the semantic web -- an overview -- dr yuri a. tijerino computer science department brigham young...
Post on 22-Dec-2015
218 views
TRANSCRIPT

The Semantic Web -- an overview --
Dr Yuri A. TijerinoComputer Science DepartmentBrigham Young University

The Book of Genesis tells of a great tower built by men not only from fear of a second Flood but above all “to make a name for themselves”. Gods’ punishment was the Babylonian confusion of tongues, with men unable to understand each other, the result being that the
tower was never finished.

Today’s Web
information overload massive, heterogeneous data sets unstructured documents (e.g. e-mails) lack of context and meaning
new forms of content software programs, sensors, ambient devices
… blur between content & services
mixing Web content with “smart” executables

Limitations of the Web Today…

The Semantic Web
Tim Berners-Lee “an extension of the current web in
which information is given well-defined meaning, better enabling computers and people to work in cooperation”
An open platform allowing information to be shared and processed automatically adding context and structure via
metadata

The Agent Computing Paradigm
The old way of thinking about computer programs: a program
begins executing takes input gives output finishes executing
The new way: programs interact with each other are always active should be robust (ie, able to deal
with the unexpected)

From Agents to Knowledge Markup
Almost everything we need to know is on the web.
What a great resource for agents! But … Agents don’t understand web pages.
Natural Language processing is too hard for computers, and will remain so for a long time.
The solution: Knowledge Markup.

Knowledge Markup in a Nutshell
A web page describes objects. Datasets, human beings, services, items for sale,
etc.
The semantics of an object are defined by the place it occupies in some domain ontology.
The basic idea of knowledge markup is to use ontologies to markup a web page according to the location its objects occupy in the ontology.
Essentially, knowledge markup is knowledge representation done in ontologies.

Benefits of Knowledge Markup
Agents can parse a page, and immediately understand its semantics. No need for natural language processing.
Searches can be done on concepts. The inheritance mechanisms of the back-end knowledge base obviate the need for keywords.
Data and knowledge sharing.

Knowledge Markup Example (Hypothetical)
You ask the system “Show me all universities near the beach.”
The UCLA page doesn’t say anything about the beach, but it does say (through knowledge markup) that it’s near the Pacific Ocean.
UCLA makes use of a geography ontology which includes the rule “Ocean(x) hasBeaches(x)”.
When your search agent parses the UCLA page, it loads in the relevant ontologies, deduces that UCLA is near the beach, and returns the page.
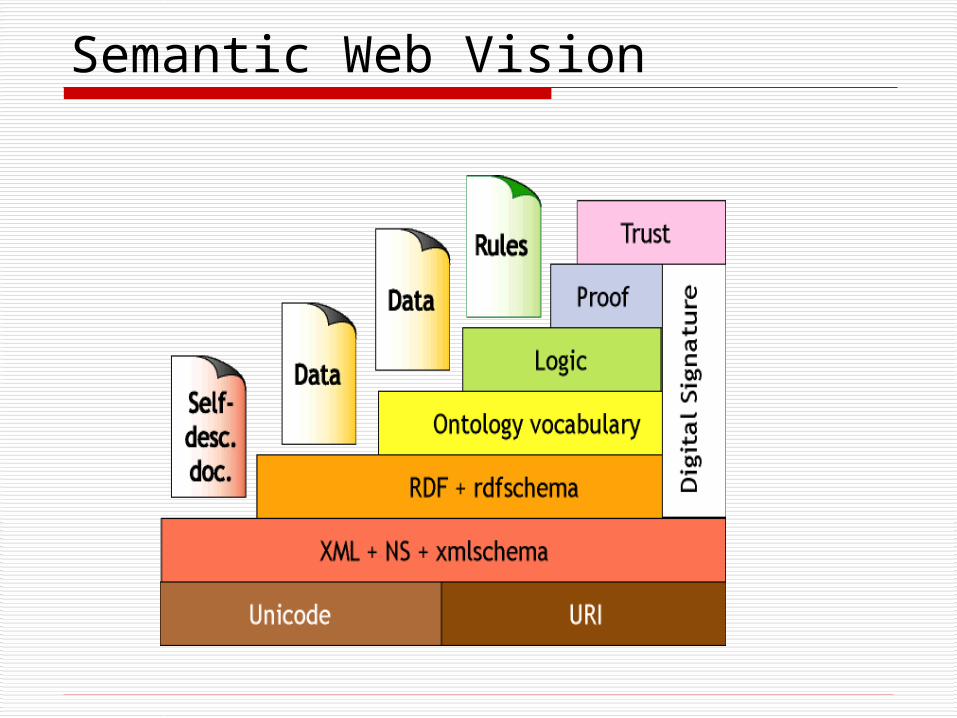
Semantic Web Vision

XML is a first step
Semantic markup HTML layout XML meaning
Metadata within documents not across documents

XML example
<play>
<title>The Life and Death of King John</title>
<Dramatis Personae>
<persona>The Earl of PEMBROKE</persona>
<persona>The Earl of ESSEX</persona>
……
</Dramatis Personae>
<Stagedir>SCENE England, the Court.</Stagedir>
<act>Act 1
<scene>Scene I.
<speech>
<speaker>JOHN</speaker>
<line>Now, Chatillon, what would France with us?</line>
</speech>

Resource Description Framework (RDF)
A standard of W3C Relationships between documents
(or parts of documents) Can be an XML application Consisting of triples or sentences:
subject property or predicate (“verb”) object
RDF & RDFS used to define ontologies
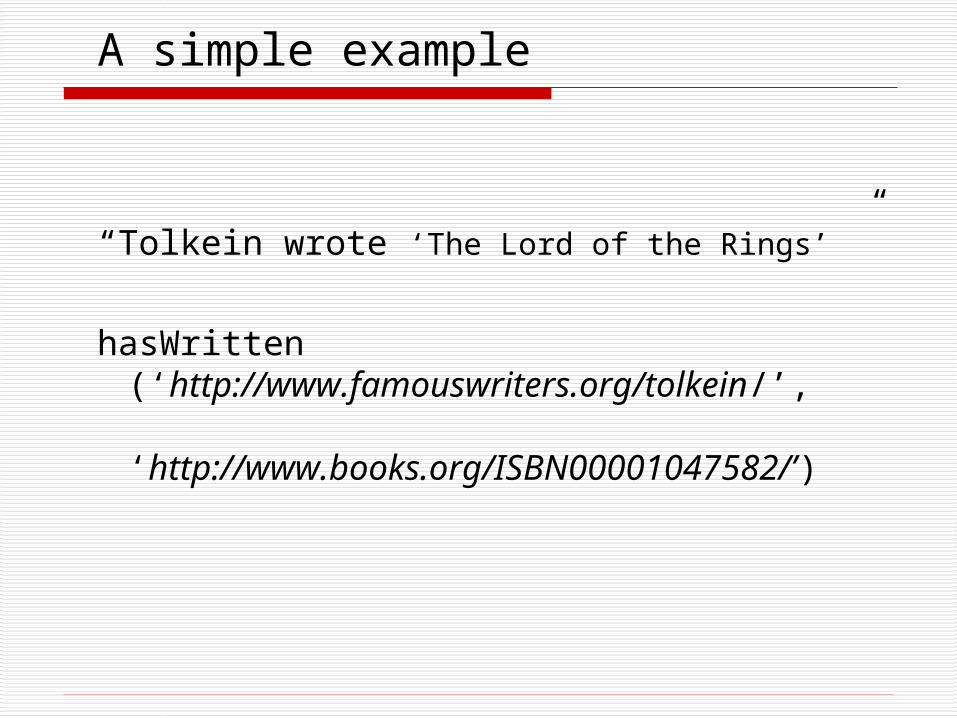
A simple example
“Tolkein wrote ‘The Lord of the Rings’ ”
hasWritten (‘http://www.famouswriters.org/tolkein/’,
‘http://www.books.org/ISBN00001047582/’)

RDF Schema
RDF Schema is a frame based language used for defining RDF vocabularies. Introduces properties
rdfs:subPropertyOf and rdfs:subClassOf Defines semantics for inheritance and
transitivity. Introduces notions of rdfs:Domain and
rdfs:Range Also provides
rdfs:ConstraintProperty
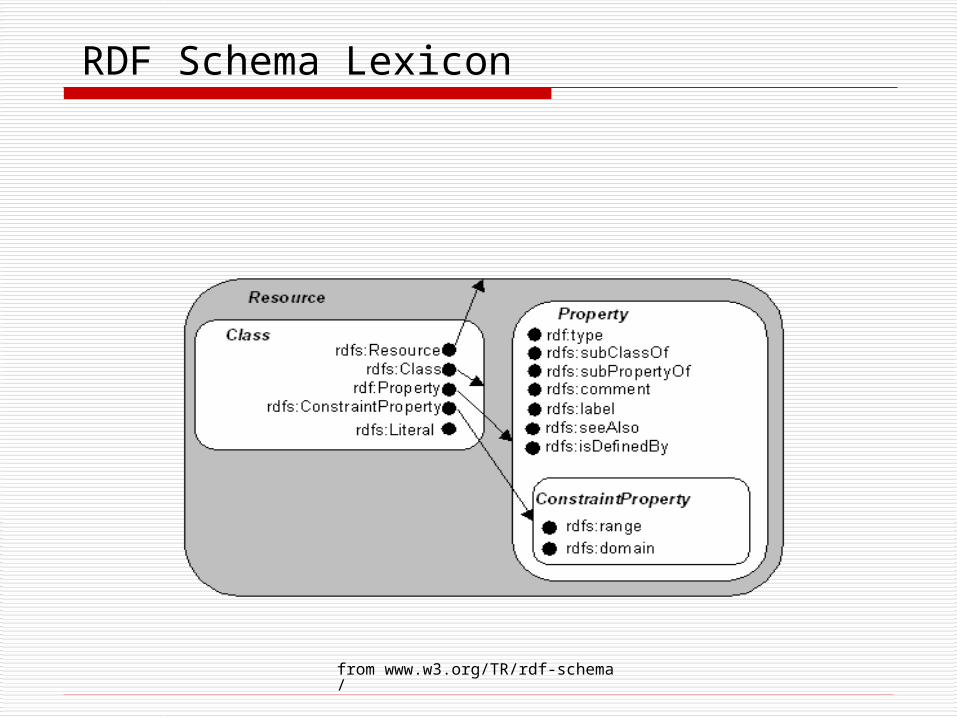
from www.w3.org/TR/rdf-schema/
RDF Schema Lexicon

The Recapitulation of AI Research
The last 5 years have seen a recapitulation of 40 years of AI history. Data Structures XML Semantic Networks RDF Early Frame Based Systems RDFS
As a mechanism for metadata encapsulation,
RDFS works just fine. But it is unsuited for general purpose knowledge representation. This is where the AI community steps in, saying, essentially, “We know how to do this; please let us help.”

What are Ontologies?
Ontologies provide a shared and common understanding of a domain
a (shared) specification of a conceptualisation
concept map a simple example - Yahoo
Business&Economy > Finance > Banking universal, non-consensual, manual,
changes slowly for WWW, defined using RDF-Schema
(RDFS)

A History of Knowledge Representation
Knowledge representation (KR) is the branch of artificial intelligence (AI) that deals with the construction, description and use of ontologies. How do we model a domain for input into the
machine? Ontology is the branch of philosophy that answers the
question “what is there?”
Some big names in ontology: Parmenides, Plato, Aristotle, Kant, Pierce, Husserl
For a program to reason, it must have a conceptual understanding of the world. This understanding is provided by us. Thus we have to answer questions that we’ve been considering for several thousand years.
Today, in computer science, an ontology is typically a hierarchical collection of classes, permissible relationships amongst those classes, and inference rules

Ontology as Taxonomy
Computer Networks
Network Architectures
ATM ISDNWireless Communication
Client/ Server
Network OS
Distributed Systems

Ontology of People and their Roles
Employee
Manager Expert Analyst
Programme Mgr Project Mgr
funds
advises
Contractor

Ontology and Logic
Reasoning over ontologies Inferencing capabilities
X is author of Y Y is written by XX is supplier to Y; Y is supplier to Z X and Z are part of the same supply chain
Based on Description Logic research

Example Ontology (Scientific Pedagogy)
ClassesExperimental science (ES)Theoretical science (TS)Good Teaching Example (GTE)
RelationshipsMotivates A particular instance of TS may motivate an
instance of ES.Demonstrates A particular instance of ES may
demonstrate an instance of TS.
Inference RulesES(X) and TS(Y) and Demonstrates(X,Y) GTE(X,Y)

The DAML Program DAML: DARPA Agent Markup Language
Defense Advanced Research Agency (DARPA) program Program Managers: James Hendler, Murray Burke Begin in August 2000
Goal: achieve semantic interoperability between Web pages, databases, programs, and sensors
Integration contractor and 16 technology development teams MIT (Tim Berners-Lee, Ben Grosof) Stanford (Gio Weiderhold, Richard Fikes, Deborah McGuinness) UMBC (Tim Finin) U West Florida (Pay Hayes) Yale (Drew McDermott)…
Advisors: Ramanthan Guha, Peter Patel-Schneider, …
Cycorp (Doug Lenat)
Nokia (Ora Lassila)
Teknowledge (Bob Balzer)
Web site: http://www.daml.org/

DAML+OIL = OWL
A representation language for user-defined ontologies An ontology added to RDF and RDF-Schema Specification document:
http://www.daml.org/2001/03/daml+oil-index.html
Expressive power analogous to: Description logics (e.g., CLASSIC) Monotonic frame languages (e.g., OKBC knowledge model)
Designed in collaboration with the European Community
Designers of the Ontology Inference Layer (OIL)
Basis for Web Ontology Language (OWL), the candidate W3C
standard

DAML+OIL Classes
Thing
Restriction
List
Ontology
AbstractProperty
TransitiveProperty
DatatypeProperty
UniqueProperty
UnambiguousProperty
Nothing

DAML+OIL Properties
EquivalenceequivalentTo, sameClassAs,
samePropertyAs
Listsfirst, rest, item
PropertiesinverseOf
OntologiesversionInfo, imports
ClassesdisjointWith
Defining Non-primitive classesunionOf, disjointUnionOf, intersectionOf,
complementOf, oneOf
RestrictionsonProperty, toClass, hasValue, hasClass,
hasClassQ
minCardinality, maxCardinality, cardinality
minCardinalityQ, maxCardinalityQ, cardinalityQ

Property Restrictions on Classes<Class ID = "Person">
<comment> Person is a subclass of objects whose parents are persons. </comment>
<rdfs:subClassOf>
<daml:Restriction>
<daml:onProperty rdf:resource = “#hasParent” />
<daml:toClass rdf:resource = “#Person” />
</daml:Restriction>
</rdfs:subClassOf>
<comment > Person is a subclass of resources that have one father. </comment>
<rdfs:subClassOf>
<daml:Restriction>
<daml:onProperty rdf:resource = “#hasFather” />
<daml:cardinality> 1 </daml:cardinality>
</daml:Restriction>
</rdfs:subClassOf>
All objects all All objects all of whose of whose
parents are parents are personspersons
All objects that All objects that have exactly 1 have exactly 1
fatherfather
PersonPerson

Comments on DAML+OIL (OWL) Expressive power of a description logic
Representation language for both classes and instances Additional expressive power needed (at least FOL)
No rationale for excluding any axiom from an ontology that is – Not a tautology
Satisfied by the intended interpretation of the ontology Example of need for additional expressive power
“The magnitude of a physical quantity in a given unit of measure”(=> (AND (Quantity-Magnitude ?q ?u ?m) (Quantity-Dimension ?q ?d))
(AND (type Physical-Quantity ?q) (type Unit-Of-Measure ?u)
(type Magnitude ?m) (Unit-Dimension ?u ?d)))
May be too difficult for the Web community to understand Acceptance will be depend on user-friendly tools
Ok to support development of Semantic Web technology

Issues Facing OWL: Need for Really Good Annotation Tools
OWL is not meant to be read or written by human beings. Humans will make assertions through
intuitive user interfaces, which will generate the appropriate OWL markup.
In fact, the markup should “fall out” of the activity of building a web page. This requires some thought.

Proof and Trust

Example 1: Focused Crawling
Special purpose search engines will increasingly replace all-purpose engines.
The notion of an all-purpose search engine is yielding to that of special-purpose engines.
Such engines do not want to index irrelevant pages. Current “focused crawling” techniques employ
heuristics based on text mining, and collaborative filtering.
A cleaner approach would be for web sites to describe themselves with RDF or DAML. An entire site map could be expressed in RDF,
along with metadata descriptions of each node in the map.
An agent would know precisely which of the site’s pages are worth checking out.

Example 2: Indexing the Hidden Web
Search engines – google, infoseek, etc. – work by constantly crawling the web, and building huge indexes, with entries for every word encountered.
But a lot of web information is not linked to directly. It is “hidden” behind forms. eg www.allmovies.com allows you to search
a vast database of movies and actors. But it does not link to those movies and actors. You are required to enter a search term.
A web-spider, not knowing how to interact with such sites, cannot penetrate any deeper than the page with the form.

Indexing the Hidden Web (Contd.)
Now imagine that allmovies.com had some DAML attached, which said
“I am allmovies.com. I am an interface to a vast database of movie and actor information. If you input a movie title into the box, I will return a page with the following information about the movie: … If you input an actor name, I will return a page with the following information about the actor: …”

Indexing the Hidden Web (Contd.)
An OWL aware spider can come to such a page and do one of two things: If it is a spider for a specialized search engine, it may
ignore the site altogether. If not, it can say to itself: “I know some movie titles.
I’ll input them (being careful not to overwhelm the site), and index the results (and keep on spidering from the result pages).
At the least, the search engine can record the fact that“www.allmovies.com/execperson?name=x” returns information about the actor with name x.

Example 3: Knowledge Sharing/Corporate Memory
Our problem: The Church is growing, and various organizations, departments and divisions need to collaborate and share knowledge. The wheel often gets reinvented.
Our proposal: Build an ontology which captures gospel, family
history, education and other relevant knowledge. Mark up talks, scriptures, curriculum materials, etc.
according to this ontology. Harvest the information with OWL aware web-
crawlers. Build OWL aware query agents.

Example 3 (Contd.)
Leaders and members should be able to tell the query agent the current form of their data (e.g. a articles and a subject), their desired output (e.g. all other related lessons prepared by others), and get back the series of available lessons and advice necessary to prepare the lesson.
We also have a chicken and egg problem here. Leaders and members don’t want to invest time
in yet another knowledge technology. How do we do it?

DAML Example 4: ittalks.org
www.ittalks.org will be a repository of information about information technology (IT) talks given at universities and research organization across America.
A user’s information (research interests, schedule, constraints, etc.) will be stored on their personal DAML page.
When a new talk is added, the personal agents of interested users will be notified.
The personal agents will determine, based on schedule, driving time, more refined interest specifications, etc, whether or not to inform the user.

ittalks.org (Contd.)
Example Scenario You are going to be in Boston for a few days. You
enter this in your schedule, and you are automatically notified of several talks, at several Boston universities, that match your interests. You select one that you would like to attend. You get a call on your cell-phone letting you know when it is time to leave for the talk.

The Road Ahead
Enormous synergy between KM, ubiquitous computing, and agents. Start Trek, here we come.
The concept is clear, but many details need to be worked out.
Semantic Web systems can be built incrementally. Start small. Even a very modest effort
can massively improve search results.

Conclusions
To conclude: The first version of the Web lacked a metadata
framework which was needed to describe resources
W3C developed RDF to provide this framework As well as providing an framework for metadata
applications, RDF allows software to reach beyond individual Web sites
The Semantic Web will be based on registries of machine-understandable definition
The Semantic Web standard language (OWL) was derived from US and EC efforts (DAML+OIL)
The Semantic Web will be difficult to achieve It will be expensive to provide rich interoperable
services without a Semantic Web

Find Out More (1)
Semantic Web, W3C<http://www.w3c.org/2001/sw/>
Semantic Web Road map, Tim Berners-Lee<http://www.w3c.org/DesignIssues/Semantic.html>
The Semantic Web, Scientific American<http://www.sciam.com/2001/0501issue/0501berners-lee.html>
The Semantic Web Community Portal, <http://www.semanticweb.org/>
The Semantic Web: A Primer<http://www.xml.com/pub/a/2000/11/01/semanticweb/>
All found using Google to search for “semantic Web”

Find Out More (2)
An introduction to RDF <http://www-106.ibm.com/developerworks/xml/library/w-rdf/>
The Semantic Web Community Portal
<http://www.semanticweb.org/>
The Semantic Web: An Introduction
<http://infomesh.net/2001/swintro/>