university of michigan electrical engineering and computer science 1 data access partitioning for...
Post on 22-Dec-2015
216 views
TRANSCRIPT

1 University of MichiganElectrical Engineering and Computer Science
Data Access Partitioning for Data Access Partitioning for Fine-grain Parallelism on Fine-grain Parallelism on Multicore ArchitecturesMulticore Architectures
Michael Chu (Microsoft), Rajiv Ravindran (HP), Scott Mahlke
University of Michigan
April 19, 2023

2 University of MichiganElectrical Engineering and Computer Science
Multicore is HereMulticore is Here
• Power efficient design
• Decrease core complexity, Increase number of cores
• Intel Core 2 Duo (2006)AMD Athlon 64 X2 (2005)Sun Niagara (2005)
Image source: Intel

3 University of MichiganElectrical Engineering and Computer Science
LD
>>
ST
LD
+
/
>>
&
<<
ST
+
LD
LD
>>
ST
LD
+
/
>>
&
<<
ST
+
LD
Compiling in the Multicore EraCompiling in the Multicore Era• Coarse-grain vs fine-grain parallelism
LD
>>
ST
LD
+
/
>>
&
<<
ST
+
LD
Core Core
Core Core
Core
Core
Core Core Core
Core
Core
Core
Core Core Core Core
Core
Core
Core
Core
Core Core Core Core Core
Core
Core
Core
Core
Core
Core Core Core Core Core Core
Core 1 Core 2
RF RF
[Software Queues, PMUP 06],[Scalar Operand Network, HPCA 05]

4 University of MichiganElectrical Engineering and Computer Science
Objectives of this WorkObjectives of this Work
• Goal: detect and exploit available fine-grain parallelism• Compiler support is key for good performance
– Divide computation operations and data across cores– Maximize direct access to values you need
Cache 1 Cache 2
Core 1 Core 2
I F M I F M
LD
>>
&
LD
+
int x[100] int y[100]
5 University of MichiganElectrical Engineering and Computer Science
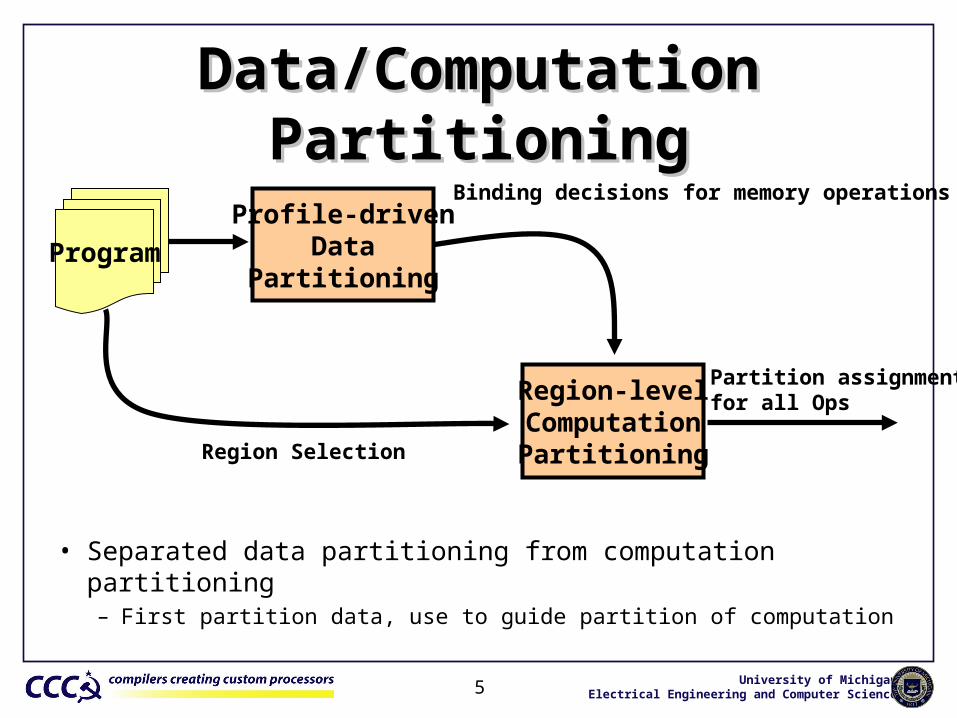
Data/Computation PartitioningData/Computation Partitioning
Profile-drivenData
PartitioningProgram
Binding decisions for memory operations
Partition assignmentfor all OpsRegion-level
ComputationPartitioningRegion Selection
• Separated data partitioning from computation partitioning– First partition data, use to guide partition of computation

6 University of MichiganElectrical Engineering and Computer Science
Data Partitioning for CachesData Partitioning for Caches
• Goals:– Maximize parallel computation– Reduce stall cycles
• Coherence traffic• Conflicts/misses
• Static analysis1
– Object granularity• Profile-driven partitioning
– Memory instruction granularity
Cache 1 Cache 2
Core 1 Core 2
I F M I F M
Coherence Network
1 Compiler-directed Object Partitioning for Multicluster Processors. [CGO 06]

7 University of MichiganElectrical Engineering and Computer Science
Memory Access GraphMemory Access Graph• Nodes: Memory operations in the
program– Node weight: working set size
• Edges: Relationship between memory operations– Edge weight: affinity
BB1
BB2

8 University of MichiganElectrical Engineering and Computer Science
...Load 2 Address 5Load 6 Address 3Load 1 Address 1Store 2 Address 5Load 3 Address 3Load 2 Address 4Load 1 Address 2Load 1 Address 1Store 3 Address 7Load 2 Address 8
...
Node Weight: Working Set EstimateNode Weight: Working Set Estimate
• Weighted average blocks required
Requires 5 cache blocks
2 2
11
10
3
1

9 University of MichiganElectrical Engineering and Computer Science
Edge Weight: Memory Op AffinityEdge Weight: Memory Op Affinity• Finds relationships between memory
accesses• Positive affinity: possible hit • Negative affinity: possible miss
C1 C2 C1 C2 C2 C2 C2 C1 C2 C2 C1 C1 C2 C2
Current Memory Access
... ...Memory Op
Block Address
Cache Line
LD1 LD2 LD4 ST1 LD3 LD2 ST1 LD2 LD1 LD2 LD4 LD2 LD4 LD4
B1 B2 B3 B4 B4 B2 B4 B1 B2 B4 B3 B3 B4 B1
Sliding Window
2 2
11
10 3
1
10 University of MichiganElectrical Engineering and Computer Science
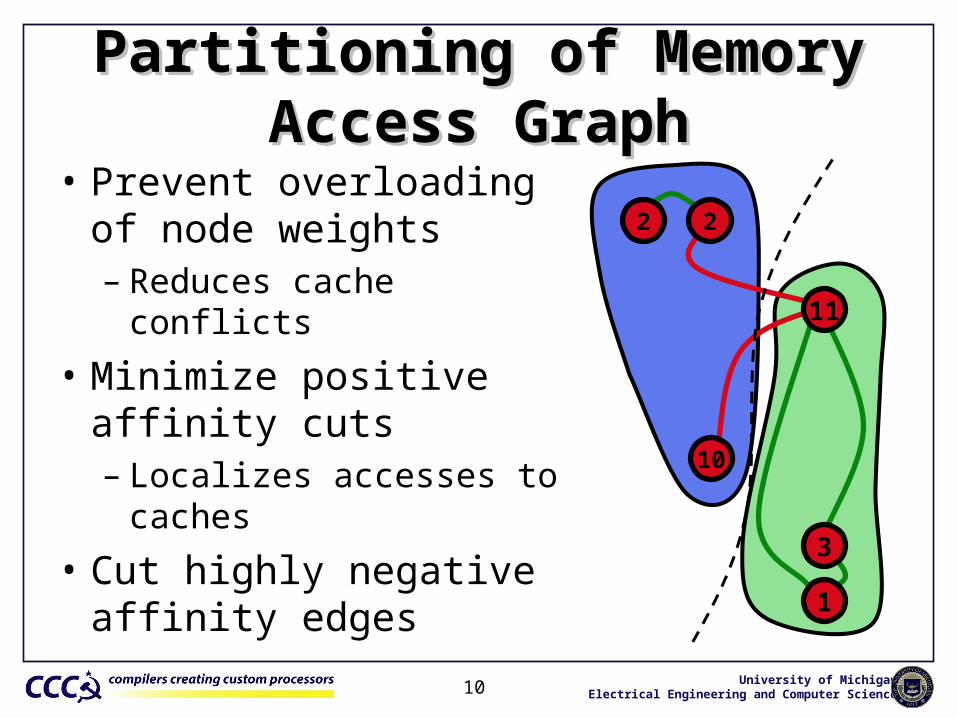
Partitioning of Memory Access GraphPartitioning of Memory Access Graph
• Prevent overloading of node weights– Reduces cache conflicts
• Minimize positive affinity cuts– Localizes accesses to caches
• Cut highly negative affinity edges
2 2
11
10
3
1

11 University of MichiganElectrical Engineering and Computer Science
Weight Calculation
GraphPartitioning
1
1
10
10
10
10
1
8
8
8
8 8
8
1 1
1 1 1
1 1
1 1
1
int main { int x; printf(…); . . .}
Program Region
Computation PartitioningComputation Partitioning
• Region-based Hierarchical Operation Partitioner [PLDI 03]– Modified Multilevel-FM graph partitioning algorithm
• Any standard operatition partitioner could be used– Must transfer data decisions down
12 University of MichiganElectrical Engineering and Computer Science
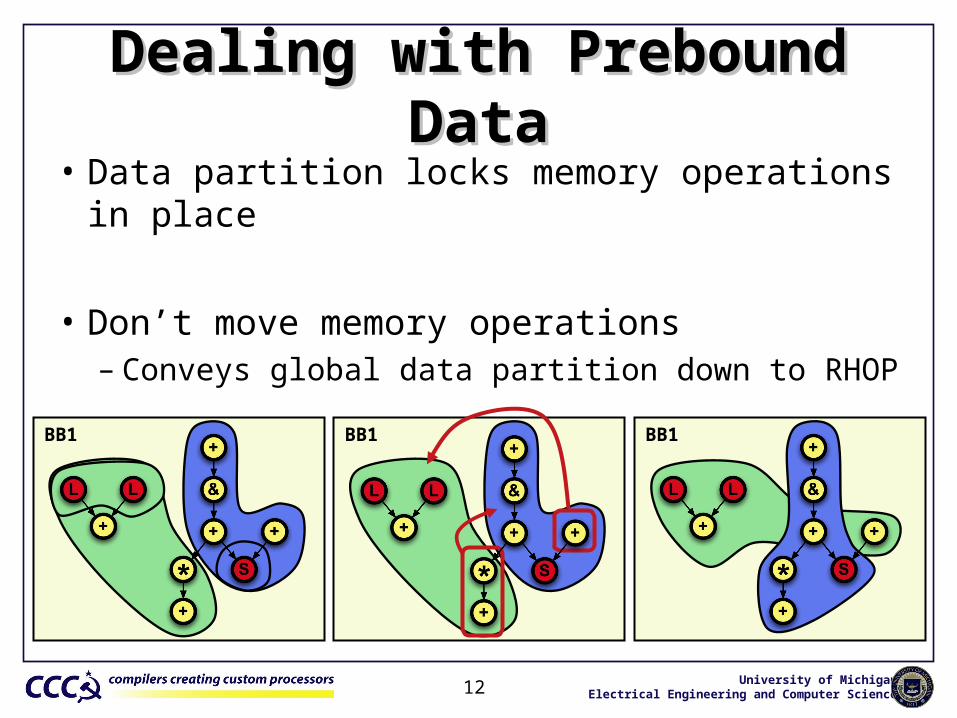
Dealing with Prebound DataDealing with Prebound Data
BB1
• Data partition locks memory operations in place
• Don’t move memory operations– Conveys global data partition down to RHOP
BB1 BB1

13 University of MichiganElectrical Engineering and Computer Science
Profile-driven PartitioningProfile-driven PartitioningBB1
BB2
Non-memory op
Memory op
Core 2
Core 1

14 University of MichiganElectrical Engineering and Computer Science
Experimental MethodologyExperimental Methodology
• Trimaran Compiler Toolset• Profiled/ran with different input sets• Machine model:
– 2, 4 cores– 512B, 1kB, 4kB, 8kB caches per core– 1, 2, 3 cycle operand network move latency per hop
15 University of MichiganElectrical Engineering and Computer Science
0
10
20
30
40
50
60
70
80
90
100
lyapunov
fsed sobelchannel
vitonelooplinescreen
cjpegdjpeg
g721encodeg721decodegsmencodegsmdecodempeg2encmpeg2decrawcaudiorawdaudio164.gzip175.vpr181.mcf
256.bzip2300.twolf171.swim172.mgrid177.mesa188.ammpAVERAGE
% Reduction in Snoops
Coherence Traffic ReductionCoherence Traffic ReductionKernels Mediabench AVGSPECint SPECfp
16 University of MichiganElectrical Engineering and Computer Science
-20
-10
0
10
20
30
40
50
60
70
80
90
100
lyapunov
fsedsobelchannel
vitonelooplinescreen
cjpegdjpeg
g721encodeg721decodegsmencodegsmdecodempeg2encmpeg2decrawcaudiorawdaudio164.gzip175.vpr181.mcf
256.bzip2300.twolf171.swim172.mgrid177.mesa188.ammpAverage
Average 2cycleAverage 3cycle
% Reduction in Stall Cycles
512 B 1 kB 4 kB 8 kB
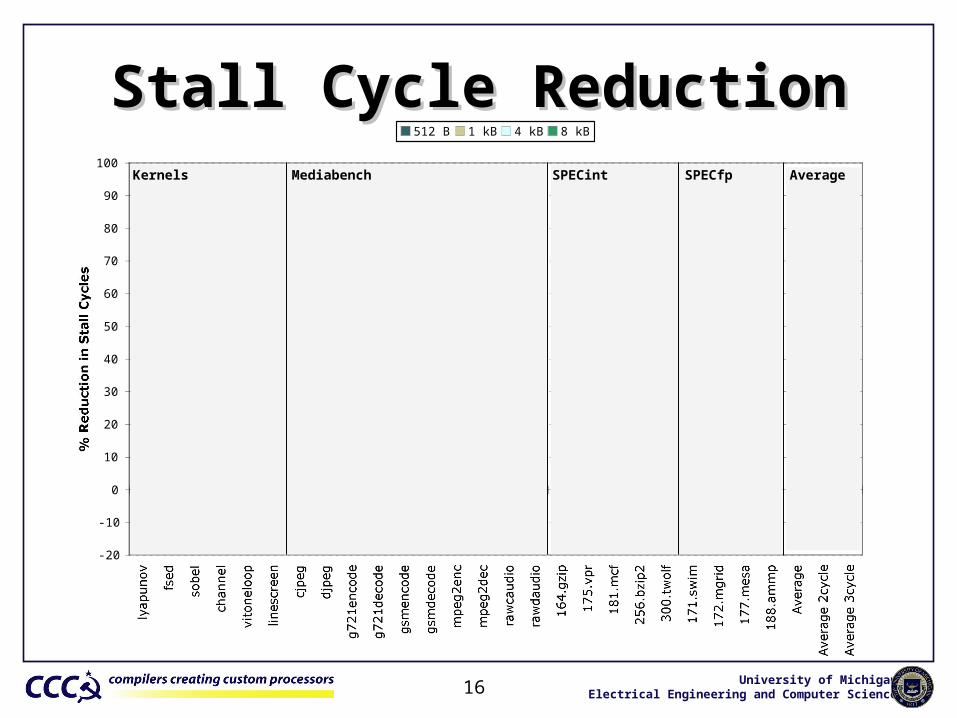
Stall Cycle ReductionStall Cycle ReductionKernels Mediabench SPECint SPECfp Average

17 University of MichiganElectrical Engineering and Computer Science
0.8
1.0
1.2
1.4
1.6
1.8
2.0
lyapunov
fsed sobelchannel
vitonelooplinescreen
cjpegdjpeg
g721encodeg721decodegsmencodegsmdecodempeg2encmpeg2decrawcaudiorawdaudio164.gzip175.vpr181.mcf
256.bzip2300.twolf171.swim172.mgrid177.mesa188.ammpAVERAGE
Speedup
Data Incognizant Data Partitioned Unified
Speedup Over Single CoreSpeedup Over Single CoreKernels Mediabench SPECfp AVGSPECint

18 University of MichiganElectrical Engineering and Computer Science
ConclusionConclusion
• Fine-grain parallelism can be exploited– Instruction-level parallelism is not dead– Coarse-grain parallelism is still important!
• Data-cognizant partitioning can improve performance– Improves stall cycles by 51%– Reduces coherence traffic by 87%

19 University of MichiganElectrical Engineering and Computer Science
Thank YouThank You
http://cccp.eecs.umich.eduhttp://cccp.eecs.umich.edu

20 University of MichiganElectrical Engineering and Computer Science
BackupBackup
21 University of MichiganElectrical Engineering and Computer Science
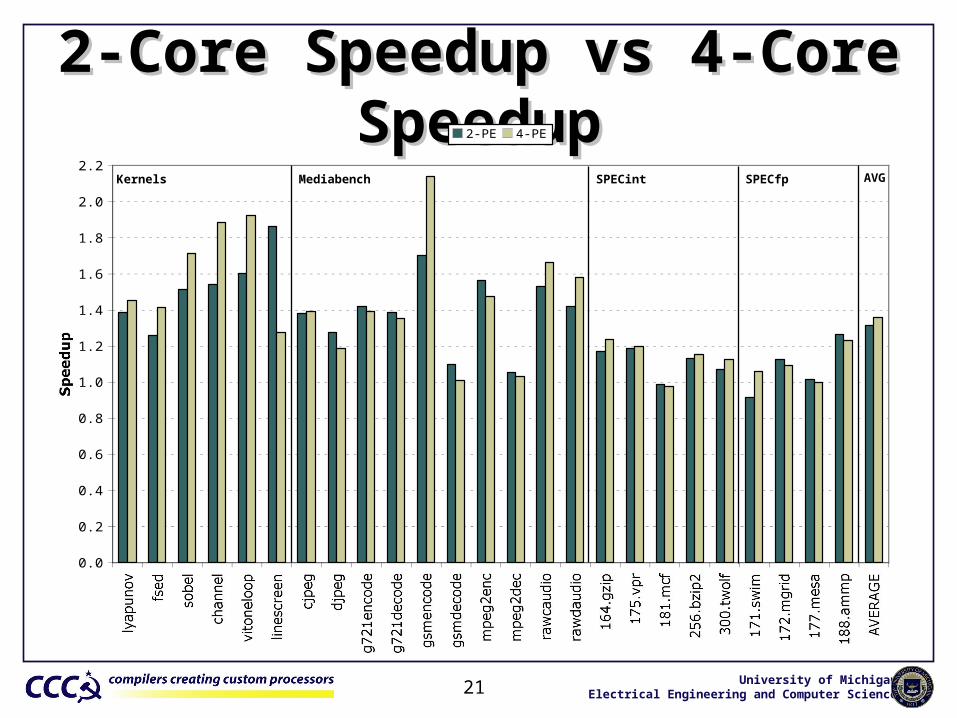
2-Core Speedup vs 4-Core Speedup2-Core Speedup vs 4-Core Speedup
0.0
0.2
0.4
0.6
0.8
1.0
1.2
1.4
1.6
1.8
2.0
2.2
lyapunov
fsedsobelchannel
vitonelooplinescreen
cjpegdjpeg
g721encodeg721decodegsmencodegsmdecodempeg2encmpeg2decrawcaudiorawdaudio164.gzip175.vpr181.mcf
256.bzip2300.twolf171.swim172.mgrid177.mesa188.ammpAVERAGE
Speedup
2-PE 4-PE
Kernels Mediabench SPECfp AVGSPECint

22 University of MichiganElectrical Engineering and Computer Science
Speedup with Four CoresSpeedup with Four Cores
0.5
1.0
1.5
2.0
2.5
3.0
lyapunov
fsed sobelchannel
vitonelooplinescreen
cjpegdjpegepic
unepic
g721encodeg721decodegsmencodegsmdecodempeg2encmpeg2decpegwitencpegwitdecrawcaudiorawdaudio164.gzip181.mcf300.twolf
AVERAGE
Speedup
Random Data Partitioned Unified
Kernels Mediabench SPEC AVG

23 University of MichiganElectrical Engineering and Computer Science
Multicore is the PastMulticore is the Past• Embedded Processors:
– Low power constraints– High performance requirements
• Examples:– Multiflow Trace [1992]– TI C6x [1997]– Lx ST/200 [2000]– Philips TM1300 [1999]– MIT Raw [1997]
Processor
I IF FM M
Data Memory
Register File
Processor
I F M
Data Memory
Register File
Intercluster Communication Network
Register File 1
Cluster 1
Register File 2
Cluster 2
I IF FM M
Data Cache 1 Data Cache 2Data Memory
Coherence Network

24 University of MichiganElectrical Engineering and Computer Science
Basics of Computation PartitioningBasics of Computation Partitioning• Goal: Minimize schedule length• Strategy:
– Exploit parallel resources– Minimize critical intercluster communication
+
>>
*
&
+
+ Intercluster move
Intercluster Communication Network
Register File
Cluster 1
Register File
Cluster 2
I IF FM M
Cache 1 Cache 2

25 University of MichiganElectrical Engineering and Computer Science
Problem #1: Local vs Region ScopeProblem #1: Local vs Region Scope
1 2
0
1
2
3
4
5
6
7
Local scope clustering Region scope clustering
1
2
6
3
7
4
8
5
9
11
12
10
1 2
0
1
2
3
4
5
6
7
1
2
6
10
5
9
11
12
3
7
4
8
1
2
6
3
7
4
8
5
9
11
12
10
1
2
6
3
7
10
12
11
4
8
5
9
mov
e
mov
emov
e
cycl
e
cycl
e
Examples: [BUG, UAS, B-ITER] Examples: [CARS, Aletà ‘01]

26 University of MichiganElectrical Engineering and Computer Science
Problem #2: Scheduler-centricProblem #2: Scheduler-centric• Cluster assignment during scheduling adds complexity• Detailed resource model/reservation tables is slow• Forces local decisions• Examples: [BUG, UAS]
1
2
6
3
7
4
8
5
9
11
12
10
X XX X
Cluster 1
X XX X
X XX X
Reservation Tables
X XX X
Cluster 2
X XX X
X XX X
cycle
1
2
1
2
1
2
cycle
1
2
1
2
1
2

27 University of MichiganElectrical Engineering and Computer Science
Our ApproachOur Approach• Opposite approach to conventional clustering• Hierarchical region view
– Graph partitioning strategy– Identify tightly coupled operations - treat uniformly
• Non scheduler-centric mindset– Pre-scheduling technique– Estimates schedule length
• Advantages: – Efficient, hierarchical, doesn’t complicate scheduler

28 University of MichiganElectrical Engineering and Computer Science
Region-based Hierarchical Operation Region-based Hierarchical Operation Partitioning (RHOP)Partitioning (RHOP)
• Code is considered region at a time• Weight calculation creates guides for good partitions• Partitioning clusters based on given weights
Weight Calculation
GraphPartitioning
1
1
10
10
10
10
1
8
8
8
8 8
8
1 1
1 1 1
1 1
1 1
1
int main { int x; printf(…); . . .}
Program Region
Region-based Hierarchical Operation Partitioning for Mulitcluster Processors [PLDI 03]

29 University of MichiganElectrical Engineering and Computer Science
Node WeightNode Weight
€
opwgtc =1
#ops that can execute on c in1 cycle
++
++
&&
I F M B
Register File
Dedicated Resources
Accounts for FU’s
• Nodes: operations in the scheduling region
• Metric for resource usage– Resources used by a single
operation per cycle• Used to estimate
overcommitment of resources

30 University of MichiganElectrical Engineering and Computer Science
Edge WeightEdge Weight• Edges: data flow between operations• Slack distribution allocates slack to certain edges
– Edge slack = identifies preferred places to cut edges– First come, first serve method used
11 22
33 55 66
1010
77
1111
1414
13131212
44
88 99
0
0
0
0
0
1 1 1 1
2 11
1
H H
H
H
H L
L
0 0 0
01
0M M M M
ML

31 University of MichiganElectrical Engineering and Computer Science
RHOP - Partitioning PhaseRHOP - Partitioning Phase• Modified Multilevel-FM algorithm [Fiduccia ‘82]• Multilevel graph partitioning consists of two stages
1. Coarsening stage2. Refinement stage
Cluster 1
Cluster 2

32 University of MichiganElectrical Engineering and Computer Science
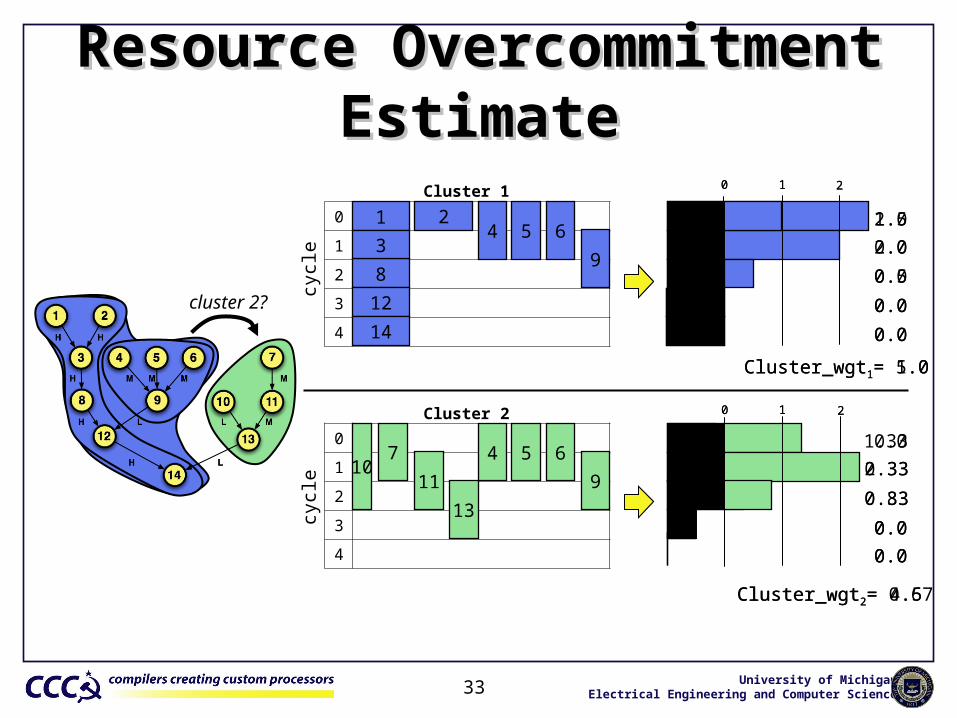
Cluster RefinementCluster Refinement
• 3 questions to answer:1. How good is the current partition? 2. Which cluster should operations move from?3. How profitable is it to move X from cluster A to B?
Cluster 1
Cluster 2
move to cluster 2?
33 University of MichiganElectrical Engineering and Computer Science
Resource Overcommitment EstimateResource Overcommitment Estimate
0
1
2
3
4
4 6
9
5
Cluster 1
Cluster 2
cycl
ecy
cle
8
12
14
1 2
3
0
1
2
3
4
7
11
13
10
0 1 2
2.5
2.0
0.5
0.0
0.0
0 1 2
Cluster_wgt1= 5.0
0.0
0.33
0.33
0.0
0.0
Cluster_wgt2= 0.67
4 6
9
5
1.0
0.0
0.0
0.0
0.0
0 1 2
Cluster_wgt1= 1.0
1.33
2.33
0.83
0.0
0.0
0 1 2
Cluster_wgt2= 4.5
cluster 2?
34 University of MichiganElectrical Engineering and Computer Science
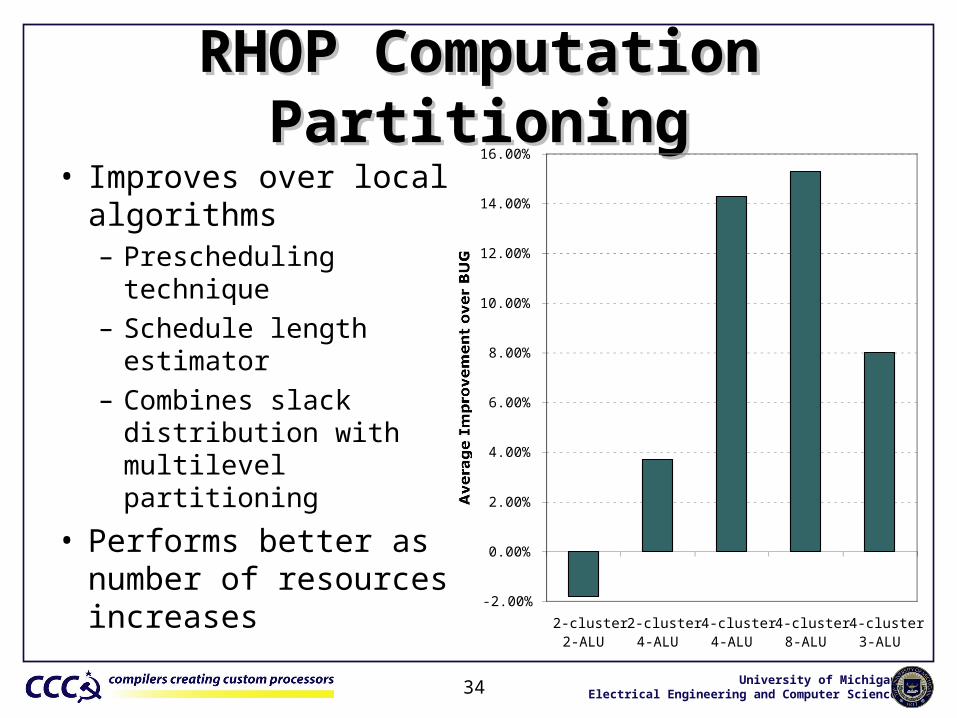
RHOP Computation PartitioningRHOP Computation Partitioning• Improves over local
algorithms– Prescheduling technique– Schedule length estimator– Combines slack
distribution with multilevel partitioning
• Performs better as number of resources increases
-2.00%
0.00%
2.00%
4.00%
6.00%
8.00%
10.00%
12.00%
14.00%
16.00%
2-cluster2-ALU
2-cluster4-ALU
4-cluster4-ALU
4-cluster8-ALU
4-cluster3-ALU
Average Improvement over BUG

35 University of MichiganElectrical Engineering and Computer Science
Profile-driven Data PartitioningProfile-driven Data Partitioning• Static analysis: coarse-grain partition
– Object granularity
• Profile: fine-grain partition– Memory instruction granularity
• Global-view for data– Consider memory relationships
throughout program
Static Data Partition
Profile-guided Partition
struct foo int bar
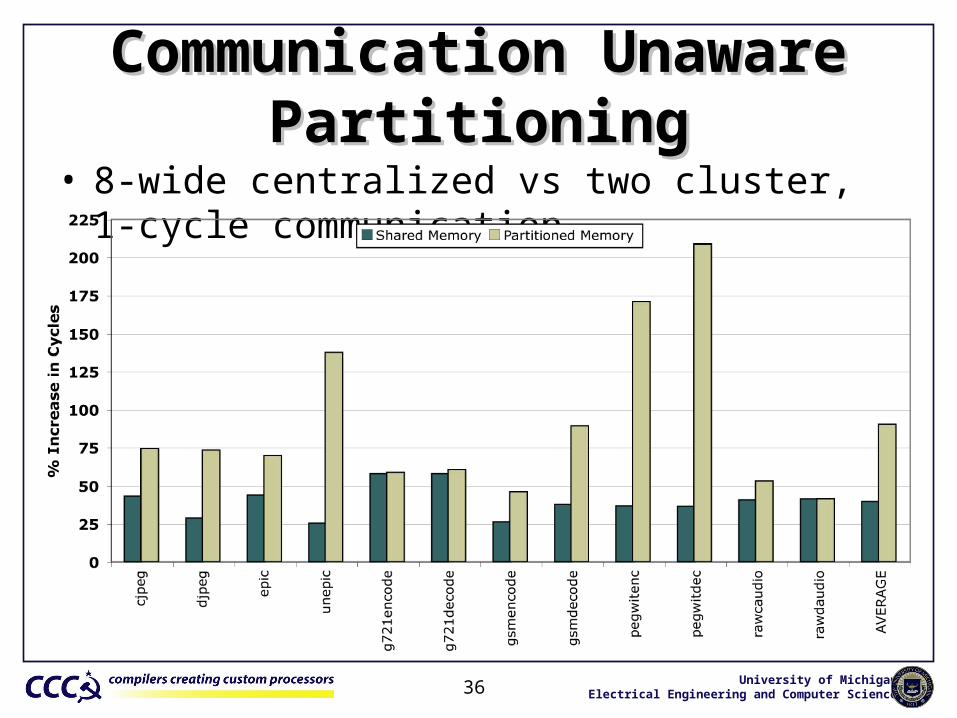
36 University of MichiganElectrical Engineering and Computer Science
Communication Unaware PartitioningCommunication Unaware Partitioning• 8-wide centralized vs two cluster, 1-cycle communication

37 University of MichiganElectrical Engineering and Computer Science
Overall Performance ImprovementOverall Performance Improvement
-10
-5
0
5
10
15
20
25
30
lyapunov
fsed sobelchannel
vitonelooplinescreen
epicunepic
g721encodeg721decodegsmencodegsmdecodempeg2encmpeg2decpegwitencpegwitdecrawcaudiorawdaudioAverage
Average 2cycleAverage 3cycle
% Improvement in Performance
512 B 1 kB 4 kB 8 kB
Kernels Mediabench Average

38 University of MichiganElectrical Engineering and Computer Science
Next Steps: Auto ParallelizationNext Steps: Auto Parallelization
• Integrate fine and coarse-grain parallelism– Better take advantage of 100’s of cores
• Future strategies for general parallelization– Analyze memory/data access patterns between threads– Break, untangle dependencies– New parallel programming models
• Balance data partitioning decisions with computation

39 University of MichiganElectrical Engineering and Computer Science
Edge Weight: Memory Op AffinityEdge Weight: Memory Op Affinity
• Finds relationships between memory accesses• Positive affinity: possible hit • Negative affinity: possible miss
Memory OpAccessedBlock
LD1 LD2 LD4 ST1 LD3 LD2 ST1 LD2 LD1 LD2 LD4 LD2 LD4 LD4
B1 B2 B3 B4 B4 B2 B4 B1 B2 B4 B3 B3 B4 B1
C1 C2 C1 C2 C2 C2 C2 C1 C2 C2 C1 C1 C2 C2
Current Memory Access
Sliding Window
... ...Memory Op
Block Address
Cache Line

40 University of MichiganElectrical Engineering and Computer Science
RHOP Computation PartitioningRHOP Computation Partitioning• Improves over local algorithms
– Prescheduling technique– Estimates on schedule length used
instead of scheduler– Combines slack distribution with
multilevel partitioning• Performs better as number of
resources increases
Machine RHOP vs BUG
2-cluster8-issue
-1.8%
2-cluster10-issue
3.7%
4-cluster16-issue
14.3%
4-cluster18-issue
15.3%
4-cluster H13-issue
8.0%
Average Improvement
41 University of MichiganElectrical Engineering and Computer Science
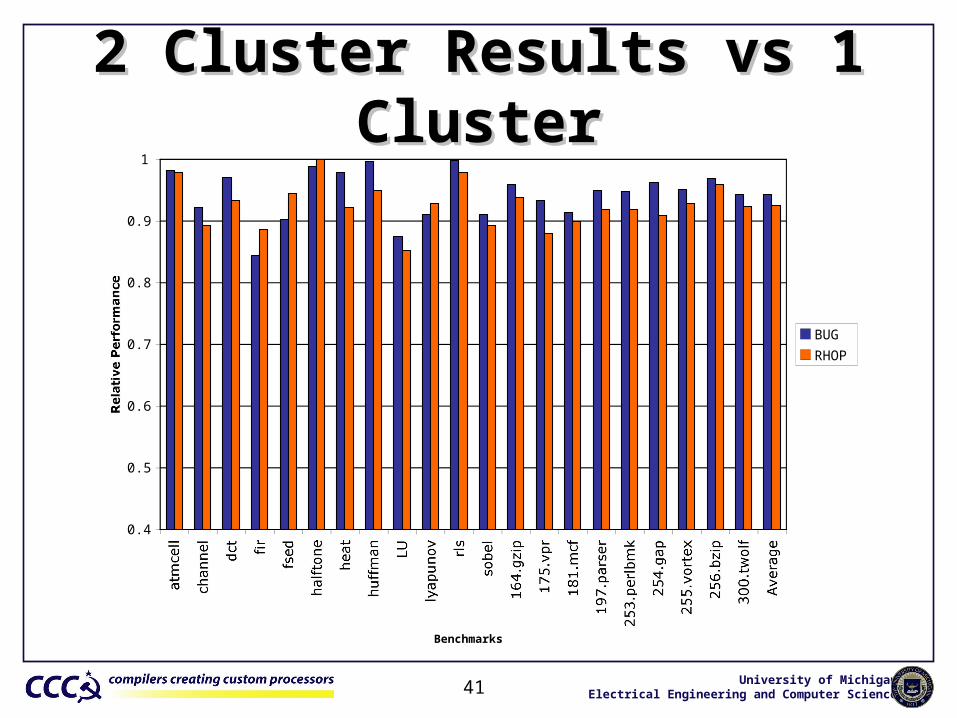
2 Cluster Results vs 2 Cluster Results vs 11 Cluster Cluster
0.4
0.5
0.6
0.7
0.8
0.9
1
atmcellchannel
dct firfsed
halftone
heat
huffman
LU
lyapunov
rlssobel
164.gzip175.vpr181.mcf197.parser
253.perlbmk
254.gap255.vortex
256.bzip300.twolfAverage
Benchmarks
Relative Performance
BUG
RHOP

42 University of MichiganElectrical Engineering and Computer Science
4 Cluster Results vs 4 Cluster Results vs 11 Cluster Cluster
0.4
0.5
0.6
0.7
0.8
0.9
1
atmcellchannel
dct firfsed
halftone
heat
huffman
LU
lyapunov
rlssobel
164.gzip175.vpr181.mcf197.parser
253.perlbmk
254.gap255.vortex
256.bzip300.twolfAverage
Benchmarks
Relative Performance
BUG
RHOP

43 University of MichiganElectrical Engineering and Computer Science
Experimental EvaluationExperimental Evaluation• Trimaran toolset: a retargetable VLIW compiler• Evaluated DSP kernels and SPECint2000• Baseline: centralized processor, sum of clustered resources
Name Configuration
2-cluster8-issue
2 Homogenous clusters
1 I, 1 F, 1 M, 1 B per cluster
2-cluster10-issue
2 Homogenous clusters
2 I, 1 F, 1 M, 1 B per cluster
4-cluster16-issue
4 Homogenous clusters
1 I, 1 F, 1 M, 1 B per cluster
4-cluster18-issue
4 Homogenous clusters
2 I, 1 F, 1 M, 1 B per cluster
4-cluster H 13-issue
4 Heterogeneous clusters
IM, IF, IB and IMF clusters
• 64 registers per cluster
• Latencies similar to Itanium
• Perfect caches

44 University of MichiganElectrical Engineering and Computer Science
Architectural ModelArchitectural Model
• Solve the easier problem: computation partitioning– Assume centralized, shared data memory– Accessible from each cluster with uniform latency
Centralized Data Memory
Cluster 1 Cluster 2
I F M I F M

45 University of MichiganElectrical Engineering and Computer Science
Cluster 1 Cluster 2
I F M I F M
Architectural ModelArchitectural Model
• Use scratchpad memories– Compiler-controlled memory– Each cluster has one memory– Each object placed in one specific memory– Data object available in the memory throughout the
lifetime of the program
int x[100] foo int y[100]

46 University of MichiganElectrical Engineering and Computer Science
Data Mem 1 Data Mem 2
Cluster 1 Cluster 2
I F M I F M
Problem: Partitioning of DataProblem: Partitioning of Data
• Determine object placement into data memories• Limited by:
– Memory sizes/capacities– Computation operations related to data
• Partitioning relevant to caches and scratchpad memories
int x[100] struct foo
int y[100]

47 University of MichiganElectrical Engineering and Computer Science
Data Unaware PartitioningData Unaware Partitioning
Lose average 30% performance by ignoring data
48 University of MichiganElectrical Engineering and Computer Science
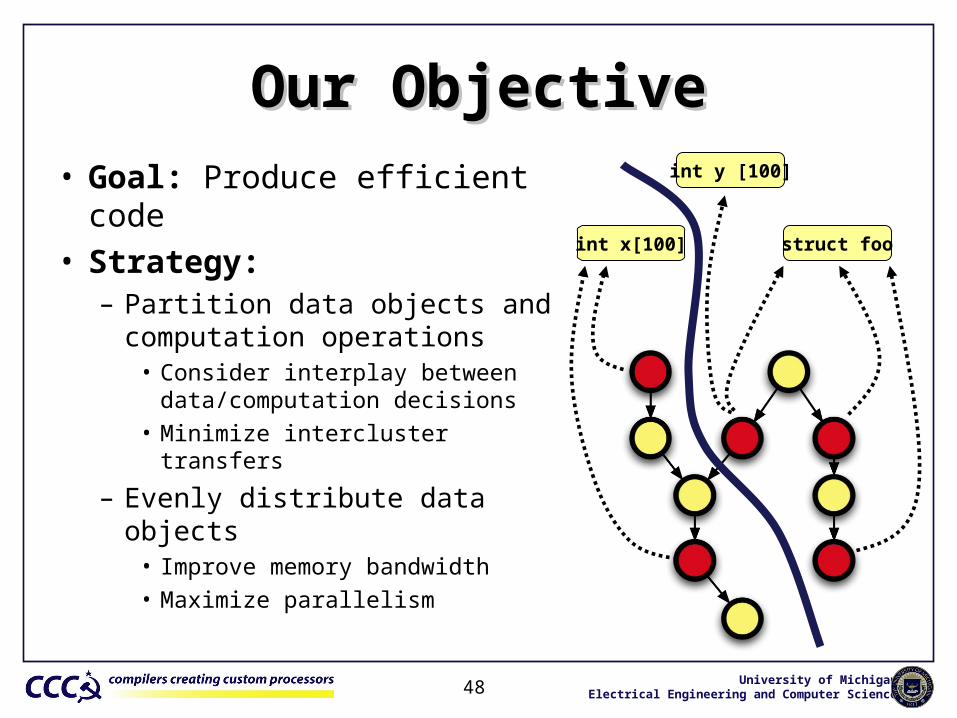
Our ObjectiveOur Objective• Goal: Produce efficient code• Strategy:
– Partition data objects and computation operations
• Consider interplay between data/computation decisions
• Minimize intercluster transfers
– Evenly distribute data objects• Improve memory bandwidth• Maximize parallelism
int x[100] struct foo
int y [100]
49 University of MichiganElectrical Engineering and Computer Science
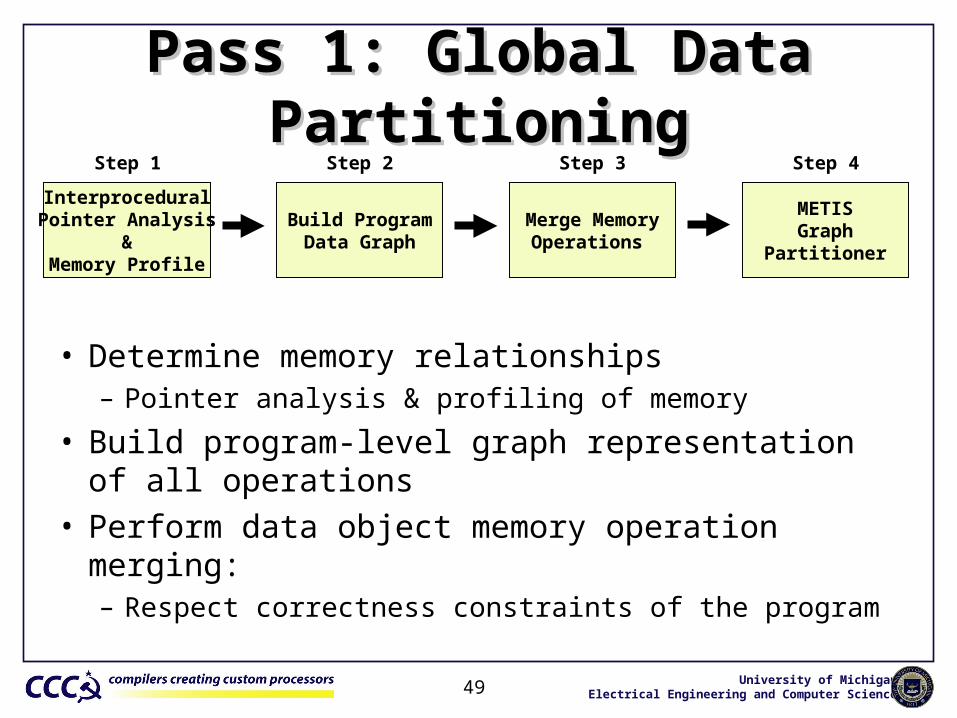
Pass 1: Global Data PartitioningPass 1: Global Data Partitioning
• Determine memory relationships– Pointer analysis & profiling of memory
• Build program-level graph representation of all operations• Perform data object memory operation merging:
– Respect correctness constraints of the program
InterproceduralPointer Analysis
&Memory Profile
Step 1
Merge MemoryOperations
Step 3
METISGraph
Partitioner
Step 4
Build ProgramData Graph
Step 2

50 University of MichiganElectrical Engineering and Computer Science
• Nodes: Operations, either memory or non-memory– Memory operations: loads, stores, malloc callsites
• Edges: Data flow between operations• Node weight: Data object size
– Sum of data sizes forreferenced objects
• Object size determined by:– Globals/locals: pointer analysis– Malloc callsites: memory profile
Global Data Graph RepresentationGlobal Data Graph Representation
int x[100] struct foomalloc site 1
400 bytes
1 Kbyte
200bytes

51 University of MichiganElectrical Engineering and Computer Science
Experimental MethodologyExperimental Methodology
• Compared to:
• 2 Clusters:– One Integer, Float, Memory, Branch unit per cluster
• All results relative to a unified, dual-ported memory
Data Partitioning Computation Partition
Global Global-view
Data-centric
Know data location
Greedy Region-view
Greedy computation-centric
Know data location
Data Unaware None, assume unified memory Assume unified memory
Unified Memory N/A Unified memory

52 University of MichiganElectrical Engineering and Computer Science
Performance: 1-cycle Remote AccessPerformance: 1-cycle Remote Access
UnifiedMemory

53 University of MichiganElectrical Engineering and Computer Science
Performance: 10-cycle Remote AccessPerformance: 10-cycle Remote Access
UnifiedMemory

54 University of MichiganElectrical Engineering and Computer Science
Global Data PartitioningGlobal Data Partitioning
• Global Data Partitioning– Data placement: first-order design principle– Global data-centric partition of computation– Phased ordered approach
• Global-view for decisions on data • Region-view for decisions on computation
• Achieves 95.2% performance of a unified memory on partitioned memories
55 University of MichiganElectrical Engineering and Computer Science
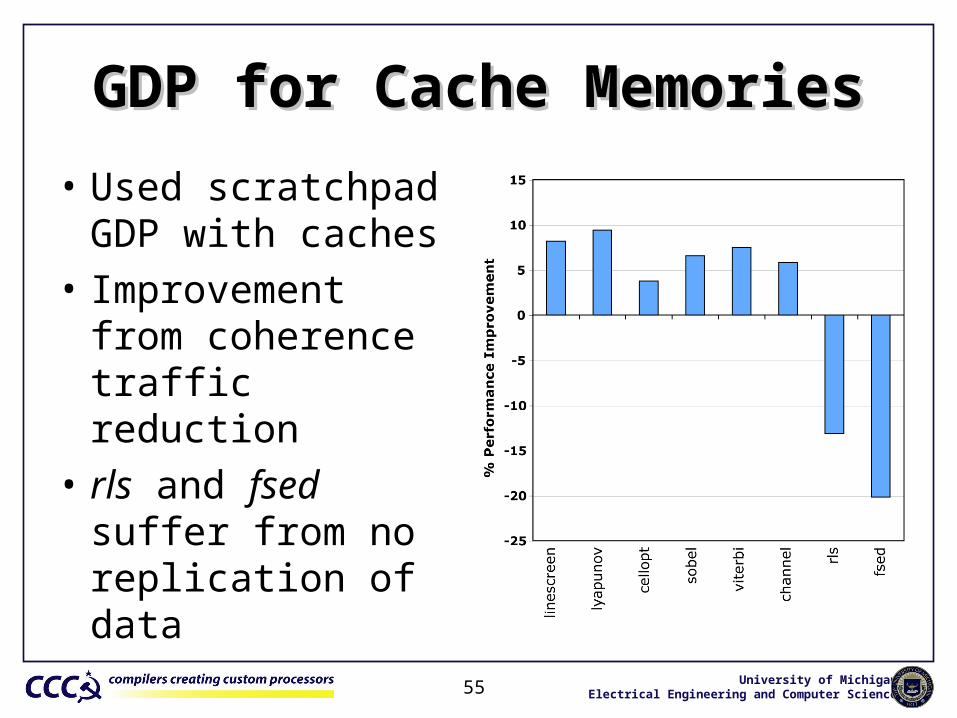
GDP for Cache MemoriesGDP for Cache Memories
• Used scratchpad GDP with caches
• Improvement from coherence traffic reduction
• rls and fsed suffer from no replication of data
56 University of MichiganElectrical Engineering and Computer Science
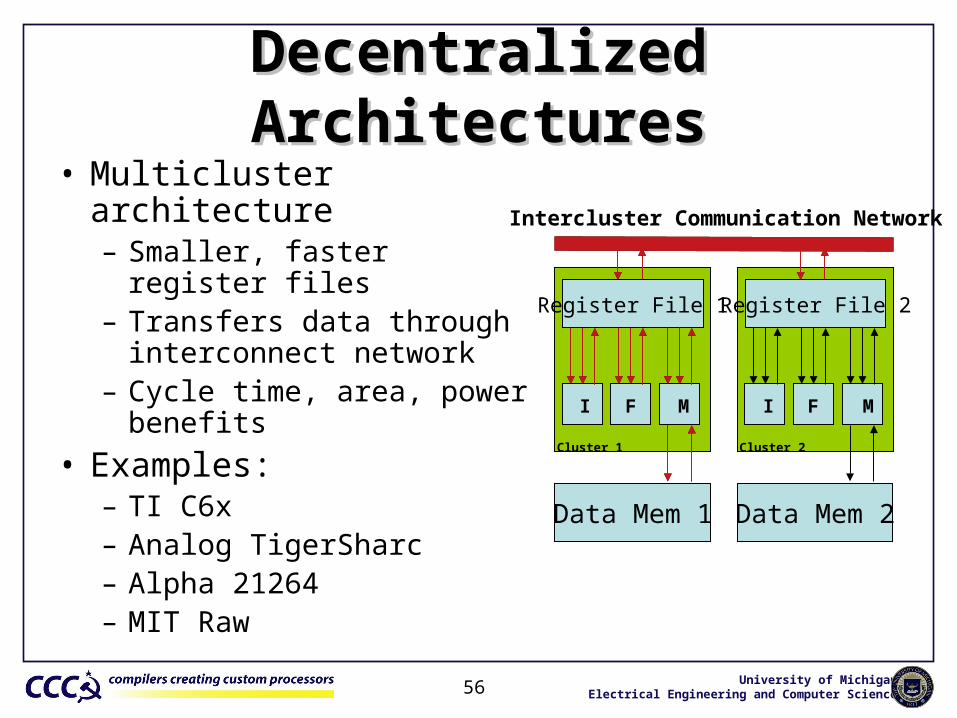
Decentralized ArchitecturesDecentralized Architectures• Multicluster architecture
– Smaller, faster register files– Transfers data through
interconnect network– Cycle time, area, power benefits
• Examples: – TI C6x – Analog TigerSharc– Alpha 21264– MIT Raw
Intercluster Communication Network
Register File 1
Cluster 1
Register File 2
Cluster 2
I IF FM M
Data Mem 1 Data Mem 2
57 University of MichiganElectrical Engineering and Computer Science
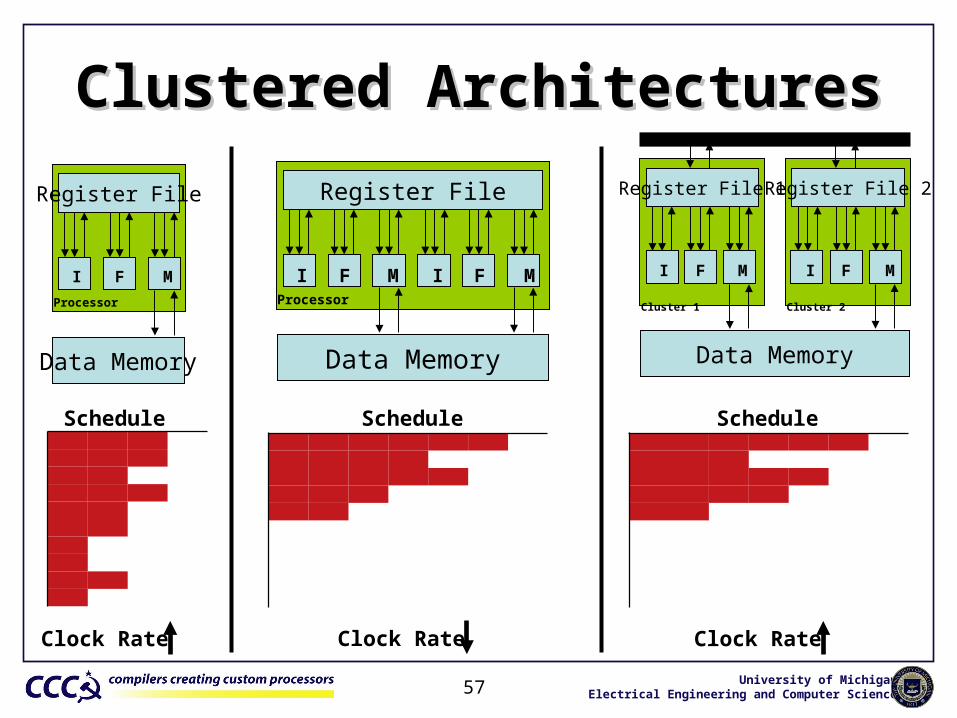
Clustered ArchitecturesClustered Architectures
Processor
I IF FM M
Data Memory
Register File
Processor
I F M
Data Memory
Register File Register File 1
Cluster 1
Register File 2
Cluster 2
I IF FM M
Data Memory
Schedule Schedule Schedule
Clock Rate Clock RateClock Rate