understanding biosynthesis of complex metabolites using computational biology d. mohanty national...
TRANSCRIPT

Understanding biosynthesis ofcomplex metabolites
using computational biology
D. MohantyNational Institute of Immunology
New Delhi

O OCH3
CH3
N
OOHO
H3C
O
O OH3C
O
OH
OCH3
CH3
H3CO
OH
H3C
O
O
O
OH
O
O
HO OH
O
NMe2
HO
O
OMeOH
OH OH
NH
O
O
O
O
OH OHO
O
O
O
O
OH
O
H3C
HCH3
O
OHO
O
CH3
O
O O
CH3H3C
H3C
OH
HO
OH3C
CH3
N
S
CH3
HO
OH
OH

Domains Involved in Protein-Protein
Interactions
Substrate Specificity of Catalytic Domains
PKS NRPS Modifying Domains
Acyl Transferase
(AT)
Adenylation
(A)
Acyl CoA Synthetases
(ACS)
Keto Synthases
(KS)
Condensation
(C)
Glycosyl Transferases
(GTr)
Chalcone Synthases
(CHS)
N-Acyl Transferases
(NAT)
KS – ACP
AT – ACP
A – PCP
C – PCP
PapA5 – ACP

Levels of Functional AnnotationSequence based methods: Fundamental for functional annotation
Drawback: Cannot predict substrate specificity

PCPSSCoA
SCoA
Amino acid Coumarate
Oxyluciferin
Amino acyl PCP
Fatty acid Acyl CoA
Coumaroyl CoA
Luciferin
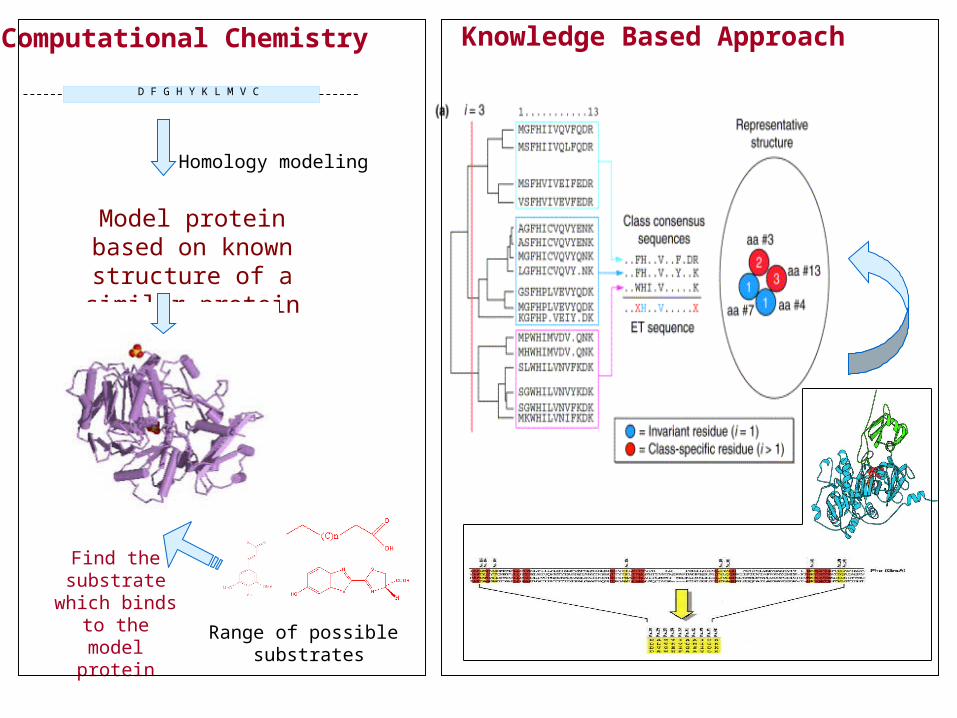
Model protein based on known structure of a similar protein
Range of possible substrates
Find the substrate which
binds to the model protein
Computational Chemistry
D F G H Y K L M V C
Knowledge Based Approach
Homology modeling

Knowledge Based ApproachSequence/structure information for large number of proteins with known
specificity
Predicting substrate specificity of new members of the familyusing evolutionary information
Design of novel proteinswith altered specificity.
Design of novel polyketides/nonribisomalpeptides
In silico identification of PKS/NRPS products
Sequence-Product correlation
Predictive rules
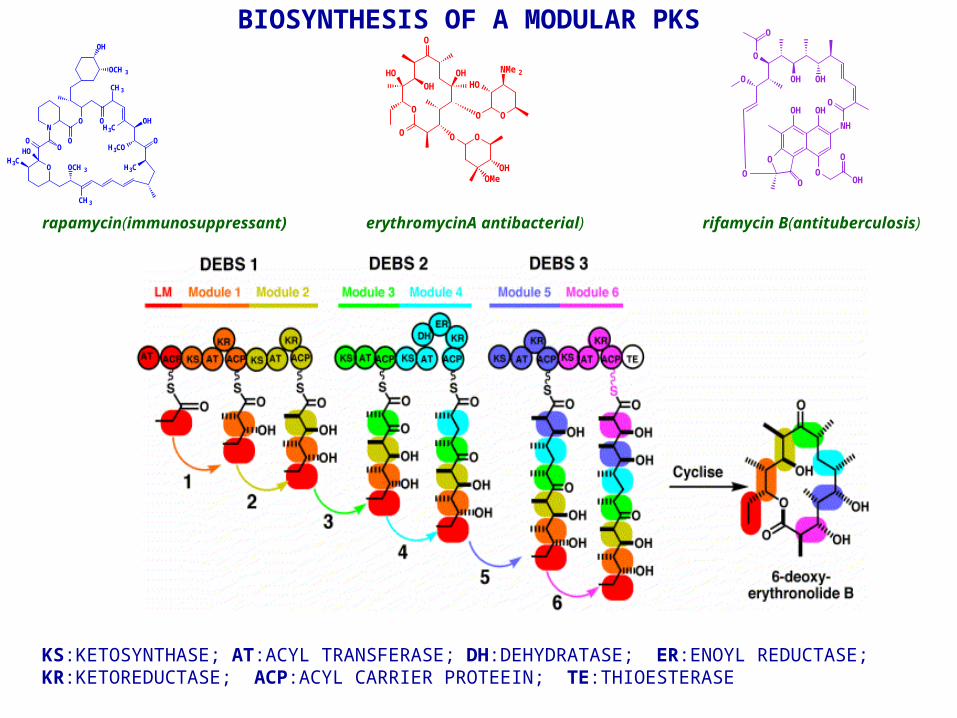
BIOSYNTHESIS OF A MODULAR PKS
KS:KETOSYNTHASE; AT:ACYL TRANSFERASE; DH:DEHYDRATASE; ER:ENOYL REDUCTASE; KR:KETOREDUCTASE; ACP:ACYL CARRIER PROTEEIN; TE:THIOESTERASE
rifamycin B(antituberculosis)erythromycinA antibacterial)
rapamycin(immunosuppressant)
O OCH3
CH3
N
OOHO
H3C
O
O OH3C
O
OH
OCH3
CH3
H3CO
OH
H3C
O
O
O
OH
O
O
HO OH
O
NMe2
HO
O
OMeOH
OH OH
NH
O
O
O
O
OH OHO
O
O
O
O
OH

POSSIBLE STARTER AND EXTENDER UNITS
FAS
HO SCoA
O O
SCoA
O
Malonyl CoA
Acetyl CoA
CoAS
O
CoAS
O
O
SCoA
Butyryl CoA
Benzoyl CoA
Isobutyryl CoA
H3C SCoA
O O
Acetoacetyl CoA
HO SCoA
O O
HO SCoA
O O
Malonyl CoA
Methylmalonyl CoASCoA
O
Acetyl CoA
SCoA
O
Acetyl CoA
PKS
SCoA
O
Propionyl CoA
ACYL TRANSFERASE (AT) DOMAIN
Involved in selection of starter and extender units during Biosynthesis of Fatty acids and Polyketides


PKSDB
Yadav G, Gokhale R.S and Mohanty D. (2003) Nucl. Acids Res. 31:3654-3658

Table 3 (a)

Yadav, G., Gokhale, R. S. and Mohanty, D. (2003)
J. Mol. Biol. 328, 335-363.
Trivedi et al. Mol Cell 2005, 17: 1-13
Substrate Specificity of AT domains of PKS

•KS domain dendrogram•Different sub-families of KS domain sequences show distinct clustering.•How to Quantify this difference?
Classification of KS sequence into subfamilies: Modular or Iterative ?

Identification of residues in KS which control number of iterations

Threading of sequence onto known structural folds
Homology Models based on highest scoring structural templates
Active site residue extraction and analyses
Cavity Analyses of various models in terms of :
Volume Hydrophobicity Topology
Comparison across iterative PKS subfamilies
Analyses of KS domains from iterative PKS

The E.coli KAS-II
Catalytic Pocket

Plots of iterative KS model cavity parameters
01020
30405060
708090
0 10 20 30 40 50 60
hydrophobicity (A F M Y L W V I )
%u
nsa
tura
tio
n
Are we analyzing the correct cavity?
Saturation of ProductVs
Hydrophobicity of CLRs
Cavity Volume Vs No. of Iterations

Shapes of Active Sites of Iterative PKSs
MSAS NAPTHOPYRONE

107 108 131 132 133 134 135 138 193 198 202 205 206 207 229 265 268 269 270 271 272 273 276 279 308 309 313 342 398 399 400 401
1KAS G I P F F V P I A G F A R A F D H M T S P P G A P A A L F G F G
AVILA C T A - - - - - L - - P G A Y D T N G I M A G Q R L M E F G Y G
CALORS T A Y T G I A V Q L A G T Y D T D G I M A G Q Q L V E F G Y G
MSAP N S P W M G I A I - - P G L Y D T N G I M A Q Q P V T E Y G Y G
MSAT N S A W M G I A L L L A G A Y D T N G I M A A Q P L T E Y G Y G
MSPG N S A H M G V A L L L A G A Y D T L G I M A A Q S L T E Y G Y S
MSPP G V A Y - - - V L - P T R V Y D T N G I M A S Q P L T E Y G Y G
THNGL F Y T Y F I T V M I L G Q F Y S A V S I T H G Q Q A T E F S A A
THNCL - T T Y Y I T V M I L G Q F Y S A I S I T H G Q Q A T E F S A A
THNND - T T Y Y I T V M I L G Q F Y S A I S I T H G Q Q A T E F S A A
AFMEL - T T Y F I P N L N L G H F Y S A V S I T R V Q Q A V E F S A A
WANA F Y T Y F I P N L N L G H F Y S A V S I T R V Q Q A V E F S A A
NAPATT S T Y F I P N L N L G H F Y C S I T R P H D Q Q A T E F S A A
AFLAT - T T Y F I T N I G L G F F Y S S E S M T R V Q Q V V E F S A A
AFTOX - T T Y F I T N I G L G F F Y S S E S M T R V Q Q V V E F S A A
STERG F H T Y F I T N I G L G F F Y S S M T R P F A Q Q V V E F S A A
ENDY2 S T P F T L A L S E F V G A F D G L T R P E G Q A V A K M G F G
ENCV T T A F T L A L S E F T G A F D G I T R P E G H A V T K M G F G
ENPKS S T P F T L A L S E F T G A F D G I T R P E G H A L T K M G F G
ENKIT T T G D T L A L S E F T G A F D G I T R P E G H A V T K M G F G
ENCRZ T T P F T L A L S E F T G A F D G I T R P E G Y A V T K M G F G
ENGHA T L P F T L A L S E F T G A F D G I T R P E G Y A V T K M G F G
C1027 T L P F T L A L S E F T G A F D G I T R P E G Y A V T K M G F G
ENMEGS T P F T L A L S E F T G A F D G I T R P E G Y S V T K M G F G
ENECO T L P F T L A L S E F T G A F D G I T R P E G Y R V T K M G F G
ENMADT L P F S L A L S E F T G A F D G I T R P E G Y E V T K M G F G
ENMIC T T P F T L A L S E F A G A F D G M T R P E G Y A V T K M G F G
ENESP T L P F S L V L S E F L G A F D G G T R P D G Q E V T K M G F G
ENCIR S L A D S L A L S E F T G A F D G I T R E A R - A L T K M G F G
BIKGF C A A F T A T L M W L A S F Y N C T P L F V S L P V A E Y G A S
BIKAV - T T Y Y I P N M N L G H F Y S S I T R P L A Q Q A V E F S A A
CMPC M T T Y S A T A I T E L N M Y D T T G I T M H Q P A Q E F G F G
LOVS M T T Y S A T A I T E L S M Y D T T G I T M H Q P A Q E F G F G
LOVGFM C Q Y G A T A I M E L S M Y D T P G L T M A Q P A R E F G F G
FUMONW G G G - - D V - - M V A Y D G M S M P S H - S V L E F G I G
ACTIVE SITE RESIDUES OF ITERATIVE KS DOMAINS

CORRECT ORDER OF ORFs WITHIN A PKS BIOSYNTHETIC CLUSTER
Simocyclinone PKS
Mupirocin PKS cluster

ROLE OF LINKERS


INTERMODULAR DOCKING INTERACTIONS
Pairs tested 66
Both charged Interactions 20
One charged Interaction 11
At least One Good Interaction 23
Percentage of Total 82%
Both Bad Interactions 0
Cognate – Non Cognate Differentiation (An example):
Pair 1 Pair 2 Interface
Ery1-C D E Ery2-N K R Ery 1-2 (cognate)
D-K E-R + +
Ery2-C D K Ery3-N R D Ery 2-3 (cognate)
D-R K-D + +
Ery 1-3
Noncognate
D-R E-D + -

PREDICTION OF ORF ORDER USING LINKER INTERACTIONS
The Spinosyn Biosynthetic clusterORFs: 1 2 3 4 5
ORDER Interface 1
Interface 2
Interface 3
Interface 4
TOTAL:
Good – Bad - Neutral
1-2-3-4-5 . . + + + + + + 6 0 2
1-2-4-3-5 . . + + + - + - 4 2 2
1-3-2-4-5 . . - - + + + + 4 2 2
1-3-4-2-5 . . + + - + + - 4 2 2
1-4-3-2-5 . . - + + + + - 4 2 2
1-4-2-3-5 . . + - - - + - 2 4 2Charged Interaction (+) Bad Interaction(-) Neutral Interaction (.)

PKS ORFs Combinations PredictionGood Bad Neutral Better Equal Worse
Albicidin 1 1 YesAmphotericin 6 24 6 0 4 0 3 20 YesAnsamitocin 4 2 2 1 3 1 0 0 NoAscomycin 3 1 YesAvermectin 4 2 1 1 4 0 1 0 YesBleomycin 1 1 YesBorrelidin 6 24 5 1 4 2 5 16 Yes
CFA 2 1 YesCompactin 1 1 YesEpothilone 4 2 0 0 6 0 1 0 Yes
Erythromycin 3 1 YesGeldanamycin 3 1 Yes
Lankacidin cplxLankamycin 3 1 YesLeinamycin 2 1 YesLovastatin 1 1 Yes
Megalomycin 3 1 YesMicrocystin 1 1 YesMonensin 8 720 10 1 3 0 720 0 NoMupirocin 3 cplx
Mycolactone 3 1 YesMyxalamid 5 6 0 0 8 0 3 2 Yes
Myxothiazol 3 1 Yesnanchangmycin 9 5040 13 1 2 480 240 4320 Yes
Niddamycin 5 6 4 1 3 1 3 2 YesNystatin 6 24 6 0 4 0 3 20 Yes
Oleandomycin 3 1 YesPederin 2 1 Yes
Pikromycin 4 2 3 0 3 0 0 1 YesPimaricin 5 6 6 0 2 0 1 4 Yes
Pyoluteorin 2 2 NoRapamycin 3 1 YesRifamycin 5 6 2 0 6 0 2 3 YesSoraphen 2 1 YesSpinosad 5 6 6 0 2 0 0 5 Yes
Stigmatellin 9 5040 2 5 9 768 1056 3216 YesTylactone 5 6 1 1 6 4 1 0 No
Vicenistatin 4 2 5 0 1 0 1 0 YesYersiniabactin 1 1 Yes
Cognate Non Cognate
ORF ORDER PREDICTION FOR PKS CLUSTERS

Naturally occurring peptides produced by NRPSs.

Substrates of NRPS

Acetyl Medium Long Coumarate Luciferase NRPSW H H I H F
* V * Y G D
T * * S F *
S G * S F *
Y * * P * *
G * * * A *
V G G G G G
G G G A G G
T A G G G *
W Y Y Y Y Y
W G G G G G
G P P P S V
* * * V A *
K
95%
K
83%
K
93%
K
92%
K
100%
K
95%
Consensus Active Site Patterns Of Six Subfamilies
* No consensus
Lys 517
Gly 324
3.02 Å
4.82 Å
Active site pattern
Specificity determining residues (SDR)

Products 22
ORFs 74
C 181
A 151
M 14
T 161
Te 22
NRPSDB
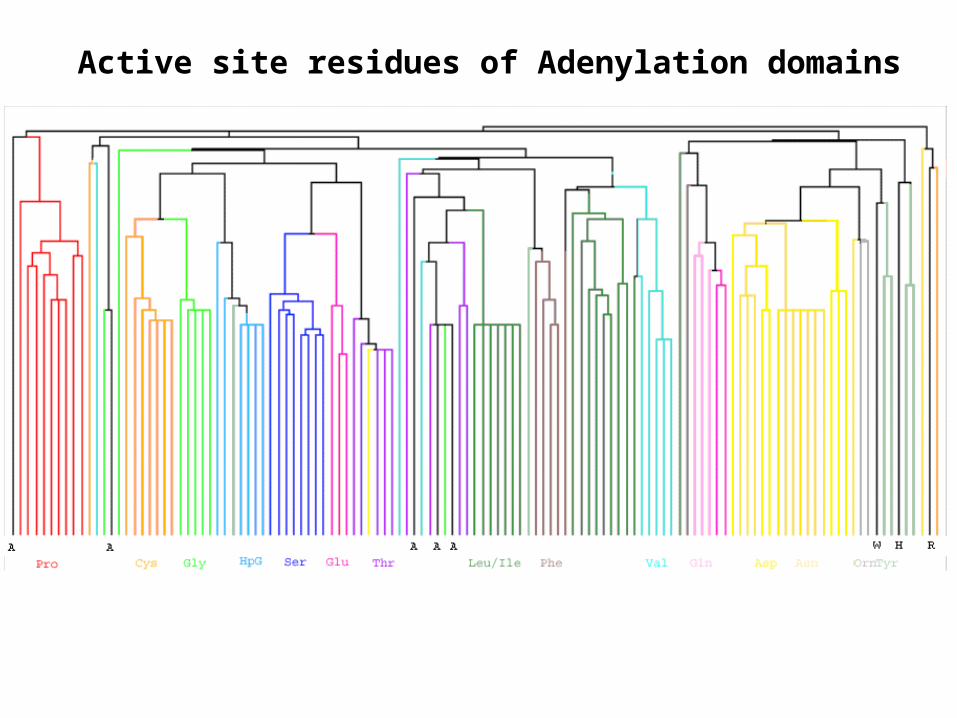
Active site residues of Adenylation domains

SEARCHNRPS
Ansari MZ, Yadav, G., Gokhale, R. S. and Mohanty, D. (2004) Nucl. Acids Res. 32:W405-13
.

Genetic algorithm for 250 runs. Grid size: 22.5 X 22.5 X 22.5 (Å)3Cluster rmsd :1.7ÅMajor cluster: 223Minor cluster: 27
How good are models at such low sequence homology ?
Crystal structure of the long chain CoA ligase (1V26)
Model of the same protein based on 1AMU
Ligand Rmsd = 2.3 Å 10/18

Glycosyltransferases (GT), enzymes that transfer sugars to other molecules.
R=nucleoside nucleoside monophosphate
R’ = Sugar, Lipid, Protein, DNA Secondary metabolites

K X calic1P Dallose tylo3A dehydrovancosamine balhi3A Lepivancosamine chlor3A Lvancosamine vanco1A Lvancosamine vanco3A Dglucose balhi2A Dglucose chlor2A Dglucose vanco2A Dglucose vanco4A NAcGlucosamine a40926.1A Nacetylglucosamine teico1A Nacetylglucosamine teico2A Ldehydrovancosamine balhi1A Lepivancosamine chlor1A Mannose a40926.2A mannose teico3F X avila4F X everni4F X avila2F X everni3F X avila3F X everni2J X nanch2H Dglucosamine butiroH X genta2H X tobra1H X genta1H X tobra2G 3OcarbamoylDmannose bleo2G Lgulose bleo1H Ldihydrostreptose streptoJ X nanch3O Dglucosamine mitoI Dglucose rebecC Dmycosamine amphoterC Dmycosamine nystaC mycosamine candiC Dmycosamine pimaC mycosamine ce108C mycosamine rimoP Lmycarose tylo2E LoleandrosylLolendrose avermK X calic2K X calic4K X calic3B X nogal3B Lrhamnose elloraT Ldigitoxose jadoQ Dfucofuranose gilvoF X everni1N Dolivose urdam1R angolosamine mederN Dolivose lando1N Dolivose lando5R Lrhodinose granaS X heda2L ChromoseAD chromo2S X heda1L DolivosylDolivose mithra3M Lnoviose novoM Lnoviose clorobioM Lnoviose coumerP TriOmethylrhamnose spino1N Dolivose lando2N Dolivose lando6N Dolivose lando4N Dolivose urdam3N Lrhodinose urdam4J 4OmethylLRhodinose nanch1D vicenisamine vicenB X aclaci1B daunosamine daunomyB X adriaB daunosamine daunoruB X aclaci2B X nogal2P Lmegosamine megalo3P Ddesosamine erythro2P Ddesosamine megalo2P Ddesosamine oleando1P Loleandrose oleando2P Dmycaminose tylo1P Ddesosamine methymycinP Ddesosamine pikroP Lmycarose erythro1P Lmycarose megalo1P Dforosamine spino2K sugar c1027N Lrhodinose urdam2N Lrhodinose lando3N Lrhodinose lando7L DolivosylDolivose mithra4B X nogal1F X avila1F X everni5L ChromoseAD chromo1L Doliose mithra2L Dolivose chromo3L Dolivose chromo4L Dolivose mithra1
Vancomycin group
Orthosomycin group
Aminoglycoside AB
Hybrid NRPS-PKS
Polyene macrolide AB
Enediyne group
Aminocoumarin AB
Angucycline AB
Anthracycline group
Macrolide group
Aureolic acid AB
GTr sequences cluster according to substrate specificity
Prediction accuracy = 77%

N-Domain
C-Domain
Linker
DVV and its binding residues
TYD and its binding residues
CGTDLMMLQMPPPELTGDDPYNTSGSDMLGKRVPRLQSAGVPGFMT
TRGELGSEVFHSGTVSRGEIGSEVHASGUA
1RRVBest MatchQuery
VVV
CTS
8
GGG
9
TTS
10
RRR
11
GGG
12
DDD
13
EEE
15
LIM
55
MML
59
MGG
60
LLK
61
QKR
62
MLV
65
PPP
66
PPR
67
PLL
68
EEQ
73
LKS
76
TSA
80
GGG
102
DDV
103
DPP
141
PKG
143
YYF
166
LLI
218
GGG
245
SSS
246
EEE
293
294
FFH
296
HGA
309
SSS
311
GGG
313
TTU
314
VLA
317
NNM
331
TTT
332
Acceptor Binding Residues
Donor Binding Residues
Identifying substrate (donor/acceptor) binding residues

MurG
GtfA
Benchmark the Prediction Accuracy
% identity ~ 20%
Correctly predicted approximately the same site and 50%
of the donor binding residues
C
C
GtfD
% identity ~ 55%
Correctly predicted the same site and 90% of the donor binding residues
C

Organization of SEARCHGTr and its backend database GTrDB
Kamra P, Gokhale RS and Mohanty D (2005) Nucl. Acids Res., In Press
amino acid

CAT Fold
O2NHC
OH
CH
NHO
CHCl3
O H3C C
O
S CoA
H2C
NNH
His
H
O2NHC
OH
CH
NHO
CHCl3
O CH3C
O
HS CoA
CAT
O R C
O
S CoA
H2C
NNH
His
H
O C HS CoA
CRAT
O
-O
N+H3C CH3
CH3
O
-O
N+H3C CH3
CH3
O
R
S
PCP 1
O
CHNH2
AA 1
S
PCP 2
O
CHNH2
AA 2
S
PCP 2
O
CHNH
AA 2 O
NH2
AA 1
C
S
PCP 1
O
CHNH2
AA 1
S
PCP 2
O
CHNH2
S
PCP 2
O
CHNH
O
NH2
AA 1
Cy
X H X H
S
PCP 2
O
CHN
X
NH2
AA 1
Cy
S
PCP 1
O
CNH2
AA 1H
ES
PCP 1
O
CNH2
AA 1H
R OH H3C C
O
S CoA CH3C
O
HS CoAR O
OH
OH
OH
R OH
CAT
NRPS
CRAT
BAHD
CH2)18(
O
(H2C)12
O
(H2C)12
OO
H3C
CH2)18(
OHHOH3CS
CH2)12(
O
ACP
SH
ACP
PapA5
O
SH S C
O
CH3
E2-Lys S CoA
H3C C
O
S CoA
O
SH SH
E2-Lys
H2C
NNH
His
E2
H
E2p
PREDICT STRUCTURAL FOLDAND CORRELATE WITH
KNOWN CHEMISTRY

NRPS Domains
ConD-XL-X
Cyc
Epi
BAHD
CRAT
CAT
NRPS
CAT Superfamily

MAS ACP(Homology Model)
PapA5(Crystal Structure)
Protein Docking
PapA5
WT R234E R312E
Identification of crucial residues involved in protein-protein interaction
Mutational studies of these crucial residues
Trivedi et. al. Mol. Cell. (2005) 17, 631-643

Acknowledgements
Gitanjali YadavMd. Zeeshan AnsariPankaj Kamra
Dr. Rajesh S. GokhaleChemical Biology Group
Dr. S.K. Basu, Director, NII
BTIS, DBT, India

Cinnamate CoumarateCaffeate
Ferulate Sinapate 3,4-DMC
Substrates of Coumarate CoA Ligases Coenzyme A
Coumarate CoALigase

Substrates of NRPS
Adenylation domain of NRPS
PCP Domain

Acetic acid
n ~ 4 - 8 : Medium chain fatty acid
n ~ 5 -11: Long chain fatty acidn > 11 : Very Long chain fatty acid
Coenzyme AFatty acid CoA
LigaseSubstrates of Fatty Acid CoA Ligases
Enzymic activation and transfer of fatty acids as acyl-adenylates in mycobacteria
Trivedi, O.A., Arora, P., Sridharan, V., Tickoo, R., Mohanty, D. and Gokhale, R.S. 2004 Nature 428:441.