unal: discriminating between literal and figurative phrasal usage using distributional statistics...
TRANSCRIPT

UNAL: Discriminating between Literal and Figurative Phrasal Usage Using Distributional
Statistics and POS tags
Alexander Gelbukh
Instituto PolitécnicoNacional, Mexico
(a participating system in the Evaluation “Phrasal Semantics”-“Semantic Compositionality in Context” TASK-5b)
Sergio Jimenez and Claudia Becerra

The Task (not a piece of cake)
FIGURATIVE “ Interoperability is easy . It 's a piece of cake! ”
LITERAL “You can come up if you want . You can have a piece of cake and a cup of coffee ”
BOTH Actual a piece of cake, whose mixing, baking anddecorating are a piece of cake.

Related Work
• [Lin, 1999]: fig. and lit. mentions have different distributional characteristics.
• [Kats and Geinsbrecht, 2006]: fig. and lit. mentions are correlated with the similarities of their contexts.
• [Fazly et al. 2009]: fig. and lit. usages are related to particular determiners, pluralizations and passivization froms.
• [Sporleder and Li, 2009]: lit. usages are more cohessive.

Our Approach
Machine learning approach using:• Cohesiveness Features
– A new simple measure of word-phrase relatedness– Pointwise Mutual Information
• Syntactic Features: NLTK POS tagger
• Stylistic Features: document length and relative position of the mention of the target phrase
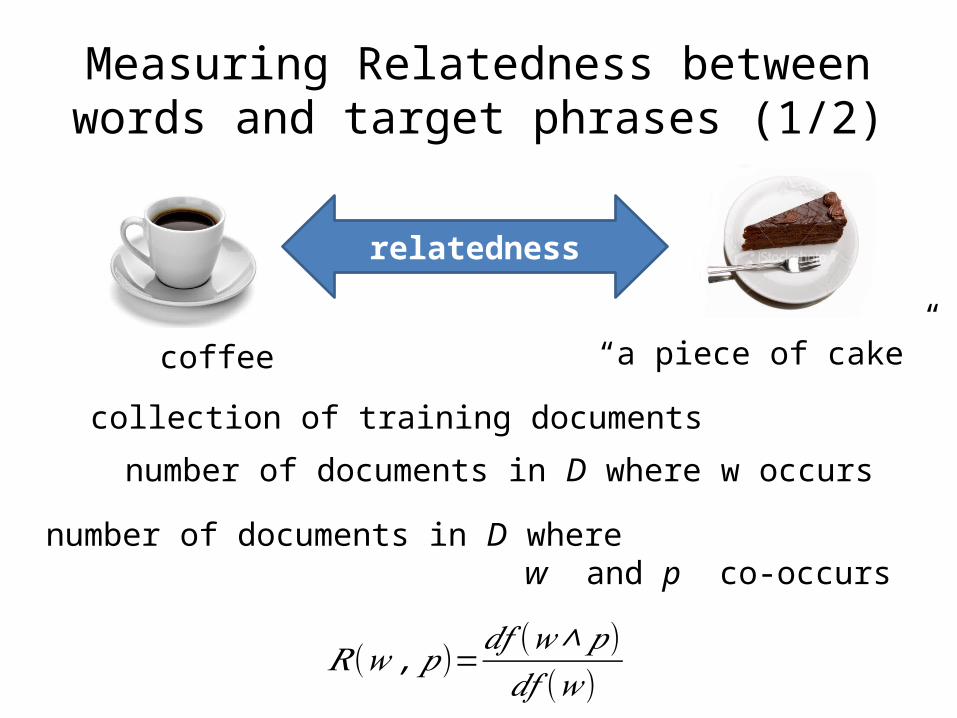
Measuring Relatedness between words and target phrases (1/2)
relatedness
coffee “a piece of cake”
collection of training documents
number of documents in D where w occurs
number of documents in D where w and p co-occurs
𝑅 (𝑤 ,𝑝)=𝑑𝑓 (𝑤∧𝑝)𝑑𝑓 (𝑤)

Measuring Relatedness between words and target phrases (2/2)
relatedness
coffee “a piece of cake”
Pointwise mutual information (PMI)
𝑃 (𝑤)≈𝑑𝑓 (𝑤)¿ 𝐷∨¿¿
𝑃𝑀𝐼 (𝑤 ,𝑝)=log 2( 𝑃 (𝑤∧𝑝)𝑃 (𝑤)⋅ 𝑃 (𝑝 ))
𝑃 (𝑝 )≈𝑑𝑓 (𝑝 )
¿𝐷∨¿¿𝑃 (𝑤∧𝑑)≈
𝑑𝑓 (𝑤∧𝑝)¿𝐷∨¿¿
𝑁𝑃𝑀𝐼 (𝑤 ,𝑝 )= 𝑃𝑀𝐼 (𝑤 ,𝑝 )− log2 (𝑃 (𝑤∧𝑝 ) )
+1

Cohesiveness Features (1/2)Features obtained by combining:
relatedness measure
point wise mutual information
normalized PMI
document term frequency
inverse document frequency
The probabilities and term weights were obtained from the training data for the task.

Cohesiveness Features (2/2)

Stylistic Features
0% 1% 2% 3% 4% 5% 6% 7% 8% 9% 10%
0.00
0.05
0.10
0.15
0.20
0.25
Approximate probability distributionsin training data
Figurative instancesLiteral instances
Relative position of the target phrase in the text

Syntactic Features
The features F25 to F67 correspond to the set of 43 part-of-speech (POS) tags of the NLTK English POS tagger [Loper and Bird, 2002]. Each feature contains the frequency of occurrence of each POS-tag in a document d.

System Description
• RUN1: 67 features combined with a logistic classifier [Cessie and Houwelingen, 1992] using WEKA.
• RUN2: 68 features, adding the target phrase as a nominal feature.

Feature Set Performance
Results for each group of features in the training set using 10-fold cross validation using a logistic classifier.

Official Results

Conclusions
• Cohesiveness and syntactic features showed to be effective for the task.
• The most-frequent-class baseline was overecame by 49.8% for “un-seen contexs” (LexSample) and by 8.5% in “un-seen phrases” (AllWords)

Soft Cardinality at *SEM and SemEval
• STS-2012, official 3th out of 89 systems• STS-2013-CORE task, 18th out of 90 systems (4th
un-official)• STS-2013-TYPED task, top-system UNITOR team• CLTE-2012, 3rd out of 29 systems (1st un-official)• CLTE-2013, among the 2-top systems• SRA-2013, among the 2-top systems
, , 1.3’