unsupervised learning (dlai d9l1 2017 upc deep learning for artificial intelligence)
TRANSCRIPT

[course site]
Xavier Giro-i-Nietoxaviergiroupcedu
Associate ProfessorUniversitat Politecnica de CatalunyaTechnical University of Catalonia
Unsupervised Learning
DLUPC
2
Acknowledegments
Kevin McGuinness ldquoUnsupervised Learningrdquo Deep Learning for Computer Vision [Slides 2016] [Slides 2017]
3
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
4
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
5
Motivation
6
Motivation
7Greff Klaus Antti Rasmus Mathias Berglund Tele Hao Harri Valpola and Juergen Schmidhuber Tagger Deep unsupervised perceptual grouping NIPS 2016 [video] [code]
Yann Lecunrsquos Black Forest cake
8
Motivation
1
= ƒ( )
ƒ( )
= ƒ( )
9
Predict label y corresponding to observation x
Estimate the distribution of observation x
Predict action y based on observation x to maximize a future reward z
Motivation
1
= ƒ( )
ƒ( )
= ƒ( )
10
Motivation
Unsupervised Learning
11
Why Unsupervised Learning
It is the nature of how intelligent beings percept the world
It can save us tons of efforts to build a human-alike intelligent agent compared to a totally supervised fashion
Vast amounts of unlabelled data
12
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
Max margin decision boundary
13
How data distribution P(x) influences decisions (1D)
Slide credit Kevin McGuinness (DLCV UPC 2017)
Semi supervised decision boundary
14
How data distribution P(x) influences decisions (1D)
Slide credit Kevin McGuinness (DLCV UPC 2017)
15
How data distribution P(x) influences decisions (2D)
Slide credit Kevin McGuinness (DLCV UPC 2017)
16
How data distribution P(x) influences decisions (2D)
Slide credit Kevin McGuinness (DLCV UPC 2017)
How P(x) is valuable for naive Bayesian classifier
17
X DataY Labels
Slide credit Kevin McGuinness (DLCV UPC 2017)
x1
x2
Not linearly separable in this 2D space (
18
How clustering is valueble for linear classifiers
Slide credit Kevin McGuinness (DLCV UPC 2017)
x1
x2Cluster 1 Cluster 2
Cluster 3Cluster 4
1 2 3 4
1 2 3 4
4D BoW representation
Separable with a linear classifiers in a 4D space
19
How clustering is valueble for linear classifiers
Slide credit Kevin McGuinness (DLCV UPC 2017)
Example from Kevin McGuinness Juyter notebook 20
How clustering is valueble for linear classifiers
21
Assumptions for unsupervised learning
Slide credit Kevin McGuinness (DLCV UPC 2017)
22
Assumptions for unsupervised learning
Slide credit Kevin McGuinness (DLCV UPC 2017)
23
Assumptions for unsupervised learning
Slide credit Kevin McGuinness (DLCV UPC 2017)
24Slide credit Kevin McGuinness (DLCV UPC 2017)
The manifold hypothesis
25
The manifold hypothesis
Slide credit Kevin McGuinness (DLCV UPC 2017)
x1
x2
Linear manifold
wTx + b
x1
x2
Non-linear manifold
26
The manifold hypothesis Energy-based models
LeCun et al A Tutorial on Energy-Based Learning Predicting Structured Data 2006 httpyannlecuncomexdbpublispdflecun-06pdf
27
Autoencoder (AE)
F Van Veen ldquoThe Neural Network Zoordquo (2016)
28
Autoencoder (AE)
ldquoDeep Learning Tutorialrdquo Dept Computer Science Stanford
Autoencoders
Predict at the output the same input data
Do not need labels
29
Autoencoder (AE)
ldquoDeep Learning Tutorialrdquo Dept Computer Science Stanford
Dimensionality reduction
Use hidden layer as a feature extractor of any desired size
30
Autoencoder (AE)
EncoderW1
DecoderW2
hdata reconstruction
Loss(reconstruction error)
Latent variables (representationfeatures)
Figure Kevin McGuinness (DLCV UPC 2017)
Pretraining1 Initialize a NN solving an
autoencoding problem
31
Autoencoder (AE)
Figure Kevin McGuinness (DLCV UPC 2017)
EncoderW1
hdata ClassifierWC
Latent variables (representationfeatures)
prediction
y Loss(cross entropy)
Pretraining1 Initialize a NN solving an
autoencoding problem2 Train for final task with ldquofewrdquo labels
32
Autoencoder (AE)
Deep Learning TV ldquoAutoencoders - Ep 10rdquo
33F Van Veen ldquoThe Neural Network Zoordquo (2016)
Restricted Boltzmann Machine (RBM)
34
Restricted Boltzmann Machine (RBM)
Figure Geoffrey Hinton (2013)
Salakhutdinov Ruslan Andriy Mnih and Geoffrey Hinton Restricted Boltzmann machines for collaborative filtering Proceedings of the 24th international conference on Machine learning ACM 2007
Shallow two-layer net
Restricted = No two nodes in a layer share a connection
Bipartite graph
Bidirectional graph Shared weights Different biases
35
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Forward pass
36
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Forward pass
37
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Forward pass
38
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Backwardpass
39
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Backwardpass
40
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Backwardpass
The reconstructed values at the visible layer are compared with the actual ones with the KL Divergence
41
Restricted Boltzmann Machine (RBM)
Figure Geoffrey Hinton (2013)
Salakhutdinov Ruslan Andriy Mnih and Geoffrey Hinton Restricted Boltzmann machines for collaborative filtering Proceedings of the 24th international conference on Machine learning ACM 2007
42
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
RBMs are a specific type of autoencoder
Unsupervisedlearning
43
Restricted Boltzmann Machine (RBM)
Deep Learning TV ldquoRestricted Boltzmann Machinesrdquo
44
Deep Belief Networks (DBN)
F Van Veen ldquoThe Neural Network Zoordquo (2016)
45
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMs
46
Deep Belief Networks (DBN)
Architecture like an MLP Training as a stack of
RBMs
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
47
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMs
48
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMs
49
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMshellip so they do not need
labels
Unsupervisedlearning
50
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
After the DBN is trained it can be fine-tuned with a reduced amount of labels to solve a supervised task with superior performance
Supervisedlearning
Softm
ax
51
Deep Belief Networks (DBN)
Deep Learning TV ldquoDeep Belief Netsrdquo
52
Deep Belief Networks (DBN)
Geoffrey Hinton Introduction to Deep Learning amp Deep Belief Netsrdquo (2012)Geoorey Hinton ldquoTutorial on Deep Belief Networksrdquo NIPS 2007
53
Deep Belief Networks (DBN)
Geoffrey Hinton
54
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
Acknowledgments
55
Junting Pan Xunyu Lin
Unsupervised Feature Learning
56
Slide credit Yann LeCun
Unsupervised Feature Learning
57
Slide credit Yann LeCun
Slide credit Junting Pan
Frame Reconstruction amp Prediction
59Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
Frame Reconstruction amp Prediction
60Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
frame prediction
Frame Reconstruction amp Prediction
61Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
frame prediction
62Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised learned features (lots of data) are fine-tuned for activity recognition (little data)
Frame Reconstruction amp Prediction
Frame Prediction
63Ranzato MarcAurelio Arthur Szlam Joan Bruna Michael Mathieu Ronan Collobert and Sumit Chopra Video (language) modeling a baseline for generative models of natural videos arXiv preprint arXiv14126604 (2014)
64Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
Video frame prediction with a ConvNet
Frame Prediction
65Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
The blurry predictions from MSE are improved with multi-scale architecture adversarial learning and an image gradient difference loss function
Frame Prediction
66Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
The blurry predictions from MSE (l1) are improved with multi-scale architecture adversarial training and an image gradient difference loss (GDL) function
Frame Prediction
67Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
Frame Prediction
68Vondrick Carl Hamed Pirsiavash and Antonio Torralba Generating videos with scene dynamics NIPS 2016
Frame Prediction
69Vondrick Carl Hamed Pirsiavash and Antonio Torralba Generating videos with scene dynamics NIPS 2016
Frame Prediction
70Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
71
Frame Prediction
Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
Given an input image probabilistic generation of future frames with a Variational AutoEncoder (VAE)
72
Frame Prediction
Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
Encodes image as feature maps and motion as and cross-convolutional kernels
73
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
First steps in video feature learning
74Le Quoc V Will Y Zou Serena Y Yeung and Andrew Y Ng Learning hierarchical invariant spatio-temporal features for action recognition with independent subspace analysis CVPR 2011
Temporal Weak Labels
75Goroshin Ross Joan Bruna Jonathan Tompson David Eigen and Yann LeCun Unsupervised learning of spatiotemporally coherent metrics ICCV 2015
Assumption adjacent video frames contain semantically similar informationAutoencoder trained with regularizations by slowliness and sparisty
76Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
77Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
78(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Temporal order of frames is exploited as the supervisory signal for learning
Temporal Weak Labels
79(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Take temporal order as the supervisory signals for learning
Shuffled sequences
Binary classification
In order
Not in order
Temporal Weak Labels
80Fernando Basura Hakan Bilen Efstratios Gavves and Stephen Gould Self-supervised video representation learning with odd-one-out networks CVPR 2017
Temporal Weak LabelsTrain a network to detect which of the video sequences contains frames wrong order
81
Spatio-Temporal Weak Labels
X Lin Campos V Giroacute-i-Nieto X Torres J and Canton-Ferrer C ldquoDisentangling Motion Foreground and Background Features in Videosrdquo in CVPR 2017 Workshop Brave New Motion Representations
kernel dec
C3D
ForegroundMotion
FirstForeground
Background
Fg
Dec
Bg
Dec
Fg
Dec Reconstruction
of foreground in last frame
Reconstruction of foreground in
first frame
Reconstruction of background in first frame
uNLC
MaskBlock
gradients
Last foreground
Kernels
shareweights
82
Spatio-Temporal Weak Labels
Pathak Deepak Ross Girshick Piotr Dollaacuter Trevor Darrell and Bharath Hariharan Learning features by watching objects move CVPR 2017
83Greff Klaus Antti Rasmus Mathias Berglund Tele Hao Harri Valpola and Juergen Schmidhuber Tagger Deep unsupervised perceptual grouping NIPS 2016 [video] [code]
Spatio-Temporal Weak Labels
84Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
85
Audio Features from Visual weak labels
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Object amp Scenes recognition in videos by analysing the audio track (only)
86Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
87Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
88Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
89
Visualization of the video frames associated to the sounds that activate some of the last hidden units of Soundnet (conv7)
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Audio Features from Visual weak labels
90
Audio amp Visual features from alignement
90Arandjelović Relja and Andrew Zisserman Look Listen and Learn ICCV 2017
Audio and visual features learned by assessing alignement
91L Chen S Srivastava Z Duan and C Xu Deep Cross-Modal Audio-Visual Generation ACM International Conference on Multimedia Thematic Workshops 2017
Audio amp Visual features from alignement
92Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
93Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
Video to Speech Representations
CNN(VGG)
Frame from a silent video
Audio feature
Post-hoc synthesis
94Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
95Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
Speech to Video Synthesis (mouth)
96Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
97Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
Speech to Video Synthesis (pose amp emotion)
98Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
99Suwajanakorn Supasorn Steven M Seitz and Ira Kemelmacher-Shlizerman Synthesizing Obama learning lip sync from audio SIGGRAPH 2017
Speech to Video Synthesis (mouth)
100
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning

2
Acknowledegments
Kevin McGuinness ldquoUnsupervised Learningrdquo Deep Learning for Computer Vision [Slides 2016] [Slides 2017]
3
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
4
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
5
Motivation
6
Motivation
7Greff Klaus Antti Rasmus Mathias Berglund Tele Hao Harri Valpola and Juergen Schmidhuber Tagger Deep unsupervised perceptual grouping NIPS 2016 [video] [code]
Yann Lecunrsquos Black Forest cake
8
Motivation
1
= ƒ( )
ƒ( )
= ƒ( )
9
Predict label y corresponding to observation x
Estimate the distribution of observation x
Predict action y based on observation x to maximize a future reward z
Motivation
1
= ƒ( )
ƒ( )
= ƒ( )
10
Motivation
Unsupervised Learning
11
Why Unsupervised Learning
It is the nature of how intelligent beings percept the world
It can save us tons of efforts to build a human-alike intelligent agent compared to a totally supervised fashion
Vast amounts of unlabelled data
12
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
Max margin decision boundary
13
How data distribution P(x) influences decisions (1D)
Slide credit Kevin McGuinness (DLCV UPC 2017)
Semi supervised decision boundary
14
How data distribution P(x) influences decisions (1D)
Slide credit Kevin McGuinness (DLCV UPC 2017)
15
How data distribution P(x) influences decisions (2D)
Slide credit Kevin McGuinness (DLCV UPC 2017)
16
How data distribution P(x) influences decisions (2D)
Slide credit Kevin McGuinness (DLCV UPC 2017)
How P(x) is valuable for naive Bayesian classifier
17
X DataY Labels
Slide credit Kevin McGuinness (DLCV UPC 2017)
x1
x2
Not linearly separable in this 2D space (
18
How clustering is valueble for linear classifiers
Slide credit Kevin McGuinness (DLCV UPC 2017)
x1
x2Cluster 1 Cluster 2
Cluster 3Cluster 4
1 2 3 4
1 2 3 4
4D BoW representation
Separable with a linear classifiers in a 4D space
19
How clustering is valueble for linear classifiers
Slide credit Kevin McGuinness (DLCV UPC 2017)
Example from Kevin McGuinness Juyter notebook 20
How clustering is valueble for linear classifiers
21
Assumptions for unsupervised learning
Slide credit Kevin McGuinness (DLCV UPC 2017)
22
Assumptions for unsupervised learning
Slide credit Kevin McGuinness (DLCV UPC 2017)
23
Assumptions for unsupervised learning
Slide credit Kevin McGuinness (DLCV UPC 2017)
24Slide credit Kevin McGuinness (DLCV UPC 2017)
The manifold hypothesis
25
The manifold hypothesis
Slide credit Kevin McGuinness (DLCV UPC 2017)
x1
x2
Linear manifold
wTx + b
x1
x2
Non-linear manifold
26
The manifold hypothesis Energy-based models
LeCun et al A Tutorial on Energy-Based Learning Predicting Structured Data 2006 httpyannlecuncomexdbpublispdflecun-06pdf
27
Autoencoder (AE)
F Van Veen ldquoThe Neural Network Zoordquo (2016)
28
Autoencoder (AE)
ldquoDeep Learning Tutorialrdquo Dept Computer Science Stanford
Autoencoders
Predict at the output the same input data
Do not need labels
29
Autoencoder (AE)
ldquoDeep Learning Tutorialrdquo Dept Computer Science Stanford
Dimensionality reduction
Use hidden layer as a feature extractor of any desired size
30
Autoencoder (AE)
EncoderW1
DecoderW2
hdata reconstruction
Loss(reconstruction error)
Latent variables (representationfeatures)
Figure Kevin McGuinness (DLCV UPC 2017)
Pretraining1 Initialize a NN solving an
autoencoding problem
31
Autoencoder (AE)
Figure Kevin McGuinness (DLCV UPC 2017)
EncoderW1
hdata ClassifierWC
Latent variables (representationfeatures)
prediction
y Loss(cross entropy)
Pretraining1 Initialize a NN solving an
autoencoding problem2 Train for final task with ldquofewrdquo labels
32
Autoencoder (AE)
Deep Learning TV ldquoAutoencoders - Ep 10rdquo
33F Van Veen ldquoThe Neural Network Zoordquo (2016)
Restricted Boltzmann Machine (RBM)
34
Restricted Boltzmann Machine (RBM)
Figure Geoffrey Hinton (2013)
Salakhutdinov Ruslan Andriy Mnih and Geoffrey Hinton Restricted Boltzmann machines for collaborative filtering Proceedings of the 24th international conference on Machine learning ACM 2007
Shallow two-layer net
Restricted = No two nodes in a layer share a connection
Bipartite graph
Bidirectional graph Shared weights Different biases
35
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Forward pass
36
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Forward pass
37
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Forward pass
38
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Backwardpass
39
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Backwardpass
40
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Backwardpass
The reconstructed values at the visible layer are compared with the actual ones with the KL Divergence
41
Restricted Boltzmann Machine (RBM)
Figure Geoffrey Hinton (2013)
Salakhutdinov Ruslan Andriy Mnih and Geoffrey Hinton Restricted Boltzmann machines for collaborative filtering Proceedings of the 24th international conference on Machine learning ACM 2007
42
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
RBMs are a specific type of autoencoder
Unsupervisedlearning
43
Restricted Boltzmann Machine (RBM)
Deep Learning TV ldquoRestricted Boltzmann Machinesrdquo
44
Deep Belief Networks (DBN)
F Van Veen ldquoThe Neural Network Zoordquo (2016)
45
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMs
46
Deep Belief Networks (DBN)
Architecture like an MLP Training as a stack of
RBMs
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
47
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMs
48
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMs
49
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMshellip so they do not need
labels
Unsupervisedlearning
50
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
After the DBN is trained it can be fine-tuned with a reduced amount of labels to solve a supervised task with superior performance
Supervisedlearning
Softm
ax
51
Deep Belief Networks (DBN)
Deep Learning TV ldquoDeep Belief Netsrdquo
52
Deep Belief Networks (DBN)
Geoffrey Hinton Introduction to Deep Learning amp Deep Belief Netsrdquo (2012)Geoorey Hinton ldquoTutorial on Deep Belief Networksrdquo NIPS 2007
53
Deep Belief Networks (DBN)
Geoffrey Hinton
54
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
Acknowledgments
55
Junting Pan Xunyu Lin
Unsupervised Feature Learning
56
Slide credit Yann LeCun
Unsupervised Feature Learning
57
Slide credit Yann LeCun
Slide credit Junting Pan
Frame Reconstruction amp Prediction
59Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
Frame Reconstruction amp Prediction
60Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
frame prediction
Frame Reconstruction amp Prediction
61Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
frame prediction
62Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised learned features (lots of data) are fine-tuned for activity recognition (little data)
Frame Reconstruction amp Prediction
Frame Prediction
63Ranzato MarcAurelio Arthur Szlam Joan Bruna Michael Mathieu Ronan Collobert and Sumit Chopra Video (language) modeling a baseline for generative models of natural videos arXiv preprint arXiv14126604 (2014)
64Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
Video frame prediction with a ConvNet
Frame Prediction
65Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
The blurry predictions from MSE are improved with multi-scale architecture adversarial learning and an image gradient difference loss function
Frame Prediction
66Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
The blurry predictions from MSE (l1) are improved with multi-scale architecture adversarial training and an image gradient difference loss (GDL) function
Frame Prediction
67Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
Frame Prediction
68Vondrick Carl Hamed Pirsiavash and Antonio Torralba Generating videos with scene dynamics NIPS 2016
Frame Prediction
69Vondrick Carl Hamed Pirsiavash and Antonio Torralba Generating videos with scene dynamics NIPS 2016
Frame Prediction
70Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
71
Frame Prediction
Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
Given an input image probabilistic generation of future frames with a Variational AutoEncoder (VAE)
72
Frame Prediction
Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
Encodes image as feature maps and motion as and cross-convolutional kernels
73
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
First steps in video feature learning
74Le Quoc V Will Y Zou Serena Y Yeung and Andrew Y Ng Learning hierarchical invariant spatio-temporal features for action recognition with independent subspace analysis CVPR 2011
Temporal Weak Labels
75Goroshin Ross Joan Bruna Jonathan Tompson David Eigen and Yann LeCun Unsupervised learning of spatiotemporally coherent metrics ICCV 2015
Assumption adjacent video frames contain semantically similar informationAutoencoder trained with regularizations by slowliness and sparisty
76Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
77Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
78(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Temporal order of frames is exploited as the supervisory signal for learning
Temporal Weak Labels
79(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Take temporal order as the supervisory signals for learning
Shuffled sequences
Binary classification
In order
Not in order
Temporal Weak Labels
80Fernando Basura Hakan Bilen Efstratios Gavves and Stephen Gould Self-supervised video representation learning with odd-one-out networks CVPR 2017
Temporal Weak LabelsTrain a network to detect which of the video sequences contains frames wrong order
81
Spatio-Temporal Weak Labels
X Lin Campos V Giroacute-i-Nieto X Torres J and Canton-Ferrer C ldquoDisentangling Motion Foreground and Background Features in Videosrdquo in CVPR 2017 Workshop Brave New Motion Representations
kernel dec
C3D
ForegroundMotion
FirstForeground
Background
Fg
Dec
Bg
Dec
Fg
Dec Reconstruction
of foreground in last frame
Reconstruction of foreground in
first frame
Reconstruction of background in first frame
uNLC
MaskBlock
gradients
Last foreground
Kernels
shareweights
82
Spatio-Temporal Weak Labels
Pathak Deepak Ross Girshick Piotr Dollaacuter Trevor Darrell and Bharath Hariharan Learning features by watching objects move CVPR 2017
83Greff Klaus Antti Rasmus Mathias Berglund Tele Hao Harri Valpola and Juergen Schmidhuber Tagger Deep unsupervised perceptual grouping NIPS 2016 [video] [code]
Spatio-Temporal Weak Labels
84Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
85
Audio Features from Visual weak labels
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Object amp Scenes recognition in videos by analysing the audio track (only)
86Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
87Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
88Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
89
Visualization of the video frames associated to the sounds that activate some of the last hidden units of Soundnet (conv7)
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Audio Features from Visual weak labels
90
Audio amp Visual features from alignement
90Arandjelović Relja and Andrew Zisserman Look Listen and Learn ICCV 2017
Audio and visual features learned by assessing alignement
91L Chen S Srivastava Z Duan and C Xu Deep Cross-Modal Audio-Visual Generation ACM International Conference on Multimedia Thematic Workshops 2017
Audio amp Visual features from alignement
92Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
93Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
Video to Speech Representations
CNN(VGG)
Frame from a silent video
Audio feature
Post-hoc synthesis
94Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
95Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
Speech to Video Synthesis (mouth)
96Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
97Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
Speech to Video Synthesis (pose amp emotion)
98Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
99Suwajanakorn Supasorn Steven M Seitz and Ira Kemelmacher-Shlizerman Synthesizing Obama learning lip sync from audio SIGGRAPH 2017
Speech to Video Synthesis (mouth)
100
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning

3
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
4
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
5
Motivation
6
Motivation
7Greff Klaus Antti Rasmus Mathias Berglund Tele Hao Harri Valpola and Juergen Schmidhuber Tagger Deep unsupervised perceptual grouping NIPS 2016 [video] [code]
Yann Lecunrsquos Black Forest cake
8
Motivation
1
= ƒ( )
ƒ( )
= ƒ( )
9
Predict label y corresponding to observation x
Estimate the distribution of observation x
Predict action y based on observation x to maximize a future reward z
Motivation
1
= ƒ( )
ƒ( )
= ƒ( )
10
Motivation
Unsupervised Learning
11
Why Unsupervised Learning
It is the nature of how intelligent beings percept the world
It can save us tons of efforts to build a human-alike intelligent agent compared to a totally supervised fashion
Vast amounts of unlabelled data
12
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
Max margin decision boundary
13
How data distribution P(x) influences decisions (1D)
Slide credit Kevin McGuinness (DLCV UPC 2017)
Semi supervised decision boundary
14
How data distribution P(x) influences decisions (1D)
Slide credit Kevin McGuinness (DLCV UPC 2017)
15
How data distribution P(x) influences decisions (2D)
Slide credit Kevin McGuinness (DLCV UPC 2017)
16
How data distribution P(x) influences decisions (2D)
Slide credit Kevin McGuinness (DLCV UPC 2017)
How P(x) is valuable for naive Bayesian classifier
17
X DataY Labels
Slide credit Kevin McGuinness (DLCV UPC 2017)
x1
x2
Not linearly separable in this 2D space (
18
How clustering is valueble for linear classifiers
Slide credit Kevin McGuinness (DLCV UPC 2017)
x1
x2Cluster 1 Cluster 2
Cluster 3Cluster 4
1 2 3 4
1 2 3 4
4D BoW representation
Separable with a linear classifiers in a 4D space
19
How clustering is valueble for linear classifiers
Slide credit Kevin McGuinness (DLCV UPC 2017)
Example from Kevin McGuinness Juyter notebook 20
How clustering is valueble for linear classifiers
21
Assumptions for unsupervised learning
Slide credit Kevin McGuinness (DLCV UPC 2017)
22
Assumptions for unsupervised learning
Slide credit Kevin McGuinness (DLCV UPC 2017)
23
Assumptions for unsupervised learning
Slide credit Kevin McGuinness (DLCV UPC 2017)
24Slide credit Kevin McGuinness (DLCV UPC 2017)
The manifold hypothesis
25
The manifold hypothesis
Slide credit Kevin McGuinness (DLCV UPC 2017)
x1
x2
Linear manifold
wTx + b
x1
x2
Non-linear manifold
26
The manifold hypothesis Energy-based models
LeCun et al A Tutorial on Energy-Based Learning Predicting Structured Data 2006 httpyannlecuncomexdbpublispdflecun-06pdf
27
Autoencoder (AE)
F Van Veen ldquoThe Neural Network Zoordquo (2016)
28
Autoencoder (AE)
ldquoDeep Learning Tutorialrdquo Dept Computer Science Stanford
Autoencoders
Predict at the output the same input data
Do not need labels
29
Autoencoder (AE)
ldquoDeep Learning Tutorialrdquo Dept Computer Science Stanford
Dimensionality reduction
Use hidden layer as a feature extractor of any desired size
30
Autoencoder (AE)
EncoderW1
DecoderW2
hdata reconstruction
Loss(reconstruction error)
Latent variables (representationfeatures)
Figure Kevin McGuinness (DLCV UPC 2017)
Pretraining1 Initialize a NN solving an
autoencoding problem
31
Autoencoder (AE)
Figure Kevin McGuinness (DLCV UPC 2017)
EncoderW1
hdata ClassifierWC
Latent variables (representationfeatures)
prediction
y Loss(cross entropy)
Pretraining1 Initialize a NN solving an
autoencoding problem2 Train for final task with ldquofewrdquo labels
32
Autoencoder (AE)
Deep Learning TV ldquoAutoencoders - Ep 10rdquo
33F Van Veen ldquoThe Neural Network Zoordquo (2016)
Restricted Boltzmann Machine (RBM)
34
Restricted Boltzmann Machine (RBM)
Figure Geoffrey Hinton (2013)
Salakhutdinov Ruslan Andriy Mnih and Geoffrey Hinton Restricted Boltzmann machines for collaborative filtering Proceedings of the 24th international conference on Machine learning ACM 2007
Shallow two-layer net
Restricted = No two nodes in a layer share a connection
Bipartite graph
Bidirectional graph Shared weights Different biases
35
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Forward pass
36
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Forward pass
37
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Forward pass
38
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Backwardpass
39
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Backwardpass
40
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Backwardpass
The reconstructed values at the visible layer are compared with the actual ones with the KL Divergence
41
Restricted Boltzmann Machine (RBM)
Figure Geoffrey Hinton (2013)
Salakhutdinov Ruslan Andriy Mnih and Geoffrey Hinton Restricted Boltzmann machines for collaborative filtering Proceedings of the 24th international conference on Machine learning ACM 2007
42
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
RBMs are a specific type of autoencoder
Unsupervisedlearning
43
Restricted Boltzmann Machine (RBM)
Deep Learning TV ldquoRestricted Boltzmann Machinesrdquo
44
Deep Belief Networks (DBN)
F Van Veen ldquoThe Neural Network Zoordquo (2016)
45
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMs
46
Deep Belief Networks (DBN)
Architecture like an MLP Training as a stack of
RBMs
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
47
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMs
48
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMs
49
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMshellip so they do not need
labels
Unsupervisedlearning
50
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
After the DBN is trained it can be fine-tuned with a reduced amount of labels to solve a supervised task with superior performance
Supervisedlearning
Softm
ax
51
Deep Belief Networks (DBN)
Deep Learning TV ldquoDeep Belief Netsrdquo
52
Deep Belief Networks (DBN)
Geoffrey Hinton Introduction to Deep Learning amp Deep Belief Netsrdquo (2012)Geoorey Hinton ldquoTutorial on Deep Belief Networksrdquo NIPS 2007
53
Deep Belief Networks (DBN)
Geoffrey Hinton
54
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
Acknowledgments
55
Junting Pan Xunyu Lin
Unsupervised Feature Learning
56
Slide credit Yann LeCun
Unsupervised Feature Learning
57
Slide credit Yann LeCun
Slide credit Junting Pan
Frame Reconstruction amp Prediction
59Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
Frame Reconstruction amp Prediction
60Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
frame prediction
Frame Reconstruction amp Prediction
61Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
frame prediction
62Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised learned features (lots of data) are fine-tuned for activity recognition (little data)
Frame Reconstruction amp Prediction
Frame Prediction
63Ranzato MarcAurelio Arthur Szlam Joan Bruna Michael Mathieu Ronan Collobert and Sumit Chopra Video (language) modeling a baseline for generative models of natural videos arXiv preprint arXiv14126604 (2014)
64Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
Video frame prediction with a ConvNet
Frame Prediction
65Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
The blurry predictions from MSE are improved with multi-scale architecture adversarial learning and an image gradient difference loss function
Frame Prediction
66Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
The blurry predictions from MSE (l1) are improved with multi-scale architecture adversarial training and an image gradient difference loss (GDL) function
Frame Prediction
67Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
Frame Prediction
68Vondrick Carl Hamed Pirsiavash and Antonio Torralba Generating videos with scene dynamics NIPS 2016
Frame Prediction
69Vondrick Carl Hamed Pirsiavash and Antonio Torralba Generating videos with scene dynamics NIPS 2016
Frame Prediction
70Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
71
Frame Prediction
Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
Given an input image probabilistic generation of future frames with a Variational AutoEncoder (VAE)
72
Frame Prediction
Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
Encodes image as feature maps and motion as and cross-convolutional kernels
73
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
First steps in video feature learning
74Le Quoc V Will Y Zou Serena Y Yeung and Andrew Y Ng Learning hierarchical invariant spatio-temporal features for action recognition with independent subspace analysis CVPR 2011
Temporal Weak Labels
75Goroshin Ross Joan Bruna Jonathan Tompson David Eigen and Yann LeCun Unsupervised learning of spatiotemporally coherent metrics ICCV 2015
Assumption adjacent video frames contain semantically similar informationAutoencoder trained with regularizations by slowliness and sparisty
76Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
77Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
78(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Temporal order of frames is exploited as the supervisory signal for learning
Temporal Weak Labels
79(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Take temporal order as the supervisory signals for learning
Shuffled sequences
Binary classification
In order
Not in order
Temporal Weak Labels
80Fernando Basura Hakan Bilen Efstratios Gavves and Stephen Gould Self-supervised video representation learning with odd-one-out networks CVPR 2017
Temporal Weak LabelsTrain a network to detect which of the video sequences contains frames wrong order
81
Spatio-Temporal Weak Labels
X Lin Campos V Giroacute-i-Nieto X Torres J and Canton-Ferrer C ldquoDisentangling Motion Foreground and Background Features in Videosrdquo in CVPR 2017 Workshop Brave New Motion Representations
kernel dec
C3D
ForegroundMotion
FirstForeground
Background
Fg
Dec
Bg
Dec
Fg
Dec Reconstruction
of foreground in last frame
Reconstruction of foreground in
first frame
Reconstruction of background in first frame
uNLC
MaskBlock
gradients
Last foreground
Kernels
shareweights
82
Spatio-Temporal Weak Labels
Pathak Deepak Ross Girshick Piotr Dollaacuter Trevor Darrell and Bharath Hariharan Learning features by watching objects move CVPR 2017
83Greff Klaus Antti Rasmus Mathias Berglund Tele Hao Harri Valpola and Juergen Schmidhuber Tagger Deep unsupervised perceptual grouping NIPS 2016 [video] [code]
Spatio-Temporal Weak Labels
84Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
85
Audio Features from Visual weak labels
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Object amp Scenes recognition in videos by analysing the audio track (only)
86Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
87Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
88Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
89
Visualization of the video frames associated to the sounds that activate some of the last hidden units of Soundnet (conv7)
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Audio Features from Visual weak labels
90
Audio amp Visual features from alignement
90Arandjelović Relja and Andrew Zisserman Look Listen and Learn ICCV 2017
Audio and visual features learned by assessing alignement
91L Chen S Srivastava Z Duan and C Xu Deep Cross-Modal Audio-Visual Generation ACM International Conference on Multimedia Thematic Workshops 2017
Audio amp Visual features from alignement
92Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
93Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
Video to Speech Representations
CNN(VGG)
Frame from a silent video
Audio feature
Post-hoc synthesis
94Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
95Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
Speech to Video Synthesis (mouth)
96Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
97Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
Speech to Video Synthesis (pose amp emotion)
98Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
99Suwajanakorn Supasorn Steven M Seitz and Ira Kemelmacher-Shlizerman Synthesizing Obama learning lip sync from audio SIGGRAPH 2017
Speech to Video Synthesis (mouth)
100
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning

4
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
5
Motivation
6
Motivation
7Greff Klaus Antti Rasmus Mathias Berglund Tele Hao Harri Valpola and Juergen Schmidhuber Tagger Deep unsupervised perceptual grouping NIPS 2016 [video] [code]
Yann Lecunrsquos Black Forest cake
8
Motivation
1
= ƒ( )
ƒ( )
= ƒ( )
9
Predict label y corresponding to observation x
Estimate the distribution of observation x
Predict action y based on observation x to maximize a future reward z
Motivation
1
= ƒ( )
ƒ( )
= ƒ( )
10
Motivation
Unsupervised Learning
11
Why Unsupervised Learning
It is the nature of how intelligent beings percept the world
It can save us tons of efforts to build a human-alike intelligent agent compared to a totally supervised fashion
Vast amounts of unlabelled data
12
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
Max margin decision boundary
13
How data distribution P(x) influences decisions (1D)
Slide credit Kevin McGuinness (DLCV UPC 2017)
Semi supervised decision boundary
14
How data distribution P(x) influences decisions (1D)
Slide credit Kevin McGuinness (DLCV UPC 2017)
15
How data distribution P(x) influences decisions (2D)
Slide credit Kevin McGuinness (DLCV UPC 2017)
16
How data distribution P(x) influences decisions (2D)
Slide credit Kevin McGuinness (DLCV UPC 2017)
How P(x) is valuable for naive Bayesian classifier
17
X DataY Labels
Slide credit Kevin McGuinness (DLCV UPC 2017)
x1
x2
Not linearly separable in this 2D space (
18
How clustering is valueble for linear classifiers
Slide credit Kevin McGuinness (DLCV UPC 2017)
x1
x2Cluster 1 Cluster 2
Cluster 3Cluster 4
1 2 3 4
1 2 3 4
4D BoW representation
Separable with a linear classifiers in a 4D space
19
How clustering is valueble for linear classifiers
Slide credit Kevin McGuinness (DLCV UPC 2017)
Example from Kevin McGuinness Juyter notebook 20
How clustering is valueble for linear classifiers
21
Assumptions for unsupervised learning
Slide credit Kevin McGuinness (DLCV UPC 2017)
22
Assumptions for unsupervised learning
Slide credit Kevin McGuinness (DLCV UPC 2017)
23
Assumptions for unsupervised learning
Slide credit Kevin McGuinness (DLCV UPC 2017)
24Slide credit Kevin McGuinness (DLCV UPC 2017)
The manifold hypothesis
25
The manifold hypothesis
Slide credit Kevin McGuinness (DLCV UPC 2017)
x1
x2
Linear manifold
wTx + b
x1
x2
Non-linear manifold
26
The manifold hypothesis Energy-based models
LeCun et al A Tutorial on Energy-Based Learning Predicting Structured Data 2006 httpyannlecuncomexdbpublispdflecun-06pdf
27
Autoencoder (AE)
F Van Veen ldquoThe Neural Network Zoordquo (2016)
28
Autoencoder (AE)
ldquoDeep Learning Tutorialrdquo Dept Computer Science Stanford
Autoencoders
Predict at the output the same input data
Do not need labels
29
Autoencoder (AE)
ldquoDeep Learning Tutorialrdquo Dept Computer Science Stanford
Dimensionality reduction
Use hidden layer as a feature extractor of any desired size
30
Autoencoder (AE)
EncoderW1
DecoderW2
hdata reconstruction
Loss(reconstruction error)
Latent variables (representationfeatures)
Figure Kevin McGuinness (DLCV UPC 2017)
Pretraining1 Initialize a NN solving an
autoencoding problem
31
Autoencoder (AE)
Figure Kevin McGuinness (DLCV UPC 2017)
EncoderW1
hdata ClassifierWC
Latent variables (representationfeatures)
prediction
y Loss(cross entropy)
Pretraining1 Initialize a NN solving an
autoencoding problem2 Train for final task with ldquofewrdquo labels
32
Autoencoder (AE)
Deep Learning TV ldquoAutoencoders - Ep 10rdquo
33F Van Veen ldquoThe Neural Network Zoordquo (2016)
Restricted Boltzmann Machine (RBM)
34
Restricted Boltzmann Machine (RBM)
Figure Geoffrey Hinton (2013)
Salakhutdinov Ruslan Andriy Mnih and Geoffrey Hinton Restricted Boltzmann machines for collaborative filtering Proceedings of the 24th international conference on Machine learning ACM 2007
Shallow two-layer net
Restricted = No two nodes in a layer share a connection
Bipartite graph
Bidirectional graph Shared weights Different biases
35
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Forward pass
36
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Forward pass
37
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Forward pass
38
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Backwardpass
39
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Backwardpass
40
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Backwardpass
The reconstructed values at the visible layer are compared with the actual ones with the KL Divergence
41
Restricted Boltzmann Machine (RBM)
Figure Geoffrey Hinton (2013)
Salakhutdinov Ruslan Andriy Mnih and Geoffrey Hinton Restricted Boltzmann machines for collaborative filtering Proceedings of the 24th international conference on Machine learning ACM 2007
42
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
RBMs are a specific type of autoencoder
Unsupervisedlearning
43
Restricted Boltzmann Machine (RBM)
Deep Learning TV ldquoRestricted Boltzmann Machinesrdquo
44
Deep Belief Networks (DBN)
F Van Veen ldquoThe Neural Network Zoordquo (2016)
45
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMs
46
Deep Belief Networks (DBN)
Architecture like an MLP Training as a stack of
RBMs
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
47
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMs
48
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMs
49
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMshellip so they do not need
labels
Unsupervisedlearning
50
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
After the DBN is trained it can be fine-tuned with a reduced amount of labels to solve a supervised task with superior performance
Supervisedlearning
Softm
ax
51
Deep Belief Networks (DBN)
Deep Learning TV ldquoDeep Belief Netsrdquo
52
Deep Belief Networks (DBN)
Geoffrey Hinton Introduction to Deep Learning amp Deep Belief Netsrdquo (2012)Geoorey Hinton ldquoTutorial on Deep Belief Networksrdquo NIPS 2007
53
Deep Belief Networks (DBN)
Geoffrey Hinton
54
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
Acknowledgments
55
Junting Pan Xunyu Lin
Unsupervised Feature Learning
56
Slide credit Yann LeCun
Unsupervised Feature Learning
57
Slide credit Yann LeCun
Slide credit Junting Pan
Frame Reconstruction amp Prediction
59Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
Frame Reconstruction amp Prediction
60Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
frame prediction
Frame Reconstruction amp Prediction
61Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
frame prediction
62Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised learned features (lots of data) are fine-tuned for activity recognition (little data)
Frame Reconstruction amp Prediction
Frame Prediction
63Ranzato MarcAurelio Arthur Szlam Joan Bruna Michael Mathieu Ronan Collobert and Sumit Chopra Video (language) modeling a baseline for generative models of natural videos arXiv preprint arXiv14126604 (2014)
64Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
Video frame prediction with a ConvNet
Frame Prediction
65Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
The blurry predictions from MSE are improved with multi-scale architecture adversarial learning and an image gradient difference loss function
Frame Prediction
66Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
The blurry predictions from MSE (l1) are improved with multi-scale architecture adversarial training and an image gradient difference loss (GDL) function
Frame Prediction
67Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
Frame Prediction
68Vondrick Carl Hamed Pirsiavash and Antonio Torralba Generating videos with scene dynamics NIPS 2016
Frame Prediction
69Vondrick Carl Hamed Pirsiavash and Antonio Torralba Generating videos with scene dynamics NIPS 2016
Frame Prediction
70Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
71
Frame Prediction
Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
Given an input image probabilistic generation of future frames with a Variational AutoEncoder (VAE)
72
Frame Prediction
Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
Encodes image as feature maps and motion as and cross-convolutional kernels
73
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
First steps in video feature learning
74Le Quoc V Will Y Zou Serena Y Yeung and Andrew Y Ng Learning hierarchical invariant spatio-temporal features for action recognition with independent subspace analysis CVPR 2011
Temporal Weak Labels
75Goroshin Ross Joan Bruna Jonathan Tompson David Eigen and Yann LeCun Unsupervised learning of spatiotemporally coherent metrics ICCV 2015
Assumption adjacent video frames contain semantically similar informationAutoencoder trained with regularizations by slowliness and sparisty
76Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
77Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
78(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Temporal order of frames is exploited as the supervisory signal for learning
Temporal Weak Labels
79(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Take temporal order as the supervisory signals for learning
Shuffled sequences
Binary classification
In order
Not in order
Temporal Weak Labels
80Fernando Basura Hakan Bilen Efstratios Gavves and Stephen Gould Self-supervised video representation learning with odd-one-out networks CVPR 2017
Temporal Weak LabelsTrain a network to detect which of the video sequences contains frames wrong order
81
Spatio-Temporal Weak Labels
X Lin Campos V Giroacute-i-Nieto X Torres J and Canton-Ferrer C ldquoDisentangling Motion Foreground and Background Features in Videosrdquo in CVPR 2017 Workshop Brave New Motion Representations
kernel dec
C3D
ForegroundMotion
FirstForeground
Background
Fg
Dec
Bg
Dec
Fg
Dec Reconstruction
of foreground in last frame
Reconstruction of foreground in
first frame
Reconstruction of background in first frame
uNLC
MaskBlock
gradients
Last foreground
Kernels
shareweights
82
Spatio-Temporal Weak Labels
Pathak Deepak Ross Girshick Piotr Dollaacuter Trevor Darrell and Bharath Hariharan Learning features by watching objects move CVPR 2017
83Greff Klaus Antti Rasmus Mathias Berglund Tele Hao Harri Valpola and Juergen Schmidhuber Tagger Deep unsupervised perceptual grouping NIPS 2016 [video] [code]
Spatio-Temporal Weak Labels
84Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
85
Audio Features from Visual weak labels
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Object amp Scenes recognition in videos by analysing the audio track (only)
86Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
87Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
88Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
89
Visualization of the video frames associated to the sounds that activate some of the last hidden units of Soundnet (conv7)
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Audio Features from Visual weak labels
90
Audio amp Visual features from alignement
90Arandjelović Relja and Andrew Zisserman Look Listen and Learn ICCV 2017
Audio and visual features learned by assessing alignement
91L Chen S Srivastava Z Duan and C Xu Deep Cross-Modal Audio-Visual Generation ACM International Conference on Multimedia Thematic Workshops 2017
Audio amp Visual features from alignement
92Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
93Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
Video to Speech Representations
CNN(VGG)
Frame from a silent video
Audio feature
Post-hoc synthesis
94Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
95Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
Speech to Video Synthesis (mouth)
96Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
97Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
Speech to Video Synthesis (pose amp emotion)
98Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
99Suwajanakorn Supasorn Steven M Seitz and Ira Kemelmacher-Shlizerman Synthesizing Obama learning lip sync from audio SIGGRAPH 2017
Speech to Video Synthesis (mouth)
100
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning

5
Motivation
6
Motivation
7Greff Klaus Antti Rasmus Mathias Berglund Tele Hao Harri Valpola and Juergen Schmidhuber Tagger Deep unsupervised perceptual grouping NIPS 2016 [video] [code]
Yann Lecunrsquos Black Forest cake
8
Motivation
1
= ƒ( )
ƒ( )
= ƒ( )
9
Predict label y corresponding to observation x
Estimate the distribution of observation x
Predict action y based on observation x to maximize a future reward z
Motivation
1
= ƒ( )
ƒ( )
= ƒ( )
10
Motivation
Unsupervised Learning
11
Why Unsupervised Learning
It is the nature of how intelligent beings percept the world
It can save us tons of efforts to build a human-alike intelligent agent compared to a totally supervised fashion
Vast amounts of unlabelled data
12
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
Max margin decision boundary
13
How data distribution P(x) influences decisions (1D)
Slide credit Kevin McGuinness (DLCV UPC 2017)
Semi supervised decision boundary
14
How data distribution P(x) influences decisions (1D)
Slide credit Kevin McGuinness (DLCV UPC 2017)
15
How data distribution P(x) influences decisions (2D)
Slide credit Kevin McGuinness (DLCV UPC 2017)
16
How data distribution P(x) influences decisions (2D)
Slide credit Kevin McGuinness (DLCV UPC 2017)
How P(x) is valuable for naive Bayesian classifier
17
X DataY Labels
Slide credit Kevin McGuinness (DLCV UPC 2017)
x1
x2
Not linearly separable in this 2D space (
18
How clustering is valueble for linear classifiers
Slide credit Kevin McGuinness (DLCV UPC 2017)
x1
x2Cluster 1 Cluster 2
Cluster 3Cluster 4
1 2 3 4
1 2 3 4
4D BoW representation
Separable with a linear classifiers in a 4D space
19
How clustering is valueble for linear classifiers
Slide credit Kevin McGuinness (DLCV UPC 2017)
Example from Kevin McGuinness Juyter notebook 20
How clustering is valueble for linear classifiers
21
Assumptions for unsupervised learning
Slide credit Kevin McGuinness (DLCV UPC 2017)
22
Assumptions for unsupervised learning
Slide credit Kevin McGuinness (DLCV UPC 2017)
23
Assumptions for unsupervised learning
Slide credit Kevin McGuinness (DLCV UPC 2017)
24Slide credit Kevin McGuinness (DLCV UPC 2017)
The manifold hypothesis
25
The manifold hypothesis
Slide credit Kevin McGuinness (DLCV UPC 2017)
x1
x2
Linear manifold
wTx + b
x1
x2
Non-linear manifold
26
The manifold hypothesis Energy-based models
LeCun et al A Tutorial on Energy-Based Learning Predicting Structured Data 2006 httpyannlecuncomexdbpublispdflecun-06pdf
27
Autoencoder (AE)
F Van Veen ldquoThe Neural Network Zoordquo (2016)
28
Autoencoder (AE)
ldquoDeep Learning Tutorialrdquo Dept Computer Science Stanford
Autoencoders
Predict at the output the same input data
Do not need labels
29
Autoencoder (AE)
ldquoDeep Learning Tutorialrdquo Dept Computer Science Stanford
Dimensionality reduction
Use hidden layer as a feature extractor of any desired size
30
Autoencoder (AE)
EncoderW1
DecoderW2
hdata reconstruction
Loss(reconstruction error)
Latent variables (representationfeatures)
Figure Kevin McGuinness (DLCV UPC 2017)
Pretraining1 Initialize a NN solving an
autoencoding problem
31
Autoencoder (AE)
Figure Kevin McGuinness (DLCV UPC 2017)
EncoderW1
hdata ClassifierWC
Latent variables (representationfeatures)
prediction
y Loss(cross entropy)
Pretraining1 Initialize a NN solving an
autoencoding problem2 Train for final task with ldquofewrdquo labels
32
Autoencoder (AE)
Deep Learning TV ldquoAutoencoders - Ep 10rdquo
33F Van Veen ldquoThe Neural Network Zoordquo (2016)
Restricted Boltzmann Machine (RBM)
34
Restricted Boltzmann Machine (RBM)
Figure Geoffrey Hinton (2013)
Salakhutdinov Ruslan Andriy Mnih and Geoffrey Hinton Restricted Boltzmann machines for collaborative filtering Proceedings of the 24th international conference on Machine learning ACM 2007
Shallow two-layer net
Restricted = No two nodes in a layer share a connection
Bipartite graph
Bidirectional graph Shared weights Different biases
35
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Forward pass
36
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Forward pass
37
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Forward pass
38
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Backwardpass
39
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Backwardpass
40
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Backwardpass
The reconstructed values at the visible layer are compared with the actual ones with the KL Divergence
41
Restricted Boltzmann Machine (RBM)
Figure Geoffrey Hinton (2013)
Salakhutdinov Ruslan Andriy Mnih and Geoffrey Hinton Restricted Boltzmann machines for collaborative filtering Proceedings of the 24th international conference on Machine learning ACM 2007
42
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
RBMs are a specific type of autoencoder
Unsupervisedlearning
43
Restricted Boltzmann Machine (RBM)
Deep Learning TV ldquoRestricted Boltzmann Machinesrdquo
44
Deep Belief Networks (DBN)
F Van Veen ldquoThe Neural Network Zoordquo (2016)
45
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMs
46
Deep Belief Networks (DBN)
Architecture like an MLP Training as a stack of
RBMs
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
47
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMs
48
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMs
49
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMshellip so they do not need
labels
Unsupervisedlearning
50
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
After the DBN is trained it can be fine-tuned with a reduced amount of labels to solve a supervised task with superior performance
Supervisedlearning
Softm
ax
51
Deep Belief Networks (DBN)
Deep Learning TV ldquoDeep Belief Netsrdquo
52
Deep Belief Networks (DBN)
Geoffrey Hinton Introduction to Deep Learning amp Deep Belief Netsrdquo (2012)Geoorey Hinton ldquoTutorial on Deep Belief Networksrdquo NIPS 2007
53
Deep Belief Networks (DBN)
Geoffrey Hinton
54
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
Acknowledgments
55
Junting Pan Xunyu Lin
Unsupervised Feature Learning
56
Slide credit Yann LeCun
Unsupervised Feature Learning
57
Slide credit Yann LeCun
Slide credit Junting Pan
Frame Reconstruction amp Prediction
59Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
Frame Reconstruction amp Prediction
60Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
frame prediction
Frame Reconstruction amp Prediction
61Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
frame prediction
62Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised learned features (lots of data) are fine-tuned for activity recognition (little data)
Frame Reconstruction amp Prediction
Frame Prediction
63Ranzato MarcAurelio Arthur Szlam Joan Bruna Michael Mathieu Ronan Collobert and Sumit Chopra Video (language) modeling a baseline for generative models of natural videos arXiv preprint arXiv14126604 (2014)
64Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
Video frame prediction with a ConvNet
Frame Prediction
65Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
The blurry predictions from MSE are improved with multi-scale architecture adversarial learning and an image gradient difference loss function
Frame Prediction
66Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
The blurry predictions from MSE (l1) are improved with multi-scale architecture adversarial training and an image gradient difference loss (GDL) function
Frame Prediction
67Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
Frame Prediction
68Vondrick Carl Hamed Pirsiavash and Antonio Torralba Generating videos with scene dynamics NIPS 2016
Frame Prediction
69Vondrick Carl Hamed Pirsiavash and Antonio Torralba Generating videos with scene dynamics NIPS 2016
Frame Prediction
70Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
71
Frame Prediction
Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
Given an input image probabilistic generation of future frames with a Variational AutoEncoder (VAE)
72
Frame Prediction
Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
Encodes image as feature maps and motion as and cross-convolutional kernels
73
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
First steps in video feature learning
74Le Quoc V Will Y Zou Serena Y Yeung and Andrew Y Ng Learning hierarchical invariant spatio-temporal features for action recognition with independent subspace analysis CVPR 2011
Temporal Weak Labels
75Goroshin Ross Joan Bruna Jonathan Tompson David Eigen and Yann LeCun Unsupervised learning of spatiotemporally coherent metrics ICCV 2015
Assumption adjacent video frames contain semantically similar informationAutoencoder trained with regularizations by slowliness and sparisty
76Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
77Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
78(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Temporal order of frames is exploited as the supervisory signal for learning
Temporal Weak Labels
79(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Take temporal order as the supervisory signals for learning
Shuffled sequences
Binary classification
In order
Not in order
Temporal Weak Labels
80Fernando Basura Hakan Bilen Efstratios Gavves and Stephen Gould Self-supervised video representation learning with odd-one-out networks CVPR 2017
Temporal Weak LabelsTrain a network to detect which of the video sequences contains frames wrong order
81
Spatio-Temporal Weak Labels
X Lin Campos V Giroacute-i-Nieto X Torres J and Canton-Ferrer C ldquoDisentangling Motion Foreground and Background Features in Videosrdquo in CVPR 2017 Workshop Brave New Motion Representations
kernel dec
C3D
ForegroundMotion
FirstForeground
Background
Fg
Dec
Bg
Dec
Fg
Dec Reconstruction
of foreground in last frame
Reconstruction of foreground in
first frame
Reconstruction of background in first frame
uNLC
MaskBlock
gradients
Last foreground
Kernels
shareweights
82
Spatio-Temporal Weak Labels
Pathak Deepak Ross Girshick Piotr Dollaacuter Trevor Darrell and Bharath Hariharan Learning features by watching objects move CVPR 2017
83Greff Klaus Antti Rasmus Mathias Berglund Tele Hao Harri Valpola and Juergen Schmidhuber Tagger Deep unsupervised perceptual grouping NIPS 2016 [video] [code]
Spatio-Temporal Weak Labels
84Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
85
Audio Features from Visual weak labels
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Object amp Scenes recognition in videos by analysing the audio track (only)
86Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
87Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
88Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
89
Visualization of the video frames associated to the sounds that activate some of the last hidden units of Soundnet (conv7)
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Audio Features from Visual weak labels
90
Audio amp Visual features from alignement
90Arandjelović Relja and Andrew Zisserman Look Listen and Learn ICCV 2017
Audio and visual features learned by assessing alignement
91L Chen S Srivastava Z Duan and C Xu Deep Cross-Modal Audio-Visual Generation ACM International Conference on Multimedia Thematic Workshops 2017
Audio amp Visual features from alignement
92Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
93Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
Video to Speech Representations
CNN(VGG)
Frame from a silent video
Audio feature
Post-hoc synthesis
94Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
95Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
Speech to Video Synthesis (mouth)
96Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
97Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
Speech to Video Synthesis (pose amp emotion)
98Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
99Suwajanakorn Supasorn Steven M Seitz and Ira Kemelmacher-Shlizerman Synthesizing Obama learning lip sync from audio SIGGRAPH 2017
Speech to Video Synthesis (mouth)
100
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning

6
Motivation
7Greff Klaus Antti Rasmus Mathias Berglund Tele Hao Harri Valpola and Juergen Schmidhuber Tagger Deep unsupervised perceptual grouping NIPS 2016 [video] [code]
Yann Lecunrsquos Black Forest cake
8
Motivation
1
= ƒ( )
ƒ( )
= ƒ( )
9
Predict label y corresponding to observation x
Estimate the distribution of observation x
Predict action y based on observation x to maximize a future reward z
Motivation
1
= ƒ( )
ƒ( )
= ƒ( )
10
Motivation
Unsupervised Learning
11
Why Unsupervised Learning
It is the nature of how intelligent beings percept the world
It can save us tons of efforts to build a human-alike intelligent agent compared to a totally supervised fashion
Vast amounts of unlabelled data
12
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
Max margin decision boundary
13
How data distribution P(x) influences decisions (1D)
Slide credit Kevin McGuinness (DLCV UPC 2017)
Semi supervised decision boundary
14
How data distribution P(x) influences decisions (1D)
Slide credit Kevin McGuinness (DLCV UPC 2017)
15
How data distribution P(x) influences decisions (2D)
Slide credit Kevin McGuinness (DLCV UPC 2017)
16
How data distribution P(x) influences decisions (2D)
Slide credit Kevin McGuinness (DLCV UPC 2017)
How P(x) is valuable for naive Bayesian classifier
17
X DataY Labels
Slide credit Kevin McGuinness (DLCV UPC 2017)
x1
x2
Not linearly separable in this 2D space (
18
How clustering is valueble for linear classifiers
Slide credit Kevin McGuinness (DLCV UPC 2017)
x1
x2Cluster 1 Cluster 2
Cluster 3Cluster 4
1 2 3 4
1 2 3 4
4D BoW representation
Separable with a linear classifiers in a 4D space
19
How clustering is valueble for linear classifiers
Slide credit Kevin McGuinness (DLCV UPC 2017)
Example from Kevin McGuinness Juyter notebook 20
How clustering is valueble for linear classifiers
21
Assumptions for unsupervised learning
Slide credit Kevin McGuinness (DLCV UPC 2017)
22
Assumptions for unsupervised learning
Slide credit Kevin McGuinness (DLCV UPC 2017)
23
Assumptions for unsupervised learning
Slide credit Kevin McGuinness (DLCV UPC 2017)
24Slide credit Kevin McGuinness (DLCV UPC 2017)
The manifold hypothesis
25
The manifold hypothesis
Slide credit Kevin McGuinness (DLCV UPC 2017)
x1
x2
Linear manifold
wTx + b
x1
x2
Non-linear manifold
26
The manifold hypothesis Energy-based models
LeCun et al A Tutorial on Energy-Based Learning Predicting Structured Data 2006 httpyannlecuncomexdbpublispdflecun-06pdf
27
Autoencoder (AE)
F Van Veen ldquoThe Neural Network Zoordquo (2016)
28
Autoencoder (AE)
ldquoDeep Learning Tutorialrdquo Dept Computer Science Stanford
Autoencoders
Predict at the output the same input data
Do not need labels
29
Autoencoder (AE)
ldquoDeep Learning Tutorialrdquo Dept Computer Science Stanford
Dimensionality reduction
Use hidden layer as a feature extractor of any desired size
30
Autoencoder (AE)
EncoderW1
DecoderW2
hdata reconstruction
Loss(reconstruction error)
Latent variables (representationfeatures)
Figure Kevin McGuinness (DLCV UPC 2017)
Pretraining1 Initialize a NN solving an
autoencoding problem
31
Autoencoder (AE)
Figure Kevin McGuinness (DLCV UPC 2017)
EncoderW1
hdata ClassifierWC
Latent variables (representationfeatures)
prediction
y Loss(cross entropy)
Pretraining1 Initialize a NN solving an
autoencoding problem2 Train for final task with ldquofewrdquo labels
32
Autoencoder (AE)
Deep Learning TV ldquoAutoencoders - Ep 10rdquo
33F Van Veen ldquoThe Neural Network Zoordquo (2016)
Restricted Boltzmann Machine (RBM)
34
Restricted Boltzmann Machine (RBM)
Figure Geoffrey Hinton (2013)
Salakhutdinov Ruslan Andriy Mnih and Geoffrey Hinton Restricted Boltzmann machines for collaborative filtering Proceedings of the 24th international conference on Machine learning ACM 2007
Shallow two-layer net
Restricted = No two nodes in a layer share a connection
Bipartite graph
Bidirectional graph Shared weights Different biases
35
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Forward pass
36
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Forward pass
37
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Forward pass
38
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Backwardpass
39
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Backwardpass
40
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Backwardpass
The reconstructed values at the visible layer are compared with the actual ones with the KL Divergence
41
Restricted Boltzmann Machine (RBM)
Figure Geoffrey Hinton (2013)
Salakhutdinov Ruslan Andriy Mnih and Geoffrey Hinton Restricted Boltzmann machines for collaborative filtering Proceedings of the 24th international conference on Machine learning ACM 2007
42
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
RBMs are a specific type of autoencoder
Unsupervisedlearning
43
Restricted Boltzmann Machine (RBM)
Deep Learning TV ldquoRestricted Boltzmann Machinesrdquo
44
Deep Belief Networks (DBN)
F Van Veen ldquoThe Neural Network Zoordquo (2016)
45
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMs
46
Deep Belief Networks (DBN)
Architecture like an MLP Training as a stack of
RBMs
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
47
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMs
48
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMs
49
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMshellip so they do not need
labels
Unsupervisedlearning
50
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
After the DBN is trained it can be fine-tuned with a reduced amount of labels to solve a supervised task with superior performance
Supervisedlearning
Softm
ax
51
Deep Belief Networks (DBN)
Deep Learning TV ldquoDeep Belief Netsrdquo
52
Deep Belief Networks (DBN)
Geoffrey Hinton Introduction to Deep Learning amp Deep Belief Netsrdquo (2012)Geoorey Hinton ldquoTutorial on Deep Belief Networksrdquo NIPS 2007
53
Deep Belief Networks (DBN)
Geoffrey Hinton
54
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
Acknowledgments
55
Junting Pan Xunyu Lin
Unsupervised Feature Learning
56
Slide credit Yann LeCun
Unsupervised Feature Learning
57
Slide credit Yann LeCun
Slide credit Junting Pan
Frame Reconstruction amp Prediction
59Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
Frame Reconstruction amp Prediction
60Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
frame prediction
Frame Reconstruction amp Prediction
61Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
frame prediction
62Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised learned features (lots of data) are fine-tuned for activity recognition (little data)
Frame Reconstruction amp Prediction
Frame Prediction
63Ranzato MarcAurelio Arthur Szlam Joan Bruna Michael Mathieu Ronan Collobert and Sumit Chopra Video (language) modeling a baseline for generative models of natural videos arXiv preprint arXiv14126604 (2014)
64Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
Video frame prediction with a ConvNet
Frame Prediction
65Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
The blurry predictions from MSE are improved with multi-scale architecture adversarial learning and an image gradient difference loss function
Frame Prediction
66Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
The blurry predictions from MSE (l1) are improved with multi-scale architecture adversarial training and an image gradient difference loss (GDL) function
Frame Prediction
67Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
Frame Prediction
68Vondrick Carl Hamed Pirsiavash and Antonio Torralba Generating videos with scene dynamics NIPS 2016
Frame Prediction
69Vondrick Carl Hamed Pirsiavash and Antonio Torralba Generating videos with scene dynamics NIPS 2016
Frame Prediction
70Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
71
Frame Prediction
Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
Given an input image probabilistic generation of future frames with a Variational AutoEncoder (VAE)
72
Frame Prediction
Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
Encodes image as feature maps and motion as and cross-convolutional kernels
73
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
First steps in video feature learning
74Le Quoc V Will Y Zou Serena Y Yeung and Andrew Y Ng Learning hierarchical invariant spatio-temporal features for action recognition with independent subspace analysis CVPR 2011
Temporal Weak Labels
75Goroshin Ross Joan Bruna Jonathan Tompson David Eigen and Yann LeCun Unsupervised learning of spatiotemporally coherent metrics ICCV 2015
Assumption adjacent video frames contain semantically similar informationAutoencoder trained with regularizations by slowliness and sparisty
76Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
77Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
78(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Temporal order of frames is exploited as the supervisory signal for learning
Temporal Weak Labels
79(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Take temporal order as the supervisory signals for learning
Shuffled sequences
Binary classification
In order
Not in order
Temporal Weak Labels
80Fernando Basura Hakan Bilen Efstratios Gavves and Stephen Gould Self-supervised video representation learning with odd-one-out networks CVPR 2017
Temporal Weak LabelsTrain a network to detect which of the video sequences contains frames wrong order
81
Spatio-Temporal Weak Labels
X Lin Campos V Giroacute-i-Nieto X Torres J and Canton-Ferrer C ldquoDisentangling Motion Foreground and Background Features in Videosrdquo in CVPR 2017 Workshop Brave New Motion Representations
kernel dec
C3D
ForegroundMotion
FirstForeground
Background
Fg
Dec
Bg
Dec
Fg
Dec Reconstruction
of foreground in last frame
Reconstruction of foreground in
first frame
Reconstruction of background in first frame
uNLC
MaskBlock
gradients
Last foreground
Kernels
shareweights
82
Spatio-Temporal Weak Labels
Pathak Deepak Ross Girshick Piotr Dollaacuter Trevor Darrell and Bharath Hariharan Learning features by watching objects move CVPR 2017
83Greff Klaus Antti Rasmus Mathias Berglund Tele Hao Harri Valpola and Juergen Schmidhuber Tagger Deep unsupervised perceptual grouping NIPS 2016 [video] [code]
Spatio-Temporal Weak Labels
84Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
85
Audio Features from Visual weak labels
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Object amp Scenes recognition in videos by analysing the audio track (only)
86Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
87Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
88Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
89
Visualization of the video frames associated to the sounds that activate some of the last hidden units of Soundnet (conv7)
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Audio Features from Visual weak labels
90
Audio amp Visual features from alignement
90Arandjelović Relja and Andrew Zisserman Look Listen and Learn ICCV 2017
Audio and visual features learned by assessing alignement
91L Chen S Srivastava Z Duan and C Xu Deep Cross-Modal Audio-Visual Generation ACM International Conference on Multimedia Thematic Workshops 2017
Audio amp Visual features from alignement
92Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
93Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
Video to Speech Representations
CNN(VGG)
Frame from a silent video
Audio feature
Post-hoc synthesis
94Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
95Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
Speech to Video Synthesis (mouth)
96Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
97Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
Speech to Video Synthesis (pose amp emotion)
98Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
99Suwajanakorn Supasorn Steven M Seitz and Ira Kemelmacher-Shlizerman Synthesizing Obama learning lip sync from audio SIGGRAPH 2017
Speech to Video Synthesis (mouth)
100
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning

7Greff Klaus Antti Rasmus Mathias Berglund Tele Hao Harri Valpola and Juergen Schmidhuber Tagger Deep unsupervised perceptual grouping NIPS 2016 [video] [code]
Yann Lecunrsquos Black Forest cake
8
Motivation
1
= ƒ( )
ƒ( )
= ƒ( )
9
Predict label y corresponding to observation x
Estimate the distribution of observation x
Predict action y based on observation x to maximize a future reward z
Motivation
1
= ƒ( )
ƒ( )
= ƒ( )
10
Motivation
Unsupervised Learning
11
Why Unsupervised Learning
It is the nature of how intelligent beings percept the world
It can save us tons of efforts to build a human-alike intelligent agent compared to a totally supervised fashion
Vast amounts of unlabelled data
12
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
Max margin decision boundary
13
How data distribution P(x) influences decisions (1D)
Slide credit Kevin McGuinness (DLCV UPC 2017)
Semi supervised decision boundary
14
How data distribution P(x) influences decisions (1D)
Slide credit Kevin McGuinness (DLCV UPC 2017)
15
How data distribution P(x) influences decisions (2D)
Slide credit Kevin McGuinness (DLCV UPC 2017)
16
How data distribution P(x) influences decisions (2D)
Slide credit Kevin McGuinness (DLCV UPC 2017)
How P(x) is valuable for naive Bayesian classifier
17
X DataY Labels
Slide credit Kevin McGuinness (DLCV UPC 2017)
x1
x2
Not linearly separable in this 2D space (
18
How clustering is valueble for linear classifiers
Slide credit Kevin McGuinness (DLCV UPC 2017)
x1
x2Cluster 1 Cluster 2
Cluster 3Cluster 4
1 2 3 4
1 2 3 4
4D BoW representation
Separable with a linear classifiers in a 4D space
19
How clustering is valueble for linear classifiers
Slide credit Kevin McGuinness (DLCV UPC 2017)
Example from Kevin McGuinness Juyter notebook 20
How clustering is valueble for linear classifiers
21
Assumptions for unsupervised learning
Slide credit Kevin McGuinness (DLCV UPC 2017)
22
Assumptions for unsupervised learning
Slide credit Kevin McGuinness (DLCV UPC 2017)
23
Assumptions for unsupervised learning
Slide credit Kevin McGuinness (DLCV UPC 2017)
24Slide credit Kevin McGuinness (DLCV UPC 2017)
The manifold hypothesis
25
The manifold hypothesis
Slide credit Kevin McGuinness (DLCV UPC 2017)
x1
x2
Linear manifold
wTx + b
x1
x2
Non-linear manifold
26
The manifold hypothesis Energy-based models
LeCun et al A Tutorial on Energy-Based Learning Predicting Structured Data 2006 httpyannlecuncomexdbpublispdflecun-06pdf
27
Autoencoder (AE)
F Van Veen ldquoThe Neural Network Zoordquo (2016)
28
Autoencoder (AE)
ldquoDeep Learning Tutorialrdquo Dept Computer Science Stanford
Autoencoders
Predict at the output the same input data
Do not need labels
29
Autoencoder (AE)
ldquoDeep Learning Tutorialrdquo Dept Computer Science Stanford
Dimensionality reduction
Use hidden layer as a feature extractor of any desired size
30
Autoencoder (AE)
EncoderW1
DecoderW2
hdata reconstruction
Loss(reconstruction error)
Latent variables (representationfeatures)
Figure Kevin McGuinness (DLCV UPC 2017)
Pretraining1 Initialize a NN solving an
autoencoding problem
31
Autoencoder (AE)
Figure Kevin McGuinness (DLCV UPC 2017)
EncoderW1
hdata ClassifierWC
Latent variables (representationfeatures)
prediction
y Loss(cross entropy)
Pretraining1 Initialize a NN solving an
autoencoding problem2 Train for final task with ldquofewrdquo labels
32
Autoencoder (AE)
Deep Learning TV ldquoAutoencoders - Ep 10rdquo
33F Van Veen ldquoThe Neural Network Zoordquo (2016)
Restricted Boltzmann Machine (RBM)
34
Restricted Boltzmann Machine (RBM)
Figure Geoffrey Hinton (2013)
Salakhutdinov Ruslan Andriy Mnih and Geoffrey Hinton Restricted Boltzmann machines for collaborative filtering Proceedings of the 24th international conference on Machine learning ACM 2007
Shallow two-layer net
Restricted = No two nodes in a layer share a connection
Bipartite graph
Bidirectional graph Shared weights Different biases
35
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Forward pass
36
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Forward pass
37
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Forward pass
38
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Backwardpass
39
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Backwardpass
40
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Backwardpass
The reconstructed values at the visible layer are compared with the actual ones with the KL Divergence
41
Restricted Boltzmann Machine (RBM)
Figure Geoffrey Hinton (2013)
Salakhutdinov Ruslan Andriy Mnih and Geoffrey Hinton Restricted Boltzmann machines for collaborative filtering Proceedings of the 24th international conference on Machine learning ACM 2007
42
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
RBMs are a specific type of autoencoder
Unsupervisedlearning
43
Restricted Boltzmann Machine (RBM)
Deep Learning TV ldquoRestricted Boltzmann Machinesrdquo
44
Deep Belief Networks (DBN)
F Van Veen ldquoThe Neural Network Zoordquo (2016)
45
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMs
46
Deep Belief Networks (DBN)
Architecture like an MLP Training as a stack of
RBMs
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
47
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMs
48
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMs
49
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMshellip so they do not need
labels
Unsupervisedlearning
50
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
After the DBN is trained it can be fine-tuned with a reduced amount of labels to solve a supervised task with superior performance
Supervisedlearning
Softm
ax
51
Deep Belief Networks (DBN)
Deep Learning TV ldquoDeep Belief Netsrdquo
52
Deep Belief Networks (DBN)
Geoffrey Hinton Introduction to Deep Learning amp Deep Belief Netsrdquo (2012)Geoorey Hinton ldquoTutorial on Deep Belief Networksrdquo NIPS 2007
53
Deep Belief Networks (DBN)
Geoffrey Hinton
54
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
Acknowledgments
55
Junting Pan Xunyu Lin
Unsupervised Feature Learning
56
Slide credit Yann LeCun
Unsupervised Feature Learning
57
Slide credit Yann LeCun
Slide credit Junting Pan
Frame Reconstruction amp Prediction
59Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
Frame Reconstruction amp Prediction
60Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
frame prediction
Frame Reconstruction amp Prediction
61Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
frame prediction
62Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised learned features (lots of data) are fine-tuned for activity recognition (little data)
Frame Reconstruction amp Prediction
Frame Prediction
63Ranzato MarcAurelio Arthur Szlam Joan Bruna Michael Mathieu Ronan Collobert and Sumit Chopra Video (language) modeling a baseline for generative models of natural videos arXiv preprint arXiv14126604 (2014)
64Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
Video frame prediction with a ConvNet
Frame Prediction
65Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
The blurry predictions from MSE are improved with multi-scale architecture adversarial learning and an image gradient difference loss function
Frame Prediction
66Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
The blurry predictions from MSE (l1) are improved with multi-scale architecture adversarial training and an image gradient difference loss (GDL) function
Frame Prediction
67Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
Frame Prediction
68Vondrick Carl Hamed Pirsiavash and Antonio Torralba Generating videos with scene dynamics NIPS 2016
Frame Prediction
69Vondrick Carl Hamed Pirsiavash and Antonio Torralba Generating videos with scene dynamics NIPS 2016
Frame Prediction
70Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
71
Frame Prediction
Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
Given an input image probabilistic generation of future frames with a Variational AutoEncoder (VAE)
72
Frame Prediction
Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
Encodes image as feature maps and motion as and cross-convolutional kernels
73
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
First steps in video feature learning
74Le Quoc V Will Y Zou Serena Y Yeung and Andrew Y Ng Learning hierarchical invariant spatio-temporal features for action recognition with independent subspace analysis CVPR 2011
Temporal Weak Labels
75Goroshin Ross Joan Bruna Jonathan Tompson David Eigen and Yann LeCun Unsupervised learning of spatiotemporally coherent metrics ICCV 2015
Assumption adjacent video frames contain semantically similar informationAutoencoder trained with regularizations by slowliness and sparisty
76Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
77Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
78(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Temporal order of frames is exploited as the supervisory signal for learning
Temporal Weak Labels
79(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Take temporal order as the supervisory signals for learning
Shuffled sequences
Binary classification
In order
Not in order
Temporal Weak Labels
80Fernando Basura Hakan Bilen Efstratios Gavves and Stephen Gould Self-supervised video representation learning with odd-one-out networks CVPR 2017
Temporal Weak LabelsTrain a network to detect which of the video sequences contains frames wrong order
81
Spatio-Temporal Weak Labels
X Lin Campos V Giroacute-i-Nieto X Torres J and Canton-Ferrer C ldquoDisentangling Motion Foreground and Background Features in Videosrdquo in CVPR 2017 Workshop Brave New Motion Representations
kernel dec
C3D
ForegroundMotion
FirstForeground
Background
Fg
Dec
Bg
Dec
Fg
Dec Reconstruction
of foreground in last frame
Reconstruction of foreground in
first frame
Reconstruction of background in first frame
uNLC
MaskBlock
gradients
Last foreground
Kernels
shareweights
82
Spatio-Temporal Weak Labels
Pathak Deepak Ross Girshick Piotr Dollaacuter Trevor Darrell and Bharath Hariharan Learning features by watching objects move CVPR 2017
83Greff Klaus Antti Rasmus Mathias Berglund Tele Hao Harri Valpola and Juergen Schmidhuber Tagger Deep unsupervised perceptual grouping NIPS 2016 [video] [code]
Spatio-Temporal Weak Labels
84Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
85
Audio Features from Visual weak labels
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Object amp Scenes recognition in videos by analysing the audio track (only)
86Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
87Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
88Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
89
Visualization of the video frames associated to the sounds that activate some of the last hidden units of Soundnet (conv7)
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Audio Features from Visual weak labels
90
Audio amp Visual features from alignement
90Arandjelović Relja and Andrew Zisserman Look Listen and Learn ICCV 2017
Audio and visual features learned by assessing alignement
91L Chen S Srivastava Z Duan and C Xu Deep Cross-Modal Audio-Visual Generation ACM International Conference on Multimedia Thematic Workshops 2017
Audio amp Visual features from alignement
92Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
93Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
Video to Speech Representations
CNN(VGG)
Frame from a silent video
Audio feature
Post-hoc synthesis
94Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
95Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
Speech to Video Synthesis (mouth)
96Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
97Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
Speech to Video Synthesis (pose amp emotion)
98Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
99Suwajanakorn Supasorn Steven M Seitz and Ira Kemelmacher-Shlizerman Synthesizing Obama learning lip sync from audio SIGGRAPH 2017
Speech to Video Synthesis (mouth)
100
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning

Yann Lecunrsquos Black Forest cake
8
Motivation
1
= ƒ( )
ƒ( )
= ƒ( )
9
Predict label y corresponding to observation x
Estimate the distribution of observation x
Predict action y based on observation x to maximize a future reward z
Motivation
1
= ƒ( )
ƒ( )
= ƒ( )
10
Motivation
Unsupervised Learning
11
Why Unsupervised Learning
It is the nature of how intelligent beings percept the world
It can save us tons of efforts to build a human-alike intelligent agent compared to a totally supervised fashion
Vast amounts of unlabelled data
12
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
Max margin decision boundary
13
How data distribution P(x) influences decisions (1D)
Slide credit Kevin McGuinness (DLCV UPC 2017)
Semi supervised decision boundary
14
How data distribution P(x) influences decisions (1D)
Slide credit Kevin McGuinness (DLCV UPC 2017)
15
How data distribution P(x) influences decisions (2D)
Slide credit Kevin McGuinness (DLCV UPC 2017)
16
How data distribution P(x) influences decisions (2D)
Slide credit Kevin McGuinness (DLCV UPC 2017)
How P(x) is valuable for naive Bayesian classifier
17
X DataY Labels
Slide credit Kevin McGuinness (DLCV UPC 2017)
x1
x2
Not linearly separable in this 2D space (
18
How clustering is valueble for linear classifiers
Slide credit Kevin McGuinness (DLCV UPC 2017)
x1
x2Cluster 1 Cluster 2
Cluster 3Cluster 4
1 2 3 4
1 2 3 4
4D BoW representation
Separable with a linear classifiers in a 4D space
19
How clustering is valueble for linear classifiers
Slide credit Kevin McGuinness (DLCV UPC 2017)
Example from Kevin McGuinness Juyter notebook 20
How clustering is valueble for linear classifiers
21
Assumptions for unsupervised learning
Slide credit Kevin McGuinness (DLCV UPC 2017)
22
Assumptions for unsupervised learning
Slide credit Kevin McGuinness (DLCV UPC 2017)
23
Assumptions for unsupervised learning
Slide credit Kevin McGuinness (DLCV UPC 2017)
24Slide credit Kevin McGuinness (DLCV UPC 2017)
The manifold hypothesis
25
The manifold hypothesis
Slide credit Kevin McGuinness (DLCV UPC 2017)
x1
x2
Linear manifold
wTx + b
x1
x2
Non-linear manifold
26
The manifold hypothesis Energy-based models
LeCun et al A Tutorial on Energy-Based Learning Predicting Structured Data 2006 httpyannlecuncomexdbpublispdflecun-06pdf
27
Autoencoder (AE)
F Van Veen ldquoThe Neural Network Zoordquo (2016)
28
Autoencoder (AE)
ldquoDeep Learning Tutorialrdquo Dept Computer Science Stanford
Autoencoders
Predict at the output the same input data
Do not need labels
29
Autoencoder (AE)
ldquoDeep Learning Tutorialrdquo Dept Computer Science Stanford
Dimensionality reduction
Use hidden layer as a feature extractor of any desired size
30
Autoencoder (AE)
EncoderW1
DecoderW2
hdata reconstruction
Loss(reconstruction error)
Latent variables (representationfeatures)
Figure Kevin McGuinness (DLCV UPC 2017)
Pretraining1 Initialize a NN solving an
autoencoding problem
31
Autoencoder (AE)
Figure Kevin McGuinness (DLCV UPC 2017)
EncoderW1
hdata ClassifierWC
Latent variables (representationfeatures)
prediction
y Loss(cross entropy)
Pretraining1 Initialize a NN solving an
autoencoding problem2 Train for final task with ldquofewrdquo labels
32
Autoencoder (AE)
Deep Learning TV ldquoAutoencoders - Ep 10rdquo
33F Van Veen ldquoThe Neural Network Zoordquo (2016)
Restricted Boltzmann Machine (RBM)
34
Restricted Boltzmann Machine (RBM)
Figure Geoffrey Hinton (2013)
Salakhutdinov Ruslan Andriy Mnih and Geoffrey Hinton Restricted Boltzmann machines for collaborative filtering Proceedings of the 24th international conference on Machine learning ACM 2007
Shallow two-layer net
Restricted = No two nodes in a layer share a connection
Bipartite graph
Bidirectional graph Shared weights Different biases
35
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Forward pass
36
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Forward pass
37
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Forward pass
38
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Backwardpass
39
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Backwardpass
40
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Backwardpass
The reconstructed values at the visible layer are compared with the actual ones with the KL Divergence
41
Restricted Boltzmann Machine (RBM)
Figure Geoffrey Hinton (2013)
Salakhutdinov Ruslan Andriy Mnih and Geoffrey Hinton Restricted Boltzmann machines for collaborative filtering Proceedings of the 24th international conference on Machine learning ACM 2007
42
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
RBMs are a specific type of autoencoder
Unsupervisedlearning
43
Restricted Boltzmann Machine (RBM)
Deep Learning TV ldquoRestricted Boltzmann Machinesrdquo
44
Deep Belief Networks (DBN)
F Van Veen ldquoThe Neural Network Zoordquo (2016)
45
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMs
46
Deep Belief Networks (DBN)
Architecture like an MLP Training as a stack of
RBMs
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
47
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMs
48
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMs
49
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMshellip so they do not need
labels
Unsupervisedlearning
50
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
After the DBN is trained it can be fine-tuned with a reduced amount of labels to solve a supervised task with superior performance
Supervisedlearning
Softm
ax
51
Deep Belief Networks (DBN)
Deep Learning TV ldquoDeep Belief Netsrdquo
52
Deep Belief Networks (DBN)
Geoffrey Hinton Introduction to Deep Learning amp Deep Belief Netsrdquo (2012)Geoorey Hinton ldquoTutorial on Deep Belief Networksrdquo NIPS 2007
53
Deep Belief Networks (DBN)
Geoffrey Hinton
54
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
Acknowledgments
55
Junting Pan Xunyu Lin
Unsupervised Feature Learning
56
Slide credit Yann LeCun
Unsupervised Feature Learning
57
Slide credit Yann LeCun
Slide credit Junting Pan
Frame Reconstruction amp Prediction
59Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
Frame Reconstruction amp Prediction
60Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
frame prediction
Frame Reconstruction amp Prediction
61Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
frame prediction
62Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised learned features (lots of data) are fine-tuned for activity recognition (little data)
Frame Reconstruction amp Prediction
Frame Prediction
63Ranzato MarcAurelio Arthur Szlam Joan Bruna Michael Mathieu Ronan Collobert and Sumit Chopra Video (language) modeling a baseline for generative models of natural videos arXiv preprint arXiv14126604 (2014)
64Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
Video frame prediction with a ConvNet
Frame Prediction
65Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
The blurry predictions from MSE are improved with multi-scale architecture adversarial learning and an image gradient difference loss function
Frame Prediction
66Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
The blurry predictions from MSE (l1) are improved with multi-scale architecture adversarial training and an image gradient difference loss (GDL) function
Frame Prediction
67Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
Frame Prediction
68Vondrick Carl Hamed Pirsiavash and Antonio Torralba Generating videos with scene dynamics NIPS 2016
Frame Prediction
69Vondrick Carl Hamed Pirsiavash and Antonio Torralba Generating videos with scene dynamics NIPS 2016
Frame Prediction
70Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
71
Frame Prediction
Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
Given an input image probabilistic generation of future frames with a Variational AutoEncoder (VAE)
72
Frame Prediction
Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
Encodes image as feature maps and motion as and cross-convolutional kernels
73
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
First steps in video feature learning
74Le Quoc V Will Y Zou Serena Y Yeung and Andrew Y Ng Learning hierarchical invariant spatio-temporal features for action recognition with independent subspace analysis CVPR 2011
Temporal Weak Labels
75Goroshin Ross Joan Bruna Jonathan Tompson David Eigen and Yann LeCun Unsupervised learning of spatiotemporally coherent metrics ICCV 2015
Assumption adjacent video frames contain semantically similar informationAutoencoder trained with regularizations by slowliness and sparisty
76Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
77Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
78(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Temporal order of frames is exploited as the supervisory signal for learning
Temporal Weak Labels
79(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Take temporal order as the supervisory signals for learning
Shuffled sequences
Binary classification
In order
Not in order
Temporal Weak Labels
80Fernando Basura Hakan Bilen Efstratios Gavves and Stephen Gould Self-supervised video representation learning with odd-one-out networks CVPR 2017
Temporal Weak LabelsTrain a network to detect which of the video sequences contains frames wrong order
81
Spatio-Temporal Weak Labels
X Lin Campos V Giroacute-i-Nieto X Torres J and Canton-Ferrer C ldquoDisentangling Motion Foreground and Background Features in Videosrdquo in CVPR 2017 Workshop Brave New Motion Representations
kernel dec
C3D
ForegroundMotion
FirstForeground
Background
Fg
Dec
Bg
Dec
Fg
Dec Reconstruction
of foreground in last frame
Reconstruction of foreground in
first frame
Reconstruction of background in first frame
uNLC
MaskBlock
gradients
Last foreground
Kernels
shareweights
82
Spatio-Temporal Weak Labels
Pathak Deepak Ross Girshick Piotr Dollaacuter Trevor Darrell and Bharath Hariharan Learning features by watching objects move CVPR 2017
83Greff Klaus Antti Rasmus Mathias Berglund Tele Hao Harri Valpola and Juergen Schmidhuber Tagger Deep unsupervised perceptual grouping NIPS 2016 [video] [code]
Spatio-Temporal Weak Labels
84Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
85
Audio Features from Visual weak labels
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Object amp Scenes recognition in videos by analysing the audio track (only)
86Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
87Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
88Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
89
Visualization of the video frames associated to the sounds that activate some of the last hidden units of Soundnet (conv7)
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Audio Features from Visual weak labels
90
Audio amp Visual features from alignement
90Arandjelović Relja and Andrew Zisserman Look Listen and Learn ICCV 2017
Audio and visual features learned by assessing alignement
91L Chen S Srivastava Z Duan and C Xu Deep Cross-Modal Audio-Visual Generation ACM International Conference on Multimedia Thematic Workshops 2017
Audio amp Visual features from alignement
92Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
93Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
Video to Speech Representations
CNN(VGG)
Frame from a silent video
Audio feature
Post-hoc synthesis
94Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
95Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
Speech to Video Synthesis (mouth)
96Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
97Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
Speech to Video Synthesis (pose amp emotion)
98Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
99Suwajanakorn Supasorn Steven M Seitz and Ira Kemelmacher-Shlizerman Synthesizing Obama learning lip sync from audio SIGGRAPH 2017
Speech to Video Synthesis (mouth)
100
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
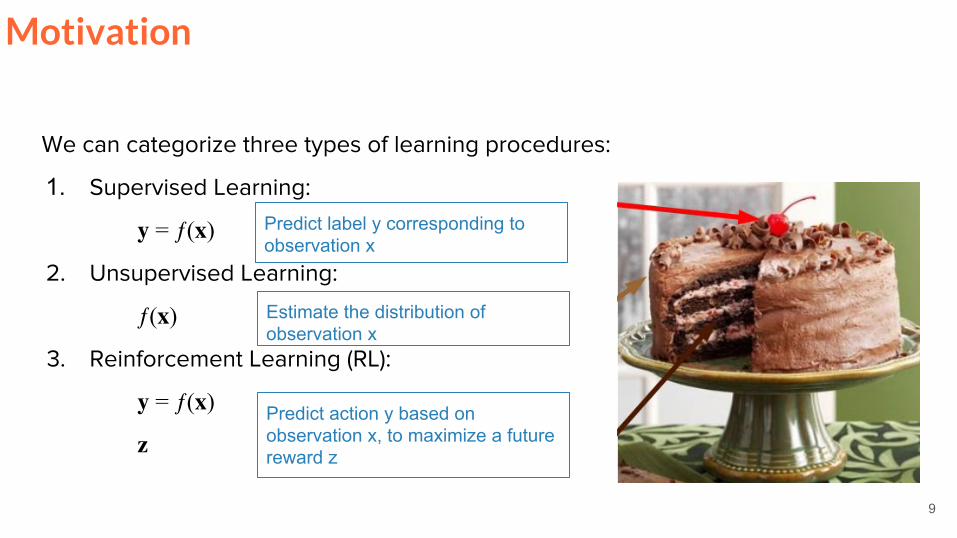
1
= ƒ( )
ƒ( )
= ƒ( )
9
Predict label y corresponding to observation x
Estimate the distribution of observation x
Predict action y based on observation x to maximize a future reward z
Motivation
1
= ƒ( )
ƒ( )
= ƒ( )
10
Motivation
Unsupervised Learning
11
Why Unsupervised Learning
It is the nature of how intelligent beings percept the world
It can save us tons of efforts to build a human-alike intelligent agent compared to a totally supervised fashion
Vast amounts of unlabelled data
12
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
Max margin decision boundary
13
How data distribution P(x) influences decisions (1D)
Slide credit Kevin McGuinness (DLCV UPC 2017)
Semi supervised decision boundary
14
How data distribution P(x) influences decisions (1D)
Slide credit Kevin McGuinness (DLCV UPC 2017)
15
How data distribution P(x) influences decisions (2D)
Slide credit Kevin McGuinness (DLCV UPC 2017)
16
How data distribution P(x) influences decisions (2D)
Slide credit Kevin McGuinness (DLCV UPC 2017)
How P(x) is valuable for naive Bayesian classifier
17
X DataY Labels
Slide credit Kevin McGuinness (DLCV UPC 2017)
x1
x2
Not linearly separable in this 2D space (
18
How clustering is valueble for linear classifiers
Slide credit Kevin McGuinness (DLCV UPC 2017)
x1
x2Cluster 1 Cluster 2
Cluster 3Cluster 4
1 2 3 4
1 2 3 4
4D BoW representation
Separable with a linear classifiers in a 4D space
19
How clustering is valueble for linear classifiers
Slide credit Kevin McGuinness (DLCV UPC 2017)
Example from Kevin McGuinness Juyter notebook 20
How clustering is valueble for linear classifiers
21
Assumptions for unsupervised learning
Slide credit Kevin McGuinness (DLCV UPC 2017)
22
Assumptions for unsupervised learning
Slide credit Kevin McGuinness (DLCV UPC 2017)
23
Assumptions for unsupervised learning
Slide credit Kevin McGuinness (DLCV UPC 2017)
24Slide credit Kevin McGuinness (DLCV UPC 2017)
The manifold hypothesis
25
The manifold hypothesis
Slide credit Kevin McGuinness (DLCV UPC 2017)
x1
x2
Linear manifold
wTx + b
x1
x2
Non-linear manifold
26
The manifold hypothesis Energy-based models
LeCun et al A Tutorial on Energy-Based Learning Predicting Structured Data 2006 httpyannlecuncomexdbpublispdflecun-06pdf
27
Autoencoder (AE)
F Van Veen ldquoThe Neural Network Zoordquo (2016)
28
Autoencoder (AE)
ldquoDeep Learning Tutorialrdquo Dept Computer Science Stanford
Autoencoders
Predict at the output the same input data
Do not need labels
29
Autoencoder (AE)
ldquoDeep Learning Tutorialrdquo Dept Computer Science Stanford
Dimensionality reduction
Use hidden layer as a feature extractor of any desired size
30
Autoencoder (AE)
EncoderW1
DecoderW2
hdata reconstruction
Loss(reconstruction error)
Latent variables (representationfeatures)
Figure Kevin McGuinness (DLCV UPC 2017)
Pretraining1 Initialize a NN solving an
autoencoding problem
31
Autoencoder (AE)
Figure Kevin McGuinness (DLCV UPC 2017)
EncoderW1
hdata ClassifierWC
Latent variables (representationfeatures)
prediction
y Loss(cross entropy)
Pretraining1 Initialize a NN solving an
autoencoding problem2 Train for final task with ldquofewrdquo labels
32
Autoencoder (AE)
Deep Learning TV ldquoAutoencoders - Ep 10rdquo
33F Van Veen ldquoThe Neural Network Zoordquo (2016)
Restricted Boltzmann Machine (RBM)
34
Restricted Boltzmann Machine (RBM)
Figure Geoffrey Hinton (2013)
Salakhutdinov Ruslan Andriy Mnih and Geoffrey Hinton Restricted Boltzmann machines for collaborative filtering Proceedings of the 24th international conference on Machine learning ACM 2007
Shallow two-layer net
Restricted = No two nodes in a layer share a connection
Bipartite graph
Bidirectional graph Shared weights Different biases
35
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Forward pass
36
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Forward pass
37
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Forward pass
38
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Backwardpass
39
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Backwardpass
40
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Backwardpass
The reconstructed values at the visible layer are compared with the actual ones with the KL Divergence
41
Restricted Boltzmann Machine (RBM)
Figure Geoffrey Hinton (2013)
Salakhutdinov Ruslan Andriy Mnih and Geoffrey Hinton Restricted Boltzmann machines for collaborative filtering Proceedings of the 24th international conference on Machine learning ACM 2007
42
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
RBMs are a specific type of autoencoder
Unsupervisedlearning
43
Restricted Boltzmann Machine (RBM)
Deep Learning TV ldquoRestricted Boltzmann Machinesrdquo
44
Deep Belief Networks (DBN)
F Van Veen ldquoThe Neural Network Zoordquo (2016)
45
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMs
46
Deep Belief Networks (DBN)
Architecture like an MLP Training as a stack of
RBMs
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
47
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMs
48
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMs
49
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMshellip so they do not need
labels
Unsupervisedlearning
50
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
After the DBN is trained it can be fine-tuned with a reduced amount of labels to solve a supervised task with superior performance
Supervisedlearning
Softm
ax
51
Deep Belief Networks (DBN)
Deep Learning TV ldquoDeep Belief Netsrdquo
52
Deep Belief Networks (DBN)
Geoffrey Hinton Introduction to Deep Learning amp Deep Belief Netsrdquo (2012)Geoorey Hinton ldquoTutorial on Deep Belief Networksrdquo NIPS 2007
53
Deep Belief Networks (DBN)
Geoffrey Hinton
54
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
Acknowledgments
55
Junting Pan Xunyu Lin
Unsupervised Feature Learning
56
Slide credit Yann LeCun
Unsupervised Feature Learning
57
Slide credit Yann LeCun
Slide credit Junting Pan
Frame Reconstruction amp Prediction
59Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
Frame Reconstruction amp Prediction
60Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
frame prediction
Frame Reconstruction amp Prediction
61Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
frame prediction
62Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised learned features (lots of data) are fine-tuned for activity recognition (little data)
Frame Reconstruction amp Prediction
Frame Prediction
63Ranzato MarcAurelio Arthur Szlam Joan Bruna Michael Mathieu Ronan Collobert and Sumit Chopra Video (language) modeling a baseline for generative models of natural videos arXiv preprint arXiv14126604 (2014)
64Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
Video frame prediction with a ConvNet
Frame Prediction
65Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
The blurry predictions from MSE are improved with multi-scale architecture adversarial learning and an image gradient difference loss function
Frame Prediction
66Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
The blurry predictions from MSE (l1) are improved with multi-scale architecture adversarial training and an image gradient difference loss (GDL) function
Frame Prediction
67Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
Frame Prediction
68Vondrick Carl Hamed Pirsiavash and Antonio Torralba Generating videos with scene dynamics NIPS 2016
Frame Prediction
69Vondrick Carl Hamed Pirsiavash and Antonio Torralba Generating videos with scene dynamics NIPS 2016
Frame Prediction
70Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
71
Frame Prediction
Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
Given an input image probabilistic generation of future frames with a Variational AutoEncoder (VAE)
72
Frame Prediction
Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
Encodes image as feature maps and motion as and cross-convolutional kernels
73
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
First steps in video feature learning
74Le Quoc V Will Y Zou Serena Y Yeung and Andrew Y Ng Learning hierarchical invariant spatio-temporal features for action recognition with independent subspace analysis CVPR 2011
Temporal Weak Labels
75Goroshin Ross Joan Bruna Jonathan Tompson David Eigen and Yann LeCun Unsupervised learning of spatiotemporally coherent metrics ICCV 2015
Assumption adjacent video frames contain semantically similar informationAutoencoder trained with regularizations by slowliness and sparisty
76Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
77Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
78(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Temporal order of frames is exploited as the supervisory signal for learning
Temporal Weak Labels
79(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Take temporal order as the supervisory signals for learning
Shuffled sequences
Binary classification
In order
Not in order
Temporal Weak Labels
80Fernando Basura Hakan Bilen Efstratios Gavves and Stephen Gould Self-supervised video representation learning with odd-one-out networks CVPR 2017
Temporal Weak LabelsTrain a network to detect which of the video sequences contains frames wrong order
81
Spatio-Temporal Weak Labels
X Lin Campos V Giroacute-i-Nieto X Torres J and Canton-Ferrer C ldquoDisentangling Motion Foreground and Background Features in Videosrdquo in CVPR 2017 Workshop Brave New Motion Representations
kernel dec
C3D
ForegroundMotion
FirstForeground
Background
Fg
Dec
Bg
Dec
Fg
Dec Reconstruction
of foreground in last frame
Reconstruction of foreground in
first frame
Reconstruction of background in first frame
uNLC
MaskBlock
gradients
Last foreground
Kernels
shareweights
82
Spatio-Temporal Weak Labels
Pathak Deepak Ross Girshick Piotr Dollaacuter Trevor Darrell and Bharath Hariharan Learning features by watching objects move CVPR 2017
83Greff Klaus Antti Rasmus Mathias Berglund Tele Hao Harri Valpola and Juergen Schmidhuber Tagger Deep unsupervised perceptual grouping NIPS 2016 [video] [code]
Spatio-Temporal Weak Labels
84Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
85
Audio Features from Visual weak labels
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Object amp Scenes recognition in videos by analysing the audio track (only)
86Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
87Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
88Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
89
Visualization of the video frames associated to the sounds that activate some of the last hidden units of Soundnet (conv7)
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Audio Features from Visual weak labels
90
Audio amp Visual features from alignement
90Arandjelović Relja and Andrew Zisserman Look Listen and Learn ICCV 2017
Audio and visual features learned by assessing alignement
91L Chen S Srivastava Z Duan and C Xu Deep Cross-Modal Audio-Visual Generation ACM International Conference on Multimedia Thematic Workshops 2017
Audio amp Visual features from alignement
92Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
93Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
Video to Speech Representations
CNN(VGG)
Frame from a silent video
Audio feature
Post-hoc synthesis
94Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
95Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
Speech to Video Synthesis (mouth)
96Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
97Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
Speech to Video Synthesis (pose amp emotion)
98Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
99Suwajanakorn Supasorn Steven M Seitz and Ira Kemelmacher-Shlizerman Synthesizing Obama learning lip sync from audio SIGGRAPH 2017
Speech to Video Synthesis (mouth)
100
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning

1
= ƒ( )
ƒ( )
= ƒ( )
10
Motivation
Unsupervised Learning
11
Why Unsupervised Learning
It is the nature of how intelligent beings percept the world
It can save us tons of efforts to build a human-alike intelligent agent compared to a totally supervised fashion
Vast amounts of unlabelled data
12
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
Max margin decision boundary
13
How data distribution P(x) influences decisions (1D)
Slide credit Kevin McGuinness (DLCV UPC 2017)
Semi supervised decision boundary
14
How data distribution P(x) influences decisions (1D)
Slide credit Kevin McGuinness (DLCV UPC 2017)
15
How data distribution P(x) influences decisions (2D)
Slide credit Kevin McGuinness (DLCV UPC 2017)
16
How data distribution P(x) influences decisions (2D)
Slide credit Kevin McGuinness (DLCV UPC 2017)
How P(x) is valuable for naive Bayesian classifier
17
X DataY Labels
Slide credit Kevin McGuinness (DLCV UPC 2017)
x1
x2
Not linearly separable in this 2D space (
18
How clustering is valueble for linear classifiers
Slide credit Kevin McGuinness (DLCV UPC 2017)
x1
x2Cluster 1 Cluster 2
Cluster 3Cluster 4
1 2 3 4
1 2 3 4
4D BoW representation
Separable with a linear classifiers in a 4D space
19
How clustering is valueble for linear classifiers
Slide credit Kevin McGuinness (DLCV UPC 2017)
Example from Kevin McGuinness Juyter notebook 20
How clustering is valueble for linear classifiers
21
Assumptions for unsupervised learning
Slide credit Kevin McGuinness (DLCV UPC 2017)
22
Assumptions for unsupervised learning
Slide credit Kevin McGuinness (DLCV UPC 2017)
23
Assumptions for unsupervised learning
Slide credit Kevin McGuinness (DLCV UPC 2017)
24Slide credit Kevin McGuinness (DLCV UPC 2017)
The manifold hypothesis
25
The manifold hypothesis
Slide credit Kevin McGuinness (DLCV UPC 2017)
x1
x2
Linear manifold
wTx + b
x1
x2
Non-linear manifold
26
The manifold hypothesis Energy-based models
LeCun et al A Tutorial on Energy-Based Learning Predicting Structured Data 2006 httpyannlecuncomexdbpublispdflecun-06pdf
27
Autoencoder (AE)
F Van Veen ldquoThe Neural Network Zoordquo (2016)
28
Autoencoder (AE)
ldquoDeep Learning Tutorialrdquo Dept Computer Science Stanford
Autoencoders
Predict at the output the same input data
Do not need labels
29
Autoencoder (AE)
ldquoDeep Learning Tutorialrdquo Dept Computer Science Stanford
Dimensionality reduction
Use hidden layer as a feature extractor of any desired size
30
Autoencoder (AE)
EncoderW1
DecoderW2
hdata reconstruction
Loss(reconstruction error)
Latent variables (representationfeatures)
Figure Kevin McGuinness (DLCV UPC 2017)
Pretraining1 Initialize a NN solving an
autoencoding problem
31
Autoencoder (AE)
Figure Kevin McGuinness (DLCV UPC 2017)
EncoderW1
hdata ClassifierWC
Latent variables (representationfeatures)
prediction
y Loss(cross entropy)
Pretraining1 Initialize a NN solving an
autoencoding problem2 Train for final task with ldquofewrdquo labels
32
Autoencoder (AE)
Deep Learning TV ldquoAutoencoders - Ep 10rdquo
33F Van Veen ldquoThe Neural Network Zoordquo (2016)
Restricted Boltzmann Machine (RBM)
34
Restricted Boltzmann Machine (RBM)
Figure Geoffrey Hinton (2013)
Salakhutdinov Ruslan Andriy Mnih and Geoffrey Hinton Restricted Boltzmann machines for collaborative filtering Proceedings of the 24th international conference on Machine learning ACM 2007
Shallow two-layer net
Restricted = No two nodes in a layer share a connection
Bipartite graph
Bidirectional graph Shared weights Different biases
35
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Forward pass
36
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Forward pass
37
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Forward pass
38
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Backwardpass
39
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Backwardpass
40
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Backwardpass
The reconstructed values at the visible layer are compared with the actual ones with the KL Divergence
41
Restricted Boltzmann Machine (RBM)
Figure Geoffrey Hinton (2013)
Salakhutdinov Ruslan Andriy Mnih and Geoffrey Hinton Restricted Boltzmann machines for collaborative filtering Proceedings of the 24th international conference on Machine learning ACM 2007
42
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
RBMs are a specific type of autoencoder
Unsupervisedlearning
43
Restricted Boltzmann Machine (RBM)
Deep Learning TV ldquoRestricted Boltzmann Machinesrdquo
44
Deep Belief Networks (DBN)
F Van Veen ldquoThe Neural Network Zoordquo (2016)
45
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMs
46
Deep Belief Networks (DBN)
Architecture like an MLP Training as a stack of
RBMs
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
47
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMs
48
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMs
49
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMshellip so they do not need
labels
Unsupervisedlearning
50
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
After the DBN is trained it can be fine-tuned with a reduced amount of labels to solve a supervised task with superior performance
Supervisedlearning
Softm
ax
51
Deep Belief Networks (DBN)
Deep Learning TV ldquoDeep Belief Netsrdquo
52
Deep Belief Networks (DBN)
Geoffrey Hinton Introduction to Deep Learning amp Deep Belief Netsrdquo (2012)Geoorey Hinton ldquoTutorial on Deep Belief Networksrdquo NIPS 2007
53
Deep Belief Networks (DBN)
Geoffrey Hinton
54
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
Acknowledgments
55
Junting Pan Xunyu Lin
Unsupervised Feature Learning
56
Slide credit Yann LeCun
Unsupervised Feature Learning
57
Slide credit Yann LeCun
Slide credit Junting Pan
Frame Reconstruction amp Prediction
59Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
Frame Reconstruction amp Prediction
60Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
frame prediction
Frame Reconstruction amp Prediction
61Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
frame prediction
62Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised learned features (lots of data) are fine-tuned for activity recognition (little data)
Frame Reconstruction amp Prediction
Frame Prediction
63Ranzato MarcAurelio Arthur Szlam Joan Bruna Michael Mathieu Ronan Collobert and Sumit Chopra Video (language) modeling a baseline for generative models of natural videos arXiv preprint arXiv14126604 (2014)
64Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
Video frame prediction with a ConvNet
Frame Prediction
65Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
The blurry predictions from MSE are improved with multi-scale architecture adversarial learning and an image gradient difference loss function
Frame Prediction
66Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
The blurry predictions from MSE (l1) are improved with multi-scale architecture adversarial training and an image gradient difference loss (GDL) function
Frame Prediction
67Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
Frame Prediction
68Vondrick Carl Hamed Pirsiavash and Antonio Torralba Generating videos with scene dynamics NIPS 2016
Frame Prediction
69Vondrick Carl Hamed Pirsiavash and Antonio Torralba Generating videos with scene dynamics NIPS 2016
Frame Prediction
70Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
71
Frame Prediction
Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
Given an input image probabilistic generation of future frames with a Variational AutoEncoder (VAE)
72
Frame Prediction
Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
Encodes image as feature maps and motion as and cross-convolutional kernels
73
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
First steps in video feature learning
74Le Quoc V Will Y Zou Serena Y Yeung and Andrew Y Ng Learning hierarchical invariant spatio-temporal features for action recognition with independent subspace analysis CVPR 2011
Temporal Weak Labels
75Goroshin Ross Joan Bruna Jonathan Tompson David Eigen and Yann LeCun Unsupervised learning of spatiotemporally coherent metrics ICCV 2015
Assumption adjacent video frames contain semantically similar informationAutoencoder trained with regularizations by slowliness and sparisty
76Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
77Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
78(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Temporal order of frames is exploited as the supervisory signal for learning
Temporal Weak Labels
79(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Take temporal order as the supervisory signals for learning
Shuffled sequences
Binary classification
In order
Not in order
Temporal Weak Labels
80Fernando Basura Hakan Bilen Efstratios Gavves and Stephen Gould Self-supervised video representation learning with odd-one-out networks CVPR 2017
Temporal Weak LabelsTrain a network to detect which of the video sequences contains frames wrong order
81
Spatio-Temporal Weak Labels
X Lin Campos V Giroacute-i-Nieto X Torres J and Canton-Ferrer C ldquoDisentangling Motion Foreground and Background Features in Videosrdquo in CVPR 2017 Workshop Brave New Motion Representations
kernel dec
C3D
ForegroundMotion
FirstForeground
Background
Fg
Dec
Bg
Dec
Fg
Dec Reconstruction
of foreground in last frame
Reconstruction of foreground in
first frame
Reconstruction of background in first frame
uNLC
MaskBlock
gradients
Last foreground
Kernels
shareweights
82
Spatio-Temporal Weak Labels
Pathak Deepak Ross Girshick Piotr Dollaacuter Trevor Darrell and Bharath Hariharan Learning features by watching objects move CVPR 2017
83Greff Klaus Antti Rasmus Mathias Berglund Tele Hao Harri Valpola and Juergen Schmidhuber Tagger Deep unsupervised perceptual grouping NIPS 2016 [video] [code]
Spatio-Temporal Weak Labels
84Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
85
Audio Features from Visual weak labels
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Object amp Scenes recognition in videos by analysing the audio track (only)
86Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
87Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
88Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
89
Visualization of the video frames associated to the sounds that activate some of the last hidden units of Soundnet (conv7)
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Audio Features from Visual weak labels
90
Audio amp Visual features from alignement
90Arandjelović Relja and Andrew Zisserman Look Listen and Learn ICCV 2017
Audio and visual features learned by assessing alignement
91L Chen S Srivastava Z Duan and C Xu Deep Cross-Modal Audio-Visual Generation ACM International Conference on Multimedia Thematic Workshops 2017
Audio amp Visual features from alignement
92Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
93Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
Video to Speech Representations
CNN(VGG)
Frame from a silent video
Audio feature
Post-hoc synthesis
94Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
95Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
Speech to Video Synthesis (mouth)
96Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
97Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
Speech to Video Synthesis (pose amp emotion)
98Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
99Suwajanakorn Supasorn Steven M Seitz and Ira Kemelmacher-Shlizerman Synthesizing Obama learning lip sync from audio SIGGRAPH 2017
Speech to Video Synthesis (mouth)
100
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning

Unsupervised Learning
11
Why Unsupervised Learning
It is the nature of how intelligent beings percept the world
It can save us tons of efforts to build a human-alike intelligent agent compared to a totally supervised fashion
Vast amounts of unlabelled data
12
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
Max margin decision boundary
13
How data distribution P(x) influences decisions (1D)
Slide credit Kevin McGuinness (DLCV UPC 2017)
Semi supervised decision boundary
14
How data distribution P(x) influences decisions (1D)
Slide credit Kevin McGuinness (DLCV UPC 2017)
15
How data distribution P(x) influences decisions (2D)
Slide credit Kevin McGuinness (DLCV UPC 2017)
16
How data distribution P(x) influences decisions (2D)
Slide credit Kevin McGuinness (DLCV UPC 2017)
How P(x) is valuable for naive Bayesian classifier
17
X DataY Labels
Slide credit Kevin McGuinness (DLCV UPC 2017)
x1
x2
Not linearly separable in this 2D space (
18
How clustering is valueble for linear classifiers
Slide credit Kevin McGuinness (DLCV UPC 2017)
x1
x2Cluster 1 Cluster 2
Cluster 3Cluster 4
1 2 3 4
1 2 3 4
4D BoW representation
Separable with a linear classifiers in a 4D space
19
How clustering is valueble for linear classifiers
Slide credit Kevin McGuinness (DLCV UPC 2017)
Example from Kevin McGuinness Juyter notebook 20
How clustering is valueble for linear classifiers
21
Assumptions for unsupervised learning
Slide credit Kevin McGuinness (DLCV UPC 2017)
22
Assumptions for unsupervised learning
Slide credit Kevin McGuinness (DLCV UPC 2017)
23
Assumptions for unsupervised learning
Slide credit Kevin McGuinness (DLCV UPC 2017)
24Slide credit Kevin McGuinness (DLCV UPC 2017)
The manifold hypothesis
25
The manifold hypothesis
Slide credit Kevin McGuinness (DLCV UPC 2017)
x1
x2
Linear manifold
wTx + b
x1
x2
Non-linear manifold
26
The manifold hypothesis Energy-based models
LeCun et al A Tutorial on Energy-Based Learning Predicting Structured Data 2006 httpyannlecuncomexdbpublispdflecun-06pdf
27
Autoencoder (AE)
F Van Veen ldquoThe Neural Network Zoordquo (2016)
28
Autoencoder (AE)
ldquoDeep Learning Tutorialrdquo Dept Computer Science Stanford
Autoencoders
Predict at the output the same input data
Do not need labels
29
Autoencoder (AE)
ldquoDeep Learning Tutorialrdquo Dept Computer Science Stanford
Dimensionality reduction
Use hidden layer as a feature extractor of any desired size
30
Autoencoder (AE)
EncoderW1
DecoderW2
hdata reconstruction
Loss(reconstruction error)
Latent variables (representationfeatures)
Figure Kevin McGuinness (DLCV UPC 2017)
Pretraining1 Initialize a NN solving an
autoencoding problem
31
Autoencoder (AE)
Figure Kevin McGuinness (DLCV UPC 2017)
EncoderW1
hdata ClassifierWC
Latent variables (representationfeatures)
prediction
y Loss(cross entropy)
Pretraining1 Initialize a NN solving an
autoencoding problem2 Train for final task with ldquofewrdquo labels
32
Autoencoder (AE)
Deep Learning TV ldquoAutoencoders - Ep 10rdquo
33F Van Veen ldquoThe Neural Network Zoordquo (2016)
Restricted Boltzmann Machine (RBM)
34
Restricted Boltzmann Machine (RBM)
Figure Geoffrey Hinton (2013)
Salakhutdinov Ruslan Andriy Mnih and Geoffrey Hinton Restricted Boltzmann machines for collaborative filtering Proceedings of the 24th international conference on Machine learning ACM 2007
Shallow two-layer net
Restricted = No two nodes in a layer share a connection
Bipartite graph
Bidirectional graph Shared weights Different biases
35
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Forward pass
36
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Forward pass
37
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Forward pass
38
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Backwardpass
39
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Backwardpass
40
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Backwardpass
The reconstructed values at the visible layer are compared with the actual ones with the KL Divergence
41
Restricted Boltzmann Machine (RBM)
Figure Geoffrey Hinton (2013)
Salakhutdinov Ruslan Andriy Mnih and Geoffrey Hinton Restricted Boltzmann machines for collaborative filtering Proceedings of the 24th international conference on Machine learning ACM 2007
42
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
RBMs are a specific type of autoencoder
Unsupervisedlearning
43
Restricted Boltzmann Machine (RBM)
Deep Learning TV ldquoRestricted Boltzmann Machinesrdquo
44
Deep Belief Networks (DBN)
F Van Veen ldquoThe Neural Network Zoordquo (2016)
45
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMs
46
Deep Belief Networks (DBN)
Architecture like an MLP Training as a stack of
RBMs
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
47
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMs
48
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMs
49
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMshellip so they do not need
labels
Unsupervisedlearning
50
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
After the DBN is trained it can be fine-tuned with a reduced amount of labels to solve a supervised task with superior performance
Supervisedlearning
Softm
ax
51
Deep Belief Networks (DBN)
Deep Learning TV ldquoDeep Belief Netsrdquo
52
Deep Belief Networks (DBN)
Geoffrey Hinton Introduction to Deep Learning amp Deep Belief Netsrdquo (2012)Geoorey Hinton ldquoTutorial on Deep Belief Networksrdquo NIPS 2007
53
Deep Belief Networks (DBN)
Geoffrey Hinton
54
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
Acknowledgments
55
Junting Pan Xunyu Lin
Unsupervised Feature Learning
56
Slide credit Yann LeCun
Unsupervised Feature Learning
57
Slide credit Yann LeCun
Slide credit Junting Pan
Frame Reconstruction amp Prediction
59Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
Frame Reconstruction amp Prediction
60Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
frame prediction
Frame Reconstruction amp Prediction
61Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
frame prediction
62Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised learned features (lots of data) are fine-tuned for activity recognition (little data)
Frame Reconstruction amp Prediction
Frame Prediction
63Ranzato MarcAurelio Arthur Szlam Joan Bruna Michael Mathieu Ronan Collobert and Sumit Chopra Video (language) modeling a baseline for generative models of natural videos arXiv preprint arXiv14126604 (2014)
64Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
Video frame prediction with a ConvNet
Frame Prediction
65Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
The blurry predictions from MSE are improved with multi-scale architecture adversarial learning and an image gradient difference loss function
Frame Prediction
66Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
The blurry predictions from MSE (l1) are improved with multi-scale architecture adversarial training and an image gradient difference loss (GDL) function
Frame Prediction
67Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
Frame Prediction
68Vondrick Carl Hamed Pirsiavash and Antonio Torralba Generating videos with scene dynamics NIPS 2016
Frame Prediction
69Vondrick Carl Hamed Pirsiavash and Antonio Torralba Generating videos with scene dynamics NIPS 2016
Frame Prediction
70Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
71
Frame Prediction
Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
Given an input image probabilistic generation of future frames with a Variational AutoEncoder (VAE)
72
Frame Prediction
Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
Encodes image as feature maps and motion as and cross-convolutional kernels
73
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
First steps in video feature learning
74Le Quoc V Will Y Zou Serena Y Yeung and Andrew Y Ng Learning hierarchical invariant spatio-temporal features for action recognition with independent subspace analysis CVPR 2011
Temporal Weak Labels
75Goroshin Ross Joan Bruna Jonathan Tompson David Eigen and Yann LeCun Unsupervised learning of spatiotemporally coherent metrics ICCV 2015
Assumption adjacent video frames contain semantically similar informationAutoencoder trained with regularizations by slowliness and sparisty
76Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
77Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
78(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Temporal order of frames is exploited as the supervisory signal for learning
Temporal Weak Labels
79(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Take temporal order as the supervisory signals for learning
Shuffled sequences
Binary classification
In order
Not in order
Temporal Weak Labels
80Fernando Basura Hakan Bilen Efstratios Gavves and Stephen Gould Self-supervised video representation learning with odd-one-out networks CVPR 2017
Temporal Weak LabelsTrain a network to detect which of the video sequences contains frames wrong order
81
Spatio-Temporal Weak Labels
X Lin Campos V Giroacute-i-Nieto X Torres J and Canton-Ferrer C ldquoDisentangling Motion Foreground and Background Features in Videosrdquo in CVPR 2017 Workshop Brave New Motion Representations
kernel dec
C3D
ForegroundMotion
FirstForeground
Background
Fg
Dec
Bg
Dec
Fg
Dec Reconstruction
of foreground in last frame
Reconstruction of foreground in
first frame
Reconstruction of background in first frame
uNLC
MaskBlock
gradients
Last foreground
Kernels
shareweights
82
Spatio-Temporal Weak Labels
Pathak Deepak Ross Girshick Piotr Dollaacuter Trevor Darrell and Bharath Hariharan Learning features by watching objects move CVPR 2017
83Greff Klaus Antti Rasmus Mathias Berglund Tele Hao Harri Valpola and Juergen Schmidhuber Tagger Deep unsupervised perceptual grouping NIPS 2016 [video] [code]
Spatio-Temporal Weak Labels
84Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
85
Audio Features from Visual weak labels
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Object amp Scenes recognition in videos by analysing the audio track (only)
86Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
87Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
88Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
89
Visualization of the video frames associated to the sounds that activate some of the last hidden units of Soundnet (conv7)
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Audio Features from Visual weak labels
90
Audio amp Visual features from alignement
90Arandjelović Relja and Andrew Zisserman Look Listen and Learn ICCV 2017
Audio and visual features learned by assessing alignement
91L Chen S Srivastava Z Duan and C Xu Deep Cross-Modal Audio-Visual Generation ACM International Conference on Multimedia Thematic Workshops 2017
Audio amp Visual features from alignement
92Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
93Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
Video to Speech Representations
CNN(VGG)
Frame from a silent video
Audio feature
Post-hoc synthesis
94Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
95Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
Speech to Video Synthesis (mouth)
96Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
97Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
Speech to Video Synthesis (pose amp emotion)
98Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
99Suwajanakorn Supasorn Steven M Seitz and Ira Kemelmacher-Shlizerman Synthesizing Obama learning lip sync from audio SIGGRAPH 2017
Speech to Video Synthesis (mouth)
100
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning

12
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
Max margin decision boundary
13
How data distribution P(x) influences decisions (1D)
Slide credit Kevin McGuinness (DLCV UPC 2017)
Semi supervised decision boundary
14
How data distribution P(x) influences decisions (1D)
Slide credit Kevin McGuinness (DLCV UPC 2017)
15
How data distribution P(x) influences decisions (2D)
Slide credit Kevin McGuinness (DLCV UPC 2017)
16
How data distribution P(x) influences decisions (2D)
Slide credit Kevin McGuinness (DLCV UPC 2017)
How P(x) is valuable for naive Bayesian classifier
17
X DataY Labels
Slide credit Kevin McGuinness (DLCV UPC 2017)
x1
x2
Not linearly separable in this 2D space (
18
How clustering is valueble for linear classifiers
Slide credit Kevin McGuinness (DLCV UPC 2017)
x1
x2Cluster 1 Cluster 2
Cluster 3Cluster 4
1 2 3 4
1 2 3 4
4D BoW representation
Separable with a linear classifiers in a 4D space
19
How clustering is valueble for linear classifiers
Slide credit Kevin McGuinness (DLCV UPC 2017)
Example from Kevin McGuinness Juyter notebook 20
How clustering is valueble for linear classifiers
21
Assumptions for unsupervised learning
Slide credit Kevin McGuinness (DLCV UPC 2017)
22
Assumptions for unsupervised learning
Slide credit Kevin McGuinness (DLCV UPC 2017)
23
Assumptions for unsupervised learning
Slide credit Kevin McGuinness (DLCV UPC 2017)
24Slide credit Kevin McGuinness (DLCV UPC 2017)
The manifold hypothesis
25
The manifold hypothesis
Slide credit Kevin McGuinness (DLCV UPC 2017)
x1
x2
Linear manifold
wTx + b
x1
x2
Non-linear manifold
26
The manifold hypothesis Energy-based models
LeCun et al A Tutorial on Energy-Based Learning Predicting Structured Data 2006 httpyannlecuncomexdbpublispdflecun-06pdf
27
Autoencoder (AE)
F Van Veen ldquoThe Neural Network Zoordquo (2016)
28
Autoencoder (AE)
ldquoDeep Learning Tutorialrdquo Dept Computer Science Stanford
Autoencoders
Predict at the output the same input data
Do not need labels
29
Autoencoder (AE)
ldquoDeep Learning Tutorialrdquo Dept Computer Science Stanford
Dimensionality reduction
Use hidden layer as a feature extractor of any desired size
30
Autoencoder (AE)
EncoderW1
DecoderW2
hdata reconstruction
Loss(reconstruction error)
Latent variables (representationfeatures)
Figure Kevin McGuinness (DLCV UPC 2017)
Pretraining1 Initialize a NN solving an
autoencoding problem
31
Autoencoder (AE)
Figure Kevin McGuinness (DLCV UPC 2017)
EncoderW1
hdata ClassifierWC
Latent variables (representationfeatures)
prediction
y Loss(cross entropy)
Pretraining1 Initialize a NN solving an
autoencoding problem2 Train for final task with ldquofewrdquo labels
32
Autoencoder (AE)
Deep Learning TV ldquoAutoencoders - Ep 10rdquo
33F Van Veen ldquoThe Neural Network Zoordquo (2016)
Restricted Boltzmann Machine (RBM)
34
Restricted Boltzmann Machine (RBM)
Figure Geoffrey Hinton (2013)
Salakhutdinov Ruslan Andriy Mnih and Geoffrey Hinton Restricted Boltzmann machines for collaborative filtering Proceedings of the 24th international conference on Machine learning ACM 2007
Shallow two-layer net
Restricted = No two nodes in a layer share a connection
Bipartite graph
Bidirectional graph Shared weights Different biases
35
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Forward pass
36
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Forward pass
37
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Forward pass
38
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Backwardpass
39
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Backwardpass
40
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Backwardpass
The reconstructed values at the visible layer are compared with the actual ones with the KL Divergence
41
Restricted Boltzmann Machine (RBM)
Figure Geoffrey Hinton (2013)
Salakhutdinov Ruslan Andriy Mnih and Geoffrey Hinton Restricted Boltzmann machines for collaborative filtering Proceedings of the 24th international conference on Machine learning ACM 2007
42
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
RBMs are a specific type of autoencoder
Unsupervisedlearning
43
Restricted Boltzmann Machine (RBM)
Deep Learning TV ldquoRestricted Boltzmann Machinesrdquo
44
Deep Belief Networks (DBN)
F Van Veen ldquoThe Neural Network Zoordquo (2016)
45
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMs
46
Deep Belief Networks (DBN)
Architecture like an MLP Training as a stack of
RBMs
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
47
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMs
48
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMs
49
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMshellip so they do not need
labels
Unsupervisedlearning
50
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
After the DBN is trained it can be fine-tuned with a reduced amount of labels to solve a supervised task with superior performance
Supervisedlearning
Softm
ax
51
Deep Belief Networks (DBN)
Deep Learning TV ldquoDeep Belief Netsrdquo
52
Deep Belief Networks (DBN)
Geoffrey Hinton Introduction to Deep Learning amp Deep Belief Netsrdquo (2012)Geoorey Hinton ldquoTutorial on Deep Belief Networksrdquo NIPS 2007
53
Deep Belief Networks (DBN)
Geoffrey Hinton
54
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
Acknowledgments
55
Junting Pan Xunyu Lin
Unsupervised Feature Learning
56
Slide credit Yann LeCun
Unsupervised Feature Learning
57
Slide credit Yann LeCun
Slide credit Junting Pan
Frame Reconstruction amp Prediction
59Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
Frame Reconstruction amp Prediction
60Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
frame prediction
Frame Reconstruction amp Prediction
61Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
frame prediction
62Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised learned features (lots of data) are fine-tuned for activity recognition (little data)
Frame Reconstruction amp Prediction
Frame Prediction
63Ranzato MarcAurelio Arthur Szlam Joan Bruna Michael Mathieu Ronan Collobert and Sumit Chopra Video (language) modeling a baseline for generative models of natural videos arXiv preprint arXiv14126604 (2014)
64Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
Video frame prediction with a ConvNet
Frame Prediction
65Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
The blurry predictions from MSE are improved with multi-scale architecture adversarial learning and an image gradient difference loss function
Frame Prediction
66Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
The blurry predictions from MSE (l1) are improved with multi-scale architecture adversarial training and an image gradient difference loss (GDL) function
Frame Prediction
67Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
Frame Prediction
68Vondrick Carl Hamed Pirsiavash and Antonio Torralba Generating videos with scene dynamics NIPS 2016
Frame Prediction
69Vondrick Carl Hamed Pirsiavash and Antonio Torralba Generating videos with scene dynamics NIPS 2016
Frame Prediction
70Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
71
Frame Prediction
Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
Given an input image probabilistic generation of future frames with a Variational AutoEncoder (VAE)
72
Frame Prediction
Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
Encodes image as feature maps and motion as and cross-convolutional kernels
73
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
First steps in video feature learning
74Le Quoc V Will Y Zou Serena Y Yeung and Andrew Y Ng Learning hierarchical invariant spatio-temporal features for action recognition with independent subspace analysis CVPR 2011
Temporal Weak Labels
75Goroshin Ross Joan Bruna Jonathan Tompson David Eigen and Yann LeCun Unsupervised learning of spatiotemporally coherent metrics ICCV 2015
Assumption adjacent video frames contain semantically similar informationAutoencoder trained with regularizations by slowliness and sparisty
76Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
77Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
78(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Temporal order of frames is exploited as the supervisory signal for learning
Temporal Weak Labels
79(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Take temporal order as the supervisory signals for learning
Shuffled sequences
Binary classification
In order
Not in order
Temporal Weak Labels
80Fernando Basura Hakan Bilen Efstratios Gavves and Stephen Gould Self-supervised video representation learning with odd-one-out networks CVPR 2017
Temporal Weak LabelsTrain a network to detect which of the video sequences contains frames wrong order
81
Spatio-Temporal Weak Labels
X Lin Campos V Giroacute-i-Nieto X Torres J and Canton-Ferrer C ldquoDisentangling Motion Foreground and Background Features in Videosrdquo in CVPR 2017 Workshop Brave New Motion Representations
kernel dec
C3D
ForegroundMotion
FirstForeground
Background
Fg
Dec
Bg
Dec
Fg
Dec Reconstruction
of foreground in last frame
Reconstruction of foreground in
first frame
Reconstruction of background in first frame
uNLC
MaskBlock
gradients
Last foreground
Kernels
shareweights
82
Spatio-Temporal Weak Labels
Pathak Deepak Ross Girshick Piotr Dollaacuter Trevor Darrell and Bharath Hariharan Learning features by watching objects move CVPR 2017
83Greff Klaus Antti Rasmus Mathias Berglund Tele Hao Harri Valpola and Juergen Schmidhuber Tagger Deep unsupervised perceptual grouping NIPS 2016 [video] [code]
Spatio-Temporal Weak Labels
84Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
85
Audio Features from Visual weak labels
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Object amp Scenes recognition in videos by analysing the audio track (only)
86Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
87Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
88Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
89
Visualization of the video frames associated to the sounds that activate some of the last hidden units of Soundnet (conv7)
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Audio Features from Visual weak labels
90
Audio amp Visual features from alignement
90Arandjelović Relja and Andrew Zisserman Look Listen and Learn ICCV 2017
Audio and visual features learned by assessing alignement
91L Chen S Srivastava Z Duan and C Xu Deep Cross-Modal Audio-Visual Generation ACM International Conference on Multimedia Thematic Workshops 2017
Audio amp Visual features from alignement
92Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
93Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
Video to Speech Representations
CNN(VGG)
Frame from a silent video
Audio feature
Post-hoc synthesis
94Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
95Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
Speech to Video Synthesis (mouth)
96Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
97Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
Speech to Video Synthesis (pose amp emotion)
98Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
99Suwajanakorn Supasorn Steven M Seitz and Ira Kemelmacher-Shlizerman Synthesizing Obama learning lip sync from audio SIGGRAPH 2017
Speech to Video Synthesis (mouth)
100
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning

Max margin decision boundary
13
How data distribution P(x) influences decisions (1D)
Slide credit Kevin McGuinness (DLCV UPC 2017)
Semi supervised decision boundary
14
How data distribution P(x) influences decisions (1D)
Slide credit Kevin McGuinness (DLCV UPC 2017)
15
How data distribution P(x) influences decisions (2D)
Slide credit Kevin McGuinness (DLCV UPC 2017)
16
How data distribution P(x) influences decisions (2D)
Slide credit Kevin McGuinness (DLCV UPC 2017)
How P(x) is valuable for naive Bayesian classifier
17
X DataY Labels
Slide credit Kevin McGuinness (DLCV UPC 2017)
x1
x2
Not linearly separable in this 2D space (
18
How clustering is valueble for linear classifiers
Slide credit Kevin McGuinness (DLCV UPC 2017)
x1
x2Cluster 1 Cluster 2
Cluster 3Cluster 4
1 2 3 4
1 2 3 4
4D BoW representation
Separable with a linear classifiers in a 4D space
19
How clustering is valueble for linear classifiers
Slide credit Kevin McGuinness (DLCV UPC 2017)
Example from Kevin McGuinness Juyter notebook 20
How clustering is valueble for linear classifiers
21
Assumptions for unsupervised learning
Slide credit Kevin McGuinness (DLCV UPC 2017)
22
Assumptions for unsupervised learning
Slide credit Kevin McGuinness (DLCV UPC 2017)
23
Assumptions for unsupervised learning
Slide credit Kevin McGuinness (DLCV UPC 2017)
24Slide credit Kevin McGuinness (DLCV UPC 2017)
The manifold hypothesis
25
The manifold hypothesis
Slide credit Kevin McGuinness (DLCV UPC 2017)
x1
x2
Linear manifold
wTx + b
x1
x2
Non-linear manifold
26
The manifold hypothesis Energy-based models
LeCun et al A Tutorial on Energy-Based Learning Predicting Structured Data 2006 httpyannlecuncomexdbpublispdflecun-06pdf
27
Autoencoder (AE)
F Van Veen ldquoThe Neural Network Zoordquo (2016)
28
Autoencoder (AE)
ldquoDeep Learning Tutorialrdquo Dept Computer Science Stanford
Autoencoders
Predict at the output the same input data
Do not need labels
29
Autoencoder (AE)
ldquoDeep Learning Tutorialrdquo Dept Computer Science Stanford
Dimensionality reduction
Use hidden layer as a feature extractor of any desired size
30
Autoencoder (AE)
EncoderW1
DecoderW2
hdata reconstruction
Loss(reconstruction error)
Latent variables (representationfeatures)
Figure Kevin McGuinness (DLCV UPC 2017)
Pretraining1 Initialize a NN solving an
autoencoding problem
31
Autoencoder (AE)
Figure Kevin McGuinness (DLCV UPC 2017)
EncoderW1
hdata ClassifierWC
Latent variables (representationfeatures)
prediction
y Loss(cross entropy)
Pretraining1 Initialize a NN solving an
autoencoding problem2 Train for final task with ldquofewrdquo labels
32
Autoencoder (AE)
Deep Learning TV ldquoAutoencoders - Ep 10rdquo
33F Van Veen ldquoThe Neural Network Zoordquo (2016)
Restricted Boltzmann Machine (RBM)
34
Restricted Boltzmann Machine (RBM)
Figure Geoffrey Hinton (2013)
Salakhutdinov Ruslan Andriy Mnih and Geoffrey Hinton Restricted Boltzmann machines for collaborative filtering Proceedings of the 24th international conference on Machine learning ACM 2007
Shallow two-layer net
Restricted = No two nodes in a layer share a connection
Bipartite graph
Bidirectional graph Shared weights Different biases
35
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Forward pass
36
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Forward pass
37
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Forward pass
38
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Backwardpass
39
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Backwardpass
40
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Backwardpass
The reconstructed values at the visible layer are compared with the actual ones with the KL Divergence
41
Restricted Boltzmann Machine (RBM)
Figure Geoffrey Hinton (2013)
Salakhutdinov Ruslan Andriy Mnih and Geoffrey Hinton Restricted Boltzmann machines for collaborative filtering Proceedings of the 24th international conference on Machine learning ACM 2007
42
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
RBMs are a specific type of autoencoder
Unsupervisedlearning
43
Restricted Boltzmann Machine (RBM)
Deep Learning TV ldquoRestricted Boltzmann Machinesrdquo
44
Deep Belief Networks (DBN)
F Van Veen ldquoThe Neural Network Zoordquo (2016)
45
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMs
46
Deep Belief Networks (DBN)
Architecture like an MLP Training as a stack of
RBMs
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
47
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMs
48
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMs
49
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMshellip so they do not need
labels
Unsupervisedlearning
50
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
After the DBN is trained it can be fine-tuned with a reduced amount of labels to solve a supervised task with superior performance
Supervisedlearning
Softm
ax
51
Deep Belief Networks (DBN)
Deep Learning TV ldquoDeep Belief Netsrdquo
52
Deep Belief Networks (DBN)
Geoffrey Hinton Introduction to Deep Learning amp Deep Belief Netsrdquo (2012)Geoorey Hinton ldquoTutorial on Deep Belief Networksrdquo NIPS 2007
53
Deep Belief Networks (DBN)
Geoffrey Hinton
54
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
Acknowledgments
55
Junting Pan Xunyu Lin
Unsupervised Feature Learning
56
Slide credit Yann LeCun
Unsupervised Feature Learning
57
Slide credit Yann LeCun
Slide credit Junting Pan
Frame Reconstruction amp Prediction
59Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
Frame Reconstruction amp Prediction
60Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
frame prediction
Frame Reconstruction amp Prediction
61Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
frame prediction
62Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised learned features (lots of data) are fine-tuned for activity recognition (little data)
Frame Reconstruction amp Prediction
Frame Prediction
63Ranzato MarcAurelio Arthur Szlam Joan Bruna Michael Mathieu Ronan Collobert and Sumit Chopra Video (language) modeling a baseline for generative models of natural videos arXiv preprint arXiv14126604 (2014)
64Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
Video frame prediction with a ConvNet
Frame Prediction
65Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
The blurry predictions from MSE are improved with multi-scale architecture adversarial learning and an image gradient difference loss function
Frame Prediction
66Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
The blurry predictions from MSE (l1) are improved with multi-scale architecture adversarial training and an image gradient difference loss (GDL) function
Frame Prediction
67Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
Frame Prediction
68Vondrick Carl Hamed Pirsiavash and Antonio Torralba Generating videos with scene dynamics NIPS 2016
Frame Prediction
69Vondrick Carl Hamed Pirsiavash and Antonio Torralba Generating videos with scene dynamics NIPS 2016
Frame Prediction
70Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
71
Frame Prediction
Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
Given an input image probabilistic generation of future frames with a Variational AutoEncoder (VAE)
72
Frame Prediction
Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
Encodes image as feature maps and motion as and cross-convolutional kernels
73
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
First steps in video feature learning
74Le Quoc V Will Y Zou Serena Y Yeung and Andrew Y Ng Learning hierarchical invariant spatio-temporal features for action recognition with independent subspace analysis CVPR 2011
Temporal Weak Labels
75Goroshin Ross Joan Bruna Jonathan Tompson David Eigen and Yann LeCun Unsupervised learning of spatiotemporally coherent metrics ICCV 2015
Assumption adjacent video frames contain semantically similar informationAutoencoder trained with regularizations by slowliness and sparisty
76Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
77Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
78(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Temporal order of frames is exploited as the supervisory signal for learning
Temporal Weak Labels
79(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Take temporal order as the supervisory signals for learning
Shuffled sequences
Binary classification
In order
Not in order
Temporal Weak Labels
80Fernando Basura Hakan Bilen Efstratios Gavves and Stephen Gould Self-supervised video representation learning with odd-one-out networks CVPR 2017
Temporal Weak LabelsTrain a network to detect which of the video sequences contains frames wrong order
81
Spatio-Temporal Weak Labels
X Lin Campos V Giroacute-i-Nieto X Torres J and Canton-Ferrer C ldquoDisentangling Motion Foreground and Background Features in Videosrdquo in CVPR 2017 Workshop Brave New Motion Representations
kernel dec
C3D
ForegroundMotion
FirstForeground
Background
Fg
Dec
Bg
Dec
Fg
Dec Reconstruction
of foreground in last frame
Reconstruction of foreground in
first frame
Reconstruction of background in first frame
uNLC
MaskBlock
gradients
Last foreground
Kernels
shareweights
82
Spatio-Temporal Weak Labels
Pathak Deepak Ross Girshick Piotr Dollaacuter Trevor Darrell and Bharath Hariharan Learning features by watching objects move CVPR 2017
83Greff Klaus Antti Rasmus Mathias Berglund Tele Hao Harri Valpola and Juergen Schmidhuber Tagger Deep unsupervised perceptual grouping NIPS 2016 [video] [code]
Spatio-Temporal Weak Labels
84Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
85
Audio Features from Visual weak labels
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Object amp Scenes recognition in videos by analysing the audio track (only)
86Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
87Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
88Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
89
Visualization of the video frames associated to the sounds that activate some of the last hidden units of Soundnet (conv7)
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Audio Features from Visual weak labels
90
Audio amp Visual features from alignement
90Arandjelović Relja and Andrew Zisserman Look Listen and Learn ICCV 2017
Audio and visual features learned by assessing alignement
91L Chen S Srivastava Z Duan and C Xu Deep Cross-Modal Audio-Visual Generation ACM International Conference on Multimedia Thematic Workshops 2017
Audio amp Visual features from alignement
92Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
93Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
Video to Speech Representations
CNN(VGG)
Frame from a silent video
Audio feature
Post-hoc synthesis
94Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
95Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
Speech to Video Synthesis (mouth)
96Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
97Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
Speech to Video Synthesis (pose amp emotion)
98Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
99Suwajanakorn Supasorn Steven M Seitz and Ira Kemelmacher-Shlizerman Synthesizing Obama learning lip sync from audio SIGGRAPH 2017
Speech to Video Synthesis (mouth)
100
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning

Semi supervised decision boundary
14
How data distribution P(x) influences decisions (1D)
Slide credit Kevin McGuinness (DLCV UPC 2017)
15
How data distribution P(x) influences decisions (2D)
Slide credit Kevin McGuinness (DLCV UPC 2017)
16
How data distribution P(x) influences decisions (2D)
Slide credit Kevin McGuinness (DLCV UPC 2017)
How P(x) is valuable for naive Bayesian classifier
17
X DataY Labels
Slide credit Kevin McGuinness (DLCV UPC 2017)
x1
x2
Not linearly separable in this 2D space (
18
How clustering is valueble for linear classifiers
Slide credit Kevin McGuinness (DLCV UPC 2017)
x1
x2Cluster 1 Cluster 2
Cluster 3Cluster 4
1 2 3 4
1 2 3 4
4D BoW representation
Separable with a linear classifiers in a 4D space
19
How clustering is valueble for linear classifiers
Slide credit Kevin McGuinness (DLCV UPC 2017)
Example from Kevin McGuinness Juyter notebook 20
How clustering is valueble for linear classifiers
21
Assumptions for unsupervised learning
Slide credit Kevin McGuinness (DLCV UPC 2017)
22
Assumptions for unsupervised learning
Slide credit Kevin McGuinness (DLCV UPC 2017)
23
Assumptions for unsupervised learning
Slide credit Kevin McGuinness (DLCV UPC 2017)
24Slide credit Kevin McGuinness (DLCV UPC 2017)
The manifold hypothesis
25
The manifold hypothesis
Slide credit Kevin McGuinness (DLCV UPC 2017)
x1
x2
Linear manifold
wTx + b
x1
x2
Non-linear manifold
26
The manifold hypothesis Energy-based models
LeCun et al A Tutorial on Energy-Based Learning Predicting Structured Data 2006 httpyannlecuncomexdbpublispdflecun-06pdf
27
Autoencoder (AE)
F Van Veen ldquoThe Neural Network Zoordquo (2016)
28
Autoencoder (AE)
ldquoDeep Learning Tutorialrdquo Dept Computer Science Stanford
Autoencoders
Predict at the output the same input data
Do not need labels
29
Autoencoder (AE)
ldquoDeep Learning Tutorialrdquo Dept Computer Science Stanford
Dimensionality reduction
Use hidden layer as a feature extractor of any desired size
30
Autoencoder (AE)
EncoderW1
DecoderW2
hdata reconstruction
Loss(reconstruction error)
Latent variables (representationfeatures)
Figure Kevin McGuinness (DLCV UPC 2017)
Pretraining1 Initialize a NN solving an
autoencoding problem
31
Autoencoder (AE)
Figure Kevin McGuinness (DLCV UPC 2017)
EncoderW1
hdata ClassifierWC
Latent variables (representationfeatures)
prediction
y Loss(cross entropy)
Pretraining1 Initialize a NN solving an
autoencoding problem2 Train for final task with ldquofewrdquo labels
32
Autoencoder (AE)
Deep Learning TV ldquoAutoencoders - Ep 10rdquo
33F Van Veen ldquoThe Neural Network Zoordquo (2016)
Restricted Boltzmann Machine (RBM)
34
Restricted Boltzmann Machine (RBM)
Figure Geoffrey Hinton (2013)
Salakhutdinov Ruslan Andriy Mnih and Geoffrey Hinton Restricted Boltzmann machines for collaborative filtering Proceedings of the 24th international conference on Machine learning ACM 2007
Shallow two-layer net
Restricted = No two nodes in a layer share a connection
Bipartite graph
Bidirectional graph Shared weights Different biases
35
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Forward pass
36
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Forward pass
37
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Forward pass
38
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Backwardpass
39
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Backwardpass
40
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Backwardpass
The reconstructed values at the visible layer are compared with the actual ones with the KL Divergence
41
Restricted Boltzmann Machine (RBM)
Figure Geoffrey Hinton (2013)
Salakhutdinov Ruslan Andriy Mnih and Geoffrey Hinton Restricted Boltzmann machines for collaborative filtering Proceedings of the 24th international conference on Machine learning ACM 2007
42
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
RBMs are a specific type of autoencoder
Unsupervisedlearning
43
Restricted Boltzmann Machine (RBM)
Deep Learning TV ldquoRestricted Boltzmann Machinesrdquo
44
Deep Belief Networks (DBN)
F Van Veen ldquoThe Neural Network Zoordquo (2016)
45
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMs
46
Deep Belief Networks (DBN)
Architecture like an MLP Training as a stack of
RBMs
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
47
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMs
48
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMs
49
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMshellip so they do not need
labels
Unsupervisedlearning
50
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
After the DBN is trained it can be fine-tuned with a reduced amount of labels to solve a supervised task with superior performance
Supervisedlearning
Softm
ax
51
Deep Belief Networks (DBN)
Deep Learning TV ldquoDeep Belief Netsrdquo
52
Deep Belief Networks (DBN)
Geoffrey Hinton Introduction to Deep Learning amp Deep Belief Netsrdquo (2012)Geoorey Hinton ldquoTutorial on Deep Belief Networksrdquo NIPS 2007
53
Deep Belief Networks (DBN)
Geoffrey Hinton
54
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
Acknowledgments
55
Junting Pan Xunyu Lin
Unsupervised Feature Learning
56
Slide credit Yann LeCun
Unsupervised Feature Learning
57
Slide credit Yann LeCun
Slide credit Junting Pan
Frame Reconstruction amp Prediction
59Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
Frame Reconstruction amp Prediction
60Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
frame prediction
Frame Reconstruction amp Prediction
61Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
frame prediction
62Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised learned features (lots of data) are fine-tuned for activity recognition (little data)
Frame Reconstruction amp Prediction
Frame Prediction
63Ranzato MarcAurelio Arthur Szlam Joan Bruna Michael Mathieu Ronan Collobert and Sumit Chopra Video (language) modeling a baseline for generative models of natural videos arXiv preprint arXiv14126604 (2014)
64Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
Video frame prediction with a ConvNet
Frame Prediction
65Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
The blurry predictions from MSE are improved with multi-scale architecture adversarial learning and an image gradient difference loss function
Frame Prediction
66Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
The blurry predictions from MSE (l1) are improved with multi-scale architecture adversarial training and an image gradient difference loss (GDL) function
Frame Prediction
67Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
Frame Prediction
68Vondrick Carl Hamed Pirsiavash and Antonio Torralba Generating videos with scene dynamics NIPS 2016
Frame Prediction
69Vondrick Carl Hamed Pirsiavash and Antonio Torralba Generating videos with scene dynamics NIPS 2016
Frame Prediction
70Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
71
Frame Prediction
Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
Given an input image probabilistic generation of future frames with a Variational AutoEncoder (VAE)
72
Frame Prediction
Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
Encodes image as feature maps and motion as and cross-convolutional kernels
73
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
First steps in video feature learning
74Le Quoc V Will Y Zou Serena Y Yeung and Andrew Y Ng Learning hierarchical invariant spatio-temporal features for action recognition with independent subspace analysis CVPR 2011
Temporal Weak Labels
75Goroshin Ross Joan Bruna Jonathan Tompson David Eigen and Yann LeCun Unsupervised learning of spatiotemporally coherent metrics ICCV 2015
Assumption adjacent video frames contain semantically similar informationAutoencoder trained with regularizations by slowliness and sparisty
76Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
77Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
78(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Temporal order of frames is exploited as the supervisory signal for learning
Temporal Weak Labels
79(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Take temporal order as the supervisory signals for learning
Shuffled sequences
Binary classification
In order
Not in order
Temporal Weak Labels
80Fernando Basura Hakan Bilen Efstratios Gavves and Stephen Gould Self-supervised video representation learning with odd-one-out networks CVPR 2017
Temporal Weak LabelsTrain a network to detect which of the video sequences contains frames wrong order
81
Spatio-Temporal Weak Labels
X Lin Campos V Giroacute-i-Nieto X Torres J and Canton-Ferrer C ldquoDisentangling Motion Foreground and Background Features in Videosrdquo in CVPR 2017 Workshop Brave New Motion Representations
kernel dec
C3D
ForegroundMotion
FirstForeground
Background
Fg
Dec
Bg
Dec
Fg
Dec Reconstruction
of foreground in last frame
Reconstruction of foreground in
first frame
Reconstruction of background in first frame
uNLC
MaskBlock
gradients
Last foreground
Kernels
shareweights
82
Spatio-Temporal Weak Labels
Pathak Deepak Ross Girshick Piotr Dollaacuter Trevor Darrell and Bharath Hariharan Learning features by watching objects move CVPR 2017
83Greff Klaus Antti Rasmus Mathias Berglund Tele Hao Harri Valpola and Juergen Schmidhuber Tagger Deep unsupervised perceptual grouping NIPS 2016 [video] [code]
Spatio-Temporal Weak Labels
84Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
85
Audio Features from Visual weak labels
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Object amp Scenes recognition in videos by analysing the audio track (only)
86Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
87Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
88Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
89
Visualization of the video frames associated to the sounds that activate some of the last hidden units of Soundnet (conv7)
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Audio Features from Visual weak labels
90
Audio amp Visual features from alignement
90Arandjelović Relja and Andrew Zisserman Look Listen and Learn ICCV 2017
Audio and visual features learned by assessing alignement
91L Chen S Srivastava Z Duan and C Xu Deep Cross-Modal Audio-Visual Generation ACM International Conference on Multimedia Thematic Workshops 2017
Audio amp Visual features from alignement
92Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
93Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
Video to Speech Representations
CNN(VGG)
Frame from a silent video
Audio feature
Post-hoc synthesis
94Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
95Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
Speech to Video Synthesis (mouth)
96Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
97Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
Speech to Video Synthesis (pose amp emotion)
98Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
99Suwajanakorn Supasorn Steven M Seitz and Ira Kemelmacher-Shlizerman Synthesizing Obama learning lip sync from audio SIGGRAPH 2017
Speech to Video Synthesis (mouth)
100
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning

15
How data distribution P(x) influences decisions (2D)
Slide credit Kevin McGuinness (DLCV UPC 2017)
16
How data distribution P(x) influences decisions (2D)
Slide credit Kevin McGuinness (DLCV UPC 2017)
How P(x) is valuable for naive Bayesian classifier
17
X DataY Labels
Slide credit Kevin McGuinness (DLCV UPC 2017)
x1
x2
Not linearly separable in this 2D space (
18
How clustering is valueble for linear classifiers
Slide credit Kevin McGuinness (DLCV UPC 2017)
x1
x2Cluster 1 Cluster 2
Cluster 3Cluster 4
1 2 3 4
1 2 3 4
4D BoW representation
Separable with a linear classifiers in a 4D space
19
How clustering is valueble for linear classifiers
Slide credit Kevin McGuinness (DLCV UPC 2017)
Example from Kevin McGuinness Juyter notebook 20
How clustering is valueble for linear classifiers
21
Assumptions for unsupervised learning
Slide credit Kevin McGuinness (DLCV UPC 2017)
22
Assumptions for unsupervised learning
Slide credit Kevin McGuinness (DLCV UPC 2017)
23
Assumptions for unsupervised learning
Slide credit Kevin McGuinness (DLCV UPC 2017)
24Slide credit Kevin McGuinness (DLCV UPC 2017)
The manifold hypothesis
25
The manifold hypothesis
Slide credit Kevin McGuinness (DLCV UPC 2017)
x1
x2
Linear manifold
wTx + b
x1
x2
Non-linear manifold
26
The manifold hypothesis Energy-based models
LeCun et al A Tutorial on Energy-Based Learning Predicting Structured Data 2006 httpyannlecuncomexdbpublispdflecun-06pdf
27
Autoencoder (AE)
F Van Veen ldquoThe Neural Network Zoordquo (2016)
28
Autoencoder (AE)
ldquoDeep Learning Tutorialrdquo Dept Computer Science Stanford
Autoencoders
Predict at the output the same input data
Do not need labels
29
Autoencoder (AE)
ldquoDeep Learning Tutorialrdquo Dept Computer Science Stanford
Dimensionality reduction
Use hidden layer as a feature extractor of any desired size
30
Autoencoder (AE)
EncoderW1
DecoderW2
hdata reconstruction
Loss(reconstruction error)
Latent variables (representationfeatures)
Figure Kevin McGuinness (DLCV UPC 2017)
Pretraining1 Initialize a NN solving an
autoencoding problem
31
Autoencoder (AE)
Figure Kevin McGuinness (DLCV UPC 2017)
EncoderW1
hdata ClassifierWC
Latent variables (representationfeatures)
prediction
y Loss(cross entropy)
Pretraining1 Initialize a NN solving an
autoencoding problem2 Train for final task with ldquofewrdquo labels
32
Autoencoder (AE)
Deep Learning TV ldquoAutoencoders - Ep 10rdquo
33F Van Veen ldquoThe Neural Network Zoordquo (2016)
Restricted Boltzmann Machine (RBM)
34
Restricted Boltzmann Machine (RBM)
Figure Geoffrey Hinton (2013)
Salakhutdinov Ruslan Andriy Mnih and Geoffrey Hinton Restricted Boltzmann machines for collaborative filtering Proceedings of the 24th international conference on Machine learning ACM 2007
Shallow two-layer net
Restricted = No two nodes in a layer share a connection
Bipartite graph
Bidirectional graph Shared weights Different biases
35
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Forward pass
36
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Forward pass
37
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Forward pass
38
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Backwardpass
39
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Backwardpass
40
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Backwardpass
The reconstructed values at the visible layer are compared with the actual ones with the KL Divergence
41
Restricted Boltzmann Machine (RBM)
Figure Geoffrey Hinton (2013)
Salakhutdinov Ruslan Andriy Mnih and Geoffrey Hinton Restricted Boltzmann machines for collaborative filtering Proceedings of the 24th international conference on Machine learning ACM 2007
42
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
RBMs are a specific type of autoencoder
Unsupervisedlearning
43
Restricted Boltzmann Machine (RBM)
Deep Learning TV ldquoRestricted Boltzmann Machinesrdquo
44
Deep Belief Networks (DBN)
F Van Veen ldquoThe Neural Network Zoordquo (2016)
45
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMs
46
Deep Belief Networks (DBN)
Architecture like an MLP Training as a stack of
RBMs
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
47
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMs
48
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMs
49
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMshellip so they do not need
labels
Unsupervisedlearning
50
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
After the DBN is trained it can be fine-tuned with a reduced amount of labels to solve a supervised task with superior performance
Supervisedlearning
Softm
ax
51
Deep Belief Networks (DBN)
Deep Learning TV ldquoDeep Belief Netsrdquo
52
Deep Belief Networks (DBN)
Geoffrey Hinton Introduction to Deep Learning amp Deep Belief Netsrdquo (2012)Geoorey Hinton ldquoTutorial on Deep Belief Networksrdquo NIPS 2007
53
Deep Belief Networks (DBN)
Geoffrey Hinton
54
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
Acknowledgments
55
Junting Pan Xunyu Lin
Unsupervised Feature Learning
56
Slide credit Yann LeCun
Unsupervised Feature Learning
57
Slide credit Yann LeCun
Slide credit Junting Pan
Frame Reconstruction amp Prediction
59Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
Frame Reconstruction amp Prediction
60Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
frame prediction
Frame Reconstruction amp Prediction
61Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
frame prediction
62Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised learned features (lots of data) are fine-tuned for activity recognition (little data)
Frame Reconstruction amp Prediction
Frame Prediction
63Ranzato MarcAurelio Arthur Szlam Joan Bruna Michael Mathieu Ronan Collobert and Sumit Chopra Video (language) modeling a baseline for generative models of natural videos arXiv preprint arXiv14126604 (2014)
64Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
Video frame prediction with a ConvNet
Frame Prediction
65Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
The blurry predictions from MSE are improved with multi-scale architecture adversarial learning and an image gradient difference loss function
Frame Prediction
66Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
The blurry predictions from MSE (l1) are improved with multi-scale architecture adversarial training and an image gradient difference loss (GDL) function
Frame Prediction
67Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
Frame Prediction
68Vondrick Carl Hamed Pirsiavash and Antonio Torralba Generating videos with scene dynamics NIPS 2016
Frame Prediction
69Vondrick Carl Hamed Pirsiavash and Antonio Torralba Generating videos with scene dynamics NIPS 2016
Frame Prediction
70Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
71
Frame Prediction
Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
Given an input image probabilistic generation of future frames with a Variational AutoEncoder (VAE)
72
Frame Prediction
Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
Encodes image as feature maps and motion as and cross-convolutional kernels
73
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
First steps in video feature learning
74Le Quoc V Will Y Zou Serena Y Yeung and Andrew Y Ng Learning hierarchical invariant spatio-temporal features for action recognition with independent subspace analysis CVPR 2011
Temporal Weak Labels
75Goroshin Ross Joan Bruna Jonathan Tompson David Eigen and Yann LeCun Unsupervised learning of spatiotemporally coherent metrics ICCV 2015
Assumption adjacent video frames contain semantically similar informationAutoencoder trained with regularizations by slowliness and sparisty
76Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
77Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
78(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Temporal order of frames is exploited as the supervisory signal for learning
Temporal Weak Labels
79(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Take temporal order as the supervisory signals for learning
Shuffled sequences
Binary classification
In order
Not in order
Temporal Weak Labels
80Fernando Basura Hakan Bilen Efstratios Gavves and Stephen Gould Self-supervised video representation learning with odd-one-out networks CVPR 2017
Temporal Weak LabelsTrain a network to detect which of the video sequences contains frames wrong order
81
Spatio-Temporal Weak Labels
X Lin Campos V Giroacute-i-Nieto X Torres J and Canton-Ferrer C ldquoDisentangling Motion Foreground and Background Features in Videosrdquo in CVPR 2017 Workshop Brave New Motion Representations
kernel dec
C3D
ForegroundMotion
FirstForeground
Background
Fg
Dec
Bg
Dec
Fg
Dec Reconstruction
of foreground in last frame
Reconstruction of foreground in
first frame
Reconstruction of background in first frame
uNLC
MaskBlock
gradients
Last foreground
Kernels
shareweights
82
Spatio-Temporal Weak Labels
Pathak Deepak Ross Girshick Piotr Dollaacuter Trevor Darrell and Bharath Hariharan Learning features by watching objects move CVPR 2017
83Greff Klaus Antti Rasmus Mathias Berglund Tele Hao Harri Valpola and Juergen Schmidhuber Tagger Deep unsupervised perceptual grouping NIPS 2016 [video] [code]
Spatio-Temporal Weak Labels
84Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
85
Audio Features from Visual weak labels
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Object amp Scenes recognition in videos by analysing the audio track (only)
86Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
87Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
88Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
89
Visualization of the video frames associated to the sounds that activate some of the last hidden units of Soundnet (conv7)
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Audio Features from Visual weak labels
90
Audio amp Visual features from alignement
90Arandjelović Relja and Andrew Zisserman Look Listen and Learn ICCV 2017
Audio and visual features learned by assessing alignement
91L Chen S Srivastava Z Duan and C Xu Deep Cross-Modal Audio-Visual Generation ACM International Conference on Multimedia Thematic Workshops 2017
Audio amp Visual features from alignement
92Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
93Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
Video to Speech Representations
CNN(VGG)
Frame from a silent video
Audio feature
Post-hoc synthesis
94Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
95Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
Speech to Video Synthesis (mouth)
96Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
97Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
Speech to Video Synthesis (pose amp emotion)
98Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
99Suwajanakorn Supasorn Steven M Seitz and Ira Kemelmacher-Shlizerman Synthesizing Obama learning lip sync from audio SIGGRAPH 2017
Speech to Video Synthesis (mouth)
100
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning

16
How data distribution P(x) influences decisions (2D)
Slide credit Kevin McGuinness (DLCV UPC 2017)
How P(x) is valuable for naive Bayesian classifier
17
X DataY Labels
Slide credit Kevin McGuinness (DLCV UPC 2017)
x1
x2
Not linearly separable in this 2D space (
18
How clustering is valueble for linear classifiers
Slide credit Kevin McGuinness (DLCV UPC 2017)
x1
x2Cluster 1 Cluster 2
Cluster 3Cluster 4
1 2 3 4
1 2 3 4
4D BoW representation
Separable with a linear classifiers in a 4D space
19
How clustering is valueble for linear classifiers
Slide credit Kevin McGuinness (DLCV UPC 2017)
Example from Kevin McGuinness Juyter notebook 20
How clustering is valueble for linear classifiers
21
Assumptions for unsupervised learning
Slide credit Kevin McGuinness (DLCV UPC 2017)
22
Assumptions for unsupervised learning
Slide credit Kevin McGuinness (DLCV UPC 2017)
23
Assumptions for unsupervised learning
Slide credit Kevin McGuinness (DLCV UPC 2017)
24Slide credit Kevin McGuinness (DLCV UPC 2017)
The manifold hypothesis
25
The manifold hypothesis
Slide credit Kevin McGuinness (DLCV UPC 2017)
x1
x2
Linear manifold
wTx + b
x1
x2
Non-linear manifold
26
The manifold hypothesis Energy-based models
LeCun et al A Tutorial on Energy-Based Learning Predicting Structured Data 2006 httpyannlecuncomexdbpublispdflecun-06pdf
27
Autoencoder (AE)
F Van Veen ldquoThe Neural Network Zoordquo (2016)
28
Autoencoder (AE)
ldquoDeep Learning Tutorialrdquo Dept Computer Science Stanford
Autoencoders
Predict at the output the same input data
Do not need labels
29
Autoencoder (AE)
ldquoDeep Learning Tutorialrdquo Dept Computer Science Stanford
Dimensionality reduction
Use hidden layer as a feature extractor of any desired size
30
Autoencoder (AE)
EncoderW1
DecoderW2
hdata reconstruction
Loss(reconstruction error)
Latent variables (representationfeatures)
Figure Kevin McGuinness (DLCV UPC 2017)
Pretraining1 Initialize a NN solving an
autoencoding problem
31
Autoencoder (AE)
Figure Kevin McGuinness (DLCV UPC 2017)
EncoderW1
hdata ClassifierWC
Latent variables (representationfeatures)
prediction
y Loss(cross entropy)
Pretraining1 Initialize a NN solving an
autoencoding problem2 Train for final task with ldquofewrdquo labels
32
Autoencoder (AE)
Deep Learning TV ldquoAutoencoders - Ep 10rdquo
33F Van Veen ldquoThe Neural Network Zoordquo (2016)
Restricted Boltzmann Machine (RBM)
34
Restricted Boltzmann Machine (RBM)
Figure Geoffrey Hinton (2013)
Salakhutdinov Ruslan Andriy Mnih and Geoffrey Hinton Restricted Boltzmann machines for collaborative filtering Proceedings of the 24th international conference on Machine learning ACM 2007
Shallow two-layer net
Restricted = No two nodes in a layer share a connection
Bipartite graph
Bidirectional graph Shared weights Different biases
35
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Forward pass
36
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Forward pass
37
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Forward pass
38
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Backwardpass
39
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Backwardpass
40
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Backwardpass
The reconstructed values at the visible layer are compared with the actual ones with the KL Divergence
41
Restricted Boltzmann Machine (RBM)
Figure Geoffrey Hinton (2013)
Salakhutdinov Ruslan Andriy Mnih and Geoffrey Hinton Restricted Boltzmann machines for collaborative filtering Proceedings of the 24th international conference on Machine learning ACM 2007
42
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
RBMs are a specific type of autoencoder
Unsupervisedlearning
43
Restricted Boltzmann Machine (RBM)
Deep Learning TV ldquoRestricted Boltzmann Machinesrdquo
44
Deep Belief Networks (DBN)
F Van Veen ldquoThe Neural Network Zoordquo (2016)
45
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMs
46
Deep Belief Networks (DBN)
Architecture like an MLP Training as a stack of
RBMs
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
47
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMs
48
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMs
49
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMshellip so they do not need
labels
Unsupervisedlearning
50
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
After the DBN is trained it can be fine-tuned with a reduced amount of labels to solve a supervised task with superior performance
Supervisedlearning
Softm
ax
51
Deep Belief Networks (DBN)
Deep Learning TV ldquoDeep Belief Netsrdquo
52
Deep Belief Networks (DBN)
Geoffrey Hinton Introduction to Deep Learning amp Deep Belief Netsrdquo (2012)Geoorey Hinton ldquoTutorial on Deep Belief Networksrdquo NIPS 2007
53
Deep Belief Networks (DBN)
Geoffrey Hinton
54
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
Acknowledgments
55
Junting Pan Xunyu Lin
Unsupervised Feature Learning
56
Slide credit Yann LeCun
Unsupervised Feature Learning
57
Slide credit Yann LeCun
Slide credit Junting Pan
Frame Reconstruction amp Prediction
59Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
Frame Reconstruction amp Prediction
60Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
frame prediction
Frame Reconstruction amp Prediction
61Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
frame prediction
62Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised learned features (lots of data) are fine-tuned for activity recognition (little data)
Frame Reconstruction amp Prediction
Frame Prediction
63Ranzato MarcAurelio Arthur Szlam Joan Bruna Michael Mathieu Ronan Collobert and Sumit Chopra Video (language) modeling a baseline for generative models of natural videos arXiv preprint arXiv14126604 (2014)
64Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
Video frame prediction with a ConvNet
Frame Prediction
65Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
The blurry predictions from MSE are improved with multi-scale architecture adversarial learning and an image gradient difference loss function
Frame Prediction
66Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
The blurry predictions from MSE (l1) are improved with multi-scale architecture adversarial training and an image gradient difference loss (GDL) function
Frame Prediction
67Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
Frame Prediction
68Vondrick Carl Hamed Pirsiavash and Antonio Torralba Generating videos with scene dynamics NIPS 2016
Frame Prediction
69Vondrick Carl Hamed Pirsiavash and Antonio Torralba Generating videos with scene dynamics NIPS 2016
Frame Prediction
70Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
71
Frame Prediction
Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
Given an input image probabilistic generation of future frames with a Variational AutoEncoder (VAE)
72
Frame Prediction
Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
Encodes image as feature maps and motion as and cross-convolutional kernels
73
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
First steps in video feature learning
74Le Quoc V Will Y Zou Serena Y Yeung and Andrew Y Ng Learning hierarchical invariant spatio-temporal features for action recognition with independent subspace analysis CVPR 2011
Temporal Weak Labels
75Goroshin Ross Joan Bruna Jonathan Tompson David Eigen and Yann LeCun Unsupervised learning of spatiotemporally coherent metrics ICCV 2015
Assumption adjacent video frames contain semantically similar informationAutoencoder trained with regularizations by slowliness and sparisty
76Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
77Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
78(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Temporal order of frames is exploited as the supervisory signal for learning
Temporal Weak Labels
79(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Take temporal order as the supervisory signals for learning
Shuffled sequences
Binary classification
In order
Not in order
Temporal Weak Labels
80Fernando Basura Hakan Bilen Efstratios Gavves and Stephen Gould Self-supervised video representation learning with odd-one-out networks CVPR 2017
Temporal Weak LabelsTrain a network to detect which of the video sequences contains frames wrong order
81
Spatio-Temporal Weak Labels
X Lin Campos V Giroacute-i-Nieto X Torres J and Canton-Ferrer C ldquoDisentangling Motion Foreground and Background Features in Videosrdquo in CVPR 2017 Workshop Brave New Motion Representations
kernel dec
C3D
ForegroundMotion
FirstForeground
Background
Fg
Dec
Bg
Dec
Fg
Dec Reconstruction
of foreground in last frame
Reconstruction of foreground in
first frame
Reconstruction of background in first frame
uNLC
MaskBlock
gradients
Last foreground
Kernels
shareweights
82
Spatio-Temporal Weak Labels
Pathak Deepak Ross Girshick Piotr Dollaacuter Trevor Darrell and Bharath Hariharan Learning features by watching objects move CVPR 2017
83Greff Klaus Antti Rasmus Mathias Berglund Tele Hao Harri Valpola and Juergen Schmidhuber Tagger Deep unsupervised perceptual grouping NIPS 2016 [video] [code]
Spatio-Temporal Weak Labels
84Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
85
Audio Features from Visual weak labels
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Object amp Scenes recognition in videos by analysing the audio track (only)
86Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
87Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
88Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
89
Visualization of the video frames associated to the sounds that activate some of the last hidden units of Soundnet (conv7)
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Audio Features from Visual weak labels
90
Audio amp Visual features from alignement
90Arandjelović Relja and Andrew Zisserman Look Listen and Learn ICCV 2017
Audio and visual features learned by assessing alignement
91L Chen S Srivastava Z Duan and C Xu Deep Cross-Modal Audio-Visual Generation ACM International Conference on Multimedia Thematic Workshops 2017
Audio amp Visual features from alignement
92Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
93Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
Video to Speech Representations
CNN(VGG)
Frame from a silent video
Audio feature
Post-hoc synthesis
94Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
95Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
Speech to Video Synthesis (mouth)
96Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
97Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
Speech to Video Synthesis (pose amp emotion)
98Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
99Suwajanakorn Supasorn Steven M Seitz and Ira Kemelmacher-Shlizerman Synthesizing Obama learning lip sync from audio SIGGRAPH 2017
Speech to Video Synthesis (mouth)
100
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning

How P(x) is valuable for naive Bayesian classifier
17
X DataY Labels
Slide credit Kevin McGuinness (DLCV UPC 2017)
x1
x2
Not linearly separable in this 2D space (
18
How clustering is valueble for linear classifiers
Slide credit Kevin McGuinness (DLCV UPC 2017)
x1
x2Cluster 1 Cluster 2
Cluster 3Cluster 4
1 2 3 4
1 2 3 4
4D BoW representation
Separable with a linear classifiers in a 4D space
19
How clustering is valueble for linear classifiers
Slide credit Kevin McGuinness (DLCV UPC 2017)
Example from Kevin McGuinness Juyter notebook 20
How clustering is valueble for linear classifiers
21
Assumptions for unsupervised learning
Slide credit Kevin McGuinness (DLCV UPC 2017)
22
Assumptions for unsupervised learning
Slide credit Kevin McGuinness (DLCV UPC 2017)
23
Assumptions for unsupervised learning
Slide credit Kevin McGuinness (DLCV UPC 2017)
24Slide credit Kevin McGuinness (DLCV UPC 2017)
The manifold hypothesis
25
The manifold hypothesis
Slide credit Kevin McGuinness (DLCV UPC 2017)
x1
x2
Linear manifold
wTx + b
x1
x2
Non-linear manifold
26
The manifold hypothesis Energy-based models
LeCun et al A Tutorial on Energy-Based Learning Predicting Structured Data 2006 httpyannlecuncomexdbpublispdflecun-06pdf
27
Autoencoder (AE)
F Van Veen ldquoThe Neural Network Zoordquo (2016)
28
Autoencoder (AE)
ldquoDeep Learning Tutorialrdquo Dept Computer Science Stanford
Autoencoders
Predict at the output the same input data
Do not need labels
29
Autoencoder (AE)
ldquoDeep Learning Tutorialrdquo Dept Computer Science Stanford
Dimensionality reduction
Use hidden layer as a feature extractor of any desired size
30
Autoencoder (AE)
EncoderW1
DecoderW2
hdata reconstruction
Loss(reconstruction error)
Latent variables (representationfeatures)
Figure Kevin McGuinness (DLCV UPC 2017)
Pretraining1 Initialize a NN solving an
autoencoding problem
31
Autoencoder (AE)
Figure Kevin McGuinness (DLCV UPC 2017)
EncoderW1
hdata ClassifierWC
Latent variables (representationfeatures)
prediction
y Loss(cross entropy)
Pretraining1 Initialize a NN solving an
autoencoding problem2 Train for final task with ldquofewrdquo labels
32
Autoencoder (AE)
Deep Learning TV ldquoAutoencoders - Ep 10rdquo
33F Van Veen ldquoThe Neural Network Zoordquo (2016)
Restricted Boltzmann Machine (RBM)
34
Restricted Boltzmann Machine (RBM)
Figure Geoffrey Hinton (2013)
Salakhutdinov Ruslan Andriy Mnih and Geoffrey Hinton Restricted Boltzmann machines for collaborative filtering Proceedings of the 24th international conference on Machine learning ACM 2007
Shallow two-layer net
Restricted = No two nodes in a layer share a connection
Bipartite graph
Bidirectional graph Shared weights Different biases
35
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Forward pass
36
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Forward pass
37
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Forward pass
38
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Backwardpass
39
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Backwardpass
40
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Backwardpass
The reconstructed values at the visible layer are compared with the actual ones with the KL Divergence
41
Restricted Boltzmann Machine (RBM)
Figure Geoffrey Hinton (2013)
Salakhutdinov Ruslan Andriy Mnih and Geoffrey Hinton Restricted Boltzmann machines for collaborative filtering Proceedings of the 24th international conference on Machine learning ACM 2007
42
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
RBMs are a specific type of autoencoder
Unsupervisedlearning
43
Restricted Boltzmann Machine (RBM)
Deep Learning TV ldquoRestricted Boltzmann Machinesrdquo
44
Deep Belief Networks (DBN)
F Van Veen ldquoThe Neural Network Zoordquo (2016)
45
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMs
46
Deep Belief Networks (DBN)
Architecture like an MLP Training as a stack of
RBMs
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
47
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMs
48
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMs
49
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMshellip so they do not need
labels
Unsupervisedlearning
50
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
After the DBN is trained it can be fine-tuned with a reduced amount of labels to solve a supervised task with superior performance
Supervisedlearning
Softm
ax
51
Deep Belief Networks (DBN)
Deep Learning TV ldquoDeep Belief Netsrdquo
52
Deep Belief Networks (DBN)
Geoffrey Hinton Introduction to Deep Learning amp Deep Belief Netsrdquo (2012)Geoorey Hinton ldquoTutorial on Deep Belief Networksrdquo NIPS 2007
53
Deep Belief Networks (DBN)
Geoffrey Hinton
54
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
Acknowledgments
55
Junting Pan Xunyu Lin
Unsupervised Feature Learning
56
Slide credit Yann LeCun
Unsupervised Feature Learning
57
Slide credit Yann LeCun
Slide credit Junting Pan
Frame Reconstruction amp Prediction
59Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
Frame Reconstruction amp Prediction
60Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
frame prediction
Frame Reconstruction amp Prediction
61Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
frame prediction
62Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised learned features (lots of data) are fine-tuned for activity recognition (little data)
Frame Reconstruction amp Prediction
Frame Prediction
63Ranzato MarcAurelio Arthur Szlam Joan Bruna Michael Mathieu Ronan Collobert and Sumit Chopra Video (language) modeling a baseline for generative models of natural videos arXiv preprint arXiv14126604 (2014)
64Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
Video frame prediction with a ConvNet
Frame Prediction
65Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
The blurry predictions from MSE are improved with multi-scale architecture adversarial learning and an image gradient difference loss function
Frame Prediction
66Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
The blurry predictions from MSE (l1) are improved with multi-scale architecture adversarial training and an image gradient difference loss (GDL) function
Frame Prediction
67Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
Frame Prediction
68Vondrick Carl Hamed Pirsiavash and Antonio Torralba Generating videos with scene dynamics NIPS 2016
Frame Prediction
69Vondrick Carl Hamed Pirsiavash and Antonio Torralba Generating videos with scene dynamics NIPS 2016
Frame Prediction
70Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
71
Frame Prediction
Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
Given an input image probabilistic generation of future frames with a Variational AutoEncoder (VAE)
72
Frame Prediction
Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
Encodes image as feature maps and motion as and cross-convolutional kernels
73
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
First steps in video feature learning
74Le Quoc V Will Y Zou Serena Y Yeung and Andrew Y Ng Learning hierarchical invariant spatio-temporal features for action recognition with independent subspace analysis CVPR 2011
Temporal Weak Labels
75Goroshin Ross Joan Bruna Jonathan Tompson David Eigen and Yann LeCun Unsupervised learning of spatiotemporally coherent metrics ICCV 2015
Assumption adjacent video frames contain semantically similar informationAutoencoder trained with regularizations by slowliness and sparisty
76Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
77Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
78(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Temporal order of frames is exploited as the supervisory signal for learning
Temporal Weak Labels
79(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Take temporal order as the supervisory signals for learning
Shuffled sequences
Binary classification
In order
Not in order
Temporal Weak Labels
80Fernando Basura Hakan Bilen Efstratios Gavves and Stephen Gould Self-supervised video representation learning with odd-one-out networks CVPR 2017
Temporal Weak LabelsTrain a network to detect which of the video sequences contains frames wrong order
81
Spatio-Temporal Weak Labels
X Lin Campos V Giroacute-i-Nieto X Torres J and Canton-Ferrer C ldquoDisentangling Motion Foreground and Background Features in Videosrdquo in CVPR 2017 Workshop Brave New Motion Representations
kernel dec
C3D
ForegroundMotion
FirstForeground
Background
Fg
Dec
Bg
Dec
Fg
Dec Reconstruction
of foreground in last frame
Reconstruction of foreground in
first frame
Reconstruction of background in first frame
uNLC
MaskBlock
gradients
Last foreground
Kernels
shareweights
82
Spatio-Temporal Weak Labels
Pathak Deepak Ross Girshick Piotr Dollaacuter Trevor Darrell and Bharath Hariharan Learning features by watching objects move CVPR 2017
83Greff Klaus Antti Rasmus Mathias Berglund Tele Hao Harri Valpola and Juergen Schmidhuber Tagger Deep unsupervised perceptual grouping NIPS 2016 [video] [code]
Spatio-Temporal Weak Labels
84Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
85
Audio Features from Visual weak labels
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Object amp Scenes recognition in videos by analysing the audio track (only)
86Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
87Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
88Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
89
Visualization of the video frames associated to the sounds that activate some of the last hidden units of Soundnet (conv7)
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Audio Features from Visual weak labels
90
Audio amp Visual features from alignement
90Arandjelović Relja and Andrew Zisserman Look Listen and Learn ICCV 2017
Audio and visual features learned by assessing alignement
91L Chen S Srivastava Z Duan and C Xu Deep Cross-Modal Audio-Visual Generation ACM International Conference on Multimedia Thematic Workshops 2017
Audio amp Visual features from alignement
92Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
93Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
Video to Speech Representations
CNN(VGG)
Frame from a silent video
Audio feature
Post-hoc synthesis
94Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
95Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
Speech to Video Synthesis (mouth)
96Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
97Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
Speech to Video Synthesis (pose amp emotion)
98Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
99Suwajanakorn Supasorn Steven M Seitz and Ira Kemelmacher-Shlizerman Synthesizing Obama learning lip sync from audio SIGGRAPH 2017
Speech to Video Synthesis (mouth)
100
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning

x1
x2
Not linearly separable in this 2D space (
18
How clustering is valueble for linear classifiers
Slide credit Kevin McGuinness (DLCV UPC 2017)
x1
x2Cluster 1 Cluster 2
Cluster 3Cluster 4
1 2 3 4
1 2 3 4
4D BoW representation
Separable with a linear classifiers in a 4D space
19
How clustering is valueble for linear classifiers
Slide credit Kevin McGuinness (DLCV UPC 2017)
Example from Kevin McGuinness Juyter notebook 20
How clustering is valueble for linear classifiers
21
Assumptions for unsupervised learning
Slide credit Kevin McGuinness (DLCV UPC 2017)
22
Assumptions for unsupervised learning
Slide credit Kevin McGuinness (DLCV UPC 2017)
23
Assumptions for unsupervised learning
Slide credit Kevin McGuinness (DLCV UPC 2017)
24Slide credit Kevin McGuinness (DLCV UPC 2017)
The manifold hypothesis
25
The manifold hypothesis
Slide credit Kevin McGuinness (DLCV UPC 2017)
x1
x2
Linear manifold
wTx + b
x1
x2
Non-linear manifold
26
The manifold hypothesis Energy-based models
LeCun et al A Tutorial on Energy-Based Learning Predicting Structured Data 2006 httpyannlecuncomexdbpublispdflecun-06pdf
27
Autoencoder (AE)
F Van Veen ldquoThe Neural Network Zoordquo (2016)
28
Autoencoder (AE)
ldquoDeep Learning Tutorialrdquo Dept Computer Science Stanford
Autoencoders
Predict at the output the same input data
Do not need labels
29
Autoencoder (AE)
ldquoDeep Learning Tutorialrdquo Dept Computer Science Stanford
Dimensionality reduction
Use hidden layer as a feature extractor of any desired size
30
Autoencoder (AE)
EncoderW1
DecoderW2
hdata reconstruction
Loss(reconstruction error)
Latent variables (representationfeatures)
Figure Kevin McGuinness (DLCV UPC 2017)
Pretraining1 Initialize a NN solving an
autoencoding problem
31
Autoencoder (AE)
Figure Kevin McGuinness (DLCV UPC 2017)
EncoderW1
hdata ClassifierWC
Latent variables (representationfeatures)
prediction
y Loss(cross entropy)
Pretraining1 Initialize a NN solving an
autoencoding problem2 Train for final task with ldquofewrdquo labels
32
Autoencoder (AE)
Deep Learning TV ldquoAutoencoders - Ep 10rdquo
33F Van Veen ldquoThe Neural Network Zoordquo (2016)
Restricted Boltzmann Machine (RBM)
34
Restricted Boltzmann Machine (RBM)
Figure Geoffrey Hinton (2013)
Salakhutdinov Ruslan Andriy Mnih and Geoffrey Hinton Restricted Boltzmann machines for collaborative filtering Proceedings of the 24th international conference on Machine learning ACM 2007
Shallow two-layer net
Restricted = No two nodes in a layer share a connection
Bipartite graph
Bidirectional graph Shared weights Different biases
35
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Forward pass
36
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Forward pass
37
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Forward pass
38
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Backwardpass
39
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Backwardpass
40
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Backwardpass
The reconstructed values at the visible layer are compared with the actual ones with the KL Divergence
41
Restricted Boltzmann Machine (RBM)
Figure Geoffrey Hinton (2013)
Salakhutdinov Ruslan Andriy Mnih and Geoffrey Hinton Restricted Boltzmann machines for collaborative filtering Proceedings of the 24th international conference on Machine learning ACM 2007
42
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
RBMs are a specific type of autoencoder
Unsupervisedlearning
43
Restricted Boltzmann Machine (RBM)
Deep Learning TV ldquoRestricted Boltzmann Machinesrdquo
44
Deep Belief Networks (DBN)
F Van Veen ldquoThe Neural Network Zoordquo (2016)
45
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMs
46
Deep Belief Networks (DBN)
Architecture like an MLP Training as a stack of
RBMs
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
47
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMs
48
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMs
49
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMshellip so they do not need
labels
Unsupervisedlearning
50
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
After the DBN is trained it can be fine-tuned with a reduced amount of labels to solve a supervised task with superior performance
Supervisedlearning
Softm
ax
51
Deep Belief Networks (DBN)
Deep Learning TV ldquoDeep Belief Netsrdquo
52
Deep Belief Networks (DBN)
Geoffrey Hinton Introduction to Deep Learning amp Deep Belief Netsrdquo (2012)Geoorey Hinton ldquoTutorial on Deep Belief Networksrdquo NIPS 2007
53
Deep Belief Networks (DBN)
Geoffrey Hinton
54
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
Acknowledgments
55
Junting Pan Xunyu Lin
Unsupervised Feature Learning
56
Slide credit Yann LeCun
Unsupervised Feature Learning
57
Slide credit Yann LeCun
Slide credit Junting Pan
Frame Reconstruction amp Prediction
59Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
Frame Reconstruction amp Prediction
60Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
frame prediction
Frame Reconstruction amp Prediction
61Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
frame prediction
62Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised learned features (lots of data) are fine-tuned for activity recognition (little data)
Frame Reconstruction amp Prediction
Frame Prediction
63Ranzato MarcAurelio Arthur Szlam Joan Bruna Michael Mathieu Ronan Collobert and Sumit Chopra Video (language) modeling a baseline for generative models of natural videos arXiv preprint arXiv14126604 (2014)
64Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
Video frame prediction with a ConvNet
Frame Prediction
65Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
The blurry predictions from MSE are improved with multi-scale architecture adversarial learning and an image gradient difference loss function
Frame Prediction
66Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
The blurry predictions from MSE (l1) are improved with multi-scale architecture adversarial training and an image gradient difference loss (GDL) function
Frame Prediction
67Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
Frame Prediction
68Vondrick Carl Hamed Pirsiavash and Antonio Torralba Generating videos with scene dynamics NIPS 2016
Frame Prediction
69Vondrick Carl Hamed Pirsiavash and Antonio Torralba Generating videos with scene dynamics NIPS 2016
Frame Prediction
70Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
71
Frame Prediction
Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
Given an input image probabilistic generation of future frames with a Variational AutoEncoder (VAE)
72
Frame Prediction
Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
Encodes image as feature maps and motion as and cross-convolutional kernels
73
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
First steps in video feature learning
74Le Quoc V Will Y Zou Serena Y Yeung and Andrew Y Ng Learning hierarchical invariant spatio-temporal features for action recognition with independent subspace analysis CVPR 2011
Temporal Weak Labels
75Goroshin Ross Joan Bruna Jonathan Tompson David Eigen and Yann LeCun Unsupervised learning of spatiotemporally coherent metrics ICCV 2015
Assumption adjacent video frames contain semantically similar informationAutoencoder trained with regularizations by slowliness and sparisty
76Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
77Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
78(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Temporal order of frames is exploited as the supervisory signal for learning
Temporal Weak Labels
79(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Take temporal order as the supervisory signals for learning
Shuffled sequences
Binary classification
In order
Not in order
Temporal Weak Labels
80Fernando Basura Hakan Bilen Efstratios Gavves and Stephen Gould Self-supervised video representation learning with odd-one-out networks CVPR 2017
Temporal Weak LabelsTrain a network to detect which of the video sequences contains frames wrong order
81
Spatio-Temporal Weak Labels
X Lin Campos V Giroacute-i-Nieto X Torres J and Canton-Ferrer C ldquoDisentangling Motion Foreground and Background Features in Videosrdquo in CVPR 2017 Workshop Brave New Motion Representations
kernel dec
C3D
ForegroundMotion
FirstForeground
Background
Fg
Dec
Bg
Dec
Fg
Dec Reconstruction
of foreground in last frame
Reconstruction of foreground in
first frame
Reconstruction of background in first frame
uNLC
MaskBlock
gradients
Last foreground
Kernels
shareweights
82
Spatio-Temporal Weak Labels
Pathak Deepak Ross Girshick Piotr Dollaacuter Trevor Darrell and Bharath Hariharan Learning features by watching objects move CVPR 2017
83Greff Klaus Antti Rasmus Mathias Berglund Tele Hao Harri Valpola and Juergen Schmidhuber Tagger Deep unsupervised perceptual grouping NIPS 2016 [video] [code]
Spatio-Temporal Weak Labels
84Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
85
Audio Features from Visual weak labels
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Object amp Scenes recognition in videos by analysing the audio track (only)
86Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
87Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
88Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
89
Visualization of the video frames associated to the sounds that activate some of the last hidden units of Soundnet (conv7)
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Audio Features from Visual weak labels
90
Audio amp Visual features from alignement
90Arandjelović Relja and Andrew Zisserman Look Listen and Learn ICCV 2017
Audio and visual features learned by assessing alignement
91L Chen S Srivastava Z Duan and C Xu Deep Cross-Modal Audio-Visual Generation ACM International Conference on Multimedia Thematic Workshops 2017
Audio amp Visual features from alignement
92Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
93Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
Video to Speech Representations
CNN(VGG)
Frame from a silent video
Audio feature
Post-hoc synthesis
94Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
95Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
Speech to Video Synthesis (mouth)
96Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
97Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
Speech to Video Synthesis (pose amp emotion)
98Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
99Suwajanakorn Supasorn Steven M Seitz and Ira Kemelmacher-Shlizerman Synthesizing Obama learning lip sync from audio SIGGRAPH 2017
Speech to Video Synthesis (mouth)
100
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning

x1
x2Cluster 1 Cluster 2
Cluster 3Cluster 4
1 2 3 4
1 2 3 4
4D BoW representation
Separable with a linear classifiers in a 4D space
19
How clustering is valueble for linear classifiers
Slide credit Kevin McGuinness (DLCV UPC 2017)
Example from Kevin McGuinness Juyter notebook 20
How clustering is valueble for linear classifiers
21
Assumptions for unsupervised learning
Slide credit Kevin McGuinness (DLCV UPC 2017)
22
Assumptions for unsupervised learning
Slide credit Kevin McGuinness (DLCV UPC 2017)
23
Assumptions for unsupervised learning
Slide credit Kevin McGuinness (DLCV UPC 2017)
24Slide credit Kevin McGuinness (DLCV UPC 2017)
The manifold hypothesis
25
The manifold hypothesis
Slide credit Kevin McGuinness (DLCV UPC 2017)
x1
x2
Linear manifold
wTx + b
x1
x2
Non-linear manifold
26
The manifold hypothesis Energy-based models
LeCun et al A Tutorial on Energy-Based Learning Predicting Structured Data 2006 httpyannlecuncomexdbpublispdflecun-06pdf
27
Autoencoder (AE)
F Van Veen ldquoThe Neural Network Zoordquo (2016)
28
Autoencoder (AE)
ldquoDeep Learning Tutorialrdquo Dept Computer Science Stanford
Autoencoders
Predict at the output the same input data
Do not need labels
29
Autoencoder (AE)
ldquoDeep Learning Tutorialrdquo Dept Computer Science Stanford
Dimensionality reduction
Use hidden layer as a feature extractor of any desired size
30
Autoencoder (AE)
EncoderW1
DecoderW2
hdata reconstruction
Loss(reconstruction error)
Latent variables (representationfeatures)
Figure Kevin McGuinness (DLCV UPC 2017)
Pretraining1 Initialize a NN solving an
autoencoding problem
31
Autoencoder (AE)
Figure Kevin McGuinness (DLCV UPC 2017)
EncoderW1
hdata ClassifierWC
Latent variables (representationfeatures)
prediction
y Loss(cross entropy)
Pretraining1 Initialize a NN solving an
autoencoding problem2 Train for final task with ldquofewrdquo labels
32
Autoencoder (AE)
Deep Learning TV ldquoAutoencoders - Ep 10rdquo
33F Van Veen ldquoThe Neural Network Zoordquo (2016)
Restricted Boltzmann Machine (RBM)
34
Restricted Boltzmann Machine (RBM)
Figure Geoffrey Hinton (2013)
Salakhutdinov Ruslan Andriy Mnih and Geoffrey Hinton Restricted Boltzmann machines for collaborative filtering Proceedings of the 24th international conference on Machine learning ACM 2007
Shallow two-layer net
Restricted = No two nodes in a layer share a connection
Bipartite graph
Bidirectional graph Shared weights Different biases
35
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Forward pass
36
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Forward pass
37
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Forward pass
38
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Backwardpass
39
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Backwardpass
40
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Backwardpass
The reconstructed values at the visible layer are compared with the actual ones with the KL Divergence
41
Restricted Boltzmann Machine (RBM)
Figure Geoffrey Hinton (2013)
Salakhutdinov Ruslan Andriy Mnih and Geoffrey Hinton Restricted Boltzmann machines for collaborative filtering Proceedings of the 24th international conference on Machine learning ACM 2007
42
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
RBMs are a specific type of autoencoder
Unsupervisedlearning
43
Restricted Boltzmann Machine (RBM)
Deep Learning TV ldquoRestricted Boltzmann Machinesrdquo
44
Deep Belief Networks (DBN)
F Van Veen ldquoThe Neural Network Zoordquo (2016)
45
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMs
46
Deep Belief Networks (DBN)
Architecture like an MLP Training as a stack of
RBMs
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
47
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMs
48
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMs
49
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMshellip so they do not need
labels
Unsupervisedlearning
50
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
After the DBN is trained it can be fine-tuned with a reduced amount of labels to solve a supervised task with superior performance
Supervisedlearning
Softm
ax
51
Deep Belief Networks (DBN)
Deep Learning TV ldquoDeep Belief Netsrdquo
52
Deep Belief Networks (DBN)
Geoffrey Hinton Introduction to Deep Learning amp Deep Belief Netsrdquo (2012)Geoorey Hinton ldquoTutorial on Deep Belief Networksrdquo NIPS 2007
53
Deep Belief Networks (DBN)
Geoffrey Hinton
54
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
Acknowledgments
55
Junting Pan Xunyu Lin
Unsupervised Feature Learning
56
Slide credit Yann LeCun
Unsupervised Feature Learning
57
Slide credit Yann LeCun
Slide credit Junting Pan
Frame Reconstruction amp Prediction
59Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
Frame Reconstruction amp Prediction
60Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
frame prediction
Frame Reconstruction amp Prediction
61Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
frame prediction
62Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised learned features (lots of data) are fine-tuned for activity recognition (little data)
Frame Reconstruction amp Prediction
Frame Prediction
63Ranzato MarcAurelio Arthur Szlam Joan Bruna Michael Mathieu Ronan Collobert and Sumit Chopra Video (language) modeling a baseline for generative models of natural videos arXiv preprint arXiv14126604 (2014)
64Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
Video frame prediction with a ConvNet
Frame Prediction
65Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
The blurry predictions from MSE are improved with multi-scale architecture adversarial learning and an image gradient difference loss function
Frame Prediction
66Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
The blurry predictions from MSE (l1) are improved with multi-scale architecture adversarial training and an image gradient difference loss (GDL) function
Frame Prediction
67Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
Frame Prediction
68Vondrick Carl Hamed Pirsiavash and Antonio Torralba Generating videos with scene dynamics NIPS 2016
Frame Prediction
69Vondrick Carl Hamed Pirsiavash and Antonio Torralba Generating videos with scene dynamics NIPS 2016
Frame Prediction
70Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
71
Frame Prediction
Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
Given an input image probabilistic generation of future frames with a Variational AutoEncoder (VAE)
72
Frame Prediction
Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
Encodes image as feature maps and motion as and cross-convolutional kernels
73
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
First steps in video feature learning
74Le Quoc V Will Y Zou Serena Y Yeung and Andrew Y Ng Learning hierarchical invariant spatio-temporal features for action recognition with independent subspace analysis CVPR 2011
Temporal Weak Labels
75Goroshin Ross Joan Bruna Jonathan Tompson David Eigen and Yann LeCun Unsupervised learning of spatiotemporally coherent metrics ICCV 2015
Assumption adjacent video frames contain semantically similar informationAutoencoder trained with regularizations by slowliness and sparisty
76Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
77Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
78(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Temporal order of frames is exploited as the supervisory signal for learning
Temporal Weak Labels
79(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Take temporal order as the supervisory signals for learning
Shuffled sequences
Binary classification
In order
Not in order
Temporal Weak Labels
80Fernando Basura Hakan Bilen Efstratios Gavves and Stephen Gould Self-supervised video representation learning with odd-one-out networks CVPR 2017
Temporal Weak LabelsTrain a network to detect which of the video sequences contains frames wrong order
81
Spatio-Temporal Weak Labels
X Lin Campos V Giroacute-i-Nieto X Torres J and Canton-Ferrer C ldquoDisentangling Motion Foreground and Background Features in Videosrdquo in CVPR 2017 Workshop Brave New Motion Representations
kernel dec
C3D
ForegroundMotion
FirstForeground
Background
Fg
Dec
Bg
Dec
Fg
Dec Reconstruction
of foreground in last frame
Reconstruction of foreground in
first frame
Reconstruction of background in first frame
uNLC
MaskBlock
gradients
Last foreground
Kernels
shareweights
82
Spatio-Temporal Weak Labels
Pathak Deepak Ross Girshick Piotr Dollaacuter Trevor Darrell and Bharath Hariharan Learning features by watching objects move CVPR 2017
83Greff Klaus Antti Rasmus Mathias Berglund Tele Hao Harri Valpola and Juergen Schmidhuber Tagger Deep unsupervised perceptual grouping NIPS 2016 [video] [code]
Spatio-Temporal Weak Labels
84Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
85
Audio Features from Visual weak labels
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Object amp Scenes recognition in videos by analysing the audio track (only)
86Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
87Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
88Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
89
Visualization of the video frames associated to the sounds that activate some of the last hidden units of Soundnet (conv7)
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Audio Features from Visual weak labels
90
Audio amp Visual features from alignement
90Arandjelović Relja and Andrew Zisserman Look Listen and Learn ICCV 2017
Audio and visual features learned by assessing alignement
91L Chen S Srivastava Z Duan and C Xu Deep Cross-Modal Audio-Visual Generation ACM International Conference on Multimedia Thematic Workshops 2017
Audio amp Visual features from alignement
92Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
93Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
Video to Speech Representations
CNN(VGG)
Frame from a silent video
Audio feature
Post-hoc synthesis
94Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
95Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
Speech to Video Synthesis (mouth)
96Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
97Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
Speech to Video Synthesis (pose amp emotion)
98Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
99Suwajanakorn Supasorn Steven M Seitz and Ira Kemelmacher-Shlizerman Synthesizing Obama learning lip sync from audio SIGGRAPH 2017
Speech to Video Synthesis (mouth)
100
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning

Example from Kevin McGuinness Juyter notebook 20
How clustering is valueble for linear classifiers
21
Assumptions for unsupervised learning
Slide credit Kevin McGuinness (DLCV UPC 2017)
22
Assumptions for unsupervised learning
Slide credit Kevin McGuinness (DLCV UPC 2017)
23
Assumptions for unsupervised learning
Slide credit Kevin McGuinness (DLCV UPC 2017)
24Slide credit Kevin McGuinness (DLCV UPC 2017)
The manifold hypothesis
25
The manifold hypothesis
Slide credit Kevin McGuinness (DLCV UPC 2017)
x1
x2
Linear manifold
wTx + b
x1
x2
Non-linear manifold
26
The manifold hypothesis Energy-based models
LeCun et al A Tutorial on Energy-Based Learning Predicting Structured Data 2006 httpyannlecuncomexdbpublispdflecun-06pdf
27
Autoencoder (AE)
F Van Veen ldquoThe Neural Network Zoordquo (2016)
28
Autoencoder (AE)
ldquoDeep Learning Tutorialrdquo Dept Computer Science Stanford
Autoencoders
Predict at the output the same input data
Do not need labels
29
Autoencoder (AE)
ldquoDeep Learning Tutorialrdquo Dept Computer Science Stanford
Dimensionality reduction
Use hidden layer as a feature extractor of any desired size
30
Autoencoder (AE)
EncoderW1
DecoderW2
hdata reconstruction
Loss(reconstruction error)
Latent variables (representationfeatures)
Figure Kevin McGuinness (DLCV UPC 2017)
Pretraining1 Initialize a NN solving an
autoencoding problem
31
Autoencoder (AE)
Figure Kevin McGuinness (DLCV UPC 2017)
EncoderW1
hdata ClassifierWC
Latent variables (representationfeatures)
prediction
y Loss(cross entropy)
Pretraining1 Initialize a NN solving an
autoencoding problem2 Train for final task with ldquofewrdquo labels
32
Autoencoder (AE)
Deep Learning TV ldquoAutoencoders - Ep 10rdquo
33F Van Veen ldquoThe Neural Network Zoordquo (2016)
Restricted Boltzmann Machine (RBM)
34
Restricted Boltzmann Machine (RBM)
Figure Geoffrey Hinton (2013)
Salakhutdinov Ruslan Andriy Mnih and Geoffrey Hinton Restricted Boltzmann machines for collaborative filtering Proceedings of the 24th international conference on Machine learning ACM 2007
Shallow two-layer net
Restricted = No two nodes in a layer share a connection
Bipartite graph
Bidirectional graph Shared weights Different biases
35
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Forward pass
36
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Forward pass
37
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Forward pass
38
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Backwardpass
39
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Backwardpass
40
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Backwardpass
The reconstructed values at the visible layer are compared with the actual ones with the KL Divergence
41
Restricted Boltzmann Machine (RBM)
Figure Geoffrey Hinton (2013)
Salakhutdinov Ruslan Andriy Mnih and Geoffrey Hinton Restricted Boltzmann machines for collaborative filtering Proceedings of the 24th international conference on Machine learning ACM 2007
42
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
RBMs are a specific type of autoencoder
Unsupervisedlearning
43
Restricted Boltzmann Machine (RBM)
Deep Learning TV ldquoRestricted Boltzmann Machinesrdquo
44
Deep Belief Networks (DBN)
F Van Veen ldquoThe Neural Network Zoordquo (2016)
45
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMs
46
Deep Belief Networks (DBN)
Architecture like an MLP Training as a stack of
RBMs
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
47
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMs
48
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMs
49
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMshellip so they do not need
labels
Unsupervisedlearning
50
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
After the DBN is trained it can be fine-tuned with a reduced amount of labels to solve a supervised task with superior performance
Supervisedlearning
Softm
ax
51
Deep Belief Networks (DBN)
Deep Learning TV ldquoDeep Belief Netsrdquo
52
Deep Belief Networks (DBN)
Geoffrey Hinton Introduction to Deep Learning amp Deep Belief Netsrdquo (2012)Geoorey Hinton ldquoTutorial on Deep Belief Networksrdquo NIPS 2007
53
Deep Belief Networks (DBN)
Geoffrey Hinton
54
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
Acknowledgments
55
Junting Pan Xunyu Lin
Unsupervised Feature Learning
56
Slide credit Yann LeCun
Unsupervised Feature Learning
57
Slide credit Yann LeCun
Slide credit Junting Pan
Frame Reconstruction amp Prediction
59Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
Frame Reconstruction amp Prediction
60Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
frame prediction
Frame Reconstruction amp Prediction
61Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
frame prediction
62Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised learned features (lots of data) are fine-tuned for activity recognition (little data)
Frame Reconstruction amp Prediction
Frame Prediction
63Ranzato MarcAurelio Arthur Szlam Joan Bruna Michael Mathieu Ronan Collobert and Sumit Chopra Video (language) modeling a baseline for generative models of natural videos arXiv preprint arXiv14126604 (2014)
64Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
Video frame prediction with a ConvNet
Frame Prediction
65Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
The blurry predictions from MSE are improved with multi-scale architecture adversarial learning and an image gradient difference loss function
Frame Prediction
66Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
The blurry predictions from MSE (l1) are improved with multi-scale architecture adversarial training and an image gradient difference loss (GDL) function
Frame Prediction
67Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
Frame Prediction
68Vondrick Carl Hamed Pirsiavash and Antonio Torralba Generating videos with scene dynamics NIPS 2016
Frame Prediction
69Vondrick Carl Hamed Pirsiavash and Antonio Torralba Generating videos with scene dynamics NIPS 2016
Frame Prediction
70Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
71
Frame Prediction
Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
Given an input image probabilistic generation of future frames with a Variational AutoEncoder (VAE)
72
Frame Prediction
Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
Encodes image as feature maps and motion as and cross-convolutional kernels
73
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
First steps in video feature learning
74Le Quoc V Will Y Zou Serena Y Yeung and Andrew Y Ng Learning hierarchical invariant spatio-temporal features for action recognition with independent subspace analysis CVPR 2011
Temporal Weak Labels
75Goroshin Ross Joan Bruna Jonathan Tompson David Eigen and Yann LeCun Unsupervised learning of spatiotemporally coherent metrics ICCV 2015
Assumption adjacent video frames contain semantically similar informationAutoencoder trained with regularizations by slowliness and sparisty
76Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
77Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
78(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Temporal order of frames is exploited as the supervisory signal for learning
Temporal Weak Labels
79(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Take temporal order as the supervisory signals for learning
Shuffled sequences
Binary classification
In order
Not in order
Temporal Weak Labels
80Fernando Basura Hakan Bilen Efstratios Gavves and Stephen Gould Self-supervised video representation learning with odd-one-out networks CVPR 2017
Temporal Weak LabelsTrain a network to detect which of the video sequences contains frames wrong order
81
Spatio-Temporal Weak Labels
X Lin Campos V Giroacute-i-Nieto X Torres J and Canton-Ferrer C ldquoDisentangling Motion Foreground and Background Features in Videosrdquo in CVPR 2017 Workshop Brave New Motion Representations
kernel dec
C3D
ForegroundMotion
FirstForeground
Background
Fg
Dec
Bg
Dec
Fg
Dec Reconstruction
of foreground in last frame
Reconstruction of foreground in
first frame
Reconstruction of background in first frame
uNLC
MaskBlock
gradients
Last foreground
Kernels
shareweights
82
Spatio-Temporal Weak Labels
Pathak Deepak Ross Girshick Piotr Dollaacuter Trevor Darrell and Bharath Hariharan Learning features by watching objects move CVPR 2017
83Greff Klaus Antti Rasmus Mathias Berglund Tele Hao Harri Valpola and Juergen Schmidhuber Tagger Deep unsupervised perceptual grouping NIPS 2016 [video] [code]
Spatio-Temporal Weak Labels
84Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
85
Audio Features from Visual weak labels
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Object amp Scenes recognition in videos by analysing the audio track (only)
86Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
87Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
88Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
89
Visualization of the video frames associated to the sounds that activate some of the last hidden units of Soundnet (conv7)
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Audio Features from Visual weak labels
90
Audio amp Visual features from alignement
90Arandjelović Relja and Andrew Zisserman Look Listen and Learn ICCV 2017
Audio and visual features learned by assessing alignement
91L Chen S Srivastava Z Duan and C Xu Deep Cross-Modal Audio-Visual Generation ACM International Conference on Multimedia Thematic Workshops 2017
Audio amp Visual features from alignement
92Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
93Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
Video to Speech Representations
CNN(VGG)
Frame from a silent video
Audio feature
Post-hoc synthesis
94Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
95Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
Speech to Video Synthesis (mouth)
96Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
97Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
Speech to Video Synthesis (pose amp emotion)
98Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
99Suwajanakorn Supasorn Steven M Seitz and Ira Kemelmacher-Shlizerman Synthesizing Obama learning lip sync from audio SIGGRAPH 2017
Speech to Video Synthesis (mouth)
100
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning

21
Assumptions for unsupervised learning
Slide credit Kevin McGuinness (DLCV UPC 2017)
22
Assumptions for unsupervised learning
Slide credit Kevin McGuinness (DLCV UPC 2017)
23
Assumptions for unsupervised learning
Slide credit Kevin McGuinness (DLCV UPC 2017)
24Slide credit Kevin McGuinness (DLCV UPC 2017)
The manifold hypothesis
25
The manifold hypothesis
Slide credit Kevin McGuinness (DLCV UPC 2017)
x1
x2
Linear manifold
wTx + b
x1
x2
Non-linear manifold
26
The manifold hypothesis Energy-based models
LeCun et al A Tutorial on Energy-Based Learning Predicting Structured Data 2006 httpyannlecuncomexdbpublispdflecun-06pdf
27
Autoencoder (AE)
F Van Veen ldquoThe Neural Network Zoordquo (2016)
28
Autoencoder (AE)
ldquoDeep Learning Tutorialrdquo Dept Computer Science Stanford
Autoencoders
Predict at the output the same input data
Do not need labels
29
Autoencoder (AE)
ldquoDeep Learning Tutorialrdquo Dept Computer Science Stanford
Dimensionality reduction
Use hidden layer as a feature extractor of any desired size
30
Autoencoder (AE)
EncoderW1
DecoderW2
hdata reconstruction
Loss(reconstruction error)
Latent variables (representationfeatures)
Figure Kevin McGuinness (DLCV UPC 2017)
Pretraining1 Initialize a NN solving an
autoencoding problem
31
Autoencoder (AE)
Figure Kevin McGuinness (DLCV UPC 2017)
EncoderW1
hdata ClassifierWC
Latent variables (representationfeatures)
prediction
y Loss(cross entropy)
Pretraining1 Initialize a NN solving an
autoencoding problem2 Train for final task with ldquofewrdquo labels
32
Autoencoder (AE)
Deep Learning TV ldquoAutoencoders - Ep 10rdquo
33F Van Veen ldquoThe Neural Network Zoordquo (2016)
Restricted Boltzmann Machine (RBM)
34
Restricted Boltzmann Machine (RBM)
Figure Geoffrey Hinton (2013)
Salakhutdinov Ruslan Andriy Mnih and Geoffrey Hinton Restricted Boltzmann machines for collaborative filtering Proceedings of the 24th international conference on Machine learning ACM 2007
Shallow two-layer net
Restricted = No two nodes in a layer share a connection
Bipartite graph
Bidirectional graph Shared weights Different biases
35
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Forward pass
36
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Forward pass
37
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Forward pass
38
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Backwardpass
39
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Backwardpass
40
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Backwardpass
The reconstructed values at the visible layer are compared with the actual ones with the KL Divergence
41
Restricted Boltzmann Machine (RBM)
Figure Geoffrey Hinton (2013)
Salakhutdinov Ruslan Andriy Mnih and Geoffrey Hinton Restricted Boltzmann machines for collaborative filtering Proceedings of the 24th international conference on Machine learning ACM 2007
42
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
RBMs are a specific type of autoencoder
Unsupervisedlearning
43
Restricted Boltzmann Machine (RBM)
Deep Learning TV ldquoRestricted Boltzmann Machinesrdquo
44
Deep Belief Networks (DBN)
F Van Veen ldquoThe Neural Network Zoordquo (2016)
45
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMs
46
Deep Belief Networks (DBN)
Architecture like an MLP Training as a stack of
RBMs
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
47
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMs
48
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMs
49
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMshellip so they do not need
labels
Unsupervisedlearning
50
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
After the DBN is trained it can be fine-tuned with a reduced amount of labels to solve a supervised task with superior performance
Supervisedlearning
Softm
ax
51
Deep Belief Networks (DBN)
Deep Learning TV ldquoDeep Belief Netsrdquo
52
Deep Belief Networks (DBN)
Geoffrey Hinton Introduction to Deep Learning amp Deep Belief Netsrdquo (2012)Geoorey Hinton ldquoTutorial on Deep Belief Networksrdquo NIPS 2007
53
Deep Belief Networks (DBN)
Geoffrey Hinton
54
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
Acknowledgments
55
Junting Pan Xunyu Lin
Unsupervised Feature Learning
56
Slide credit Yann LeCun
Unsupervised Feature Learning
57
Slide credit Yann LeCun
Slide credit Junting Pan
Frame Reconstruction amp Prediction
59Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
Frame Reconstruction amp Prediction
60Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
frame prediction
Frame Reconstruction amp Prediction
61Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
frame prediction
62Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised learned features (lots of data) are fine-tuned for activity recognition (little data)
Frame Reconstruction amp Prediction
Frame Prediction
63Ranzato MarcAurelio Arthur Szlam Joan Bruna Michael Mathieu Ronan Collobert and Sumit Chopra Video (language) modeling a baseline for generative models of natural videos arXiv preprint arXiv14126604 (2014)
64Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
Video frame prediction with a ConvNet
Frame Prediction
65Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
The blurry predictions from MSE are improved with multi-scale architecture adversarial learning and an image gradient difference loss function
Frame Prediction
66Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
The blurry predictions from MSE (l1) are improved with multi-scale architecture adversarial training and an image gradient difference loss (GDL) function
Frame Prediction
67Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
Frame Prediction
68Vondrick Carl Hamed Pirsiavash and Antonio Torralba Generating videos with scene dynamics NIPS 2016
Frame Prediction
69Vondrick Carl Hamed Pirsiavash and Antonio Torralba Generating videos with scene dynamics NIPS 2016
Frame Prediction
70Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
71
Frame Prediction
Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
Given an input image probabilistic generation of future frames with a Variational AutoEncoder (VAE)
72
Frame Prediction
Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
Encodes image as feature maps and motion as and cross-convolutional kernels
73
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
First steps in video feature learning
74Le Quoc V Will Y Zou Serena Y Yeung and Andrew Y Ng Learning hierarchical invariant spatio-temporal features for action recognition with independent subspace analysis CVPR 2011
Temporal Weak Labels
75Goroshin Ross Joan Bruna Jonathan Tompson David Eigen and Yann LeCun Unsupervised learning of spatiotemporally coherent metrics ICCV 2015
Assumption adjacent video frames contain semantically similar informationAutoencoder trained with regularizations by slowliness and sparisty
76Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
77Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
78(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Temporal order of frames is exploited as the supervisory signal for learning
Temporal Weak Labels
79(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Take temporal order as the supervisory signals for learning
Shuffled sequences
Binary classification
In order
Not in order
Temporal Weak Labels
80Fernando Basura Hakan Bilen Efstratios Gavves and Stephen Gould Self-supervised video representation learning with odd-one-out networks CVPR 2017
Temporal Weak LabelsTrain a network to detect which of the video sequences contains frames wrong order
81
Spatio-Temporal Weak Labels
X Lin Campos V Giroacute-i-Nieto X Torres J and Canton-Ferrer C ldquoDisentangling Motion Foreground and Background Features in Videosrdquo in CVPR 2017 Workshop Brave New Motion Representations
kernel dec
C3D
ForegroundMotion
FirstForeground
Background
Fg
Dec
Bg
Dec
Fg
Dec Reconstruction
of foreground in last frame
Reconstruction of foreground in
first frame
Reconstruction of background in first frame
uNLC
MaskBlock
gradients
Last foreground
Kernels
shareweights
82
Spatio-Temporal Weak Labels
Pathak Deepak Ross Girshick Piotr Dollaacuter Trevor Darrell and Bharath Hariharan Learning features by watching objects move CVPR 2017
83Greff Klaus Antti Rasmus Mathias Berglund Tele Hao Harri Valpola and Juergen Schmidhuber Tagger Deep unsupervised perceptual grouping NIPS 2016 [video] [code]
Spatio-Temporal Weak Labels
84Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
85
Audio Features from Visual weak labels
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Object amp Scenes recognition in videos by analysing the audio track (only)
86Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
87Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
88Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
89
Visualization of the video frames associated to the sounds that activate some of the last hidden units of Soundnet (conv7)
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Audio Features from Visual weak labels
90
Audio amp Visual features from alignement
90Arandjelović Relja and Andrew Zisserman Look Listen and Learn ICCV 2017
Audio and visual features learned by assessing alignement
91L Chen S Srivastava Z Duan and C Xu Deep Cross-Modal Audio-Visual Generation ACM International Conference on Multimedia Thematic Workshops 2017
Audio amp Visual features from alignement
92Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
93Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
Video to Speech Representations
CNN(VGG)
Frame from a silent video
Audio feature
Post-hoc synthesis
94Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
95Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
Speech to Video Synthesis (mouth)
96Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
97Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
Speech to Video Synthesis (pose amp emotion)
98Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
99Suwajanakorn Supasorn Steven M Seitz and Ira Kemelmacher-Shlizerman Synthesizing Obama learning lip sync from audio SIGGRAPH 2017
Speech to Video Synthesis (mouth)
100
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning

22
Assumptions for unsupervised learning
Slide credit Kevin McGuinness (DLCV UPC 2017)
23
Assumptions for unsupervised learning
Slide credit Kevin McGuinness (DLCV UPC 2017)
24Slide credit Kevin McGuinness (DLCV UPC 2017)
The manifold hypothesis
25
The manifold hypothesis
Slide credit Kevin McGuinness (DLCV UPC 2017)
x1
x2
Linear manifold
wTx + b
x1
x2
Non-linear manifold
26
The manifold hypothesis Energy-based models
LeCun et al A Tutorial on Energy-Based Learning Predicting Structured Data 2006 httpyannlecuncomexdbpublispdflecun-06pdf
27
Autoencoder (AE)
F Van Veen ldquoThe Neural Network Zoordquo (2016)
28
Autoencoder (AE)
ldquoDeep Learning Tutorialrdquo Dept Computer Science Stanford
Autoencoders
Predict at the output the same input data
Do not need labels
29
Autoencoder (AE)
ldquoDeep Learning Tutorialrdquo Dept Computer Science Stanford
Dimensionality reduction
Use hidden layer as a feature extractor of any desired size
30
Autoencoder (AE)
EncoderW1
DecoderW2
hdata reconstruction
Loss(reconstruction error)
Latent variables (representationfeatures)
Figure Kevin McGuinness (DLCV UPC 2017)
Pretraining1 Initialize a NN solving an
autoencoding problem
31
Autoencoder (AE)
Figure Kevin McGuinness (DLCV UPC 2017)
EncoderW1
hdata ClassifierWC
Latent variables (representationfeatures)
prediction
y Loss(cross entropy)
Pretraining1 Initialize a NN solving an
autoencoding problem2 Train for final task with ldquofewrdquo labels
32
Autoencoder (AE)
Deep Learning TV ldquoAutoencoders - Ep 10rdquo
33F Van Veen ldquoThe Neural Network Zoordquo (2016)
Restricted Boltzmann Machine (RBM)
34
Restricted Boltzmann Machine (RBM)
Figure Geoffrey Hinton (2013)
Salakhutdinov Ruslan Andriy Mnih and Geoffrey Hinton Restricted Boltzmann machines for collaborative filtering Proceedings of the 24th international conference on Machine learning ACM 2007
Shallow two-layer net
Restricted = No two nodes in a layer share a connection
Bipartite graph
Bidirectional graph Shared weights Different biases
35
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Forward pass
36
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Forward pass
37
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Forward pass
38
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Backwardpass
39
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Backwardpass
40
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Backwardpass
The reconstructed values at the visible layer are compared with the actual ones with the KL Divergence
41
Restricted Boltzmann Machine (RBM)
Figure Geoffrey Hinton (2013)
Salakhutdinov Ruslan Andriy Mnih and Geoffrey Hinton Restricted Boltzmann machines for collaborative filtering Proceedings of the 24th international conference on Machine learning ACM 2007
42
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
RBMs are a specific type of autoencoder
Unsupervisedlearning
43
Restricted Boltzmann Machine (RBM)
Deep Learning TV ldquoRestricted Boltzmann Machinesrdquo
44
Deep Belief Networks (DBN)
F Van Veen ldquoThe Neural Network Zoordquo (2016)
45
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMs
46
Deep Belief Networks (DBN)
Architecture like an MLP Training as a stack of
RBMs
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
47
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMs
48
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMs
49
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMshellip so they do not need
labels
Unsupervisedlearning
50
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
After the DBN is trained it can be fine-tuned with a reduced amount of labels to solve a supervised task with superior performance
Supervisedlearning
Softm
ax
51
Deep Belief Networks (DBN)
Deep Learning TV ldquoDeep Belief Netsrdquo
52
Deep Belief Networks (DBN)
Geoffrey Hinton Introduction to Deep Learning amp Deep Belief Netsrdquo (2012)Geoorey Hinton ldquoTutorial on Deep Belief Networksrdquo NIPS 2007
53
Deep Belief Networks (DBN)
Geoffrey Hinton
54
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
Acknowledgments
55
Junting Pan Xunyu Lin
Unsupervised Feature Learning
56
Slide credit Yann LeCun
Unsupervised Feature Learning
57
Slide credit Yann LeCun
Slide credit Junting Pan
Frame Reconstruction amp Prediction
59Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
Frame Reconstruction amp Prediction
60Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
frame prediction
Frame Reconstruction amp Prediction
61Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
frame prediction
62Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised learned features (lots of data) are fine-tuned for activity recognition (little data)
Frame Reconstruction amp Prediction
Frame Prediction
63Ranzato MarcAurelio Arthur Szlam Joan Bruna Michael Mathieu Ronan Collobert and Sumit Chopra Video (language) modeling a baseline for generative models of natural videos arXiv preprint arXiv14126604 (2014)
64Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
Video frame prediction with a ConvNet
Frame Prediction
65Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
The blurry predictions from MSE are improved with multi-scale architecture adversarial learning and an image gradient difference loss function
Frame Prediction
66Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
The blurry predictions from MSE (l1) are improved with multi-scale architecture adversarial training and an image gradient difference loss (GDL) function
Frame Prediction
67Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
Frame Prediction
68Vondrick Carl Hamed Pirsiavash and Antonio Torralba Generating videos with scene dynamics NIPS 2016
Frame Prediction
69Vondrick Carl Hamed Pirsiavash and Antonio Torralba Generating videos with scene dynamics NIPS 2016
Frame Prediction
70Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
71
Frame Prediction
Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
Given an input image probabilistic generation of future frames with a Variational AutoEncoder (VAE)
72
Frame Prediction
Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
Encodes image as feature maps and motion as and cross-convolutional kernels
73
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
First steps in video feature learning
74Le Quoc V Will Y Zou Serena Y Yeung and Andrew Y Ng Learning hierarchical invariant spatio-temporal features for action recognition with independent subspace analysis CVPR 2011
Temporal Weak Labels
75Goroshin Ross Joan Bruna Jonathan Tompson David Eigen and Yann LeCun Unsupervised learning of spatiotemporally coherent metrics ICCV 2015
Assumption adjacent video frames contain semantically similar informationAutoencoder trained with regularizations by slowliness and sparisty
76Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
77Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
78(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Temporal order of frames is exploited as the supervisory signal for learning
Temporal Weak Labels
79(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Take temporal order as the supervisory signals for learning
Shuffled sequences
Binary classification
In order
Not in order
Temporal Weak Labels
80Fernando Basura Hakan Bilen Efstratios Gavves and Stephen Gould Self-supervised video representation learning with odd-one-out networks CVPR 2017
Temporal Weak LabelsTrain a network to detect which of the video sequences contains frames wrong order
81
Spatio-Temporal Weak Labels
X Lin Campos V Giroacute-i-Nieto X Torres J and Canton-Ferrer C ldquoDisentangling Motion Foreground and Background Features in Videosrdquo in CVPR 2017 Workshop Brave New Motion Representations
kernel dec
C3D
ForegroundMotion
FirstForeground
Background
Fg
Dec
Bg
Dec
Fg
Dec Reconstruction
of foreground in last frame
Reconstruction of foreground in
first frame
Reconstruction of background in first frame
uNLC
MaskBlock
gradients
Last foreground
Kernels
shareweights
82
Spatio-Temporal Weak Labels
Pathak Deepak Ross Girshick Piotr Dollaacuter Trevor Darrell and Bharath Hariharan Learning features by watching objects move CVPR 2017
83Greff Klaus Antti Rasmus Mathias Berglund Tele Hao Harri Valpola and Juergen Schmidhuber Tagger Deep unsupervised perceptual grouping NIPS 2016 [video] [code]
Spatio-Temporal Weak Labels
84Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
85
Audio Features from Visual weak labels
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Object amp Scenes recognition in videos by analysing the audio track (only)
86Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
87Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
88Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
89
Visualization of the video frames associated to the sounds that activate some of the last hidden units of Soundnet (conv7)
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Audio Features from Visual weak labels
90
Audio amp Visual features from alignement
90Arandjelović Relja and Andrew Zisserman Look Listen and Learn ICCV 2017
Audio and visual features learned by assessing alignement
91L Chen S Srivastava Z Duan and C Xu Deep Cross-Modal Audio-Visual Generation ACM International Conference on Multimedia Thematic Workshops 2017
Audio amp Visual features from alignement
92Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
93Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
Video to Speech Representations
CNN(VGG)
Frame from a silent video
Audio feature
Post-hoc synthesis
94Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
95Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
Speech to Video Synthesis (mouth)
96Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
97Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
Speech to Video Synthesis (pose amp emotion)
98Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
99Suwajanakorn Supasorn Steven M Seitz and Ira Kemelmacher-Shlizerman Synthesizing Obama learning lip sync from audio SIGGRAPH 2017
Speech to Video Synthesis (mouth)
100
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning

23
Assumptions for unsupervised learning
Slide credit Kevin McGuinness (DLCV UPC 2017)
24Slide credit Kevin McGuinness (DLCV UPC 2017)
The manifold hypothesis
25
The manifold hypothesis
Slide credit Kevin McGuinness (DLCV UPC 2017)
x1
x2
Linear manifold
wTx + b
x1
x2
Non-linear manifold
26
The manifold hypothesis Energy-based models
LeCun et al A Tutorial on Energy-Based Learning Predicting Structured Data 2006 httpyannlecuncomexdbpublispdflecun-06pdf
27
Autoencoder (AE)
F Van Veen ldquoThe Neural Network Zoordquo (2016)
28
Autoencoder (AE)
ldquoDeep Learning Tutorialrdquo Dept Computer Science Stanford
Autoencoders
Predict at the output the same input data
Do not need labels
29
Autoencoder (AE)
ldquoDeep Learning Tutorialrdquo Dept Computer Science Stanford
Dimensionality reduction
Use hidden layer as a feature extractor of any desired size
30
Autoencoder (AE)
EncoderW1
DecoderW2
hdata reconstruction
Loss(reconstruction error)
Latent variables (representationfeatures)
Figure Kevin McGuinness (DLCV UPC 2017)
Pretraining1 Initialize a NN solving an
autoencoding problem
31
Autoencoder (AE)
Figure Kevin McGuinness (DLCV UPC 2017)
EncoderW1
hdata ClassifierWC
Latent variables (representationfeatures)
prediction
y Loss(cross entropy)
Pretraining1 Initialize a NN solving an
autoencoding problem2 Train for final task with ldquofewrdquo labels
32
Autoencoder (AE)
Deep Learning TV ldquoAutoencoders - Ep 10rdquo
33F Van Veen ldquoThe Neural Network Zoordquo (2016)
Restricted Boltzmann Machine (RBM)
34
Restricted Boltzmann Machine (RBM)
Figure Geoffrey Hinton (2013)
Salakhutdinov Ruslan Andriy Mnih and Geoffrey Hinton Restricted Boltzmann machines for collaborative filtering Proceedings of the 24th international conference on Machine learning ACM 2007
Shallow two-layer net
Restricted = No two nodes in a layer share a connection
Bipartite graph
Bidirectional graph Shared weights Different biases
35
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Forward pass
36
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Forward pass
37
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Forward pass
38
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Backwardpass
39
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Backwardpass
40
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Backwardpass
The reconstructed values at the visible layer are compared with the actual ones with the KL Divergence
41
Restricted Boltzmann Machine (RBM)
Figure Geoffrey Hinton (2013)
Salakhutdinov Ruslan Andriy Mnih and Geoffrey Hinton Restricted Boltzmann machines for collaborative filtering Proceedings of the 24th international conference on Machine learning ACM 2007
42
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
RBMs are a specific type of autoencoder
Unsupervisedlearning
43
Restricted Boltzmann Machine (RBM)
Deep Learning TV ldquoRestricted Boltzmann Machinesrdquo
44
Deep Belief Networks (DBN)
F Van Veen ldquoThe Neural Network Zoordquo (2016)
45
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMs
46
Deep Belief Networks (DBN)
Architecture like an MLP Training as a stack of
RBMs
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
47
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMs
48
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMs
49
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMshellip so they do not need
labels
Unsupervisedlearning
50
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
After the DBN is trained it can be fine-tuned with a reduced amount of labels to solve a supervised task with superior performance
Supervisedlearning
Softm
ax
51
Deep Belief Networks (DBN)
Deep Learning TV ldquoDeep Belief Netsrdquo
52
Deep Belief Networks (DBN)
Geoffrey Hinton Introduction to Deep Learning amp Deep Belief Netsrdquo (2012)Geoorey Hinton ldquoTutorial on Deep Belief Networksrdquo NIPS 2007
53
Deep Belief Networks (DBN)
Geoffrey Hinton
54
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
Acknowledgments
55
Junting Pan Xunyu Lin
Unsupervised Feature Learning
56
Slide credit Yann LeCun
Unsupervised Feature Learning
57
Slide credit Yann LeCun
Slide credit Junting Pan
Frame Reconstruction amp Prediction
59Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
Frame Reconstruction amp Prediction
60Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
frame prediction
Frame Reconstruction amp Prediction
61Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
frame prediction
62Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised learned features (lots of data) are fine-tuned for activity recognition (little data)
Frame Reconstruction amp Prediction
Frame Prediction
63Ranzato MarcAurelio Arthur Szlam Joan Bruna Michael Mathieu Ronan Collobert and Sumit Chopra Video (language) modeling a baseline for generative models of natural videos arXiv preprint arXiv14126604 (2014)
64Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
Video frame prediction with a ConvNet
Frame Prediction
65Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
The blurry predictions from MSE are improved with multi-scale architecture adversarial learning and an image gradient difference loss function
Frame Prediction
66Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
The blurry predictions from MSE (l1) are improved with multi-scale architecture adversarial training and an image gradient difference loss (GDL) function
Frame Prediction
67Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
Frame Prediction
68Vondrick Carl Hamed Pirsiavash and Antonio Torralba Generating videos with scene dynamics NIPS 2016
Frame Prediction
69Vondrick Carl Hamed Pirsiavash and Antonio Torralba Generating videos with scene dynamics NIPS 2016
Frame Prediction
70Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
71
Frame Prediction
Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
Given an input image probabilistic generation of future frames with a Variational AutoEncoder (VAE)
72
Frame Prediction
Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
Encodes image as feature maps and motion as and cross-convolutional kernels
73
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
First steps in video feature learning
74Le Quoc V Will Y Zou Serena Y Yeung and Andrew Y Ng Learning hierarchical invariant spatio-temporal features for action recognition with independent subspace analysis CVPR 2011
Temporal Weak Labels
75Goroshin Ross Joan Bruna Jonathan Tompson David Eigen and Yann LeCun Unsupervised learning of spatiotemporally coherent metrics ICCV 2015
Assumption adjacent video frames contain semantically similar informationAutoencoder trained with regularizations by slowliness and sparisty
76Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
77Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
78(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Temporal order of frames is exploited as the supervisory signal for learning
Temporal Weak Labels
79(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Take temporal order as the supervisory signals for learning
Shuffled sequences
Binary classification
In order
Not in order
Temporal Weak Labels
80Fernando Basura Hakan Bilen Efstratios Gavves and Stephen Gould Self-supervised video representation learning with odd-one-out networks CVPR 2017
Temporal Weak LabelsTrain a network to detect which of the video sequences contains frames wrong order
81
Spatio-Temporal Weak Labels
X Lin Campos V Giroacute-i-Nieto X Torres J and Canton-Ferrer C ldquoDisentangling Motion Foreground and Background Features in Videosrdquo in CVPR 2017 Workshop Brave New Motion Representations
kernel dec
C3D
ForegroundMotion
FirstForeground
Background
Fg
Dec
Bg
Dec
Fg
Dec Reconstruction
of foreground in last frame
Reconstruction of foreground in
first frame
Reconstruction of background in first frame
uNLC
MaskBlock
gradients
Last foreground
Kernels
shareweights
82
Spatio-Temporal Weak Labels
Pathak Deepak Ross Girshick Piotr Dollaacuter Trevor Darrell and Bharath Hariharan Learning features by watching objects move CVPR 2017
83Greff Klaus Antti Rasmus Mathias Berglund Tele Hao Harri Valpola and Juergen Schmidhuber Tagger Deep unsupervised perceptual grouping NIPS 2016 [video] [code]
Spatio-Temporal Weak Labels
84Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
85
Audio Features from Visual weak labels
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Object amp Scenes recognition in videos by analysing the audio track (only)
86Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
87Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
88Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
89
Visualization of the video frames associated to the sounds that activate some of the last hidden units of Soundnet (conv7)
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Audio Features from Visual weak labels
90
Audio amp Visual features from alignement
90Arandjelović Relja and Andrew Zisserman Look Listen and Learn ICCV 2017
Audio and visual features learned by assessing alignement
91L Chen S Srivastava Z Duan and C Xu Deep Cross-Modal Audio-Visual Generation ACM International Conference on Multimedia Thematic Workshops 2017
Audio amp Visual features from alignement
92Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
93Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
Video to Speech Representations
CNN(VGG)
Frame from a silent video
Audio feature
Post-hoc synthesis
94Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
95Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
Speech to Video Synthesis (mouth)
96Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
97Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
Speech to Video Synthesis (pose amp emotion)
98Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
99Suwajanakorn Supasorn Steven M Seitz and Ira Kemelmacher-Shlizerman Synthesizing Obama learning lip sync from audio SIGGRAPH 2017
Speech to Video Synthesis (mouth)
100
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning

24Slide credit Kevin McGuinness (DLCV UPC 2017)
The manifold hypothesis
25
The manifold hypothesis
Slide credit Kevin McGuinness (DLCV UPC 2017)
x1
x2
Linear manifold
wTx + b
x1
x2
Non-linear manifold
26
The manifold hypothesis Energy-based models
LeCun et al A Tutorial on Energy-Based Learning Predicting Structured Data 2006 httpyannlecuncomexdbpublispdflecun-06pdf
27
Autoencoder (AE)
F Van Veen ldquoThe Neural Network Zoordquo (2016)
28
Autoencoder (AE)
ldquoDeep Learning Tutorialrdquo Dept Computer Science Stanford
Autoencoders
Predict at the output the same input data
Do not need labels
29
Autoencoder (AE)
ldquoDeep Learning Tutorialrdquo Dept Computer Science Stanford
Dimensionality reduction
Use hidden layer as a feature extractor of any desired size
30
Autoencoder (AE)
EncoderW1
DecoderW2
hdata reconstruction
Loss(reconstruction error)
Latent variables (representationfeatures)
Figure Kevin McGuinness (DLCV UPC 2017)
Pretraining1 Initialize a NN solving an
autoencoding problem
31
Autoencoder (AE)
Figure Kevin McGuinness (DLCV UPC 2017)
EncoderW1
hdata ClassifierWC
Latent variables (representationfeatures)
prediction
y Loss(cross entropy)
Pretraining1 Initialize a NN solving an
autoencoding problem2 Train for final task with ldquofewrdquo labels
32
Autoencoder (AE)
Deep Learning TV ldquoAutoencoders - Ep 10rdquo
33F Van Veen ldquoThe Neural Network Zoordquo (2016)
Restricted Boltzmann Machine (RBM)
34
Restricted Boltzmann Machine (RBM)
Figure Geoffrey Hinton (2013)
Salakhutdinov Ruslan Andriy Mnih and Geoffrey Hinton Restricted Boltzmann machines for collaborative filtering Proceedings of the 24th international conference on Machine learning ACM 2007
Shallow two-layer net
Restricted = No two nodes in a layer share a connection
Bipartite graph
Bidirectional graph Shared weights Different biases
35
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Forward pass
36
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Forward pass
37
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Forward pass
38
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Backwardpass
39
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Backwardpass
40
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Backwardpass
The reconstructed values at the visible layer are compared with the actual ones with the KL Divergence
41
Restricted Boltzmann Machine (RBM)
Figure Geoffrey Hinton (2013)
Salakhutdinov Ruslan Andriy Mnih and Geoffrey Hinton Restricted Boltzmann machines for collaborative filtering Proceedings of the 24th international conference on Machine learning ACM 2007
42
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
RBMs are a specific type of autoencoder
Unsupervisedlearning
43
Restricted Boltzmann Machine (RBM)
Deep Learning TV ldquoRestricted Boltzmann Machinesrdquo
44
Deep Belief Networks (DBN)
F Van Veen ldquoThe Neural Network Zoordquo (2016)
45
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMs
46
Deep Belief Networks (DBN)
Architecture like an MLP Training as a stack of
RBMs
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
47
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMs
48
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMs
49
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMshellip so they do not need
labels
Unsupervisedlearning
50
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
After the DBN is trained it can be fine-tuned with a reduced amount of labels to solve a supervised task with superior performance
Supervisedlearning
Softm
ax
51
Deep Belief Networks (DBN)
Deep Learning TV ldquoDeep Belief Netsrdquo
52
Deep Belief Networks (DBN)
Geoffrey Hinton Introduction to Deep Learning amp Deep Belief Netsrdquo (2012)Geoorey Hinton ldquoTutorial on Deep Belief Networksrdquo NIPS 2007
53
Deep Belief Networks (DBN)
Geoffrey Hinton
54
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
Acknowledgments
55
Junting Pan Xunyu Lin
Unsupervised Feature Learning
56
Slide credit Yann LeCun
Unsupervised Feature Learning
57
Slide credit Yann LeCun
Slide credit Junting Pan
Frame Reconstruction amp Prediction
59Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
Frame Reconstruction amp Prediction
60Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
frame prediction
Frame Reconstruction amp Prediction
61Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
frame prediction
62Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised learned features (lots of data) are fine-tuned for activity recognition (little data)
Frame Reconstruction amp Prediction
Frame Prediction
63Ranzato MarcAurelio Arthur Szlam Joan Bruna Michael Mathieu Ronan Collobert and Sumit Chopra Video (language) modeling a baseline for generative models of natural videos arXiv preprint arXiv14126604 (2014)
64Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
Video frame prediction with a ConvNet
Frame Prediction
65Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
The blurry predictions from MSE are improved with multi-scale architecture adversarial learning and an image gradient difference loss function
Frame Prediction
66Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
The blurry predictions from MSE (l1) are improved with multi-scale architecture adversarial training and an image gradient difference loss (GDL) function
Frame Prediction
67Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
Frame Prediction
68Vondrick Carl Hamed Pirsiavash and Antonio Torralba Generating videos with scene dynamics NIPS 2016
Frame Prediction
69Vondrick Carl Hamed Pirsiavash and Antonio Torralba Generating videos with scene dynamics NIPS 2016
Frame Prediction
70Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
71
Frame Prediction
Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
Given an input image probabilistic generation of future frames with a Variational AutoEncoder (VAE)
72
Frame Prediction
Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
Encodes image as feature maps and motion as and cross-convolutional kernels
73
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
First steps in video feature learning
74Le Quoc V Will Y Zou Serena Y Yeung and Andrew Y Ng Learning hierarchical invariant spatio-temporal features for action recognition with independent subspace analysis CVPR 2011
Temporal Weak Labels
75Goroshin Ross Joan Bruna Jonathan Tompson David Eigen and Yann LeCun Unsupervised learning of spatiotemporally coherent metrics ICCV 2015
Assumption adjacent video frames contain semantically similar informationAutoencoder trained with regularizations by slowliness and sparisty
76Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
77Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
78(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Temporal order of frames is exploited as the supervisory signal for learning
Temporal Weak Labels
79(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Take temporal order as the supervisory signals for learning
Shuffled sequences
Binary classification
In order
Not in order
Temporal Weak Labels
80Fernando Basura Hakan Bilen Efstratios Gavves and Stephen Gould Self-supervised video representation learning with odd-one-out networks CVPR 2017
Temporal Weak LabelsTrain a network to detect which of the video sequences contains frames wrong order
81
Spatio-Temporal Weak Labels
X Lin Campos V Giroacute-i-Nieto X Torres J and Canton-Ferrer C ldquoDisentangling Motion Foreground and Background Features in Videosrdquo in CVPR 2017 Workshop Brave New Motion Representations
kernel dec
C3D
ForegroundMotion
FirstForeground
Background
Fg
Dec
Bg
Dec
Fg
Dec Reconstruction
of foreground in last frame
Reconstruction of foreground in
first frame
Reconstruction of background in first frame
uNLC
MaskBlock
gradients
Last foreground
Kernels
shareweights
82
Spatio-Temporal Weak Labels
Pathak Deepak Ross Girshick Piotr Dollaacuter Trevor Darrell and Bharath Hariharan Learning features by watching objects move CVPR 2017
83Greff Klaus Antti Rasmus Mathias Berglund Tele Hao Harri Valpola and Juergen Schmidhuber Tagger Deep unsupervised perceptual grouping NIPS 2016 [video] [code]
Spatio-Temporal Weak Labels
84Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
85
Audio Features from Visual weak labels
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Object amp Scenes recognition in videos by analysing the audio track (only)
86Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
87Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
88Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
89
Visualization of the video frames associated to the sounds that activate some of the last hidden units of Soundnet (conv7)
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Audio Features from Visual weak labels
90
Audio amp Visual features from alignement
90Arandjelović Relja and Andrew Zisserman Look Listen and Learn ICCV 2017
Audio and visual features learned by assessing alignement
91L Chen S Srivastava Z Duan and C Xu Deep Cross-Modal Audio-Visual Generation ACM International Conference on Multimedia Thematic Workshops 2017
Audio amp Visual features from alignement
92Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
93Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
Video to Speech Representations
CNN(VGG)
Frame from a silent video
Audio feature
Post-hoc synthesis
94Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
95Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
Speech to Video Synthesis (mouth)
96Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
97Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
Speech to Video Synthesis (pose amp emotion)
98Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
99Suwajanakorn Supasorn Steven M Seitz and Ira Kemelmacher-Shlizerman Synthesizing Obama learning lip sync from audio SIGGRAPH 2017
Speech to Video Synthesis (mouth)
100
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning

25
The manifold hypothesis
Slide credit Kevin McGuinness (DLCV UPC 2017)
x1
x2
Linear manifold
wTx + b
x1
x2
Non-linear manifold
26
The manifold hypothesis Energy-based models
LeCun et al A Tutorial on Energy-Based Learning Predicting Structured Data 2006 httpyannlecuncomexdbpublispdflecun-06pdf
27
Autoencoder (AE)
F Van Veen ldquoThe Neural Network Zoordquo (2016)
28
Autoencoder (AE)
ldquoDeep Learning Tutorialrdquo Dept Computer Science Stanford
Autoencoders
Predict at the output the same input data
Do not need labels
29
Autoencoder (AE)
ldquoDeep Learning Tutorialrdquo Dept Computer Science Stanford
Dimensionality reduction
Use hidden layer as a feature extractor of any desired size
30
Autoencoder (AE)
EncoderW1
DecoderW2
hdata reconstruction
Loss(reconstruction error)
Latent variables (representationfeatures)
Figure Kevin McGuinness (DLCV UPC 2017)
Pretraining1 Initialize a NN solving an
autoencoding problem
31
Autoencoder (AE)
Figure Kevin McGuinness (DLCV UPC 2017)
EncoderW1
hdata ClassifierWC
Latent variables (representationfeatures)
prediction
y Loss(cross entropy)
Pretraining1 Initialize a NN solving an
autoencoding problem2 Train for final task with ldquofewrdquo labels
32
Autoencoder (AE)
Deep Learning TV ldquoAutoencoders - Ep 10rdquo
33F Van Veen ldquoThe Neural Network Zoordquo (2016)
Restricted Boltzmann Machine (RBM)
34
Restricted Boltzmann Machine (RBM)
Figure Geoffrey Hinton (2013)
Salakhutdinov Ruslan Andriy Mnih and Geoffrey Hinton Restricted Boltzmann machines for collaborative filtering Proceedings of the 24th international conference on Machine learning ACM 2007
Shallow two-layer net
Restricted = No two nodes in a layer share a connection
Bipartite graph
Bidirectional graph Shared weights Different biases
35
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Forward pass
36
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Forward pass
37
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Forward pass
38
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Backwardpass
39
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Backwardpass
40
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Backwardpass
The reconstructed values at the visible layer are compared with the actual ones with the KL Divergence
41
Restricted Boltzmann Machine (RBM)
Figure Geoffrey Hinton (2013)
Salakhutdinov Ruslan Andriy Mnih and Geoffrey Hinton Restricted Boltzmann machines for collaborative filtering Proceedings of the 24th international conference on Machine learning ACM 2007
42
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
RBMs are a specific type of autoencoder
Unsupervisedlearning
43
Restricted Boltzmann Machine (RBM)
Deep Learning TV ldquoRestricted Boltzmann Machinesrdquo
44
Deep Belief Networks (DBN)
F Van Veen ldquoThe Neural Network Zoordquo (2016)
45
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMs
46
Deep Belief Networks (DBN)
Architecture like an MLP Training as a stack of
RBMs
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
47
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMs
48
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMs
49
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMshellip so they do not need
labels
Unsupervisedlearning
50
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
After the DBN is trained it can be fine-tuned with a reduced amount of labels to solve a supervised task with superior performance
Supervisedlearning
Softm
ax
51
Deep Belief Networks (DBN)
Deep Learning TV ldquoDeep Belief Netsrdquo
52
Deep Belief Networks (DBN)
Geoffrey Hinton Introduction to Deep Learning amp Deep Belief Netsrdquo (2012)Geoorey Hinton ldquoTutorial on Deep Belief Networksrdquo NIPS 2007
53
Deep Belief Networks (DBN)
Geoffrey Hinton
54
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
Acknowledgments
55
Junting Pan Xunyu Lin
Unsupervised Feature Learning
56
Slide credit Yann LeCun
Unsupervised Feature Learning
57
Slide credit Yann LeCun
Slide credit Junting Pan
Frame Reconstruction amp Prediction
59Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
Frame Reconstruction amp Prediction
60Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
frame prediction
Frame Reconstruction amp Prediction
61Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
frame prediction
62Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised learned features (lots of data) are fine-tuned for activity recognition (little data)
Frame Reconstruction amp Prediction
Frame Prediction
63Ranzato MarcAurelio Arthur Szlam Joan Bruna Michael Mathieu Ronan Collobert and Sumit Chopra Video (language) modeling a baseline for generative models of natural videos arXiv preprint arXiv14126604 (2014)
64Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
Video frame prediction with a ConvNet
Frame Prediction
65Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
The blurry predictions from MSE are improved with multi-scale architecture adversarial learning and an image gradient difference loss function
Frame Prediction
66Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
The blurry predictions from MSE (l1) are improved with multi-scale architecture adversarial training and an image gradient difference loss (GDL) function
Frame Prediction
67Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
Frame Prediction
68Vondrick Carl Hamed Pirsiavash and Antonio Torralba Generating videos with scene dynamics NIPS 2016
Frame Prediction
69Vondrick Carl Hamed Pirsiavash and Antonio Torralba Generating videos with scene dynamics NIPS 2016
Frame Prediction
70Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
71
Frame Prediction
Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
Given an input image probabilistic generation of future frames with a Variational AutoEncoder (VAE)
72
Frame Prediction
Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
Encodes image as feature maps and motion as and cross-convolutional kernels
73
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
First steps in video feature learning
74Le Quoc V Will Y Zou Serena Y Yeung and Andrew Y Ng Learning hierarchical invariant spatio-temporal features for action recognition with independent subspace analysis CVPR 2011
Temporal Weak Labels
75Goroshin Ross Joan Bruna Jonathan Tompson David Eigen and Yann LeCun Unsupervised learning of spatiotemporally coherent metrics ICCV 2015
Assumption adjacent video frames contain semantically similar informationAutoencoder trained with regularizations by slowliness and sparisty
76Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
77Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
78(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Temporal order of frames is exploited as the supervisory signal for learning
Temporal Weak Labels
79(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Take temporal order as the supervisory signals for learning
Shuffled sequences
Binary classification
In order
Not in order
Temporal Weak Labels
80Fernando Basura Hakan Bilen Efstratios Gavves and Stephen Gould Self-supervised video representation learning with odd-one-out networks CVPR 2017
Temporal Weak LabelsTrain a network to detect which of the video sequences contains frames wrong order
81
Spatio-Temporal Weak Labels
X Lin Campos V Giroacute-i-Nieto X Torres J and Canton-Ferrer C ldquoDisentangling Motion Foreground and Background Features in Videosrdquo in CVPR 2017 Workshop Brave New Motion Representations
kernel dec
C3D
ForegroundMotion
FirstForeground
Background
Fg
Dec
Bg
Dec
Fg
Dec Reconstruction
of foreground in last frame
Reconstruction of foreground in
first frame
Reconstruction of background in first frame
uNLC
MaskBlock
gradients
Last foreground
Kernels
shareweights
82
Spatio-Temporal Weak Labels
Pathak Deepak Ross Girshick Piotr Dollaacuter Trevor Darrell and Bharath Hariharan Learning features by watching objects move CVPR 2017
83Greff Klaus Antti Rasmus Mathias Berglund Tele Hao Harri Valpola and Juergen Schmidhuber Tagger Deep unsupervised perceptual grouping NIPS 2016 [video] [code]
Spatio-Temporal Weak Labels
84Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
85
Audio Features from Visual weak labels
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Object amp Scenes recognition in videos by analysing the audio track (only)
86Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
87Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
88Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
89
Visualization of the video frames associated to the sounds that activate some of the last hidden units of Soundnet (conv7)
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Audio Features from Visual weak labels
90
Audio amp Visual features from alignement
90Arandjelović Relja and Andrew Zisserman Look Listen and Learn ICCV 2017
Audio and visual features learned by assessing alignement
91L Chen S Srivastava Z Duan and C Xu Deep Cross-Modal Audio-Visual Generation ACM International Conference on Multimedia Thematic Workshops 2017
Audio amp Visual features from alignement
92Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
93Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
Video to Speech Representations
CNN(VGG)
Frame from a silent video
Audio feature
Post-hoc synthesis
94Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
95Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
Speech to Video Synthesis (mouth)
96Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
97Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
Speech to Video Synthesis (pose amp emotion)
98Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
99Suwajanakorn Supasorn Steven M Seitz and Ira Kemelmacher-Shlizerman Synthesizing Obama learning lip sync from audio SIGGRAPH 2017
Speech to Video Synthesis (mouth)
100
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning

26
The manifold hypothesis Energy-based models
LeCun et al A Tutorial on Energy-Based Learning Predicting Structured Data 2006 httpyannlecuncomexdbpublispdflecun-06pdf
27
Autoencoder (AE)
F Van Veen ldquoThe Neural Network Zoordquo (2016)
28
Autoencoder (AE)
ldquoDeep Learning Tutorialrdquo Dept Computer Science Stanford
Autoencoders
Predict at the output the same input data
Do not need labels
29
Autoencoder (AE)
ldquoDeep Learning Tutorialrdquo Dept Computer Science Stanford
Dimensionality reduction
Use hidden layer as a feature extractor of any desired size
30
Autoencoder (AE)
EncoderW1
DecoderW2
hdata reconstruction
Loss(reconstruction error)
Latent variables (representationfeatures)
Figure Kevin McGuinness (DLCV UPC 2017)
Pretraining1 Initialize a NN solving an
autoencoding problem
31
Autoencoder (AE)
Figure Kevin McGuinness (DLCV UPC 2017)
EncoderW1
hdata ClassifierWC
Latent variables (representationfeatures)
prediction
y Loss(cross entropy)
Pretraining1 Initialize a NN solving an
autoencoding problem2 Train for final task with ldquofewrdquo labels
32
Autoencoder (AE)
Deep Learning TV ldquoAutoencoders - Ep 10rdquo
33F Van Veen ldquoThe Neural Network Zoordquo (2016)
Restricted Boltzmann Machine (RBM)
34
Restricted Boltzmann Machine (RBM)
Figure Geoffrey Hinton (2013)
Salakhutdinov Ruslan Andriy Mnih and Geoffrey Hinton Restricted Boltzmann machines for collaborative filtering Proceedings of the 24th international conference on Machine learning ACM 2007
Shallow two-layer net
Restricted = No two nodes in a layer share a connection
Bipartite graph
Bidirectional graph Shared weights Different biases
35
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Forward pass
36
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Forward pass
37
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Forward pass
38
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Backwardpass
39
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Backwardpass
40
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Backwardpass
The reconstructed values at the visible layer are compared with the actual ones with the KL Divergence
41
Restricted Boltzmann Machine (RBM)
Figure Geoffrey Hinton (2013)
Salakhutdinov Ruslan Andriy Mnih and Geoffrey Hinton Restricted Boltzmann machines for collaborative filtering Proceedings of the 24th international conference on Machine learning ACM 2007
42
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
RBMs are a specific type of autoencoder
Unsupervisedlearning
43
Restricted Boltzmann Machine (RBM)
Deep Learning TV ldquoRestricted Boltzmann Machinesrdquo
44
Deep Belief Networks (DBN)
F Van Veen ldquoThe Neural Network Zoordquo (2016)
45
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMs
46
Deep Belief Networks (DBN)
Architecture like an MLP Training as a stack of
RBMs
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
47
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMs
48
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMs
49
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMshellip so they do not need
labels
Unsupervisedlearning
50
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
After the DBN is trained it can be fine-tuned with a reduced amount of labels to solve a supervised task with superior performance
Supervisedlearning
Softm
ax
51
Deep Belief Networks (DBN)
Deep Learning TV ldquoDeep Belief Netsrdquo
52
Deep Belief Networks (DBN)
Geoffrey Hinton Introduction to Deep Learning amp Deep Belief Netsrdquo (2012)Geoorey Hinton ldquoTutorial on Deep Belief Networksrdquo NIPS 2007
53
Deep Belief Networks (DBN)
Geoffrey Hinton
54
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
Acknowledgments
55
Junting Pan Xunyu Lin
Unsupervised Feature Learning
56
Slide credit Yann LeCun
Unsupervised Feature Learning
57
Slide credit Yann LeCun
Slide credit Junting Pan
Frame Reconstruction amp Prediction
59Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
Frame Reconstruction amp Prediction
60Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
frame prediction
Frame Reconstruction amp Prediction
61Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
frame prediction
62Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised learned features (lots of data) are fine-tuned for activity recognition (little data)
Frame Reconstruction amp Prediction
Frame Prediction
63Ranzato MarcAurelio Arthur Szlam Joan Bruna Michael Mathieu Ronan Collobert and Sumit Chopra Video (language) modeling a baseline for generative models of natural videos arXiv preprint arXiv14126604 (2014)
64Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
Video frame prediction with a ConvNet
Frame Prediction
65Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
The blurry predictions from MSE are improved with multi-scale architecture adversarial learning and an image gradient difference loss function
Frame Prediction
66Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
The blurry predictions from MSE (l1) are improved with multi-scale architecture adversarial training and an image gradient difference loss (GDL) function
Frame Prediction
67Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
Frame Prediction
68Vondrick Carl Hamed Pirsiavash and Antonio Torralba Generating videos with scene dynamics NIPS 2016
Frame Prediction
69Vondrick Carl Hamed Pirsiavash and Antonio Torralba Generating videos with scene dynamics NIPS 2016
Frame Prediction
70Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
71
Frame Prediction
Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
Given an input image probabilistic generation of future frames with a Variational AutoEncoder (VAE)
72
Frame Prediction
Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
Encodes image as feature maps and motion as and cross-convolutional kernels
73
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
First steps in video feature learning
74Le Quoc V Will Y Zou Serena Y Yeung and Andrew Y Ng Learning hierarchical invariant spatio-temporal features for action recognition with independent subspace analysis CVPR 2011
Temporal Weak Labels
75Goroshin Ross Joan Bruna Jonathan Tompson David Eigen and Yann LeCun Unsupervised learning of spatiotemporally coherent metrics ICCV 2015
Assumption adjacent video frames contain semantically similar informationAutoencoder trained with regularizations by slowliness and sparisty
76Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
77Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
78(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Temporal order of frames is exploited as the supervisory signal for learning
Temporal Weak Labels
79(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Take temporal order as the supervisory signals for learning
Shuffled sequences
Binary classification
In order
Not in order
Temporal Weak Labels
80Fernando Basura Hakan Bilen Efstratios Gavves and Stephen Gould Self-supervised video representation learning with odd-one-out networks CVPR 2017
Temporal Weak LabelsTrain a network to detect which of the video sequences contains frames wrong order
81
Spatio-Temporal Weak Labels
X Lin Campos V Giroacute-i-Nieto X Torres J and Canton-Ferrer C ldquoDisentangling Motion Foreground and Background Features in Videosrdquo in CVPR 2017 Workshop Brave New Motion Representations
kernel dec
C3D
ForegroundMotion
FirstForeground
Background
Fg
Dec
Bg
Dec
Fg
Dec Reconstruction
of foreground in last frame
Reconstruction of foreground in
first frame
Reconstruction of background in first frame
uNLC
MaskBlock
gradients
Last foreground
Kernels
shareweights
82
Spatio-Temporal Weak Labels
Pathak Deepak Ross Girshick Piotr Dollaacuter Trevor Darrell and Bharath Hariharan Learning features by watching objects move CVPR 2017
83Greff Klaus Antti Rasmus Mathias Berglund Tele Hao Harri Valpola and Juergen Schmidhuber Tagger Deep unsupervised perceptual grouping NIPS 2016 [video] [code]
Spatio-Temporal Weak Labels
84Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
85
Audio Features from Visual weak labels
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Object amp Scenes recognition in videos by analysing the audio track (only)
86Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
87Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
88Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
89
Visualization of the video frames associated to the sounds that activate some of the last hidden units of Soundnet (conv7)
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Audio Features from Visual weak labels
90
Audio amp Visual features from alignement
90Arandjelović Relja and Andrew Zisserman Look Listen and Learn ICCV 2017
Audio and visual features learned by assessing alignement
91L Chen S Srivastava Z Duan and C Xu Deep Cross-Modal Audio-Visual Generation ACM International Conference on Multimedia Thematic Workshops 2017
Audio amp Visual features from alignement
92Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
93Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
Video to Speech Representations
CNN(VGG)
Frame from a silent video
Audio feature
Post-hoc synthesis
94Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
95Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
Speech to Video Synthesis (mouth)
96Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
97Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
Speech to Video Synthesis (pose amp emotion)
98Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
99Suwajanakorn Supasorn Steven M Seitz and Ira Kemelmacher-Shlizerman Synthesizing Obama learning lip sync from audio SIGGRAPH 2017
Speech to Video Synthesis (mouth)
100
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
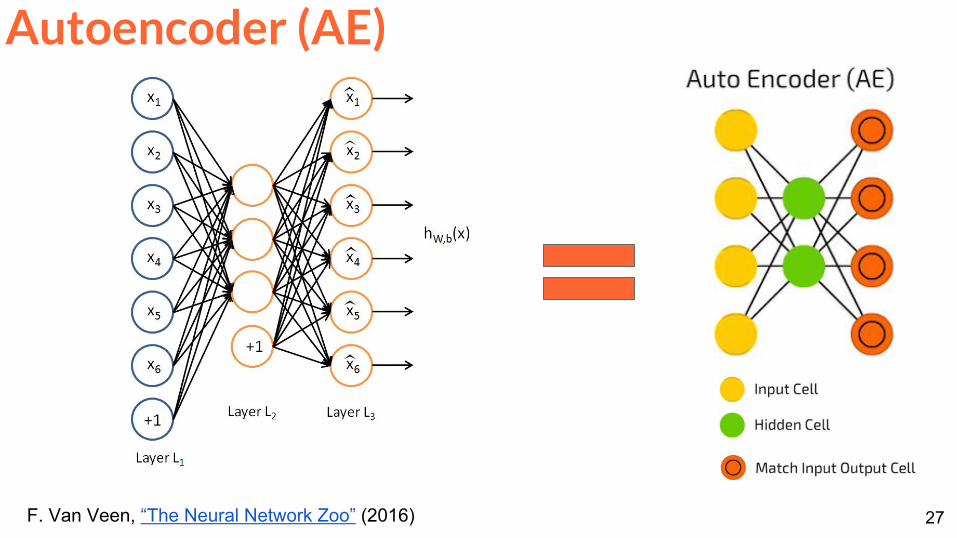
27
Autoencoder (AE)
F Van Veen ldquoThe Neural Network Zoordquo (2016)
28
Autoencoder (AE)
ldquoDeep Learning Tutorialrdquo Dept Computer Science Stanford
Autoencoders
Predict at the output the same input data
Do not need labels
29
Autoencoder (AE)
ldquoDeep Learning Tutorialrdquo Dept Computer Science Stanford
Dimensionality reduction
Use hidden layer as a feature extractor of any desired size
30
Autoencoder (AE)
EncoderW1
DecoderW2
hdata reconstruction
Loss(reconstruction error)
Latent variables (representationfeatures)
Figure Kevin McGuinness (DLCV UPC 2017)
Pretraining1 Initialize a NN solving an
autoencoding problem
31
Autoencoder (AE)
Figure Kevin McGuinness (DLCV UPC 2017)
EncoderW1
hdata ClassifierWC
Latent variables (representationfeatures)
prediction
y Loss(cross entropy)
Pretraining1 Initialize a NN solving an
autoencoding problem2 Train for final task with ldquofewrdquo labels
32
Autoencoder (AE)
Deep Learning TV ldquoAutoencoders - Ep 10rdquo
33F Van Veen ldquoThe Neural Network Zoordquo (2016)
Restricted Boltzmann Machine (RBM)
34
Restricted Boltzmann Machine (RBM)
Figure Geoffrey Hinton (2013)
Salakhutdinov Ruslan Andriy Mnih and Geoffrey Hinton Restricted Boltzmann machines for collaborative filtering Proceedings of the 24th international conference on Machine learning ACM 2007
Shallow two-layer net
Restricted = No two nodes in a layer share a connection
Bipartite graph
Bidirectional graph Shared weights Different biases
35
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Forward pass
36
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Forward pass
37
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Forward pass
38
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Backwardpass
39
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Backwardpass
40
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Backwardpass
The reconstructed values at the visible layer are compared with the actual ones with the KL Divergence
41
Restricted Boltzmann Machine (RBM)
Figure Geoffrey Hinton (2013)
Salakhutdinov Ruslan Andriy Mnih and Geoffrey Hinton Restricted Boltzmann machines for collaborative filtering Proceedings of the 24th international conference on Machine learning ACM 2007
42
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
RBMs are a specific type of autoencoder
Unsupervisedlearning
43
Restricted Boltzmann Machine (RBM)
Deep Learning TV ldquoRestricted Boltzmann Machinesrdquo
44
Deep Belief Networks (DBN)
F Van Veen ldquoThe Neural Network Zoordquo (2016)
45
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMs
46
Deep Belief Networks (DBN)
Architecture like an MLP Training as a stack of
RBMs
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
47
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMs
48
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMs
49
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMshellip so they do not need
labels
Unsupervisedlearning
50
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
After the DBN is trained it can be fine-tuned with a reduced amount of labels to solve a supervised task with superior performance
Supervisedlearning
Softm
ax
51
Deep Belief Networks (DBN)
Deep Learning TV ldquoDeep Belief Netsrdquo
52
Deep Belief Networks (DBN)
Geoffrey Hinton Introduction to Deep Learning amp Deep Belief Netsrdquo (2012)Geoorey Hinton ldquoTutorial on Deep Belief Networksrdquo NIPS 2007
53
Deep Belief Networks (DBN)
Geoffrey Hinton
54
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
Acknowledgments
55
Junting Pan Xunyu Lin
Unsupervised Feature Learning
56
Slide credit Yann LeCun
Unsupervised Feature Learning
57
Slide credit Yann LeCun
Slide credit Junting Pan
Frame Reconstruction amp Prediction
59Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
Frame Reconstruction amp Prediction
60Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
frame prediction
Frame Reconstruction amp Prediction
61Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
frame prediction
62Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised learned features (lots of data) are fine-tuned for activity recognition (little data)
Frame Reconstruction amp Prediction
Frame Prediction
63Ranzato MarcAurelio Arthur Szlam Joan Bruna Michael Mathieu Ronan Collobert and Sumit Chopra Video (language) modeling a baseline for generative models of natural videos arXiv preprint arXiv14126604 (2014)
64Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
Video frame prediction with a ConvNet
Frame Prediction
65Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
The blurry predictions from MSE are improved with multi-scale architecture adversarial learning and an image gradient difference loss function
Frame Prediction
66Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
The blurry predictions from MSE (l1) are improved with multi-scale architecture adversarial training and an image gradient difference loss (GDL) function
Frame Prediction
67Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
Frame Prediction
68Vondrick Carl Hamed Pirsiavash and Antonio Torralba Generating videos with scene dynamics NIPS 2016
Frame Prediction
69Vondrick Carl Hamed Pirsiavash and Antonio Torralba Generating videos with scene dynamics NIPS 2016
Frame Prediction
70Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
71
Frame Prediction
Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
Given an input image probabilistic generation of future frames with a Variational AutoEncoder (VAE)
72
Frame Prediction
Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
Encodes image as feature maps and motion as and cross-convolutional kernels
73
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
First steps in video feature learning
74Le Quoc V Will Y Zou Serena Y Yeung and Andrew Y Ng Learning hierarchical invariant spatio-temporal features for action recognition with independent subspace analysis CVPR 2011
Temporal Weak Labels
75Goroshin Ross Joan Bruna Jonathan Tompson David Eigen and Yann LeCun Unsupervised learning of spatiotemporally coherent metrics ICCV 2015
Assumption adjacent video frames contain semantically similar informationAutoencoder trained with regularizations by slowliness and sparisty
76Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
77Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
78(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Temporal order of frames is exploited as the supervisory signal for learning
Temporal Weak Labels
79(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Take temporal order as the supervisory signals for learning
Shuffled sequences
Binary classification
In order
Not in order
Temporal Weak Labels
80Fernando Basura Hakan Bilen Efstratios Gavves and Stephen Gould Self-supervised video representation learning with odd-one-out networks CVPR 2017
Temporal Weak LabelsTrain a network to detect which of the video sequences contains frames wrong order
81
Spatio-Temporal Weak Labels
X Lin Campos V Giroacute-i-Nieto X Torres J and Canton-Ferrer C ldquoDisentangling Motion Foreground and Background Features in Videosrdquo in CVPR 2017 Workshop Brave New Motion Representations
kernel dec
C3D
ForegroundMotion
FirstForeground
Background
Fg
Dec
Bg
Dec
Fg
Dec Reconstruction
of foreground in last frame
Reconstruction of foreground in
first frame
Reconstruction of background in first frame
uNLC
MaskBlock
gradients
Last foreground
Kernels
shareweights
82
Spatio-Temporal Weak Labels
Pathak Deepak Ross Girshick Piotr Dollaacuter Trevor Darrell and Bharath Hariharan Learning features by watching objects move CVPR 2017
83Greff Klaus Antti Rasmus Mathias Berglund Tele Hao Harri Valpola and Juergen Schmidhuber Tagger Deep unsupervised perceptual grouping NIPS 2016 [video] [code]
Spatio-Temporal Weak Labels
84Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
85
Audio Features from Visual weak labels
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Object amp Scenes recognition in videos by analysing the audio track (only)
86Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
87Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
88Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
89
Visualization of the video frames associated to the sounds that activate some of the last hidden units of Soundnet (conv7)
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Audio Features from Visual weak labels
90
Audio amp Visual features from alignement
90Arandjelović Relja and Andrew Zisserman Look Listen and Learn ICCV 2017
Audio and visual features learned by assessing alignement
91L Chen S Srivastava Z Duan and C Xu Deep Cross-Modal Audio-Visual Generation ACM International Conference on Multimedia Thematic Workshops 2017
Audio amp Visual features from alignement
92Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
93Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
Video to Speech Representations
CNN(VGG)
Frame from a silent video
Audio feature
Post-hoc synthesis
94Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
95Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
Speech to Video Synthesis (mouth)
96Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
97Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
Speech to Video Synthesis (pose amp emotion)
98Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
99Suwajanakorn Supasorn Steven M Seitz and Ira Kemelmacher-Shlizerman Synthesizing Obama learning lip sync from audio SIGGRAPH 2017
Speech to Video Synthesis (mouth)
100
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning

28
Autoencoder (AE)
ldquoDeep Learning Tutorialrdquo Dept Computer Science Stanford
Autoencoders
Predict at the output the same input data
Do not need labels
29
Autoencoder (AE)
ldquoDeep Learning Tutorialrdquo Dept Computer Science Stanford
Dimensionality reduction
Use hidden layer as a feature extractor of any desired size
30
Autoencoder (AE)
EncoderW1
DecoderW2
hdata reconstruction
Loss(reconstruction error)
Latent variables (representationfeatures)
Figure Kevin McGuinness (DLCV UPC 2017)
Pretraining1 Initialize a NN solving an
autoencoding problem
31
Autoencoder (AE)
Figure Kevin McGuinness (DLCV UPC 2017)
EncoderW1
hdata ClassifierWC
Latent variables (representationfeatures)
prediction
y Loss(cross entropy)
Pretraining1 Initialize a NN solving an
autoencoding problem2 Train for final task with ldquofewrdquo labels
32
Autoencoder (AE)
Deep Learning TV ldquoAutoencoders - Ep 10rdquo
33F Van Veen ldquoThe Neural Network Zoordquo (2016)
Restricted Boltzmann Machine (RBM)
34
Restricted Boltzmann Machine (RBM)
Figure Geoffrey Hinton (2013)
Salakhutdinov Ruslan Andriy Mnih and Geoffrey Hinton Restricted Boltzmann machines for collaborative filtering Proceedings of the 24th international conference on Machine learning ACM 2007
Shallow two-layer net
Restricted = No two nodes in a layer share a connection
Bipartite graph
Bidirectional graph Shared weights Different biases
35
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Forward pass
36
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Forward pass
37
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Forward pass
38
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Backwardpass
39
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Backwardpass
40
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Backwardpass
The reconstructed values at the visible layer are compared with the actual ones with the KL Divergence
41
Restricted Boltzmann Machine (RBM)
Figure Geoffrey Hinton (2013)
Salakhutdinov Ruslan Andriy Mnih and Geoffrey Hinton Restricted Boltzmann machines for collaborative filtering Proceedings of the 24th international conference on Machine learning ACM 2007
42
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
RBMs are a specific type of autoencoder
Unsupervisedlearning
43
Restricted Boltzmann Machine (RBM)
Deep Learning TV ldquoRestricted Boltzmann Machinesrdquo
44
Deep Belief Networks (DBN)
F Van Veen ldquoThe Neural Network Zoordquo (2016)
45
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMs
46
Deep Belief Networks (DBN)
Architecture like an MLP Training as a stack of
RBMs
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
47
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMs
48
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMs
49
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMshellip so they do not need
labels
Unsupervisedlearning
50
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
After the DBN is trained it can be fine-tuned with a reduced amount of labels to solve a supervised task with superior performance
Supervisedlearning
Softm
ax
51
Deep Belief Networks (DBN)
Deep Learning TV ldquoDeep Belief Netsrdquo
52
Deep Belief Networks (DBN)
Geoffrey Hinton Introduction to Deep Learning amp Deep Belief Netsrdquo (2012)Geoorey Hinton ldquoTutorial on Deep Belief Networksrdquo NIPS 2007
53
Deep Belief Networks (DBN)
Geoffrey Hinton
54
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
Acknowledgments
55
Junting Pan Xunyu Lin
Unsupervised Feature Learning
56
Slide credit Yann LeCun
Unsupervised Feature Learning
57
Slide credit Yann LeCun
Slide credit Junting Pan
Frame Reconstruction amp Prediction
59Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
Frame Reconstruction amp Prediction
60Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
frame prediction
Frame Reconstruction amp Prediction
61Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
frame prediction
62Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised learned features (lots of data) are fine-tuned for activity recognition (little data)
Frame Reconstruction amp Prediction
Frame Prediction
63Ranzato MarcAurelio Arthur Szlam Joan Bruna Michael Mathieu Ronan Collobert and Sumit Chopra Video (language) modeling a baseline for generative models of natural videos arXiv preprint arXiv14126604 (2014)
64Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
Video frame prediction with a ConvNet
Frame Prediction
65Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
The blurry predictions from MSE are improved with multi-scale architecture adversarial learning and an image gradient difference loss function
Frame Prediction
66Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
The blurry predictions from MSE (l1) are improved with multi-scale architecture adversarial training and an image gradient difference loss (GDL) function
Frame Prediction
67Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
Frame Prediction
68Vondrick Carl Hamed Pirsiavash and Antonio Torralba Generating videos with scene dynamics NIPS 2016
Frame Prediction
69Vondrick Carl Hamed Pirsiavash and Antonio Torralba Generating videos with scene dynamics NIPS 2016
Frame Prediction
70Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
71
Frame Prediction
Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
Given an input image probabilistic generation of future frames with a Variational AutoEncoder (VAE)
72
Frame Prediction
Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
Encodes image as feature maps and motion as and cross-convolutional kernels
73
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
First steps in video feature learning
74Le Quoc V Will Y Zou Serena Y Yeung and Andrew Y Ng Learning hierarchical invariant spatio-temporal features for action recognition with independent subspace analysis CVPR 2011
Temporal Weak Labels
75Goroshin Ross Joan Bruna Jonathan Tompson David Eigen and Yann LeCun Unsupervised learning of spatiotemporally coherent metrics ICCV 2015
Assumption adjacent video frames contain semantically similar informationAutoencoder trained with regularizations by slowliness and sparisty
76Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
77Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
78(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Temporal order of frames is exploited as the supervisory signal for learning
Temporal Weak Labels
79(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Take temporal order as the supervisory signals for learning
Shuffled sequences
Binary classification
In order
Not in order
Temporal Weak Labels
80Fernando Basura Hakan Bilen Efstratios Gavves and Stephen Gould Self-supervised video representation learning with odd-one-out networks CVPR 2017
Temporal Weak LabelsTrain a network to detect which of the video sequences contains frames wrong order
81
Spatio-Temporal Weak Labels
X Lin Campos V Giroacute-i-Nieto X Torres J and Canton-Ferrer C ldquoDisentangling Motion Foreground and Background Features in Videosrdquo in CVPR 2017 Workshop Brave New Motion Representations
kernel dec
C3D
ForegroundMotion
FirstForeground
Background
Fg
Dec
Bg
Dec
Fg
Dec Reconstruction
of foreground in last frame
Reconstruction of foreground in
first frame
Reconstruction of background in first frame
uNLC
MaskBlock
gradients
Last foreground
Kernels
shareweights
82
Spatio-Temporal Weak Labels
Pathak Deepak Ross Girshick Piotr Dollaacuter Trevor Darrell and Bharath Hariharan Learning features by watching objects move CVPR 2017
83Greff Klaus Antti Rasmus Mathias Berglund Tele Hao Harri Valpola and Juergen Schmidhuber Tagger Deep unsupervised perceptual grouping NIPS 2016 [video] [code]
Spatio-Temporal Weak Labels
84Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
85
Audio Features from Visual weak labels
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Object amp Scenes recognition in videos by analysing the audio track (only)
86Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
87Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
88Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
89
Visualization of the video frames associated to the sounds that activate some of the last hidden units of Soundnet (conv7)
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Audio Features from Visual weak labels
90
Audio amp Visual features from alignement
90Arandjelović Relja and Andrew Zisserman Look Listen and Learn ICCV 2017
Audio and visual features learned by assessing alignement
91L Chen S Srivastava Z Duan and C Xu Deep Cross-Modal Audio-Visual Generation ACM International Conference on Multimedia Thematic Workshops 2017
Audio amp Visual features from alignement
92Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
93Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
Video to Speech Representations
CNN(VGG)
Frame from a silent video
Audio feature
Post-hoc synthesis
94Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
95Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
Speech to Video Synthesis (mouth)
96Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
97Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
Speech to Video Synthesis (pose amp emotion)
98Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
99Suwajanakorn Supasorn Steven M Seitz and Ira Kemelmacher-Shlizerman Synthesizing Obama learning lip sync from audio SIGGRAPH 2017
Speech to Video Synthesis (mouth)
100
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning

29
Autoencoder (AE)
ldquoDeep Learning Tutorialrdquo Dept Computer Science Stanford
Dimensionality reduction
Use hidden layer as a feature extractor of any desired size
30
Autoencoder (AE)
EncoderW1
DecoderW2
hdata reconstruction
Loss(reconstruction error)
Latent variables (representationfeatures)
Figure Kevin McGuinness (DLCV UPC 2017)
Pretraining1 Initialize a NN solving an
autoencoding problem
31
Autoencoder (AE)
Figure Kevin McGuinness (DLCV UPC 2017)
EncoderW1
hdata ClassifierWC
Latent variables (representationfeatures)
prediction
y Loss(cross entropy)
Pretraining1 Initialize a NN solving an
autoencoding problem2 Train for final task with ldquofewrdquo labels
32
Autoencoder (AE)
Deep Learning TV ldquoAutoencoders - Ep 10rdquo
33F Van Veen ldquoThe Neural Network Zoordquo (2016)
Restricted Boltzmann Machine (RBM)
34
Restricted Boltzmann Machine (RBM)
Figure Geoffrey Hinton (2013)
Salakhutdinov Ruslan Andriy Mnih and Geoffrey Hinton Restricted Boltzmann machines for collaborative filtering Proceedings of the 24th international conference on Machine learning ACM 2007
Shallow two-layer net
Restricted = No two nodes in a layer share a connection
Bipartite graph
Bidirectional graph Shared weights Different biases
35
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Forward pass
36
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Forward pass
37
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Forward pass
38
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Backwardpass
39
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Backwardpass
40
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Backwardpass
The reconstructed values at the visible layer are compared with the actual ones with the KL Divergence
41
Restricted Boltzmann Machine (RBM)
Figure Geoffrey Hinton (2013)
Salakhutdinov Ruslan Andriy Mnih and Geoffrey Hinton Restricted Boltzmann machines for collaborative filtering Proceedings of the 24th international conference on Machine learning ACM 2007
42
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
RBMs are a specific type of autoencoder
Unsupervisedlearning
43
Restricted Boltzmann Machine (RBM)
Deep Learning TV ldquoRestricted Boltzmann Machinesrdquo
44
Deep Belief Networks (DBN)
F Van Veen ldquoThe Neural Network Zoordquo (2016)
45
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMs
46
Deep Belief Networks (DBN)
Architecture like an MLP Training as a stack of
RBMs
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
47
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMs
48
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMs
49
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMshellip so they do not need
labels
Unsupervisedlearning
50
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
After the DBN is trained it can be fine-tuned with a reduced amount of labels to solve a supervised task with superior performance
Supervisedlearning
Softm
ax
51
Deep Belief Networks (DBN)
Deep Learning TV ldquoDeep Belief Netsrdquo
52
Deep Belief Networks (DBN)
Geoffrey Hinton Introduction to Deep Learning amp Deep Belief Netsrdquo (2012)Geoorey Hinton ldquoTutorial on Deep Belief Networksrdquo NIPS 2007
53
Deep Belief Networks (DBN)
Geoffrey Hinton
54
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
Acknowledgments
55
Junting Pan Xunyu Lin
Unsupervised Feature Learning
56
Slide credit Yann LeCun
Unsupervised Feature Learning
57
Slide credit Yann LeCun
Slide credit Junting Pan
Frame Reconstruction amp Prediction
59Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
Frame Reconstruction amp Prediction
60Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
frame prediction
Frame Reconstruction amp Prediction
61Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
frame prediction
62Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised learned features (lots of data) are fine-tuned for activity recognition (little data)
Frame Reconstruction amp Prediction
Frame Prediction
63Ranzato MarcAurelio Arthur Szlam Joan Bruna Michael Mathieu Ronan Collobert and Sumit Chopra Video (language) modeling a baseline for generative models of natural videos arXiv preprint arXiv14126604 (2014)
64Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
Video frame prediction with a ConvNet
Frame Prediction
65Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
The blurry predictions from MSE are improved with multi-scale architecture adversarial learning and an image gradient difference loss function
Frame Prediction
66Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
The blurry predictions from MSE (l1) are improved with multi-scale architecture adversarial training and an image gradient difference loss (GDL) function
Frame Prediction
67Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
Frame Prediction
68Vondrick Carl Hamed Pirsiavash and Antonio Torralba Generating videos with scene dynamics NIPS 2016
Frame Prediction
69Vondrick Carl Hamed Pirsiavash and Antonio Torralba Generating videos with scene dynamics NIPS 2016
Frame Prediction
70Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
71
Frame Prediction
Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
Given an input image probabilistic generation of future frames with a Variational AutoEncoder (VAE)
72
Frame Prediction
Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
Encodes image as feature maps and motion as and cross-convolutional kernels
73
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
First steps in video feature learning
74Le Quoc V Will Y Zou Serena Y Yeung and Andrew Y Ng Learning hierarchical invariant spatio-temporal features for action recognition with independent subspace analysis CVPR 2011
Temporal Weak Labels
75Goroshin Ross Joan Bruna Jonathan Tompson David Eigen and Yann LeCun Unsupervised learning of spatiotemporally coherent metrics ICCV 2015
Assumption adjacent video frames contain semantically similar informationAutoencoder trained with regularizations by slowliness and sparisty
76Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
77Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
78(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Temporal order of frames is exploited as the supervisory signal for learning
Temporal Weak Labels
79(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Take temporal order as the supervisory signals for learning
Shuffled sequences
Binary classification
In order
Not in order
Temporal Weak Labels
80Fernando Basura Hakan Bilen Efstratios Gavves and Stephen Gould Self-supervised video representation learning with odd-one-out networks CVPR 2017
Temporal Weak LabelsTrain a network to detect which of the video sequences contains frames wrong order
81
Spatio-Temporal Weak Labels
X Lin Campos V Giroacute-i-Nieto X Torres J and Canton-Ferrer C ldquoDisentangling Motion Foreground and Background Features in Videosrdquo in CVPR 2017 Workshop Brave New Motion Representations
kernel dec
C3D
ForegroundMotion
FirstForeground
Background
Fg
Dec
Bg
Dec
Fg
Dec Reconstruction
of foreground in last frame
Reconstruction of foreground in
first frame
Reconstruction of background in first frame
uNLC
MaskBlock
gradients
Last foreground
Kernels
shareweights
82
Spatio-Temporal Weak Labels
Pathak Deepak Ross Girshick Piotr Dollaacuter Trevor Darrell and Bharath Hariharan Learning features by watching objects move CVPR 2017
83Greff Klaus Antti Rasmus Mathias Berglund Tele Hao Harri Valpola and Juergen Schmidhuber Tagger Deep unsupervised perceptual grouping NIPS 2016 [video] [code]
Spatio-Temporal Weak Labels
84Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
85
Audio Features from Visual weak labels
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Object amp Scenes recognition in videos by analysing the audio track (only)
86Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
87Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
88Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
89
Visualization of the video frames associated to the sounds that activate some of the last hidden units of Soundnet (conv7)
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Audio Features from Visual weak labels
90
Audio amp Visual features from alignement
90Arandjelović Relja and Andrew Zisserman Look Listen and Learn ICCV 2017
Audio and visual features learned by assessing alignement
91L Chen S Srivastava Z Duan and C Xu Deep Cross-Modal Audio-Visual Generation ACM International Conference on Multimedia Thematic Workshops 2017
Audio amp Visual features from alignement
92Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
93Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
Video to Speech Representations
CNN(VGG)
Frame from a silent video
Audio feature
Post-hoc synthesis
94Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
95Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
Speech to Video Synthesis (mouth)
96Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
97Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
Speech to Video Synthesis (pose amp emotion)
98Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
99Suwajanakorn Supasorn Steven M Seitz and Ira Kemelmacher-Shlizerman Synthesizing Obama learning lip sync from audio SIGGRAPH 2017
Speech to Video Synthesis (mouth)
100
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
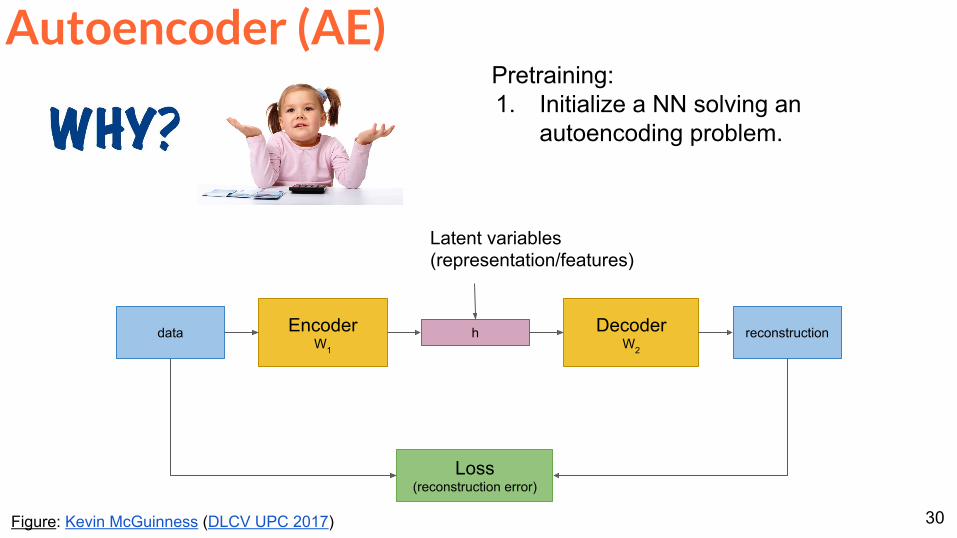
30
Autoencoder (AE)
EncoderW1
DecoderW2
hdata reconstruction
Loss(reconstruction error)
Latent variables (representationfeatures)
Figure Kevin McGuinness (DLCV UPC 2017)
Pretraining1 Initialize a NN solving an
autoencoding problem
31
Autoencoder (AE)
Figure Kevin McGuinness (DLCV UPC 2017)
EncoderW1
hdata ClassifierWC
Latent variables (representationfeatures)
prediction
y Loss(cross entropy)
Pretraining1 Initialize a NN solving an
autoencoding problem2 Train for final task with ldquofewrdquo labels
32
Autoencoder (AE)
Deep Learning TV ldquoAutoencoders - Ep 10rdquo
33F Van Veen ldquoThe Neural Network Zoordquo (2016)
Restricted Boltzmann Machine (RBM)
34
Restricted Boltzmann Machine (RBM)
Figure Geoffrey Hinton (2013)
Salakhutdinov Ruslan Andriy Mnih and Geoffrey Hinton Restricted Boltzmann machines for collaborative filtering Proceedings of the 24th international conference on Machine learning ACM 2007
Shallow two-layer net
Restricted = No two nodes in a layer share a connection
Bipartite graph
Bidirectional graph Shared weights Different biases
35
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Forward pass
36
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Forward pass
37
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Forward pass
38
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Backwardpass
39
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Backwardpass
40
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Backwardpass
The reconstructed values at the visible layer are compared with the actual ones with the KL Divergence
41
Restricted Boltzmann Machine (RBM)
Figure Geoffrey Hinton (2013)
Salakhutdinov Ruslan Andriy Mnih and Geoffrey Hinton Restricted Boltzmann machines for collaborative filtering Proceedings of the 24th international conference on Machine learning ACM 2007
42
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
RBMs are a specific type of autoencoder
Unsupervisedlearning
43
Restricted Boltzmann Machine (RBM)
Deep Learning TV ldquoRestricted Boltzmann Machinesrdquo
44
Deep Belief Networks (DBN)
F Van Veen ldquoThe Neural Network Zoordquo (2016)
45
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMs
46
Deep Belief Networks (DBN)
Architecture like an MLP Training as a stack of
RBMs
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
47
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMs
48
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMs
49
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMshellip so they do not need
labels
Unsupervisedlearning
50
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
After the DBN is trained it can be fine-tuned with a reduced amount of labels to solve a supervised task with superior performance
Supervisedlearning
Softm
ax
51
Deep Belief Networks (DBN)
Deep Learning TV ldquoDeep Belief Netsrdquo
52
Deep Belief Networks (DBN)
Geoffrey Hinton Introduction to Deep Learning amp Deep Belief Netsrdquo (2012)Geoorey Hinton ldquoTutorial on Deep Belief Networksrdquo NIPS 2007
53
Deep Belief Networks (DBN)
Geoffrey Hinton
54
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
Acknowledgments
55
Junting Pan Xunyu Lin
Unsupervised Feature Learning
56
Slide credit Yann LeCun
Unsupervised Feature Learning
57
Slide credit Yann LeCun
Slide credit Junting Pan
Frame Reconstruction amp Prediction
59Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
Frame Reconstruction amp Prediction
60Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
frame prediction
Frame Reconstruction amp Prediction
61Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
frame prediction
62Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised learned features (lots of data) are fine-tuned for activity recognition (little data)
Frame Reconstruction amp Prediction
Frame Prediction
63Ranzato MarcAurelio Arthur Szlam Joan Bruna Michael Mathieu Ronan Collobert and Sumit Chopra Video (language) modeling a baseline for generative models of natural videos arXiv preprint arXiv14126604 (2014)
64Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
Video frame prediction with a ConvNet
Frame Prediction
65Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
The blurry predictions from MSE are improved with multi-scale architecture adversarial learning and an image gradient difference loss function
Frame Prediction
66Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
The blurry predictions from MSE (l1) are improved with multi-scale architecture adversarial training and an image gradient difference loss (GDL) function
Frame Prediction
67Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
Frame Prediction
68Vondrick Carl Hamed Pirsiavash and Antonio Torralba Generating videos with scene dynamics NIPS 2016
Frame Prediction
69Vondrick Carl Hamed Pirsiavash and Antonio Torralba Generating videos with scene dynamics NIPS 2016
Frame Prediction
70Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
71
Frame Prediction
Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
Given an input image probabilistic generation of future frames with a Variational AutoEncoder (VAE)
72
Frame Prediction
Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
Encodes image as feature maps and motion as and cross-convolutional kernels
73
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
First steps in video feature learning
74Le Quoc V Will Y Zou Serena Y Yeung and Andrew Y Ng Learning hierarchical invariant spatio-temporal features for action recognition with independent subspace analysis CVPR 2011
Temporal Weak Labels
75Goroshin Ross Joan Bruna Jonathan Tompson David Eigen and Yann LeCun Unsupervised learning of spatiotemporally coherent metrics ICCV 2015
Assumption adjacent video frames contain semantically similar informationAutoencoder trained with regularizations by slowliness and sparisty
76Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
77Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
78(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Temporal order of frames is exploited as the supervisory signal for learning
Temporal Weak Labels
79(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Take temporal order as the supervisory signals for learning
Shuffled sequences
Binary classification
In order
Not in order
Temporal Weak Labels
80Fernando Basura Hakan Bilen Efstratios Gavves and Stephen Gould Self-supervised video representation learning with odd-one-out networks CVPR 2017
Temporal Weak LabelsTrain a network to detect which of the video sequences contains frames wrong order
81
Spatio-Temporal Weak Labels
X Lin Campos V Giroacute-i-Nieto X Torres J and Canton-Ferrer C ldquoDisentangling Motion Foreground and Background Features in Videosrdquo in CVPR 2017 Workshop Brave New Motion Representations
kernel dec
C3D
ForegroundMotion
FirstForeground
Background
Fg
Dec
Bg
Dec
Fg
Dec Reconstruction
of foreground in last frame
Reconstruction of foreground in
first frame
Reconstruction of background in first frame
uNLC
MaskBlock
gradients
Last foreground
Kernels
shareweights
82
Spatio-Temporal Weak Labels
Pathak Deepak Ross Girshick Piotr Dollaacuter Trevor Darrell and Bharath Hariharan Learning features by watching objects move CVPR 2017
83Greff Klaus Antti Rasmus Mathias Berglund Tele Hao Harri Valpola and Juergen Schmidhuber Tagger Deep unsupervised perceptual grouping NIPS 2016 [video] [code]
Spatio-Temporal Weak Labels
84Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
85
Audio Features from Visual weak labels
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Object amp Scenes recognition in videos by analysing the audio track (only)
86Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
87Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
88Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
89
Visualization of the video frames associated to the sounds that activate some of the last hidden units of Soundnet (conv7)
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Audio Features from Visual weak labels
90
Audio amp Visual features from alignement
90Arandjelović Relja and Andrew Zisserman Look Listen and Learn ICCV 2017
Audio and visual features learned by assessing alignement
91L Chen S Srivastava Z Duan and C Xu Deep Cross-Modal Audio-Visual Generation ACM International Conference on Multimedia Thematic Workshops 2017
Audio amp Visual features from alignement
92Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
93Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
Video to Speech Representations
CNN(VGG)
Frame from a silent video
Audio feature
Post-hoc synthesis
94Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
95Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
Speech to Video Synthesis (mouth)
96Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
97Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
Speech to Video Synthesis (pose amp emotion)
98Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
99Suwajanakorn Supasorn Steven M Seitz and Ira Kemelmacher-Shlizerman Synthesizing Obama learning lip sync from audio SIGGRAPH 2017
Speech to Video Synthesis (mouth)
100
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
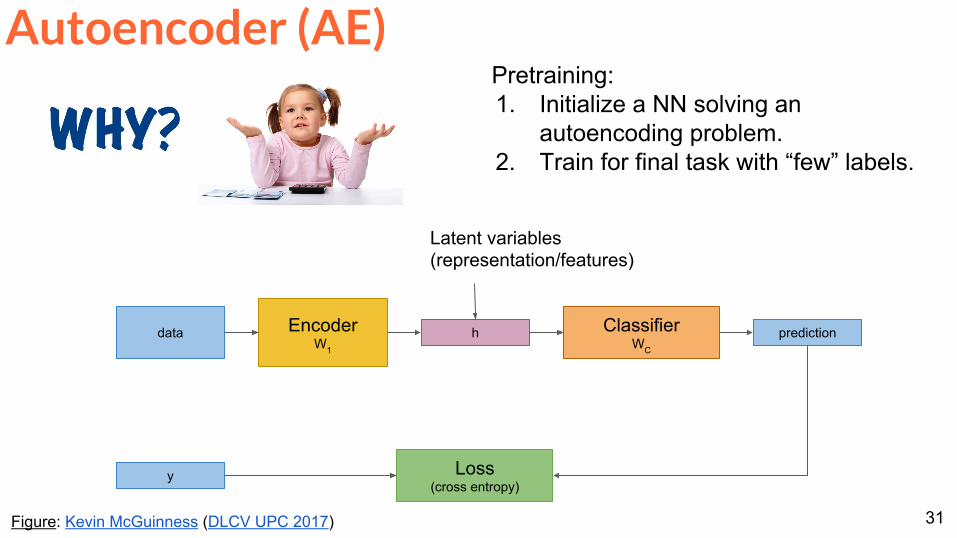
31
Autoencoder (AE)
Figure Kevin McGuinness (DLCV UPC 2017)
EncoderW1
hdata ClassifierWC
Latent variables (representationfeatures)
prediction
y Loss(cross entropy)
Pretraining1 Initialize a NN solving an
autoencoding problem2 Train for final task with ldquofewrdquo labels
32
Autoencoder (AE)
Deep Learning TV ldquoAutoencoders - Ep 10rdquo
33F Van Veen ldquoThe Neural Network Zoordquo (2016)
Restricted Boltzmann Machine (RBM)
34
Restricted Boltzmann Machine (RBM)
Figure Geoffrey Hinton (2013)
Salakhutdinov Ruslan Andriy Mnih and Geoffrey Hinton Restricted Boltzmann machines for collaborative filtering Proceedings of the 24th international conference on Machine learning ACM 2007
Shallow two-layer net
Restricted = No two nodes in a layer share a connection
Bipartite graph
Bidirectional graph Shared weights Different biases
35
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Forward pass
36
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Forward pass
37
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Forward pass
38
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Backwardpass
39
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Backwardpass
40
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Backwardpass
The reconstructed values at the visible layer are compared with the actual ones with the KL Divergence
41
Restricted Boltzmann Machine (RBM)
Figure Geoffrey Hinton (2013)
Salakhutdinov Ruslan Andriy Mnih and Geoffrey Hinton Restricted Boltzmann machines for collaborative filtering Proceedings of the 24th international conference on Machine learning ACM 2007
42
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
RBMs are a specific type of autoencoder
Unsupervisedlearning
43
Restricted Boltzmann Machine (RBM)
Deep Learning TV ldquoRestricted Boltzmann Machinesrdquo
44
Deep Belief Networks (DBN)
F Van Veen ldquoThe Neural Network Zoordquo (2016)
45
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMs
46
Deep Belief Networks (DBN)
Architecture like an MLP Training as a stack of
RBMs
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
47
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMs
48
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMs
49
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMshellip so they do not need
labels
Unsupervisedlearning
50
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
After the DBN is trained it can be fine-tuned with a reduced amount of labels to solve a supervised task with superior performance
Supervisedlearning
Softm
ax
51
Deep Belief Networks (DBN)
Deep Learning TV ldquoDeep Belief Netsrdquo
52
Deep Belief Networks (DBN)
Geoffrey Hinton Introduction to Deep Learning amp Deep Belief Netsrdquo (2012)Geoorey Hinton ldquoTutorial on Deep Belief Networksrdquo NIPS 2007
53
Deep Belief Networks (DBN)
Geoffrey Hinton
54
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
Acknowledgments
55
Junting Pan Xunyu Lin
Unsupervised Feature Learning
56
Slide credit Yann LeCun
Unsupervised Feature Learning
57
Slide credit Yann LeCun
Slide credit Junting Pan
Frame Reconstruction amp Prediction
59Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
Frame Reconstruction amp Prediction
60Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
frame prediction
Frame Reconstruction amp Prediction
61Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
frame prediction
62Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised learned features (lots of data) are fine-tuned for activity recognition (little data)
Frame Reconstruction amp Prediction
Frame Prediction
63Ranzato MarcAurelio Arthur Szlam Joan Bruna Michael Mathieu Ronan Collobert and Sumit Chopra Video (language) modeling a baseline for generative models of natural videos arXiv preprint arXiv14126604 (2014)
64Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
Video frame prediction with a ConvNet
Frame Prediction
65Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
The blurry predictions from MSE are improved with multi-scale architecture adversarial learning and an image gradient difference loss function
Frame Prediction
66Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
The blurry predictions from MSE (l1) are improved with multi-scale architecture adversarial training and an image gradient difference loss (GDL) function
Frame Prediction
67Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
Frame Prediction
68Vondrick Carl Hamed Pirsiavash and Antonio Torralba Generating videos with scene dynamics NIPS 2016
Frame Prediction
69Vondrick Carl Hamed Pirsiavash and Antonio Torralba Generating videos with scene dynamics NIPS 2016
Frame Prediction
70Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
71
Frame Prediction
Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
Given an input image probabilistic generation of future frames with a Variational AutoEncoder (VAE)
72
Frame Prediction
Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
Encodes image as feature maps and motion as and cross-convolutional kernels
73
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
First steps in video feature learning
74Le Quoc V Will Y Zou Serena Y Yeung and Andrew Y Ng Learning hierarchical invariant spatio-temporal features for action recognition with independent subspace analysis CVPR 2011
Temporal Weak Labels
75Goroshin Ross Joan Bruna Jonathan Tompson David Eigen and Yann LeCun Unsupervised learning of spatiotemporally coherent metrics ICCV 2015
Assumption adjacent video frames contain semantically similar informationAutoencoder trained with regularizations by slowliness and sparisty
76Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
77Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
78(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Temporal order of frames is exploited as the supervisory signal for learning
Temporal Weak Labels
79(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Take temporal order as the supervisory signals for learning
Shuffled sequences
Binary classification
In order
Not in order
Temporal Weak Labels
80Fernando Basura Hakan Bilen Efstratios Gavves and Stephen Gould Self-supervised video representation learning with odd-one-out networks CVPR 2017
Temporal Weak LabelsTrain a network to detect which of the video sequences contains frames wrong order
81
Spatio-Temporal Weak Labels
X Lin Campos V Giroacute-i-Nieto X Torres J and Canton-Ferrer C ldquoDisentangling Motion Foreground and Background Features in Videosrdquo in CVPR 2017 Workshop Brave New Motion Representations
kernel dec
C3D
ForegroundMotion
FirstForeground
Background
Fg
Dec
Bg
Dec
Fg
Dec Reconstruction
of foreground in last frame
Reconstruction of foreground in
first frame
Reconstruction of background in first frame
uNLC
MaskBlock
gradients
Last foreground
Kernels
shareweights
82
Spatio-Temporal Weak Labels
Pathak Deepak Ross Girshick Piotr Dollaacuter Trevor Darrell and Bharath Hariharan Learning features by watching objects move CVPR 2017
83Greff Klaus Antti Rasmus Mathias Berglund Tele Hao Harri Valpola and Juergen Schmidhuber Tagger Deep unsupervised perceptual grouping NIPS 2016 [video] [code]
Spatio-Temporal Weak Labels
84Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
85
Audio Features from Visual weak labels
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Object amp Scenes recognition in videos by analysing the audio track (only)
86Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
87Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
88Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
89
Visualization of the video frames associated to the sounds that activate some of the last hidden units of Soundnet (conv7)
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Audio Features from Visual weak labels
90
Audio amp Visual features from alignement
90Arandjelović Relja and Andrew Zisserman Look Listen and Learn ICCV 2017
Audio and visual features learned by assessing alignement
91L Chen S Srivastava Z Duan and C Xu Deep Cross-Modal Audio-Visual Generation ACM International Conference on Multimedia Thematic Workshops 2017
Audio amp Visual features from alignement
92Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
93Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
Video to Speech Representations
CNN(VGG)
Frame from a silent video
Audio feature
Post-hoc synthesis
94Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
95Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
Speech to Video Synthesis (mouth)
96Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
97Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
Speech to Video Synthesis (pose amp emotion)
98Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
99Suwajanakorn Supasorn Steven M Seitz and Ira Kemelmacher-Shlizerman Synthesizing Obama learning lip sync from audio SIGGRAPH 2017
Speech to Video Synthesis (mouth)
100
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning

32
Autoencoder (AE)
Deep Learning TV ldquoAutoencoders - Ep 10rdquo
33F Van Veen ldquoThe Neural Network Zoordquo (2016)
Restricted Boltzmann Machine (RBM)
34
Restricted Boltzmann Machine (RBM)
Figure Geoffrey Hinton (2013)
Salakhutdinov Ruslan Andriy Mnih and Geoffrey Hinton Restricted Boltzmann machines for collaborative filtering Proceedings of the 24th international conference on Machine learning ACM 2007
Shallow two-layer net
Restricted = No two nodes in a layer share a connection
Bipartite graph
Bidirectional graph Shared weights Different biases
35
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Forward pass
36
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Forward pass
37
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Forward pass
38
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Backwardpass
39
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Backwardpass
40
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Backwardpass
The reconstructed values at the visible layer are compared with the actual ones with the KL Divergence
41
Restricted Boltzmann Machine (RBM)
Figure Geoffrey Hinton (2013)
Salakhutdinov Ruslan Andriy Mnih and Geoffrey Hinton Restricted Boltzmann machines for collaborative filtering Proceedings of the 24th international conference on Machine learning ACM 2007
42
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
RBMs are a specific type of autoencoder
Unsupervisedlearning
43
Restricted Boltzmann Machine (RBM)
Deep Learning TV ldquoRestricted Boltzmann Machinesrdquo
44
Deep Belief Networks (DBN)
F Van Veen ldquoThe Neural Network Zoordquo (2016)
45
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMs
46
Deep Belief Networks (DBN)
Architecture like an MLP Training as a stack of
RBMs
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
47
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMs
48
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMs
49
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMshellip so they do not need
labels
Unsupervisedlearning
50
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
After the DBN is trained it can be fine-tuned with a reduced amount of labels to solve a supervised task with superior performance
Supervisedlearning
Softm
ax
51
Deep Belief Networks (DBN)
Deep Learning TV ldquoDeep Belief Netsrdquo
52
Deep Belief Networks (DBN)
Geoffrey Hinton Introduction to Deep Learning amp Deep Belief Netsrdquo (2012)Geoorey Hinton ldquoTutorial on Deep Belief Networksrdquo NIPS 2007
53
Deep Belief Networks (DBN)
Geoffrey Hinton
54
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
Acknowledgments
55
Junting Pan Xunyu Lin
Unsupervised Feature Learning
56
Slide credit Yann LeCun
Unsupervised Feature Learning
57
Slide credit Yann LeCun
Slide credit Junting Pan
Frame Reconstruction amp Prediction
59Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
Frame Reconstruction amp Prediction
60Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
frame prediction
Frame Reconstruction amp Prediction
61Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
frame prediction
62Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised learned features (lots of data) are fine-tuned for activity recognition (little data)
Frame Reconstruction amp Prediction
Frame Prediction
63Ranzato MarcAurelio Arthur Szlam Joan Bruna Michael Mathieu Ronan Collobert and Sumit Chopra Video (language) modeling a baseline for generative models of natural videos arXiv preprint arXiv14126604 (2014)
64Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
Video frame prediction with a ConvNet
Frame Prediction
65Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
The blurry predictions from MSE are improved with multi-scale architecture adversarial learning and an image gradient difference loss function
Frame Prediction
66Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
The blurry predictions from MSE (l1) are improved with multi-scale architecture adversarial training and an image gradient difference loss (GDL) function
Frame Prediction
67Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
Frame Prediction
68Vondrick Carl Hamed Pirsiavash and Antonio Torralba Generating videos with scene dynamics NIPS 2016
Frame Prediction
69Vondrick Carl Hamed Pirsiavash and Antonio Torralba Generating videos with scene dynamics NIPS 2016
Frame Prediction
70Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
71
Frame Prediction
Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
Given an input image probabilistic generation of future frames with a Variational AutoEncoder (VAE)
72
Frame Prediction
Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
Encodes image as feature maps and motion as and cross-convolutional kernels
73
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
First steps in video feature learning
74Le Quoc V Will Y Zou Serena Y Yeung and Andrew Y Ng Learning hierarchical invariant spatio-temporal features for action recognition with independent subspace analysis CVPR 2011
Temporal Weak Labels
75Goroshin Ross Joan Bruna Jonathan Tompson David Eigen and Yann LeCun Unsupervised learning of spatiotemporally coherent metrics ICCV 2015
Assumption adjacent video frames contain semantically similar informationAutoencoder trained with regularizations by slowliness and sparisty
76Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
77Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
78(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Temporal order of frames is exploited as the supervisory signal for learning
Temporal Weak Labels
79(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Take temporal order as the supervisory signals for learning
Shuffled sequences
Binary classification
In order
Not in order
Temporal Weak Labels
80Fernando Basura Hakan Bilen Efstratios Gavves and Stephen Gould Self-supervised video representation learning with odd-one-out networks CVPR 2017
Temporal Weak LabelsTrain a network to detect which of the video sequences contains frames wrong order
81
Spatio-Temporal Weak Labels
X Lin Campos V Giroacute-i-Nieto X Torres J and Canton-Ferrer C ldquoDisentangling Motion Foreground and Background Features in Videosrdquo in CVPR 2017 Workshop Brave New Motion Representations
kernel dec
C3D
ForegroundMotion
FirstForeground
Background
Fg
Dec
Bg
Dec
Fg
Dec Reconstruction
of foreground in last frame
Reconstruction of foreground in
first frame
Reconstruction of background in first frame
uNLC
MaskBlock
gradients
Last foreground
Kernels
shareweights
82
Spatio-Temporal Weak Labels
Pathak Deepak Ross Girshick Piotr Dollaacuter Trevor Darrell and Bharath Hariharan Learning features by watching objects move CVPR 2017
83Greff Klaus Antti Rasmus Mathias Berglund Tele Hao Harri Valpola and Juergen Schmidhuber Tagger Deep unsupervised perceptual grouping NIPS 2016 [video] [code]
Spatio-Temporal Weak Labels
84Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
85
Audio Features from Visual weak labels
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Object amp Scenes recognition in videos by analysing the audio track (only)
86Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
87Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
88Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
89
Visualization of the video frames associated to the sounds that activate some of the last hidden units of Soundnet (conv7)
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Audio Features from Visual weak labels
90
Audio amp Visual features from alignement
90Arandjelović Relja and Andrew Zisserman Look Listen and Learn ICCV 2017
Audio and visual features learned by assessing alignement
91L Chen S Srivastava Z Duan and C Xu Deep Cross-Modal Audio-Visual Generation ACM International Conference on Multimedia Thematic Workshops 2017
Audio amp Visual features from alignement
92Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
93Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
Video to Speech Representations
CNN(VGG)
Frame from a silent video
Audio feature
Post-hoc synthesis
94Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
95Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
Speech to Video Synthesis (mouth)
96Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
97Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
Speech to Video Synthesis (pose amp emotion)
98Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
99Suwajanakorn Supasorn Steven M Seitz and Ira Kemelmacher-Shlizerman Synthesizing Obama learning lip sync from audio SIGGRAPH 2017
Speech to Video Synthesis (mouth)
100
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning

33F Van Veen ldquoThe Neural Network Zoordquo (2016)
Restricted Boltzmann Machine (RBM)
34
Restricted Boltzmann Machine (RBM)
Figure Geoffrey Hinton (2013)
Salakhutdinov Ruslan Andriy Mnih and Geoffrey Hinton Restricted Boltzmann machines for collaborative filtering Proceedings of the 24th international conference on Machine learning ACM 2007
Shallow two-layer net
Restricted = No two nodes in a layer share a connection
Bipartite graph
Bidirectional graph Shared weights Different biases
35
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Forward pass
36
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Forward pass
37
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Forward pass
38
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Backwardpass
39
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Backwardpass
40
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Backwardpass
The reconstructed values at the visible layer are compared with the actual ones with the KL Divergence
41
Restricted Boltzmann Machine (RBM)
Figure Geoffrey Hinton (2013)
Salakhutdinov Ruslan Andriy Mnih and Geoffrey Hinton Restricted Boltzmann machines for collaborative filtering Proceedings of the 24th international conference on Machine learning ACM 2007
42
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
RBMs are a specific type of autoencoder
Unsupervisedlearning
43
Restricted Boltzmann Machine (RBM)
Deep Learning TV ldquoRestricted Boltzmann Machinesrdquo
44
Deep Belief Networks (DBN)
F Van Veen ldquoThe Neural Network Zoordquo (2016)
45
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMs
46
Deep Belief Networks (DBN)
Architecture like an MLP Training as a stack of
RBMs
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
47
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMs
48
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMs
49
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMshellip so they do not need
labels
Unsupervisedlearning
50
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
After the DBN is trained it can be fine-tuned with a reduced amount of labels to solve a supervised task with superior performance
Supervisedlearning
Softm
ax
51
Deep Belief Networks (DBN)
Deep Learning TV ldquoDeep Belief Netsrdquo
52
Deep Belief Networks (DBN)
Geoffrey Hinton Introduction to Deep Learning amp Deep Belief Netsrdquo (2012)Geoorey Hinton ldquoTutorial on Deep Belief Networksrdquo NIPS 2007
53
Deep Belief Networks (DBN)
Geoffrey Hinton
54
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
Acknowledgments
55
Junting Pan Xunyu Lin
Unsupervised Feature Learning
56
Slide credit Yann LeCun
Unsupervised Feature Learning
57
Slide credit Yann LeCun
Slide credit Junting Pan
Frame Reconstruction amp Prediction
59Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
Frame Reconstruction amp Prediction
60Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
frame prediction
Frame Reconstruction amp Prediction
61Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
frame prediction
62Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised learned features (lots of data) are fine-tuned for activity recognition (little data)
Frame Reconstruction amp Prediction
Frame Prediction
63Ranzato MarcAurelio Arthur Szlam Joan Bruna Michael Mathieu Ronan Collobert and Sumit Chopra Video (language) modeling a baseline for generative models of natural videos arXiv preprint arXiv14126604 (2014)
64Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
Video frame prediction with a ConvNet
Frame Prediction
65Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
The blurry predictions from MSE are improved with multi-scale architecture adversarial learning and an image gradient difference loss function
Frame Prediction
66Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
The blurry predictions from MSE (l1) are improved with multi-scale architecture adversarial training and an image gradient difference loss (GDL) function
Frame Prediction
67Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
Frame Prediction
68Vondrick Carl Hamed Pirsiavash and Antonio Torralba Generating videos with scene dynamics NIPS 2016
Frame Prediction
69Vondrick Carl Hamed Pirsiavash and Antonio Torralba Generating videos with scene dynamics NIPS 2016
Frame Prediction
70Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
71
Frame Prediction
Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
Given an input image probabilistic generation of future frames with a Variational AutoEncoder (VAE)
72
Frame Prediction
Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
Encodes image as feature maps and motion as and cross-convolutional kernels
73
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
First steps in video feature learning
74Le Quoc V Will Y Zou Serena Y Yeung and Andrew Y Ng Learning hierarchical invariant spatio-temporal features for action recognition with independent subspace analysis CVPR 2011
Temporal Weak Labels
75Goroshin Ross Joan Bruna Jonathan Tompson David Eigen and Yann LeCun Unsupervised learning of spatiotemporally coherent metrics ICCV 2015
Assumption adjacent video frames contain semantically similar informationAutoencoder trained with regularizations by slowliness and sparisty
76Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
77Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
78(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Temporal order of frames is exploited as the supervisory signal for learning
Temporal Weak Labels
79(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Take temporal order as the supervisory signals for learning
Shuffled sequences
Binary classification
In order
Not in order
Temporal Weak Labels
80Fernando Basura Hakan Bilen Efstratios Gavves and Stephen Gould Self-supervised video representation learning with odd-one-out networks CVPR 2017
Temporal Weak LabelsTrain a network to detect which of the video sequences contains frames wrong order
81
Spatio-Temporal Weak Labels
X Lin Campos V Giroacute-i-Nieto X Torres J and Canton-Ferrer C ldquoDisentangling Motion Foreground and Background Features in Videosrdquo in CVPR 2017 Workshop Brave New Motion Representations
kernel dec
C3D
ForegroundMotion
FirstForeground
Background
Fg
Dec
Bg
Dec
Fg
Dec Reconstruction
of foreground in last frame
Reconstruction of foreground in
first frame
Reconstruction of background in first frame
uNLC
MaskBlock
gradients
Last foreground
Kernels
shareweights
82
Spatio-Temporal Weak Labels
Pathak Deepak Ross Girshick Piotr Dollaacuter Trevor Darrell and Bharath Hariharan Learning features by watching objects move CVPR 2017
83Greff Klaus Antti Rasmus Mathias Berglund Tele Hao Harri Valpola and Juergen Schmidhuber Tagger Deep unsupervised perceptual grouping NIPS 2016 [video] [code]
Spatio-Temporal Weak Labels
84Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
85
Audio Features from Visual weak labels
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Object amp Scenes recognition in videos by analysing the audio track (only)
86Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
87Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
88Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
89
Visualization of the video frames associated to the sounds that activate some of the last hidden units of Soundnet (conv7)
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Audio Features from Visual weak labels
90
Audio amp Visual features from alignement
90Arandjelović Relja and Andrew Zisserman Look Listen and Learn ICCV 2017
Audio and visual features learned by assessing alignement
91L Chen S Srivastava Z Duan and C Xu Deep Cross-Modal Audio-Visual Generation ACM International Conference on Multimedia Thematic Workshops 2017
Audio amp Visual features from alignement
92Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
93Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
Video to Speech Representations
CNN(VGG)
Frame from a silent video
Audio feature
Post-hoc synthesis
94Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
95Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
Speech to Video Synthesis (mouth)
96Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
97Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
Speech to Video Synthesis (pose amp emotion)
98Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
99Suwajanakorn Supasorn Steven M Seitz and Ira Kemelmacher-Shlizerman Synthesizing Obama learning lip sync from audio SIGGRAPH 2017
Speech to Video Synthesis (mouth)
100
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
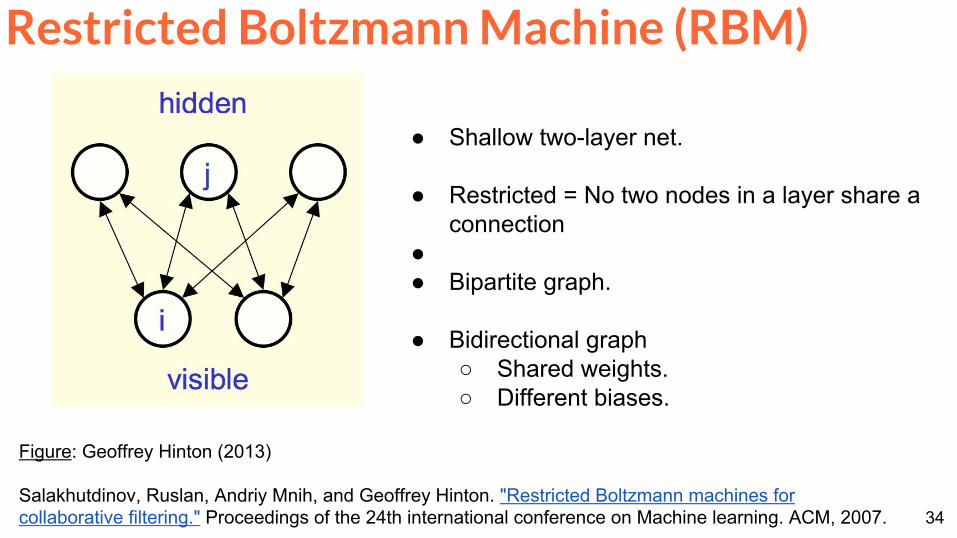
34
Restricted Boltzmann Machine (RBM)
Figure Geoffrey Hinton (2013)
Salakhutdinov Ruslan Andriy Mnih and Geoffrey Hinton Restricted Boltzmann machines for collaborative filtering Proceedings of the 24th international conference on Machine learning ACM 2007
Shallow two-layer net
Restricted = No two nodes in a layer share a connection
Bipartite graph
Bidirectional graph Shared weights Different biases
35
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Forward pass
36
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Forward pass
37
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Forward pass
38
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Backwardpass
39
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Backwardpass
40
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Backwardpass
The reconstructed values at the visible layer are compared with the actual ones with the KL Divergence
41
Restricted Boltzmann Machine (RBM)
Figure Geoffrey Hinton (2013)
Salakhutdinov Ruslan Andriy Mnih and Geoffrey Hinton Restricted Boltzmann machines for collaborative filtering Proceedings of the 24th international conference on Machine learning ACM 2007
42
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
RBMs are a specific type of autoencoder
Unsupervisedlearning
43
Restricted Boltzmann Machine (RBM)
Deep Learning TV ldquoRestricted Boltzmann Machinesrdquo
44
Deep Belief Networks (DBN)
F Van Veen ldquoThe Neural Network Zoordquo (2016)
45
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMs
46
Deep Belief Networks (DBN)
Architecture like an MLP Training as a stack of
RBMs
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
47
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMs
48
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMs
49
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMshellip so they do not need
labels
Unsupervisedlearning
50
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
After the DBN is trained it can be fine-tuned with a reduced amount of labels to solve a supervised task with superior performance
Supervisedlearning
Softm
ax
51
Deep Belief Networks (DBN)
Deep Learning TV ldquoDeep Belief Netsrdquo
52
Deep Belief Networks (DBN)
Geoffrey Hinton Introduction to Deep Learning amp Deep Belief Netsrdquo (2012)Geoorey Hinton ldquoTutorial on Deep Belief Networksrdquo NIPS 2007
53
Deep Belief Networks (DBN)
Geoffrey Hinton
54
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
Acknowledgments
55
Junting Pan Xunyu Lin
Unsupervised Feature Learning
56
Slide credit Yann LeCun
Unsupervised Feature Learning
57
Slide credit Yann LeCun
Slide credit Junting Pan
Frame Reconstruction amp Prediction
59Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
Frame Reconstruction amp Prediction
60Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
frame prediction
Frame Reconstruction amp Prediction
61Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
frame prediction
62Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised learned features (lots of data) are fine-tuned for activity recognition (little data)
Frame Reconstruction amp Prediction
Frame Prediction
63Ranzato MarcAurelio Arthur Szlam Joan Bruna Michael Mathieu Ronan Collobert and Sumit Chopra Video (language) modeling a baseline for generative models of natural videos arXiv preprint arXiv14126604 (2014)
64Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
Video frame prediction with a ConvNet
Frame Prediction
65Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
The blurry predictions from MSE are improved with multi-scale architecture adversarial learning and an image gradient difference loss function
Frame Prediction
66Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
The blurry predictions from MSE (l1) are improved with multi-scale architecture adversarial training and an image gradient difference loss (GDL) function
Frame Prediction
67Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
Frame Prediction
68Vondrick Carl Hamed Pirsiavash and Antonio Torralba Generating videos with scene dynamics NIPS 2016
Frame Prediction
69Vondrick Carl Hamed Pirsiavash and Antonio Torralba Generating videos with scene dynamics NIPS 2016
Frame Prediction
70Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
71
Frame Prediction
Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
Given an input image probabilistic generation of future frames with a Variational AutoEncoder (VAE)
72
Frame Prediction
Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
Encodes image as feature maps and motion as and cross-convolutional kernels
73
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
First steps in video feature learning
74Le Quoc V Will Y Zou Serena Y Yeung and Andrew Y Ng Learning hierarchical invariant spatio-temporal features for action recognition with independent subspace analysis CVPR 2011
Temporal Weak Labels
75Goroshin Ross Joan Bruna Jonathan Tompson David Eigen and Yann LeCun Unsupervised learning of spatiotemporally coherent metrics ICCV 2015
Assumption adjacent video frames contain semantically similar informationAutoencoder trained with regularizations by slowliness and sparisty
76Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
77Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
78(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Temporal order of frames is exploited as the supervisory signal for learning
Temporal Weak Labels
79(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Take temporal order as the supervisory signals for learning
Shuffled sequences
Binary classification
In order
Not in order
Temporal Weak Labels
80Fernando Basura Hakan Bilen Efstratios Gavves and Stephen Gould Self-supervised video representation learning with odd-one-out networks CVPR 2017
Temporal Weak LabelsTrain a network to detect which of the video sequences contains frames wrong order
81
Spatio-Temporal Weak Labels
X Lin Campos V Giroacute-i-Nieto X Torres J and Canton-Ferrer C ldquoDisentangling Motion Foreground and Background Features in Videosrdquo in CVPR 2017 Workshop Brave New Motion Representations
kernel dec
C3D
ForegroundMotion
FirstForeground
Background
Fg
Dec
Bg
Dec
Fg
Dec Reconstruction
of foreground in last frame
Reconstruction of foreground in
first frame
Reconstruction of background in first frame
uNLC
MaskBlock
gradients
Last foreground
Kernels
shareweights
82
Spatio-Temporal Weak Labels
Pathak Deepak Ross Girshick Piotr Dollaacuter Trevor Darrell and Bharath Hariharan Learning features by watching objects move CVPR 2017
83Greff Klaus Antti Rasmus Mathias Berglund Tele Hao Harri Valpola and Juergen Schmidhuber Tagger Deep unsupervised perceptual grouping NIPS 2016 [video] [code]
Spatio-Temporal Weak Labels
84Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
85
Audio Features from Visual weak labels
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Object amp Scenes recognition in videos by analysing the audio track (only)
86Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
87Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
88Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
89
Visualization of the video frames associated to the sounds that activate some of the last hidden units of Soundnet (conv7)
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Audio Features from Visual weak labels
90
Audio amp Visual features from alignement
90Arandjelović Relja and Andrew Zisserman Look Listen and Learn ICCV 2017
Audio and visual features learned by assessing alignement
91L Chen S Srivastava Z Duan and C Xu Deep Cross-Modal Audio-Visual Generation ACM International Conference on Multimedia Thematic Workshops 2017
Audio amp Visual features from alignement
92Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
93Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
Video to Speech Representations
CNN(VGG)
Frame from a silent video
Audio feature
Post-hoc synthesis
94Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
95Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
Speech to Video Synthesis (mouth)
96Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
97Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
Speech to Video Synthesis (pose amp emotion)
98Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
99Suwajanakorn Supasorn Steven M Seitz and Ira Kemelmacher-Shlizerman Synthesizing Obama learning lip sync from audio SIGGRAPH 2017
Speech to Video Synthesis (mouth)
100
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning

35
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Forward pass
36
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Forward pass
37
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Forward pass
38
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Backwardpass
39
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Backwardpass
40
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Backwardpass
The reconstructed values at the visible layer are compared with the actual ones with the KL Divergence
41
Restricted Boltzmann Machine (RBM)
Figure Geoffrey Hinton (2013)
Salakhutdinov Ruslan Andriy Mnih and Geoffrey Hinton Restricted Boltzmann machines for collaborative filtering Proceedings of the 24th international conference on Machine learning ACM 2007
42
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
RBMs are a specific type of autoencoder
Unsupervisedlearning
43
Restricted Boltzmann Machine (RBM)
Deep Learning TV ldquoRestricted Boltzmann Machinesrdquo
44
Deep Belief Networks (DBN)
F Van Veen ldquoThe Neural Network Zoordquo (2016)
45
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMs
46
Deep Belief Networks (DBN)
Architecture like an MLP Training as a stack of
RBMs
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
47
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMs
48
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMs
49
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMshellip so they do not need
labels
Unsupervisedlearning
50
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
After the DBN is trained it can be fine-tuned with a reduced amount of labels to solve a supervised task with superior performance
Supervisedlearning
Softm
ax
51
Deep Belief Networks (DBN)
Deep Learning TV ldquoDeep Belief Netsrdquo
52
Deep Belief Networks (DBN)
Geoffrey Hinton Introduction to Deep Learning amp Deep Belief Netsrdquo (2012)Geoorey Hinton ldquoTutorial on Deep Belief Networksrdquo NIPS 2007
53
Deep Belief Networks (DBN)
Geoffrey Hinton
54
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
Acknowledgments
55
Junting Pan Xunyu Lin
Unsupervised Feature Learning
56
Slide credit Yann LeCun
Unsupervised Feature Learning
57
Slide credit Yann LeCun
Slide credit Junting Pan
Frame Reconstruction amp Prediction
59Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
Frame Reconstruction amp Prediction
60Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
frame prediction
Frame Reconstruction amp Prediction
61Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
frame prediction
62Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised learned features (lots of data) are fine-tuned for activity recognition (little data)
Frame Reconstruction amp Prediction
Frame Prediction
63Ranzato MarcAurelio Arthur Szlam Joan Bruna Michael Mathieu Ronan Collobert and Sumit Chopra Video (language) modeling a baseline for generative models of natural videos arXiv preprint arXiv14126604 (2014)
64Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
Video frame prediction with a ConvNet
Frame Prediction
65Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
The blurry predictions from MSE are improved with multi-scale architecture adversarial learning and an image gradient difference loss function
Frame Prediction
66Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
The blurry predictions from MSE (l1) are improved with multi-scale architecture adversarial training and an image gradient difference loss (GDL) function
Frame Prediction
67Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
Frame Prediction
68Vondrick Carl Hamed Pirsiavash and Antonio Torralba Generating videos with scene dynamics NIPS 2016
Frame Prediction
69Vondrick Carl Hamed Pirsiavash and Antonio Torralba Generating videos with scene dynamics NIPS 2016
Frame Prediction
70Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
71
Frame Prediction
Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
Given an input image probabilistic generation of future frames with a Variational AutoEncoder (VAE)
72
Frame Prediction
Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
Encodes image as feature maps and motion as and cross-convolutional kernels
73
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
First steps in video feature learning
74Le Quoc V Will Y Zou Serena Y Yeung and Andrew Y Ng Learning hierarchical invariant spatio-temporal features for action recognition with independent subspace analysis CVPR 2011
Temporal Weak Labels
75Goroshin Ross Joan Bruna Jonathan Tompson David Eigen and Yann LeCun Unsupervised learning of spatiotemporally coherent metrics ICCV 2015
Assumption adjacent video frames contain semantically similar informationAutoencoder trained with regularizations by slowliness and sparisty
76Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
77Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
78(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Temporal order of frames is exploited as the supervisory signal for learning
Temporal Weak Labels
79(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Take temporal order as the supervisory signals for learning
Shuffled sequences
Binary classification
In order
Not in order
Temporal Weak Labels
80Fernando Basura Hakan Bilen Efstratios Gavves and Stephen Gould Self-supervised video representation learning with odd-one-out networks CVPR 2017
Temporal Weak LabelsTrain a network to detect which of the video sequences contains frames wrong order
81
Spatio-Temporal Weak Labels
X Lin Campos V Giroacute-i-Nieto X Torres J and Canton-Ferrer C ldquoDisentangling Motion Foreground and Background Features in Videosrdquo in CVPR 2017 Workshop Brave New Motion Representations
kernel dec
C3D
ForegroundMotion
FirstForeground
Background
Fg
Dec
Bg
Dec
Fg
Dec Reconstruction
of foreground in last frame
Reconstruction of foreground in
first frame
Reconstruction of background in first frame
uNLC
MaskBlock
gradients
Last foreground
Kernels
shareweights
82
Spatio-Temporal Weak Labels
Pathak Deepak Ross Girshick Piotr Dollaacuter Trevor Darrell and Bharath Hariharan Learning features by watching objects move CVPR 2017
83Greff Klaus Antti Rasmus Mathias Berglund Tele Hao Harri Valpola and Juergen Schmidhuber Tagger Deep unsupervised perceptual grouping NIPS 2016 [video] [code]
Spatio-Temporal Weak Labels
84Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
85
Audio Features from Visual weak labels
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Object amp Scenes recognition in videos by analysing the audio track (only)
86Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
87Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
88Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
89
Visualization of the video frames associated to the sounds that activate some of the last hidden units of Soundnet (conv7)
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Audio Features from Visual weak labels
90
Audio amp Visual features from alignement
90Arandjelović Relja and Andrew Zisserman Look Listen and Learn ICCV 2017
Audio and visual features learned by assessing alignement
91L Chen S Srivastava Z Duan and C Xu Deep Cross-Modal Audio-Visual Generation ACM International Conference on Multimedia Thematic Workshops 2017
Audio amp Visual features from alignement
92Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
93Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
Video to Speech Representations
CNN(VGG)
Frame from a silent video
Audio feature
Post-hoc synthesis
94Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
95Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
Speech to Video Synthesis (mouth)
96Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
97Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
Speech to Video Synthesis (pose amp emotion)
98Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
99Suwajanakorn Supasorn Steven M Seitz and Ira Kemelmacher-Shlizerman Synthesizing Obama learning lip sync from audio SIGGRAPH 2017
Speech to Video Synthesis (mouth)
100
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning

36
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Forward pass
37
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Forward pass
38
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Backwardpass
39
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Backwardpass
40
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Backwardpass
The reconstructed values at the visible layer are compared with the actual ones with the KL Divergence
41
Restricted Boltzmann Machine (RBM)
Figure Geoffrey Hinton (2013)
Salakhutdinov Ruslan Andriy Mnih and Geoffrey Hinton Restricted Boltzmann machines for collaborative filtering Proceedings of the 24th international conference on Machine learning ACM 2007
42
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
RBMs are a specific type of autoencoder
Unsupervisedlearning
43
Restricted Boltzmann Machine (RBM)
Deep Learning TV ldquoRestricted Boltzmann Machinesrdquo
44
Deep Belief Networks (DBN)
F Van Veen ldquoThe Neural Network Zoordquo (2016)
45
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMs
46
Deep Belief Networks (DBN)
Architecture like an MLP Training as a stack of
RBMs
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
47
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMs
48
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMs
49
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMshellip so they do not need
labels
Unsupervisedlearning
50
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
After the DBN is trained it can be fine-tuned with a reduced amount of labels to solve a supervised task with superior performance
Supervisedlearning
Softm
ax
51
Deep Belief Networks (DBN)
Deep Learning TV ldquoDeep Belief Netsrdquo
52
Deep Belief Networks (DBN)
Geoffrey Hinton Introduction to Deep Learning amp Deep Belief Netsrdquo (2012)Geoorey Hinton ldquoTutorial on Deep Belief Networksrdquo NIPS 2007
53
Deep Belief Networks (DBN)
Geoffrey Hinton
54
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
Acknowledgments
55
Junting Pan Xunyu Lin
Unsupervised Feature Learning
56
Slide credit Yann LeCun
Unsupervised Feature Learning
57
Slide credit Yann LeCun
Slide credit Junting Pan
Frame Reconstruction amp Prediction
59Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
Frame Reconstruction amp Prediction
60Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
frame prediction
Frame Reconstruction amp Prediction
61Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
frame prediction
62Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised learned features (lots of data) are fine-tuned for activity recognition (little data)
Frame Reconstruction amp Prediction
Frame Prediction
63Ranzato MarcAurelio Arthur Szlam Joan Bruna Michael Mathieu Ronan Collobert and Sumit Chopra Video (language) modeling a baseline for generative models of natural videos arXiv preprint arXiv14126604 (2014)
64Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
Video frame prediction with a ConvNet
Frame Prediction
65Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
The blurry predictions from MSE are improved with multi-scale architecture adversarial learning and an image gradient difference loss function
Frame Prediction
66Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
The blurry predictions from MSE (l1) are improved with multi-scale architecture adversarial training and an image gradient difference loss (GDL) function
Frame Prediction
67Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
Frame Prediction
68Vondrick Carl Hamed Pirsiavash and Antonio Torralba Generating videos with scene dynamics NIPS 2016
Frame Prediction
69Vondrick Carl Hamed Pirsiavash and Antonio Torralba Generating videos with scene dynamics NIPS 2016
Frame Prediction
70Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
71
Frame Prediction
Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
Given an input image probabilistic generation of future frames with a Variational AutoEncoder (VAE)
72
Frame Prediction
Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
Encodes image as feature maps and motion as and cross-convolutional kernels
73
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
First steps in video feature learning
74Le Quoc V Will Y Zou Serena Y Yeung and Andrew Y Ng Learning hierarchical invariant spatio-temporal features for action recognition with independent subspace analysis CVPR 2011
Temporal Weak Labels
75Goroshin Ross Joan Bruna Jonathan Tompson David Eigen and Yann LeCun Unsupervised learning of spatiotemporally coherent metrics ICCV 2015
Assumption adjacent video frames contain semantically similar informationAutoencoder trained with regularizations by slowliness and sparisty
76Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
77Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
78(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Temporal order of frames is exploited as the supervisory signal for learning
Temporal Weak Labels
79(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Take temporal order as the supervisory signals for learning
Shuffled sequences
Binary classification
In order
Not in order
Temporal Weak Labels
80Fernando Basura Hakan Bilen Efstratios Gavves and Stephen Gould Self-supervised video representation learning with odd-one-out networks CVPR 2017
Temporal Weak LabelsTrain a network to detect which of the video sequences contains frames wrong order
81
Spatio-Temporal Weak Labels
X Lin Campos V Giroacute-i-Nieto X Torres J and Canton-Ferrer C ldquoDisentangling Motion Foreground and Background Features in Videosrdquo in CVPR 2017 Workshop Brave New Motion Representations
kernel dec
C3D
ForegroundMotion
FirstForeground
Background
Fg
Dec
Bg
Dec
Fg
Dec Reconstruction
of foreground in last frame
Reconstruction of foreground in
first frame
Reconstruction of background in first frame
uNLC
MaskBlock
gradients
Last foreground
Kernels
shareweights
82
Spatio-Temporal Weak Labels
Pathak Deepak Ross Girshick Piotr Dollaacuter Trevor Darrell and Bharath Hariharan Learning features by watching objects move CVPR 2017
83Greff Klaus Antti Rasmus Mathias Berglund Tele Hao Harri Valpola and Juergen Schmidhuber Tagger Deep unsupervised perceptual grouping NIPS 2016 [video] [code]
Spatio-Temporal Weak Labels
84Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
85
Audio Features from Visual weak labels
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Object amp Scenes recognition in videos by analysing the audio track (only)
86Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
87Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
88Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
89
Visualization of the video frames associated to the sounds that activate some of the last hidden units of Soundnet (conv7)
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Audio Features from Visual weak labels
90
Audio amp Visual features from alignement
90Arandjelović Relja and Andrew Zisserman Look Listen and Learn ICCV 2017
Audio and visual features learned by assessing alignement
91L Chen S Srivastava Z Duan and C Xu Deep Cross-Modal Audio-Visual Generation ACM International Conference on Multimedia Thematic Workshops 2017
Audio amp Visual features from alignement
92Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
93Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
Video to Speech Representations
CNN(VGG)
Frame from a silent video
Audio feature
Post-hoc synthesis
94Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
95Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
Speech to Video Synthesis (mouth)
96Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
97Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
Speech to Video Synthesis (pose amp emotion)
98Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
99Suwajanakorn Supasorn Steven M Seitz and Ira Kemelmacher-Shlizerman Synthesizing Obama learning lip sync from audio SIGGRAPH 2017
Speech to Video Synthesis (mouth)
100
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
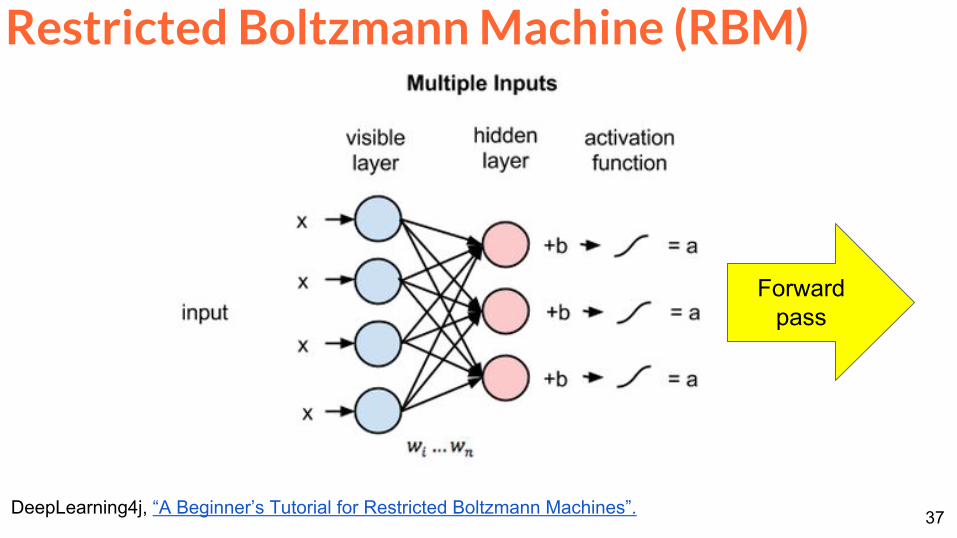
37
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Forward pass
38
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Backwardpass
39
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Backwardpass
40
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Backwardpass
The reconstructed values at the visible layer are compared with the actual ones with the KL Divergence
41
Restricted Boltzmann Machine (RBM)
Figure Geoffrey Hinton (2013)
Salakhutdinov Ruslan Andriy Mnih and Geoffrey Hinton Restricted Boltzmann machines for collaborative filtering Proceedings of the 24th international conference on Machine learning ACM 2007
42
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
RBMs are a specific type of autoencoder
Unsupervisedlearning
43
Restricted Boltzmann Machine (RBM)
Deep Learning TV ldquoRestricted Boltzmann Machinesrdquo
44
Deep Belief Networks (DBN)
F Van Veen ldquoThe Neural Network Zoordquo (2016)
45
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMs
46
Deep Belief Networks (DBN)
Architecture like an MLP Training as a stack of
RBMs
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
47
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMs
48
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMs
49
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMshellip so they do not need
labels
Unsupervisedlearning
50
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
After the DBN is trained it can be fine-tuned with a reduced amount of labels to solve a supervised task with superior performance
Supervisedlearning
Softm
ax
51
Deep Belief Networks (DBN)
Deep Learning TV ldquoDeep Belief Netsrdquo
52
Deep Belief Networks (DBN)
Geoffrey Hinton Introduction to Deep Learning amp Deep Belief Netsrdquo (2012)Geoorey Hinton ldquoTutorial on Deep Belief Networksrdquo NIPS 2007
53
Deep Belief Networks (DBN)
Geoffrey Hinton
54
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
Acknowledgments
55
Junting Pan Xunyu Lin
Unsupervised Feature Learning
56
Slide credit Yann LeCun
Unsupervised Feature Learning
57
Slide credit Yann LeCun
Slide credit Junting Pan
Frame Reconstruction amp Prediction
59Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
Frame Reconstruction amp Prediction
60Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
frame prediction
Frame Reconstruction amp Prediction
61Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
frame prediction
62Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised learned features (lots of data) are fine-tuned for activity recognition (little data)
Frame Reconstruction amp Prediction
Frame Prediction
63Ranzato MarcAurelio Arthur Szlam Joan Bruna Michael Mathieu Ronan Collobert and Sumit Chopra Video (language) modeling a baseline for generative models of natural videos arXiv preprint arXiv14126604 (2014)
64Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
Video frame prediction with a ConvNet
Frame Prediction
65Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
The blurry predictions from MSE are improved with multi-scale architecture adversarial learning and an image gradient difference loss function
Frame Prediction
66Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
The blurry predictions from MSE (l1) are improved with multi-scale architecture adversarial training and an image gradient difference loss (GDL) function
Frame Prediction
67Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
Frame Prediction
68Vondrick Carl Hamed Pirsiavash and Antonio Torralba Generating videos with scene dynamics NIPS 2016
Frame Prediction
69Vondrick Carl Hamed Pirsiavash and Antonio Torralba Generating videos with scene dynamics NIPS 2016
Frame Prediction
70Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
71
Frame Prediction
Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
Given an input image probabilistic generation of future frames with a Variational AutoEncoder (VAE)
72
Frame Prediction
Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
Encodes image as feature maps and motion as and cross-convolutional kernels
73
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
First steps in video feature learning
74Le Quoc V Will Y Zou Serena Y Yeung and Andrew Y Ng Learning hierarchical invariant spatio-temporal features for action recognition with independent subspace analysis CVPR 2011
Temporal Weak Labels
75Goroshin Ross Joan Bruna Jonathan Tompson David Eigen and Yann LeCun Unsupervised learning of spatiotemporally coherent metrics ICCV 2015
Assumption adjacent video frames contain semantically similar informationAutoencoder trained with regularizations by slowliness and sparisty
76Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
77Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
78(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Temporal order of frames is exploited as the supervisory signal for learning
Temporal Weak Labels
79(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Take temporal order as the supervisory signals for learning
Shuffled sequences
Binary classification
In order
Not in order
Temporal Weak Labels
80Fernando Basura Hakan Bilen Efstratios Gavves and Stephen Gould Self-supervised video representation learning with odd-one-out networks CVPR 2017
Temporal Weak LabelsTrain a network to detect which of the video sequences contains frames wrong order
81
Spatio-Temporal Weak Labels
X Lin Campos V Giroacute-i-Nieto X Torres J and Canton-Ferrer C ldquoDisentangling Motion Foreground and Background Features in Videosrdquo in CVPR 2017 Workshop Brave New Motion Representations
kernel dec
C3D
ForegroundMotion
FirstForeground
Background
Fg
Dec
Bg
Dec
Fg
Dec Reconstruction
of foreground in last frame
Reconstruction of foreground in
first frame
Reconstruction of background in first frame
uNLC
MaskBlock
gradients
Last foreground
Kernels
shareweights
82
Spatio-Temporal Weak Labels
Pathak Deepak Ross Girshick Piotr Dollaacuter Trevor Darrell and Bharath Hariharan Learning features by watching objects move CVPR 2017
83Greff Klaus Antti Rasmus Mathias Berglund Tele Hao Harri Valpola and Juergen Schmidhuber Tagger Deep unsupervised perceptual grouping NIPS 2016 [video] [code]
Spatio-Temporal Weak Labels
84Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
85
Audio Features from Visual weak labels
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Object amp Scenes recognition in videos by analysing the audio track (only)
86Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
87Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
88Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
89
Visualization of the video frames associated to the sounds that activate some of the last hidden units of Soundnet (conv7)
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Audio Features from Visual weak labels
90
Audio amp Visual features from alignement
90Arandjelović Relja and Andrew Zisserman Look Listen and Learn ICCV 2017
Audio and visual features learned by assessing alignement
91L Chen S Srivastava Z Duan and C Xu Deep Cross-Modal Audio-Visual Generation ACM International Conference on Multimedia Thematic Workshops 2017
Audio amp Visual features from alignement
92Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
93Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
Video to Speech Representations
CNN(VGG)
Frame from a silent video
Audio feature
Post-hoc synthesis
94Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
95Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
Speech to Video Synthesis (mouth)
96Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
97Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
Speech to Video Synthesis (pose amp emotion)
98Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
99Suwajanakorn Supasorn Steven M Seitz and Ira Kemelmacher-Shlizerman Synthesizing Obama learning lip sync from audio SIGGRAPH 2017
Speech to Video Synthesis (mouth)
100
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
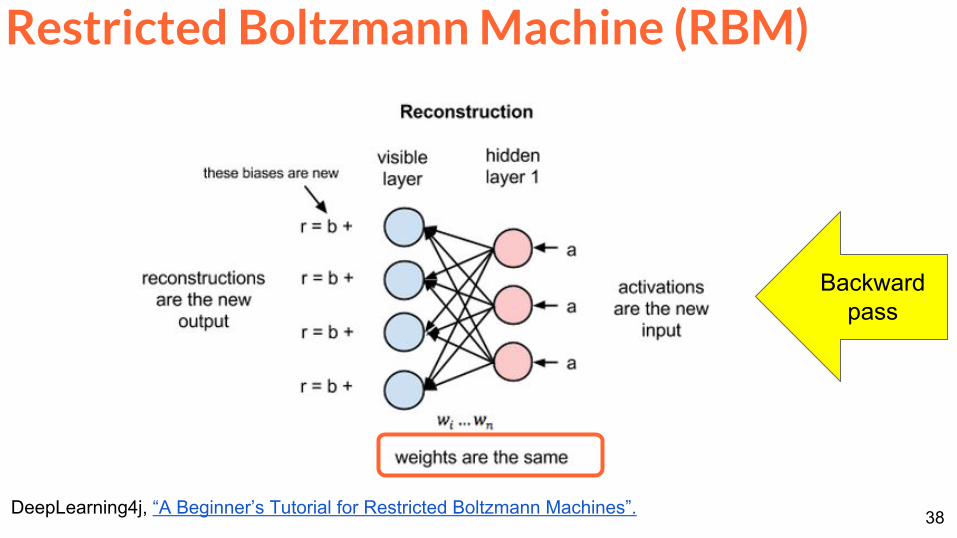
38
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Backwardpass
39
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Backwardpass
40
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Backwardpass
The reconstructed values at the visible layer are compared with the actual ones with the KL Divergence
41
Restricted Boltzmann Machine (RBM)
Figure Geoffrey Hinton (2013)
Salakhutdinov Ruslan Andriy Mnih and Geoffrey Hinton Restricted Boltzmann machines for collaborative filtering Proceedings of the 24th international conference on Machine learning ACM 2007
42
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
RBMs are a specific type of autoencoder
Unsupervisedlearning
43
Restricted Boltzmann Machine (RBM)
Deep Learning TV ldquoRestricted Boltzmann Machinesrdquo
44
Deep Belief Networks (DBN)
F Van Veen ldquoThe Neural Network Zoordquo (2016)
45
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMs
46
Deep Belief Networks (DBN)
Architecture like an MLP Training as a stack of
RBMs
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
47
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMs
48
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMs
49
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMshellip so they do not need
labels
Unsupervisedlearning
50
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
After the DBN is trained it can be fine-tuned with a reduced amount of labels to solve a supervised task with superior performance
Supervisedlearning
Softm
ax
51
Deep Belief Networks (DBN)
Deep Learning TV ldquoDeep Belief Netsrdquo
52
Deep Belief Networks (DBN)
Geoffrey Hinton Introduction to Deep Learning amp Deep Belief Netsrdquo (2012)Geoorey Hinton ldquoTutorial on Deep Belief Networksrdquo NIPS 2007
53
Deep Belief Networks (DBN)
Geoffrey Hinton
54
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
Acknowledgments
55
Junting Pan Xunyu Lin
Unsupervised Feature Learning
56
Slide credit Yann LeCun
Unsupervised Feature Learning
57
Slide credit Yann LeCun
Slide credit Junting Pan
Frame Reconstruction amp Prediction
59Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
Frame Reconstruction amp Prediction
60Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
frame prediction
Frame Reconstruction amp Prediction
61Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
frame prediction
62Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised learned features (lots of data) are fine-tuned for activity recognition (little data)
Frame Reconstruction amp Prediction
Frame Prediction
63Ranzato MarcAurelio Arthur Szlam Joan Bruna Michael Mathieu Ronan Collobert and Sumit Chopra Video (language) modeling a baseline for generative models of natural videos arXiv preprint arXiv14126604 (2014)
64Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
Video frame prediction with a ConvNet
Frame Prediction
65Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
The blurry predictions from MSE are improved with multi-scale architecture adversarial learning and an image gradient difference loss function
Frame Prediction
66Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
The blurry predictions from MSE (l1) are improved with multi-scale architecture adversarial training and an image gradient difference loss (GDL) function
Frame Prediction
67Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
Frame Prediction
68Vondrick Carl Hamed Pirsiavash and Antonio Torralba Generating videos with scene dynamics NIPS 2016
Frame Prediction
69Vondrick Carl Hamed Pirsiavash and Antonio Torralba Generating videos with scene dynamics NIPS 2016
Frame Prediction
70Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
71
Frame Prediction
Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
Given an input image probabilistic generation of future frames with a Variational AutoEncoder (VAE)
72
Frame Prediction
Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
Encodes image as feature maps and motion as and cross-convolutional kernels
73
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
First steps in video feature learning
74Le Quoc V Will Y Zou Serena Y Yeung and Andrew Y Ng Learning hierarchical invariant spatio-temporal features for action recognition with independent subspace analysis CVPR 2011
Temporal Weak Labels
75Goroshin Ross Joan Bruna Jonathan Tompson David Eigen and Yann LeCun Unsupervised learning of spatiotemporally coherent metrics ICCV 2015
Assumption adjacent video frames contain semantically similar informationAutoencoder trained with regularizations by slowliness and sparisty
76Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
77Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
78(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Temporal order of frames is exploited as the supervisory signal for learning
Temporal Weak Labels
79(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Take temporal order as the supervisory signals for learning
Shuffled sequences
Binary classification
In order
Not in order
Temporal Weak Labels
80Fernando Basura Hakan Bilen Efstratios Gavves and Stephen Gould Self-supervised video representation learning with odd-one-out networks CVPR 2017
Temporal Weak LabelsTrain a network to detect which of the video sequences contains frames wrong order
81
Spatio-Temporal Weak Labels
X Lin Campos V Giroacute-i-Nieto X Torres J and Canton-Ferrer C ldquoDisentangling Motion Foreground and Background Features in Videosrdquo in CVPR 2017 Workshop Brave New Motion Representations
kernel dec
C3D
ForegroundMotion
FirstForeground
Background
Fg
Dec
Bg
Dec
Fg
Dec Reconstruction
of foreground in last frame
Reconstruction of foreground in
first frame
Reconstruction of background in first frame
uNLC
MaskBlock
gradients
Last foreground
Kernels
shareweights
82
Spatio-Temporal Weak Labels
Pathak Deepak Ross Girshick Piotr Dollaacuter Trevor Darrell and Bharath Hariharan Learning features by watching objects move CVPR 2017
83Greff Klaus Antti Rasmus Mathias Berglund Tele Hao Harri Valpola and Juergen Schmidhuber Tagger Deep unsupervised perceptual grouping NIPS 2016 [video] [code]
Spatio-Temporal Weak Labels
84Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
85
Audio Features from Visual weak labels
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Object amp Scenes recognition in videos by analysing the audio track (only)
86Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
87Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
88Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
89
Visualization of the video frames associated to the sounds that activate some of the last hidden units of Soundnet (conv7)
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Audio Features from Visual weak labels
90
Audio amp Visual features from alignement
90Arandjelović Relja and Andrew Zisserman Look Listen and Learn ICCV 2017
Audio and visual features learned by assessing alignement
91L Chen S Srivastava Z Duan and C Xu Deep Cross-Modal Audio-Visual Generation ACM International Conference on Multimedia Thematic Workshops 2017
Audio amp Visual features from alignement
92Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
93Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
Video to Speech Representations
CNN(VGG)
Frame from a silent video
Audio feature
Post-hoc synthesis
94Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
95Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
Speech to Video Synthesis (mouth)
96Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
97Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
Speech to Video Synthesis (pose amp emotion)
98Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
99Suwajanakorn Supasorn Steven M Seitz and Ira Kemelmacher-Shlizerman Synthesizing Obama learning lip sync from audio SIGGRAPH 2017
Speech to Video Synthesis (mouth)
100
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning

39
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Backwardpass
40
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Backwardpass
The reconstructed values at the visible layer are compared with the actual ones with the KL Divergence
41
Restricted Boltzmann Machine (RBM)
Figure Geoffrey Hinton (2013)
Salakhutdinov Ruslan Andriy Mnih and Geoffrey Hinton Restricted Boltzmann machines for collaborative filtering Proceedings of the 24th international conference on Machine learning ACM 2007
42
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
RBMs are a specific type of autoencoder
Unsupervisedlearning
43
Restricted Boltzmann Machine (RBM)
Deep Learning TV ldquoRestricted Boltzmann Machinesrdquo
44
Deep Belief Networks (DBN)
F Van Veen ldquoThe Neural Network Zoordquo (2016)
45
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMs
46
Deep Belief Networks (DBN)
Architecture like an MLP Training as a stack of
RBMs
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
47
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMs
48
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMs
49
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMshellip so they do not need
labels
Unsupervisedlearning
50
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
After the DBN is trained it can be fine-tuned with a reduced amount of labels to solve a supervised task with superior performance
Supervisedlearning
Softm
ax
51
Deep Belief Networks (DBN)
Deep Learning TV ldquoDeep Belief Netsrdquo
52
Deep Belief Networks (DBN)
Geoffrey Hinton Introduction to Deep Learning amp Deep Belief Netsrdquo (2012)Geoorey Hinton ldquoTutorial on Deep Belief Networksrdquo NIPS 2007
53
Deep Belief Networks (DBN)
Geoffrey Hinton
54
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
Acknowledgments
55
Junting Pan Xunyu Lin
Unsupervised Feature Learning
56
Slide credit Yann LeCun
Unsupervised Feature Learning
57
Slide credit Yann LeCun
Slide credit Junting Pan
Frame Reconstruction amp Prediction
59Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
Frame Reconstruction amp Prediction
60Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
frame prediction
Frame Reconstruction amp Prediction
61Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
frame prediction
62Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised learned features (lots of data) are fine-tuned for activity recognition (little data)
Frame Reconstruction amp Prediction
Frame Prediction
63Ranzato MarcAurelio Arthur Szlam Joan Bruna Michael Mathieu Ronan Collobert and Sumit Chopra Video (language) modeling a baseline for generative models of natural videos arXiv preprint arXiv14126604 (2014)
64Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
Video frame prediction with a ConvNet
Frame Prediction
65Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
The blurry predictions from MSE are improved with multi-scale architecture adversarial learning and an image gradient difference loss function
Frame Prediction
66Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
The blurry predictions from MSE (l1) are improved with multi-scale architecture adversarial training and an image gradient difference loss (GDL) function
Frame Prediction
67Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
Frame Prediction
68Vondrick Carl Hamed Pirsiavash and Antonio Torralba Generating videos with scene dynamics NIPS 2016
Frame Prediction
69Vondrick Carl Hamed Pirsiavash and Antonio Torralba Generating videos with scene dynamics NIPS 2016
Frame Prediction
70Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
71
Frame Prediction
Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
Given an input image probabilistic generation of future frames with a Variational AutoEncoder (VAE)
72
Frame Prediction
Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
Encodes image as feature maps and motion as and cross-convolutional kernels
73
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
First steps in video feature learning
74Le Quoc V Will Y Zou Serena Y Yeung and Andrew Y Ng Learning hierarchical invariant spatio-temporal features for action recognition with independent subspace analysis CVPR 2011
Temporal Weak Labels
75Goroshin Ross Joan Bruna Jonathan Tompson David Eigen and Yann LeCun Unsupervised learning of spatiotemporally coherent metrics ICCV 2015
Assumption adjacent video frames contain semantically similar informationAutoencoder trained with regularizations by slowliness and sparisty
76Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
77Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
78(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Temporal order of frames is exploited as the supervisory signal for learning
Temporal Weak Labels
79(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Take temporal order as the supervisory signals for learning
Shuffled sequences
Binary classification
In order
Not in order
Temporal Weak Labels
80Fernando Basura Hakan Bilen Efstratios Gavves and Stephen Gould Self-supervised video representation learning with odd-one-out networks CVPR 2017
Temporal Weak LabelsTrain a network to detect which of the video sequences contains frames wrong order
81
Spatio-Temporal Weak Labels
X Lin Campos V Giroacute-i-Nieto X Torres J and Canton-Ferrer C ldquoDisentangling Motion Foreground and Background Features in Videosrdquo in CVPR 2017 Workshop Brave New Motion Representations
kernel dec
C3D
ForegroundMotion
FirstForeground
Background
Fg
Dec
Bg
Dec
Fg
Dec Reconstruction
of foreground in last frame
Reconstruction of foreground in
first frame
Reconstruction of background in first frame
uNLC
MaskBlock
gradients
Last foreground
Kernels
shareweights
82
Spatio-Temporal Weak Labels
Pathak Deepak Ross Girshick Piotr Dollaacuter Trevor Darrell and Bharath Hariharan Learning features by watching objects move CVPR 2017
83Greff Klaus Antti Rasmus Mathias Berglund Tele Hao Harri Valpola and Juergen Schmidhuber Tagger Deep unsupervised perceptual grouping NIPS 2016 [video] [code]
Spatio-Temporal Weak Labels
84Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
85
Audio Features from Visual weak labels
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Object amp Scenes recognition in videos by analysing the audio track (only)
86Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
87Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
88Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
89
Visualization of the video frames associated to the sounds that activate some of the last hidden units of Soundnet (conv7)
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Audio Features from Visual weak labels
90
Audio amp Visual features from alignement
90Arandjelović Relja and Andrew Zisserman Look Listen and Learn ICCV 2017
Audio and visual features learned by assessing alignement
91L Chen S Srivastava Z Duan and C Xu Deep Cross-Modal Audio-Visual Generation ACM International Conference on Multimedia Thematic Workshops 2017
Audio amp Visual features from alignement
92Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
93Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
Video to Speech Representations
CNN(VGG)
Frame from a silent video
Audio feature
Post-hoc synthesis
94Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
95Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
Speech to Video Synthesis (mouth)
96Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
97Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
Speech to Video Synthesis (pose amp emotion)
98Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
99Suwajanakorn Supasorn Steven M Seitz and Ira Kemelmacher-Shlizerman Synthesizing Obama learning lip sync from audio SIGGRAPH 2017
Speech to Video Synthesis (mouth)
100
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
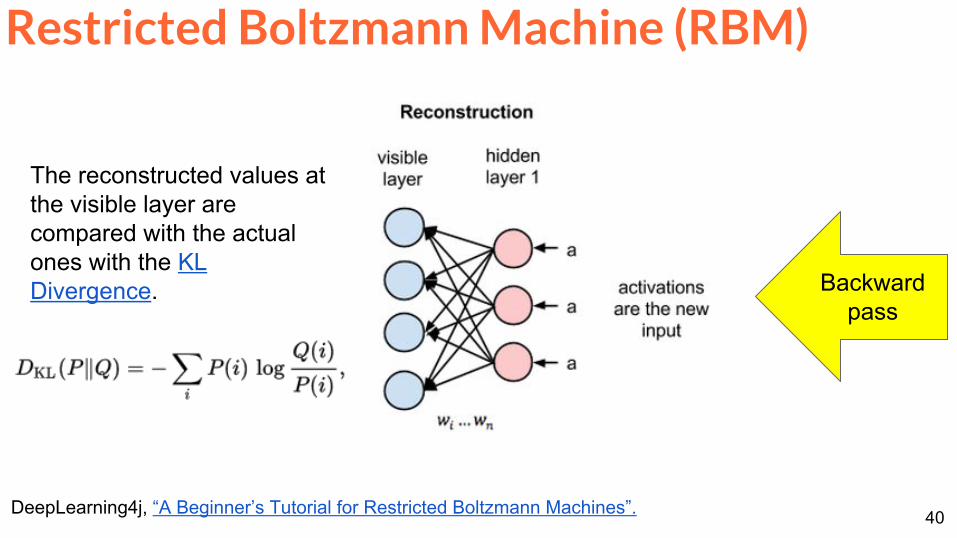
40
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
Backwardpass
The reconstructed values at the visible layer are compared with the actual ones with the KL Divergence
41
Restricted Boltzmann Machine (RBM)
Figure Geoffrey Hinton (2013)
Salakhutdinov Ruslan Andriy Mnih and Geoffrey Hinton Restricted Boltzmann machines for collaborative filtering Proceedings of the 24th international conference on Machine learning ACM 2007
42
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
RBMs are a specific type of autoencoder
Unsupervisedlearning
43
Restricted Boltzmann Machine (RBM)
Deep Learning TV ldquoRestricted Boltzmann Machinesrdquo
44
Deep Belief Networks (DBN)
F Van Veen ldquoThe Neural Network Zoordquo (2016)
45
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMs
46
Deep Belief Networks (DBN)
Architecture like an MLP Training as a stack of
RBMs
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
47
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMs
48
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMs
49
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMshellip so they do not need
labels
Unsupervisedlearning
50
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
After the DBN is trained it can be fine-tuned with a reduced amount of labels to solve a supervised task with superior performance
Supervisedlearning
Softm
ax
51
Deep Belief Networks (DBN)
Deep Learning TV ldquoDeep Belief Netsrdquo
52
Deep Belief Networks (DBN)
Geoffrey Hinton Introduction to Deep Learning amp Deep Belief Netsrdquo (2012)Geoorey Hinton ldquoTutorial on Deep Belief Networksrdquo NIPS 2007
53
Deep Belief Networks (DBN)
Geoffrey Hinton
54
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
Acknowledgments
55
Junting Pan Xunyu Lin
Unsupervised Feature Learning
56
Slide credit Yann LeCun
Unsupervised Feature Learning
57
Slide credit Yann LeCun
Slide credit Junting Pan
Frame Reconstruction amp Prediction
59Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
Frame Reconstruction amp Prediction
60Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
frame prediction
Frame Reconstruction amp Prediction
61Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
frame prediction
62Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised learned features (lots of data) are fine-tuned for activity recognition (little data)
Frame Reconstruction amp Prediction
Frame Prediction
63Ranzato MarcAurelio Arthur Szlam Joan Bruna Michael Mathieu Ronan Collobert and Sumit Chopra Video (language) modeling a baseline for generative models of natural videos arXiv preprint arXiv14126604 (2014)
64Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
Video frame prediction with a ConvNet
Frame Prediction
65Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
The blurry predictions from MSE are improved with multi-scale architecture adversarial learning and an image gradient difference loss function
Frame Prediction
66Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
The blurry predictions from MSE (l1) are improved with multi-scale architecture adversarial training and an image gradient difference loss (GDL) function
Frame Prediction
67Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
Frame Prediction
68Vondrick Carl Hamed Pirsiavash and Antonio Torralba Generating videos with scene dynamics NIPS 2016
Frame Prediction
69Vondrick Carl Hamed Pirsiavash and Antonio Torralba Generating videos with scene dynamics NIPS 2016
Frame Prediction
70Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
71
Frame Prediction
Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
Given an input image probabilistic generation of future frames with a Variational AutoEncoder (VAE)
72
Frame Prediction
Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
Encodes image as feature maps and motion as and cross-convolutional kernels
73
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
First steps in video feature learning
74Le Quoc V Will Y Zou Serena Y Yeung and Andrew Y Ng Learning hierarchical invariant spatio-temporal features for action recognition with independent subspace analysis CVPR 2011
Temporal Weak Labels
75Goroshin Ross Joan Bruna Jonathan Tompson David Eigen and Yann LeCun Unsupervised learning of spatiotemporally coherent metrics ICCV 2015
Assumption adjacent video frames contain semantically similar informationAutoencoder trained with regularizations by slowliness and sparisty
76Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
77Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
78(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Temporal order of frames is exploited as the supervisory signal for learning
Temporal Weak Labels
79(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Take temporal order as the supervisory signals for learning
Shuffled sequences
Binary classification
In order
Not in order
Temporal Weak Labels
80Fernando Basura Hakan Bilen Efstratios Gavves and Stephen Gould Self-supervised video representation learning with odd-one-out networks CVPR 2017
Temporal Weak LabelsTrain a network to detect which of the video sequences contains frames wrong order
81
Spatio-Temporal Weak Labels
X Lin Campos V Giroacute-i-Nieto X Torres J and Canton-Ferrer C ldquoDisentangling Motion Foreground and Background Features in Videosrdquo in CVPR 2017 Workshop Brave New Motion Representations
kernel dec
C3D
ForegroundMotion
FirstForeground
Background
Fg
Dec
Bg
Dec
Fg
Dec Reconstruction
of foreground in last frame
Reconstruction of foreground in
first frame
Reconstruction of background in first frame
uNLC
MaskBlock
gradients
Last foreground
Kernels
shareweights
82
Spatio-Temporal Weak Labels
Pathak Deepak Ross Girshick Piotr Dollaacuter Trevor Darrell and Bharath Hariharan Learning features by watching objects move CVPR 2017
83Greff Klaus Antti Rasmus Mathias Berglund Tele Hao Harri Valpola and Juergen Schmidhuber Tagger Deep unsupervised perceptual grouping NIPS 2016 [video] [code]
Spatio-Temporal Weak Labels
84Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
85
Audio Features from Visual weak labels
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Object amp Scenes recognition in videos by analysing the audio track (only)
86Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
87Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
88Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
89
Visualization of the video frames associated to the sounds that activate some of the last hidden units of Soundnet (conv7)
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Audio Features from Visual weak labels
90
Audio amp Visual features from alignement
90Arandjelović Relja and Andrew Zisserman Look Listen and Learn ICCV 2017
Audio and visual features learned by assessing alignement
91L Chen S Srivastava Z Duan and C Xu Deep Cross-Modal Audio-Visual Generation ACM International Conference on Multimedia Thematic Workshops 2017
Audio amp Visual features from alignement
92Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
93Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
Video to Speech Representations
CNN(VGG)
Frame from a silent video
Audio feature
Post-hoc synthesis
94Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
95Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
Speech to Video Synthesis (mouth)
96Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
97Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
Speech to Video Synthesis (pose amp emotion)
98Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
99Suwajanakorn Supasorn Steven M Seitz and Ira Kemelmacher-Shlizerman Synthesizing Obama learning lip sync from audio SIGGRAPH 2017
Speech to Video Synthesis (mouth)
100
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning

41
Restricted Boltzmann Machine (RBM)
Figure Geoffrey Hinton (2013)
Salakhutdinov Ruslan Andriy Mnih and Geoffrey Hinton Restricted Boltzmann machines for collaborative filtering Proceedings of the 24th international conference on Machine learning ACM 2007
42
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
RBMs are a specific type of autoencoder
Unsupervisedlearning
43
Restricted Boltzmann Machine (RBM)
Deep Learning TV ldquoRestricted Boltzmann Machinesrdquo
44
Deep Belief Networks (DBN)
F Van Veen ldquoThe Neural Network Zoordquo (2016)
45
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMs
46
Deep Belief Networks (DBN)
Architecture like an MLP Training as a stack of
RBMs
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
47
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMs
48
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMs
49
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMshellip so they do not need
labels
Unsupervisedlearning
50
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
After the DBN is trained it can be fine-tuned with a reduced amount of labels to solve a supervised task with superior performance
Supervisedlearning
Softm
ax
51
Deep Belief Networks (DBN)
Deep Learning TV ldquoDeep Belief Netsrdquo
52
Deep Belief Networks (DBN)
Geoffrey Hinton Introduction to Deep Learning amp Deep Belief Netsrdquo (2012)Geoorey Hinton ldquoTutorial on Deep Belief Networksrdquo NIPS 2007
53
Deep Belief Networks (DBN)
Geoffrey Hinton
54
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
Acknowledgments
55
Junting Pan Xunyu Lin
Unsupervised Feature Learning
56
Slide credit Yann LeCun
Unsupervised Feature Learning
57
Slide credit Yann LeCun
Slide credit Junting Pan
Frame Reconstruction amp Prediction
59Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
Frame Reconstruction amp Prediction
60Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
frame prediction
Frame Reconstruction amp Prediction
61Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
frame prediction
62Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised learned features (lots of data) are fine-tuned for activity recognition (little data)
Frame Reconstruction amp Prediction
Frame Prediction
63Ranzato MarcAurelio Arthur Szlam Joan Bruna Michael Mathieu Ronan Collobert and Sumit Chopra Video (language) modeling a baseline for generative models of natural videos arXiv preprint arXiv14126604 (2014)
64Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
Video frame prediction with a ConvNet
Frame Prediction
65Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
The blurry predictions from MSE are improved with multi-scale architecture adversarial learning and an image gradient difference loss function
Frame Prediction
66Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
The blurry predictions from MSE (l1) are improved with multi-scale architecture adversarial training and an image gradient difference loss (GDL) function
Frame Prediction
67Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
Frame Prediction
68Vondrick Carl Hamed Pirsiavash and Antonio Torralba Generating videos with scene dynamics NIPS 2016
Frame Prediction
69Vondrick Carl Hamed Pirsiavash and Antonio Torralba Generating videos with scene dynamics NIPS 2016
Frame Prediction
70Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
71
Frame Prediction
Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
Given an input image probabilistic generation of future frames with a Variational AutoEncoder (VAE)
72
Frame Prediction
Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
Encodes image as feature maps and motion as and cross-convolutional kernels
73
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
First steps in video feature learning
74Le Quoc V Will Y Zou Serena Y Yeung and Andrew Y Ng Learning hierarchical invariant spatio-temporal features for action recognition with independent subspace analysis CVPR 2011
Temporal Weak Labels
75Goroshin Ross Joan Bruna Jonathan Tompson David Eigen and Yann LeCun Unsupervised learning of spatiotemporally coherent metrics ICCV 2015
Assumption adjacent video frames contain semantically similar informationAutoencoder trained with regularizations by slowliness and sparisty
76Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
77Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
78(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Temporal order of frames is exploited as the supervisory signal for learning
Temporal Weak Labels
79(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Take temporal order as the supervisory signals for learning
Shuffled sequences
Binary classification
In order
Not in order
Temporal Weak Labels
80Fernando Basura Hakan Bilen Efstratios Gavves and Stephen Gould Self-supervised video representation learning with odd-one-out networks CVPR 2017
Temporal Weak LabelsTrain a network to detect which of the video sequences contains frames wrong order
81
Spatio-Temporal Weak Labels
X Lin Campos V Giroacute-i-Nieto X Torres J and Canton-Ferrer C ldquoDisentangling Motion Foreground and Background Features in Videosrdquo in CVPR 2017 Workshop Brave New Motion Representations
kernel dec
C3D
ForegroundMotion
FirstForeground
Background
Fg
Dec
Bg
Dec
Fg
Dec Reconstruction
of foreground in last frame
Reconstruction of foreground in
first frame
Reconstruction of background in first frame
uNLC
MaskBlock
gradients
Last foreground
Kernels
shareweights
82
Spatio-Temporal Weak Labels
Pathak Deepak Ross Girshick Piotr Dollaacuter Trevor Darrell and Bharath Hariharan Learning features by watching objects move CVPR 2017
83Greff Klaus Antti Rasmus Mathias Berglund Tele Hao Harri Valpola and Juergen Schmidhuber Tagger Deep unsupervised perceptual grouping NIPS 2016 [video] [code]
Spatio-Temporal Weak Labels
84Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
85
Audio Features from Visual weak labels
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Object amp Scenes recognition in videos by analysing the audio track (only)
86Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
87Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
88Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
89
Visualization of the video frames associated to the sounds that activate some of the last hidden units of Soundnet (conv7)
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Audio Features from Visual weak labels
90
Audio amp Visual features from alignement
90Arandjelović Relja and Andrew Zisserman Look Listen and Learn ICCV 2017
Audio and visual features learned by assessing alignement
91L Chen S Srivastava Z Duan and C Xu Deep Cross-Modal Audio-Visual Generation ACM International Conference on Multimedia Thematic Workshops 2017
Audio amp Visual features from alignement
92Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
93Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
Video to Speech Representations
CNN(VGG)
Frame from a silent video
Audio feature
Post-hoc synthesis
94Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
95Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
Speech to Video Synthesis (mouth)
96Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
97Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
Speech to Video Synthesis (pose amp emotion)
98Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
99Suwajanakorn Supasorn Steven M Seitz and Ira Kemelmacher-Shlizerman Synthesizing Obama learning lip sync from audio SIGGRAPH 2017
Speech to Video Synthesis (mouth)
100
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning

42
Restricted Boltzmann Machine (RBM)
DeepLearning4j ldquoA Beginnerrsquos Tutorial for Restricted Boltzmann Machinesrdquo
RBMs are a specific type of autoencoder
Unsupervisedlearning
43
Restricted Boltzmann Machine (RBM)
Deep Learning TV ldquoRestricted Boltzmann Machinesrdquo
44
Deep Belief Networks (DBN)
F Van Veen ldquoThe Neural Network Zoordquo (2016)
45
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMs
46
Deep Belief Networks (DBN)
Architecture like an MLP Training as a stack of
RBMs
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
47
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMs
48
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMs
49
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMshellip so they do not need
labels
Unsupervisedlearning
50
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
After the DBN is trained it can be fine-tuned with a reduced amount of labels to solve a supervised task with superior performance
Supervisedlearning
Softm
ax
51
Deep Belief Networks (DBN)
Deep Learning TV ldquoDeep Belief Netsrdquo
52
Deep Belief Networks (DBN)
Geoffrey Hinton Introduction to Deep Learning amp Deep Belief Netsrdquo (2012)Geoorey Hinton ldquoTutorial on Deep Belief Networksrdquo NIPS 2007
53
Deep Belief Networks (DBN)
Geoffrey Hinton
54
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
Acknowledgments
55
Junting Pan Xunyu Lin
Unsupervised Feature Learning
56
Slide credit Yann LeCun
Unsupervised Feature Learning
57
Slide credit Yann LeCun
Slide credit Junting Pan
Frame Reconstruction amp Prediction
59Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
Frame Reconstruction amp Prediction
60Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
frame prediction
Frame Reconstruction amp Prediction
61Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
frame prediction
62Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised learned features (lots of data) are fine-tuned for activity recognition (little data)
Frame Reconstruction amp Prediction
Frame Prediction
63Ranzato MarcAurelio Arthur Szlam Joan Bruna Michael Mathieu Ronan Collobert and Sumit Chopra Video (language) modeling a baseline for generative models of natural videos arXiv preprint arXiv14126604 (2014)
64Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
Video frame prediction with a ConvNet
Frame Prediction
65Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
The blurry predictions from MSE are improved with multi-scale architecture adversarial learning and an image gradient difference loss function
Frame Prediction
66Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
The blurry predictions from MSE (l1) are improved with multi-scale architecture adversarial training and an image gradient difference loss (GDL) function
Frame Prediction
67Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
Frame Prediction
68Vondrick Carl Hamed Pirsiavash and Antonio Torralba Generating videos with scene dynamics NIPS 2016
Frame Prediction
69Vondrick Carl Hamed Pirsiavash and Antonio Torralba Generating videos with scene dynamics NIPS 2016
Frame Prediction
70Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
71
Frame Prediction
Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
Given an input image probabilistic generation of future frames with a Variational AutoEncoder (VAE)
72
Frame Prediction
Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
Encodes image as feature maps and motion as and cross-convolutional kernels
73
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
First steps in video feature learning
74Le Quoc V Will Y Zou Serena Y Yeung and Andrew Y Ng Learning hierarchical invariant spatio-temporal features for action recognition with independent subspace analysis CVPR 2011
Temporal Weak Labels
75Goroshin Ross Joan Bruna Jonathan Tompson David Eigen and Yann LeCun Unsupervised learning of spatiotemporally coherent metrics ICCV 2015
Assumption adjacent video frames contain semantically similar informationAutoencoder trained with regularizations by slowliness and sparisty
76Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
77Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
78(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Temporal order of frames is exploited as the supervisory signal for learning
Temporal Weak Labels
79(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Take temporal order as the supervisory signals for learning
Shuffled sequences
Binary classification
In order
Not in order
Temporal Weak Labels
80Fernando Basura Hakan Bilen Efstratios Gavves and Stephen Gould Self-supervised video representation learning with odd-one-out networks CVPR 2017
Temporal Weak LabelsTrain a network to detect which of the video sequences contains frames wrong order
81
Spatio-Temporal Weak Labels
X Lin Campos V Giroacute-i-Nieto X Torres J and Canton-Ferrer C ldquoDisentangling Motion Foreground and Background Features in Videosrdquo in CVPR 2017 Workshop Brave New Motion Representations
kernel dec
C3D
ForegroundMotion
FirstForeground
Background
Fg
Dec
Bg
Dec
Fg
Dec Reconstruction
of foreground in last frame
Reconstruction of foreground in
first frame
Reconstruction of background in first frame
uNLC
MaskBlock
gradients
Last foreground
Kernels
shareweights
82
Spatio-Temporal Weak Labels
Pathak Deepak Ross Girshick Piotr Dollaacuter Trevor Darrell and Bharath Hariharan Learning features by watching objects move CVPR 2017
83Greff Klaus Antti Rasmus Mathias Berglund Tele Hao Harri Valpola and Juergen Schmidhuber Tagger Deep unsupervised perceptual grouping NIPS 2016 [video] [code]
Spatio-Temporal Weak Labels
84Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
85
Audio Features from Visual weak labels
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Object amp Scenes recognition in videos by analysing the audio track (only)
86Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
87Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
88Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
89
Visualization of the video frames associated to the sounds that activate some of the last hidden units of Soundnet (conv7)
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Audio Features from Visual weak labels
90
Audio amp Visual features from alignement
90Arandjelović Relja and Andrew Zisserman Look Listen and Learn ICCV 2017
Audio and visual features learned by assessing alignement
91L Chen S Srivastava Z Duan and C Xu Deep Cross-Modal Audio-Visual Generation ACM International Conference on Multimedia Thematic Workshops 2017
Audio amp Visual features from alignement
92Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
93Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
Video to Speech Representations
CNN(VGG)
Frame from a silent video
Audio feature
Post-hoc synthesis
94Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
95Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
Speech to Video Synthesis (mouth)
96Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
97Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
Speech to Video Synthesis (pose amp emotion)
98Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
99Suwajanakorn Supasorn Steven M Seitz and Ira Kemelmacher-Shlizerman Synthesizing Obama learning lip sync from audio SIGGRAPH 2017
Speech to Video Synthesis (mouth)
100
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning

43
Restricted Boltzmann Machine (RBM)
Deep Learning TV ldquoRestricted Boltzmann Machinesrdquo
44
Deep Belief Networks (DBN)
F Van Veen ldquoThe Neural Network Zoordquo (2016)
45
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMs
46
Deep Belief Networks (DBN)
Architecture like an MLP Training as a stack of
RBMs
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
47
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMs
48
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMs
49
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMshellip so they do not need
labels
Unsupervisedlearning
50
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
After the DBN is trained it can be fine-tuned with a reduced amount of labels to solve a supervised task with superior performance
Supervisedlearning
Softm
ax
51
Deep Belief Networks (DBN)
Deep Learning TV ldquoDeep Belief Netsrdquo
52
Deep Belief Networks (DBN)
Geoffrey Hinton Introduction to Deep Learning amp Deep Belief Netsrdquo (2012)Geoorey Hinton ldquoTutorial on Deep Belief Networksrdquo NIPS 2007
53
Deep Belief Networks (DBN)
Geoffrey Hinton
54
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
Acknowledgments
55
Junting Pan Xunyu Lin
Unsupervised Feature Learning
56
Slide credit Yann LeCun
Unsupervised Feature Learning
57
Slide credit Yann LeCun
Slide credit Junting Pan
Frame Reconstruction amp Prediction
59Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
Frame Reconstruction amp Prediction
60Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
frame prediction
Frame Reconstruction amp Prediction
61Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
frame prediction
62Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised learned features (lots of data) are fine-tuned for activity recognition (little data)
Frame Reconstruction amp Prediction
Frame Prediction
63Ranzato MarcAurelio Arthur Szlam Joan Bruna Michael Mathieu Ronan Collobert and Sumit Chopra Video (language) modeling a baseline for generative models of natural videos arXiv preprint arXiv14126604 (2014)
64Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
Video frame prediction with a ConvNet
Frame Prediction
65Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
The blurry predictions from MSE are improved with multi-scale architecture adversarial learning and an image gradient difference loss function
Frame Prediction
66Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
The blurry predictions from MSE (l1) are improved with multi-scale architecture adversarial training and an image gradient difference loss (GDL) function
Frame Prediction
67Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
Frame Prediction
68Vondrick Carl Hamed Pirsiavash and Antonio Torralba Generating videos with scene dynamics NIPS 2016
Frame Prediction
69Vondrick Carl Hamed Pirsiavash and Antonio Torralba Generating videos with scene dynamics NIPS 2016
Frame Prediction
70Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
71
Frame Prediction
Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
Given an input image probabilistic generation of future frames with a Variational AutoEncoder (VAE)
72
Frame Prediction
Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
Encodes image as feature maps and motion as and cross-convolutional kernels
73
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
First steps in video feature learning
74Le Quoc V Will Y Zou Serena Y Yeung and Andrew Y Ng Learning hierarchical invariant spatio-temporal features for action recognition with independent subspace analysis CVPR 2011
Temporal Weak Labels
75Goroshin Ross Joan Bruna Jonathan Tompson David Eigen and Yann LeCun Unsupervised learning of spatiotemporally coherent metrics ICCV 2015
Assumption adjacent video frames contain semantically similar informationAutoencoder trained with regularizations by slowliness and sparisty
76Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
77Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
78(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Temporal order of frames is exploited as the supervisory signal for learning
Temporal Weak Labels
79(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Take temporal order as the supervisory signals for learning
Shuffled sequences
Binary classification
In order
Not in order
Temporal Weak Labels
80Fernando Basura Hakan Bilen Efstratios Gavves and Stephen Gould Self-supervised video representation learning with odd-one-out networks CVPR 2017
Temporal Weak LabelsTrain a network to detect which of the video sequences contains frames wrong order
81
Spatio-Temporal Weak Labels
X Lin Campos V Giroacute-i-Nieto X Torres J and Canton-Ferrer C ldquoDisentangling Motion Foreground and Background Features in Videosrdquo in CVPR 2017 Workshop Brave New Motion Representations
kernel dec
C3D
ForegroundMotion
FirstForeground
Background
Fg
Dec
Bg
Dec
Fg
Dec Reconstruction
of foreground in last frame
Reconstruction of foreground in
first frame
Reconstruction of background in first frame
uNLC
MaskBlock
gradients
Last foreground
Kernels
shareweights
82
Spatio-Temporal Weak Labels
Pathak Deepak Ross Girshick Piotr Dollaacuter Trevor Darrell and Bharath Hariharan Learning features by watching objects move CVPR 2017
83Greff Klaus Antti Rasmus Mathias Berglund Tele Hao Harri Valpola and Juergen Schmidhuber Tagger Deep unsupervised perceptual grouping NIPS 2016 [video] [code]
Spatio-Temporal Weak Labels
84Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
85
Audio Features from Visual weak labels
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Object amp Scenes recognition in videos by analysing the audio track (only)
86Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
87Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
88Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
89
Visualization of the video frames associated to the sounds that activate some of the last hidden units of Soundnet (conv7)
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Audio Features from Visual weak labels
90
Audio amp Visual features from alignement
90Arandjelović Relja and Andrew Zisserman Look Listen and Learn ICCV 2017
Audio and visual features learned by assessing alignement
91L Chen S Srivastava Z Duan and C Xu Deep Cross-Modal Audio-Visual Generation ACM International Conference on Multimedia Thematic Workshops 2017
Audio amp Visual features from alignement
92Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
93Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
Video to Speech Representations
CNN(VGG)
Frame from a silent video
Audio feature
Post-hoc synthesis
94Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
95Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
Speech to Video Synthesis (mouth)
96Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
97Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
Speech to Video Synthesis (pose amp emotion)
98Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
99Suwajanakorn Supasorn Steven M Seitz and Ira Kemelmacher-Shlizerman Synthesizing Obama learning lip sync from audio SIGGRAPH 2017
Speech to Video Synthesis (mouth)
100
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning

44
Deep Belief Networks (DBN)
F Van Veen ldquoThe Neural Network Zoordquo (2016)
45
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMs
46
Deep Belief Networks (DBN)
Architecture like an MLP Training as a stack of
RBMs
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
47
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMs
48
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMs
49
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMshellip so they do not need
labels
Unsupervisedlearning
50
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
After the DBN is trained it can be fine-tuned with a reduced amount of labels to solve a supervised task with superior performance
Supervisedlearning
Softm
ax
51
Deep Belief Networks (DBN)
Deep Learning TV ldquoDeep Belief Netsrdquo
52
Deep Belief Networks (DBN)
Geoffrey Hinton Introduction to Deep Learning amp Deep Belief Netsrdquo (2012)Geoorey Hinton ldquoTutorial on Deep Belief Networksrdquo NIPS 2007
53
Deep Belief Networks (DBN)
Geoffrey Hinton
54
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
Acknowledgments
55
Junting Pan Xunyu Lin
Unsupervised Feature Learning
56
Slide credit Yann LeCun
Unsupervised Feature Learning
57
Slide credit Yann LeCun
Slide credit Junting Pan
Frame Reconstruction amp Prediction
59Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
Frame Reconstruction amp Prediction
60Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
frame prediction
Frame Reconstruction amp Prediction
61Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
frame prediction
62Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised learned features (lots of data) are fine-tuned for activity recognition (little data)
Frame Reconstruction amp Prediction
Frame Prediction
63Ranzato MarcAurelio Arthur Szlam Joan Bruna Michael Mathieu Ronan Collobert and Sumit Chopra Video (language) modeling a baseline for generative models of natural videos arXiv preprint arXiv14126604 (2014)
64Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
Video frame prediction with a ConvNet
Frame Prediction
65Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
The blurry predictions from MSE are improved with multi-scale architecture adversarial learning and an image gradient difference loss function
Frame Prediction
66Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
The blurry predictions from MSE (l1) are improved with multi-scale architecture adversarial training and an image gradient difference loss (GDL) function
Frame Prediction
67Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
Frame Prediction
68Vondrick Carl Hamed Pirsiavash and Antonio Torralba Generating videos with scene dynamics NIPS 2016
Frame Prediction
69Vondrick Carl Hamed Pirsiavash and Antonio Torralba Generating videos with scene dynamics NIPS 2016
Frame Prediction
70Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
71
Frame Prediction
Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
Given an input image probabilistic generation of future frames with a Variational AutoEncoder (VAE)
72
Frame Prediction
Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
Encodes image as feature maps and motion as and cross-convolutional kernels
73
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
First steps in video feature learning
74Le Quoc V Will Y Zou Serena Y Yeung and Andrew Y Ng Learning hierarchical invariant spatio-temporal features for action recognition with independent subspace analysis CVPR 2011
Temporal Weak Labels
75Goroshin Ross Joan Bruna Jonathan Tompson David Eigen and Yann LeCun Unsupervised learning of spatiotemporally coherent metrics ICCV 2015
Assumption adjacent video frames contain semantically similar informationAutoencoder trained with regularizations by slowliness and sparisty
76Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
77Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
78(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Temporal order of frames is exploited as the supervisory signal for learning
Temporal Weak Labels
79(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Take temporal order as the supervisory signals for learning
Shuffled sequences
Binary classification
In order
Not in order
Temporal Weak Labels
80Fernando Basura Hakan Bilen Efstratios Gavves and Stephen Gould Self-supervised video representation learning with odd-one-out networks CVPR 2017
Temporal Weak LabelsTrain a network to detect which of the video sequences contains frames wrong order
81
Spatio-Temporal Weak Labels
X Lin Campos V Giroacute-i-Nieto X Torres J and Canton-Ferrer C ldquoDisentangling Motion Foreground and Background Features in Videosrdquo in CVPR 2017 Workshop Brave New Motion Representations
kernel dec
C3D
ForegroundMotion
FirstForeground
Background
Fg
Dec
Bg
Dec
Fg
Dec Reconstruction
of foreground in last frame
Reconstruction of foreground in
first frame
Reconstruction of background in first frame
uNLC
MaskBlock
gradients
Last foreground
Kernels
shareweights
82
Spatio-Temporal Weak Labels
Pathak Deepak Ross Girshick Piotr Dollaacuter Trevor Darrell and Bharath Hariharan Learning features by watching objects move CVPR 2017
83Greff Klaus Antti Rasmus Mathias Berglund Tele Hao Harri Valpola and Juergen Schmidhuber Tagger Deep unsupervised perceptual grouping NIPS 2016 [video] [code]
Spatio-Temporal Weak Labels
84Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
85
Audio Features from Visual weak labels
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Object amp Scenes recognition in videos by analysing the audio track (only)
86Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
87Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
88Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
89
Visualization of the video frames associated to the sounds that activate some of the last hidden units of Soundnet (conv7)
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Audio Features from Visual weak labels
90
Audio amp Visual features from alignement
90Arandjelović Relja and Andrew Zisserman Look Listen and Learn ICCV 2017
Audio and visual features learned by assessing alignement
91L Chen S Srivastava Z Duan and C Xu Deep Cross-Modal Audio-Visual Generation ACM International Conference on Multimedia Thematic Workshops 2017
Audio amp Visual features from alignement
92Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
93Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
Video to Speech Representations
CNN(VGG)
Frame from a silent video
Audio feature
Post-hoc synthesis
94Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
95Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
Speech to Video Synthesis (mouth)
96Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
97Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
Speech to Video Synthesis (pose amp emotion)
98Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
99Suwajanakorn Supasorn Steven M Seitz and Ira Kemelmacher-Shlizerman Synthesizing Obama learning lip sync from audio SIGGRAPH 2017
Speech to Video Synthesis (mouth)
100
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning

45
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMs
46
Deep Belief Networks (DBN)
Architecture like an MLP Training as a stack of
RBMs
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
47
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMs
48
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMs
49
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMshellip so they do not need
labels
Unsupervisedlearning
50
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
After the DBN is trained it can be fine-tuned with a reduced amount of labels to solve a supervised task with superior performance
Supervisedlearning
Softm
ax
51
Deep Belief Networks (DBN)
Deep Learning TV ldquoDeep Belief Netsrdquo
52
Deep Belief Networks (DBN)
Geoffrey Hinton Introduction to Deep Learning amp Deep Belief Netsrdquo (2012)Geoorey Hinton ldquoTutorial on Deep Belief Networksrdquo NIPS 2007
53
Deep Belief Networks (DBN)
Geoffrey Hinton
54
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
Acknowledgments
55
Junting Pan Xunyu Lin
Unsupervised Feature Learning
56
Slide credit Yann LeCun
Unsupervised Feature Learning
57
Slide credit Yann LeCun
Slide credit Junting Pan
Frame Reconstruction amp Prediction
59Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
Frame Reconstruction amp Prediction
60Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
frame prediction
Frame Reconstruction amp Prediction
61Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
frame prediction
62Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised learned features (lots of data) are fine-tuned for activity recognition (little data)
Frame Reconstruction amp Prediction
Frame Prediction
63Ranzato MarcAurelio Arthur Szlam Joan Bruna Michael Mathieu Ronan Collobert and Sumit Chopra Video (language) modeling a baseline for generative models of natural videos arXiv preprint arXiv14126604 (2014)
64Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
Video frame prediction with a ConvNet
Frame Prediction
65Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
The blurry predictions from MSE are improved with multi-scale architecture adversarial learning and an image gradient difference loss function
Frame Prediction
66Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
The blurry predictions from MSE (l1) are improved with multi-scale architecture adversarial training and an image gradient difference loss (GDL) function
Frame Prediction
67Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
Frame Prediction
68Vondrick Carl Hamed Pirsiavash and Antonio Torralba Generating videos with scene dynamics NIPS 2016
Frame Prediction
69Vondrick Carl Hamed Pirsiavash and Antonio Torralba Generating videos with scene dynamics NIPS 2016
Frame Prediction
70Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
71
Frame Prediction
Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
Given an input image probabilistic generation of future frames with a Variational AutoEncoder (VAE)
72
Frame Prediction
Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
Encodes image as feature maps and motion as and cross-convolutional kernels
73
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
First steps in video feature learning
74Le Quoc V Will Y Zou Serena Y Yeung and Andrew Y Ng Learning hierarchical invariant spatio-temporal features for action recognition with independent subspace analysis CVPR 2011
Temporal Weak Labels
75Goroshin Ross Joan Bruna Jonathan Tompson David Eigen and Yann LeCun Unsupervised learning of spatiotemporally coherent metrics ICCV 2015
Assumption adjacent video frames contain semantically similar informationAutoencoder trained with regularizations by slowliness and sparisty
76Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
77Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
78(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Temporal order of frames is exploited as the supervisory signal for learning
Temporal Weak Labels
79(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Take temporal order as the supervisory signals for learning
Shuffled sequences
Binary classification
In order
Not in order
Temporal Weak Labels
80Fernando Basura Hakan Bilen Efstratios Gavves and Stephen Gould Self-supervised video representation learning with odd-one-out networks CVPR 2017
Temporal Weak LabelsTrain a network to detect which of the video sequences contains frames wrong order
81
Spatio-Temporal Weak Labels
X Lin Campos V Giroacute-i-Nieto X Torres J and Canton-Ferrer C ldquoDisentangling Motion Foreground and Background Features in Videosrdquo in CVPR 2017 Workshop Brave New Motion Representations
kernel dec
C3D
ForegroundMotion
FirstForeground
Background
Fg
Dec
Bg
Dec
Fg
Dec Reconstruction
of foreground in last frame
Reconstruction of foreground in
first frame
Reconstruction of background in first frame
uNLC
MaskBlock
gradients
Last foreground
Kernels
shareweights
82
Spatio-Temporal Weak Labels
Pathak Deepak Ross Girshick Piotr Dollaacuter Trevor Darrell and Bharath Hariharan Learning features by watching objects move CVPR 2017
83Greff Klaus Antti Rasmus Mathias Berglund Tele Hao Harri Valpola and Juergen Schmidhuber Tagger Deep unsupervised perceptual grouping NIPS 2016 [video] [code]
Spatio-Temporal Weak Labels
84Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
85
Audio Features from Visual weak labels
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Object amp Scenes recognition in videos by analysing the audio track (only)
86Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
87Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
88Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
89
Visualization of the video frames associated to the sounds that activate some of the last hidden units of Soundnet (conv7)
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Audio Features from Visual weak labels
90
Audio amp Visual features from alignement
90Arandjelović Relja and Andrew Zisserman Look Listen and Learn ICCV 2017
Audio and visual features learned by assessing alignement
91L Chen S Srivastava Z Duan and C Xu Deep Cross-Modal Audio-Visual Generation ACM International Conference on Multimedia Thematic Workshops 2017
Audio amp Visual features from alignement
92Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
93Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
Video to Speech Representations
CNN(VGG)
Frame from a silent video
Audio feature
Post-hoc synthesis
94Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
95Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
Speech to Video Synthesis (mouth)
96Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
97Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
Speech to Video Synthesis (pose amp emotion)
98Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
99Suwajanakorn Supasorn Steven M Seitz and Ira Kemelmacher-Shlizerman Synthesizing Obama learning lip sync from audio SIGGRAPH 2017
Speech to Video Synthesis (mouth)
100
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning

46
Deep Belief Networks (DBN)
Architecture like an MLP Training as a stack of
RBMs
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
47
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMs
48
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMs
49
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMshellip so they do not need
labels
Unsupervisedlearning
50
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
After the DBN is trained it can be fine-tuned with a reduced amount of labels to solve a supervised task with superior performance
Supervisedlearning
Softm
ax
51
Deep Belief Networks (DBN)
Deep Learning TV ldquoDeep Belief Netsrdquo
52
Deep Belief Networks (DBN)
Geoffrey Hinton Introduction to Deep Learning amp Deep Belief Netsrdquo (2012)Geoorey Hinton ldquoTutorial on Deep Belief Networksrdquo NIPS 2007
53
Deep Belief Networks (DBN)
Geoffrey Hinton
54
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
Acknowledgments
55
Junting Pan Xunyu Lin
Unsupervised Feature Learning
56
Slide credit Yann LeCun
Unsupervised Feature Learning
57
Slide credit Yann LeCun
Slide credit Junting Pan
Frame Reconstruction amp Prediction
59Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
Frame Reconstruction amp Prediction
60Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
frame prediction
Frame Reconstruction amp Prediction
61Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
frame prediction
62Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised learned features (lots of data) are fine-tuned for activity recognition (little data)
Frame Reconstruction amp Prediction
Frame Prediction
63Ranzato MarcAurelio Arthur Szlam Joan Bruna Michael Mathieu Ronan Collobert and Sumit Chopra Video (language) modeling a baseline for generative models of natural videos arXiv preprint arXiv14126604 (2014)
64Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
Video frame prediction with a ConvNet
Frame Prediction
65Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
The blurry predictions from MSE are improved with multi-scale architecture adversarial learning and an image gradient difference loss function
Frame Prediction
66Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
The blurry predictions from MSE (l1) are improved with multi-scale architecture adversarial training and an image gradient difference loss (GDL) function
Frame Prediction
67Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
Frame Prediction
68Vondrick Carl Hamed Pirsiavash and Antonio Torralba Generating videos with scene dynamics NIPS 2016
Frame Prediction
69Vondrick Carl Hamed Pirsiavash and Antonio Torralba Generating videos with scene dynamics NIPS 2016
Frame Prediction
70Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
71
Frame Prediction
Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
Given an input image probabilistic generation of future frames with a Variational AutoEncoder (VAE)
72
Frame Prediction
Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
Encodes image as feature maps and motion as and cross-convolutional kernels
73
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
First steps in video feature learning
74Le Quoc V Will Y Zou Serena Y Yeung and Andrew Y Ng Learning hierarchical invariant spatio-temporal features for action recognition with independent subspace analysis CVPR 2011
Temporal Weak Labels
75Goroshin Ross Joan Bruna Jonathan Tompson David Eigen and Yann LeCun Unsupervised learning of spatiotemporally coherent metrics ICCV 2015
Assumption adjacent video frames contain semantically similar informationAutoencoder trained with regularizations by slowliness and sparisty
76Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
77Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
78(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Temporal order of frames is exploited as the supervisory signal for learning
Temporal Weak Labels
79(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Take temporal order as the supervisory signals for learning
Shuffled sequences
Binary classification
In order
Not in order
Temporal Weak Labels
80Fernando Basura Hakan Bilen Efstratios Gavves and Stephen Gould Self-supervised video representation learning with odd-one-out networks CVPR 2017
Temporal Weak LabelsTrain a network to detect which of the video sequences contains frames wrong order
81
Spatio-Temporal Weak Labels
X Lin Campos V Giroacute-i-Nieto X Torres J and Canton-Ferrer C ldquoDisentangling Motion Foreground and Background Features in Videosrdquo in CVPR 2017 Workshop Brave New Motion Representations
kernel dec
C3D
ForegroundMotion
FirstForeground
Background
Fg
Dec
Bg
Dec
Fg
Dec Reconstruction
of foreground in last frame
Reconstruction of foreground in
first frame
Reconstruction of background in first frame
uNLC
MaskBlock
gradients
Last foreground
Kernels
shareweights
82
Spatio-Temporal Weak Labels
Pathak Deepak Ross Girshick Piotr Dollaacuter Trevor Darrell and Bharath Hariharan Learning features by watching objects move CVPR 2017
83Greff Klaus Antti Rasmus Mathias Berglund Tele Hao Harri Valpola and Juergen Schmidhuber Tagger Deep unsupervised perceptual grouping NIPS 2016 [video] [code]
Spatio-Temporal Weak Labels
84Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
85
Audio Features from Visual weak labels
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Object amp Scenes recognition in videos by analysing the audio track (only)
86Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
87Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
88Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
89
Visualization of the video frames associated to the sounds that activate some of the last hidden units of Soundnet (conv7)
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Audio Features from Visual weak labels
90
Audio amp Visual features from alignement
90Arandjelović Relja and Andrew Zisserman Look Listen and Learn ICCV 2017
Audio and visual features learned by assessing alignement
91L Chen S Srivastava Z Duan and C Xu Deep Cross-Modal Audio-Visual Generation ACM International Conference on Multimedia Thematic Workshops 2017
Audio amp Visual features from alignement
92Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
93Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
Video to Speech Representations
CNN(VGG)
Frame from a silent video
Audio feature
Post-hoc synthesis
94Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
95Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
Speech to Video Synthesis (mouth)
96Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
97Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
Speech to Video Synthesis (pose amp emotion)
98Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
99Suwajanakorn Supasorn Steven M Seitz and Ira Kemelmacher-Shlizerman Synthesizing Obama learning lip sync from audio SIGGRAPH 2017
Speech to Video Synthesis (mouth)
100
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
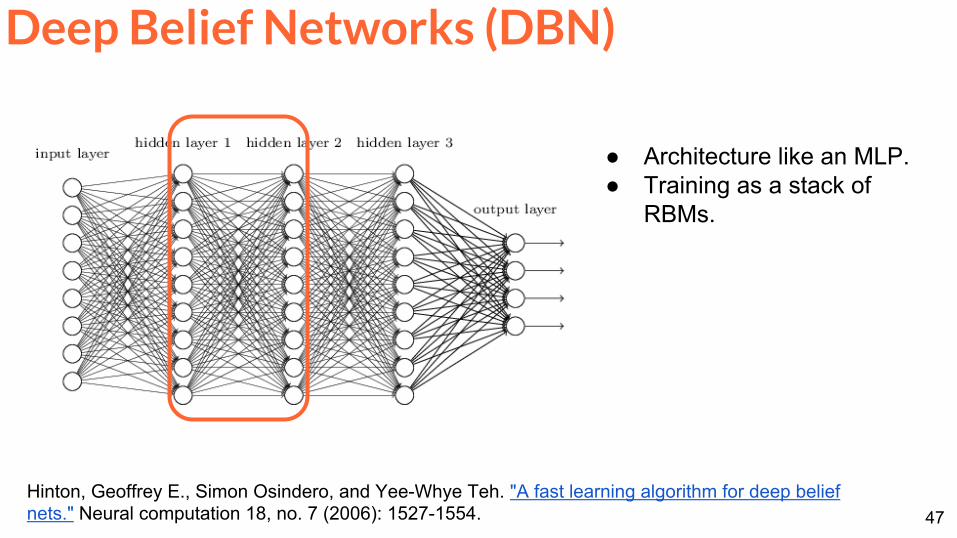
47
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMs
48
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMs
49
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMshellip so they do not need
labels
Unsupervisedlearning
50
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
After the DBN is trained it can be fine-tuned with a reduced amount of labels to solve a supervised task with superior performance
Supervisedlearning
Softm
ax
51
Deep Belief Networks (DBN)
Deep Learning TV ldquoDeep Belief Netsrdquo
52
Deep Belief Networks (DBN)
Geoffrey Hinton Introduction to Deep Learning amp Deep Belief Netsrdquo (2012)Geoorey Hinton ldquoTutorial on Deep Belief Networksrdquo NIPS 2007
53
Deep Belief Networks (DBN)
Geoffrey Hinton
54
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
Acknowledgments
55
Junting Pan Xunyu Lin
Unsupervised Feature Learning
56
Slide credit Yann LeCun
Unsupervised Feature Learning
57
Slide credit Yann LeCun
Slide credit Junting Pan
Frame Reconstruction amp Prediction
59Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
Frame Reconstruction amp Prediction
60Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
frame prediction
Frame Reconstruction amp Prediction
61Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
frame prediction
62Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised learned features (lots of data) are fine-tuned for activity recognition (little data)
Frame Reconstruction amp Prediction
Frame Prediction
63Ranzato MarcAurelio Arthur Szlam Joan Bruna Michael Mathieu Ronan Collobert and Sumit Chopra Video (language) modeling a baseline for generative models of natural videos arXiv preprint arXiv14126604 (2014)
64Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
Video frame prediction with a ConvNet
Frame Prediction
65Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
The blurry predictions from MSE are improved with multi-scale architecture adversarial learning and an image gradient difference loss function
Frame Prediction
66Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
The blurry predictions from MSE (l1) are improved with multi-scale architecture adversarial training and an image gradient difference loss (GDL) function
Frame Prediction
67Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
Frame Prediction
68Vondrick Carl Hamed Pirsiavash and Antonio Torralba Generating videos with scene dynamics NIPS 2016
Frame Prediction
69Vondrick Carl Hamed Pirsiavash and Antonio Torralba Generating videos with scene dynamics NIPS 2016
Frame Prediction
70Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
71
Frame Prediction
Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
Given an input image probabilistic generation of future frames with a Variational AutoEncoder (VAE)
72
Frame Prediction
Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
Encodes image as feature maps and motion as and cross-convolutional kernels
73
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
First steps in video feature learning
74Le Quoc V Will Y Zou Serena Y Yeung and Andrew Y Ng Learning hierarchical invariant spatio-temporal features for action recognition with independent subspace analysis CVPR 2011
Temporal Weak Labels
75Goroshin Ross Joan Bruna Jonathan Tompson David Eigen and Yann LeCun Unsupervised learning of spatiotemporally coherent metrics ICCV 2015
Assumption adjacent video frames contain semantically similar informationAutoencoder trained with regularizations by slowliness and sparisty
76Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
77Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
78(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Temporal order of frames is exploited as the supervisory signal for learning
Temporal Weak Labels
79(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Take temporal order as the supervisory signals for learning
Shuffled sequences
Binary classification
In order
Not in order
Temporal Weak Labels
80Fernando Basura Hakan Bilen Efstratios Gavves and Stephen Gould Self-supervised video representation learning with odd-one-out networks CVPR 2017
Temporal Weak LabelsTrain a network to detect which of the video sequences contains frames wrong order
81
Spatio-Temporal Weak Labels
X Lin Campos V Giroacute-i-Nieto X Torres J and Canton-Ferrer C ldquoDisentangling Motion Foreground and Background Features in Videosrdquo in CVPR 2017 Workshop Brave New Motion Representations
kernel dec
C3D
ForegroundMotion
FirstForeground
Background
Fg
Dec
Bg
Dec
Fg
Dec Reconstruction
of foreground in last frame
Reconstruction of foreground in
first frame
Reconstruction of background in first frame
uNLC
MaskBlock
gradients
Last foreground
Kernels
shareweights
82
Spatio-Temporal Weak Labels
Pathak Deepak Ross Girshick Piotr Dollaacuter Trevor Darrell and Bharath Hariharan Learning features by watching objects move CVPR 2017
83Greff Klaus Antti Rasmus Mathias Berglund Tele Hao Harri Valpola and Juergen Schmidhuber Tagger Deep unsupervised perceptual grouping NIPS 2016 [video] [code]
Spatio-Temporal Weak Labels
84Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
85
Audio Features from Visual weak labels
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Object amp Scenes recognition in videos by analysing the audio track (only)
86Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
87Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
88Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
89
Visualization of the video frames associated to the sounds that activate some of the last hidden units of Soundnet (conv7)
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Audio Features from Visual weak labels
90
Audio amp Visual features from alignement
90Arandjelović Relja and Andrew Zisserman Look Listen and Learn ICCV 2017
Audio and visual features learned by assessing alignement
91L Chen S Srivastava Z Duan and C Xu Deep Cross-Modal Audio-Visual Generation ACM International Conference on Multimedia Thematic Workshops 2017
Audio amp Visual features from alignement
92Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
93Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
Video to Speech Representations
CNN(VGG)
Frame from a silent video
Audio feature
Post-hoc synthesis
94Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
95Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
Speech to Video Synthesis (mouth)
96Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
97Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
Speech to Video Synthesis (pose amp emotion)
98Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
99Suwajanakorn Supasorn Steven M Seitz and Ira Kemelmacher-Shlizerman Synthesizing Obama learning lip sync from audio SIGGRAPH 2017
Speech to Video Synthesis (mouth)
100
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
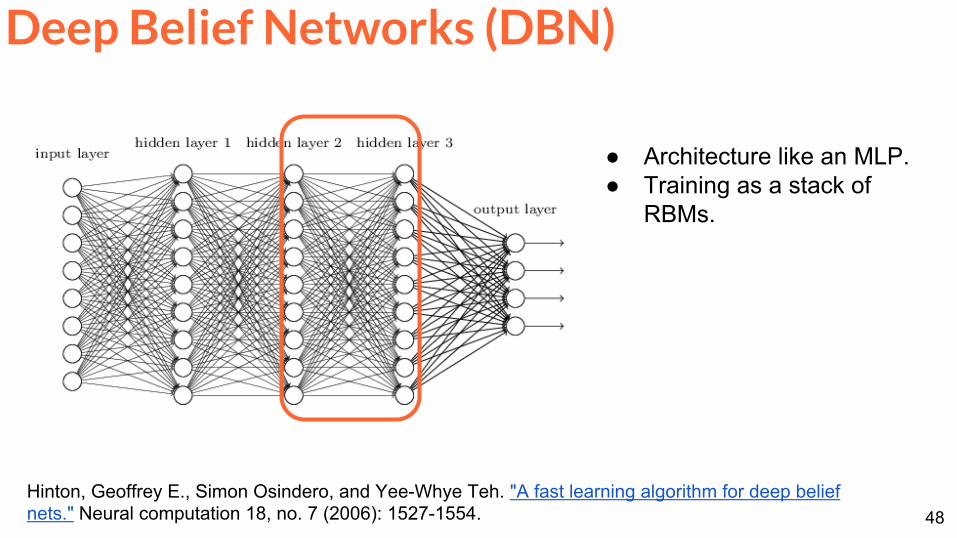
48
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMs
49
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMshellip so they do not need
labels
Unsupervisedlearning
50
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
After the DBN is trained it can be fine-tuned with a reduced amount of labels to solve a supervised task with superior performance
Supervisedlearning
Softm
ax
51
Deep Belief Networks (DBN)
Deep Learning TV ldquoDeep Belief Netsrdquo
52
Deep Belief Networks (DBN)
Geoffrey Hinton Introduction to Deep Learning amp Deep Belief Netsrdquo (2012)Geoorey Hinton ldquoTutorial on Deep Belief Networksrdquo NIPS 2007
53
Deep Belief Networks (DBN)
Geoffrey Hinton
54
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
Acknowledgments
55
Junting Pan Xunyu Lin
Unsupervised Feature Learning
56
Slide credit Yann LeCun
Unsupervised Feature Learning
57
Slide credit Yann LeCun
Slide credit Junting Pan
Frame Reconstruction amp Prediction
59Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
Frame Reconstruction amp Prediction
60Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
frame prediction
Frame Reconstruction amp Prediction
61Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
frame prediction
62Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised learned features (lots of data) are fine-tuned for activity recognition (little data)
Frame Reconstruction amp Prediction
Frame Prediction
63Ranzato MarcAurelio Arthur Szlam Joan Bruna Michael Mathieu Ronan Collobert and Sumit Chopra Video (language) modeling a baseline for generative models of natural videos arXiv preprint arXiv14126604 (2014)
64Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
Video frame prediction with a ConvNet
Frame Prediction
65Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
The blurry predictions from MSE are improved with multi-scale architecture adversarial learning and an image gradient difference loss function
Frame Prediction
66Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
The blurry predictions from MSE (l1) are improved with multi-scale architecture adversarial training and an image gradient difference loss (GDL) function
Frame Prediction
67Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
Frame Prediction
68Vondrick Carl Hamed Pirsiavash and Antonio Torralba Generating videos with scene dynamics NIPS 2016
Frame Prediction
69Vondrick Carl Hamed Pirsiavash and Antonio Torralba Generating videos with scene dynamics NIPS 2016
Frame Prediction
70Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
71
Frame Prediction
Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
Given an input image probabilistic generation of future frames with a Variational AutoEncoder (VAE)
72
Frame Prediction
Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
Encodes image as feature maps and motion as and cross-convolutional kernels
73
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
First steps in video feature learning
74Le Quoc V Will Y Zou Serena Y Yeung and Andrew Y Ng Learning hierarchical invariant spatio-temporal features for action recognition with independent subspace analysis CVPR 2011
Temporal Weak Labels
75Goroshin Ross Joan Bruna Jonathan Tompson David Eigen and Yann LeCun Unsupervised learning of spatiotemporally coherent metrics ICCV 2015
Assumption adjacent video frames contain semantically similar informationAutoencoder trained with regularizations by slowliness and sparisty
76Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
77Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
78(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Temporal order of frames is exploited as the supervisory signal for learning
Temporal Weak Labels
79(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Take temporal order as the supervisory signals for learning
Shuffled sequences
Binary classification
In order
Not in order
Temporal Weak Labels
80Fernando Basura Hakan Bilen Efstratios Gavves and Stephen Gould Self-supervised video representation learning with odd-one-out networks CVPR 2017
Temporal Weak LabelsTrain a network to detect which of the video sequences contains frames wrong order
81
Spatio-Temporal Weak Labels
X Lin Campos V Giroacute-i-Nieto X Torres J and Canton-Ferrer C ldquoDisentangling Motion Foreground and Background Features in Videosrdquo in CVPR 2017 Workshop Brave New Motion Representations
kernel dec
C3D
ForegroundMotion
FirstForeground
Background
Fg
Dec
Bg
Dec
Fg
Dec Reconstruction
of foreground in last frame
Reconstruction of foreground in
first frame
Reconstruction of background in first frame
uNLC
MaskBlock
gradients
Last foreground
Kernels
shareweights
82
Spatio-Temporal Weak Labels
Pathak Deepak Ross Girshick Piotr Dollaacuter Trevor Darrell and Bharath Hariharan Learning features by watching objects move CVPR 2017
83Greff Klaus Antti Rasmus Mathias Berglund Tele Hao Harri Valpola and Juergen Schmidhuber Tagger Deep unsupervised perceptual grouping NIPS 2016 [video] [code]
Spatio-Temporal Weak Labels
84Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
85
Audio Features from Visual weak labels
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Object amp Scenes recognition in videos by analysing the audio track (only)
86Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
87Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
88Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
89
Visualization of the video frames associated to the sounds that activate some of the last hidden units of Soundnet (conv7)
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Audio Features from Visual weak labels
90
Audio amp Visual features from alignement
90Arandjelović Relja and Andrew Zisserman Look Listen and Learn ICCV 2017
Audio and visual features learned by assessing alignement
91L Chen S Srivastava Z Duan and C Xu Deep Cross-Modal Audio-Visual Generation ACM International Conference on Multimedia Thematic Workshops 2017
Audio amp Visual features from alignement
92Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
93Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
Video to Speech Representations
CNN(VGG)
Frame from a silent video
Audio feature
Post-hoc synthesis
94Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
95Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
Speech to Video Synthesis (mouth)
96Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
97Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
Speech to Video Synthesis (pose amp emotion)
98Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
99Suwajanakorn Supasorn Steven M Seitz and Ira Kemelmacher-Shlizerman Synthesizing Obama learning lip sync from audio SIGGRAPH 2017
Speech to Video Synthesis (mouth)
100
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
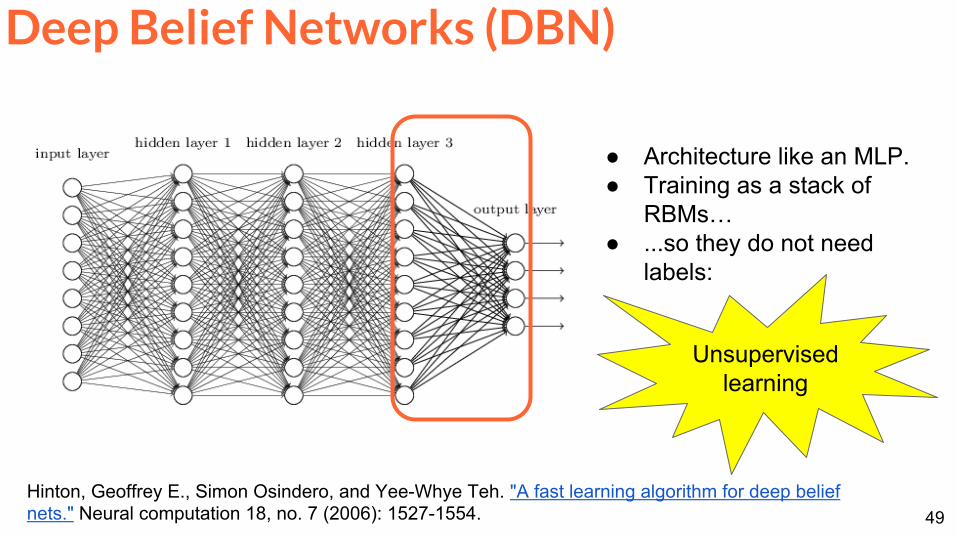
49
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
Architecture like an MLP Training as a stack of
RBMshellip so they do not need
labels
Unsupervisedlearning
50
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
After the DBN is trained it can be fine-tuned with a reduced amount of labels to solve a supervised task with superior performance
Supervisedlearning
Softm
ax
51
Deep Belief Networks (DBN)
Deep Learning TV ldquoDeep Belief Netsrdquo
52
Deep Belief Networks (DBN)
Geoffrey Hinton Introduction to Deep Learning amp Deep Belief Netsrdquo (2012)Geoorey Hinton ldquoTutorial on Deep Belief Networksrdquo NIPS 2007
53
Deep Belief Networks (DBN)
Geoffrey Hinton
54
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
Acknowledgments
55
Junting Pan Xunyu Lin
Unsupervised Feature Learning
56
Slide credit Yann LeCun
Unsupervised Feature Learning
57
Slide credit Yann LeCun
Slide credit Junting Pan
Frame Reconstruction amp Prediction
59Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
Frame Reconstruction amp Prediction
60Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
frame prediction
Frame Reconstruction amp Prediction
61Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
frame prediction
62Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised learned features (lots of data) are fine-tuned for activity recognition (little data)
Frame Reconstruction amp Prediction
Frame Prediction
63Ranzato MarcAurelio Arthur Szlam Joan Bruna Michael Mathieu Ronan Collobert and Sumit Chopra Video (language) modeling a baseline for generative models of natural videos arXiv preprint arXiv14126604 (2014)
64Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
Video frame prediction with a ConvNet
Frame Prediction
65Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
The blurry predictions from MSE are improved with multi-scale architecture adversarial learning and an image gradient difference loss function
Frame Prediction
66Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
The blurry predictions from MSE (l1) are improved with multi-scale architecture adversarial training and an image gradient difference loss (GDL) function
Frame Prediction
67Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
Frame Prediction
68Vondrick Carl Hamed Pirsiavash and Antonio Torralba Generating videos with scene dynamics NIPS 2016
Frame Prediction
69Vondrick Carl Hamed Pirsiavash and Antonio Torralba Generating videos with scene dynamics NIPS 2016
Frame Prediction
70Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
71
Frame Prediction
Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
Given an input image probabilistic generation of future frames with a Variational AutoEncoder (VAE)
72
Frame Prediction
Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
Encodes image as feature maps and motion as and cross-convolutional kernels
73
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
First steps in video feature learning
74Le Quoc V Will Y Zou Serena Y Yeung and Andrew Y Ng Learning hierarchical invariant spatio-temporal features for action recognition with independent subspace analysis CVPR 2011
Temporal Weak Labels
75Goroshin Ross Joan Bruna Jonathan Tompson David Eigen and Yann LeCun Unsupervised learning of spatiotemporally coherent metrics ICCV 2015
Assumption adjacent video frames contain semantically similar informationAutoencoder trained with regularizations by slowliness and sparisty
76Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
77Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
78(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Temporal order of frames is exploited as the supervisory signal for learning
Temporal Weak Labels
79(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Take temporal order as the supervisory signals for learning
Shuffled sequences
Binary classification
In order
Not in order
Temporal Weak Labels
80Fernando Basura Hakan Bilen Efstratios Gavves and Stephen Gould Self-supervised video representation learning with odd-one-out networks CVPR 2017
Temporal Weak LabelsTrain a network to detect which of the video sequences contains frames wrong order
81
Spatio-Temporal Weak Labels
X Lin Campos V Giroacute-i-Nieto X Torres J and Canton-Ferrer C ldquoDisentangling Motion Foreground and Background Features in Videosrdquo in CVPR 2017 Workshop Brave New Motion Representations
kernel dec
C3D
ForegroundMotion
FirstForeground
Background
Fg
Dec
Bg
Dec
Fg
Dec Reconstruction
of foreground in last frame
Reconstruction of foreground in
first frame
Reconstruction of background in first frame
uNLC
MaskBlock
gradients
Last foreground
Kernels
shareweights
82
Spatio-Temporal Weak Labels
Pathak Deepak Ross Girshick Piotr Dollaacuter Trevor Darrell and Bharath Hariharan Learning features by watching objects move CVPR 2017
83Greff Klaus Antti Rasmus Mathias Berglund Tele Hao Harri Valpola and Juergen Schmidhuber Tagger Deep unsupervised perceptual grouping NIPS 2016 [video] [code]
Spatio-Temporal Weak Labels
84Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
85
Audio Features from Visual weak labels
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Object amp Scenes recognition in videos by analysing the audio track (only)
86Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
87Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
88Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
89
Visualization of the video frames associated to the sounds that activate some of the last hidden units of Soundnet (conv7)
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Audio Features from Visual weak labels
90
Audio amp Visual features from alignement
90Arandjelović Relja and Andrew Zisserman Look Listen and Learn ICCV 2017
Audio and visual features learned by assessing alignement
91L Chen S Srivastava Z Duan and C Xu Deep Cross-Modal Audio-Visual Generation ACM International Conference on Multimedia Thematic Workshops 2017
Audio amp Visual features from alignement
92Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
93Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
Video to Speech Representations
CNN(VGG)
Frame from a silent video
Audio feature
Post-hoc synthesis
94Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
95Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
Speech to Video Synthesis (mouth)
96Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
97Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
Speech to Video Synthesis (pose amp emotion)
98Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
99Suwajanakorn Supasorn Steven M Seitz and Ira Kemelmacher-Shlizerman Synthesizing Obama learning lip sync from audio SIGGRAPH 2017
Speech to Video Synthesis (mouth)
100
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning

50
Deep Belief Networks (DBN)
Hinton Geoffrey E Simon Osindero and Yee-Whye Teh A fast learning algorithm for deep belief nets Neural computation 18 no 7 (2006) 1527-1554
After the DBN is trained it can be fine-tuned with a reduced amount of labels to solve a supervised task with superior performance
Supervisedlearning
Softm
ax
51
Deep Belief Networks (DBN)
Deep Learning TV ldquoDeep Belief Netsrdquo
52
Deep Belief Networks (DBN)
Geoffrey Hinton Introduction to Deep Learning amp Deep Belief Netsrdquo (2012)Geoorey Hinton ldquoTutorial on Deep Belief Networksrdquo NIPS 2007
53
Deep Belief Networks (DBN)
Geoffrey Hinton
54
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
Acknowledgments
55
Junting Pan Xunyu Lin
Unsupervised Feature Learning
56
Slide credit Yann LeCun
Unsupervised Feature Learning
57
Slide credit Yann LeCun
Slide credit Junting Pan
Frame Reconstruction amp Prediction
59Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
Frame Reconstruction amp Prediction
60Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
frame prediction
Frame Reconstruction amp Prediction
61Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
frame prediction
62Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised learned features (lots of data) are fine-tuned for activity recognition (little data)
Frame Reconstruction amp Prediction
Frame Prediction
63Ranzato MarcAurelio Arthur Szlam Joan Bruna Michael Mathieu Ronan Collobert and Sumit Chopra Video (language) modeling a baseline for generative models of natural videos arXiv preprint arXiv14126604 (2014)
64Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
Video frame prediction with a ConvNet
Frame Prediction
65Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
The blurry predictions from MSE are improved with multi-scale architecture adversarial learning and an image gradient difference loss function
Frame Prediction
66Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
The blurry predictions from MSE (l1) are improved with multi-scale architecture adversarial training and an image gradient difference loss (GDL) function
Frame Prediction
67Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
Frame Prediction
68Vondrick Carl Hamed Pirsiavash and Antonio Torralba Generating videos with scene dynamics NIPS 2016
Frame Prediction
69Vondrick Carl Hamed Pirsiavash and Antonio Torralba Generating videos with scene dynamics NIPS 2016
Frame Prediction
70Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
71
Frame Prediction
Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
Given an input image probabilistic generation of future frames with a Variational AutoEncoder (VAE)
72
Frame Prediction
Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
Encodes image as feature maps and motion as and cross-convolutional kernels
73
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
First steps in video feature learning
74Le Quoc V Will Y Zou Serena Y Yeung and Andrew Y Ng Learning hierarchical invariant spatio-temporal features for action recognition with independent subspace analysis CVPR 2011
Temporal Weak Labels
75Goroshin Ross Joan Bruna Jonathan Tompson David Eigen and Yann LeCun Unsupervised learning of spatiotemporally coherent metrics ICCV 2015
Assumption adjacent video frames contain semantically similar informationAutoencoder trained with regularizations by slowliness and sparisty
76Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
77Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
78(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Temporal order of frames is exploited as the supervisory signal for learning
Temporal Weak Labels
79(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Take temporal order as the supervisory signals for learning
Shuffled sequences
Binary classification
In order
Not in order
Temporal Weak Labels
80Fernando Basura Hakan Bilen Efstratios Gavves and Stephen Gould Self-supervised video representation learning with odd-one-out networks CVPR 2017
Temporal Weak LabelsTrain a network to detect which of the video sequences contains frames wrong order
81
Spatio-Temporal Weak Labels
X Lin Campos V Giroacute-i-Nieto X Torres J and Canton-Ferrer C ldquoDisentangling Motion Foreground and Background Features in Videosrdquo in CVPR 2017 Workshop Brave New Motion Representations
kernel dec
C3D
ForegroundMotion
FirstForeground
Background
Fg
Dec
Bg
Dec
Fg
Dec Reconstruction
of foreground in last frame
Reconstruction of foreground in
first frame
Reconstruction of background in first frame
uNLC
MaskBlock
gradients
Last foreground
Kernels
shareweights
82
Spatio-Temporal Weak Labels
Pathak Deepak Ross Girshick Piotr Dollaacuter Trevor Darrell and Bharath Hariharan Learning features by watching objects move CVPR 2017
83Greff Klaus Antti Rasmus Mathias Berglund Tele Hao Harri Valpola and Juergen Schmidhuber Tagger Deep unsupervised perceptual grouping NIPS 2016 [video] [code]
Spatio-Temporal Weak Labels
84Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
85
Audio Features from Visual weak labels
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Object amp Scenes recognition in videos by analysing the audio track (only)
86Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
87Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
88Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
89
Visualization of the video frames associated to the sounds that activate some of the last hidden units of Soundnet (conv7)
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Audio Features from Visual weak labels
90
Audio amp Visual features from alignement
90Arandjelović Relja and Andrew Zisserman Look Listen and Learn ICCV 2017
Audio and visual features learned by assessing alignement
91L Chen S Srivastava Z Duan and C Xu Deep Cross-Modal Audio-Visual Generation ACM International Conference on Multimedia Thematic Workshops 2017
Audio amp Visual features from alignement
92Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
93Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
Video to Speech Representations
CNN(VGG)
Frame from a silent video
Audio feature
Post-hoc synthesis
94Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
95Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
Speech to Video Synthesis (mouth)
96Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
97Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
Speech to Video Synthesis (pose amp emotion)
98Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
99Suwajanakorn Supasorn Steven M Seitz and Ira Kemelmacher-Shlizerman Synthesizing Obama learning lip sync from audio SIGGRAPH 2017
Speech to Video Synthesis (mouth)
100
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning

51
Deep Belief Networks (DBN)
Deep Learning TV ldquoDeep Belief Netsrdquo
52
Deep Belief Networks (DBN)
Geoffrey Hinton Introduction to Deep Learning amp Deep Belief Netsrdquo (2012)Geoorey Hinton ldquoTutorial on Deep Belief Networksrdquo NIPS 2007
53
Deep Belief Networks (DBN)
Geoffrey Hinton
54
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
Acknowledgments
55
Junting Pan Xunyu Lin
Unsupervised Feature Learning
56
Slide credit Yann LeCun
Unsupervised Feature Learning
57
Slide credit Yann LeCun
Slide credit Junting Pan
Frame Reconstruction amp Prediction
59Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
Frame Reconstruction amp Prediction
60Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
frame prediction
Frame Reconstruction amp Prediction
61Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
frame prediction
62Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised learned features (lots of data) are fine-tuned for activity recognition (little data)
Frame Reconstruction amp Prediction
Frame Prediction
63Ranzato MarcAurelio Arthur Szlam Joan Bruna Michael Mathieu Ronan Collobert and Sumit Chopra Video (language) modeling a baseline for generative models of natural videos arXiv preprint arXiv14126604 (2014)
64Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
Video frame prediction with a ConvNet
Frame Prediction
65Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
The blurry predictions from MSE are improved with multi-scale architecture adversarial learning and an image gradient difference loss function
Frame Prediction
66Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
The blurry predictions from MSE (l1) are improved with multi-scale architecture adversarial training and an image gradient difference loss (GDL) function
Frame Prediction
67Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
Frame Prediction
68Vondrick Carl Hamed Pirsiavash and Antonio Torralba Generating videos with scene dynamics NIPS 2016
Frame Prediction
69Vondrick Carl Hamed Pirsiavash and Antonio Torralba Generating videos with scene dynamics NIPS 2016
Frame Prediction
70Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
71
Frame Prediction
Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
Given an input image probabilistic generation of future frames with a Variational AutoEncoder (VAE)
72
Frame Prediction
Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
Encodes image as feature maps and motion as and cross-convolutional kernels
73
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
First steps in video feature learning
74Le Quoc V Will Y Zou Serena Y Yeung and Andrew Y Ng Learning hierarchical invariant spatio-temporal features for action recognition with independent subspace analysis CVPR 2011
Temporal Weak Labels
75Goroshin Ross Joan Bruna Jonathan Tompson David Eigen and Yann LeCun Unsupervised learning of spatiotemporally coherent metrics ICCV 2015
Assumption adjacent video frames contain semantically similar informationAutoencoder trained with regularizations by slowliness and sparisty
76Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
77Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
78(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Temporal order of frames is exploited as the supervisory signal for learning
Temporal Weak Labels
79(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Take temporal order as the supervisory signals for learning
Shuffled sequences
Binary classification
In order
Not in order
Temporal Weak Labels
80Fernando Basura Hakan Bilen Efstratios Gavves and Stephen Gould Self-supervised video representation learning with odd-one-out networks CVPR 2017
Temporal Weak LabelsTrain a network to detect which of the video sequences contains frames wrong order
81
Spatio-Temporal Weak Labels
X Lin Campos V Giroacute-i-Nieto X Torres J and Canton-Ferrer C ldquoDisentangling Motion Foreground and Background Features in Videosrdquo in CVPR 2017 Workshop Brave New Motion Representations
kernel dec
C3D
ForegroundMotion
FirstForeground
Background
Fg
Dec
Bg
Dec
Fg
Dec Reconstruction
of foreground in last frame
Reconstruction of foreground in
first frame
Reconstruction of background in first frame
uNLC
MaskBlock
gradients
Last foreground
Kernels
shareweights
82
Spatio-Temporal Weak Labels
Pathak Deepak Ross Girshick Piotr Dollaacuter Trevor Darrell and Bharath Hariharan Learning features by watching objects move CVPR 2017
83Greff Klaus Antti Rasmus Mathias Berglund Tele Hao Harri Valpola and Juergen Schmidhuber Tagger Deep unsupervised perceptual grouping NIPS 2016 [video] [code]
Spatio-Temporal Weak Labels
84Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
85
Audio Features from Visual weak labels
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Object amp Scenes recognition in videos by analysing the audio track (only)
86Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
87Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
88Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
89
Visualization of the video frames associated to the sounds that activate some of the last hidden units of Soundnet (conv7)
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Audio Features from Visual weak labels
90
Audio amp Visual features from alignement
90Arandjelović Relja and Andrew Zisserman Look Listen and Learn ICCV 2017
Audio and visual features learned by assessing alignement
91L Chen S Srivastava Z Duan and C Xu Deep Cross-Modal Audio-Visual Generation ACM International Conference on Multimedia Thematic Workshops 2017
Audio amp Visual features from alignement
92Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
93Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
Video to Speech Representations
CNN(VGG)
Frame from a silent video
Audio feature
Post-hoc synthesis
94Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
95Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
Speech to Video Synthesis (mouth)
96Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
97Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
Speech to Video Synthesis (pose amp emotion)
98Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
99Suwajanakorn Supasorn Steven M Seitz and Ira Kemelmacher-Shlizerman Synthesizing Obama learning lip sync from audio SIGGRAPH 2017
Speech to Video Synthesis (mouth)
100
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning

52
Deep Belief Networks (DBN)
Geoffrey Hinton Introduction to Deep Learning amp Deep Belief Netsrdquo (2012)Geoorey Hinton ldquoTutorial on Deep Belief Networksrdquo NIPS 2007
53
Deep Belief Networks (DBN)
Geoffrey Hinton
54
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
Acknowledgments
55
Junting Pan Xunyu Lin
Unsupervised Feature Learning
56
Slide credit Yann LeCun
Unsupervised Feature Learning
57
Slide credit Yann LeCun
Slide credit Junting Pan
Frame Reconstruction amp Prediction
59Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
Frame Reconstruction amp Prediction
60Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
frame prediction
Frame Reconstruction amp Prediction
61Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
frame prediction
62Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised learned features (lots of data) are fine-tuned for activity recognition (little data)
Frame Reconstruction amp Prediction
Frame Prediction
63Ranzato MarcAurelio Arthur Szlam Joan Bruna Michael Mathieu Ronan Collobert and Sumit Chopra Video (language) modeling a baseline for generative models of natural videos arXiv preprint arXiv14126604 (2014)
64Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
Video frame prediction with a ConvNet
Frame Prediction
65Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
The blurry predictions from MSE are improved with multi-scale architecture adversarial learning and an image gradient difference loss function
Frame Prediction
66Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
The blurry predictions from MSE (l1) are improved with multi-scale architecture adversarial training and an image gradient difference loss (GDL) function
Frame Prediction
67Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
Frame Prediction
68Vondrick Carl Hamed Pirsiavash and Antonio Torralba Generating videos with scene dynamics NIPS 2016
Frame Prediction
69Vondrick Carl Hamed Pirsiavash and Antonio Torralba Generating videos with scene dynamics NIPS 2016
Frame Prediction
70Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
71
Frame Prediction
Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
Given an input image probabilistic generation of future frames with a Variational AutoEncoder (VAE)
72
Frame Prediction
Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
Encodes image as feature maps and motion as and cross-convolutional kernels
73
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
First steps in video feature learning
74Le Quoc V Will Y Zou Serena Y Yeung and Andrew Y Ng Learning hierarchical invariant spatio-temporal features for action recognition with independent subspace analysis CVPR 2011
Temporal Weak Labels
75Goroshin Ross Joan Bruna Jonathan Tompson David Eigen and Yann LeCun Unsupervised learning of spatiotemporally coherent metrics ICCV 2015
Assumption adjacent video frames contain semantically similar informationAutoencoder trained with regularizations by slowliness and sparisty
76Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
77Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
78(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Temporal order of frames is exploited as the supervisory signal for learning
Temporal Weak Labels
79(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Take temporal order as the supervisory signals for learning
Shuffled sequences
Binary classification
In order
Not in order
Temporal Weak Labels
80Fernando Basura Hakan Bilen Efstratios Gavves and Stephen Gould Self-supervised video representation learning with odd-one-out networks CVPR 2017
Temporal Weak LabelsTrain a network to detect which of the video sequences contains frames wrong order
81
Spatio-Temporal Weak Labels
X Lin Campos V Giroacute-i-Nieto X Torres J and Canton-Ferrer C ldquoDisentangling Motion Foreground and Background Features in Videosrdquo in CVPR 2017 Workshop Brave New Motion Representations
kernel dec
C3D
ForegroundMotion
FirstForeground
Background
Fg
Dec
Bg
Dec
Fg
Dec Reconstruction
of foreground in last frame
Reconstruction of foreground in
first frame
Reconstruction of background in first frame
uNLC
MaskBlock
gradients
Last foreground
Kernels
shareweights
82
Spatio-Temporal Weak Labels
Pathak Deepak Ross Girshick Piotr Dollaacuter Trevor Darrell and Bharath Hariharan Learning features by watching objects move CVPR 2017
83Greff Klaus Antti Rasmus Mathias Berglund Tele Hao Harri Valpola and Juergen Schmidhuber Tagger Deep unsupervised perceptual grouping NIPS 2016 [video] [code]
Spatio-Temporal Weak Labels
84Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
85
Audio Features from Visual weak labels
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Object amp Scenes recognition in videos by analysing the audio track (only)
86Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
87Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
88Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
89
Visualization of the video frames associated to the sounds that activate some of the last hidden units of Soundnet (conv7)
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Audio Features from Visual weak labels
90
Audio amp Visual features from alignement
90Arandjelović Relja and Andrew Zisserman Look Listen and Learn ICCV 2017
Audio and visual features learned by assessing alignement
91L Chen S Srivastava Z Duan and C Xu Deep Cross-Modal Audio-Visual Generation ACM International Conference on Multimedia Thematic Workshops 2017
Audio amp Visual features from alignement
92Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
93Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
Video to Speech Representations
CNN(VGG)
Frame from a silent video
Audio feature
Post-hoc synthesis
94Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
95Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
Speech to Video Synthesis (mouth)
96Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
97Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
Speech to Video Synthesis (pose amp emotion)
98Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
99Suwajanakorn Supasorn Steven M Seitz and Ira Kemelmacher-Shlizerman Synthesizing Obama learning lip sync from audio SIGGRAPH 2017
Speech to Video Synthesis (mouth)
100
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning

53
Deep Belief Networks (DBN)
Geoffrey Hinton
54
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
Acknowledgments
55
Junting Pan Xunyu Lin
Unsupervised Feature Learning
56
Slide credit Yann LeCun
Unsupervised Feature Learning
57
Slide credit Yann LeCun
Slide credit Junting Pan
Frame Reconstruction amp Prediction
59Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
Frame Reconstruction amp Prediction
60Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
frame prediction
Frame Reconstruction amp Prediction
61Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
frame prediction
62Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised learned features (lots of data) are fine-tuned for activity recognition (little data)
Frame Reconstruction amp Prediction
Frame Prediction
63Ranzato MarcAurelio Arthur Szlam Joan Bruna Michael Mathieu Ronan Collobert and Sumit Chopra Video (language) modeling a baseline for generative models of natural videos arXiv preprint arXiv14126604 (2014)
64Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
Video frame prediction with a ConvNet
Frame Prediction
65Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
The blurry predictions from MSE are improved with multi-scale architecture adversarial learning and an image gradient difference loss function
Frame Prediction
66Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
The blurry predictions from MSE (l1) are improved with multi-scale architecture adversarial training and an image gradient difference loss (GDL) function
Frame Prediction
67Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
Frame Prediction
68Vondrick Carl Hamed Pirsiavash and Antonio Torralba Generating videos with scene dynamics NIPS 2016
Frame Prediction
69Vondrick Carl Hamed Pirsiavash and Antonio Torralba Generating videos with scene dynamics NIPS 2016
Frame Prediction
70Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
71
Frame Prediction
Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
Given an input image probabilistic generation of future frames with a Variational AutoEncoder (VAE)
72
Frame Prediction
Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
Encodes image as feature maps and motion as and cross-convolutional kernels
73
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
First steps in video feature learning
74Le Quoc V Will Y Zou Serena Y Yeung and Andrew Y Ng Learning hierarchical invariant spatio-temporal features for action recognition with independent subspace analysis CVPR 2011
Temporal Weak Labels
75Goroshin Ross Joan Bruna Jonathan Tompson David Eigen and Yann LeCun Unsupervised learning of spatiotemporally coherent metrics ICCV 2015
Assumption adjacent video frames contain semantically similar informationAutoencoder trained with regularizations by slowliness and sparisty
76Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
77Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
78(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Temporal order of frames is exploited as the supervisory signal for learning
Temporal Weak Labels
79(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Take temporal order as the supervisory signals for learning
Shuffled sequences
Binary classification
In order
Not in order
Temporal Weak Labels
80Fernando Basura Hakan Bilen Efstratios Gavves and Stephen Gould Self-supervised video representation learning with odd-one-out networks CVPR 2017
Temporal Weak LabelsTrain a network to detect which of the video sequences contains frames wrong order
81
Spatio-Temporal Weak Labels
X Lin Campos V Giroacute-i-Nieto X Torres J and Canton-Ferrer C ldquoDisentangling Motion Foreground and Background Features in Videosrdquo in CVPR 2017 Workshop Brave New Motion Representations
kernel dec
C3D
ForegroundMotion
FirstForeground
Background
Fg
Dec
Bg
Dec
Fg
Dec Reconstruction
of foreground in last frame
Reconstruction of foreground in
first frame
Reconstruction of background in first frame
uNLC
MaskBlock
gradients
Last foreground
Kernels
shareweights
82
Spatio-Temporal Weak Labels
Pathak Deepak Ross Girshick Piotr Dollaacuter Trevor Darrell and Bharath Hariharan Learning features by watching objects move CVPR 2017
83Greff Klaus Antti Rasmus Mathias Berglund Tele Hao Harri Valpola and Juergen Schmidhuber Tagger Deep unsupervised perceptual grouping NIPS 2016 [video] [code]
Spatio-Temporal Weak Labels
84Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
85
Audio Features from Visual weak labels
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Object amp Scenes recognition in videos by analysing the audio track (only)
86Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
87Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
88Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
89
Visualization of the video frames associated to the sounds that activate some of the last hidden units of Soundnet (conv7)
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Audio Features from Visual weak labels
90
Audio amp Visual features from alignement
90Arandjelović Relja and Andrew Zisserman Look Listen and Learn ICCV 2017
Audio and visual features learned by assessing alignement
91L Chen S Srivastava Z Duan and C Xu Deep Cross-Modal Audio-Visual Generation ACM International Conference on Multimedia Thematic Workshops 2017
Audio amp Visual features from alignement
92Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
93Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
Video to Speech Representations
CNN(VGG)
Frame from a silent video
Audio feature
Post-hoc synthesis
94Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
95Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
Speech to Video Synthesis (mouth)
96Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
97Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
Speech to Video Synthesis (pose amp emotion)
98Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
99Suwajanakorn Supasorn Steven M Seitz and Ira Kemelmacher-Shlizerman Synthesizing Obama learning lip sync from audio SIGGRAPH 2017
Speech to Video Synthesis (mouth)
100
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning

54
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
Acknowledgments
55
Junting Pan Xunyu Lin
Unsupervised Feature Learning
56
Slide credit Yann LeCun
Unsupervised Feature Learning
57
Slide credit Yann LeCun
Slide credit Junting Pan
Frame Reconstruction amp Prediction
59Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
Frame Reconstruction amp Prediction
60Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
frame prediction
Frame Reconstruction amp Prediction
61Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
frame prediction
62Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised learned features (lots of data) are fine-tuned for activity recognition (little data)
Frame Reconstruction amp Prediction
Frame Prediction
63Ranzato MarcAurelio Arthur Szlam Joan Bruna Michael Mathieu Ronan Collobert and Sumit Chopra Video (language) modeling a baseline for generative models of natural videos arXiv preprint arXiv14126604 (2014)
64Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
Video frame prediction with a ConvNet
Frame Prediction
65Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
The blurry predictions from MSE are improved with multi-scale architecture adversarial learning and an image gradient difference loss function
Frame Prediction
66Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
The blurry predictions from MSE (l1) are improved with multi-scale architecture adversarial training and an image gradient difference loss (GDL) function
Frame Prediction
67Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
Frame Prediction
68Vondrick Carl Hamed Pirsiavash and Antonio Torralba Generating videos with scene dynamics NIPS 2016
Frame Prediction
69Vondrick Carl Hamed Pirsiavash and Antonio Torralba Generating videos with scene dynamics NIPS 2016
Frame Prediction
70Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
71
Frame Prediction
Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
Given an input image probabilistic generation of future frames with a Variational AutoEncoder (VAE)
72
Frame Prediction
Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
Encodes image as feature maps and motion as and cross-convolutional kernels
73
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
First steps in video feature learning
74Le Quoc V Will Y Zou Serena Y Yeung and Andrew Y Ng Learning hierarchical invariant spatio-temporal features for action recognition with independent subspace analysis CVPR 2011
Temporal Weak Labels
75Goroshin Ross Joan Bruna Jonathan Tompson David Eigen and Yann LeCun Unsupervised learning of spatiotemporally coherent metrics ICCV 2015
Assumption adjacent video frames contain semantically similar informationAutoencoder trained with regularizations by slowliness and sparisty
76Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
77Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
78(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Temporal order of frames is exploited as the supervisory signal for learning
Temporal Weak Labels
79(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Take temporal order as the supervisory signals for learning
Shuffled sequences
Binary classification
In order
Not in order
Temporal Weak Labels
80Fernando Basura Hakan Bilen Efstratios Gavves and Stephen Gould Self-supervised video representation learning with odd-one-out networks CVPR 2017
Temporal Weak LabelsTrain a network to detect which of the video sequences contains frames wrong order
81
Spatio-Temporal Weak Labels
X Lin Campos V Giroacute-i-Nieto X Torres J and Canton-Ferrer C ldquoDisentangling Motion Foreground and Background Features in Videosrdquo in CVPR 2017 Workshop Brave New Motion Representations
kernel dec
C3D
ForegroundMotion
FirstForeground
Background
Fg
Dec
Bg
Dec
Fg
Dec Reconstruction
of foreground in last frame
Reconstruction of foreground in
first frame
Reconstruction of background in first frame
uNLC
MaskBlock
gradients
Last foreground
Kernels
shareweights
82
Spatio-Temporal Weak Labels
Pathak Deepak Ross Girshick Piotr Dollaacuter Trevor Darrell and Bharath Hariharan Learning features by watching objects move CVPR 2017
83Greff Klaus Antti Rasmus Mathias Berglund Tele Hao Harri Valpola and Juergen Schmidhuber Tagger Deep unsupervised perceptual grouping NIPS 2016 [video] [code]
Spatio-Temporal Weak Labels
84Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
85
Audio Features from Visual weak labels
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Object amp Scenes recognition in videos by analysing the audio track (only)
86Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
87Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
88Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
89
Visualization of the video frames associated to the sounds that activate some of the last hidden units of Soundnet (conv7)
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Audio Features from Visual weak labels
90
Audio amp Visual features from alignement
90Arandjelović Relja and Andrew Zisserman Look Listen and Learn ICCV 2017
Audio and visual features learned by assessing alignement
91L Chen S Srivastava Z Duan and C Xu Deep Cross-Modal Audio-Visual Generation ACM International Conference on Multimedia Thematic Workshops 2017
Audio amp Visual features from alignement
92Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
93Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
Video to Speech Representations
CNN(VGG)
Frame from a silent video
Audio feature
Post-hoc synthesis
94Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
95Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
Speech to Video Synthesis (mouth)
96Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
97Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
Speech to Video Synthesis (pose amp emotion)
98Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
99Suwajanakorn Supasorn Steven M Seitz and Ira Kemelmacher-Shlizerman Synthesizing Obama learning lip sync from audio SIGGRAPH 2017
Speech to Video Synthesis (mouth)
100
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning

Acknowledgments
55
Junting Pan Xunyu Lin
Unsupervised Feature Learning
56
Slide credit Yann LeCun
Unsupervised Feature Learning
57
Slide credit Yann LeCun
Slide credit Junting Pan
Frame Reconstruction amp Prediction
59Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
Frame Reconstruction amp Prediction
60Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
frame prediction
Frame Reconstruction amp Prediction
61Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
frame prediction
62Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised learned features (lots of data) are fine-tuned for activity recognition (little data)
Frame Reconstruction amp Prediction
Frame Prediction
63Ranzato MarcAurelio Arthur Szlam Joan Bruna Michael Mathieu Ronan Collobert and Sumit Chopra Video (language) modeling a baseline for generative models of natural videos arXiv preprint arXiv14126604 (2014)
64Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
Video frame prediction with a ConvNet
Frame Prediction
65Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
The blurry predictions from MSE are improved with multi-scale architecture adversarial learning and an image gradient difference loss function
Frame Prediction
66Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
The blurry predictions from MSE (l1) are improved with multi-scale architecture adversarial training and an image gradient difference loss (GDL) function
Frame Prediction
67Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
Frame Prediction
68Vondrick Carl Hamed Pirsiavash and Antonio Torralba Generating videos with scene dynamics NIPS 2016
Frame Prediction
69Vondrick Carl Hamed Pirsiavash and Antonio Torralba Generating videos with scene dynamics NIPS 2016
Frame Prediction
70Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
71
Frame Prediction
Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
Given an input image probabilistic generation of future frames with a Variational AutoEncoder (VAE)
72
Frame Prediction
Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
Encodes image as feature maps and motion as and cross-convolutional kernels
73
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
First steps in video feature learning
74Le Quoc V Will Y Zou Serena Y Yeung and Andrew Y Ng Learning hierarchical invariant spatio-temporal features for action recognition with independent subspace analysis CVPR 2011
Temporal Weak Labels
75Goroshin Ross Joan Bruna Jonathan Tompson David Eigen and Yann LeCun Unsupervised learning of spatiotemporally coherent metrics ICCV 2015
Assumption adjacent video frames contain semantically similar informationAutoencoder trained with regularizations by slowliness and sparisty
76Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
77Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
78(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Temporal order of frames is exploited as the supervisory signal for learning
Temporal Weak Labels
79(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Take temporal order as the supervisory signals for learning
Shuffled sequences
Binary classification
In order
Not in order
Temporal Weak Labels
80Fernando Basura Hakan Bilen Efstratios Gavves and Stephen Gould Self-supervised video representation learning with odd-one-out networks CVPR 2017
Temporal Weak LabelsTrain a network to detect which of the video sequences contains frames wrong order
81
Spatio-Temporal Weak Labels
X Lin Campos V Giroacute-i-Nieto X Torres J and Canton-Ferrer C ldquoDisentangling Motion Foreground and Background Features in Videosrdquo in CVPR 2017 Workshop Brave New Motion Representations
kernel dec
C3D
ForegroundMotion
FirstForeground
Background
Fg
Dec
Bg
Dec
Fg
Dec Reconstruction
of foreground in last frame
Reconstruction of foreground in
first frame
Reconstruction of background in first frame
uNLC
MaskBlock
gradients
Last foreground
Kernels
shareweights
82
Spatio-Temporal Weak Labels
Pathak Deepak Ross Girshick Piotr Dollaacuter Trevor Darrell and Bharath Hariharan Learning features by watching objects move CVPR 2017
83Greff Klaus Antti Rasmus Mathias Berglund Tele Hao Harri Valpola and Juergen Schmidhuber Tagger Deep unsupervised perceptual grouping NIPS 2016 [video] [code]
Spatio-Temporal Weak Labels
84Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
85
Audio Features from Visual weak labels
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Object amp Scenes recognition in videos by analysing the audio track (only)
86Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
87Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
88Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
89
Visualization of the video frames associated to the sounds that activate some of the last hidden units of Soundnet (conv7)
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Audio Features from Visual weak labels
90
Audio amp Visual features from alignement
90Arandjelović Relja and Andrew Zisserman Look Listen and Learn ICCV 2017
Audio and visual features learned by assessing alignement
91L Chen S Srivastava Z Duan and C Xu Deep Cross-Modal Audio-Visual Generation ACM International Conference on Multimedia Thematic Workshops 2017
Audio amp Visual features from alignement
92Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
93Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
Video to Speech Representations
CNN(VGG)
Frame from a silent video
Audio feature
Post-hoc synthesis
94Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
95Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
Speech to Video Synthesis (mouth)
96Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
97Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
Speech to Video Synthesis (pose amp emotion)
98Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
99Suwajanakorn Supasorn Steven M Seitz and Ira Kemelmacher-Shlizerman Synthesizing Obama learning lip sync from audio SIGGRAPH 2017
Speech to Video Synthesis (mouth)
100
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning

Unsupervised Feature Learning
56
Slide credit Yann LeCun
Unsupervised Feature Learning
57
Slide credit Yann LeCun
Slide credit Junting Pan
Frame Reconstruction amp Prediction
59Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
Frame Reconstruction amp Prediction
60Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
frame prediction
Frame Reconstruction amp Prediction
61Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
frame prediction
62Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised learned features (lots of data) are fine-tuned for activity recognition (little data)
Frame Reconstruction amp Prediction
Frame Prediction
63Ranzato MarcAurelio Arthur Szlam Joan Bruna Michael Mathieu Ronan Collobert and Sumit Chopra Video (language) modeling a baseline for generative models of natural videos arXiv preprint arXiv14126604 (2014)
64Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
Video frame prediction with a ConvNet
Frame Prediction
65Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
The blurry predictions from MSE are improved with multi-scale architecture adversarial learning and an image gradient difference loss function
Frame Prediction
66Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
The blurry predictions from MSE (l1) are improved with multi-scale architecture adversarial training and an image gradient difference loss (GDL) function
Frame Prediction
67Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
Frame Prediction
68Vondrick Carl Hamed Pirsiavash and Antonio Torralba Generating videos with scene dynamics NIPS 2016
Frame Prediction
69Vondrick Carl Hamed Pirsiavash and Antonio Torralba Generating videos with scene dynamics NIPS 2016
Frame Prediction
70Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
71
Frame Prediction
Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
Given an input image probabilistic generation of future frames with a Variational AutoEncoder (VAE)
72
Frame Prediction
Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
Encodes image as feature maps and motion as and cross-convolutional kernels
73
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
First steps in video feature learning
74Le Quoc V Will Y Zou Serena Y Yeung and Andrew Y Ng Learning hierarchical invariant spatio-temporal features for action recognition with independent subspace analysis CVPR 2011
Temporal Weak Labels
75Goroshin Ross Joan Bruna Jonathan Tompson David Eigen and Yann LeCun Unsupervised learning of spatiotemporally coherent metrics ICCV 2015
Assumption adjacent video frames contain semantically similar informationAutoencoder trained with regularizations by slowliness and sparisty
76Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
77Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
78(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Temporal order of frames is exploited as the supervisory signal for learning
Temporal Weak Labels
79(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Take temporal order as the supervisory signals for learning
Shuffled sequences
Binary classification
In order
Not in order
Temporal Weak Labels
80Fernando Basura Hakan Bilen Efstratios Gavves and Stephen Gould Self-supervised video representation learning with odd-one-out networks CVPR 2017
Temporal Weak LabelsTrain a network to detect which of the video sequences contains frames wrong order
81
Spatio-Temporal Weak Labels
X Lin Campos V Giroacute-i-Nieto X Torres J and Canton-Ferrer C ldquoDisentangling Motion Foreground and Background Features in Videosrdquo in CVPR 2017 Workshop Brave New Motion Representations
kernel dec
C3D
ForegroundMotion
FirstForeground
Background
Fg
Dec
Bg
Dec
Fg
Dec Reconstruction
of foreground in last frame
Reconstruction of foreground in
first frame
Reconstruction of background in first frame
uNLC
MaskBlock
gradients
Last foreground
Kernels
shareweights
82
Spatio-Temporal Weak Labels
Pathak Deepak Ross Girshick Piotr Dollaacuter Trevor Darrell and Bharath Hariharan Learning features by watching objects move CVPR 2017
83Greff Klaus Antti Rasmus Mathias Berglund Tele Hao Harri Valpola and Juergen Schmidhuber Tagger Deep unsupervised perceptual grouping NIPS 2016 [video] [code]
Spatio-Temporal Weak Labels
84Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
85
Audio Features from Visual weak labels
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Object amp Scenes recognition in videos by analysing the audio track (only)
86Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
87Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
88Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
89
Visualization of the video frames associated to the sounds that activate some of the last hidden units of Soundnet (conv7)
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Audio Features from Visual weak labels
90
Audio amp Visual features from alignement
90Arandjelović Relja and Andrew Zisserman Look Listen and Learn ICCV 2017
Audio and visual features learned by assessing alignement
91L Chen S Srivastava Z Duan and C Xu Deep Cross-Modal Audio-Visual Generation ACM International Conference on Multimedia Thematic Workshops 2017
Audio amp Visual features from alignement
92Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
93Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
Video to Speech Representations
CNN(VGG)
Frame from a silent video
Audio feature
Post-hoc synthesis
94Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
95Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
Speech to Video Synthesis (mouth)
96Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
97Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
Speech to Video Synthesis (pose amp emotion)
98Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
99Suwajanakorn Supasorn Steven M Seitz and Ira Kemelmacher-Shlizerman Synthesizing Obama learning lip sync from audio SIGGRAPH 2017
Speech to Video Synthesis (mouth)
100
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning

Unsupervised Feature Learning
57
Slide credit Yann LeCun
Slide credit Junting Pan
Frame Reconstruction amp Prediction
59Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
Frame Reconstruction amp Prediction
60Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
frame prediction
Frame Reconstruction amp Prediction
61Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
frame prediction
62Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised learned features (lots of data) are fine-tuned for activity recognition (little data)
Frame Reconstruction amp Prediction
Frame Prediction
63Ranzato MarcAurelio Arthur Szlam Joan Bruna Michael Mathieu Ronan Collobert and Sumit Chopra Video (language) modeling a baseline for generative models of natural videos arXiv preprint arXiv14126604 (2014)
64Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
Video frame prediction with a ConvNet
Frame Prediction
65Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
The blurry predictions from MSE are improved with multi-scale architecture adversarial learning and an image gradient difference loss function
Frame Prediction
66Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
The blurry predictions from MSE (l1) are improved with multi-scale architecture adversarial training and an image gradient difference loss (GDL) function
Frame Prediction
67Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
Frame Prediction
68Vondrick Carl Hamed Pirsiavash and Antonio Torralba Generating videos with scene dynamics NIPS 2016
Frame Prediction
69Vondrick Carl Hamed Pirsiavash and Antonio Torralba Generating videos with scene dynamics NIPS 2016
Frame Prediction
70Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
71
Frame Prediction
Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
Given an input image probabilistic generation of future frames with a Variational AutoEncoder (VAE)
72
Frame Prediction
Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
Encodes image as feature maps and motion as and cross-convolutional kernels
73
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
First steps in video feature learning
74Le Quoc V Will Y Zou Serena Y Yeung and Andrew Y Ng Learning hierarchical invariant spatio-temporal features for action recognition with independent subspace analysis CVPR 2011
Temporal Weak Labels
75Goroshin Ross Joan Bruna Jonathan Tompson David Eigen and Yann LeCun Unsupervised learning of spatiotemporally coherent metrics ICCV 2015
Assumption adjacent video frames contain semantically similar informationAutoencoder trained with regularizations by slowliness and sparisty
76Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
77Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
78(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Temporal order of frames is exploited as the supervisory signal for learning
Temporal Weak Labels
79(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Take temporal order as the supervisory signals for learning
Shuffled sequences
Binary classification
In order
Not in order
Temporal Weak Labels
80Fernando Basura Hakan Bilen Efstratios Gavves and Stephen Gould Self-supervised video representation learning with odd-one-out networks CVPR 2017
Temporal Weak LabelsTrain a network to detect which of the video sequences contains frames wrong order
81
Spatio-Temporal Weak Labels
X Lin Campos V Giroacute-i-Nieto X Torres J and Canton-Ferrer C ldquoDisentangling Motion Foreground and Background Features in Videosrdquo in CVPR 2017 Workshop Brave New Motion Representations
kernel dec
C3D
ForegroundMotion
FirstForeground
Background
Fg
Dec
Bg
Dec
Fg
Dec Reconstruction
of foreground in last frame
Reconstruction of foreground in
first frame
Reconstruction of background in first frame
uNLC
MaskBlock
gradients
Last foreground
Kernels
shareweights
82
Spatio-Temporal Weak Labels
Pathak Deepak Ross Girshick Piotr Dollaacuter Trevor Darrell and Bharath Hariharan Learning features by watching objects move CVPR 2017
83Greff Klaus Antti Rasmus Mathias Berglund Tele Hao Harri Valpola and Juergen Schmidhuber Tagger Deep unsupervised perceptual grouping NIPS 2016 [video] [code]
Spatio-Temporal Weak Labels
84Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
85
Audio Features from Visual weak labels
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Object amp Scenes recognition in videos by analysing the audio track (only)
86Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
87Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
88Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
89
Visualization of the video frames associated to the sounds that activate some of the last hidden units of Soundnet (conv7)
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Audio Features from Visual weak labels
90
Audio amp Visual features from alignement
90Arandjelović Relja and Andrew Zisserman Look Listen and Learn ICCV 2017
Audio and visual features learned by assessing alignement
91L Chen S Srivastava Z Duan and C Xu Deep Cross-Modal Audio-Visual Generation ACM International Conference on Multimedia Thematic Workshops 2017
Audio amp Visual features from alignement
92Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
93Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
Video to Speech Representations
CNN(VGG)
Frame from a silent video
Audio feature
Post-hoc synthesis
94Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
95Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
Speech to Video Synthesis (mouth)
96Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
97Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
Speech to Video Synthesis (pose amp emotion)
98Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
99Suwajanakorn Supasorn Steven M Seitz and Ira Kemelmacher-Shlizerman Synthesizing Obama learning lip sync from audio SIGGRAPH 2017
Speech to Video Synthesis (mouth)
100
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning

Slide credit Junting Pan
Frame Reconstruction amp Prediction
59Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
Frame Reconstruction amp Prediction
60Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
frame prediction
Frame Reconstruction amp Prediction
61Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
frame prediction
62Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised learned features (lots of data) are fine-tuned for activity recognition (little data)
Frame Reconstruction amp Prediction
Frame Prediction
63Ranzato MarcAurelio Arthur Szlam Joan Bruna Michael Mathieu Ronan Collobert and Sumit Chopra Video (language) modeling a baseline for generative models of natural videos arXiv preprint arXiv14126604 (2014)
64Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
Video frame prediction with a ConvNet
Frame Prediction
65Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
The blurry predictions from MSE are improved with multi-scale architecture adversarial learning and an image gradient difference loss function
Frame Prediction
66Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
The blurry predictions from MSE (l1) are improved with multi-scale architecture adversarial training and an image gradient difference loss (GDL) function
Frame Prediction
67Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
Frame Prediction
68Vondrick Carl Hamed Pirsiavash and Antonio Torralba Generating videos with scene dynamics NIPS 2016
Frame Prediction
69Vondrick Carl Hamed Pirsiavash and Antonio Torralba Generating videos with scene dynamics NIPS 2016
Frame Prediction
70Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
71
Frame Prediction
Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
Given an input image probabilistic generation of future frames with a Variational AutoEncoder (VAE)
72
Frame Prediction
Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
Encodes image as feature maps and motion as and cross-convolutional kernels
73
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
First steps in video feature learning
74Le Quoc V Will Y Zou Serena Y Yeung and Andrew Y Ng Learning hierarchical invariant spatio-temporal features for action recognition with independent subspace analysis CVPR 2011
Temporal Weak Labels
75Goroshin Ross Joan Bruna Jonathan Tompson David Eigen and Yann LeCun Unsupervised learning of spatiotemporally coherent metrics ICCV 2015
Assumption adjacent video frames contain semantically similar informationAutoencoder trained with regularizations by slowliness and sparisty
76Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
77Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
78(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Temporal order of frames is exploited as the supervisory signal for learning
Temporal Weak Labels
79(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Take temporal order as the supervisory signals for learning
Shuffled sequences
Binary classification
In order
Not in order
Temporal Weak Labels
80Fernando Basura Hakan Bilen Efstratios Gavves and Stephen Gould Self-supervised video representation learning with odd-one-out networks CVPR 2017
Temporal Weak LabelsTrain a network to detect which of the video sequences contains frames wrong order
81
Spatio-Temporal Weak Labels
X Lin Campos V Giroacute-i-Nieto X Torres J and Canton-Ferrer C ldquoDisentangling Motion Foreground and Background Features in Videosrdquo in CVPR 2017 Workshop Brave New Motion Representations
kernel dec
C3D
ForegroundMotion
FirstForeground
Background
Fg
Dec
Bg
Dec
Fg
Dec Reconstruction
of foreground in last frame
Reconstruction of foreground in
first frame
Reconstruction of background in first frame
uNLC
MaskBlock
gradients
Last foreground
Kernels
shareweights
82
Spatio-Temporal Weak Labels
Pathak Deepak Ross Girshick Piotr Dollaacuter Trevor Darrell and Bharath Hariharan Learning features by watching objects move CVPR 2017
83Greff Klaus Antti Rasmus Mathias Berglund Tele Hao Harri Valpola and Juergen Schmidhuber Tagger Deep unsupervised perceptual grouping NIPS 2016 [video] [code]
Spatio-Temporal Weak Labels
84Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
85
Audio Features from Visual weak labels
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Object amp Scenes recognition in videos by analysing the audio track (only)
86Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
87Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
88Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
89
Visualization of the video frames associated to the sounds that activate some of the last hidden units of Soundnet (conv7)
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Audio Features from Visual weak labels
90
Audio amp Visual features from alignement
90Arandjelović Relja and Andrew Zisserman Look Listen and Learn ICCV 2017
Audio and visual features learned by assessing alignement
91L Chen S Srivastava Z Duan and C Xu Deep Cross-Modal Audio-Visual Generation ACM International Conference on Multimedia Thematic Workshops 2017
Audio amp Visual features from alignement
92Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
93Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
Video to Speech Representations
CNN(VGG)
Frame from a silent video
Audio feature
Post-hoc synthesis
94Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
95Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
Speech to Video Synthesis (mouth)
96Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
97Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
Speech to Video Synthesis (pose amp emotion)
98Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
99Suwajanakorn Supasorn Steven M Seitz and Ira Kemelmacher-Shlizerman Synthesizing Obama learning lip sync from audio SIGGRAPH 2017
Speech to Video Synthesis (mouth)
100
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning

Frame Reconstruction amp Prediction
59Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
Frame Reconstruction amp Prediction
60Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
frame prediction
Frame Reconstruction amp Prediction
61Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
frame prediction
62Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised learned features (lots of data) are fine-tuned for activity recognition (little data)
Frame Reconstruction amp Prediction
Frame Prediction
63Ranzato MarcAurelio Arthur Szlam Joan Bruna Michael Mathieu Ronan Collobert and Sumit Chopra Video (language) modeling a baseline for generative models of natural videos arXiv preprint arXiv14126604 (2014)
64Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
Video frame prediction with a ConvNet
Frame Prediction
65Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
The blurry predictions from MSE are improved with multi-scale architecture adversarial learning and an image gradient difference loss function
Frame Prediction
66Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
The blurry predictions from MSE (l1) are improved with multi-scale architecture adversarial training and an image gradient difference loss (GDL) function
Frame Prediction
67Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
Frame Prediction
68Vondrick Carl Hamed Pirsiavash and Antonio Torralba Generating videos with scene dynamics NIPS 2016
Frame Prediction
69Vondrick Carl Hamed Pirsiavash and Antonio Torralba Generating videos with scene dynamics NIPS 2016
Frame Prediction
70Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
71
Frame Prediction
Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
Given an input image probabilistic generation of future frames with a Variational AutoEncoder (VAE)
72
Frame Prediction
Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
Encodes image as feature maps and motion as and cross-convolutional kernels
73
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
First steps in video feature learning
74Le Quoc V Will Y Zou Serena Y Yeung and Andrew Y Ng Learning hierarchical invariant spatio-temporal features for action recognition with independent subspace analysis CVPR 2011
Temporal Weak Labels
75Goroshin Ross Joan Bruna Jonathan Tompson David Eigen and Yann LeCun Unsupervised learning of spatiotemporally coherent metrics ICCV 2015
Assumption adjacent video frames contain semantically similar informationAutoencoder trained with regularizations by slowliness and sparisty
76Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
77Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
78(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Temporal order of frames is exploited as the supervisory signal for learning
Temporal Weak Labels
79(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Take temporal order as the supervisory signals for learning
Shuffled sequences
Binary classification
In order
Not in order
Temporal Weak Labels
80Fernando Basura Hakan Bilen Efstratios Gavves and Stephen Gould Self-supervised video representation learning with odd-one-out networks CVPR 2017
Temporal Weak LabelsTrain a network to detect which of the video sequences contains frames wrong order
81
Spatio-Temporal Weak Labels
X Lin Campos V Giroacute-i-Nieto X Torres J and Canton-Ferrer C ldquoDisentangling Motion Foreground and Background Features in Videosrdquo in CVPR 2017 Workshop Brave New Motion Representations
kernel dec
C3D
ForegroundMotion
FirstForeground
Background
Fg
Dec
Bg
Dec
Fg
Dec Reconstruction
of foreground in last frame
Reconstruction of foreground in
first frame
Reconstruction of background in first frame
uNLC
MaskBlock
gradients
Last foreground
Kernels
shareweights
82
Spatio-Temporal Weak Labels
Pathak Deepak Ross Girshick Piotr Dollaacuter Trevor Darrell and Bharath Hariharan Learning features by watching objects move CVPR 2017
83Greff Klaus Antti Rasmus Mathias Berglund Tele Hao Harri Valpola and Juergen Schmidhuber Tagger Deep unsupervised perceptual grouping NIPS 2016 [video] [code]
Spatio-Temporal Weak Labels
84Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
85
Audio Features from Visual weak labels
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Object amp Scenes recognition in videos by analysing the audio track (only)
86Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
87Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
88Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
89
Visualization of the video frames associated to the sounds that activate some of the last hidden units of Soundnet (conv7)
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Audio Features from Visual weak labels
90
Audio amp Visual features from alignement
90Arandjelović Relja and Andrew Zisserman Look Listen and Learn ICCV 2017
Audio and visual features learned by assessing alignement
91L Chen S Srivastava Z Duan and C Xu Deep Cross-Modal Audio-Visual Generation ACM International Conference on Multimedia Thematic Workshops 2017
Audio amp Visual features from alignement
92Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
93Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
Video to Speech Representations
CNN(VGG)
Frame from a silent video
Audio feature
Post-hoc synthesis
94Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
95Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
Speech to Video Synthesis (mouth)
96Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
97Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
Speech to Video Synthesis (pose amp emotion)
98Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
99Suwajanakorn Supasorn Steven M Seitz and Ira Kemelmacher-Shlizerman Synthesizing Obama learning lip sync from audio SIGGRAPH 2017
Speech to Video Synthesis (mouth)
100
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning

Frame Reconstruction amp Prediction
60Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
frame prediction
Frame Reconstruction amp Prediction
61Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
frame prediction
62Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised learned features (lots of data) are fine-tuned for activity recognition (little data)
Frame Reconstruction amp Prediction
Frame Prediction
63Ranzato MarcAurelio Arthur Szlam Joan Bruna Michael Mathieu Ronan Collobert and Sumit Chopra Video (language) modeling a baseline for generative models of natural videos arXiv preprint arXiv14126604 (2014)
64Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
Video frame prediction with a ConvNet
Frame Prediction
65Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
The blurry predictions from MSE are improved with multi-scale architecture adversarial learning and an image gradient difference loss function
Frame Prediction
66Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
The blurry predictions from MSE (l1) are improved with multi-scale architecture adversarial training and an image gradient difference loss (GDL) function
Frame Prediction
67Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
Frame Prediction
68Vondrick Carl Hamed Pirsiavash and Antonio Torralba Generating videos with scene dynamics NIPS 2016
Frame Prediction
69Vondrick Carl Hamed Pirsiavash and Antonio Torralba Generating videos with scene dynamics NIPS 2016
Frame Prediction
70Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
71
Frame Prediction
Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
Given an input image probabilistic generation of future frames with a Variational AutoEncoder (VAE)
72
Frame Prediction
Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
Encodes image as feature maps and motion as and cross-convolutional kernels
73
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
First steps in video feature learning
74Le Quoc V Will Y Zou Serena Y Yeung and Andrew Y Ng Learning hierarchical invariant spatio-temporal features for action recognition with independent subspace analysis CVPR 2011
Temporal Weak Labels
75Goroshin Ross Joan Bruna Jonathan Tompson David Eigen and Yann LeCun Unsupervised learning of spatiotemporally coherent metrics ICCV 2015
Assumption adjacent video frames contain semantically similar informationAutoencoder trained with regularizations by slowliness and sparisty
76Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
77Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
78(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Temporal order of frames is exploited as the supervisory signal for learning
Temporal Weak Labels
79(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Take temporal order as the supervisory signals for learning
Shuffled sequences
Binary classification
In order
Not in order
Temporal Weak Labels
80Fernando Basura Hakan Bilen Efstratios Gavves and Stephen Gould Self-supervised video representation learning with odd-one-out networks CVPR 2017
Temporal Weak LabelsTrain a network to detect which of the video sequences contains frames wrong order
81
Spatio-Temporal Weak Labels
X Lin Campos V Giroacute-i-Nieto X Torres J and Canton-Ferrer C ldquoDisentangling Motion Foreground and Background Features in Videosrdquo in CVPR 2017 Workshop Brave New Motion Representations
kernel dec
C3D
ForegroundMotion
FirstForeground
Background
Fg
Dec
Bg
Dec
Fg
Dec Reconstruction
of foreground in last frame
Reconstruction of foreground in
first frame
Reconstruction of background in first frame
uNLC
MaskBlock
gradients
Last foreground
Kernels
shareweights
82
Spatio-Temporal Weak Labels
Pathak Deepak Ross Girshick Piotr Dollaacuter Trevor Darrell and Bharath Hariharan Learning features by watching objects move CVPR 2017
83Greff Klaus Antti Rasmus Mathias Berglund Tele Hao Harri Valpola and Juergen Schmidhuber Tagger Deep unsupervised perceptual grouping NIPS 2016 [video] [code]
Spatio-Temporal Weak Labels
84Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
85
Audio Features from Visual weak labels
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Object amp Scenes recognition in videos by analysing the audio track (only)
86Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
87Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
88Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
89
Visualization of the video frames associated to the sounds that activate some of the last hidden units of Soundnet (conv7)
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Audio Features from Visual weak labels
90
Audio amp Visual features from alignement
90Arandjelović Relja and Andrew Zisserman Look Listen and Learn ICCV 2017
Audio and visual features learned by assessing alignement
91L Chen S Srivastava Z Duan and C Xu Deep Cross-Modal Audio-Visual Generation ACM International Conference on Multimedia Thematic Workshops 2017
Audio amp Visual features from alignement
92Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
93Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
Video to Speech Representations
CNN(VGG)
Frame from a silent video
Audio feature
Post-hoc synthesis
94Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
95Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
Speech to Video Synthesis (mouth)
96Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
97Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
Speech to Video Synthesis (pose amp emotion)
98Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
99Suwajanakorn Supasorn Steven M Seitz and Ira Kemelmacher-Shlizerman Synthesizing Obama learning lip sync from audio SIGGRAPH 2017
Speech to Video Synthesis (mouth)
100
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning

Frame Reconstruction amp Prediction
61Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised feature learning (no labels) for
frame prediction
62Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised learned features (lots of data) are fine-tuned for activity recognition (little data)
Frame Reconstruction amp Prediction
Frame Prediction
63Ranzato MarcAurelio Arthur Szlam Joan Bruna Michael Mathieu Ronan Collobert and Sumit Chopra Video (language) modeling a baseline for generative models of natural videos arXiv preprint arXiv14126604 (2014)
64Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
Video frame prediction with a ConvNet
Frame Prediction
65Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
The blurry predictions from MSE are improved with multi-scale architecture adversarial learning and an image gradient difference loss function
Frame Prediction
66Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
The blurry predictions from MSE (l1) are improved with multi-scale architecture adversarial training and an image gradient difference loss (GDL) function
Frame Prediction
67Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
Frame Prediction
68Vondrick Carl Hamed Pirsiavash and Antonio Torralba Generating videos with scene dynamics NIPS 2016
Frame Prediction
69Vondrick Carl Hamed Pirsiavash and Antonio Torralba Generating videos with scene dynamics NIPS 2016
Frame Prediction
70Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
71
Frame Prediction
Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
Given an input image probabilistic generation of future frames with a Variational AutoEncoder (VAE)
72
Frame Prediction
Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
Encodes image as feature maps and motion as and cross-convolutional kernels
73
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
First steps in video feature learning
74Le Quoc V Will Y Zou Serena Y Yeung and Andrew Y Ng Learning hierarchical invariant spatio-temporal features for action recognition with independent subspace analysis CVPR 2011
Temporal Weak Labels
75Goroshin Ross Joan Bruna Jonathan Tompson David Eigen and Yann LeCun Unsupervised learning of spatiotemporally coherent metrics ICCV 2015
Assumption adjacent video frames contain semantically similar informationAutoencoder trained with regularizations by slowliness and sparisty
76Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
77Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
78(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Temporal order of frames is exploited as the supervisory signal for learning
Temporal Weak Labels
79(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Take temporal order as the supervisory signals for learning
Shuffled sequences
Binary classification
In order
Not in order
Temporal Weak Labels
80Fernando Basura Hakan Bilen Efstratios Gavves and Stephen Gould Self-supervised video representation learning with odd-one-out networks CVPR 2017
Temporal Weak LabelsTrain a network to detect which of the video sequences contains frames wrong order
81
Spatio-Temporal Weak Labels
X Lin Campos V Giroacute-i-Nieto X Torres J and Canton-Ferrer C ldquoDisentangling Motion Foreground and Background Features in Videosrdquo in CVPR 2017 Workshop Brave New Motion Representations
kernel dec
C3D
ForegroundMotion
FirstForeground
Background
Fg
Dec
Bg
Dec
Fg
Dec Reconstruction
of foreground in last frame
Reconstruction of foreground in
first frame
Reconstruction of background in first frame
uNLC
MaskBlock
gradients
Last foreground
Kernels
shareweights
82
Spatio-Temporal Weak Labels
Pathak Deepak Ross Girshick Piotr Dollaacuter Trevor Darrell and Bharath Hariharan Learning features by watching objects move CVPR 2017
83Greff Klaus Antti Rasmus Mathias Berglund Tele Hao Harri Valpola and Juergen Schmidhuber Tagger Deep unsupervised perceptual grouping NIPS 2016 [video] [code]
Spatio-Temporal Weak Labels
84Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
85
Audio Features from Visual weak labels
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Object amp Scenes recognition in videos by analysing the audio track (only)
86Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
87Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
88Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
89
Visualization of the video frames associated to the sounds that activate some of the last hidden units of Soundnet (conv7)
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Audio Features from Visual weak labels
90
Audio amp Visual features from alignement
90Arandjelović Relja and Andrew Zisserman Look Listen and Learn ICCV 2017
Audio and visual features learned by assessing alignement
91L Chen S Srivastava Z Duan and C Xu Deep Cross-Modal Audio-Visual Generation ACM International Conference on Multimedia Thematic Workshops 2017
Audio amp Visual features from alignement
92Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
93Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
Video to Speech Representations
CNN(VGG)
Frame from a silent video
Audio feature
Post-hoc synthesis
94Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
95Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
Speech to Video Synthesis (mouth)
96Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
97Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
Speech to Video Synthesis (pose amp emotion)
98Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
99Suwajanakorn Supasorn Steven M Seitz and Ira Kemelmacher-Shlizerman Synthesizing Obama learning lip sync from audio SIGGRAPH 2017
Speech to Video Synthesis (mouth)
100
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning

62Srivastava Nitish Elman Mansimov and Ruslan Salakhutdinov Unsupervised Learning of Video Representations using LSTMs In ICML 2015 [Github]
Unsupervised learned features (lots of data) are fine-tuned for activity recognition (little data)
Frame Reconstruction amp Prediction
Frame Prediction
63Ranzato MarcAurelio Arthur Szlam Joan Bruna Michael Mathieu Ronan Collobert and Sumit Chopra Video (language) modeling a baseline for generative models of natural videos arXiv preprint arXiv14126604 (2014)
64Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
Video frame prediction with a ConvNet
Frame Prediction
65Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
The blurry predictions from MSE are improved with multi-scale architecture adversarial learning and an image gradient difference loss function
Frame Prediction
66Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
The blurry predictions from MSE (l1) are improved with multi-scale architecture adversarial training and an image gradient difference loss (GDL) function
Frame Prediction
67Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
Frame Prediction
68Vondrick Carl Hamed Pirsiavash and Antonio Torralba Generating videos with scene dynamics NIPS 2016
Frame Prediction
69Vondrick Carl Hamed Pirsiavash and Antonio Torralba Generating videos with scene dynamics NIPS 2016
Frame Prediction
70Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
71
Frame Prediction
Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
Given an input image probabilistic generation of future frames with a Variational AutoEncoder (VAE)
72
Frame Prediction
Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
Encodes image as feature maps and motion as and cross-convolutional kernels
73
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
First steps in video feature learning
74Le Quoc V Will Y Zou Serena Y Yeung and Andrew Y Ng Learning hierarchical invariant spatio-temporal features for action recognition with independent subspace analysis CVPR 2011
Temporal Weak Labels
75Goroshin Ross Joan Bruna Jonathan Tompson David Eigen and Yann LeCun Unsupervised learning of spatiotemporally coherent metrics ICCV 2015
Assumption adjacent video frames contain semantically similar informationAutoencoder trained with regularizations by slowliness and sparisty
76Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
77Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
78(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Temporal order of frames is exploited as the supervisory signal for learning
Temporal Weak Labels
79(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Take temporal order as the supervisory signals for learning
Shuffled sequences
Binary classification
In order
Not in order
Temporal Weak Labels
80Fernando Basura Hakan Bilen Efstratios Gavves and Stephen Gould Self-supervised video representation learning with odd-one-out networks CVPR 2017
Temporal Weak LabelsTrain a network to detect which of the video sequences contains frames wrong order
81
Spatio-Temporal Weak Labels
X Lin Campos V Giroacute-i-Nieto X Torres J and Canton-Ferrer C ldquoDisentangling Motion Foreground and Background Features in Videosrdquo in CVPR 2017 Workshop Brave New Motion Representations
kernel dec
C3D
ForegroundMotion
FirstForeground
Background
Fg
Dec
Bg
Dec
Fg
Dec Reconstruction
of foreground in last frame
Reconstruction of foreground in
first frame
Reconstruction of background in first frame
uNLC
MaskBlock
gradients
Last foreground
Kernels
shareweights
82
Spatio-Temporal Weak Labels
Pathak Deepak Ross Girshick Piotr Dollaacuter Trevor Darrell and Bharath Hariharan Learning features by watching objects move CVPR 2017
83Greff Klaus Antti Rasmus Mathias Berglund Tele Hao Harri Valpola and Juergen Schmidhuber Tagger Deep unsupervised perceptual grouping NIPS 2016 [video] [code]
Spatio-Temporal Weak Labels
84Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
85
Audio Features from Visual weak labels
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Object amp Scenes recognition in videos by analysing the audio track (only)
86Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
87Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
88Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
89
Visualization of the video frames associated to the sounds that activate some of the last hidden units of Soundnet (conv7)
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Audio Features from Visual weak labels
90
Audio amp Visual features from alignement
90Arandjelović Relja and Andrew Zisserman Look Listen and Learn ICCV 2017
Audio and visual features learned by assessing alignement
91L Chen S Srivastava Z Duan and C Xu Deep Cross-Modal Audio-Visual Generation ACM International Conference on Multimedia Thematic Workshops 2017
Audio amp Visual features from alignement
92Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
93Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
Video to Speech Representations
CNN(VGG)
Frame from a silent video
Audio feature
Post-hoc synthesis
94Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
95Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
Speech to Video Synthesis (mouth)
96Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
97Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
Speech to Video Synthesis (pose amp emotion)
98Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
99Suwajanakorn Supasorn Steven M Seitz and Ira Kemelmacher-Shlizerman Synthesizing Obama learning lip sync from audio SIGGRAPH 2017
Speech to Video Synthesis (mouth)
100
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning

Frame Prediction
63Ranzato MarcAurelio Arthur Szlam Joan Bruna Michael Mathieu Ronan Collobert and Sumit Chopra Video (language) modeling a baseline for generative models of natural videos arXiv preprint arXiv14126604 (2014)
64Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
Video frame prediction with a ConvNet
Frame Prediction
65Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
The blurry predictions from MSE are improved with multi-scale architecture adversarial learning and an image gradient difference loss function
Frame Prediction
66Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
The blurry predictions from MSE (l1) are improved with multi-scale architecture adversarial training and an image gradient difference loss (GDL) function
Frame Prediction
67Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
Frame Prediction
68Vondrick Carl Hamed Pirsiavash and Antonio Torralba Generating videos with scene dynamics NIPS 2016
Frame Prediction
69Vondrick Carl Hamed Pirsiavash and Antonio Torralba Generating videos with scene dynamics NIPS 2016
Frame Prediction
70Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
71
Frame Prediction
Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
Given an input image probabilistic generation of future frames with a Variational AutoEncoder (VAE)
72
Frame Prediction
Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
Encodes image as feature maps and motion as and cross-convolutional kernels
73
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
First steps in video feature learning
74Le Quoc V Will Y Zou Serena Y Yeung and Andrew Y Ng Learning hierarchical invariant spatio-temporal features for action recognition with independent subspace analysis CVPR 2011
Temporal Weak Labels
75Goroshin Ross Joan Bruna Jonathan Tompson David Eigen and Yann LeCun Unsupervised learning of spatiotemporally coherent metrics ICCV 2015
Assumption adjacent video frames contain semantically similar informationAutoencoder trained with regularizations by slowliness and sparisty
76Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
77Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
78(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Temporal order of frames is exploited as the supervisory signal for learning
Temporal Weak Labels
79(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Take temporal order as the supervisory signals for learning
Shuffled sequences
Binary classification
In order
Not in order
Temporal Weak Labels
80Fernando Basura Hakan Bilen Efstratios Gavves and Stephen Gould Self-supervised video representation learning with odd-one-out networks CVPR 2017
Temporal Weak LabelsTrain a network to detect which of the video sequences contains frames wrong order
81
Spatio-Temporal Weak Labels
X Lin Campos V Giroacute-i-Nieto X Torres J and Canton-Ferrer C ldquoDisentangling Motion Foreground and Background Features in Videosrdquo in CVPR 2017 Workshop Brave New Motion Representations
kernel dec
C3D
ForegroundMotion
FirstForeground
Background
Fg
Dec
Bg
Dec
Fg
Dec Reconstruction
of foreground in last frame
Reconstruction of foreground in
first frame
Reconstruction of background in first frame
uNLC
MaskBlock
gradients
Last foreground
Kernels
shareweights
82
Spatio-Temporal Weak Labels
Pathak Deepak Ross Girshick Piotr Dollaacuter Trevor Darrell and Bharath Hariharan Learning features by watching objects move CVPR 2017
83Greff Klaus Antti Rasmus Mathias Berglund Tele Hao Harri Valpola and Juergen Schmidhuber Tagger Deep unsupervised perceptual grouping NIPS 2016 [video] [code]
Spatio-Temporal Weak Labels
84Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
85
Audio Features from Visual weak labels
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Object amp Scenes recognition in videos by analysing the audio track (only)
86Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
87Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
88Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
89
Visualization of the video frames associated to the sounds that activate some of the last hidden units of Soundnet (conv7)
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Audio Features from Visual weak labels
90
Audio amp Visual features from alignement
90Arandjelović Relja and Andrew Zisserman Look Listen and Learn ICCV 2017
Audio and visual features learned by assessing alignement
91L Chen S Srivastava Z Duan and C Xu Deep Cross-Modal Audio-Visual Generation ACM International Conference on Multimedia Thematic Workshops 2017
Audio amp Visual features from alignement
92Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
93Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
Video to Speech Representations
CNN(VGG)
Frame from a silent video
Audio feature
Post-hoc synthesis
94Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
95Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
Speech to Video Synthesis (mouth)
96Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
97Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
Speech to Video Synthesis (pose amp emotion)
98Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
99Suwajanakorn Supasorn Steven M Seitz and Ira Kemelmacher-Shlizerman Synthesizing Obama learning lip sync from audio SIGGRAPH 2017
Speech to Video Synthesis (mouth)
100
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning

64Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
Video frame prediction with a ConvNet
Frame Prediction
65Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
The blurry predictions from MSE are improved with multi-scale architecture adversarial learning and an image gradient difference loss function
Frame Prediction
66Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
The blurry predictions from MSE (l1) are improved with multi-scale architecture adversarial training and an image gradient difference loss (GDL) function
Frame Prediction
67Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
Frame Prediction
68Vondrick Carl Hamed Pirsiavash and Antonio Torralba Generating videos with scene dynamics NIPS 2016
Frame Prediction
69Vondrick Carl Hamed Pirsiavash and Antonio Torralba Generating videos with scene dynamics NIPS 2016
Frame Prediction
70Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
71
Frame Prediction
Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
Given an input image probabilistic generation of future frames with a Variational AutoEncoder (VAE)
72
Frame Prediction
Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
Encodes image as feature maps and motion as and cross-convolutional kernels
73
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
First steps in video feature learning
74Le Quoc V Will Y Zou Serena Y Yeung and Andrew Y Ng Learning hierarchical invariant spatio-temporal features for action recognition with independent subspace analysis CVPR 2011
Temporal Weak Labels
75Goroshin Ross Joan Bruna Jonathan Tompson David Eigen and Yann LeCun Unsupervised learning of spatiotemporally coherent metrics ICCV 2015
Assumption adjacent video frames contain semantically similar informationAutoencoder trained with regularizations by slowliness and sparisty
76Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
77Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
78(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Temporal order of frames is exploited as the supervisory signal for learning
Temporal Weak Labels
79(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Take temporal order as the supervisory signals for learning
Shuffled sequences
Binary classification
In order
Not in order
Temporal Weak Labels
80Fernando Basura Hakan Bilen Efstratios Gavves and Stephen Gould Self-supervised video representation learning with odd-one-out networks CVPR 2017
Temporal Weak LabelsTrain a network to detect which of the video sequences contains frames wrong order
81
Spatio-Temporal Weak Labels
X Lin Campos V Giroacute-i-Nieto X Torres J and Canton-Ferrer C ldquoDisentangling Motion Foreground and Background Features in Videosrdquo in CVPR 2017 Workshop Brave New Motion Representations
kernel dec
C3D
ForegroundMotion
FirstForeground
Background
Fg
Dec
Bg
Dec
Fg
Dec Reconstruction
of foreground in last frame
Reconstruction of foreground in
first frame
Reconstruction of background in first frame
uNLC
MaskBlock
gradients
Last foreground
Kernels
shareweights
82
Spatio-Temporal Weak Labels
Pathak Deepak Ross Girshick Piotr Dollaacuter Trevor Darrell and Bharath Hariharan Learning features by watching objects move CVPR 2017
83Greff Klaus Antti Rasmus Mathias Berglund Tele Hao Harri Valpola and Juergen Schmidhuber Tagger Deep unsupervised perceptual grouping NIPS 2016 [video] [code]
Spatio-Temporal Weak Labels
84Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
85
Audio Features from Visual weak labels
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Object amp Scenes recognition in videos by analysing the audio track (only)
86Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
87Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
88Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
89
Visualization of the video frames associated to the sounds that activate some of the last hidden units of Soundnet (conv7)
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Audio Features from Visual weak labels
90
Audio amp Visual features from alignement
90Arandjelović Relja and Andrew Zisserman Look Listen and Learn ICCV 2017
Audio and visual features learned by assessing alignement
91L Chen S Srivastava Z Duan and C Xu Deep Cross-Modal Audio-Visual Generation ACM International Conference on Multimedia Thematic Workshops 2017
Audio amp Visual features from alignement
92Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
93Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
Video to Speech Representations
CNN(VGG)
Frame from a silent video
Audio feature
Post-hoc synthesis
94Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
95Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
Speech to Video Synthesis (mouth)
96Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
97Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
Speech to Video Synthesis (pose amp emotion)
98Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
99Suwajanakorn Supasorn Steven M Seitz and Ira Kemelmacher-Shlizerman Synthesizing Obama learning lip sync from audio SIGGRAPH 2017
Speech to Video Synthesis (mouth)
100
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning

65Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
The blurry predictions from MSE are improved with multi-scale architecture adversarial learning and an image gradient difference loss function
Frame Prediction
66Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
The blurry predictions from MSE (l1) are improved with multi-scale architecture adversarial training and an image gradient difference loss (GDL) function
Frame Prediction
67Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
Frame Prediction
68Vondrick Carl Hamed Pirsiavash and Antonio Torralba Generating videos with scene dynamics NIPS 2016
Frame Prediction
69Vondrick Carl Hamed Pirsiavash and Antonio Torralba Generating videos with scene dynamics NIPS 2016
Frame Prediction
70Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
71
Frame Prediction
Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
Given an input image probabilistic generation of future frames with a Variational AutoEncoder (VAE)
72
Frame Prediction
Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
Encodes image as feature maps and motion as and cross-convolutional kernels
73
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
First steps in video feature learning
74Le Quoc V Will Y Zou Serena Y Yeung and Andrew Y Ng Learning hierarchical invariant spatio-temporal features for action recognition with independent subspace analysis CVPR 2011
Temporal Weak Labels
75Goroshin Ross Joan Bruna Jonathan Tompson David Eigen and Yann LeCun Unsupervised learning of spatiotemporally coherent metrics ICCV 2015
Assumption adjacent video frames contain semantically similar informationAutoencoder trained with regularizations by slowliness and sparisty
76Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
77Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
78(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Temporal order of frames is exploited as the supervisory signal for learning
Temporal Weak Labels
79(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Take temporal order as the supervisory signals for learning
Shuffled sequences
Binary classification
In order
Not in order
Temporal Weak Labels
80Fernando Basura Hakan Bilen Efstratios Gavves and Stephen Gould Self-supervised video representation learning with odd-one-out networks CVPR 2017
Temporal Weak LabelsTrain a network to detect which of the video sequences contains frames wrong order
81
Spatio-Temporal Weak Labels
X Lin Campos V Giroacute-i-Nieto X Torres J and Canton-Ferrer C ldquoDisentangling Motion Foreground and Background Features in Videosrdquo in CVPR 2017 Workshop Brave New Motion Representations
kernel dec
C3D
ForegroundMotion
FirstForeground
Background
Fg
Dec
Bg
Dec
Fg
Dec Reconstruction
of foreground in last frame
Reconstruction of foreground in
first frame
Reconstruction of background in first frame
uNLC
MaskBlock
gradients
Last foreground
Kernels
shareweights
82
Spatio-Temporal Weak Labels
Pathak Deepak Ross Girshick Piotr Dollaacuter Trevor Darrell and Bharath Hariharan Learning features by watching objects move CVPR 2017
83Greff Klaus Antti Rasmus Mathias Berglund Tele Hao Harri Valpola and Juergen Schmidhuber Tagger Deep unsupervised perceptual grouping NIPS 2016 [video] [code]
Spatio-Temporal Weak Labels
84Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
85
Audio Features from Visual weak labels
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Object amp Scenes recognition in videos by analysing the audio track (only)
86Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
87Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
88Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
89
Visualization of the video frames associated to the sounds that activate some of the last hidden units of Soundnet (conv7)
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Audio Features from Visual weak labels
90
Audio amp Visual features from alignement
90Arandjelović Relja and Andrew Zisserman Look Listen and Learn ICCV 2017
Audio and visual features learned by assessing alignement
91L Chen S Srivastava Z Duan and C Xu Deep Cross-Modal Audio-Visual Generation ACM International Conference on Multimedia Thematic Workshops 2017
Audio amp Visual features from alignement
92Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
93Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
Video to Speech Representations
CNN(VGG)
Frame from a silent video
Audio feature
Post-hoc synthesis
94Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
95Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
Speech to Video Synthesis (mouth)
96Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
97Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
Speech to Video Synthesis (pose amp emotion)
98Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
99Suwajanakorn Supasorn Steven M Seitz and Ira Kemelmacher-Shlizerman Synthesizing Obama learning lip sync from audio SIGGRAPH 2017
Speech to Video Synthesis (mouth)
100
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
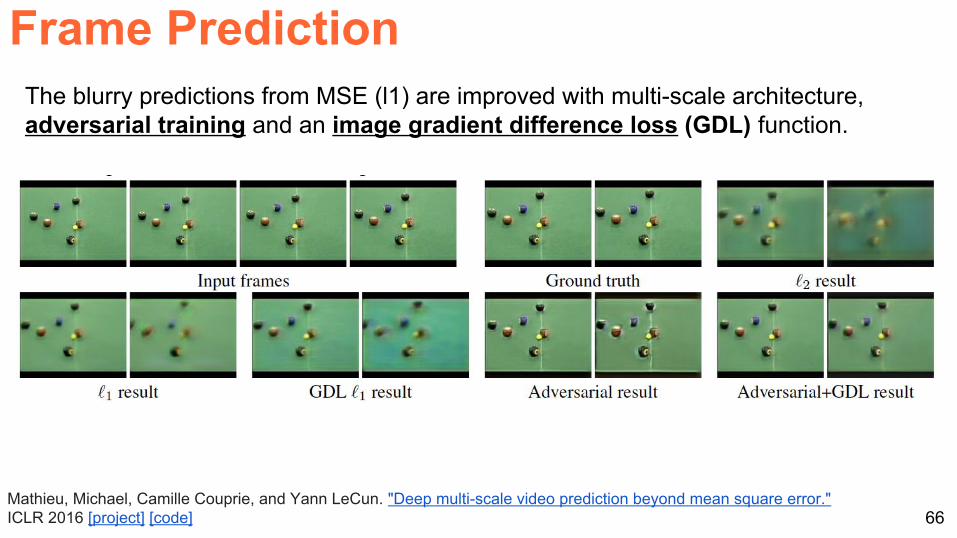
66Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
The blurry predictions from MSE (l1) are improved with multi-scale architecture adversarial training and an image gradient difference loss (GDL) function
Frame Prediction
67Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
Frame Prediction
68Vondrick Carl Hamed Pirsiavash and Antonio Torralba Generating videos with scene dynamics NIPS 2016
Frame Prediction
69Vondrick Carl Hamed Pirsiavash and Antonio Torralba Generating videos with scene dynamics NIPS 2016
Frame Prediction
70Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
71
Frame Prediction
Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
Given an input image probabilistic generation of future frames with a Variational AutoEncoder (VAE)
72
Frame Prediction
Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
Encodes image as feature maps and motion as and cross-convolutional kernels
73
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
First steps in video feature learning
74Le Quoc V Will Y Zou Serena Y Yeung and Andrew Y Ng Learning hierarchical invariant spatio-temporal features for action recognition with independent subspace analysis CVPR 2011
Temporal Weak Labels
75Goroshin Ross Joan Bruna Jonathan Tompson David Eigen and Yann LeCun Unsupervised learning of spatiotemporally coherent metrics ICCV 2015
Assumption adjacent video frames contain semantically similar informationAutoencoder trained with regularizations by slowliness and sparisty
76Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
77Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
78(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Temporal order of frames is exploited as the supervisory signal for learning
Temporal Weak Labels
79(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Take temporal order as the supervisory signals for learning
Shuffled sequences
Binary classification
In order
Not in order
Temporal Weak Labels
80Fernando Basura Hakan Bilen Efstratios Gavves and Stephen Gould Self-supervised video representation learning with odd-one-out networks CVPR 2017
Temporal Weak LabelsTrain a network to detect which of the video sequences contains frames wrong order
81
Spatio-Temporal Weak Labels
X Lin Campos V Giroacute-i-Nieto X Torres J and Canton-Ferrer C ldquoDisentangling Motion Foreground and Background Features in Videosrdquo in CVPR 2017 Workshop Brave New Motion Representations
kernel dec
C3D
ForegroundMotion
FirstForeground
Background
Fg
Dec
Bg
Dec
Fg
Dec Reconstruction
of foreground in last frame
Reconstruction of foreground in
first frame
Reconstruction of background in first frame
uNLC
MaskBlock
gradients
Last foreground
Kernels
shareweights
82
Spatio-Temporal Weak Labels
Pathak Deepak Ross Girshick Piotr Dollaacuter Trevor Darrell and Bharath Hariharan Learning features by watching objects move CVPR 2017
83Greff Klaus Antti Rasmus Mathias Berglund Tele Hao Harri Valpola and Juergen Schmidhuber Tagger Deep unsupervised perceptual grouping NIPS 2016 [video] [code]
Spatio-Temporal Weak Labels
84Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
85
Audio Features from Visual weak labels
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Object amp Scenes recognition in videos by analysing the audio track (only)
86Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
87Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
88Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
89
Visualization of the video frames associated to the sounds that activate some of the last hidden units of Soundnet (conv7)
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Audio Features from Visual weak labels
90
Audio amp Visual features from alignement
90Arandjelović Relja and Andrew Zisserman Look Listen and Learn ICCV 2017
Audio and visual features learned by assessing alignement
91L Chen S Srivastava Z Duan and C Xu Deep Cross-Modal Audio-Visual Generation ACM International Conference on Multimedia Thematic Workshops 2017
Audio amp Visual features from alignement
92Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
93Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
Video to Speech Representations
CNN(VGG)
Frame from a silent video
Audio feature
Post-hoc synthesis
94Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
95Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
Speech to Video Synthesis (mouth)
96Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
97Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
Speech to Video Synthesis (pose amp emotion)
98Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
99Suwajanakorn Supasorn Steven M Seitz and Ira Kemelmacher-Shlizerman Synthesizing Obama learning lip sync from audio SIGGRAPH 2017
Speech to Video Synthesis (mouth)
100
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning

67Mathieu Michael Camille Couprie and Yann LeCun Deep multi-scale video prediction beyond mean square error ICLR 2016 [project] [code]
Frame Prediction
68Vondrick Carl Hamed Pirsiavash and Antonio Torralba Generating videos with scene dynamics NIPS 2016
Frame Prediction
69Vondrick Carl Hamed Pirsiavash and Antonio Torralba Generating videos with scene dynamics NIPS 2016
Frame Prediction
70Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
71
Frame Prediction
Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
Given an input image probabilistic generation of future frames with a Variational AutoEncoder (VAE)
72
Frame Prediction
Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
Encodes image as feature maps and motion as and cross-convolutional kernels
73
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
First steps in video feature learning
74Le Quoc V Will Y Zou Serena Y Yeung and Andrew Y Ng Learning hierarchical invariant spatio-temporal features for action recognition with independent subspace analysis CVPR 2011
Temporal Weak Labels
75Goroshin Ross Joan Bruna Jonathan Tompson David Eigen and Yann LeCun Unsupervised learning of spatiotemporally coherent metrics ICCV 2015
Assumption adjacent video frames contain semantically similar informationAutoencoder trained with regularizations by slowliness and sparisty
76Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
77Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
78(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Temporal order of frames is exploited as the supervisory signal for learning
Temporal Weak Labels
79(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Take temporal order as the supervisory signals for learning
Shuffled sequences
Binary classification
In order
Not in order
Temporal Weak Labels
80Fernando Basura Hakan Bilen Efstratios Gavves and Stephen Gould Self-supervised video representation learning with odd-one-out networks CVPR 2017
Temporal Weak LabelsTrain a network to detect which of the video sequences contains frames wrong order
81
Spatio-Temporal Weak Labels
X Lin Campos V Giroacute-i-Nieto X Torres J and Canton-Ferrer C ldquoDisentangling Motion Foreground and Background Features in Videosrdquo in CVPR 2017 Workshop Brave New Motion Representations
kernel dec
C3D
ForegroundMotion
FirstForeground
Background
Fg
Dec
Bg
Dec
Fg
Dec Reconstruction
of foreground in last frame
Reconstruction of foreground in
first frame
Reconstruction of background in first frame
uNLC
MaskBlock
gradients
Last foreground
Kernels
shareweights
82
Spatio-Temporal Weak Labels
Pathak Deepak Ross Girshick Piotr Dollaacuter Trevor Darrell and Bharath Hariharan Learning features by watching objects move CVPR 2017
83Greff Klaus Antti Rasmus Mathias Berglund Tele Hao Harri Valpola and Juergen Schmidhuber Tagger Deep unsupervised perceptual grouping NIPS 2016 [video] [code]
Spatio-Temporal Weak Labels
84Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
85
Audio Features from Visual weak labels
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Object amp Scenes recognition in videos by analysing the audio track (only)
86Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
87Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
88Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
89
Visualization of the video frames associated to the sounds that activate some of the last hidden units of Soundnet (conv7)
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Audio Features from Visual weak labels
90
Audio amp Visual features from alignement
90Arandjelović Relja and Andrew Zisserman Look Listen and Learn ICCV 2017
Audio and visual features learned by assessing alignement
91L Chen S Srivastava Z Duan and C Xu Deep Cross-Modal Audio-Visual Generation ACM International Conference on Multimedia Thematic Workshops 2017
Audio amp Visual features from alignement
92Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
93Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
Video to Speech Representations
CNN(VGG)
Frame from a silent video
Audio feature
Post-hoc synthesis
94Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
95Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
Speech to Video Synthesis (mouth)
96Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
97Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
Speech to Video Synthesis (pose amp emotion)
98Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
99Suwajanakorn Supasorn Steven M Seitz and Ira Kemelmacher-Shlizerman Synthesizing Obama learning lip sync from audio SIGGRAPH 2017
Speech to Video Synthesis (mouth)
100
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning

68Vondrick Carl Hamed Pirsiavash and Antonio Torralba Generating videos with scene dynamics NIPS 2016
Frame Prediction
69Vondrick Carl Hamed Pirsiavash and Antonio Torralba Generating videos with scene dynamics NIPS 2016
Frame Prediction
70Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
71
Frame Prediction
Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
Given an input image probabilistic generation of future frames with a Variational AutoEncoder (VAE)
72
Frame Prediction
Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
Encodes image as feature maps and motion as and cross-convolutional kernels
73
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
First steps in video feature learning
74Le Quoc V Will Y Zou Serena Y Yeung and Andrew Y Ng Learning hierarchical invariant spatio-temporal features for action recognition with independent subspace analysis CVPR 2011
Temporal Weak Labels
75Goroshin Ross Joan Bruna Jonathan Tompson David Eigen and Yann LeCun Unsupervised learning of spatiotemporally coherent metrics ICCV 2015
Assumption adjacent video frames contain semantically similar informationAutoencoder trained with regularizations by slowliness and sparisty
76Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
77Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
78(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Temporal order of frames is exploited as the supervisory signal for learning
Temporal Weak Labels
79(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Take temporal order as the supervisory signals for learning
Shuffled sequences
Binary classification
In order
Not in order
Temporal Weak Labels
80Fernando Basura Hakan Bilen Efstratios Gavves and Stephen Gould Self-supervised video representation learning with odd-one-out networks CVPR 2017
Temporal Weak LabelsTrain a network to detect which of the video sequences contains frames wrong order
81
Spatio-Temporal Weak Labels
X Lin Campos V Giroacute-i-Nieto X Torres J and Canton-Ferrer C ldquoDisentangling Motion Foreground and Background Features in Videosrdquo in CVPR 2017 Workshop Brave New Motion Representations
kernel dec
C3D
ForegroundMotion
FirstForeground
Background
Fg
Dec
Bg
Dec
Fg
Dec Reconstruction
of foreground in last frame
Reconstruction of foreground in
first frame
Reconstruction of background in first frame
uNLC
MaskBlock
gradients
Last foreground
Kernels
shareweights
82
Spatio-Temporal Weak Labels
Pathak Deepak Ross Girshick Piotr Dollaacuter Trevor Darrell and Bharath Hariharan Learning features by watching objects move CVPR 2017
83Greff Klaus Antti Rasmus Mathias Berglund Tele Hao Harri Valpola and Juergen Schmidhuber Tagger Deep unsupervised perceptual grouping NIPS 2016 [video] [code]
Spatio-Temporal Weak Labels
84Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
85
Audio Features from Visual weak labels
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Object amp Scenes recognition in videos by analysing the audio track (only)
86Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
87Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
88Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
89
Visualization of the video frames associated to the sounds that activate some of the last hidden units of Soundnet (conv7)
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Audio Features from Visual weak labels
90
Audio amp Visual features from alignement
90Arandjelović Relja and Andrew Zisserman Look Listen and Learn ICCV 2017
Audio and visual features learned by assessing alignement
91L Chen S Srivastava Z Duan and C Xu Deep Cross-Modal Audio-Visual Generation ACM International Conference on Multimedia Thematic Workshops 2017
Audio amp Visual features from alignement
92Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
93Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
Video to Speech Representations
CNN(VGG)
Frame from a silent video
Audio feature
Post-hoc synthesis
94Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
95Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
Speech to Video Synthesis (mouth)
96Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
97Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
Speech to Video Synthesis (pose amp emotion)
98Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
99Suwajanakorn Supasorn Steven M Seitz and Ira Kemelmacher-Shlizerman Synthesizing Obama learning lip sync from audio SIGGRAPH 2017
Speech to Video Synthesis (mouth)
100
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning

69Vondrick Carl Hamed Pirsiavash and Antonio Torralba Generating videos with scene dynamics NIPS 2016
Frame Prediction
70Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
71
Frame Prediction
Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
Given an input image probabilistic generation of future frames with a Variational AutoEncoder (VAE)
72
Frame Prediction
Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
Encodes image as feature maps and motion as and cross-convolutional kernels
73
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
First steps in video feature learning
74Le Quoc V Will Y Zou Serena Y Yeung and Andrew Y Ng Learning hierarchical invariant spatio-temporal features for action recognition with independent subspace analysis CVPR 2011
Temporal Weak Labels
75Goroshin Ross Joan Bruna Jonathan Tompson David Eigen and Yann LeCun Unsupervised learning of spatiotemporally coherent metrics ICCV 2015
Assumption adjacent video frames contain semantically similar informationAutoencoder trained with regularizations by slowliness and sparisty
76Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
77Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
78(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Temporal order of frames is exploited as the supervisory signal for learning
Temporal Weak Labels
79(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Take temporal order as the supervisory signals for learning
Shuffled sequences
Binary classification
In order
Not in order
Temporal Weak Labels
80Fernando Basura Hakan Bilen Efstratios Gavves and Stephen Gould Self-supervised video representation learning with odd-one-out networks CVPR 2017
Temporal Weak LabelsTrain a network to detect which of the video sequences contains frames wrong order
81
Spatio-Temporal Weak Labels
X Lin Campos V Giroacute-i-Nieto X Torres J and Canton-Ferrer C ldquoDisentangling Motion Foreground and Background Features in Videosrdquo in CVPR 2017 Workshop Brave New Motion Representations
kernel dec
C3D
ForegroundMotion
FirstForeground
Background
Fg
Dec
Bg
Dec
Fg
Dec Reconstruction
of foreground in last frame
Reconstruction of foreground in
first frame
Reconstruction of background in first frame
uNLC
MaskBlock
gradients
Last foreground
Kernels
shareweights
82
Spatio-Temporal Weak Labels
Pathak Deepak Ross Girshick Piotr Dollaacuter Trevor Darrell and Bharath Hariharan Learning features by watching objects move CVPR 2017
83Greff Klaus Antti Rasmus Mathias Berglund Tele Hao Harri Valpola and Juergen Schmidhuber Tagger Deep unsupervised perceptual grouping NIPS 2016 [video] [code]
Spatio-Temporal Weak Labels
84Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
85
Audio Features from Visual weak labels
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Object amp Scenes recognition in videos by analysing the audio track (only)
86Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
87Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
88Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
89
Visualization of the video frames associated to the sounds that activate some of the last hidden units of Soundnet (conv7)
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Audio Features from Visual weak labels
90
Audio amp Visual features from alignement
90Arandjelović Relja and Andrew Zisserman Look Listen and Learn ICCV 2017
Audio and visual features learned by assessing alignement
91L Chen S Srivastava Z Duan and C Xu Deep Cross-Modal Audio-Visual Generation ACM International Conference on Multimedia Thematic Workshops 2017
Audio amp Visual features from alignement
92Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
93Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
Video to Speech Representations
CNN(VGG)
Frame from a silent video
Audio feature
Post-hoc synthesis
94Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
95Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
Speech to Video Synthesis (mouth)
96Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
97Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
Speech to Video Synthesis (pose amp emotion)
98Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
99Suwajanakorn Supasorn Steven M Seitz and Ira Kemelmacher-Shlizerman Synthesizing Obama learning lip sync from audio SIGGRAPH 2017
Speech to Video Synthesis (mouth)
100
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
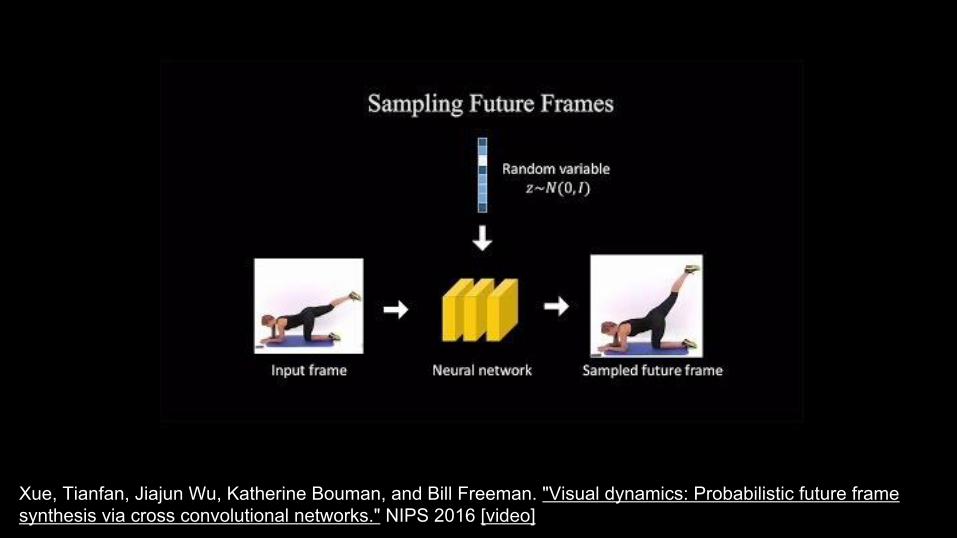
70Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
71
Frame Prediction
Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
Given an input image probabilistic generation of future frames with a Variational AutoEncoder (VAE)
72
Frame Prediction
Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
Encodes image as feature maps and motion as and cross-convolutional kernels
73
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
First steps in video feature learning
74Le Quoc V Will Y Zou Serena Y Yeung and Andrew Y Ng Learning hierarchical invariant spatio-temporal features for action recognition with independent subspace analysis CVPR 2011
Temporal Weak Labels
75Goroshin Ross Joan Bruna Jonathan Tompson David Eigen and Yann LeCun Unsupervised learning of spatiotemporally coherent metrics ICCV 2015
Assumption adjacent video frames contain semantically similar informationAutoencoder trained with regularizations by slowliness and sparisty
76Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
77Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
78(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Temporal order of frames is exploited as the supervisory signal for learning
Temporal Weak Labels
79(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Take temporal order as the supervisory signals for learning
Shuffled sequences
Binary classification
In order
Not in order
Temporal Weak Labels
80Fernando Basura Hakan Bilen Efstratios Gavves and Stephen Gould Self-supervised video representation learning with odd-one-out networks CVPR 2017
Temporal Weak LabelsTrain a network to detect which of the video sequences contains frames wrong order
81
Spatio-Temporal Weak Labels
X Lin Campos V Giroacute-i-Nieto X Torres J and Canton-Ferrer C ldquoDisentangling Motion Foreground and Background Features in Videosrdquo in CVPR 2017 Workshop Brave New Motion Representations
kernel dec
C3D
ForegroundMotion
FirstForeground
Background
Fg
Dec
Bg
Dec
Fg
Dec Reconstruction
of foreground in last frame
Reconstruction of foreground in
first frame
Reconstruction of background in first frame
uNLC
MaskBlock
gradients
Last foreground
Kernels
shareweights
82
Spatio-Temporal Weak Labels
Pathak Deepak Ross Girshick Piotr Dollaacuter Trevor Darrell and Bharath Hariharan Learning features by watching objects move CVPR 2017
83Greff Klaus Antti Rasmus Mathias Berglund Tele Hao Harri Valpola and Juergen Schmidhuber Tagger Deep unsupervised perceptual grouping NIPS 2016 [video] [code]
Spatio-Temporal Weak Labels
84Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
85
Audio Features from Visual weak labels
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Object amp Scenes recognition in videos by analysing the audio track (only)
86Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
87Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
88Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
89
Visualization of the video frames associated to the sounds that activate some of the last hidden units of Soundnet (conv7)
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Audio Features from Visual weak labels
90
Audio amp Visual features from alignement
90Arandjelović Relja and Andrew Zisserman Look Listen and Learn ICCV 2017
Audio and visual features learned by assessing alignement
91L Chen S Srivastava Z Duan and C Xu Deep Cross-Modal Audio-Visual Generation ACM International Conference on Multimedia Thematic Workshops 2017
Audio amp Visual features from alignement
92Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
93Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
Video to Speech Representations
CNN(VGG)
Frame from a silent video
Audio feature
Post-hoc synthesis
94Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
95Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
Speech to Video Synthesis (mouth)
96Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
97Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
Speech to Video Synthesis (pose amp emotion)
98Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
99Suwajanakorn Supasorn Steven M Seitz and Ira Kemelmacher-Shlizerman Synthesizing Obama learning lip sync from audio SIGGRAPH 2017
Speech to Video Synthesis (mouth)
100
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
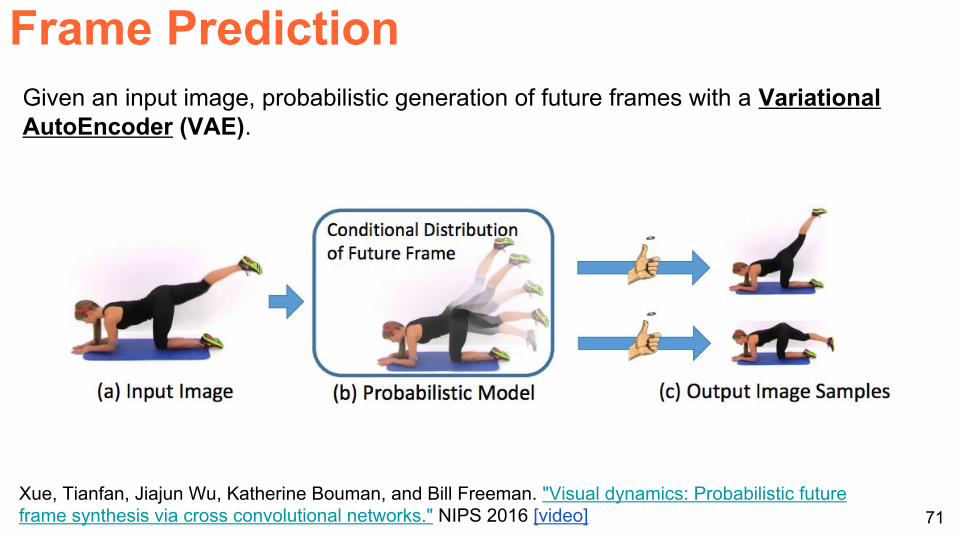
71
Frame Prediction
Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
Given an input image probabilistic generation of future frames with a Variational AutoEncoder (VAE)
72
Frame Prediction
Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
Encodes image as feature maps and motion as and cross-convolutional kernels
73
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
First steps in video feature learning
74Le Quoc V Will Y Zou Serena Y Yeung and Andrew Y Ng Learning hierarchical invariant spatio-temporal features for action recognition with independent subspace analysis CVPR 2011
Temporal Weak Labels
75Goroshin Ross Joan Bruna Jonathan Tompson David Eigen and Yann LeCun Unsupervised learning of spatiotemporally coherent metrics ICCV 2015
Assumption adjacent video frames contain semantically similar informationAutoencoder trained with regularizations by slowliness and sparisty
76Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
77Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
78(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Temporal order of frames is exploited as the supervisory signal for learning
Temporal Weak Labels
79(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Take temporal order as the supervisory signals for learning
Shuffled sequences
Binary classification
In order
Not in order
Temporal Weak Labels
80Fernando Basura Hakan Bilen Efstratios Gavves and Stephen Gould Self-supervised video representation learning with odd-one-out networks CVPR 2017
Temporal Weak LabelsTrain a network to detect which of the video sequences contains frames wrong order
81
Spatio-Temporal Weak Labels
X Lin Campos V Giroacute-i-Nieto X Torres J and Canton-Ferrer C ldquoDisentangling Motion Foreground and Background Features in Videosrdquo in CVPR 2017 Workshop Brave New Motion Representations
kernel dec
C3D
ForegroundMotion
FirstForeground
Background
Fg
Dec
Bg
Dec
Fg
Dec Reconstruction
of foreground in last frame
Reconstruction of foreground in
first frame
Reconstruction of background in first frame
uNLC
MaskBlock
gradients
Last foreground
Kernels
shareweights
82
Spatio-Temporal Weak Labels
Pathak Deepak Ross Girshick Piotr Dollaacuter Trevor Darrell and Bharath Hariharan Learning features by watching objects move CVPR 2017
83Greff Klaus Antti Rasmus Mathias Berglund Tele Hao Harri Valpola and Juergen Schmidhuber Tagger Deep unsupervised perceptual grouping NIPS 2016 [video] [code]
Spatio-Temporal Weak Labels
84Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
85
Audio Features from Visual weak labels
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Object amp Scenes recognition in videos by analysing the audio track (only)
86Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
87Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
88Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
89
Visualization of the video frames associated to the sounds that activate some of the last hidden units of Soundnet (conv7)
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Audio Features from Visual weak labels
90
Audio amp Visual features from alignement
90Arandjelović Relja and Andrew Zisserman Look Listen and Learn ICCV 2017
Audio and visual features learned by assessing alignement
91L Chen S Srivastava Z Duan and C Xu Deep Cross-Modal Audio-Visual Generation ACM International Conference on Multimedia Thematic Workshops 2017
Audio amp Visual features from alignement
92Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
93Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
Video to Speech Representations
CNN(VGG)
Frame from a silent video
Audio feature
Post-hoc synthesis
94Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
95Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
Speech to Video Synthesis (mouth)
96Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
97Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
Speech to Video Synthesis (pose amp emotion)
98Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
99Suwajanakorn Supasorn Steven M Seitz and Ira Kemelmacher-Shlizerman Synthesizing Obama learning lip sync from audio SIGGRAPH 2017
Speech to Video Synthesis (mouth)
100
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning

72
Frame Prediction
Xue Tianfan Jiajun Wu Katherine Bouman and Bill Freeman Visual dynamics Probabilistic future frame synthesis via cross convolutional networks NIPS 2016 [video]
Encodes image as feature maps and motion as and cross-convolutional kernels
73
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
First steps in video feature learning
74Le Quoc V Will Y Zou Serena Y Yeung and Andrew Y Ng Learning hierarchical invariant spatio-temporal features for action recognition with independent subspace analysis CVPR 2011
Temporal Weak Labels
75Goroshin Ross Joan Bruna Jonathan Tompson David Eigen and Yann LeCun Unsupervised learning of spatiotemporally coherent metrics ICCV 2015
Assumption adjacent video frames contain semantically similar informationAutoencoder trained with regularizations by slowliness and sparisty
76Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
77Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
78(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Temporal order of frames is exploited as the supervisory signal for learning
Temporal Weak Labels
79(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Take temporal order as the supervisory signals for learning
Shuffled sequences
Binary classification
In order
Not in order
Temporal Weak Labels
80Fernando Basura Hakan Bilen Efstratios Gavves and Stephen Gould Self-supervised video representation learning with odd-one-out networks CVPR 2017
Temporal Weak LabelsTrain a network to detect which of the video sequences contains frames wrong order
81
Spatio-Temporal Weak Labels
X Lin Campos V Giroacute-i-Nieto X Torres J and Canton-Ferrer C ldquoDisentangling Motion Foreground and Background Features in Videosrdquo in CVPR 2017 Workshop Brave New Motion Representations
kernel dec
C3D
ForegroundMotion
FirstForeground
Background
Fg
Dec
Bg
Dec
Fg
Dec Reconstruction
of foreground in last frame
Reconstruction of foreground in
first frame
Reconstruction of background in first frame
uNLC
MaskBlock
gradients
Last foreground
Kernels
shareweights
82
Spatio-Temporal Weak Labels
Pathak Deepak Ross Girshick Piotr Dollaacuter Trevor Darrell and Bharath Hariharan Learning features by watching objects move CVPR 2017
83Greff Klaus Antti Rasmus Mathias Berglund Tele Hao Harri Valpola and Juergen Schmidhuber Tagger Deep unsupervised perceptual grouping NIPS 2016 [video] [code]
Spatio-Temporal Weak Labels
84Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
85
Audio Features from Visual weak labels
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Object amp Scenes recognition in videos by analysing the audio track (only)
86Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
87Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
88Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
89
Visualization of the video frames associated to the sounds that activate some of the last hidden units of Soundnet (conv7)
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Audio Features from Visual weak labels
90
Audio amp Visual features from alignement
90Arandjelović Relja and Andrew Zisserman Look Listen and Learn ICCV 2017
Audio and visual features learned by assessing alignement
91L Chen S Srivastava Z Duan and C Xu Deep Cross-Modal Audio-Visual Generation ACM International Conference on Multimedia Thematic Workshops 2017
Audio amp Visual features from alignement
92Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
93Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
Video to Speech Representations
CNN(VGG)
Frame from a silent video
Audio feature
Post-hoc synthesis
94Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
95Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
Speech to Video Synthesis (mouth)
96Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
97Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
Speech to Video Synthesis (pose amp emotion)
98Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
99Suwajanakorn Supasorn Steven M Seitz and Ira Kemelmacher-Shlizerman Synthesizing Obama learning lip sync from audio SIGGRAPH 2017
Speech to Video Synthesis (mouth)
100
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning

73
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
First steps in video feature learning
74Le Quoc V Will Y Zou Serena Y Yeung and Andrew Y Ng Learning hierarchical invariant spatio-temporal features for action recognition with independent subspace analysis CVPR 2011
Temporal Weak Labels
75Goroshin Ross Joan Bruna Jonathan Tompson David Eigen and Yann LeCun Unsupervised learning of spatiotemporally coherent metrics ICCV 2015
Assumption adjacent video frames contain semantically similar informationAutoencoder trained with regularizations by slowliness and sparisty
76Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
77Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
78(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Temporal order of frames is exploited as the supervisory signal for learning
Temporal Weak Labels
79(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Take temporal order as the supervisory signals for learning
Shuffled sequences
Binary classification
In order
Not in order
Temporal Weak Labels
80Fernando Basura Hakan Bilen Efstratios Gavves and Stephen Gould Self-supervised video representation learning with odd-one-out networks CVPR 2017
Temporal Weak LabelsTrain a network to detect which of the video sequences contains frames wrong order
81
Spatio-Temporal Weak Labels
X Lin Campos V Giroacute-i-Nieto X Torres J and Canton-Ferrer C ldquoDisentangling Motion Foreground and Background Features in Videosrdquo in CVPR 2017 Workshop Brave New Motion Representations
kernel dec
C3D
ForegroundMotion
FirstForeground
Background
Fg
Dec
Bg
Dec
Fg
Dec Reconstruction
of foreground in last frame
Reconstruction of foreground in
first frame
Reconstruction of background in first frame
uNLC
MaskBlock
gradients
Last foreground
Kernels
shareweights
82
Spatio-Temporal Weak Labels
Pathak Deepak Ross Girshick Piotr Dollaacuter Trevor Darrell and Bharath Hariharan Learning features by watching objects move CVPR 2017
83Greff Klaus Antti Rasmus Mathias Berglund Tele Hao Harri Valpola and Juergen Schmidhuber Tagger Deep unsupervised perceptual grouping NIPS 2016 [video] [code]
Spatio-Temporal Weak Labels
84Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
85
Audio Features from Visual weak labels
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Object amp Scenes recognition in videos by analysing the audio track (only)
86Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
87Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
88Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
89
Visualization of the video frames associated to the sounds that activate some of the last hidden units of Soundnet (conv7)
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Audio Features from Visual weak labels
90
Audio amp Visual features from alignement
90Arandjelović Relja and Andrew Zisserman Look Listen and Learn ICCV 2017
Audio and visual features learned by assessing alignement
91L Chen S Srivastava Z Duan and C Xu Deep Cross-Modal Audio-Visual Generation ACM International Conference on Multimedia Thematic Workshops 2017
Audio amp Visual features from alignement
92Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
93Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
Video to Speech Representations
CNN(VGG)
Frame from a silent video
Audio feature
Post-hoc synthesis
94Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
95Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
Speech to Video Synthesis (mouth)
96Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
97Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
Speech to Video Synthesis (pose amp emotion)
98Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
99Suwajanakorn Supasorn Steven M Seitz and Ira Kemelmacher-Shlizerman Synthesizing Obama learning lip sync from audio SIGGRAPH 2017
Speech to Video Synthesis (mouth)
100
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning

First steps in video feature learning
74Le Quoc V Will Y Zou Serena Y Yeung and Andrew Y Ng Learning hierarchical invariant spatio-temporal features for action recognition with independent subspace analysis CVPR 2011
Temporal Weak Labels
75Goroshin Ross Joan Bruna Jonathan Tompson David Eigen and Yann LeCun Unsupervised learning of spatiotemporally coherent metrics ICCV 2015
Assumption adjacent video frames contain semantically similar informationAutoencoder trained with regularizations by slowliness and sparisty
76Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
77Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
78(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Temporal order of frames is exploited as the supervisory signal for learning
Temporal Weak Labels
79(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Take temporal order as the supervisory signals for learning
Shuffled sequences
Binary classification
In order
Not in order
Temporal Weak Labels
80Fernando Basura Hakan Bilen Efstratios Gavves and Stephen Gould Self-supervised video representation learning with odd-one-out networks CVPR 2017
Temporal Weak LabelsTrain a network to detect which of the video sequences contains frames wrong order
81
Spatio-Temporal Weak Labels
X Lin Campos V Giroacute-i-Nieto X Torres J and Canton-Ferrer C ldquoDisentangling Motion Foreground and Background Features in Videosrdquo in CVPR 2017 Workshop Brave New Motion Representations
kernel dec
C3D
ForegroundMotion
FirstForeground
Background
Fg
Dec
Bg
Dec
Fg
Dec Reconstruction
of foreground in last frame
Reconstruction of foreground in
first frame
Reconstruction of background in first frame
uNLC
MaskBlock
gradients
Last foreground
Kernels
shareweights
82
Spatio-Temporal Weak Labels
Pathak Deepak Ross Girshick Piotr Dollaacuter Trevor Darrell and Bharath Hariharan Learning features by watching objects move CVPR 2017
83Greff Klaus Antti Rasmus Mathias Berglund Tele Hao Harri Valpola and Juergen Schmidhuber Tagger Deep unsupervised perceptual grouping NIPS 2016 [video] [code]
Spatio-Temporal Weak Labels
84Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
85
Audio Features from Visual weak labels
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Object amp Scenes recognition in videos by analysing the audio track (only)
86Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
87Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
88Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
89
Visualization of the video frames associated to the sounds that activate some of the last hidden units of Soundnet (conv7)
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Audio Features from Visual weak labels
90
Audio amp Visual features from alignement
90Arandjelović Relja and Andrew Zisserman Look Listen and Learn ICCV 2017
Audio and visual features learned by assessing alignement
91L Chen S Srivastava Z Duan and C Xu Deep Cross-Modal Audio-Visual Generation ACM International Conference on Multimedia Thematic Workshops 2017
Audio amp Visual features from alignement
92Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
93Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
Video to Speech Representations
CNN(VGG)
Frame from a silent video
Audio feature
Post-hoc synthesis
94Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
95Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
Speech to Video Synthesis (mouth)
96Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
97Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
Speech to Video Synthesis (pose amp emotion)
98Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
99Suwajanakorn Supasorn Steven M Seitz and Ira Kemelmacher-Shlizerman Synthesizing Obama learning lip sync from audio SIGGRAPH 2017
Speech to Video Synthesis (mouth)
100
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning

Temporal Weak Labels
75Goroshin Ross Joan Bruna Jonathan Tompson David Eigen and Yann LeCun Unsupervised learning of spatiotemporally coherent metrics ICCV 2015
Assumption adjacent video frames contain semantically similar informationAutoencoder trained with regularizations by slowliness and sparisty
76Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
77Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
78(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Temporal order of frames is exploited as the supervisory signal for learning
Temporal Weak Labels
79(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Take temporal order as the supervisory signals for learning
Shuffled sequences
Binary classification
In order
Not in order
Temporal Weak Labels
80Fernando Basura Hakan Bilen Efstratios Gavves and Stephen Gould Self-supervised video representation learning with odd-one-out networks CVPR 2017
Temporal Weak LabelsTrain a network to detect which of the video sequences contains frames wrong order
81
Spatio-Temporal Weak Labels
X Lin Campos V Giroacute-i-Nieto X Torres J and Canton-Ferrer C ldquoDisentangling Motion Foreground and Background Features in Videosrdquo in CVPR 2017 Workshop Brave New Motion Representations
kernel dec
C3D
ForegroundMotion
FirstForeground
Background
Fg
Dec
Bg
Dec
Fg
Dec Reconstruction
of foreground in last frame
Reconstruction of foreground in
first frame
Reconstruction of background in first frame
uNLC
MaskBlock
gradients
Last foreground
Kernels
shareweights
82
Spatio-Temporal Weak Labels
Pathak Deepak Ross Girshick Piotr Dollaacuter Trevor Darrell and Bharath Hariharan Learning features by watching objects move CVPR 2017
83Greff Klaus Antti Rasmus Mathias Berglund Tele Hao Harri Valpola and Juergen Schmidhuber Tagger Deep unsupervised perceptual grouping NIPS 2016 [video] [code]
Spatio-Temporal Weak Labels
84Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
85
Audio Features from Visual weak labels
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Object amp Scenes recognition in videos by analysing the audio track (only)
86Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
87Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
88Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
89
Visualization of the video frames associated to the sounds that activate some of the last hidden units of Soundnet (conv7)
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Audio Features from Visual weak labels
90
Audio amp Visual features from alignement
90Arandjelović Relja and Andrew Zisserman Look Listen and Learn ICCV 2017
Audio and visual features learned by assessing alignement
91L Chen S Srivastava Z Duan and C Xu Deep Cross-Modal Audio-Visual Generation ACM International Conference on Multimedia Thematic Workshops 2017
Audio amp Visual features from alignement
92Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
93Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
Video to Speech Representations
CNN(VGG)
Frame from a silent video
Audio feature
Post-hoc synthesis
94Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
95Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
Speech to Video Synthesis (mouth)
96Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
97Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
Speech to Video Synthesis (pose amp emotion)
98Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
99Suwajanakorn Supasorn Steven M Seitz and Ira Kemelmacher-Shlizerman Synthesizing Obama learning lip sync from audio SIGGRAPH 2017
Speech to Video Synthesis (mouth)
100
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning

76Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
77Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
78(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Temporal order of frames is exploited as the supervisory signal for learning
Temporal Weak Labels
79(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Take temporal order as the supervisory signals for learning
Shuffled sequences
Binary classification
In order
Not in order
Temporal Weak Labels
80Fernando Basura Hakan Bilen Efstratios Gavves and Stephen Gould Self-supervised video representation learning with odd-one-out networks CVPR 2017
Temporal Weak LabelsTrain a network to detect which of the video sequences contains frames wrong order
81
Spatio-Temporal Weak Labels
X Lin Campos V Giroacute-i-Nieto X Torres J and Canton-Ferrer C ldquoDisentangling Motion Foreground and Background Features in Videosrdquo in CVPR 2017 Workshop Brave New Motion Representations
kernel dec
C3D
ForegroundMotion
FirstForeground
Background
Fg
Dec
Bg
Dec
Fg
Dec Reconstruction
of foreground in last frame
Reconstruction of foreground in
first frame
Reconstruction of background in first frame
uNLC
MaskBlock
gradients
Last foreground
Kernels
shareweights
82
Spatio-Temporal Weak Labels
Pathak Deepak Ross Girshick Piotr Dollaacuter Trevor Darrell and Bharath Hariharan Learning features by watching objects move CVPR 2017
83Greff Klaus Antti Rasmus Mathias Berglund Tele Hao Harri Valpola and Juergen Schmidhuber Tagger Deep unsupervised perceptual grouping NIPS 2016 [video] [code]
Spatio-Temporal Weak Labels
84Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
85
Audio Features from Visual weak labels
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Object amp Scenes recognition in videos by analysing the audio track (only)
86Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
87Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
88Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
89
Visualization of the video frames associated to the sounds that activate some of the last hidden units of Soundnet (conv7)
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Audio Features from Visual weak labels
90
Audio amp Visual features from alignement
90Arandjelović Relja and Andrew Zisserman Look Listen and Learn ICCV 2017
Audio and visual features learned by assessing alignement
91L Chen S Srivastava Z Duan and C Xu Deep Cross-Modal Audio-Visual Generation ACM International Conference on Multimedia Thematic Workshops 2017
Audio amp Visual features from alignement
92Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
93Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
Video to Speech Representations
CNN(VGG)
Frame from a silent video
Audio feature
Post-hoc synthesis
94Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
95Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
Speech to Video Synthesis (mouth)
96Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
97Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
Speech to Video Synthesis (pose amp emotion)
98Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
99Suwajanakorn Supasorn Steven M Seitz and Ira Kemelmacher-Shlizerman Synthesizing Obama learning lip sync from audio SIGGRAPH 2017
Speech to Video Synthesis (mouth)
100
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning

77Jayaraman Dinesh and Kristen Grauman Slow and steady feature analysis higher order temporal coherence in video CVPR 2016 [video]
Temporal Weak Labels
78(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Temporal order of frames is exploited as the supervisory signal for learning
Temporal Weak Labels
79(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Take temporal order as the supervisory signals for learning
Shuffled sequences
Binary classification
In order
Not in order
Temporal Weak Labels
80Fernando Basura Hakan Bilen Efstratios Gavves and Stephen Gould Self-supervised video representation learning with odd-one-out networks CVPR 2017
Temporal Weak LabelsTrain a network to detect which of the video sequences contains frames wrong order
81
Spatio-Temporal Weak Labels
X Lin Campos V Giroacute-i-Nieto X Torres J and Canton-Ferrer C ldquoDisentangling Motion Foreground and Background Features in Videosrdquo in CVPR 2017 Workshop Brave New Motion Representations
kernel dec
C3D
ForegroundMotion
FirstForeground
Background
Fg
Dec
Bg
Dec
Fg
Dec Reconstruction
of foreground in last frame
Reconstruction of foreground in
first frame
Reconstruction of background in first frame
uNLC
MaskBlock
gradients
Last foreground
Kernels
shareweights
82
Spatio-Temporal Weak Labels
Pathak Deepak Ross Girshick Piotr Dollaacuter Trevor Darrell and Bharath Hariharan Learning features by watching objects move CVPR 2017
83Greff Klaus Antti Rasmus Mathias Berglund Tele Hao Harri Valpola and Juergen Schmidhuber Tagger Deep unsupervised perceptual grouping NIPS 2016 [video] [code]
Spatio-Temporal Weak Labels
84Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
85
Audio Features from Visual weak labels
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Object amp Scenes recognition in videos by analysing the audio track (only)
86Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
87Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
88Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
89
Visualization of the video frames associated to the sounds that activate some of the last hidden units of Soundnet (conv7)
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Audio Features from Visual weak labels
90
Audio amp Visual features from alignement
90Arandjelović Relja and Andrew Zisserman Look Listen and Learn ICCV 2017
Audio and visual features learned by assessing alignement
91L Chen S Srivastava Z Duan and C Xu Deep Cross-Modal Audio-Visual Generation ACM International Conference on Multimedia Thematic Workshops 2017
Audio amp Visual features from alignement
92Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
93Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
Video to Speech Representations
CNN(VGG)
Frame from a silent video
Audio feature
Post-hoc synthesis
94Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
95Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
Speech to Video Synthesis (mouth)
96Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
97Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
Speech to Video Synthesis (pose amp emotion)
98Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
99Suwajanakorn Supasorn Steven M Seitz and Ira Kemelmacher-Shlizerman Synthesizing Obama learning lip sync from audio SIGGRAPH 2017
Speech to Video Synthesis (mouth)
100
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning

78(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Temporal order of frames is exploited as the supervisory signal for learning
Temporal Weak Labels
79(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Take temporal order as the supervisory signals for learning
Shuffled sequences
Binary classification
In order
Not in order
Temporal Weak Labels
80Fernando Basura Hakan Bilen Efstratios Gavves and Stephen Gould Self-supervised video representation learning with odd-one-out networks CVPR 2017
Temporal Weak LabelsTrain a network to detect which of the video sequences contains frames wrong order
81
Spatio-Temporal Weak Labels
X Lin Campos V Giroacute-i-Nieto X Torres J and Canton-Ferrer C ldquoDisentangling Motion Foreground and Background Features in Videosrdquo in CVPR 2017 Workshop Brave New Motion Representations
kernel dec
C3D
ForegroundMotion
FirstForeground
Background
Fg
Dec
Bg
Dec
Fg
Dec Reconstruction
of foreground in last frame
Reconstruction of foreground in
first frame
Reconstruction of background in first frame
uNLC
MaskBlock
gradients
Last foreground
Kernels
shareweights
82
Spatio-Temporal Weak Labels
Pathak Deepak Ross Girshick Piotr Dollaacuter Trevor Darrell and Bharath Hariharan Learning features by watching objects move CVPR 2017
83Greff Klaus Antti Rasmus Mathias Berglund Tele Hao Harri Valpola and Juergen Schmidhuber Tagger Deep unsupervised perceptual grouping NIPS 2016 [video] [code]
Spatio-Temporal Weak Labels
84Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
85
Audio Features from Visual weak labels
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Object amp Scenes recognition in videos by analysing the audio track (only)
86Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
87Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
88Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
89
Visualization of the video frames associated to the sounds that activate some of the last hidden units of Soundnet (conv7)
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Audio Features from Visual weak labels
90
Audio amp Visual features from alignement
90Arandjelović Relja and Andrew Zisserman Look Listen and Learn ICCV 2017
Audio and visual features learned by assessing alignement
91L Chen S Srivastava Z Duan and C Xu Deep Cross-Modal Audio-Visual Generation ACM International Conference on Multimedia Thematic Workshops 2017
Audio amp Visual features from alignement
92Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
93Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
Video to Speech Representations
CNN(VGG)
Frame from a silent video
Audio feature
Post-hoc synthesis
94Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
95Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
Speech to Video Synthesis (mouth)
96Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
97Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
Speech to Video Synthesis (pose amp emotion)
98Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
99Suwajanakorn Supasorn Steven M Seitz and Ira Kemelmacher-Shlizerman Synthesizing Obama learning lip sync from audio SIGGRAPH 2017
Speech to Video Synthesis (mouth)
100
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
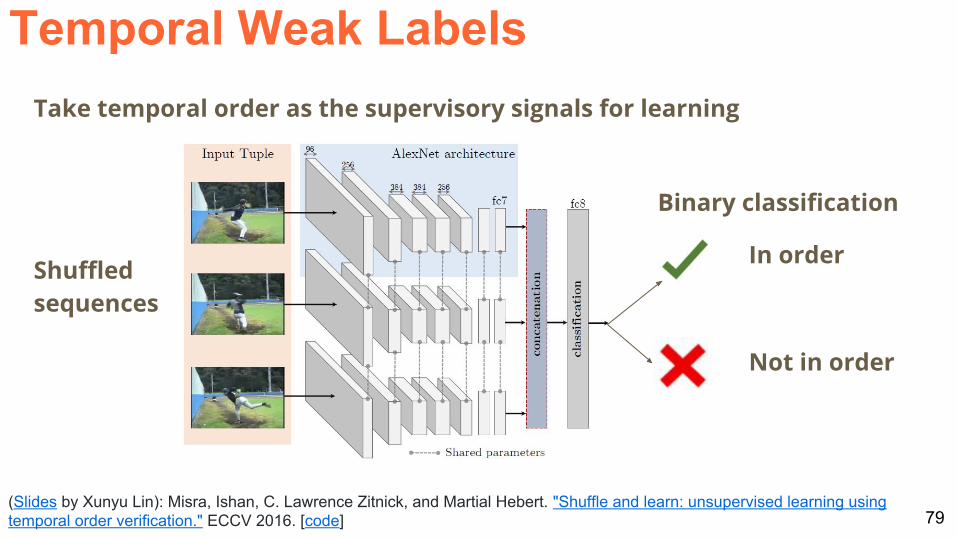
79(Slides by Xunyu Lin) Misra Ishan C Lawrence Zitnick and Martial Hebert Shuffle and learn unsupervised learning using temporal order verification ECCV 2016 [code]
Take temporal order as the supervisory signals for learning
Shuffled sequences
Binary classification
In order
Not in order
Temporal Weak Labels
80Fernando Basura Hakan Bilen Efstratios Gavves and Stephen Gould Self-supervised video representation learning with odd-one-out networks CVPR 2017
Temporal Weak LabelsTrain a network to detect which of the video sequences contains frames wrong order
81
Spatio-Temporal Weak Labels
X Lin Campos V Giroacute-i-Nieto X Torres J and Canton-Ferrer C ldquoDisentangling Motion Foreground and Background Features in Videosrdquo in CVPR 2017 Workshop Brave New Motion Representations
kernel dec
C3D
ForegroundMotion
FirstForeground
Background
Fg
Dec
Bg
Dec
Fg
Dec Reconstruction
of foreground in last frame
Reconstruction of foreground in
first frame
Reconstruction of background in first frame
uNLC
MaskBlock
gradients
Last foreground
Kernels
shareweights
82
Spatio-Temporal Weak Labels
Pathak Deepak Ross Girshick Piotr Dollaacuter Trevor Darrell and Bharath Hariharan Learning features by watching objects move CVPR 2017
83Greff Klaus Antti Rasmus Mathias Berglund Tele Hao Harri Valpola and Juergen Schmidhuber Tagger Deep unsupervised perceptual grouping NIPS 2016 [video] [code]
Spatio-Temporal Weak Labels
84Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
85
Audio Features from Visual weak labels
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Object amp Scenes recognition in videos by analysing the audio track (only)
86Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
87Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
88Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
89
Visualization of the video frames associated to the sounds that activate some of the last hidden units of Soundnet (conv7)
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Audio Features from Visual weak labels
90
Audio amp Visual features from alignement
90Arandjelović Relja and Andrew Zisserman Look Listen and Learn ICCV 2017
Audio and visual features learned by assessing alignement
91L Chen S Srivastava Z Duan and C Xu Deep Cross-Modal Audio-Visual Generation ACM International Conference on Multimedia Thematic Workshops 2017
Audio amp Visual features from alignement
92Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
93Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
Video to Speech Representations
CNN(VGG)
Frame from a silent video
Audio feature
Post-hoc synthesis
94Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
95Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
Speech to Video Synthesis (mouth)
96Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
97Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
Speech to Video Synthesis (pose amp emotion)
98Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
99Suwajanakorn Supasorn Steven M Seitz and Ira Kemelmacher-Shlizerman Synthesizing Obama learning lip sync from audio SIGGRAPH 2017
Speech to Video Synthesis (mouth)
100
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning

80Fernando Basura Hakan Bilen Efstratios Gavves and Stephen Gould Self-supervised video representation learning with odd-one-out networks CVPR 2017
Temporal Weak LabelsTrain a network to detect which of the video sequences contains frames wrong order
81
Spatio-Temporal Weak Labels
X Lin Campos V Giroacute-i-Nieto X Torres J and Canton-Ferrer C ldquoDisentangling Motion Foreground and Background Features in Videosrdquo in CVPR 2017 Workshop Brave New Motion Representations
kernel dec
C3D
ForegroundMotion
FirstForeground
Background
Fg
Dec
Bg
Dec
Fg
Dec Reconstruction
of foreground in last frame
Reconstruction of foreground in
first frame
Reconstruction of background in first frame
uNLC
MaskBlock
gradients
Last foreground
Kernels
shareweights
82
Spatio-Temporal Weak Labels
Pathak Deepak Ross Girshick Piotr Dollaacuter Trevor Darrell and Bharath Hariharan Learning features by watching objects move CVPR 2017
83Greff Klaus Antti Rasmus Mathias Berglund Tele Hao Harri Valpola and Juergen Schmidhuber Tagger Deep unsupervised perceptual grouping NIPS 2016 [video] [code]
Spatio-Temporal Weak Labels
84Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
85
Audio Features from Visual weak labels
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Object amp Scenes recognition in videos by analysing the audio track (only)
86Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
87Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
88Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
89
Visualization of the video frames associated to the sounds that activate some of the last hidden units of Soundnet (conv7)
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Audio Features from Visual weak labels
90
Audio amp Visual features from alignement
90Arandjelović Relja and Andrew Zisserman Look Listen and Learn ICCV 2017
Audio and visual features learned by assessing alignement
91L Chen S Srivastava Z Duan and C Xu Deep Cross-Modal Audio-Visual Generation ACM International Conference on Multimedia Thematic Workshops 2017
Audio amp Visual features from alignement
92Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
93Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
Video to Speech Representations
CNN(VGG)
Frame from a silent video
Audio feature
Post-hoc synthesis
94Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
95Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
Speech to Video Synthesis (mouth)
96Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
97Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
Speech to Video Synthesis (pose amp emotion)
98Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
99Suwajanakorn Supasorn Steven M Seitz and Ira Kemelmacher-Shlizerman Synthesizing Obama learning lip sync from audio SIGGRAPH 2017
Speech to Video Synthesis (mouth)
100
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning

81
Spatio-Temporal Weak Labels
X Lin Campos V Giroacute-i-Nieto X Torres J and Canton-Ferrer C ldquoDisentangling Motion Foreground and Background Features in Videosrdquo in CVPR 2017 Workshop Brave New Motion Representations
kernel dec
C3D
ForegroundMotion
FirstForeground
Background
Fg
Dec
Bg
Dec
Fg
Dec Reconstruction
of foreground in last frame
Reconstruction of foreground in
first frame
Reconstruction of background in first frame
uNLC
MaskBlock
gradients
Last foreground
Kernels
shareweights
82
Spatio-Temporal Weak Labels
Pathak Deepak Ross Girshick Piotr Dollaacuter Trevor Darrell and Bharath Hariharan Learning features by watching objects move CVPR 2017
83Greff Klaus Antti Rasmus Mathias Berglund Tele Hao Harri Valpola and Juergen Schmidhuber Tagger Deep unsupervised perceptual grouping NIPS 2016 [video] [code]
Spatio-Temporal Weak Labels
84Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
85
Audio Features from Visual weak labels
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Object amp Scenes recognition in videos by analysing the audio track (only)
86Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
87Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
88Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
89
Visualization of the video frames associated to the sounds that activate some of the last hidden units of Soundnet (conv7)
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Audio Features from Visual weak labels
90
Audio amp Visual features from alignement
90Arandjelović Relja and Andrew Zisserman Look Listen and Learn ICCV 2017
Audio and visual features learned by assessing alignement
91L Chen S Srivastava Z Duan and C Xu Deep Cross-Modal Audio-Visual Generation ACM International Conference on Multimedia Thematic Workshops 2017
Audio amp Visual features from alignement
92Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
93Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
Video to Speech Representations
CNN(VGG)
Frame from a silent video
Audio feature
Post-hoc synthesis
94Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
95Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
Speech to Video Synthesis (mouth)
96Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
97Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
Speech to Video Synthesis (pose amp emotion)
98Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
99Suwajanakorn Supasorn Steven M Seitz and Ira Kemelmacher-Shlizerman Synthesizing Obama learning lip sync from audio SIGGRAPH 2017
Speech to Video Synthesis (mouth)
100
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning

82
Spatio-Temporal Weak Labels
Pathak Deepak Ross Girshick Piotr Dollaacuter Trevor Darrell and Bharath Hariharan Learning features by watching objects move CVPR 2017
83Greff Klaus Antti Rasmus Mathias Berglund Tele Hao Harri Valpola and Juergen Schmidhuber Tagger Deep unsupervised perceptual grouping NIPS 2016 [video] [code]
Spatio-Temporal Weak Labels
84Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
85
Audio Features from Visual weak labels
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Object amp Scenes recognition in videos by analysing the audio track (only)
86Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
87Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
88Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
89
Visualization of the video frames associated to the sounds that activate some of the last hidden units of Soundnet (conv7)
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Audio Features from Visual weak labels
90
Audio amp Visual features from alignement
90Arandjelović Relja and Andrew Zisserman Look Listen and Learn ICCV 2017
Audio and visual features learned by assessing alignement
91L Chen S Srivastava Z Duan and C Xu Deep Cross-Modal Audio-Visual Generation ACM International Conference on Multimedia Thematic Workshops 2017
Audio amp Visual features from alignement
92Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
93Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
Video to Speech Representations
CNN(VGG)
Frame from a silent video
Audio feature
Post-hoc synthesis
94Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
95Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
Speech to Video Synthesis (mouth)
96Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
97Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
Speech to Video Synthesis (pose amp emotion)
98Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
99Suwajanakorn Supasorn Steven M Seitz and Ira Kemelmacher-Shlizerman Synthesizing Obama learning lip sync from audio SIGGRAPH 2017
Speech to Video Synthesis (mouth)
100
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning

83Greff Klaus Antti Rasmus Mathias Berglund Tele Hao Harri Valpola and Juergen Schmidhuber Tagger Deep unsupervised perceptual grouping NIPS 2016 [video] [code]
Spatio-Temporal Weak Labels
84Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
85
Audio Features from Visual weak labels
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Object amp Scenes recognition in videos by analysing the audio track (only)
86Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
87Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
88Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
89
Visualization of the video frames associated to the sounds that activate some of the last hidden units of Soundnet (conv7)
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Audio Features from Visual weak labels
90
Audio amp Visual features from alignement
90Arandjelović Relja and Andrew Zisserman Look Listen and Learn ICCV 2017
Audio and visual features learned by assessing alignement
91L Chen S Srivastava Z Duan and C Xu Deep Cross-Modal Audio-Visual Generation ACM International Conference on Multimedia Thematic Workshops 2017
Audio amp Visual features from alignement
92Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
93Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
Video to Speech Representations
CNN(VGG)
Frame from a silent video
Audio feature
Post-hoc synthesis
94Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
95Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
Speech to Video Synthesis (mouth)
96Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
97Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
Speech to Video Synthesis (pose amp emotion)
98Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
99Suwajanakorn Supasorn Steven M Seitz and Ira Kemelmacher-Shlizerman Synthesizing Obama learning lip sync from audio SIGGRAPH 2017
Speech to Video Synthesis (mouth)
100
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning

84Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
85
Audio Features from Visual weak labels
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Object amp Scenes recognition in videos by analysing the audio track (only)
86Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
87Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
88Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
89
Visualization of the video frames associated to the sounds that activate some of the last hidden units of Soundnet (conv7)
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Audio Features from Visual weak labels
90
Audio amp Visual features from alignement
90Arandjelović Relja and Andrew Zisserman Look Listen and Learn ICCV 2017
Audio and visual features learned by assessing alignement
91L Chen S Srivastava Z Duan and C Xu Deep Cross-Modal Audio-Visual Generation ACM International Conference on Multimedia Thematic Workshops 2017
Audio amp Visual features from alignement
92Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
93Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
Video to Speech Representations
CNN(VGG)
Frame from a silent video
Audio feature
Post-hoc synthesis
94Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
95Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
Speech to Video Synthesis (mouth)
96Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
97Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
Speech to Video Synthesis (pose amp emotion)
98Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
99Suwajanakorn Supasorn Steven M Seitz and Ira Kemelmacher-Shlizerman Synthesizing Obama learning lip sync from audio SIGGRAPH 2017
Speech to Video Synthesis (mouth)
100
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning

85
Audio Features from Visual weak labels
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Object amp Scenes recognition in videos by analysing the audio track (only)
86Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
87Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
88Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
89
Visualization of the video frames associated to the sounds that activate some of the last hidden units of Soundnet (conv7)
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Audio Features from Visual weak labels
90
Audio amp Visual features from alignement
90Arandjelović Relja and Andrew Zisserman Look Listen and Learn ICCV 2017
Audio and visual features learned by assessing alignement
91L Chen S Srivastava Z Duan and C Xu Deep Cross-Modal Audio-Visual Generation ACM International Conference on Multimedia Thematic Workshops 2017
Audio amp Visual features from alignement
92Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
93Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
Video to Speech Representations
CNN(VGG)
Frame from a silent video
Audio feature
Post-hoc synthesis
94Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
95Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
Speech to Video Synthesis (mouth)
96Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
97Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
Speech to Video Synthesis (pose amp emotion)
98Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
99Suwajanakorn Supasorn Steven M Seitz and Ira Kemelmacher-Shlizerman Synthesizing Obama learning lip sync from audio SIGGRAPH 2017
Speech to Video Synthesis (mouth)
100
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning

86Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
87Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
88Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
89
Visualization of the video frames associated to the sounds that activate some of the last hidden units of Soundnet (conv7)
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Audio Features from Visual weak labels
90
Audio amp Visual features from alignement
90Arandjelović Relja and Andrew Zisserman Look Listen and Learn ICCV 2017
Audio and visual features learned by assessing alignement
91L Chen S Srivastava Z Duan and C Xu Deep Cross-Modal Audio-Visual Generation ACM International Conference on Multimedia Thematic Workshops 2017
Audio amp Visual features from alignement
92Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
93Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
Video to Speech Representations
CNN(VGG)
Frame from a silent video
Audio feature
Post-hoc synthesis
94Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
95Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
Speech to Video Synthesis (mouth)
96Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
97Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
Speech to Video Synthesis (pose amp emotion)
98Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
99Suwajanakorn Supasorn Steven M Seitz and Ira Kemelmacher-Shlizerman Synthesizing Obama learning lip sync from audio SIGGRAPH 2017
Speech to Video Synthesis (mouth)
100
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
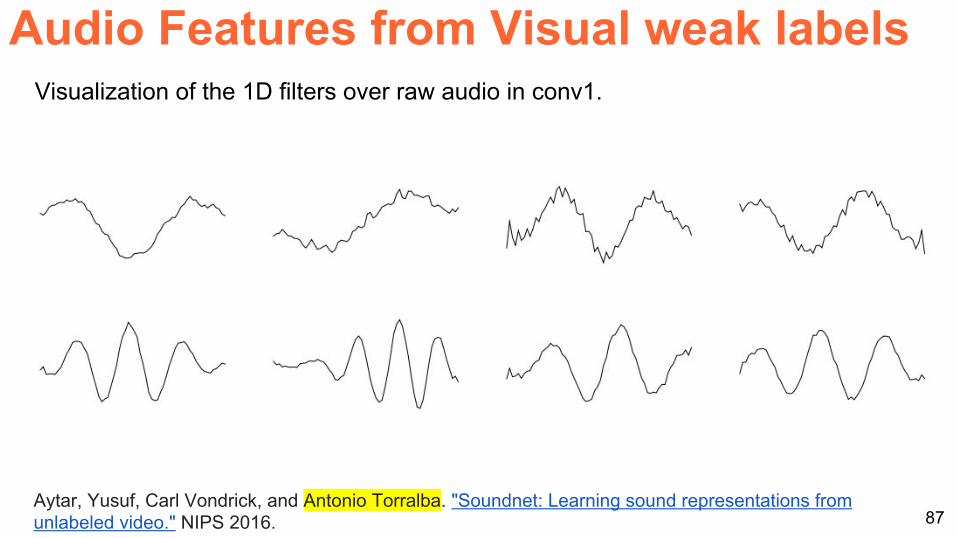
87Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
88Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
89
Visualization of the video frames associated to the sounds that activate some of the last hidden units of Soundnet (conv7)
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Audio Features from Visual weak labels
90
Audio amp Visual features from alignement
90Arandjelović Relja and Andrew Zisserman Look Listen and Learn ICCV 2017
Audio and visual features learned by assessing alignement
91L Chen S Srivastava Z Duan and C Xu Deep Cross-Modal Audio-Visual Generation ACM International Conference on Multimedia Thematic Workshops 2017
Audio amp Visual features from alignement
92Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
93Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
Video to Speech Representations
CNN(VGG)
Frame from a silent video
Audio feature
Post-hoc synthesis
94Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
95Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
Speech to Video Synthesis (mouth)
96Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
97Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
Speech to Video Synthesis (pose amp emotion)
98Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
99Suwajanakorn Supasorn Steven M Seitz and Ira Kemelmacher-Shlizerman Synthesizing Obama learning lip sync from audio SIGGRAPH 2017
Speech to Video Synthesis (mouth)
100
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning

88Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Visualization of the 1D filters over raw audio in conv1
Audio Features from Visual weak labels
89
Visualization of the video frames associated to the sounds that activate some of the last hidden units of Soundnet (conv7)
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Audio Features from Visual weak labels
90
Audio amp Visual features from alignement
90Arandjelović Relja and Andrew Zisserman Look Listen and Learn ICCV 2017
Audio and visual features learned by assessing alignement
91L Chen S Srivastava Z Duan and C Xu Deep Cross-Modal Audio-Visual Generation ACM International Conference on Multimedia Thematic Workshops 2017
Audio amp Visual features from alignement
92Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
93Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
Video to Speech Representations
CNN(VGG)
Frame from a silent video
Audio feature
Post-hoc synthesis
94Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
95Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
Speech to Video Synthesis (mouth)
96Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
97Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
Speech to Video Synthesis (pose amp emotion)
98Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
99Suwajanakorn Supasorn Steven M Seitz and Ira Kemelmacher-Shlizerman Synthesizing Obama learning lip sync from audio SIGGRAPH 2017
Speech to Video Synthesis (mouth)
100
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning

89
Visualization of the video frames associated to the sounds that activate some of the last hidden units of Soundnet (conv7)
Aytar Yusuf Carl Vondrick and Antonio Torralba Soundnet Learning sound representations from unlabeled video NIPS 2016
Audio Features from Visual weak labels
90
Audio amp Visual features from alignement
90Arandjelović Relja and Andrew Zisserman Look Listen and Learn ICCV 2017
Audio and visual features learned by assessing alignement
91L Chen S Srivastava Z Duan and C Xu Deep Cross-Modal Audio-Visual Generation ACM International Conference on Multimedia Thematic Workshops 2017
Audio amp Visual features from alignement
92Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
93Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
Video to Speech Representations
CNN(VGG)
Frame from a silent video
Audio feature
Post-hoc synthesis
94Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
95Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
Speech to Video Synthesis (mouth)
96Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
97Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
Speech to Video Synthesis (pose amp emotion)
98Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
99Suwajanakorn Supasorn Steven M Seitz and Ira Kemelmacher-Shlizerman Synthesizing Obama learning lip sync from audio SIGGRAPH 2017
Speech to Video Synthesis (mouth)
100
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning
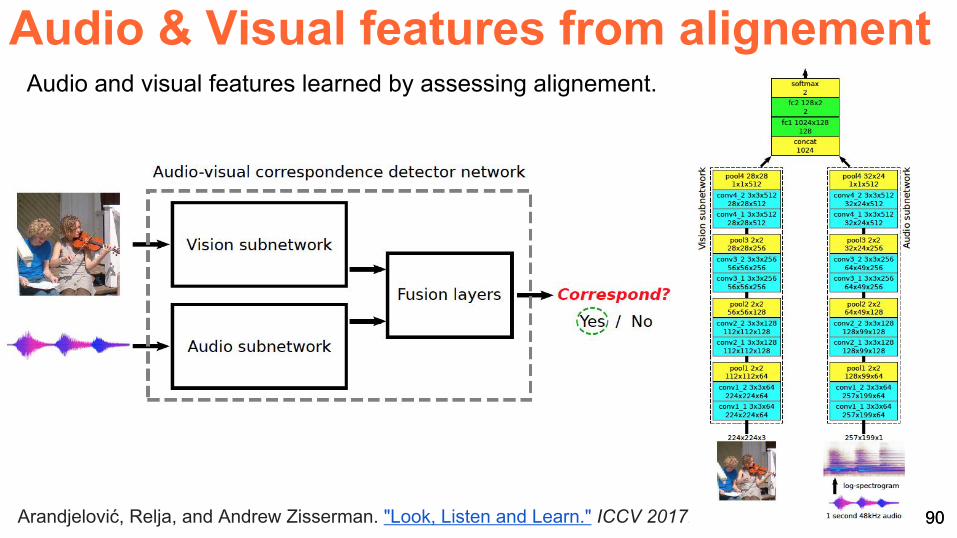
90
Audio amp Visual features from alignement
90Arandjelović Relja and Andrew Zisserman Look Listen and Learn ICCV 2017
Audio and visual features learned by assessing alignement
91L Chen S Srivastava Z Duan and C Xu Deep Cross-Modal Audio-Visual Generation ACM International Conference on Multimedia Thematic Workshops 2017
Audio amp Visual features from alignement
92Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
93Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
Video to Speech Representations
CNN(VGG)
Frame from a silent video
Audio feature
Post-hoc synthesis
94Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
95Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
Speech to Video Synthesis (mouth)
96Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
97Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
Speech to Video Synthesis (pose amp emotion)
98Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
99Suwajanakorn Supasorn Steven M Seitz and Ira Kemelmacher-Shlizerman Synthesizing Obama learning lip sync from audio SIGGRAPH 2017
Speech to Video Synthesis (mouth)
100
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning

91L Chen S Srivastava Z Duan and C Xu Deep Cross-Modal Audio-Visual Generation ACM International Conference on Multimedia Thematic Workshops 2017
Audio amp Visual features from alignement
92Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
93Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
Video to Speech Representations
CNN(VGG)
Frame from a silent video
Audio feature
Post-hoc synthesis
94Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
95Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
Speech to Video Synthesis (mouth)
96Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
97Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
Speech to Video Synthesis (pose amp emotion)
98Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
99Suwajanakorn Supasorn Steven M Seitz and Ira Kemelmacher-Shlizerman Synthesizing Obama learning lip sync from audio SIGGRAPH 2017
Speech to Video Synthesis (mouth)
100
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning

92Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
93Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
Video to Speech Representations
CNN(VGG)
Frame from a silent video
Audio feature
Post-hoc synthesis
94Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
95Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
Speech to Video Synthesis (mouth)
96Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
97Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
Speech to Video Synthesis (pose amp emotion)
98Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
99Suwajanakorn Supasorn Steven M Seitz and Ira Kemelmacher-Shlizerman Synthesizing Obama learning lip sync from audio SIGGRAPH 2017
Speech to Video Synthesis (mouth)
100
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning

93Ephrat Ariel and Shmuel Peleg Vid2speech Speech Reconstruction from Silent Video ICASSP 2017
Video to Speech Representations
CNN(VGG)
Frame from a silent video
Audio feature
Post-hoc synthesis
94Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
95Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
Speech to Video Synthesis (mouth)
96Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
97Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
Speech to Video Synthesis (pose amp emotion)
98Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
99Suwajanakorn Supasorn Steven M Seitz and Ira Kemelmacher-Shlizerman Synthesizing Obama learning lip sync from audio SIGGRAPH 2017
Speech to Video Synthesis (mouth)
100
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning

94Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
95Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
Speech to Video Synthesis (mouth)
96Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
97Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
Speech to Video Synthesis (pose amp emotion)
98Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
99Suwajanakorn Supasorn Steven M Seitz and Ira Kemelmacher-Shlizerman Synthesizing Obama learning lip sync from audio SIGGRAPH 2017
Speech to Video Synthesis (mouth)
100
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning

95Chung Joon Son Amir Jamaludin and Andrew Zisserman You said that BMVC 2017
Speech to Video Synthesis (mouth)
96Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
97Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
Speech to Video Synthesis (pose amp emotion)
98Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
99Suwajanakorn Supasorn Steven M Seitz and Ira Kemelmacher-Shlizerman Synthesizing Obama learning lip sync from audio SIGGRAPH 2017
Speech to Video Synthesis (mouth)
100
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning

96Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
97Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
Speech to Video Synthesis (pose amp emotion)
98Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
99Suwajanakorn Supasorn Steven M Seitz and Ira Kemelmacher-Shlizerman Synthesizing Obama learning lip sync from audio SIGGRAPH 2017
Speech to Video Synthesis (mouth)
100
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning

97Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
Speech to Video Synthesis (pose amp emotion)
98Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
99Suwajanakorn Supasorn Steven M Seitz and Ira Kemelmacher-Shlizerman Synthesizing Obama learning lip sync from audio SIGGRAPH 2017
Speech to Video Synthesis (mouth)
100
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning

98Karras Tero Timo Aila Samuli Laine Antti Herva and Jaakko Lehtinen Audio-driven facial animation by joint end-to-end learning of pose and emotion SIGGRAPH 2017
99Suwajanakorn Supasorn Steven M Seitz and Ira Kemelmacher-Shlizerman Synthesizing Obama learning lip sync from audio SIGGRAPH 2017
Speech to Video Synthesis (mouth)
100
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning

99Suwajanakorn Supasorn Steven M Seitz and Ira Kemelmacher-Shlizerman Synthesizing Obama learning lip sync from audio SIGGRAPH 2017
Speech to Video Synthesis (mouth)
100
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning

100
Outline
1 Motivation
2 Unsupervised Learning
3 Predictive Learning
4 Self-supervised Learning