesignentscheidungen aufgezeigt und begründet. Weiterhin wird die Implementie-rung des eingangs definierten Szenarios zur Validierung des Konzepts behandelt.Den Abschluss der Arbeit bildet die Zusammenfassung und Bewertung der Er-
gebnisse sowie der Ausblick auf mögliche weiterführende Arbeiten in Kapitel 6.
Zusammenfassend können als Beiträge der Arbeit folgende Punkte genannt werden:
• Umfangreiche Untersuchung bestehender Lösungen für die semantische Be-schreibung, das Auffinden und Sortieren von Komponenten und Web Servicessowie die Überbrückung von Heterogenität auszutauschender Daten.
• Weiterentwicklung einer Beschreibungssprache zur semantischen Annotationvon Mashup-Komponenten und Erstellung der zugrundeliegenden Ontologien.
• Konzeption der Nutzung der semantischen Beschreibungssprache im Rahmender CRUISe-Architektur zur Suche, Rangfolgebildung und Mediation von Da-ten für die Integration und den Austausch von Mashup-Komponenten.
Copyright TU Dresden, Carsten Radeck 3

Semantische Komposition in Mashups Kapitel 2 Grundlagen und Anforderungsanalyse
2Grundlagen und
AnforderungsanalyseDas vorliegende Kapitel konzentriert sich auf die Feststellung der Anforderungenan eine Kompositionsinfrastruktur für komposite Webanwendungen basierend aufsemantischen Komponentenbeschreibungen. Als Einstieg folgt die Klärung funda-mentaler Begrifflichkeiten und der Vorstellung der mannigfaltigen Verwendungs-möglichkeiten der semantischen Dienstbeschreibung im Kontext von Web Services.Anschließend dient die Betrachtung des Forschungsprojekts CRUISe der Ableitungvon Rahmenbedingungen für das Konzept. Auf Grundlage dieser, der Diskussionder Nutzung semantischer Komponentenbeschreibungen in CRUISe und eines dar-auf aufsetzenden Szenarios folgt schließlich die Anforderungsanalyse.
2.1 BegriffsdefinitionenDiese Arbeit beinhaltet mehrere grundlegende Begriffe die einleitend erläutert wer-den, um ein gemeinsames Verständnis herzustellen.
2.1.1 Mashups als komposite WebanwendungenEine aus prinzipiell unabhängigen, wiederverwendbaren Einzelbestandteilen (Kom-ponenten) zusammengesetzte Anwendung zur Ausführung in einem Webbrowserwird im Rahmen dieser Arbeit als komposite Webanwendung bezeichnet. Kom-posite Webanwendungen integrieren und kombinieren vorhandene Daten, Anwen-dungslogik und gegebenenfalls Bestandteile der Benutzerschnittstelle, die von Diens-ten über plattform- und sprachunabhängige Schnittstellen bereitgestellt werden.Die Komponentenorientierung ist eine entscheidende Eigenschaft, wobei auf die
gängige Definition des Begriffs »Softwarekomponente« von Szyperski Bezug genom-men wird [Szy02]. Demnach sind Softwarekomponenten Einheiten zur Kompositionund verfügen über eine klar definierte Schnittstelle, welche nur explizite Abhän-gigkeiten bezüglich ihres Kontexts aufweist. Sie sind konfigurierbar und unabhängigvoneinander implementier- und austauschbar. Dabei unterliegt eine Softwarekompo-nente einem bestimmten Komponentenmodell, das u. a. deren Form (Schnittstelle,Inhalt), Kommunikationsart und Schnittstelle zur Laufzeitumgebung definiert, und
Copyright TU Dresden, Carsten Radeck 4

Semantische Komposition in Mashups Kapitel 2 Grundlagen und Anforderungsanalyse
einem Kompositionsmodell, welches Möglichkeiten zur Komposition von Komponen-ten spezifiziert.Ein neues und an Bedeutung gewinnendes Modell für die Konstruktion von Web-
anwendungen sind Mashups. Ein Mashup ist eine hybride, situative Webanwen-dung, die durch Integration und Kombination vorhandener Daten und Funktiona-litäten aus verschiedenen Quellen einen Mehrwert erbringt [Mer06, FBN08]. UnterVerwendung öffentlicher1 Schnittstellen werden heterogene Datenquellen, wie z. B.Feeds oder Web Services, abgefragt und client- oder serverseitig komponiert. Vonder Serviceorientierung abstammende Vorteile, wie ein im Vergleich zu herkömmli-chen Webanwendungen beschleunigter Entwicklungsprozess und erhöhte Wiederver-wendbarkeit, können somit erzielt werden (vgl. [LHSL07, Pie10]). Waren Mashupsursprünglich auf die Kombination von Anwendungslogik und Daten beschränkt, exis-tieren Forschungsansätze, welche das Prinzip zusätzlich auf die Präsentationsschichtübertragen (UI Integration [DYB+07]). Zudem wurden zur strukturierten, kompo-nentenbasierten Entwicklung Komponenten- und Kompositionsmodelle für Mashupsvorgeschlagen, u. a. [LHSL07, AGM08], sodass diese den kompositen Webanwen-dungen zugeordnet werden können. Sogenannte »universelle« Komponentenmodelle[DCBS09, Pie10] wenden das Komponentenkonzept konsistent auf Daten-, Logik-und Präsentationsebene des Mashups an. In diese Kategorie lässt sich das Kompo-nentenmodell von CRUISe einordnen, welches in Kapitel 2.2.1 vertieft wird.
2.1.2 Semantic Web
Das Web war in seiner ursprünglichen Form auf Kommunikation zwischen Men-schen (Austausch von statischen Informationen) ausgelegt und Inhalte wurden reinsyntaktisch beschrieben. Daraus resultierende Limitierungen betreffen u. a. das au-tomatische Suchen, Extrahieren und Kombinieren von Daten. Im Jahre 2001 prägteBerners-Lee die Vision des Semantic Webs [BLHL01], eine Erweiterung des bestehen-den, in dem Informationen eine klar definierte Bedeutung zugeordnet wird, sodasssie auch für Computer verständlich sind. Um dies zu erreichen und die (idealerweiseohne menschliches Einwirken ablaufende) Kommunikation von Computern im Webzu ermöglichen, ist Semantik der Schlüssel [FKZ08]. Unter Semantik wird im Rah-men dieser Arbeit in Anlehnung an [AFM+05] die Bedeutung von Informationenverstanden2. Im Kontext von Web Services wurden insbesondere folgende Arten vonSemantik als notwendig identifiziert (siehe z. B. [VS07, KVF09a]):
• Data semantics/ Information model: Formale Beschreibung der Daten, die mitdem Web Service ausgetauscht werden.• Functional semantics: Formale Beschreibung der angebotenen Funktionalität
des Web Service.
1Bei den im Unternehmensbereich angesiedelten »Enterprise Mashups« sind die Schnittstellenmeistens nur in einem begrenzten Netzwerk verfügbar.
2Nach Fensel et al. ist Semantik im Kontext von SWS als eine Erweiterung der Definition imBereich Linguistik (Bedeutung linguistischer Ausdrücke) und dem vorherigen Verständnis derInformatik (formale Semantik von Programmiersprachen) anzusehen. Daher wird Semantikähnlich definiert: als maschinen-nutzbarer Inhalt. [FKZ08, S.10]
Copyright TU Dresden, Carsten Radeck 5

Semantische Komposition in Mashups Kapitel 2 Grundlagen und Anforderungsanalyse
• Non-Functional semantics: Formale Beschreibung von Service Level Agree-ments, Quality of Service (QoS) und anderen nicht-funktionalen Eigenschaftendes Web Service.• Execution/Behavioral semantics: Formales Modell des Verhaltens eines Web
Service beim Aufruf. Kopecký et al. [KVF09a] unterscheiden internes (Wie istder Web Service aus anderen komponiert?) und externes Verhalten (Wie musser aufgerufen werden, um die Funktionalität zu liefern?).
Grundlegende Technologien des Semantischen Webs zur Anreicherung von Infor-mationen mit Semantik umfasst der Semantic Web Stack des W3C3. Er veranschau-licht die geschichtete Anordnung standardisierter Sprachen. Die bereits spezifiziertenSchichten werden anhand folgender Auflistung kurz umrissen.
Uniform Resource Identifier (URI) [BLFM05] Dieser Standard beschreibt die Syn-tax von Zeichenketten zur eindeutigen Identifizierung von Ressourcen im Web.
Extensible Markup Language (XML) [BPSM+08] ist eine Auszeichnungssprachefür hierarchische Daten und definiert somit die grundlegende, maschinell ver-arbeitbare Syntax. Darauf aufsetzend bietet XML-Schema [FW04] die Mög-lichkeit Schemata für anwendungsspezifische XML-Sprachen zu beschreiben,welche die Struktur und den Inhalt einschränken.
Resource Description Framework (RDF) [KC04] dient der formalen Beschreibungvon Ressourcen, die durch eine URI identifizierbar sind, und deren Beziehun-gen untereinander. Es basiert auf Tripeln, Aussagen aus Subjekt, Prädikat undObjekt, die in ihrer Gesamtheit den RDF-Graphen bilden. Zur Serialisierungvon RDF-Graphen für deren Austausch existieren mehrere Optionen, wobei imWeb oftmals XML zum Einsatz kommt. Für die durch RDF gegebene Syntaxmuss zur Interpretation ein gemeinsames Vokabular definiert werden, wofürRDF-Schema [BG04] vom World Wide Web Consortium (W3C) empfohlenwird. RDF-Schema bietet einfache Konstrukte zur Definition von Klassen, de-ren Eigenschaften, den Werte- und Definitionsbereich von Eigenschaften sowieVererbungsrelationen an.
Mit RDF-Schema können somit einfache Ontologien definiert werden. Im Kon-text der Informatik gibt es eine Vielzahl von Definitionen dieses Begriffs. Die wohlmeistzitierte stammt von Gruber, hier in aktualisierter Version:
»In the context of computer and information sciences, an ontology defi-nes a set of representational primitives with which to model a domain ofknowledge or discourse.«[Gru07]
Zu den grundlegenden Bestandteilen einer Ontologie, die typische Ausprägungen der»representational primitives« sind, zählen Begriffe (Klassen, Konzepte), deren Attri-bute und Relationen, also ein Begriffssystem zur Strukturierung und dem Austauschvon Informationen. Daneben gehören Integritätsregeln zur Konsistenzsicherung undInferenzregeln, die eine Schlussfolgerung von neuem aus vorhandenem Wissen er-lauben, hinzu. Weitere Komponenten sind Axiome, d. h. wahre Aussagen innerhalbder Ontologie, die nicht geschlussfolgert werden können, und Instanzen. Ontologie-basierte Modelle besitzen einen hohen Formalisierungsgrad, erlauben die Definition
3http://www.w3.org/2007/03/layerCake.png
Copyright TU Dresden, Carsten Radeck 6

Semantische Komposition in Mashups Kapitel 2 Grundlagen und Anforderungsanalyse
gemeinsamen Wissens und die explizite Repräsentation von Semantik. Somit sindOntologien ein wesentlicher Bestandteil des Semantic Webs.
Web Ontology Language (OWL) [MvH04] ist eine standardisierte Sprachfamiliezur Spezifikation von Ontologien, deren einzelne Vertreter sich durch ihre Aus-drucksmächtigkeit voneinander abgrenzen. OWL DL (für Description Logic)ist zu einer entscheidbaren Untermenge der Prädikatenlogik erster Stufe äqui-valent und bietet mit einer Vielzahl von Konstrukten eine hohe Ausdrucks-mächtigkeit. Es reichert RDF(-Schema) u. a. um mengentheoretische Kon-strukte zur Klassenbildung, Kardinalitäten für Eigenschaften, die Angabe vontransitiven und inversen Eigenschaften, sowie der Gleichheit von Instanzen an.
SPARQL Protocol and RDF Query Language (SPARQL) [PS08] ist eine vomW3C empfohlene Anfragesprache für RDF-Graphen und orientiert sich dabeian der zugrundeliegenden Tripelsyntax. In einer Anfrage wird ein Graphmus-ter definiert, welches gegen die Datenbasis abgeglichen wird. Dabei könnenVariablen (vorangestelltes ?) an allen Positionen eines Tripels vorkommen. Da-neben existieren zahlreiche Operatoren und Konstrukte u. a. zur Sortierung,Filterung, dem Ausdrücken von Optionen und der Vereinigung von Alterna-tiven. Zur Serialisierung des Resultat einer Anfrage spezifiziert das W3C dasSPARQL Query Results XML Format [BB08].
Unter Zuhilfenahme genannter Technologien können vorhandene und neue stati-sche Informationen im Web semantisch annotiert, miteinander verknüpft und somitbeispielsweise von intelligenten Suchmaschinen erfasst und zur Beantwortung vonAnfragen verwendet werden.
2.1.3 Semantic Web ServicesDynamische Inhalte werden zunehmend durch Web Services bereitgestellt, die stan-dardmäßig mittels der WSDL [CCMW01] beschrieben werden. Dabei stehen syntak-tische Schnittstelleninformationen im Mittelpunkt, z. B. die Definition der genutztenDatentypen in XML-Schema, Nachrichten, Operationen und der Bindung an konkre-te Transportprotokolle. Somit ist die Schnittstelle zwar maschinenlesbar, aber ihreBedeutung nicht maschinell interpretierbar. Beispielsweise erwartet die OperationgetTemperature eines fiktivenWeb Service u. a. einen Parameter vom Typ int. Dasses sich dabei um eine Postleitzahl handelt, ist für einen Computer nicht ableitbar.Auch Beziehungen zwischen Operationen und damit mögliche sinnvolle Abfolgen de-rer können nicht erkannt werden, z. B. wenn getPostalCode die Postleitzahl für denNamen einer gegebenen Stadt liefert. Daher ist bei der Suche und der Kompositionvon in WSDL beschriebenen Web Services der Entwickler gefordert. Ähnliches giltfür die zahlreichen REST-basierten Web Services, deren Beschreibungen in WADL[Had09] oder in HTML eingebettet vorliegen.
Semantic Web Services (SWS) reichern diese Informationen mit ihrer Bedeu-tung an, wobei auf die bekannten Technologien des Semantic Webs zugegriffen wird.Durch die explizite und formale Semantik, die – geeignete Werkzeuge und Laufzeit-umgebungen vorausgesetzt – zur Entwurfs- und Laufzeit interpretiert und genutztwerden kann, sind zahlreiche Vorteile erreichbar. Ziel ist es, die semantischen Infor-mationen in wichtigen Teilaufgaben im Zusammenhang mit Web Services (bis hin
Copyright TU Dresden, Carsten Radeck 7

Semantische Komposition in Mashups Kapitel 2 Grundlagen und Anforderungsanalyse
zum gesamten Lebenszyklus) zu nutzen, um die automatisierte dynamische Verwen-dung derer zu verbessern [AFM+05, MBM+07, FKZ08, MSZ01, PLL06]. Initiativenim Bereich SWS untergliedern sich in die Definition konzeptioneller Modelle, z. B.Web Ontology Language for Web Services (OWL-S) [MBM+07], und die daraufaufsetzende Entwicklung und Spezifikation von Werkzeugen und Ausführungsumge-bungen. Nähere Informationen enthält Kapitel 3.1 der vorliegenden Arbeit.
2.2 CRUISeDie vorliegende Arbeit ist im Umfeld des Forschungsprojekts CRUISe (Compositionof Rich User Interface Services) angesiedelt, weshalb dieses nachfolgend genauer vor-gestellt wird. Zudem ergeben sich daraus Anforderungen und Rahmenbedingungenfür das zu erstellende Konzept. Weiterhin wird die Gesamtarchitektur von CRUISe[Pie10] überblicksartig vorgestellt. Anschließend werden einzelne Bestandteile desIntegrationsprozesses genauer betrachtet und schließlich dessen derzeitige Problemeaufgezeigt.
2.2.1 Architektonischer ÜberblickCRUISe definiert einen modellgetriebenen Entwicklungsprozess und eine Laufzeit-umgebung zur Konstruktion von kontextsensitiven kompositen Webanwendungen.In seiner Gesamtheit umfasst dieser drei wesentliche, aufeinanderfolgende Schritte,welche nachfolgend geschildert werden (vgl. Abbildung 2.1): (1) Anwendungsgene-rierung, (2) Integration und (3) die Bindung der Mashup-Komponenten.
Authoring Tool
Application Server
Integration Task
Context Service
UIS Registry
Contextualization Discovery
Application Generation
Ranking
UIS Binding User Interface Service Integration
Integration ServiceUI Logic and Resources
User Interface Service
RankingStrategy
?
?
? ?
Mashup Skeleton
Component Description
Integration Request
Component Request
UI Component
CRUISe Runtime
Application Request
Composite Mashup Application
Composition Model
M2C
Application Skeleton
Modeling Generation /Interpretation InitIntegration
Abbildung 2.1: Kompositionsprozess in der CRUISe-Architektur
Zur Entwurfszeit wird die Anwendung initial mit den vom Metamodell angebote-nen Konzepten werkzeuggestützt modelliert (1). Das plattformunabhängige Kom-positionsmodell [PTR+10] bietet Mittel zur Modellierung sämtlicher Anwendungs-aspekte. Anwendungsweite Konzepte beschreibt das Conceptual Model. Dazu ge-hören (komplexe) Datentypen und die Komponenten des Mashups. Letztere wur-den von Komponentenentwicklern implementiert und in MCDL beschrieben und
Copyright TU Dresden, Carsten Radeck 8

Semantische Komposition in Mashups Kapitel 2 Grundlagen und Anforderungsanalyse
werden anhand ihrer MCDL in das Modell eingefügt. Das Komponentenmodellspezifiziert drei abstrakte Charakteristika von Mashup-Komponenten: Ereignisse,Properties und Operationen. Properties entsprechen dem Zustand der Komponenteund werden als Menge von Schlüssel-Wert-Paaren repräsentiert. Jede Komponentekann Ereignisse auslösen und somit Zustandsänderungen publizieren. Ein Ereignisist durch einen Namen und eine Menge typisierter Parameter gekennzeichnet. Ope-rationen sind die parametrisierten Methoden der Komponente und werden durchdas Auftreten von Ereignissen ausgelöst. Es findet eine Unterteilung in UI- undNicht-UI-Komponenten statt. Zu letzteren gehören Logikkomponenten, die für Da-tentransformation angedacht sind, und Servicekomponenten, deren Aufgabe der Zu-griff auf entfernte Ressourcen darstellt. Anschließend erfolgt ein schrittweiser Trans-formationsprozess, der sowohl statisch als auch dynamisch, d. h. bei Eingang einerAnfrage, angestoßen werden kann und mit dem eigentlichen Mashup bzw. dem soge-nannten UI-Skeleton endet. Zur Laufzeit wird das Skeleton, welches Platzhalter fürdie zu integrierenden Mashup-Komponenten enthält, an den Client gesendet. DiesePlatzhalter oder alternativ direkt das Kompositionsmodell werden von der Laufzeit-umgebung interpretiert, um die Beschreibung einer passenden Mashup-Komponentevom Integration Service zu beziehen (2). Darin enthaltene Informationen verarbei-tet die Laufzeitumgebung und initiiert den Lebenszyklus und die ereignisbasierteVerdrahtung der erhaltenen Komponenten (3).Der modellgetriebene Ansatz von CRUISe erlaubt die statische, manuelle Kom-
position von Mashup-Komponenten. Aufgrund des Komponentenmodells und derdienstbasierten Bereitstellung der Komponenten ist die Vergleichbarkeit zur WebService-Komposition begründet. Zusätzlich beinhaltet das Kompositionsmodell vonCRUISe ebenfalls das Konzept von komponierten Komponenten, die ihre Funktio-nalität durch eine eigene Subkomposition erbringen.
2.2.2 Integration von Mashup-KomponentenIn diesem Kapitel werden die an der Integration und Komposition beteiligten Archi-tekturbestandteile von CRUISe genauer betrachtet und analysiert, um Ansatzpunk-te für die Verwendung einer semantischen Beschreibung von Mashup-Komponentenzu identifizieren.
2.2.2.1 MCDL
Als notwendige Grundlage des Integrationsprozesses von Mashup-Komponenten ineine komposite Webanwendung im Rahmen von CRUISe ist an dieser Stelle zunächstdie derzeitige Komponentenbeschreibung vorzustellen. Die Mashup Component De-scription Language (MCDL) deckt alle Konzepte des bereits besprochenen Kompo-nentenmodells ab und wird zur Publikation, Suche und Realisierung des Lebenszy-klus einer Komponente durch die Laufzeitumgebung benötigt. Sie entspricht, bis aufsyntaktische Abweichungen, dem Teil des Kompositionsmodells, der die Komponen-ten und ihre Datentypen beschreibt. Der MCDL liegt eine XML-Schema-Definitionzugrunde und sie untergliedert sich dem Klassenkonzept entsprechend in zwei Teile.Die MCDL-C definiert Komponentenklassen. Eine solche ist u. a. durch die At-
tribute id zur eindeutigen Identifizierung, name als menschenlesbaren Namen und
Copyright TU Dresden, Carsten Radeck 9

Semantische Komposition in Mashups Kapitel 2 Grundlagen und Anforderungsanalyse
isPresentation für die Unterscheidung von UI- und Nicht-UI-Komponenten cha-rakterisiert. Hinzu kommt superclasses, welches Mehrfachvererbung in der Klas-sifikation zulässt. Wesentliche Elemente einer Klasse sind Metadaten, eine einfacheListe von assoziierten Schlüsselworten, die Definition der Schnittstelle konform zumKomponentenmodell und ein XML-Schema zwecks Definition der von der Schnitt-stelle verwendeten Datentypen. Sowohl Schnittstelle als auch alle darin beschrie-benen Properties, Operationen und Ereignisse können außerdem mit dem AttributmodelReference, einer Liste von URIs, versehen werden. Diese Notation ist von Se-mantic Annotations for WSDL (SAWSDL) (siehe Kapitel 3.1.3) übernommen unddient der Referenzierung semantischer Konzepte in einem externen Modell.Die Bindung einer konkreten Implementation an mindestens eine Klasse wird
in der MCDL-B vorgenommen. Das Instanzdokument einer Komponente, künftigkurz Binding, umfasst zunächst die IDs aller implementierten Klassen und optionaldie Deklaration zusätzlicher Metainformationen, wie den Preis, unterstützte Spra-chen und die Eignung der Komponente für verschiedene Endgeräte. Das wesentlicheElement ist das sogenannte Interface Binding: Es beschreibt, wie die aus den Klas-sen resultierende Schnittstelle aus Operationen, Ereignissen und Properties auf diekonkrete Implementation in einer bestimmten Programmiersprache abgebildet wird.Dazu sind die Abhängigkeiten zu externen Ressourcen, z. B. Quellcodes und Style-sheets, und der Konstruktor anzugeben. Auf Basis der Informationen im Bindingmuss eine Laufzeitumgebung also in der Lage sein, den kompletten Lebenszyklusder Komponente zu verwirklichen.Zusammenfassend ist festzustellen, dass die MCDL Mittel zur syntaktischen Be-
schreibung der funktionalen und einiger nicht-funktionaler Eigenschaften sowie dieGrundlage für die semantische Annotation der funktionalen Schnittstelle einer Mash-up-Komponente bereitstellt.
2.2.2.2 Laufzeitumgebung
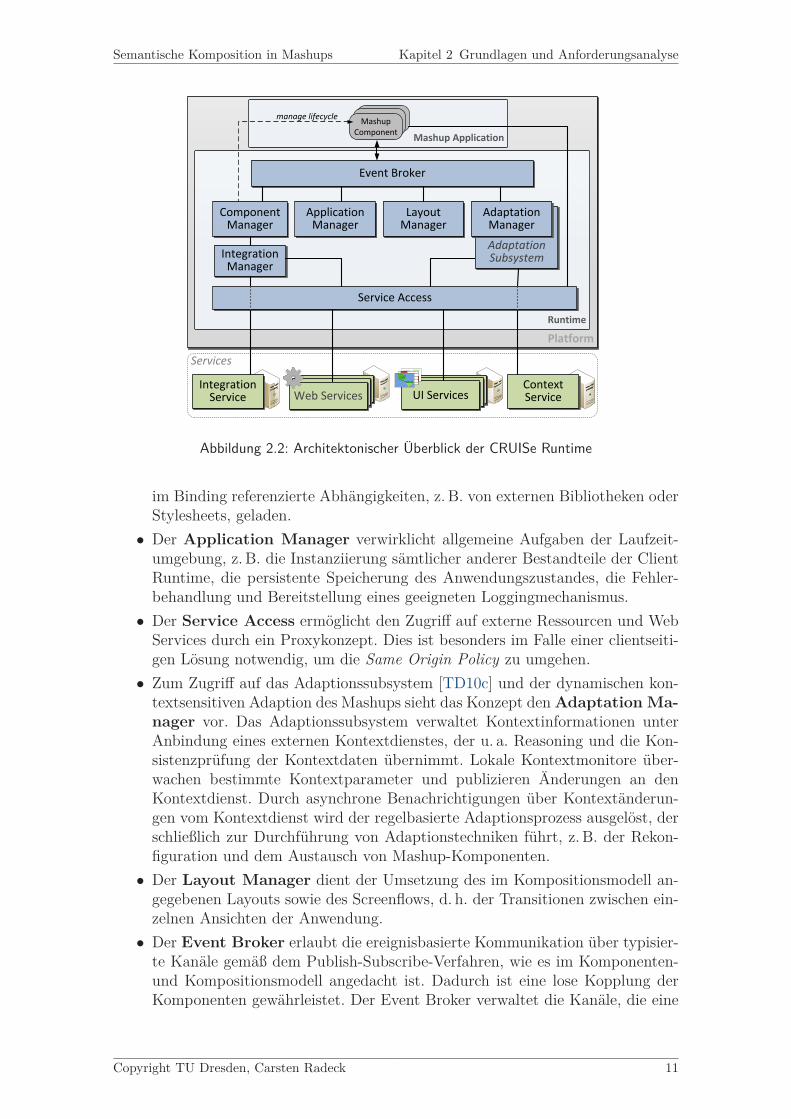
In diesem Kapitel wird die in [TD10b] spezifizierte CRUISe Runtime vorgestellt, dadiese eine zentrale Rolle im Integrationsprozess von CRUISe einnimmt und somit fürdie Konzeption relevant ist. Eine Laufzeitumgebung ist prinzipiell unabhängig vonVerteilungsaspekten ihrer Komponenten, wobei sowohl rein clientseitige [PWM10]als auch zwischen Client und Server verteilte Varianten konzipiert und umgesetztwurden. Die folgende Übersicht illustriert die plattformunabhängigen Komponenteneiner CRUISe Runtime (siehe Abbildung 2.2).
• Der Component Manager verkörpert die zentrale Instanz zur uniformenVerwaltung von Mashup-Komponenten. Zu seinen Aufgaben gehört die Anfor-derung der Komponenten unter Zuhilfenahme des Integration Managers unddie Realisierung des kompletten Lebenszyklus von Komponenten beginnendbei der Integration, über die Instanziierung, Initialisierung, Ausführung bishin zur Destruktion.• Integration Manager: Hierbei handelt es sich um das Bindeglied zwischen
der Runtime und dem Integration Service. In dieser Position nimmt er An-forderungen des Component Managers, d. h. die ID einer Klasse oder eineskonkreten Bindings, entgegen und leitet diese an den Integration Service wei-ter, um ein oder mehrere geordnete Bindings zu erhalten. Nachfolgend werden
Copyright TU Dresden, Carsten Radeck 10
Semantische Komposition in Mashups Kapitel 2 Grundlagen und Anforderungsanalyse
Platform
Mashup Application
Runtime
ComponentManager
Integration Manager
ApplicationManager
Event Broker
Service Access
Web ServicesWeb ServicesWeb Services UI ServicesUI ServicesUI Services
Services
Layout Manager
AdaptationSubsystem
AdaptationManager
Context ComponentContext
ComponentMashup
Component
IntegrationService
ContextService
manage lifecycle
Abbildung 2.2: Architektonischer Überblick der CRUISe Runtime
im Binding referenzierte Abhängigkeiten, z. B. von externen Bibliotheken oderStylesheets, geladen.• Der Application Manager verwirklicht allgemeine Aufgaben der Laufzeit-
umgebung, z. B. die Instanziierung sämtlicher anderer Bestandteile der ClientRuntime, die persistente Speicherung des Anwendungszustandes, die Fehler-behandlung und Bereitstellung eines geeigneten Loggingmechanismus.• Der Service Access ermöglicht den Zugriff auf externe Ressourcen und Web
Services durch ein Proxykonzept. Dies ist besonders im Falle einer clientseiti-gen Lösung notwendig, um die Same Origin Policy zu umgehen.• Zum Zugriff auf das Adaptionssubsystem [TD10c] und der dynamischen kon-
textsensitiven Adaption des Mashups sieht das Konzept den Adaptation Ma-nager vor. Das Adaptionssubsystem verwaltet Kontextinformationen unterAnbindung eines externen Kontextdienstes, der u. a. Reasoning und die Kon-sistenzprüfung der Kontextdaten übernimmt. Lokale Kontextmonitore über-wachen bestimmte Kontextparameter und publizieren Änderungen an denKontextdienst. Durch asynchrone Benachrichtigungen über Kontextänderun-gen vom Kontextdienst wird der regelbasierte Adaptionsprozess ausgelöst, derschließlich zur Durchführung von Adaptionstechniken führt, z. B. der Rekon-figuration und dem Austausch von Mashup-Komponenten.• Der Layout Manager dient der Umsetzung des im Kompositionsmodell an-
gegebenen Layouts sowie des Screenflows, d. h. der Transitionen zwischen ein-zelnen Ansichten der Anwendung.• Der Event Broker erlaubt die ereignisbasierte Kommunikation über typisier-
te Kanäle gemäß dem Publish-Subscribe-Verfahren, wie es im Komponenten-und Kompositionsmodell angedacht ist. Dadurch ist eine lose Kopplung derKomponenten gewährleistet. Der Event Broker verwaltet die Kanäle, die eine
Copyright TU Dresden, Carsten Radeck 11

Semantische Komposition in Mashups Kapitel 2 Grundlagen und Anforderungsanalyse
m:n-Kommunikation zwischen Mashup-Komponenten erlauben. Dabei werdenausgelöste Ereignisse des Publishers mit Operationen des Subscribers verbun-den. Neben den anwendungsspezifischen Kanälen und Ereignissen existierenvon der CRUISe Runtime vordefinierte, z. B. um die erfolgreiche Initialisie-rung der Anwendung oder Fehlerfälle zu signalisieren.
Die Laufzeitumgebung realisiert schließlich die auf Modellebene zur Entwurfszeiterstellte Komposition von Mashup-Komponenten. Dabei wird die Komponenten-beschreibung ausgewertet und Mechanismen zur Fehlerbehandlung und Adaptionbereitgestellt. Im Zuge dessen kann eine zumindest partielle Änderung der Kompo-sition stattfinden, indem Komponenten ausgetauscht oder entfernt werden.
2.2.2.3 Integration Service
Die zentrale, intern modular aufgebaute Komponente der Architektur dient der Aus-wahl und Integration von Mashup-Komponenten in komposite Webanwendungen.Der Integration Service bietet der Laufzeitumgebung eine definierte Dienstschnitt-stelle an. Eingehende Anfragen an diese enthalten die ID eines konkreten Bindingsoder einer Klasse sowie Kontextinformationen und werden vom Integration Managerentgegengenommen. Dieser löst die Abarbeitung einer Integration Task, die den wei-teren Daten- und Kontrollfluss verwaltet, aus. An der Abarbeitung einer IntegrationTask sind folgende Module beteiligt (vgl. Abbildung 2.3):
Integration Service
Discovery Module
Ranking Module
Context Module Plattformadapter
Inte
grat
ion
M
anag
er
Integration Task
Context ServiceComponent Repository
Integration-
request
Ru
nti
me
Binding
Abbildung 2.3: Struktur des Integration Service
• Das Discovery Module trägt die Verantwortlichkeit, für eine gegebene Schnitt-stellenbeschreibung konkrete Implementierungen (Bindings) aufzufinden. Da-zu findet eine Anbindung an das Component Repository (siehe Kapitel 2.2.2.4),welches die Beschreibung aller verfügbaren Komponenten und Klassen beinhal-tet, statt. Wurde eine Komponentenklasse angefordert, resultiert die Anfragean das Repository in einer (unbewerteten) Ergebnismenge von Bindings. ImFalle, dass ein konkretes und bekanntes Binding angefordert wird, liefert dasRepository dieses und die nachfolgenden Schritte sind nicht notwendig.• Zur Bildung einer Rangfolge aller Kandidaten hinsichtlich der Übereinstim-
mung mit den Anforderungen und Kontextinformationen dient anschließenddas Ranking Module. Auf Basis einer Strategie, die z. B. kontextsensitiv ge-wählt wird, erfolgt das Ranking. Eine solche Strategie umfasst eine Menge vonRegeln, die auf alle Kandidaten angewendet werden und jeweils ein Ergebnisi ∈ [0, 1] liefern. Optional kann jede Regel über eine vor ihrer Anwendung
Copyright TU Dresden, Carsten Radeck 12

Semantische Komposition in Mashups Kapitel 2 Grundlagen und Anforderungsanalyse
zu prüfende kontextspezifische Bedingung verfügen. Die Beziehung der Regelnuntereinander zur Berechnung des Gesamtergebnisses ist ebenfalls spezifischfür die Strategie. Ein Beispiel einer Regel ist eine OccuranceRule: Sie drückteine binäre Entscheidung über die Erfüllung einer Bedingung aus, z. B. ob dieKomponente eine bestimmte Sprache unterstützt oder ihr Preis unter einemHöchstwert liegt.• Das Context Module stellt Mittel zur Kommunikation mit einem externen
Kontextdienst bereit, um Kontextinformationen abzufragen. Dies ist u. a. fürdas Ranking Module notwendig, damit referenzierte Kontextparameter in Re-geln aufgelöst werden können.• Falls kein Binding für die angeforderte Plattform existiert, versucht der Platt-
formadapter ein passendes Binding aus vorhandenen zu erzeugen, indemtemplate-basiert ein plattformspezifischer Wrapper generiert wird.
Der Integration Service bietet die zur Integration der dienstbasiert bereitgestell-ten Mashup-Komponenten notwendige Funktionalität an. Die Suche und Rangfol-gebildung sind auf das Klassenkonzept zugeschnitten und sehen derzeit nicht dieVerwendung semantischer Komponentenbeschreibungen vor.
2.2.2.4 Repository
Im Rahmen von CRUISe obliegt dem Component Repository [TD10a] die Verwaltungvon Komponenten- und Klassenbeschreibungen. Es bietet dem Dienstanbieter typi-sche Verwaltungsaktivitäten an, d. h. im Wesentlichen die Möglichkeit zum Hinzu-fügen, Entfernen und Aktualisieren von Komponenten- und Klassenbeschreibungen.Dem Dienstnutzer erlaubt das Component Repository die Suche nach Bindings undwird diesbezüglich zur Laufzeit vom Integration Service und zur Entwicklungszeit(Modellierung der kompositen Webanwendung) vom Autorenwerkzeug kontaktiert.Bei der Suche sind Bindings sowohl direkt als auch per Angabe der gewünschtenKlasse abrufbar. Weiterhin existieren verschiedene Suchmethoden, z. B. anhand vonIDs oder Schlüsselworten.Das konzipierte Repository nutzt intern die Sprache Web Service Modeling Lan-
guage (WSML) (siehe Kapitel 3.1.2.2) zur Beschreibung der Komponenten. Daherist eine Transformation von MCDL (C und B) nötig, die transparent geschieht.Basierend auf definierten Basis- und Domänenontologien werden zumindest die Me-tadaten mit expliziter Semantik versehen. Die Basisontologie spezifiziert für Meta-Elemente der MCDL passende Konzepte, während Domänenontologien bspw. Kom-ponentenklassen repräsentieren. Für jedes Binding wird eine Beschreibung in WSMLgeneriert, die diese Ontologien importiert und die Konzepte der Metainformationengemäß den enthaltenen Werten instanziiert. Die persistente Speicherung der MCDL(C und B) sowie der WSML-Beschreibungen erfolgt in einer Datenbank.Zusammenfassend ist festzustellen, dass das Component Repository für die Ver-
waltung der Komponentenbeschreibungen über eine definierte Schnittstelle zustän-dig ist. Diese Schnittstelle ist, wie der gesamte Integrationsprozess, auf das Klas-senkonzept abgestimmt und muss daher im Rahmen einer Konzeption überdachtwerden.
Copyright TU Dresden, Carsten Radeck 13

Semantische Komposition in Mashups Kapitel 2 Grundlagen und Anforderungsanalyse
2.2.3 Vorhandene DefiziteNachdem der Ansatz zur Integration von Mashup-Komponenten von CRUISe er-läutert wurde, werden in diesem Abschnitt dessen derzeitige Probleme und Defiziteidentifiziert und somit potentielle Anwendungsgebiete für die semantische Beschrei-bung der Komponenten aufgezeigt.
• Klassenkonzept: Die Erstellung einer geeigneten Klassifikation für Komponen-ten ist aufwändig zu realisieren, da diese u. a. vollständig und präzise seinsollte. Die vergebliche Suche nach passenden Klassen für die Einordnung neu-er Komponenten führt nicht selten zur Neudefinition einer (zu) spezifischenKlasse, die nur bedingt wiederverwendbar ist. Das Klassenkonzept bedingt zu-dem eine Trennung von MCDL-B und -C, was zusätzlichen Verwaltungs- undWartungsaufwand bedeutet. Die Discovery basiert auf den URIs der Klassenund besitzt eine begrenzte Genauigkeit, denn die tatsächlich geforderte Funk-tionalität ist nicht zwangsläufig hinreichend genau durch eine Mengenbildungvon Klassen abdeckbar. Weiterhin ist die Klassifikation bisher nicht seman-tisch modelliert, d. h., ein gemeinsames Vokabular fehlt und logische Inferenzist nicht direkt möglich. Die Einteilung in Klassen auf Ebene der Schnittstelleerlaubt eine schnelle (da vergleichbar mit schlüsselwortbasierten Ansätzen),auf der anderen Seite aber abstrakte Suche, da die Bedeutung der angebote-nen Operationen, Ereignisse etc. nicht betrachtet wird. Die Suche nach einerbestimmten Funktionalität erfolgt daher nur implizit anhand der Klasse, diezudem mehr als die gewünschte umfassen kann. Dies führt zu Problemen imRahmen der Komposition, die scheitert, falls für eine angegebene Klasse zurLaufzeit keine Komponente bereitsteht. Unter semantischer Angabe der gefor-derten Funktionalität könnte in diesem Fall versucht werden eine Teilkompo-sition zu berechnen. Zwar führt auch das nicht garantiert zu einem Ergebnis,aber die Wahrscheinlichkeit dafür wird erhöht.
• Die MCDL bietet zwar Mittel zur semantischen Annotation, diese werden aberim aktuellen Integrationsprozess für Mashup-Komponenten nicht verarbeitetund interpretiert. Der Integrationsprozess ist komplett auf das Klassenkon-zept zugeschnitten. Die Möglichkeiten zur Annotation sind generisch, es feh-len jedoch Richtlinien, die einschränken, welche Art von Konzepten an welcheElemente der MCDL geknüpft werden sollen/dürfen. Zudem existieren keinesemantischen Modelle, welche die Annotationen referenzieren könnten.
• Die Suche nach Komponenten und Rangfolgebildung im Integration Servicestützt sich auf rein syntaktische Aspekte und einige nicht-funktionale Eigen-schaften, für die aber keine explizite semantische Beschreibung existiert. DieSuche nach einer Klasse erfolgt anhand ihrer ID und unterstellt eine identischeSyntax der funktionalen Schnittstelle aller zugeordneten Komponenten.
Im Fokus dieser Arbeit stehen die semantische Beschreibung von Komponentenund Laufzeitaspekte zu deren Nutzung im Rahmen des Integrationsprozesses. Daherordnet sich die Arbeit an die in Kapitel 2.2.2 vorgestellten Stellen der CRUISe Archi-tektur ein. Eine Erweiterung des Autorenwerkzeugs wird hingegen nicht angestrebt.
Copyright TU Dresden, Carsten Radeck 14

Semantische Komposition in Mashups Kapitel 2 Grundlagen und Anforderungsanalyse
Nachfolgend wird die Übertragung von Anwendungsgebieten semantischer Dienst-beschreibungen aus dem Bereich SWS auf die Kompositionsinfrastruktur CRUISediskutiert.
2.3 Übertragung der Nutzung semantischerDienstbeschreibungen in SWS auf CRUISe
Mit zunehmender Anzahl verfügbarer Dienste in offenen serviceorientierten Archi-tekturen wird eine Automatisierung von Arbeitsschritten vorteilhafter, da diese ma-nuell sehr zeitaufwändig und potentiell fehleranfällig sind. Dies gilt auch für dieEntwicklung von Mashups, wie in CRUISe, aufgrund ihres schnelllebigen Charak-ters und da auch weniger versierte Entwickler, z. T. Endnutzer, angenommen werden.Grundlage für die Automatisierung ist eine semantische Beschreibung der Web Ser-vices. Diese kann auf verschiedensten logischen Formalismen basieren, die jeweilseinen bestimmten Kompromiss aus Ausdrucksfähigkeit und Berechenbarkeit besit-zen und deren Auswahl vom Anwendungsfall abhängt [FKZ08]. Die Anwendungsge-biete der semantischen Informationen in SWS werden im Folgenden in Anlehnungan den SWS Usage Process [ATR+04], der in mehreren Schritten eine nutzerde-finierte Aufgabe erfüllt (siehe Abbildung 2.4), überblicksartig vorgestellt, um dieVorteile von semantischen Dienstbeschreibungen zu vertiefen. Gleichzeitig wird aufwesentliche Herausforderungen eingegangen. Zudem wird die Übertragung der An-wendungsmöglichkeiten auf die Kompositionsinfrastruktur CRUISe untersucht, umdie zuvor identifizierten Defizite zu beheben.
Legende
DiscoveryRanking &
SelektionKomposition
AusführungZiel Ergebnis
Mediation
Nutzerpräferenzen
Nutzt
Ein-/Ausgabe
Prozessschritt
Dienstbeschreibungen
Abbildung 2.4: SWS Usage Process
Discovery beschreibt die Aufgabe Web Services, welche die vom Nutzer (im Wei-teren auch im Sinne eines Softwareagenten) gestellten Anforderungen erfüllen, zuidentifizieren und zu lokalisieren. Somit stellt sie eine essentielle Aufgabe im Rahmeneiner serviceorientierten Architektur dar (vgl. [FKZ08, S.87]). Im Wesentlichen wer-den Gemeinsamkeiten zwischen Anfrage und Angebot analysiert, was als Matchma-king bezeichnet wird. Um die Präzision der Suche nach geeigneten Kandidaten zuerhöhen, sind semantische Beschreibungen von Anforderungen und verfügbaren WebServices, insbesondere funktionale Eigenschaften, notwendig [Klu08, FKZ08]. Wei-terhin sind zum Formalismus der Beschreibung passende Reasoningmechanismenerforderlich, auf denen das Matchmaking beruht. Idealerweise wird die Anfrage innatürlicher Sprache verfasst und auf ein semantisches Modell abgebildet [ATR+04].Einen Überblick zu Discovery-Verfahren samt Kategorisierung gewährt [Klu08]. DieVerfahren unterscheiden sich demnach hinsichtlich des verwendeten Teils der Dienst-
Copyright TU Dresden, Carsten Radeck 15

Semantische Komposition in Mashups Kapitel 2 Grundlagen und Anforderungsanalyse
beschreibung und der Art des Schlussfolgerns (logikbasiert, nicht-logikbasiert, hy-brid) zur Berechnung des Grades der funktionalen Übereinstimmung.
Ranking und Selektion Aufgrund dessen, dass die Discovery typischerweise eineMenge von Dienstkandidaten liefert, ist anschließend eine Auswahl von konkretenWeb Services durchzuführen, die den Präferenzen des Nutzers am besten gerechtwerden. Die Selektion erfolgt dabei anhand von nicht-funktionalen Eigenschaften,wie z. B. Performanz, Zuverlässigkeit, Sicherheit, Unterstützung von Transaktionenund finanziellen Regelungen [ATR+04]. Auf Basis verschiedener Algorithmen wirdzunächst eine Rangfolge der gefundenen Kandidaten gebildet (Ranking) und schließ-lich ein oder mehrere ausgewählt. Die nicht-funktionalen Eigenschaften sollten se-mantisch modelliert werden, um ein automatisches Schlussfolgern zu ermöglichen,und Kontextinformationen sowie soziale Aspekte, wie Nutzerfeedback, in das Ran-king einfließen [FKZ08, S.88f].
→ Abbildung von Discovery und Selektion auf CRUISe:
• Einordnung: In der Architektur von CRUISe übernimmt der Integration Ser-vice in Kooperation mit dem Component Repository und dem KontextdienstDiscovery, Ranking und Selektion der zur Anfrage der Runtime am bestenpassenden Komponenten. Zur Entwicklungszeit eines Mashups nutzt das Au-torenwerkzeug das Component Repository zur Suche passender Komponenten.Die Suche und Auswahl einer Komponente auf Anfrage der CRUISe Runtimespielt zum einen bei der initialen Integration in das Mashup, zum anderenbeim Austausch von Mashup-Komponenten eine Rolle.• Übertragung: Sowohl zur Entwicklungszeit (Suche passender Komponenten für
eine Anwendung) als auch Laufzeit (Auswertung des Kompositionsmodells)kann eine semantische Komponentenbeschreibung die Präzision der Discove-ry verbessern. Zu den identifizierten Defiziten des Klassenkonzeptes gehört,dass nur ein Matchmaking bezüglich der Klassen-ID stattfindet. Daher undaufgrund weiterer zuvor genannter Defizite soll das Klassenkonzept entfallen,sodass bei der Discovery die Syntax der Datentypen von Properties, Operatio-nen und Ereignissen auf Übereinstimmung zu untersuchen ist. Zudem sollten–wie bereits motiviert– deren semantische Konzepte in den Vorgang einflie-ßen. In der Konsequenz wären die Verfahren zur Discovery sowie die derzeitigeSchnittstelle zwischen Runtime und Integration Service anzupassen, da nichtmehr anhand einer Klassen- oder Binding-ID, sondern syntaktischer und se-mantischer Anforderungen angefragt wird. Falls eine semantische, aber keinesyntaktische Übereinstimmung festgestellt wird, ist eine Mediation auf Date-nebene nötig.In CRUISe könnte die semantische Beschreibung nicht-funktionaler Eigen-schaften vorgenommen werden, um den konkreten Wert letzterer dynamischzu schlussfolgern. Dazu kann eine formale (Regel-) Sprache definiert werden,um gegen die Anfrage evaluiert zu werden. Ontologien könnten der Metadaten-Sektion der MCDL eine explizite Bedeutung verleihen.• Abgrenzung: Beim Austausch von Komponenten steht zunächst der Fall des
Tauschs genau einer Komponente gegen eine andere im Vordergrund. Die Kon-
Copyright TU Dresden, Carsten Radeck 16

Semantische Komposition in Mashups Kapitel 2 Grundlagen und Anforderungsanalyse
zeption von Verfahren zum syntaktischen Matchmaking von XML-Schematader MCDL steht nicht im Blickpunkt dieser Arbeit, sondern auf vorhandenesoll, falls notwendig, aufgesetzt werden.Im Rahmen von CRUISe ist die Discovery und Rangfolgebildung zur Entwick-lungs- und Laufzeit möglich. Jedoch unterscheidet sich der Abstraktionsgradder Anfragen bei beiden: Bei der Erstellung eines Kompositionsmodells wirdein Entwickler zunächst abstrakt nach Komponenten suchen, welche eine be-nötigte Funktionalität anbieten. Zur Laufzeit stammt die Anfrage hingegenvon der Runtime und sie umfasst konkretere Informationen, da beispielsweisebenötigte Ereignisse und Operationen bekannt sind. Zusätzliche Details, diedie Discovery und Selektion beeinflussen, liefern Präferenzen und Kontextin-formationen aus dem Kontextmodell des Nutzers. Im Fokus dieser Arbeit stehtdie Discovery und Selektion zur Laufzeit. Ein solcher Detailgrad, wie er bei derZieldefinitionen in SWS typischerweise auftritt, z. B. in WSML, ist zunächstnicht im Blickpunkt. Denn dieser umfasst i. d. R. konkrete Instanzdaten fürdie Eingabe eines geeigneten Web Service, was in CRUISe der Suche nach pas-senden Komponenten aus Sicht einer Komponente pro ausgelöstem Ereignisentspräche. Solch detaillierte Anfragen wären für die Discovery im Rahmeneines Autorenwerkzeugs für End-User-Development nützlich, was aber überdiese Arbeit hinaus geht.
Komposition Falls kein einzelner Web Service die Anforderungen des Nutzers er-füllen kann oder eine Kombination anderer hinsichtlich nicht-funktionaler Eigen-schaften zu bevorzugen ist, stellt die Komposition von Web Services eine Optiondar (vgl. [ATR+04]). Sie beschreibt den Prozess der (rekursiven) Bildung zusam-mengesetzter Web Services [DS05] und ist eine der vielversprechendsten Ideen vonWeb Services. Dabei ist zwischen Orchestrierung und Choreographie zu unterschei-den. Erstere beschreibt einen neuen Web Service, der zur Erbringung der Funktio-nalität vorhandene nutzt, während eine Choreographie die Kollaboration von WebServices, d. h. die auszutauschenden Nachrichten, definiert, sodass die Kompositionverteilt ausgeführt wird (vgl. [MP09]). Einen Überblick über vorgestellte Ansätzezur Komposition von Web Services verschaffen u. a. [DS05, RS05, MP09]. Dustaret al. [DS05] unterscheiden existierende Kompositionsansätze bezüglich der Ein-ordnung in statische oder dynamische und manuelle oder automatische. ManuelleKomposition ist jedoch schwierig und fehleranfällig, sodass eine Automatisierung dieEntwicklungsdauer und -kosten senken kann [MP09]. Die automatische Kompositi-on nutzt oftmals die formalen Grundlagen der Planung aus dem Bereich künstlicherIntelligenz (AI Planning). Sie wird dabei als ein zustandsbasiertes Planungsproblemaufgefasst: Ausgehend von einem Initialzustand und einem Zielzustand der Welt(Anforderungen) sowie einer Menge durchführbarer Aktionen (Dienstaufrufe) mitVorbedingungen und Effekten wird durch existierende Planungsalgorithmen ein Plan(Komposition) berechnet. Übliche Ansätze sind dabei vorwärts- oder rückwärtsver-kettende (beginnend beim Initial- oder Zielzustand) Algorithmen. Die Autoren in[RS05] beurteilen semi-automatische Ansätze positiv, da es kompliziert ist, das Ver-halten von Web Services ausreichend detailliert zu beschreiben und vollautomatischzu komponieren. Für die prominentesten Beschreibungssprachen für SWS (OWL-S,WSML, SAWSDL) existieren Planer zur automatischen Komposition (vgl. [Klu08]).
Copyright TU Dresden, Carsten Radeck 17

Semantische Komposition in Mashups Kapitel 2 Grundlagen und Anforderungsanalyse
→ Abbildung auf CRUISe:
• Einordnung: Die Komposition der Anwendung findet zur Entwicklungszeit mit-tels des Autorenwerkzeugs auf Basis des Kompositionsmodells statt.• Übertragung: Die Kompositionsarchitektur CRUISe könnte von Erkenntnissen
aus dem Bereich der Komposition von SWS auf verschiedene Weisen profi-tieren. Das Autorenwerkzeug könnte von der Komposition basierend auf dersemantischen Komponentenbeschreibung Gebrauch machen, um den Entwick-ler zu unterstützen, z. B. vergleichbar den Ansätzen in [HMH+10, BAM10].Somit wäre eine (semi-) automatische Anwendungsentwicklung möglich – ent-sprechende Planungsalgorithmen unterstellt. Weiterhin könnte zur Laufzeitdas Fehlen von einzelnen Komponenten, welche die Anfrage erfüllen, durchKombination mehrerer kompensiert werden. Der Integration Service bzw. eindediziertes Modul müsste auf Basis der Anfrage und unter Zuhilfenahme derDiscovery die Komposition berechnen und die Runtime müsste u. a. in derLage sein, das generierte Teilmodell in das vorhandene zu integrieren und zuinterpretieren.• Abgrenzung: Aufgrund des beschriebenen modellgetriebenen Entwicklungspro-
zesses von CRUISe, der eine statische und manuelle Komposition mittels desAutorenwerkzeugs vorsieht, ist die Nutzung der semantischen Komponenten-beschreibungen zur dynamischen, automatischen Komposition der Anwendungnicht im Fokus dieser Arbeit. Das zugrundeliegende Kompositionsmodell wirdals gegeben angesehen. Die Erweiterung des Autorenwerkzeugs zur semi- auto-matischen Komposition geht über die vorliegende Arbeit hinaus, da im Blick-punkt dieser die Laufzeitaspekte zur Nutzung von semantischen Komponen-tenbeschreibungen stehen.Es wird angenommen, dass im Entwicklungsprozess sichergestellt wird, dass zuintegrierende Komponenten existieren oder neu erstellt werden und somit vomIntegration Service bzw. Component Repository bereitgestellt werden. Dahersteht die Berechnung einer Teilkomposition im Falle fehlender Komponentenzur Laufzeit zunächst nicht im Fokus dieser Arbeit.Die Kommunikation erfolgt in CRUISe gemäß dem Publish-Subscribe-Modell,sodass kein gezielter Nachrichtenaustausch stattfindet. Zudem ist in CRUISeim Allgemeinen keine Beziehung zwischen Ein- und Ausgaben zu unterstellen.Hinzu kommt der interaktive Charakters der bereitgestellten Mashups (Ereig-nisse sind u. a. abhängig von Nutzeraktivität). Daher existiert kein vordefinier-ter Zielzustand, sodass die automatische Ausführung einer Choreographie undProzessmediation nicht angestrebt werden.
Ausführung des (zusammengesetzten) Web Service. Dabei sind diverse unterstüt-zende Aktivitäten, wie Monitoring, Mediation und Fehlerbehandlung, von Nöten, dieteilweise ebenfalls von einer semantischen Dienstbeschreibung profitieren können. Sosehen Fensel et al. [FKZ08, S.92f] zumindest konzeptionell die Option, durch Reaso-ning über die semantische Dienstbeschreibung, eine intelligente, automatische Feh-lerbehandlung zu erzielen. Monitoring-Lösungen, bei denen die überwachten Para-meter mit Ontologien beschrieben sind, erlauben eine höhere Ausdrucksfähigkeit alsderzeitige XML-Schemata [ebd.]. Zudem ist ein Grounding erforderlich, um die auf
Copyright TU Dresden, Carsten Radeck 18

Semantische Komposition in Mashups Kapitel 2 Grundlagen und Anforderungsanalyse
semantischer Ebene verwalteten Informationen auf die syntaktische Ebene der ge-nutzten Protokolle und Technologien abzubilden, z. B. Instanzen der Ontologiekon-zepte auf Instanzdokumente konform zum XML-Schema der WSDL-Beschreibung.Somit ist die Anbindung an vorhandene Standards gewährleistet.
→ Abbildung auf CRUISe:
• Einordnung: Die CRUISe Runtime verwendet vom Integration Service erhal-tene Komponentenbeschreibungen, um die Komponenten zu integrieren undsomit die Komposition gemäß dem Kompositionsmodell umzusetzen. Die Aus-führung von Komponenten umfasst deren Lebenszyklus samt ereignisbasier-ter Kommunikation, welche die Ausführung von Operationen nach sich zieht.Die CRUISe Runtime stellt unterstützende Aktivitäten, wie Fehlerbehandlung(auch auf Basis von Adaptionsregeln), bereit.• Übertragung: Die MCDL basiert auf XML-Schemata für die Syntax von Pro-
perties der Komponenten sowie Ereignis- und Operationsparametern. DieseDefinitionen könnten für das Grounding von semantischen Konzepten verwen-det werden. Sollten identischen semantischen Konzepten verschiedene Sche-mata in Komponentenbeschreibungen zugrundeliegen, können im Rahmen vonCRUISe Abbildungen zwischen syntaktischer und semantische Ebene zur Da-tenmediation genutzt werden.• Abgrenzung: Die Nutzung semantischer Komponentenbeschreibungen zum Mo-
nitoring und zur Fehlerbehandlung geht über die Zielstellung der vorliegendenArbeit hinaus.
Mediation spielt immer dann eine entscheidende Rolle, wenn Heterogenität auf-tritt. Sie kann dabei auf Daten-, Protokoll- und Prozessebene notwendig sein, umdurch die Auflösung von Inkompatibilitäten die Interoperabilität von Web Serviceszu gewährleisten. Daher ist sie mit dem gesamten Usage Process, v. a. der Kompo-sition, Ausführung und Discovery, verflochten [ATR+04].Mediation von Daten ist erforderlich, wenn diesen unterschiedliche Konzeptiona-
lisierungen zugrunde liegen, oder die selben Konzepte strukturell verschieden re-präsentiert sind. Eine umfassende Auflistung von Problemen auf Datenebene (imRahmen von Web Services, somit XML) nebst Beispielen offerieren die Autoren in[NVSM07]. Sie klassifizieren strukturelle und semantische Diskrepanzen der Datenderart: (1) Inkompatibilitäten der Domäne auf Attributebene, z. B. Namen, Skalen-und Repräsentationskonflikte von Datentypen, (2) Inkompatibilitäten von Entitäts-definitionen, z. B. Namens- und Isomorphismusprobleme, (3) Abstraktionsinkompa-tibilitäten, wie Generalisations- und Aggregationsprobleme. Wie bereits erwähnt,definieren und kontrollieren Ontologien das Vokabular im Umfeld von SWS. Onto-logien erlauben Lösungsstrategien für solche Probleme auf semantischer Ebene, wel-che zur Laufzeit auf Instanzdaten appliziert werden können (vgl. [FKZ08, S.214f]).Dabei spielt die (semi-) automatische Identifizierung von Ähnlichkeiten und das Be-schreiben dieser in Abbildungen zwischen den Ontologien (Ontology Alignment undOntology Relation, siehe [MCS+05]) eine tragende Rolle.Mediation auf Prozessebene handhabt Unterschiede in den Kommunikationsmus-
tern zwischen den Kollaborationspartnern. Fensel et al. unterscheiden dabei lösbare
Copyright TU Dresden, Carsten Radeck 19

Semantische Komposition in Mashups Kapitel 2 Grundlagen und Anforderungsanalyse
und unlösbare Diskrepanzen [FKZ08, S.225ff]. Zu ersteren gehören z. B. unerwarteteNachrichten, das Aufsplitten oder Verschmelzen von Nachrichten und das Verändernvon deren Reihenfolge. Unlösbar hingegen ist z. B. eine Verklemmung. Mediation aufProzessebene bedingt eine ausreichend mächtige semantische Beschreibung der Cho-reographie der Web Services.
→ Abbildung auf CRUISe:
• Einordnung: Mediation auf Datenebene verwirklichen in CRUISe Logikkom-ponenten als Teil des Kompositionsmodells.• Übertragung: Im oben besprochenen Fall einer semantischen, aber keiner syn-
taktischen Übereinstimmung von Komponentenschnittstellen ist Mediation aufDatenebene anzuwenden, um die Kommunikation der Komponenten zur Lauf-zeit zu gewährleisten. Wäre eine Choreographie (geordneter Nachrichtenaus-tausch) zwischen Komponenten in CRUISe vorgesehen, könnte ihre semanti-sche Beschreibung zur Mediation auf Prozessebene dienen, um z.B. die Rei-henfolge von Nachrichten, d. h. von Ereignissen, anzupassen.• Abgrenzung: Es wird angenommen, dass ein gemeinsames Vokabular für die se-
mantischen Konzepte existiert, sodass keine Abbildungen zwischen Ontologienzur Entwurfszeit spezifiziert werden müssen. Mediation auf Prozessebene stehtnicht im Fokus dieser Arbeit (siehe dazu die Diskussion zur Komposition).
Dies schließt die Diskussion der Übertragung und Abgrenzung von Anwendungs-gebieten semantischer Komponentenbeschreibungen der SWS auf CRUISe ab.
2.4 ReferenzszenarioNachdem die Realisierung von komponentenbasierten Mashups in der Kompositi-onsinfrastruktur CRUISe charakterisiert wurde, folgte die Diskussion der Übertra-gung der Anwendungsgebiete von semantischer Beschreibung von Web Services aufCRUISe. Ausgehend von dabei getroffenen Übertragungen und Abgrenzungen wirdnun ein beispielhafter Anwendungsfall im Szenario eines kontextsensitiven kompo-siten Mashups zur Reiseplanung (siehe Abbildung 2.5) veranschaulicht, um als Be-zugspunkt für nachfolgende Kapitel zu dienen.Ein Nutzer sucht nach Verbindungsauskünften und setzt diese komposite Anwen-
dung ein, um sich Routen zu gewünschten Zielpunkten kalkulieren und visualisierenzu lassen. Zudem möchte er zusätzliche Informationen zu Übernachtungsmöglichkei-ten in Hotels, Veranstaltungen in der Nähe des Zielorts sowie das Wetter am Zielorterhalten. Dazu ist das Mashup aus mehreren UI- und Nicht-UI-Komponenten zu-sammengefügt. Zunächst steht dem Nutzer eine UI-Komponente zur Angabe undDarstellung des Start- und Zielorts in Form einer Karte oder eines Formulars zurVerfügung (oben rechts). Diese dient außerdem der Darstellung von Hotels undVeranstaltungsorten, um diese als Start oder Ziel auswählen zu können. Zudemist eine UI-Komponente zur Definition der Ankunfts- und Abfahrtszeit der Reisevorgesehen (oben links). Diese Eingaben werden von einer Nicht-UI-Komponenteverarbeitet und auf Basis von angebundenen Web Services eine Route mit den öf-fentlichen Verkehrsmitteln berechnet. Das Resultat erscheint anschließend in einer
Copyright TU Dresden, Carsten Radeck 20
Semantische Komposition in Mashups Kapitel 2 Grundlagen und Anforderungsanalyse
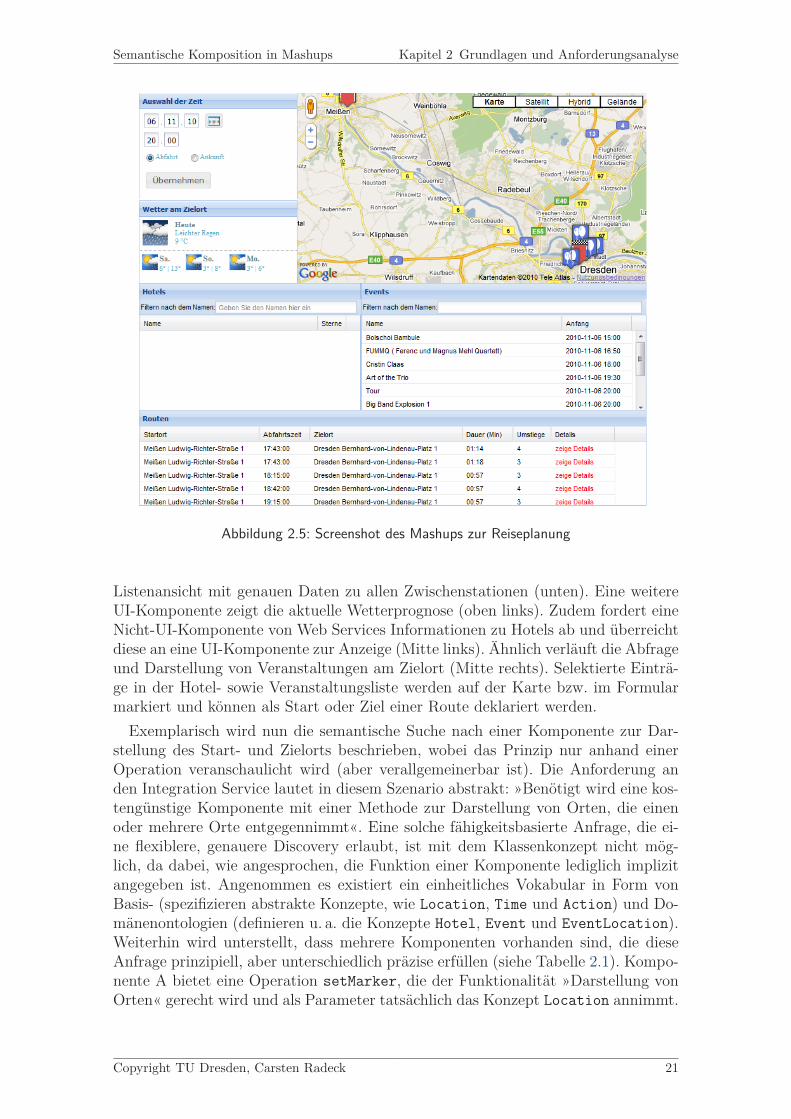
Abbildung 2.5: Screenshot des Mashups zur Reiseplanung
Listenansicht mit genauen Daten zu allen Zwischenstationen (unten). Eine weitereUI-Komponente zeigt die aktuelle Wetterprognose (oben links). Zudem fordert eineNicht-UI-Komponente von Web Services Informationen zu Hotels ab und überreichtdiese an eine UI-Komponente zur Anzeige (Mitte links). Ähnlich verläuft die Abfrageund Darstellung von Veranstaltungen am Zielort (Mitte rechts). Selektierte Einträ-ge in der Hotel- sowie Veranstaltungsliste werden auf der Karte bzw. im Formularmarkiert und können als Start oder Ziel einer Route deklariert werden.Exemplarisch wird nun die semantische Suche nach einer Komponente zur Dar-
stellung des Start- und Zielorts beschrieben, wobei das Prinzip nur anhand einerOperation veranschaulicht wird (aber verallgemeinerbar ist). Die Anforderung anden Integration Service lautet in diesem Szenario abstrakt: »Benötigt wird eine kos-tengünstige Komponente mit einer Methode zur Darstellung von Orten, die einenoder mehrere Orte entgegennimmt«. Eine solche fähigkeitsbasierte Anfrage, die ei-ne flexiblere, genauere Discovery erlaubt, ist mit dem Klassenkonzept nicht mög-lich, da dabei, wie angesprochen, die Funktion einer Komponente lediglich implizitangegeben ist. Angenommen es existiert ein einheitliches Vokabular in Form vonBasis- (spezifizieren abstrakte Konzepte, wie Location, Time und Action) und Do-mänenontologien (definieren u. a. die Konzepte Hotel, Event und EventLocation).Weiterhin wird unterstellt, dass mehrere Komponenten vorhanden sind, die dieseAnfrage prinzipiell, aber unterschiedlich präzise erfüllen (siehe Tabelle 2.1). Kompo-nente A bietet eine Operation setMarker, die der Funktionalität »Darstellung vonOrten« gerecht wird und als Parameter tatsächlich das Konzept Location annimmt.
Copyright TU Dresden, Carsten Radeck 21

Semantische Komposition in Mashups Kapitel 2 Grundlagen und Anforderungsanalyse
Komponente Operation Funktionalität Parameter (Konzept) Param. (Schemades Datentyps)
A setMarker Darstellung Location iB setLocation Darstellung EventLocation jC splitLocation Abspalten Location iD setMarker Darstellung Location k»Anfrage« showMarker Darstellung Location i
Tabelle 2.1: Anfrage und verfügbare Komponenten des Szenarios
Komponente B besitzt die Operation showLocation, die speziellere EventLocationsunterstützt. Aufgrund der logischen Beziehung beider Konzepte könnte B ebenfallsals Kandidat in Frage kommen – wenn auch mit niedrigerem Übereinstimmungsgrad.Eine weitere Komponente C hat eine Methode splitLocation, die zwar ebenfallsLocations verarbeitet, jedoch eine andere Funktionalität (Abspalten der geografi-schen Position) statt deren Darstellung bietet. Somit ist C nicht geeignet. Bei denKomponenten A und C wird unterstellt, dass auch die Syntax des Parameters mitder geforderten übereinstimmen. Komponente D gleicht A bis auf den Umstand,dass die XML-Syntax der Locations abweicht. Im Klassenkonzept wäre eine ver-schiedene Syntax bei offensichtlich gleicher Funktionalität nicht möglich. A und Dmüssten in disjunkte Klassen(teilhierarchien) eingeordnet werden und wären für dieDiscovery unterschiedlich.Aufgrund der semantischen und direkten syntaktischen Übereinstimmung sowie
der nicht-funktionalen Rangfolgebildung wird schließlich Komponente A ausgewähltund in das Mashup integriert. Im Rahmen der dynamischen Adaption der Anwen-dung muss Komponente A ausgetauscht werden, da sie der QoS-Eigenschaft Perfor-manz nicht mehr ausreichend gerecht wird. Diesmal wird Komponente D selektiert.Nun ist eine Mediation auf Datenebene durchzuführen, wofür die Runtime basie-rend auf der semantischen Komponentenbeschreibung Mittel bereitstellt. Mit demKlassenkonzept wäre ein Austausch in diesem Fall wegen mangelnder Alternativenunmöglich.Wie verdeutlicht wurde, kann das bisherige Konzept das beschrieben Szenario
in dieser Art nicht umsetzen. Daher ist ein neues Konzept zu entwickeln, für dasanschließend zu lösende Aufgaben als Anforderungen aufgestellt werden.
2.5 Anforderungsanalyse
Im bisherigen Verlauf wurden die Gegebenheiten von CRUISe, relevante Übertra-gungen zur Nutzung semantischer Komponentenbeschreibungen aus dem BereichSWS untersucht und Abgrenzungen vorgenommenen. Zusammenfassend sind diewesentlichen Herausforderungen für das zu entwickelnde Konzept: die Bereitstel-lung einer semantischen Komponentenbeschreibung, die Nutzung dieser durch dieam Integrationsprozess beteiligten Komponenten und die Anpassung des Kompo-nentenmodells. Sich daraus ableitende Anforderungen, die im weiteren Verlauf derArbeit als Bewertungsmaßstab für verwandte Ansätze und schließlich das Konzeptdienen, stellt das vorliegende Kapitel auf.
Copyright TU Dresden, Carsten Radeck 22

Semantische Komposition in Mashups Kapitel 2 Grundlagen und Anforderungsanalyse
2.5.1 Anforderungen an die semantischeKomponentenbeschreibung
Die Grundlage für das zu entwickelndes Konzept ist eine semantische Komponen-tenbeschreibung anhand konzeptioneller Modelle. Folgende Anforderungen werdenan diese gestellt, um vorhandene Ansätze aus Forschung und Technik und die be-stehende MCDL zu bewerten.
1 Zusammenführung von MCDL-C und B Aufgrund der identifizierten Defizitemuss das Klassenkonzept durch die Nutzung semantischer Beschreibung derMashup-Komponenten abgelöst werden. Daher ist die Trennung der MCDLin Klassen- und Bindingteil nicht mehr nötig, sodass dadurch entstandenerOverhead entfällt.
2 Aufsetzen auf bestehende Beschreibungssprache Die vorhandene MCDL istaus Kompatibilitätsgründen beizubehalten und, falls als notwendig erachtet,zur semantischen Annotation von Komponenten redundanzfrei zu erweitern.Die Erweiterungen müssen in das XML-Schema der MCDL eingefügt werden.
3 Ontologiebasierte semantische Modelle Die Semantik der Mashup-Komponen-ten muss auf Basis von Ontologien explizit formalisiert werden, damit auto-matische Schlussfolgerungen möglich sind. Vorhandene (domänenspezifische)Ontologien müssen in die Beschreibung eingebunden werden können und wer-den einheitlich von verschiedenen Komponentenanbietern zur Annotation ver-wendet. Voraussetzung ist die Identifizierung und Formalisierung von domä-nenabhängigen und -unabhängigen Ontologien, wobei auf bestehende Arbeitenaufgesetzt wird.
4 Separation der semantischen Modelle Um Wiederverwendbarkeit zu steigern,müssen die Ontologien von der Komponentenbeschreibung getrennt werdenkönnen. Zusätzlich sollte eine Trennung von domänenspezifischen und -unab-hängigen Ontologien möglich sein.
5 Unterstützung verschiedener Arten von Semantik Die Semantik von Mashup-Komponenten soll auf mehreren Ebenen beschrieben werden:
5.1 Funktionale Semantik Die MCDLmuss die Funktionalität einer Mashup-Komponente und ihrer Operationen beschreiben.
5.2 Datensemantik Die MCDL muss die Anreicherung der Datentypen derParameter von Operationen und Ereignissen sowie der Properties derMashup-Komponenten mit ihrer Bedeutung erlauben.
5.3 Nicht-funktionale Semantik Die Unterstützung explizit formalisierternicht-funktionaler Eigenschaften von Mashup-Komponenten durch dieMCDL ist wünschenswert, z. B. durch Annotation der vorhandenen Meta-daten-Sektion.
5.4 Verhaltenssemantik Die Angabe einer Choreographie ist wünschenswert,um beispielsweise erwartete Abfolgen von Ereignissen zu beschreiben.
Copyright TU Dresden, Carsten Radeck 23

Semantische Komposition in Mashups Kapitel 2 Grundlagen und Anforderungsanalyse
6 Einfachheit Der zugrundeliegende Formalisierungsgrad der semantischen Beschrei-bung (insbesondere der Funktionalität) ist ein Kompromiss aus Komplexität,Ausdrucksfähigkeit und dem Aufwand bei der Beschreibung durch Anbieter derKomponenten und Anwendungsentwickler (Form der semantischen Anfrage beider Suche nach Komponenten). Die formale Sprache sollte nur so ausdrucks-fähig sein, wie für die zu beschreibende Semantik der Komponente nötig, umdie Entscheidbarkeit und einen möglichst geringen Aufwand von Berechnun-gen zu gewährleisten. Da CRUISe auf einem leichtgewichtigen Mashup-Ansatzberuht, ist auf Einfachheit und möglichst geringen Aufwand der semantischenBeschreibung zu achten.
2.5.2 Anforderungen an die Komponenten desIntegrationsprozesses
Auf der semantischen Komponentenbeschreibung aufbauend ist die Zielstellung dieNutzung dieser zur Integration und zum Austausch von Komponenten. Dies führtzu folgenden Anforderungen an die daran beteiligten Architekturkomponenten.
7 Spezifikation der Schnittstelle zwischen der Runtime und Integration ServiceWurde bei Anfragen an das CIS bisher lediglich die ID einer Klasse oder einesBindings benötigt, müssen nun alle zur Discovery und Selektion erforderlichensyntaktischen und semantischen Informationen übermittelt werden. Auch dieForm der Rückgabe des Integration Service ist zu spezifizieren.
8 Semantische Discovery im Integration Service Matchmaking muss auf Basissemantischer Informationen geschehen, um die fehlende Eindeutigkeit der Syn-tax zu umgehen. Zusätzliches syntaktisches Matchmaking wäre wünschens-wert, da damit die Präzision gesteigert werden kann [KK08]. Der Grad derfunktionalen Übereinstimmung war bisher entweder gegeben oder nicht (durchVergleich der Klassen-IDs). Da das zu entwickelnde Konzept nicht mehr aufKlassen beruhen soll, muss der Grad der Übereinstimmung berechnet und indie Gesamtrangfolge einbezogen werden.
9 Bereitstellung von Mediation auf Datenebene Wird bei der Discovery festge-stellt, dass eine Komponente zwar semantisch, aber nicht syntaktisch der An-frage gerecht wird, sollen Mittel zur Auflösung der Heterogenität von Opera-tionen, Ereignissen und Properties durch die Runtime angeboten werden.
10 Spezifikation der Schnittstelle zum Component Repository Ein Nutzer vonKomponenten, d. h. das Autorenwerkzeug und der Integration Service, mussanhand einer Anfrage passende MCDLs bzw. Referenzen darauf vom Com-ponent Repository geliefert bekommen. Die Ausprägung dieser Anfrage mussspezifiziert werden, da sie bisher auf das Klassenkonzept zugeschnitten ist.
11 Integration von Komponenten In der Gesamtheit müssen die Runtime, der In-tegration Service und das Component Repository die Integration von seman-tisch beschriebenen Komponenten in ein Mashup unterstützen. Die Runtimemuss dabei die semantisch erweiterte Komponentenbeschreibung interpretie-ren, verwalten und zur Integration von Komponenten verwenden.
Copyright TU Dresden, Carsten Radeck 24

Semantische Komposition in Mashups Kapitel 2 Grundlagen und Anforderungsanalyse
12 Austausch von Komponenten Zur Laufzeit muss basierend auf dem semanti-schen Integrationsprozess ein Austausch von einer Komponente gegen eineandere realisiert werden. Dazu sind vorhandene, auf das Klassenkonzept aus-gerichtete Austauschmechanismen anzupassen, d. h. der Algorithmus und Ad-aptionsregeln.
13 Unterstützung von partiellen semantischen Beschreibungen Eine vollständi-ge semantische Beschreibung sollte nicht notwendig sein, da diese bei einerVielzahl von Komponenten eine zeit- und kostenaufwändige Angelegenheitdarstellt. Der Integrationsprozess von Mashup-Komponenten (auch beim Aus-tausch) sollte auch nicht vollständige semantische Komponentenbeschreibun-gen handhaben können, damit betroffene Komponenten ebenfalls integrierbarsind.
14 Fehlerbehandlung Bei sämtlichen Teilaufgaben während der Integration seman-tisch beschriebener Komponenten, wie der Discovery, dem Ranking und demZugriff auf den Kontextdienst, sowie zur Laufzeit, z. B. beim Komponenten-austausch und der Mediation auszutauschender Daten, sind auftretende Fehlerdurch die entsprechende Architekturkomponente zu behandeln und zu kom-munizieren. Dazu gehört auch die Validierung der Komponentenbeschreibungund des Kompositionsmodells.
Nicht-funktionale Anforderungen:
15 Effizienz, Performanz Die Nutzung der semantischen Informationen im Inte-grationsprozess soll einen möglichst geringen Einfluss auf dessen Laufzeitver-halten ausüben, da er als zeitkritisch einzuschätzen ist.
16 Erweiterbarkeit Auf die Erweiterbarkeit der Discovery um alternative Algorith-men und der semantischen Annotationsmittel der MCDL soll geachtet werden.Wünschenswert wäre die Erweiterbarkeit des Austauschmechanismus hin zun:m-Fällen.
17 Unterstützung von Standards Im Konzept sollte auf die Unterützung von Stan-dards geachtet werden, da diese auf einem Entwicklungsprozess beruhend be-währte Lösungen bieten und i. d. R. weitgehend anerkannt sind.
2.5.3 Anforderungen an das KompositionsmodellZusätzliche Anforderungen richten sich an das Kompositionsmodell, da die Konzeptezur Modellierung von Komponenten im Kompositionsmodell als eine Repräsentationder MCDL verstanden werden können.
18 Anpassung des Kompositionsmodells Das Kompositionsmodell muss zumin-dest an die Ablösung des Klassenkonzeptes angepasst werden. Die Erweite-rungen der MCDL zur Annotation von Mashup-Komponenten betreffen we-gen der einleitend erläuterten Beziehung auch das Komponentenmodell undmüssen betrachtet werden.
Welche Lösungsansätze für einzelne Herausforderungen in Forschung und Technikderzeit existieren, legt das folgende Kapitel dar.
Copyright TU Dresden, Carsten Radeck 25

Semantische Komposition in Mashups Kapitel 3 Stand der Forschung und Technik
3Stand der Forschung und Technik
Nachdem Anforderungen an das Konzept zur Nutzung semantischer Komponen-tenbeschreibung im Integrationsprozess von CRUISe hergeleitet wurden, beschreibtdieses Kapitel bestehende Vorschläge zur Umsetzung einzelner Problemstellungenaus verwandten Forschungsgebieten und die Eignung derer für das zu entwickelndeKonzept. Hierzu wird zuerst der derzeitige Stand der semantischen BeschreibungKomponenten, v. a. Web Services, analysiert. Anschließend stehen prinzipielle Ver-fahren zur semantischen Discovery und Selektion von Web Services bzw. Kompo-nenten und Mediation von Daten im Blickpunkt.
3.1 Semantische Beschreibung von Web Services undKomponenten
An dieser Stelle werden existierende Vorschläge zur semantischen Beschreibung vonWeb Services und klassischen Softwarekomponenten untersucht. Dies ist notwendig,da eine solche explizite Beschreibung der Semantik die Basis zur weiteren Nutzungbei der Integration und dem Austausch von Komponenten in CRUISe ist. Ausgehendvon zugrundeliegenden Formalismen wird die Beschreibungen von SWS analysiert,die sich in zwei wesentliche Ansätze, Top-Down und Bottom-Up, untergliedern.
3.1.1 Überblick zu zugrundeliegenden formalen SprachenEs gibt eine Reihe von logischen Formalismen, welche der semantischen Beschrei-bung von Komponenten und Web Services zugrunde liegen können, wobei jedereinen bestimmten Kompromiss aus Ausdrucksfähigkeit, Berechenbarkeit und Auf-wand bei der Beschreibung besitzt. Welcher Formalismus adäquat ist, hängt dabeivom Anwendungsfall und der zu beschreibenden Semantik (vgl. Kapitel 2.1.2) ab.Zur Formalisierung der Datensemantik, die für Interoperabilität und Discove-
ry wichtig ist, dienen üblicherweise Ontologien auf Basis von Beschreibungslogik[BCM+03]. Für die Beschreibung der Funktionalität eines Web Service oder einerKomponente, die insbesondere für die Discovery relevant ist, wurden verschiedeneFormalismen untersucht. So unterscheiden Fensel et al. [FKZ08, S.174ff.] eine »ein-fache« und eine »reichhaltige« semantische Beschreibung. Erstere beruht auf einemdurch Ontologien kontrollierten Vokabular und fasst die Anfrage des Clients und den
Copyright TU Dresden, Carsten Radeck 26

Semantische Komposition in Mashups Kapitel 3 Stand der Forschung und Technik
Web Service samt Eingaben, Ausgaben und Effekten als Mengen von Konzepten derOntologie auf. Beschreibungslogiken weisen jedoch eine begrenzte Ausdrucksfähig-keit auf, z. B. bezüglich der Formulierung von Regeln. Die reichhaltige Beschreibungist zustandsbasiert, wobei der Zustand der Welt und des Informationsraumes desWeb Service in Prädikatenlogik erster Stufe formuliert wird. Ein Web Service wirddabei im Wesentlichen als eine Folge von Zustandsübergängen verstanden. Zwar er-laubt dieser Ansatz eine präzise Beschreibung eines Web Service, zieht aber einenhohen Aufwand bei der Erstellung der Beschreibung nach sich und erfordert einhohes Maß an Fachwissen. Ein ähnliches Modell zur Spezifikation von Softwarekom-ponenten durch Angabe von Zusicherungen in Form von Vor-, Nachbedingungenund Invarianten wurde zuvor bereits vorgeschlagen [Mey92]. Für die Spezifikationdes Verhaltens von Komponenten wurden in der Forschung diverse formale Metho-den entwickelt, anhand derer Beweise über die Interoperabilität von Komponentengeführt werden, um u. a. die Korrektheit und Verklemmungsfreiheit einer Komposi-tion zu prüfen. Zu den zugrundeliegenden Formalismen gehören (vgl. z. B. [Tes03,S.48–51]) Prozesskalküle (u. a. π-Kalkül), logikbasierte Ansätze, graphbasierte An-sätze (z. B. Petrinetze) und endliche Automaten sowie Zusicherungen. Diese wurdenauf Web Services übertragen, z. B. basieren Choreographien in Web Service Mo-deling Ontology (WSMO) auf abstrakten Zustandsmaschinen. Nicht-funktionaleEigenschaften und Präferenzen, die v. a. in die Selektion einfließen, werden ty-pischerweise in Ontologien, semantischer Repräsentation von Policen oder in einerRegelsprache formuliert, z. B. in WSML [FKZ08] oder Semantic Web Rule Language(SWRL) [HPSB+04], wie bei [VGS+05], und von einem Reasoner ausgewertet.
3.1.2 Top-Down AnsätzeDer Grundgedanke bei diesen Ansätzen zur semantischen Beschreibung von WebServices ist die Bereitstellung von konzeptionellen Modellen, i. d. R. Ontologien, dieals Ausgangspunkt für die Beschreibung dienen. Ein Web Service wird zunächstunabhängig von Technologien zur Kommunikation etc. anhand der Konzepte dergegebenen Modelle und unter Einbeziehung weiterer (domänenspezifischer) Ontolo-gien modelliert. Das vorrangige Ziel ist die komplette Automatisierung sämtlicherAbläufe im Kontext von SWS durch ein Framework oder eine Middleware basierendauf den konzeptionellen Modellen. Dementsprechend weitreichend sind die verfüg-baren Konzepte, da u. a. auch die Komposition beschreibbar sein muss. Um externeWeb Services, die nicht zwangsläufig im gleichen Modell semantisch beschriebensind, aufzurufen, findet ein Grounding in vorhandene, standardisierte Web ServiceTechnologien, v. a. WSDL, statt. In der Kategorie der Top-Down Ansätze wurdezahlreiche Vorschläge unterbreitet, wie OWL-S, WSMO, USDL [Res10], CoSMoS[FS09], RDF4S [ZHS08] und DSD [KKRM05]. An dieser Stelle werden nur die be-kanntesten Vertreter vorgestellt, da für diese im Vergleich zu anderen bereits zahl-reiche Implementierungen existieren oder Standardisierungsbemühungen existieren.
3.1.2.1 OWL-S
OWL-S [MBH+04, MBM+07] bietet ein begriffliches Rahmenwerk zur semantischenBeschreibung von Web Services, das die Automatisierung von deren Lebenszyklusunterstützen soll. OWL-S ist eine Ontologie und baut auf vorhandenen Standards
Copyright TU Dresden, Carsten Radeck 27

Semantische Komposition in Mashups Kapitel 3 Stand der Forschung und Technik
des Semantic Webs auf: Zum einen basiert es auf OWL DL, zum anderen könnenvorhandene Vokabulare in RDF-Schema und OWL importiert werden. Ein WebService wird durch das Konzept Service repräsentiert und durch Verknüpfung mitden drei Hauptkonzepten Profile, Process Model und Grounding, die in entsprechen-den Subontologien gekapselt sind, beschrieben (siehe Abbildung 3.1). Eine konkreteBeschreibung eines Web Service erfolgt durch Instanziierung dieser Konzepte bzw.davon abgeleiteten Subklassen.
Service
Process ModelProfile Grounding
presents
describedBy
supports
„Was macht er?“ „Wie greift man darauf zu?“„Wie funktioniert er?“
Abbildung 3.1: Hauptkonzepte von OWL-S (in Version 1.2)
• Profile: Das Profile dient der Publikation eines Web Service durch den Anbieterund der Suche nach passenden Web Services durch einen Nutzer (Discovery).Es beschreibt im Wesentlichen drei Aspekte eines Web Service (vgl. Listing3.1): die Funktionalität durch Angabe von Ein- und Ausgaben sowie Vorbe-dingungen und Effekten (IOPE, Zeile 13-16), eine Klassifikation durch Re-ferenzierung bestehender Taxonomien und die nicht-funktionalen Eigenschaf-ten anhand des Dienstnamens, der Kontaktinformationen, einer textuellen Be-schreibung (Zeile 9-11) und des generischen Konzepts ServiceParameter.• Process Model: Hierbei handelt es sich um eine prozessorientierte Beschreibung
davon, wie die Funktionalität des Web Service erreicht wird. Die Prozessonto-logie unterscheidet dafür drei Arten von Prozessen. Ein AtomicProcess ist einelementarer Bestandteil, der komplett durch IOPE und lokale Variablen defi-niert wird und in einem einzigen Schritt ausführbar ist. Vorbedingungen undEffekte werden als logische Ausdrücke in einem bestimmten Formalismus, wieSWRL [HPSB+04] und SPARQL, definiert und treffen typischerweise Aussa-gen über die in Ein- und Ausgaben referenzierten Entitäten. Neben Beschrei-bungslogik sollte ein Reasoner für OWL-S daher auch die eingebetteten Forma-lismen unterstützen. Ein CompositeProcess dient der Komposition von Atomic-und SimpleProcesses und spezifiziert den Kontroll- und Datenfluss über diese.Ersterer wird mittels Kontrollstrukturen angegeben, z. B. sequence, iterate,split, if-then-else. Ein SimpleProcess entspricht einer abstrakten, nichtausführbaren Sicht auf eine der beiden anderen Prozessarten.• Grounding: Es beschreibt die Nutzung des Web Service, indem es konkrete
Informationen u. a. zu Nachrichtenformaten, Transportprotokollen und Adres-sierung liefert. Bisher ist ein WSDL-Grouding als Brücke zwischen der syntax-und protokollorientierten WSDL und semantischen Konzepten in OWL-DLdefiniert. Dabei werden AtomicProcesses an Operationen und Konzepte derEin- und Ausgaben an Datentypen der Nachrichten der WSDL gebunden.Weiterhin wurde WSDL um Attribute erweitert, um die Abbildung in die an-dere Richtung zu erlauben: owl-s-process an Operationen und owl-s-parameteran Nachrichten oder deren Teilen. Weiterhin wurde vorgeschlagen, SAWSDL(Kapitel 3.1.3) für das Grounding zu verwenden [PWM07].
Copyright TU Dresden, Carsten Radeck 28

Semantische Komposition in Mashups Kapitel 3 Stand der Forschung und Technik
Die Syntax von Dienstbeschreibungen entspricht RDF/XML (vgl. Listing 3.1) odereiner in diese übersetzbare, aber kompaktere Presentation Syntax [MBM+07]. OWL-S bietet Mittel zur Discovery und Orchestrierung von Web Services. Da Web Servicesals atomar angesehen werden, beinhaltet OWL-S kein Modell für Choreographien[FKZ08, S.295]. Auch Mediation ist nicht explizit vorgesehen, da der Standpunktvertreten wird, dass Mediatoren als semantische Web Services bereitstehen und alssolche komponierbar sind [MBM+07].
1 <rdf:RDF xmlns :rdf= "..." ... >2 <owl: Ontology rdf: about ="">3 <owl: imports rdf: resource ="& service ;" />4 <owl: imports rdf: resource ="& profileHierarchy ;" /> ...5 </owl:Ontology >6
7 <!-- Anmerkung : BookSelling ist vom OWL -S- Konzept Profile abgeleitet -->8 <profileHierarchy : BookSelling rdf:ID=" Profile_Congo_BookBuying_Service "> ...9 <profile : serviceName > Congo_BookBuying_Agent </ profile : serviceName >
10 <profile : textDescription >... </ profile : textDescription >11 <profile : contactInformation >... </ profile : contactInformation >12
13 <profile : hasInput rdf: resource ="& congoProc ;# ExpressCongoBuyBookISBN "/>14 <profile : hasPrecondition rdf: resource ="& congoProc ;# ExpressCongoBuyAcctExists "/>15 <profile : hasResult rdf: resource ="& congoProc ;# ExpressCongoBuyPositiveResult "/>16 <profile : hasOutput rdf: resource ="& congoProc ;# ExpressCongoBuyOutput "/>17 ...18 </ profileHierarchy : BookSelling >19 </rdf:RDF >
Listing 3.1: Ausschnitt einer Beschreibung eines Web Service in OWL-S (Profile) (nach http://www.ai.sri.com/daml/services/owl-s/1.2/CongoProfile.owl)
Um im Rahmen des Referenzszenarios (Kapitel 2.4) Komponenten zu beschreiben,könnte das Process Model verwendet werden, wobei atomare Prozesse Operationenmodellieren könnten. Da ein OWL-S Service höchstens ein Prozessmodell besitzt,müsste ein kompositer Prozess definiert werden, der die atomaren durch ein geeig-netes Kontrollkonstrukt aufnimmt. Eine andere Möglichkeit wäre die Beschränkungauf das Profile und die Zuordnung der IOPE auf Teile der MCDL im Grounding.
Fazit In OWL-S sind die wesentlichen geforderten Semantiken beschreibbar, ledig-lich Choreographien werden nicht angeboten. Für das Konzept besonders relevant istdas Profile, da es der Discovery dient. Die Idee der Anfrage anhand einer »idealen«Vorlage kann in die Konzeption übernommen werden, ebenso die Auffassung vonMediatoren als Web Services, d. h. Komponenten in CRUISe. In OWL-S formulierteKonzepte könnten das konzeptionelle Modell für die Annotationen in MCDL lie-fern. Die Verwendung verschiedener Regelsprachen für Vorbedingungen und Effekteerlaubt zwar Flexibilität, auf der anderen Seite müssen diese zur Evaluation alleunterstützt werden. OWL-S ist ontologiebasiert und weitere (domänenspezifische)Ontologien sind leicht separier- und integrierbar, sodass diese Anforderungen er-füllt sind. Problematisch für eine direkte Verwendung sind folgende Punkte: OWL-Sliegt ein anderes Komponentenmodell zugrunde, dem z.B. das Konzept der Pro-perties fehlt. Die aufwändig zu definierenden Vor- und Nachbedingungen beziehensich auf Instanzdaten der Ein- und Ausgaben, was in CRUISe derzeit nicht vorge-sehen ist (vgl. Kapitel 2.3). Um die MCDL zu erhalten, könnte ein zu definierendesGrounding der Ontologiekonzepte in sie stattfinden, was aber zwei Komponentenbe-schreibungen nach sich zieht. Eine andere Option wäre daher die Einbindung einerSerialisierung der OWL-S-Beschreibung direkt in die MCDL.
Copyright TU Dresden, Carsten Radeck 29

Semantische Komposition in Mashups Kapitel 3 Stand der Forschung und Technik
3.1.2.2 WSMO und WSML
Die WSMO1 [FKZ08, S.43-65] ist ein in MOF [Gro06] formuliertes Metamodell zursemantischen Beschreibung von Web Services und mit diesen verbundenen Aspektenund beinhaltet vier Hauptelemente: Ontologies, Web Services, Goals und Mediators.Alle Elemente können mit nicht-funktionalen Eigenschaften annotiert werden.
• Ontologien stellen das notwendige Vokabular für alle anderen Elemente derBeschreibung des Web Service bereit und können ihrerseits bestehende On-tologien importieren. Letzteres geschieht ggf. unter Angabe eines Mediators,um Diskrepanzen aufzulösen. Eine Ontologie bietet Mittel zur Definition vonKonzepten mit deren Attributen und Vererbung, Relationen zwischen Konzep-ten, Funktionen, Instanzen von Konzepten und Relationen sowie Axiome zurEinbindung logischer Ausdrücke.• Web Services sind eine formale Beschreibung der Funktionalität von Web Ser-
vices und der erforderlichen Interaktion mit diesen. Die Funktionalität wird inForm von Capabilities beschrieben, indem mit Vorbedingungen, Annahmen,Nachbedingungen und Effekten die Transition des Zustands der Welt und desWeb Service formalisiert wird. Vor- und Nachbedingungen werden an den In-formationsraum des Web Service gestellt, d. h., welche Informationen für dieAusführung benötigt werden und welche nach Ausführung verfügbar sind. An-nahmen und Effekte definieren hingegen den Zustand der Welt vor und nachAusführung des Web Service. Das Interface gibt Aufschluss darüber, wie dieFunktionalität durch Interaktion mit dem Web Service erreicht werden kann.Die formale Basis in WSMO sind hierbei abstrakte Zustandsmaschinen, umdas Interface als eine Choreographie und Orchestrierung zu modellieren. DieChoreographie spezifiziert mittels einer Zustandssignatur die Dienstzustände(Ein- und Ausgaben) und durch Transitionsregeln die Zustandsübergänge samtÄnderung der Instanzdaten. Orchestration soll ähnlich wie eine Choreographiedefiniert werden, ist aber noch nicht weitreichend spezifiziert. Das Groundingin die WSDL kann alternativ in der Choreographie oder SAWSDL erfolgen.• Goals: Goals enthalten sämtliche Aspekte im Zusammenhang mit den Anfor-
derungen des Dienstnutzers. Ein Goal entspricht einem potentiell geeignetenWeb Service und beinhaltet ein angefordertes Interface und benötigte Capa-bilities (nur mit Nachbedingungen und Effekten). Im Rahmen der Discoverydienen Goals dem Abgleich mit den Capabilities angebotener Web Services.• Mediators: WSMO sieht mit den Mediators ein spezielles Konzept zur Auflö-
sung von Heterogenitäten zwischen den zuvor genannten Elementen vor. Wiein [MCS+05, FKZ08] dargelegt, entsprechen WSMO-Mediators einer seman-tischen Beschreibung dessen, was Mediatoren bei der Vermittlung zwischeneiner Quelle und einem Ziel durchführen. Sogenannte MediationServices hin-gegen nehmen die tatsächliche Mediation (auf Instanzebene zur Laufzeit) vor.
Das Metamodell von WSMO kann in verschiedenste konkrete Sprachen abgebil-det bzw. von diesen umgesetzt werden. Hierfür wurde die WSML als formale Spra-che, die Beschreibungslogik und Logikprogrammierung kombiniert, entwickelt. Sie
1http://www.wsmo.org/
Copyright TU Dresden, Carsten Radeck 30

Semantische Komposition in Mashups Kapitel 3 Stand der Forschung und Technik
liegt in mehreren Varianten vor, welche sich hinsichtlich ihrer Ausdrucksmächtigkeitund somit ihrer Komplexität unterscheiden. WSML setzt auf diverse Standards desSemantic Webs auf: Es nutzt URIs und kann zum Austausch zwischen Rechnernauf XML, RDF und OWL abgebildet werden. Die menschenlesbare WSML-Syntax(vgl. Listing 3.2) untergliedert sich in die konzeptionelle und die Syntax der logi-schen Ausdrücke. Erstere besteht aus WSMO-basierten Schlüsselworten zur Model-lierung der konzeptionellen Elemente, wie interface, choreography, webService,capability, goal (siehe z. B. Zeile 1, 24-26), und ist unabhängig von der zugrunde-liegenden Logik der jeweiligen Sprachvariante. Die Syntax der logischen Ausdrückeerlaubt den vollen Zugriff auf die zugrundeliegende Logik, unterliegt daher abhän-gig von Sprachvarianten diversen Restriktionen und wird v. a. in Axiomen, Vor- undNachbedingungen, Effekten und Annahmen genutzt (siehe z. B. Zeile 12-18).
1 webService _"http :// example .org/ Germany / BirthRegistration "2 nfp3 dc# title hasValue " Birth registration service for Germany "4 dc#type hasValue _"http :// www.wsmo.org/TR/d2/v1 .2/# services "5 endnfp6 usesMediator { _"http :// example .org/ ooMediator " }7 importsOntology { _"http :// www. example .org/ ontologies / example "... }8
9 capability10 sharedVariables ? child11 precondition definedBy12 ? child memberOf Child13 and ? child [ hasBirthdate hasValue ? birthdate ]14 and wsml# dateLessThan (? birthdate ,wsml# currentDate ())15 and ? child [ hasBirthplace hasValue ? location ]16 and ? location [ locatedIn hasValue oo#de]17 or (? child [ hasParent hasValue ? parent ]18 and? parent [ hasCitizenship hasValue oo#de ]).19 assumption definedBy20 ? child memberOf Child and naf ? child [ hasObit hasValue ?x].21 effect definedBy22 ? child memberOf Child and ? child [ hasCitizenship hasValue oo#de ].23
24 interface25 choreography _"http :// example .org/ tobedone "26 orchestration _"http :// example .org/ tobedone "
Listing 3.2: Ausschnitt einer Beschreibung eines Web Service in WSML (nach http://www.wsmo.org/TR/d16/d16.1/v0.21/)
Zur semantischen Beschreibung der Komponenten im Referenzszenario (Kapitel 2.4)wäre je ein Web Service, dessen Ein- und Ausgabekonzepte in der Choreographiesamt Grounding in MCDL und für die Funktionalität die Capability zu definieren.
Fazit WSMO/L unterstützt die Beschreibung der geforderten Semantiken. Wiebei OWL-S können die Anforderungen bezüglich der ontologiebasierten Beschrei-bung von Komponenten sowie Einbindung und Trennung weiterer Ontologien er-füllt werden. Übertragbare Ideen sind die strikte Trennung der Beschreibung vonAngebot und Nachfrage und die Bereitstellung von Mediatoren als Web Servicebzw. Komponente. In WSML-Ontologien formulierte Konzepte könnten das konzep-tionelle Modell für die Annotationen in MCDL liefern. Ein Pluspunkt von WSMList die Modularisierung in verschiedene Varianten, wodurch über Beschreibungs-logik hinausführende Sprachelemente, wie logische Regeln, verwendbar sind, ohneeine Mischung mit anderen Sprachen zu erfordern. Problematisch für eine direkteAnwendung im Konzept sind folgende Punkte: Es fehlt auch hier ein Konzept für
Copyright TU Dresden, Carsten Radeck 31

Semantische Komposition in Mashups Kapitel 3 Stand der Forschung und Technik
Properties, während Operationen als die Eingaben und Ereignisse als die Ausga-ben aufgefasst werden können. WSMO basiert auf einer reichhaltigen semantischenBeschreibung der Funktionalität in Capability und Interface auf Basis von Zustands-übergängen. Dieses Modell ist sehr detailliert, aber aufwändig zu erstellen. Zudemexistiert dabei ein direkter Bezug auf die in Nachrichten erhaltenen Instanzdaten,was in CRUISe derzeit nicht vorgesehen ist (vgl. Kapitel 2.3). Für die Einbindungin MCDL gilt Ähnliches wie bezüglich OWL-S diskutiert.
3.1.2.3 USDL
Die Universal Service Description Language (USDL, derzeit in Version 3.0) [Res10]wurde in mehreren Projekten von SAP-Research entwickelt. Sie bietet einen Top-Down Ansatz auf Basis eines Metamodells in MOF [Gro06] mit dem Ziel einervereinheitlichten Beschreibung generischer Dienste. Das heißt, dass USDL nicht aufautomatische Web Services beschränkt ist, sondern auch semi-automatische und ma-nuelle, z. B. handwerkliche, Dienste unterstützt. Dabei liegt der Fokus auf geschäft-lichen Aspekten und Geschäftsprozessen, um die bisher bestehende Lücke zwischendiesen und der technischen Perspektive auf Dienste zu schließen. USDL ergänztbestehende Technologien, wie WSDL, referenziert diese und bietet somit einen ein-heitlichen Ansatzpunkt.Das Metamodell ist in mehrere Module untergliedert, die in der Gesamtheit alle
Aspekte eines Dienstes abdecken. Das Foundation Module enthält Basiskonzepte,wie Agent, Classification und ElementDescription. Letzteres dient der Beschreibunganderer Elemente durch natürlichsprachliche Texte, Schlüsselworte oder Referenzenauf externe Ontologien und ist für die meisten Elemente vorgesehen. Das FunctionalModule dient zur Modellierung der konzeptionellen Funktionalität (auf Basis infor-meller Capabilities, die mehrere Actions mit IOPE umfassen) und optional ihrertechnischen Realisierung (Protokolle, Interface aus Operationen samt IO und Be-dingungen in beliebiger formaler Sprache). Im Interaction Module wird das externbeobachtbare Verhalten des Dienstes im Interaktionsprotokoll beschrieben. Diesesumfasst Phasen, die wiederum eine geordnete Menge von Interaktionen beinhalten.Eine formale Verhaltensbeschreibung ist nicht anvisiert, kann aber referenziert wer-den. Der Anbieter, Beteiligte an der Bereitstellung und Zielgruppen des Diensteskönnen anhand des Participation Module modelliert werden. Konzepte bezüglichder Preisgestaltung eines Dienstes umfasst das Pricing Module. Weitere Module fürrechtliche Regelungen und Service Level Agreements sind in Entwicklung. Schließ-lich definiert das Core Module Konzepte für (komponierte) Dienste und verbindetsie mit denen anderer Module zur gesamten Dienstbeschreibung.
Fazit USDL profitiert von stetigen Bemühungen, z. B. hin zur offenen Standardi-sierung, und aktiver Entwicklung. Derzeit wurde jedoch noch keine konkrete Syntaxspezifiziert, was eine direkte Nutzung erschwert. Da USDL auch durch Personenverwendet werden soll, tritt weniger formale Semantik als z. B. bei WSMO/L auf,jedoch sind natürlichsprachliche Texte weniger relevant für das Konzept. Aufgrunddes Fokus auf generische Dienste würde in CRUISe derzeit nur eine Teilmenge allerUSDL-Konzepte benötigt, die restlichen stünden aber bei Bedarf bereit. ElementDe-scription und Bedingungen erlauben die semantische Beschreibung der technischen
Copyright TU Dresden, Carsten Radeck 32

Semantische Komposition in Mashups Kapitel 3 Stand der Forschung und Technik
Schnittstelle von Diensten, sodass wichtige Semantiken abgedeckt sind. Für eine di-rekte Nutzung in CRUISe fehlt USDL aber z. B. das Konzept von Properties undim Vergleich zum Kompositionsmodell UI-bezogene Konzepte, wie Layouts. Anre-gungen, wie ElementDescription oder Elemente, um auch geschäftliche und pro-zessorientierte Aspekte zu modellieren, können jedoch in das Kompositionsmodelleinfließen.
3.1.3 Bottom-Up AnsätzeWSMO und OWL-S verstecken die WSDL hinter Groundingmechanismen und visie-ren die vollständige Automatisierung der Nutzung von Web Services an. Nach Ko-pecký und Vitvar [KV08] sei diese, wie die Praxis zeige, jedoch unerreichbar und dieWSDL wegen ihrer Bekanntheit ein zentraler Bestandteil von Frameworks für SWS.Zudem sollte keine komplette semantische Beschreibung von Web Services gefor-dert sein, sondern je nach benötigter Automatisierung eine stückweise [ebd.]. Daherwerden leichtgewichtige Bottom-Up Ansätze motiviert, die auf den bewährten Stan-dards (WSDL) aufsetzen, diese inkrementell (und weiterhin standardkonform) mitSemantik anreichern und mit herkömmlichen Werkzeugen genutzt werden können.In diese Kategorie gehören mehrere Vorschläge, wie WSDL-S [AFM+05], SAWSDL[FL07], SESMA [Pee05] und USDL [KBS+09]. SESMA wird jedoch nicht weiter-entwickelt und USDL-Annotationen basieren auf der WordNet-Ontologie2, was mitEinschränkungen (auf Englisch und linguistische Beziehungen zwischen Konzepten,wie Synonym) einhergeht. Daher werden diese Ansätze nicht weiter betrachtet.
SAWSDL [FL07] nutzt die Erweiterbarkeit der WSDL aus und basiert auf WSDL-S, das im Projekt METEOR-S entwickelt wurde [AFM+05]. Es reichert die WSDL-Beschreibung eines Web Service um mehrere Attribute an (vgl. Listing 3.3). DasAttribut modelReference erlaubt es, verschiedenste Elemente einer Beschreibung inWSDL mit einer Liste von URIs zu annotieren. Diese URIs referenzieren Konzeptein einem typischerweise externen Modell3, dessen Repräsentation und Formalismusnicht vorgeschrieben ist. Auch eine Beziehung zwischen mehren Annotationen istnicht spezifiziert. Das Attribut kann an die XML Schema Definition (XSD) für Ele-mente, Attribute und Typen (Zeile 4-6), sowie an WSDL-Elemente, wie interface,operation und fault, gebunden werden (Zeile 11-12). Als Brücke zwischen der syn-taktischen und semantischen Ebene dienen Schema Mappings: liftingSchemaMap-ping enthält Referenzen (URIs) auf Abbildungen von XML-Schema Definitionen aufsemantische Konzepte und loweringSchemaMapping auf Abbildungen für die entge-gengesetzte Richtung. Die verwendete Transformationssprache ist prinzipiell nichtvorgeschrieben und wiederum können mehrere URIs für alternative Transformati-onssprachen angegeben werden. Schema Mappings sind für Laufzeitaspekte, v. a.Mediation, relevant, während Modellreferenzen insbesondere zur Discovery dienen.Die in WSDL-S vorgesehenen erweiternden Elemente zur Angabe von Vorbedin-
gungen und Effekten von WSDL-Operationen wurden in SAWSDL verworfen, dadarüber keine Einigung in der SWS Community herrscht [FKZ08, S.298]. Auch daszusätzliche Element category ist in SAWSDL nicht mehr vorzufinden. Angemerkt
2siehe z. B. http://www.w3.org/TR/wordnet-rdf/3Auch eine Integration von RDF-Graphen in WSDL ist mittels des <rdf:RDF>-Tags möglich.
Copyright TU Dresden, Carsten Radeck 33

Semantische Komposition in Mashups Kapitel 3 Stand der Forschung und Technik
sei, dass diese Annotationen unter Zuhilfenahme von modelReferences trotzdem rea-lisierbar sind.
1 <wsdl11 : definitions name=" OrderService " ... >2 <wsdl11 :types >3 <xs: schema ... >4 <xs: element name=" OrderRequest "5 sawsdl : modelReference ="http ://.../ purchaseorder # OrderRequest "6 sawsdl : liftingSchemaMapping ="http ://.../ Response2Ont .xslt">7 </xs:element > ...8 </xs:schema >9 </ wsdl11 :types > ...
10 <wsdl11 : message name=" OrderResponseMessage ">11 <wsdl11 :part name=" OrderResponse " type=" Confirmation "12 sawsdl : modelReference = "http ://.../ purchaseorder # OrderConfirmation "/>13 </ wsdl11 :message > ...
Listing 3.3: Ausschnitt einer Beschreibung eines Web Service SAWSDL (nach [FL07])
SAWSDL ermöglicht partielle semantische Beschreibungen von Web Services undzeichnet sich durch seine hohe Flexibilität und Einfachheit aus. Damit einhergehendwerden in der Literatur aber Nachteile attestiert: Fragestellungen nach Komplexitätund Ausdrucksmächtigkeit der Modellierungssprache werden nur verlagert [LHK09]und Interoperabilitätsprobleme bei der Vermischung verschiedener Frameworks zurAnnotation können auftreten [PWM07]. Zudem sind zusätzliche Spezifikationen vonKonventionen und Richtlinien zur Nutzung der sehr generischen Attribute in einemkonkreten Anwendungskontext essentiell [MPW07], z. B. hinsichtlich der referenzier-ten Konzepte, der Ontologie- und Transformationssprache sowie Details der tatsäch-lichen Verwendung der Schema Mappings, z. B. woher die semantischen Daten zumLowering stammen.Martin et al. [MBM+07] unterbreiten Vorschläge für Richtlinien zur Verwendung
von SAWSDL im Zusammenspiel mit OWL-S, d. h., welche OWL-S-Konzepte durchmodelReferences an welchen WSDL-Elementen referenziert werden sollten. Beispiels-weise wird nahegelegt, WSDL-Interfaces mit einem Profile zu annotieren.YASA [CTO10] erweitert den SAWSDL-Ansatz um das Attribut serviceConcept
(vgl. Listing 3.4), welches eine Liste von Verweisen auf ein »technisches« Konzeptder Ontologie eines Komponentenmodells beinhaltet. Die Reihenfolge der Einträgevon serviceConcept und modelReference ist bei der Annotation genau zu beachten,da beide Listen korrespondieren, d. h., dass im Beispiel »yetFreePlace« eine Annah-me und »confirmation« ein Effekt ist. Dieses Prinzip könnte in das zu entwickelndeKonzept einfließen, da somit verschiedene Annotationen, z. B. an Operationen, ein-fach unterschieden werden können, ohne die Erweiterbarkeit zu beeinträchtigen.
1 <wsdl: operation name=" confirmReservation "2 serviceConcept =" Assumption Effect "3 modelReference =" yetFreePlace confirmation "> ...
Listing 3.4: YASA Erweiterung von SAWSDL (nach [CTO10])
Eine weitere Möglichkeit, das Fehlen eines expliziten konzeptionellen Modells zukompensieren, ist WSMO-Lite [KV08, KVF09a]. Dabei handelt es sich um eineOntologie in RDF-Schema zur semantischen Beschreibung von Web Services, diedirekt auf SAWSDL aufsetzt. Sie ist modular, sodass je nach benötigter Automati-sierung unterschiedlich umfangreiche Annotation nötig sind. WSMO-Lite adaptiertdas Modell von WSMO und »erleichtert« dessen Semantik, z. B. werden nur Vorbe-dingungen und Effekte unterschieden und Verhaltenssemantik nicht explizit definiert[KVF09a]. WSMO-Lite umfasst folgende Hauptkonzepte:
Copyright TU Dresden, Carsten Radeck 34

Semantische Komposition in Mashups Kapitel 3 Stand der Forschung und Technik
• Ontology dient zur Einbeziehung von Ontologien, die das Information Modelbeschreiben, und erbt von der OWL-Klasse Ontology.• FunctionalClassificationRoot ist die Wurzel einer funktionalen Klassifikation
von Web Services.• NonFunctionalParameter definiert einen Platzhalter für eine konkrete nicht-
funktionale Eigenschaften der Domänenontologie.• Condition und Effect werden in einer Logiksprache verfasst und ergeben zu-
sammen eine Capability.Auf Basis dieser Konzepte kann eine domänenspezifische Dienstontologie erstellt undihre Konzepte folglich in SAWSDL referenziert werden. Hierfür sind fünf Annotati-onsarten definiert (vgl. Abbildung 3.2): Annotation des XML-Schemas der WSDLmit Ontologiekonzepten (A1) und Abbildungen zur Transformation zwischen dersyntaktischen und semantischen Ebene (A2); funktionale Annotation von WSDL-Interface und Service (A3) oder Operationen (A4) mit einer Kategorisierung oderCapabilities; nicht-funktionale Annotation von WSDL-Service (A5).
WSMO-Lite Service Ontology
WSDL
ServiceInterfaceOperationXML Schema (Typ
oder Element)
Ontologiekonzept Transformation Capability KategorieNicht-funktionale
Eigenschaft
A1 A2 A5A3A4
Se
ma
ntisch
e
Eb
en
e
Syn
taktisch
e
Eb
en
eAbbildung 3.2: Annotationen in WSMO-Lite (nach [KVF09a])
Das grundlegende Prinzip von SAWSDL wurde auch auf die Beschreibung vonREST-basierten Web Services, die oftmals in HTML-Seiten dokumentiert sind,übertragen. Diverse Ansätze, wie MicroWSMO [MKP09, KVF09b] und SemanticAnnotations for REST (SA-REST) [SGL07], setzen an dieser Stelle an: Verschie-dene Microformate, d. h. annotierte und somit maschinell verarbeitbare HTML-Beschreibungen, werden um die Einbettung semantischer Annotationen erweitert.Diese Annotationen orientieren sich am Konzept der Modellreferenzen und auch Ab-bildungen zum Lifting und Lowering sind vorgesehen. Für die Beschreibung vonMashup-Komponenten wurde ebenfalls die Übertragung des Prinzips [BAM10]oder die direkte Nutzung [NCSyP10] von SAWSDL vorgeschlagen. Dem Ansatz vonBianchini et al. [BAM10] liegt ein ähnliches Komponentenmodell wie in CRUISezugrunde: Semantic Descriptors beschreiben eine Komponente durch Kategorien,Operationen und Ereignisse, beide mit Ein- bzw. Ausgabeparametern, und annotie-ren diese mit Ontologiekonzepten. Dies untermauert die Eignung des Prinzips fürdas Konzept. Aufgrund der prinzipiellen Übereinstimmung mit SAWSDL werden dieAnsätze jedoch nicht näher vorgestellt.
Fazit Mit SAWSDL können die wichtigsten geforderten Semantiken beschriebenwerden. Bei Bedarf ist es in Kombination mit WSMO-Lite zudem möglich, aus den
Copyright TU Dresden, Carsten Radeck 35

Semantische Komposition in Mashups Kapitel 3 Stand der Forschung und Technik
Operationen und deren Vorbedingungen und Effekten eine Choreographie in WSMLabzuleiten. Ontologien liegen separat vor und können implizit durch Referenzierungeingebunden werden. Aufgrund der Integration in WSDL, die ein anderes Kom-ponentenmodell als in CRUISe unterstellt, ist SAWSDL nicht direkt im Konzeptnutzbar. Aber das Grundprinzip, die Erweiterung um Annotationsattribute, kannauf MCDL angewendet werden. Neben dem vorhandenen Attribut modelReferenceder MCDL, könnten auch die Schema Mappings übertragen werden. Der Erhalt derMCDL wäre wegen des Bottom-Up Ansatzes gegeben und für das Referenzszenario(Kapitel 2.4) wären die MCDLs nur um Referenzen anzureichern. Grundlegend trittjedoch das erwähnte Problem fehlender Richtlinien und Konventionen auf. Solchesind für eine konkrete Verwendung unbedingt zu definieren, um den Ansatz sinnvollzu nutzen. Als Vorbild können z. B. die Annotationen von WSMO-Lite dienen.
3.1.4 Beschreibung von Komponenten im Bereich CBSEBestehende Beschreibungssprachen für Komponenten der industriellen Praxis ausdem Bereich komponentenbasierter Softwareentwicklung (CBSE), z. B. der Deploy-ment Descriptor von Enterprise JavaBeans, sind auf die deklarative, syntaktischeDefinition von Operationen, Datentypen, Abhängigkeiten und die Konfiguration vonMiddlewareaspekten, wie Transaktion, fokussiert. Diese Informationen sind primärauf das Deployment ausgerichtet [Tes03, S.46]. Forschungsansätze konzentrieren sichinsbesondere auf die Verhaltenssemantik basierend auf den in Kapitel 3.1.1 erwähn-ten Formalismen. Ansätze zur semantischen Annotation von Komponenten wurdenvorgeschlagen, z. B. Semantic Properties, die auf dem Formalismus der Typtheorieberuhen [Kin02] und in die Dokumentation im Quellcode eingebracht werden. Diesesind jedoch nicht direkt geeignet, da in CRUISe eine externe Komponentenbeschrei-bung vorliegt. Besonders im Hinblick auf Wiederverwendbarkeit und Auffinden vonKomponenten wurden schlüsselwortbasierte und Ansätze auf Basis von (Facetten-)Klassifikationen untersucht [NXX10]. Vorteil ersterer ist die Einfachheit und ho-he Geschwindigkeit, aber logische Beziehungen werden nicht ausgenutzt. Auch dieNutzung externer Komponentenbeschreibungen, die mit Beschreibungslogik angerei-chert werden, wurde vor geraumer Zeit vorgeschlagen [BD99]. Die Ideen des Seman-tic Webs bzw. SWS flossen ebenfalls in die Beschreibung von Softwarekomponentenein. Da diese ähnliche Konzepte wie die in Kapitel 3.1.2 und 3.1.3 betrachteten An-sätze umfassen, sollen sie an dieser Stelle nur kurz erwähnt werden. So erstellen dieAutoren in [LWCL08, NXX10] Ontologien in OWL. Beide sehen u. a. Basisinforma-tionen, wie Name und Anbieter, die funktionale Schnittstelle und QoS-Eigenschaftender Komponente vor. Pahl [Pah07] schlägt ebenfalls die Verwendung von Ontologienvor und entwickelt dafür eine eigene Beschreibungslogik, in der Operationen mit Vor-, Nachbedingungen und Invarianten, und die Verhaltenssemantik von Komponentenmit Interaktionsprotokollen beschrieben werden. Einer direkten Nutzung der Ansät-ze steht deren fehlende Unterstützung von Konzepten des Komponentenmodells vonCRUISe entgegen. Der Ansatz von Yao et al. [YEV08] analysiert Softwarekompo-nenten und transformiert das extrahierte Wissen in einen RDF-Graphen basierendauf OWL-Ontologien. Korthaus et al. [KSS07] annotieren vorhandene (graphische)Komponentenbeschreibungen mit Ontologiekonzepten und repräsentieren diese so-mit in RDF-Schema oder OWL. Oberle et al. [OESV04] nutzen eine Beschreibung
Copyright TU Dresden, Carsten Radeck 36

Semantische Komposition in Mashups Kapitel 3 Stand der Forschung und Technik
von Komponenten basierend auf OWL-S im Kontext eines Java Anwendungsservers.Bestehende Beschreibungen, z. B. web.xml, und Annotationen im Quellcode werdenin die Ontologiekonzepte konvertiert. Die Ontologie enthält generische und domä-nenspezifische Module. Erstere umfassen z. B. die Beschreibung der Funktionalitätvon Operationen in einer Taxonomie, die Semantik der Parameter und der Fähig-keiten der Komponente. Somit deckt der Ansatz wesentliche Semantiken ab, müssteaber ebenfalls für die Nutzung in CRUISe hinsichtlich des Komponentenmodells umKonzepte, wie Properties, erweitert werden.
3.1.5 FazitWie an den Vertretern deutlich wurde, erlauben Top-Down Ansätze eine umfas-sende semantische Beschreibung von Web Services. Ein Vorteil des Ansatzes ist,dass sie Mittel für alle geforderten Arten der Semantik bieten. Somit ist theoretischdie komplette Automatisierung beginnend bei der Suche bis zur Ausführung vonSWS möglich. Ein Nachteil von Top-Down Ansätzen ist der hohe Aufwand bei derEinbindung bestehender nicht-semantischer Beschreibungen, d. h. sie in Bottom-Up-Manier zu verwenden [KV08], und bei der Erstellung neuer Beschreibungen. Dies istinsbesondere ihrer Komplexität geschuldet. Zudem existieren mindestens zwei Be-schreibungen eines Web Service und neue Ausführungsumgebungen und Werkzeugesind zu implementieren. Die vorgeschlagenen Modelle nehmen eine vergleichbareStellung wie die Teile des Kompositionsmodells von CRUISe ein, welche die Kom-ponenten und deren Komposition beschreiben. Eine Option für das zu entwickelndeKonzept wäre daher die Repräsentation des Komponentenmodells von CRUISe ineiner Ontologie und Auffassung von MCDLs als Instanzen dieser. Damit wäre Re-asoning und eine analoge Hierarchie der MOF-Ebenen [Gro06] wie bei WSMO/Lmöglich (auf M2: WSMO � Kompositionsmodell, auf M1/0: WSML-Ontologien �»Komponentenontologie«). Weiterhin sind vorgeschlagene Konzepte auf das Kom-positionsmodell übertragbar, z. B. Mediators und ElementDescription.Der Vorteil von Bottom-Up Ansätzen ist der Erhalt vorhandener Technologien und
die einfache inkrementelle Erweiterung um wirklich benötigte Mittel zur semanti-schen Beschreibung. Sollte der flexible Ansatz von SAWSDL im Konzept genutztwerden, so ist die genaue Verwendung der Attribute zur Annotation mit Konventio-nen zu klären. Hierfür wurde die Kombination von SAWSDL und den konzeptionel-len Modellen von Top-Down Ansätzen vorgeschlagen, d. h., das Grounding wird mitAnnotationen der WSDL vorgenommen, oder anders herum, die Referenzen zeigenauf Instanzen der Modelle. Eine solche Kombination, z. B. mit der oben erwähn-ten Ontologie des Komponentenmodells, ist für das Konzept unnötig, da die MCDLeinem Ausschnitt des Kompositionsmodells entspricht (siehe Kapitel 2.2.2.1). Ei-ne Option wäre die Übertragung z. B. in WSMO-Lite vorgeschlagener Richtlinienfür die Annotationen. Durch die Annotation der MCDL wäre ihr Erhalt und dieErweiterbarkeit der Komponentenbeschreibung gewährleistet.
3.2 DiscoveryDa für das zu entwickelnde Konzept eine semantische Discovery gefordert ist, werdennun unterbreitete Ansätze dafür aus der Forschung untersucht.
Copyright TU Dresden, Carsten Radeck 37

Semantische Komposition in Mashups Kapitel 3 Stand der Forschung und Technik
Klusch [Klu08] unterscheidet Verfahren zur Suche passender Web Services abhän-gig von den verwendeten Reasoningmitteln in drei Kategorien. Logikbasierte Verfah-ren nutzen logische Inferenz über die semantischen Annotationen der Web Services.Nicht-logikbasierte nutzen implizite Semantik aus und basieren auf verschiedenenMethoden, wie Metriken der syntaktischen Ähnlichkeit, Graphvergleiche, linguisti-sche Vergleiche, Mustersuche, pfadtiefenbasierte Ähnlichkeit von Konzepten und derHäufigkeit von Termen in der Beschreibung. Hybride Verfahren zum Matchmakingkombinieren beide Ansätze. [SVSM03] motivieren neben den Ein- und Ausgabenauch Vor- und Nachbedingungen in das Matchmaking einzubeziehen, da ansonstendie Funktionalität möglicherweise nicht mit der Anfrage übereinstimmt. Zum Bei-spiel passt der Eingabeparameter von Komponente C im Referenzszenario (Kapitel2.4) zur Anfrage, aber ein anderer Effekt ist zu erwarten.Verfahren zur Discovery sind neben Komplexitätsbetrachtungen anhand von Prä-
zision, d. h. der Anteil der relevanten gefundenen Komponenten an allen gefundenKomponenten, und Trefferquote, d. h. der Anteil der gefundenen relevanten Kompo-nenten an allen relevanten Komponenten, bewertbar. Diese sind im Allgemeinen in-direkt proportional zueinander, sodass ein guter Kompromiss angestrebt wird [Tes03,S.5]. Küster et al. argumentieren, dass verglichen mit den Anstrengungen der For-schung bezüglich Verfahren zur SWS Discovery, die immer ausgereifter werden, zuwenige Methoden und Testumgebungen zur komparativen Evaluation der verschie-denen Ansätze entwickelt wurden [KLKR08]. Eine solche Evaluation ist in dieserArbeit nicht angestrebt, jedoch werden nachfolgend prinzipielle Verfahren anhandder Anforderungen im Rahmen von CRUISe analysiert.In diesem Unterkapitel stehen verschiedene Gesichtspunkte bezüglich Discovery
im Blickpunkt, um mögliche Lösungsstrategien für das Konzept abzuleiten. Zunächstwerden Optionen der Art der Anfrage an die Discovery betrachtet. Anschließendfolgt die Analyse ausgewählter Verfahren zum logikbasierten, nicht-logikbasiertenund hybriden Matchmaking sowie zur semantischen Rangfolgebildung.
3.2.1 Alternativen für die Art der AnfrageEine grundlegende Herausforderung für die Discovery ist es, eine geeignete Artder Anfrage, die das zu erfüllende Ziel beinhaltet, zu definieren. So wurde natürli-che Sprache vorgeschlagen, die verarbeitet und semantisch repräsentiert wird (z. B.[YEV08]). Problematisch hierbei ist jedoch die Unterstützung verschiedener Spra-chen und die maschinelle Nutzung. Weiterhin sind dedizierte Anfragesprachen, z. B.SPARQL in [SMM10], nutzbar, was aber von der zugrundeliegenden Repräsentati-on, z. B. RDF, und der Ausdrucksfähigkeit der Sprache abhängt. Im Rahmen vonSWS erfolgt die Anfrage i. d. R. direkt in der Beschreibungssprache des Web Serviceselbst, z. B. in Form eines WSML-Dokuments. Prinzipiell lässt sich dabei unterschei-den, ob verschiedene konzeptionelle Elemente für die Beschreibung von Angebot undNachfrage existieren. So wird z. B. bei Ansätzen, die auf OWL-S (Kapitel 3.1.2.1)beruhen, das Profile für beide Fälle genutzt. Die Anfrage kann dann als Vorlage füreinen »idealen« Web Service aufgefasst werden. Eine strikte konzeptionelle Trennungerfolgt hingegen z. B. in WSMO (Kapitel 3.1.2.2). Abhängig von der Beschreibungkönnen beide Ansätze die notwendigen (semantischen) Informationen bereitstellen.Die Unterscheidung bei WSMO verbessert die Trennung der Belange, da ein Nutzer
Copyright TU Dresden, Carsten Radeck 38

Semantische Komposition in Mashups Kapitel 3 Stand der Forschung und Technik
sein Ziel aus eigener Sicht und in eigenem Vokabular angeben kann. StrukturelleUnterschiede zwischen Goal und Web Service sind hingegen marginal, insbesonderedie Angabe gewünschter Capabilities im Goal ist auf Nachbedingungen und Effektebeschränkt. Daher ist auch dieser Ansatz letztlich als eine Vorlage zu verstehen.
Fazit Für diese Arbeit ist das Grundprinzip von Vorlagen für »ideale« Kompo-nenten vielversprechend, da die betrachtete Anfrage in CRUISe von der Runtimestammt und davon ausgegangen wird, dass die Anwendung zur Entwicklungszeitmit vorhandenen Komponenten modelliert wird. Daher ist auch die Perspektive desNutzers nur mittelbar relevant – diese kann im Integration Service durch Kontext-informationen einfließen.
3.2.2 Discovery auf Basis von BeschreibungslogikGrundgedanke bei Verfahren zur Discovery auf Basis von Ontologien in Beschrei-bungslogik [BCM+03] ist die Auffassung von Request (R) und Advertisement (A)als Konzepte der Ontologien. Anschließend wird durch Schlussfolgerung logischerBeziehungen zwischen Request und Advertisement der Grad der Übereinstimmungberechnet. In Beschreibungslogik ist Subsumption (C v D . . .D subsumiert C, d. h.,die Menge von Instanzen, die zu C gehören, ist Teilmenge der Instanzen von D) einentscheidendes Mittel zur Schlussfolgerung. Darauf aufsetzend schlagen Li und Hor-rocks [LH03] – basierend auf Ergebnissen aus [PKPS02] – die folgenden Grade inabsteigender Ordnung vor:
Exact R ≡ A: R und A sind äquivalent.PlugIn R v A: R wird von A subsumiert, d. h., R ist Subkonzept von A.Subsume A v R: A wird von R subsumiert, d. h., R ist ein Superkonzept von A.Intersection ¬(R u A v ⊥): Es existieren Überschneidungen zwischen R und A.Disjoint R u A v ⊥: Es existieren keinerlei Überschneidungen zwischen R und A.
Anhand des Referenzszenarios (Kapitel 2.4) soll der Unterschied zwischen PlugInund Subsume verdeutlicht werden. Angenommen das Konzept (Class in OWL DL)EventLocation spezialisiert Location, z. B. durch eine subClassOf-Beziehung inOWL DL, um eine Rolle (Property in OWL DL) hasEvent und die Übereinstim-mung für den Parameter einer Operation der angefragten und angebotenen Kompo-nente ist gesucht. Für Komponente B gilt A v R (Subsume), da sie EventLocationunterstützt und Location angefragt wird. Somit ist nicht anzunehmen, dass dieOperation setLocation jede Location als Eingabe verarbeiten kann, falls hasEventfehlt. Würde sie das Parameterkonzept Location bieten und EventLocation in derAnfrage benötigt werden, läge PlugIn vor.Fensel et al. [FKZ08, S.174ff] erweitern diese Beziehungen um die Intention des
Dienstnutzers und -anbieters bei der Angabe von R bzw. A und differenzieren uni-verselle (alle Konzepte gefordert) und existentielle (einige Konzepte gefordert). Da-durch ergibt sich eine präzisere Unterscheidung der Übereinstimmungsgrade, dennz. B. eine mengentheoretische Intersection entspricht einem Match, falls das Angebotuniversell und die Anfrage existentiell verstanden wird. Dieses Prinzip kann in dasKonzept einfließen, falls ein solches Verfahren zur Discovery genutzt wird.
Copyright TU Dresden, Carsten Radeck 39

Semantische Komposition in Mashups Kapitel 3 Stand der Forschung und Technik
Ein Matchmaking basierend auf Ontologien in Beschreibungslogik wird von einerVielzahl von Ansätzen benutzt, z. B. [PKPS02, SVSM03, HMH+10, CTO10, ZHS08,JRGL+05], wobei typischerweise die Ein- und Ausgaben geprüft werden.
Abbildung 3.3: Vorschlag zum Matchmaking von [JRGL+05]
Stellvertretend wird der Ansatz von Jaeger et al. [JRGL+05] vorgestellt, da dieserzusätzlich die funktionale Kategorie und nutzerdefinierte Anforderungen einbezieht.Der Algorithmus zum Matchmaking von in OWL-S beschriebenen Web Services um-fasst vier Schritte (siehe Abbildung 3.3): Die Ontologiekonzepte der Eingaben, Aus-gaben sowie der Kategorie des Web Service werden durch Subsumptionsanfragen ab-geglichen. Dabei unterscheiden die Autoren drei Übereinstimmungsgrade: Fail, Sub-sumes, Exact. Bei Ein- und Ausgaben kommt das Konzept der Contravariance zumTragen: Die Subsumes-Beziehung ist für beide umgekehrt, d. h. subsumes(reqInputi,provInputj) und subsumes(provOutputm, reqOutputn). Schließlich können nutzer-definierte Anforderungen sichergestellt werden, was nicht durch Reasoning über dieOntologie möglich wäre. Als Beispiel sind kontextspezifische, z. B. die Verfügbarkeiteines Dienstes an einer geografischen Position, oder QoS-Anforderungen, wie dasEinhalten eines Mindestwerts für Verfügbarkeit, zu nennen. Die ersten drei Stufenliefern ein ganzzahliges Ergebnis, das den Übereinstimmungsgrad reflektiert. DasGesamtergebnis errechnet sich aus der Aggregation mit Schritt vier, wobei nichtfestgeschrieben ist, wie und in welchem Wertebereich. So können unterschiedlicheGewichtungen vorgenommen werden, um einen numerischen Wert zu liefern, odernur die boolesche Aussage, ob der Web Service den Anforderungen gerecht wird.YASA-M [CTO10] basiert auf einer Erweiterung von SAWSDL (siehe Kapitel
3.1.3) und führt ebenfalls logikbasiertes Matchmaking durch, unterscheidet jedochweitere Übereinstimmungsgrade, wie Has-Same-Class, der ausdrückt, dass die Kon-zepte von Anfrage und Angebot Subkonzepte eines selben Konzepts sind. Die Funk-tionalität wird durch Einbeziehung von Effekten und Bedingungen in das Matchingabgeglichen. Zudem findet eine Vorselektion in Frage kommender Web Services statt:Eine SPARQL-Anfrage an ein Repositorium basierend auf RDF filtert alle Kandida-ten, die von der Anzahl der Interfaces, Operationen, Ein- und Ausgaben überhauptgeeignet wären. Ein ähnliches Vorgehen könnte auf das Konzept übertragen werden.
Copyright TU Dresden, Carsten Radeck 40

Semantische Komposition in Mashups Kapitel 3 Stand der Forschung und Technik
Fazit Das semantische Matchmaking auf Basis von Subsumptionsbeziehungen zwi-schen Ontologiekonzepten in Beschreibungslogik erlaubt das Auffinden von Kompo-nenten unabhängig von der Uneindeutigkeit der Syntax und ist durch seine Ent-scheidbarkeit charakterisiert. Weiterhin liegt eine mengentheoretische Anschauungvon Anfrage und Angebot zugrunde, die einfach und intuitiv ist (vgl. [FKZ08,S.182]). Zwar ist die Genauigkeit des Verfahrens limitiert, da – im Gegensatz zur»reichhaltigen« Beschreibung (vgl. Kapitel 3.1.1) – die tatsächliche Beziehung zwi-schen Ein- und Ausgaben nicht beschrieben wird [ebd.]. Dafür ist die Komplexitätund somit der Berechnungsaufwand bei der Discovery geringer. Außerdem ist inCRUISe im Allgemeinen keine Beziehung zwischen Ein- und Ausgaben zu unter-stellen (vgl. Kapitel 2.3). Typische Anfragen, die an die Discovery gestellt werden(vgl. Kapitel 2.3), sind auf Basis einer »einfachen« semantischen Beschreibung be-reits realisierbar. Somit ist das hier vorgestellte Verfahren zum Matchmaking imKonzept geeignet. Im Referenzszenario (Kapitel 2.4) würde z. B. festgestellt werden,dass die Funktionalität von Komponente C, aufgefasst als Ontologiekonzept, in kei-ner Beziehung zur angeforderten steht. Ein rein semantisches Matchmaking kannden Anforderungen jedoch nicht gerecht werden, weil auch syntaktische Informatio-nen, wie Datentypen, auf Übereinstimmung mit der Anfrage zu prüfen sind. Dahermüsste der Ansatz erweitert werden.
3.2.3 Nicht-logikbasierte Discovery mit XML-Schema-MatchingSchema-Matching ist die Identifizierung von Korrespondenzen zwischen Entitätenzweier Schemata. Letztere sind dabei prinzipiell nicht auf XML-Schema-Definitionenbegrenzt, sondern u. a. auch Ontologien und Entity-Relationship-Modelle könnenzur Beschreibung der Schemata dienen. In diesem Kapitel liegt der Fokus jedoch aufXML-Schema-Definitionen, da Datentypen in MCDL auf diesen aufbauen. Weil dasMatching manuell aufwändig und fehleranfällig ist, wird eine zumindest teilweiseAutomatisierung dessen angestrebt. Schema-Matching kann als ein Prozess aufge-fasst werden, der als Eingabe die Schemata, Parameter, z. B. Schwellenwerte undGewichtungen, und externe Ressourcen, wie Thesauri, verwendet, um die Beziehun-gen zwischen Entitäten der Schemata auszugeben (das Schema-Mapping).Einen oft zitierten Überblick samt Klassifikation von Verfahren, deren Informati-
onsquelle einzig das Schema und keine Instanzdaten sind, bieten Shvaiko and Eu-zenat [SE05]. Sie schlagen dabei zwei Klassifikationsbäume mit gemeinsamen Blät-tern, die die elementaren Techniken beinhalten, vor. Exemplarisch wird der erstevorgestellt. Er unterscheidet Verfahren nach der Granularität (Element- und Struk-turebene) und der Interpretation der Eingaben (rein syntaktisch, mit Ausnutzungformaler Semantik oder externen Wissens, wie Thesauri). Auf Elementebene werdenEntitäten in Isolation betrachtet. Typische elementare Techniken sind dabei:
• Stringbasiert (syntaktisch): Vergleich der Namen oder Beschreibungen von En-titäten, z. B. Elementen in XML-Schema-Definitionen. Ein Beispiel für ein kon-kretes Verfahren ist die Berechnung der Edit-Distanz : Sie ist ein Maß für dieminimale Anzahl von Einfüge-, Löschoperationen und Ersetzungen, die nötigsind, um die Eingabe in die Ausgabe zu überführen.• Linguistisch (syntaktisch): Diese Verfahren interpretieren die Namen von En-
titäten als Wörter einer natürlichen Sprache. Typische Verfahren verarbeiten
Copyright TU Dresden, Carsten Radeck 41

Semantische Komposition in Mashups Kapitel 3 Stand der Forschung und Technik
die Zeichenketten z. B. durch Tokenisierung, Überführung in die Grundformund Auflösung von Abkürzungen.• Constraint-based (syntaktisch): Diese Algorithmen handhaben Zusicherungen
der Definition von Entitäten, z. B. Datentypen, und vergleichen sie.• Linguistische Ressourcen (extern): Hierbei werden externe Wissensquellen, wie
Thesauri einbezogen, um die Ähnlichkeit von Namen von Entitäten basierendauf linguistischen Beziehungen, wie Synonym, festzustellen. [KA09] weisendaraufhin, dass die beim XML-Schema-Matching oftmals praktizierte Einbe-ziehung von Thesauri, i. d. R. WordNet4, problematisch ist, da dieser Ansatzscheitert, sobald das Schema in einer anderen Sprache verfasst ist.
Verfahren auf Strukturebene analysieren die Strukturen, in denen Entitäten auftre-ten. Dazu zählt u. a. folgende Kategorie von elementaren Techniken.
• Graphbasiert (syntaktisch): Die Eingabe wird als ein Graph verstanden, wobeidie Entitäten den Knoten entsprechen. Die Ähnlichkeit zweier Knoten beziehti. d. R. auch umgebende Knoten ein. Im Kontext von XML-Schemata könnendabei die Vorfahren, Geschwister und Nachfahren der zu vergleichenden Kno-ten untersucht werden.
Eine Übersicht prominenter Schema-Matcher und deren Einordnung in obige Klas-sifikation ist in [SE05] gegeben. Festzustellen ist, dass derzeitige Vertreter i. d. R.semi-automatisch arbeiten und eine sequentielle oder parallele Kombination elemen-tarer Techniken vornehmen.
Fazit Ein Schema-Matching (und Mapping) spielt für diese Arbeit insofern eineRolle, als nicht davon auszugehen ist, dass Entwickler von Komponenten eine über-einstimmende Syntax für semantisch identische Konzepte verwenden. Bei der Disco-very muss daher zumindest festgestellt werden, ob die Schemata identisch sind. Diesemi-automatische Definition von direkten Abbildungen zwischen Schemata ist nurbedingt für das Konzept geeignet, da ein Ziel der Austausch gegen zuvor unbekann-te Komponenten ist. Eine automatische Herleitung von Abbildungen zur Laufzeit,die zur Mediation nutzbar sind, unterstellt generische vollautomatische Algorith-men, deren Existenz fraglich ist. Semi-automatische Definition von Abbildungen derXML-Schemata in eine standardisierte Zwischenrepräsentation zur Entwicklungs-zeit ist eine Option. Eine Alternative, die für die Konzeption zu diskutieren ist,wäre die Verwendung von standardisierten Groundings der Ontologiekonzepte inXML-Schemata, sodass ein Matching derer entfällt.
3.2.4 Hybride Beschreibungslogik-basierte DiscoveryHybride Ansätze zur semantischen Discovery auf Basis von Ontologien in Beschrei-bungslogik kombinieren die zuvor vorgestellten Prinzipien mit der impliziten Seman-tik der Syntax von Anfrage und Angebot, da somit die Präzision des Matchmakingsverbessert werden kann (vgl. [KK08]). Es wurden zahlreiche hybride Algorithmen,z. B. [SMSA+05], und Matchmaker, über die z. B. [Klu08, CTO10] einen umfassen-den Überblick geben, vorgeschlagen.
4http://wordnet.princeton.edu/
Copyright TU Dresden, Carsten Radeck 42

Semantische Komposition in Mashups Kapitel 3 Stand der Forschung und Technik
SAWSDL-MX [KK08, KKZ09] ist ein hybrider Matchmaker für Web Services,die in SAWSDL beschrieben sind. Dieser Ansatz wird vorgestellt, da er von eineraktiven Forschungsgruppe, die auch hybride Matchmaker mit hoher Präzision fürOWL-S und WSMO entwickelt, implementiert und evaluiert, stammt. Zudem zeigter Lösungen für Probleme des Annotationsansatz von SAWSDL im Rahmen desMatchmakings auf (vgl. Tabelle 3.1), die für das Konzept relevant sind.
Problem KonventionKeine festgelegte Ontologiesprache (Jede Referenz kann aufOntologie in anderer Sprache verweisen was zu Interoperabili-tätsproblemen führt.)
Festlegung auf Beschreibungslogi-ken, v. a. OWL-DL.
Multiple Referenzen an einem Element (Sind sie gleich oderkomplementär? Wie sind sie in beiden Fällen zu handhaben?)
Auswahl der ersten. (Eine Weiter-entwicklung ist angestrebt.)
Vorgehen bei der Annotation (Vorgesehen sind top-down undbottom-up, auch kombiniert. Was ist gerade in letzterem Fallbeim Matchmaking durchzuführen?)
Nur die Top-Level-Annotationenvon Parametern der Operationenwerden beachtet.
Tabelle 3.1: Pragmatische Annahmen für SAWSDL-MX [KK08]
SAWSDL-MX bestimmt die Übereinstimmung von Web Services durch logikba-siertes Matchmaking der annotierten Konzepte und/oder nicht-logikbasiertes aufBasis von Techniken der Information Retrieval. SAWSDL-MX bietet mehrere Va-rianten: M0 nimmt lediglich logikbasiertes Matching vor, während MX1 und MX2hybride Verfahren darstellen. Es wird ein Graph zwischen Operationen der Anfrageund des angebotenen Service berechnet, wobei die Knoten den Operationen entspre-chen, die mit dem Übereinstimmungsgrad gewichteten Kanten verbunden sind (vgl.Abbildung 3.4). Die bestmögliche Verknüpfung der Operationen bestimmt schließlichdas Gesamtergebnis für den angebotenen Web Service, indem es dem schlechtestenWert einer Kante entspricht. Die Übereinstimmung von Operationen ergibt sich beimlogikbasierten Matching (M0) aus ähnlichen Graden wie in Kapitel 3.2.2 vorgestellt:exact > plug-in > subsumes > subsumed-by > fail. Um Dienstkandidaten mit derselben logikbasierten Übereinstimmung zu ordnen, gibt es weitere Varianten. Einesolche namens M0+WA nimmt einen Vergleich der WSDL von Anfrage und Ange-bot vor, um rekursiv strukturelle Ähnlichkeiten der Baumstruktur festzustellen. BeiMX1 wird neben der logikbasierten eine textuelle Ähnlichkeit bestimmt: Die anno-tierten Konzepte von Angebot und Nachfrage werden dabei als Text aufgefasst, inden Ontologien aufgefalten, in einen Vektor von Schlüsselwörtern überführt und aufBasis verschiedener Metriken verglichen. Die Kombination von logikbasierten undnicht-logikbasierten Verfahren kann dabei kompensierend (nur im Falle von logikba-siertem Fail wird syntaktische Ähnlichkeit betrachtet) und integrativ (syntaktischeÄhnlichkeit wird außer bei exact immer mit betrachtet) erfolgen, um falsch negati-ve bzw. falsch positive Ergebnisse zu vermindern. MX2 kalkuliert die logikbasierte,strukturelle und textuelle Ähnlichkeit separat und verknüpft diese anhand einer anTrainingsdaten adaptierten Aggregationsfunktion.
Fazit Die Prinzipien dieses Ansatzes sind vielversprechend für das Konzept, dadurch die Kombination der Suche nach semantischen als auch syntaktischen Über-einstimmungen eine höhere Präzision erreichbar ist. Zudem kann die Discovery trotzfehlender Annotationen auf Basis von Information Retrieval- Techniken durchge-führt werden. So könnte im Referenzszenario (Kapitel 2.4) beispielsweise der Name
Copyright TU Dresden, Carsten Radeck 43

Semantische Komposition in Mashups Kapitel 3 Stand der Forschung und Technik
Web Service 1 Web Service 2
Output 1
Output 2 Input 2
Input 1Exact
Plug-In
Fail
Match = Plug-In
Abbildung 3.4: Aggregation der Einzelergebnisse in SAWSDL-MX
von Operationen verglichen werden. Die oftmals unterstützte Anbindung eines The-saurus, z. B. WordNet in SAWSDL-MX, unterstellt eine einheitliche Sprache in denBeschreibungen von Web Services, was eine streitbare Annahme ist. Wie deutlichwurde, ist für einen Ansatz ähnlich SAWSDL die Nutzung der Modellreferenzeneinzuschränken, wofür die Annahmen von SAWSDL-MX als Vorbild dienen können.Die vorgestellten Prinzipien sind übertragbar, müssten aber hinsichtlich der Kon-zepte von MCDL angepasst werden, da sie auf WSDL zugeschnitten sind und somitbeispielsweise Properties nicht direkt unterstützen.
3.2.5 Semantische Rangfolgebildung und SelektionWährend in den bisherigen Unterkapiteln Aspekte der Discovery betrachtet wur-den, stehen nun das sich an die Discovery anschließende Ranking und die Selektionvon Dienstkandidaten im Fokus (vgl. Kapitel 2.3). Das Prinzip des semantischenRankings ist die Sortierung von Web Services bzw. Komponenten auf Basis von mit-tels Ontologiekonzepten und Regeln formalisierten nicht-funktionalen Eigenschaften.Dieses Gebiet ist verglichen mit der Komposition und Discovery von SWS wenigererforscht. Exemplarisch wird der Ansatz im Rahmen von WSMO untersucht, dabasierend auf Regeln in WSML die Ausprägung beliebiger nicht-funktionaler Eigen-schaften dynamisch geschlussfolgert und somit die Rangfolge der Dienstkandidaten,die in der Discovery gefunden wurden, berechnet wird.Das in [FKZ08, S.201ff] vorgestellte Verfahren unterstützt das Ranking anhand
mehrerer Kriterien. Es basiert auf Ontologien für nicht-funktionalen Eigenschaf-ten, wie Orts- und Zeitbezug, Verfügbarkeit, Preis, Zuverlässigkeit, Sicherheits- undrechtliche Aspekte sowie Einheiten und Währungen. Weiterhin wird sowohl in derBeschreibung des Web Service als auch des Ziels auf die nicht-funktionalen Eigen-schaften Bezug genommen: Der Anfragesteller kann im Goal (vgl. Listing 3.5) dienicht-funktionalen Eigenschaften (kurz NFP) als Kriterien (Zeile 5) sowie den Ord-nungssinn (Zeile 4) und die Anzahl auszuwählender Web Services (Zeile 6) angeben.
1 namespace { _"Goal.wsml#", so _" Shipment .wsml#", up _" UpperOnto .wsml#" ,...}2 goal Goal13 annotations4 up# order hasValue pref# ascending5 up#nfp hasValue obl# Obligation6 up#top hasValue "1"7 endAnnotations ...
Listing 3.5: Goal mit Angabe einer nicht-funktionalen Eigenschaft (nach [FKZ08, S.200])
Die Beschreibung eines Web Service wird um die Definition der Eigenschaften an-gereichert. Dabei werden logische Regeln über dem von den Ontologien bereitgestell-ten Vokabular formuliert. Das Beispiel in Listing 3.6 definiert die nicht-funktionaleEigenschaft Obligation (Verbindlichkeit) anhand von Regeln in WSML. Beispiels-
Copyright TU Dresden, Carsten Radeck 44

Semantische Komposition in Mashups Kapitel 3 Stand der Forschung und Technik
weise definiert die Regel in den Zeilen 7-9, dass die Haftung des Versandunterneh-mens für ein verlorenes oder beschädigtes Paket dem deklarierten Wert des Paketsentspricht, jedoch maximal 150$.
1 namespace { _" WSRunner .wsml#", runner _" WSRunner .wsml#", ...}2 webService runnerService3 nonFunctionalProperty obligations4 definition definedBy5 // in case the package is lost or damaged Runners liability is6 // the declared value of the package but no more than 150 USD7 hasPackageLiability (? package , 150):- ? package [so \# packageStatus hasValue ?
status ] and8 (? status = so \# packageDamaged or ? status = so \# packageLost ) and9 packageDeclaredValue (? package , ? value ) and ?value >150.
10
11 hasPackageLiability (? package , ? value ):- ? package [so \# packageStatushasValue ? status ] and
12 (? status = so \# packageDamaged or ? status = so \# packageLost ) and13 packageDeclaredValue (? package , ? value ) and ? value =< 150.14 ...15 // in case the package is not lost or damaged Runners liability is 016 hasPackageLiability (? package , 0):- ...17 packageDeclaredValue (? package , ? value ):- ...18 capability runnerOrderSystemCapability19 interface runnerOrderSystemInterface
Listing 3.6: Definition einer nicht-funktionalen Eigenschaft in WSML (nach [FKZ08, S.199f])
Die Eingaben für den vorgeschlagenen Algorithmus zum Ranking sind das Ziel unddie Beschreibungen der Dienstkandidaten aus der Discovery. Anschließend folgenVorverarbeitungsschritte, u. a. die Extraktion der nicht-funktionalen Eigenschaftenund deren Gewichtung, des Ordnungssinnes und von Instanzdaten aus dem Ziel. Da-nach wird für jeden Web Service geprüft, ob für jede NFP des Ziels eine Definitionin der Beschreibung vorhanden ist und diese bezüglich der gegebenen Instanzda-ten von einem Reasoner evaluiert. Daraus ergibt sich der konkrete Wert für dieseEigenschaft. Ist in der Dienstbeschreibung keine Angabe zur NFP des Ziels, wirddiese mit 0 bewertet und gewichtet. Der Gesamtwert des Dienstkandidaten errechnetsich letztlich aus der Summe aller gewichteten und normalisierten Werte der nicht-funktionalen Eigenschaften. Die finale Rangfolge ergibt sich aus Sortierung der WebServices im angegebenen Ordnungssinn.
Fazit Die Grundprinzipien dieses Ansatzes lassen sich auf CRUISe übertragen undkönnen in das Konzept einfließen, auch wenn sie nicht dessen Schwerpunkt bilden.So sind die Ontologiekonzepte für nicht-funktionale Eigenschaften verwendbar undim Rahmen von Mashups ebenfalls relevant. Die regelbasierte Definition der nicht-funktionalen Eigenschaften erlaubt die dynamische Berechnung des konkreten Wer-tes derer und somit flexiblere Rankings als bei statischer Annotation zur Entwick-lungszeit der Komponente, ist aber aufwändig. Im Konzept könnte eine Unterschei-dung zwischen statischen und dynamischen nicht-funktionalen Eigenschaften statt-finden. Für letztere wäre eine (Regel-) Sprache zur dynamischen Berechnung, wieWSML, notwendig. Abzuwägen wäre, ob dabei logische Regeln zum Einsatz kom-men, die von einem Reasoner ausgewertet werden. Wie am Beispiel deutlich wird,basieren die Definitionen der NFP auf Instanzdaten der Anfrage. Dies ist im Rah-men von CRUISe beim Ranking zur Laufzeit nicht möglich, da konkrete Instanzenerst als Ereignisse nach Integration der Komponente an diese getragen werden. DieRegeln könnten jedoch über Kontextinformationen parametrisiert werden. Bezogen
Copyright TU Dresden, Carsten Radeck 45

Semantische Komposition in Mashups Kapitel 3 Stand der Forschung und Technik
auf das Referenzszenario (Kapitel 2.4) könnte z. B. der Preis der Komponenten inAbhängigkeit vom Nutzerkontext berechnet werden.
3.3 Mediation von DatenEine wesentliche Herausforderung bei der Integration von Mashup-Komponentenbzw. Web Services in eine Komposition ist die Mediation auf Datenebene. Sie istinsbesondere zum Zeitpunkt der Kommunikation mit oder zwischen Web Servicesbzw. Komponenten relevant, um auftretende Heterogenitäten (vgl. Kapitel 2.3) auf-zulösen. Allgemein notwendige Schritte hierfür sind die Identifikation von Abbil-dungen zwischen Schemata, Repräsentation dieser und letztlich ihre Anwendungzur Laufzeit [NVSM07]. Nachfolgend werden vielversprechende Ansätze auf Basissemantischer Komponentenbeschreibungen vorgestellt. Dabei legt der Schwerpunktauf dem Fall gemeinsamer Ontologien, weshalb z. B. die im Kontext von WSMOentstandenen Lösungen zur Mediation [FKZ08, S.211ff] nicht betrachtet werden.
3.3.1 Mehrstufige Mediation mit ontologiebasierterZwischenrepräsentation
Corcho et al. [CLB07] unterscheiden prinzipiell zwei Ansätze zur Mediation von Da-ten: Transformation in einem Schritt, die typischerweise speziell implementiert wirdund sämtliche Transformationen auf einmal handhabt, und mehrstufige Transfor-mation, bei der Daten zunächst in eine kanonische Repräsentation überführt wer-den. In diesem Abschnitt wird der zweite Ansatz untersucht, da er leichter – wennauch aufwändiger – zu erstellen und leichter wartbar ist [ebd.]. Außerdem ist erbesser skalierbar, weil die Anzahl benötigter Transformationen linear steigt. DasGrundprinzip sieht eine Überführung des Nachrichtenformates in eine Zwischensyn-tax (Lifting), die anschließende optionale Mediation von Ontologien und schließlichdas Transformieren in die Zielsyntax (Lowering) vor [CLB07]. Im Folgenden wirddavon ausgegangen, dass die Zwischensyntax durch Ontologien kontrolliert wird,z. B. RDF/XML, und das Ausgangs- und Zielformat auf XML basieren. Zum Bei-spiel wird im Referenzszenario (Kapitel 2.4) das Konzept Location in KomponenteA als ein Element mit Unterelementen für den Namen und die geografische Positionbeschrieben. Komponente D nimmt jedoch an, dass der Name ein Attribut ist. Durchdie Verwendung einer Zwischensyntax kann diese Heterogenität aufgelöst werden.Eine Reihe von Vorschlägen, die dem genannten Prinzip folgen, wurden unterbrei-
tet, z. B. [SPM06, CLB07, NVSM07, SL04]. Oftmals findet das Lifting/Lowering ineinem Schritt statt, z. B. von XML direkt in einen RDF-Graphen gemäß der Zie-lontologie und umgekehrt, wobei die Transformation auf XML arbeitet. In [CLB07]wird hingegen erst automatisch in eine »Ontologie für XML« abstrahiert und dieTransformation, die von einem Reasoner anhand spezifizierter Regeln durchgeführtwird, übersetzt dies in die Zielontologie (und umgekehrt). Dem höheren Aufwandstehen die weiterführende Möglichkeiten eines Reasoners, z. B. Inferenz oder wennzwischen verschiedenen Ontologien zu vermitteln ist, gegenüber. Dies wäre für eineÜbertragung auf das Konzept abzuwägen.Nachfolgend wird stellvertretend der Ansatz von WSDL-S bzw. SAWSDL vor-
gestellt, da dieser äußerst flexibel ist, was angesichts verschiedener Plattformen in
Copyright TU Dresden, Carsten Radeck 46

Semantische Komposition in Mashups Kapitel 3 Stand der Forschung und Technik
CRUISe vorteilhaft ist. Der grundlegende Ansatz zur Mediation gestaltet sich wiefolgt [NVSM07, FL07]. Wie in Kapitel 3.1.3 erörtert, sind die Attribute lifting/lo-weringSchemaMapping zur Auflösung von syntaktischer Inkompatibilitäten vorgese-hen. Sie referenzieren Skripte in beliebigen Transformationssprachen, um Instanzdo-kumente in XML auf eine Instanz des annotierten Konzepts der Ontologie abzubildenund umgekehrt. Zur Entwicklungszeit erfolgt zunächst die semi-automatische odermanuelle Definition der Abbildungen auf Schemaebene. Vorgeschlagene Transforma-tionssprachen sind XSL Transformation (XSLT), XQuery und SPARQL, wobei dieForschung im Rahmen von METEOR-S sich auf XSLT und XQuery konzentriertund annimmt, dass diese mächtig genug sind, um die meisten Heterogenitäten zuüberwinden [NVSM07]. Zur Laufzeit werden die Transformationen auf Instanzebeneangewendet. Auf Basis dieser Abbildungen kann eine Middleware den Aufruf einesWeb Service mit gültigen Eingaben realisieren. Abbildung 3.5 zeigt den Basisfall miteiner gemeinsamen Ontologie. Falls unterschiedliche Ontologien verwendet werden,ist zusätzlich eine Transformation zwischen diesen notwendig. Um die Verwendung
Domänenontologie
Web Service 1
Nachricht n
(Ausgabe)
Web Service 2
Nachricht m
(Eingabe)Syntaktische Diskrepanz,
semantische Übereinstimmung
C1
modelReference modelReferenceTransformationsskript
XML -> Ontologiesprache
Transformationsskript
Ontologiesprache -> XML
XML Instanzdaten XML InstanzdatenliftingSchemaMapping loweringSchemaMapping
Instanz von C1
Abbildung 3.5: Mediation inkompatibler XML-Daten in SAWSDL mit gemeinsamer Ontologie
der Attribute zu konkretisieren, wurden folgende Regelungen für SAWSDL getrof-fen: Sie werden an globale Element- und/oder Typdeklarationen annotiert, wobeiletztere von denjenigen an Elementen überschrieben werden. Mehrere Referenzen ineinem Attribut sind als Alternativen handzuhaben. Ähnliche Konventionen wärenfür das Konzept wichtig, falls dieser Ansatz übertragen wird.
Fazit Das Grundprinzip des Ansatzes ist für das Konzept geeignet, da analog dazudie Datentypen in XML-Schema-Definitionen vorliegen und Ontologien das Voka-bular vorgeben sollen. Zudem erlaubt der Ansatz in Ausprägung von SAWSDL einehohe Flexibilität, da Transformationssprachen nicht festgelegt sind und Alternati-ven angegeben werden können. Somit sind plattformspezifische Abbildungen leichtdeklarierbar, z. B. in JavaScript statt XSLT, und der Mediator kann abhängig vonverfügbaren Transformatoren ein Skript auswählen. Ein Nachteil ist die Notwendig-keit, zur Entwurfszeit die Transformationsvorschriften semi-automatisch oder manu-ell zu definieren. Auf das Referenzszenario (Kapitel 2.4) übertragen hieße dies, dasssämtliche Datentypen der Komponenten mit Attributen zum Lifting und/oder Lo-wering zu versehen und die Transformationen bereitzustellen sind. Andererseits istein menschliches Eingreifen wichtig, um die Plausibilität der Abbildungen zu sichernoder ein Fehlschlagen automatischer Verfahren auszugleichen. Für eine konkrete Um-
Copyright TU Dresden, Carsten Radeck 47

Semantische Komposition in Mashups Kapitel 3 Stand der Forschung und Technik
setzung bliebe zu klären, ob z. B. ein Web Service oder die Ausführungsumgebungdie Mediation vornimmt und was passiert, wenn keine Alternative anwendbar ist.
3.3.2 Mediation mit automatischer Generierung derTransformationsvorschriften
Mussten die Transformationsvorschriften in den zuvor erläuterten Ansätzen zur Ent-wurfszeit bereits erstellt werden, zielen verschiedene Verfahren, wie [BL04, BZG08,SL04], auf die automatische Ableitung solcher Abbildungen ab.Bowers und Ludäscher [BL04] assoziieren den syntaktischen (XML-basiert) mit
dem semantischen Typ (OWL-Konzept) von Ein- und Ausgaben einer Komponentedurch vorgegebene Abbildungen (Registration Mapping, vergleichbar Modellreferen-zen) auf Basis von XPath. Aus diesen können Correspondence Mappings abgeleitetwerden. Eine solche Abbildung verknüpft genau dann zwei syntaktische Typen p1und p2, wenn für deren semantische Typen C1 v C2 gilt. Zur Mediation können Cor-respondence Mappings in XQuery-Transformationen übersetzt werden, wobei jedochvereinfachende Annahmen getroffen werden, z. B. sind keine Transformationen vonDatentypen bzw. Einheiten vorgesehen. Verglichen mit den Ansätzen im vorigenKapitel findet keine Abbildung in eine Zwischenrepräsentation statt.Der Ansatz von Bleul et al. [BZG08] verwendet eine Erweiterung der WSDL um
Referenzen auf Datentyp, Einheit und semantische Konzepte in Ontologien. Im Rah-men der Discovery, der eine erwartete WSDL als Vorlage übermittelt wird, wird ne-ben der semantischen Übereinstimmung von Ein- und Ausgaben auch die Strukturder WSDL inklusive XML-Schemata abgeglichen. Zuerst werden Operationen hin-sichtlich Eingabe-, Ausgabe- und Fehlernachrichten überprüft. Anschließend wer-den die Schemata auszutauschender Nachrichten rekursiv auf passende Elementeuntersucht. Hierbei werden Arrays, Enumerationen sowie komplexe und einfacheDatentypen abgeglichen. Auf Ebene von einfachen Datentypen erfolgt ein semanti-scher Vergleich anhand von Subsumption (vgl. Kapitel 3.2). Auf diese Weise wirdnach Dienstkandidaten gesucht, die ausreichend viele äquivalente Elemente der aus-zutauschenden Nachrichten besitzen, sodass eine Kommunikation stattfinden kann.Darüber hinaus generiert der Matchingalgorithmus eine Abbildung in XSLT zurMediation bei syntaktischen Diskrepanzen. Folgende Funktionen bieten die erzeug-ten XSL-Transformationen an: Umbenennen von Identifiern und Namensräumen,Entfernen von Dokumentknoten, Ausschneiden und Einfügen von Substrukturen inandere sowie Kopieren von Knoten. Bei Letzterem wird auf Kardinalitäten geach-tet: Wird ein Array erwartet, aber im Quellschema ist keines vorgesehen, wird dieStruktur als ein Array kopiert. Anders herum wird nur das erste Element einesArrays kopiert. Falls inhaltliche Konvertierungen notwendig sind, z. B. bei verschie-denen Währungen, werden registrierte Plug-ins semantisch gesucht und potentiellsequentiell angeordnet. Zur Laufzeit wird das Message Mediation Subsystem mit denXSL-Transformationen und Plug-ins konfiguriert und wendet sie auf die Instanzdo-kumente der WSDL-Nachrichten an.
Fazit Die Idee, Transformationsvorschriften automatisch beim Matchmaking abzu-leiten und über XSLT hinausgehende Abbildungen bereitzustellen (Plug-ins), könn-te in das Konzept einfließen, z. B. indem Logikkomponenten generiert und verkettet
Copyright TU Dresden, Carsten Radeck 48

Semantische Komposition in Mashups Kapitel 3 Stand der Forschung und Technik
werden oder die Runtime einen Dienst bzw. eine Architekturkomponente bereit-stellt. Die Übertragung des Ansatzes von Bleul et al. würde nach sich ziehen, dassalle XML-Schemata auf Ebene einfacher Datentypen zu annotieren wären, was einenhohen Aufwand bedeutet. Dem steht gegenüber, dass keine Transformationen anzu-geben sind. Der Ansatz gibt vor, komplett automatisch Schemata abzugleichen undTransformationen zu definieren. Es ist aber fraglich (und eine verlässliche Evaluationfehlt), ob dies im Allgemeinen funktioniert. Nagarajan et al. halten eine automati-sche Generierung von Abbildungen abhängig von zu lösenden Heterogenitäten fürschwierig bis nahezu unmöglich [NVSM07]. Daher sind Vereinfachungen notwendig,wie auch der Vorschlag von Bowers et al. verdeutlicht. Eine Option wäre die Ein-bindung der Generierung in die Discovery und die Bewertung einer Komponente alsungeeignet, falls Transformation benötigt, aber nicht ableitbar sind.
3.4 ZusammenfassungDieses Kapitel stellte grundlegende Prinzipien und ausgewählte Ansätze für die Er-füllung zuvor identifizierter Anforderungen an das Konzept vor und bewertete diese.Hierbei lag der Schwerpunkt auf der semantischen Beschreibung von Komponen-ten und Web Services, der semantischen Suche und Auswahl, sowie vorgeschlage-nen Verfahren zur Mediation, weil diese zentrale Herausforderungen für die Um-stellung der Integration und des Austauschs von Komponenten in CRUISe auf dieNutzung semantischer Komponentenbeschreibung sind. Wie die Darstellung des ak-tuellen Forschungsstandes zeigte, sind hinsichtlich wesentlicher HerausforderungenAnsätze vorhanden, die jedoch aufgrund der speziellen Charakteristika von Mashupsund CRUISe nicht immer direkt auf das Konzept übertragbar sind.Bezüglich semantischer Beschreibungen von Web Services wurden in Kapitel 3.1
zwei konträre Konzepte illustriert. Top-Down Ansätze sehen eine semantische undi. d. R. ontologiebasierte Beschreibung, die erst im Falle des Aufrufs des Web Ser-vice auf bestehende Technologien aufsetzt, vor. Probleme für eine direkte Nutzungsind der Aufwand bei der Erstellung und ein unterschiedliches Komponentenmodell.Bottom-Up Ansätze, allen voran die W3C-Empfehlung SAWSDL, erweitern beste-hende Technologien um semantische Annotationen. Dieser Ansatz ist einfacher beider Erstellung und flexibel, muss jedoch für eine Verwendung in CRUISe konkre-tisiert werden. Zusätzlich wurden zugrundeliegende Formalismen analysiert, wobeifür die Funktionalität einer Mashup-Komponente insbesondere die »einfache« Be-schreibung in Beschreibungslogik ein geeigneter Lösungsansatz ist.Eine Kernaufgabe des zu entwickelnden Konzepts ist die Suche und Auswahl pas-
sender Komponenten. Daher wurden in Kapitel 3.2 zunächst Optionen für die An-frage an die Discovery untersucht. Festzustellen ist, dass Vorlagen, d. h. die Beschrei-bung einer idealen Komponente, für das Konzept geeignet sind. Anschließend stan-den Grundprinzipien für die Discovery auf Basis von syntaktischen und insbesonderesemantischen Informationen der Komponentenbeschreibung im Fokus. Matchmakingauf Basis von Beschreibungslogik ist aufgrund seiner Entscheidbarkeit eine geeigneteGrundlage und kann zur Verbesserung der Präzision mit nicht-logikbasierten Me-thoden kombiniert werden.Weiterhin wurden in Kapitel 3.3 Ansätze zur Mediation auszutauschender Daten
untersucht, wobei der Einsatz einer gemeinsamen Ontologie unterstellt wurde. Die
Copyright TU Dresden, Carsten Radeck 49

Semantische Komposition in Mashups Kapitel 3 Stand der Forschung und Technik
Nutzung einer ontologiebasierten Zwischenrepräsentation kann als Anregung in dasKonzept einfließen. Problematisch dabei ist die Definition der Transformationender Daten in die Zwischenrepräsentation und von dieser in die Zielsyntax. Daherwurden Verfahren mit Generierung der Transformationsvorschriften analysiert. Sieerfordern jedoch eine detaillierte Annotation der (XML-) Schemata oder schränkendie zu überbrückenden Heterogenitäten zwischen der Ursprungs- und Zielsyntax derDaten ein.Die gewonnenen Erkenntnisse fließen nachfolgend in die Konzeption ein, um die
zuvor skizzierten Defizite des Integrationsprozesses von CRUISe (siehe Kapitel 2.2.3)zu lösen und daraus abgeleitete Anforderungen zu erfüllen.
Copyright TU Dresden, Carsten Radeck 50

Semantische Komposition in Mashups Kapitel 4 Konzeption
4Konzeption
Im bisherigen Verlauf der vorliegenden Arbeit wurden Grundlagen, Rahmenbedin-gungen der CRUISe-Architektur und die Übertragbarkeit von Ergebnissen aus demBereich SWS auf CRUISe untersucht. Weiterhin standen Lösungsstrategien für iden-tifizierte Herausforderungen bei der Nutzung semantischer Komponentenbeschrei-bungen im Integrationsprozess von CRUISe im Blickpunkt. Basierend auf den ge-wonnenen Erkenntnissen und den aufgestellten Anforderungen ist die Zielstellungdieses Kapitels die Konzeption zur Nutzung der um Mittel zur semantischen Be-schreibung erweiterten MCDL im Rahmen der CRUISe-Architektur zur Integrationund zum Austausch von Komponenten in Mashups. Dazu wird zuerst die Spra-che zur semantischen Komponentenbeschreibung und ihre formale Basis spezifiziert.Weiterhin stehen die Auswirkungen auf das Kompositionsmodell im Fokus, wobeidas Konzept der Vorlagen eingeführt wird. Anschließend bildet die überblicksartigeBetrachtung zu lösender Aufgaben im Integrationsprozess semantisch beschriebenerKomponenten und die daraus abgeleitete Architektur den Schwerpunkt. Abschlie-ßend erfolgt die detaillierte Definition des Zusammenwirkens von Discovery, Rankingund Mediation bei der Integration und dem Austausch von Komponenten.
4.1 Semantische KomponentenbeschreibungEine zentrale Rolle der Konzeption nimmt die semantische Komponentenbeschrei-bung ein und findet zur Entwicklungszeit der Anwendung (Suche und Kompositionvon Komponenten) sowie zur Laufzeit (Integration und Austausch von Komponen-ten) Verwendung. An dieser Stelle wird zunächst die formale Grundlage der seman-tischen Komponentenbeschreibung erläutert.Die semantische Komponentenbeschreibung stützt sich, wie in Anforderung 3
vorgesehen, auf Ontologien zur Definition des gültigen Vokabulars und ist somitim Einklang mit der grundlegenden Idee der SWS. Dazu wird OWL DL, das mitSWRL-Regeln1 angereichert sein kann, als Sprache vorgeschlagen, da es standardi-siert und wegen der Abbildbarkeit auf Beschreibungslogik entscheidbar ist. Zudemstehen Werkzeuge zur Arbeit mit OWL DL bereit, d. h. Editoren, wie Protegé2, undReasoner, wie Pellet3.
1Zumindest mit der Teilmenge sogenannter DL-safe Rules, die Entscheidbarkeit gewährleisten.2http://protege.stanford.edu/3http://clarkparsia.com/pellet/
Copyright TU Dresden, Carsten Radeck 51

Semantische Komposition in Mashups Kapitel 4 Konzeption
Das Konzept sieht vor, dass Basisontologien für Einheiten, nicht-funktionale Ei-genschaften und zur Repräsentation der Konzepte der Komponentenbeschreibunggemäß dem Komponentenmodell fest vordefiniert sind. Prinzipiell können beliebi-ge domänenspezifische Ontologien verwendet werden. Es wird jedoch vorausgesetzt,dass alle Komponentenentwickler die selben Ontologien einer Domäne referenzieren.Eine spätere Entwicklung hin zu verschiedenen Vokabularen einer Domäne ist mög-lich. Dabei sind beispielsweise semi-automatisch spezifizierte Abbildungen zwischenOntologien, wie in WSMO, »Brückenontologien«, die Aussagen über äquivalenteKlassen und Properties treffen, oder die Verwendung von Thesauri, wie bei Bian-chini et al. [BAM10], anwendbar.Weiterhin erfolgt eine ontologiebasierte Repräsentation der Komponenten im Com-
ponent Repository. Hierfür ist die oben genannte Ontologie des Komponentenmo-dells notwendig, die in Anlehnung an den Ansatz von WSMO-Lite (vgl. Kapitel3.1.3) das Vokabular für diese Repräsentation bietet. Alle in der Semantic Mas-hup Component Description Language (SMCDL) bereitgestellten Konstrukte sinddamit modellierbar. Als logische Folge wird dem Komponentenentwickler die Op-tion geboten, Komponenten direkt als eine Ontologieinstanz zu beschreiben, wobeiihm weiterführende Konzepte, wie z. B. Vorbedingungen an die Funktionalität vonOperationen in Abhängigkeit des aktuellen Nutzerkontexts zugänglich sind. DemEntwickler steht es somit frei, wie bisher XML-Instanzdokumente nach dem Schemader SMCDL zu erstellen und diese zu annotieren oder direkt eine Ontologieinstanzzu modellieren und für den Austausch zu serialisieren. Das Component Repositorybietet für beide Formate eine Schnittstelle, um die Komponentenbeschreibungen zuregistrieren.Daraus resultiert eine stufenweise Weiterentwicklung der MCDL, die als Mengen-
diagramm bezüglich der verfügbaren Beschreibungsmittel in Abbildung 4.1 darge-stellt ist. Während MCDL als Ausgangsbasis dient und durch die SMCDL abgelöstwird, stellt die Ontologievariante Mashup Component Description Ontology (MC-DO) eine Alternative zu letzterer dar. Diese Trennung wird aus Kompatibilitäts-gründen vorgenommen. Weiterhin kann die SMCDL somit leichtgewichtig gehaltenwerden. Die volle Mächtigkeit erschließt sich einem Entwickler jedoch erst unter Ver-wendung der ontologiebasierten Alternative. Das Konzept der Vorlagen beinhaltetdie Repräsentation eines erweiterten Teils der SMCDL im Kompositionsmodell unddient primär der dynamischen Suche von Komponenten zur Laufzeit.
MCDO
SMCDL
MCDL
Vorlage
Abbildung 4.1: Mengendarstellung der verschiedenen Varianten zur semantischen Komponen-tenbeschreibung bzw. -repräsentation
Die anschließenden Abschnitte behandeln sukzessive die Spezifikation der dreiwesentlichen Varianten der Komponentenbeschreibung bzw. -repräsentation.
Copyright TU Dresden, Carsten Radeck 52

Semantische Komposition in Mashups Kapitel 4 Konzeption
4.1.1 SMCDLAus Kompatibilitätsgründen wird auch weiterhin ein einfaches XML-Schema zurBeschreibung von Komponenten in CRUISe angeboten. Dabei wird die bestehendeMCDL weitestgehend beibehalten, sodass vorhandene Dokumente mit kleinen Än-derungen verwendet werden können und Anforderung 2 erfüllt ist. Die SMCDLverfolgt einen Bottom-Up Ansatz (vgl. Kapitel 3.1.3) und basiert maßgeblich aufdem in MCDL bereits vorgesehenen, aber bisher durch die Infrastruktur nicht aus-genutzten Annotationsansatz von SAWSDL. Die Verwendung der Annotationen,d. h. die zu referenzierenden Konzepte und deren Anzahl wird, wie im Folgendennäher beschrieben, konkretisiert. Dabei werden Ergebnisse von WSMO-Lite (vgl.Kapitel 3.1.3) berücksichtigt. Zudem werden im Hinblick auf Mediation von Datenbenötigte Erweiterungen vorgenommen.Im Vergleich zur bisherigen MCDL wird die Trennung in Klassen- und Bindungs-
teil aufgehoben, da sie nicht mehr nötig ist (Anforderung 1). Abbildung 4.2 zeigt dasWurzelelement mcdl des vereinigten Schemas samt dessen Typdefinition (rechts). Esbesteht aus allen Teilen der beiden vorherigen Schemata mit Ausnahme des Elementsdatatypes, dessen Wegfall später erklärt wird.
Abbildung 4.2: Oberste Ebene des XML-Schemas der SMCDL
Semantische Annotationen, im Folgenden auch Modellreferenzen genannt, werdenprinzipiell in zwei Kategorien eingeteilt: Zum einen werden Klassen und Datatype-Properties zur Typisierung von Parametern von Operationen und Ereignissen sowieProperties referenziert (Datensemantik, mehr dazu in Kapitel 4.1.1.1). Dabei istnur genau eine Annotation pro Element erlaubt. Zum anderen können Klassen zurBeschreibung der funktionalen Semantik annotiert werden, was in Kapitel 4.1.1.2ausgeführt wird. Hierbei sind mehrere Referenzen, die als komplementär interpretiertwerden, an einer Operation, einem Ereignis oder dem Wurzelelement mcdl zulässig.Es sollte sichergestellt sein, dass dabei keine redundanten Referenzen auftreten, d. h.keine äquivalenten oder Konzepte in Vererbungsrelationen, da dies einen erhöhtenAufwand beim Matching von Komponenten verursacht.Im Gegensatz zu funktionalen Annotationen ist die Angabe der semantischen Ty-
pen obligatorisch. Deshalb sind vorhandene MCDL-Dokumente erst nach der ent-sprechenden Umstellung verwendbar. Ohne weitere semantische Annotationen kann
Copyright TU Dresden, Carsten Radeck 53

Semantische Komposition in Mashups Kapitel 4 Konzeption
eine Komponente dann zumindest per ID integriert werden, was zur Erfüllung vonAnforderung 13 beiträgt. Im Bezug auf die Mengendarstellung in Abbildung 4.1entspricht dies der MCDL. Um auch im Rahmen der semantischen Discovery (sieheKapitel 4.3.2) auffindbar zu sein, sind hingegen Modellreferenzen zur Beschreibungder Funktionalität essentiell.Die Einbeziehung von Ontologien erfolgt in SMCDL mittels der Namensräume
von XML am Wurzelelement mcdl, um den Anforderungen 3 und 4 gerecht zu wer-den. Dabei ist der Namensraum identisch zur URI der Ontologie. Modellreferenzenwerden anschließend zur Verminderung von Redundanzen statt als URI in Formkompakterer Qualified Names, bestehend aus einem eindeutigen Präfix als Abkür-zung für die URI des Namensraumes und einem innerhalb des letzteren gültigenNamen, repräsentiert. Listing 4.1 zeigt in Zeile 2 die Definition des Namensraums,der anschließend in Zeile 4 genutzt wird.
1 <mcdl xmlns ="..." xmlns :meta="..."2 xmlns : travel ="http :// mmt.inf.tu - dresden .de/ cruise / travel .owl#"3 id="..." name =" Weather Panel " version ="1.0" type ="ui"4 functionality =" travel : DisplayWeather " >...
Listing 4.1: Import von Ontologien in SMCDL
SMCDL unterstützt bereits alle für die Suche und Integration essentiellen seman-tischen Basisinformationen, die in den nachfolgenden Abschnitten behandelt undbegründet werden. Hierbei wird die Unterteilung gemäß den geforderten Arten vonSemantiken aufgegriffen (siehe Kapitel 2.1.2 und Anforderung 5). Abbildung 4.3zeigt die Assoziation zwischen SMCDL und semantischen Konzepten und die Ana-logie zu den Annotation A1-A5 von WSMO-Lite (vgl. Kapitel 3.1.3).
Ontologien
SMCDL
Metadaten
InterfaceOperation n
Ereignis m
Binding
Nicht-Funktionale
Semantik
(Konzepte)
Datensemantik
(Konzept der Parameter)
Funktionale Semantik
(funktionale Kategorie)
Datensemantik
(Konzept)
Referenzierung
URL einer
Transformationsvorschrift
(bei nutzerdefinierten
XML Schemata)
Property k
NFP BasiskonzepteDomänenkonzepte
Kapitel 4.1.1.1
Kapitel 4.1.1.4
Kapitel 4.1.1.1
Kapitel 4.1.1.2
Kapitel 4.1.1.1
A2
A1
A4A1A5
Funktionale Semantik
(funktionale Kategorie)
Kapitel 4.1.1.2
A3
Abbildung 4.3: Überblick der semantischen Annotation der SMCDL
4.1.1.1 Datensemantik
Eine grundlegende Veränderung bringt die semantische Typisierung der Kom-ponenten mit sich. Sie besagt, dass die Parameter von Operationen und Ereignissensowie Properties von Komponenten mit einem Ontologiekonzept typisiert werden.
Copyright TU Dresden, Carsten Radeck 54

Semantische Komposition in Mashups Kapitel 4 Konzeption
Hierfür können Klassen (z. B. Location) und, damit eine Erstellung von Klassenfür sämtliche Konzepte verhindert wird, Datatype-Properties (z. B. hasID) von On-tologien genutzt werden. Bei Object-Properties wäre der tatsächliche Wertebereichohne Angabe der Domäne nicht klar, da er z. B. in Subklassen eingeschränkt wer-den kann, wodurch sich auch die syntaktische Typdefinition ändert. Somit könntekeine sinnvolle Typprüfung und Mediation stattfinden. Bei Datatype-Properties än-dert sich im Gegensatz dazu nichts am grundlegenden (primitiven) Datentyp. Fürdie semantische Typisierung wird das bestehende Attribut type an Parametern vonOperationen und Ereignissen sowie Properties verwendet, wie in Listing 4.2 zu sehenist. Das Element datatypes der MCDL entfällt, was den Vorteil hat, dass redundan-te Angaben von Datentypen vermieden werden. Mit der semantischen Typisierungvon Ein- und Ausgaben ist die Basis für dynamische Kompositionsansätze wie in[HMH+10] geschaffen.
1 <property name =" currentLocation " required =" false " type =" travel : Location " />
Listing 4.2: Semantische Typisierung einer Property
Wie im Rahmen von Top-Down Ansätzen (vgl. Kapitel 3.1.2) deutlich wurde,ist ein Grounding der semantischen Typen notwendig. CRUISe setzt, wie Web Ser-vices, zwecks Plattform- und Sprachunabhängigkeit auf XML zum Austausch vonDaten in Form von Ereignissen. Daher ist eine Repräsentation der semantischenKonzepte in XML-Schemata nötig. Hierfür werden standardisierte Groundingsvorgeschlagen. Dazu gehört ein XML-Schema und zwei Transformationen: eine vonXML-Instanzdokumenten auf die semantische Ebene (Lifting), d. h. in einen RDF-Graphen, und eine für die umgekehrte Richtung (Lowering). Die Art der Bereitstel-lung dieser Artefakte ist konzeptionell nicht vorgeschrieben, da mehrere adäquateOptionen existieren. So können z. B. Domänenexperten diese pro Konzept einmal de-finieren oder ein Algorithmus wird verwendet, um, wie bei Szomszor et al. [SPM06],zumindest das XML-Schema zu generieren. Datatype-Properties werden entwederüber die in OWL zulässigen primitiven Datentypen von XML-Schema oder ein (kom-plexes oder einfaches) Schema typisiert und ein Lifting und Lowering ist für sie nichtnotwendig und nicht möglich, da kein Individuum erzeugt werden kann.
Abbildung 4.4: Aufbau von Transformationen in das vorgegebene Schema
Die Motivation hinter diesem Ansatz ist eng mit der geforderten Mediation vonDaten verknüpft, die daher an dieser Stelle kurz erläutert wird. Näheres zur Me-diation enthält Kapitel 4.3.4. Als Grundprinzip wird der mehrstufige Ansatz mit
Copyright TU Dresden, Carsten Radeck 55

Semantische Komposition in Mashups Kapitel 4 Konzeption
einer Zwischenrepräsentation (vgl. Kapitel 3.3.1) gewählt, wobei Ontologien als Ve-hikel zur Überbrückung von syntaktischen Diskrepanzen dienen. Der Vorteil ist, dassdurch den konkreten Bezugspunkt die Anzahl der Transformationen nur linear steigt.Die Vorgabe von standardisierten Schemata wird vorgeschlagen, da es Komponen-tenentwickler von der obligatorischen Erstellung von Transformationsvorschriftenwie bei SAWSDL befreit, insofern er Standardschemata übernimmt. Ist dies nichtmöglich oder gewünscht, können optional explizit Transformationen angegeben wer-den, wodurch die Interoperabilität und Wiederverwendbarkeit bestehender Imple-mentierungen erhöht wird, da diese nicht intern anzupassen sind. Weil das Bindingvon SMCDL für die Anbindung einer Implementierung an das definierte Interfacedient (vgl. Kapitel 2.2.2.1), bietet es die Möglichkeit explizit Transformationsvor-schriften für Properties und Parameter von Operationen und Ereignissen anzuge-ben (vgl. Abbildung 4.4). Dazu können alternativ XSLT-Stylesheets, die entwederdirekt eingefügt oder, um ihre Wiederverwendbarkeit zu erhöhen, frei zugänglichanhand einer Unified Resource Locator (URL) referenziert werden, oder Codefrag-mente in einer Skriptsprache, z. B. JavaScript, angegeben werden. Die (syntaktische)Korrektheit beider ist zur Entwicklungszeit sicherzustellen, damit zur Laufzeit ihreFunktionstüchtigkeit angenommen werden kann. XSLT stellt wegen seiner Stan-dardisierung und der Mächtigkeit zur Transformation von XML-Dokumenten einegeeignete Wahl dar, während JavaScript z. B. für die Konvertierung von primitivenDatentypen oder JavaScript Object Notation (JSON) geeignet ist. Es wird unter-stellt, dass der Code aus verlässlicher Quelle stammt, sodass Sicherheitsbedenkenausgeblendet werden können. Solcher Code kann im Falle von JavaScript Platzhal-ter, die zur Laufzeit mit den tatsächlichen Werten ersetzt werden, beinhalten undanschließend mittels eval interpretiert werden. Ein Beispiel, bei dem Eingabedaten,z. B. eine Property, in die benötigte JSON-Datenstruktur überführt werden, kannso aussehen: convertToJSON(@data@). Die angegebene Funktion muss dabei durcheine Dependency im Binding (referenziert u. a. einzubindende Quellcodedateien) be-reitgestellt werden. In der SMCDL existieren Elemente für Transformationen zurÜberführung von vorgegebenen in komponenteninterne Schemata und umgekehrt(Abbildung 4.4 zeigt letzteres). Somit kann sichergestellt werden, dass nur für denjeweiligen Typ von Transformationen passende Parameter angegeben werden, daz. B. eine Transformation in ein eigenes Schema nur bei Operationsparametern inFrage kommt. Jedes Transformationselement kann zur Vermeidung von Redundanzmehrere Referenzen auf Properties oder Parameter enthalten. Alternativ kann ei-ne Transformation für einen semantischen Typ definiert werden. Die Zuordnung zuentsprechenden Parametern oder Properties ist dann durch die Runtime sicherzu-stellen. Wie bei Szomszor et al. [SPM06] wird somit primär eine ontologiebasierteXML-Notation als Zwischensyntax verwendet. Dies hat den Vorteil, dass auch reinclientseitige Runtimes die Transformationen vornehmen können und ein Lifting aufdie semantische Ebene und ein anschließendes Lowering erst durchgeführt wird, fallsPlugIn-Beziehungen zwischen Klassen auftreten, da dies aufwändiger ist und abhän-gig von der Runtime in externe Dienste ausgelagert werden muss.
4.1.1.2 Funktionale Semantik
Für die angebotene Funktionalität von Mashup-Komponenten wird die Verwendungeiner »einfachen« semantischen Beschreibung (siehe Kapitel 3.1.1) vorgeschlagen.
Copyright TU Dresden, Carsten Radeck 56

Semantische Komposition in Mashups Kapitel 4 Konzeption
Hierbei dienen Ontologien der Modellierung der Konzepte. Von der »reichhaltigen«semantischen Beschreibung, wie sie z. B. bei WSMO und OWL-S Anwendung findet,wird aus mehreren Gründen abgesehen, um Anforderung 6 besser gerecht zu wer-den. Zunächst ist die zustandsbasierte Modellierung sowohl für den Komponenten-als auch den Anwendungsentwickler, der passende Anfragen zur Suche formulie-ren muss, aufwändig. Nach Meinung des Autors können in Entwicklungswerkzeugenzwar teilweise Abstraktionen vom zugrundeliegenden logischen Formalismus vorge-nommen werden, aber keine komplette Transparenz gewährleistet werden. Ange-sichts des Mashup-Charakters von CRUISe erscheint die Komplexität daher nichtangebracht. Weiterhin unterstellt der Ansatz die Definition von Vor- und Nachbe-dingungen, die über die Ein- und Ausgaben eines Web Service spezifiziert sind, wasdas Vorhandensein von konkreten Instanzdaten zum Zeitpunkt der Discovery be-darf. Wie in Kapitel 2.3 bereits argumentiert, ist dies für das Konzept ungeeignet,da die Discovery im Rahmen dessen stattfindet, bevor Instanzdaten vorliegen.Oftmals werden Typprüfungen als implizite Vorbedingungen verstanden. Dies ist
im Konzept durch die semantische Typisierung, deren Grounding und die Typprü-fung von Instanzdaten durch die Runtime gegeben.Operationen und Ereignisse von Komponenten können über mehrere Modellrefe-
renzen im Attribut functionality verfügen. Sie beziehen sich auf domänenspezifi-sche Konzepte, welche ihre Bedeutung durch funktionale Kategorien, erledigte Auf-gaben oder – angelehnt an den Ansatz von CoSMoS [FS09] – Aktionen beschreiben.Gerade letzteres ist intuitiver als eine zustandsbasierte Modellierung [ebd.]. Spezi-ell für Ereignisse sind zudem Interaktionskonzepte geeignet. Beispielhafte Konzeptesind OrderConfirmation und LocationSelection. Listing 4.3 illustriert den Aus-schnitt einer SMCDL mit funktionaler Annotation von Ereignissen (Zeile 1) undOperationen (u. a. Zeile 4). Parallel zur vorliegenden Arbeit wurde ein Verfahrenkonzipiert, bei dem ausgehend von Aufgabenmodellen passende Komponenten auf-gefunden werden [Bli11]. Dafür spielen die funktionalen Annotationen eine wesentli-che Rolle und notwendige Ontologien wurden formalisiert. Auf diese kann aufgesetztwerden, da die Erstellung von Domänenmodellen nicht im Fokus der vorliegendenArbeit steht (Anforderung 3).
1 <event name =" routes " functionality ="ont: RoutesCalculated " dependsOn ="ont:RoutesStartSelection ...">
2 <parameter name =" result " type ="ont: RouteList "/>3 </event >4 <operation name =" setStart " functionality ="ont: RoutesStartSelection ">5 <parameter name =" location " type ="geo: Location " />6 </ operation >7 <operation name =" setDest " functionality ="ont: RoutesDestinationSelection ">8 <parameter name =" location " type ="geo: Location "/>9 </ operation >
10 <operation name =" setStartTime " functionality ="ont: RouteStarttimeSelection ">11 <parameter name ="time" type ="time:Time"/>12 </ operation >13 <operation name =" setDestTime " functionality ="ont: RouteEndtimeSelection ">14 <parameter name ="time" type ="time:Time"/>15 </ operation >
Listing 4.3: Funktionale Annotation von Operationen und Ereignissen
Angesichts der Tatsache, dass auch Komponenten ohne Operationen und Ereig-nisse existieren können und Grundfunktionalitäten auch ohne Operationsaufrufe er-bracht werden können, muss es eine weitere Option zur Beschreibung der funktio-nalen Semantik geben. Deshalb sind, angelehnt an WSMO-Lite, am Wurzelelement
Copyright TU Dresden, Carsten Radeck 57

Semantische Komposition in Mashups Kapitel 4 Konzeption
der SMCDL im Attribut functionality mehrere Modellreferenzen zu diesem Zweckerlaubt, um ein semantisches Auffinden der Komponenten zu ermöglichen.Durch die Verwendung von Ontologien in Beschreibungslogik können auch kom-
plexere Zusammenhänge ausgenutzt werden, um die semantische Kompatibilität vonKomponenten bezüglich der Funktionalität zu erkennen. Im Rahmen des Referenz-szenarios (Kapitel 2.4) kann beispielsweise durch das (domänenspezifische) Wissengeschlussfolgert werden, dass zwei Operationen, von denen eine mit der Funktio-nalität RouteStartSelection und die andere mit RouteDestinationSelectionannotiert ist, die Anfrage nach einer Operation mit der funktionalen KategorieRouteCalculation erfüllen können. Dabei wird angenommen, dass die Parameterausreichend übereinstimmen und in der Ontologie beschrieben ist, dass die Schnitt-menge der beiden Konzepte äquivalent zu RouteCalculation ist.Weiterhin besteht die Möglichkeit, die Beziehung zwischen Ereignissen und Ope-
rationen einer Komponente zu spezifizieren. Dies ist optional, da eine solche nichtimmer zu unterstellen ist, z. B. bei Ereignissen, die aus Nutzerinteraktionen stam-men. Ereignisse können auf verschiedene Weise ausgelöst werden und auch Kompo-nenten mit mehr als den angeforderten Operationen sind als Ergebnisse der Disco-very erlaubt. Deshalb kann es vorkommen, dass ein in der Komposition benötigtesEreignis von einer der zusätzlichen Operationen abhängt und somit niemals ausge-löst wird. Solche Fälle sollten erkannt und betroffene Komponenten beim Matchingaussortiert werden. Abbildung 4.5 zeigt ein Beispiel. In der Vorlage wird nur eineOperation und ein Ereignis gefordert, zu denen Operation 1 und Ereignis 1 vondie Komponente 1 semantisch passen. Ereignis 1 ist jedoch als abhängig von derFunktionalität RouteStartSelection deklariert, die nur von Operation 2 angebo-ten wird. Zusätzliche Ereignisse sind hingegen weniger kritisch, da unterstellt wird,dass die Runtime Mechanismen bereitstellt, um zu erkennen, dass eine Komponentelaut Kompositionsmodell dieses Ereignis nicht auslöst und es folglich verwirft.
Vorlage Komponente 1
Operation
LocationVisualization
Operation 2
RouteStartSelection
Operation 1
LocationVisualization
Ereignis
RouteStartSelected
Ereignis 1
RouteStartSelected
Abbildung 4.5: Beispiel eines abhängigen Ereignisses
Zur Angabe des Auslösers von Ereignissen existiert nun das Attribut trigger,das mindestens einen der folgenden Werte enthält: interaction, operation undinternal. Im genannten Problemfall ist einzig operation gesetzt. Um dann dieAbhängigkeit zu Operationen zu definieren, bietet SMCDL das Attribut dependsOndes Elements event an, das eine Menge von funktionalen Kategorien von Opera-tionen enthält, die alle gegeben sein müssen. Das ist feingranularer als die Referen-zierung der Operation, da letztere mehrere Funktionalitäten anbieten kann. DurchAutorenwerkzeuge ist sicherzustellen, dass für jeden Eintrag eine Entsprechung anOperationen existiert. Ohne Angabe von trigger dürften Abhängigkeiten nicht an-gegeben werden, wenn das Ereignis z. B. auch durch Interaktion ausgelöst wird.Auf dieser Basis kann ein Matching-Algorithmus die nötigen Schlüsse zur Detektionangesprochener Fälle ziehen. Das Konzept sieht eine Konjunktion der Ontologiekon-zepte vor, aber die Komplexität kann bei Bedarf beliebig gesteigert werden, wobeidann die Auslagerung in ein Element sinnvoll erscheint.
Copyright TU Dresden, Carsten Radeck 58

Semantische Komposition in Mashups Kapitel 4 Konzeption
4.1.1.3 Verhaltenssemantik
Die formale Beschreibung des Verhaltens einer Mashup-Komponente, das sich inexternes (Choreographie) und internes (Orchestrierung) untergliedert, wird nichtexplizit unterstützt. Die notwendige Argumentation wurde bereits im Rahmen derDiskussion in Kapitel 2.3 geliefert. Zudem zeigen die existierenden Ansätze aus Ka-pitel 3.1, dass eine solche Beschreibung einen hohen Detailgrad erfordert, um dieangestrebte Automatisierung tatsächlich zu erreichen.Ungeachtet dessen ist festzustellen, dass zumindest das äußere Verhalten implizit
aus der funktionalen Semantik und Datensemantik von Operationen und Ereignissenund durch die Abhängigkeiten zwischen letzteren hervorgeht.
4.1.1.4 Nicht-Funktionale Semantik
Die semantische Beschreibung nicht-funktionaler Eigenschaften ist ein komplexesThema und die Unterstützung durch die SMCDL wird an dieser Stelle aufgezeigt.Wie eingangs festgehalten, wird eine feste Ontologie für die nicht-funktionalen Eigen-schaften unterstellt. Sie stellt das zulässige Vokabular in Form von Klassen, Relatio-nen und Individuen bereit und ist durch ein XML-Schema in die Metadaten-Sektionabgebildet (Beispiel siehe Listing 4.4). Durch die Verwendung der semantischen Kon-zepte wird die fehlende Eindeutigkeit der bisher an vielen Stellen auf beliebigen Zei-chenketten basierenden Metadaten vermieden. Weiterhin können logische Beziehun-gen, wie Vererbungsrelationen, zwischen Konzepten ausgenutzt werden. Angesichtsder vorgegebenen Ontologie wären semantische Annotationen redundant. Stattdes-sen bietet das XML-Schema auf das Vokabular der Ontologie begrenzte Elementeund Attribute an, letztere, wo notwendig, mit einem durch Mittel von XML-Schemabegrenzten Wertebereich. Zum Beispiel wird in Zeile 5 von Listing 4.4 für die Wäh-rung statt einer beliebigen Zeichenkette die URI (wieder als Qualified Name) einesIndividuums der OWL-Klasse Currency referenziert. Dies erlaubt eine leichtere Er-weiterbarkeit als z. B. die Verwendung von Enumerationen, da das XML-Schemaangesichts neuer Währungen nicht angepasst werden muss. Weiterhin ist bei diesemAnsatz Eindeutigkeit gegeben – insofern sichergestellt ist, dass die URI gültig ist.
1 <meta: metadata >2 <meta:keywords >map , route </ meta:keywords >3 <meta: license id="nfp: LGPLv3 " />4 <meta:price >5 <absolutePrice currency ="nfp:EUR" value ="10" />6 </meta:price >7 </meta: metadata >
Listing 4.4: Beispielhafte Metadaten einer SMCDL-Instanz
Als Vorbild für die prinzipiell beliebige Ontologie der nicht-funktionalen Eigen-schaften können bestehende dienen. Ein Beispiel ist die Ontologie von O’Sullivan[O’S06], welche auch auf WSMO (vgl. Kapitel 3.1.2.2) übertragen wurde. Sie bie-tet ein umfangreiches Vokabular zur Definition verschiedenster nicht-funktionalerAspekte an. Der Fokus liegt jedoch auf nicht-funktionalen Eigenschaften von (Web)Services, sodass nur eine Teilmenge unmittelbar relevant ist, aber die Konzeptekönnten je nach Anforderung verwendet werden. Weitere Konzepte bieten zahlrei-che QoS-Ontologien samt Metriken. Aufgrund der enormen Weitläufigkeit des The-mas QoS, wird es an dieser Stelle jedoch nicht näher ausgeführt. Die Identifizierung
Copyright TU Dresden, Carsten Radeck 59

Semantische Komposition in Mashups Kapitel 4 Konzeption
und Formalisierung geeigneter Qualitätsmerkmale, -modelle und deren Metriken fürMashup-Komponenten und insbesondere die sinnvolle Verknüpfung mit der Kompo-nentenbeschreibung bietet bereits genügend Umfang für eine eigenständige Arbeit.Deshalb liegt der Schwerpunkt zunächst auf den bestehenden nicht-funktionalenEigenschaften. Diese wurden in einer einfachen Ontologie modelliert und an aus-gewählten Stellen erweitert. Abbildung 4.6 illustriert die Vererbungshierarchie dereinzelnen Konzepte. Die Klasse MetaData dient der Verknüpfung mit der Kompo-nente und besitzt diverse Relationen zu anderen Konzepten der Ontologie. Darüberhinaus wurden Kontaktinformationen, die sich am OWL-S Profile orientieren, zuAutoren der Komponente hinzugefügt. Zur Modellierung von Preisen und Lizenzenwurden weiterführende Konzepte und Individuen bereitgestellt, um deren Verwen-dung im Rahmen des Rankings (vgl. Kapitel 4.3.3) exemplarisch zu demonstrieren.
Abbildung 4.6: Klassenhierarchie der nicht-funktionalen Eigenschaften
Eine weitere kleine Änderung wird bezüglich des Elements binding vorgeschla-gen. Wurde hier bisher ein Attribut language verwendet, sieht die Konzeption dieVerlagerung des zuvor in den Metadaten untergebrachten Elements runtimes indas Binding vor. Um die Eignung einer Komponente für eine Laufzeitumgebungzu definieren, ist die Aussagekraft der Programmiersprache angesichts von Browser-Plug-ins und Client-Server-Architekturen limitiert. Andererseits ist die Kompatibili-tät mit verschiedenen Runtimes zwar keine funktionale Eigenschaft, aber wegen deressentiellen Bedeutung für die allgemeine Funktionstüchtigkeit einer Komponentenach Auffassung des Autors an dieser Stelle besser aufgehoben als in den Metada-ten. Listing 4.5 illustriert die Verwendung. Wie in Zeile 3 ersichtlich ist, wird durchdie Nutzung einer URI als ID der Runtime die Eindeutigkeit gewährleistet.
1 <binding >2 <runtimes >3 <runtime id="http ://.../ TSR" version ="1.4"/>4 </runtimes >...
Listing 4.5: Angabe von kompatiblen CRUISe Runtimes im Binding
Copyright TU Dresden, Carsten Radeck 60

Semantische Komposition in Mashups Kapitel 4 Konzeption
4.1.2 Komponenten als OntologieinstanzenAlternativ sieht das Konzept die Beschreibung von Komponenten in Form von OWL-Instanzen vor. Dabei stehen alle besprochenen Konzepte der SMCDL zur Verfügung.Als Erweiterung kann exklusiv auf folgende semantische Beschreibungsmittel zuge-griffen werden.Zum einen sind Vorbedingungen an die Funktionalität von Operationen de-
finierbar. Im Bezug auf WSMO (vgl. Kapitel 3.1.2.2) handelt es sich dabei um An-nahmen an den Zustand der Welt, genauer des Nutzerkontexts. Diese ermöglichenes, festzustellen, ob die Funktionalität im aktuellen Kontext tatsächlich erbrachtwerden kann. Beispielsweise kann die Operation einer Komponente die Routenpla-nung nur innerhalb Deutschlands durchführen. Somit ist eine genauere Suche undAuswahl von Komponenten möglich, die das Potential der CRUISe-Architektur, dieeinen externen Kontextdienst und Mittel zur Erfassung von Kontextinformationendurch die Runtime vorsieht, ausschöpft. Die Repräsentationsform des Kontextdiens-tes ist in CRUISe nicht vorgeschrieben. Damit eine möglichst konkrete Spezifikationder Vorbedingungen stattfinden kann, wird jedoch unterstellt, dass der Kontext-dienst eine Schnittstelle auf Basis von SPARQL anbietet. Ob intern tatsächlich eineRDF-basierte Persistenz vorliegt, ist für das Konzept irrelevant.Konzeptionell ist die Syntax der Vorbedingungen nicht vordefiniert. In der Onto-
logie des Komponentenmodells wird ähnlich dem Ansatz von OWL-S eine generischeKlasse Precondition vorgeschlagen, die mit einer oder mehreren Modellreferenzenassoziiert ist. Von dieser sind konkrete Subklassen zu bilden. Im Hinblick auf diezuvor getroffene Festlegung wird empfohlen, eine Subklasse SPARQLPreconditionabzuleiten, die eine beliebig komplexe SPARQL ASK-Anfrage an das Kontextmo-dell des Nutzers als Zeichenkette in der Eigenschaft isDefinedBy aufweist.Durch den in Kapitel 3.2.5 vorgestellten Ansatz inspiriert ist in der Ontologie-
variante die dynamische Berechnung von nicht-funktionalen Eigenschaftenmöglich. Dabei kann auf Basis von Regeln ein statisch definierter Wert überschrie-ben werden, oder gänzlich neue Definitionen von Metadaten hinzugefügt werden.Dieser Ansatz wird unterstützt, da er eine hohe Flexibilität erlaubt. Somit sindnicht-funktionale Eigenschaften in Abhängigkeit von nutzerspezifischen Kontextin-formationen formulierbar. Ein konkreter Anwendungsfall im Bezug auf das Refe-renzszenario (Kapitel 2.4) ist beispielsweise die dynamische Berechnung des Preisesder Nicht-UI-Komponente zur Routenplanung, abhängig davon, ob der Nutzer einenPremiumaccount besitzt.Die Sprache der Regeln ist prinzipiell nicht vorgeschrieben, sondern implemen-
tierungsspezifisch. Es wird jedoch gefordert, dass es möglich sein muss kontextspe-zifische Bedingungen zu verwenden und dass die Regeln ausschließlich die seman-tisch repräsentierten Metadaten manipulieren. Die Auswertung der Regeln erfolgtvor der Anwendung der Rankingregeln. Die Ontologie der nicht-funktionalen Eigen-schaften (vgl. Kapitel 4.1.1.4) bietet dazu die Möglichkeit, mehrere Regeln über dieEigenschaft hasRule mit der Klasse MetaData zu verbinden. Der Wertebereich isteine abstrakte Klasse Rule. Konkrete Regelsprachen sind durch Subklassenbildungdefinierbar. Eine geeignete Regelsprache ist Jena Rules4 (siehe Beispiel in Listing4.6), da bei diesen die Möglichkeit besteht, eigene Built-Ins, wie queryContext, zu
4http://jena.sourceforge.net/inference/index.html#rules
Copyright TU Dresden, Carsten Radeck 61

Semantische Komposition in Mashups Kapitel 4 Konzeption
definieren und als Java-Klassen zu implementieren, die zur Auswertung von Anfra-gen an das Kontextmodell des Nutzers dienen können. Dazu existiert die SubklasseJenaRule, deren Definition in die Datatype-Property isDefinedBy aufgenommenwird. Das Beispiel setzt den Wert des vorhandenen Preises, modelliert durch einenAbsolutePrice, auf 10, falls eine nicht näher beschriebene SPARQL-Anfrage aufwahr ausgewertet wird.
1 [ inferPriceRule1 : queryContext ("SPARQL -ASK"), ? price a nfp: AbsolutePrice ->2 ? price nfp: hasValue 10]
Listing 4.6: Beispiel einer Jena Rule zur dynamischen Berechnung des Preises
Eine grundlegende Herausforderung beider Konzepte ist die Referenzierung des ak-tuellen Nutzers, da die Regeln unabhängig von diesem vom Komponentenentwicklerverfasst werden. Somit ist durch eine Implementierung ein passender Mechanismusbereitzustellen, um die Regeln mit dem korrekten Nutzerkontext zu assoziieren. Hier-bei gibt es mehrere Optionen. Ausgehend von den vorgestellten SPARQL-basiertenAnsätzen könnten u. a. die SPARQL-Anfragen umgeschrieben werden, z. B. unterVerwendung von Platzhaltern, oder der Kontextdienst stellt eine dedizierte Metho-de bereit, die sicherstellt, dass nur das Modell des angegebenen Nutzers angefragtwird. Ersteres ist jedoch aufgrund der einfacheren Erweiterbarkeit und der nichtnotwendigen Anpassung des Kontextdienstes, die zudem nicht in jedem Fall erlaubtist, der geeignetere Weg.
4.1.3 Repräsentation von Komponenten und Vorlagen imKompositionsmodell
Die dargestellten Erweiterungen der Komponentenbeschreibung um semantische Mit-tel, das Konzept der Vorlagen und die Umstellung auf semantische Typisierung ha-ben Auswirkungen auf das Kompositionsmetamodell von CRUISe. Diese werdennun, wie in Anforderung 18 festgehalten, betrachtet.Zur Repräsentation der semantischen Typisierung wird das Interface ITypable
angepasst. Referenzierte es bisher einen DataType, der mit Attributen für den Na-men, Namensraum und ein XML-Schema des repräsentierten Datentyps ausgestat-tet war, wird nun lediglich die URI des entsprechenden Ontologiekonzepts benötigt.Dadurch werden Operationen, Ereignisse, Parameter, Properties und Kommunikati-onskanäle konsistent semantisch typisiert. Zudem sind DataType und dessen Unter-klassen Element und Type hinfällig, weil im Hinblick auf XSD vorhanden. Weiterhinentfällt die Container-Klasse DataTypes und die Assoziation der zentralen KlasseConceptualModel zu ihr, da in der SMCDL keine Datentypen mehr hinterlegt sind.Wie in Kapitel 2.2.1 dargelegt, wird im Entwicklungsprozess des Mashups von
existierenden Komponenten ausgegangen und deren Beschreibungen durch den An-wendungsentwickler in das Kompositionsmodell importiert. Damit neben konkretenKomponenten auch eine abstrahierte Schablone, die erst zur Laufzeit mit einer kom-patiblen konkreten Komponenten befüllt wird, angegeben werden kann, sieht dieKonzeption vor, dass im Kompositionsmodell das Prinzip von Vorlagen für zu in-tegrierende Komponenten genutzt werden kann. Vorlagen dienen der Anfrage an dieDiscovery, beschreiben also das Ziel des Anfragenden. Die Eignung dieses Ansatzeswurde in Kapitel 3.2.1 diskutiert. Im Gegensatz z. B. zu OWL-S-basierten Ansätzen
Copyright TU Dresden, Carsten Radeck 62

Semantische Komposition in Mashups Kapitel 4 Konzeption
findet in Anlehnung an Goals der WSMO (vgl. Kapitel 3.1.2.2) eine stärkere Tren-nung zwischen der Ziel- und Komponentenbeschreibung statt. Dies hat den Vorteil,dass ein Anwendungsentwickler seine Anforderungen an eine geeignete Komponentedetaillierter ausdrücken kann. Das Konzept der Vorlagen hat weitere wesentlicheAuswirkungen auf das Kompositionsmetamodell, die nachfolgend dargelegt werden.Formal entspricht eine Vorlage einer erweiterten Teilmenge der Konzepte der SM-
CDL, was in Abbildung 4.1 illustriert ist. Das bedeutet, dass im Kompositionsmodellnur ein Teil der Komponentenbeschreibung repräsentiert und um zusätzliche Datenangereichert wird. Die Informationen werden aus der SMCDL bzw. MCDO extra-hiert, in das Kompositionsmodell eingefügt und optional manuell mit den erweiter-ten Konzepten angereichert. Zur Vermeidung unnötiger Dopplungen wird das selbeElement des Kompositionsmetamodells, AtomicMashupComponent und dessen Sub-klassen, zur Repräsentation von konkreten Komponenten und Vorlagen verwendet,aber erweitert. Um dies zu verdeutlichen und zu begründen werden nachfolgend dieeinzelnen Bestandteile aufgelistet und anhand von Abbildung 4.7 veranschaulicht.Eine grüne Färbung kennzeichnet Änderungen oder Erweiterungen.
Abbildung 4.7: Ausschnitt des aktualisierten Kompositionsmetamodells
• Der Name der Vorlage bzw. Komponente.• Das neue boolesche Attribut isTemplate indiziert, dass es sich um eine Vor-
lage handelt. Der Wert ist standardmäßig auf false gesetzt, nachdem eineKomponentenbeschreibung in das Modell importiert wurde.• Eine ID, die der eindeutigen Unterscheidung von Vorlagen bzw. konkreten
Komponenten untereinander dient. Die ID von Vorlagen wird vom Autoren-werkzeug generiert, z. B. basierend auf der der importierten Komponente. Siewird zur Laufzeit bei der Kommunikation zwischen Runtime und ComponentRepository benötigt, was in Kapitel 4.3.1 vertieft wird.
Copyright TU Dresden, Carsten Radeck 63

Semantische Komposition in Mashups Kapitel 4 Konzeption
• Ein weiterer Bestandteil sind Operationen, Ereignisse, Properties, die weitest-gehend dem SMCDL-Interface der Komponente bzw. Vorlage entsprechen, je-doch ohne Vorbedingungen, referenzierte Transformationsvorschriften, das At-tribut required sowie Standardwerte von Properties, da diese weder im Rahmendes Matchings noch für die Komposition im Anwendungsmodell relevant sind.• Die optionale Gewichtung von Modellreferenzen an Operationen und Ereig-
nissen dient, in Anlehnung an Goals der WSMO, der Definition der Sicht desNutzers von Komponenten, d. h. des Anwendungsentwicklers. Standardmäßigsind diese mit 1.0 belegt, was anzeigt, dass das annotierte Konzept unbedingtvon einer konkreten Komponente gegeben sein muss. Auf diese Weise kanneine gesuchte Komponente genauer beschrieben werden, da auch fakultati-ve Eigenschaften ausgedrückt werden können, was vergleichbar der Intentiondes Dienstnutzers im Ansatz von Fensel et al. in Kapitel 3.2.2 ist. Das Kom-positionsmetamodell stellt zur Repräsentation von Modellreferenzen, die diefunktionale Semantikbeschreiben, die Klasse ModelReference bereit, was durchdie ElementDescription von USDL (vgl. Kapitel 3.1.2.3) inspiriert ist. Sie be-sitzt neben der URI und einer menschenlesbaren Beschreibung des Konzepteszusätzlich die Gewichtung weight ∈ [0, 1] (siehe Abbildung 4.7).Neben gewichteten Modellreferenzen wären prinzipiell auch optionale Opera-tionen und Ereignisse möglich. Das Konzept beschränkt sich auf erstere, daoptionale Operationen und Ereignisse zwar für die Komponentensuche zurEntwicklungszeit wichtig sind, jedoch zur Integrationszeit, die im Fokus dieserArbeit steht, nichts bringen: Zusätzliche Operationen und Ereignisse wärenaufgrund des Fehlens im Kompositionsmodell nicht in die Kommunikationsin-frastruktur einbezogen; solche hingegen, die wegen der Optionalität entfallen,aber im Modell vorgesehen sind, können die Funktionstüchtigkeit der gesamtenAnwendung gefährden.• Optional kann die Menge der für diese Vorlage relevanten Rankingregeln re-
ferenziert werden. Diese wurden bisher noch nicht im Kompositionsmodellrepräsentiert. Dazu wird die Klasse RankingRules angegeben und mit demConceptualModel in Beziehung gesetzt. Sie enthält mehrere RankingRules,die jede Vorlage referenzieren kann, um Redundanzen zu vermeiden. Zudemist eine Rankingregel mittels isGlobal als anwendungsweit deklarierbar undgilt dann für alle Vorlagen. Formale Zusicherungen können sicherstellen, dasskeine anwendungsweiten Rankingregeln referenziert werden. Angesichts derImplementierung des Kompositionsmetamodells in Ecore5, das auf einer Un-termenge der Meta Object Facility (MOF) basiert, ist die Object ConstraintLanguage (OCL) dafür eine passende Wahl.
Die Erweiterungen, d. h. die Rankingregeln und Gewichtungen, wurden somit er-örtert. Vorlagen sind eine Teilmenge der SMCDL, da z. B. die Metadaten nichterfasst werden. Dies ist nicht nötig, da sie nicht in das Matching der Vorlage gegenKomponenten einfließen, sondern separat in das anschließende Ranking.Das resultierende Vorgehen der Einbeziehung von Komponenten bietet dem An-
wendungsentwickler somit zwei Alternativen. Der direkte Weg ist die Beibehaltung5http://www.eclipse.org/modeling/emf/?project=emf
Copyright TU Dresden, Carsten Radeck 64

Semantische Komposition in Mashups Kapitel 4 Konzeption
des Wertes false von isTemplate. Dann wird die konkrete Komponente anhandihrer ID in die Anwendung integriert. Auch die erweiterten Konzepte sind in diesemFall unerheblich. Da Vorlagen nahezu deckungsgleich mit konkreten Komponentenim Kompositionsmodell repräsentiert werden, ist auch der Austausch der Kompo-nente später möglich, indem die Modellrepräsentation als Vorlage verstanden wird.Wurden die erweiterten Konzepte nicht gesetzt, greifen dann die Standardwerte,d. h., dass alle Modellreferenzen obligatorisch sind und nur die anwendungsweitenRankingregeln verwendet werden.Falls der Anwendungsentwickler isTemplate auf true setzt, wird zur Laufzeit
eine semantisch passende Komponente gesucht. Dabei handelt es sich keineswegszwangsläufig um genau die ursprüngliche Komponente, deren Beschreibung in dasKompositionsmodell importiert wurde. Denn zum einen kann die ausgewählte Kom-ponente potentiell mehr Operationen, Ereignisse etc. aufweisen, als in der Vorlageangegeben, zum anderen wird ein Ranking durchgeführt, das z. B. Spezifika desNutzerkontexts und der aktuellen Laufzeitumgebung einbezieht, während das Kom-positionsmodell davon unabhängig erstellt wird. Zudem spielen die gewichteten Mo-dellreferenzen bei der Lockerung der Anforderungen an die gesuchte Komponenteeine wesentliche Rolle, sodass die Kandidatenmenge weiter vergrößert wird.
4.2 Architektonischer ÜberblickBevor die Architektur und interne Abläufe im Detail spezifiziert werden, steht dieüberblicksartige Betrachtung zu lösender Aufgaben im erweiterten Integrationspro-zess auf Basis der semantischen Komponentenbeschreibung im Blickpunkt.
4.2.1 VorbetrachtungenIn Anlehnung an den SWS Usage Process (vgl. Kapitel 2.3) ergibt sich folgenderAblauf, der anhand Abbildung 4.8 veranschaulicht wird. Die sich aus den Aufgabenableitenden notwendigen Funktionalitäten und deren Verteilung auf die Architektur-komponenten, d. h. getrennte logische Einzelsysteme, werden im Folgenden erörtert.
MatchingModellinter-pretation
Ausführung
Kontextver-waltung
Verwaltung von Komponenten-beschreibungen
Realisierung Lebenszyklus
Verwaltung vorgegebener Typdefinitionen und Liftings/Lowerings
Typprüfung
Komponentenaustausch
Ranking & Selektion
Mediation
KontextmodellKompositionsmodell
Abbildung 4.8: Grundlegende Aufgaben
Ausgangspunkt ist das statisch erstellte Kompositionsmodell, das eine deklarativeBeschreibung der Anwendung beinhaltet und dessen Realisierung als das Ziel desIntegrationsprozesses aufgefasst werden kann. Im Rahmen der Modellinterpretationwird es geladen und ausgewertet. Diese Aufgabe übernimmt der Model Interpre-ter als Teil der Runtime, da der Runtime die Umsetzung der Mashup-Anwendung
Copyright TU Dresden, Carsten Radeck 65

Semantische Komposition in Mashups Kapitel 4 Konzeption
gemäß dem Kompositionsmodell obliegt. Dazu gehört u. a. die Integration der ent-haltenen Mashup-Komponenten, wobei zwischen Vorlagen und konkreten Kompo-nenten zu unterscheiden ist. Blau markierte Aufgaben sind nur für erstere notwendig.Für konkrete Komponenten reduziert sich das Matching auf die Suche anhand derID und die Mediation auf die am Binding angegebenen Transformationen. Im Fallevon Vorlagen ist hingegen Matching sowie Ranking und Selektion durchzuführen,erlaubt aber die Einbindung kompatibler Komponenten, deren Schnittstelle syntak-tisch nicht identisch sein muss (im Gegensatz zum Klassenkonzept). Dafür notwen-dige Eingaben stammen von der Verwaltung von Komponentenbeschreibungen unddem Kontextmodell des Nutzers der Anwendung. Zur persistenten Speicherung undBereitstellung von Komponentenbeschreibungen dient das Component Reposito-ry. Das Matching wird ihm konzeptionell ebenfalls übertragen, da es als ein kom-plexer Filter für die Suche und Abfrage von Komponentenbeschreibungen aufgefasstwerden kann. Zudem sind hier sämtliche Komponentenbeschreibungen registriertund anders als bisher basiert das Matching auf komplexeren Algorithmen und derAusnutzung logischer Beziehungen zwischen annotierten Konzepten. Die Verwaltungder Kontextinformationen ist fest dem Context Service zugewiesen und verbleibtin einer eigenständigen Architekturkomponente, damit er anwendungsübergreifendund auch unabhängig von CRUISe Kontextinformationen sammeln und bereitstellenkann. Um mögliche Alternativen für eine konkrete Komponente, die als austausch-bar deklariert ist, zu erhalten, kann die Repräsentation im Kompositionsmodell alsVorlage aufgefasst und für diese Matching und Ranking ausgeführt werden. Ist einekonkrete Komponente bestimmt, wird sie anhand ihrer Beschreibung in das Mash-up integriert und ihr Lebenszyklus realisiert, wofür die Runtime zuständig ist. ZurGewährleistung einer funktionierenden Kommunikation zwischen Komponenten istbezüglich der ausgetauschten Daten eine Typprüfung und Mediation bereitzustellen.Da die Runtime, wie in Kapitel 2.2.2.2 erörtert, die Kommunikationsinfrastrukturfür die Komponenten samt Typprüfung zur Verfügung stellt, wird die Mediationihr zugeordnet, woraus der Mediator resultiert (Details siehe Kapitel 4.3.4). Ty-pprüfung und Mediation basieren auf der Verwaltung vorgegebener Typdefinitionenund Liftings/Lowerings der Ontologiekonzepte (vgl. Kapitel 4.1.1.1). Dazu dient dasType Repository, das konzeptionell in das Component Repository aufgenommenwird, da diese Aufgabe anwendungsunabhängig ist und um Probleme bei der Syn-chronisation mit den dort registrierten Ontologien zu vermeiden. Das Ergebnis desganzen Prozesses ist die funktionstüchtige Mashup-Anwendung.Unter Beachtung von Performanz und Praktikabilität ist das Konzept nicht auf
eine Thin-Server-Runtime abbildbar. Aufgaben, wie die Mediation von Daten unddas Ranking, die eine Unterstützung von semantischen Daten und einer Wissens-basis der Ontologien erfordern, müssen auf Seite des Servers erbracht werden. Dadann auszutauschende Daten zwischen Komponenten zur Mediation über einen Ser-ver versendet werden, kann nicht mehr von einer Thin-Server-Runtime gesprochenwerden. Daher ist für das Konzept eine Client-Server-Runtime sinnvoll.Die entscheidende Frage ist, an welcher Stelle das Ranking stattfindet. Um die
letztendliche Verteilung im Konzept abzuleiten, erfolgt zunächst eine Diskussionmöglicher Alternativen.
Verteilungsstrategie a: In dieser Variante übernimmt der Integration Service dasRanking, sodass die derzeitige Architektur von CRUISe beibehalten wird, wie
Copyright TU Dresden, Carsten Radeck 66

Semantische Komposition in Mashups Kapitel 4 Konzeption
Integration Service
Context Service
Component Repository
Ranking
Runtime
Knowledgebase
MCDL-O
Query, update
Matching Type Repository
Query
Context Model
MCDO
a) b)
Std XSD + Lifting/Lowering
Std XSD + Lifting/Lowering
Context Service
Component Repository
Ranking
Runtime
Knowledgebase
MCDL-O
Query, update
Matching
Type Repository
MediatorModel Interpreter
Composition Model
MCDO
Std XSD + Lifting/Lowering
Std XSD + Lifting/Lowering
Query
Context ModelQuery
MediatorModel Interpreter
Composition Model
Abbildung 4.9: Alternative Verteilungsstrategien
links in Abbildung 4.9 zu erkennen ist. Die Unabhängigkeit der Runtime vomComponent Repository und somit die Option mehrerer Repositories, die fürdie Runtime transparent abgefragt werden, ist vorteilhaft. Zusätzlich werdendie Belange der nutzer- und anwendungsspezifischen Auswahl und des funk-tionalen Matchings getrennt und die Runtime kann direkt auf den SMCDLarbeiten. Als nachteilig muss der erhöhte Datenverkehr bewertet werden. Erresultiert aus der Übergabe von Vorlage und Rankingregeln an den IntegrationService, der Weitergabe der Vorlage an das Component Repository, der Rück-gabe der Kandidatenliste in Form von serialisierten Ontologieinstanzen undder Delegation der Anfragen an das Type Repository. Weiterhin muss auchder Integration Service wegen des Rankings semantische Daten unterstützenund Kenntnis über die Ontologien besitzen. Zudem müssen Mittel zur Syn-chronisation der Typdefinitionen und registrierten Ontologien bereitstehen,falls mehrere Repositories verwendet werden.
Verteilungsstrategie b: Eine weitere Option ist die Verteilung nach dem Schemaauf der rechten Seite der Abbildung. Hierbei ist auch das Ranking im Com-ponent Repository angesiedelt. Der Vorteil ist, dass nur die Komponenten-beschreibung der selektierten Komponente an die Runtime übermittelt wer-den muss. Weiterhin muss die Runtime nicht zwangsläufig semantische Kom-ponentenbeschreibungen, auf denen das Ranking beruht, handhaben können,sondern kann direkt auf SMCDL arbeiten. Diese Variante ist auf ein logischzentralisiertes Component Repository beschränkt. Da letzteres zum RankingZugriff auf den Kontextdienst benötigt, ist die Herstellung von Kontextbezugauch im funktionalen Matching unmittelbar möglich. Dies geht jedoch da-mit einher, dass das Component Repository nicht mehr mit rein funktionalenMatching vertraut ist, sondern auch nutzer- und anwendungsspezifische In-formationen einbezieht, d. h., dass diese Belange nicht sauber getrennt wären.Zudem sind die Rankingregeln von der Runtime zu übertragen.
Verteilungsstrategie c: Die dritte Option, die wegen der Ähnlichkeit zu Varian-te b nicht in der Abbildung auftaucht, ist die Verlagerung des Rankings indie Runtime. Dadurch verbleiben die Rankingregeln, da sie Teil des Komposi-tionsmodells sind, in der Runtime. Das einzelne Component Repository wird
Copyright TU Dresden, Carsten Radeck 67

Semantische Komposition in Mashups Kapitel 4 Konzeption
von den anwendungs- und nutzerbezogenen Aufgaben entlastet, sodass die Zu-ständigkeiten getrennt sind und es nur optional Zugriff auf den Kontextdienstbraucht, falls Kontextbezug im Matching gewünscht ist. Bei dieser Varian-te entsteht ein höherer Datentransfer als in Variante b, da die semantischenDaten der Ontologiebeschreibung aller Kandidaten an die Runtime gesendetwerden müssen. Die Runtime muss diese verarbeiten können, sodass bestehen-de Umsetzungen grundlegend anzupassen sind. Zudem braucht sie Kenntnisseüber die Ontologien für nicht-funktionale Eigenschaften und das Komponen-tenmodell, um das Ranking durchzuführen.
4.2.2 Konzipierte ArchitekturAngesichts der Vorbetrachtungen und insbesondere der jeweiligen Vor- und Nach-teile der alternativen Verteilungsstrategien wird folgende Architektur vorgeschlagen.Abbildung 4.10 zeigt das Blockbild der Verteilung der Aufgaben zwischen Runtimeund Component Repository. Wie deutlich wird, entspricht es im Wesentlichen derOption b, bei der das Component Repository den Integration Service anbietet. DenAusschlag hierbei gibt letztlich der Ersparnis an Datentransfer, um in realistischenSzenarien mit tausenden Komponenten die Performanz der Architektur, insbeson-dere beim Anwendungsstart, gewährleisten zu können. Dies trägt zur Erfüllung vonAnforderung 15 bei und geht mit dem Kompromiss einher, dass anwendungs- undnutzerspezifische Informationen im Component Repository benötigt werden. Daswird jedoch dadurch entschärft, dass sämtliche Algorithmen generisch sind und überdie Anfrage von der Runtime konfiguriert werden.Letztlich kann die Verteilungsfrage nicht allgemeingültig beantwortet werden. Alle
Varianten haben klare Vor- und Nachteile und je nach Anforderungen im jeweiligenKontext werden andere Ansprüche an Effizienz oder Variabilität der Architekturgestellt. Es kann problemlos eine alternative Verteilung vorgenommen werden, z. B.falls mehrere Component Repositories benötigt werden, denn an den grundlegendenAufgaben und dem daraus resultierenden Ablauf ändert sich nichts.Der Plattformadapter (2.2.2.3) und insbesondere dessen Zusammenspiel mit der
Mediation wird für diese Arbeit ausgeklammert, da unterstellt wird, dass das Mat-ching sicherstellt, dass die Komponente für die geforderte Plattform geeignet ist.Dies kann bedeuten, dass die Komponente dem Ergebnis einer vorhergegangenenAdaption einer anderen Komponente entspricht.Im Folgenden werden wesentliche Komponenten der Architektur beschrieben.Zur persistenten Speicherung und Verwaltung von Komponentenbeschreibungen
dient das logisch zentralisierte Component Repository und verfügt dementsprechendüber eine Schnittstelle zum Registrieren, Entfernen (Management) und Suchenvon Komponenten (Querying). Letztere bietet mehreren Abfrageoptionen, die inKapitel 4.3.2 näher beschrieben werden, und die zur Suche von Komponenten imIntegrationsprozess benötigte Schnittstelle, die in Abschnitt 4.3.1 behandelt wird.Wie in Kapitel 2.2.2.3 beschrieben, bearbeitet eine Integration Task eine Anfrageund steuert den Kontrollfluss über die Module zum Zugriff auf den Kontextdienst(Context), für das Matching und Ranking. Da eine semantische Repräsentationder Komponentenbeschreibung vorgeschlagen wird, können neben Beschreibungenin SMCDL auch direkt serialisierte Ontologieinstanzen registriert werden. Erstere
Copyright TU Dresden, Carsten Radeck 68

Semantische Komposition in Mashups Kapitel 4 Konzeption
Ontologies
Context Service
Component Repository
register
SMCDL
Integratio
n Task
Integratio
n Task
Integratio
n Task
Ranking
Strategy
Querying
Runtime
KnowledgebaseReasoner
Development Time
NFP Ontology MCDL OntologyTop Level OntologyTop Level Ontology Domain OntologyDomain Ontology
Query, update
register
Matching
ManagementType Repository
Mediation Service Std XSD +
Lifting/Lowering
Model Interpreter
Composition Model
Context
Query
Std XSD + Lifting/Lowering
Std XSD + Lifting/Lowering
Notify
Tem
pla
te
SMC
DL
Ra
nki
ng
Ru
les
Context Model
MCDO
Domain Ontology
MCDOMCDO
Abbildung 4.10: Übersicht der Architektur
sind zunächst in eine Ontologieinstanz zu überführen. Weiterhin wird die Validitätder Beschreibung geprüft. Ist diese nicht gegeben, erfolgt die Kommunikation desFehlers und die Instanz wird verworfen (Anforderung 14). Alle Komponentenbe-schreibungen befinden sich in der Knowlegdebase, die auf Basis gängiger OWL-Reasoner implizites Wissen schließen kann. Beim Component Repository sind überdie Management-Schnittstelle weiterhin alle Ontologien mit ihrer URL zu registrie-ren, damit die in Kapitel 4.1 geschilderte gemeinsame Nutzung der Ontologien undsomit die Gültigkeit der Komponentenbeschreibungen gewährleistet werden kann.Neue Ontologien stehen somit künftig in der Knowledgebase bereit und können vomMediator und bei der werkzeuggestützten Erstellung der Komponentenbeschreibungauf ihre URL aufgelöst werden. Bei letzterem spielt die Suche nach passenden Kon-zepten eine wesentliche Rolle. Die genaue Spezifikation einer solchen Schnittstellesteht jedoch nicht im Fokus dieser Arbeit.Zur Verwaltung der Standardschemata und der zugehörigen Transformationen,
die zusammen mit neuen Ontologien im Component Repository zu registrieren sind,wird ein Type Repository vorgesehen. Dies hat den Vorteil, dass die redundanteAngabe der Schemata in Komponentenbeschreibungen und Kompositionsmodellenverhindert wird. Es bietet eine Schnittstelle zur Erbringung folgender Funktionen.
• Abfragen der Typdefinition in XSD für die gegebene URI eines Ontologiekon-zepts. Dies ist für die Runtime relevant, um im Rahmen der Modellinterpreta-tion die Schemata der semantischen Parametertypen der Kanäle zu erhalten,die im Zuge der Typprüfung im Event Broker benötigt werden.• Abrufen der vordefinierten Transformationsvorschrift des Liftings und des Lo-
werings anhand der URI eines Ontologiekonzepts.• Hinzufügen und Entfernen von Typdefinitionen sowie Liftings und Lowerings
anhand der URI eines Ontologiekonzepts.
Copyright TU Dresden, Carsten Radeck 69

Semantische Komposition in Mashups Kapitel 4 Konzeption
Auftretende Fehler betreffen insbesondere unbekannte URI und werden kommuni-ziert, z. B. durch HTTP-Statuscodes. Das Schema der Antwort auf die Anfrage derTypdefinition besteht entweder aus einer primitiven Typdefinition, die nur für anno-tierte Datatype-Properties relevant sind, z. B. xsd:string, oder einem komplettenXML-Schema. Ein Lowering umfasst neben einer SPARQL-Anfrage auch ein XSLT-Stylesheet, während Liftings lediglich letzteres beinhalten. Die Runtime nutzt dieseSchnittstelle, um während der Modellinterpretation die Typdefinition der Kommu-nikationskanäle abzurufen. Auch der Mediator benötigt Zugriff darauf, damit dienotwendigen Transformationen für Lifting und Lowering bezogen werden können.Die Wahl dieser Schnittstelle erfolgt in Anlehnung an den SAWSDL Usage Guide6.XSLT ist für das Lifting geeignet, da die semantischen RDF-Daten in einer standar-disierten XML-Serialisierung (RDF/XML) vorliegen können, weshalb eine Trans-formation des XML-Instanzdokuments ausreichend ist. Beim Lowering ist hingegennicht klar in welcher Repräsentation die semantischen Daten vorliegen. Und selbstwenn RDF/XML unterstellt wird, sind viele syntaktische Variationen möglich. Diesealle in einer XSL-Transformation zu handhaben, scheint kein sinnvolles Vorgehen.Da mit SPARQL eine Anfragesprache existiert, die unabhängig von solchen Seriali-sierungsproblemen ist, liegt es nahe, diese zur Abfrage der semantischen Daten zunutzen und das SPARQL Query Results XML Format mit seiner standardisiertenSyntax als Ausgangspunkt für eine XSL-Transformation zu verwenden.Die vorgeschlagene Architektur erlaubt die Erbringung der definierten Aufgaben,
wobei der Datentransfer möglichst niedrig gehalten wird. Bisher nur grob umrisseneBestandteile der Architektur und Abläufe werden im nächsten Kapitel detailliertbesprochen.
4.3 Integrationsprozess von KomponentenIn diesem Kapitel wird das Zusammenspiel der eingangs erwähnten Architekturkom-ponenten bei der Integration von semantisch beschriebenen Mashup-Komponentengenau definiert (Anforderung 11). Dazu wird die Execution Semantics, d. h. die for-male Beschreibung des operationellen Verhaltens eines Systems [FKZ08, S.119], an-hand eines Aktivitätsdiagramms in der Unified Modelling Language (UML) [Gro09]spezifiziert und erläutert. Für die Nutzung der UML spricht ihre Standardisierung,Verbreitung und Akzeptanz. Aktivitätsdiagramme stellen das Verhalten eines Sys-tems als koordinierte Menge von Aktivitäten, deren Kontroll- und Datenfluss dar.Daher sind sie gut geeignet, um die Bedeutung der Abläufe bei der Integration unddem Austausch von Komponenten zu spezifizieren.Aus der zuvor getroffenen Verteilung der Aufgaben in der Architektur ergibt sich
der folgende Ablauf in abstrahierter Darstellung (vgl. Abbildung 4.11), dessen ein-zelnen Aktivitäten in den nachfolgenden Abschnitten sukzessive verfeinert und Ent-scheidungen begründet werden. Beim Anwendungsstart interpretiert die Runtimedas Kompositionsmodell und initiiert die Integration der darin enthaltenen Kom-ponenten. Abhängig davon, ob es sich dabei um eine konkrete Komponente odereine Vorlage handelt, wird die Anfrage an das Component Repository gewählt. Die-se wird in Kapitel 4.3.1 spezifiziert. Im Falle konkreter Komponenten wird deren
6http://www.w3.org/TR/sawsdl-guide/
Copyright TU Dresden, Carsten Radeck 70

Semantische Komposition in Mashups Kapitel 4 Konzeption
Modell interpretieren
AtomicMashupComponent integrieren
Semantische Discovery
Discovery per ID
[isTemplate=true]
[isTemplate=false]
Lebenszyklus realisieren
Mediation konfigurieren
Ranking
Component Repository
Komponente per ID abfragen
Antwort aus SMCDL+MatchingResult erzeugen
Context ServiceRuntime
Kontextmodell anfragen
Anfrage per Vorlage
Anfrage per ID
Kontextmodell anfragen
Discovery per ID
Abbildung 4.11: Aktivitäten bei der Integration von Komponenten
Beschreibung anhand ihrer ID abgefragt, d. h., dass die Discovery auf den syntak-tischen Vergleich von IDs reduziert ist und ein Ranking entfällt. Im Falle von Vor-lagen findet die semantische Discovery (Kapitel 4.3.2) und das Ranking (Kapitel4.3.3) statt, wobei Kontextinformationen vom Context Service abgerufen werden.Die resultierende Kandidatenliste wird der Runtime übermittelt, die nachfolgendfür die gewünschte Komponente per ID die notwendigen Informationen zur erfolg-reichen Integration abruft. Anschließend werden Mittel zur Mediation (Aktivität»Mediation konfigurieren«; Kapitel 4.3.4) bereitstellt, bevor der Lebenszyklus derKomponente realisiert wird. Auf Basis dieses Ablaufs kann zudem der Austauschvon Komponenten erfolgen, was in Abschnitt 4.4 vertieft wird.
4.3.1 ModellinterpretationDer Integrationsprozess von Komponenten beginnt mit der Modellinterpretationdurch die Runtime. Prinzipiell können Komponenten per ID und per Vorlage imKompositionsmodell adressiert sein. Die daraus resultierende Schnittstelle zwischenRuntime und Component Repository wird nun spezifiziert (Anforderung 7 und 10).
Fall 1: Angabe einer Vorlage Für diesen Fall existiert eine Methode, die auf Ba-sis von Discovery-Algorithmen semantisch zur Vorlage passende Kandidaten liefert.Dabei wird die zuvor im Integration Service vorhandene Schnittstelle aufgegriffen,die zwischen einer Methode zur Abfrage einer geordneten Liste von IDs der Kompo-nenten und dem eigentlichen Erhalt einer Komponentenbeschreibung unterscheidet.Dafür spricht die klare Trennung der Belange.Abbildung 4.12 zeigt die zeitliche Abfolge der Schritte. Die Anfrage zum Erhalt
der Kandidatenliste (1) umfasst als Parameter die Serialisierung der Vorlage, dieID und Version der Runtime und die URL des Kontextdienstes sowie die eindeutigeKennung des aktuellen Nutzers zum Zugriff auf dessen Kontextmodell. Weiterhinkann die maximale Anzahl zu liefernder Kandidaten (standardmäßig alle) definiertwerden, um das Datenvolumen einzugrenzen. Optional wird eine Liste von IDs aus-zuschließender Komponenten übergeben, damit beim Austausch von Komponentennicht die selbe erneut integriert wird. Zudem kann die komplette Historie zuvor
Copyright TU Dresden, Carsten Radeck 71

Semantische Komposition in Mashups Kapitel 4 Konzeption
Runtime Component Repository
Komponenten- und Vorlagen-ID übermitteln
SMCDL und Matching Result zurückliefern
4
5
Liste von Kandidaten für eine Vorlage abfragen
Geordnete Liste aus Tupeln <Komponenten-ID, Rating>
1
3Discovery,
Ranking
2
- Vorlage- Nutzerkennung, URL des Kontextdienstes- ID und Version der Runtime- maximale Anzahl von Kandidaten*- Blacklist* *optional
Abbildung 4.12: Schnittstelle für die Integration einer Komponente per Vorlage
wegen mangelnder QoS oder aufgetretener Fehler ausgetauschter Komponenten füreine Vorlage ausgeschlossen werden. Anschließend erfolgt die semantische Discoveryund das Ranking (2), die in den nachfolgenden Kapiteln 4.3.2 und 4.3.3 im Detailerläutert werden. Die zurückgelieferte Liste enthält Paare von IDs konkreter Kom-ponenten und deren Rankingwert (3). Listing 4.7 veranschaulicht den Aufbau derAntwort. Auf Basis dieser Informationen liegen der Runtime mögliche Alternativenvor, die dem Nutzer z. B. in einem Interaktionselement visualisiert werden können,sodass er sie manuell austauschen kann. Durch die Übertragung der Blacklist wirddas Matching und Ranking für diese Komponenten gespart, was nicht möglich wäre,wenn die Runtime erst die erhaltene Liste der Kandidaten filtern würde.
1 <components >2 <component id="..." rating ="..." />3 <component id="..." rating ="..." />4 </ components >
Listing 4.7: Grober Aufbau der Antwort mit einer Kandidatenliste in XML
Abbildung 4.13: Schematischer Aufbau eines Matching Results
Daraus wählt die Runtime die geeignetste Komponente – i. d. R. diejenige mitder höchsten Bewertung – und fordert deren SMCDL und Matching Result, dasbeschreibt, wie die Operationen, Ereignisse, Parameter und Properties der Vorlagedenen der Komponente zugeordnet werden (siehe Abbildung 4.13 für die Struktureines Matching Results), an (4). Dazu übermittelt die Runtime die ID der Vorla-ge und der gewünschten Komponente, die notwendig sind, um zusammen mit deraktuellen Sitzung, die vom Component Repository verwaltet werden muss, eine ein-deutige Zuordnung zum passenden Matching Result zu ermöglichen. Letztere sindaufgrund der Trennung beider Operationen zwischenzuspeichern und spielen für dieMediation, die in Abschnitt 4.3.4 detailliert dargestellt wird, eine tragende Rolle.Strategien zur Freigabe des Speichers stehen nicht im Fokus dieser Arbeit. Da mitder SMCDL ein definiertes Schema existiert, das zudem alle von der Runtime zurIntegration und den Austausch der Komponente benötigten Informationen enthält,wird sie direkt verwendet (5). Einzig die Metadaten und die Dokumentation können
Copyright TU Dresden, Carsten Radeck 72

Semantische Komposition in Mashups Kapitel 4 Konzeption
(schemakonform) aus Effizienzgründen ausgespart werden, da diese für die Runtimenicht essentiell sind. Weil das Component Repository eine ontologiebasierte Persis-tenz nutzt, muss die SMCDL daraus generiert oder zusätzlich gespeichert werden.
Fall 2: Angabe einer Komponente mittels ID In diesem Fall muss das Com-ponent Repository eine Methode zur Abfrage der SMCDL per ID bereitstellen. Essucht unter den registrierten Komponenten diejenige mit der angeforderten ID undgibt deren SMCDL zurück.Die semantische Discovery und das Ranking entfällt in diesem Fall. Sollte die Kom-
ponente nicht auffindbar sein, wird der Fehler kommuniziert und die Runtime kanndie Repräsentation der Komponente im Kompositionsmodell als Vorlage auffassenund eine Anfrage wie in Fall 1 stellen (Anforderung 14). Ein Matching Result istunnötig, weil eine perfekte Übereinstimmung angenommen wird, da das Kompositi-onsmodell ansonsten inkonsistent wäre. Abbildung 4.14 illustriert die besprochenenSchritte und deren zeitliche Abfolge.
Runtime Component Repository
Komponenten-ID übermitteln
SMCDL zurückliefern
1
2
Abbildung 4.14: Schnittstelle für die Integration einer Komponente per ID
Für alle der vorgestellten Operationen können spezifische Varianten existieren,welche die Antwort in unterschiedlichen Formaten ausliefern, damit eine optimier-te Verarbeitung durch die Runtime stattfinden kann. Standardmäßig wird XMLangeboten, aber z. B. kann angesichts möglicher clientseitiger Integration von Kom-ponenten auch JSON empfohlen werden. Es obliegt der Runtime die korrekte Ope-ration zu wählen. Von einem Parameter zur Auswahl des Formats wird abgesehen,da die konkrete Syntax, z. B. zwischen XML und JSON, grundverschieden ist unddie Spezifikation der Rückgabe somit nur umständlich angegeben werden könnte.
4.3.2 Semantische DiscoveryDie Discovery führt das funktionale Matching der angefragten Vorlage gegen po-tentielle Kandidatenkomponenten durch und dient somit dem Auffinden funktionalkompatibler Komponenten. Wie zuvor begründet, obliegt diese Verantwortlichkeitdem Component Repository. Grundlegend sind zwei Fälle der Discovery zu iden-tifizieren, die unterschiedliche Anforderungen an die Genauigkeit und somit denverwendeten Algorithmus stellen.
Discovery zur Entwicklungszeit der Anwendung Zur Entwicklungszeit liegt derFokus i. d. R. darauf, eine möglichst komplette Menge aller ähnlichen Kompo-nenten zu finden. Zudem spielen andere Suchanfragen eine Rolle, z. B. anhandvon Schlüsselworten oder vorhandener Operationen. Algorithmen, wie z. B. inKapitel 3.2.4 bezüglich SAWSDL-MX vorgestellt, liefern einen numerischenWert der Übereinstimmung und es ist nicht garantiert, dass die Komponen-te ohne weiteres integrierbar ist. Für die Discovery zur Entwicklungszeit sind
Copyright TU Dresden, Carsten Radeck 73

Semantische Komposition in Mashups Kapitel 4 Konzeption
sie trotzdem geeignet, da etwaige Unstimmigkeiten vom Anwendungsentwick-ler manuell behoben werden können – im Zweifelsfall durch Anpassung desKompositionsmodells.
Discovery zur Laufzeit der Anwendung Hierbei bildet die Suche definitiv kompa-tibler Komponenten den Schwerpunkt. Dabei sind Abweichungen nur bis zudem Grad tolerierbar, wie sie durch Mediation automatisch überbrückbar sind.Daher handelt es sich eigentlich um eine boolesche Entscheidung, wobei dieerbrachte Funktionalität von Operationen und Ereignissen sowie deren Ein-und Ausgaben einen entscheidenden Faktor darstellen. Zum Beispiel hilft dieFeststellung, dass das Konzept eines Parameters zwar in keiner bekanntenlogischen Beziehung zur Anfrage steht, aber eine hohe textuelle Ähnlichkeitauftritt, zur Laufzeit wenig, da die Kompatibilität nicht garantiert ist.
Basierend auf diesen Vorbetrachtungen wird in diesem Abschnitt ein Algorith-mus konzipiert, der den Anforderungen der Discovery zur Laufzeit der Anwendunggerecht wird und generisch, d. h. nicht für bestimmte (Domänen-) Ontologien zu-geschnitten, ist. Daneben wird die Option vorgesehen, alternative Verfahren zumMatchmaking im Component Repository anzubieten, die zur Entwicklungszeit rele-vant sind, um zur Erfüllung von Anforderung 16 beizutragen. Die Lösung dafür wirdan dieser Stelle kurz beschrieben, da der Fokus anschließend auf dem Algorithmusfür die Discovery zur Laufzeit liegt. Es wird eine extra Methode von der Querying-Schnittstelle bereitgestellt, die vom Autorenwerkzeug genutzt werden kann, da dieBestimmung des Matching Results für das Autorenwerkzeug i. d. R. nicht relevantist. Ihr wird der Identifier des anzuwendenden Algorithmus, ein Schwellenwert, derdie Mindestübereinstimmung der Kandidaten angibt, und die maximale Anzahl zuliefernder Ergebnisse übermittelt.
4.3.2.1 Theoretische Grundlagen
Der Matching-Algorithmus nutzt die annotierten Modellreferenzen an Operationenund Ereignissen sowie die semantische Typisierung der Parameter und Properties derKomponenten aus, um primär logisches Matching durchzuführen. Im Hinblick aufdie in Kapitel 3.2.2 vorgestellten Übereinstimmungsgrade werden nur Exact, PlugIn,Subsumes und Fail unterstützt, um die Kompatibilität zu gewährleisten. Subsumeswird bei der Datensemantik nicht verwendet, da nicht sicher ist, ob die Komponen-te die Eingabe verarbeiten kann. Somit steht es der Zielstellung, Komponenten ineine funktionierende Mashup-Anwendung gemäß dem Kompositionsmodell zu inte-grieren, entgegen. Bezüglich funktionaler Semantik ist es wesentlich von der Art derModellierung der Domänenmodelle abhängig, ob Subsumes angeboten werden sollte:Während bei gesuchter Funktionalität Search eine Subklasse wie BookSearch we-nig passend scheint, ist ein Kandidat, der SecureLogin bei gesuchtem Login bietetdurchaus geeignet. Daher wird die Konfigurierbarkeit der Unterstützung von Subsu-mes im Component Repository vorgesehen. Das Matching von XML-Schemata, wiein Kapitel 3.2.3 beschrieben, entfällt zur Laufzeit wegen der Standardgroundings.Somit sind aufwändige Vergleiche und die Definition von Mappings nicht notwendig.Folgende Definition beschreibt die formale Basis des logischen Matchings. Ein
elementarer Match, d. h. die Übereinstimmung zweier annotierter Konzepte oder se-mantischer Typen, ergibt sich aus dem subsumptionsbasierten Matching, definiert
Copyright TU Dresden, Carsten Radeck 74

Semantische Komposition in Mashups Kapitel 4 Konzeption
über subClassOf. Dabei wird zwischen Klassen und Datatype-Properties unterschie-den. Bei letzteren wird zunächst nur Exact unterstützt, da ein Lifting nicht möglichist (vgl. Kapitel 4.1.1.1). Grundlage ist die Fähigkeit gängiger Reasoner eine Klas-sifikation der Ontologiekonzepte zu berechnen und auf diese Weise explizit bekanntzu machen. Zur Bildung eines aggregierten Übereinstimmungsgrades wird den ele-mentaren Ergebnissen ein numerischer Wert (Exact = 3, P lugIn = Subsumes =1, Fail = 0) zugewiesen. Exact wird deutlich höher bewertet, da es einen geringe-ren Aufwand bei der Mediation (siehe Kapitel 4.3.4) nach sich zieht und daher zubevorzugen ist. Falls Subsumes zugelassen ist, wird es wie PlugIn ebenfalls mit 1bewertet, da nicht allgemeingültig festgelegt werden, was besser geeignet ist.
ElementalMatch(C1, C2) =
Exact ⇔ C1 ≡ C2PlugIn ⇔ C1 v C2Subsumes ⇔ C2 v C1Fail else
Das Konzept sieht auch den Transfer der im Rahmen des Ansatzes von Jaeger et al.(vgl. Kapitel 3.2.2) beschriebenen Contravariance auf Operationen und Ereignisse inCRUISe vor. Demnach ist das Matching von Parameterkonzepten zwischen Vorlageund Komponente für Operationen und Ereignisse gerade umgekehrt:
Operation: ElementalMatch(Ctemplate, Ccomponent)Ereignis: ElementalMatch(Ccomponent, Ctemplate)
Der Hintergrund ist, dass entlang des Datenflusses niemals ein »Down-Cast« statt-finden darf, da dies einer Subsumes-Beziehung gleicht, die aus genannten Gründen zuvermeiden ist. Ein Beispiel aus dem Referenzszenario (Kapitel 2.4) verdeutlicht dies:Ausgehend davon, dass die semantischen Typen von Vorlage und Kanal identischsind, ist in der in Abbildung 4.15 dargestellten Situation Komponente 1 wegen derContravariance geeignet, obwohl das angebotene Parameterkonzept des Ereignissesspezifischer ist, als das angefragte, d. h., es gilt A v R (Subsume). Bei Kompo-nente 2 verhält es sich umgekehrt und ohne Contravariance wäre sie als geeignetdeklariert worden, da sowohl für den Parameter der Operation als auch des Ereig-nisses PlugIn vorliegt (R v A). Jedoch ist dann nicht garantiert, dass tatsächlicheine EventLocation auf dem Kanal publiziert wird. Deshalb ist Komponente 2 keingeeigneter Kandidat.
Vorlage=RequestKanal Semantischer Parametertyp:
EventLocation
EventLocation EventLocation Kanal Semantischer Parametertyp:
EventLocationupdate e1
Komponente 1
showEvent event4
EventLocation ConferenceLocation
Komponente 2
anyName Ereignis_e
LocationLocation
Es gilt: ConferenceLocation subClassOf
EventLocation subClassOf Location
Abbildung 4.15: Einfluss der Contravariance auf das Matching
Eine Vorberechnung der Ähnlichkeiten von Komponenten beim Hinzufügen dererin das Component Repository ähnlich dem Ansatz von Bianchini et al. [BAM10]
Copyright TU Dresden, Carsten Radeck 75

Semantische Komposition in Mashups Kapitel 4 Konzeption
ist für das Konzept nur bedingt sinnvoll, da sie auf das Auffinden bzw. Vorschlagenähnlicher Komponenten im Entwicklungsprozess ausgerichtet ist. Die Basis dafürist durch das Konzept zwar gegeben, aber davon wird abgesehen, da es lediglichbei der Suche nach kompatiblen Alternativen für Komponenten, die per ID ins Mo-dell eingebunden sind, geeignet wäre. Für Vorlagen müsste trotzdem ein Matchingstattfinden, um das Matching Result abzuleiten. Zudem könnten keine kontextab-hängigen Funktionalitäten einbezogen werden.Erweiterte Matchingtechniken, wie die in Abschnitt 4.1.1.2 angedeutete Bildung
von Schnittmengen von Konzepten, bilden zunächst nicht den Schwerpunkt des Al-gorithmus, da sie die Komplexität und den Berechnungsaufwand erheblich beein-flussen können. Dies betrifft z. B. auch die Prüfung, ob die Menge von funktionalenAnnotationen und die Parameter einer geforderten Operation durch mehrere Ope-rationen der Komponente erbracht werden kann. Hierbei wären grundlegende Frage-stellungen zu betrachten, u. a. ob Überschneidungen der funktionalen Annotationenzulässig wären, oder ob Parameter auf mehrere Operationen verteilt werden dürften.Dadurch könnten unvorhersehbare Folgen auftreten, da eine hinreichende Sorgfaltder Implementierung im Allgemeinen (leider) nicht unterstellt werden kann.
4.3.2.2 Matching-Algorithmus
Der Algorithmus nimmt die Vorlage, Informationen zur Runtime, die Nutzerken-nung, die URL des Kontextdienstes und die Blacklist entgegen. Er arbeitet auf derKnowledgebase der registrierten Ontologien und liefert eine Liste semantisch kom-patibler Komponenten mit deren Übereinstimmungsgrad sowie passendem MatchingResult. Einen Überblick in Pseudocode verschafft Algorithmus 1 im Anhang A.1.In Anlehnung an YASA-M (vgl. Kapitel 3.2.2) erfolgt zunächst eine grobe Vor-
selektion, um die Kandidatenmenge einzugrenzen bevor das detaillierte Matchingstattfindet. Anders als dort vorgeschlagen werden auch Komponenten mit mehr Ein-und Ausgaben, d. h. Operationen und Ereignissen, zugelassen. Die Vorselektion be-zieht zunächst die in der Anfrage enthaltene Blacklist sowie die Art der Komponente,d. h. UI-, Service- oder Logikkomponente, und die unterstützte Runtime ein. Sollteein Kriterium nicht erfüllt sein, ist die Komponente ungeeignet und wird verworfen.Anschließend liegen nur noch Komponenten vor, die nicht in der Blacklist enthal-ten sind, deren Art mit der angeforderten übereinstimmt und bei denen eine imBinding deklarierte unterstützte Runtime hinsichtlich Version und ID identisch zurbenötigten ist. Zusätzlich werden aus Effizienzgründen alle verbleibenden Kandida-ten hinsichtlich der Anzahl an Operationen, Ereignissen und Properties untersucht.Sollten weniger als gefordert zur Verfügung stehen, wird die Komponente aussortiert,um zur Erfüllung von Anforderung 15 beizutragen.Nach der Vorselektion, die insbesondere syntaktische Informationen einbezieht,
findet das präzise Matchmaking in vier Schritten für die Grundfunktionalität, dieProperties, Operationen und Ereignisse der Komponente statt.Beim Matching der Grundfunktionalität, d. h. den funktionalen Annotation
auf Ebene der gesamten Komponente (vgl. Kapitel 4.1.1.2), werden die annotier-ten Konzepte der Vorlage mit denen des Kandidaten paarweise elementar verglichenund die Einzelwerte abgespeichert. Anschließend wird – vergleichbar dem Ansatzvon SAWSDL-MX in Kapitel 3.2.4 – die beste Zuordnung der Konzepte berechnet.Bei der Aggregation der elementaren Ergebnisse sind außerdem die Gewichtungen
Copyright TU Dresden, Carsten Radeck 76

Semantische Komposition in Mashups Kapitel 4 Konzeption
in der Vorlage zu beachten. Dabei wird vorgesehen, obligatorische Modellreferen-zen gesondert zu behandeln, da für diese nicht Fail vorliegen darf. Wurde für al-le obligatorischen Konzepte eine Zuordnung ungleich Fail identifiziert, ergibt sichder Übereinstimmungsgrad Matchcompfunct aus dem Durchschnitt aller elementarenWerte. Tabelle 4.1 veranschaulicht die Aggregation von Matches der vier funktiona-len Modellreferenzen in der Vorlage mit denen der Kandidaten. Ist keine Zuordnungmöglich, bricht das Matching für diese Komponente an dieser Stelle ab.
Gewichtung der Modellreferenz (Vorlage) MatchcompfunctKomponente 1.0 1.0 0.5 0.3Komponente 1 3 3 3 0 2.68Komponente 2 1 3 3 3 2.29
Tabelle 4.1: Beispiel der Aggregation elementarer Matches von vier funktionalen Modellrefe-renzen auf Ebene der gesamten Komponente
Das Matching von Properties bestimmt zuerst die bestmögliche Zuordnungjeder Property der Vorlage zu einer des Kandidaten hinsichtlich der semantischenTypisierung. Dabei findet ein paarweiser elementarer Match statt und das Ergebniswird in einer Datenstruktur gespeichert (siehe Abbildung 4.16). Die beste Zuord-nung BestAssignproperties enthält Tupel aus dem Namen der Property der Vorlage,der Komponente und dem numerischen Wert der Übereinstimmung und wird gespei-chert. Wurde für eine Property der Vorlage keine Zuordnung mit ÜbereinstimmungExact zu einer der Komponente gefunden, z. B. für »id« bezüglich Komponente 2in der Abbildung, wird der Kandidat verworfen und das Matching endet für ihnvorzeitig, was unnötigen Aufwand verhindert. Exact ist notwendig, da der Zustandder Komponente ausgelesen werden muss, z. B. beim Austausch oder dem Persistie-ren des Anwendungszustandes. Wäre dann PlugIn zulässig, müsste bei einer anderenKomponente, die exakt zur Vorlage passt, eine Konvertierung in die Subklasse statt-finden, was nicht garantiert funktioniert. Zudem ist zu beachten, dass eine Proper-ty, die als required deklariert ist (muss zur Initialisierung der Komponente gesetztsein) und für die die Komponentenbeschreibung keinen Standardwert enthält, einPendant in der Vorlage aufweisen muss. Demnach wäre im Beispiel Komponente 1nicht geeignet, falls Property »location« die genannten Kriterien erfüllt. Ein beson-derer Problemfall ist das Auftreten von mehreren Properties des selben semantischenTyps, bei dem keine eindeutige Zuordnung definiert werden kann. In diesem Fallwird das Einbeziehen der textuellen Ähnlichkeit vorgeschlagen, was das Problemaber auch nicht sicher lösen kann. Daher sind solche Fälle bei der Entwicklung zuvermeiden, z. B. indem die Typisierung konkretisiert wird.Anschließend folgt das Matching der Operationen, d. h. für jede Operation der
Vorlage wird die passendste des Kandidaten gesucht (vgl. Abbildung 4.17). Dabei istzuerst sicher zu stellen, dass nicht mehr Parameter angeboten als gefordert werden.Weniger Parameter bei selber Funktionalität sind hingegen zulässig. Weiterhin istdie Passgenauigkeit der annotierten Modellreferenzen unter Beachtung der Gewich-tung festzustellen (Matching der funktionalen Semantik). Dazu sind möglicherweisevorhandene Bedingungen einer funktionalen Kategorie an den Nutzerkontext auszu-werten. Ist die Bedingung nicht erfüllt, darf die betroffene Modellreferenz nicht indas Matching einfließen. Danach wird Matchfunctionality, wie für die Grundfunktio-nalität beschrieben, berechnet. Ist dabei für eine Modellreferenz keine Zuordnung
Copyright TU Dresden, Carsten Radeck 77

Semantische Komposition in Mashups Kapitel 4 Konzeption
Vorlage
Vorlage
Komponente 1
Komponente 2
Property „ort“
Type= EventLocation
Property „id“
Type= hasID
Property „p1"
Type= EventLocation
Property „p2"
Type= Hotel
Property „location“
Type= Location
Property „ID“
Type= hasID
Property „ort“
Type= EventLocation
Property „id“
Type= hasID
Exact Beste Zuordnung:
ort -> p1 (3.0)
id -> -- (0.0)
Beste Zuordnung:
ort -> target (3.0)
id -> ID (3.0)
PlugIn
Exact
Property „target“
Type= EventLocation
Exact
Übereinstimmungsgrad Fail
Abbildung 4.16: Bestimmung der Übereinstimmung der Properties für zwei Kandidaten
ungleich Fail möglich, bricht das Matching für diese Operation der Komponentean dieser Stelle ab und bewertet sie mit Fail. Ansonsten werden die Parameter nä-her betrachtet (Matching der Datensemantik). Jedem Parameter der Operation derKomponente ist einer der Operation der Vorlage mit mindestens PlugIn-Beziehungzuzuweisen. Somit ist gewährleistet, dass die Operation alle benötigten Eingaben er-hält, aber nicht notwendiger Weise alle der Vorlage. Konnte keine solche Zuordnungfür die Parameter definiert werden, wird die Operation mit Fail bewertet. Andern-falls wird der Durchschnitt aller elementaren Übereinstimmungsgrade der Parameter(Matchparameters) erzeugt und gleich gewichtet mit Matchfunctionality zum ResultatMatchoperationi verrechnet. Somit ist die funktionale und Datensemantik unabhängigvon der Anzahl von Modellreferenzen bzw. Parametern einbezogen. Die Zuordnungder Parameter wird abgespeichert.Als Ergebnis liegt für jede Operation der Vorlage eine Menge von Matchoperationi
für alle Operationen der Komponente vor. Daraus wird die beste Zuordnung derOperationen BestAssignoperations bestimmt. Dabei handelt es sich um eine Menge,die für jede Operation der Vorlage ein Tupel aus Operationsnamen in der Vorla-ge und der Komponente, Matchoperationi sowie der Parameterzuordnung beinhaltet.Kann einer Operation der Vorlage keine des Kandidaten zugewiesen werden, d. h.,die Zuordnung enthält ein Tupel mit Übereinstimmungsgrad Fail, bricht das Mat-ching für diese Komponente ab, da die Komponente inkompatibel ist.
Vorlage Komponente 1
Beste Zuordnung (Operationen):
{(update -> showEvent, 3.0,
{(param -> event, 3.0)} )}
Beste Zuordnung (Parameter)
Operation „update“
Parameter „param“
Type= EventLocation
Operation „setLocation“
Operation „hide“
Parameter „p1"
Type= EventLocation
Parameter „p2"
Type= Hotel
Operation „showEvent“
Parameter „event"
Type= EventLocation
Exact
Anzahl Parameter größer
als in Vorlage
Matchfunctionality = 0.0
Matchfunctionality = 3.0
Matchparameters = 3.0
-> Matchoperation = 3.0
Operation „setMarker“
Parameter „location"
Type= Location
PlugIn
3.0
2.0
0.0
0.0
Matchfunctionality = 3.0
Matchparameters = 1.0
-> Matchoperation = 2.0Die funktionale Semantik der Vorlage und Komponente
wurde der Übersicht halber ausgeblendet.
Abbildung 4.17: Matching von Operationen zwischen Vorlage und Kandidat
Das Matching von Ereignissen verläuft analog zu dem der Operationen und be-rechnet BestAssignevents, aber mit folgenden Erweiterungen. Die Abhängigkeiten zu
Copyright TU Dresden, Carsten Radeck 78

Semantische Komposition in Mashups Kapitel 4 Konzeption
Operationen sind zu prüfen, falls das Attribut trigger einzig den Wert operation(vgl. Kapitel 4.1.1.2) umfasst: Für die Menge der funktionalen Annotationen allerzugeordneten Operationen der Komponente ist zu testen, ob sie die Konzepte desAttributs dependsOn enthält. Sollte eine nicht vorhanden sein, wird das Ereignis mitFail bewertet. Bezüglich der Parameter ist im Gegensatz zu Operationen festzustel-len, ob mindestens die geforderten angeboten werden, damit alle nötigen Daten aufdem Kanal publiziert werden.
Zuordnung Name (Vorlage) Name (Komponente) ÜbereinstimmungsgradBestAssignproperties ort target 3.00
id ID 3.00BestAssignevents e1 event4 1.57BestAssignoperations update showEvent 3.00
Matchcompfunct= 2.68,Matchcomponent= 2.65
Tabelle 4.2: Beispiel der Berechnung des Gesamtergebnisses von Komponente 1
Abschließend liegen nur noch kompatible Kandidaten vor, d. h., für jede Property,Operation und jedes Ereignis der Vorlage existiert eine Zuordnung ungleich Fail.Nach folgender Formel wird das Gesamtergebnis Matchcomponent berechnet (Beispielsiehe Tabelle 4.2). BA steht für BestAssign.
Matchcomponent =Matchcompfunct+
∑|BAop|i=1 BAop,i.rating+
∑|BAev |j=1 BAev,j .rating+
∑|BApr |k=1 BApr,k.rating
1+|BAop|+|BAev |+|BApr|
Die funktionale Rangfolge der Kandidaten ergibt sich aus dem Vergleich allerMatchcomponent. Daraus resultiert eine (geordnete) Liste von Tupeln aus Gesamter-gebnis und Komponenten-ID. Aus den getroffenen Zuordnungen von Operationen,Ereignissen, Parametern und Properties wird das Matching Result für jede Kompo-nente der Liste gebildet und wegen der in Kapitel 4.3.1 beschriebenen Aufteilungder Schnittstelle in zwei Operationen im Sitzungskontext zusammen mit der ID derVorlage und der Komponente abgelegt, damit eine eindeutige Zuordnung bei derAbfrage der Komponentenbeschreibung samt Matching Result möglich ist.Insgesamt sind auf Basis syntaktischer und semantischer Informationen der Kom-
ponentenbeschreibung kompatible Komponenten für eine Vorlage zur Laufzeit auf-findbar. Nachfolgend wird behandelt, wie die Kandidaten anhand nicht-funktionalerEigenschaften sortiert werden.
4.3.3 RankingWie im SWS Usage Process (vgl. Kapitel 2.3) charakterisiert, schließt sich an dasfunktionale Matchmaking im Rahmen der Discovery die Bildung einer Rangfolgealler Kandidaten an. Diese basiert auf nicht-funktionalen Eigenschaften der Kom-ponente und Kontextinformationen des Nutzers. Wie beim Ansatz, der in Abschnitt3.2.5 veranschaulicht wurde, dient die Beschreibung des Ziels der Angabe der rele-vanten nicht-funktionalen Eigenschaften. Im Konzept stellt die Vorlage die Ziel-beschreibung dar und die für sie relevanten Rankingregeln definieren die nicht-funktionalen Eigenschaften.Das Ranking arbeitet auf den semantisch repräsentierten nicht-funktionalen Ei-
genschaften der SMCDL, wofür die in Abschnitt 4.1.1.4 eingeführte Ontologie die
Copyright TU Dresden, Carsten Radeck 79

Semantische Komposition in Mashups Kapitel 4 Konzeption
Grundlage bildet. Die Eingabe stellt die maximale Anzahl gewünschter Kompo-nenten und die Liste von Tupeln aus funktionalem Rankingwert Matchcomponentund Komponenten-ID dar. Weiterhin wird die Vorlage überreicht, damit die Ran-kingregeln vorliegen. Zudem ist die Nutzerkennung und die Referenz auf den zunutzenden Kontextdienst essentiell, um Zugriff auf den Nutzerkontext zu erlangen.
4.3.3.1 Rankingregeln
Rankingregeln werden nun ebenfalls im Kompositionsmodell der kompositen Weban-wendung modelliert. Neben den in Abschnitt 4.1.3 genannten Eigenschaften besitztjede Regel optional eine für ihre Anwendung zu erfüllende Bedingung über Kontext-parameter und Literale. Die zuvor vorhandenen Arten von Rankingregeln werdenbeibehalten. Occurance Rules verknüpfen Kontextparameter des aktuellen Nut-zers mit den Metadaten der Kandidaten in zu erfüllenden Bedingungen. NormalizeRules dienen der Sortierung aller Komponenten bezüglich der natürlichen Ordnungoder deren Inverse eines bestimmten Metadatums mit numerischem Wertebereich.Der Rankingwert ergibt sich aus der Normalisierung des Bereichs zwischen minima-lem und maximalem Wert aller Komponenten auf den Bereich [0, 1]. Zur Abbildungdes nicht-numerischen Werts eines Metadatums auf einen bestimmten Rankingwertexistieren schließlich Mapping Rules.Zudem wurde die Art der Adressierung der nicht-funktionalen Eigenschaft über-
arbeitet, da diese auf das einfache XML-Schema zugeschnitten ist und eine pfadba-sierte Syntax aufweist. Beispielsweise stößt dieser Ansatz an Grenzen, wenn wegenSubklassen unterschiedliche Eigenschaften zu vergleichen wären: Wird im Referenz-szenario (Kapitel 2.4) z. B. gefordert, dass nur Komponenten, deren Nutzung wenigerals x Euro kostet, zu integrieren sind, könnten sowohl absolute Preise als auch Preis-spannen gehandhabt werden. Jedoch wäre für erstere z. B. die Eigenschaft hasValueund für letztere hasUpperBound in den Vergleich einzubeziehen.Da eine RDF-basierte Repräsentation der nicht-funktionalen Eigenschaften vor-
liegt, ist der W3C-Standard SPARQL eine geeignete Wahl, um solche Probleme zuvermeiden. Statt wie bisher einen einfachen Pfad, wie hasPrice/hasValue, der imoben geschilderten Fall ausschließlich absolute Preise erfassen könnte, sind SPARQL-Anfragen in der Eigenschaft metadata der Rankingregeln zu definieren (vgl. Ab-bildung 4.7). Dies erlaubt eine generische Abfrage von Informationen des RDF-Graphen, sodass die unterstützte Ausdrucksstärke der Ontologie nicht unnötig be-schränkt wird. Zudem können Bedingungen an die Metadaten direkt in SPARQL(mittels des Konstrukts FILTER) formuliert werden und die im Standard vorgese-henen Extension Functions ermöglichen es, z. B. auf das Kontextmodell des aktu-ellen Nutzers zuzugreifen. Durch die Implementierung ist der Zugriff auf den Kon-textdienst (unter Zuhilfenahme der eingegebenen Referenz und Nutzerkennung) beiAufruf dieser Funktion bereitzustellen, um das Ergebnis in einen FILTER-Ausdruckeinzubinden. Weiterhin können optionale Tripel (Konstrukt OPTIONAL) und Al-ternativen (UNION) angegeben werden, sodass im obigen Beispiel beide Subklassenvon Preisen handhabbar sind.Für die genau Ausprägung der SPARQL-Aussagen kommen verschiedene Optio-
nen in Frage. Die tatsächliche Umsetzung ist im Rahmen einer Implementierungzu entscheiden, da implementierungsspezifische Parameter und Anforderungen, wiePerformanz, den wesentlichen Ausschlag geben.
Copyright TU Dresden, Carsten Radeck 80

Semantische Komposition in Mashups Kapitel 4 Konzeption
Den Vorteilen des Ansatzes steht der Aufwand gegenüber. Da nicht zwangsläufigdavon auszugehen ist, dass ein Anwendungsentwickler sich mit SPARQL ausreichendauskennt, sollte das Autorenwerkzeug die entstehende Komplexität verstecken, z. B.indem es die korrekten SPARQL-Aussagen generiert.Die Konsistenz der Regeln, insbesondere des SPARQL-Teils, sollte zur Entwick-
lungszeit garantiert werden, da dies zur Laufzeit aufwändig ist und mögliche Re-aktionen auf Fehler sich auf Aktionen wie den Ausschluss der Regel beschränken.Validität kann hingegen zur Laufzeit durch den Abgleich mit der XSD bzw. derSPARQL-Syntax geprüft werden, aber auch hier ist die Fehlerbehandlung im We-sentlichen auf den Ausschluss der Regel begrenzt (Anforderung 14).
4.3.3.2 Ablauf des Rankings
Falls Rankingregeln vorliegen, wird vor der eigentlichen Bildung der Rangfolge füralle Komponenten der Kandidatenliste optional die Regelmenge zur Berechnungvon nicht-funktionalen Eigenschaften ausgewertet. Damit die Ergebnisse nicht dau-erhaft in die Komponentenbeschreibung einfließen und dort eventuell vorhandeneStandardwerte nicht überschreiben, ist sicherzustellen, dass dies auf einer isoliertenKopie der Metadaten stattfindet. Die Beantwortung von SPARQL-Anfragen an denNutzerkontext ist dabei durch oben genannte Eingaben realisierbar. Wie in Kapitel2.2.2.3 beschrieben, erfolgt nun die Auswertung der Rankingregeln, deren Bedingungerfüllt ist, und die Kombination der Ergebnisse in einer strategiespezifischen Weise.Hinzu kommt die Verrechnung der funktionalen Übereinstimmung der Komponentenmit der Vorlage (Matchcomponent) aus der Discovery, wie in Anforderung 8 gefordert.Dies erfolgt ebenfalls gemäß der Strategie, z. B. durch Mittelung vonMatchcomponent(normiert auf [0, 1]) mit dem nicht-funktionalen Rankingwert, sodass auch implizitder Aufwand der Mediation einbezogen wird. Sind keinerlei Rankingregeln definiert,bestimmt einzig der normierte Matchcomponent die Rangfolge. Die Ausgabe des Ran-kings ist somit eine geordnete Liste mit maximal der gewünschten Anzahl von Paarenaus der ID einer kompatiblen Komponente und deren Ranking r ∈ [0, 1].Zusammenfassend ist festzuhalten, dass das Konzept hinsichtlich der unterschied-
lichen Aspekte eines Rankingalgorithmus nach Fensel et al. [FKZ08] (vgl. Kapitel2.3) das Ranking anhand mehrerer Kriterien, unter Einbeziehung von Kontextinfor-mationen und auf Basis semantischer Modelle unterstützt.
4.3.4 Unterstützung von Mediation auf DatenebeneWerden Komponenten ausgetauscht oder anhand einer Vorlage integriert, sind syn-taktische Unterschiede der Schnittstelle im Vergleich zum Kompositionsmodell, wieheterogene XML-basierte Daten, wahrscheinlich und zu überbrücken. Die Grundla-gen für die Auflösung der Diskrepanzen zur Laufzeit sind die semantische Typisie-rung der Komponenten und der Kommunikationskanäle (vgl. Kapitel 4.1.1.1 und4.1.3), die Angabe von Transformationsvorschriften in der SMCDL und das Mat-ching Result der tatsächlich integrierten Komponenten, das neben der SMCDL vomComponent Manager verwaltet wird. Auf Basis dieser Informationen obliegt es derRuntime die nachfolgend vorgestellten Module bereitzustellen und zu konfigurieren.In ihrer Gesamtheit sorgen diese für die Mediation auf Datenebene und daher fürdie Erfüllung von Anforderung 9.
Copyright TU Dresden, Carsten Radeck 81

Semantische Komposition in Mashups Kapitel 4 Konzeption
Folgende Aufgaben sind bei der Mediation grundlegend zu lösen:
• Ausführung der am Binding definierten Transformationen von einem kompo-nenteninternen in das vorgegebene Schema oder umgekehrt. Dies gilt auch fürper ID integrierte Komponenten.• Überführung einer Instanz in eine Instanz aus Sicht einer ihrer Superklassen
(künftig kurz als Up-Cast bezeichnet).• Umbenennung von Operationen, Ereignissen, Parametern und Properties.• Umsortierung und Filterung von Parameter
Komponente 1
EventLocation
Eigenes Schema
(z.B. JSON, XML)
Komponente 2
Location
Eigenes
Schema
Ontologie
Location
EventLocation
EventLocationL
ifti
ng
Lo
we
ring
Location
Ereignis
Operation
EventLocation
Standard
XML-Schema
Location
Standard
XML-Schema
Up
Ca
st
Semantische Ebene
Syntaktische Ebene
Alte Komponente
Neue Komponente
KomponenteKompositionsmodellLocation
Eigenes
Schema
EventLocation
Standard
XML-Schema
Location
Standard
XML-Schema
EventLocation
Eigenes
Schema
Transformation TransformationEventLocation
Standard
XML-Schema
a)
b)
c)
Transformation
Transformation
EventLocation
Eigenes Schema
(z.B. JSON, XML)
Transformation
Instanz von XX
Abbildung 4.18: Grundlegende Aufgaben bei der Mediation von Daten
Insgesamt sind in CRUISe drei Fälle zu unterscheiden, bei denen diese Aufgabenauftreten können (siehe Abbildung 4.18).
a Ereignisbasierte Kommunikation Hierbei wird von einer Komponente ein Ereig-nis ausgelöst, auf dem Kanal publiziert und an alle registrierten Komponentenverteilt. Dies ist der Standardfall und alle Aufgaben sind relevant.
b Direkte Zugriffe auf Komponenten Beim Anwendungsstart sind modellierte in-itiale Operationsaufrufe durchzuführen, wobei alle Aufgaben auftreten können.Weiterhin wird die initiale Konfiguration aus dem Kompositionsmodell übersetProperty an die Komponenten gereicht. Zu späteren Zeitpunkten kanndie in Adaptionsregeln modellierte Rekonfiguration von Komponenten statt-finden. In diesen Fällen entfallen Up-Casts wegen der Beschränkung auf denÜbereinstimmungsgrad Exact für Properties (vgl. Kapitel 4.3.2).
c Austausch von Komponenten Dabei liest die Runtime den aktuellen Zustandüber die Methode getProperty der alten Komponente aus und injiziert ihnmittels setProperty in die neue. Wie in Fall b entfallen Up-Casts.
Nachfolgend wird im Detail auf die Aufgaben eingegangen. Die Ausführung derTransformationen in XSLT oder Skriptsprache, die für Parameter und Propertiesam Binding angegeben werden können (vgl. Kapitel 4.1.1.1), findet rein auf syntak-tischer Ebene statt. Dabei werden Daten aus dem Standardschema in ein eigenesüberführt oder umgekehrt. Hierbei sind auch Unterschiede im verwendeten Datenfor-mat handhabbar: Nutzt eine Komponente intern JSON oder primitive Datentypen,
Copyright TU Dresden, Carsten Radeck 82

Semantische Komposition in Mashups Kapitel 4 Konzeption
während das standardisierte Grounding ein XML-Schema vorsieht, muss das Bin-ding die Konvertierung definieren. Falls für einen Parameter bei der Discovery dieÜbereinstimmung PlugIn festgestellt wurde, ist ein Up-Cast nötig. Da Komponen-ten in CRUISe i. d. R. von Drittanbietern stammen und es wegen der XML-Syntaxzu aufwändigen Typunterscheidungen käme, wird die komponenteninterne Hand-habung verschiedener Subklassen nicht vom Entwickler abverlangt. Daher wird si-chergestellt, dass die Daten gemäß dem deklarierten Konzept geliefert werden. Dazuwird das Eingabedokument in XML, z. B. der Parameter eines Ereignisses, durchdas standardisierte Lifting, eine XML-Transformation (siehe Kapitel 4.2), in einenRDF-Graphen überführt. Dieser entspricht einem Individuum der OWL-Klasse desParameters, z. B. EventLocation in Abbildung 4.18. Der Reasoner macht alle Klas-sen, denen das Individuum angehört, explizit bekannt. Daher kann die SPARQL-Anfrage des Lowerings der Superklasse, z. B. Location, angewendet werden. DieXSL-Transformation erzeugt schließlich das auszugebende XML-Dokument. SolltenDatatype-Properties als Typ eines Parameters angegeben sein, entfallen Up-Casts,da nur der Übereinstimmungsgrad Exact unterstützt wird (vgl. Kapitel 4.3.2).Neben diesen beiden Aufgaben, die sich primär auf die ausgetauschten Daten be-
ziehen, behandeln die übrigen drei die syntaktischen Unterschiede der Schnittstelleder integrierten Komponente im Vergleich zur Vorlage (und somit dem Kompo-sitionsmodell). Die Umbenennung von Operationen, Ereignissen, Parametern undProperties beim Zugriff auf die Komponente ist notwendig. Auch die Umsortierungder Parameter von Operationen und Ereignissen ist durchzuführen, da CRUISe ei-ne geordnete Parameterliste unterstellt. Zudem müssen überflüssige Parameter beiausgehenden Ereignissen und dem Aufruf von Operationen gefiltert werden, um dieKonformität zum Kompositionsmodell zu wahren.Bei der Mediation könnten Konvertierungen zwischen den Konzepten der semanti-
schen Typisierung beachtet werden, z. B. im Falle unterschiedlicher Währungen undMaßeinheiten zwischen Vorlage und konkreter Komponente. Hierzu wären Konverterzu definieren, zu suchen und von der Runtime bereitzustellen. Für Maßeinheiten sindstatische Konvertierungsvorschriften hinreichend und je nach Transformationsspra-che direkt in dieser definierbar. Angesichts dynamischer Wechselkurse für Währun-gen müssten externe Web Services angebunden werden, wodurch ein beachtlicherAufwand entstünde. Konvertierungen werden daher für diese Arbeit ausgeblendetund eine entsprechende Modellierung der Ontologie bzw. eine komponenteninterneAnpassungen der Daten von Backend-Services, sodass die Parameter publizierterEreignisse dem annotierten Konzept entsprechen, unterstellt.Zur Erbringung der Funktionalitäten zur Durchführung von Up-Casts und XML-
Transformationen wurde der Mediator als Teil der Runtime konzipiert. Die imBinding referenzierten Transformationsvorschriften sind einmalig von ihrer URL zubeziehen und können danach lokal gespeichert werden. Lifting und Lowering werdenvom Type Repository abgerufen und anschließend gespeichert, sodass spätere Anfra-gen unnötig sind. Dabei und bei der Transformation auftretende Fehler werden kom-muniziert, wobei z. B. Ausnahmen in einer Programmiersprache Verwendung finden.Bei Erfolg wird das transformierte XML-Dokument geliefert. Die physikalische Ver-teilung der beiden Verantwortlichkeiten des Mediators kann variieren. So erscheintdie Auslagerung der Up-Cast-Funktionalität auf die Serverseite sinnvoll, da dafürsemantische Daten unterstützt und eine Wissensbasis der Ontologien bereitgestellt
Copyright TU Dresden, Carsten Radeck 83

Semantische Komposition in Mashups Kapitel 4 Konzeption
werden muss. Eine Alternative zur Realisierung von Up-Casts wäre die (sequentielle)Ausführung von XSL-Transformationen entlang der Vererbungshierarchie. Dies wirdjedoch wegen des Erstellungs- und Ausführungsaufwandes als nicht praktikabel an-gesehen. Die Verantwortlichkeit der Durchführung von XML-Transformationen kannhingegen auch auf dem Client umgesetzt werden, da die meisten Web-Browser einenprogrammatischen Zugriff (mittels JavaScript) auf ihren XSLT-Prozessor erlauben.Für die Verteilung der Verantwortlichkeit der Mediation über die Runtime und
somit den Aufruf des Mediators gibt es verschiedene Optionen. Zum einen wäre eineisolierte Realisierung dieses Belangs möglich. Dabei stellt ein Wrapper sicher, dassdie Komponente genau der im Modell spezifizierten Schnittstelle entspricht undz. B. Daten gemäß dem standardisierten Schema genau des Konzepts des jeweili-gen Kanalparameters publiziert bzw. verarbeitet. Das zöge nach sich, dass Wrapperbereits die Durchführung von Up-Casts an den Mediator delegieren. Dies würdeden Verwaltungsaufwand für die Runtime zwar senken. Ein entscheidender Nachteilist jedoch, dass gerade aufwändige Up-Casts möglicherweise mehrfach durchgeführtwerden, falls mehrere Subscriber das selbe Konzept nutzen, und auch zwei Up-Castsentlang des Kanals nicht in einem Schritt bewältigt werden können. Zum anderenkönnten die bisherigen Module der Runtime angepasst bzw. rekonfiguriert werden,syntaktische Diskrepanzen, wie unterschiedliche Operationsnamen, selbst auflösenund den Mediator kontaktieren, sobald eine Funktionalität benötigt wird. Opti-mierungen könnten durch das Aufbrechen der isolierten Behandlung vorgenommenwerden, aber der Verwaltungsaufwand steigt und der Belang ist stärker verteilt.
Mediator
Wrapper
Komponente
Ereignis
Operation
JSON XMLPrimitive
Schnittstelle gemäß
Kompositionsmodell
Schnittstelle gemäß
Komponentenbeschreibung
Event BrokerEvent Handler Ereignisse
set/getProperty invokeOperation publish
vorgegebene XML-Schemata
Binding
Implementation
Umbenennung, Umsortierung, Filterung
Tra
ns-
form
atio
n
Aufgabe
XSLT-Prozessor
Abbildung 4.19: Aufgaben des Wrappers und resultierende Beziehungen zur Laufzeit
Angesichts dieser Betrachtung und dass das Kompositionsmodell als fix ange-nommen wird, wird vorgeschlagen, beide Optionen zu kombinieren: Ein Wrappersorgt in Anlehnung an das Entwurfsmuster Adapter [GHJV94] dafür, syntaktischeUnterschiede der Schnittstelle der Komponenten im Vergleich zur Vorlage zu über-brücken (siehe Abbildung 4.19). Dies betrifft alle Aufgaben außer der Delegationvon Up-Casts. Es wird vorgeschlagen, die von CRUISe vorgeschriebenen Methodenset/getProperty und invokeOperation von Komponenten sowie den von der Run-time bereitgestellten Event Handler auszunutzen. Letzterer ist ein Proxy [GHJV94]für die Kommunikation zwischen dem Event Broker und der von ihm verdecktenKomponente und dient zur Publikation von Ereignissen und dem Komponentenaus-tausch. Damit der Wrapper auch Ereignisse anpassen kann, ohne den Belang der
Copyright TU Dresden, Carsten Radeck 84

Semantische Komposition in Mashups Kapitel 4 Konzeption
Mediation auf den Event Handler auszuweiten, muss er die Schnittstelle des EventHandlers implementieren und nimmt eine Stellung zwischen diesem und der Kom-ponente ein. Der Wrapper delegiert Anfragen zur Publikation von Ereignissen derKomponente nach erfolgter Mediation an den Event Handler, der nun eine Referenzauf den Wrapper statt auf die Komponente besitzt. XSL-Transformationen delegiertder Wrapper an den Mediator. Codefragmente interpretiert er selbst.Im Bezug auf das Referenzszenario (Kapitel 2.4) müsste der Wrapper von Kom-
ponente D zum einen den Namen der Operation auf setMarker abbilden, was ggf.auch für deren Parameter, der jedoch im Referenzszenario nicht benannt wurde, gilt.Zum anderen sind die Daten eingehender Ereignisse für den einzigen Parameter indas XML-Schema k zu transformieren (siehe Tabelle 2.1).Die Runtime muss die Option bieten, einen generischen Wrapper mit der benötig-
ten Konfiguration zu instanziieren. Diese Konfiguration enthält sämtliche währendder Discovery erkannten Zuordnungen von Operationen, Ereignissen, Parameternund Properties der Komponente zu denen der Vorlage. Außerdem umfasst sie die imBinding definierten Transformationen und die Zuweisung derer zu den passendenParametern und/oder Properties. Die notwendigen Informationen können aus demMatching Result und der SMCDL für die integrierte Komponente geschlussfolgertwerden. Die Syntax der Konfiguration ist spezifisch für die Laufzeitumgebung.
Komponente 1 Kanal Semantischer Parametertyp:
EventLocation
Komponente 2 Komponente 3
Komponente 4
Mediator
Wrapper
Up-CastXSLT-Prozessor
EventLocation
ConferenceLocationLocation
EventLocation
Es gilt: ConferenceLocation subClassOf EventLocation subClassOf Location
Komponente 5
Location
Ereignis
Operation
Text
Datenfluss
Parameterkonzept
Abbildung 4.20: Beispielhafte Situation der Mediation zur Laufzeit
Weiterhin wird vorgeschlagen, dass im Falle der ereignisbasierten Kommunikati-on die Kommunikationskanäle über die Notwendigkeit von Up-Casts entschei-den, sodass Optimierungen möglich sind. Der Kanal ist somit nur mit den nötigstenAufgaben vertraut. Der resultierende Ablauf der Mediation von Daten wird anhandAbbildung 4.20 mit Konzepten aus dem Referenzszenario (Kapitel 2.4) erläutert. DieRuntime stellt sicher, dass jeder Kommunikationskanal seine semantischen Parame-tertypen sowie die der ausgehenden Ereignisse der Publisher bzw. der Operationender Subscriber anhand ihrer URI verwaltet. Die dazu benötigten Informationen sinddem Kompositionsmodell, den Beschreibungen der integrierten Komponenten undden Matching Results zu entnehmen. Im Beispiel wird der Einfachheit halber an-genommen, dass der Kanal nur ein komplexes Datum vom Typ EventLocationtransportiert. Auf Basis der Wrapper wird garantiert, dass die Transformation zwi-schen eigenen und vordefinierten XML-Schemata realisiert wird, sodass über einenKanal immer letztere fließen. Im Beispiel verwendet lediglich Komponente 2 ein ei-genes Schema und ihr Wrapper sorgt für die nötige Transformation. Angemerkt sei,dass auch andere Komponenten einen Wrapper besitzen können, der jedoch ausge-blendet ist, falls keine Transformation durchzuführen ist. Anschließend entscheidet
Copyright TU Dresden, Carsten Radeck 85

Semantische Komposition in Mashups Kapitel 4 Konzeption
der Kanal durch einen Vergleich der URI, ob für den aktuellen Subscriber ein Up-Cast erforderlich ist. Dies ist ausreichend, da unterstellt wird, dass das Matchingnur kompatible Konzepte zulässt. Ist ein Up-Cast notwendig, weil ein PlugIn-Matcheines Parameters vorliegt, z. B. wenn Komponente 2 ein Ereignis auslöst, wird derMediator mit den oben beschriebenen Eingaben aufgerufen und die Typprüfung er-folgt durch ihn, d. h., dass das Datum beim Auftreten von Fehlern nicht weitergeleitetwird. Liegen identische URI und somit Typen vor, z. B. zwischen Komponente 1 und4, findet die Typprüfung gegen das XML-Schema des semantischen Parametertypsdes Kanals statt. Vorteile der Auslagerung der Entscheidung über Up-Casts in denKanal sind die Optimierungsmöglichkeiten: Es sind zwei Up-Casts in einem Schrittrealisierbar, z. B. zwischen Komponente 2 und 3, und Ergebnisse von Up-Casts sindwiederverwendbar, z. B. die Eingabe für Komponente 3 und 5.Somit sind die Anwendungsfälle a und c bereits realisierbar. Einzig bei der in-
itialen Ausführung von Operationen in Fall b muss zusätzliche Sorgfalt aufgebrachtwerden, da potentiell benötigte Up-Casts vor dem Aufruf durchzuführen sind. Diesmuss die Runtime feststellen, was anhand der eingangs erwähnten Artefakte für diebetroffene Komponente möglich ist. Da dem Component Manager bereits die Ver-waltung der Komponentenbeschreibung und des Matching Results obliegt, erscheintdie Zuständigkeit bei ihm sinnvoll aufgehoben. Daher bietet er die neue MethodeinvokeOperation(Component, Operation, Parameters) an. Bei der Modellinter-pretation werden die modellierten Aufrufe beim Application Manager hinterlegt, derderen Ausführung an genannte Operation delegiert.Insgesamt erlaubt das Konzept die Integration semantisch kompatibler Kompo-
nenten für eine Vorlage unabhängig von syntaktischen Diskrepanzen, wie abweichen-den XML-Schemata oder Datenformaten semantisch übereinstimmender Daten undunterschiedlichen Namen von Operationen.
4.4 Austausch von KomponentenDas bestehende Verfahren zum Austausch von Komponenten kann weitestgehendbeibehalten werden. Hinsichtlich des Zusammenspiels der Architekturkomponentenliegt im Prinzip das gleiche Vorgehen wie bei der initialen Integration einer Kom-ponente zugrunde. Es sind jedoch Besonderheiten zu beachten, die insbesondere dieRuntime betreffen, da diese für die Ausführung des Austauschs verantwortlich ist.• Wie in Kapitel 4.1.3 erörtert, ist jede Repräsentation einer Komponente im
Kompositionsmodell auch als Vorlage interpretierbar. Es ist somit unerheblichob eine konkrete Komponente angegeben ist – zum Austausch werden dieInformationen als eine Vorlage verstanden. Der Austausch beginnt also analogzum initialen Integrationsprozess mit der Anfrage an die Discovery auf Basisder Vorlage, wie in Abschnitt 4.3.1 beschrieben.• Es ist dafür Sorge zu tragen, dass nicht die selbe Komponente erneut selektiert
wird. Zwar ist aufgrund der Kontextabhängigkeit des Rankings nicht immerdie selbe Rangfolge zu erwarten, aber die Möglichkeit besteht. Daher übermit-telt die Runtime eine Liste von Komponenten-IDs, die mindestens die ID derderzeit integrierten Komponente enthält, wie in Kapitel 4.3.1 dargestellt andas Component Repository. Während der Discovery erfolgt die Filterung derKandidaten (vgl. Kapitel 4.3.2.2).
Copyright TU Dresden, Carsten Radeck 86

Semantische Komposition in Mashups Kapitel 4 Konzeption
• Wegen der Wrapping-Mechanismen wurde der bisherige Algorithmus zum Aus-tausch von Komponenten erweitert. Zunächst ist der Wrapper der auszutau-schenden Komponente nach der erfolgreichen Instantiierung der neuen Kom-ponente und dem Auslesen des Zustands der alten abzubauen, um Ressourcenfreizugeben. Anschließend wird der Wrapper der neuen Komponente erstelltund konfiguriert, wobei ihm auch eine Referenz auf den Event Handler über-reicht wird. Erst jetzt kann der Zustandstransfer in die neue Komponente, d. h.deren Initialisierung, beginnen, da ansonsten keine Mediation durchführbar ist.Zudem benötigt der Event Handler die Referenz des neuen Wrappers.• Um im Rahmen des Zustandstransfers alle benötigten Properties zu erfassen,
wird das Interface aus der SMCDL genutzt. Nur hier sind diese gelistet undihr Standardwert hinterlegt, sodass das Binding nicht ausreichend wäre.• Wie Anforderung 12 beinhaltet, wurden die Auswirkungen auf die Adapti-
onsregeln [TD10c] untersucht. Diese können grundlegend beibehalten werden.Folgende Punkte sind jedoch zu beachten. Zunächst ist in der Anwendungsent-wicklung bei der Angabe von Instanzdaten in der Aktion einer Regel, z. B. beireconfigureComponent, darauf zu achten, dass das standardisierte Schemades Konzepts gemäß dem Kompositionsmodell verwendet wird. Im Pointcutvon Regeln, deren Aktionen Komponenten betreffen, wie exchangeComponent,sind im Falle von Vorlagen deren ID anzugeben, da die zur Laufzeit integrierteKomponente unbekannt ist. Die Runtime ist dafür verantwortlich, die Aktio-nen auf die korrekte Komponente anzuwenden, z. B. indem eine Zuordnungder Vorlagen-ID zur ID der aktuellen Komponente verwaltet wird. Die Proble-matik tritt ebenfalls nach dem Austausch einer konkreten Komponente auf.
Somit kann der Komponentenaustausch auf Basis des Integrationsprozesses undder semantischen Komponentenbeschreibung erfolgen (Anforderung 12).
4.5 ZusammenfassungIn diesem Kapitel wurde das Konzept zur Nutzung semantischer Komponentenbe-schreibungen bei der Integration und dem Austausch von Komponenten in CRUISeentwickelt. Es basiert auf empfohlenen Semantic-Web-Standards, wie in Anforde-rung 17 gefordert und motiviert. Dem Konzept liegt der Grundidee von SWS fol-gend eine ontologiebasierte Komponentenbeschreibung zugrunde, wie in Abschnitt4.1 definiert. Dabei bieten Ontologien in OWL DL, die zunächst von allen Kompo-nentenentwickler gemeinsam genutzt werden, das notwendige Vokabular. Dadurchkönnen Konzepte formal definiert und Mechanismen zur Inferenz ausgenutzt werden.Aus Gründen der Kompatibilität kann zur Komponentenbeschreibung zum einen
die SMCDL genutzt werden. Basierend auf der bestehenden MCDL verfolgt sie einenAnnotationsansatz ähnlich dem von SAWSDL. Dabei wird die Funktionalität vonKomponenten, deren Operationen und Ereignissen durch Ontologiekonzepte in OWLDL beschrieben, was in MCDL nicht oder nur implizit möglich war. Prägenden Ein-fluss haben die Top Down-Ansätze bei der semantischen Typisierung: Properties undParameter von Operationen sowie Ereignissen von Komponenten werden durch On-tologiekonzepte definiert, sodass die in Kapitel 1 beschriebene fehlende Eindeutigkeitder Syntax umgangen werden kann. Dadurch ist eine Abbildung, das Grounding, in
Copyright TU Dresden, Carsten Radeck 87

Semantische Komposition in Mashups Kapitel 4 Konzeption
die jeweilige Syntax der Plattform notwendig – im Falle von CRUISe XML. Zur Min-derung des Aufwandes der Komponentenerstellung werden vorgegebene Groundingsvorgeschlagen, nach denen sich ein Entwickler richten kann und die im Kompositi-onsmodell genutzt werden, sodass die redundante Angabe von XSD in der SMCDLentfällt. Zur Anpassung bestehender Komponenten an das Grounding sind Trans-formationsvorschriften im Binding der SMCDL definierbar. Zum anderen kann ei-ne Komponente als Ontologieinstanz beschrieben werden, wofür eine Ontologie desKomponentenmodells und für die nicht-funktionalen Eigenschaften bereitsteht. Beidieser Variante können weiterführende Beschreibungsmittel genutzt werden, wie dy-namisch zu berechnende nicht-funktionale Eigenschaften.Das Konzept sieht vor, dass neben konkreten Komponenten auch abstrahierte Vor-
lagen im Kompositionsmodell angegeben werden können. Im Vergleich zum Klassen-konzept erlauben sie eine detailliertere Beschreibung der benötigten Komponente.In Abschnitt 4.2 wurden die zu lösenden Aufgaben im Integrationsprozess auf
Basis der semantischen Komponentenbeschreibung skizziert und mögliche Vertei-lungsvarianten auf die Architekturkomponenten diskutiert. In der resultierendenArchitektur verwaltet das Component Repository die Komponentenbeschreibungenontologiebasiert und bietet die Option sowohl SMCDL-Dokumente als auch Onto-logieinstanzen zu registrieren. Es stellt das Type Repository zur Verwaltung vonvorgegebenen Groundings und zur Verringerung von Datentransfer den IntegrationService samt Discovery und Ranking bereit. Die Runtime ist für die Interpretationdes Kompositionsmodells, die Integration und Ausführung von Komponenten unddie Bereitstellung von Mitteln zur Überbrückung von Heterogenitäten der Schnitt-stelle von Komponenten im Vergleich zum Kompositionsmodell (Mediation) zustän-dig. Letzteres erlaubt die Verwendung semantisch kompatibler Komponenten auchwenn syntaktische Diskrepanzen, z. B. abweichende Namen von Operationen, auf-treten, was auf Basis des Klassenkonzepts nicht möglich war.Das Zusammenspiel dieser Aufgaben behandelte Abschnitt 4.3 im Detail. Ausge-
hend vom Kompositionsmodell der Anwendung ist im Falle von Vorlagen die Suchenach funktional kompatiblen Komponenten in der Discovery notwendig. Vorlagenfungieren als Zielbeschreibung für den spezifizierten Algorithmus, der v. a. logikba-siertes Matching durchführt und Zuordnungen von Operationen etc. zwischen Vorla-ge und Komponente bestimmt, wodurch flexibler als zuvor passende Komponentengefunden werden. Anschließend findet eine nutzer- und kontextspezifische Sortierungder Kandidaten im Ranking statt. Die von der Runtime selektierte Komponente wirdanhand ihrer Komponentenbeschreibung in das Mashup integriert. Dabei dient einWrapper zur Überbrückung von syntaktischen Unterschieden und der Mediator kon-vertiert Daten, z. B. falls die Komponente ein generelleres Konzept erwartet als inder Vorlage definiert ist. Weiterhin können konkrete Komponenten anhand ihrer IDintegriert werden, wobei die Discovery auf ID-Vergleiche und die Mediation auf dieDurchführung der im Binding deklarierten Transformationen reduziert wird und dasRanking entfällt. In Abschnitt 4.4 wurde abschließend erörtert, wie der Austauschvon Komponenten auf Basis des Integrationsprozesses realisierbar ist.In den einzelnen Unterkapiteln wurde gezeigt, dass die in Abschnitt 2.5 gestellten
Anforderungen, die unabhängig vom Prototypen sind, vom Konzept erfüllt werden.
Copyright TU Dresden, Carsten Radeck 88

Semantische Komposition in Mashups Kapitel 5 Implementation
5Implementation
Nachdem im vorherigen Kapitel das Konzept zur Nutzung der semantischen Kompo-nentenbeschreibung zur Integration und zum Austausch von Mashup-Komponentenin CRUISe vorgestellt wurde, folgt nun die Betrachtung der prototypischen Imple-mentierung ausgewählter Aspekte dessen. Anhand der Umsetzung des Referenzsze-narios (Kapitel 2.4) als Beispielanwendung wird das Konzept validiert.
5.1 Verwendete TechnologienAn dieser Stelle wird ein kurzer Überblick über gegebene Programmierschnittstellenund Technologien gewährt, auf denen die Implementierung aufsetzt.
Component Repository Der Prototyp stützt sich auf das Java-basierte Compo-nent Repository, welches im Rahmen eines Komplexpraktikums1 parallel zur Arbeitentwickelt wurde. Es erlaubt die Registrierung von SMCDL-Instanzdokumenten undderen ontologiebasierte Verwaltung, indem eine Transformation in MCDO stattfin-det. Beide Beschreibungen werden auf syntaktische Validität überprüft und neben-einander persistent gespeichert, sodass eine Generierung der SMCDL zur Laufzeitauf Kosten eines erhöhten Speicherbedarfs entfällt.Im Rahmen dieser Arbeit gestellte Anforderungen und Konzepte flossen in die
Umsetzung des Component Repository ein. Das Schema der SMCDL, die MCDOund die Ontologie der nicht-funktionalen Eigenschaften wurden vom Autor in EclipseHelios2 bzw. Protegé implementiert und vom Komplexpraktikum verwendet.Das Fundament für die ontologiebasierte Persistenz bildet eine Teilmenge des Pro-
totyps des ebenfalls am Lehrstuhl Multimediatechnik durchgeführten Forschungs-projekts K-IMM (Knowledge through Intelligent Media Management) [Mit10], ins-besondere die Programmierschnittstelle zur Modellverwaltung KIMMModel. Sie bie-tet Mittel zur Abstraktion vom zugrunde liegenden RDF-Framework, indem sie einezusätzliche Schicht von Java-Klassen und Interfaces für Klassen, Properties undIndividuen von Ontologien bereithält (Modell-API). Der verwendete Prototyp vonK-IMM nutzt dabei intern das Framework Jena3 zur Verwaltung, SPARQL-basierten
1http://www.mmt.inf.tu-dresden.de/Lehre/Wintersemester_10_11/KP_MMT2/index.html2http://www.eclipse.org/3http://jena.sourceforge.net/
Copyright TU Dresden, Carsten Radeck 89

Semantische Komposition in Mashups Kapitel 5 Implementation
Anfrage und Reasoning von RDF- und OWL-basierten Modellen. Jena erlaubt dar-über hinaus die Anbindung verschiedener Reasoner wie Pellet, die Definition vonInferenzregeln in einer eigenen Syntax und die Registrierung beliebiger SPARQLExtension Functions, die in Java-Klassen gekapselt werden. Die Komponente KIMM-Model unterstützt die domänenspezfische Anpassung der oben genannten abstraktenSchnittstellen, indem analog zu den Vererbungsrelationen der Ontologie(n) ein ent-sprechendes Java-Objektmodell statisch generiert wird. Dies findet insbesondere beider MCDO und der Ontologie der nicht-funktionalen Eigenschaften Anwendung, daes die Programmierung vereinfacht: Für sämtliche Ontologieklassen steht ein Pen-dant in Java bereit, z. B. de.tudresden.inf.cruise.mcdl.(impl.)Operation fürhttp://inf.tu-dresden.de/cruise/mcdl.owl#Operation, die wie gewohnt perKonstruktor instantiierbar sind und über Methoden, wie set/getHasName, die Ab-frage und Manipulation der zugrundeliegenden Individuen erlauben.Zur Protokollierung dient das etablierte Framework log4j4 und auch für die Verar-
beitung von XML-Dokumenten und Schemata kommen bewährte Java Technologien,wie JAXB5, zum Einsatz. Intern untergliedert sich das Component Repository in ver-schiedene Java Pakete: Unter de.tudresden.inf.cruise.mcdl findet sich das vonJAXB erzeugte Objektmodell zur Repräsentation von SMCDL-Dokumenten, wäh-rend de.tudresden.inf.cruise.repository das eigentliche Component Reposito-ry beinhaltet. Das Unterpaket soap ist wesentlich für die vorliegende Arbeit, da esdie äußere Schnittstelle des Component Repository in Form eines SOAP [GHM+07]Web Service bereitstellt, wobei Apache Axis26 die Grundlage bildet. Der relevan-te Ansatzpunkt ist die Klasse CoReService. Sie bietet Methoden zum Hinzufügen,Entfernen sowie der Abfrage von Komponentenbeschreibungen in SMCDL und ent-spricht somit weitgehend der konzipierten Querying- und Management-Schnittstelle(vgl. Kapitel 4.2.2). Nur die Registrierung von MCDO-Instanzen und die in Kapitel4.3.1 spezifizierte Schnittstelle zur Integration per Vorlage fehlen.
Runtime Obgleich in Kapitel 4.2.1 eine Client-Server-Runtime empfohlen wurde,setzt der implementierte Prototyp auf die Thin-Server Runtime (TSR) [PWM10]auf, da nur diese aktiv entwickelt wurde und die komplette Umsetzung einer (neuen)Client-Server-Runtime über den Fokus dieser Arbeit hinausgeht.Die grundlegende verwendete Sprache der TSR ist JavaScript. Darauf aufsetzend
wird das Framework Ext Core7 in Version 3.3 verwendet, welches die wichtigstenFunktionen zur clientseitigen Anwendungsentwicklung bereitstellt. Es bietet u. a.Mittel zur objektorientierten Programmierung (Namensräume, Überschreiben undErweitern von Prototypen), zur ereignisbasierten Kommunikation (nach dem Ent-wurfsmuster Observer [GHJV94]), für die Verarbeitung der Datenformate JSON undXML, zur Manipulation des DOM und zur Kommunikation mittels AJAX. Für dieProtokollierung kommt log4javascript8 zum Einsatz, welches typische Funktionali-tät, wie z. B. unterschiedliche Log-Level, anbietet. Zum Zugriff auf domänenfremdeRessourcen steht ein in Java implementierter Proxy bereit, dessen Nutzung der Ser-vice Access der Runtime sicherstellt (vgl. Kapitel 2.2.2.2).
4http://logging.apache.org/log4j/5http://jaxb.java.net/6http://axis.apache.org/axis2/java/core/7http://www.extjs.com8http://log4javascript.org
Copyright TU Dresden, Carsten Radeck 90

Semantische Komposition in Mashups Kapitel 5 Implementation
5.2 Erweiterung vorhandener ImplementierungenDieser Abschnitt behandelt die zur Umsetzung des Konzeptes durchgeführten Er-weiterungen der zuvor erörterten Grundlagen. Als Entwicklungsumgebung für dieArbeit am Component Repository in Java kam Eclipse Helios zum Einsatz. ZurAnpassung der TSR diente das Aptana Studio9 in Version 2.0.
5.2.1 Testfälle und -system zur PerformanzanalyseWie in Anforderung 15 vorgesehen und motiviert, ist die Performanz des Integrati-onsprozesses ein wichtiger Faktor, der die Benutzbarkeit einer kompositen Weban-wendung in CRUISe maßgeblich beeinflusst – gerade beim Anwendungsstart. Des-halb wird an dieser Stelle das Testumfeld beschrieben, das in späteren Kapitelnaufgegriffen wird, um getroffene Designentscheidungen zu erläutern. Zunächst wer-den anhand wesentlicher Kenngrößen zwei exemplarische Testfälle definiert.
• Testfall 1: Von 16 Komponenten im Component Repository durchlaufen 9 dasMatching und schließlich 3 das Ranking. Dabei handelt es sich um die Kom-ponentenbeschreibungen der Beispielanwendung zuzüglich alternativer, welchez. B. die im Referenzszenario (Kapitel 2.4) angesprochenen Fälle abdecken (sie-he Tabelle 2.1). Da dies kaum als realistisches Mengengerüst bezeichnet werdenkann, wurde ein weiterer Testfall genutzt.• Testfall 2: Von 150 Komponenten im Component Repository durchlaufen 87
das Matching und schließlich 27 das Ranking. Aufgrund des Fehlens einersolchen Anzahl an Komponenten wurden aus den in Testfall 1 genanntenSMCDL nach dem Zufallsprinzip automatisiert Kopien angelegt, wobei dieKomponenten-IDs verändert wurden, was die Eindeutigkeit nicht gefährdet.
Zudem ist die Threadsicherheit der Implementierung sicherzustellen, sodass inbeiden Fällen neben einem einzelnen auch zehn Threads zur Anwendung kommen.Die Anfrage entspricht der Vorlage, die zur Abfrage der Komponente zur Darstel-
lung des Start- und Zielorts aus dem Referenzszenario (Kapitel 2.4) dient. Sie ent-hält zwei Rankingregeln, die bezüglich des Ranking Moduls noch genauer betrach-tet werden: eine Mapping sowie eine Occurance Rule. Das Testsystem verfügt übereinen Intel Core 2 Duo T5870 mit 2GHz und 3GB Arbeitsspeicher. Windows VistaSP2, Firefox 3.6.13, Java 1.6.0.23, Tomcat 6.0.29, Jena 2.6.3 und Pellet 2.1 stellendie grundlegende Software bereit. Als Leistungsindikator wird die durchschnittlicheAbarbeitungszeit eines Algorithmus oder Moduls gewählt, da die Gesamtdauer desIntegrationsprozesses (bzw. des Komponentenaustauschs) wesentlichen Einfluss aufdie Benutzbarkeit der Anwendung hat.
5.2.2 RuntimeZur Umsetzung des Konzepts waren zahlreiche Änderungen vorhandener Klassenund Erweiterungen der TSR notwendig, die den Schwerpunkt dieses Abschnitts dar-stellen.
9http://www.aptana.org/products/studio2
Copyright TU Dresden, Carsten Radeck 91

Semantische Komposition in Mashups Kapitel 5 Implementation
Modellinterpretation Die TSR arbeitet nun direkt auf dem Kompositionsmodelldes Mashups und interpretiert es zur Laufzeit. Da die XSD verwendeter Datentypenentfallen (siehe Kapitel 4.1.3) sinkt der Umfang einer Modellinstanz deutlich. Zudemerforderten auch die vorher genutzten Platzhalter im HTML-Gerüst der Anwendungdas Parsen von XML. Messungen der mittleren Startzeit der Beispielanwendung(vgl. Kapitel 5.3) zeigen in der alten und neuen Version vergleichbare Werte um 2 s.Außerdem erübrigt die direkte Interpretation die doppelte Wartung von Model-to-Code-Transformationen und Quellcode der Runtime.Die Klasse ApplicationManager dient der Initialisierung der gesamten Runtime
und wird daher um das Abrufen und die Verwaltung der Modellinstanz erweitert.Zusätzlich obliegt ihm die grundlegende Modellinterpretation: Er stellt die im Kom-positionsmodell deklarierten Kommunikationskanäle fest und delegiert deren Er-stellung an den Event Broker. Weiterhin liest er die modellierten Komponenten ausund initiiert deren Integration durch den ComponentManager. Analog dazu werdennach erfolgreicher Integration sämtlicher Komponenten initiale Operationsaufrufeund die Konfiguration des Layouts vom Application Manager extrahiert und an denComponent- (invokeOperation) bzw. LayoutManager weitergeleitet.Nachdem der ComponentManager die Aufforderung zur Integration der Komponen-
ten erhält, wird abhängig davon, ob es sich jeweils um eine konkrete Komponenteper ID oder eine Vorlage handelt, der entsprechende Ablauf im Zusammenspiel mitdem IntegrationManager durchgeführt.
Integration per ID: Sie erfolgt durch den Aufruf der Methode fetchSMCDLByID desIntegration Managers. Diese wiederum dient der Anbindung an die OperationgetComponentById der Schnittstelle des Component Repository und liefert dieerhaltene SMCDL an den Component Manager (processSMCDL).
Integration per Vorlage: Hierbei wird durch den IntegrationManager in der Me-thode fetchSMCDLByTemplate zunächst der Integration Request konstruiertund an die Operation getComponentsByTemplate des Component Repositorygeschickt (vgl. Abbildung 5.1). Die erhaltene Kandidatenliste wird vom Com-ponent Manager in der Methode handleCandidateList verarbeitet. Dabeiwerden Alternativen gespeichert und der höchstbewertete Kandidat selektiert.Anschließend wird mittels fetchSMCDLMatch des Integration Managers vonder Operation getSMCDLMatch des Component Repository die SMCDL unddas Matching Result bezogen. Das Resultat wird an den Component Managergeleitet (handleSMCDLMatch).
ComponentManager IntegrationManager CoReService
getComponentsByTemplate
CandidateList
fetchSMCDLByTemplate
handleCandidateList
fetchSMCDLMatch getSMCDLMatch
SMCDL & Matching ResulthandleSMCDLMatch
Kommunikation mittels Service Access
Abbildung 5.1: Sequenzdiagramm des Ablaufs der Integration per Vorlage
Anschließend berechnet der Component Manager ein JSON-Objekt, das die Schnitt-stelleninformationen der Komponente aus Sicht des Kompositionsmodells samt für
Copyright TU Dresden, Carsten Radeck 92

Semantische Komposition in Mashups Kapitel 5 Implementation
die Mediation relevante Daten enthält (MediationConfig). Im Falle von Komponen-ten per ID reduzieren sich letztere auf potentiell im Binding vorhandene Transforma-tionen. Für Vorlagen beschreibt die Datenstruktur zudem Unterschiede im Vergleichzum Modell, z. B. verschiedene Namen von Operationen und differente Indizes odersemantische Typen von Parametern. Dafür notwendige Informationen stammen indiesem Fall aus dem Matching Result, der SMCDL und dem Kompositionsmodell.Darauffolgend beginnt der Component Manager die Verarbeitung des Bindings
und somit der Realisierung des Lebenszyklus der Komponente. Dies verläuft – bisauf Anpassungen an das Schema der SMCDL und das Kompositionsmodell – im We-sentlichen analog zum bisherigen Vorgehen. Dazu gehört die Bereitstellung der an-gegebenen Abhängigkeiten zu externen Ressourcen, das Instantiieren, Initialisierenund Einbinden der Komponente in die Kommunikationsinfrastruktur. Nachdem dieKomponente instantiiert wurde, kommt, falls notwendig, die Erzeugung des Wrap-pers erweiternd hinzu. Dazu existiert die neue Klasse Ext.cruise.client.Wrapper,deren Instanzen die von CRUISe vorgegebene Komponentenschnittstelle implemen-tieren und zudem als Event Handler für die Komponente agieren (vgl. Kapitel 4.3.4).Durch die Übergabe einer Referenz auf die MediationConfig für die gekapselte Kom-ponente liegen dem Wrapper alle notwendigen Kenntnisse vor, um seinen Aufgabengerecht zu werden, wie der nachfolgenden Abschnitt erörtert.
Mediation Wie in Kapitel 4.3.4 diskutiert, wird die Funktionalität des Mediatorsverteilt. Zur Erbringung der in Kapitel 4.3.4 spezifizierten Up-Cast-Funktionalitätwurde ein externer Web Service umgesetzt. Der Mediation Service besitzt die Me-thode convert, welche mittels Axis2 über eine SOAP-Schnittstelle bereitsteht. Sienimmt drei Parameter entgegen: (1) das XML-Dokument der zu transformierendenDaten gemäß dem Grounding ihrer Klasse, die (2) per URI angegeben wird, sowie (3)die URI der Zielklasse. Zur Verarbeitung und Transformation der eingehenden Da-ten nutzt der Mediation Service gängige Java-APIs, wie JAXP10. Die Handhabungvon RDF-Graphen sowie die Durchführung von SPARQL-Anfragen basiert auf demfrei verfügbaren Framework Jena in Kombination mit dem Reasoner Pellet. Einzu-bindende Ontologien werden initial vom Component Repository bezogen und lokalgespeichert, falls nicht bereits vorhanden, und anschließend in die Knowledgebasegeladen. Zudem greift der Mediation Service auf das entwickelte Type Repositoryzu, um Liftings und Lowerings zu beziehen. Aus Performanzgründen werden dieselokal in einem Cache abgelegt und weiterhin kann deren initiale Abfrage konfigu-riert werden. Ausnahmen werden ausgelöst und als SOAP-Faults kommuniziert, fallsFehler bei der Verarbeitung der Eingabe oder bei der Transformation auftreten.Die Umsetzung des in Kapitel 4.3.4 vorgeschlagenen Vorgehens bei Up-Casts konn-
te verwirklicht werden, wie das folgende Beispiel veranschaulicht. Listing 5.1 zeigtdie Eingabedaten nach der vorgegebenen XSD der Klasse EventLocation, die zurKonvertierung in eine Location an den Mediator geschickt werden.
1 <def:eventLocation xmlns:def =".../ vvo">2 <name >... </name >3 <coordinates >4 <latitude >51.08989 </ latitude >5 <longitude >13.76843 </ longitude >6 </ coordinates >7 <event >
10http://jaxp.java.net/
Copyright TU Dresden, Carsten Radeck 93

Semantische Komposition in Mashups Kapitel 5 Implementation
8 <name >Up in Smoke Roadfestival VOL I</name >9 <time >2011 -02 -12 T16:27:00 </time >
10 <details >11 <description >... </ description >12 <address >... </ address >13 </ details >14 </ event >15 </ def:eventLocation >
Listing 5.1: Zu konvertierendes Instanzdokument
Daraus wird unter Zuhilfenahme genannter API ein Java-Objekt erzeugt undnachfolgend das Lifting in Form eines XSLT-Stylesheets angewendet (siehe Listing5.2). Das Ergebnis ist ein RDF-Graph, der durch Jena in ein Modell geladen wird.
1 <xsl: stylesheet version ="2.0" xmlns :def=".../ vvo" ... >2 <xsl: template match ="// def: eventLocation ">3 <rdf:RDF xmlns ="http :// mmt.inf.tu - dresden .de/ cruise / travel .owl#"... >4 <Event rdf:ID=" tempEvent ">5 <hasName rdf: datatype ="...# string ">6 <xsl:value -of select =" event /name/text ()" /></ hasName >7 <hasTime rdf: datatype ="...# dateTime ">8 <xsl:value -of select =" event /time/text ()" /></ hasTime >9 <hasLocation rdf: resource ="# tempEventLocation "/>
10 <hasDescription rdf: datatype ="...# string ">11 <xsl:value -of select =" event / details / description /text ()"/></ hasDescription >12 </Event >13 <EventLocation rdf:ID=" tempEventLocation "> <!-- analog zum Event -->14 </ EventLocation >15 </rdf:RDF >16 </xsl: template >17 </xsl: stylesheet >
Listing 5.2: Lifting der Klasse EventLocation
Durch den Reasoner wird die eingegebene Instanz klassifiziert und validiert. Da-nach beginnt das Lowering, indem die Informationen aus Sicht der SuperklasseLocation mit SPARQL abgefragt werden (vgl. Listing 5.3).
1 PREFIX travel : <http :// mmt.inf.tu - dresden .de/ cruise / travel .owl#>2 SELECT * WHERE {3 _:loc a travel : Location .4 _:loc travel : hasName ?name. _:loc travel : hasLatitude ?lat. _:loc travel :
hasLongitude ?lon. }
Listing 5.3: SPARQL-Anfrage des Lowerings
Auf das resultierende Ergebnis im SPARQL Query Results XML Format (vgl.Listing 5.4) wird anschließend das XSLT-Stylesheet des Lowerings angewendet.
1 <sparql xmlns ="http :// www.w3.org /2005/ sparql - results #">2 <head >< variable name="name"/>< variable name="lat"/>< variable name="lon"/>3 </head >4 <results >5 <result >6 <binding name="name">7 <literal datatype ="...">Up in Smoke Roadfestival VOL I </ literal >8 </ binding >9 <binding name="lat">
10 <literal datatype ="..." >51.08989 </ literal >11 </ binding >12 <binding name="lon">13 <literal datatype ="..." >13.76843 </ literal >14 </ binding >15 </result >16 </ results >17 </sparql >
Listing 5.4: Ergebnis der SPARQL-Abfrage des Lowerings
Copyright TU Dresden, Carsten Radeck 94

Semantische Komposition in Mashups Kapitel 5 Implementation
Das Gesamtergebnis ist ein XML-Instanzdokument gemäß dem vorgegebenen Sche-ma der Zielklasse Location (siehe Listing 5.5).
1 <def:location xmlns:def =".../ vvo"... >2 <def:name >Up in Smoke Roadfestival VOL I</ def:name >3 <def:coordinates >4 <def:latitude >51.08989 </ def:latitude >5 <def:longitude >13.76843 </ def:longitude >6 </ def:coordinates >7 </ def:location >
Listing 5.5: Ergebnis der Konvertierung
Unter Zuhilfenahme von SOAP-UI11 konnte für das Beispiel eine durchschnittli-che Antwortzeit von 85ms (ein Thread) und 440ms (10 Threads) ermittelt werden.Es ist anzunehmen, dass die Größe bzw. Komplexität sämtlicher EingabeartefakteEinfluss auf diesen Wert nehmen, was jedoch einer genaueren Untersuchung bedarf.Aus Gründen der Threadsicherheit sind die Teile des Algorithmus, die auf dem Mo-dell arbeiten, zu synchronisieren. Hierzu sollten zukünftig Alternativen untersuchtwerden, um die Skalierbarkeit zu gewährleisten.Als Teil der TSR existiert nun der Ext.cruise.client.Mediator. Er dient ei-
nerseits der Anbindung an den Mediation Service mittels folgender Methode.
• convert(String data, String sourceClassURI, String targetClassUR):Steht in synchroner und asynchroner Variante bereit und adaptiert die SOAP-Schnittstelle des Mediation Service mittels des Service Access der TSR.
Die zu nutzende URL des Mediation Service ist per Konstruktor konfigurierbar.Weiterhin übernimmt der Mediator die Durchführung von XSL-Transformationendirekt auf dem Client und bietet dafür diese Methoden.
• transformByStylesheetRef(String data, String xslt_url): Wendet dasreferenzierte Stylesheet nach dem Herunterladen auf die Nutzdaten an. Ca-ching verhindert mehrfaches Abrufen des Stylesheets.• transformByStylesheet(String data, Document xslt): Wendet ein direkt
als DOM vorliegendes Stylesheet auf die Nutzdaten an.
Wie in Kapitel 4.3.4 spezifiziert, wurden die Kommunikationskanäle der TSR er-weitert. Sie werden durch die Klasse Ext.cruise.client.Channel definiert, vomEventBoker verwaltet und repräsentieren je einen Channel des Metamodells. DieFunktionalität der Methode publish(eventName, eventData, cid) wurde wie folgtangepasst. Sie nimmt den Namen des zu veröffentlichenden Ereignisses, die Nutz-daten und die Kennung der Komponente entgegen. Systemeigene Kanäle werdenseparat behandelt, da sie von den Neuerungen wegen des Fehlens der semantischenTypisierung nicht betroffen sind. Bei anwendungsspezifischen Kanälen vergleichtdie Methode die semantischen Typen der Parameter des Publishers (Event) unddes jeweiligen Subscribers (Operation) anhand der URI, die in der MediationCon-fig hinterlegt sind. Stimmen diese nicht überein, wird die Operation convert desMediators zwecks Up-Cast aufgerufen. Zudem werden Ergebnisse zwischengespei-chert, um unnötigen Aufwand zu verhindern, wie in Kapitel 4.3.4 motiviert.11http://www.soapui.org/
Copyright TU Dresden, Carsten Radeck 95

Semantische Komposition in Mashups Kapitel 5 Implementation
Die Funktionsweise des Wrappers entspricht der konzipierten (vgl. Kapitel 4.3.4).Die Methoden set/getProperty, invokeOperation sowie publish stützen sich aufdie MediationConfig für die gekapselte Komponente. Auf Basis dieser können unter-schiedliche Namen von Operationen, Properties und Events durch Umbenennung,abweichende Indizes von Parametern durch Umsortierung und zusätzliche Parame-ter durch Verwerfen überbrückt werden. Zudem nutzt der Wrapper den Mediatorzur Durchführung von XML-Transformationen. Bei Codetemplates werden zuerstalle Platzhalter @data@ expandiert, sodass eine Referenz auf die Nutzdaten vorhan-den ist. Schließlich wird der Code mittels eval interpretiert. Die Rückgabe oder,falls diese nicht existiert, die (manipulierten) Nutzdaten werden weitergeleitet.
Komponentenaustausch Zur Realisierung des Austauschs von Komponenten wares notwendig, den Algorithmus zum Zustandstransfer zu überarbeiten, da dieserauf die Trennung von MCDL-B und -C sowie das XML-Schema der Platzhalterausgerichtet war. Die überarbeitete Version liest alle im Kompositionsmodell defi-nierten Properties der alten Komponente ein und speichert sie in einem Memento[GHJV94]. Zur Injektion des Zustandes in die neue Komponente wird zuerst das Me-mento herangezogen. Falls dort kein Eintrag hinterlegt ist, wird nach dem Wert imKompositionsmodell und als letzte Lösung nach dem Standardwert in der SMCDLder neuen Komponente gesucht.Der Ablauf des Austausch stimmt weitgehend mit dem der Integration per Vorlage
überein. Lediglich die ID der aktuellen Komponente wird gespeichert und anschlie-ßend der Auswahlliste für Alternativen hinzugefügt, da sie durch die Verwendungder Blacklist bei der Discovery ignoriert wird.
5.2.3 Component Repository samt Integration ServiceDie eingangs beschriebene Implementierung des Component Repository wurde ei-nerseits um die in Kapitel 4.3.1 definierten Schnittstellen erweitert. Die bestehen-de Klasse CoReService wurde im Zuge dessen um die Methoden getSMCDLMatchund getComponentsByTemplate angereichert. Erste nimmt einen Integration Re-quest entgegen, der in einer XSD spezifiziert wurde (siehe Abbildung A.4 im An-hang). Er umfasst alle benötigten Informationen zur Suche und zum Ranking vonKandidaten für eine Vorlage.Weiterhin wurde die Logik zur Erbringung der Funktionalität dieser Schnittstellen
implementiert. Dabei dient das Paket de.tudresden.inf.cruise.integration derklaren Kapselung und ist intern gemäß den beiden Aufgaben Discovery und Rankingsowie dem Zugriff auf den Kontextdienst weiter strukturiert. Zudem wurde auf dieTrennung von Schnittstellendefinitionen und deren Implementation geachtet, wasauch die Pakethierarchie widerspiegelt. Das Klassendiagramm zeigt Abbildung A.4im Anhang. Transport-, protokoll- und frameworkspezifische Charakteristika werdenin der jeweiligen Schnittstellenklasse des Component Repository gekapselt, sodasseine Erweiterung um z.B. eine REST-Schnittstelle leicht möglich ist. Dies betrifftinsbesondere die Sitzungsverwaltung, die im Falle des CoReService auf Basis vonMechanismen, die Axis2 zur Verfügung stellt, implementiert wurde. Auf diese Weisekönnen die meisten Parameter eines Integration Request, wie die Nutzer-ID undInformationen über die Runtime, im Sitzungskontext abgelegt werden und müssen
Copyright TU Dresden, Carsten Radeck 96

Semantische Komposition in Mashups Kapitel 5 Implementation
nicht in jeder Anfrage erneut mitgeliefert werden. Zudem wird im aktuellen Sit-zungskontext, falls notwendig, ein neuer IMatchingResultStore angelegt. Dieserdient der flüchtigen Speicherung von Matching Results, die während des Matchingsberechnet werden (vgl. Kapitel 4.3.2.2). Auch Konvertierungen zwischen den interngenutzten Java-Objekten und dem Datenformat der äußeren Schnittstelle finden imCoReService statt (siehe Abbildung 5.2).
CoReService
IntegrationTask IRankingStrategyIMatcher
getComponentsByTemplate
getComponentsByTemplate(IntegrationRequest) match
Map<Mcdl, Float>
rank(Map<Mcdl, Float>)
List<Component>
Manage Session, Convert Data
List<Component>
Convert Data
SOAP Envelope
SOAP Envelope
Abbildung 5.2: Sequenzdiagramm des Ablaufs bei der Suche anhand einer Vorlage
Den zentralen Einstiegspunkt in das Subsystem zur Integration bildet die Klas-se IntegrationTask. Sie wird pro Anfrage an getComponentsByTemplate vomCoReService instantiiert und die Anfrage an die Instanz weitergeleitet (vgl. Abbil-dung 5.2). Daraufhin steuert ein IntegrationTask den Kontrollfluss über die Modulezur Discovery und zum Ranking (siehe unten), damit dies nicht in jeder Schnittstel-lenklasse notwendig ist. Die Erzeugung konkreter Objekte von Matchingalgorithmenund Rankingstrategien erfolgt dabei durch eine abstrakte Fabrik [GHJV94], dereninitiale Erstellung ebenso wie die Unterstützung von Subsumes-Matches in der Dateiconfig.properties konfigurierbar ist.Wie in Kapitel 4.3.1 spezifiziert, erfolgt bei der Integration einer Komponente per
Vorlage eine zweite Anfrage, mit der die SMCDL und das Matching Result abgeru-fen wird. Dafür dient die Methode getSMCDLMatch des CoReService. Hierbei wirdkeine IntegrationTask gestartet, sondern direkt das im Sitzungskontext hinterlegteIMatchingResultStore anhand der übertragenen Komponenten- und Vorlagen-IDdurchsucht. Nach erfolgter Abfrage wird der Eintrag aus diesem entfernt, um Spei-cher freizugeben. Das Schema der Antwort entspricht dem von Axis2 automatischaus der Java-Klasse SMCDLMatch generierten.Damit nicht für jede Domänenontologie ein Objektmodell für die Modell-API
generiert werden muss, erfolgt die Einbindung der Ontologien separat und arbeitetdirekt auf dem zugrundeliegenden OntModel von Jena. Die Registrierung erfolgt imPrototypen in der Datei model.properties, die vom ConfigLoader des ComponentRepository interpretiert wird. Zudem wurden zusätzliche Methoden im CoReServiceangelegt: listRegisteredOntologies dient zur Abfrage der URIs aller registriertenOntologien und getOntology(String uri) liefert eine serialisierte Ontologie. Dieserlaubt es dem Mediator benötigte Modelle zu laden, ohne dass sie bei ihm ebenfallsregistriert sind (vgl. Abschnitt 5.2.2).Nachfolgend werden die Module für die Discovery und das Ranking vorgestellt.
Copyright TU Dresden, Carsten Radeck 97

Semantische Komposition in Mashups Kapitel 5 Implementation
Discovery-Modul Das Discovery-Modul liegt im Unterpaket discovery(.impl)vor und bietet im Wesentlichen die Umsetzung des in Kapitel 4.3.2.2 konzipier-ten Matching-Algorithmus in der Klasse DefaultMatcher. Alternative Algorithmenkönnen durch Implementierung des Java-Interface IMatcher erstellt und von derentsprechenden Fabrik für die IntegrationTask ausgewählt werden.Die Vorselektion geeigneter Kandidaten wird mittels einer SPARQL-Anfrage an
das Modell des Component Repository realisiert. Die Modell-API gibt passende In-stanzen von Mcdl zurück, die einzelne Komponentenbeschreibungen repräsentieren.Für alle der so festgestellten Kandidaten erfolgt anschließend die Abarbeitung derspezifizierten Schritte. Alle der in Kapitel 4.3.2.2 geschilderten Fälle, z. B. Contra-variance und Abhängigkeiten von Events zu Operationen des Kandidaten, wurdenbeachtet und durch Komponentenbeschreibungen der Testfälle erfolgreich getestet.Offen bleibt die Einbeziehung von Vorbedingungen an die Funktionalität von Ope-rationen, da das Component Repository bisher nur die Registrierung von SMCDLunterstützt. Dies ist über die Referenz auf eine Instanz von IContext umsetzbar.Zur Berechnung der bestmöglichen Zuordnungen im Rahmen des Algorithmus
zum Matching (vgl. Kapitel 4.3.2.2) kommt der Kuhn-Munkres-Algorithmus, auchals Ungarische Methode bezeichnet, zum Einsatz (Originalpublikation [Kuh55], seit-dem mehrfach überarbeitet). Er berechnet eine eindeutige Zuordnung zwischen zweiGruppen von Objekten, wobei die »Kosten« der einzelnen Zuordnungen minimiertwerden und die Zeitkomplexität O(|n3|) beträgt. Bezogen auf die Problemstellungdes Matching-Algorithmus sind die Gruppen die in den jeweiligen Teilschritten be-trachteten Elemente von Vorlage und Komponente und die Kosten werden von denÜbereinstimmungsgraden abgeleitet. Da ein Minimierung stattfindet, werden diesenegiert. Es wird die gleiche Java-Implementierung (Klasse BestAssignmentSolver)wie bei der praktischen Umsetzung von SAWSDL-MX (vgl. Kapitel 3.2.4) verwen-det. Listing 5.6 verdeutlicht die Funktionsweise an einem Beispiel. Die Eingabe kannals Matrix interpretiert werden, die die negierten numerischen Werte der Überein-stimmungsgrade zwischen zwei Elementen der Vorlage und dreien des Kandidatenbeinhaltet (Zeile 1-2). Das Ergebnis ist eine Matrix, welche die »kostengünstigste«Zuordnung darstellt: Im Beispiel wird z. B. dem zweiten Element der Vorlage dasdritte des Kandidaten zugewiesen (Zeile 6). Die konkrete Ausprägung der Daten-struktur der Eingabe wird durch den Algorithmus generisch in Abhängigkeit vonVorlage und Kandidat zur Laufzeit bestimmt.
1 double [][] input = new double [][]{ { -3, -1, 0},2 { -1, 0,-3} }3
4 byte [][] result = (new BestAssignmentSolver ( input )). munkres ();5 // mit result = { { 1, 0, 0 }6 // { 0, 0, 1 } }
Listing 5.6: Beispiel der Ein- und Ausgabe des BestAssignmentSolvers
Für alle kompatiblen Kandidaten wird das MatchingResult instantiiert und imIMatchingResultStore des aktuellen Sitzungskontexts hinterlegt.Die durchschnittlich gemessene Zeit des Matchings beträgt bei einem einzelnen
Thread 56ms bzw. 310ms in Testfall 1 bzw. 2. Eine erhebliche Reduktion der Zeitkonnte durch die Minimierung der Aufrufe an die Modell-API erreicht werden. Ei-ne zukünftig in Betracht zu ziehende Option ist daher die direkte Nutzung einessemantischen Frameworks, wie Jena, im Component Repository.
Copyright TU Dresden, Carsten Radeck 98

Semantische Komposition in Mashups Kapitel 5 Implementation
Ranking-Modul Das Unterpaket ranking(.impl) enthält sämtliche Schnittstel-lendefinitionen und Implementierungen zur Realisierung des Rankings. Dabei han-delt es sich in der Hauptsache um Rankingstrategien.
• AbstractRankingStrategy: Die abstrakte Klasse bietet grundlegende Funk-tionalität für konkrete Strategien an. Dazu zählt insbesondere die Auswertungvon Bedingungen von Rankingregeln in der Methode checkCondition, welchedie in einem Objektmodell repräsentierte Metamodellklasse BoolExpression(siehe Abbildung 4.1.3) rekursiv auswertet.• NormalizeFunctionalRating: Die einfachste Implementierung normalisiert
zur Rangfolgebildung lediglich den funktionalen Übereinstimmungsgrad. Siewird von der IntegrationTask gewählt, wenn keine Rankingregeln in derVorlage vorhanden sind.• MultiplicativeRankingStrategy: Bei dieser Strategie werden die Einzeler-
gebnisse von Rankingregeln multiplikativ verknüpft.
Zunächst werden Alternativen für die konkrete Umsetzung der Rankingregelndiskutiert. Letztere sind Teil der Vorlage und werden im IntegrationRequest re-präsentiert, wobei die Serialisierung der Regeln aus dem Kompositionsmodell gemäßeiner generierten XSD zum Einsatz kommt. Angemerkt sei, dass in den folgendenListings die SPARQL-Aussage aus Gründen der Lesbarkeit keine Maskierungszei-chen enthält, während solche im Instanzdokument durchaus auftreten können, umdie Wohlgeformtheit des XML-Dokuments zu garantieren.Listing 5.7 zeigt das Beispiel einer Occurance Rule, die prüft, ob eine Kompo-
nente kostenlos ist. Bedingungen werden mit FILTER formuliert und eine ExtensionFunction kommt zum Einsatz (Zeile 6). Letztere enthält einen Pfad zur Adressie-rung der angeforderten Kontextinformation, wie er auch bisher verwendet wurde. DieRegistrierung der implementierenden Klasse (ContextAccessExtensionFunction)erfolgt bei der FunctionRegistry des SPARQL-Subsystems von Jena. Sie ist voneiner Basisklasse von Jena für Funktionen abgeleitet und kann dem Zugriff auf denKontextdienst dienen, wobei die benötigte Kontextinformation in Form eines Pfadesüberreicht wird. Unter Zuhilfenahme einer Instanz von IContext und des Parserscontext.impl.PathToSPARQL wird die korrespondierende SPARQL-Query generiertund an den Kontextdienst übermittelt.Da Occurance Rules eine boolesche Entscheidung darstellen, sind SPARQL ASK-Ausdrücke eine naheliegende Wahl, weil ihr Resultat unmittelbar das der OccuranceRule bilden kann. In diesem Fall können Platzhalter für die Zuordnung des Er-gebnisses zum passenden Kandidaten dienen: Zeile 4 veranschaulicht das, wobei[metadata] zur Laufzeit mit der URI des Individuums der Klasse Metadata, daseindeutig zum aktuellen Kandidaten gehört, ersetzt wird. Dadurch sind die Regelnnicht unmittelbar standardkonform und müssen pro Kandidat angewendet werden.
1 <rankingRule xsi:type="ccm: OccuranceRule " id=" maxPrice " isGlobal ="true"2 metadata =" PREFIX xsd: <http :// www.w3.org /2001/ XMLSchema #>3 ASK {4 [ metadata ] nfp: hasPricing ?p.5 {?p nfp: hasValue ?v.} UNION {?p nfp: hasUpperBound ?v.}6 FILTER (xsd: float (?v) <= 0.0 && mcdl: queryContext (’/ pers:
hasPreferredCurrency /’)).}" >7 </ rankingRule >
Listing 5.7: Beispiel einer Occurance Rule mit Platzhalter
Copyright TU Dresden, Carsten Radeck 99

Semantische Komposition in Mashups Kapitel 5 Implementation
Eine Alternative ist die Nutzung von SELECT-Konstrukten zur einmaligen Abfra-ge aller Metadata, welche die Bedingung erfüllen (siehe Listing 5.8). Dabei kommenkeine Platzhalter zum Einsatz, sondern das Metadata ist als zusätzliche Variablemetadata abzufragen. Anschließend findet eine programmatische Zuordnung zu denKandidaten statt.
1 <rankingRule xsi:type="ccm: OccuranceRule " id=" maxPrice " isGlobal ="true"2 metadata =" PREFIX xsd: <http :// www.w3.org /2001/ XMLSchema #>3 SELECT ? metadata WHERE { ? metadata nfp: hasPricing ?p. ...}" >4 </ rankingRule >
Listing 5.8: Beispiel einer Occurance Rule ohne Platzhalter
Listing 5.9 zeigt eine Normalize Rule für den Preis mit inverser Ordnung. Hier-bei werden SELECT-Ausdrücke zur Adressierung des Metadatums genutzt, damitder konkrete Wert in einer Variable vorliegt. Auch hier sind beide Ansätze für dieZuordnung der korrekten Komponente möglich.
1 <rankingRule xsi:type="ccm: NormalizeRule " id="..." proportionality =" inverse "2 metadata =" SELECT ? metadata ?v { ? metadata nfp: hasPricing ?p.3 {?p nfp: hasValue ?v.} UNION {?p nfp: hasUpperBound ?v.}}" >4 </ rankingRule >
Listing 5.9: Beispiel einer Normalize Rule
Eine Mapping Rule für den Energieverbrauch illustriert Listing 5.10. Es existiertein standardmäßiger Rankingwert (Zeile 1), der genutzt wird, falls keine Abbildunggreift. Mapping Rules können einerseits auf CONSTRUCT-Anfragen in SPARQL ab-gebildet werden, wobei die Fallunterscheidung in FILTER-Ausdrücken auftritt. DerErgebnisgraph muss ein Tripel mit einer festen Datatype-Property, z. B. hasRating,beinhalten und anschließend wird mittels SELECT deren Wert angefragt. Eine weni-ger komplexe Variante ist die Verwendung einer SELECT-Anfrage und die Definitionder Abbildungen als Elemente der Regel selbst. Dabei ist wieder ein Ansatz mit undohne Platzhaltern möglich (Listing 5.10 illustriert letzteres). Im Falle von Platz-haltern ist eine beliebige Variable zu selektieren, auf deren Wert die Abbildungenangewendet werden. Ohne Platzhalter ist die Variable metadata reserviert.
1 <rankingRule xsi:type="ccm: MappingRule " id=" green_IT " defaultrating ="0.3"2 metadata =" SELECT ? metadata ? consumption WHERE {3 ? metadata nfp: hasEnergyConsumption ? consumption . }" >4 <mapping value ="http :// inf.tu - dresden .de/ cruise /nfp.owl# Medium " rating ="0.5"/>5 <mapping value ="http :// inf.tu - dresden .de/ cruise /nfp.owl#Low" rating ="0.9"/>6 </ rankingRule >
Listing 5.10: Beispiel einer Mapping Rule
Regel 1 (Mapping Rule) Regel 2 (Occurance Rule)
0
10
20
30
40
50
3,34 5,521,49
4,77
23,07
42,1
3,18
18,21Testfall 1 (mit Platzhalter)
Testfall 1 (ohne Platzhalter)
Testfall 2 (mit Platzhalter)
Testfall 2 (ohne Platzhalter)
Rankingregel
Zeit
(ms)
Abbildung 5.3: Vergleich der durchschnittlichen Laufzeiten zweier Regeln
Copyright TU Dresden, Carsten Radeck 100

Semantische Komposition in Mashups Kapitel 5 Implementation
Im Prototypen wird die Verwendung des Ansatzes ohne Platzhalter aufgegriffen.Wie in Abbildung 5.3 zu erkennen ist, kann das gewählte Verfahren die durchschnitt-liche Berechnungszeit (ohne Auswertung von Vorbedingungen) einer einzelnen Ran-kingregel z. T. erheblich senken. Zwar nähern sich beide Werte in Testfall 1 an. Beieiner größeren Anzahl an Kandidaten, die in das Ranking einfließt, wird der Unter-schied jedoch deutlich. Die Entscheidung fällt unter Betrachtung der Performanz aufMapping Rules mit SELECT-Konstrukten (siehe Abbildung 5.3), da bezüglich derVariante mit CONSTRUCT-Anfragen bereits ohne Platzhalter in Testfall 1 durch-schnittlich 11,73ms und in Testfall 2 im Mittel 117,73ms gemessen wurden.
Gesamtzeit der Anfrage Abschließend erfolgt kurz die Vorstellung der Gesamt-zeit einer Anfrage an die Schnittstelle des Component Repository zur Abfrage vonKomponenten per Vorlage. Für die Operation getComponentsByTemplate wurdemittels SOAP-UI in Testfall 1 eine durchschnittliche Antwortzeit von 104ms (1Thread) sowie 230ms (10 Threads) gemessen. Wenig überraschend steigt der Wertin Testfall 2 an: 474ms (1 Thread) und 1,3 s (10 Threads). Letzter Wert resul-tiert insbesondere aus dem Matching und ist kritisch zu sehen, sodass weitere Opti-mierungsmöglichkeiten untersucht werden sollten. Eine detaillierte Betrachtung derOperation getSMCDLMatch wurde nicht vorgenommen, da dieser keine zeitkritischeAnwendungslogik zugrunde liegt.
5.2.4 Type RepositoryDas Type Repository wurde als eigenständiger SOAP Web Service in Java 1.6 mit-tels Apache Axis2 implementiert. Es bietet die komplette konzeptionell vorgesehe-ne Funktionalität (vgl. Kapitel 4.2.2) und nutzt eine dateibasierte Persistenz. AufErweiterbarkeit hin zu alternativen Ansätzen der Speicherung, wie relationalen Da-tenbanken, wurde durch Verwendung von Interfaces und Mitteln zur Konfigurationder reflexiven Instanziierung von Objekten geachtet. Der umgesetzte Prototyp unter-stützt noch keine Mechanismen zur Auflösung oder Verschmelzung von importiertenXSD, da zunächst die grundlegende Funktionalität im Fokus stand. Zur Trennungder Belange untergliedert sich die Schnittstelle in den Query und den Update Ser-vice. Während ersterer die Funktionalität zum Abfragen von Typdefinitionen, Lif-tings und Lowerings anbietet (vgl. Listing 5.11), erlaubt der Update Service dasHinzufügen, Entfernen und Aktualisieren der Artefakte. Die Schemata letzterer ent-sprechen den von Axis2 aus den Java-Klassen generierten. Für die Kommunikationvon Fehlern, z. B. bei einer unbekannten URI, werden Ausnahmen in Java ausgelöstund schließlich auf SOAP-Faults abgebildet.
1 // Lists all URIs of concepts for which at least one information exists .2 public String [] listKnownURI ();3 // Returns the Lowering for the specified concept .4 public Lowering getLowering ( String uri);5 // Returns the TypeDefinition for the specified concept .6 public TypeDefinition getTypeDefinition ( String uri);7 // Returns the Lifting for the specified concept .8 public Lifting getLifting ( String uri);9 // Returns the Lifting and Lowering for the specified concept .
10 public LiftingLowering getLiftingAndLowering ( String uri);
Listing 5.11: Java-Interface des Query Service
Copyright TU Dresden, Carsten Radeck 101

Semantische Komposition in Mashups Kapitel 5 Implementation
5.3 BeispielanwendungDas Referenzszenario (Kapitel 2.4) orientiert sich maßgeblich am vorhandenen VVO-Demonstrator. Im Rahmen dessen entwickelte Komponenten sowie das Kompositi-onsmodell wurden aufgegriffen und auf das vorgeschlagene Konzept übertragen, wasnachfolgend auszugsweise illustriert wird.Ontologien stellen die Grundpfeiler des entwickelten Konzeptes dar (vgl. Kapitel
4.1). Daher wurden vom Autor dieser Arbeit wesentliche Konzepte, die im vorhan-denen VVO-Demonstrator zur Typisierung von Parametern und Properties genutztwerden, in eine Ontologie übertragen und exemplarisch erweitert (vgl. AbbildungA.3 im Anhang), um anhand verschiedener Komponentenbeschreibungen das Kon-zept zu validieren. Zur Annotation der Funktionalität dienen die Ergebnisse ausder parallel abgelaufenen Arbeit von Gregor Blichmann [Bli11]. Dabei entstandenKonzeptionalisierungen von durchführbaren Aufgaben und Ereignissen in der Do-mäne der Reiseplanung (siehe Abbildungen A.1 und A.2 in Anhang), die sich derUnterteilung in domänenspezifische und -unspezifische Konzepte entsprechend inTeilontologien gliedern. Auf Grundlage dieser Ontologien, die allesamt in OWL DLformalisiert sind, erfolgte schließlich die Erstellung der Komponentenbeschreibun-gen in SMCDL, basierend auf den vorhandenen MCDL-Dokumenten. Abbildung5.4 zeigt einen Ausschnitt der SMCDL der UI-Komponente zur Visualisierung vonVeranstaltungen und die Beziehung zu den Ontologiekonzepten.
<mcdl xmlns="http://inf.tu-dresden.de/cruise/mcdl" xmlns:meta="http://inf.tu-dresden.de/cruise/mcdl/metadata" xmlns:nfp="http://inf.tu-dresden.de/cruise/nfp.owl#" xmlns:mcdl="http://inf.tu-dresden.de/cruise/mcdl.owl#" xmlns:travel="http://mmt.inf.tu-dresden.de/cruise/travel.owl#" xmlns:events="http://.../travelplanningevents.owl#" xmlns:actions="http://.../travelplanningactions.owl#" name="Event List" id="..." version="1.0" functionality=“actions:Sort“> <meta:metadata>...</meta:metadata> <interface> <property type="mcdl:hasTitle" required="true" name="title"/> <property type="mcdl:hasWidth" required="true" name="width"/> <property type="mcdl:hasHeight" required="true" name="height"/> <event name="locationSelected" functionality="events:LocationSelected">
<parameter name="location" type="travel:Location"/> </event> <event name="timeSelected" functionality="events:DateTimeSelected">
<parameter name="time" type="travel:hasDestinationTime"/> </event> <operation name="update" functionality="actions:OutputEventList">
<parameter name="events" type="travel:EventList"/> </operation> </interface>…</mcdl>
Location
List
EventListRoute
hasDestinationTime:DateTime
Thing
subClassOf
subClassOf
hasStartTime:DateTime
Action
Output Sort
OutputEventlist
subClassOf
subClassOf
Event
OnOutput
DateTimeSelected
LocationSelected
subClassOf
subClassOf
Abbildung 5.4: Beispiel einer SMCDL und der annotierten Ontologiekonzepte
Die in Abschnitt 4.1.3 vorgestellten Änderungen und Erweiterungen am Komposi-tionsmodell wurden auf Basis des Eclipse Modeling Frameworks umgesetzt. Es bietetden Vorteil, dass u. a. ein Java-Objektmodell und ein darauf aufbauender Editor alsEclipse Plug-In generiert werden können. Letzterer erlaubt es, in der gewohntenEntwicklungsumgebung konkrete Kompositionsmodelle gemäß dem Metamodell zuerstellen, zu validieren und z. B. in ein vorgefertigtes XML-Schema zu exportieren.
Copyright TU Dresden, Carsten Radeck 102

Semantische Komposition in Mashups Kapitel 5 Implementation
Auf diese Weise wurde das Kompositionsmodell für die Beispielanwendung unterEinbeziehung der oben erwähnten SMCDL-Instanzdokumente erstellt und in XMLzur Interpretation durch die Runtime serialisiert und gespeichert.Das Kompositionsmodell beinhaltet neun Komponenten, von denen zwei als Vor-
lage definiert sind: die UI-Komponente zur Angabe von Start- und Zielort (Mitteoben in Abbildung 5.5) sowie jene zur Anzeige von Veranstaltungen (unten rechts).Für beide Vorlagen existieren jeweils zwei kompatible Kandidaten, sodass eine Aus-wahlliste im Titelbereich visualisiert wird, um den manuellen Austausch zu erlauben.
Abbildung 5.5: Screenshot der Beispielanwendung
Zur Validierung der Konzepte zur Mediation (vgl. Kapitel 4.3.4) wurde folgendeBeispiele in die Komponentenbeschreibungen eingefügt und auf Basis der implemen-tierten Mechanismen erfolgreich erprobt.
• Die Service-Komponente zur Bestimmung von Hotels deklariert eine Transfor-mation am Binding, die das Konzept HotelList in das vorgegebene Groundingüberführt. Das dazu notwendige XSLT-Stylesheet wurde erstellt und in derSMCDL referenziert. Die Ausführung der Transformation hat keine spürbarenAuswirkungen auf die Bedienbarkeit, da nach erfolgter Zwischenspeicherungdes Stylesheets im Mittel lediglich 4ms benötigt werden.• Die alternative UI-Komponente zur Auflistung von Veranstaltungen veröffent-
licht bei Selektion eines Eintrags speziellere EventLocations. Daher erfolgtein Up-Cast in die im Kompositionsmodell vorgesehene Klasse Location. Zu-dem ist das Ereignis zur Publikation der Uhrzeit des ausgewählten Eintragsumzubenennen, um dem Kompositionsmodell zu entsprechen.• Die Karten-Komponente zur Auswahl und Darstellung von Start- und Zielort
weist von der Vorlage abweichende Operationsnamen auf (setMarker(s) stattsetLocation(s)), sodass eine Umbenennung beim Aufruf nötig ist. Außerdemerwarten die Operationen ihre zwei Parameter in umgekehrter Ordnung.• Alternativ steht für die Karte ein Formular bereit. Seine Operationen zur
Ortsdarstellung (setLocation(s)) benötigen nur einen der zwei in der Vorlagevorgesehenen Parameter, sodass der Wrapper den überflüssigen verwirft.
Copyright TU Dresden, Carsten Radeck 103

Semantische Komposition in Mashups Kapitel 5 Implementation
Die Auswahl der jeweiligen Alternative pro Vorlage hängt insbesondere von dernicht-funktionalen Rangfolge ab. Die dazu definierten Rankingregeln sind in denListings 5.8 und 5.10 dargestellt. Die Anwendung der Mapping Rule ist an eine kon-textspezifische Bedingung geknüpft, die das Listing 5.10 nicht zeigt. Falls sie erfülltist, wird das Formular selektiert, obwohl es eine geringere funktionale Übereinstim-mung aufweist, die aus einer nicht erfüllten optionalen Funktionalität der Vorlageresultiert. Ansonsten erhält die Karte den Vorrang.
5.4 ZusammenfassungDieses Kapitel behandelte die prototypische Umsetzung des entwickelten Konzepts.Dazu wurden zunächst die technologischen Grundlagen in Form vorhandener Imple-mentierungen und genutzter Frameworks vorgestellt.Anschließend standen die umfangreichen Erweiterungen und Anpassungen an den
vom Konzept betroffenen Bestandteilen der CRUISe-Architektur im Blickpunkt.Als Laufzeitumgebung wurde die TSR gewählt, die nun das Kompositionsmodell
direkt interpretiert. Aus Sicht der Performanz hat diese Entscheidung keine signifi-kanten Auswirkungen und erlaubt die unmittelbare Veränderung der Anwendung.Die Schrittfolge bei der Integration von Komponenten konnte erfolgreich an dieKonzeption für Vorlagen adaptiert werden. Ein weiterer Schwerpunkt ist die Unter-stützung der erarbeiteten Verfahren zur Mediation. Wrapper unterstützen sämtlichedefinierten Aufgaben. Zwecks Konvertierung von Daten steht der externe MediationService bereit. Dessen Performanz für eine Vielzahl von parallelen Anfragen kannoptimiert werden, da zunächst der Fokus auf der Funktionalität lag, die nachgewie-sen werden konnte.Wesentlich für den Prototypen ist die Umstellung des Component Repository auf
die Anforderungen des Konzepts. Dazu wurde die parallel zur vorliegenden Arbeitentwickelte Implementierung um die notwendige Schnittstelle sowie das Subsystemzur Erbringung der Aufgaben bei der Integration von Komponenten zur Laufzeiterfolgreich ergänzt. Der spezifizierte Algorithmus zur Discovery steht zur Verfügungund deckt den Großteil des Konzepts ab. Weiterhin wurde die genaue Syntax derRankingregeln in SPARQL unter Beachtung der Performanz definiert und die Um-setzbarkeit gezeigt. Offen bleiben erweiterte Konzepte, die sich auf MCDO stützen,da das Component Repository bisher auf die Registrierung von SMCDL beschränktist. Zusätzlich stellt das Component Repository im Prototypen eine Schnittstellezur Abfrage von registrierten Domänenontolgien bereit, sodass eine grundlegendeSynchronisation des Mediation Service stattfindet und Ontologien nicht mehrfachregistriert werden müssen. Das weiterhin implementierte Type Repository bietetBasismittel für seine Verantwortlichkeiten und erlaubt dem Mediation Service dieAbfrage benötigter Artefakte zum Lifting und Lowering.Abschließend wurde das Zusammenspiel der Bestandteile anhand des Referenz-
szenarios (Kapitel 2.4) validiert. Auf Basis des an die konzeptionellen Erfordernis-se angepassten Kompositionsmetamodells, der XSD für SMCDL sowie entwickelterOntologien wurden die Komponentenbeschreibungen semantisch annotiert und dasAnwendungsmodell instantiiert. Durch mehrere Testfälle konnten die Mechanismendes Integrationsprozesses validiert werden. Daher bleibt festzuhalten, dass die Um-setzbarkeit des Konzepts demonstriert werden konnte.
Copyright TU Dresden, Carsten Radeck 104

Semantische Komposition in Mashups Kapitel 6 Zusammenfassung und Ausblick
6Zusammenfassung und Ausblick
In diesem Kapitel werden die Ergebnisse der vorliegenden Arbeit zusammengefasstund ein Ausblick auf mögliche weiterführende Themen gegeben.
6.1 ErgebnisseDas Ziel dieser Arbeit war die Nutzung semantischer Komponentenbeschreibungenim Rahmen der Integration und des Austauschs von Komponenten in Mashups aufBasis der CRUISe-Architektur. Dazu wurden in Kapitel 2 zunächst grundlegendeBegriffe und Technologien erörtert. Anschließend erfolgte die Charakterisierung deran der Integration von Komponenten beteiligten Bestandteile von CRUISe und dieDiskussion vorhandener Probleme. Daraufhin wurde wesentliche Anwendungsfeldereiner semantischen Beschreibung vonWeb Services geschildert und ihre Übertragbar-keit auf CRUISe detailliert untersucht. Somit wurde der Fokus der Arbeit definiert.Zu lösende Herausforderungen wurden in einem praxisnahen Szenario verdeutlichtund letztlich die Anforderungen an das Konzept formuliert.In Kapitel 3 folgte die Analyse bestehender Lösungsansätze unter Betrachtung der
aufgestellten Anforderungen und Rahmenbedingungen von CRUISe. Im Mittelpunktstanden dabei zuerst Vorschläge zur semantischen Beschreibung von Web Services.Wie deutlich wurde, untergliedern diese sich in die zwei konträre Prinzipien Bottom-Up und Top-Down, deren Vor- und Nachteile herausgestellt wurden. Zudem wurdeaufgezeigt, dass die Erkenntnisse der SWS auch in die Komponentenbeschreibungenaus dem Bereich CBSE einfließen. Bezüglich der Spezifikation der Funktionalitäteiner Komponente wurde die Eignung des »einfachen« Ansatzes in Beschreibungs-logik beschrieben. Weiterhin erfolgte eine Untersuchung von Verfahren zur Sucheund Rangfolgebildung von Kandidaten. Es wurde festgestellt, dass mit logikbasier-ten Suchverfahren, die zusätzlich mit nicht-logikbasierten kombinierbar sind, ge-eignete Ansätze existieren, um die fehlende Eindeutigkeit einer Komponentensucheanhand rein syntaktischer Merkmale zu umgehen. Weiterhin wurden gängige Artender Zielbeschreibung für die Komponentensuche betrachtet und festgehalten, dass inCRUISe ein Vorlagen-basierter Ansatz besonders geeignet ist. Darüber hinaus bilde-te die Überbrückung von Heterogenität auszutauschender Daten einen Schwerpunkt.Daraus konnten wichtige Anregungen, wie die Verwendung einer ontologiebasiertenZwischenrepräsentation zur Mediation, für das Konzept abgleitet werden.
Copyright TU Dresden, Carsten Radeck 105

Semantische Komposition in Mashups Kapitel 6 Zusammenfassung und Ausblick
Kapitel 4 behandelt die entwickelte Konzeption. Zur semantischen Beschreibungvon Komponenten wurde die SMCDL als Erweiterung der vorhandenen MCDL spe-zifiziert. Sie verfolgt einen Annotationsansatz nach dem Vorbild von SAWSDL undbaut auf den Erkenntnissen von WSMO-Lite auf. Somit erlaubt sie die Referen-zierung von Konzepten, die in externen Ontologien formalisiert sind, für die funk-tionale Semantik und die Datensemantik. Zur Definition der Funktionalität, diedurch diese Arbeit ermöglicht wurde, dient eine Beschreibung durch Konzepte inBeschreibungslogik, sodass die resultierende Komplexität, aber auch die Ausdrucks-mächtigkeit begrenzt ist. Die Angabe der XSD von Parametern und Properties einerKomponente entfällt, da vorgegebene XML-Schemata für die referenzierten Onto-logiekonzepte vorgesehen werden. Somit wird der Erstellungsaufwand der Kompo-nenten gesenkt und Redundanz der Komponentenbeschreibung und des Komposi-tionsmodells vermieden. Zur Flexibilisierung der Komponentenentwicklung ist dieAnpassung komponentenintern verwendeter Schemata an die Vorgabe durch dasBinding möglich. Weiterhin existiert die Option, Komponenten direkt als Ontologi-einstanz zu beschreiben, wobei weiterführende Beschreibungsmittel in der MCDOverfügbar sind. Durch diese Alternative kann die SMCDL leichtgewichtig gehaltenwerden. Die Modellierung der Anwendung stützt sich neben konkreten Komponen-ten auf das Konzept der Vorlagen für »ideale« Komponenten. Im an die seman-tische Komponentenbeschreibung angepassten Integrationsprozess erlauben sie diedynamische Suche und Auswahl der zu integrierenden Komponente anhand funk-tionaler und nicht-funktionaler Kriterien. Dies leistet einen wesentlichen Beitragzur flexiblen Integration von Komponenten. Im Gegensatz zum bisherigen Vorgehensind Unterschiede der Komponente im Vergleich zur Vorlage zulässig, da Mittelnzur Überbrückung dieser spezifiziert wurden (Mediation). Zwar sind dabei klareGrenzen gesteckt, aber die unterstützte Umbenennung von Operationen etc., dieUmsortierung und Filterung von Parametern sowie die Konvertierung von Datenbei Subklassen-Beziehungen stellen bereits einen deutlichen Mehrwert dar. Letz-tere hat den Vorteil hat, dass generische Komponenten leichter wiederverwendbarsind. Der konzipierte Matching-Algorithmus ist in der Lage semantisch kompati-ble Komponenten und die notwendigen Abbildungsvorschriften zur Mediation zubestimmen. Mit den Rankingregeln und deren SPARQL-basierter Adressierung derMetadaten stehen ausdrucksstarke Konstrukte zur Sortierung der Kandidaten imRanking bereit. Durch den Zugriff auf den Kontextdienst ist die Kontextualisierungdieses Vorgangs gewährleistet. Grundlegende Bestandteile der CRUISe-Architekturexistieren weiterhin, jedoch wurde im Konzept von einem separaten Integration Ser-vice abgesehen. Dieser ist nun aus dargelegten Gründen dem Component Repositoryzugeordnet, sodass der Datentransfer gerade beim Anwendungsstart möglichst ge-ring ausfällt.
Kapitel 5 beinhaltet die prototypische Umsetzung und Diskussion des Konzeptsund die damit verbundenen Anpassungen und Erweiterungen der Architektur, wo-bei stets auf Performanz und Erweiterbarkeit geachtet wurde. Mittels der daraufaufsetzenden Beispielanwendung konnte das Konzept erfolgreich validiert werden.
Wie in diesem Abschnitt zusammenfassend aufgezeigt, konnte die Zielstellung derArbeit (vgl. Kapitel 1.2) vollständig umgesetzt und zudem weiterführende Ergeb-nisse, wie die Mediation, erreicht werden. Somit stellt das Konzept die notwendigen
Copyright TU Dresden, Carsten Radeck 106

Semantische Komposition in Mashups Kapitel 6 Zusammenfassung und Ausblick
Mechanismen für die CRUISe-Architektur zur Integration und den Austausch se-mantisch beschriebener Komponenten bereit.
6.2 AusblickDie semantische Beschreibung und Komposition von Komponenten ist ein äußerstumfangreiches und komplexes Gebiet. Die vorliegende Arbeit ist ein erster Schrittund kann als Grundlage für zahlreiche weiterführende wissenschaftliche Arbeitendienen. Dabei können u. a. folgende bei der Bearbeitung des Themas identifizierteProblemstellungen und Ansätze aufgegriffen werden.
(Semi-) Automatische Komposition Eine Entwicklung in Richtung der automa-tischen Komposition des Mashups könnte vorgenommen werden. Bestehende Lö-sungen aus dem Bereich SWS und Service Mashups wären dabei zu evaluieren (vgl.Kapitel 2.3). Zur Entwicklungszeit kann ein semi-automatischer Ansatz verfolgt wer-den, der dem Anwendungsentwickler z. B. mehrere Komponenten in eine Teilkompo-sition aggregiert, falls keine einzelne geeignet ist. Eine Übertragung auf die Laufzeiterfordert wegen steigender Anforderungen weitere Untersuchungen. Weiterhin könn-ten Strategien entwickelt werden, um aus einer abstrahierten Zielbeschreibung desNutzers dynamisch ein Kompositionsmodell abzuleiten.
Extraktion semantischer Beschreibungen Der Entwicklungsprozess von CRUISesieht vor, dass auch die Beschreibung bestehender Web Services (WSDL, WADL)im Autorenwerkzeug importiert und in eine Komponente gekapselt werden kann.Ein interessante Erweiterung wäre die Extraktion von semantischer Beschreibungen,z. B. aus SAWSDL, und Übertragung auf SMCDL (zumindest der Datensemantik).Dabei sind im Allgemeinen auch Abbildungen zwischen Ontologien notwendig.
Erweiterte Matchingtechniken Der konzipierte Matching-Algorithmus bietet denVorteil, unabhängig von bestimmten (Domänen-) Ontologien zu operieren. Damiteinhergehend sind seine Möglichkeiten derzeit auf die Nutzung von Vererbungsre-lationen begrenzt. In Kapitel 4.3.2.1 wurde angedeutet, dass weiterführende Tech-niken angewendet werden können, z. B. die Schnittmengenbildung von Konzeptenund das Ableiten, dass mehrere annotierte OWL-Properties hinreichend für einegesuchte Klasse sind. Auch die Überprüfung, ob n:m-Beziehungen z. B. von Ope-rationen zwischen Vorlage und Kandidat möglich sind, zählt dazu. Eine intensiveKosten-Nutzen-Analyse ist angesichts steigender Komplexität jedoch zu empfehlen.Auch die Unterstützung des OWL-Konstrukts equivalentClass bei der Datenseman-tik stellt eine mögliche Weiterentwicklung dar und hätte v. a. Auswirkungen aufdie Mediation, die aufgrund abweichender Groundings ähnlich dem Vorgehen beiPlugIn-Matches gehandhabt werden kann. Zudem könnten Verfahren implementiertwerden, die auf bestimmte Problemfelder zugeschnitten sind und ihnen bekannteOntologien ausnutzen.
Erweiterung des Mediationansatzes Im Rahmen dieser Arbeit wurde zunächstvon gemeinsamen Ontologien für Domänen ausgegangen. Werden verschiedene zu-gelassen, ist zudem die Mediation zwischen Ontologiekonzepten unter Verwendungvon Ontologiemappings notwendig, die eine Erweiterung des Mediators erfordert.
Copyright TU Dresden, Carsten Radeck 107

Semantische Komposition in Mashups Kapitel 6 Zusammenfassung und Ausblick
Zur weiteren Flexibilisierung des Konzepts wäre die Unterstützung von Konvertie-rungen zu betrachten. Dieser Sachverhalt sowie zu lösende Fragestellungen wurdenin Kapitel 4.3.4 bereits behandelt. In enger Verknüpfung zu erweiterten Matching-verfahren wären die resultierenden Anforderungen an die Mediation zu analysierenund Lösungen zu konzipieren.
Alternativen zum Wrapperansatz Unterstützt eine Runtime die Änderung desAnwendungsmodells, kann dieses an die integrierten Komponenten angepasst wer-den, sodass ein Wrapping von Komponenten entfallen könnte. Dazu wäre die Über-wachung des Modells notwendig, um die Rekonfiguration der Runtime-Module vor-zunehmen. Dabei sind zahlreiche Fragestellungen zu klären, z. B. wie die Synchro-nisation gewährleistet werden kann, ob das initiale Modells zu speichern ist, welcheVersion der Vorlagen bei einem späteren Austausch genutzt wird und wie überflüs-sige Parameter einer Operation gehandhabt werden.
Nutzung der semantischen Annotationen zur Adaption Es könnte untersuchtwerden, inwieweit die semantischen Annotationen bzw. das referenzierte Domänen-wissen im Rahmen der Adaption nutzbar sind. Beispielsweise können sie zur Nut-zermodellierung eingesetzt werden, indem abgeleitet wird, dass das Minimieren oderEntfernen einer Komponente ein geringeres Interesse des Nutzers an den annotier-ten Konzepten bedeutet. Dazu wären Adaptionsregeln zu definieren, die auf dieseEreignisse reagieren und das Nutzermodell aktualisieren.
Autorenprozess und Werkzeugunterstützung Im Rahmen der Erstellung undValidierung der Artefakte für die Mediation (vorgegebenes Grounding, Lifting, Lo-wering) sollte der Entwickler zur Vereinfachung durch Autorenwerkzeuge unterstütztwerden. Bestehende Lösungen, z. B. zur Generierung von XSD aus Ontologien, soll-ten evaluiert werden. Auch für den Anwendungs- und Komponentenentwickler wäreeine Werkzeugunterstützung bei der Identifikation von Konzepten und der korrek-ten Annotation von Vorlagen bzw. Komponenten hilfreich, da sinnvolle SMCDLsfür den Mehrwert des Konzepts entscheidend sind. Dazu sollten der Autorenprozessund daran beteiligte Rollen näher untersucht werden.
Copyright TU Dresden, Carsten Radeck 108

Semantische Komposition in Mashups Anhang A Anhang
AAnhang
A.1 Matching-Algorithmus
Algorithmus 1 Matching-AlgorithmusEingabe: T //VorlageEingabe: K //Menge registrierter KomponentenEingabe: Blacklist //auszuschließende KomponentenEingabe: Runtime //ID und Version der RuntimeEingabe: Context //Nutzer-ID und URL des KontextdienstesAusgabe: L //Geordnete Liste von Tupeln <Komponenten-ID, Matchcomponent>Ausgabe: M //Menge von Tupeln <T.id, Komponenten-ID, MatchingResult>1: K ′ ← preSelection(K,T,Blacklist, Runtime) //K ′ ⊆ K2: L← ∅,M ← ∅3: for all k ∈ K ′ do4: Matchcompfunct = matchFunctionality(T, k)5: if Matchcompfunct == 0.0 then6: continue7: end if8: BestAssignp = matchProperties(T, k)9: if ∀x ∈ BestAssignp : x.rating == 3.0 then10: BestAssigno = matchOperations(T, k, Context)11: if ∀y ∈ BestAssigno : y.rating 6= 0.0 then12: BestAssigne = matchEvents(T, k)13: if ∀z ∈ BestAssigne : z.rating 6= 0.0 then14: Matchcomponent ← calculateResult(Matchcompfunct, BestAssignp,o,e)15: MatchingResultk ← buildMatchingResult(BestAssignp,o,e)16: L← L ∪ < k.id,Matchcomponent >17: M ←M ∪ < T.id, k.id,MatchingResultk >18: end if19: end if20: end if21: end for22: return L← sort(L),M
Copyright TU Dresden, Carsten Radeck i
Semantische Komposition in Mashups Anhang A Anhang
A.2 Ontologien der Beispielanwendung
Action
Output
subClassOf
Input
subClassOf
subClassOf
EditSelect
subClassOf subClassOf
ManipulateZoom
Compare
Calculate
Sort
Rank
subClassOf
subClassOf
SearchRestaurant
SearchEvent
SearchHotel
SearchRoute
SearchSight
OutputList
OutputDateTime
OutputWeather
OutputLocation
subClassOf
OutputRestaurantList
OutputHotelList
OutputEventList
OutputSightList
OutputRouteList
subClassOf
OutputDestinationLocation
OutputStartLocation
OutputRoute
subClassOf
subClassOf
TravelPlanning
InputHotel
InputRoute
InputDateTime
InputEventsubClassOf
InputLocation
InputStartLocation
InputDestinationLocation
subClassOf
subClassOfDomain Specific Action
Domain Unspecific Action
OutputLocationList
Search
SortHotelList
subClassOf
subClassOf
Login
subClassOf
EmailLogin
subClassOfPasswordOnly
subClassOf
subClassOf
subClassOf
Inheritance
InputEventLocation
Filter
subClassOf
Abbildung A.1: Ontologie von Aufgaben in der Domäne der Beispielanwendung [Bli11]
Event
OnOutput
subClassOf
OnError
OnInput OnManipulate
subClassOfOnTimeOut
OnValidation
subClassOf
OnSearchedsubClassOf
EventSearched
RouteSearched
HotelSearched
SightSearched
subClassOf
OnDelete
OnSet
OnSelect
OnUpdate
subClassOf
LocationUpdated
subClassOf
RouteUpdated
DateTimeUpdated
HotelSelected
LocationSelected
DateTimeSelectedsubClassOf
StartLocationUpdated
DestinationLocationUpdatedsubClassOf
Domain Specific Action
Domain Unspecific Action
Inheritance
Abbildung A.2: Ontologie von Ereignissen in der Domäne der Beispielanwendung (nach [Bli11])
Copyright TU Dresden, Carsten Radeck ii
Semantische
Kom
positionin
Mashups
Anhang
AAnhang
Location
LocationList
hasLocation
hasName:String
hasLatitude:String
hasLongitude:String
List
subClassOf
Event
EventList
hasEvent
subClassOf
Hotel
HotelList
subClassOf
Route
RouteListRouteParthasRoutePart
hasName:String
Adress
hasPlace:String
hasStreet:String
hasStreetNumber:int
hasZipcode:string
subClassOfhasPhone:String
hasStars:int
Building hasAdress
hasAdress hasTime:String
hasDescription:String
Conference
Concert
subClassOfEventLocation
subClassOf
ConferenceLocation
subClassOf
hasStartLocation
hasDestinationLocation
isLocationOf
hasStartTime:DateTime
hasDestinationTime:DateTime
hasDuration:DateTime
hasStartTime:DateTime
hasDestinationTime:DateTime
hasStartStation:String
hasRoute
hasDestStation:String
hasTransportName:String
hasTransportTypeID:String
hasHotel
Datatype Property
Object Property
Inheritance
Class
hasLocation
hasLocation
Abbildung A.3: Ausschnitt der Ontologie zur Beschreibung der Domäne der Beispielanwendung
Copyright
TU
Dresden,C
arstenRadeck
iii

Semantische Komposition in Mashups Anhang A Anhang
A.3 Schemata
Abbildung A.4: XML-Schema für Integration Requests
A.4 KlassendiagrammAbbildung A.5 zeigt das Klassendiagramm des erweiterten Component Repository.Aus Gründen der Übersichtlichkeit wurden einige Klassen, Attribute und Methodenweggelassen. Weitere Anmerkungen enthält das Diagramm.
Copyright TU Dresden, Carsten Radeck iv

Semantische
Kom
positionin
Mashups
Anhang
AAnhang
Abbildung A.5: Klassendiagramm des erweiterten Component Repository
Copyright
TU
Dresden,C
arstenRadeck
v

Semantische Komposition in Mashups Literaturverzeichnis
Literaturverzeichnis[AFM+05] Akkiraju, Rama, Joel Farrell, John Miller, Meenakshi Na-
garajan,Marc-Thomas Schmidt,Amit Sheth undKunal Ver-ma: Web Service Semantics - WSDL-S. Technischer Bericht, IBM andthe University of Georgia, April 2005.
[AGM08] Abiteboul, Serge, Ohad Greenshpan und Tova Milo: Mode-ling the Mashup Space. In: Proc. of the 10th Intl. Workshop on WebInformation and Data Management (WIDM). ACM, Oktober 2008.
[ATR+04] Arroyo, Sinuhé, Ioan Toma, Dumitru Roman, Chris-tian Drumm, Marin Dimitrov, Murray Spork, GaborNagypal, John Domingue und Jan Henke: Data, Infor-mation, and Process Integration with Semantic Web Services(DIP) : Deliverable D3.1 Report on State of the Art and Re-quirements analysis. http://dip.semanticweb.org/documents/D31-20040716-v1-final.pdf, Juli 2004. letzter Zugriff: 26.02.2011.
[BAM10] Bianchini, Devis, Valeria De Antonellis und Michele Mel-chiori: Semantic-driven Mashup Design. In: iiWAS2010: Proceedingsof the 12th International Conference on Information Integration andWeb-based Applications & Services, Seiten 245–252, November 2010.
[BB08] Beckett, Dave und Jeen Broekstra: SPARQL Query ResultsXML Format. http://www.w3.org/TR/rdf-sparql-XMLres, Januar2008. letzter Zugriff: 26.02.2011.
[BCM+03] Baader, Franz, Diego Calvanese, Deborah L. McGuinness,Daniele Nardi und Peter F. Patel-Schneider (Herausgeber):The description logic handbook: theory, implementation, and applicati-ons. Cambridge University Press, New York, NY, USA, Januar 2003.
[BD99] Borgida, Alex und Premkumar Devanbu: Adding more "DL"toIDL: towards more knowledgeable component inter-operability. In: IC-SE ’99: Proceedings of the 21st international conference on Softwareengineering, Seiten 378–387, New York, NY, USA, 1999. ACM.
[BDS08] Benslimane, Djamal, Schahram Dustdar undAmit Sheth: Ser-vice Mashups: The New Generation of Web Applications. IEEE InternetComputing, 12(5):13–15, September/Oktober 2008.
[BG04] Brickley, Dan und R.V. Guha: RDF Vocabulary Description Lan-guage 1.0: RDF Schema. http://www.w3.org/TR/rdf-concepts/, Fe-bruar 2004. letzter Zugriff: 26.02.2011.
Copyright TU Dresden, Carsten Radeck vi

Semantische Komposition in Mashups Literaturverzeichnis
[BL04] Bowers, Shawn und Bertram Ludäscher: An Ontology-DrivenFramework for Data Transformation in Scientific Workflows. In:Rahm, Erhard (Herausgeber): Data Integration in the Life Sciences,Band 2994 der Reihe Lecture Notes in Computer Science, Seiten 1–16.Springer Berlin / Heidelberg, 2004.
[BLFM05] Berners-Lee, T., R. Fielding und L. Masinter: Uniform Resour-ce Identifier (URI): Generic Syntax. http://tools.ietf.org/html/rfc3986, Januar 2005. letzter Zugriff: 26.02.2011.
[BLHL01] Berners-Lee, Tim, James Hendler und Ora Lassila: The Se-mantic Web: a new form of Web content that is meaningful to compu-ters will unleash a revolution of new possibilities. Scientific American,284(5):34–43, Mai 2001. letzter Zugriff: 26.02.2011.
[Bli11] Blichmann, Gregor: Entwicklung eines Verfahrens für das Auffin-den von UI-Mashup-Komponenten anhand aufgabenspezifischer Merk-male. Diplomarbeit, Fakultät Informatik, Institut für Software- undMultimediatechnik, Professur für Multimediatechnik, Technische Uni-versität Dresden, Februar 2011.
[BPSM+08] Bray, Tim, Jean Paoli, C. M. Sperberg-McQueen, Eve Malerund François Yergeau: Extensible Markup Language (XML) 1.0(Fifth Edition). http://www.w3.org/TR/xml/, November 2008. letzterZugriff: 26.02.2011.
[BZG08] Bleul, Steffen, Michael Zapf und Kurt Geihs: Self-Integrationof Web Services in BPEL Processes. In: Proceedings of the WorkshopSAKS 2008, Wiesbaden, Germany, März 2008.
[CCMW01] Christensen, Erik, Francisco Curbera, Greg Meredithund Sanjiva Weerawarana: Web Services Description Language(WSDL) 1.1. http://www.w3.org/TR/wsdl.html, März 2001. letz-ter Zugriff: 26.02.2011.
[CLB07] Corcho, Oscar, Silvestre Losada und Richard Benjamins:Mediation: Bridging between HeterogeneousWeb Service Systems. In:Studer, Rudi, Stephan Grimm und Andreas Abecker (Heraus-geber): Semantic Web Services, Seiten 287–308. Springer Berlin Heidel-berg, 2007.
[CTO10] Chabeb, Yassin, Samir Tata und Alain Ozanne: YASA-M: ASemantic Web Service Matchmaker. Advanced Information Networkingand Applications, International Conference on, 0:966–973, April 2010.
[DCBS09] Daniel, Florian, Fabio Casati, Boualem Benatallah undMing-Chien Shan: Hosted Universal Composition: Models, Languagesand Infrastructure in mashArt. In: Proceedings of the 28th InternationalConference on Conceptual Modeling, November 2009.
Copyright TU Dresden, Carsten Radeck vii

Semantische Komposition in Mashups Literaturverzeichnis
[DS05] Dustdar, Schahram und Wolfgang Schreiner: A Survey onWeb Services Composition. International Journal of Web and GridServices, 1(1):1–30, 2005.
[DYB+07] Daniel, Florian, Jin Yu, Boualem Benatallah, Fabio Casati,Maristella Matera und Regis Saint-Paul: Understanding UIIntegration: A Survey of Problems, Technologies, and Opportunities.IEEE Internet Computing, 11(3):59–66, Mai/Juni 2007.
[FBN08] Fischer, Thomas, Fedor Bakalov und Andreas Nauerz: To-wards an Automatic Service Composition for Generation of User-Sensitive Mashups, 2008.
[FKZ08] Fensel, Dieter, Mick Kerrigan und Michal Zaremba: Imple-menting Semantic Web Services: The SESA Framework. Springer, 2008.
[FL07] Farrell, Joel und Holger Lausen: Semantic Annotations forWSDL and XML Schema. http://www.w3.org/TR/sawsdl/, August2007. letzter Zugriff: 26.02.2011.
[FS09] Fujii, Keita und Tatsuya Suda: Semantics-based context-aware dy-namic service composition. ACM Trans. Auton. Adapt. Syst., 4(2):1–31,Mai 2009.
[FW04] Fallside, David C. und Priscilla Walmsley: XML Schema Part0: Primer Second Edition. http://www.w3.org/TR/xmlschema-0/,Oktober 2004. letzter Zugriff: 26.02.2011.
[GHJV94] Gamma, Erich, Richard Helm, Ralph Johnson und John Vlis-sides: Design Patterns: Elements of Reusable Object-Oriented Softwa-re. Addison-Wesley, 1994.
[GHM+07] Gudgin, Martin, Marc Hadley, Noah Mendelsohn, Jean-Jacques Moreau, Henrik Frystyk Nielsen, Anish Karmar-kar und Yves Lafon: SOAP Version 1.2 Part 1: Messaging Frame-work (Second Edition). http://www.w3.org/TR/soap12-part1/, April2007. letzter Zugriff: 26.02.2011.
[Gro06] Group, Object Management: Meta Object Facility (MOF) Co-re Specification. http://www.omg.org/spec/MOF/2.0/, Januar 2006.letzter Zugriff: 26.02.2011.
[Gro09] Group, Object Management: Unified Modeling Language. http://www.omg.org/spec/UML/2.2/, Februar 2009. letzter Zugriff:26.02.2011.
[Gru07] Gruber, Thomas R.: Ontology. Encyclopedia of Database Sys-tems, Springer Verlag, 2007. http://tomgruber.org/writing/ontology-definition-2007.htm, letzter Zugriff: 26.02.2011.
[Had09] Hadley, Marc:Web Application Description Language. http://www.w3.org/Submission/wadl/, August 2009. letzter Zugriff: 26.02.2011.
Copyright TU Dresden, Carsten Radeck viii

Semantische Komposition in Mashups Literaturverzeichnis
[HMH+10] Hristoskova, Anna, Dieter Moeyersoon, Sofie Van Hoecke,Stijn Verstichel, Johan Decruyenaere und Filip De Turck:Dynamic composition of medical support services in the ICU: Platformand algorithm design details. Computer Methods and Programs in Bio-medicine, In Press, Corrected Proof:–, 2010.
[HPSB+04] Horrocks, Ian, Peter F. Patel-Schneider, Harold Boley,Said Tabet, Benjamin Grosof und Mike Dean: SWRL: A Se-mantic Web Rule Language Combining OWL and RuleML. http://www.w3.org/Submission/SWRL/, Mai 2004. letzter Zugriff: 26.02.2011.
[JRGL+05] Jaeger, Michael, Gregor Rojec-Goldmann, Christoph Lie-betruth, Gero Mühl und Kurt Geihs: Ranked Matching for Ser-vice Descriptions Using OWL-S. In: Brauer, W., Paul Müller,Reinhard Gotzhein und Jens Schmitt (Herausgeber): Kommuni-kation in Verteilten Systemen (KiVS), Informatik aktuell, Seiten 91–102. Springer Berlin Heidelberg, Februar 2005.
[KA09] Kılıç, Yasin Ozan und Mehmet N. Aydin: Automatic XML Sche-ma Matching. In: Proceedings of the European and Mediterranean Con-ference on Information Systems (EMCIS) Late Breaking Papers, TheCrowne Plaza, Izmir, Turkey, Juli 2009.
[KBS+09] Kona, Srividya, Ajay Bansal, Luke Simon, Ajay Mallya, Go-pal Gupta und Thomas D. Hite: USDL: A Service-Semantics De-scription Language for Automatic Service Discovery and Composition.Int. J. Web Service Res., 6(1):20–48, 2009.
[KC04] Klyne, Graham und Jeremy J. Carroll: Resource DescriptionFramework (RDF): Concepts and Abstract Syntax. http://www.w3.org/TR/rdf-concepts/, Februar 2004. letzter Zugriff: 26.02.2011.
[Kin02] Kiniry, Joseph: Semantic Component Composition. CoRR,cs.SE/0204036, April 2002.
[KK08] Klusch, Matthias und Patrick Kapahnke: Semantic Web ServiceSelection with SAWSDL-MX. In: Proceedings of the 2nd Workshop onService Matchmaking and Resource Retrieval in the Semantic Web atthe ISWC 2008, Seiten 3–18, 2008.
[KKRM05] Klein, Michael, Birgitta König-Ries und Michael Müssig:What is Needed for Semantic Service Descriptions? - A Proposal forSuitable Language Constructs. International Journal on Web and GridServices (IJWGS), 1:328–364, 2005.
[KKZ09] Klusch, Matthias, Patrick Kapahnke und Ingo Zinnikus:SAWSDL-MX2: A Machine-Learning Approach for Integrating Seman-tic Web Service Matchmaking Variants. In: Proceedings of the ICWS2009, Seiten 335–342, Juli 2009.
Copyright TU Dresden, Carsten Radeck ix

Semantische Komposition in Mashups Literaturverzeichnis
[KLKR08] Küster, Ulrich, Holger Lausen und Birgitta König-Ries:Evaluation of Semantic Service Discovery - A Survey and Directions forFuture Research. In: Calisti, Monique, Marius Walliser, Ste-fan Brantschen, Marc Herbstritt, Thomas Gschwind undCesare Pautasso (Herausgeber): Emerging Web Services Technolo-gy, Volume II, Whitestein Series in Software Agent Technologies andAutonomic Computing, Seiten 41–58. Birkhäuser Basel, 2008.
[Klu08] Klusch, Matthias: Semantic Web Service Coordination. In: Ca-listi, Monique, Marius Walliser, Stefan Brantschen, MarcHerbstritt, Michael Schumacher, Helko Schuldt und Helk-ki Helin (Herausgeber): CASCOM: Intelligent Service Coordinationin the Semantic Web, Whitestein Series in Software Agent Technolo-gies and Autonomic Computing, Kapitel 4. Birkhäuser Basel, 2008.
[KSS07] Korthaus, Axel,Michael Schwind und Stefan Seedorf: Lever-aging Semantic Web technologies for business component specification.Web Semant., 5(2):130–141, Juni 2007.
[Kuh55] Kuhn, Harold W.: The Hungarian method for the assignment pro-blem. Naval Research Logistics Quarterly, 2:83–97, März 1955.
[KV08] Kopecký, J. und T. Vitvar: WSMO-Lite: Lowering the SemanticWeb Services Barrier with Modular and Light-Weight Annotations. In:Semantic Computing, 2008 IEEE International Conference on, Seiten238 –244, August 2008.
[KVF09a] Kopecký, Jacek, Tomas Vitvar und Dieter Fensel: SOA4AllDeliverable 3.4.2: WSMO-Lite: Lightweight Semantic Descriptionsfor Services on the Web. http://www.soa4all.eu/docs/D3.4.2%20Defining%20WSMO%20Lite%20as%20an%20extension%20of%20SAWSDL.pdf, 2009. letzter Zugriff: 26.02.2011.
[KVF09b] Kopecký, Jacek, Tomas Vitvar und Dieter Fensel: SOA4AllDeliverable 3.4.3: MicroWSMO and hRESTS. http://sweet.kmi.open.ac.uk/pub/microWSMO.pdf, 2009. letzter Zugriff: 26.02.2011.
[LH03] Li, Lei und Ian Horrocks: A software framework for matchmakingbased on semantic web technology. In: Proceedings of the 12th inter-national conference on World Wide Web, WWW ’03, Seiten 331–339,New York, NY, USA, Mai 2003. ACM.
[LHK09] Loosli, Gabriela,David Heim undGerhard F. Knolmayer: IT-Governance bei Wiederverwendung von Services. Technischer Bericht,Institut für Wirtschaftsinformatik der Universität Bern, Juli 2009.
[LHSL07] Liu, Xuanzhe, Yi Hui,Wei Sun und Haiqi Liang: Towards ServiceComposition Based on Mashup. In: IEEE Congress on Services, Seiten332–339, Juli 2007.
Copyright TU Dresden, Carsten Radeck x

Semantische Komposition in Mashups Literaturverzeichnis
[LWCL08] Liu, Lei, Zhijian Wang, Jianhong Chen und Liangming Li: In-terface Semantic Extension for Web Component Service Matching andComposition. In: Wireless Communications, Networking and MobileComputing, 2008. WiCOM ’08. 4th International Conference on, Sei-ten 1 –4, Oktober 2008.
[MBH+04] Martin, David, Mark Burstein, Jerry Hobbs, Ora Lassila,Drew McDermott, Sheila McIlraith, Srini Narayanan,Mas-simo Paolucci, Bijan Parsia, Terry Payne, Evren Sirin, Na-veen Srinivasan und Katia Sycara: OWL-S: Semantic Markupfor Web Services. http://www.w3.org/Submission/OWL-S, November2004. letzter Zugriff: 26.02.2011.
[MBM+07] Martin, David, Mark Burstein, Drew McDermott, SheilaMcIlraith, Massimo Paolucci, Katia Sycara, Deborah Mc-Guinness, Evren Sirin und Naveen Srinivasan: Bringing Seman-tics to Web Services with OWL-S. World Wide Web, 10:243–277, Sep-tember 2007. 10.1007/s11280-007-0033-x.
[MCS+05] Mocan, Adrian, Emilia Cimpian, Michael Stollberg, Fran-cois Scharffe und James Scicluna: D29v0.1 WSMO Mediators.http://www.wsmo.org/TR/d29/v0.1/index.pdf, Dezember 2005.
[Mer06] Merrill, Duane: Mashups: The new breed of Web app. http://www.ibm.com/developerworks/library/x-mashups.html, August2006. letzter Zugriff: 26.02.2011.
[Mey92] Meyer, Bertrand: Applying »Design by Contract«. Computer,25(10):40–51, Oktober 1992.
[Mit10] Mitschick, Annett: Ontologiebasierte Indexierung und Kontextua-lisierung multimedialer Dokumente für das persönliche Wissensmana-gement. Doktorarbeit, Technische Universität Dresden, Fakultät Infor-matik, März 2010.
[MKP09] Maleshkova, Maria, Jacek Kopeck’y und Carlos Pedrinaci:Adapting SAWSDL for Semantic Annotations of RESTful Services. In:Meersman, Robert, Pilar Herrero und Tharam Dillon (Her-ausgeber): On the Move to Meaningful Internet Systems: OTM 2009Workshops, Band 5872 der Reihe Lecture Notes in Computer Science,Seiten 917–926. Springer Berlin / Heidelberg, 2009.
[MP09] Marconi, Annapaola und Marco Pistore: Synthesis and Compo-sition of Web Services. In: Bernardo, Marco, Luca Padovani undGianluigi Zavattaro (Herausgeber): Formal Methods for Web Ser-vices, Band 5569 der Reihe Lecture Notes in Computer Science, Seiten89–157. Springer Berlin / Heidelberg, 2009.
[MPW07] Martin, David, Massimo Paolucci und Matthias Wagner:Bringing semantic annotations to web services: OWL-S from the
Copyright TU Dresden, Carsten Radeck xi

Semantische Komposition in Mashups Literaturverzeichnis
SAWSDL perspective. In: ISWC’07/ASWC’07: Proceedings of the 6thinternational The semantic web and 2nd Asian conference on Asian se-mantic web conference, Seiten 340–352, Berlin, Heidelberg, November2007. Springer-Verlag.
[MSZ01] McIlraith, Sheila A., Tran Cao Son und Honglei Zeng: Se-mantic Web services. Intelligent Systems, IEEE, 16:46 – 53, 2001.
[MvH04] McGuinness, Deborah L. und Frank van Harmelen: OWL WebOntology Language. http://www.w3.org/TR/owl-features/, Februar2004. letzter Zugriff: 26.02.2011.
[NCSyP10] Ngu, Anne H.H., Michael P. Carlson, Quan Z. Sheng undHye young Paik: Semantic-Based Mashup of Composite Applications.IEEE Transactions on Services Computing, 99(PrePrints):2–15, 2010.
[NVSM07] Nagarajan, Meenakshi, Kunal Verma, Amit P. Sheth undJohn A. Miller: Ontology Driven Data Mediation in Web Services,2007.
[NXX10] Nianfang, Xu, Yang Xiaohui und Li Xinke: Software ComponentsDescription Based on Ontology. In: Computer Modeling and Simulation,2010. ICCMS ’10. Second International Conference on, Band 4, Seiten423 –426, Januar 2010.
[OESV04] Oberle, Daniel, Andreas Eberhart, Steffen Staab und Ra-phael Volz: Developing and managing software components in anontology-based application server. In: Middleware ’04: Proceedings ofthe 5th ACM/IFIP/USENIX international conference on Middleware,Seiten 459–477, New York, NY, USA, 2004. Springer-Verlag New York.
[O’S06] O’Sullivan, Justin: Towards a Precise Understanding of Service Pro-perties. Doktorarbeit, Queensland University of Technology, 2006.
[Pah07] Pahl, Claus: An ontology for software component matching. Inter-national Journal on Software Tools for Technology Transfer (STTT),9:169–178, Juli 2007. 10.1007/s10009-006-0015-9.
[Pee05] Peer, Joachim: Semantic Service Markup with SESMA. In: Procee-dings of the Web Service Semantics Workshop (WSS’05) at the Four-teenth International World Wide Web Conference (WWW’05), 2005.
[Pie10] Pietschmann, Stefan: A Model-Driven Development Process andRuntime Platform for Adaptive Composite Web Applications. Intl. Jour-nal on Advances in Internet Technology, 4, März 2010.
[PKPS02] Paolucci, Massimo, Takahiro Kawamura, Terry Payne undKatia Sycara: Semantic Matching of Web Services Capabilities. In:Horrocks, Ian und James Hendler (Herausgeber): The SemanticWeb – ISWC 2002, Band 2342 der Reihe Lecture Notes in ComputerScience, Seiten 333–347. Springer Berlin / Heidelberg, 2002.
Copyright TU Dresden, Carsten Radeck xii

Semantische Komposition in Mashups Literaturverzeichnis
[PLL06] Polleres, Axel, Holger Lausen und Rubén Lara: SemanticWeb, Kapitel Semantische Beschreibung von Web Services, Seiten 505–521. Springer, 2006.
[PS08] Prud’hommeaux, Eric undAndy Seaborne: SPARQL Query Lan-guage for RDF. http://www.w3.org/TR/rdf-sparql-query/, Januar2008. letzter Zugriff: 26.02.2011.
[PTR+10] Pietschmann, Stefan, Vincent Tietz, Jan Reimann, Christi-an Liebing, Michél Pohle und Klaus Meißner: A Metamodelfor Context- Aware Component-Based Mashup Applications. In: Proc.of the Intl. Conf. on Information Integration and Web-based Applicati-ons & Services, November 2010.
[PWM07] Paolucci, Massimo, Matthias Wagner und David Martin:Grounding OWL-S in SAWSDL. In: ICSOC ’07: Proceedings of the 5thinternational conference on Service-Oriented Computing, Seiten 416–421, Berlin, Heidelberg, September 2007. Springer-Verlag.
[PWM10] Pietschmann, Stefan, Johannes Waltsgott und Klaus Meiß-ner: A Thin-Server Runtime Platform for Composite Web Applicati-ons. In: Proceedings of the 5th International Conference on Internetand Web Applications and Services (ICIW 2010), Seiten 390–395, Bar-celona, Spain, Mai 2010. IEEE CPS.
[Res10] Research, SAP: Unified Service Description Language (USDL).http://www.internet-of-services.com/index.php?id=297, 2010.letzter Zugriff: 26.02.2011.
[RS05] Rao, Jinghai und Xiaomeng Su: A Survey of Automated Web Ser-vice Composition Methods. In: Cardoso, Jorge und Amit Sheth(Herausgeber): Semantic Web Services and Web Process Composition,Band 3387 der Reihe Lecture Notes in Computer Science, Seiten 43–54.Springer Berlin / Heidelberg, 2005.
[SE05] Shvaiko, Pavel und Jérôme Euzenat: A Survey of Schema-BasedMatching Approaches. In: Spaccapietra, Stefano (Herausgeber):Journal on Data Semantics IV, Band 3730 der Reihe Lecture Notes inComputer Science, Seiten 146–171. Springer Berlin / Heidelberg, 2005.
[SGL07] Sheth, Amit P.,Karthik Gomadam und Jon Lathem: SA-REST:Semantically Interoperable and Easier-to-Use Services and Mashups.IEEE Internet Computing, 11:91–94, November/Dezember 2007.
[SL04] Spencer, Bruce und Sandy Liu: Inferring Data Transformation Ru-les to Integrate Semantic Web Services. In: McIlraith, Sheila A.,Dimitris Plexousakis und Frank van Harmelen (Herausgeber):The Semantic Web - ISWC 2004, Band 3298 der Reihe Lecture Notes inComputer Science, Seiten 456–470. Springer Berlin / Heidelberg, 2004.
Copyright TU Dresden, Carsten Radeck xiii

Semantische Komposition in Mashups Literaturverzeichnis
[SMM10] Sbodio, Marco Luca, David Martin und Claude Moulin: Dis-covering Semantic Web services using SPARQL and intelligent agents.Web Semantics: Science, Services and Agents on the World Wide Web,In Press, Corrected Proof:–, 2010.
[SMSA+05] Syeda-Mahmood, T., G. Shah, R. Akkiraju, A.-A. Ivan undR. Goodwin: Searching service repositories by combining semanticand ontological matching. In: Web Services, 2005. ICWS 2005. Pro-ceedings. 2005 IEEE International Conference on, Seiten 13 – 20 vol.1,Juli 2005.
[SPM06] Szomszor, M., T.R. Payne und L. Moreau: Automated SyntacticMedation for Web Service Integration. In: Web Services, 2006. ICWS’06. International Conference on, Seiten 127 –136, September 2006.
[SVSM03] Sivashanmugam, Kaarthik, Kunal Verma, Amit Sheth undJohn Miller: Adding Semantics to Web Services Standards, 2003.
[Szy02] Szyperski, Clemens: Component Software: Beyond Object-OrientedProgramming. Addison-Wesley Professional, 2 Auflage, November 2002.ISBN 0-201-74572-0.
[TD10a] TU Dresden, CAS Software AG, xima media GmbH: CRUISeDeliverable E10: Konzeption und Implementierung eines UIS Reposito-ry, Juli 2010.
[TD10b] TU Dresden, CAS Software AG, xima media GmbH: CRUISeDeliverable E13: Spezifikation der Laufzeitumgebung, Juni 2010.
[TD10c] TU Dresden, CAS Software AG, xima media GmbH: CRUISeDeliverable E14: Specification of Adaption Mechanisms and ContextManagement in CRUISe, Juni 2010.
[Tes03] Teschke, Thorsten: Semantische Komponentensuche auf Basis vonGeschäftsprozessmodellen. Doktorarbeit, Carl von Ossietzky Universi-tät Oldenburg, 2003.
[VGS+05] Verma, Kunal, Karthik Gomadam, Amit P. Sheth, John A.Miller und Zixin Wu: The METEOR-S Approach for Configuringand Executing Dynamic Web Processes. Technischer Bericht, LSDISLab, University of Georgia, Athens, Georgia, 2005.
[VS07] Verma, K. und A. Sheth: Semantically Annotating a Web Service.Internet Computing, IEEE, 11(2):83 –85, März 2007.
[YEV08] Yao, H, L. H. Etzkorn und S. Virani: Automated classificationand retrieval of reusable software components. Journal of the AmericanSociety for Information Science and Technology, 59:613–627, 2008.
[ZHS08] Zhi-Hao, Zeng und Ying Shi: RDF4S Based Semantic Web ServiceMatchmaking Framework. In: Semantic Computing and Systems, 2008.WSCS ’08. IEEE International Workshop on, Seiten 95 –100, Juli 2008.
Copyright TU Dresden, Carsten Radeck xiv