tti's gender prediction system using bootstrapping and identical-hierarchy mohammad golam...
TRANSCRIPT

TTI's Gender Prediction System using Bootstrapping and
Identical-Hierarchy
Mohammad Golam Sohrab
2015.05.20
Computational Intelligence Laboratory
Toyota Technological Institute

Outline
Introduction Original dataset
Session Augmentation Unique IDs Decomposing Identical-Hierarchy Context window
Text to vector representation Binary weighting
Bootstrapping approach2

Introduction
3
Training and Test Dataset A single product viewing log is composed of four columns
u10001,2014-11-14 00:02:14,2014-11-14 00:02:20,A00001/B00001/C00001/D00001/ u10001 Session ID 2014-11-14 00:02:14 session.startTime
! features 2014-11-14 00:02:20 session.endTime
! features A00001/B00001/C00001/D00001/ Unique ID
fetures
Training and Test Dataset 15,000 (labeled), 15,000(un-labeled)
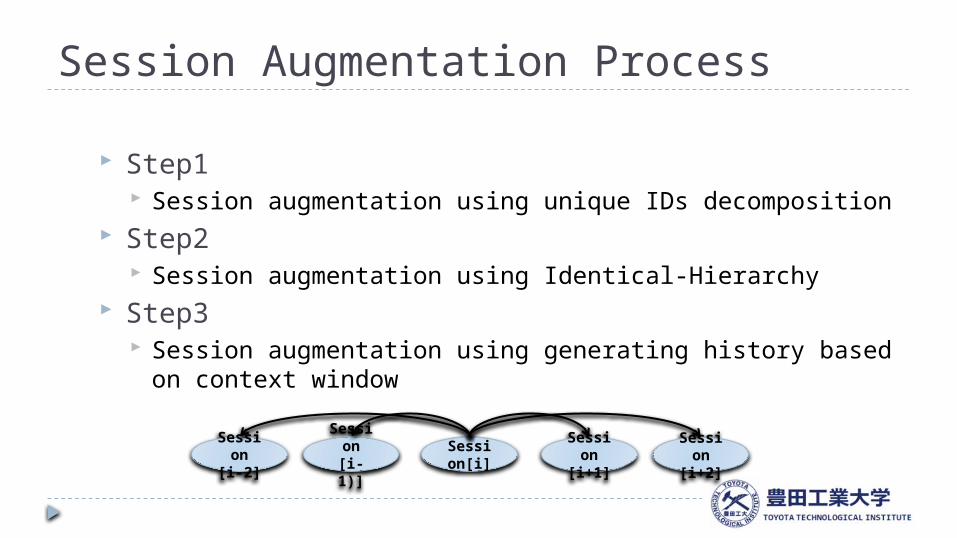
Session Augmentation Process
4
Step1 Session augmentation using unique IDs decomposition
Step2 Session augmentation using Identical-Hierarchy
Step3 Session augmentation using generating history based
on context window
Session[i-2]
Session[i-1)]
Session[i]
Session[i+1]
Session[i+2]

Session Augmentation: Unique IDs Decomposing
5
Recall: Training data u10001,2014-11-14 00:02:14,2014-11-14
00:02:20,A00001/B00001/C00001/D00001/
To generate text to vector representation Each Unique ID can be decomposed into features
using different combinations A00001/B00001/C00001/D00001
Uni-gram, Bi-gram, Tri-gram Unique

Unique IDs Decomposing (cont.)
6
Text to vector representation: Uni-gram A distribution of unique product IDs in the data is
decomposed into eight different features For each Unique ID
A00001/B00001/C00001/D00001 A00001, B00001, C00001, D00001, A00001-label, B0000l-
label, C00001-label, and D00001-label Adding more features

Session Augmentation: Identical-Hierarchy
7
First: Generate hierarchy A category hierarchy of
A000001/B000001/C000001/D000001
A00001 B00001B00001 C00001C00001 D00001

Second: Determining the Identical-Hierarchy
8
Identical categories The product IDs which are only appears in certain
category Compute the class space density in female category and Compute the class space density in male category
Identical-Hierarchy Is the complete parent- and child-list of a certain
identical category Identical-hierarchies are extracted from training data
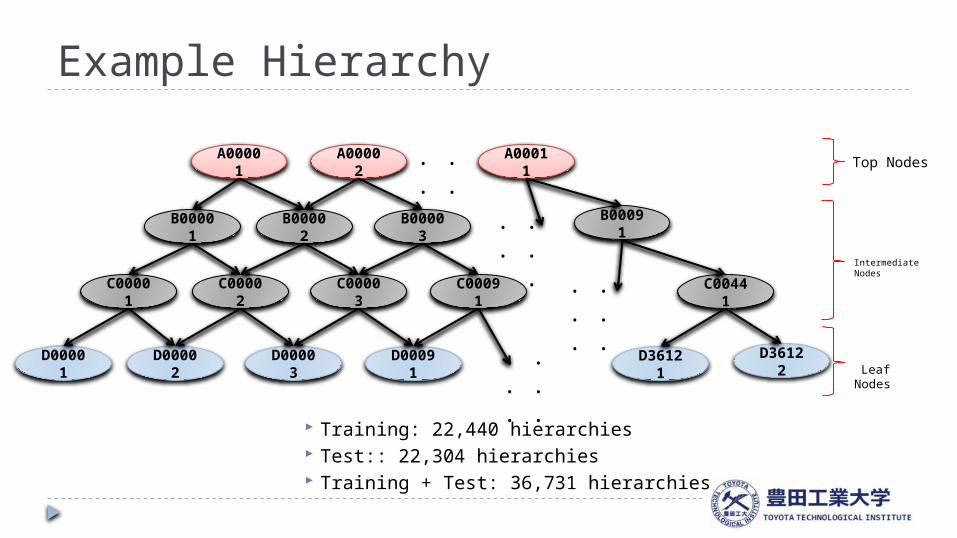
Example Hierarchy
9
A00001 A00002 A00011. . . . . .
B00001 B00002 B00003 . . . . . .
B00091
C00001 C00002 C00003 C00091 C00441. . . . . .
D00001 D00002 D00003 D00091 D36121. . . . . .
D36122 Leaf Nodes
Intermediate Nodes
Top Nodes
Training: 22,440 hierarchies Test:: 22,304 hierarchies Training + Test: 36,731 hierarchies

Session Augmentation: Identical-Hierarchy
10
Motivation Augment the training and test data with more
features Why???
Exchange info between training and test using identical-hierarchy How???

Analyze: Training Data based on hierarchy
11
A00001/B00001/C00001/D00001 A: Most General Categories
A00001 – A00011 (Appear: All, Missing: 0)
B: Sub-categories B00001 – B00091 (Appear: 86, Missing: 5)
C: Sub-subcategories C00001 – C00441 (Appear: 383, Missing: 58
D: Individual Products D00001 – D36122 (Appear: 21880, Missing: 14242)

Analyze: Test Data based on hierarchy
12
A00001/B00001/C00001/D00001 A: Most General Categories
A00001 – A00011 (Appear: All, Missing: 0) B: Sub-categories
B00001 – B00091 (Appear: 84, Missing: 7) C: Sub-subcategories
C00001 – C00441 (Appear: 392, Missing: 49) D: Individual Products
D00001 – D36122 (Appear: 21739, Missing: 14383)

Building Combined Hierarchy: Training + Test
13
A00001/B00001/C00001/D00001 A: Most General Categories
A00001 – A00011 (Appear: All, Missing: 0)
B: Sub-categories B00001 – B00091 (Appear: 91, Missing: 0)
C: Sub-subcategories C00001 – C00441 (Appear: 440, Missing: 1)
D: Individual Products D00001 – D36122 (Appear: 36092, Missing: 30)
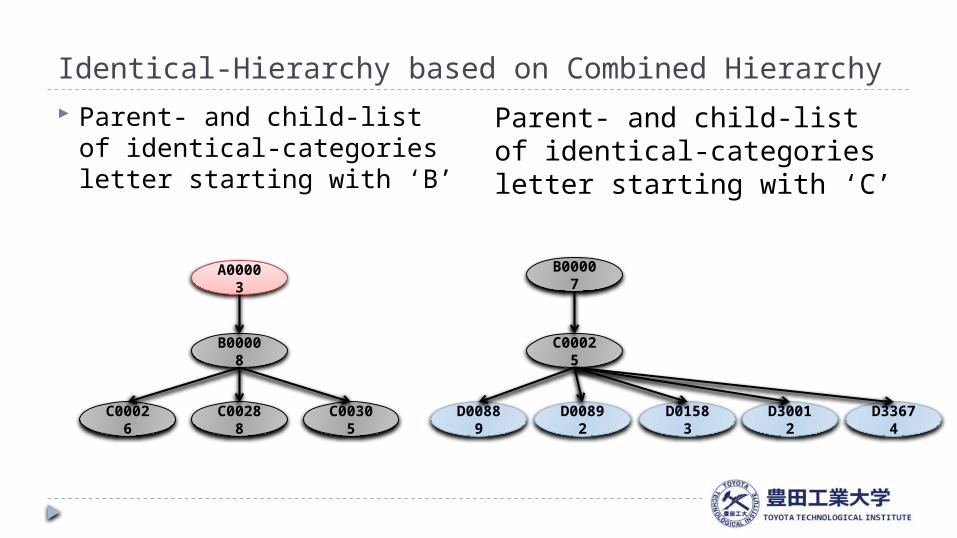
Identical-Hierarchy based on Combined Hierarchy Parent- and child-list
of identical-categories letter starting with ‘B’
Parent- and child-list of identical-categories letter starting with ‘C’
A00003
B00008
C00026 C00288 C00305
B00007
C00025
D00889 D00892 D01583 D30012 D33674
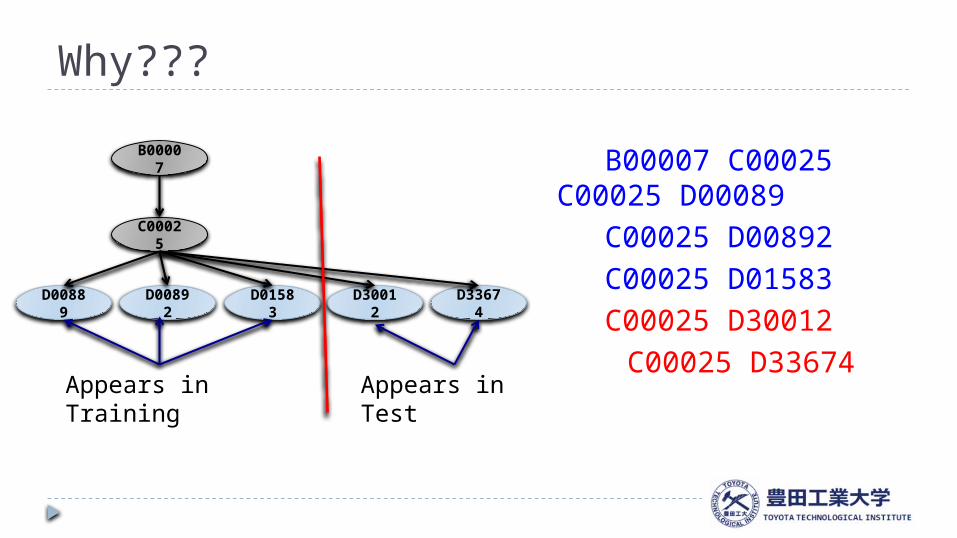
Why???
15
B00007 C00025C00025 D00089C00025 D00892 C00025 D01583 C00025 D30012
C00025 D33674
B00007
C00025
D00889 D00892 D01583 D30012 D33674
Appears in Training
Appears in Test

Adding Identical Categories from ‘B’
16
A00003/B00008/C000026/D00070 Extract parent- and child-list from hierarchy based on Identical-Hierarchy
A00003 B00008= B00008 C00026B00008 C00288 B00008 C00305
A00003/B00008/C000026/D00070;C00288/C00305
A00003
B00008
C00026 C00288 C00305
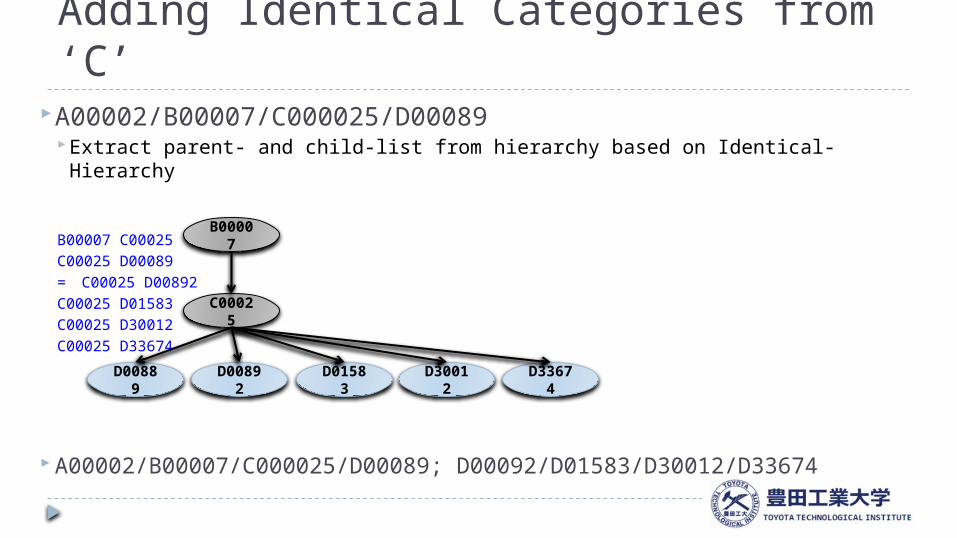
Adding Identical Categories from ‘C’
17
A00002/B00007/C000025/D00089 Extract parent- and child-list from hierarchy based on Identical-Hierarchy
B00007 C00025C00025 D00089= C00025 D00892 C00025 D01583 C00025 D30012C00025 D33674
A00002/B00007/C000025/D00089; D00092/D01583/D30012/D33674
B00007
C00025
D00889 D00892 D01583 D30012 D33674
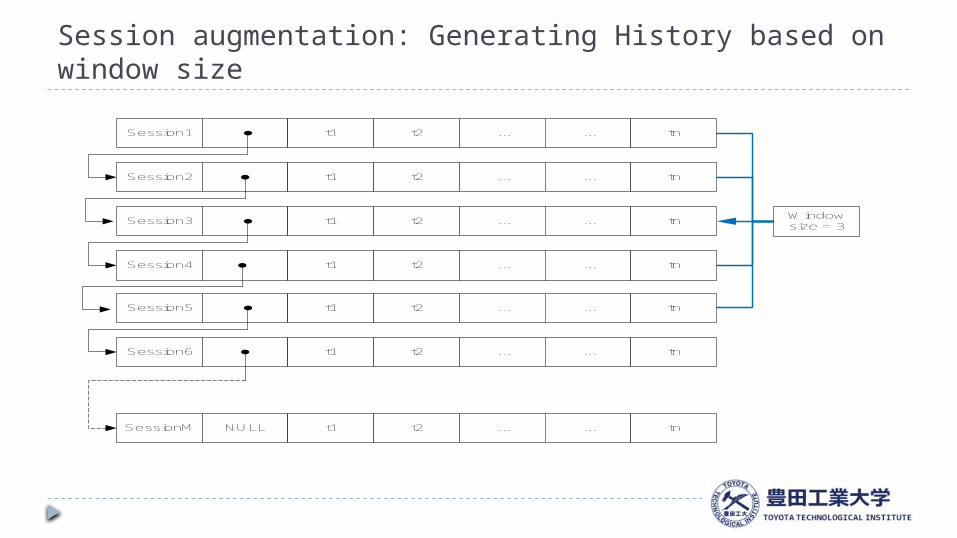
Session augmentation: Generating History based on window size
18
Session1 t1 t2 ... ... tn
Session2 t1 t2 ... ... tn
Session3 t1 t2 ... ... tn
Session4 t1 t2 ... ... tn
Session5 t1 t2 ... ... tn
Session6 t1 t2 ... ... tn
SessionM NULL t1 t2 ... ... tn
Window size = 3

Generating History: Set window size = 3
19
Current Session: curSession.prevSession.endTime < curSession.startTime
Build History curSession.endTime < curSession.nextSession.startTime
Build History
Session1 Start Time End Time Unique ID
Session2 Start Time End Time Unique ID
Session3 Start Time End Time Unique ID
Session4 Start Time End Time Unique ID
Session5 Start Time End Time Unique ID
Session6 Start Time End Time Unique ID
SessionM NULL Start Time End Time Unique ID
Window size = 3

Session Augmentation: Pros and Cons
20
Pros: Generate text to vector for a certain session
uniformly Increase feature size Increase the system performance
Cons It increase the system computational time

Term Weighting
21
Different Weighting approaches Term frequency (TF) TF.IDF
IDF Inverse Document Frequency TF.IDF.ICSdF
ICSdF Inverse Category Space Density Frequency

Term Weighting: Applied
22
Binary Weighting Approach
Normalize the session

Bootstrapping: The Basic Idea
23
Bootstrapping is the process of re-sampling method to estimating the precision of sample by using subsets of available data. In the re-sampling process exchanging labels on
data points when performing significant test.

Bootstrapping process
24
Perform 4-iteration for re-sampling the data If first_iteration
Input: Training data (15000) 10-fold cross validation
9-fold for training data 1-fold for development data
Build Training model
Provide Test data (15000) Predict labels

Bootstrapping process (cont.)
25
If !first_iteration Input: Training + Test (30000)
Assign labels Training: Gold labels Test: Predicted labels
10-fold cross validation 9-fold for training data 1-fold for development data
Build Training model
Provide Test data (15000) New predicted labels

Classification: LIBLINEAR
26
LIBLINEAR is a simple package for solving large-scale regularized linear classification Option parameters:
-s 1 L2-regularized L2 loss support vector classification
-c 1 -B 1 -wi weight: set the parameter C of class i to weight*C
nfemale/nmale

Results: Bootstrapping Approach with LIBLINEAR
27
Iteration 0 Mean Accuracy: 0.960156
Accuracy for (female, male) = 0.966761, 0.953551
Iteration1 Mean Accuracy: 0.966785
Accuracy for (female, male) = 0.967530, 0.966040
Iteration 2 Mean Accuracy: 0.966834
Accuracy for (female, male) = 0.967188, 0.966480
Iteration 3 Mean Accuracy: 0.967122
Accuracy for (female, male) = 0.967444, 0.966800
Iteration 4 Mean Accuracy: 0.967122
Accuracy for (female, male) = 0.967444, 0.966800 (Remain unchanged)

Final Results: Bootstrapping Approach with LIBLINEAR
28
Predicted Labels using Bootstrapping Using submission system
85.47% Final Result
85.103191%

Summary
29
In this work Session augmentation
Identical-Hierarchy Generating conditional history using context window
Term weighting Binary weighting
Re-sampling process Bootstrapping
Classification problem SVM classifier

!!! Thank you !!!
30