the performance of evolutionary artificial neural networks in ambiguous and unambiguous learning...
TRANSCRIPT

The Performance of Evolutionary Artificial Neural Networks in Ambiguous and Unambiguous
Learning Situations
Melissa K. CarrollOctober, 2004

Artificial Neural Networks and Supervised Learning
Inputs Outputs Inputs Outputs
Time 1 Time 2
1
0
1
1
0
1
0
1
1
1

Backpropagation and Associated Parameters: Gain
•Activation Function: Used to compute output of neuron from its inputs
•Sigmoid function: ye ax
1
1
•As gain increases, slope of activation function of neurons increases:
Red: gain =1Blue: gain = 2Green: gain = .5
Diagram source:http://www.willamette.edu/~gorr/classes/cs449/Maple/ActivationFuncs/active.html

Effects of Learning Rate
Diagram source: http://www.willamette.edu/~gorr/classes/cs449/linear2.html

Methods to Ensure or Speed Up Convergence that Often Work
•Adjust architecture: add more layers or more neurons per layer
•Adjust topology, or connections between neurons
•Add bias neuron that outputs 1•No learning can occur with backprop when neuron is outputting 0•Equivalent to shifting the range of the activation function•Reduces number of neurons outputting 0
•Add momentum term to weight adjustment equations:
•Smoothes learning to allow high learning rate without divergence
•ANN programmer must manipulate all of these parameters using expert knowledge

Introduction: Genetic Algorithms (GAs)•Another set of adaptive algorithms derived from natural process (evolution)
•Organisms possess chromosomes made up of genes encoding for traits
•There is variability among organisms
•Some individuals will naturally be able to reproduce more in a particular environment, making them more “fit” for that environment
•By definition, genes of the more fit individuals will become more numerous in the population
•Population is skewed towards more fit individuals for the given environment
•Forces of variability then act on these genes, leading to new, more “fit” discoveries

The Genetic Algorithm1. Create a population of a preset number of random chromosomes
designed to encode an individual that is a candidate solution to agiven problem
2. Evaluate the fitness of each individual in the population using afitness function defined by the programmer for the task for which asolution is being sought
3. Generate a new population by repeating the following steps until thenew population size reaches the preset population size:
a) Select two parent chromosomes from the population, givingpreference to highly fit chromosomes
b) Subject the two offspring to mutation and crossover
c) Copy the offspring into the new population
4. Replace the old population with the new one
5. Repeat steps 2 through 4 for a given number of generations

Designing and Training ANNs with GAs: Rationale
•Designing the right ANN for a particular task requires manipulating all of the parameters described previously, which requires expertise and much trial and error (and sometimes luck!)
•GAs are optimizers and can optimize these parameters
•Traditional training algorithms like backpropagation have a tendency to get stuck in local minima of multimodal or “hilly” error curves, missing the global minimum:
•GAs perform a “global search” and are hence more likely to find the global minimum
Diagram source:http://www.willamette.edu/~gorr/classes/cs449/momrate.html

Designing and Training ANNs With GAs: Implementation
Direct (Matrix) Encoding
00101
00110
00001
00001
00000
0101 110 01 1
(ANN) (Matrix) (Bit String)
5
3
2
4
1
•Some classes of GAs for evolving ANNs:•Darwinian•Hybrid Darwinian•Baldwinian•Lamarckian

Introduction: Wisconsin Card Sorting Test (WCST)
•Psychological task requiring adaptive thinking: measures flexibility in thought; therefore interesting for testing properties of ANN learning
•Requires subject to resolve ambiguities…
•Which card was the correct card when negative feedback is given?
•Which rule was the current rule when a stimulus card matches a target card on more than one dimension?

Purpose and Implementation



Hypotheses Regarding Learning
•Highly accurate network trained on unambiguous pattern should produce output identical to the training set
•Accuracy rate of rule-to-card network should be 100%
•Calculus proof led to prediction that network trained on ambiguous pattern would output, at each node, the probability of the corresponding rule being the current rule
•Accuracy rates should be 100%, 50%, and 33.3% for input patterns with 1, 2, and 3 associated target patterns, respectively
•Minimum error rate for ambiguous pattern is a very high .22916
•When whole model is combined, will be interesting to see if networks can generalize to data not seen in training

Experiment Performed•Compare the performance of six GAs and one non-GA algorithm
•Algorithms tested:•Non-GA “brute force” algorithm: try all combinations of parameters•Darwinian evolution-only (Pure Darwinian)•Darwinian with additional backpropagation training (Hybrid Darwinian)•Baldwinian evolving architecture only•Baldwinian evolving architecture and weights•Lamarckian•One “made up” algorithm: “Reverse Baldwinian”
•Motivation for Reverse Baldwinian: produce greater variability and evaluate fitness over longer training periods without increasing computation time

Hypotheses Regarding Algorithm Performance
•Good chance GAs would outperform non-GA, but some doubts due to known problems with GAs
•Hybrid Darwinian more effective than Pure Darwinian based on previous research
•Baldwinian and Lamarckian more effective than Darwinian based on previous research
•Lamarckian more effective than Baldwinian due to relatively short runs (app. 40 generations)

Results and Discussion
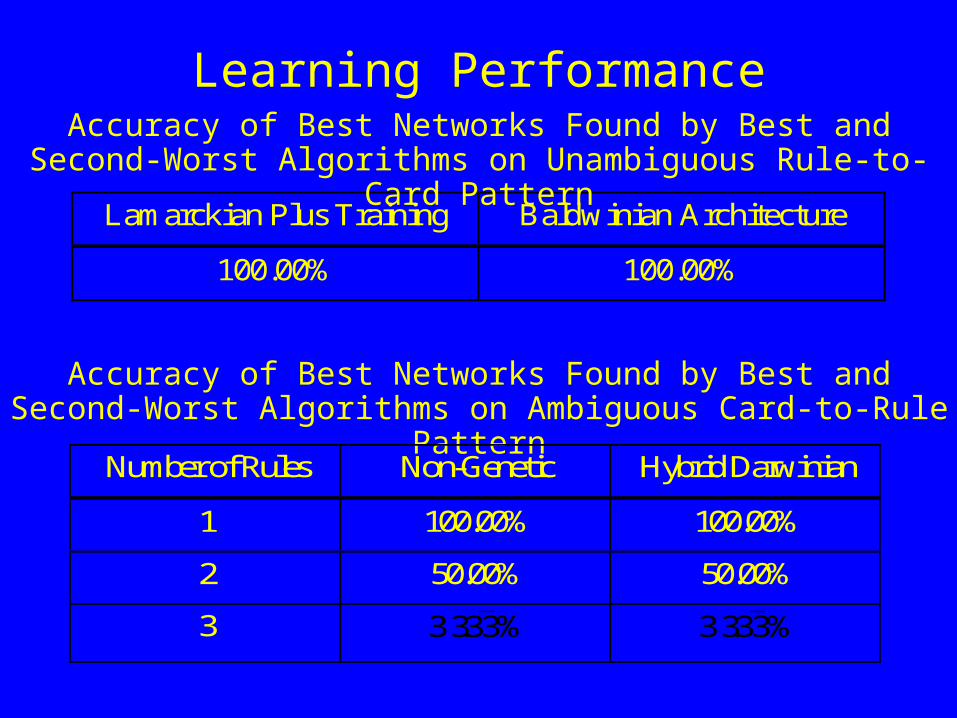
Learning Performance
Lamarckian Plus Training Baldwinian Architecture
100.00% 100.00%
Accuracy of Best Networks Found by Best and Second-Worst Algorithms on Unambiguous Rule-to-Card Pattern
Accuracy of Best Networks Found by Best and Second-Worst Algorithms on Ambiguous Card-to-Rule Pattern
Number of Rules Non-Genetic Hybrid Darwinian
1 100.00% 100.00%
2 50.00% 50.00%
3 %33.33 %33.33

Sample Output of Best Card-to-Rule Learner
Number of Rules Target Output(s) Actual Output1 010 0.000,0.998,0.0001 100 0.993,0.000,0.0001 001 0.000,0.000,1.0001 100 0.997,0.000,0.0002 010,001 0.010,0.497,0.5002 100,001 0.501,0.009,0.5022 100,001 0.503,0.008,0.5032 100,001 0.503,0.012,0.5003 100,010,001 0.345,0.345,0.3463 100,010,001 0.344,0.344,0.3453 100,010,001 0.336,0.336,0.3373 100,010,001 0.334,0.335,0.335
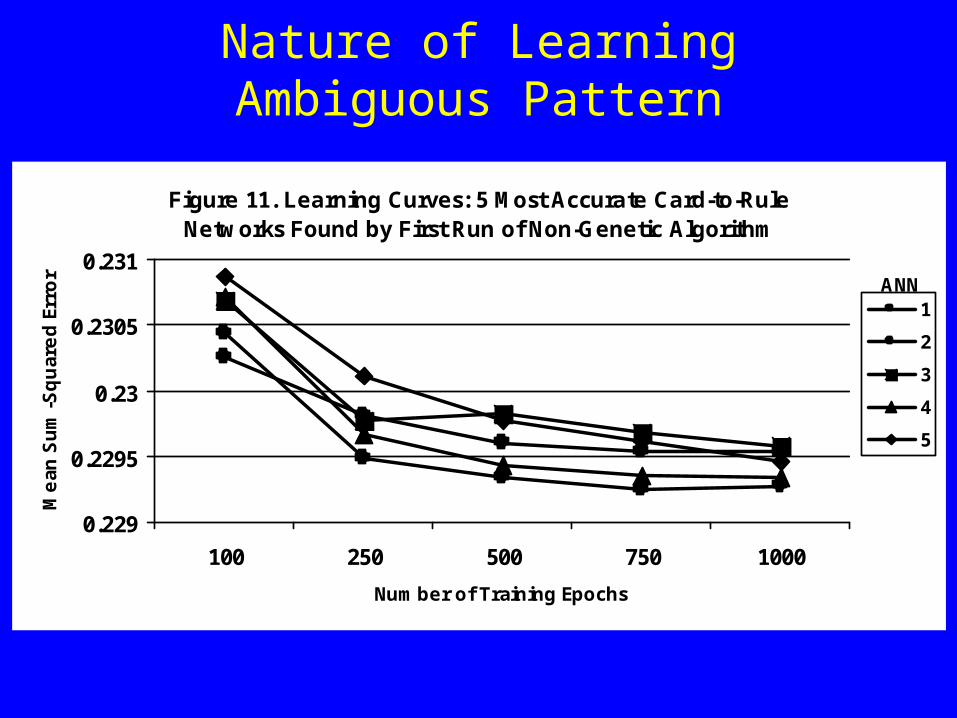
Nature of Learning Ambiguous Pattern
Figure 11. Learning Curves: 5 Most Accurate Card-to-Rule Networks Found by First Run of Non-Genetic Algorithm
0.229
0.2295
0.23
0.2305
0.231
100 250 500 750 1000
Number of Training Epochs
Me
an S
um
-Sq
uar
ed
Err
or
1
2
3
4
5
ANN

Parameters of Best Non-GA Nets
Best Card-to-Rule Networks
Run
Number
Layers Nodes Bias Learning
Rate
Momentum
Term
Gain
Parameter
Error
2 4 13 false 0.9 0.9 0.5 0.2297247
1 4 11 false 0.5 0.9 0.5 0.2302518
2 4 15 false 0.7 0.9 0.5 0.2302945
1 4 9 false 0.5 0.9 1 0.2304330
2 4 15 false 0.7 0.7 1 0.2305249
Best Rule-to-Card Networks
Run
Number
Layers Nodes Bias Learning
Rate
Momentum
Term
Gain
Parameter
Error
1 4 13 true 0.9 0.9 1 5.20089E-06
2 4 15 true 0.9 0.9 1 7.71045E-06
1 4 15 true 0.7 0.9 1 9.17560E-06
2 4 15 true 0.7 0.9 1 9.86984E-06
2 4 15 true 0.7 0.9 1 1.02872E-05

Lowest Error Rate Found by All AlgorithmsRule-to-Card PatternAlgorithm Lowest
MSSEEpochs
Non-Genetic 8.15863E-07 1000PureDarwinian
0.565961080 **
HybridDarwinian
5.75368E-06 1000
BaldwinianArchitecture
6.40738E-06 1000
BaldwinianArch-Weights
2.87095E-06 1000
LamarckianAlone
6.59655E-07 **
LamarckianPlus Training
2.95987E-07 1000
ReverseBaldwinian
2.69630E-06 1000
Card-to-Rule PatternAlgorithm Lowest
MSSEEpochs
Non-Genetic 0.229225774 750PureDarwinian
0.670455248 **
HybridDarwinian
0.230726399 1000
BaldwinianArchitecture
0.230454397 500
BaldwinianArch-Weights
0.229996319 1000
LamarckianAlone
0.229718264 **
LamarckianPlus Training
0.229627977 1000
ReverseBaldwinian
0.229817464 1000
**Algorithms did not include additional 1000 training epochs; error values are the lowest attained by any of the networks produced by the GA run alone.

Performance of Pure Darwinian Algorithm
Accuracy Rate forUnambiguousRule-to-Card
Pattern55.73%
A ccu ra c y R ates fo r A m b ig u o u s C ard -to -R u le P at te rn
N u m ber o f R u les A ccu ra c y1 %88.382 %431.93 %33.33

Sample Output of Best Pure Darwinian Net on Card-to-Rule Pattern
Number of Rules Target Output(s) Actual Output1 010 0.420,0.306,0.3201 100 0.355,0.285,0.3021 001 0.285,0.300,0.3791 100 0.287,0.293,0.3772 010,001 0.362,0.336,0.3442 100,001 0.273,0.329,0.3922 100,001 0.324,0.276,0.3212 010,001 0.341,0.333,0.3793 100,010,001 0.304,0.315,0.3443 100,010,001 0.325,0.313,0.3133 100,010,001 0.331,0.348,0.4043 100,010,001 0.336,0.298,0.343
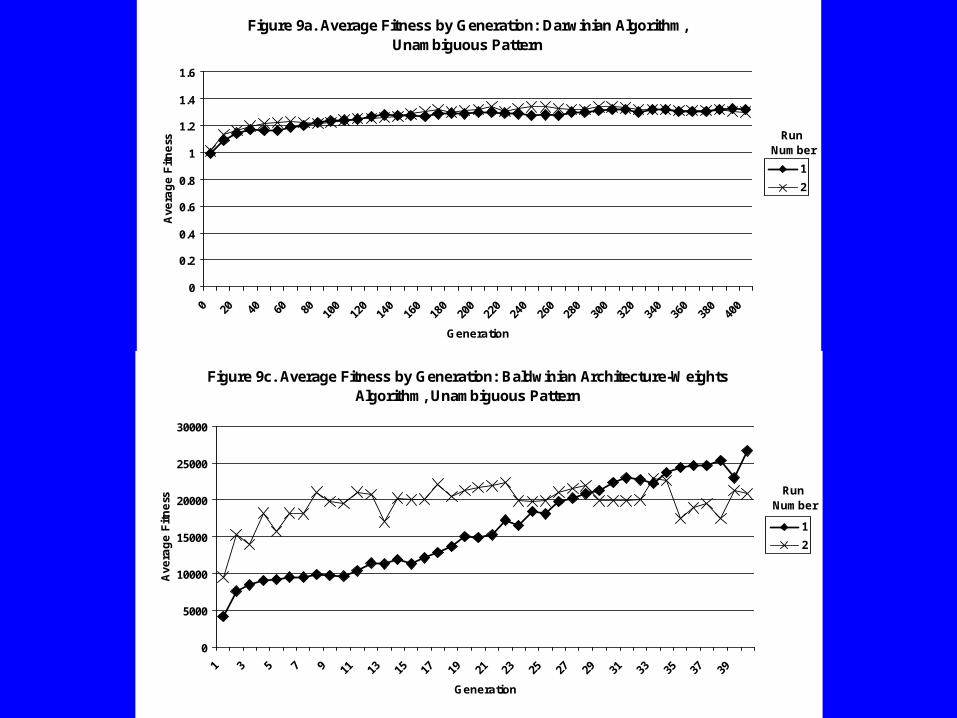
Figure 9a. Average Fitness by Generation: Darwinian Algorithm, Unambiguous Pattern
0
0.2
0.4
0.6
0.8
1
1.2
1.4
1.6
0 20 40 60 80 100
120
140
160
180
200
220
240
260
280
300
320
340
360
380
400
Generation
Ave
rag
e F
itn
ess
1
2
Run Number
Figure 9c. Average Fitness by Generation: Baldwinian Architecture-Weights Algorithm, Unambiguous Pattern
0
5000
10000
15000
20000
25000
30000
1 3 5 7 9 11 13 15 17 19 21 23 25 27 29 31 33 35 37 39
Generation
Ave
rag
e F
itn
ess
1
2
Run Number

Figure 9d. Average Fitness by Generation: Lamarckian Algorithm, Unambiguous Pattern
0
100000
200000
300000
400000
500000
600000
1 3 5 7 9 11 13 15 17 19 21 23 25 27 29 31 33 35 37 39
Generation
Ave
rag
e F
itn
ess
1
2
Run Number

Figure 9c. Average Fitness by Generation: Baldwinian Architecture-Weights Algorithm, Unambiguous Pattern
0
5000
10000
15000
20000
25000
30000
1 3 5 7 9 11 13 15 17 19 21 23 25 27 29 31 33 35 37 39
Generation
Ave
rag
e F
itn
ess
1
2
Run Number
Figure 10c. Average Fitness by Generation: Baldwinian Architecture-Weights Algorithm, Ambiguous Pattern
3.85
3.9
3.95
4
4.05
4.1
4.15
4.2
4.25
4.3
1 3 5 7 9 11 13 15 17 19 21 23 25 27 29 31 33 35 37 39
Generation
Ave
rag
e F
itn
ess
1
2
Run Number

Figure 10d. Average Fitness by Generation: Lamarckian Algorithm, Ambiguous Pattern
3
3.2
3.4
3.6
3.8
4
4.2
1 3 5 7 9 11 13 15 17 19 21 23 25 27 29 31 33 35 37 39
Generation
Ave
rag
e F
itn
ess
1
2
Run Number
Figure 10e. Average Fitness by Generation: Reverse Baldwinian Algorithm, Ambiguous Pattern
0
0.5
1
1.5
2
2.5
3
3.5
4
4.5
Generation
Ave
rag
e F
itn
ess
1
2
Run Number

Did Evolution Work At All?
•Fitness graphs generally show increase in fitness over generations
•T-tests show that selection mechanism selected more fit individuals
•Best Lamarckian nets still “better” than best non-GA net after equivalent amounts of training
•T-tests show that error rates of nets during Lamarckian run were significantly better than error rates for random nets at equivalent time points for unambiguous pattern
•However, results were the reverse for the ambiguous pattern
•Due to the nature of the paired t-test performed, these results can’t easily be explained by the theory about assessment time point being critical

To Evolve or Not To EvolveGeneral reasons why evolution may not have been
appropriate in this case (in addition to those specific to the ambiguous pattern):
•Patterns may have been easy to learn; backpropagation often outperforms GAs on weight training for easy patterns
•Crossover often not effective when using matrix encoding scheme
•Although one GA did outperform non-GA, difference was almost irrelevant since both were highly successful
•Non-GA is easier to program and almost five times faster to run

Suggestions for Future Work
•Attempt to combine and train the entire ANN model
•Manipulate GA parameters, such as mutation rate, crossover rate, population size, and number of generations
•Try different selection mechanisms
•Use different encoding scheme
•Experiment with new fitness function for ambiguous pattern
•Test different GAs or other evolutionary algorithms altogether
•Investigate ambiguous patterns further, including the role of momentum in their non-linear learning curve

What Does It All Mean?
•Learning power of ANNs: ANNs learned two sub-tasks that are difficult for many humans
•Ambiguous patterns may be more difficult to design and train with GAs
•Training ambiguous patterns may require special modifications such as eliminating the momentum term
•Additional support for existing theories based on prior research
•GAs not as effective on easy-to-learn patterns
•Hybrid algorithms generally outperform evolution-only algorithms
•Clarifying properties of ANNs and GAs is tremendously useful for engineering and may also elucidate properties of natural processes