universidade federal de vicosa - qe - computer … · universidade federal de vicosa run time...
TRANSCRIPT

Universidade Federal de Vicosa
Run time adaptive processing units using coarse and fine grain
reconfigurable fabric
Ricardo dos Santos [email protected]
Sabbatical TU Delft in collaboration with Stephan Wong

Outline
Where is Vicosa ?
Research Lines
Big Picture: Run Time
1. Coarse-Grained Architecture and Modulo Scheduling - SAMOS paper - Paper to submit
2. Placement and Routing for FPGA - FPL paper

Where in the world is Viçosa?
Luigi Carro - UFRGS
me

Brazil - Minas Gerais - Viçosa
Brazil:
area: 8.514.877 km2 (5th) population: 192 million (5th) economy:
GDP: U$ 2,5 trillion (6th) per capita: U$ 13.000

1700km Porto Alegre - UFRGS
Porto Alegre


UNIVERSIDADE FEDERAL DE VIÇOSA
Number of students: 20.517 undergraduate: 14.720 graduate: 2.791 graduate non degree: 1.293 high school: 1713

Student Life $
No tuition fees for exchange students Master and PhD students can apply for a
regular Brazilian scholarship : € 500.00 / month for Master € 750.00 / month for PhD
university restaurant meals:< € 1 for undergraduate and graduate students room in a student house:
around € 160.00 / month

UndergraduateAgribusinessAgronomyAnimal ScienceAgricultural EconomicsAgricultural EngineeringEnvironmental EngineeringDairy ScienceForestryBiochemistryBiological SciencesMedicineNursingNutritionPhysical EducationVeterinary Medicine
ArchitectureChemistryChemical EngineeringCivil Engineering
Computer ScienceElectrical EngineeringFood EngineeringMathematicsPhysicsProduction EngineeringAdministrationBusiness AdministrationEconomicsGeographyHistoryLaw....

GraduateAgricultural Sciences
Agriculture BiochemistryAgricultural EngineeringAgricultural MeteorologyAgrochemistryAgroecologyAgricultural MicrobiologyCellulose and PaperEntomologyForestryGenetics and Breeding
Plant Health ProtectionPlant PathologyPlant ProductionRural ExtensionSoils and Plant Nutrition

Biological and Health SciencesMicrobiologyAnimal BiologyAnimal ScienceBotanyEcologyCellular BiologyNutritionPhysical EducationPlant ScienceVeterinary Medicine
Graduate

Exact SciencesApplied PhysicsApplied StatisticsArchitectureCivil EngineeringComputer Science MscFood ScienceMathematics
Graduate

Research
* GPU/FPGA and Bioinformatics:
Gene Regulatory Networks
* Interconnections: run time Multistage Networks
* run time scheduling, placement and routing for CGRA
* run time FPGA place&route

Goals.....
* algorithms for just-in-time analysis of binary code
* runtime scheduling, placement and routing
* reconfigurable fabric architectures and hardware support for runtime accelerator implementation

Big Picture
Sofware Apps
VEX VEX
Accelerators:
CGRA
FPGA
Per program phase;Minimum energy;Max performance
ISA
VEX VEXVEX
Previous Work

Outline
Where is Vicosa ?
Big Picture: Run Time
1. Coarse-Grained Architectures and Modulo Scheduling - SAMOS paper - Paper to submit
2. Placement and Routing for FPGA - FPL paper

13th International Conference onEmbedded Computer Systems: Architectures,
MOdeling, and Simulation
Samos, Greece, July 15–18,2013
A Just-In-Time Modulo Scheduling for Virtual Coarse-Grained Reconfigurable
Architectures
Ricardo Ferreira, Vinicius Duarte, Waldir MeirelesUniversidade Federal de Viçosa, Brazil
Email:[email protected]
Monica Pereira, Luigi Carro, and Stephan WongUFRN, Brazil UFRGS,Brazil TU Delft
Netherlands

Stream Computing
Every day, we create 2.5 quintillion bytes of data — so much that 90% of the data in the world today has been created in the last two years alone.
IBM Big-Data

Modulo Scheduling = software Pipeline
A B
C E
F
D
G H
I J
A B
C E
F
D
G H
I J
A B
C E
F
D
G H
I J
A B
C E
F
D
G H
I J
A B
C E
F
D
G H
I J
A B
C E
F
D
G H
I J
A B
C E
F
D
G H
I J
A B
C E
F
D
G H
I J
Iteration i
Iteration i+1
Iteration i+2
Iteration i+3
At same time, all operations are executed.....
One Clock Cycle THROUGHPUT !
ILP=10
Tim
e

Scheduling and Mapping in a CGRA
A B
C E
F
D
G H
I J
A B
C E
F
D
G H
I J
A B
C E
F
D
G H
I J
A B
C E
F
D
G H
I J
A B
C E
F
D
G H
I J
A B
C E
F
D
G H
I J
A B
C E
F
D
G H
I J
A B
C E
F
D
G H
I J
Iteration i
Iteration i+1
Iteration i+2
Iteration i+3
Physical Architecture
FU
FU
FU
FU
FU
FU
FU
FU
FU
FU
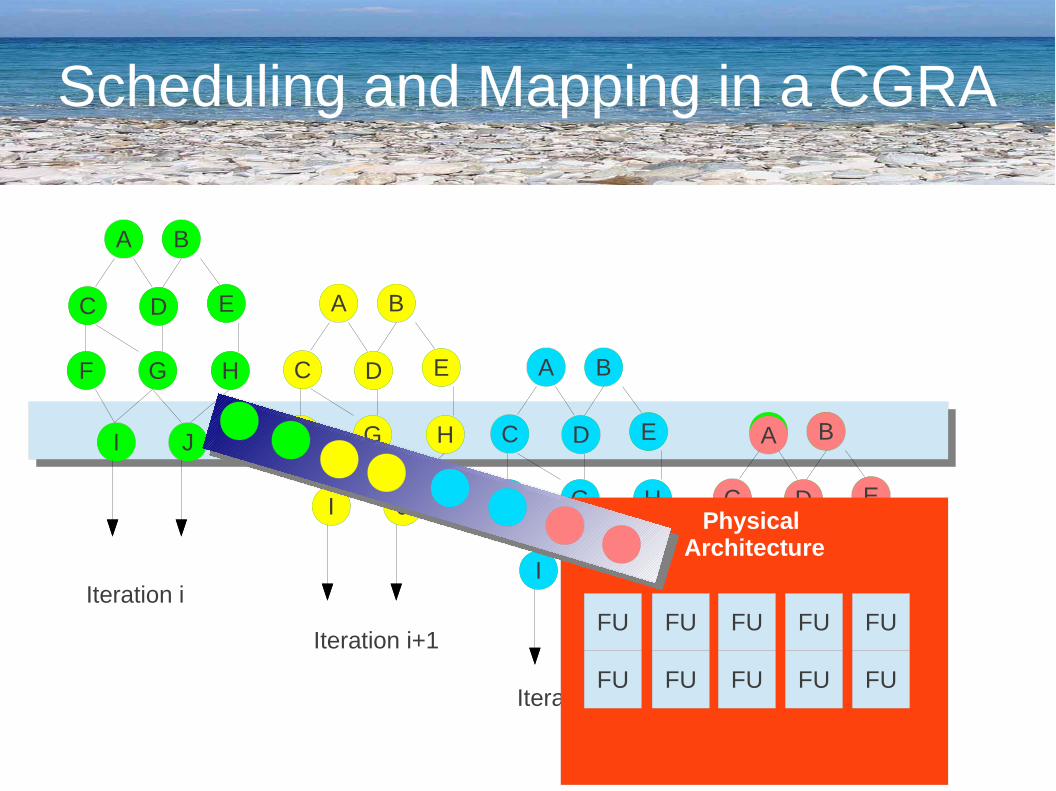
Scheduling and Mapping in a CGRA
A B
C E
F
D
G H
I J
A B
C E
F
D
G H
I J
A B
C E
F
D
G H
I J
A B
C E
F
D
G H
I J
A B
C E
F
D
G H
I J
A B
C E
F
D
G H
I J
A B
C E
F
D
G H
I J
A B
C E
F
D
G H
I J
Iteration i
Iteration i+1
Iteration i+2
Iteration i+3
Physical Architecture
FU
FU
FU
FU
FU
FU
FU
FU
FU
FU
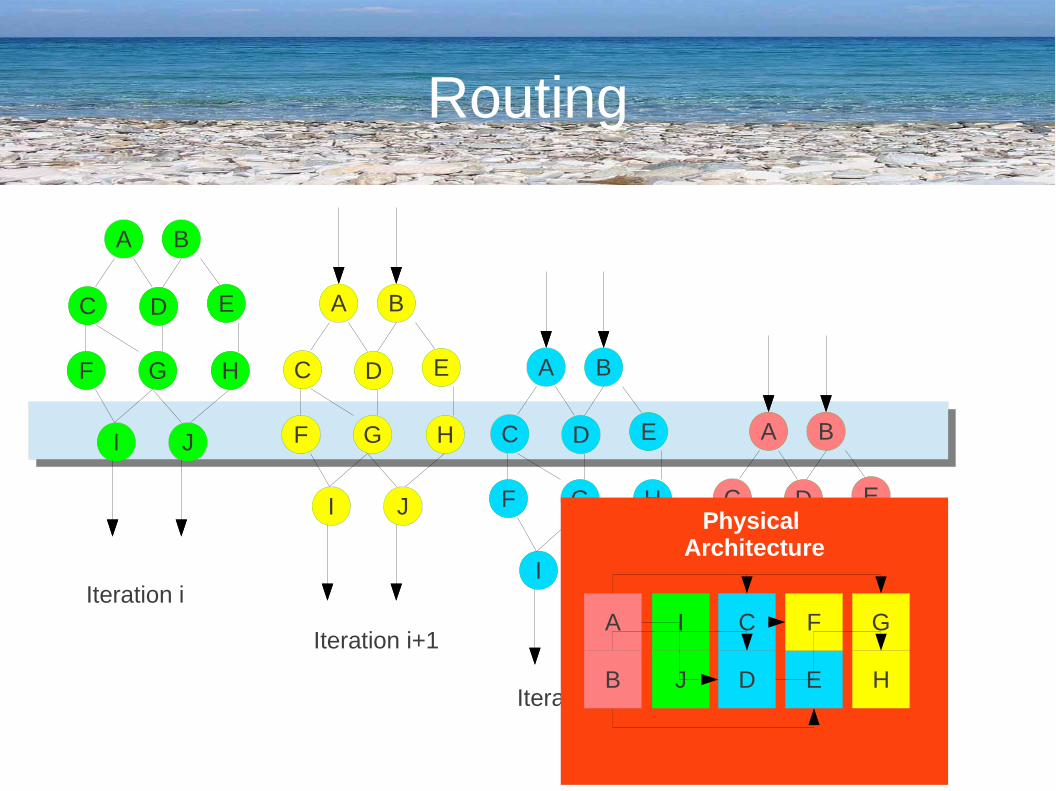
Routing
A B
C E
F
D
G H
I J
A B
C E
F
D
G H
I J
A B
C E
F
D
G H
I J
A B
C E
F
D
G H
I J
A B
C E
F
D
G H
I J
A B
C E
F
D
G H
I J
A B
C E
F
D
G H
I J
A B
C E
F
D
G H
I J
Iteration i
Iteration i+1
Iteration i+2
Iteration i+3
Physical Architecture
A
B
I
J
C
D
F
E
G
H

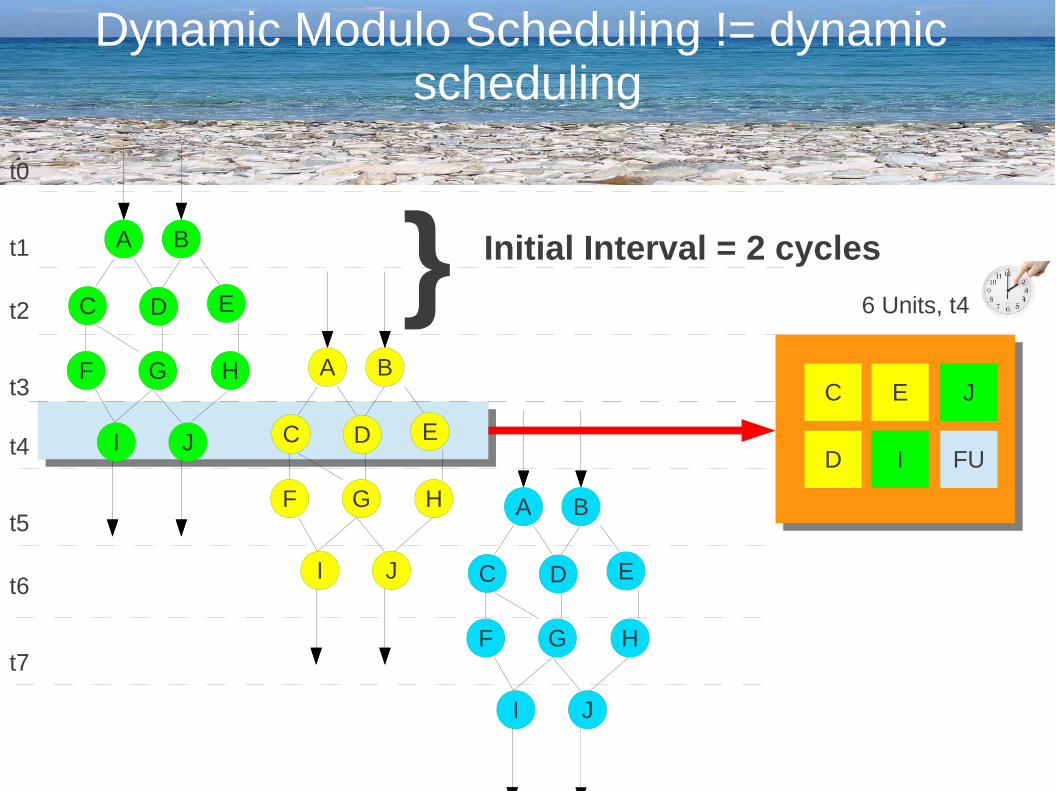
Dynamic Modulo Scheduling != dynamic scheduling
A B
C E
F
D
G H
I J
A B
C E
F
D
G H
I J
A B
C E
F
D
G H
I J
A B
C E
F
D
G H
I J
A B
C E
F
D
G H
I J
A B
C E
F
D
G H
I J
B
A
G
F
FU
H
t0
t1
t2
t3
t4
t5
t6
t7
6 Units, t3
Initial Interval = 2 cycles}
A B
C E
F
D
G H
I J
A B
C E
F
D
G H
I J
A B
C E
F
D
G H
I J
A B
C E
F
D
G H
I J
A B
C E
F
D
G H
I J
A B
C E
F
D
G H
I J
D
C
I
E
FU
J
t0
t1
t2
t3
t4
t5
t6
t7
6 Units, t4
Initial Interval = 2 cycles}
Dynamic Modulo Scheduling != dynamic scheduling
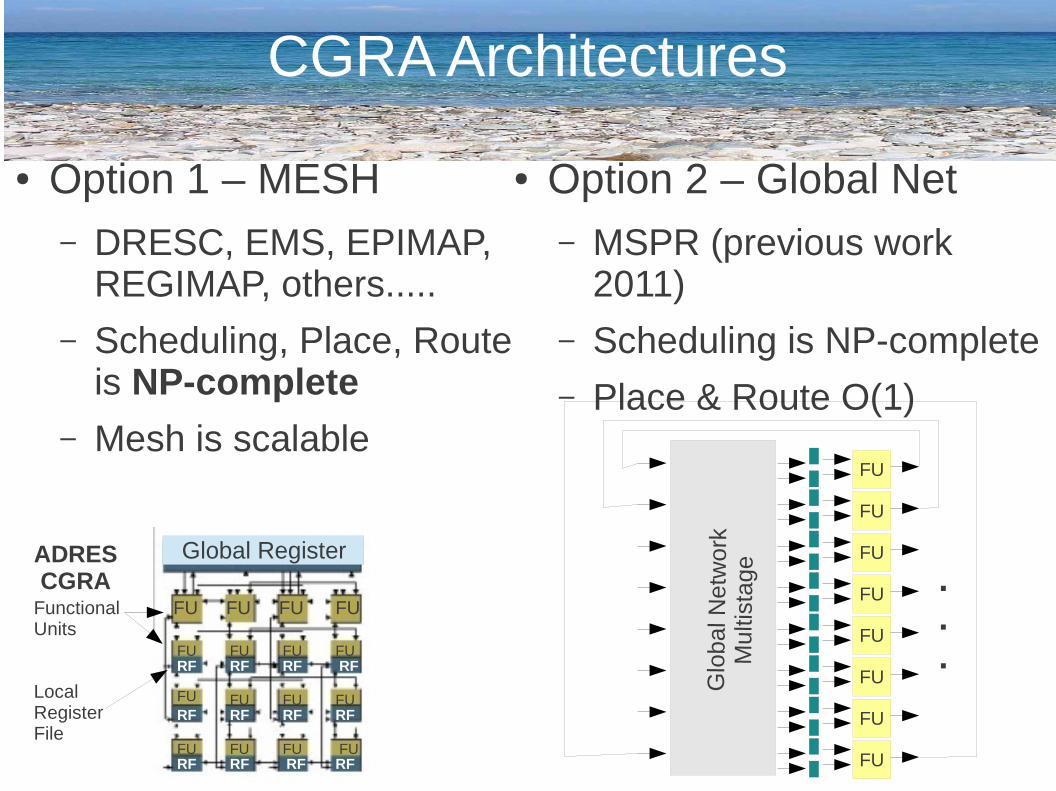
CGRA Architectures
● Option 1 – MESH– DRESC, EMS, EPIMAP,
REGIMAP, others.....
– Scheduling, Place, Route is NP-complete
– Mesh is scalable
● Option 2 – Global Net– MSPR (previous work
2011)
– Scheduling is NP-complete
– Place & Route O(1)
Global Register
FUFUFUFU
FUFUFUFU
FU
FU
FU
FU
FU FU
FU FU
RF RF RF RF
RF
RF
RF
RF
RF
RF
RF
RF
Functional Units
LocalRegisterFile
ADRES CGRA
FU
FU
FU
FU
FU
FU
FU
FU
Glo
bal N
e tw
ork
Mul
tista
ge ...

CGRA Architectures
● Option 1 – MESH– DRESC, EMS,
EPIMAP, REGIMAP, others.....
– Scheduling, Place, Route is NP-complete
– Mesh is scalable
● Option 2 – Global Net– MSPR
– Scheduling is NP-complete
– Place & Route O(1)
Global Register
FUFUFUFU
FUFUFUFU
FU
FU
FU
FU
FU FU
FU FU
RF RF RF RF
RF
RF
RF
RF
RF
RF
RF
RF
Functional Units
LocalRegisterFile
ADRES CGRA
FU
FU
FU
FU
FU
FU
FU
FU
Glo
bal N
e tw
ork
.
.
.
- Runtime
- 16 Units - it is enough for more than 90% Loops
- cost(Global) is similar to cost(Mesh)

Crossbar – Area O(n²)
● Contribution
Cost of MESH ADRES is similar to CGRA Crossbar for 16 Functional Units !
Global Register
FUFUFUFU
FUFUFUFU
FU
FU
FU
FU
FU FU
FU FU
RF RF RF RF
RF
RF
RF
RF
RF
RF
RF
RF
Virtual CGRA on the top of Commercial FPGA XILINX XC6VLX75T
FlipFlop 2.5 %LUTs 14.7 % Mem Bank 16.0 %Clock 110 Mhz
FU
FU
FU
FU
FU
FU
FU
FU
Glo
bal N
etw
ork
.
.
.
FlipFlop 2.7 %LUTs 17.6 % Mem Bank 4.5 %Clock 90 Mhz

Scheduling Quality
ARF
3
MOT
ARF
EWF
FIR2
EWF
FIR
CPX
FIR16
H2V2
FEEd
RGB
COL
COS1
COS2
DCT
BMP
5
7
9
11
Our Approach
Minimal (optimal) Initial Interval

Scheduling Quality
ARF
3
MOT
ARF
EWF
FIR2
EWF
FIR
CPX
FIR16
H2V2
FEEd
RGB
COL
COS1
COS2
DCT
BMP
5
7
9
11
Our Approach
Minimal (optimal) Initial Interval
Optimal 10 / 15

Instruction Level Parallelism
ARF
3
MOT
ARF
EWF
FIR2
EWF
FIR
CPX
FIR16
H2V2
FEEd
RGB
COL
COS1
COS2
DCT
BMP
5
7
9
119.3 8 .0 8.5 10 7.3 11.5 12.3 10.2 8.8 11.4 11.8 13.2 10.1 13.1 10.6
35 126 operations
16Units

Instruction Level Parallelism
ARF
3
MOT
ARF
EWF
FIR2
EWF
FIR
CPX
FIR16
H2V2
FEEd
RGB
COL
COS1
COS2
DCT
BMP
5
7
9
119.3 8 .0 8.5 10 7.3 11.5 12.3 10.2 8.8 11.4 11.8 13.2 10.1 13.1 10.6
35 126 operations
16Units
Dataflow 40 ops
40 / 16 →II=3
40/3 → 13.3
Dataflow 40 ops
40 / 16 →II=3
40/3 → 13.3
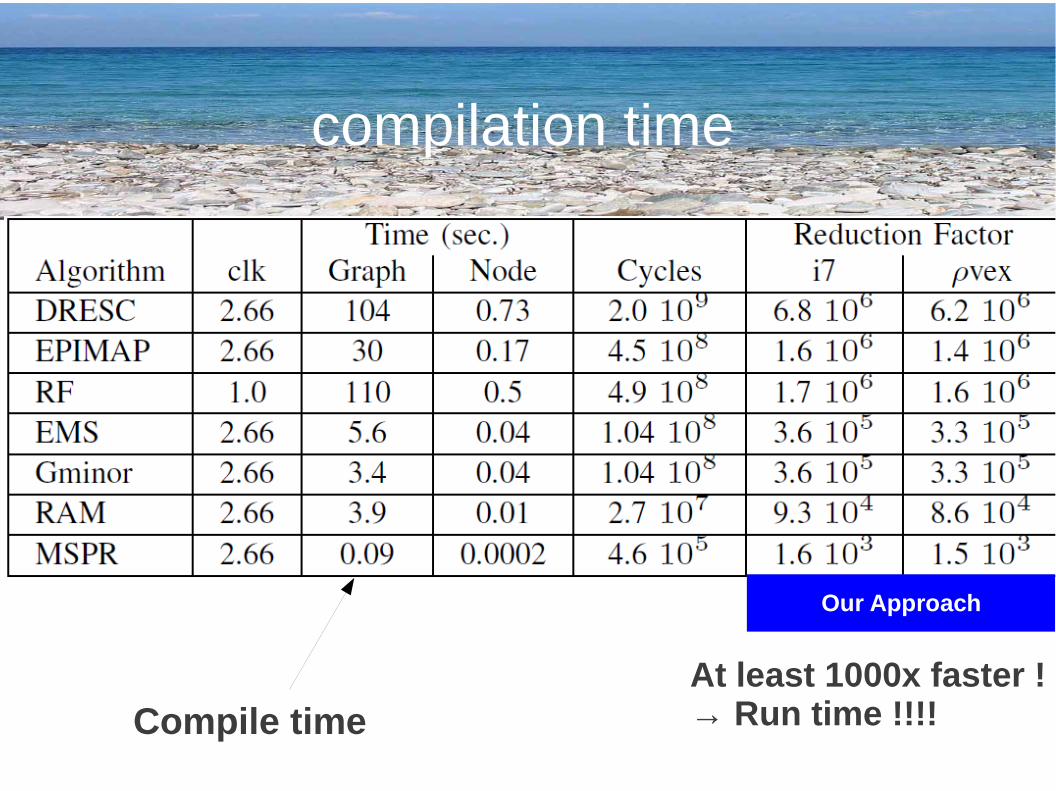
compilation time
Our Approach
At least 1000x faster !→ Run time !!!!Compile time

On Going Work
Vex Binary Code Detect and TranslateThe inner loops
CGRA Accelerator
Previous work
Compiler → Dataflow Graph → Run time Modulo Scheduling → CGRA
Current work
Domain specific language
Stream language

Binary → Translate → Configuration Memory
# load/Store# mults# units

mapping
ld
add
st
ld
st
code
ld
add
st
ld
add
add
st
Ideal
Only 1 ld/st per cycle ?Only 1 ld/st per cycle ?

mapping
ld
add
st
ld
st
code
ld
add
st
ld
add
add
st
Only 1 ld/st per cycle ?





Outline
Where is Vicosa ?
Big Picture: Run Time
1. Coarse-Grained Architectures and Modulo Scheduling - SAMOS paper - Paper to submit
2. Placement and Routing for FPGA - Winner for the M. Servit Award Fpl2013

FPL 2013
A RUN-TIME GRAPH-BASED POLYNOMIAL PLACEMENT AND ROUTING ALGORITHM
FOR VIRTUAL FPGAS
Ricardo Ferreira* L. Rocha, A. Santos, J. Nacif – UFVBrazil
Stephan Wong - *TU Delft - NetherlandsLuigi Carro – UFRGS - Brazil

Motivation
● Run-time Place & Routing– Dynamic Behavior (Multitask Applications)
● Share resources and increase the resource utilization● Previous Works
– Configuration Bit stream were pre-computed at design time
– Faults
– Fragmented Regions
FPGA
Used Used
UsedUsed
MyModulo
MyModulo

Context for Run-time
● Medium Complexity Modules● Sequential x Parallel
– Acceleration Parallel Part → Spatial and Temporal
● Bitstream Size (on-the-fly)– No need to store detail info (switches, wires)
ApplicationModulo
ApplicationModulo
ApplicationModulo
Bitstream
ApplicationModulo
Bitstream
RuntimeP&R
RuntimeP&R
FPGAFPGA
UsedUsed
portabilityportability
flexibilityflexibility

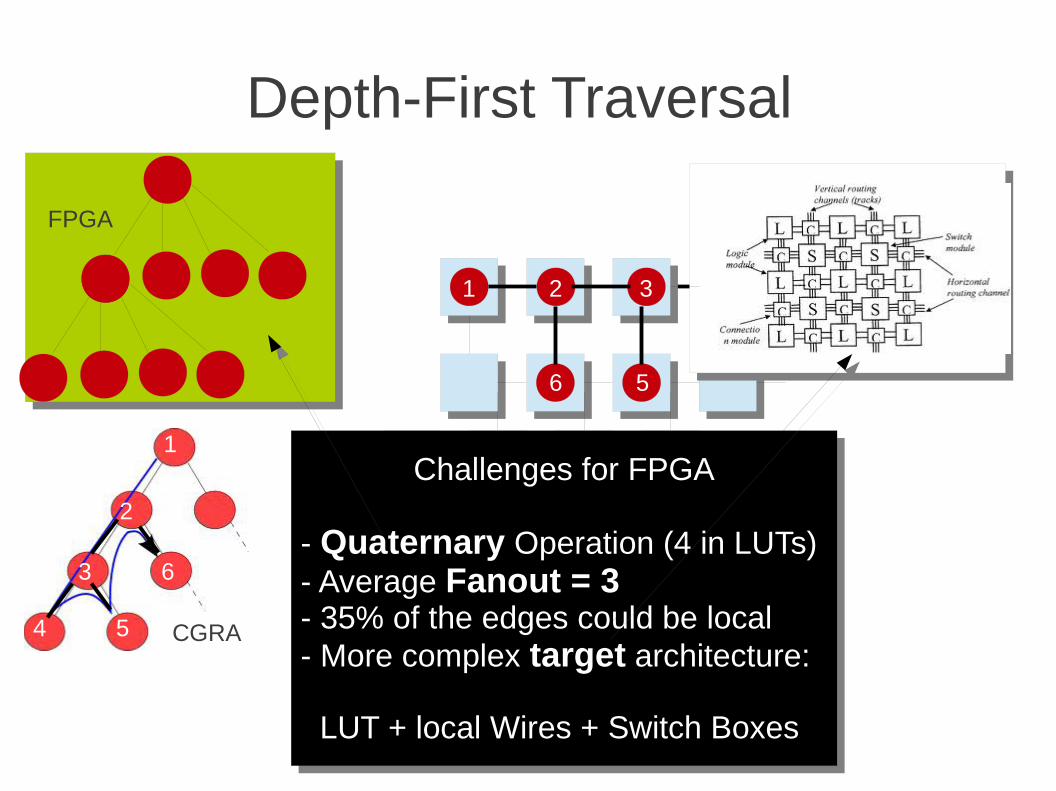
Depth-First Traversal
● Previous Work – CGRA [Ferreira&Cardoso,07]
1
2
3
4 5
6
2 3 4
56
1
SimpleApplication is a graphTarget Architecture is a graph...
Depth-first in both GRAPHS

Depth-First Traversal
● Previous Work – CGRA [Ferreira&Cardoso,07]
usedused1
2
3
4 5
6
2 3
56
1
Flexible - Used area
4
usedused
4
Depth-First Traversal
1
2
3
4 5
6
2 3
56
1
Challenges for FPGA
- Quaternary Operation (4 in LUTs)- Average Fanout = 3- 35% of the edges could be local- More complex target architecture:
LUT + local Wires + Switch Boxes
Challenges for FPGA
- Quaternary Operation (4 in LUTs)- Average Fanout = 3- 35% of the edges could be local- More complex target architecture:
LUT + local Wires + Switch Boxes
CGRA
FPGA

Graph model for the FPGA
LUT
wire SW
wireLUT
FPGA
Three Node types: LUT, Wires and switches
a
b

Nodes ID and Implicit Connections
LUT
wire SW
wireLUT
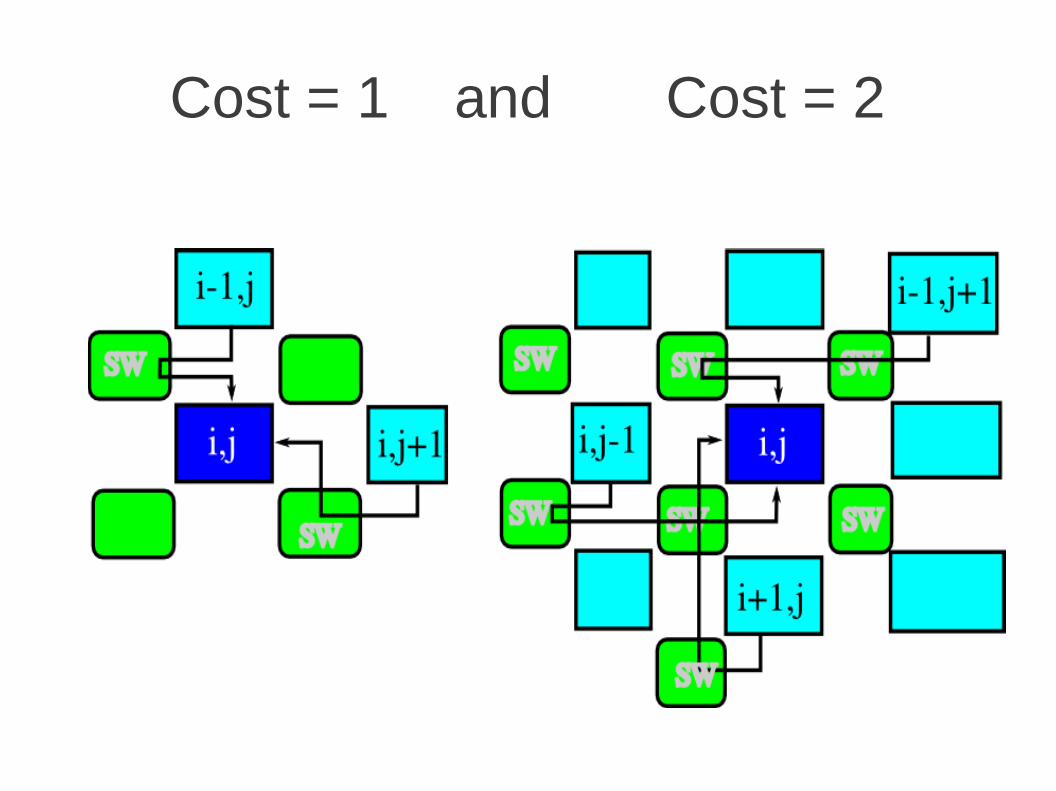
Cost = 1 and Cost = 2

Adjacent Nodes

Adjacent Nodes
2

Adjacent Nodes
2

Adjacent Nodes
2
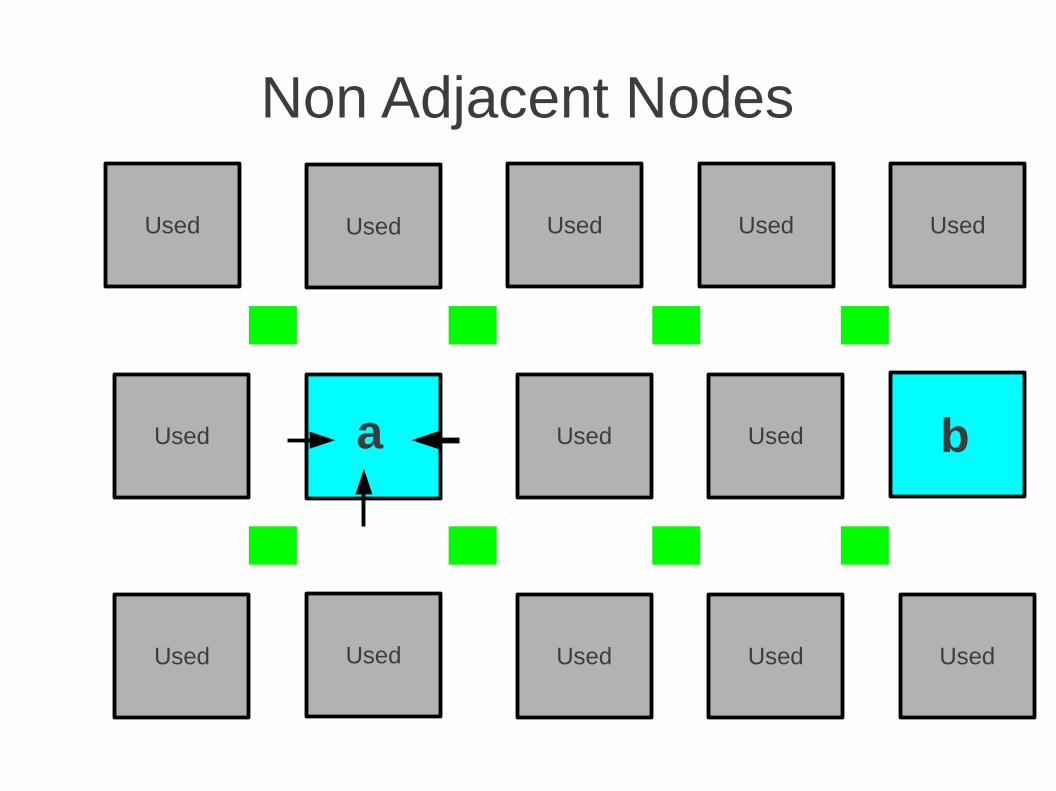
Non Adjacent Nodes
UsedUsed
Used
Used
Used
Used
Used
Used
Used
Used
Used
UsedUsed
a b

Non Adjacent Nodes
UsedUsed
Used
Used
Used
Used
Used
Used
Used
Used
Used
UsedUsed
a b
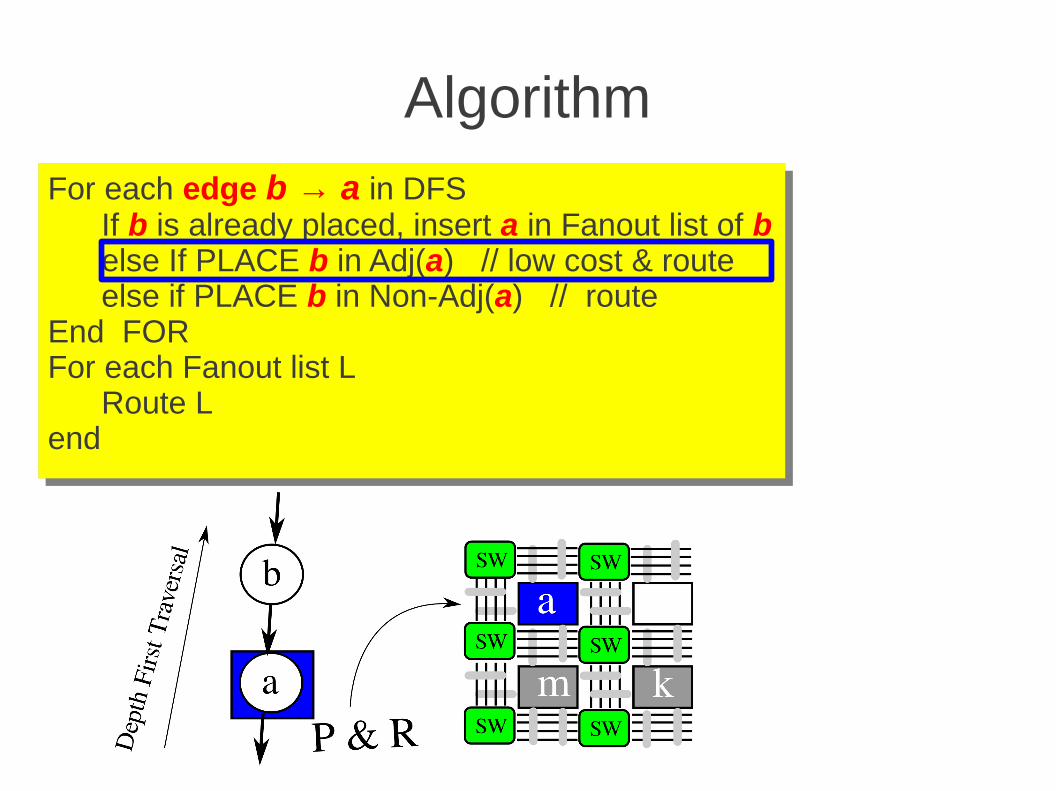
Algorithm
For each edge b → a in DFS If b is already placed, insert a in Fanout list of b else If PLACE b in Adj(a) // low cost & route else if PLACE b in Non-Adj(a) // routeEnd FORFor each Fanout list L Route Lend

Algorithm
For each edge b → a in DFS If b is already placed, insert a in Fanout list of b else If PLACE b in Adj(a) // low cost & route else if PLACE b in Non-Adj(a) // routeEnd FORFor each Fanout list L Route Lend
UsedUsed
Used
Used
Used
Used
Used
Used
Used
Used
Used
UsedUsed
a b

Algorithm
For each edge b → a in DFS If b is already placed, insert a in Fanout list of b else If PLACE b in Adj(a) // low cost & route else if PLACE b in Non-Adj(a) // routeEnd FORFor each Fanout list L Route Lend
Low cost

Execution Time P&R400 to 1500 times faster
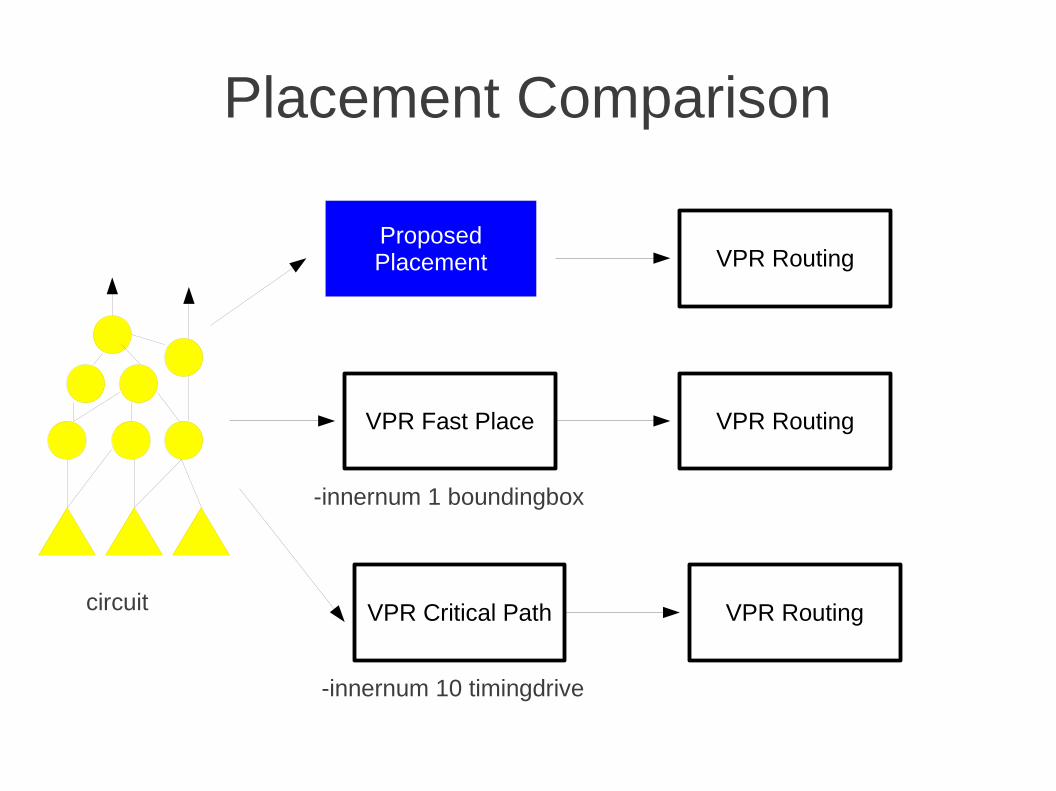
Placement Comparison
ProposedPlacement
circuit
VPR Fast Place
VPR Critical Path
VPR Routing
VPR Routing
VPR Routing
-innernum 1 boundingbox
-innernum 10 timingdrive

Placement Execution Time
ProposedPlacement
VPR Fast Place
VPR Critical Path13215× faster
1024× faster
ProposedPlacement
0.3 to 2.2 msec

Critical Path after VPR routing
ProposedPlacement
VPR Fast Place
VPR Critical Path26% worst
=
ProposedPlacement
critical
critical
critical
+ wires

More Wires...
ProposedPlacement
VPR Fast Place
VPR Critical Path46% worstProposedPlacement
46% worst

Fragmentation
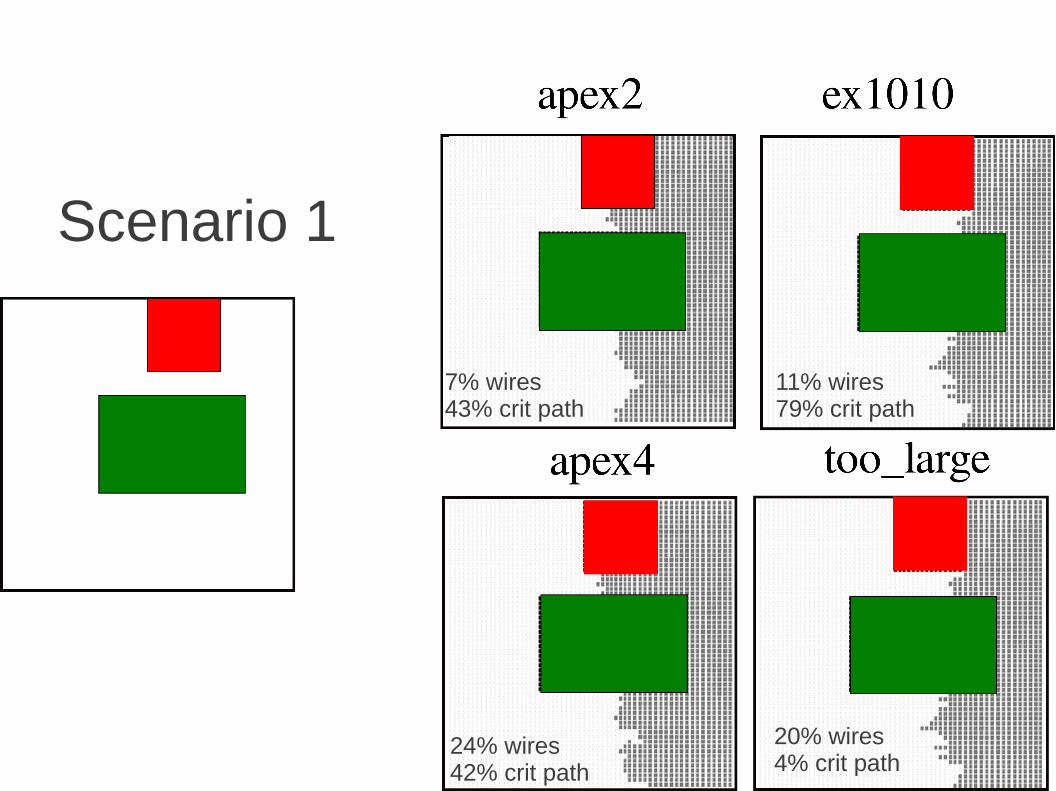
Scenario 1
7% wires43% crit path
24% wires42% crit path
20% wires4% crit path
11% wires79% crit path

Scenario 2
23% wires48% crit path
54% wires35% crit path
12% wires19% crit path
42% wires69% crit path

About P&R for FPGA
● P&R is NP-complete but.....– Digital circuits are not random graphs....
– Fanout=3, …..
● It is possible to be three orders of magnitude faster than VPR● Graph Model + Adjacent Node● Greedy Approach
– Just visit each node once based on the locality
● Optimize the Critical Path with greedy Place is possible● Run-Time P&R is possible 1ms for 3000 LUTs !● Flexible and manage fragmented regions

Future works for Run time P&R
● Explore others proprieties● Domain specific applications
● Accelerators for hardware models in Bioinformatics and Data mining
● Dynamic Datapaths● Routing should be improved....

Conclusions

Adaptive platformProgramming Language
Compiler
Runtime System
Hardware Platform with Adaptive Units
Adaptive Solver
Optimization Plans
Binary
Adapted Binary
Optimization Function
Source Code Maintain SW abstraction
Adapt SW and HWas a function of the QoSas a function of required FT
