the possibility and probability of establishing a global neuroscience information framework: lessons...
TRANSCRIPT

The possibility and probability of establishing a global neuroscience
information framework:lessons learned from practical experiences in
data integration for neuroscience
Maryann Martone, Ph. D.University of California, San Diego

“Neural Choreography”
“A grand challenge in neuroscience is to elucidate brain function in relation to its multiple layers of organization that operate at different spatial and temporal scales. Central to this effort is tackling “neural choreography” -- the integrated functioning of neurons into brain circuits--their spatial organization, local and long-distance connections, their temporal orchestration, and their dynamic features. Neural choreography cannot be understood via a purely reductionist approach. Rather, it entails the convergent use of analytical and synthetic tools to gather, analyze and mine information from each level of analysis, and capture the emergence of new layers of function (or dysfunction) as we move from studying genes and proteins, to cells, circuits, thought, and behavior....
However, the neuroscience community is not yet fully engaged in exploiting the rich array of data currently available, nor is it adequately poised to capitalize on the forthcoming data explosion. “
Akil et al., Science, Feb 11, 2011

On the other hand... In that same issue of Science
Asked peer reviewers from last year about the availability and use of data About half of those polled store their data only in their
laboratories—not an ideal long-term solution. Many bemoaned the lack of common metadata and
archives as a main impediment to using and storing data, and most of the respondents have no funding to support archiving
And even where accessible, much data in many fields is too poorly organized to enable it to be efficiently used.
“...it is a growing challenge to ensure that data produced during the course of reported research are appropriately described, standardized, archived, and available to all.” Lead Science editorial (Science 11 February 2011: Vol. 331 no. 6018 p. 649 )

We speak piously of taking measurements and making small studies that will add another brick to the temple
of science. Most such bricks just lie around the
brickyard.
Platt, J.R. (1964) Strong Inference. Science. 146:
347-353.
"We now have unprecedented ability to collect data about nature…but there is now a crisis developing in biology, in that completely unstructured information does not enhance understanding”
-Sidney Brenner

The Encyclopedia of Life
A…
Access to data has changed
over the years
Tim Berner-s Lee: Web of data
Wikipedia defines Linked Data as "a term used to describe a recommended best practice for exposing, sharing, and connecting pieces of data, information, and knowledge on the Semantic Web using URIs and RDF.” http://linkeddata.org/
Genbank
PDB

Are we there yet?We’d like to be able to find: What is known****:
What is the average diameter of a Purkinje neuron
Is GRM1 expressed In cerebral cortex?
What are the projections of hippocampus
What genes have been found to be upregulated in chronic drug abuse in adults
What studies used my monoclonal mouse antibody against GAD in humans?
Find all instances of spines that contain membrane-bound organelles ****by combining data from
different sources and different groups
What is not known: Connections among data Gaps in knowledge
We’d like it to be really simple to implement and use:– Query interface– Search strategies– Data sources– Infrastructure– Results display
– Trust– Context
– Analysis tools
– Tools for translating existing content into linkable form
– Tools for creating new data ready to be linked

NIF is an initiative of the NIH Blueprint consortium of institutes What types of resources (data, tools, materials,
services) are available to the neuroscience community?
How many are there? What domains do they cover? What domains do
they not cover? Where are they?
Web sites Databases Literature Supplementary material
Who uses them? Who creates them? How can we find them? How can we make them better in the future?
http://neuinfo.org
A look into the brickyard
• PDF files
• Desk drawers

How many resources are there?
•NIF Registry: A catalog of neuroscience-relevant resources
• > 3500 currently described
• > 1700 databases
•Another 3000 awaiting curation•And we are finding more every day

But we have Google!
Current web is designed to share documents Documents are
unstructured data Much of the content
of digital resources is part of the “hidden web”
Wikipedia: The Deep Web (also called Deepnet, the invisible Web, DarkNet, Undernet or the hidden Web) refers to World Wide Web content that is not part of the Surface Web, which is indexed by standard search engines.

A tip of the “resourceome”
Microarray9, 535, 440
Model organisms246, 639
Connectivity
26, 443
Antibodies890, 571
Pathways43, 013
Brain Activation
Foci56, 591
65 databases

But we have Pub Med!
Bulk of neuroscience data is published as part of papers > 20,000,000
Structured vs unstructured information
“...it is a growing challenge to ensure that data produced during the course of reported research are appropriately described, standardized, archived, and available to all.” Lead Science editorial (Science 11 February 2011: Vol. 331 no. 6018 p. 649 )
Author, year, journal, keywords
Content

The Neuroscience Information Framework: Discovery and utilization of web-based
resources for neuroscience
A portal for finding and using neuroscience resources
A consistent framework for describing resources
Provides simultaneous search of multiple types of information, organized by category
Supported by an expansive ontology for neuroscience
Utilizes advanced technologies to search the “hidden web”
http://neuinfo.org
UCSD, Yale, Cal Tech, George Mason, Washington Univ
Supported by NIH Blueprint
Literature
Database Federation
Registry

Neuroscience is unlikely to be served by a few large databases like the genomics and proteomics community
Whole brain data (20 um microscopic
MRI) Mosiac LM images (1
GB+)
Conventional LM images
Individual cell morphologies
EM volumes & reconstruction
s
Solved molecular structures
No single technology serves these all equally well.Multiple data types;
multiple scales; multiple databases
A data federation problem

NIF Data Federation Too many databases to visit
Registry not adequate for finding and using them Capturing content in a few keywords is difficult if not impossible
Access to deep content; currently searches over 30 million records from > 65 different databases Flexible tools for resource providers to make their content available as
easily and meaningfully as possible Organized according to level of nervous system and data type,
e.g., brain activation foci Link to host resource: these databases are independent!
Provides simplified and unified views to help users navigate very different resources Common vocabularies Common data models for basic neuroscience data Laying the foundations for data integration for neuroscience

What are the connections of the hippocampus?
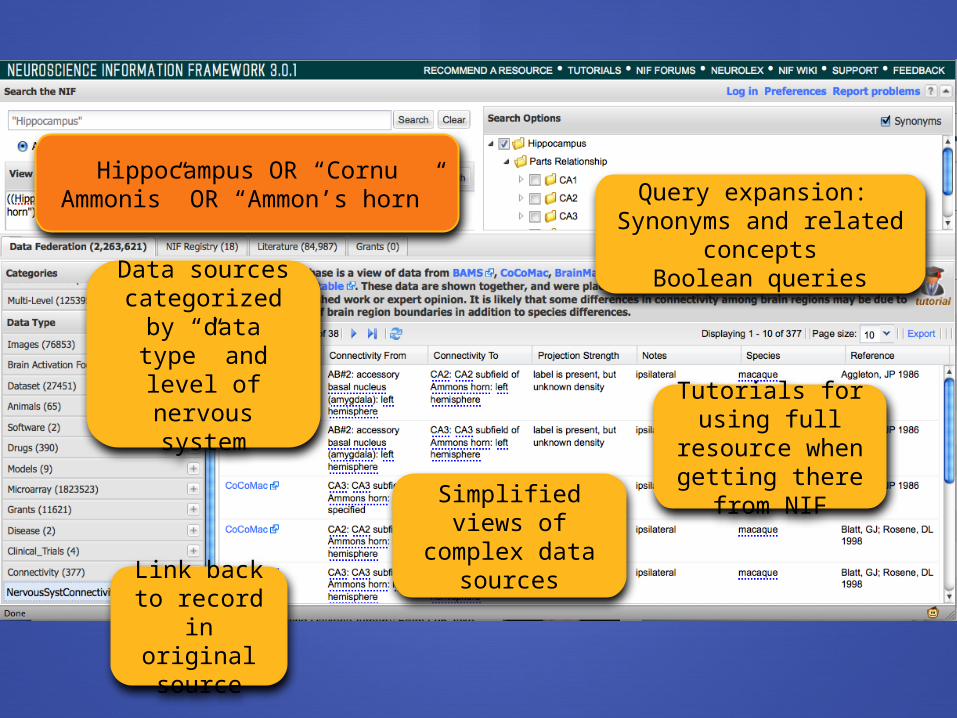
Hippocampus OR “Cornu Ammonis” OR “Ammon’s horn” Query expansion:
Synonyms and related concepts
Boolean queriesData sources
categorized by “data type” and level of nervous
system
Simplified views of complex data
sources
Tutorials for using full
resource when getting there
from NIF
Link back to record in
original source

What are the connections of the hippocampus?
Connects to
Synapsed with
Synapsed by
Input region
innervates
Axon innervates
Projects to
Cellular contact
Subcellular contact
Source site
Target site
Each resource implements a different, though related model; systems are complex and difficult to learn, in many cases

NIF: Minimum requirements to use shared data
You (and the machine) have to be able to find it Accessible through the web Structured or semi-structured Annotations
You (and the machine) have to be able to use it Data type specified and in a usable form
You (and the machine) have to know what the data mean
Semantics Context: Experimental metadata
Reporting neuroscience data within a consistent framework helps enormously

Is GRM1 in cerebral cortex?
NIF system allows easy search over multiple sources of information But, we have difficulty finding data Well known difficulties in search
Inconsistent and sparse annotation of scientific data Many different names for the same thing The same name means many things “Hidden semantics”: 1 = male; 1 = present; 1=mouse
Allen Brain Atlas
MGD
Gensat

Cerebral CortexAtlas Children Parent
Genepaint Neocortex, Olfactory cortex (Olfactory bulb; piriform cortex), hippocampus
Telencephalon
Allen Brain Atlas Cortical plate, Olfactory areas, Hippocampal Formation
Cerebrum
MBAT (cortex) Hippocampus, Olfactory, Frontal, Perirhinal cortex, entorhinal cortex
Forebrain
GENSAT Not defined Telencephalon
BrainInfo frontal lobe, insula, temporal lobe, limbic lobe, occipital lobe
Telencephalon
BrainmapsEntorhinal, insular, 6, 8, 4, A SII 17, Prp, SI
Telencephalon

What is an ontology?
Brain
Cerebellum
Purkinje Cell Layer
Purkinje cell
neuron
has a
has a
has a
is a
Ontology: an explicit, formal representation of concepts relationships among them within a particular domain that expresses human knowledge in a machine readable form
Branch of philosophy: a theory of what is
e.g., Gene ontologies

What can ontology do for us?
Express neuroscience concepts in a way that is machine readable Synonyms, lexical variants Definitions
Provide means of disambiguation of strings Nucleus part of cell; nucleus part of brain; nucleus part of atom
Rules by which a class is defined, e.g., a GABAergic neuron is neuron that releases GABA as a neurotransmitter
Properties Provide universals for navigating across different data
sources Semantic “index” Perform reasoning Link data through relationships not just one-to-one
mappings Provide the basis for concept-based queries to probe
and mine data As a branch of philosophy, make us think about the
nature of the things we are trying to describe, e.g., synapse is a site

Linking datatypes to semantics: What is the
average diameter of a Purkinje neuron dendrite?
Branch structure not a tree, not a set of blood vessels, not a road map but a DENDRITE
Because anyone who uses Neurolucida uses the same concepts: axon, dendrite, cell body, dendritic spine, information systems can combine the data together in meaningful ways
Neurolucida doesn’t, however, tell you that dendrite belongs to a neuron of a particular type or whether this dendrite is a neural dendrite at all
( (Color Yellow) ; [10,1] (Dendrite) ( 5.04 -44.40 -89.00 1.32) ; Root ( 3.39 -44.40 -89.00 1.32) ; R, 1 ( ( 2.81 -45.10 -90.00 0.91) ; R-1, 1 ( 2.81 -45.18 -90.00 0.91) ; R-1, 2 ( 1.90 -46.01 -90.00 0.91) ; R-1, 3 ( 1.82 -46.09 -90.00 0.91) ; R-1, 4 ( 0.91 -46.59 -90.00 0.91) ; R-1, 5 ( 0.41 -46.83 -92.50 0.91) ; R-1, 6 ( ( -0.66 -46.92 -88.50 0.74) ; R-1-1, 1 ( -0.74 -46.92 -88.50 0.74) ; R-1-1, 2 ( -2.15 -47.25 -88.00 0.74) ; R-1-1, 3 ( -2.15 -47.33 -88.00 0.74) ; R-1-1, 4 ( -3.06 -47.00 -87.00 0.74) ; R-1-1, 5 ( -4.05 -46.92 -86.00 0.74) ; R-1-1, 6
Output of Neurolucida neuron trace

“A rose by any other name...”:
Identity: Entities are uniquely identifiable Name is a meaningless numerical identifier (URI: Uniform
resource identifier) Any number of human readable labels can be assigned to it
Definition: Genera: is a type of (cell, anatomical structure, cell part) Differentia: “has a” A set of properties that distinguish among
members of that class Can include necessary and sufficient conditions
Implementation: How is this definition expressed Depending on the nature of the concept or entity and the needs
of the information system, we can say more or fewer things Different languages; can express different things about the
concept that can be computed upon OWL W3C standard, RDF

Comprehensive Ontology
NIF covers multiple structural scales and domains of relevance to neuroscience
Aggregate of community ontologies with some extensions for neuroscience, e.g., Gene Ontology, Chebi, Protein Ontology
Simple, basic “is a : hierarchies that can be used “as is” or to form the building blocks for more complex representations
NIFSTD
Organism
NS FunctionMolecule InvestigationSubcellular structure
Macromolecule Gene
Molecule Descriptors
Techniques
Reagent Protocols
Cell
Resource Instrument
Dysfunction QualityAnatomical Structure

Query across resources: Snca and
striatum
NIF uses the NIFSTD ontologies to query across sources that use very different terminologies, symbolic notations and levels of granularity

Entity mapping
BIRNLex_435 Brodmann.3
Explicit mapping of database content helps disambiguate non-unique and custom terminology

Concept-based search: search by meaning
Search Google: GABAergic neuron Search NIF: GABAergic neuron
NIF automatically searches for types of GABAergic neurons
Types of GABAergic neurons

Data mining through interrogation
What genes are upregulated by drugs of abuse in the adult mouse?
MorphineIncreased expression
Adult Mouse

Integration of knowledge based on relationships
Looking for commonalities and distinctions among animal models and human conditions based on phenotypes
Sarah Maynard, Chris Mungall, Suzie Lewis
NINDS
Thalamus
Cellular inclusion
Midline nuclear group
Lewy Body
Paracentral nucleus
Cellular inclusion

And now, the literature
The scientific article remains the currency of science
Vast majority of neuroscience data is published in the literatureComputational biologists like to consume
dataNeuroscientists like to produce it
Two NIF projects: 1) Resource identification from the literature
Identifying antibodies used in scientific studies from text
2) Extracting data from tables and supplementary material

Neuroscience is fundamentally reliant on antibodies
Neuroscientists spend a lot of time searching for antibodies that will work in their system for the target of interest and troubleshooting experiments that didn’t work
The scientific literature is a major source of information on antibodies
Proposal Use text mining strategies to identify
antibodies, protocol type and subject organism from materials and methods section of J. Neuroscience
Problem: antibodies

Midfrontal cortex tissue samples from neurologically unimpaired subjects (n9) and from subjects with AD (n11) were obtained from the Rapid Autopsy Program
Immunoblot analysis and antibodies
The following antibodies were used for immunoblotting: -actin mAb (1:10,000 dilution, Sigma-Aldrich); -tubulin mAb (1:10,000, Abcam); T46 mAb (specific to tau 404–441, 1:1000, Invitrogen); Tau-5 mAb (human tau 218–225, 1:1000, BD Biosciences) (Porzig et al., 2007); AT8 mAb (phospho-tau Ser199, Ser202, and Thr205, 1:500, Innogenetics); PHF-1 mAb (phospho-tau Ser396 and Ser404, 1:250, gift from P. Davies); 12E8 mAb (phospho-tau Ser262 and Ser356, 1:1000, gift from P. Seubert); NMDA receptors 2A, 2B and 2D goat pAbs (C terminus, 1:1000, Santa Cruz Biotechnology)…
Semantic annotation: Entity mapping by humanSato et al., J. Neurosci. 2008 Subject is
Human
Antibody #7
"12E8" is a Monoclonal antibody birnlex_2027Antibody reagent has target human PHF tau
Waiting for Neurolex ID
Protein product ofAntibody reagent has provider Peter SeubertAntibody reagent has catalog #Antibody reagent
has source organism Mouse birnlex_167 NCBI Taxonomic ID: 10090
Antibody reagent has id "12E8"
Provider has locationElan Pharmaceuticals, South San Francisco, CA
Provider has url

Try this Watson!
•95 antibodies were identified in 8 articles•52 did not contain enough information to determine the antibody used• Some provided details in another paper
• And another paper, and another...• Failed to give species, clonality, vendor, or
catalog number• But, many provided the location of the vendor
because the instructions to authors said to do so
• no antibodies had lot numbers associated We never got to test the algorithms!

NIF along with several other large informatics projects recommends that all authors provide vendor and catalog # for all reagents use
But...vendors merge and sell each other’s antibodies, making it difficult to track down exactly which reagent was used in some cases
Catalog numbers get replaced; many variants on the same product, e.g., HRP-conjugated, 200 ul vs 500 ul
Clone names are not unique Universal antibody ID
Publishing for the 21st Century

NIF Antibody Registry• We have created an antibody
registry database• Assigns each antibody a
persistent identifier to both commercial and non-commercial antibodies
• ID will persist even if company goes out of business or the antibody is sold by multiple vendors
• The data model is being formalized into a rigorous ontology in collaboration with others:
• We negotiated with antibody aggregators to pull data for over 800,000 commercial antibodies, 200 vendors
• Can be used to register homegrown antibodies as well• http://
antibodyregistry.org

“Find studies that used a rabbit polyclonal antibody against GFAP that
recognizes human in immunocytochemisty”
Paz et al, J Neurosci, 2010
(AB_310775)

Demo 2: Extracting data from tables and supplementary material
Challenge: Extract data on gene expression in brain from studies relevant to drug abuse
Workflow:
Find articlesExtract
results from tables
Standardize results
Load into NIF
Current DB: 140 tables from 54 articles
Andrea Arnaud-Stagg, Anita Bandrowski

Gene for tyrosine hydroxylase has increased expression in locus coeruleus of mouse compared to control when given chronic morphineTranslations:
Upregulated p < 0.05 = increased expressionLC = locus coeruleusProbe ID = gene name
Extract data and meaning of data from tables

Challenges working with tables and supplemental data
Difficult data arrangements PDF, JPG, TXT, CSV, XLS Difficult styles: colors, symbols, data arrangements
(results combined into one column, multiple comparisons in one table, legends defining values, unclearly described data (eg., unclear significance)
Not clear what tables/values represent nothing in paper about the supplementary data file and table has no
heading Probe ID’s are given but not gene identifiers
No link from supplemental material back to article; lose provenanceResults are presented but values of significance unclear
Neither curator (nor machine) could distinguish between no difference and not reported

What affects SMN1 expression?
Researchers often report results in a way where curators cannot extract full information from a study

Common theme•We are not publishing data in a form that is easy to integrate
• What we mean isn’t clear to a search engine (or even to a human)
• We use many different data structures to say the same thing
• We don’t provide crucial information
•Searching and navigating across individual resources takes an inordinate amount of human effortTempus Pecunia Est Painting by
Richard Harpum

When I talk to neuroscientists (and journal editors)...

Collaboration, competition, coordination, cooperation
The diversity and dynamism of neuroscience will make data integration challenging alwaysNeural space is vast: No one group or individual can do everythingWe don’t have to solve everything to make it betterGlobal partnership with room for everyone:
Neuroscientists Curators Resource developers Funders Computational biologists Text miners Computer scientists Watson

Hopeful signs...
•Means for sharing data on the web becoming more routine
•With availability, growing recognition for a role of standards and curation
•For neuroscience, we now have organizations that can help coordinate
•NIF, NITRC (http://nitrc.org)•Neuroimaging Tools and Resource Clearinghouse
•International Neuroinformatics Coordinating Facility
•Educate neuroscientists on what is necessary•Bring together stakeholders to define what is necessary for interoperation•Implement structures and procedures for developing neuroscience resources within a framework
Click icon to add picture
http://incf.org

We don’t know everything but we do know some things
1. Register your resource with NIF!!!!
3: Be mindful
Resource providers: Mindfulness that your resource is contributing data to a global federation Link to shared ontology identifiers
where possible Stable and unique identifiers for data Explicit semantics Database, model, atlas
Researchers: Mindfulness when publishing data that it is to be consumed by machines and not just your colleagues Accession numbers for genes and
species Catalog numbers for reagents Provide supplemental data in a form
where it is is easy to re-use
2. Become involved with NIF and INCF

Learn about neuroinformatics

Many thanks to...Amarnath Gupta, UCSD, Co Investigator
Jeff Grethe, UCSD, Co Investigator
Anita Bandrowski, NIF Curator
Gordon Shepherd, Yale University
Perry Miller
Luis Marenco
David Van Essen, Washington University
Erin Reid
Paul Sternberg, Cal Tech
Arun Rangarajan
Hans Michael Muller
Giorgio Ascoli, George Mason University
Sridevi Polavarum
Fahim Imam, NIF Ontology Engineer
Karen Skinner, NIH, Program Officer
Mark Ellisman
Lee Hornbrook
Kara Lu
Vadim Astakhov
Xufei Qian
Chris Condit
Stephen Larson
Sarah Maynard
Bill Bug

Register your resource to NIF!

How old is an adult squirrel?
Definitions can be quantitative
Arbitrary but defensible
Qualitative categories for quantitative attributes Best practice to
provide ages of subjects, but for query, need to translate into qualitative concepts
Jonathan Cachat, Anita Bandrowski

But there are no databases for siRNA
NIF Registry is probably the most complete accounting we have of what is out there