towards semantic apis for research data services (invited talk)
TRANSCRIPT

CLICK TO EDIT MASTER TITLE STYLE
Towards Semantic APIs for Research Data Services
Anna Fensel
© Copyright 2016 | www.sti-innsbruck.at
22.06.2016
Metadata e-infrastructures workshop @ University of Vienna, Austria

• Motivation and Introduction to Research Data Service (RDS)• Modeling RDS• Managing and programming RDS• Disseminating RDS• Conclusions
Outline
2016 www.sti-innsbruck.at 2

• Motivation and Introduction to Research Data Service (RDS)• Modeling RDS• Managing and programming RDS• Disseminating RDS• Conclusions
Outline
2016 www.sti-innsbruck.at 3

• Acceptance of the open science* principle entails open access not only to research data but also to tools that allow researchers to perform various types of activities over these data including mining, visualization, and analysis.
• Research Data Services (RDSs) enable researchers to conduct efficiently and effectively their research activities.
• One of the challenges faced by researchers, in a globally networked scientific world, is to be able to locate RDSs that fulfill their research needs. By Research Data Service Discoverability we mean the capability of automatically locating research data services that fulfill a researcher goal.
• Making a RDS discoverable should enables the service (re-)use.
* https://ec.europa.eu/digital-single-market/en/open-science
Motivation
2016 www.sti-innsbruck.at 4

Research Data Service (RDS):•is a subclass of Service in a general sense (it has a service provider and service consumer, added value,…),•is a data service, part of data economy,•applicable in scenarios implementing some part of research process,•may be delivered by a program/IT system, but also via other means e.g. a human.
What is a “Research Data Service”?
2016 www.sti-innsbruck.at 5
Wikipedia: Research comprises "creative work undertaken on a systematic basis in order to increase the stock of knowledge, including knowledge of humans, culture and society, and the use of this stock of knowledge to devise new applications."
Wikipedia: Research comprises "creative work undertaken on a systematic basis in order to increase the stock of knowledge, including knowledge of humans, culture and society, and the use of this stock of knowledge to devise new applications."

Definition at an abstract level: a “research data service is a rule of correspondence between two sets”, or
“A Concrete Research Data Tool on which there exists an Institutional Commitment in the form of a Service-Level Agreement.”.
These and more definitions are to be comprehensively presented at “White paper on Research Data Service Discoverability” of the RDA Europe project (European Union’s Horizon 2020 research and innovation programme) – ongoing work.
What is a “Research Data Service”?
2016 www.sti-innsbruck.at 6

• Web services are essentially a programmatic layer on top of distributed systems.
• Research Data Service is defined in this presentation earlier.– So it may or may not be implemented as Web service.– And has specific characteristics related to research.
Differences between a Research Data Service and a Web Service
2016 www.sti-innsbruck.at 7

• Motivation and Introduction to Research Data Service (RDS)• Modeling RDS• Managing and programming RDS• Disseminating RDS• Conclusions
Outline
2016 www.sti-innsbruck.at 8

Applicable to RDS: Web Service properties
• Functional – contains the formal specification of what exactly the
service can do.
• Behavioral– how the functionality of the service can be achieved
in terms of interaction with the service and as well in terms of functionality required from the other Web services.
• Non-functional properties– captures constraints over the previous mentioned
properties.

Applicable to RDS: Web Service related tasks
• Discovery: “Find services that matches to the service requester specification” .
• Selection and Ranking: “Choose the most appropriate services among the available ones”
• Composition: “Assembly of services based in order to achieve a given goal and provide a higher order of functionality”.
• Mediation: “Solve mismatches among domain knowledge used to describe the services, protocols used in the communication, data exchanged in the interaction (types used, and meaning of the information) and business models of the different parties”.
• Execution: “Invocation of a concrete set of services, arranged in a particular way following programmatic conventions that realizes a given task”.
• Monitoring: “Supervision of the correct execution of services and dealing with exceptions thrown by composed services or the composition workflow itself”.
• Handover: “Replacement of services by equivalent ones, which solely or in combination can realize the same functionality as the replaced one, in case of failure while execution”.

• Going mainstream: schema.org
• Linked Open Data cloud counts 25 billion triples
• Open government initiatives• BBC, Facebook, Google, Yahoo,
etc. use semantics• SPARQL becomes W3C
recommendation• Life science and other scientific
communities use ontologies• RDF, OWL become W3C
recommedations• Research field on ontologies and
semantics appears• Term „Semantic Web“ has been
„seeded“, Scientific American article, Tim Berners-Lee et al.
Semantic Web Evolution in One Slide
2008
2001
2010
2004 Source: Open Knowledge Foundation

5-star Linked OPEN Data: Applicable to Any, also Research Data
★ Available on the web (whatever format) but with an open lisence, to be Open Data
★★ Available as machine-readable structured data (e.g. excel instead of image scan of a table)
★★★ as (2) plus non-proprietary format (e.g. CSV instead of excel)★★★★ All the above plus, Use open standards from W3C (URIs, RDF and SPARQL) to identify things, so that people can point at your stuff
★★★★★ All the above, plus: Link your data to other people’s data to provide context

What is Schema.org?
• Schema.org provides a collection of shared vocabularies.
• Launched in June 2011 by Bing, Goolge and Yahoo
• Yandex joins in November
• Purpose:
Create a common set of schemas for webmasters to mark-up with structured data their websites.
13

Motivation: What for?
1) Lead to the generation of rich snippets in search engine results more attractive for the users
14
14

Motivation: What for?
2) Query/Answer based Search Engine
•Semantic Search
•Making use of structured data, the search engine can understand the content of your web site and make use of it to give a more accurate search result.
15
15

Advantages
• Webmasters can use schema.org to mark up their web pages (creating enriched snippets) in a way that is recognized by major search engines.
• The enriched snippets enable search engines to understand the information on web pages that results in richer and more attractive search results for the users Easier for users to find relevant and right information on the web.
• Search engines including Bing, Google, Yahoo! and Yandex rely on this markup to improve the display of search results.
• Helps webmasters to rank higher in search results
• This markup has the potential to enhance the CTR (click through ratio) from the search results from anywhere between 10-25%. 16

Advantages
• Schema.org can be also used for structured data interoperability.
• Its usage can also lead to the development of new tools, for example Google Recipe Search, which may open up other marketing channels if not now, in the near future.
• Obviously also relevant for RDS.
Information from: http://builtvisible.com/micro-data-schema-org-guide-generating-rich-snippets/#schemaorg17

Input: •Aim of the task/part of the research process to be executed (goal),•Context and implementation restrictions (functional and non-functional properties):
– Domain, QoS, scalability, price...
Output:•Information, data,•Research process step completed,•Knowledge (if e.g. the service has a human in the loop),•Change of state (can be intangible).
Metadata semantics needed for the description of the “input set” (domain) and the “output set” (co-domain)
2016 www.sti-innsbruck.at 18

• In “ideal” world, yes.• Also yes in perspective, as the amount of research data services
increased & research steering service economy tends to be more interdisciplinary.– It becomes more difficult to identify and find relevant services.
• In real world however, simpler things and models spread better. – E.g. programmableweb still does not have semantic descriptions for
service APIs
• Yet, here is a clear progressive usage potential here, as the research community is a good choice to be early adopters.
Do we need to specify the syntax and semantics of the elements of the domain and co-domain?
2016 www.sti-innsbruck.at 19

• A Research Data Service instance definitely changes with time – E.g. its quality may alter, its non-functional properties change– Its context and usage vary– It may appear and disappear
– Its implementation may change– …
• However, modeling programmatically such state changes is difficult, and make them widely used is even more difficult.
• Therefore, Research Data Services should be designed as stateless.
RDS: “stateless” or “state-based”?
2016 www.sti-innsbruck.at 20

• Aimed dataset or service,• Scientific discipline, • Scientific method,• Domain,• Information about quantity, quality, availability, creator(s)/provider(s),• Access and license policies,• Origin and annotation of reused/subcontracted sources (when
applicable).
(Some – even all - of the above can be optional.)
Examples:• “compare performance of my semantic repository at criteria X”,• “find datasets with energy consumption of fridges in Vienna”.
What should be included in a RDS profile in order to appropriately describe its functionality?
2016 www.sti-innsbruck.at 21

• Possibly e.g. in conjunction with research method description.– Think BPEL, etc.
Scientific workflows: appropriate for describing the process model of a Research Data Service
2016 www.sti-innsbruck.at 22
Basing on an USDL and Linked USDL example,source: Cardoso, J., Lopes, R., Poels, G. “Service Systems”, Springer, 2014. ISBN 978-3-319-10813-1.

• Motivation and Introduction to Research Data Service (RDS)• Modeling RDS• Managing and programming RDS• Disseminating RDS• Conclusions
Outline
2016 www.sti-innsbruck.at 23

• In most cases existing service description frameworks like OWL-S and WSMO are too complex, except.– In genetics, for example, some data annotations are made
using OWL, and building a service on top of it would be a natural extension.
• But in many cases it would not be the best choice.– Most data are not shared on the Web with OWL, in
particular.– OWL is too complex and too expressive.
• Using real data in research more essential, so eventually the frameworks in which the real data mostly is, are important, so eventually linked (open) data, schema.org
Using Semantic Web Services for RDS?
2016 www.sti-innsbruck.at 24

An Option: Applying Linked Service System (LSS) Model Structure
Source: Cardoso, J., Lopes, R., Poels, G. “Service Systems”, Springer, 2014. ISBN 978-3-319-10813-1.

LSS Implementation Example - Goals
Source: Cardoso, J., Lopes, R., Poels, G. “Service Systems”, Springer, 2014. ISBN 978-3-319-10813-1.

LSS Implementation Example - Locations
Source: Cardoso, J., Lopes, R., Poels, G. “Service Systems”, Springer, 2014. ISBN 978-3-319-10813-1.

• Presence of the ways to annotate the functionality, domain,…• Assumption of “incorrectness and incompleteness” (LarKC project),• Much of matchmaking and reasoning should be moved to the
applications – but: semantics can support maintenance of community-generated reusable mapping (e.g. stating that two service parts are the same).
Main characteristics and capabilities of a knowledge representation language appropriate for the description of the functionality of a data service as well as for effectively supporting reasoning in the matchmaking process
2016 www.sti-innsbruck.at 28
• Possible assuming a non 100% performance and a human in the loop.
Example: ongoing STI’s PhD of Ioannis Stavrakantonakis (winner of Netidee scholarship 2015 as one of the best Internet-related dissertations in Austria)
Towards Automatic Matching of APIs
2016 www.sti-innsbruck.at 29
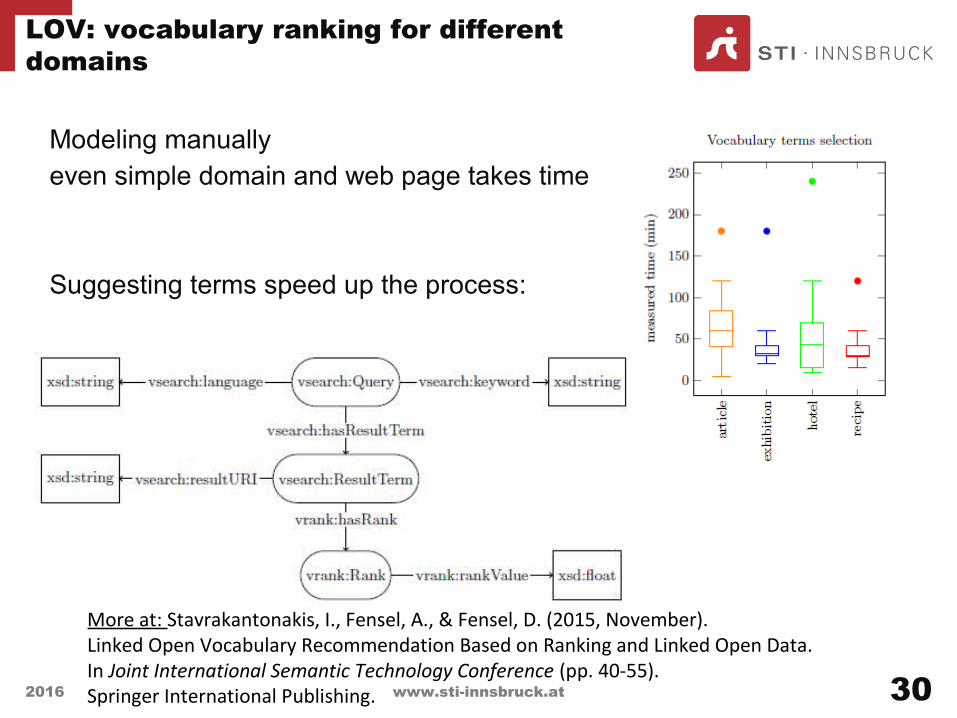
Modeling manuallyeven simple domain and web page takes time
Suggesting terms speed up the process:
LOV: vocabulary ranking for different domains
2016 www.sti-innsbruck.at 30
More at: Stavrakantonakis, I., Fensel, A., & Fensel, D. (2015, November). Linked Open Vocabulary Recommendation Based on Ranking and Linked Open Data. In Joint International Semantic Technology Conference (pp. 40-55). Springer International Publishing.

We need it, particularly because: • Data sets vary from domain to domain, and often the research is
domain specific,• Eases discoverability.
Also in agreement with other trends in the area e.g. microservices.
Discipline-specific classification of data services (classes of data services) supported by discipline-specific ontologies
2016 www.sti-innsbruck.at 31
Danado, J., Davies, M., Ricca, P., & Fensel, A. (2010). An authoring tool for user generated mobile services. In Future Internet-FIS 2010 (pp. 118-127). Springer Berlin Heidelberg.
Davies, M., Carrez, F., Heinilä, J., Fensel, A., Narganes, M., & Carlos dos Santos Danado, J. (2011). m: Ciudad: enabling end-user mobile service creation. International Journal of Pervasive Computing and Communications, 7(4), 384-414.
• A single point to make services discovered.– A meta- Research Data Service in itself.
• Ideologically like UDDI, or like programmableweb for Web APIs now.
On the role and architecture of Registries/Directories/Catalogs of Services
2016 www.sti-innsbruck.at 32

• By data, by domain, by functionality,… • The classifications do not have to be created apriori, but could be
created ad hoc once the annotations are there – not to restrict the usage.
• De facto seem to be classified by provider platforms e.g. in area:
How to classify RDS? “stateless/state-based”, “type of input data: discrete data/vectors/functions/streaming data”, “types of output data”, etc.
2016 www.sti-innsbruck.at 33
For publications –numerous repositories e.g. from publishers,Zenodo, GoogleScholar

• It is a necessity and a criterion.• But the situation when the citations number is decisive in the ranking
(e.g. how Google Scholar does – most cited on top) is not optimal, as such search may overlook data with a closest match, and the output itself also impacts citations.
Is “citation” instrumental in making research data service discoverable?
2016 www.sti-innsbruck.at 34
Matthew 25:29 New American Standard Bible "For to everyone who has, more shall be given, and he will have an abundance; but from the one who does not have, even what he does have shall be taken away.
Matthew 25:29 New American Standard Bible "For to everyone who has, more shall be given, and he will have an abundance; but from the one who does not have, even what he does have shall be taken away.

• Motivation and Introduction to Research Data Service (RDS)• Modeling RDS• Managing and programming RDS• Disseminating RDS• Conclusions
Outline
2016 www.sti-innsbruck.at 35

• Research is disseminated nowadays also via social media• Social media is arguably used by young generations more commonly
than email• There are many social media channels allowing research
communication existing, to name a few:– ResearchGate– Academia.edu– Google Scholar– SlideShare
– …
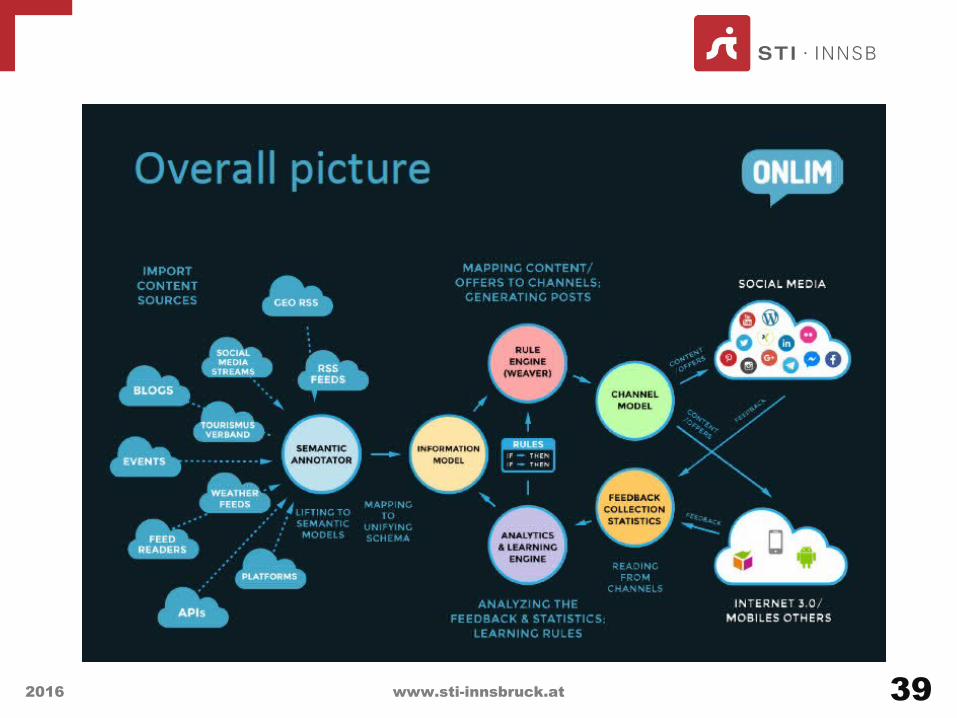
• ONLIM is a start-up of STI Innsbruck delivering a solution to efficient dissemination on social media, based on semantics (schema.org)
• ONLIM is available as a tool at www.onlim.com
The world is multi-channel now: being present everywhere to be seen
2016 www.sti-innsbruck.at 36

2016 www.sti-innsbruck.at 37

2016 www.sti-innsbruck.at 38
2016 www.sti-innsbruck.at 39

2016 www.sti-innsbruck.at 40

www.onlim.com
ONLIM: Dashboard with suggested posts
2016 www.sti-innsbruck.at 41
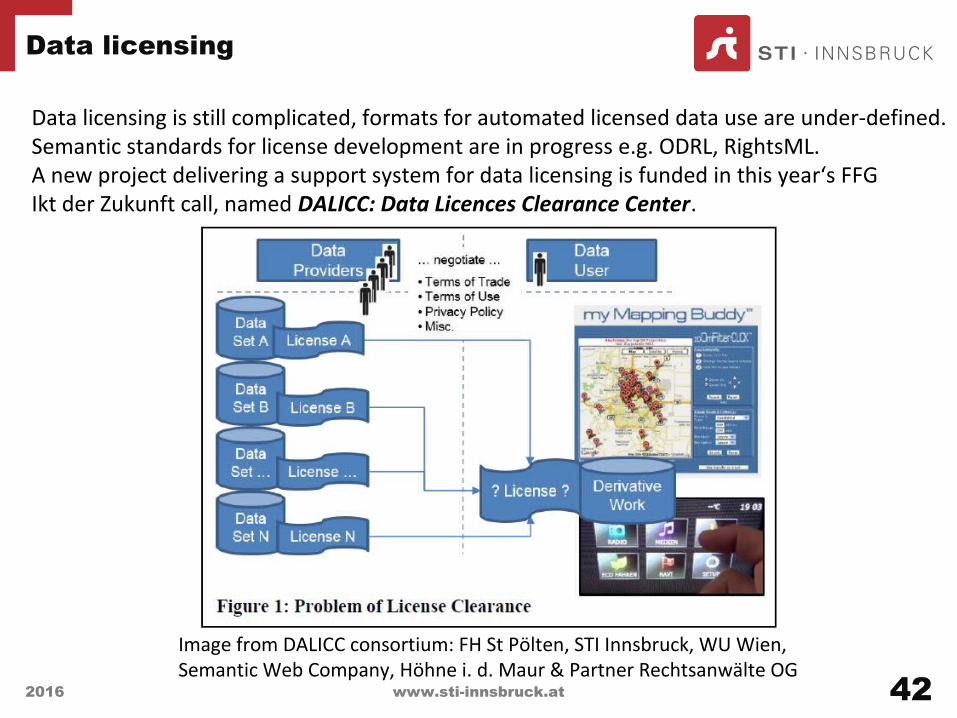
Data licensing
2016 www.sti-innsbruck.at 42Image from DALICC consortium: FH St Pölten, STI Innsbruck, WU Wien, Semantic Web Company, Höhne i. d. Maur & Partner Rechtsanwälte OG
Data licensing is still complicated, formats for automated licensed data use are under-defined.Semantic standards for license development are in progress e.g. ODRL, RightsML.A new project delivering a support system for data licensing is funded in this year‘s FFGIkt der Zukunft call, named DALICC: Data Licences Clearance Center.

• Motivation and Introduction to Research Data Service (RDS)• Modeling RDS• Managing and programming RDS• Disseminating RDS• Conclusions
Outline
2016 www.sti-innsbruck.at 43

• Research Data Services are data services, and surely belong to the data service value chain.
• There exist promising semantic languages and technologies to be applied to solutions of RDS modeling and discovery problems e.g. linked services, linked data, schema.org.
• Efficient dissemination of research is very important. Also dissemination needs to multi-channel now, and new kind of channels appear e.g. social media.
• Relevant data value chain techniques and tools are in development e.g. on (semantic) data licensing.
• See more of smart data development at
Summary
2016 www.sti-innsbruck.at 4429-30 June 2016, 12-15 September 2016,Eindhoven Leipzig

• C. Thanos (2014) Mediation: The Technological Foundation of Modern Science. Data Science Journal, Vol.13, pp.88–105. DOI: 10.2481/dsj.14-016
• T. Gruber, “Towards Principles for the Design of Ontologies Used for Knowledge Sharing” in “Formal Ontology in Conceptual Analysis and Knowledge Representation”, Technical Report KSL 93-04, Knowledge Systems Laboratory, Stanford University.
• D. Fensel, F. Facca, E. Simperl and I.Toma. Semantic Web Services Textbook, Springer, 2011.
• Silvio Peroni, Alexander Dutton, Tanya Gray, David Shotton (2015). Setting our bibliographic references free: towards open citation data. Journal of Documentation, 71 (2): 253-277. http://dx.doi.org/10.1108/JD-12-2013-0166
• Fensel, A., Toma, I., García, J. M., Stavrakantonakis, I., & Fensel, D. (2014). Enabling customers engagement and collaboration for small and medium-sized enterprises in ubiquitous multi-channel ecosystems. Computers in Industry, 65(5), 891-904.
References
2016 www.sti-innsbruck.at 45
CLICK TO EDIT MASTER TITLE STYLE
Thank youQuestions