the tickertaip parallel raid architecture - hp labs · 3 2 the tickertaip architecture a tickertaip...
TRANSCRIPT

The TickerTAIP Parallel RAIDArchitecture
Pei Cao*, Swee Boon Lim**,Shivakumar Venkataraman***, John WilkesComputer Systems LaboratoryHPL-92-151November, 1992
RAID disk array,parallelprogramming,performance, I/Osystems andarchitecture
Traditional RAID arrays have a centralized architecture,with a single controller through which all requests flow.Such a controller is a single point of failure, and itsperformance limits the maximum size that the array cangrow to. We describe here TickerTAIP, a parallelarchitecture for RAID arrays that distributes the controllerfunctions across several loosely-coupled processors. Theresult is better scalability, fault tolerance, and flexibility.
This paper presents the TickerTAIP architecture and anevaluation of its behavior. We demonstrate the feasibilityby an existence proof; describe a family of distributedalgorithms for RAID parity calculation; discuss techniquesfor establishing request atomicity, sequencing and recovery;and provide a performance evaluation of the TickerTAIPdesign space in both absolute terms and by comparison to acentralized RAID implementation. We conclude that theTickerTAIP architectural approach is feasible, useful, andeffective.
*Princeton University, Princeton, NJ, **University of Illinois, Urbana-Champaign, IL, ***Universityof Wisconsin, Madison, WIAlso published as Operating Systems Research Department report HPL-OSR-92-6 Copyright Hewlett-Packard Company 1992
Internal Accession Date Only

1
1 IntroductionA disk array is a structure that connects several small disks together to extend the cost, power andspace advantages of small disks to high capacity configurations. By providing partial redundancysuch as parity, availability can be increased as well. Such RAID arrays (for Redundant Arrays ofInexpensive Disks) were first described in the early 1980s [Lawlor81, Park86], and popularized bythe work of a group at UC Berkeley [Patterson88, Patterson89].
The traditional architecture of a RAID array, shown in Figure 1, has a central controller, one or moredisks, and multiple head-of-string disk interfaces. The RAID controller interfaces to the host,processes read and write requests, and carries out parity calculations, block placement, and datarecovery after a disk failure.
The RAID controller is crucial to the performance and availability of the system. If its bandwidth,processing power, or capacity are inadequate, the performance of the array as a whole will suffer.(This is increasingly likely to happen: parity calculation is memory-bound, and memory speedshave not kept pace with recent CPU performance improvements [Ousterhout90].) Latencythrough the controller can reduce the performance of small requests. The single point of failurethat the controller represents can also be a concern: published failure rates for disk drives andpackaged electronics are now similar. Although some commercial products include spare RAIDcontrollers, they are not normally simultaneously active: one typically acts as a backup for theother, and is held in reserve until it is needed because of failure of the primary. This is expensive:the backup has to have all the capacity of the primary controller.
To address these concerns, we have developed the TickerTAIP1 architecture for parallel RAIDarrays (Figure 2). There is no central controller in a TickerTAIP disk array: it has been replaced bya cooperating set of array controller nodes that together provide all the functions needed. TheTickerTAIP architecture offers fault-tolerance (no central controller to break), performancescalability (no central bottleneck), smooth incremental growth (add another node), and flexibility(mix and match components).
This paper provides an evaluation of the TickerTAIP architecture.
1. Because tickerTAIP is used in all the best pa(rallel)RAIDs!
Figure 1 : traditional RAID array architecture.
host interconnect
disksdisk controllercentral RAIDcontroller

2
1.1 Related work
Many papers have been published on RAID reliability, performance, and on design variations forparity placement and recovery schemes, such as [Clark88a, Gibson88, Menon89, Schulze89,Dunphy90, Gray90, Lee90, Muntz90, Holland92]. Our work builds on these studies: weconcentrate here on the architectural issues of parallelizing the techniques used in a centralizedRAID array, so we take such work as a given.
Something similar to the TickerTAIP physical architecture has been realized in the HP7937 familyof disks [HPdisks89]. Here, the disks can be connected together by a 10MB/s bus, which allowsaccess to “remote” disks as well as fast switch-over between attached hosts in the event of systemfailure. No multi-disk functions (such as a disk array) are provided, however.
A proposal was made to connect networks of processors to form a widely-distributed RAIDcontroller in [Stonebraker89]. This approach was called RADD—Redundant Arrays of DistributedDisks. It proposed using disks spread across a wide-area network to improve availability in theface of a site failure. In contrast to the RADD study, we emphasize the use of parallelism inside asingle RAID server; we assume the kind of fast, reliable interconnect that is easily constructedinside a single server cabinet; we closely couple processors and disks, so that a node failure istreated as (one or more) disk failures; and we provide much improved performance analyses([Stonebraker89] used “all disk operations take 30ms”). The result is a new, detailedcharacterization of the parallel RAID design approach in a significantly different environment.
1.2 Paper outline
We begin this paper by describing the TickerTAIP architecture, including descriptions andevaluations of algorithms for parity calculation, recovery from controller failure, and extensionsto provide sequencing of concurrent requests from multiple hosts.
To evaluate TickerTAIP we constructed a working prototype as existence proof and functionaltestbed, and then a detailed event-based simulation that we calibrated against the prototype.These tools are presented as background material for the performance analysis of TickerTAIP thatfollows, with particular emphasis on comparing it against a centralized RAID implementation.
We conclude the paper with a summary of our results.
Figure 2 : TickerTAIP array architecture.
hostinterconnect(s)
array controller nodes
small-area network

3
2 The TickerTAIP architectureA TickerTAIP array is composed of a number of worker nodes, which are nodes with one or morelocal disks connected through a SCSI bus. The nodes are connected to one another by a high-performance small-area network with sufficient redundancy to tolerate single failures. (Mesh-based switching fabrics can achieve this with reasonable cost and complexity. A design that wouldmeet the performance, scalability and fault-tolerance needs of a TickerTAIP array is described in[Wilkes91].)
Figure 3 shows the environment in which we envision a TickerTAIP array operating. The arrayprovides disk services to one or more host computers. These connect to the array at originatornodes. There may be several originator nodes, each connected to a different host; alternatively, asingle host can be connected to multiple originators for higher performance and greater failureresilience. For simplicity, we require that all data for a request be returned to the host along thepath used to issue the request.
Figure 2 shows all nodes being both workers and originators: they have both host and diskconnections. A second design, shown in Figure 4, dedicates separate kinds of node to the workerand originator functions. This makes it easy to support a TickerTAIP array that has multipledifferent kinds of host interface. Also, since each node is plug-compatible from the point of viewof the internal interconnect, it is easy to configure an array with any desired ratio of worker andoriginator nodes. This is a flexibility less easily achieved in the traditional centralized architecture.
In the context of this model, a traditional RAID array looks like a TickerTAIP array with severalunintelligent worker nodes and a single originator node on which all the parity calculations takeplace.
3 Design issuesThis section describes the TickerTAIP design issues in greater detail. It begins with an examinationof normal mode operation and then examines the support needed to cope with failures.
TickerTAIParray
client processes
host’s I/O interface
Hosts
Figure 3 : TickerTAIP system environment.

4
3.1 The RAIDmap
When a request arrives at an originator, it must be scheduled and partitioned amongst theparticipating nodes. In the general case, each node is both an originator for its own requests anda worker for others. Our first design retained a great deal of centralized authority: the originatortried to coordinate the actions taking place at each of the different nodes (reads and writes, paritycalculations). We soon found ourselves faced with the messy problem of coping with a complexset of interdependent actions taking place on multiple remote nodes.
We then developed a new approach: rather than assume that each of the workers needed to be toldwhat to do, assume that they would do whatever was necessary without further interaction. Oncethe workers are told the original request (its starting point and length, and whether it was a reador a write) and given any data they needed, they can proceed on their own. We call this approachcollaborative execution: it is characterized by each node assuming that other nodes are already doingtheir part of the request. For example, if node A needs data from node B, A can rely on B togenerate and ship the data to A with no further prompting.
To orchestrate the work, we developed a structure known as a RAIDmap, a rectangular array withan entry for each column (worker) and each stripe. Each worker builds its column of theRAIDmap, filling in the blanks as a function of the operation (read or write), the layout policy andthe execution policy. The layout policy determines where data and parity blocks are placed in theRAID array (e.g., RAID 0, 4, or 5). The execution policy determines the algorithm used to servicethe request (e.g., where parity is to be calculated). A simplified RAIDmap is shown in Figure 5.
Figure 4 : alternative TickerTAIP host interconnection architecture with dedicated originator nodes.
hostinterconnect(s)
originatornodes
workernodes
node 0 node 1 node 2 node 3
Stripe 0 (–,–,–,unused) (–,–,–,unused) (2,0,3,data) (–,0,–,parity) small stripeStripe 1 (4,1,2,data) (5,1,2,data) (–,1,–,parity) (3,1,2,data) full stripeStripe 2 (–,–,–,unused) (–,2,–,parity) (6,2,1,data) (7,2,1,data) large stripe
Figure 5 : RAIDmap example for a write request spanning logical blocks 2 through 7.Each tuple contains: logical and physical block number, node to send parity data to, and a blocktype. The rightmost column is discussed further in section 3.3.

5
One component of the RAIDmap is a state table for each block (the states are described in Table1). It is this table that the layout and execution policies fill out. A request enters the states in order,leaving each one when the associated function has been completed, or immediately if the state ismarked as “not needed” for this request. For example, a read request will enter state 1 (to read thedata), skip through state 2 to state 3 (to send it to the originator), and then skip through theremaining states. This design of the RAIDmap proved to be a flexible mechanism, allowing us totest out several different policy alternatives (e.g., whether to calculate partial parity results locally,or whether to send the data to the originator or parity nodes).
The goal of any RAID implementation is to maximize disk utilization and minimize requestlatency. To help achieve this, the RAIDmap computation is overlapped with other operations suchas moving data or accessing disks. Similarly, workers send data needed elsewhere beforeservicing their own parity computations or local disk transfers.
It was also important to optimize the disk accesses themselves. When we delayed writes in ourprototype implementation until the parity data was available, throughput increased by 25–30%.This was because coalescing the data and parity writes on a node into a single disk requestconsiderably reduced the number of disk seeks.
3.2 Normal (fault-free) mode reads
In normal mode, read requests are straightforward since no parity computation is required: thedata is read at the workers and forwarded to the originator. A RAIDmap is still generated tospecify the placement of blocks and parity data to skip over. We found it beneficial to performsequential reads of both data and parity, and then to discard the parity blocks, rather than togenerate requests that skipped over the parity.
3.3 Normal-mode writes
In a RAID array, writes require calculation or modification of stored parity to maintain the partialdata redundancy. Each stripe is considered separately in determining the method and site forparity computation. The following choices arise.
Table 1 : state-space for each block at a worker node
State Function Other information
1 Read old data disk address2 XOR old with new data3 Send old data (or XOR’d old
data) to another nodenode to send it to
4 Await incoming data (orXOR’d data)
number of blocksto wait for
5 XOR incoming data withlocal old data/parity
6 Write new data or parity disk address

6
3.3.1 How to calculate new parity
The first design choice is how to calculate the new parity. There are three alternatives, whichdepend on the amount of the stripe being updated (Figure 7):
• full stripe: all of the data blocks in the stripes have to be written; parity can be calculatedentirely from the new data;
• small stripe: less than half of the data blocks in a stripe are to be written; parity is calculatedby first reading the old data of the blocks which will be written, XORing them with the newdata and then XORing the results with the old parity block data;
• large stripe: more than half of the data blocks in the stripe are to be written; the new parityblock can be computed by reading the data blocks in the stripe that are not being written andXORing them with the new data (i.e., reducing this to the full-stripe case) [Chen90].
Depending on its size, a single IO request will involve one or more stripe size types. The effect onperformance of the large-stripe mode is discussed later.
3.3.2 Where to calculate new parity
The second design consideration is where the parity is to be calculated. Traditional centralizedRAID architectures calculate all parity at the originator node, since only it has the necessaryprocessing capability. In TickerTAIP, since every node has a processor, there are several choices.The key design goal is to load balance the work amongst the nodes—in particular, to spread outthe parity calculations over as many nodes as possible. Here are three possibilities (shown inFigure 7):
• at originator: all parity calculations are done at the originator;
• solely-parity: all parity calculations for a stripe take place at the parity node for that stripe;
• at parity: as for solely-parity, except that partial results during a small-stripe write are calculated atthe worker nodes and shipped to the parity node.
The solely-parity scheme always uses more messages than the at parity one, so we did not pursueit further. We provide performance comparisons between the other two later in the paper.
3.4 Single failures—request atomicity
We begin with a discussion of single-point failures. The goal of a regular RAID array is to survivesingle-point failures except for the controller. We extend that protection to include a failure in our
Figure 6 : the three different stripe update size policies.
× ×
Full stripe Large stripe Small stripe
parity blockdata blocks
×
data blockbeing read
read-modify-write cycles

7
(distributed) controller. (We have legislated internal single-fault-tolerance for the interconnectfabric, so this is not a concern.)
3.4.1 Disk failure
Disk failures are treated in just the same way as in a traditional RAID array: the array continuesoperation in degraded (failed) mode until the disk is repaired or replaced; the contents of the newdisk are reconstructed; and execution resumes in normal mode. From the outside of the array, theeffect is as if nothing has happened. Inside, appropriate data reconstructions occur on reads andsome writes, and I/O operations to the failed disk are suppressed. Just as in normal mode, theRAIDmap indicates to each node how it is to behave, but now it is filled out in such a way as toreflect the failure mode operations.
3.4.2 Worker failure
A TickerTAIP worker failure is treated just like a disk failure, and is masked in just the same way.(As with a regular RAID controller with multiple disks per head-of-string controller, a failingworker means that an entire column of disks is lost at once, but the same recovery algorithmsapply.) We assume fail-silent nodes: the isolation offered by the networking protocols used tocommunicate between nodes is likely to make this assumption realistic in practice for all but themost extreme cases—for which RAID arrays are probably not appropriate choices. A node issuspected to have failed if it does not respond within a reasonable time; the node that detects thisinitiates a status check of the rest of the array, and propagates its conclusions to the survivors, sothat they all enter failure mode at the same time.2
3.4.3 Originator failure and request atomicity
By contrast with a traditional RAID array, we are extending the single-fault-masking semantics toinclude failure of a part of our distributed controller: we do not make the simplifying assumptionthat the controller is not a possible failure point. Worker failure has already been covered.Originator failure brings new concerns: a channel to a host is lost and the fate of requests that werein flight needs to be determined. When an originator failure occurs during a read operation theread operation is aborted since there is no longer a route to communicate its results back to thehost.
2. Multiple node or disk failures cause the array to shut itself down safely to prevent possible data corruption.
Figure 7 : three different places to calculate parity.
∅ ×
×∅
×
∅×
At originator Solely-parity At parity

8
Since failures can occur at any point during the execution of a write operation, the differentportions of the write can be at different stages unless extra steps are taken. This is obviouslyundesirable since the consistency of the stripe could be compromised. Worse is failure of a nodethat is both a worker and an originator, since it will be the only one with a copy of the datadestined for its own disk. (For example, if this node fails during a partial-stripe write after someof the blocks in the stripe have been written, it may not be possible to reconstruct the state of theentire stripe, violating the rule that a single failure must be masked.)
Our solution is to both these concerns is to ensure write atomicity: that is, either a write operationcompletes successfully or it does nothing. To achieve this, we added a two-phase commit protocolto write operations. Before a write can proceed sufficient data must be saved in the array to restartand complete the operation even if any node fails. If this cannot be achieved, the request isaborted.
There are two approaches to implementing the two phase commit. We call the first early commitbecause it tries to make the decision as quickly as possible; we call the second late commit becausewe thought of it after early commit (and because it delays its commit decision until after parityhas been calculated).
In early commit, the goal is for the array to get to its commit point (when it decides whether tocontinue or not) as quickly as possible during the execution of the request. This requires thatsufficient data is replicated to ensure that the write operation can continue or be restarted after afailure. As a minimum, the new data destined for the originator/worker node has to be replicatedelsewhere (in case the originator fails after commit), as does any old data being read as part of alarge-stripe write (in case the reading node fails before it can provide the data). We duplicate thisdata on the parity nodes of the affected stripes because this involves sending no additional datain the case of parity calculations at the parity node (which we will see is the preferred mode ofoperation). The commit point is reached as soon as the necessary redundancy has been achieved.
In late commit, the commit point is reached only after the parity has been computed to provide theneeded partial redundancy: all that happens after the commit point is the writes. Late commit ismuch easier to implement, but has potentially reduced concurrency and higher request latency.We explore this cost later.
A write operation is aborted if any involved worker does not reach its commit point. When aworker node fails, the originator is responsible for restarting the operation. In the event of anoriginator failure, a temporary originator is elected to complete or abort the processing of therequest.3 To implement the two phase commit protocols, new states were added to the worker andoriginator node state tables. The placement of these additional states determines the commitpolicy: for early commit, as soon as possible; for late commit, just before the writes.
3.5 Multiple failures—request sequencing
This section discusses measures designed to help limit the effects of multiple concurrent failures.The TickerTAIP architecture tolerates any single hardware failure. However, as so far described,it provides no behavior guarantees in the event of multiple failures (especially powerfail), and it
3. The election algorithm selects a temporary new originator from amongst those nodes that were alreadyparticipating in the request, since this simplifies recovery.

9
does not ensure the independence of overlapping requests that are executing simultaneously. Inthe terminology of [Lampson81], multiple failures are catastrophes: events outside the coveredfault set for RAID. We introduced the notion of request sequencing into TickerTAIP to help addressthese issues.
3.5.1 Requirements
File system designers typically rely on the presence of ordering invariants to allow them torecover from crashes or power failure. For example, in 4.2BSD-based file systems, metadata (inodeand directory) writes must occur before the data to which they refer is allowed to reach the disk[McKusick84]. The simplest way to achieve this is to not issue the data write until the metadatawrite has completed. Unfortunately, this can severely limit concurrency: for example, paritycalculations can no longer be overlapped with the execution of the previous request. A better wayto achieve the desired invariant is to provide—and preserve—partial write orderings. Thistechnique can significantly improve file system performance. From our perspective as RAID arraydesigners, it also allows the RAID array to make more intelligent decisions about requestscheduling, using rotation position information that is not readily available in the host[Jacobson91].
TickerTAIP also provides support for multiple hosts. Some mechanism needs to be provided to letrequests from different hosts be serialized without recourse to either sending all requests througha single host, or requiring one request to complete before the next can be issued.
Finally, multiple overlapping requests can be in flight simultaneously which could lead to partsof one write replacing parts of another in a non-serializable fashion. This should clearly beprevented. (Our write commit protocols provide atomicity for each request, but no serializabilityguarantees.)
3.5.2 Request sequencing
To address these requirements, we introduced a request sequencing mechanism using partialorderings for both reads and writes. Internally, these are represented in the form of directed acyclicgraphs (DAGs): each request is represented by a node in the DAG, while the edges of the DAGrepresent dependencies between requests.
To express the DAG, each request is given a unique identifier. A request is allowed to list one ormore requests on which it explicitly depends; TickerTAIP guarantees that the effect is as if no requestbegins until the requests on which it depends complete.4 If a request is aborted, all requests thatexplicitly depend on it are also aborted (and so on, transitively). In addition, TickerTAIP willassign sufficient (arbitrary) implicit dependencies to prevent overlapping requests from executingconcurrently. Aborts are not propagated across implicit dependencies. In the absence of explicitdependencies, the order in which requests are serviced is some arbitrary serializable schedule.
3.5.3 Sequencer states
The management of sequencing is performed through a high-level state table, with the followingstates (diagrammed, with their transitions, in Figure 8):
4. There are certain freedoms to perform eager evaluation, some of which we exploit in our current implementation.

10
• NotIssued: the request itself has not yet reached TickerTAIP, but another request has referredto this request in its dependency list.
• Unresolved: the request has been issued, but it depends on a request that has not yet reachedthe TickerTAIP array.
• Resolved: all of the requests that this one depends on have arrived at the array, but at least one hasyet to complete.
• InProgress: all of a request’s dependencies have been satisfied, so it has begun executing.
• Completed: a request has successfully finished.
• Aborted: a request was aborted, or a request on which this request explicitly depended has beenaborted.
Old request state has to be garbage collected. We do this by requiring that the hosts number theirrequests sequentially, and by maintaining a counter that keeps track of the oldest incompleterequest from each host. As such requests complete, the counter is advanced, and the request andany lower-numbered ones can have be deleted. Any request that depends on a request numberedlower than the counter can then consider the dependency immediately satisfied.
Aborts are an important exception to this mechanism since a request that depends on an abortedrequest should itself be aborted, whenever it occurred. (There is a race condition between therequest being aborted and the host issuing requests that depend on it.) Our solution is to maintain
NotIssued
Unresolved
Resolved
InProgress
Completed Aborted
Figure 8 : states of a request. An “anti-dependent” is a request that this request is waiting for.
anti-dependentsresolved
anti-dependentscompleted
requestaborted
requestcompleted
an anti-dependentaborted
issuedby a host
issued by a host
referenced by another request

11
state about aborted requests for a guaranteed minimum time—10 seconds in our prototype.Similarly, a time-out on the NotIssued state can be used to detect errors such as a host that neverissues a request other requests are waiting for.
3.5.4 Sequencer design alternatives
We considered four designs for the sequencer mechanism:
1. Fully centralized: a single, central sequencer manages the state table and its transitions.(Actually, a primary and a backup are used to eliminate a single point of failure.) Each
request suffers two additional round-trip message latency times.5
2. Partially centralized: a centralized sequencer handles the state table until all the dependencieshave been resolved, at which point the responsibility is shifted to the worker nodes involvedin the request. This requires that the status of every request be sent to all the workers, toallow them to do the resolution of subsequent transitions. This has more concurrency, butrequires a broadcast on every request completion.
3. Originator-driven: in place of a central sequencer, the originator nodes (since there willtypically be fewer of these than the workers) conduct a distributed-consensus protocol todetermine the overlaps and sequence constraints, after which the partially-centralizedapproach is used. This always generates more messages than the centralized schemes.
4. Worker-driven: the workers are responsible for all the states and their transitions. Thiswidens the distributed-consensus protocol to every node in the array, and still requires theend-of-request broadcast.
Although the earlier of the above designs potentially increase concurrency, they do so at the costof increased message traffic and complexity. They perform better in the face of large requests withlow degrees of overlap, while the later approaches perform better with many smaller requests, orwith high degrees of overlap.
We chose to implement the fully centralized model in our prototype, largely because of thecomplexity of the failure-recovery protocols required for the alternatives. We measured theresulting latency to be that of two round-trip messages (440µs) plus a few tens of microseconds ofstate table management. We find the addition overhead to provide request sequencing acceptablefor the benefits that it provides, although we also made it optional.
4 Evaluating TickerTAIPThis section presents the vehicles we used to evaluate the design choices and performance of theTickerTAIP architecture.
4.1 The prototype
We first constructed a working prototype implementation of the TickerTAIP design, including all thefault tolerance features described above. The intent of this implementation was a functional
5. In the case of no conflicts, the two round-trips are: between the originator and the sequencer, and between thesequencer and its backup. One of these trips is unneeded if the originator is co-located with the sequencer.

12
testbed, to help ensure that we had made our design complete. (For example, we were able to testour fault recovery code by telling nodes to “die”.) The prototype also let us measure path lengthsand get some early performance data.
We implemented the designs on our DataMesh hardware. This is an array of seven storage nodes,each comprised of a Parsytec MSC card with a T800 transputer, 4MB of RAM, and a local SCSIinterface, connected to a local SCSI disk drive. The disks were spin-synchronized for theseexperiments. A stripe unit (the block-level interleave unit) was 4KB. Each node had an HP79560disk with the properties shown in Table 2.
The prototype was built in C to run on Helios [Perihelion91]: a small, lightweight operatingsystem nucleus. The one-way message latency for short messages between directly-connectednodes is about 110µs; the peak bandwidth about 1.6MB/s. Performance was limited by therelatively slow processors, and because the design of the Parsytec cards means that they cannotoverlap computation and data transfer across their SCSI bus. Nevertheless, the prototype provideduseful comparative performance data for design choices, and served as the calibration point of oursimulator.
The prototype comprised a total of 13.3k lines of code, including comments and test routines.About 12k of this was directly associated with the RAID functionality.
4.2 The simulator
We also built a detailed event driven simulator using the AT&T C++ tasking library. This enabledus to explore the effects of changing link and processor speeds, and to experiment with largerconfigurations than our prototype. Our model encompassed the following components:
• Workloads: both fixed (all requests of a single type) and imitative (patterns that simulate existingworkload patterns); we used a closed queueing model, and a method similar to that of[Pawlikowski90] to obtain steady-state measurements.
• Host: a collection of workloads sharing an access port to the TickerTAIP array; disk driver pathlengths were estimated from measurements made on our local HP-UX systems.
• TickerTAIP nodes (workers and originators): code path lengths were derived from measurements of thealgorithms running on the working prototype and our HP-UX workstations (we assumed that theParsytec MSC limitations would not occur in a real design).
• Disk: we modelled the HP79560 disks as used on the prototype implementation, using data takenfrom measurements of the real hardware. The disk model included:
– the seek time profile from Table 2, plus different settling times for reads and writes;– track- and cylinder-skews, including track switch times during a data transfer;
Table 2 : characteristics of the HP79560 disk drive
diameter 5.25” disk transfer rate 2.2MB/ssurfaces/heads 19 data, 1 servo SCSI bus transfer rate 5MB/s
formatted capacity 1.3GB controller overhead 1mstrack size 72 sectors track-to-track switch time 1.67ms
sector size 512 bytes seeks ≤ 12 cylinders 1.28 + 1.15√d msrotation speed 4002 RPM seeks > 12 cylinders 4.84 + 0.193√d + 0.00494d ms

13
– rotation position;– SCSI bus and controller overheads, including overlapped data transfers from the mechanism into
a disk track buffer and transmissions across the SCSI bus: the granularity used was 4KB.• Links: represent communication channels such as the small-area network and the SCSI busses. For
simplicity, we report here data from a complete point-to-point interconnect design with a DMAengine per link; however, preliminary studies suggest that similar results would be obtained frommesh-based switching fabrics.
Under the same design choice and performance parameters, our simulation results agreed withthe prototype (real) implementation within 3% most of the time, and always within 6%. This gaveus confidence in the predictive abilities of the simulator.
The system we evaluate here is a RAID5 disk array with left-symmetric parity [Lee90], 4KB block-level interleave, spin-synchronized disks, FIFO disk scheduling, and with no data replication,spare blocks, floating parity or indirect-writes. The configuration has 4 hosts and 11 worker nodes,each worker with a single HP96760 disk attached to it via a 5MB/s SCSI bus. Four of the workernodes were also originators.
Throughput numbers are obtained when the system is driven to saturation; response times withonly one request in the system at a time. For throughput we timed 10000 requests in each run; forlatency 2000. Each data point on a graph represents the average of two independent runs, with allvariances less than 1.5%, and most less than 0.5%. Each value in a table is the average of five suchruns; the variances are reported with each table.
4.3 Read performance
Table 3 shows the performance of our simulated 11-disk array for random read requests across arange of link speeds. There is no significant difference in throughput for any link speed above1MB/s, but 10MB/s or more is needed to minimize request latencies for the larger transfers.
Figure 9 : effect of large-stripe policy on throughput and response time as a function of request size.
0
2
4
6
8
10
12
10 100 1000 10000
Throughput (MB/s)
Request Size (KB) (log scale)
Throughput vs Request Size (10 MIPS, 10 MB/s)
WithWithout
0
0.02
0.04
0.06
0.08
0.1
0.12
0.14
10 100 1000 10000
Response Time (seconds)
Request Size (KB) (log scale)
Response Times vs Request Size (10 MIPS, 10 MB/s)
WithWithout

14
4.4 Design alternatives: writes
We first consider the effect of the large stripe policy. Figure 9 shows the result: in general, applyingthe large write policy gives slightly better throughput results, so that is what we used for theremainder of the experiments.
Next, we compare two policies for parity calculation: at originator, and at parity nodes. Figure 10gives the results. Overall, performing parity computations at the parity node is best because itspreads the work most evenly, so we used it for the remainder of our experiments. As expected,the difference is biggest for large write requests and slow processors.
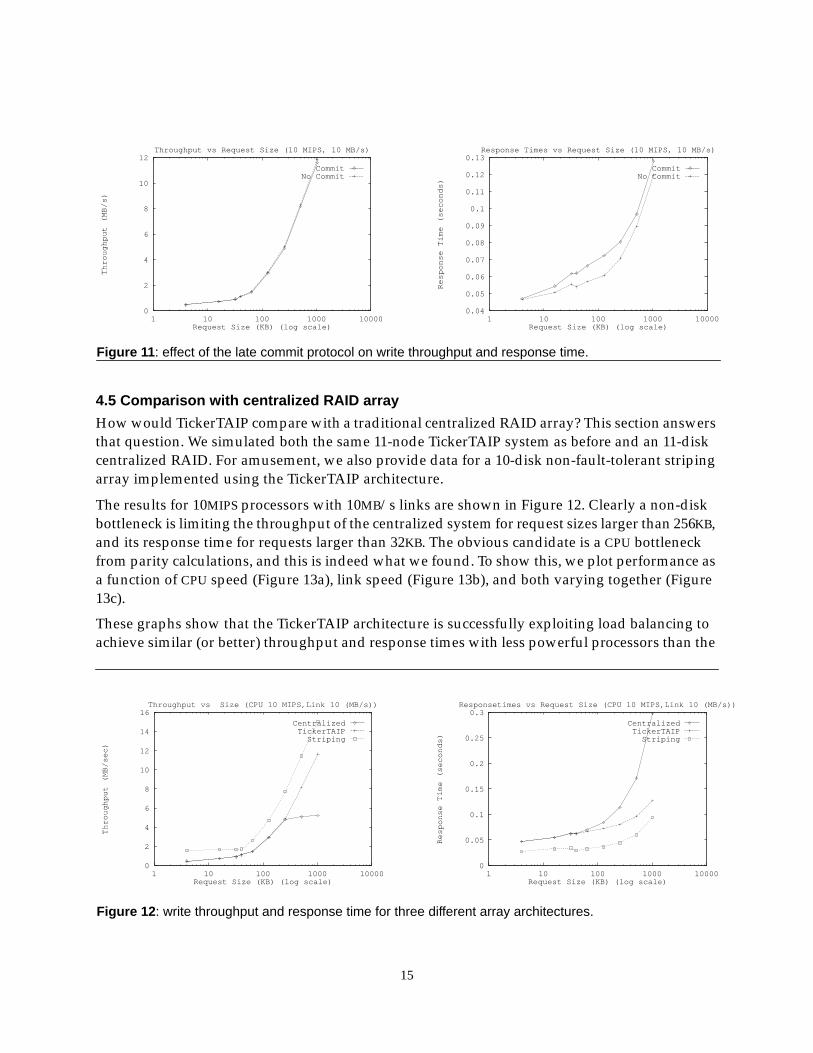
The effect of the late commit protocol on performance is shown in Figure 11. (Although notshown, the performance of early commit is slightly better than that of late commit, but not as goodas no commit). The effect of the commit protocol on throughput is small (< 2%), but the effect onresponse time is more marked: the commit point is acting as a synchronization barrier thatprevents some of the usual overlaps between disk accesses and other operations. For example, adisk that is only doing writes for a request will not start seeking until the commit message is given.(This could be avoided by having it do a seek in parallel with the other pre-commit work.
Nonetheless, we recommend late commit overall: its throughput is almost as good as no commitprotocol at all, and it is much easier to implement than early commit.
Table 3 : read performance for fixed-size workloads, with varying link speeds. (All variances less than 2%.)
Requestsize
throughputMB/s
latency in ms
1MB/s10MB/
s100MB/
s
4KB 0.94 33 31 3040KB 1.79 38 34 331MB 15.2 178 86 76
10MB 21.1 1520 610 520
Figure 10 : effect of parity calculation policy on throughput and response times for 1MB random writes.
0
2
4
6
8
10
12
0 5 10 15 20 25 30
Throughput (MB/sec)
Link(MB/s) & CPU(MIPS)
Throughput vs Link and CPU (Random 1MB)
at Originatorat Parity
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0 5 10 15 20 25 30
Response Time (seconds)
Link Speed (MB/s) CPU (MIPS)
Responsetime vs Link and CPU (Random 1MB)
at Originatorat Parity
15
4.5 Comparison with centralized RAID array
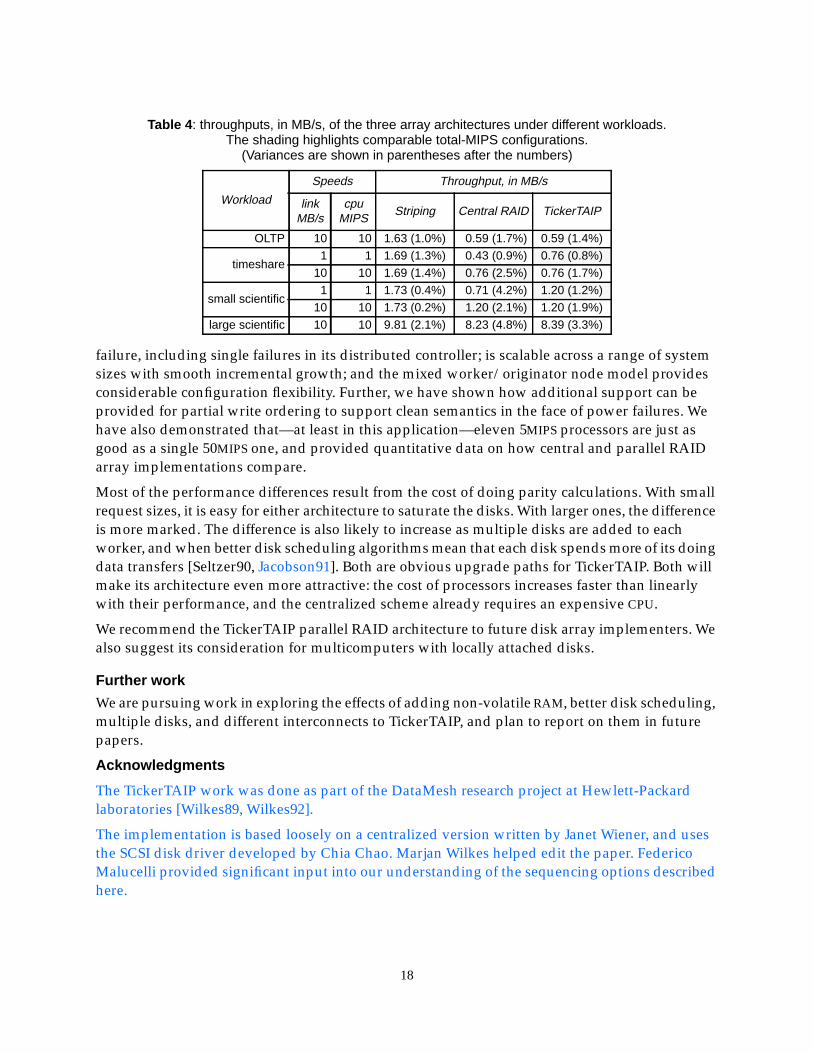
How would TickerTAIP compare with a traditional centralized RAID array? This section answersthat question. We simulated both the same 11-node TickerTAIP system as before and an 11-diskcentralized RAID. For amusement, we also provide data for a 10-disk non-fault-tolerant stripingarray implemented using the TickerTAIP architecture.
The results for 10MIPS processors with 10MB/s links are shown in Figure 12. Clearly a non-diskbottleneck is limiting the throughput of the centralized system for request sizes larger than 256KB,and its response time for requests larger than 32KB. The obvious candidate is a CPU bottleneckfrom parity calculations, and this is indeed what we found. To show this, we plot performance asa function of CPU speed (Figure 13a), link speed (Figure 13b), and both varying together (Figure13c).
These graphs show that the TickerTAIP architecture is successfully exploiting load balancing toachieve similar (or better) throughput and response times with less powerful processors than the
Figure 11 : effect of the late commit protocol on write throughput and response time.
0
2
4
6
8
10
12
1 10 100 1000 10000
Throughput (MB/s)
Request Size (KB) (log scale)
Throughput vs Request Size (10 MIPS, 10 MB/s)
CommitNo Commit
0.04
0.05
0.06
0.07
0.08
0.09
0.1
0.11
0.12
0.13
1 10 100 1000 10000
Response Time (seconds)
Request Size (KB) (log scale)
Response Times vs Request Size (10 MIPS, 10 MB/s)
CommitNo Commit
Figure 12 : write throughput and response time for three different array architectures.
0
2
4
6
8
10
12
14
16
1 10 100 1000 10000
Throughput (MB/sec)
Request Size (KB) (log scale)
Throughput vs Size (CPU 10 MIPS,Link 10 (MB/s))
CentralizedTickerTAIPStriping
0
0.05
0.1
0.15
0.2
0.25
0.3
1 10 100 1000 10000
Response Time (seconds)
Request Size (KB) (log scale)
Responsetimes vs Request Size (CPU 10 MIPS,Link 10 (MB/s))
CentralizedTickerTAIP
Striping

16
Figure 13b : throughput and response time as a function of link speed. 1MB random writes.
Figure 13a : throughput and response time as a function of CPU speed. 1MB random writes.
Figure 13c : throughput and response time as a function of CPU and link speeds. 1MB random writes.
0
2
4
6
8
10
12
0 5 10 15 20 25 30 35 40 45 50
Throughput (MB/sec)
MIPS
Throughput vs CPU (Random 1MB, Link 100 (MB/s))
CentralizedTickerTAIP
0
0.2
0.4
0.6
0.8
1
0 10 20 30 40 50 60 70 80 90 100
Response Time (seconds)
MIPS
Responsetime vs CPU (Random 1 MB, Link 100 (MB/s))
CentralizedTickerTAIP
0
2
4
6
8
10
12
0 0.5 1 1.5 2 2.5 3 3.5 4 4.5 5
Throughput (MB/sec)
Link Speed (MB/Sec)
Throughput vs Link(Random 1MB, CPU 100 MIPS)
CentralizedTickerTAIP
0
0.05
0.1
0.15
0.2
0.25
1 2 3 4 5 6 7 8 9 10
Response Time (seconds)
Link Speed (MB/sec)
Responsetime vs Link (Random 1MB, CPU 100 MIPS)
CentralizedTickerTAIP
0
2
4
6
8
10
12
14
16
0 5 10 15 20 25 30 35 40 45 50
Throughput (MB/sec)
Link(MB/sec) and CPU(MIPS)
Throughput vs Link and CPU (Random 1MB I/O)
CentralizedTickerTAIPStriping
0
0.2
0.4
0.6
0.8
1
1.2
0 10 20 30 40 50 60 70 80 90 100
Response Time (seconds)
Link (MB/sec) CPU (MIPS)
Responsetime vs Link speed and CPU (Random 1MB I/O)
CentralizedTickerTAIP
Striping

17
centralized architecture. For 1MB write requests, TickerTAIP’s 5MIPS processors and 2–5MB/slinks give comparable throughput to 25MIPS and 5MB/s for the centralized array. The centralizedarray needs a 50MIPS processor to get similar response times as TickerTAIP.
Finally, we looked at the effect of scaling the number of workers in the array, with both constant(400KB) and varying request size (ten full stripes); 4 of the nodes were also originators in all cases.The results are seen in Figure 12. With varying request size, the TickerTAIP architecture continuesto scale linearly over the range we investigated; with constant request size, it degrades somewhatas the disks are kept less busy doing useful work.
4.6 Synthetic workloads
The results reported so far have been from fixed, constant-sized workloads. To test our hypothesisthat TickerTAIP performance would scale as well over some other workloads, we tested a numberof additional workload mixtures, designed to model “real world” applications:
• OLTP: based on the TPC-A database benchmark;
• Timeshare: based on measurements of a local UNIX timesharing system [Ruemmler93];
• Scientific: based on measurements taken from supercomputer applications running on a Cray[Miller91]; “large” has a mean request size of about 0.3MB, “small” has a mean around 30KB.
Table 4 gives the throughputs of the disk arrays under these workloads for a range of processorand link speeds. As expected, TickerTAIP outperforms the centralized architecture at lower CPUspeeds, although both are eventually able to drive the disks to saturation—mostly because therequest sizes are quite small. TickerTAIP’s availability is still higher, of course.
5 ConclusionsTickerTAIP is a new parallel architecture for RAID arrays. Our experience is that it is eminentlypractical (for example, our prototype implementation took only 12k lines of commented code).The TickerTAIP architecture exploits its physical redundancy to tolerate any single point of
Figure 14 : effect of TickerTAIP array size on performance.
0
5
10
15
20
25
0 5 10 15 20 25 30 35
Throughput (MB/s)
# of Nodes (n) Request Size ((n-1)x40K)
Throughput vs Array Size & Request Size
scaled write sizes
0
2
4
6
8
10
0 5 10 15 20 25 30 35
Throughput (MB/s)
# of Nodes (n)
Throughput vs Array Size (400KB random write requests)
400KB writes
18
failure, including single failures in its distributed controller; is scalable across a range of systemsizes with smooth incremental growth; and the mixed worker/originator node model providesconsiderable configuration flexibility. Further, we have shown how additional support can beprovided for partial write ordering to support clean semantics in the face of power failures. Wehave also demonstrated that—at least in this application—eleven 5MIPS processors are just asgood as a single 50MIPS one, and provided quantitative data on how central and parallel RAIDarray implementations compare.
Most of the performance differences result from the cost of doing parity calculations. With smallrequest sizes, it is easy for either architecture to saturate the disks. With larger ones, the differenceis more marked. The difference is also likely to increase as multiple disks are added to eachworker, and when better disk scheduling algorithms mean that each disk spends more of its doingdata transfers [Seltzer90, Jacobson91]. Both are obvious upgrade paths for TickerTAIP. Both willmake its architecture even more attractive: the cost of processors increases faster than linearlywith their performance, and the centralized scheme already requires an expensive CPU.
We recommend the TickerTAIP parallel RAID architecture to future disk array implementers. Wealso suggest its consideration for multicomputers with locally attached disks.
Further work
We are pursuing work in exploring the effects of adding non-volatile RAM, better disk scheduling,multiple disks, and different interconnects to TickerTAIP, and plan to report on them in futurepapers.
Acknowledgments
The TickerTAIP work was done as part of the DataMesh research project at Hewlett-Packardlaboratories [Wilkes89, Wilkes92].
The implementation is based loosely on a centralized version written by Janet Wiener, and usesthe SCSI disk driver developed by Chia Chao. Marjan Wilkes helped edit the paper. FedericoMalucelli provided significant input into our understanding of the sequencing options describedhere.
Table 4 : throughputs, in MB/s, of the three array architectures under different workloads.The shading highlights comparable total-MIPS configurations.
(Variances are shown in parentheses after the numbers)
Workload
Speeds Throughput, in MB/s
linkMB/s
cpuMIPS
Striping Central RAID TickerTAIP
OLTP 10 10 1.63 (1.0%) 0.59 (1.7%) 0.59 (1.4%)
timeshare1 1 1.69 (1.3%) 0.43 (0.9%) 0.76 (0.8%)
10 10 1.69 (1.4%) 0.76 (2.5%) 0.76 (1.7%)
small scientific1 1 1.73 (0.4%) 0.71 (4.2%) 1.20 (1.2%)
10 10 1.73 (0.2%) 1.20 (2.1%) 1.20 (1.9%)large scientific 10 10 9.81 (2.1%) 8.23 (4.8%) 8.39 (3.3%)

19
References[Chen90] Peter M. Chen, Garth A. Gibson, Randy H. Katz, and David A. Patterson. An evaluation
of redundant arrays of disks using an Amdahl 5890. Proceedings of SIGMETRICS (Boulder,Colorado), pages 74–85, 22–25 May 1990.
[Dunphy90] Robert H. Dunphy, Jr, Robert Walsh, and John H. Bowers. Disk drive memory.Technical report 4 914 656, 3 April 1990. United States patent, filed 28 June 1988.
[Gray90] Jim Gray, Bob Horst, and Mark Walker. Parity striping of disc arrays: low-cost reliablestorage with acceptable throughput. Proceedings of the 16th International Conference on VeryLarge Databases (Brisbane, Australia), pages 148–159, 13–16 August 1990.
[Holland92] Mark Holland and Garth A. Gibson. Parity declustering for continuous operation inredundant disk arrays. Proceedings of 5th International Conference on Architectural Support forProgramming Languages and Operating Systems (Boston, MA). Published as ComputerArchitecture News 20 (special issue):23–35, 12–15 October 1992.
[HPdisks89] Hewlett-Packard Company. HP 7936 and HP 7937 disc drives hardware support manual,part number 07937-90903, July 1989.
[Jacobson91] David M. Jacobson and John Wilkes. Disk scheduling algorithms based on rotationalposition. Technical report HPL–CSP–91–7. Hewlett-Packard Laboratories, 24 February 1991.
[Lampson81] B. W. Lampson and H. E. Sturgis. Atomic transactions. In B. W. Lampson, M. Paul,and H. J. Siegert, editors, Distributed Systems—Architecture and Implementation: an AdvancedCourse, volume 105 of Lecture Notes in Computer Science, pages 246–65. Springer-Verlag,New York, 1981.
[Lawlor81] F. D. Lawlor. Efficient mass storage parity recovery mechanism. IBM TechnicalDisclosure Bulletin 24(2):986–7, July 1981.
[Lee90] Edward K. Lee. Software and performance issues in the implementation of a RAIDprototype. UCB/CSD 90/573. Computer Science Division, Department of ElectricalEngineering and Computer Science, University of California at Berkeley, May 1990.
[McKusick84] Marshall K. McKusick, William N. Joy, Samuel J. Leffler, and Robert S. Fabry. Afast file system for UNIX. ACM Transactions on Computer Systems 2(3):181–97, August 1984.
[Miller91] Ethan L. Miller and Randy H. Katz. Analyzing the I/O behavior of supercomputerapplications. Digest of papers, 11th IEEE Symposium on Mass Storage Systems (Monterey, CA),pages 51–9, 7–10 October 1991.
[Muntz90] Richard R. Muntz and John C. S. Lui. Performance analysis of disk arrays underfailure. Proceedings of 16th International Conference on Very Large Data Bases (Brisbane,Australia), pages 162–73, Dennis McLeod, Ron Sacks-Davis, and Hans Schek, editors, 13–16August 1990.
[Ousterhout90] John K. Ousterhout. Why aren’t operating systems getting faster as fast ashardware? USENIX Summer Conference (Anaheim, CA), pages 247–56, 11–15 June 1990.
[Park86] Arvin Park and K. Balasubramanian. Providing fault tolerance in parallel secondarystorage systems. Technical report CS–TR–057–86. Department of Computer Science, PrincetonUniversity, November 1986.
[Patterson88] David A. Patterson, Garth Gibson, and Randy H. Katz. A case for redundant arraysof inexpensive disks (RAID). Proceedings of SIGMOD (Chicago, IL), 1–3 June 1988.

20
[Patterson89] David A. Patterson, Peter Chen, Garth Gibson, and Randy H. Katz. Introduction toredundant arrays of inexpensive disks (RAID). Spring COMPCON’89 (San Francisco, CA),pages 112–17. IEEE, March 1989.
[Pawlikowski90] Krzysztof Pawlikowski. Steady-state simulation of queueing processes: a surveyof problems and solutions. Computing Surveys 22(2):123–70, June 1990.
[Perihelion91] Perihelion Software. The Helios parallel operating system. Prentice-Hall International,London, 1991.
[Rosenblum92] Mendel Rosenblum and John K. Ousterhout. The design and implementation of alog-structured file system. ACM Transactions on Computer Systems 10(1):26–52, February 1992.
[Ruemmler93] Chris Ruemmler and John Wilkes. UNIX disk access patterns. USENIX WinterTechnical Conference Proceedings (San Diego, CA), 27–29 Jan. 1993. (To appear.)
[Seltzer90] Margo Seltzer, Peter Chen, and John Ousterhout. Disk scheduling revisited.Proceedings of Winter 1990 USENIX Conference (Washington, D.C.), pages 313–23, 22–26January 1990.
[Stonebraker89] Michael Stonebraker. Distributed RAID – a new multiple copy algorithm.UCB/ERL M89/56. Electronics Research Laboratory, University of California at Berkeley, 15May 1989.
[Wilkes89] John Wilkes. DataMesh—scope and objectives: a commentary. Technical report HPL–DSD–89–44. Distributed Systems Department, Hewlett-Packard Laboratories, 18 July 1989.
[Wilkes91] John Wilkes. The DataMesh research project. Transputing’91 (Sunnyvale, CA), volume2, pages 547–53, Peter Welch, Dyke Stiles, Tosiyasu L. Kunii, and AndréBakkers, editors. IOSPress, Amsterdam, 22–26 April 1991.
[Wilkes92] John Wilkes. DataMesh research project, phase 1. USENIX Workshop on File Systems(Ann Arbor, MI), pages 63–9, 21–22 May 1992.

HPLaboratoriesTechnicalReport
Traditional RAID arrays have a centralized architecture, with a singlecontroller through which all requests flow. Such a controller is a singlepoint of failure, and its performance limits the maximum size that thearray can grow to. We describe here TickerTAIP, a parallel architecture forRAID arrays that distributes the controller functions across severalloosely-coupled processors. The result is better scalability, fault tolerance,and flexibility.
This paper presents the TickerTAIP architecture and an evaluation of itsbehavior. We demonstrate the feasibility by an existence proof; describe afamily of distributed algorithms for RAID parity calculation; discusstechniques for establishing request atomicity, sequencing and recovery;and provide a performance evaluation of the TickerTAIP design space inboth absolute terms and by comparison to a centralized RAIDimplementation. We conclude that the TickerTAIP architectural approachis feasible, useful, and effective.
*Princeton University, Princeton, NJ. †University of Illinois, Urbana-Champaign, IL. ‡University of Wisconsin, Madison, WI.
© Copyright Hewlett-Packard Company 1992
The TickerTAIP parallel RAID architecture
Pei Cao,* Swee Boon Lim,†Shivakumar Venkataraman‡, John WilkesComputer Systems LaboratoryHPL–92–151December, 1992