universidade do vale do itajaÍ centro de ciÊncias ...siaibib01.univali.br/pdf/jonas rosa.pdf ·...
TRANSCRIPT

UNIVERSIDADE DO VALE DO ITAJAÍ CENTRO DE CIÊNCIAS TECNOLÓGICAS DA TERRA E DO MAR
CURSO DE CIÊNCIA DA COMPUTAÇÃO
DESENVOLVIMENTO DE UMA FERRMANENTA PARA ANÁLISE DE AJUSTE DE DESEMPENHO DO BANCO DE DADOS ORACLE
Área de Banco de Dados
por
Jonas Rosa
Adriana Gomes Alves, M.Eng. Orientadora
Itajaí (SC), junho de 2005

i
UNIVERSIDADE DO VALE DO ITAJAÍ CENTRO DE CIÊNCIAS TECNOLÓGICAS DA TERRA E DO MAR
CURSO DE CIÊNCIA DA COMPUTAÇÃO
DESENVOLVIMENTO DE UMA FERRMANENTA PARA ANÁLISE DE AJUSTE DE DESEMPENHO DO BANCO DE DADOS ORACLE
Área de Banco de Dados
por
Jonas Rosa Relatório apresentado à Banca Examinadora do Trabalho de Conclusão do Curso de Ciência da Computação para análise e aprovação. Orientador: Adriana Gomes Alves, M.Eng.
Itajaí (SC), junho de 2005

SUMÁRIO
LISTA DE ABREVIATURAS..................................................................v
LISTA DE FIGURAS ..............................................................................vi LISTA DE TABELAS.............................................................................vii RESUMO ................................................................................................viii ABSTRACT ..............................................................................................ix
1. INTRODUÇÃO.....................................................................................1 1.1. OBJETIVOS ........................................................................................................ 3 1.1.1. Objetivo Geral ................................................................................................... 3 1.1.2. Objetivos Específicos ........................................................................................ 3 1.2. METODOLOGIA................................................................................................ 4 1.3. ESTRUTURA DO TRABALHO ....................................................................... 5
2. FUNDAMENTAÇÃO TEÓRICA .......................................................7 2.1. BANCO DE DADOS ORACLE......................................................................... 7 2.1.1. A Historia do Banco de Dados Oracle ............................................................ 7 2.2. SISTEMA DE GERENCIADOR DE BANCO DE DADOS ORACLE ......... 9 2.2.1. Estrutura Física................................................................................................. 9 2.2.2. Estrutura da Memória.................................................................................... 11 2.2.3. Estrutura Lógica ............................................................................................. 14 2.2.4. Seqüência de UNDO ....................................................................................... 16 2.3. CONCEITO DE AJUSTE DE DESEMPENHO ............................................ 17 2.3.1. Localização de Gargalos................................................................................. 18 2.3.2. Parâmetros Ajustáveis.................................................................................... 19 2.3.3. Ajuste de Esquemas ........................................................................................ 21 2.3.4. Ajuste de Índices ............................................................................................. 22 2.3.5. Ajuste de Transações ...................................................................................... 23 2.3.6. Simulação de Desempenho ............................................................................. 24 2.4. AJUSTE DE DESEMPENHO.......................................................................... 25 2.4.1. Administração Básica de Banco de Dados.................................................... 25 2.4.2. Performance Tuning....................................................................................... 26 2.5. FERRAMENTAS DE TUNING PARA ORACLE ........................................ 31 2.5.1. Oracle Enterprise Manager (OEM).............................................................. 31 2.5.2. Oracle SQL Scratchpad ................................................................................. 34 2.5.3. TOAD ............................................................................................................... 35 2.6. ESTUDO SOBRE SISTEMAS E PROJETOS SIMILARES ....................... 36 2.6.1. GURU - Uma ferramenta Para Administrar Banco de Dados Através da Web 37 2.6.2. Análise de Desempenho do Banco de Dados Oracle 9i................................ 41

iii
2.7. CONCLUSÕES DA FUNDAMENTAÇÃO TEÓRICA ................................ 42
3. PROJETO............................................................................................44 3.1. REQUISITOS .................................................................................................... 44 3.2. DIAGRAMA DE CONTEXTO........................................................................ 44 3.3. DIAGRAMAS DE FLUXO DE DADOS......................................................... 46 3.3.1. Solicita Acesso ao Banco de Dados................................................................ 46 3.3.2. Solicita Instalação da Ferramenta................................................................. 48 3.3.3. Solicita Visualização da Estrutura Lógica da Memória ............................. 50 3.3.4. Solicita Visualização do Shared Pool ............................................................ 52 3.3.5. Solicita Análise do Plano de Execução.......................................................... 54 3.3.6. Solicita Reconstrução de Índices do Banco de Dados.................................. 56 3.3.7. Solicita Ajuste de Esquemas .......................................................................... 58 3.3.8. Solicita Consulta de Acessos ao Banco de Dados......................................... 68 3.3.9. Solicita Consulta de Análise de Índices......................................................... 70 3.4. MODELAGEM ENTIDADE RELACIONAMENTO................................... 71 3.5. FERRAMENTAS UTILIZADAS .................................................................... 72
4. VALIDAÇÃO......................................................................................73 4.1. ESTRUTURA LÓGICA DA MEMÓRIA....................................................... 73 4.1.1. Shared Pool...................................................................................................... 73 4.1.2. Database Buffer Cache ................................................................................... 74 4.1.3. Redo Log Buffer .............................................................................................. 74 4.1.4. Java Pool .......................................................................................................... 74 4.1.5. Large Pool........................................................................................................ 75 4.2. VISUALIZAÇÃO DA SHARED POOL ......................................................... 75 4.2.1. Shared Pool...................................................................................................... 75 4.2.2. Dictionary Cache............................................................................................. 75 4.2.3. Library Cache ................................................................................................. 76 4.3. RECONSTRUÇÃO DE ÍNDICES................................................................... 76 4.4. PLANO DE EXECUÇÃO................................................................................. 76 4.5. AJUSTE DE ESQUEMAS................................................................................ 77 4.5.1. Visualização de Tabelas.................................................................................. 77 4.5.2. Criação de Tabelas.......................................................................................... 78 4.5.3. Visualização de Índices................................................................................... 78 4.5.4. Criação de Índices........................................................................................... 78 4.6. COMPARATIVO ENTRE PROJETOS ESTUDADOS E PROJETO IMPLEMENTADO................................................................................................... 78
5. CONCLUSÕES...................................................................................80
REFERÊNCIAS BIBLIOGRÁFICAS ..................................................83
APÊNDICE A – MODELAGEM DE DADOS .....................................85
APÊNDICE B – ESPECIFICAÇÃO DAS FUNÇÕES.........................87

iv
APÊNDICE C – INSTALAÇÃO DA FERRAMENTA .....................110
ANEXO I – RESUMO PUBLICADO NO CRICTE 2004 .................112
ANEXO II – ARTIGO ..........................................................................113

LISTA DE ABREVIATURAS
CBO Cost Based Optimizer CKPT Recover CPU Central Processing Unit DBA Database Administrator DBWR Database Write DDL Data Definition Language DML Data Manipulation Language DSS Decision Support System I/O Input/Output LGWR Log Write LRU Least Recently Used OLTP On-line Transaction Processing PC Personal Computer PGA Process Global Area PMON Process Monitor RAM Random Access Memory RBO Rule Based Optimizer SGA System Global Area SGBD Sistema de Gerenciamento de Banco de Dados SMON System Monitor TCC Trabalho de Conclusão de Curso UNIVALI Universidade do Vale do Itajaí

LISTA DE FIGURAS
Figura 1: Estrutura Física Fonte: Adaptado de Fanderuff (2003) ......................................................11 Figura 2. Estrutura de memória utilizada pelo banco de dados Oracle Fonte: Adaptado de Zegger
(2001) .........................................................................................................................................12 Figura 3. Inicialização de uma instância no Oracle Fonte: Adaptado de Ramalho (1999)................14 Figura 4. Estrutura Lógica Fonte: Adaptado de Fanderuff (2003).....................................................15 Figura 5. Estrutura de um bloco de dados Fonte: Adaptado de Ramalho (1999) ..............................16 Figura 6. Análise de Explain Plan .....................................................................................................31 Figura 7. Ferramenta Oracle Enterprise Manager..............................................................................32 Figura 8. Funcionalidades da Pasta Instância.....................................................................................33 Figura 9. Funcionalidades da Pasta de Armazenamento....................................................................34 Figura 10. Ferramenta SQL Scratchpad. ............................................................................................35 Figura 11. Ferramenta TOAD ............................................................................................................36 Figura 12. Diagrama de Contexto ......................................................................................................45 Figura 13. Solicita Acesso ao Banco de Dados..................................................................................46 Figura 14. Tela do Controle de Acesso ao Banco de Dados. .............................................................48 Figura 15. Solicita Instalação da Ferramenta .....................................................................................49 Figura 16. Tela de Configuração da Ferramenta................................................................................50 Figura 17. Solicita Visualização da Estrutura Lógica da Memória....................................................51 Figura 18. Tela de Visualização da Estrutura Lógica da Memória ....................................................52 Figura 19. Solicita Visualização da Shared Pool. ..............................................................................53 Figura 20. Tela de Visualização da Shared Pool ...............................................................................54 Figura 21. Solicita Análise do Plano de Execução.............................................................................55 Figura 22. Tela de Análise do Plano de Execução.............................................................................56 Figura 23. Solicita Reconstrução de Índices do Banco de Dados. .....................................................57 Figura 24. Tela de Reconstrução de Índices ......................................................................................58 Figura 25. Solicita Ajuste de Esquemas.............................................................................................59 Figura 26. Tela de Ajustes de Esquemas............................................................................................60 Figura 27. Visualização de Tabelas....................................................................................................60 Figura 28. Tela de Visualização de Tabelas.......................................................................................61 Figura 29. Criação de Tabelas............................................................................................................62 Figura 30. Tela de Criação de Tabelas...............................................................................................63 Figura 31. Visualização de Índices. ...................................................................................................64 Figura 32. Tela de Visualização de Tabelas.......................................................................................65 Figura 33. Criação de Índices.............................................................................................................66 Figura 34. Tela de Criação de Tabelas...............................................................................................67 Figura 35. Consulta de Acessos ao Banco de Dados. ........................................................................68 Figura 36. Tela de Consulta de Acessos ............................................................................................69 Figura 37. Consulta de Análise de Índices.........................................................................................70 Figura 38. Tela de Consulta de Índices Reconstruídos ......................................................................71 Figura 39. Diagrama de Entidade/Relacionamento............................................................................72

LISTA DE TABELAS
Tabela 1. Parâmetros envolvidos no desempenho do banco de dados...............................................19 Tabela 2. Quadro de vantagens e desvantagens .................................................................................40 Tabela 3. Quadro de vantagens e desvantagens .................................................................................42 Tabela 4. Descrição das tabelas utilizadas no sistema .......................................................................71 Tabela 5. Tabela de vantagens e desvantagens entre ferramentas .....................................................78 Tabela 6. Dicionário de dados da tabela acoes...................................................................................85 Tabela 7. Dicionário de dados da tabela esquemas............................................................................85 Tabela 8. Dicionário de dados da tabela indices ................................................................................85 Tabela 9. Dicionário de dados da tabela instancias............................................................................85 Tabela 10. Dicionário de dados da tabela memoria_logicas..............................................................86 Tabela 11. Dicionário de dados da tabela plano_execucoes ..............................................................86 Tabela 12. Dicionário de dados da tabela shared_pools ....................................................................86

RESUMO
ROSA, Jonas. Desenvolvimento de uma Ferramenta para Análise de Ajuste de Desempenho do Banco de Dados Oracle. Itajaí, 2005. 88 f. Trabalho de Conclusão de Curso (Graduação em Ciência da Computação) - Centro de Ciências Tecnológicas da Terra e do Mar, Universidade do Vale do Itajaí, Itajaí, 2005. A finalidade de um banco de dados é auxiliar na organização e na recuperação de dados. Em um banco de dados, há dois tipos distintos de acessos, um quando não há um SGBD (Sistema de Gerenciamento de Banco de Dados) e, no outro caso, quando o acesso a um banco de dados é realizado através de um SGBD. É justamente nessa segunda situação que o gerenciador assume a responsabilidade de buscar todas as informações necessárias controlando, assim, os dados e tendo o DBA (Database Administrator) como responsável por esse controle. Um DBA, por sua vez, tem diversas funções e, entre essas está a de ajustar o sistema para obter o melhor desempenho do banco de dados. O ajuste de desempenho (performance tuning) de um banco de dados pode ser feito de duas formas: através da elaboração de projetos que visam melhorar o desempenho de uma aplicação especifica; e/ ou através de ajustes de vários parâmetros. Ao se aprofundar nessas formas de ajuste de desempenho, fica evidente a necessidade de utilizar ferramentas para ajuste de desempenho que viabilizem e auxiliem esse processo de ajuste de desempenho. Sendo assim, este trabalho visa desenvolver uma ferramenta que auxilie no ajuste de desempenho do banco de dados Oracle. Entre as suas funcionalidades, estão: mostrar dados estatísticos através de gráficos; apresentar formas de melhorar a performance de um banco de dados; gerar scripts para realização da manutenção de um banco de dados e, por fim, manter um histórico das ações desta ferramenta. Palavras-chave: Ajuste de Desempenho. Sistema Gerenciador de Banco de Dados. Oracle.

ABSTRACT
The aim of a database is to aid in the organization and the recovery of data. And, in a database, there are two distinct Kinds of accesses, one when there is not a database management system (DMS), and, in other case, when the access is accomplished through the DMS. It is just in the second situation that the administrator takes over the responsibility of searching all the necessary information controlling, then, the data and being the database administrator (DBA) as responsible by this control. However, a DBA has several functions and among these there is the function of adjusting the system to get the best performance of database .The adjust of performance (performance tuning) of a database can be done of two forms: throught the elaboration of projects that aim to improve the performance of a scientific application, and/ or thought regulations of several parameters. When it is made a profound study of these regulation forms of performance, it is evident the necessity of using tools (optimizers) that turn possible and aid this process of performance regulation of Oracle database. Among its functions are: to show statistics data throught the graphics, to present forms of improving the performance of a database, to generate scripts to the accomplishment of database maintenance and lastly to keep description of the actions of this tool. Keywords: Performance Tuning, Database Management System and Oracle.

1. INTRODUÇÃO
Um banco de dados tem a finalidade de auxiliar na organização e na recuperação de
dados. Não necessariamente um sistema de processamento de dados utiliza um SGBD (Sistema
de Gerenciamento de Banco de Dados) para recuperação de informações, sendo que nesse caso,
cabe ao desenvolvedor criar formas dessa recuperação. Porém, quando o acesso a um banco de
dados é realizado através de um SGBD, cabe ao gerenciador assumir a responsabilidade de
buscar todas as informações especificadas. (FANDERUFF, 2003).
Sendo assim, a principal função de um SGBD é ter o controle centralizado dos dados,
tendo o DBA (Database Administrator), como responsável por esse controle. Entre as funções
de um DBA, de acordo com Fanderuff (2003), estão: definir quais dados serão armazenados e
quais os acessos mais freqüentes; disponibilizar os dados desejados pelo usuário; fazer regras de
acessos e os backups e como realizar a recuperação de informação quando da perda ou
danificação dos dados; e ajustar o sistema para obter o melhor desempenho do banco de dados.
É justamente essa última função, que consiste no ajuste do sistema para melhorar o desempenho
do banco de dados, o foco desse trabalho.
Fanderuff (2003) relata que quando o desempenho de um banco de dados não é o
esperado, então há dois motivos que resultam nesse problema de desempenho: utilização de
recursos inadequados; e realização de um projeto inadequado.
De acordo com Silberschatz & Korth (1999), o ajuste de desempenho (performance
tuning) de um banco de dados pode ser feito das seguintes formas: através de ajustes de vários
parâmetros; e/ou através da elaboração de projetos que visam melhorar o desempenho de uma
aplicação especifica.
O mesmo autor destaca seis passos para que seja realizado o ajuste de desempenho de
um banco de dados: (i) localização de gargalos; (ii) ajuste do banco de dados; (iii) ajuste de
esquemas; (iv) ajuste de índices; (v) ajuste de transações; e (vi) simulação de desempenho.
Quanto ao primeiro passo, localização de gargalos, Silberschatz & Korth (1999) cita que
um programa pode estar gastando muito do seu tempo de execução em pequenos laços,
enquanto que o restante do código consome muito pouco. São justamente esses pequenos laços
que compõem o gargalo. Se um gargalo consome 80% do tempo total do sistema, mesmo que

2
seja apenas um pequeno laço, melhorá-lo irá aumentar muita a performance do programa.
Resumindo, o primeiro passo é detectar gargalos e procurar melhorar o seu desempenho.
Quando um gargalo é então neutralizado, um novo gargalo pode ser encontrado e melhorado.
O segundo passo consiste em ajudar o banco de dados, o que pode ser feito em três
níveis: O nível mais baixo é o de hardware, onde com uma simples inclusão de memória no
buffer do banco de dados pode representar melhoras no SGBD.O segundo nível é uma relação
aos parâmetros do sistema do banco de dados, como o tamanho do buffer, porém, alguns bancos
já ajustam esse buffer automaticamente. Por último, então, é o de mais alto nível, o qual diz
respeito a índices, esquemas e transações. A combinação desses três níveis é de grande
importância.
O ajuste de esquema é o terceiro passo para o ajuste de desempenho de um banco de
dado. Esses esquemas são restrições impostas pela normalização adotada, sendo que o seu ajuste
irá resultar em uma melhor distribuição dos registros, utilizando menos espaços no buffer do
banco de dados.
Como quarto passo, tem-se o ajuste de índices. Esse ajuste é realizado quando o índice é
o gargalo, podendo ser acelerado com a criação de novos índices ou da sua exclusão, quando se
faz necessário. Há casos em que o tipo de índice pode ser alterado de arvore-B para hash, ou
vice-versa.
O quinto passo diz respeito ao ajuste de transações. Muitos SGBDs já possuem
embutidos um otimizador de transações que, de acordo com Silberschatz & Korth(1999), até
mesmo consultas mal escritas podem ser realizadas com eficiência.
Por fim, o sexto e ultimo passo diz respeito á simulação de desempenho, a qual se refere
a criação de um modelo de simulação, para que seja mostrada uma diversidade de serviços,
como CPU (Central Processing Unit), discos, buffer e controles de concorrência. Nessa
simulação, diferentes experimentos podem ser feitos, de forma que o ajuste de desempenho seja
realizado antes da sua real implantação.
Vendo esses aspectos e esses passos importantes para o gerenciamento de um SGBD,
fica evidente a necessidade de utilizar ferramentas para ajustes de desempenho que viabilizem e
auxiliem este processo de ajuste de desempenho.

3
Porém, uma ferramenta para ajuste de desempenho tem que usar diversos recursos. Date
(2000) relata que uma boa ferramenta deve ter uma grande quantidade de informações
disponíveis de forma estatística, como, por exemplo, o numero de valores em cada domínio e o
número atual de tuplas em cada variável de relação básica. Uma tupla é um registro inserido em
uma tabela de banco de dados.
Date (2000) ainda cita que essas informações ficam guardadas no catalogo do sistema,
permitindo a ferramenta fazer uso e avaliar essas informações, de forma que possa projetar
estratégias de ação e escolher a implementação mais eficiente.
Em suma, uma ferramenta para ajuste de desempenho tem que ter recursos que
possibilite avaliar uma centena de possíveis estratégias para execução de uma requisição. Além
disso. Conforme são alteradas as estatísticas armazenadas, a mesma estratégia já não satisfaz a
mesma realização da requisição.
Este trabalho se insere no contexto acima apresentado e visa o desenvolvimento de uma
ferramenta que auxilie no ajuste de desempenho do banco de dados Oracle. Para isso, será feito um
estudo sobre SGBDs buscando: (i) definir o que é um tuning de banco de dados; (ii) mostrar dados
estatísticos; (iii) apresentar formas de melhorar a performance de um banco de dados. (iv) gerar
scripts para realização da manutenção de um banco de dados e, por fim, (v) manter um histórico das
ações desta ferramenta.
1.1. OBJETIVOS
1.1.1. Objetivo Geral
Desenvolver uma ferramenta que auxilie no ajuste de desempenho do banco de dados
Oracle, cuja função principal é captar dados estatísticos do banco de dados, gerar scripts para
realização da sua manutenção e manter um histórico de atuação desta ferramenta.
1.1.2. Objetivos Específicos
Os objetivos específicos deste projeto de pesquisa são:
• Pesquisar sistemas ou projetos similares;
• Especificar requisitos;

4
• Realizar um levantamento de quais recursos o Oracle dispõe para tratamento do seu
ajuste de desempenho;
• Realizar a modelagem conceitual do projeto para a busca de informações dos dados
estatísticos e como disponibilizar estes dados de modo gráfico;
• Realizar a modelagem conceitual do projeto para gerar script de ajuste de desempenho;
• Realizar a modelagem conceitual do projeto para gerar o histórico da ferramenta;
• Implementar a ferramenta;
• Testar e validar a ferramenta ; e
• Documentar o desenvolvimento do trabalho de conclusão de curso;
1.2. METODOLOGIA
As etapas para o cumprimento dos objetivos do TCC (Trabalho de Conclusão de Curso) são
descritas em seguida.
• Redação Pré-Proposta: documento que expõe um visão geral do projeto de conclusão do
Curso de Ciência da Computação relatando: introdução do projeto, objetivos, atividades,
cronograma e definição de critérios;
• Levantamento Bibliográfico: O trabalho (TCCI) iniciou com a pesquisa de material
bibliográfico: livros, artigos, periódicos, teses, Internet, a fim de fundamentar
teoricamente as tecnologias que deveriam ser abordadas no trabalho;
• Revisão Bibliográfica: Nessa etapa, houve então a fundamentação teórica do trabalho
através da utilização do levantamento bibliográfico realizado na etapa anterior, bem
como o conhecimento adquirido durante a pesquisa. Este período foi acompanhado por
reuniões semanais com o orientador e por relatórios quinzenais entregues á coordenação
do TCC;
• Análise do Projeto: foi realizada a analise do sistema bem como a modelagem do banco.
A modelagem foi realizada através de um diagrama de contexto, diagramas de fluxos de
dados e especificações de processos, sendo utilizado, também, um diagrama ER
(entidade-relacionamento) para banco de dados para o modelo relacional/objeto-
relacional dos bancos de dados tradicionais;

5
• Considerações Finais: o trabalho é brevemente recapitulando, ressaltando pontos gerais
do trabalho de conclusão de curso;
• Referências Bibliográficas: lista das referências utilizadas para o desenvolvimento desse
trabalho;
• Apêndice A: esse apêndice consta a modelagem de dados que será utilizado na
implementação da ferramenta foco desse trabalho. Essa modelagem consta o dicionário
de dados das tabelas da ferramenta relatando o nome das tabelas, assim como o nome, o
tipo e a descrição de cada campo da tabela;
• Apêndice B: nesse apêndice consta os algoritmos utilizados na implementação da
ferramenta. Entre as informações contidas nesses algoritmos estão as instruções SQL; e
• Anexo: Como anexo do trabalho de conclusão de curso esta o artigo apresentado no XIX
Congresso Regional de Iniciação e Tecnológica em Engenharia - CRICTE 2004, com o
tema “Desenvolvimento de uma Ferramenta para Análise de ajuste de Desempenho do
Banco de Dados Oracle”.
1.3. ESTRUTURA DO TRABALHO
Este trabalho tem como finalidade auxiliar na análise e no ajuste de desempenho do banco
de dados Oracle.
Para tanto, a primeira etapa deste trabalho foi fazer um levantamento bibliográfico sobre:
banco de dados Oracle; sistema de gerenciamento de banco de dados; conceito de ajuste de
desempenho; ajuste de desempenho no banco de dados Oracle; e projetos/ ou sistemas similares.
No tópico sobre o banco de dados Oracle é relatado informações referentes a sua historia.
Em sistema de gerenciamento de banco de dados dá-se uma noção de como é tratada a estrutura
física e lógica de um banco de dados, assim como a estrutura da memória.
Na etapa de conceituação de ajuste de desempenho, são retratados seis passos fundamentais
para a realização de ajustes de desempenho de um banco de dados. Ao se falar sobre ajuste de
desempenho, então são focados conceitos sobre administração de banco de dados e justamente o
ajuste de desempenho no banco de dados Oracle.

6
Por fim, então é apresentada a modelagem da analise do projeto a ser desenvolvida na
segunda etapa do trabalho de conclusão de curso.

2. FUNDAMENTAÇÃO TEÓRICA
Como pontos da fundamentação teórica desse trabalho de conclusão, estão 05 tópicos: banco
de dados Oracle; Sistema Gerenciador de Banco de Dados; Conceito de Ajuste de Desempenho;
Ajuste de Desempenho; Ferramentas de Tuning para Oracle; e Estudo sobre Sistemas e/ou Projetos
Similares.
2.1. BANCO DE DADOS ORACLE
O banco de dados foco desse trabalho de conclusão de curso será o Oracle 9i. Nesse capitulo
será mostrado seu histórico.
2.1.1. A Historia do Banco de Dados Oracle
A historia do banco de dados Oracle começou em 1970, quando Ted Codd lançou um
modelo de dados relacional, tendo como protótipos o System R e o Ingress. O System R foi
desenvolvido pela IBM, porém, ainda era um modelo não-comercial de banco de dados. Já o
Ingress, teve seu desenvolvimento na Universidade de Berkeley, na Califórnia, pela equipe liberada
por Michael Stonebaker (FANDERUFF, 2003).
A linguagem SQL, que atualmente é padrão para linguagem de banco de dados relacional,
foi desenvolvida a partir do System R. Nesse período (1977), então surge a Software Development
Laboratories, através de Bob Miner, Ed Oates, Bruce Scott e Larry Ellison, que ate então eram
analistas de sistemas que, ao estudarem sobre os dois sistemas acima citados, decidem lançar uma
versão comercial de um produto similar (ibidem).
De acordo com Oracle (2004), nessa época Larry Ellison vislumbrou, ao encontrar uma
descrição de um protótipo funcional de um banco de dados relacional, uma oportunidade que outras
companhias não haviam percebido, a de comercializar essa tecnologia. Porém, Ellison e os
confundadores da Oracle, Bob Miner e Ed Oates, não imaginavam de que transformariam “a cara da
computação empresarial para sempre”.
A empresa, em 1979, mudou o seu nome para RSI (Relational Software Incorporated),
sendo então gerado a primeira versão do Oracle, mais conhecido como Oracle V2, tendo como

8
primeiro cliente a Base da Força Aérea Patterson. Essa versão do Oracle rodava em uma maquina
DEC PDP 11(FANDERUFF, 2003).
Nesse mesmo na oferece o primeiro sistema comercial de gerenciamento de banco de dados
relacionais SQL (ORACLE, 2004).
Quando a RSI mudou seu nome para Oracle, em 1983, o Oracle V3 já rodava em PCs e
mainframes, tornando-se o sistema mais potável do mundo (FANDERRUFF, 2003).
No decorrer dos anos 80, Oracle (2004) relata que outras inovações foram desenvolvidas,
entre elas:
• Disponibiliza um primeiro banco de dados desenvolvido em C, para portabilidade
(1983);
• Oferece o primeiro banco de dados com consistência de leitura (1984);
• Oferece o primeiro banco de dados para servidores em paralelo (1985);
• Fornece suporte consultas distribuídas e desenvolve o primeiro banco de dados
cliente/servidor (1986); e
• Primeiro banco de dados a oferecer bloqueio no nível de linhas e a introduzir o PL/SQL
(1988).
Nas versões mais atuais, tem-se Oracle 08, lançada em 1997, que já comportava um limite
de 512 petabytes (um petabytes equivale a 1024 x 1024 x 1GB) de informações, além de ser um
sistema gerenciador de banco de dados objeto-relacional. Já em 1999, com o crescimento da
Internet, foi lançado o Oracle 8i, voltado para aplicações eb, sendo que, juntamente com a versão 9i,
tem o desempenho e a escalabilidade necessárias para suportar essas aplicações (FANDERUFF,
2003).
A versão focada neste trabalho é a versão 9i, que teve seu lançamento em 1º de Junho de
2001. Em relação a versão anterior, essa versão apresenta avanços em clusterização, confiabilidade
e performance(ibidem).
Como respaldo mundial. O Oracle 9i ganhou prêmios, como: Database para Linux (Linux
Journal); Business Intelligence (DM Review); e o Recorde mundial de data warehousing (TCP-H)
(ORACLE, 2004).

9
Além disso, segundo estudo da Harte-Hanks, três vezes mais clientes do banco de dados
Informix pretendem migrar para o Oracle do que para o concorrente (FANDERUFF, 2003).
2.2. SISTEMA DE GERENCIADOR DE BANCO DE DADOS ORACLE
Ramalho (1999) relata que o Oracle é um banco de dados que possui uma estrutura física e
lógica separadas no servidor, sendo que o armazenamento físico dos dados pode ser gerenciado de
forma separada do acesso ás estruturas lógicas de armazenamento.
Por conseguinte, o sistema gerenciador de banco de dados (SGBD) Oracle, segundo
Fanderuff (2003), mantêm fisicamente um conjunto de arquivos em algum ponto do disco. O
armazenamento lógico, por sua vez, é dividido em um conjunto de contas de usuário conhecidas
como esquemas. Esse esquema é acessado e manipulado através de um usuário, que possui uma
senha e privilégio de acesso.
A seguir essas estruturas serão detalhadas e caracterizadas:
2.2.1. Estrutura Física
De acordo com Ramalho (1999), a estrutura física do Oracle é determinada pelos arquivos
do sistema operacional que o constituem. Então, para cada banco de dados Oracle há pelo menos:
um arquivo datafiles, dois arquivos redo e um arquivo de controle. Abaixo estão listadas as
características de cada um desses arquivos. Após, a Figura 1 ilustra a estrutura física do Oracle.
• Datafiles:
o Descrição: De acordo com Fanderuff (2003), datafiles é um conjunto de arquivos
onde as informações estão efetivamente armazenadas, ou seja, os datafiles
armazenam os dados das tabelas, os índices e as áreas temporárias e de rollback;
o Funcionamento: Scherer (2002) relata que os dados armazenados nos datafiles são
recuperados conforme a solicitação do cliente. Esses dados são alocados em uma
memória real do servidor, tornando-a disponível para que os demais usuários possam
acessar de forma mais rápida; e
o Gerência: Como cópia de segurança para os dados contidos nos datafiles deve ser
realizado regularmente backup desses arquivos. Alguns sistemas operacionais podem

10
mostrar restrições ao tamanho do datafile, nesse caso, recomenda-se que um datafile
não ultrapasse o tamanho de 2GB. (FANDERUFF, 2003).
• Redo log files:
o Descrição: Fanderuff (2003) relata que os arquivos redo log files são utilizados para
armazenagem de transações realizadas no banco de dados com a finalidade de
refazer as operações quando da perda de dados;
o Funcionamento: Scherer (2002) diz que a função do arquivo redo log file é garantir a
armazenagem de todas as alterações realizadas sobre os dados do banco de dados.
Dessa forma é possível a recuperação para um estado seguro do banco de dados no
caso de uma eventual falha; e
o Gerencia: Há a necessidade de dois grupos de arquivos para quando um estiver cheio
o outro possa ser utilizado. Se possível, manter os arquivos em discos diferentes para
evitar gargalos, devido a um grande numero de gravação. (FANDERUFF, 2003).
• Control files:
o Descrição: Scherer (2002) conta que toda vez que o banco de dados é inicializado o
arquivo control file é lido para localização dos arquivos datafiles e redo log files. As
alterações nesses arquivos, assim como as alterações estruturais no banco de dados,
são registradas no arquivo control file. Um exemplo de alteração no banco de dados
é a inclusão de um novo arquivo datafile;
o Funcionamento: Scherer (2002) diz que um arquivo control file contém ponteiros
que especificam a estrutura física do banco de dados. Entre as informações do banco
de dados estão: nome do banco de dados; nomes e localizações dos datafiles e dos
redo log files, arquivo de redo log corrente, e time stamp de criação do banco de
dados; e
o Gerência: Deve ser realizada regularmente uma cópia do arquivo control files, assim
como ter cópias distribuídas em diferentes discos para garantir uma maior segurança.
(FANDERUFF, 2003).

11
Datafiles Control Files Redo Logs Files
Figura 1: Estrutura Física Fonte: Adaptado de Fanderuff (2003)
2.2.2. Estrutura da Memória
O Oracle divide a memória RAM (Random Access Memory) em duas partes (ZEGGER,
2001):
• O SGA (system global area) é um grupo das estruturas de memórias compartilhadas
que, quando combinadas com os processos do Oracle, compreendem uma instância do
Oracle. É dividido em quatro áreas: database buffer cache; redo log buffer; e shared
pool; e
• O PGA (process global área) é onde a memória é alocada a cada processo conectada a
base de dados. O tamanho deste alocamento é estático. O tamanho do PGA é dependente
do sistema, mas é afetado pelos seguintes parâmetros: open links; db_files; e log_files.
A figura 2 mostra como é a estrutura da memória do banco de dados Oracle.

12
Figura 2. Estrutura de memória utilizada pelo banco de dados Oracle Fonte: Adaptado de Zegger (2001)
O DB Buffer Cachê mantém cópias de todos os blocos de dados que são lidos do data files.
O Oracle mantém uma lista de blocos sujos e a LRU (Least Recently Used) para decidir-se que
blocos devem ser mantidos na memória. Os blocos sujos são blocos update escritos e ainda não
atualizados em disco. A lista de LRU identifica que são buffers livres, buffers fixados, ou buffers
sujos que não foram removidos ainda da lista suja. Se um processo que esteja tentando executar
leitura não encontra um buffer livre na lista LRU, então são utilizados esses buffers sujos
(ZEGGER, 2001).
O Redo Log Buffer é um buffer circular com um tamanho fixado. É nessa memória que os
dados alterados são armazenados até a sua transferência para o redo log files. Ressalta-se que os
dados aqui guardados não são os dados reais propriamente ditos, mas sim as instruções insert,
delete e update para construção e alteração do banco de dados. Na pratica, quando acontece um
update, por exemplo, é guardada essa instrução que passa da situação A (atual) para a situação B
(após o update), além dessa instrução, também é guardada uma instrução que equivalente ao
rollback, ou seja, da situação B (após o update) para A (atual) (FANDERRUFF, 2003).
Quando o Oracle necessita executar uma tarefa que requeira a classificação dos dados o Sort
Area é usada. Um processo do Oracle pede uma Sort Area. Essa Sort Area pode crescer até o
tamanho do parâmetro SORT_AREA_SIZE e, se esta quantidade de memória não for suficiente a

13
sort transbordará no disco. O processo pode liberar a sort area que não está sendo usada para a
SORT_AREA_RETAINED_SIZE (ZEGGER, 2001).
Para Java Pool, Maring (2002) diz que Java foi desenvolvido para impedir a alteração do
seu sistema trabalhando através de pacotes (applets), sendo assim uma linguagem segura. Esta é a
única razão para que o Oracle permita que aplicações Java possam dar carga dentro da base de
dados. Linguagens, tais como o C, podem apresentar problemas de segurança na base de dados. Por
default não é disponibilidade espaço desta memória no banco de dados, porém, podendo ser
modificado através do parâmetro java_pool_size.
O Large Pool é utilizado pelo Oracle para armazenar diferentes tipos de dados. Os dados
armazenados se referem a execução de blocos PL/SQL e de comandos SQL, dados da dictionary
cache, entre outros. (GREEN, 2002).
O Shared Poll é dividido em duas memórias cachês: Dicionário Cachê e Biblioteca Cache.
Os tamanhos são dinâmicos, de forma que aumentam e diminuem de acordo com a necessidade,
porém, se limita ao tamanho da shared pool. O custo por falta de memória na Shared Poll é mais
alto do que no buffer cache (ibidem).
Ressalta-se ainda que, quando uma instancia é iniciada, de acordo com URMAN (1999),
também são inicializados uma serie de processos em paralelo (Figura 3). Esses processos se
comunicam justamente através da SGA e, entre suas finalidade está a leitura e escrita em escrituras
de dados.
Processosde usuário
Recover(RECO)
ProcessMonitor
SystemMonitor(SMON)
DatabaseWriter
(DBWO)
LogWrite
(LGWR)
Archiver(ARCO)
System Global Area(SGA)
Usuário Usuário Usuário Usuário

14
Figura 3. Inicialização de uma instância no Oracle Fonte: Adaptado de Ramalho (1999)
A seguir estão descritos os principais processos Oracle:
• LGWR (Log Writer): é através desse processo que é gravado o conteúdo do redo log
buffer para o redo log files. Esse processo é ativado a cada gravação de 300KB no redo
log buffer, ou a cada commit, ou a cada 3 segundos;
• DBWR (Database Writer): os dados são carregados para o database buffer cache através
das operações de seleção(select, update, insert e delete), sendo esse o processo que grava
os dados alterados para os datafiles;
• CKPT (Recover): esse processo sincroniza os datafiles e os control files;
• SMON (System Monitor): desfaz tudo o que estava pendente de validação quando
houver um crash no banco de dados, limpando as áreas temporárias do banco de dados; e
• PMON (Process Monitor): processo chamado quando da ocorrência de interrupções
anormais, desfazendo transações e deslocamento registros.
2.2.3. Estrutura Lógica
A estrutura lógica de um banco de dados, de acordo com Ramalho (1999), é dividida em
unidades lógicas de armazenamento chamadas de tablespace. Sendo assim, uma tablespace é uma
estrutura lógica que dita o espaço físico do banco de dados.
Há diversos tipos de tablespaces, como: tablespace system, onde um único tablespace é
criado para cada base de dados; e tablespace UNDO, sendo exclusivo para armazenamento de
informações UNDO, podendo existir mais de uma tablespace deste tipo; default temporary
tablespace. (CYRAN, 2002)
Uma base de dados muito pequena pode necessitar apenas da tablespace system, entretanto,
de acordo com Cryan, 2002, o Oracle recomenda a utilização de ao menos uma tablespace adicional
para armazenar os dados do usuário separadamente do dicionário de dados, dando flexibilidade às
operações de administração de banco de dados e, também, irá reduzir as disputas entre objetos do
dicionário de dados e o dos schemas para os mesmos datafiles.

15
Para esta tablespace adicional de armazenamento, segundo Fanderuff (2003), o ideal é ter
uma para os dados e outra especificamente para índices. Com essa estrutura, fica mais fácil
identificar e administrar, por exemplo, o quanto cada instituição ou departamento de uma empresa
utiliza em espaço em disco.
Por fim, uma tablespace é dividida em um ou mais datafiles, sendo estes divididos em
segmentos (tabelas), que são constituídos por extents e, por fim, por blocos. Para entender melhor,
tem-se a Figura 4 mostrando essa estrutura lógica (ibidem).
Tablespace
ExtentBloco
ExtentBloco
Segmento Segmento
Figura 4. Estrutura Lógica Fonte: Adaptado de Fanderuff (2003)
Ressalta-se que visões, procedimentos, funções e pacotes não ocupam segmentos na
tablespace de armazenamento, sendo essas armazenadas na tablespace system. Após, a figura 5
mostra a estrutura de um bloco de dados.
Um bloco de dados possui a seguinte estrutura no banco Oracle:
• Cabeçalho: espaço para identificação do bloco;
• Espaço Livre: reserva um espaço no bloco para futuras atualizações. Dessa maneira,
quando da alteração dos dados de determinado bloco de dados, essas alterações
continuam no mesmo bloco de dados melhorando, assim, o seu desempenho, e
• Data: espaço de armazenagem dos dados.

16
Cabeçalho
Espaço Livre
Dados Armazenados
Tabela DiretórioLinha Diretório
Figura 5. Estrutura de um bloco de dados Fonte: Adaptado de Ramalho (1999)
Como o bloco de dados é utilizado para o armazenamento de dados, o Oracle possui um
parâmetro chamado PCTUSED que informa se o bloco de dados faz parte de uma lista de blocos
com espaço livre ou não. Quando o bloco de dados ultrapassa um valor de preenchimento o
parâmetro informa que este bloco não está disponível. (RAMALHO, 1999)
Por fim, esse bloco de dados, quando já não faz parte da lista de blocos com espaço livre,
mesmo que tenha dados excluídos retornando, assim, a ter espaço livre, para que ele volte a fazer
parte da lista de blocos livres é necessário que esse espaço ultrapasse um determinado tamanho
especificado no parâmetro acima citado (FANDERUFF, 2003).
2.2.4. Seqüência de UNDO
Há duas formas de acesso ao banco de dados, uma visa á consulta através de um select e, a
segunda forma, é realizada através da escrita, utilizando insert, update e delete.
Quando um usuário está fazendo a leitura de um dado, esse não pode star em modificação,
da mesma maneira que um dado não pode ser modificado por duas instruções distintas.
De acordo com Fanderuff (2003), para tratar esta questão o Oracle mantêm uma cópia
original dos dados em um segmento UNDO antes da sua alteração, sendo esse segmento visualizado
quando um outro usuário acessar. Um dado passa para o estado de alterado e os demais usuários
acessam esse através do segmento UNDO. Quando uma validação de comando é executada
(commit), então o seu estado volta a ser liberado e o bloco pode ser sobreposto mostrando, então, os
dados alterados para os demais usuários. Quando acontece um cancelamento de escrita (rollback) é
justamente o segmento de UNDO que irá atualizar novamente o banco de dados com as

17
informações anteriores. Recomenda-se utilizar o commit somente no final do processo para
aumento do desempenho, não necessitando continuamente a repetição desse processo.
2.3. CONCEITO DE AJUSTE DE DESEMPENHO
Em sistemas de banco de dados relacionais, de acordo com Date (2000), o ajuste de
desempenho é uma exigência para alcançar um desempenho desejado em um banco de dados. Além
disso, esse ajuste passa a ser uma oportunidade para que sistemas relacionais sejam tratados a níveis
mais altos, através de otimizadores, não ocorrendo a necessidade de usuários saberem programar o
sistema a níveis mais baixos, diminuindo os custos de sua realização.
Desta maneira, com o ajuste de desempenho, o sistema por si próprio executa operações a
níveis baixos através da otimização automática do sistema, permitindo um acesso ao usuário a um
nível mais alto e fácil de trabalhar. A utilização de uma ferramenta para ajuste de desempenho é
fundamental para esse processo.
De acordo com Date (2000), o objetivo geral de uma ferramenta de ajuste de desempenho é
avaliar a estratégia mais eficiente para implementação de uma expressão racional. A seguir, estão
relacionados motivos para realização da sua utilização:
• Uma ferramenta tem grande quantidade de informações estatísticas que normalmente o
usuário não obtém, sendo estas:
o O número de valores em cada domínio;
o O número atual de registros em cada variável de relação básica;
o O número atual de valores distintos em cada atributo de cada variável de relação
básica; e
o O número de vezes em que ocorre cada um desses valores distintos em cada um de
tais atributos.
• Através dessas e de diversas outras informações, a ferramenta deve avaliar qual
estratégia adotar para aperfeiçoar as implementações das requisições.
• Com o decorrer do tempo, através da utilização do banco de dados, as estatísticas
acabam mudando também, sendo necessário uma nova otimização e uma nova

18
estratégia. Se compararmos esse trabalho com um sistema não relacional, o ajuste
representa a reescrita da programação.
• A ferramenta, por ser um programa, é capaz de realizar centenas de estratégias de
implementação para uma única requisição, sendo que o ser humano se limita a realizar
três ou quatro maneiras de implementação.
• A ferramenta é o resultado da junção de conhecimentos de diversos programadores.
Desta maneira, os conhecimentos nele empregados são comum uso para todos.
Na visão de Silberschatz & Korth (1999), ajustar o desempenho de um banco de dados
(otimização) consiste no ajuste de diversos parâmetros e na projeção de escolhas para a sua
melhoria para cada aplicação Entre esses parâmetros estão os tamanhos do buffer, podendo se
estender a aspectos do projeto, como a constituição de esquemas e de transações e também chegar a
um nível de hardware, como no numero de discos utilizados. Todos esses aspectos interferem no
desempenho de uma aplicação, assim como todos esses aspectos podem ser ajustados buscando uma
melhoria do seu desempenho. A seguir serão apresentados pontos que o autor destaca como passos
para a busca do ajuste de desempenho:
2.3.1. Localização de Gargalos
Um gargalo é um componente que realizada determinada função, cujo tempo de execução
influi de forma definitiva no desempenho de um sistema. Como exemplo de gargalo, uma aplicação
pode ter uma função que represente 80% do tempo total de sua execução. A localização e o ajuste
dessa função irá melhorar de forma significativa o andamento do sistema. Se essa função for
melhorada em 50 % do seu desempenho, então o seu ajuste irá representar 40% do desempenho
total da aplicação.
Porém, quando da eliminação de um gargalo, novos gargalos podem aparecer, e o processo
de localização e eliminação continua até que o sistema esteja equilibrado e que nenhum componente
de forma isolada se torne gargalo.
Na visão de sistemas mais simples, o tempo gasto em cada parte da aplicação influencia no
tempo total da execução. Porém, um sistema de banco de dados envolve uma complexidade maior,
ocorrendo necessidades de vários serviços, como entrada de processos no servidor, leitura de discos,
ciclos de CPU e controle de concorrência. Esses serviços, por sua vez, estão amarrados a uma fila

19
de pequenas transações, onde pode prejudicar o desempenho, especialmente no que diz respeito a
filas de I/O de disco.
Uma forma de construção de gargalo são justamente essas filas, onde esperam a liberação de
determinados componentes. O ideal é manter um recurso com tempos de espera para a sua
utilização baixa o suficiente para que o comprimento da fila seja curto.
2.3.2. Parâmetros Ajustáveis
Há três níveis de ajuste que um administrador pode realizar em um sistema de banco de
dados, sendo esses:
• O primeiro nível é também considerado o mais baixo, sendo este de hardware. A
utilização de um ou mais discos, aumento da memória e aumento do buffer de disco são
exemplos de ajustes;
• Os parâmetros do sistema de banco de dados é o segundo nível de ajuste. Cada banco de
dados tem o seu próprio conjunto de ajuste de parâmetros. Muitos desses bancos também
ajustam os parâmetros de forma automática observando indicadores, como, por exemplo,
taxas de página por acesso (page-fault); e
• O terceiro e mais alto nível é o ajuste de esquemas e transações. Esse nível é em parte
independente do sistema.
De forma geral, os três níveis trabalham de forma conjunta para o perfeito ajuste do sistema.
A tabela 1 a seguir mostra uma diversidade de parâmetros envolvidos no desempenho de banco de
dados.
Tabela 1. Parâmetros envolvidos no desempenho do banco de dados.
Nome do Parâmetro Descrição Padrão ARCHIVE_LAG_TARGET Quantidade de dados que pode ser perdida.
Valores muito baixos, resultam em LOGs freqüentes, o que diminui o desempenho.
O
BITMAP_MERGE_AREA_SIZE
Tamanho da memória usada para a união de bitmaps
IMB
CREATE_BITMAP_AREA_SIZE
Tamanho da memória alocada para criação de bitmaps
IMB
DB_BLOCK_SIZE Tamnho padrão dos blocos de dados. Esse parâmetro é estabelecido na criacao do BD e não deve ser alterado
No NT é 8MB

20
DB_CACHE_SIZE Tamanho padrão para blocos de buffers de cache
No NT é 24 MB
DB_Nk_CACHE_SIZE Tamanho para blocos de buffers de cache para caches adicionais de n Kbytes. Como o DB_BLOCK_SIZE é 8MB, o parâmetro a ser utilizado deve ser o DB_8K_CACHE_SIZE.
8
HASH_JOIN-ENABLED Informa se o otimizador deve ou não deve usar Hash
TRUE
LARGE_POOL_SIZE Tamanho de large pool da SGA para servidores compartilhados
8MB
LOG_ARCHIVE_XXX Disponibiliza os arquivamentos de log e de redo. Neste caso XXX representa os vários parametrtos de uma mesma familia, ou seja, LOG_ARCHIVE_DEST, LOG_ARCHIVE_DEST_n, LOG_ARCHIVE_STATE_n, LOG_ARCHIVE_DUPLEX_DEST,..., LOG_ARCHIVE_TRACE. Por este motivo, não há um valor padrão, pois cada parâmetro pode assumir um valor diferente.
OPTIMIZER_DYNAMIC_SAMPLING
Controla o nível de amostra dinâmica realizada pelo otimizador ( de 0 a 10)
1
OPTIMIZER_FEATURES_ENABLE
Habilita características do otimizador, conforme a versão do Oracle
9.2.0
OPTIMIZER_INDEX_CACHING
Comportamento da otimização baseada em custo. Favorece junções de loop aninhado e iteração IN-list (de 0 a 100)
0
OPTIMIZER_INDEX__COST_ADJ
Permite o ajuste do comportamento do otimizador para seleção de caminhos de acesso, fazendo-o mais ou menos propenso a usar um caminho de acesso pelo índice ao invés de fazer uma pesquisa, na tabela inteira (de 1 a 10000)
100
OPTIMIZER_MAX_PERMUTATIONS
Número de permutações da tabela que o otimizador vai considerar em buscas com junção
2000
OPTIMIZER_MODE Comportamento padrão para a escolha de uma abordagem de otimização para a instância
CHOOSE
PGA_AGGREGATE_TARGET
Meta de memória PGA agregada disponível aos processos do servidor pertencentes á instância
No NT é 24MB
PRE_PAGE_SGA Traz (TRUE) ou não traz (FALSE) a SGA inteira para a memória ao iniciar a instancia
FALSE
QUERY_REWRITE_ENABLED
Define o uso (TRUE) ou não (FALSE) de reescrita nas operações de busca
FALSE
QUERY_REWRITE_INTEGRITY
Usa índices baseados em função para obter valores somente de expressões SQL. O parâmetro padrão, ou seja, ENFORCED, significa que o Oracle reforça e garante a integridade e a consistência dos dados.
Enforced
SGA_MAX_SIZE Tamanho máximo para a SGA. Se a soma de seus componentes for maior, esse parâmetro é
130 MB

21
ignorado. SHARED_POOL_RESERVED_SIZE
Espaço da shared pool reservado para grandes requisições contíguas de memória
No NT é de aproximadamente 2,4 MB ou 2516582 Bytes
SHARED_POOL_SIZE Tamanho da shared pool da SGA No NT é 48MB SORT_AREA-SIZE Tamanho Maximo para operações de ordenação 64 KB SQL_TRACE Habilita (TRUE) ou desabilita (FALSE) a
facilidade de trace para SQL.Estando habilitado, esse parâmetro provê informações para o ajuste de Desempenho.
FALSE
Fonte: Adaptado de Flores (2003)
2.3.3. Ajuste de Esquemas
O ajuste de esquemas é realizado nas formas normais adotadas atraves de participações
verticais, como mostra o exemplo abaixo, de acordo com Silberschatz & Korth (1999):
Conta(nome_agencia, numero_conta, saldo)
Nesta forma, a relação conta ainda pode ser particionada em duas partes, ficando desta
maneira:
agencia(numero_agencia,nome_agencia) conta_saldo(numero_agencia,numero_conta,saldo)
Como resultado desta participação, duas relações foram criadas, porém, a chave (campo
numero_conta) irá ser repetida em ambas.
Vantagens dessa participação são:
• Caso as consultas sejam mais intensas para número da conta e de saldo, a resposta dos
acessos irá ser bem mais rápida pelo fato do campo nome_agencia que, naturalmente,
possui um tamanho relativamente grande, não ser pesquisado.
• Da mesma forma, o buffer irá comportar mais registros de contas, pois o tamanho dos
resultados irá ser menor.
Desvantagens dessa partição são:

22
• Se as consultas, por sua vez, tiverem intensidade em saber também o nome da agência,
então o custo da transação irá ser maior, pois a necessidade da junção representa um
aumento de custo.
• O armazenamento em buffer também será maior, pois o campo numero_conta irá ser
replicado.
2.3.4. Ajuste de Índices
Um número grande de índices não representa necessariamente um melhor desempenho do
banco de dados, pois em muitos casos o próprio índice representa o gargalo, sendo a exclusão de
determinados índices e a criação de outros índices mais apropriados a solução para esse caso.
Há casos em que o gargalo é a atualização do banco de dados, onde os índices são
alimentados, causando então um alto custo para a sua realização. A remoção de índices pode ser a
solução.
Também é importante definir qual o tipo de índices deve ser utilizado, tendo como opções,
de forma geral para os bancos de dados, os índices hash e os índices de arvore-B.
Ainda tem-se a opção de transformar índices em índices cluster, que nada mais é do que
índices agrupados, onde apenas um índice da relação é o índice cluster, sendo este geralmente o que
irá trazer um melhor desempenho, beneficiando o maior número de consultas e atualizações.
Por fim, Peasland (2000) relata que um índice é armazenado geralmente em uma estrutura
de dados b-tree, formada de nós de folhas (ponteiros). Quando um registro é apagado a entrada no
nó da folha é removida. Caso nenhum outro registro ocupar esse nó da folha, então este
permanecerá para sempre vazio, aumentando o custo de sua utilização, a menos que o DBA venha a
reconstruir o índice.
Sendo assim, o mesmo autor diz que antes de decidir o que fazer com o índice é necessário
saber do seu estado atual, que pode ser visualizado através do comando ANALYZE INDEX
VALIDATE STRUCTURE. Através deste comando, estatísticas são computadorizadas na tabela
SYS.INDEX_STATS, como mostra o script a seguir:
SQL> ANALYZE INDEX shopping_basket_pk VALIDATE STRUCTURE; Statement processed.

23
SQL> SELECT name,height,lf_rows,lf_blks,del_lf_rows,distinct_keys,used_space FROM INDEX_STATS; NAME HEIGHT LF_ROWS LF_BLKS DEL_LF_ROW
DISTINCT_K USED_SPACE ---------------------- ------- ------- ------- ---------- -------------- ---------- SHOPPING_BASKET_PK 2 1 3 1 1 65 1 row selected.
Duas regras podem ser adotadas para determinar se o índice necessita ser reconstruído, onde
pode ser facilmente realizado pelo comando ALTER INDEX REBUILD. A primeira regra é
verificar se o índice tem um tamanho igual ou maior do que três nós, sendo que o normal é ter um
ou dois, mas há suas excessões. A segunda regra é que a porcentagem de nós de folhas apagadas
num índice não deve ultrapassar o total de vinte por cento. (PAESLAND, 2000).
2.3.5. Ajuste de Transações
As transações, tanto para consultas como para atualizações, podem ser escritas de forma em
que possam beneficiar o desempenho do banco de dados. Porém, nos últimos anos, os sistemas têm
melhorado bastante a interpretação das escritas transacionais, onde até mesmo uma transação mal
produzida pode ser executada de forma eficiente. Além disso, muitos sistemas fornecem
mecanismos para visualização do plano exato de execução, podendo ser utilizado para determinados
ajustes.
Uma forma de melhorar o desempenho de uma consulta está através do SQL embutido, onde
tem como característica a obtenção de diferentes valores para um único parâmetro. Como exemplo
tem-se uma empresa com diversos setores, onde cada setor é visto separadamente de acordo com
sus atividades. A melhora nesse caso pode ser obtida através do agrupamento de informações por
cada setor, onde não há a necessidade de varrer todos os registros relativos aos setores para buscar
as informações quando da necessidade de uma consulta, bastando filtrar apenas os dados agrupados
de determinado setor.Em um sistema cliente-servidor, os custos são diminuídos de forma acentuada,
melhorando bastante o desempenho do sistema.
Uma segunda forma de melhorar o desempenho de comunicação em sistemas cliente-
servidor está na utilização de stored procedures (procedimentos armazenados), em que transações
ficam no servidor na forma de procedimentos que são disparados ao invés da transmissão de toda a
transação.

24
A melhoria de desempenho também pode ser alcançada através da execução de
determinadas transações em horários com pouca utilização do sistema, como no horário noturno.
Como justificativa a essa afirmação, tem-se como exemplo um sistema bancário onde durante o dia
são realizadas de forma contínuas pequenas transações onde, na ocorrência de uma transação que
envolva diversas relações importantes irá bloquear todas as demais transações. Isso acontece devido
a execução concorrente, onde uma transação é bloqueado até que determinada relação seja liberada
para acesso.
Especificamente para transações de atualização, o custo pode ser maior devido á utilização
ainda do sistema de log e do tempo gasto para recuperação de quedas. Ainda há o risco do sistema
de log ficar cheio antes mesmo da transação se completar, ocorrendo a necessidade de refazer essa
transação.
A utilização de transações com poucas atualizações, porém, que resultem em custos altos,
também devem ser evitadas, pois partes antigas do sistema log não podem ser removidas, podendo
levar ao mau uso do sistema log.
Alguns sistemas para evitar esses problemas de atualizações, mantêm limitados os números
de atualização de uma transação. Outros sistemas, por sua vez, quebram a transação em diversas
partes, surgindo os chamados mini-batch (mini-lote). Porem, utilizar mini-lote requer cuidado,
como no caso da ocorrência de transações concorrentes, sendo que a ultima transação poderá não
refletir o mesmo do que se fosse feito em uma única abordagem. Também problemas podem surgir
quando da ocorrência de falhas.
2.3.6. Simulação de Desempenho
A simulação consiste em testar o desempenho do sistema antes mesmo da sua instalação ou
da ocorrência de qualquer mudança. Sendo assim, muito do sistema deve ser simulado, como por
exemplo, o tempo de serviço gasto no processamento de determinadas solicitações, envolvendo nas
simulações informações como: CPU, discos, buffer, entre outras.
Cada solicitação de processamento pode ser executada em paralelo ou através do
enfileiramento, onde um processo espera o desalocamento de determinado recurso para sua
utilização. Esta fila de espera é atendida de acordo como o sistema foi projetado, podendo ser pela
ordem de chegada das solicitações ou através de prioridades de execução, por exemplo.

25
Uma vez desenvolvido o modelo de simulação varias informações podem ser obtidas,
podendo também variar os dados de entradas, assim como os parâmetros utilizados, a fim de
observar a sensibilidade e o desempenho do sistema em situações adversas.
2.4. AJUSTE DE DESEMPENHO
2.4.1. Administração Básica de Banco de Dados
Um banco de dados tem a finalidade de auxiliar na organização e na recuperação de dados.
Não necessariamente um sistema de processamento de dados utiliza um SGBD (Sistema de
Gerenciamento de Banco de Dados) para recuperação de informações, sendo que nesse caso, cabe
ao desenvolvedor criar formas dessa recuperação. Porém, quando o acesso a um banco de dados é
realizado através de um SGBD, cabe ao gerenciador assumir a responsabilidade de buscar todas as
informações especificas (FANDERUFF, 2003).
Então, como já citado nesse trabalho, a principal função de um SGBD é ter o controle
centralizado dos dados, onde o DBA (Database Admistrator) é responsável por esse controle. O
DBA, por sua vez, possui diversas funções que, entre elas, estão: definir quais dados serão
armazenados e quais os acessos mais freqüentes; disponibilizar os dados desejados pelo usuário;
fazer regras de acessos e criar métodos para evitar inconsistência de dados; definir quando e de que
formas serão realizadas o backup e como realizar a recuperação de informação quando da perda ou
danificação dos dados; e ajustar o sistema para obter o melhor desempenho do banco de dados
(ibidem).
De acordo com Flores (2003), um banco de dados tem que se adaptar a qualquer situação,
porém, nem sempre pode atingir o máximo de desempenho que esse pode oferecer a uma aplicação
especifica.
Como ressalva a esse problema, o mesmo autor ressalta que a realização de testes relata
onde o banco de dados melhor se comporta e, ao contrário, onde este tem um pior desempenho,
necessitando apenas de ajuste dos parâmetros de inicialização do banco e da medição de
desempenho em consultas e atualizações do mesmo.
Flores (2003) dizem que há cerca de 250 parâmetros que configuram o sistema do banco de
dados Oracle, sendo o DBA o responsável pela sua configuração e manutenção. Quando há uma
modificação dos parâmetros do banco de dados, alguns desses exigem a sua reinicialização, porém,

26
no caso do Oracle, grande parte desses parâmetros muda dinamicamente sua configuração em
tempo de execução.
Esses parâmetros, ainda de acordo com Flores (2003), são classificados em três tipos,
caracterizados por seu tipo de interrupção para mudar seu valor:
• Parâmetros Estáticos: São parâmetros que quando da sua modificação há a necessidade
de reiniciar o sistema. Tem-se como exemplo deste parâmetro o DB_BLOCK_SIZE,
onde os tamanhos das tabelas e dos índices não podem ter tamanhos diferentes de
blocos, ocorrendo numa recriação completa da base de dados quando da sua alteração.
Ressalta-se que a modificação do parâmetro acima citado irá também necessitar da
reconstrução do banco dos dados;
• Parâmetros Semi- Dinâmicos: Os parâmetros alterados, nesse caso, não exigem uma
reinicializacao do sistema, contudo, esses parâmetros ainda ficam por um tempo
indisponíveis para uso; e
• Parâmetros Dinâmicos: Ao contrario estáticos, a alteração dessa classe de parâmetro
pode acontecer a qualquer instante, sem necessidade de reinicializacao do sistema e nem
de uma espera para a sua utilização.
O autor acima citado ainda destaca a divisão de parâmetros através de dois campos de
atuação, sendo: através dos parâmetros SGA (System Global Area), onde o banco Oracle torna
certas áreas de memória maiores e outras áreas menores, quando da alteração de parâmetros; e
através de parâmetros de processo, sendo estes internos, onde o Oracle cria e destrói esses de
maneira automática, sem afetar sua disponibilidade.
2.4.2. Performance Tuning
De acordo com Senegacnik (2004), há muitas definições do que é um Tuning de banco de
dados. Se o tuning está acontecendo em uma transação OLTP (On-Line Transaction Processing) se
deve pensar em vários usuários executando milhares ou milhões de pequenas transações por dia.
Caso a aplicação seja em um sistema DSS (Decision Support System) tem que trabalhar em ajuste
de tempo de resposta. Sendo assim, é muito importante saber que tipo de aplicação em que esta
funcionando o sistema.

27
O inicio no ajuste de desempenho é encontrar qual o problema que está tendo na base de
dados. As áreas possíveis para ajuste de uma base de dados do Oracle, são: CPU; Memória,
Input/Output; Rede; e Software. (SENEGACNIK, 2004a).
Para Senegacnik (2004a), a grande regra para ajuste da base de dados é nunca “mude mais
um parâmetro ao mesmo tempo”. Isso se dá pelo fato que se mudar mais de um parâmetro de uma
única vez, nunca saberá de qual dos parâmetros alterados que resultou a melhoria no desempenho
do sistema, principalmente quando não se tem certeza do que fazer.
Há diversas maneiras de encontrar os problemas em potencial. O problema mais comum
acontece quando em um único sistema o mesmo banco de dados possui aplicações que tem um
ótimo desempenho, assim como também possui aplicações que possuem um mau desempenho.
Nesse caso, obviamente há um problema com essas aplicações e não na base de dados. Se o
problema estiver em um aplicativo que esteja em uso há pouco tempo e inicialmente o desempenho
era normal, mas com o passar do tempo seu desempenho esteja piorando, devem-se então procurar
indicações de ajuste do SQL. Em 90% desse caso há um ou mais índices que falta e as consultas
estão causando varreduras cheias da tabela. Também nos casos em que o crescimento diário das
tabelas e índices, novamente no caso da utilização de uma aplicação nova, é grande as chances das
estatísticas usadas pelo CBO (cost based optimizer) não estejam exatas. Se estiver sendo usado o
CBO, então a analisa das tabelas e índices devem ser realizados regularmente.(ibidem)
O desenvolvimento do projeto do banco de dados também é muito importante no ciclo de
desenvolvimento da aplicação. Nesse estagio são identificados às entidades, seus atributos e as
relações entre si. Normalmente se faz o processo de normalização para conseguir a terceira forma
normal.A não normalização correta da base de dados pode acarretar em problemas de desempenho.
Um outro problema do projeto é um modelo simples dos dados com triggers complexos da base de
dados que usam muitos dos recursos. (SENEGACNIK, 2004a).
Fanderuff (2003) também relata que um banco de dados tem sua criação e configuração a
partir de um projeto e de cálculos sobre o seu crescimento durante a sua utilização.Porem, a autora
destaca que mesmo com todos os cuidados obtidos nessa fase há dois principais motivos para a
queda do seu desempenho: a fragmentação dos dados com a sua utilização e não conseguir o
comportamento do banco de dados esperado.

28
Quando uns destes casos acontecem, então há dois motivos para sua causa: recursos
inadequados e projeto inadequado. Par a resolução desse problema, Fanderuff (2003) também cita a
verificação da normalização do banco de dados, assim como verificar se os índices estão
condizentes com a realidade e se os arquivos físicos estão corretamente separados e definidos.
Se o problema de desempenho na aplicação ainda persistir então há a possibilidade de existir
problemas relacionados aos comandos SQL. Esta situação é a mais comum, sendo que quando as
indicações críticas irão sendo ajustadas os problemas de desempenho desaparecerão.
(SENEGACNIK, 2004b).
Para a otimização (tuning) do banco de dados quando a causa é o código SQL, Fanderuff
(2003) ressalta que são necessários os seguintes cuidados:
• Verificar se as áreas de paginação e SWAP estão de acordo com a realidade do banco de
dados;
• Se o espaço em disco está sendo utilizado por completo ou se não existe espaço para
execução de um processo do banco de dados; e
• Limitar o número de aplicações no banco de dados a somente ás necessárias.
Caso o banco de dados ainda não tenha o desempenho esperado, mesmo depois da
verificação e dos ajustes dos itens acima citados, então há a necessidade de otimização do banco de
dados.(ibidem).
Senegacnik (2004b) cita dois tipos de otimização, sendo uma baseada em regras (RBO -
Rule Based Optimizer) e outra baseada em custos (CBO - Cost Based Optimizer).
No caso da utilização do CBO é possível que a causa do problema sejam estatísticas
recolhidas no começo da fase da produção e que não foram atualizadas. Sendo assim, a primeira
regra do CBO é manter as estatísticas atualizadas. Um problema das versões anteriores do Oracle
está na não possibilidade de recolher as estatísticas de acordo com o número de mudanças na tabela.
Essa otimização é dirigida por estatísticas e suas decisões são baseadas no calculo de custo dos
objetos nas declarações SQL, tendo uma melhor performance que o RBO. Os dados estatísticos são
obtidos através do comando Analyze, juntamente com o Estimate, que reúne uma amostra das
informações do objeto no qual se baseiam suas estatísticas. (SENEGACNIK, 2004b).

29
Antes da versão 7.0 o Oracle tinha somente o RBO que, por sua vez, é dirigida pela sintaxe,
não considerando dados estatísticos e suas decisões não são baseadas em cálculos de custo. Nessa
RBO, a posição dos nomes das tabelas, assim como as restrições da cláusula where, são fatores
importantes para a otimização do banco de dados. (ibidem).
Fanderuff (2003) também cita que é importante verificar qual o plano de execução que uma
declaração SQL realiza em um banco de dados, onde se pode utilizar o recurso Explain Plan, o
qual ilustra a tabela ou índice e a ordem em que estas serão acessadas com a declaração. Este
procedimento é extremamente útil para se verificar a forma como o Oracle resolveu a execução de
um comando e então interferir para sua melhora de performance.
Urmam (1999) destaca que é através desse plano de execução que a base de dados
processará a instrução SQL efetivamente, incluindo tabelas e índices que necessitam ter acesso,
além, também dos métodos de acesso utilizados, entre outras características.
2.4.2.1. Métodos de Acesso
Essa forma que o Oracle resolve a execução de um comando para adotar uma tabela é
apresentada de seis formas distintas, sendo essas apresentadas a seguir, de acordo com Fanderuff
(2003):
• Full Table Scan: Todas as linhas de uma tabela descrita na declaração são retornadas
através da pesquisa completa da mesma (do começo ao fim). No RBO pode ainda ser
feito por índices e, no CBO, o otimizador é obrigado a fazer a leitura completa em busca
de estatísticas para constatar que o pequeno número de linhas possui o menor custo para
Full;
• Index Unique Scan: Localiza através de um único índice uma única chave;
• Index Range Scan: Acessa coluna com múltiplos valores, sendo utilizado range (>,>,<>,
between, etc). A comparação = (igual) não é utilizada no range;
• Index Full Scan: Ao invés de realizar um range, todo o índice é lido. No CBO, pode ser
determinado através da estatística, se é ou não uma boa idéia;
• Index Fast Full Scan: é o scan de todos os blocos de índices e os registros não são
retornados de forma odenada; e

30
• Rowid: Método mais rápido de acesso. O Oracle recupera um bloco especifico e extrai
somente os registros desejados.
2.4.2.2. Join
Quando duas ou mais tabelas são unidas o Oracle cria um Result Set (conjunto de resultados)
temporário, sendo guardada na tablespace temporary, contendo a combinação de linhas. Há cinco
métodos para essa junção, sendo principais os métodos nested loop, sort merge join e hash join
.(FANDERUFF, 2003).
• Sort Merge Join: É utilizado quando as tabelas têm números de linhas semelhantes e a
maioria das linhas são retornadas. O seu funcionamento é baseado na classificação de
ambas as tabelas pela coluna de junão. Tem alto custom de operação. Os resultados são
vistos após a realização de todo o processo de vinculação;
• Nested Loops: É utilizado quando a tabela principal é menor e quando um único índice é
definido na coluna de junção. O seu funcionamento consiste na leitura de uma linha da
tabela principal e é verificada na outra tabela. O retorno das linhas é quase imediato, não
necessitando da total vinculação do processo;
• Hash Join: Somente utilizado quando o parâmetro hash_join_enabled é true, sendo
disponível para o CBO. O hash join tem como funcionamento a divisão de duas tabelas
em partições e a criação de uma memória na base da tabela hash, sendo utilizado para
mapear as colunas de junção sem a necessidade de classificar/intercalar. É recomendado
para situações onde o tamanho de uma tabela é imensamente superior ao tamanho da
outra tabela;
• Cluster Join: Utilizado para acesso em tabelas fisicamente clusterizados (método para
acessar uma tabela sem a utilização de um índice). As linhas das colunas unidas são
alinhadas dentro do mesmo bloco de dados aumentando a eficiência, visto a necessidade
de um único I/O do banco de dados; e
• Index Join: Se todos os dados de retorno da declaração estiverem em um único índice é
dispensada a estrutura subjacente da tabela.
Fanderuff (2003) ainda relata dicas para aprimorar a execução de comandos SQL:
• Utilizar IN ao NOT (o NOT não permite a utilização de índices);

31
• Utilizar <= e >= ao NOT (o NOT não permite a utilização de índices);
• Não realizar cálculos na clásula WHERE ou em colunas indexadas;
• Não utilizar índice quando 20% das linhas serão retornadas em uma consulta; e
• Utilizar subquerys (subconsultas) somente quando não houver outra solução.
A Figura XX mostra a utilização da instrução SQL Explain Plan, baseado em Urman
(1999).
Select Count(P.CD_INSTITUICAO)From PONTOS_APOIOS P, INSTITUICOES IWhere P.CD_INSTITUICAO = I.CD_INSTITUICAOAnd I.CD_MATRIZ = 2;
Select lpad(' ', 2 * (LEVEL - 1)) || operation || ' ' || options ||object_name || ' ' || decode(id, 0, 'Cost = ' || position) “Execution Plan”from plan_tablestart with id=0 andtimestamp = (select max(timestamp) from plan_table where id=0)connect by prior id = parent_idand prior nvl(statement_id, 'SQL_001') = nvl(statement_id, 'SQL_001')and prior timestamp <= timestamporder by id, position;
Execution Plan---------------------------------------------SELECT STATEMENT Cost = SORT AGGREGATE NESTED LOOPS TABLE ACCESS BY INDEX ROWIDINSTITUICOES INDEX RANGE SCANIX_01_INSTITUICOES INDEX RANGE SCANIX_01_PONTOS_APOIOS
EXPLAIN PLAN SET STATEMENT_ID = 'SQL_001' FORCabeçalho
Comando SQL para análise
Comando SQL do Explain Plan
Resultado para análise
Figura 6. Análise de Explain Plan Fonte: Adaptado de Urman (1999)
2.5. FERRAMENTAS DE TUNING PARA ORACLE
De acordo com Niemiec (2003), uma maneira de garantir que o desempenho do sistema seja
ótimo é monitorá-lo em busca de pequenos problemas de desempenho antes que possam se tornar
grandes problemas. Este monitoramento pode ser facilitado através de ferramentas, como estas a
seguir.
2.5.1. Oracle Enterprise Manager (OEM)

32
A ferramenta OEM oferece um ambiente integrado do banco de dados ao DBA através de
um console de gerenciamento central e packs adicionais: o diagnostics pack e tuning pack
(Niemiec, 2003). A Figura 7 mostra a tela da ferramenta OEM.
Figura 7. Ferramenta Oracle Enterprise Manager
Entre as suas funcionalidades, estão: a administração completa do Oracle; diagnosticar,
modificar e ajustar bancos de dados; programar tarefas em diversos sistemas com intervalos de
tempos distintos; compartilhar tarefas entre administradores de banco de dados; entre tantas outras
funções (MANAGER, 1998). O que irá ser visto adiante é a descrição de maneira global dos
principais recursos da ferramenta OEM.
2.5.1.1. Pasta Instância
Entre as diversas pastas da ferramenta OEM, a pasta instância tráz informações sobre
sessões individuais, bloqueios, planos de recursos e os parâmetros de inicialização no nível do
sistema, como pode ser visto na Figura 8.

33
Figura 8. Funcionalidades da Pasta Instância
2.5.1.2. Pasta Esquemas
Esta pasta mostra mais a fundo uma instância, mostrando um esquema individual e os
objetos associados a esse esquema (Niemiec, 2003). Entre as opções disponíveis estão: tabelas,
índices, visões, seqüências, clusters, entre outras funções.
2.5.1.3. Pasta Segurança
Através desta pasta há uma rápida visualização das limitações de acesso de cada usuário
individualmente. Entre as funcionalidades estão a alteração de senhas de um usuário, cotas da
tablespace, privilégios do sistema e funções atribuídas ao usuário.
2.5.1.4. Pasta Armazenamento
Tem como principal função monitorar e modificar tablespace, arquivos de dados e
segmentos de rollback. Niemiec (2003) nos diz que a pasta de armazenamento é uma área
extremamente perigosa para realizar alterações, podendo afetar seriamente seus usuários. Abaixo, a
Figura 9 mostra a pasta de armazenamento.

34
Figura 9. Funcionalidades da Pasta de Armazenamento
2.5.2. Oracle SQL Scratchpad
Esta ferramenta é de utilidade de desenvolvedores e DBAs. Entre as suas funcionalidades
Oferece uma interface ao usuário onde é possível editar e executar instruções SQL. Além destes
recursos, a ferramenta ainda possibilita salvar as instruções SQL para uso posterior; carga e
salvamento de arquivos de script; suporte a instruções DDL (Data Definition Language) e DML
(Data Manipulation Language); exibição do explain plan; e os resultados são ilustrados em formato
tabular (MANAGER, 1998). A figura 10 mostra a ferramenta SQL Scratchpad.

35
Figura 10. Ferramenta SQL Scratchpad.
O SQL Scratchpad também pode salvar os resultados obtidos em arquivos HTML ou no
formato csv. Esta ferramenta está disponível a partir da ferramenta OEM. (MANAGER, 1998).
2.5.3. TOAD
A ferramenta TOAD tem com principal funcionalidade o gerenciamento do banco de dados
Oracle. Também possui diversas outras funções, como: execução de instruções SQL; explain plan;
visualização de esquemas (tabelas, índices); constraints; informações da SGA; entre outras funções.
Abaixo, a Figura 11 mostra a ferramenta executando uma instrução SQL.

36
Figura 11. Ferramenta TOAD
A ferramenta TOAD também dispõe de um help auxiliando na sua utilização. Como
ressalvo, assim como as ferramentas da Oracle, esta ferramenta não é gratuita, necessitando de
licença para a sua utilização.
2.6. ESTUDO SOBRE SISTEMAS E PROJETOS SIMILARES
Para o desenvolvimento do projeto, inicialmente ocorreram pesquisas em sistemas e projetos
similares objetivando estimar o que hoje há de informação sobre o tema deste trabalho de conclusão
de curso.
Dois projetos foram estudados, sendo esses:
• GURU - Uma ferramenta para administrar banco de dados através de Web. (SCHERER,
2002); e
• Análise de desempenho do banco de dados Oracle 9i. (FLORES, 2003).
Esse estudo propiciou conhecer as dificuldades que DBAs encontram para constatar
problemas relacionados a desempenho do banco de dados, assim como a dificuldade em realiar as
alterações necessárias para o ajuste.

37
Além disso, através da pesquisa nesses projetos é possível verificar quais parâmetros e quais
formas de ajustes de desempenho foram adotadas, para que se possa constatar se realmente esses
itens surtem o efeito necessário para melhorar o desempenho do banco de dados. A seguir, esses
projetos serão apresentados.
2.6.1. GURU - Uma ferramenta Para Administrar Banco de Dados Através da Web
Esta dissertação (mestrado) foi desenvolvida na Universidade Federal do Rio Grande do Sul
(UFRGS), tendo como fruto de seu trabalho uma ferramenta para administrar banco de dados
através da Web (SCHERER, 2002).
Esse trabalho tem como objetivo desenvolver uma ferramenta para auxiliar o DBA a
detector e resolver problemas de desempenho de banco de dados.
Como principal característica está à utilização da internet como instrumento. Em outras
palavras, a ferramenta é Web e o DBA pode utilizar na resolução de problemas a qualquer
momento, independente da localização física e lógica do banco de dados.
A ferramenta é independente de plataforma. Para tanto foi utilizado a linguagem Java que,
dentre suas características, tem a portabilidade que facilita a criação de programas para a internet.
Dois SGBDs foram focalizados para a realização do projeto. O primeiro SGBD é o Oracle,
que recebeu destaque por ser, segundo a autora, o mais utilizado atualmente. O segundo SGBD que
a ferramenta focalize é o SQL Server que também está sendo amplamente utilizado no Mercado,
segundo a autora. Como funcionalidades do trabalho, têm-se as seguintes opções de gerenciamento:
2.6.1.1. Gerenciamento de espaço
Realizar um controle de armazenamento de objetos e suas informações, de acordo com a
autora, é uma prática de grande carga no trabalho do administrador que pode influenciar de forma
direta na operação geral do banco de dados. Esse tópico é focado no banco de dados Oracle. Os
itens dessa função são:
• Maxextents: Identifica o número de extents uitlizados em cada segmento, assim como
informar quais segmentos estão se aproximando de sua capacidade máxima;

38
• Tabelas sem espaço: Visualiza uma previsão de tabelas que não têm espaço disponível o
suficiente para a próxima gravação do extent em uma tablespace;
• Tamanho médio da linha: Com base nesse tamanho médio irão ser baseados os valores
para os parâmetros de ocupação do bloco Oracle especificamente, também, o tamanho de
espaço livre para os blocos de dados para a sua expansão;
• Tamanho máximo da linha: Utilizado em casos de tratamento de encadeamento das
linhas que causam uma overhead (estouro do bloco de dados);
• Marca D’água: Server para recuperar o espaço não utilizado de uma tabela, sendo que a
visualização da marca d’água só é possível após a atualização do dicionário de dados
com os valores atualizados; e
• Coalesce: Dá ênfase a fragmentação do espaço livre dentro das tablespaces. A
fragmentação focalizada é a honeycomb (nessa fragmentação, os extents livres ficam
localizados lado a lado).
2.6.1.2. Avaliação de Desempenho
Nesse tópico é determinada a disponibilidade do banco de dados. Nessa disponibilidade está
o seu desempenho quanto a tempo de resposta. Esse tópico tem como foco o banco de dados Oracle.
Os itens dessa funcionalidade são:
• System Global Area (SGA): Ponto crítico da memória onde ocorrem as operações da
instância, sendo dividida em:
o Database buffer cache: Mostra a taxa de hits do buffer de dados, que mede a
quantidade de vezes que o Oracle encontrou os blocos de dados que precisava na
memória, não necessitando, assim, ler do disco. A ferramenta ainda informa o valor
aceitável da taxa de hits e ainda dá dicas de como deve atuar o DBA; e
o Shared pool: Essa funcionalidade ainda se divide em dois outros pontos, sendo essas
a “library cache” e o “dicionário de dados” sendo que em ambas as opções mostram
a taxa de hits, avaliação e dicas;
• Area sort: Nessa area são armazenadas consultas SQL que necessitam de cláusulas que
necessitam de classificação, como a cláusula order by. O desempenho obtido com esse

39
ajuste, segundo a autora, afeta todo o sistema e não somente quando da necessidade de
uma classificação. Essa funão é dividida em três pontos:
o Sort memória x sort disco: Conta o número de classificações realizadas em memória
e em disco, traçando uma percentagem para classificações. Quando maior a
percentagem de classificação em memória, melhor o desempenho do banco de
dados. Uma avaliação é realizada pela ferramenta; e
o Definição de usuários: Quando ocorre a classificação em disco, há a necessidade que
essas sejam realizadas em tablespace temporaries e não permanents. Essa
funcionalidade indica os usuários mal definidos que utilizam tablespace permanente;
• Armazenamento: Essa funcionalidade envolve três pontos:
o Encadeamento de linhas banco de dados: Esse encadeamento ocorre quando uma
linha é maior do que o tamanho de um bloco de dados. A interface da ferramenta
ilustra o número de linhas encadeadas do banco de dados, assim como uma avaliação
e dicas;
o Encadeamento de linhas tabelas: Verificado que há linhas encadeadas no banco de
dados, então há a necessidade de verificar em quais tabelas há esse encadeamento; e
o Extents: De acordo com a autora, há fortes evidências que a redução do crescimento
dos extents melhora o desempenho do banco de dados. Essa função mostra o número
de extents que determinado objeto ocupa;
• SQL: A ferramenta mostra oa DBA quais são as declarações que mais consomem
recursos do servidor:
o Consumo de disco: Permite ver o número de acesos que determinada declaração fez
ao disco, assim como o número de vezes em que foi executada, além do nome do
usuário; e
o Consumo de CPU: Semelhante ao item anterior, porém, ao invés de indicar o número
de acesso a disco, indica o número de leituras feitas na memória;
2.6.1.3. Gerenciamento de schema
Permite ver os diferentes tipos de objetos que pertencem os diferentes schemas da instância
conectada pela ferramenta. É dividida em três pontos:

40
• Índices: Disponível apenas para Oracle nessa ferramenta, há as opções de listagem,
criação e exclusão de indices;
• Tabelas: Além do Oracle, também está disponível para o SQL Server e possui, também,
as opções de listagem, criação e exclusão de tabelas; e
• Visões: Funcionalidade apenas para Oracle, possui as opções de listagem, criação e
exclusão de visões.
2.6.1.4. Área de SQL
A ferramenta ainda possui uma área para livre execução de comandos SQL, sendo, segundo
a autora, imprescindível para administração de um banco de dados, resolvendo, assim, problemas
mais complexos ou específicos.
De uma forma geral, com esta ferramenta o administrador do banco pode acessar as tabelas
do dicionário de dados para identificar e corrigir os problemas que estão afetando a operabilidade
do banco de dados. A ferramenta acessa banco de dados em unidades distribuídas separadas física e
logicamente umas das outras.
A Tabela 2 a seguir ilustra um resumo das vantagens e desvantagens do projeto em resumo:
Tabela 2. Quadro de vantagens e desvantagens
Vantagens Desvantagens Todos os módulos da ferramenta funcionam através da Web, permitindo acesso em banco de dados de organizações que possuem softwares de seguranças para proteção de sua rede interna, chamados de firewalls. A ferramenta ainda possibilita a utilização de pacotes próprios de criptografia.
Os módulos da ferramenta não abrangem todos os aspectos dos bancos de dados.
A ferramenta mantém a sua personalização mesmo com a inclusão de novos módulos.
Não possui um histórico dos diferentes estados do banco de dados, ao longo de seu acompanhamento.
Existe um módulo para executar comandos SQL. Não há resultados mostrados de forma gráfica para facilitar a interpretação dos resultados obtidos na simulação.
A ferramenta não é proprietária. É possível acessar bancos de dados de diferentes fornecedores.

41
Em suma, esse projeto alcançou suas metas mostrando que é possível implantar uma
ferramenta que possibilite, via internet, a administração de banco de dados, independente da
localização física do Administrador do Banco de Dados ou do Bando de Dados.
Entre trabalhos futuros a esse, a autora destaca: a inclusão de um módulo para executar
backup lógico do banco de dados e permitir que o módulo “Área do SQL” execute programas SQL.
2.6.2. Análise de Desempenho do Banco de Dados Oracle 9i
Esta monografia (graduação) foi desenvolvida na Universidade Luterana do Brasil, Campus
Canoas (ULBRA), tendo como fruto de seu trabalh uma ferramenta para análise de desempenho do
banco de dados Oracle 9i (FLORES, 2003).
O objetivo do trabalho é ter uma visão geral do banco de dados Oracle, assim como
identificar os parâmetros que envolvem concorrência, desempenho e recuperação de dados. Feito
isto, então são utilizadas ferramentas para medir e avaliar o desempenho do banco de dados. Por
fim, uma análise dos resultados obtidos é realizada.
O projeto consiste em medir o desempenho do banco de dados para consultas e atualizações,
conforme os parâmetros de inicialização do Oracle são alterados. Os parâmetros selecionados para
ajuste de desempenho nesse projeto são:
• DB_BLOCK_BUFFERS: Niemiec (2003) comenta que esse campo é desaconselhável
para utilização na versão 9i do Oracle, pois o mesmo desativa muitos recursos dessa
versão. Esse parâmetro, de acordo com Myoracle (2004), determina o número de
database buffer em um buffer cache;
• DB_CACHE_SIZE: Primeiro parâmetro a ser examinado no init.ora e compõe a area da
SGA que é usada para armazenar e processor dados da memória. (NIEMIEC, 2003);
• DB_FILE_MULTIBLOCK_READ_COUNT: De acordo com Myoracle (2004), esse
parâmetro é utilizado para limitar a duração de I/O (entrada e saída) durante a leitura de
tabelas. Sendo assim, o DB_FILE_MULTIBLOCK_READ_COUNT especifica o
número de blocos lidos em uma operação de I/O; e
• GLOBAL_CONTEXT_POOL_SIZE: Especifica o tamanho da memória alocada no
SGA para armazenagem e gerenciamento global da aplicação (MYORACLE, 2004);

42
Além desses parâmetros, ainda têm-se: LOCK_SGA; LOG_CHECKPOINT_TIMEOUT;
OPTIMIZER_INDEX_CACHING; SORT_AREA_SIZE; SGA_MAX_SIZE; PRE_PAGE_SGA;
QUERY_REWRITE_ENABLED; ROW_LOCKING; OPTMIZER_MODE;
QUERY_REWRITE_INTEGRITY; OPTIMIZER_MAX_PERMUTATIONS; e
OPTIMIZER_INDEX_COST_ADJ.
É um aplicativo que roda consultas ou atualizações concorrentemente através do uso de
threads. Sendo assim, o aplicativo é executado em um cliente, onde as threads irão similar um
sistema multiusuário. São disparados 10 processos que irão realizar consultas e atualizações na base
de dados concorrentemente, simulando um sistema multiusuário com 10 clientes conectados ao
banco. O aplicativo foi desenvolvido em Delphi. A Tabela 3 a seguir ilustra um resumo das
vantagens e desvantagens do projeto em estudo.
Tabela 3. Quadro de vantagens e desvantagens
Vantagens Desvantagens A medida de desempenho é realizada através de uma simulação, onde irá mostrar o melhor ajuste de desempenho antes da sua aplicação real no banco de dados.
Poucos parâmetros foram abordados no projeto devido a complexidade e ao tempo necessário para a sua implementação.
Os resultados são mostrados de forma gráfica facilitando, assim, a interpretação dos resultados obtidos na simulação.
Não possui um histórico dos diferentes estados do banco de dados, ao longo de seu acompanhamento.
Esse trabalho apresentou um estudo sobre os principais parâmetros para ajuste de
desempenho do banco de dados Oracle, assim como mostrou ferramentas para o seu manuseio. Por
fim, ocorreu a implementação de uma ferramenta que visa ilustrar, de modo gráfico ao
administrador do banco de dados, parâmetros específicos através da simulação de resultados,
mostrando o que pode ocorrer no bando de dados antes da sua real implantação.
2.7. CONCLUSÕES DA FUNDAMENTAÇÃO TEÓRICA
Como conclusão do estudo realizado, se tem como destaque a importância do banco de
dados como pioneiro em diversos avanços tecnológicos. Inúmeros foram os avanços que
contribuíram para a atual situação em que se encontram os sistemas de gerenciamento de banco de
dados que atualmente são utilizados.
O estudo continuou mostrando como o SGBD do Oracle trata pontos, como: estrutura física,
onde ilustra a organização dos arquivos físicos; estrutura da memória, onde mostra como a memória

43
RAM é dividida e como interagem as diferentes partes da memória com os processos instanciados
pelos usuários; estrutura lógica, onde demonstra como o Oracle organiza logicamente os arquivos
na memória; e, por fim, a seqüência de UNDO, onde ilustra como são realizadas as operações de
acesso e recuperação de dados.
Num outro momento, foi definida a conceituação do que é um ajuste de desempenho no
banco de dados, para então mostrar como o banco de dados Oracle trabalha com seus parâmetros de
ajuste.
Finalmente, foram mencionados projetos que também focalizam o ajuste de desempenho em
banco de dados servindo como base, juntamente com o restante do estudo, para definir os
parâmetros a serem abordados como requisitos desse trabalho.
Então, através desses requisitos levantados o presente projeto tem como objetivo
desenvolver uma ferramenta que auxilie no ajuste de desempenho do banco de dados Oracle,
ilustrando dados estatísticos, gerando scripts para realização da sua manutenção e mantendo um
histórico de atuação desta ferramenta.

44
3. PROJETO
O projeto proposto nesse trabalho tem como objetivo organizar e gerenciar os dados da
ferramenta para análise e ajuste de desempenho do banco de dados Oracle.
As etapas que compõem esse capítulo são:
• Listagem dos requisitos do projeto;
• Visualização do diagrama de contexto com as funções do sistema; e
• Visualização, descrição do fluxo de dados e visualização da tela.
3.1. REQUISITOS
Os requisitos que o sistema deverá contemplar são:
• Função de controle de acesso;
• Função para instalação da ferramenta;
• Função para visualização da estrutura lógica da memória;
• Função para visualização da shared pool;
• Função para análise do plano de execução;
• Função de análise e reconstrução dos índices da base de dados;
• Função para ajuste de esquemas;
• Função para consulta de acessos; e
• Função para consulta da análise de índices.
3.2. DIAGRAMA DE CONTEXTO
O diagrama de contexto representa a relação das entidades com as funções do sistema:

45
Figura 12. Diagrama de Contexto
Descrição:
• O diagrama de contexto possui as seguintes entidades:
o Usuário; e
o Banco de Dados.
• O diagrama de contexto possui as seguintes funções:
o Solicita Acesso ao Banco de Dados;
o Solicita Instalação da Ferramenta;
o Solicita Visualização da Estrutura da Memória Lógica;
o Solicita Visualização da Shared Pool;
o Solicita Análise do Plano de Execução;
o Solicita Reconstrução de Índices do Banco de Dados;
o Solicita Ajuste de Desempenho;

46
o Consulta de Acessos; e
o Consulta de Análise de Índices.
3.3. DIAGRAMAS DE FLUXO DE DADOS
O fluxo de dados fornece uma visão geral das ações das entidades com determinada função
do sistema.
3.3.1. Solicita Acesso ao Banco de Dados
Para utilização dessa ferramenta há a necessidade de sua instalação para cada banco de
dados a ser realizado o ajuste de desempenho.
Usuário
01Acesso ao banco de
dados
Solicita acesso aobanco de dados
Acesso ao bancode dados permitido
Banco de Dados
Informa dados paraacessar banco de dados
Resposta de acessoao banco de dados
Usuarios
Grava usuário
Figura 13. Solicita Acesso ao Banco de Dados.
Descrição:
• Essa é a primeira função que o usuário irá acessar ao entrar no sistema, sendo a função
de conexão com o banco de dados.

47
• Ao acessar essa função, o usuário irá informar três dados:
o Login;
o Senha; e
o Banco de Dados.
• Após o usuário informar os dados, o sistema confirma a conexão com o banco de dados;
e
• A conexão é registrada na tabela INSTANCIAS.
Regras de Negócio
• Para cada banco de dados a ser realizado o ajuste de desempenho deve ter a necessidade
de instalação da base de dados repositório da ferramenta;
• O banco de dados da ferramenta deve estar instalado em um usuário do banco de dados a
ser realizado o ajuste de desempenho;
• Caso o banco de dados informado não estiver configurado na ferramenta, então a função
de configuração do sistema é chamada;
• As outras funções do sistema serão disponibilizadas a partir dessa conexão com o banco
de dados;
• Em caso dos dados de acesso da função não estarem corretos o sistema retorna uma
mensagem ao usuário; e
• É necessário o usuário que acessou o sistema ter o privilégio de DBA, assim como o
usuário no qual está instalada a ferramenta.

48
A Figura 14 referencia a tela da função:
Figura 14. Tela do Controle de Acesso ao Banco de Dados.
3.3.2. Solicita Instalação da Ferramenta
A ferramenta para ajuste de desempenho é instalada em um dos usuários do banco de dados
a ser analisado.

49
Figura 15. Solicita Instalação da Ferramenta
Descrição
• Ferramenta busca todos os usuários do sistema;
• Caso a base de dados da ferramenta já esteja instalada no banco de dados então o usuário
tem a opção de desinstalar; e
• Caso a base de dados da ferramenta não esteja instalada no banco de dados então o
usuário seleciona um schema e esse fica como base para a instalação da ferramenta.
Regras de Negócio
• Para cada banco de dados a ser analisado é necessário a instalação da ferramenta; e
• A ferramenta é instalada somente em um usuário para cada banco de dados.

50
A Figura 16 referencia a tela da função:
Figura 16. Tela de Configuração da Ferramenta.
3.3.3. Solicita Visualização da Estrutura Lógica da Memória
Função para visualização da estrutura lógica da memória, assim como a sua utilização pelo
sistema.

51
Figura 17. Solicita Visualização da Estrutura Lógica da Memória.
Descrição
• Essa função roda um procedimento que busca as percentagens de utilização da memória
lógica, assim como o tamanho que cada item ocupa;
• Os dados que o procedimento retorna são os tamanhos e percentagem de utilização das
memórias:
o Shared Pool;
o Database Buffer Cache;
o Redo Log Buffer;
o Java Pool; e
o Large Pool.
• As informações são ilustradas de modo gráfico e são atualizadas constantemente;

52
• A ferramenta grava um registro para visualização da estrutura da memória lógica na
tabela ACOES;
Regras de Negócio
• Não possui regras de negócio;
A Figura 18 referencia a tela da função:
Figura 18. Tela de Visualização da Estrutura Lógica da Memória
3.3.4. Solicita Visualização do Shared Pool
Essa função roda um procedimento que busca informações da memória utilizada no Shared
Pool.

53
Usuário
04Visualiza
shared pool
Solicita visualizaçãoda shared pool
Visualização da sharedpool fornecida
Banco de Dados
Gera comando paravisualização da
shared pool
Acoes
Grava ação
Retorna ação
Shared_Pools
Grava dados dos índices
Resposta a visualizaçãoda shared pool
Figura 19. Solicita Visualização da Shared Pool.
Descrição
• Os dados que o procedimento retorna são:
o Alocação Total do Shared Pool;
o Utilização Total do Shared Pool;
o Memória Livre; e
o Percentagem de Utilização.
• As informações são mostradas de forma textual ao usuário;
• Também são mostradas ao usuário as últimas consultas realizadas através de um grid;
• O sistema grava um registro para análise dos índices na tabela ACOES; e
• O sistema também grava as informações dos dados retornados na tabela
SHARED_POOLS;

54
Regras de Negócio
• Não possui regras de negócio;
A Figura 20 referencia a tela da função:
Figura 20. Tela de Visualização da Shared Pool
3.3.5. Solicita Análise do Plano de Execução
A finalidade inicial dessa função é analisar o plano de execução de um comando SQL.

55
Figura 21. Solicita Análise do Plano de Execução.
Descrição
• O primeiro passo é o usuário fornecer o script, que pode ser através de um arquivo com
extensão .sql ou através de sua escrita na própria tela do sistema.
• O sistema grava um registro para a análise do plano de execução na tabela ACOES; e
• Cada análise também é registrada na tabela PLANO_EXECUCOES.
Regras de Negócio
• A sintaxe do comando SQL não é verificada nessa função, cabe ao administrador
informar a mesma de maneira correta.

56
A Figura 22 referencia a tela da função:
Figura 22. Tela de Análise do Plano de Execução
3.3.6. Solicita Reconstrução de Índices do Banco de Dados
Essa função roda um procedimento que busca todos os índices da base de dados, entretanto,
o usuário do sistema seleciona um usuário do banco de dados para fazer essa reconstrução de
índices;

57
Figura 23. Solicita Reconstrução de Índices do Banco de Dados.
Descrição
• O procedimento retorna os índices que estão com problemas, sendo esses problemas:
o Índices em que estejam acima de certa percentagem de dados já excluídos. Essa
percentagem é informada pelo usuário;
o Índices em que estejam acima de certa altura de ramos. Essa altura é informada pelo
usuário;
• Ressalta-se que esses valores podem ser configurados pelo usuário;
• Os índices retornados são mostrados num grid pelo sistema;
• O sistema grava um registro para análise dos índices na tabela ACOES;
• O sistema grava informações dos índices retornados na tabela INDICES;
• O usuário pode selecionar os índices retornados no grid e solicitar a sua reconstrução;
• O sistema grava um registro para reconstrução dos índices na tabela ACOES; e
• O sistema atualiza informações dos índices reconstruídos na tabela INDICES.

58
Regras de Negócio
• Não possui regras de negócio;
A Figura 24 referencia a tela da função:
Figura 24. Tela de Reconstrução de Índices
3.3.7. Solicita Ajuste de Esquemas
Esse é uma função inicial para execução de ajustes de esquemas, tendo como finalidade
direcionar as opções de ajustes.

59
Usuário
07Solicita Ajuste de
Esquemas
Seleciona Ação
Opção de Ajuste Selecionada
Figura 25. Solicita Ajuste de Esquemas.
Descrição
• As opções para ajustes de esquemas são os seguintes:
o Ajuste de Tabelas; e
o Ajuste de Índices;
• Para cada tipo de ajuste é chamada duas sub-funções, sendo uma para visualização e
outra para criação.
Regras de Negócio
• Não possui regras de negócio;

60
A Figura 26 referencia a tela da função:
Figura 26. Tela de Ajustes de Esquemas
3.3.7.1. Visualização de Tabelas
A finalidade dessa função é visualizar todas as tabelas de determinado usuário da base de
dados.
Figura 27. Visualização de Tabelas.

61
Descrição
• O usuário primeiro define qual usuário do banco de dados que serão visualizadas as
tabelas;
• Após a seleção do usuário então é visualizado as tabelas, onde o usuário da ferramenta
ainda pode obter as seguintes informações:
o Colunas;
o Índices; e
o Número de Registros.
Regras de Negócio
• Não possui regras de negócio;
A Figura 28 referencia a tela da função:
Figura 28. Tela de Visualização de Tabelas
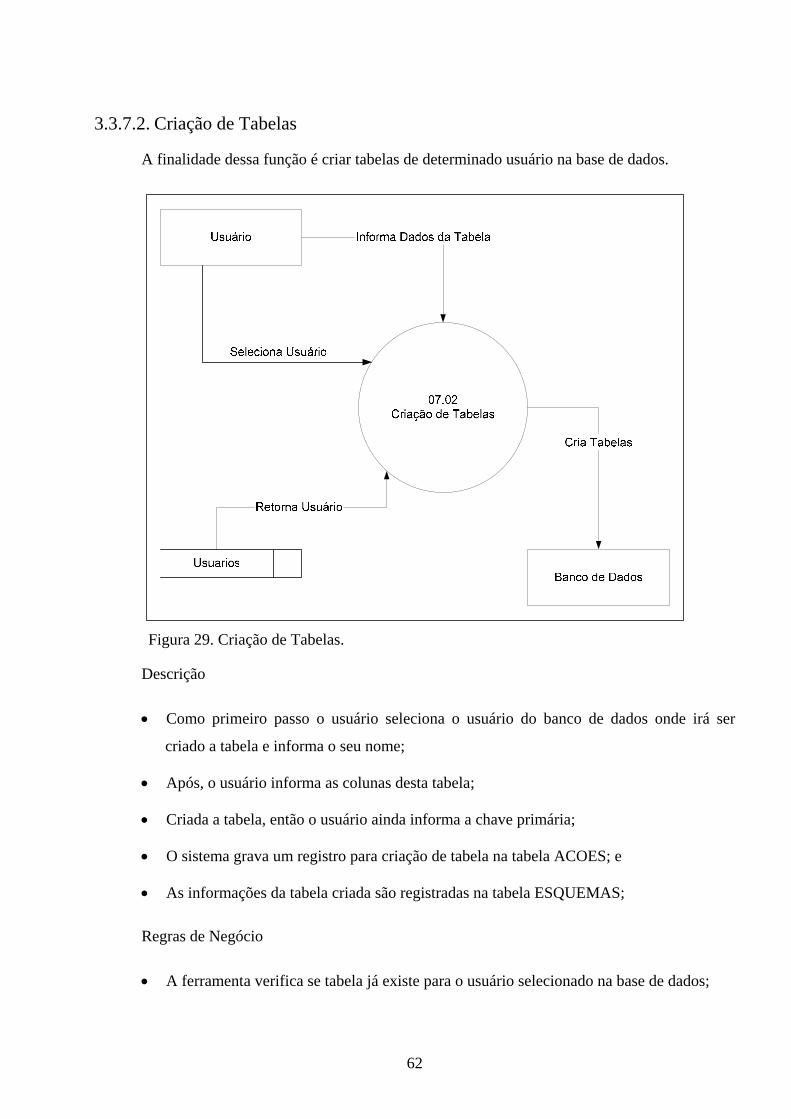
62
3.3.7.2. Criação de Tabelas
A finalidade dessa função é criar tabelas de determinado usuário na base de dados.
Figura 29. Criação de Tabelas.
Descrição
• Como primeiro passo o usuário seleciona o usuário do banco de dados onde irá ser
criado a tabela e informa o seu nome;
• Após, o usuário informa as colunas desta tabela;
• Criada a tabela, então o usuário ainda informa a chave primária;
• O sistema grava um registro para criação de tabela na tabela ACOES; e
• As informações da tabela criada são registradas na tabela ESQUEMAS;
Regras de Negócio
• A ferramenta verifica se tabela já existe para o usuário selecionado na base de dados;

63
A Figura 30 referencia a tela da função:
Figura 30. Tela de Criação de Tabelas
3.3.7.3. Visualização de Índices
A finalidade dessa função é visualizar todos os índices de determinado usuário da base de
dados.

64
Figura 31. Visualização de Índices.
Descrição
• O primeiro passo é selecionar o usuário em que está a tabela a ser visualizado o índice;
• Com a seleção do usuário, o próximo passo é selecionar a tabela para visualização de
seus respectivos indices;
• Após a visualização dos índices, o usuário pode selecionar um desses e visualizar as
seguintes informações:
o Número de registros;
o Número de registros válidos; e
o Número de registros apagados;
Regras de Negócio
• Não possui regras de negócio;

65
A Figura 32 referencia a tela da função:
Figura 32. Tela de Visualização de Tabelas
3.3.7.4. Criação de Índices
A finalidade dessa função é criar tabelas de determinado usuário na base de dados.
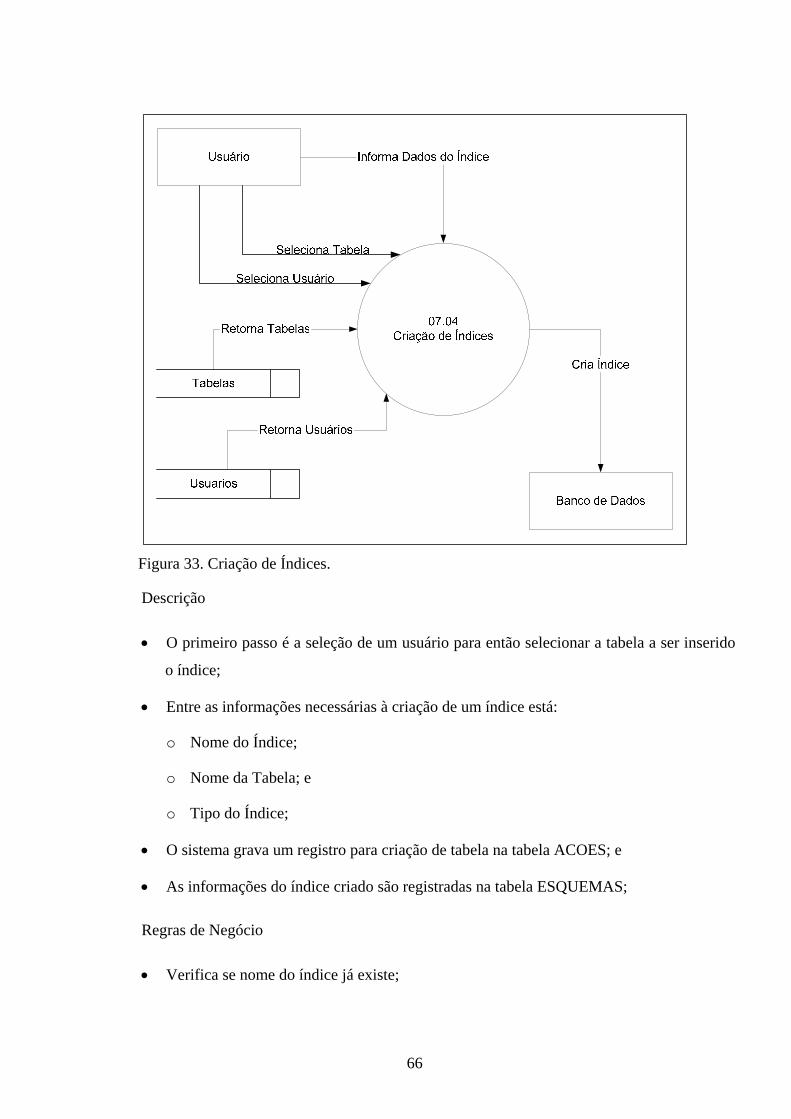
66
Figura 33. Criação de Índices.
Descrição
• O primeiro passo é a seleção de um usuário para então selecionar a tabela a ser inserido
o índice;
• Entre as informações necessárias à criação de um índice está:
o Nome do Índice;
o Nome da Tabela; e
o Tipo do Índice;
• O sistema grava um registro para criação de tabela na tabela ACOES; e
• As informações do índice criado são registradas na tabela ESQUEMAS;
Regras de Negócio
• Verifica se nome do índice já existe;
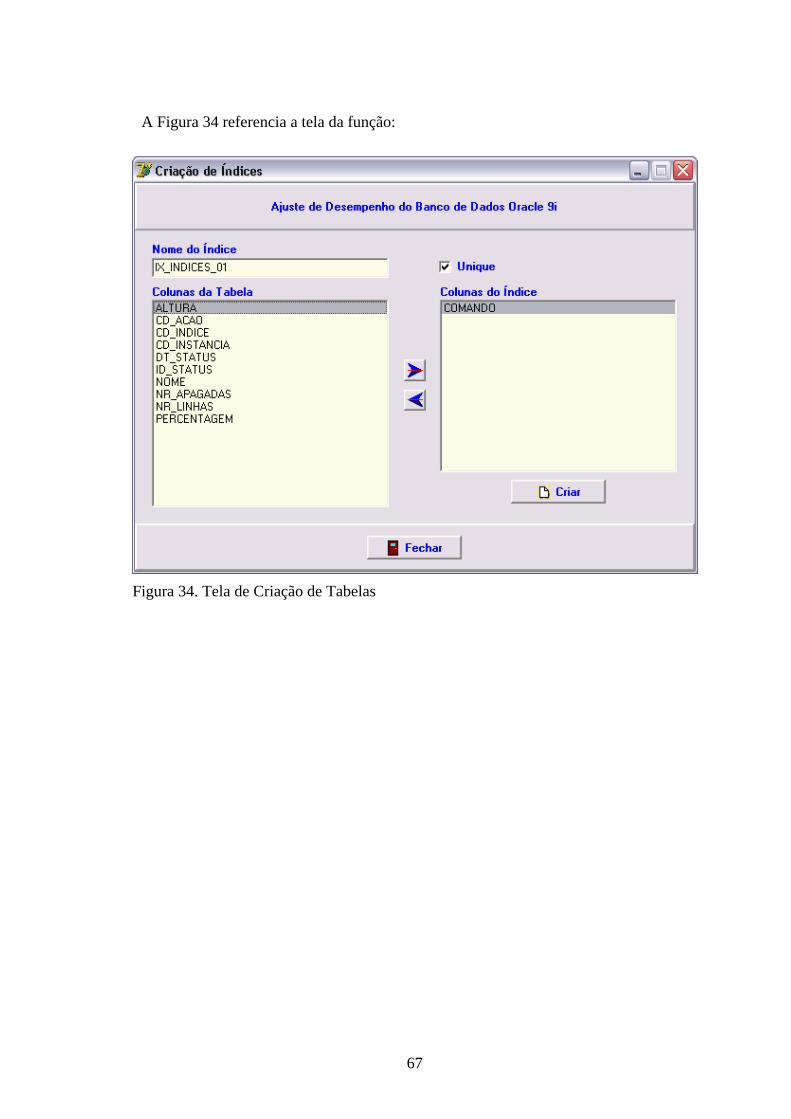
67
A Figura 34 referencia a tela da função:
Figura 34. Tela de Criação de Tabelas

68
3.3.8. Solicita Consulta de Acessos ao Banco de Dados
Usuário
08Consulta acessos ao
banco de dados
Consulta acesso aobanco de dados
Usuarios
Consulta acessos
AcoesRetorna acessos
Consulta ações
Retorna ações
Figura 35. Consulta de Acessos ao Banco de Dados.
Descrição
• A finalidade é mostrar as datas de acessos ao banco de dados através da ferramenta;
• Entre as informações como filtros estão as datas de acesso, delimitando um período; e
• Após, o usuário pode selecionar um acesso ao banco de dados e ver as ações que o
usuário realizou;
Regras de Negócio
• A consulta se restringe ao usuário e a base de dados em que o sistema está conectado;

69
A Figura 36 referencia a tela da função:
Figura 36. Tela de Consulta de Acessos

70
3.3.9. Solicita Consulta de Análise de Índices
Usuário
08Consulta Análise
de índices
Consulta reconstruçãode índices
Reconstrução deíndices consultada
Banco de Dados
Acoes
Grava açãoRetorna ação
Indices
Grava índices
Retorna usuário
Usuarios
Comando parareconstrução dos índices
Resposta a reconstruçãode índices
Consulta índices
Retorna índices
Figura 37. Consulta de Análise de Índices
Descrição
• Essa função roda um procedimento que busca todos os índices de determinado usuário
da base de dados já analisadas e reconstruídos;
Regras de Negócio
• Não possui regras de negócio.

71
A Figura 38 referencia a tela da função:
Figura 38. Tela de Consulta de Índices Reconstruídos
3.4. MODELAGEM ENTIDADE RELACIONAMENTO
A Tabela 4 mostra a descrição das tabelas que serão utilizadas no sistema. Já o Dicionário de
Dados é visualizado no Apêndice A dessa monografia.
Tabela 4. Descrição das tabelas utilizadas no sistema
Nome da tabela Descrição ACOES Tabela para registro das ações do usuário no sistema. ESQUEMAS Tabela para registro das atividades em ajuste de esquemas. INDICES Tabela para registro dos índices analisados e reconstruídos. MEMORIA_LOGICAS Tabela para registro da visualização das memórias lógicas. PLANO_EXECUCOES Tabela para registro das análises do plano de execução. SHARED_POOLS Tabela para registro da visualização da shared pool. USUARIOS Tabela para registro de acesso do usuário no banco de dados.
A Figura 39 expõe o diagrama ER, mostrando o relacionamento entre as tabelas do sistema
Diversas outras atividades podem ser incorporadas em projetos futuros, ente elas:
• Desenvolvimento de novas funcionalidades, como desfragmentação de tabelas;

72
• Agendamento de tarefas para execução das funcionalidades, independente ou não da
presença do DBA;
• Desenvolvimento de ferramentas de tuning para banco de dados free ou opensource; e
• Incluir um outro banco de dados nesta ferramenta.
INSTANCIASCD_INSTANCIA: NUMBER(6)
LOGIN: VARCHAR(20)BASE_DADOS: VARCHAR(20)DT_ACESSO: DATEDT_FINALIZACAO: DATE
ACOESCD_ACAO: NUMBER(6)CD_INSTANCIA: NUMBER(6)
DT_ACAO: DATEID_ACAO: CHAR(2)
INDICESCD_ACAO: NUMBER(6)CD_INSTANCIA: NUMBER(6)CD_INDICE: INTEGER
NOME: VARCHAR2(100)ALTURA: INTEGERNR_LINHAS: INTEGERNR_APAGADAS: INTEGERPERCENTAGEM: NUMBER(4,2)COMANDO: VARCHAR2(200)ID_STATUS: CHAR(1)DT_STATUS: DATE
SHARED_POOLSCD_INSTANCIA: NUMBER(6)CD_ACAO: NUMBER(6)CD_SHARED_POOL: NUMBER(6)
TAMANHO_TOTAL: NUMBER(12)TAMANHO_UTILIZADO: NUMBER(12)TAMANHO_LIVRE: NUMBER(12)PERCENTAGEM_UTILIZADA: NUMBER(4,2)DT_VISUALIZACAO: DATEDICIONARIO_CACHE: NUMBER(4,2)BIBLIOTECA_CACHE: NUMBER(4,2)
MEMORIA_LOGICASCD_ACAO: NUMBER(6)CD_INSTANCIA: NUMBER(6)CD_MEMORIA: NUMBER(6)
TM_SHARED_POOL: NUMBER(12)TM_DATABASE: NUMBER(12)TM_REDO_LOG: NUMBER(12)TM_JAVA_POOL: NUMBER(12)TM_LARGE_POOL: NUMBER(12)PC_SHARED_POOL: NUMBER(4,2)PC_DATABASE: NUMBER(4,2)PC_REDO_LOG: NUMBER(4,2)PC_JAVA_POOL: NUMBER(4,2)PC_LARGE_POOL: NUMBER(4,2)DT_ATUALIZACAO: DATE
ESQUEMASCD_ESQUEMA: NUMBER(6)CD_INSTANCIA: NUMBER(6)CD_ACAO: NUMBER(6)
NOME_ESQUEMA: VARCHAR2(100)ID_ESQUEMA: CHAR(1)
PLANO_EXECUCOESCD_PLANO_EXECUCOES: NUMBER(6)CD_INSTANCIA: NUMBER(6)CD_ACAO: NUMBER(6)
ANALISE: VARCHAR2(100)DT_ANALISE: DATE
Figura 39. Diagrama de Entidade/Relacionamento
3.5. FERRAMENTAS UTILIZADAS
Para desenvolvimento do presente projeto foram utilizadas as ferramentas: Delphi versão
7.0, para implentação das telas e conexão com o banco de dados Oracle; e, para a modelagem do
banco de dados foi utilizado ERwin versão 4.0.
Além dessas ferramentas também foi utilizado a ferramenta SQL Plus versão 9.2.0.1.0, da
Oracle, assim como o Oracle Enterprise Manager versão 9.2.0.1.0.

4. VALIDAÇÃO
Este capítulo tem como finalidade apresentar a validação das funções do projeto, mostrando
que os resultados obtidos estão de acordo com a realidade do banco de dados em pauta no projeto.
4.1. ESTRUTURA LÓGICA DA MEMÓRIA
Esta função tem como objetivo mostrar a utilização da partes da memória utilizada pelo
Oracle. Entre estas partes que consistem esta estrutura, Cyran (2002) cita: Shared Pool; Database
Buffer Cache; Redo Log Buffer; e Large Pool. Além dessas partes da memória, ainda é analisado a
Java Pool.
4.1.1. Shared Pool
De acordo com Green (2002), na inicialização do sistema alguns paramêtros necessitam ser
inicializados, entre eles está o shared_pool_size, que representa o tamanho da shared pool no SGA.
Este atributo pode ser visualizado através do comando abaixo descricto, conforme relata Plummer
(2004):
select pa.Value into pool_size from V$PARAMETER pa where pa.Name='shared_pool_size';
Para saber o quanto está sendo utilizado da shared pool, Kiltrack (2001) explica que são
necessários três passos:
• Para visualizar objetos armazenados como packages e views:
select sum(sharable_mem) from v$db_object_cache where type = 'PACKAGE' and type = 'PACKAGE BODY' and type = 'FUNCTION' and type = 'PROCEDURE'
• Para visualizar a utilização de memória por SQL, o mesmo autor conta que é necessário
que as instruções SQL sejam utilizadas algumas vezes para então ocupar espaço na
memória, ficando assim a instrução:
select sum(sharable_mem) as memoria_shared_sql from V$SQLAREA where executions > 5
• Por fim, o autor ainda destaca que devem ser consideradas um total de 250 bytes por
cursor aberto utilizado por cada usuário:

74
select sum(250*users_opening) as memoria_cursor from V$SQLAREA
4.1.2. Database Buffer Cache
Green (2002) diz que o parâmetro de inicialização do tamanho do database buffer cache é o
db_buffer_cache. Plummer (2004) dá o seguinte script para busca desta informação:
select Value as db_buffer_cache_size from V$PARAMETER where Name = 'db_cache_size'
Para se ter o percentual de utilização do database buffer cache, Kiltrack (2001) dá dois
parâmetros para consulta, tendo os scripts abaixo escritos:
select value as db_keep_cache_size from V$PARAMETER where name = 'db_keep_cache_size' select Value as db_recycle_cache_size from V$PARAMETER where Name = 'db_recycle_cache_size'
4.1.3. Redo Log Buffer
De acordo com Zegger (2001), o tamanho mínimo para o Redo Log Buffer é de 64Kb e o
parâmetro para obtenção está abaixo descrito:
select Value as log_buffer from V$PARAMETER where Name = 'log_buffer'
Kiltrack (2001) cita que para buscar a utilização dessa memória é necessária a utilização de
deste scritp:
SELECT VALUE FROM V$SYSSTAT WHERE NAME = 'redo buffer allocation retries' UNION SELECT VALUE FROM V$SYSSTAT WHERE NAME = 'redo entries'
4.1.4. Java Pool
O parâmetro para visualização do tamanho do java pool é o java_pool_size. É este
parâmetro que é ajustado se estiver sendo utilizados procedimentos de armazenamento em java. O
script abaixo mostra como obter essa informação. (Green, 2002).
select Value as java_pool

75
from V$PARAMETER where Name = 'java_pool_size'
Maring (2002) cita que o comando para saber a utilização do java pool é:
SELECT BYTES FROM V$SGASTAT WHERE POOL = 'java pool' AND NAME = 'memory in use';
4.1.5. Large Pool
Conforme Cyran (2002), o large pool é uma área opcional para alocação de memória do
Oracle para realização de backup e restore, para processos de I/O e, também, para sessão de
usuários. O comando para ver o tamanho dessa memória é este:
select Value as large_pool from V$PARAMETER where Name = 'large_pool_size'
Para obter o quanto de memória livre ainda tem do larte pool, o comando necessário, de
acordo com Maring (2002), está abaixo descrito. Assim, basta subtrair o valor da memória total
alocado pela memória livre para saber o quanto está sendo utilizado a memória large pool.
SELECT BYTES FROM V$SGASTAT WHERE POOL = 'large pool' AND NAME = 'free memory';
4.2. VISUALIZAÇÃO DA SHARED POOL
Além das partes apresentadas na função Estrutura Lógica da Memória, ainda restam mais
duas partes, a dictionary cache (mantêm informações do dicionário de objetos) e library cache
(armazena informações da shared pool e PL/SQL). (KILPATRICK. 2001).
Então, esta função tem como finalidade mostrar informações da shared pool, assim como
obter informações de utilização das partes anteriormente citadas.
4.2.1. Shared Pool
Para esta parte da memória o que se buscou foi o total alocado, o quanto de sua utilização, o
quanto de memória livre e o percentual de utilização. Os scripts para obtenção desses dados estão
baseados de acordo com o tópico 4.1.1.
4.2.2. Dictionary Cache

76
Green (2002) diz que as informações armazenadas na dictionary cache se refere a
informações de usuários, segmentos, tablespace, schema de objetos, entre outras informações. O
script para conseguir o percentual de sua utilização está descrito a seguir:
SELECT ROUND(SUM(GETS)/(SUM(GETS)+SUM(GETMISSES)) * 100,2) DICTIONARY_USED FROM V$ROWCACHE;
4.2.3. Library Cache
Segundo Green (2002), quando uma aplicação é executada, o Oracle busca na library cache
o seu comando para realizar uma reutilização. O comando a seguir descreve o percentual de
utilização desta parte da memória.
SELECT ROUND(SUM(PINHITS)/SUM(PINS) * 100,2) AS LIBRARY_USED FROM V$LIBRARYCACHE
4.3. RECONSTRUÇÃO DE ÍNDICES
Evoltion (2005) relata que se recria um índice para comprimi-lo e minimizar o espaço
fragmentado, ou para mudar as características de armazenamento do índice.
Lorentz (2002) diz que o primeiro é recolher informações estatísticas para analisar como
está o índice. O comando para esta visualização é o ANALYZE INDEX... ...VALIDATE
STRUCTURE.
A partir deste comando o usuário da ferramenta pode avaliar que índices devem ser
reconstruídos filtrando através dos campos HEIGHT (altura do índice) e DEL_LF_ROWS (número
de registros apagados do índice). (LORENTZ, 2002).
Por fim, para reconstrução do índice, Evoltion (2005) destaca o comando ALTER INDEX...
...REBUILD. Através deste comando REBUILD o Oracle utiliza o índice anterior para construir o
novo.
4.4. PLANO DE EXECUÇÃO
O Explain Plan determina o plano de execução de um comando específico de SQL. Este
plano de execução descreve uma fileira de cada acesso em uma tabela especificada. A partir deste
comando “EXPLAIN PLAN SET STATEMENT_ID variavel FOR comando_sql” o plano de
execução fica numa tabela temporária chamada PLAN_TABLE. (LORENTZ, 2002)

77
Com este armazenamento temporário então é possível visualizar os acessos utilizados para a
execução do comando SQL. A seguir está exposto um exemplo deste comando, segundo Lorentz
(2002).
• Passo inicial, onde o Explain Plan analisa o comando SQL:
EXPLAIN PLAN SET STATEMENT_ID = ’Raise in Tokyo’ INTO plan_table FOR UPDATE employees SET salary = salary * 1.10 WHERE department_id = (SELECT department_id FROM departments WHERE location_id = 1200);
• Comando visualização dos acessos as tabelas pelo comando SQL obtidas através do
Explain Plan:
SELECT LPAD(’ ’,2*(LEVEL-1))||operation operation, options, object_name, position FROM plan_table START WITH id = 0 AND statement_id = ’Raise in Tokyo’ CONNECT BY PRIOR id = parent_id AND statement_id = ’Raise in Tokyo’;
• Visualização dos acessos:
OPERATION OPTIONS OBJECT_NAME POSITION ------------------ ----------------- --------------- ---------- UPDATE STATEMENT 2 UPDATE EMPLOYEES 1 TABLE ACCESS FULL EMPLOYEES 1 VIEW index$_join$_00 1 HASH JOIN 1 INDEX RANGE SCAN DEPT_LOCATION_I 1 INDEX FAST FULL SCAN DEPT_ID_PK 2
4.5. AJUSTE DE ESQUEMAS
Esta função é dividida em quatro partes: Visualização das Tabelas, Criação de Tabelas,
Visualização de Índices e Criação de Índices.
4.5.1. Visualização de Tabelas
O que tem de comum entre as 04 partes desta função é a seleção de um usuário da base de
dados para a sua execução. Esta seleção é realizada através da view SYS.USER$.
A partir da seleção de um usuário são visualizadas as suas respectivas tabelas através da
tabela dba_tables.
O ultimo passo é realizar uma busca de informações pertinentes a esta tabela, envolvendo:
colunas; indices, com suas respectivas colunas; e o número de registros válidos da tabela.

78
4.5.2. Criação de Tabelas
Lorentz (2002) diz que através do comando CREATE TABLE podem ser criadas tabelas
relacionais onde, inicialmente, vem sem nenhum dado de informação e podem ser preenchidas
através do comando INSERT. Após a criação ainda é possível incluir novas colunas, partições e
CONSTRAINTS - alvo desta função.
Os tipos de campos utilizados para a criação de uma tabela foram retirados de Erwin (2001)
e estão de acordo com Lorentz (2002). A função também solicita a criação de uma chave primária e
a possibilidade de criação de constraints, onde os seus scripts de criação estão de acordo com Erwin
(2001).
4.5.3. Visualização de Índices
Para a visualização é novamente utilizado o comando “ANALYZE INDEX... ...VALIDATE
STRUCTURE”, utilizado pela função de reconstrução de índices, segundo Lorentz (2002).
Juntamente com dados estatísticos deste comando, também são mostrados dados dos índices,
envolvendo as tabelas que pertencem e suas respectivas colunas.
4.5.4. Criação de Índices
A criação de índices, assim como a criação de chave primária de constraints, descrita no
tópico 4.5.2, também segue os scripts gerados pelaa ferramenta Erwin 4.0, estando também de
acordo com Lorentz (2002).
4.6. COMPARATIVO ENTRE PROJETOS ESTUDADOS E PROJETO IMPLEMENTADO
Em relação aos projetos estudados no tópico 2.6 da fundamentação teórica, vantagens e
desvantagens podem ser destacadas, onde a Tabela 5 vislumbra essas diferenças e semelhanças.
Tabela 5. Tabela de vantagens e desvantagens entre ferramentas
Projeto Guru - Uma ferramenta para administrar banco de dados através de Web
Análise de desempenho do banco de dados Oracle 9i.
Ferramenta foco deste projeto.

79
Ferramenta Web, permitindo acesso em banco de dados de organizações que possuem softwares de seguranças para proteção de sua rede interna, chamados de firewalls.
Ferramenta desktop, permitindo acesso em banco de dados apenas através da intranet.
Ferramenta desktop, permitindo acesso em banco de dados apenas através da intranet.
Existe um módulo para executar comandos SQL.
Não possui módulo para executar comandos SQL.
Não executa comandos SQL, mas sim mostra o seu plano de execução.
A ferramenta não é proprietária. A ferramenta não é proprietária. A ferramenta não é proprietária.É possível acessar bancos de dados de diferentes fornecedores.
Somente para o banco de dados Oracle.
Somente para o banco de dados Oracle.
Não possui um histórico dos diferentes estados do banco de dados, ao longo de seu acompanhamento.
Não possui um histórico dos diferentes estados do banco de dados, ao longo de seu acompanhamento.
Possui um histórico de ações realizadas pela ferramenta.
Não há resultados mostrados de forma gráfica para facilitar a interpretação dos resultados obtidos na simulação.
Os resultados são mostrados de forma gráfica facilitando, assim, a interpretação dos resultados obtidos na simulação.
Os resultados são mostrados de forma gráfica e através de grids.
Os módulos da ferramenta abrangem diferentes aspectos do banco de dados, porém, nem todos.
Os módulos da ferramenta não abrangem todos os aspectos do banco de dados.
Os módulos da ferramenta abrangem diferentes aspectos do banco de dados, porém, nem todos.
Há a possibilidade de análise antes da realização ou não do ajuste de desempenho de alguns módulos.
A medida de desempenho é realizada através de uma simulação, onde irá mostrar o melhor ajuste de desempenho antes da sua aplicação real no banco de dados.
Há a possibilidade de análise antes da realização ou não do ajuste de desempenho de alguns módulos.
Os três projetos abordaram poucos parâmetros para ajuste de desempenho. Isso se dá devido
a complexidade e ao tempo necessário para a sua implementação. Ressalta-se que estes projetos não
tem como foco principal a implementação de uma ferramenta e sim realizar um estudo sobre esta
ajuste de desempenho.

80
5. CONCLUSÕES
O presente projeto teve como principal objetivo realizar um estudo sobre ajuste de
desempenho do banco de dados Oracle e, a partir deste estudo, selecionar parâmetros e/ou funções
para serem utilizados como funcionalidades no desenvolvimento de uma ferramenta para análise
e/ou ajuste de desempenho deste banco.
Durante a revisão bibliográfica foi determinado que a versão do banco de dados Oracle foco
deste projeto era a 9i, devido a disponibilidade de materiais e também por que a versão mais
recente, 10g, havia sido recém lançada no início dos estudos.
A fundamentação teórica se deu através do funcionamento do SGBD Oracle; do conceito de
ajuste de desempenho; de como o Oracle proporciona este ajuste de desempenho; de estudo de
ferramentas que realizam ajuste de desempenho; e, por fim, de projetos similares a este
desenvolvido.
A ferramenta desenvolvida durante o projeto não tem uma finalidade comercial, assim como
também não visa a sua utilização por um DBA experiente em um banco de dados em modo de
produção. Este ferramenta tem sim, como finalidade, a confirmação dos conceitos levantados
durante o projeto.
Como ferramenta de desenvolvimento adotou-se o Delphi, versão 7.0, utilizando como
forma de comunicação com o banco de dados, componentes da palheta dbExpress. Não foi utilizado
nenhuma API Windows, tornando capaz a sua implementação via web, porém a sua utilização é
desktop.
Entre as funções da ferramenta está a visualização da estrutura lógica da memória,
mostrando o tamanho e a porcentagem de utilização dos parâmetros: Shared Pool; Database Buffer
Cache; Redo Log Buffer; Java Pool; e Large Pool. Outra função desenvolvida é a da visualização
da Shared Pool, acresentando-se aos parâmetros apresentados a utilização do dictionary cache e da
library cache. Essas funções podem ser ampliadas futuramente com um estudo e desenvolvimento
de algoritmos para reajuste do tamanho da memória com o objetivo de se obter um melhor
desempenho.

81
A reconstrução de índices também foi abordada no projeto, através da análise dos índices,
verificando informações de altura e porcentagem de registros apagados, e sua reconstrução. Esta
função pode ser ainda melhorada através da visualização de como estava o índice antes de ser
reconstruído com o próprio índice após a sua reconstrução.
A função de ajuste de esquemas está dividida em quatro partes: visualização de tabelas, onde
são mostrados informações de colunas, índices e registros; criação de tabelas, onde são incluídas
colunas, partições e constraints; visualização de índices, mostrando a situação de determinado
índice; e, por fim, a criação de índice.
Por fim, a ferramenta tem duas funções que mostram o histórico de utilização da ferramenta,
sendo: consulta de acessos, mostrando que funções foram utilizadas; e consulta de índices
reconstruídos, mostrando quando determinado índice foi reconstruído e qual o seu estado naquele
instante.
Muitas idéias podem ser incorporadas em futuros projetos, entre elas:
• Desenvolvimento de novas funcionalidades, como:
Desfragmentação de tabelas. Para tanto, há a necessidade de um estudo sobre
tablespace;
Incorporar ao explain plan um estudo outras ferramentas e instrumentos de
diagnóstico do Oracle, como o Sql Trace e o Tkprof;
• Agendamento de tarefas para execução das funcionalidades, independente ou não da
presença do DBA;
• Um estudo comparativo do banco de dados Oracle com bancos de dados free ou
opensource;
• Adaptação da ferramenta ao banco de dados Oracle 10g;
• Inclusão de help, de dicas de ajustes e informações referentes ao estudo desenvolvido na
fundamentação teórica na ferramenta;
• Desenvolvimento de ferramentas de tuning para banco de dados free ou opensource; e
• Incluir um outro banco de dados nesta ferramenta.

82
Cabe salientar que o tópico ajuste de desempenho não é um assunto trivial na área de banco
de dados, e dificilmente é abordado nas disciplinas de graduação em Ciência da Computação, sendo
o primeiro trabalho de conclusão de curso desta universidade a tratar do tema. Desta forma acredita-
se que o mesmo pode contribuir de forma relevante para o desenvolvimento de trabalhos futuros.
O seu objetivo geral foi atingido, porém, quanto a validação da ferramenta sugere-se que
seja mais explorado com a utilização de um banco de dados em produção de grande porte, o que
não possível por questão de prazos.
Por fim, acredita-se que através de todo estudo apresentado e da ampliação do projeto
através das idéias aqui expostas para aperfeiçoamento da ferramenta, possa-se utilizar a ferramenta
para fins didáticos, auxiliando estudantes e/ou profissionais da área de informática no estudo
introdutório do ajuste de desempenho de banco de dados.

REFERÊNCIAS BIBLIOGRÁFICAS
CYRAN, M. Database Concepts, Release 2 (9.2): Part Nº A96524-01. 2002. Disponível em :< http://ocpdba.net/9idoc/server.920/a96524.pdf>. 01 jun. 2005.
DATE, C. J. Introdução a sistemas de bancos de dados. 7ª ed. Rio de Janeiro: Campus, 2000.
ERWIN: Erwin. Versão 4.0: Copyright (c). Computer Associates Internacional, Inc. 2001.
EVOLTION: Oracle 9i Database Performance Guide and Reference. 2005. Disponível em: < http://www.evolition.com.au/documents/oracle_indexes_and_clusters.pdf>. Acesso em 01 jun. 2005.
FANDERUFF, D. Dominando o Oracle 9i: modelagem e desenvolvimento. São Paulo: Pearson, 2003.
FLORES, F. M. Análise do desempenho do banco de dados Oracle 9i. 2003. 71 f. Monografia (Graduação) – Curso de Ciência da Computação, Universidade Luterana do Brasil, Canoas, 2003.
GREEN, C. D. Oracle9i Database Performance Tuning Guide and Reference, Release 2 (9.2): Part Nº A96533-02. 2002. Disponível em :< http://www.stanford.edu/dept/itss/docs/oracle/9i/server.920/a96533/>. 01 jun. 2005.
KILPATRICK, P.; RAMAN, S.; WOMACK, J. Oracle9i Performance Tuning: Studente Guide. Volume 1. 2001. Disponível em: < http://occonline.occ.cccd.edu/online/gfernandez/PerfTunvol1.pdf>. 01 jun. 2005.
LORENTZ, D. Oracle9i SQL Reference, Release 2 (9.2): Part Nº A96540-02. 2002. Disponível em :< www.cs.umb.edu/cs634/ora9idocs/server.920/a96540 />. 01 jun. 2005.
MANAGER: Oracle (R) Enterprise. Versão 9.2.0.1.0: Produção Copyright (c). Oracle Corporation 2002.
MARING, S. Oracle9i Java Developer’s Guide, Release 2 (9.2): Part Nº A96656-01. 2002. Disponível em :< http://www.lc.leidenuniv.nl/awcourse/oracle/java.920/a96656.pdf >. 01 jun. 2005.
MYORACLE: Oracle 9i Database Reference. 2004. Disponível em: <http://my.oracle.com>. Acesso em 29 out. 2004.
NIEMIEC, R. J. Oracle 9i performance tuning: dicas e técnicas. Rio de Janeiro: Campus, 2003.
ORACLE: A história da Oracle. 2004. Disponível em: <http://www.oracle.com/lang/pt/corporate/story.html>. Acesso em: 12 set. 2004.
PEASLAND, B. Knowing When To Rebuild Indexes. Eros Data Center 2000. Disponível em :< http://www.quest-pipelines.com/newsletter-v2/rebuild.htm>. 01 set. 2004.
PLUMMER, G. Playing in the Shared Pool Without a Lifeguard. 2004. Disponível em: < http://www.profissionaloracle.com.br>. 14 out. 2004a.

84
RAMALHO, J. A. Oracle. São Paulo: Berkeley Brasil, 1999.
SCHERER, A. P. Z. GURU - Uma ferramenta para administrar banco de dados através da Web. 2002. 88 f. Dissertação (Mestrado) – Programa de Pós-Graduação em Computação, Universidade Federal do Rio Grande do Sul, Porto Alegre, 2002.
SENEGACNIK, J. Database Tuning For Beginners. 2004. Disponível em: < http://www.profissionaloracle.com.br>. 14 out. 2004a.
SENEGACNIK, J. How to Tune an Application. 2004. Disponível em: < http://www.profissionaloracle.com.br>. 14 out. 2004b.
SILBERSCHATZ, A; KORTH, H. F. Sistemas de banco de dados. São Paulo: Makron, 1999.
TOAD VI: The Tool for Oracle Application Developers. Version 6.3.11.1 g: Quest Software. Disponível em: <http://www.toadsoft.com/toadfree.zip>. Acesso em: 01 mai 2005.
URMAN, S. Programação em Oracle PL/SQL. Lisboa. McGraw-Hill: 1999.
ZEGGER, C. Demystifying and tunnig oracle memory allocation. 2001. Disponível em: http://www.oracleassist.com. 12 out. 2004.

APÊNDICE A – MODELAGEM DE DADOS
Tabela 6. Dicionário de dados da tabela acoes Nome do atributo Tipo Descrição cd_instancia Number(6) Código seqüêncial gerado pelo banco de dados utilizado na tabela
INSTANCIAS. cd_acao Number(6) Código seqüêncial gerado pelo banco de dados utilizado na tabela ACOES. dt_acao Date Data em que ocorreu a ação. id_acao Char(1) Identifica o tipo da ação do usuário.
01 - Reconstrução de índice 02 - Visualização da Shared Pool 03 - Visualização da Estrutura da Memória Lógica 04 - Visualização das Tabelas 05 - Criação de Tabelas 06 - Visualização dos Índices 07 - Criação de Índices 08 - Análise do Plano de Execução
Tabela 7. Dicionário de dados da tabela esquemas Nome do atributo Tipo Descrição cd_instancia Number(6) Código seqüêncial gerado pelo banco de dados utilizado na tabela
INSTANCIAS. cd_acao Number(6) Código seqüêncial gerado pelo banco de dados utilizado na tabela ACOES. cd_esquema Number(6) Código seqüêncial gerado pelo banco de dados utilizado na tabela
ESQUEMAS. nome_esquema Varchar2(50) Nome do esquema. id_esquema Char(1) Identifica o tipo de esquema:
1 - Cria Tabela 2 - Cria Visão
Tabela 8. Dicionário de dados da tabela indices Nome do atributo Tipo Descrição cd_instancia Number(6) Código seqüêncial gerado pelo banco de dados utilizado na tabela
INSTANCIAS. cd_acao Number(6) Código seqüêncial gerado pelo banco de dados utilizado na tabela ACOES. cd_indice Number(6) Código seqüêncial gerado pelo banco de dados utilizado na tabela
INDICES. Nome Varchar2(50) Nome do índice. Altura Number(1) Altura do índice. nr_linhas Number(7) Número de linhas do índice. nr_apagadas Number(7) Número de linhas apagadas no índice. Percentagem Number(4,2) Percentagem de número de linhas apagadas no índice. Comando Varchar2(100) Comando para reconstrução do índice. id_status Char(1) Identifica o estado do índice, pode ser:
1 - Analisado 2 - Reconstruído.
dt_status Date Data do status. Tabela 9. Dicionário de dados da tabela instancias Nome do atributo Tipo Descrição cd_instancia Number(6) Código seqüêncial gerado pelo banco de dados utilizado na tabela
INSTANCIAS. Login Varchar2(20) Login do usuário.

86
base_dados Varchar2(20) Nome da base de dados. dt_acesso Date Data de acesso. Tabela 10. Dicionário de dados da tabela memoria_logicas Nome do atributo Tipo Descrição cd_instancia Number(6) Código seqüêncial gerado pelo banco de dados utilizado na tabela
INSTANCIAS. cd_acao Number(6) Código seqüêncial gerado pelo banco de dados utilizado na tabela ACOES. cd_memoria Number(6) Código seqüêncial gerado pelo banco de dados utilizado na tabela
MEMORIA_LOGICAS. tm_shared_pool Number(12) Tamanho da shared pool. tm_database Number(12) Tamanho da database buffer cache. tm_redo_log Number(12) Tamanho da redo buffer log. tm_java_pool Number(12) Tamanho da java pool. tm_large_pool Number(12) Tamanho da large pool. pc_shared_pool Number(4,2) Percentagem de utilização da shared pool. pc_database Number(4,2) Percentagem de utilização da database buffer cache. pc_redo_log Number(4,2) Percentagem de utilização da redo buffer log. pc_java_pool Number(4,2) Percentagem de utilização da java pool. pc_large_pool Number(4,2) Percentagem de utilização da large pool. dt_atualizacao Date Data de visualização da memória. Tabela 11. Dicionário de dados da tabela plano_execucoes Nome do atributo Tipo Descrição cd_instancia Number(6) Código seqüêncial gerado pelo banco de dados utilizado na tabela
INSTANCIAS. cd_acao Number(6) Código seqüêncial gerado pelo banco de dados utilizado na tabela ACOES. cd_plano_execucoes Number(6) Código seqüêncial gerado pelo banco de dados utilizado na tabela
PLANO_EXECUCOES. Analise Varchar2(100) Análise do plano de execução. dt_analise Date Data da análise. Tabela 12. Dicionário de dados da tabela shared_pools Nome do atributo Tipo Descrição cd_instancia Number(6) Código seqüêncial gerado pelo banco de dados utilizado na tabela
INSTANCIAS. cd_acao Number(6) Código seqüêncial gerado pelo banco de dados utilizado na tabela
ACOES. cd_shared_pool Number(6) Código seqüêncial gerado pelo banco de dados utilizado na tabela
SHARED_POOLS. tamanho_total Number(12) Espaço total alocado pra shared pool. tamanho_utilizado Number(12) Espaço utilizado da shared pool. tamanho_livre Number(12) Espaço livre da shared pool. Percentagem_utilizada Number(4,2) Percentagem utilizada da shared pool. dt_visualizacao Date Data de visualização da shared pool. dicionario_cache Number(4,2) Percentagem utilizada do dicionário cache. biblioteca_cache Number(4,2) Percentagem utilizada da biblioteca cache.

APÊNDICE B – ESPECIFICAÇÃO DAS FUNÇÕES
Especificação de Acesso ao Banco de Dados Fluxo de Execução: Não possui fluxo de execução Eventos dos Componentes Botão Conectar OnClick Conecta a ferramenta em um banco de dados. //campos obrigatórios para conexão Se Edit Login.Texto == Null Então
Gerar Mensagem(‘Preencher o campo Login’); Edit Login = Focalizado; Break();
Fim Se Se Edit Senha.Texto == Null Então
Gerar Mensagem(‘Preencher o campo Senha’); Edit Senha = Focalizado; Break();
Fim Se Se Edit Base de Dados.Texto == Null Então
Gerar Mensagem(‘Preencher o campo Base de Dados’); Edit Base de Dados = Focalizado; Break();
Fim Se //conectando ao banco de dados Execute = ‘Connect ‘ + Edit Login.Texto + ‘/’ + Edit Senha.Texto + ‘@’ + Edit Base de Dados.Texto + ‘;’; Se Execute == Falso Então
Gerar Mensagem(‘Conexão não Realizada. Verifique seus dados de entrada.’); Edit Login = Focalizado; Break();
Fim Se Se Execute == Verdadeiro Então
//verifica se banco de dados está configurado no sistema. Configura = falso; Abre configuracao.sql;

88
Enquanto não final do arquivo Faça Se linha do arquivo == Edit Base de Dados.Texto Então
Configurado = verdadeiro; Sai do laço;
Fim Se Fim Enquanto Se configurado == falso Então
//Chama função para configuração da ferramenta; Form_Configuração.Show;
Fim Se Se configurado == Verdadeiro Então
Tenta //Inclui registro na tabela INSTANCIAS; INSERT INTO INSTANCIAS (CD_ACESSO, LOGIN, BASE_DADOS, DT_ACESSO) VALUES (SEQ_CD_ACESSO.NEXTVAL, Edit Login.Texto, Edit Base de Dados.Texto, SysDate); Commit; Habilita funções do sistema;
Se Erro Rollback; Gerar Mensagem (“Erro na conexão ao banco de dados.”); Break;
Fim Tenta Fim Se
Fim Se Botão Desconectar OnClick Desconecta a ferramenta em um banco de dados. Execute = Disconnect; Desabilita funções do sistema; Botão Fechar OnClick Fecha a ferramenta. Form_Principal.Fechar; Especificação de Instalação da Ferramenta Fluxo de Execução: CONSULTA NAME DA TABELA SYS.USER$ ONDE TYPE# = 1

89
ORDENADO PRO NAME Memo Usuário = Consulta Acima; Edit Banco de Dados = Form_Principal.Edit Base de Dados.Texto; Se Form_Principal.configurado == Verdadeiro Então
Habilita botão Desinstalar; Memo Usuário = Desabilitado;
Fim Se Se Form_Principal.configurado == Falso Então
Habilita botão Instalar; Memo Usuário = Habilitado;
Fim Se Eventos dos Componentes Botão Instalar OnClick Instala a ferramenta no banco de dados. //só realiza a instalação se um usuário foi selecionado Se Memo.Usuario.Texto == Selecionado Então
Cria tabelas da ferramenta no usuário selecionado na base de dados. //as tabelas estão de acordo com o Apêndice A Form_Principal.configurado = verdadeiro; Habilita funções no Form_Principal;
Fim Se Botão Desinstalar OnClick Desconectar a ferramenta no banco de dados. Apaga tabelas da ferramenta no usuário selecionado na base de dados. //as tabelas estão de acordo com o Apêndice A Form_Principal.configurado = falso; Desabilita funções no Form_Principal; Botão Fechar OnClick Fecha a ferramenta. Form_Configuracao.Fechar; Especificação de Visualização da Estrutura Lógica da Memória Fluxo de Execução: //Grava informações da ação do usuário na tabela ACOES Tenta

90
INSERT INTO ACOES (CD_ACAO, CD_INSTANCIA, DT_ACAO, ID_ACAO) VALUES (SEQ_CD_ACAO.NEXTVAL, CD_INSTANCIA gerado na entrada do usuário na base de dados, SysDate, ‘03’); Commit;
Se Erro Rollback; Gerar Mensagem (“Erro na conexão ao banco de dados.”); Break();
Fim Tenta //Chama procedimento para visualização da estrutura da memória lógica Visualização; Timer = Habilitado; Eventos dos Componentes Timer OnTimer Executa o comando após intervalo de tempo de execução. //Chama procedimento para visualização da estrutura da memória lógica //Este procedimento é chamado a cada minuto Visualização; Botão Fechar OnClick Fecha a ferramenta. Form_Estrutura_Memoria_Logica.Fechar; Procedimentos Procedimento Visualização;
//Consulta informações da shared pool Consulta TAMANHO_TOTAL_SHARED_POOL as T_SHARED, TRUNCA((100 * TAMANHO_UTILIZADO_SHARED_POOL) / TAMANHO_TOTAL_SHARED_POOL) as P_SHARED Da tabela SHARED_POOL; //Atualiza dados na tela Label Shared.Texto = T_SHARED; Shared.Valor = P_SHARED; //Consulta informações da database buffer cache

91
Consulta TAMANHO_TOTAL_DATABASE_BUFFER_CACHE as T_DATABASE TRUNCA((100 * TAMANHO_UTILIZADO_ DATABASE_BUFFER_CACHE) / TAMANHO_TOTAL_ DATABASE_BUFFER_CACHE) as P_DATABASE Da tabela DATABASE_BUFFER_CACHE; //Atualiza dados na tela Label Database.Texto = T_DATABASE; Database.Valor = P_DATABASE; //Consulta informações da redo log Consulta TAMANHO_TOTAL_REDO_LOG as T_REDO TRUNCA((100 * TAMANHO_UTILIZADO_ REDO_LOG) / TAMANHO_TOTAL_ REDO_LOG) as P_REDO Da tabela REDO_LOG; //Atualiza dados na tela Label Redo.Texto = T_ REDO; Redo.Valor = P_REDO; //Consulta informações da java pool Consulta TAMANHO_TOTAL_JAVA_POOL as T_JAVA TRUNCA((100 * TAMANHO_UTILIZADO_ JAVA_POOL) / TAMANHO_TOTAL_ JAVA_POOL) as P_JAVA Da tabela JAVA_POOL; //Atualiza dados na tela Label Java.Texto = T _ JAVA; Java.Valor = P_JAVA; //Consulta informações da large pool Consulta TAMANHO_TOTAL_LARGE_POOL as T_LARGE TRUNCA((100 * TAMANHO_UTILIZADO_ LARGE_POOL) / TAMANHO_TOTAL_ LARGE_POOL) as P_LARGE Da tabela LARGE_POOL; //Atualiza dados na tela Label Large.Texto = T _ LARGE; Large.Valor = P_LARGE; Tenta
INSERT INTO MEMORIA_LOGICAS

92
(CD_MEMORIA_LOGICA, CD_INSTANCIA, CD_ACAO, TM_SHARED_POOL, TM_DATABASE, TM_REDO_LOG, TM_JAVA_POOL, TM_LARGE_POOL, PC_SHARED_POOL, PC_DATABASE, PC_REDO_LOG, PC_JAVA_POOL, PC_LARGE_POOL, DT_ATUALIZACAO) VALUES (SEQ_CD_MEMORIA_LOGICA.NEXTVAL, CD_INSTANCIA gerado na entrada do usuário na base de dados, CD_ACAO gerada na entrada da função, T _SHARED, T_DATABASE, T_REDO, T_JAVA, T_LARGE, P_SHARED, P_DATABASE, P_REDO, P_JAVA, P_LARGE, SysDate); Commit;
Se Erro Rollback; Gerar Mensagem (“Erro na conexão ao banco de dados.”); Break;
Fim Tenta
Fim Procedimento Especificação de Visualização da Shared Pool Fluxo de Execução: //Grava informações da ação do usuário na tabela ACOES Tenta
INSERT INTO ACOES (CD_ACAO, CD_INSTANCIA, DT_ACAO, ID_ACAO) VALUES (SEQ_CD_ACAO.NEXTVAL, CD_INSTANCIA gerado na entrada do usuário na base de dados, SysDate, ‘02’); Commit;
Se Erro Rollback; Gerar Mensagem (“Erro na conexão ao banco de dados.”); Break;
Fim Tenta //Declaração de variáveis memoria_total number; memoria_objeto number; memoria_shared_sql number; memoria_cursor number; memoria_utilizado number; memoria_livre number; memoria_percentagem number; dicionario_cache_percentagem number; biblioteca_cache_percentagem number; //valor total alocado para shared pool Consulta pa.Value into memoria_total

93
Da tabela V$PARAMETER pa Onde pa.Name = ‘shared_pool_size’; //valor total gasto com pacotes com armazenamento de objetos (packages, views) Consulta sum(doc.sharable_mem) into memoria_objeto Da tabela V$DB_OBJECT_CACHE doc; //valor total gasto com o shared sql //se utiliza o sql dinâmico necessita ter memória adicional Consulta sum(sa.sharable_mem) into memoria_shared_sql Da tabela V$SQLAREA sa; //supõe 250 bytes por cursor aberto, para cada usuário simultâneo Consulta sum(250*sa.users_opening) into memoria_cursor Da tabela V$SQLAREA sa; //valor total da memória utilizada memoria_utilizada = (memoria_objeto + memoria_shared_sql + memoria_cursor); //memória livre (não utilizada) no SGA: dá uma inidcaçãod e quanto de memória não //está sendo utilizada Consulta st.bytes into memoria_livre Da tabela V$SGASTAT st Onde st.Name = ‘free memory’; //consulta percentual de utilização do dicionário cache Consulta decode(sum(rc.gets),0,0,((sum(rc.gets) – sum(rc.getmisses))/sum(rc.gets))*100) into memória_dicionario_cache Da tabela V$ROWCACHE rc; //consulta percentual de utilização do biblioteca cache Consulta decode(sum(lc.pins),0,0,((sum(lc.pins) – sum(lc.reloads))/sum(lc.pins))*100) into memória_biblioteca_cache Da tabela V$LIBRARYCACHE lc; //valor percentual de utilização da memória no formato 99,99 Memória_percentagem = (memória_utilizada/memória_total)*100; //preenche componentes edits Edit Alocado.Texto = memória_alocada / 1024 / 1024 + ‘MB’; Edit Utilizado.Texto = memória_alocada / 1024 / 1024 + ‘MB’; Edit Livre.Texto = memória_alocada / 1024 / 1024 + ‘MB’; Edit Percentagem.Texto = memória_percentagem; Edit Dicionario.Texto = memória_dicionario_cache; Edit Biblioteca.Texto = memória_biblioteca_cache; Tenta
INSERT INTO SHARED_POOLS

94
(CD_SHARED_POOL, CD_INSTANCIA, CD_ACAO, TAMANHO_TOTAL, TAMANHO_UTILIZADO, TAMANHO_LIVRE, PERCENTAGEM_UTILIZADA, DT_ATUALIZACAO, DICIONARIO_CACHE, BIBLIOTECA_CACHE) VALUES (SEQ_CD_SHARED_POOL.NEXTVAL, CD_INSTANCIA gerado na entrada do usuário na base de dados, CD_ACAO gerada na entrada da função, memória_total, memória_utilizada, memória_livre, memória_percentagem, SysDate, memória_dicionario_cache, memória_biblioteca_cache); Commit;
Se Erro Rollback; Gerar Mensagem (“Erro na conexão ao banco de dados.”); Break;
Fim Tenta //consulta dados para incluir no Grid Visualizações CONSULTA TAMANHO_TOTAL, PERCENTAGEM_UTILIZADA, DICIONARIO_CACHE, BIBLIOTECA_CACHE, DT_VISUALIZACAO DA TABELA SHARED_POOLS S, ACOES A ONDE S.CD_ACAO = A.CD_ACAO E A.ID_ACAO = ‘02’ E S.CD_INSTANCIA IN (SELECT CD_INSTANCIA DA TABELA INSTANCIAS ONDE BASE_DADOS = BASE_DADOS criado na tabela ACESSOS) ORDENADO POR DT_VISUALIZACAO DESC; Eventos dos Componentes Botão Fechar OnClick Fecha a ferramenta. Form_Visualização_Shared_Pool.Fechar; Especificação de Análise do Plano de Execução Fluxo de Execução: //Grava informações da ação do usuário na tabela ACOES Tenta
INSERT INTO ACOES (CD_ACAO, CD_INSTANCIA, DT_ACAO, ID_ACAO) VALUES (SEQ_CD_ACAO.NEXTVAL, CD_INSTANCIA gerado na entrada do usuário na base de dados, SysDate, ‘08’); Commit;
Se Erro Rollback;

95
Gerar Mensagem (“Erro na conexão ao banco de dados.”); Break;
Fim Tenta Eventos dos Componentes Botão Abrir OnClick Abre arquivo para realizar a análise do plano de execução. //Chama tela para abrir arquivos e recebe arquivo selecionado Memo.Comando.Texto = Null; Memo.Comando.CarregaArquivo(nome do arquivo selecionado na tela ‘Abrir Arquivo’); Botão Salvar OnClick Salva comando SQL. //Chama tela para salvar comando SQL em arquivo Se Memo.Comando.Texto <> Null Então
Memo.Comando.SalvaArquivo(Memo.Comando.Texto para a tela ‘Salvar Arquivo’); Fim Se Botão Executar OnClick Executa comando SQL. //Executa comando SQL para análise do plano de execução Tenta
EXPLAIN PLAN [SET STATEMENT_ID = ‘COMANDO’] PARA Memo.Comando.Texto; CONSULTA LPAD(‘ ‘, 2 * (LEVEL – 1)) || operation || ‘ ’ || options || ‘ ‘ || object_name || ‘ ‘ || DECODE(id, 0, ‘Cost = || position) “Execution Plan” Da tabela plan_tab START WITH id = 0 E statement_id = ‘COMANDO’ CONNECT BY PRIOR id = parent_id E statement_id = ‘COMANDO’; Memo.Execução.Texto = Null; Memo.Execução.Texto = Campos da consulta acima;
Se Erro Rollback; Gerar Mensagem (“Sintaxe do comando SQL incorreta.”); Break;
Fim Tenta

96
Button Fechar OnClick Fecha a ferramenta. Form_Plano_Execucao.Fechar; Especificação de Reconstrução de Índices Fluxo de Execução: //seleciona usuários da base de dados Consulta DISTINCT OWNER Da tabela DBA_TABLES Combobox.Owner.Texto = Form_Principal.Edit Login.Texto; Combobox Owner.Items = Campo OWNER da consulta acima; Eventos dos Componentes Botão Analisar OnClick Este procedimento executa uma consulta para validação da estrutura de
registros na base de dados e analisa os índices. //campos obrigatórios para conexão Se Edit Percentagem.Texto == Null Então
Gerar Mensagem(‘Preencher o campo Percentagem’); Edit Percentagem = Focalizado; Break();
Fim Se Se Edit Altura.Texto == Null Então
Gerar Mensagem(‘Preencher o campo Altura’); Edit Altura = Focalizado; Break();
Fim Se //Grava informações da ação do usuário na tabela ACOES Tenta
INSERT INTO ACOES (CD_ACAO, CD_INSTANCIA, DT_ACAO, ID_ACAO) VALUES (SEQ_CD_ACAO.NEXTVAL, CD_INSTANCIA gerado na entrada do usuário na base de dados, SysDate, ‘08’); Commit;
Se Erro Rollback; Gerar Mensagem (“Erro na conexão ao banco de dados.”);

97
Break; Fim Tenta //busca índices do usuário Consulta INDEX_NAME, OWNER Da tabela DBA_INDEXES Onde OWNER = BASE_DADOS na conexão com a ferramenta; ENQUANTO Not Fim da Consulta FAÇA
//valida estruturas de índices Execute = ‘ANALYZE INDEX ‘ || OWNER da consulta acima || ‘.’ || INDEX_NAME da consulta acima || ‘ VALIDADE STRUCTURE’; //verifica se há necessidade de reconstrução de índice CONSULTA name, height, lf_rows, del_lf_rows DA TABELA INDEX_STATS; SE del_lf_rows > 0 ENTÃO
var_perc = (del_lf_rows / lf_rows) * 100; FIM SE var_analise = falso; SE Radiobutton OU == Selecionado Então
SE (height >= Edit Altura.Texto) OU (var_perc >= Edit Percentagem.Texto) ENTÃO var_analise = verdadeiro;
FIM SE Fim Se SE Radiobutton E == Selecionado Então
SE (height >= Edit Altura.Texto) E (var_perc >= Edit Percentagem.Texto) ENTÃO var_analise = verdadeiro;
FIM SE Fim Se SE var_analise == verdadeiro Então
var_comando = ‘ALTER INDEX ‘ + OWNER da consulta em dba_indexes + ‘.’ + INDEX_NAME da consulta em dba_indexes + ‘REBUILD’;
//grava informações de reconstrução do índice na tabela INDICES Tenta
INSERT INTO INDICES (CD_INDICE, CD_INSTANCIA, CD_ACAO, NOME, ALTURA, NR_LINHAS, NR_APAGADAS, PERCENTAGEM, COMANDO, ID_STATUS, DT_STATUS) VALUES (SEQ_CD_INDICE.NEXTVAL, CD_INSTANCIA gerado na entrada do usuário na base de dados, CD_ACAO gerada na entrada da função, INDEX_NAME da consulta em index_stats, HEIGHT da consulta em index_stats, LF_ROWS da consulta em index_stats, DEL_LF_ROWS da consulta em index_stats, var_perc, var_comando, ‘1’, SysDate);

98
Se Erro Rollback; Gerar Mensagem (“Erro na conexão ao banco de dados.”); Break;
Fim Tenta Fim Se Consulta em DBA_INDEXES.Próximo Registro;
FIM ENQUANTO //pega índices a serem reconstruídos para o grid índices CONSULTA CD_INDICE, NOME, ALTURA, NR_LINHAS, NR_APAGADAS, PERCENTAGEM, COMANDO DA TABELA INDICES ONDE CD_ACAO = CD_ACAO criado na tabela ACOES E ID_STATUS = 1 SE nº de registros retornados da consulta acima > 0 ENTÃO
Grid Índices = Receba dados da consulta acima; Grid Índices = Habilitado; Button Reconstruir = Habilitado;
FIM SE Botão Reconstruir OnClick Procedimento para reconstruir os índices analisados. //reconstrói índices vindos da consulta da tabela INDICES Consulta em INDICES.Primeiro Registro; ENQUANTO Not Consulta em INDICES == Fim de Registros Então
//executa reconstrução Execute(Campo COMANDO da consulta na tabela INDICES); Tenta
UPDATE INDICES SET ID_STATUS = ‘2’, DT_STATUS = SysDate
WHERE CD_INDICE = Campo CD_INDICE da consulta na tabela INDICES;
Se Erro Rollback; Gerar Mensagem (“Erro na conexão ao banco de dados.”); Break;
Fim Tenta Consulta em INDICES.Próximo Registro;
FIM ENQUANTO Botão Fechar OnClick Fecha a ferramenta.

99
Form_Plano_Execucao.Fechar; Especificação de Ajuste de Esquemas Fluxo de Execução: Não possui fluxo de execução Eventos dos Componentes Botão Visualizar Tabelas OnClick Chama tela para visualização das tabelas. Panel Visualiza_Tabelas.Show; Botão Cria Tabelas OnClick Chama tela para criação das tabelas. Panel Cria_Tabelas.Show; Botão Visualizar Índices OnClick Chama tela para visualização dos índices. Panel Visualiza_Indices.Show; Botão Cria Índices OnClick Chama tela para criação dos índices. Panel Cria_Indices.Show; Botão Fechar OnClick Fecha a ferramenta. Form_Ajuste_Esquemas.Fechar; Especificação de Visualização de Tabelas Fluxo de Execução: //Busca usuários da base de dados CONSULTA NAME DA TABELA SYS.USER$ ONDE TYPE# = 1 ORDENADO POR NAME

100
Combobox.Usuário.Texto = Form_Principal.Edit Login.Texto; Combobox.Usuário.Itens = Consulta Acima; Edit Banco de Dados = Form_Principal.Edit Base de Dados.Texto; //busca tabelas do usuário logado no sistema CONSULTA TABLE_NAME DA TABELA USER_TABLES ONDE OWNER = Form_Principal.Edit Login.Texto; Listbox Tabelas = TABLE_NAME da consulta acima; Eventos dos Componentes Combobox Usuários OnChange Seleciona usuário e mostra as tabelas desse usuário. //busca tabelas do usuário logado no sistema CONSULTA TABLE_NAME DA TABELA USER_TABLES ONDE OWNER = Combobox.Usuario.Texto.Selecionado; Listbox Tabelas = TABLE_NAME da consulta acima; Listbox Colunas = Null; Listbox Índices = Null; Edit Nº Registros = Null; Listbox Tabelas DuploClick Seleciona tabela e mostra as colunas e o número de registro dessa
tabela. Execute(‘ANALYZE TABLE ‘ + Listbox Usuario.Item.Selecionado + ‘.’ + Listbox Tabelas.Item.Selecionado + ‘ COMPUTE STATISTICS’; //busca número de registros da tabela CONSULTA NUM_ROWS DA TABELA DBA_TABLES ONDE OWNER = Listbox Usuarios.Item.Selecionado E TABLE_NAME = Listbox Tabelas.Item.Selecionado; Edit N º Registros = NUM_ROWS da consulta acima; //busca colunas da tabela CONSULTA COLUMN_NAME DA TABELA ALL_UPDATABLE_COLUMNS ONDE OWNER = Listbox Usuarios.Item.Selecionado E TABLE_NAME = Listbox Tabelas.Item.Selecionado; Consulta em ALL_UPDATABLE_COLUMNS.Primeiro_Registro; ENQUANTO Consulta em ALL_UPDATABLE_COLUMNS <> Fim dos Registros FACA
Listbox Colunas = COLUMN_NAME da consulta acima;

101
Consulta em ALL_UPDATABLE_COLUMNS.Próximo_Registro; FIM ENQUANTO //busca índices da tabela CONSULTA INDEX_NAME, INDEX_TYPE DA TABELA USER_INDEXES ONDE TABLE_OWNER = Listbox Usuarios.Item.Selecionado E TABLE_NAME = Listbox Tabelas.Item.Selecionado; Consulta em USER_INDEXES.Primeiro_Registro; ENQUANTO Consulta em USER_INDEXES <> Fim dos Registros FACA
Listbox Índices = COLUMN_NAME da consulta acima; Consulta em USER_INDEXES.Próximo_Registro;
FIM ENQUANTO Especificação de Criação de Tabelas Fluxo de Execução: //Busca usuários da base de dados CONSULTA NAME DA TABELA SYS.USER$ ONDE TYPE# = 1 ORDENADO POR NAME Combobox.Usuário.Texto = Form_Principal.Edit Login.Texto; Combobox.Usuário.Itens = Campo NAME da consulta Acima; Edit NomeTabela.Texto = Null; Memo Script.Texto = Null Botão IncluirTabela = Inabilitado; Panel Tabela = Visível; Panel Script = Visível; //Busca tabelas da base de dados CONSULTA TABLE_NAME DA TABELA USER_TABLES ONDE OWNER = Form_Principal.Edit Login.Texto; Combobox Tabelas = TABLE_NAME da consulta acima; Botão Tabela = Habilitado; Botão Campo = Desabilitado; Botão Chave Primaria = Desabilitado; Eventos dos Componentes Botão NovaTabela OnClick Dá início ao processo de criação da tabela. Se Edit NomeTabela.Texto <> Null Então

102
//Verifica se tabela já existe CONSULTA TABLE_NAME DA TABELA USER_TABLES ONDE OWNER = Form_Principal.Edit Login.Texto E TABLE_NAME = Edit NomeTabela; //Quando não existe então começa processo para criar tabela Se Nº de Registros Retornados > 0 Então
Memo Script.Texto.AdicionaLinha = ‘CREATE TABLE ‘ + Combobox Usuário.Texto + ‘.’ + Edit NomeTabela.Texto + ‘(‘; Panel Tabela = Invisível; Panel Colunas = Visível;
Fim Se //Quando existe tabela então manda mensagem Se Nº de Registros Retornados == 0 Então
Mensagem(“Tabela já existe”); Fim Se
Fim Se Botão IncluiColuna OnClick Adiciona coluna na tabela. Se Edit NomeColuna.Texto <> Null Então
Memo Script.Texto.AdicionaLinha = Edit NomeColuna.Texto + ‘,’; Botão IncluirTabela = Habilitado; Edit NomeColuna.Texto = Null;
Fim Se Botão IncluiTabela OnClick Finaliza processo de criação da tabela. Memo Script.Texto.AdicionaLinha = ‘)’; Execute(Memo.Script.Texto); //busca colunas da tabela CONSULTA COLUMN_NAME DA TABELA ALL_UPDATABLE_COLUMNS ONDE OWNER = Combobox Usuarios.Texto; E TABLE_NAME = Edit NomeTabela.Texto; ListBox Colunas = Campo COLUMN_NAME da consulta acima; Panel Colunas = Invisível; Panel Script = Invisível; Panel Chave Primária = Visível;

103
Botão IncluiChavePrimaria OnClick Adiciona chaveprimaria na tabela. Se (Listbox ChavePrimaria == Selecionado) e (Edit NomeChave <> Null) Então
var_schema = ‘ALTER TABLE ‘ + combobox.usuario.texto + ‘.‘ + Edit Tabela.Texto + ‘ADD
(CONSTRAINT ‘ var_schema = var_schema + Edit NomeChave + ‘ ( ‘; Listbox ChavePrimaria.Primeiro Registro; Enquanto Not Fim dos Registros em Listbox ChavePrimaria Faça
var_schema = var_schema + Listbox.Texto[Listbox.Item]; Se Listbox ChavePrimaria <> Último Registro Então
var_schema = var_schema + ‘,’; Fim Se Listbox ChavePrimaria.Próximo Registro;
Fim Enquanto var_schema = var_schema + ‘))’; Execute(var_schema); Panel Chave Primária = Invisível; Panel Tabela = Visível; Panel Script = Visível;
Fim Se Especificação de Visualização de Índices Fluxo de Execução: //Busca usuários da base de dados CONSULTA NAME DA TABELA SYS.USER$ ONDE TYPE# = 1 ORDENADO POR NAME Combobox.Usuário.Texto = Form_Principal.Edit Login.Texto; Combobox.Usuário.Itens = Campo NAME da consulta Acima; //busca tabelas do usuário logado no sistema CONSULTA TABLE_NAME DA TABELA USER_TABLES ONDE OWNER = Form_Principal.Edit Login.Texto; Listbox Tabelas = TABLE_NAME da consulta acima; Eventos dos Componentes Botão Visualizar

104
OnClick Visualiza os índices do usuário selecionado. //Busca índices da base de dados CONSULTA NOME_INDICES, TABLE_NAME DA TABELA DBA_INDEXES ONDE OWNER = Combobox.Texto; Se Nº de Regitros Retornados na Consulta Acima > 0 Então
Grid Índices = Campos da consulta acima; Botão Detalhes = Desabilitado;
Fim Se Se Nº de Regitros Retornados na Consulta Acima == 0 Então
Grid Índices = Null; Botão Detalhes = Desabilitado;
Fim Se Grid Índices OnClick Seleciona um registro no grid índices. //quando da seleção de um registro Botão Detalhes = Habilitado; Botão Detalhes OnClick Visualiza detalhes do índice selecionado. //Busca índices da base de dados Execute = ‘ANALYZE INDEX ‘ || Combobox Usuário.Texto || ‘.’ || INDEX_NAME do registro selecionado no grid índices || ‘ VALIDADE STRUCTURE’; //verifica se há necessidade de reconstrução de índice CONSULTA height, lf_rows, del_lf_rows DA TABELA INDEX_STATS; Edit Nº Registro = lf_rows da consulta acima; Edit Nº Registro Apagados = del_lf_rows da consulta acima; Edit Nº Registro Válidos = lf_rows – del_lf_rows da consulta acima; Especificação de Criação de Índices Fluxo de Execução: //Busca usuários da base de dados CONSULTA NAME DA TABELA SYS.USER$ ONDE TYPE# = 1 ORDENADO POR NAME

105
Combobox.Usuário.Texto = Form_Principal.Edit Login.Texto; Combobox.Usuário.Itens = Campo NAME da consulta Acima; //Busca tabelas da base de dados CONSULTA TABLE_NAME DA TABELA USER_TABLES ONDE OWNER = Form_Principal.Edit Login.Texto; Combobox Tabelas.Texto = Form_Principal.Edit Login.Texto; Combobox Tabelas.Campo = TABLE_NAME da consulta acima; Eventos dos Componentes: Combobox Usuário OnChange Inicia procedimento para criação de um novo índice. //Busca tabelas da base de dados CONSULTA TABLE_NAME DA TABELA USER_TABLES ONDE OWNER = Combobox.Usuário.Texto; Combobox Tabelas.Texto = Form_Principal.Edit Login.Texto; Botão NovoÍndice OnClick Inicia procedimento para criação de um novo índice. //Busca índices da base de dados Se Botão NovoIndice.Texto == ‘Novo Índice‘ Então
Se (Combobox TipoIndice.Texto <> Null) E (Edit NomeIndice.Texto <> Null) Então Botão CancelaÍndice = Habilitado; Botão NovoÍndice.Texto = ‘Inclui Índice’; Combobox Usuário = Desabilitado; Combobox Tabela = Desabilitado; //busca colunas da tabela CONSULTA COLUMN_NAME DA TABELA ALL_UPDATABLE_COLUMNS ONDE OWNER = Listbox Usuarios.Item.Selecionado E TABLE_NAME = Listbox Tabelas.Item.Selecionado; Botão IncluiCampo = Habilitado;
Fim Se
Senão
//verifica se coluna já existe CONSULTA COLUMN_NAME DA TABELA ALL_UPDATABLE_COLUMNS ONDE OWNER = Listbox Usuarios.Item.Selecionado E TABLE_NAME = Listbox Tabelas.Item.Selecionado

106
E COLUMN_NAME = Edit NomeIndice.Texto; Se Nº de Registros Retornados == 0 Então
var_schema = ‘CREATE INDEX ‘ + combobox.usuario.texto + ‘.‘ + Edit NomeIndice.Texto + ‘ ON ‘ + combobox.tabela.texto + ‘ (‘;
Listbox.Coluna.Primeiro Registro; Enquanto Not Fim dos Registros em Listbox Coluna Faça
var_schema = var_schema + Listbox.Coluna.Texto[Listbox.Coluna.Item]; Se Listbox Coluna <> Último Registro Então
var_schema = var_schema + ‘,’; Fim Se Listbox Coluna.Próximo Registro;
Fim Enquanto var_schema = var_schema + ‘)’; Execute(var_schema); Botão CancelaÍndice = Desabilitado; Botão NovoÍndice.Texto = ‘Novo Índice’; Combobox Usuário = Habilitado; Combobox Tabela = Habilitado; ListBox.Indices.Itens = Null;
Fim Se Se Nº de Registros Retornados > 0 Então
Mensagem(“Índice já existe.”); Fim Se
Fim Se Botão Cancelar OnClick Visualiza detalhes do índice selecionado. Botão CancelaÍndice = Desabilitado; Botão NovoÍndice.Texto = ‘Novo Índice’; Combobox Usuário = Habilitado; Combobox Tabela = Habilitado; ListBox.Indices.Itens = Null; Especificação de Consulta de Acessos Fluxo de Execução: //Busca usuários da base de dados CONSULTA NAME DA TABELA SYS.USER$ ONDE TYPE# = 1

107
ORDENADO POR NAME Combobox.Usuário.Texto = Form_Principal.Edit Login.Texto; Combobox.Usuário.Itens = Campo NAME da consulta Acima; Eventos dos Componentes Botão Visualizar Acessos OnClick Inicia procedimento para visualização dos acessos. //busca registros de acessos a ferramenta Se Combobox Usuário.Texto <> ‘TODOS’ Então
CONSULTA J.DT_ACESSO, J.CD_INSTANCIA, J.LOGIN, (CONSULTA COUNT(A.CD_INSTANCIA) DA TABELA ACOES A, INSTANCIAS I ONDE I.CD_INSTANCIA = J.CD_INSTANCIA E I.CD_INSTANCIA = A.CD_INSTANCIA E I.BASE_DADOS = Form_Principal.Edit Base Dados.Texto E I.LOGIN = Combobox.Usuario.Texto) AS NR_ACOES DA TABELA INSTANCIAS J ONDE J.LOGIN = Combobox.Usuario.Texto E J.BASE_DADOS = Form_Principal.Edit Base Dados.Texto E J.DT_ACESSO >= Edit Data Inicial.Texto E J.DT_ACESSO <= Edit Data Final.Texto;
Fim Se Se Combobox Usuário.Texto == ‘TODOS’ Então
CONSULTA J.DT_ACESSO, J.CD_INSTANCIA, J.LOGIN, (CONSULTA COUNT(A.CD_INSTANCIA) DA TABELA ACOES A, INSTANCIAS I ONDE I.CD_INSTANCIA = J.CD_INSTANCIA E I.CD_INSTANCIA = A.CD_INSTANCIA E I.BASE_DADOS = Form_Principal.Edit Base Dados.Texto) AS NR_ACOES DA TABELA INSTANCIAS J ONDE J.BASE_DADOS = Form_Principal.Edit Base Dados.Texto E J.DT_ACESSO >= Edit Data Inicial.Texto E J.DT_ACESSO <= Edit Data Final.Texto;
Fim Se Se Nº de Registros Retornados > 0 Então
Grid Acessos = Campos da consulta acima; Grid Acessos = Habilitado; Grid Ações = Habilitado;
Fim Se Se Nº de Registros Retornados == 0 Então
Grid Acessos = Desabilitado;

108
Grid Ações = Desabilitado; Botão Visualizar Ações = Desabilitado;
Fim Se Botão Visualizar Ações OnClick Inicia procedimento para visualização das ações. //busca as ações realizadas no acesso CONSULTA DT_ACAO, CASO ID_ACAO QUANDO '01' ENTÃO 'Reconstrução de Índices' QUANDO '02' ENTÃO 'Visualização da Shared Pool' QUANDO '03' ENTÃO 'Visualização da Estrutura Lógica da Memória' QUANDO '05' ENTÃO 'Criação de Tabelas' QUANDO '07' ENTÃO 'Criação de Índices' FIM DA TABELA ACOES ONDE CD_ACESSO = Campo CD_INSTANCIA do registro selecionado no Grid Acessos; Se Nº de Registros Retornados > 0 Então
Grid Ações = Campos da consulta acima; Fim Se Se Nº de Registros Retornados == 0 Então
Grid Ações = Desabilitado; Botão Visualizar Ações = Desabilitado;
Fim Se Grid Acessos OnClick Quando seleciona um registro. Botão Visualiza Acessos = Habilitado; Botão Fechar OnClick Fecha a ferramenta. Form_Consulta_Acessos.Fechar; Especificação de Consulta de Índices Fluxo de Execução: //Busca usuários da base de dados CONSULTA NAME DA TABELA SYS.USER$

109
ONDE TYPE# = 1 ORDENADO POR NAME Combobox.Usuário.Texto = Form_Principal.Edit Login.Texto; Combobox.Usuário.Itens = Campo NAME da consulta Acima; Eventos dos Componentes Botão Buscar OnClick Inicia procedimento para visualização dos índices reconstruídos. //busca registros de acessos a ferramenta CONSULTA I.NOME, I.ALTURA, I.PERCENTAGEM, I.DT_STATUS DA TABELA INDICES I, INSTANCIAS J, ACOES A ONDE J.BASE_DADOS = Combobox.Usuario.Texto E J.LOGIN = Form_Principal.Edit Base Dados.Texto E J.DT_ACESSO >= Edit Data Inicial.Texto E J.DT_ACESSO <= Edit Data Final.Texto E J.CD_INSTANCIA = A.CD_INSTANCIA E A.ID_ACAO = '01' E A.CD_ACAO = I.CD_ACAO E I.ID_STATUS = '2'; Se Nº de Registros Retornados > 0 Então
Grid Índices = Campos da consulta acima; Fim Se Button Fechar OnClick Fecha a ferramenta.
Form_Consulta_Indices.Fechar;

110
APÊNDICE C – INSTALAÇÃO DA FERRAMENTA
Para utilização da ferramenta é necessária a sua instalação no banco de dados que irá ser
realizado a análise e ajuste de desempenho.
Quando um usuário executa pela primeira vez conexão com o banco de dados através da
ferramenta se tem como passo inicial a sua instalação necessitando a seleção de um usuário desta
base de dados para a criação das tabelas que irão servir como histórico da utilização da ferramenta,
como mostra a Figura 1:
Figura 1: Início da Instalação da Ferramenta
Após a instalação da ferramenta acontece a alteração de um arquivo nomeado de
configuração.sql, onde irá constar o nome da base de dados, identificado com os caracteres “1|”, e o
usuário em que se encontra instalada a ferramenta, identificado na próxima linda. A Figura 2 relata
este arquivo.
Banco de Dados
Usuários
Mensagens Após a Instalação

111
Figura 2: Arquivo configuracao.sql
Sendo assim, quando o usuário solicitar conexão ao banco de dados, o primeiro passo é
percorrer o arquivo configuracao.sql e identificar se a base de dados possui a instalação da
ferramenta. Caso a afirmação não for confirmada, a única funcionalidade disponível ao usuário é a
instalação da mesma, porém, se há a instalação, então todas as funções ficam disponibilizadas.
Como último passo há a opção de desinstalar a ferramenta, sendo que neste caso é removido
o nome da base de dados e do usuário do arquivo configuraco.sql. Por fim, recomenda-se a criação
de um usuário específico para a utilização da ferramenta. Ressalta-se ainda que tanto o usuário que
irá se conectar à ferramenta quanto o usuário selecionado para a sua instalação tenham previlégios
de DBA.
Base de Dados
Usuários

112
ANEXO I – RESUMO PUBLICADO NO CRICTE 2004

113
ANEXO II – ARTIGO