unit- iv inter-process communication:. contents: inter-process communication process tracing pipes...
TRANSCRIPT

Unit- IV
Inter-process Communication:

Contents:• Inter-Process Communication• Process Tracing• Pipes• Sockets• System V IPC• Multiprocessor systems

IPC:• Independent processes & co-operating processes• Communicating two processes related or unrelated.• Purposes for IPC• Information Sharing• Data Transfer• Synchronization • Event Notification
• IPC mechanism:• Signal• Message Passing• Pipes• Sockets• Shared memory

Process Tracing• ptrace(cmd, pid, addr, data)• pid is the process ID• addr refers to a location• cmd: r/w, intercept, set or delete watchpoints, resume the
execution• Data: interpreted by cmd• Used by debuggers sdb or dbx
• Global trace data structure

Debugging Process :• if ((pid = fork() ) == 0)• {• //child traced process • ptrace(0, 0, 0, 0) ;• exec("name of traced process here") ;• // debugger process continues here• for (;;)• {• wait( (int *) 0) ;• read (input for tracing instructions)• ptrace(cmd,pid,addr,data) ;• if (quitting trace)• break;• }

Process Tracing
• drawbacks and limitations - child must allow tracing explicitly by invoking ptrace; - parent can control the execution of its direct children only; - extremely inefficient (requires several context switches); - cannot control a process already running;- security problems when tracing a setuid programs (user can obtain super user privileges) – to avoid this UNIX disables tracing such programs;

Pipes :
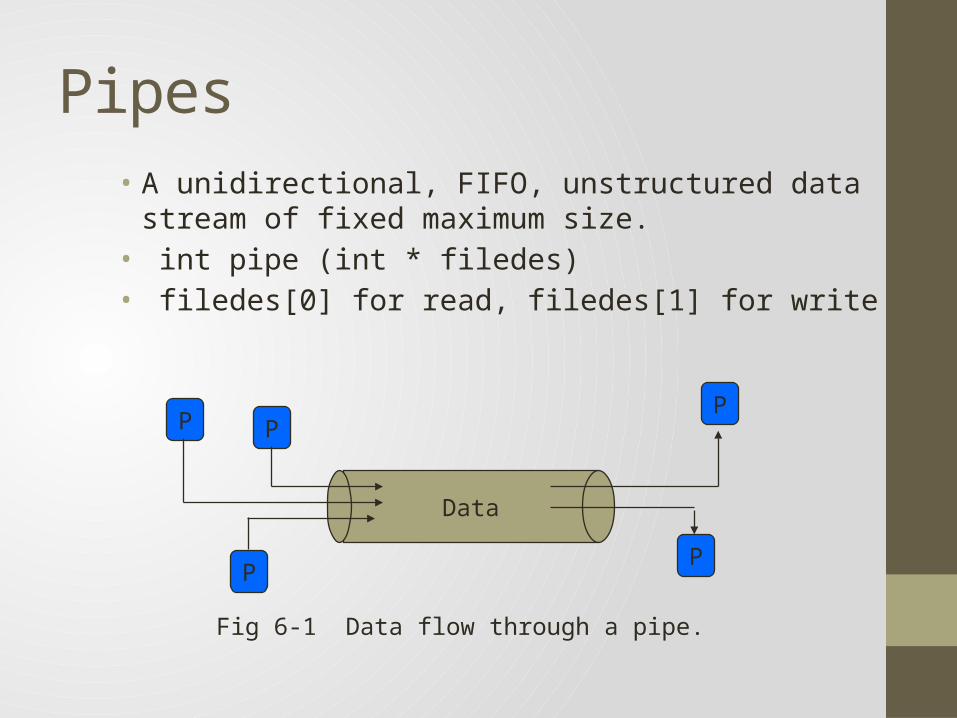
Pipes• A unidirectional, FIFO, unstructured data stream of fixed
maximum size.• int pipe (int * filedes) • filedes[0] for read, filedes[1] for write
Data
PP
P
P
P
Fig 6-1 Data flow through a pipe.

• Applications: in shell – passing output of one program to another program – e.g. cat fil1 file2 | sort
• Limitations: cannot be used for broadcasting;• Data in pipe is a byte stream• No way to distinguish between several readers or writers
• Named Pipes:• Use mknod(),mkfifo()
Pipes

Sockets :

Sockets :• A socket is defined as an endpoint for communication• Concatenation of IP address and port• Communication needs a pair of sockets

Socket Functions :• sd = socket (format, type, protocol) ;
• bind (sd, address, length) ;
• connect (sd, address, length) ;
• listen (sd, qlength)
• nsd = accept (sd, address, addrlen) ;
• count = send (sd, msg, iength, flags) ;

Socket Functions :• count = recv (sd, buf, length, flags) ;
• shutdown (sd, mode)
• getsockname(sd, name, length) ;

System V IPC• Messages: send formatted data streams to arbitrary process• Shared memory: share parts of virtual address space• Semaphores: synchronize execution

Common properties :• Table whose entries describes all instances of mechanism• Each entry contains user chosen numeric key• Each mech. contains get system call• IPC_CREAT bit in flag: new entry with given key• IPC_CREAT and IPC_EXCL bit in flag: error if entry for given key is
present• To find index into table • index=descriptor modulo (no of entries)
• Permission structure: UID, GID• Status information: PID and time of last access/modification• Control system call: set/return status info, remove entry

Messages :• Msgqid=msgget(key,flag)
• Fields of queue structure - ptr to 1st and last msg on linked list - no of msg & total no of data byte on linked list - max no of bytes of data byte on linked list - process id of last process - timestamp of last system call
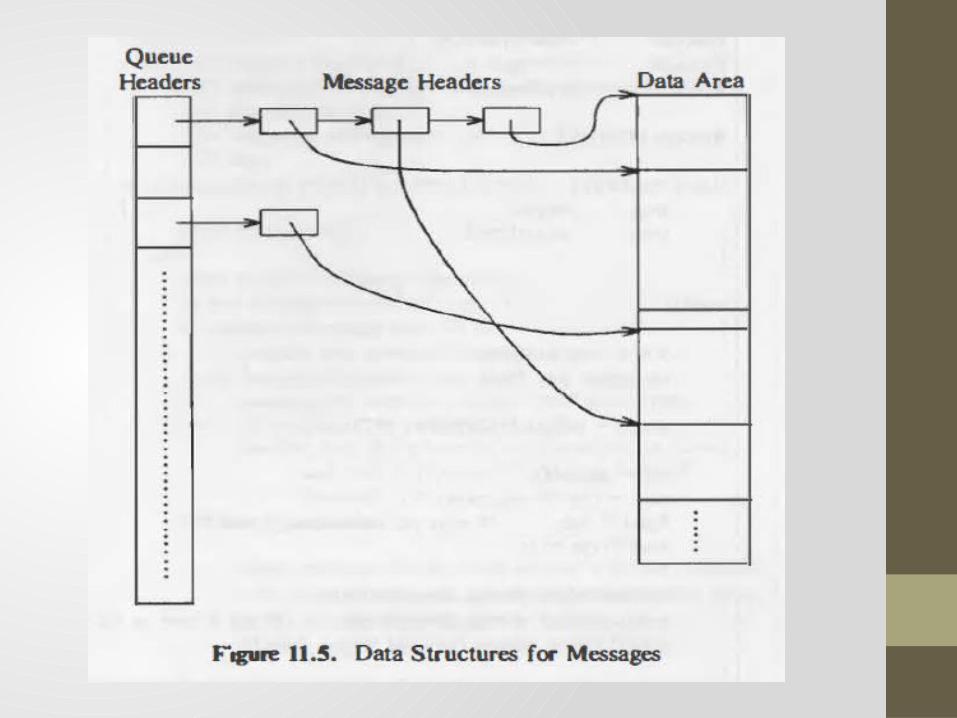

msgqid=msgget(key,flag)
When msgget called search msg queue to find id with given key if no entry allocate new queue struct initialize it return identifier else check permission & return

Msgsnd(msgqid,msg,count,flag)
• Msgqid-descriptor of msg queue returned by msgget• Msg- ptr to structure int type and char array• Count- size of data array• Flag-action taken if it runs of internal buffer space


Count=msgrcv(id,msg,maxcount,type,flag)• id- msg descriptor• Msg-address of user structure to contain rcv msg• Maxcount-size of data array in msg• Type-msg type user wants to read• Flag- what kernel should do if no msg are on the queue• Count- no of bytes returned to user


Msgctl(id,cmd,mstatbuf)• Id-msg descriptor• Cmd- type of command• Mstatbuf- address of user data structure that will contain
control parameters or result of query

Shared Memory :• Sharing part of virtual address space for reading and
writing.• Shmget()• Shmat()• Shmdt()• Shmctl()


Shmid=shmget(key,size,flag)
• Size-no of bytes in region
• Search for given key if entry present & permission return descriptor for entry if no entry & IPC_CREAT flag verify size & allocate region using allocreg saves permission modes, size, ptr to region table allocate mem when attach region

virtaddr=shmat(id,addr,flags)• Id-returned by shmget• Addr-virtual address where user wants to attach• Flags-whether region read only, etc.• Virtaddr- Virtual address where kernel attached region


• shmdt(addr) addr- address returned by shmat
• shmctl(id,cmd,shmstatbuf) id-shared mem table entry cmd- type of operation shmstatbuf-address of user level structure that
contain status information
Shared Memory detach and control :

Semaphores :

Semaphore Functions:• id=semget(key,count,flag)• No of semaphore entries• Time of last semop and semctl
• Oldval=semop(id,oplist,count);• Oplist format:-
• Sem_op• Sem_no• Flags
• Semctl(id,number,cmd,arg)• Args:-union
• Sem_val• Sem_ds• Array ptr

Change in Semaphore value a/c to operation value:• If Positive: -• Increment semaphore • Wake up processes waiting for sem value to increase
• If 0: -• If sem value=0 :- continue with other operation with array• Else put process to sleep (process waiting for sem value to be 0)
• If Negative: -• Decrements semaphore by op value• If semaphore = 0
• Wakeup all processes waiting for sem to be 0• Else
• process goes to sleep (process waiting for sem value to increase)


Flag bits :• IPC_CREAT• IPC_EXCL• IPC_NOWAIT• IPC_RMID• IPC_PRIVATE
• MSG_NOERROR
• SEM_UNDO

Multiprocessor configuration

• Greater throughput as processes run concurrently.• Each CPU executes independently but all of them execute one
copy of kernel.• Semantics for system call are same.• Drawback: Several process execute simultaneously in kernel
mode causes integrity problems.
Multiprocessor configuration


In uniprocessor Unix system integrity of kernel data structure is maintained by two policies.
1. Kernel cannot preempt a process and switch context to another process while executing in kernel mode.
2. Kernel masks out interrupts when executing a critical region of code .
Problem of multiprocessor system

• Execute all critical activity on one processor• Serialize access to critical regions of code with locking
primitives.• Redesign algorithms to avoid contention of data structure.
There are 3 methods for preventing such corruption

Master Slave Arch :

• One processor called master can execute in kernel mode and other called slave execute only in user mode.
• Master processor- handle all system calls and interrupt.• Slave processor-execute process in user mode and inform
master when makes system calls.
Solution with master and slave processors



• Corruption of kernel data structure possible in scheduler algorithm because it does not protect against having a process selected for execution on two processor.
• Master can specify the slave processor on which the process should execute (more than one process can be assign –load balancing problem).
• Kernel can allow only one processor to execute the scheduling loop at a time.
Drawback:

Mechanism for setting lock :
Mechanism for setting lock :
Solutions with semaphore :


• Partition the kernel into critical region such that at most one processor can execute code in critical region at a time.
Operations on semaphores:
• Initialization :- to a nonnegative value.• P operation :- • decrements the value of semaphore.• If value of semaphore < 0 (process that did the p goes to sleep)
• V operation :- I• increments the value of semaphore.• If the value of semaphore >= 0 (one process that has been sleeping as a
result of p operation wakes up.)
• Conditional P (CP) :-• Decrements the value of semaphore • True: if its value > 0• False: if value <= 0
Solution with semaphore

• Dijkstra- possible to implement semaphore without sp. m/c instruction.
• Pprim locks semaphore by checking value of array val.
• When lock sem. It checks to see if processor already locked(val=2) or if processor with lower ID trying to lock(val=1).
• If either cond true, resets entry =1 & tries again
Implementation of semaphore



Following sequence protects a resource• Pprim(semaphore)• Use resource here
• Vprim (semaphore)
• Disadvantage:- loops are slow so performance down
• IBM 370 - atomic compare & swap instructions.• AT & T 3B20 –atomic read & clear instructions.
Locking Mechanism:




• Buffer allocation
• Wait
• Driver-locking scheme
• Dummy process
Algorithms implemented with semaphore:

• Data structure for buffer allocation• Buffer Header• HQ of buffer• Free List Buffers
• In multiprocessor two process could manipulate the linked list of hash queue, the semaphore for the hash queue permits only one processor at a time to manipulate the linked list.
• Free list requires a semaphore as several process could corrupt it.
Buffer allocation

• Parent should miss a zombie child as it executes the wait algorithm.• Parent must not sleep waiting forever.
Wait
Multiprocessor algorithm wait{ for(;;) { search all child process; if (status of child is zombie) return; P(zombie_semaphore); /* initialized to 0*/ }}
• Perform V while exiting.

• Avoided inserting semaphore into driver code. • P & V operations at the driver entry points.
P(driver_semaphore);
Open(driver);
V(driver_semaphore):
• Same semaphore for all entry points.• Different semaphore for each driver.
Drivers :

• In uniprocessor, if no process are ready to run, kernel idles in the context of the process that last run.
• In multi processor, Kernel can not idle in context of the process executed most recently on the processor.
• Create a dummy process per processor.• When processor has no work to do context switch is done to
the dummy process & it idles the context of dummy process .• It consists of kernel stack only and can not be scheduled.
Dummy process :

• User interface compatible to Unix.• Written in Concurrent Euclid.• Solves the mutual exclusion problem.• Kernel process are activated by queuing messages for input.• Concurrent Euclid implements monitor to prevent corruption
of queues.
The Tunis system

• Methods to implement multiprocessor configuration.
1: Master – slave
2: Semaphore• The implementation of multiprocessor Unix system generalizes
to any no of processor but throughput will not increase at linear rate with no of processors.
1: Increased memory contention in h/w .
2: Wait longer period of time to gain semaphore.
3: Master processor becomes bottleneck.
Performance limitation: