the university of north carolina at chapel hill sequential pattern mining comp 790-90 seminar bcb...
TRANSCRIPT

The UNIVERSITY of NORTH CAROLINA at CHAPEL HILL
Sequential Pattern Mining
COMP 790-90 Seminar
BCB 713 Module
Spring 2011

COMP 790-090 Data Mining: Concepts, Algorithms, and Applications
2
Sequential Pattern Mining
Why sequential pattern mining?
GSP algorithm
FreeSpan and PrefixSpan
Boarder Collapsing
Constraints and extensions

COMP 790-090 Data Mining: Concepts, Algorithms, and Applications
3
Sequence Databases and Sequential Pattern Analysis
(Temporal) order is important in many situationsTime-series databases and sequence databasesFrequent patterns (frequent) sequential patterns
Applications of sequential pattern miningCustomer shopping sequences:
First buy computer, then CD-ROM, and then digital camera, within 3 months.
Medical treatment, natural disasters (e.g., earthquakes), science & engineering processes, stocks and markets, telephone calling patterns, Weblog click streams, DNA sequences and gene structures

COMP 790-090 Data Mining: Concepts, Algorithms, and Applications
4
What Is Sequential Pattern Mining?
Given a set of sequences, find the complete set of frequent subsequences
A sequence database A sequence : < (ef) (ab) (df) c b >
An element may contain a set of items.Items within an element are unorderedand we list them alphabetically.
<a(bc)dc> is a subsequence of <<a(abc)(ac)d(cf)>Given support threshold min_sup =2, <(ab)c> is
a sequential pattern
SID sequence
10 <a(abc)(ac)d(cf)>
20 <(ad)c(bc)(ae)>
30 <(ef)(ab)(df)cb>
40 <eg(af)cbc>

COMP 790-090 Data Mining: Concepts, Algorithms, and Applications
5
Challenges on Sequential Pattern Mining
A huge number of possible sequential patterns are hidden in databasesA mining algorithm should
Find the complete set of patterns satisfying the minimum support (frequency) thresholdBe highly efficient, scalable, involving only a small number of database scansBe able to incorporate various kinds of user-specific constraints

COMP 790-090 Data Mining: Concepts, Algorithms, and Applications
6
A Basic Property of Sequential Patterns: Apriori
A basic property: Apriori (Agrawal & Sirkant’94) If a sequence S is not frequent
Then none of the super-sequences of S is frequent
E.g, <hb> is infrequent so do <hab> and <(ah)b>
<a(bd)bcb(ade)>50
<(be)(ce)d>40
<(ah)(bf)abf>30
<(bf)(ce)b(fg)>20
<(bd)cb(ac)>10
SequenceSeq. IDGiven support threshold min_sup =2

COMP 790-090 Data Mining: Concepts, Algorithms, and Applications
7
Basic Algorithm : Breadth First Search (GSP)
L=1
While (ResultL != NULL)
Candidate Generate
Prune
Test
L=L+1

COMP 790-090 Data Mining: Concepts, Algorithms, and Applications
8
Finding Length-1 Sequential Patterns
Initial candidates: all singleton sequences<a>, <b>, <c>, <d>, <e>, <f>, <g>, <h>
Scan database once, count support for candidates
<a(bd)bcb(ade)>50
<(be)(ce)d>40
<(ah)(bf)abf>30
<(bf)(ce)b(fg)>20
<(bd)cb(ac)>10
SequenceSeq. ID
min_sup =2
Cand Sup
<a> 3
<b> 5
<c> 4
<d> 3
<e> 3
<f> 2
<g> 1
<h> 1

COMP 790-090 Data Mining: Concepts, Algorithms, and Applications
9
The Mining Process
<a> <b> <c> <d> <e> <f> <g> <h>
<aa> <ab> … <af> <ba> <bb> … <ff> <(ab)> … <(ef)>
<abb> <aab> <aba> <baa> <bab> …
<abba> <(bd)bc> …
<(bd)cba>
1st scan: 8 cand. 6 length-1 seq. pat.
2nd scan: 51 cand. 19 length-2 seq. pat. 10 cand. not in DB at all
3rd scan: 46 cand. 19 length-3 seq. pat. 20 cand. not in DB at all
4th scan: 8 cand. 6 length-4 seq. pat.
5th scan: 1 cand. 1 length-5 seq. pat.
Cand. cannot pass sup. threshold
Cand. not in DB at all
<a(bd)bcb(ade)>50
<(be)(ce)d>40
<(ah)(bf)abf>30
<(bf)(ce)b(fg)>20
<(bd)cb(ac)>10
SequenceSeq. ID
min_sup =2
COMP 790-090 Data Mining: Concepts, Algorithms, and Applications
10
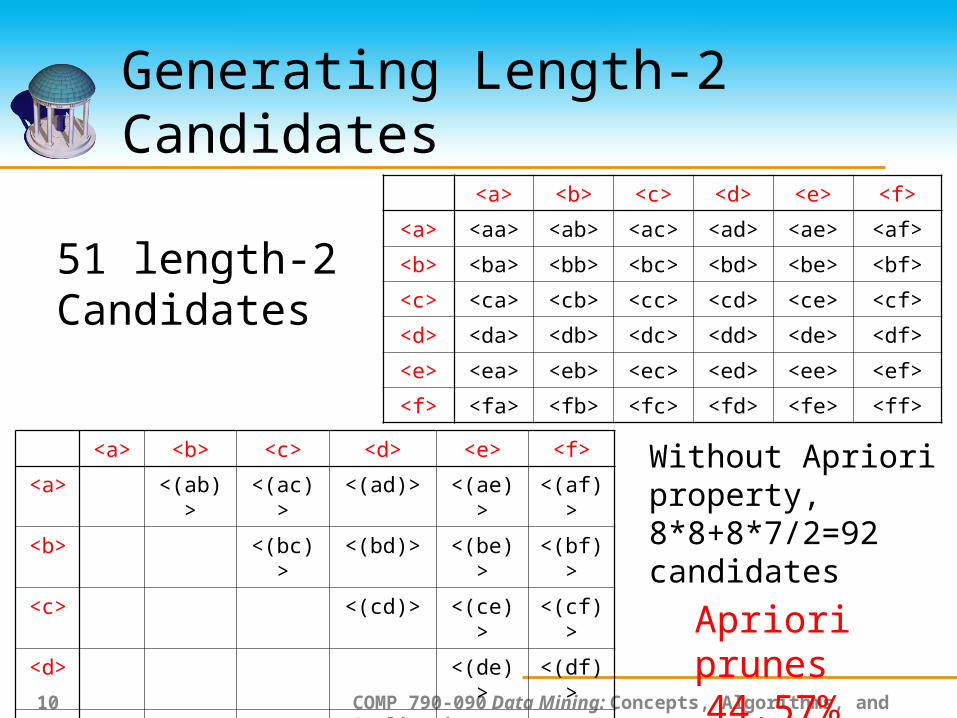
Generating Length-2 Candidates
<a> <b> <c> <d> <e> <f>
<a> <aa> <ab> <ac> <ad> <ae> <af>
<b> <ba> <bb> <bc> <bd> <be> <bf>
<c> <ca> <cb> <cc> <cd> <ce> <cf>
<d> <da> <db> <dc> <dd> <de> <df>
<e> <ea> <eb> <ec> <ed> <ee> <ef>
<f> <fa> <fb> <fc> <fd> <fe> <ff>
<a> <b> <c> <d> <e> <f>
<a> <(ab)> <(ac)> <(ad)> <(ae)> <(af)>
<b> <(bc)> <(bd)> <(be)> <(bf)>
<c> <(cd)> <(ce)> <(cf)>
<d> <(de)> <(df)>
<e> <(ef)>
<f>
51 length-2Candidates
Without Apriori property,8*8+8*7/2=92 candidates
Apriori prunes 44.57% candidates

COMP 790-090 Data Mining: Concepts, Algorithms, and Applications
12
Pattern Growth (prefixSpan)
Prefix and Suffix (Projection)
<a>, <aa>, <a(ab)> and <a(abc)> are prefixes of sequence <a(abc)(ac)d(cf)>
Given sequence <a(abc)(ac)d(cf)>
Prefix Suffix (Prefix-Based Projection)
<a> <(abc)(ac)d(cf)>
<aa> <(_bc)(ac)d(cf)>
<ab> <(_c)(ac)d(cf)>

COMP 790-090 Data Mining: Concepts, Algorithms, and Applications
13
Example
Sequence_id Sequence
10 <a(abc)(ac)d(cf)>
20 <(ad)c(bc)(ae)>
30 <(ef)(ab)(df)cb>
40 <eg(af)cbc>
An Example
( min_sup=2):
Prefix Sequential Patterns
<a> <a>,<aa>,<ab><a(bc)>,<a(bc)a>,<aba>,<abc>,<(ab)>,<(ab)c>,<(ab)d>,<(ab)f>,<(ab)dc>,<ac>,<aca>,<acb>,<acc>,<ad>,<adc>,<af>
<b> <b>, <ba>, <bc>, <(bc)>, <(bc)a>, <bd>, <bdc>,<bf>
<c> <c>, <ca>, <cb>, <cc>
<d> <d>,<db>,<dc>, <dcb>
<e> <e>,<ea>,<eab>,<eac>,<eacb>,<eb>,<ebc>,<ec>,<ecb>,<ef>,<efb>,<efc>,<efcb>
<f> <f>,<fb>,<fbc>, <fc>, <fcb>

COMP 790-090 Data Mining: Concepts, Algorithms, and Applications
14
PrefixSpan (the example to be continued)
Step1: Find length-1 sequential patterns;
<a>:4, <b>:4, <c>:4, <d>:3, <e>:3, <f>:3
patternsupport
Step2: Divide search space;
six subsets according to the six prefixes;
Step3: Find subsets of sequential patterns;
By constructing corresponding projected databases and mine
each recursively.

COMP 790-090 Data Mining: Concepts, Algorithms, and Applications
15
Example to be continued
Prefix Projected(suffix) databases Sequential Patterns
<a> <(abc)(ac)d(cf)>,
<(_d)c(bc)(ae)>,
<(_b)(df)cb>,
<(_f)cbc>
<a>,<aa>,<ab><a(bc)>,<a(bc)a>,<aba>,<abc>,<(ab)>,<(ab)c>,<(ab)d>,<(ab)f>,<(ab)dc>,<ac>,<aca>,<acb>,<acc>,<ad>,<adc>,<af>
Sequence_id Sequence Projected(suffix) databases
10 <a(abc)(ac)d(cf)> <a(abc)(ac)d(cf)>
20 <(ad)c(bc)(ae)> <(ad)c(bc)(ae)>
30 <(ef)(ab)(df)cb> <(ef)(ab)(df)cb>
40 <eg(af)cbc> <eg(af)cbc>

COMP 790-090 Data Mining: Concepts, Algorithms, and Applications
16
Example
Find sequential patterns having prefix <a>:
1. Scan sequence database S once. Sequences in S containing <a> are projected w.r.t <a> to form the <a>-projected database.
2. Scan <a>-projected database once, get six length-2 sequential patterns having prefix <a> :
<a>:2 , <b>:4, <(_b)>:2, <c>:4, <d>:2, <f>:2
<aa>:2 , <ab>:4, <(ab)>:2, <ac>:4, <ad>:2, <af>:2
3. Recursively, all sequential patterns having prefix <a> can be further partitioned into 6 subsets. Construct respective projected databases and mine each.
e.g. <aa>-projected database has two sequences :
<(_bc)(ac)d(cf)> and <(_e)>.

COMP 790-090 Data Mining: Concepts, Algorithms, and Applications
17
PrefixSpan Algorithm
PrefixSpan(, i, S|)
1. Scan S| once, find the set of frequent items b such that
• b can be assembled to the last element of to form a sequential pattern; or
• <b> can be appended to to form a sequential pattern.
2. For each frequent item b, appended it to to form a sequential pattern ’, and output ’;
3. For each ’, construct ’-projected database S|’, and call PrefixSpan(’, i+1,S|’).
Main Idea: Use frequent prefixes to divide the search space and to project sequence databases. only search the relevant sequences.

COMP 790-090 Data Mining: Concepts, Algorithms, and Applications
18
Approximate match
When you observe d1Spread count as
d1: 90%, d2: 5%, d3: 5%
Compatibility Matrix

COMP 790-090 Data Mining: Concepts, Algorithms, and Applications
19
Match
The degree to which pattern P is retained/reflected in S
M(P,S) = P(P|S)= C(p,s) when when lS=lP
M(P,S) = max over all possible when lS>lP
ExampleP S M
d1d1 d1d3 0.9*0
d1d2 d1d2 0.9*0.8
d1d2 d1d3 0.9*0.05
d1d2 d2d3 0.1*0.05
d1d2 d1d2d3 0.9*0.8

COMP 790-090 Data Mining: Concepts, Algorithms, and Applications
20
Calculate Max over all
Dynamic ProgrammingM(p1p2..pi, s1s2…sj)= Max of
M(p1p2..pi-1, s1s2…sj-1) * C(pi,sj)
M(p1p2..pi, s1s2…sj-1)
O(lP*lS)
When compatibility Matrix is sparse O(lS)

COMP 790-090 Data Mining: Concepts, Algorithms, and Applications
21
Match in D
Average over all sequences in D

COMP 790-090 Data Mining: Concepts, Algorithms, and Applications
22
Spread of match
If compatibility matrix is identity matrixMatch = support

COMP 790-090 Data Mining: Concepts, Algorithms, and Applications
23
Anti-Monotone
The match of a pattern P in a symbol sequence S is less than or equal to the match of any subpattern of P in SThe match of a pattern P in a sequence database D is less than or equal to the match of any subpattern of P in DCan use any support based algorithm
More patterns match so require efficient solutionSample based algorithms
Border collapsing of ambiguous patterns

COMP 790-090 Data Mining: Concepts, Algorithms, and Applications
24
Chernoff Bound
Given sample size=n, range R,with probability 1-true value: = sqrt([R2ln(1/)]/2n)
Distribution freeMore conservativeSample size : fit in memoryRestricted spread :
For pattern P= p1p2..pL
R=min (match[pi]) for all 1 i L
Frequent Patterns
min_match +
min_match -
Infrequent patterns

COMP 790-090 Data Mining: Concepts, Algorithms, and Applications
25
Algorithm
Scan DB: O(N*min (Ls*m, Ls+m2))
Find the match of each individual symbol
Take a random sample of sequences
Identify borders that embrace the set of ambiguous patterns O(mLp * |S| * Lp * n)
Min_match existing methods for association rule mining
Locate the border of frequent patterns in the entire DB
via border collapsing

COMP 790-090 Data Mining: Concepts, Algorithms, and Applications
26
Border Collapsing
If memory can not hold the counters of all ambiguous patternsProbe-and-collapse : binary searchProbe patterns with highest collapsing power until memory is filledIf memory can hold all patterns up to the 1/x layer
the space of ambiguous patterns can be narrowed to at least 1/x of the original onewhere x is a power of 2
If it takes a level-wise search y scans of the DB, only O(logxy) scans are necessary when the border collapsing technique is employed


COMP 790-090 Data Mining: Concepts, Algorithms, and Applications
29
Periodic Pattern
Full periodic patternABC ABC ABC
Partial periodic patternABC ADC ACC ABC
Pattern hierarchyABC ABC ABC DE DE DE DE ABC ABC ABC DE DE DE DE ABC ABC ABC DE DE DE DE

COMP 790-090 Data Mining: Concepts, Algorithms, and Applications
30
Periodic Pattern
Recent AchievementsPartial Periodic Pattern
Asynchronous Periodic Pattern
Meta Pattern
InfoMiner/InfoMiner+/STAMP

COMP 790-090 Data Mining: Concepts, Algorithms, and Applications
31
Clustering Sequential Data
CLUSEQ
ApproxMAP