treatment and analysis of data – applied statistics ...lennart/statistics2.pdf · e.t. jaynes,...
TRANSCRIPT

Sept-Oct 2006 Statistics for astronomers (L. Lindegren, Lund Observatory) Lecture 2, p. 1
Treatment and analysis of data – Applied statisticsLecture 2: Probability theory
Topics covered:
What is probability?
Classical probability theory
Probability theory as plausible reasoning
Probability distributions
Expectation and variance again
The Central Limit Theorem
The normal distribution
Some other important distributions
Multidimensional distributions
Marginal and conditional probability
Bayes’ theorem
Sept-Oct 2006 Statistics for astronomers (L. Lindegren, Lund Observatory) Lecture 2, p. 2
What is probability?
There are basically two schools of thought on the interpretation of “probability”:
1. The traditional or frequentist interpretation is that one can only talk about probabilities when dealing with well-defined random experiments;
2. The Bayesian interpretation is that probabilities can be assigned to any statement, even if no random process is involved, as a way to quantify subjective plausibility.
The controversy between “frequentism” and “Bayesianism” is at least 200 years old (although these terms are much younger), and still unresolved. A pragmatic view is to accept both viewpoints depending on the context.Examples that may or may not make sense to a frequentist:
1. The probability for “head” up when flipping this coin is 0.55
2. The probability that it will rain tomorrow is 0.2
3. The probability that this star belongs to the cluster is 0.05
4. The probability that Jupiter has a solid core is 0.9
5. The probability that the 10100th decimal of π is 0, is 0.1
Note: The term “Bayesian” derives from the reverend Thomas Bayes (1702−1761), who formulated Bayes’ theorem, a simple formula in classical probability theory that plays a central role in Bayesian reasoning. More about that later.

Sept-Oct 2006 Statistics for astronomers (L. Lindegren, Lund Observatory) Lecture 2, p. 3
Classical probability theory
Textbooks on probability theory usually start with a highly technical description based on set theory, introducing concepts such as:
sample space (Ω): the set of all possible outcomes of a random experiment
event: any subset of Ω
an associated Borel field (or σ–field) B: a collection of events including Ø and the union and complement of any other event in B
a probability measure P: a function mapping B onto the real numbers [0,1] such that
P(Ø) = 0 and P(Ω) = 1
if A1, A2, ... are disjoint events in B, then P(A1 ∪ A2 ∪ ...) = P(A1) + P(A2) + ...
This axiomatic approach, due to Andrey Kolmogorov (1933), provides a strict mathematical foundation for the theory of probability.
Note however that the assignment of probability to different events is left open(except for Ø and Ω) – the different outcomes need not have equal probability! The rules only guarantee that the probabilities are mutually consistent.
Sept-Oct 2006 Statistics for astronomers (L. Lindegren, Lund Observatory) Lecture 2, p. 4
Probability theory as the rules for consistent reasoning
In the spirit of Laplace’s statement, Keynes (1929), Jeffreys (1939), Cox (1946), Jaynes (2003), and others have investigated the quantitative rules of “common sense”, or plausible reasoning. Starting from three basic assumptions:
1. Degrees of plausibility are represented by real numbers
2. There should be qualitative correspondence with common sense (for example, if A ⇒ B, and B is seen to be true, then this increases the plausibility of A)
3. Logical consistency: If a conclusion can be reasoned out in more than one way, then every possible way must lead to the same result
it is found that the degree of plausibility must obey the rules of probability, as derived from Kolmogorov’s axioms.
Thus probability theory provides a sound basis for plausible reasoning, even without its underlying concepts (random experiments, sample space, etc).
Probability theory is nothing but common sense reduced to calculation.Pierre Simon de Laplace (1819)

Sept-Oct 2006 Statistics for astronomers (L. Lindegren, Lund Observatory) Lecture 2, p. 5
Example: The value of G
What is the precise meaning of the statement G = 6.6742 ± 0.0010 (standard error)
from a probabilistic viewpoint?
NIST = National Institute of Standards and Technology (physics.nist.gov)
Sept-Oct 2006 Statistics for astronomers (L. Lindegren, Lund Observatory) Lecture 2, p. 6
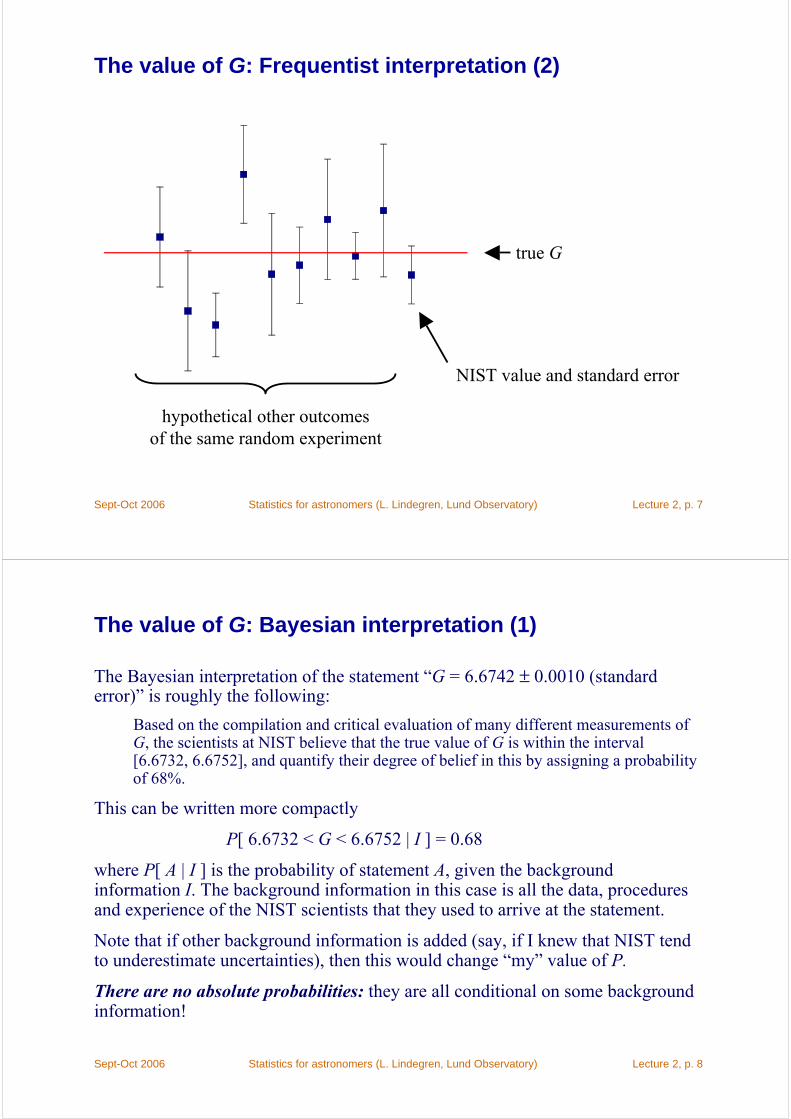
The value of G: Frequentist interpretation (1)
The frequentist’s interpretation of the statement “G = 6.6742 ± 0.0010 (standard error)” is roughly the following:
The many different measurements of G performed by laboratories around the world, as well as NIST’s compilation and critical evaluation of these measurements, essentially constitute a random experiment whose single known outcome is the estimated value (6.6742) and standard error (0.0010) calculated by NIST, or, equivalently, the 68% confidence interval [6.6732, 6.6752]. If the experiment could be repeated many times, it would in general give a different such confidence interval each time. In the long run, the resulting confidence interval would include the true value of G in 68% of the experiments.
Note that this is not the same as:
With 68% probability, the interval [6.6732, 6.6752] includes the true value of G.
This latter interpretation does not make sense to a frequentist, because there is no random element involved (the true G is either inside the interval or not).
Sept-Oct 2006 Statistics for astronomers (L. Lindegren, Lund Observatory) Lecture 2, p. 7
The value of G: Frequentist interpretation (2)
true G
NIST value and standard error
hypothetical other outcomesof the same random experiment
Sept-Oct 2006 Statistics for astronomers (L. Lindegren, Lund Observatory) Lecture 2, p. 8
The value of G: Bayesian interpretation (1)
The Bayesian interpretation of the statement “G = 6.6742 ± 0.0010 (standard error)” is roughly the following:
Based on the compilation and critical evaluation of many different measurements of G, the scientists at NIST believe that the true value of G is within the interval [6.6732, 6.6752], and quantify their degree of belief in this by assigning a probability of 68%.
This can be written more compactly
P[ 6.6732 < G < 6.6752 | I ] = 0.68
where P[ A | I ] is the probability of statement A, given the background information I. The background information in this case is all the data, procedures and experience of the NIST scientists that they used to arrive at the statement.
Note that if other background information is added (say, if I knew that NIST tend to underestimate uncertainties), then this would change “my” value of P.
There are no absolute probabilities: they are all conditional on some background information!

Sept-Oct 2006 Statistics for astronomers (L. Lindegren, Lund Observatory) Lecture 2, p. 9
The value of G: Bayesian interpretation (2)
degree of belief
true value
standard error (σ)
estimatedvalue
with 95.4% probability, the true value is within ±2σ
with 68.3% probability, the true value is within ±1σ
In the absence of any more specific information (other than just the estimated value and standard error), a Gaussian distribution must be assumed assumed.
Sept-Oct 2006 Statistics for astronomers (L. Lindegren, Lund Observatory) Lecture 2, p. 10
Frequentism versus Bayesianism
Knowing both standpoints and practices is important, because
it helps to understand what probability is
it is necessary to interpret published results correctly
it helps to formulate your own conclusions correctly
For the Bayesian viewpoint, see:
E.T. Jaynes, Probability Theory – The Logic of Science, Cambridge University Press (2003), 727 pp
A magnificent account of probability theory as the rules for plausible reasoning, by an outspoken Bayesian. Very readable and thought-provoking, but sometimes a bit heavy.
D.S. Sivia, Data Aanalysis – A Bayesian Tutorial, Oxford University Press (1996), 189 pp.
The practical companion to Jaynes’ book for scientists and engineers doing data analysis. Explains parameter estimation, probability models and hypothesis testing in a strictly Bayesian framework but very down-to-earth and with many examples.

Sept-Oct 2006 Statistics for astronomers (L. Lindegren, Lund Observatory) Lecture 2, p. 11
Cumulative distribution function (cdf)
A probability distribution specifies
the assignment of probability measures to the possible values of a random variable X(this is the classical, or frequentist, definition)
the assignment of the different degrees of plausibility to the different values of a quantity X (this is the Bayesian definition)
In either case, X may be one- or multi-dimensional, discrete or continuous.
For one-dimensional X, the cumulative distribution function (cdf)
F(x) = P[X ≤ x] (in the Bayesian case we should write F( x | I ) = P[ X ≤ x | I ])
(This is also called the probability distribution function, but this term should be avoided because of the potential confusion with probability density function, abbreviated pdf.)
For n-dimensional X = (X1, X2, ..., Xn) we have the n-dimensional cdf
F(x) ≡ F(x1, x2, ..., xn) = P[ X1 ≤ x1 ∧ X2 ≤ x2 ∧ ... ∧ Xn ≤ xn] (∧ = and)
Sept-Oct 2006 Statistics for astronomers (L. Lindegren, Lund Observatory) Lecture 2, p. 12
Cumulative distribution function (cdf), illustrations
xy
0
1
2D, continuous
x
x
0
0
1
1
1D, continuous
1D, discrete
F(x)
F(x)
F(x, y)
WARNING: Multi-dimensional cdf are conceptually and mathematically tricky. Avoid using them if possible!

Sept-Oct 2006 Statistics for astronomers (L. Lindegren, Lund Observatory) Lecture 2, p. 13
Probability density function (pdf)
For the one-dimensional cdf F(x) we have if a < b
P[a < X ≤ b] = F(b) – F(a)
For any Δx > 0 we therefore have
P[x < X ≤ x + Δx] = F(x + Δx) – F(x)
If F(x) is continuous we define the probability density function (pdf)
f (x) = dF(x)/dx
which can be interpreted as P[x < X ≤ x + dx] = f (x) dx .
In the multi-dimensional case,
f (x1, x2, ..., xn) = dnF(x1, x2, ..., xn)/dx1dx2...dxn
Sept-Oct 2006 Statistics for astronomers (L. Lindegren, Lund Observatory) Lecture 2, p. 14
Probability mass function (pmf)
For a discrete variable x, the “jumps” in F(x) at certain values correspond to the probabilities of these values:
P[X = x] = F(x) – F(x−)
The function f (x) = P[X = x] is called the probability mass function (pmf) of X.
x0
1
F(x)
x0.0
0.2
0.4
f (x)
cdf pmf

Sept-Oct 2006 Statistics for astronomers (L. Lindegren, Lund Observatory) Lecture 2, p. 15
Cdf more general than pdf or pmf
x0.0
0.2
0.4
f (x)pmf
x0
1
F(x)
cdf
x0
1
F(x)
cdf f (x)
0.0
0.1
0.2
0.3
x
identical information
identical information
Sept-Oct 2006 Statistics for astronomers (L. Lindegren, Lund Observatory) Lecture 2, p. 16
Expectation again

Sept-Oct 2006 Statistics for astronomers (L. Lindegren, Lund Observatory) Lecture 2, p. 17
Variance again
Sept-Oct 2006 Statistics for astronomers (L. Lindegren, Lund Observatory) Lecture 2, p. 18
Recall: The mean converges to the expectation
0.0
0.5
1.0
ξn
1 10 100 1000 10,000 100,000
Three series of “tossing a coin” 100,000 times
n

Sept-Oct 2006 Statistics for astronomers (L. Lindegren, Lund Observatory) Lecture 2, p. 19
Recall: Deviation of the mean from the expectation × √n
0
2
(ξn−ξ)×√n
1 10 100 1000 10,000 100,000
Three series of “tossing a coin” 100,000 times
n
1
-1
-2
Sept-Oct 2006 Statistics for astronomers (L. Lindegren, Lund Observatory) Lecture 2, p. 20
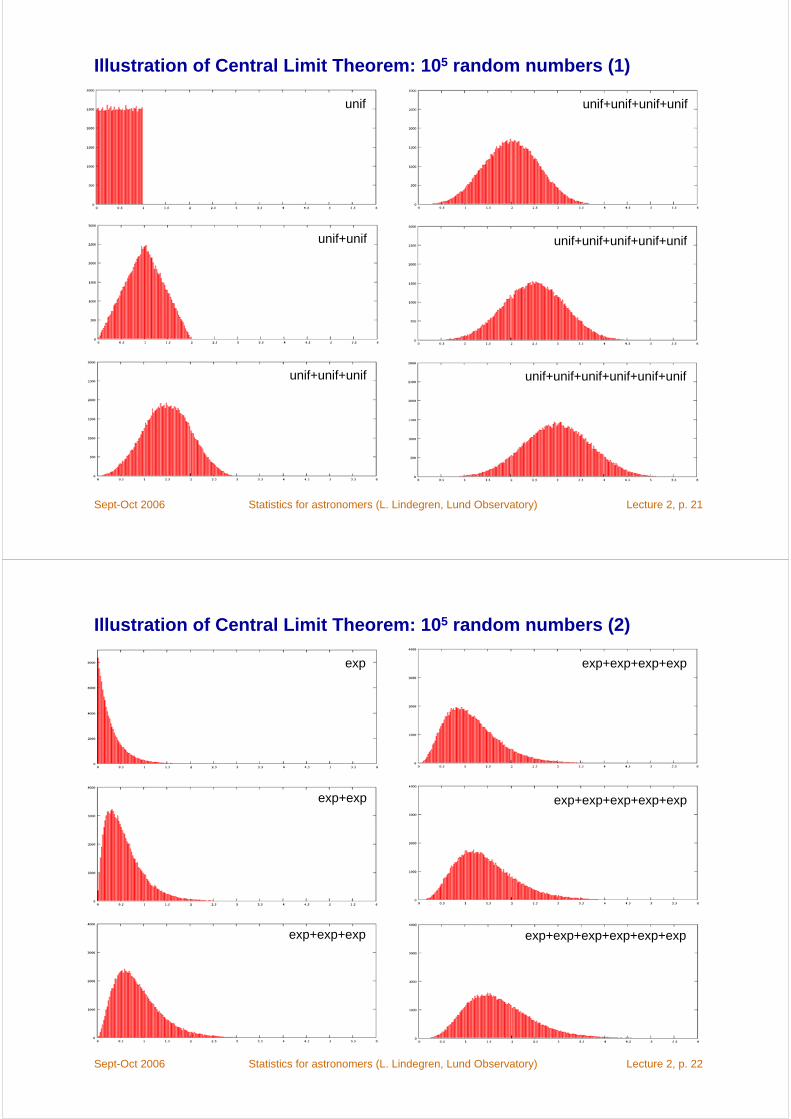
The Central Limit Theorem
Assuming that E[X] = ξ and Var[X] < ∞, we have
where N(0,1) is the standard normal (or Gaussian) distribution (mean = 0, variance = 1).
Roughly speaking, we can also express this as
(1)
where ~ means “is distributed as” and N(μ , σ 2) is the normal distribution with mean value μ and variance σ 2.
Note that (1) is a limiting distribution for large n. However, if X itself has the normal distribution, then it is valid also for small n (including n = 1)!
The Central Limit Theorem:The limiting distribution of (ξn − ξ) n1/2 is N(0,1)
Sept-Oct 2006 Statistics for astronomers (L. Lindegren, Lund Observatory) Lecture 2, p. 21
Illustration of Central Limit Theorem: 105 random numbers (1)
unif
unif+unif+unif+unif+unif+unif
unif+unif+unif+unif+unif
unif+unif+unif+unif
unif+unif+unif
unif+unif
Sept-Oct 2006 Statistics for astronomers (L. Lindegren, Lund Observatory) Lecture 2, p. 22
Illustration of Central Limit Theorem: 105 random numbers (2)
exp
exp+exp+exp+exp+exp+exp
exp+exp+exp+exp+exp
exp+exp+exp+exp
exp+exp+exp
exp+exp

Sept-Oct 2006 Statistics for astronomers (L. Lindegren, Lund Observatory) Lecture 2, p. 23
The normal distribution (1)
Sept-Oct 2006 Statistics for astronomers (L. Lindegren, Lund Observatory) Lecture 2, p. 24
The normal distribution (2)
The normal or Gaussian “law” cannot be “proved” either way. Most practical experience shows that errors tend to follow the normal law to some approximation, but that large errors are often much more common than predicted by the normal law. But nobody has been able to come up with a more useful, universal law...
The practical and theoretical importance of the normal distribution seems to be related to the following properties:
1. Its connection to the arithmetic mean (it is the unique distribution for which the arithmetic mean is the best estimate in the sense of minimizing the variance) and more generally to the method of least squares – thus, it is computationally expedient to assume the normal law.
2. Given the first two moments of a distribution (or equivalently the mean value μ and standard deviation σ), the normal distribution N(μ, σ2) has the largest entropy of all distributions. Thus, if nothing more is known about the distribution, N(μ, σ2) provides the most honest description of our state of knowledge (according to the principle of maximum entropy).
Everyone believes in the normal law, the experimenters because they imagine it is a mathematical theorem, and the mathematicians because they think it is an experimental fact.
Gabriel Lippmann, cited in Poincaré’s Calcul des probabilités (1896)

Sept-Oct 2006 Statistics for astronomers (L. Lindegren, Lund Observatory) Lecture 2, p. 25
The normal distribution (3)
Comments to the previous slide:
1. Suppose we observe x1, x2, ..., xn assumed to follow the distributionsf1(x | θ), f2(x | θ), ..., fn(x | θ) depending on some unknown parameter θ.
Gauss (1809) calculated the “most probable value” of θ by finding the maximum of the product L(θ) = f1(x | θ)× f2(x | θ)×...× fn(x | θ) and showed that the resulting estimate is the arithmetic mean (x1 + x2 +...+ xn) /n iff each fi(x | θ) is N(θ, σ2) (with the same σ). This estimation method is today known as the maximum likelihood method, and L(θ) is called the likelihood function. For normal fi(x | θ) and multidimensional θ it leads to the least-squares method.
2. The entropy of the distribution f (x) is defined as
in the discrete and continuous case, respectively. (The integral is not the limiting form of the sum.)
( ) ( ) xxfxfxfxfHx
d)(ln)()(ln)( ∫∑+∞
∞−−=−=
Sept-Oct 2006 Statistics for astronomers (L. Lindegren, Lund Observatory) Lecture 2, p. 26
The normal distribution (4)
Some properties of the normal distribution or Gaussian function (Jaynes, 2003):
A. Any smooth function with a single rounded maximum, if raised to higher and higher powers, goes into a Gaussian function.
B. The product of two Gaussian functions is another Gaussian function.
C. The convolution of two Gaussian functions is another Gaussian function.
D. The Fourier transform of a Gaussian function is another Gaussian function.
E. A Gaussian probability distribution has higher entropy than any other with the same variance.
The 2D standard normal distribution f (x, y) = (2π)−1 exp[−(x2+y2)/2] has some other interesting properties:
1. It can be factored as f (x) f (y) where f (x) is the standard normal distribution;
2. It is invariant under rotation, since it only depends on radius r = (x2+y2)1/2;
3. While many distributions have either property 1 or 2, only the 2D normal distribution has both properties (cf. the Herschel-Maxwell derivation)

Sept-Oct 2006 Statistics for astronomers (L. Lindegren, Lund Observatory) Lecture 2, p. 27
Some important distributions: Discrete distributions
Binomial distribution: k ~ Binom(n, p) is the number of successes in a sequence of n independent yes/no experiments, each of which yields success with probability p.
Probability mass function:
(k = 0, 1, ..., n)
E(k) = np
Var(k) = np(1−p)
(Source: en.wikipedia.org)
n = 10, p = 0.3
Sept-Oct 2006 Statistics for astronomers (L. Lindegren, Lund Observatory) Lecture 2, p. 28
Some important distributions: Discrete distributions
Poisson distribution: k ~ Pois(λ) is the number of events occurring in a fixed time if these events occur with a known average rate (λ per time interval), and are independent of the time since the last event.
Probability mass function:
(k = 0, 1, ... ∞)
E(k) = λ
Var(k) = λ
(Source: en.wikipedia.org)

Sept-Oct 2006 Statistics for astronomers (L. Lindegren, Lund Observatory) Lecture 2, p. 29
Some important distributions: Continuous distributions
Beta distribution: x ~ Beta(α, β), where α > 0 and β > 0, is a continuous distribution on the interval [0,1] that takes a variety of shapes depending on the parameters α and β.
Probability density function:
(0 ≤ x ≤ 1)
E(x) = α/(α+β)
Var(x) = αβ/[(α+β)2(α+β+1)]
α = β = 1 gives the uniformdistribution.
(Source: en.wikipedia.org)
Sept-Oct 2006 Statistics for astronomers (L. Lindegren, Lund Observatory) Lecture 2, p. 30
Some important distributions: Continuous distributions
Normal distribution: x ~ N(μ, σ2) is the most important distribution in the family of location-scale distributions (μ is the location, σ is the scale).
Probability density function:
(−∞ < x < +∞)
E(x) = μ
Var(x) = σ2
(Source: en.wikipedia.org)

Sept-Oct 2006 Statistics for astronomers (L. Lindegren, Lund Observatory) Lecture 2, p. 31
Some important distributions: Continuous distributions
Log-normal distribution: x ~ Log-N(μ, σ2) is the distribution of a positive variable whose natural logarithm has the normal distribution N(μ, σ2).
Probability density function:
(0 ≤ x < ∞)
E(x) = exp(μ+σ2/2)
Var(x) = [exp(σ2)−1]exp(2μ+σ2)
(Source: en.wikipedia.org)
Sept-Oct 2006 Statistics for astronomers (L. Lindegren, Lund Observatory) Lecture 2, p. 32
Some important distributions: Continuous distributions
Chi-square distribution: x ~ χ k2 is the distribution of the sum of the squares of k
independent standard normal variables. k is called the number of degrees of freedom.
Probability density function:
(0 ≤ x < ∞)
E(x) = k
Var(x) = 2k
(Source: en.wikipedia.org)

Sept-Oct 2006 Statistics for astronomers (L. Lindegren, Lund Observatory) Lecture 2, p. 33
Some important distributions: Continuous distributions
Exponential distribution: x ~ Exponential(λ) is the distribution of the time between independent events that happen at a constant average rate λ.
Probability density function:
(0 ≤ x < ∞)
E(x) = λ−1
Var(x) = λ−2
(Source: en.wikipedia.org)
Sept-Oct 2006 Statistics for astronomers (L. Lindegren, Lund Observatory) Lecture 2, p. 34
Some important distributions: Continuous distributions
Student’s t-distribution (or the t-distribution): this arises in the study of the mean of normal variables when the sample size is small (see hypothesis testing). It depends on a single parameter ν called the number of degrees of freedom.
Probability density function:
(−∞ < t < +∞)
E(t) = 0 (for ν > 1)
Var(t) = ν/(ν−2) (for ν > 2)
For ν = 1 it is a Cauchy distribution.
For ν = ∞ it is a standard normal distribution.
(Source: en.wikipedia.org)
(ν)
Sept-Oct 2006 Statistics for astronomers (L. Lindegren, Lund Observatory) Lecture 2, p. 35
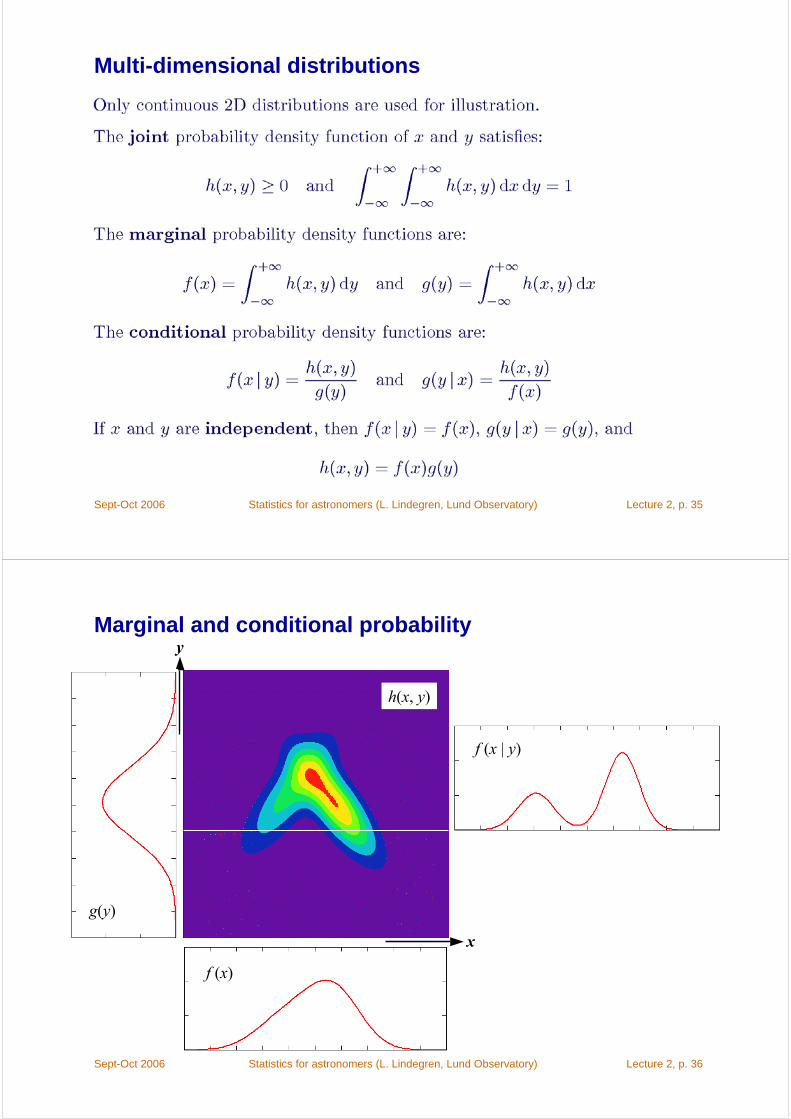
Multi-dimensional distributions
Sept-Oct 2006 Statistics for astronomers (L. Lindegren, Lund Observatory) Lecture 2, p. 36
Marginal and conditional probability
x
y
h(x, y)
g(y)
f (x)
f (x | y)

Sept-Oct 2006 Statistics for astronomers (L. Lindegren, Lund Observatory) Lecture 2, p. 37
Conditional expectation and covariance
Sept-Oct 2006 Statistics for astronomers (L. Lindegren, Lund Observatory) Lecture 2, p. 38
Bayes’ theorem