the neurobayes neural network package
TRANSCRIPT

The NeuroBayes Neural Network Package
M.Feindtab, U.Kerzel b∗
aPhi-T Physics Information Technologies GmbH, 76139 Karlsruhe, Germany (www.phi-t.de)
bInstitut fur Experimentelle Kernphysik, University of Karlsruhe, Germany
Detailed analysis of correlated data plays a vital role in modern analyses. We present a sophisticated neu-
ral network package based on Bayesian statistics which can be used for both classification and event-by-event
prediction of the complete probability density distribution for continuous quantities. The network provides nu-
merous possibilities to automatically preprocess the input variables and uses advanced regularisation and pruning
techniques to essentially eliminate the risk of overtraining. Examples from physics and industry are given.
1. Introduction
Neural networks are inspired by a simple modelof how the brain works in nature: A neuron“fires” if the stimuli received from other neuronsexceed a certain threshold. In neural networks,
this is described by xnj = g
(
∑
k wnjk · xn−1
k + µnj
)
where g(t) is a sigmoid function and the constantµn
j determines the threshold. Thus the output ofnode j in layer n is given by the weighted sum ofall nodes in layer n− 1. Network training is thenunderstood as the process of minimising a loss
function by iteratively adjusting the weights wnjk
such that the deviation of the actual network out-put from the desired output is minimised. Pop-ular choices for the loss function are the sum ofquadratic deviations or a measure of the entropy.
Neural networks are superior to other meth-ods because they are able to learn correlationsbetween the input variables, can incorporate in-formation from quality variables (e.g. the returncode of a certain algorithm) and do not requirethat all input variables are filled for each event.The latter is of particular importance when e.g.parts of a detector cannot be read out for eachconsidered candidate.
∗speaker
2. The NeuroBayes Neural Network
2.1. Overview
The NeuroBayes neural network package is ahighly sophisticated tool to perform multivariateanalysis of correlated data. A three-layered feed-forward neural network is combined with an auto-mated preprocessing of the input variables. Userscan choose from a wide range of options to opti-mally prepare both individual and all variablesfor the network training. Advanced regularisa-tion and pruning techniques ensure a small re-sulting network topology where all non-significantweights and nodes are removed.
The package is split into two parts: The Neu-roBayes Teacher and the NeuroBayes Expert.The Teacher uses the training dataset (simulatedevents or historic data) provided by the user,performs the requested preprocessing steps andtrains the network to learn the complex relation-ships between the input variables and the trainingtarget. The statistical significance of each net-work weight and node is evaluated automaticallyduring network training to ensure that only signif-icant parts of the network topology remain. Afterthe training the user is provided with a set of con-trol plots to verify that the training has been suc-cessful and all information is stored in the Neu-roBayes Expertise. The Expertise is then usedby the NeuroBayes Expert analysing the data ofinterest.
1
2 M.Feindt and U. Kerzel
2.2. The Bayesian Approach
NeuroBayes uses Bayesian statistics to incor-porate a priori knowledge. The conditional prob-ability to observe B when A has already been ob-
served is given by P (B|A) = P (B∩A)P (A) (correspond-
ingly for P (A|B)). Since P (B|A) = P (A|B), thiscan be combined to Bayes’ theorem:
P (A|B) =P (B|A)P (A)
P (B)(1)
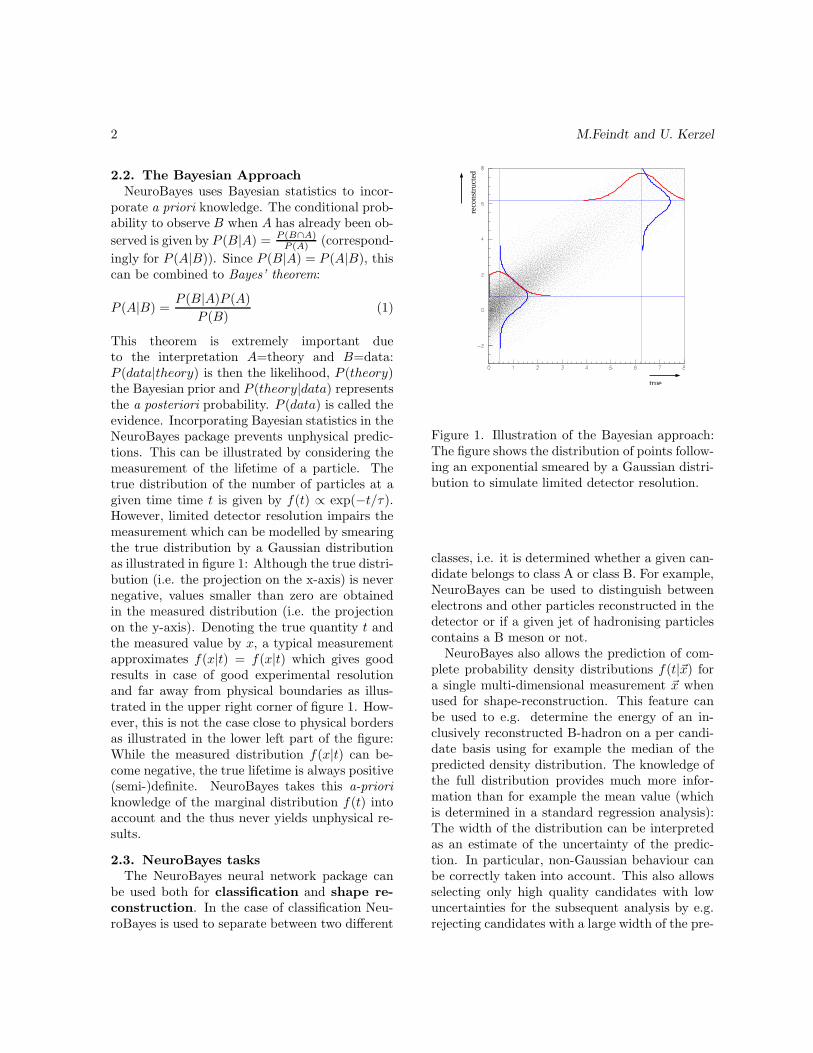
This theorem is extremely important dueto the interpretation A=theory and B=data:P (data|theory) is then the likelihood, P (theory)the Bayesian prior and P (theory|data) representsthe a posteriori probability. P (data) is called theevidence. Incorporating Bayesian statistics in theNeuroBayes package prevents unphysical predic-tions. This can be illustrated by considering themeasurement of the lifetime of a particle. Thetrue distribution of the number of particles at agiven time time t is given by f(t) ∝ exp(−t/τ).However, limited detector resolution impairs themeasurement which can be modelled by smearingthe true distribution by a Gaussian distributionas illustrated in figure 1: Although the true distri-bution (i.e. the projection on the x-axis) is nevernegative, values smaller than zero are obtainedin the measured distribution (i.e. the projectionon the y-axis). Denoting the true quantity t andthe measured value by x, a typical measurementapproximates f(x|t) = f(x|t) which gives goodresults in case of good experimental resolutionand far away from physical boundaries as illus-trated in the upper right corner of figure 1. How-ever, this is not the case close to physical bordersas illustrated in the lower left part of the figure:While the measured distribution f(x|t) can be-come negative, the true lifetime is always positive(semi-)definite. NeuroBayes takes this a-priori
knowledge of the marginal distribution f(t) intoaccount and the thus never yields unphysical re-sults.
2.3. NeuroBayes tasks
The NeuroBayes neural network package canbe used both for classification and shape re-
construction. In the case of classification Neu-roBayes is used to separate between two different
true
reco
nstr
ucte
d
Figure 1. Illustration of the Bayesian approach:The figure shows the distribution of points follow-ing an exponential smeared by a Gaussian distri-bution to simulate limited detector resolution.
classes, i.e. it is determined whether a given can-didate belongs to class A or class B. For example,NeuroBayes can be used to distinguish betweenelectrons and other particles reconstructed in thedetector or if a given jet of hadronising particlescontains a B meson or not.
NeuroBayes also allows the prediction of com-plete probability density distributions f(t|~x) fora single multi-dimensional measurement ~x whenused for shape-reconstruction. This feature canbe used to e.g. determine the energy of an in-clusively reconstructed B-hadron on a per candi-date basis using for example the median of thepredicted density distribution. The knowledge ofthe full distribution provides much more infor-mation than for example the mean value (whichis determined in a standard regression analysis):The width of the distribution can be interpretedas an estimate of the uncertainty of the predic-tion. In particular, non-Gaussian behaviour canbe correctly taken into account. This also allowsselecting only high quality candidates with lowuncertainties for the subsequent analysis by e.g.rejecting candidates with a large width of the pre-

The NeuroBayes Neural Network package 3
dicted distribution.
2.4. Preprocessing
Preprocessing the input variables prior to net-work training plays a vital role in the analysis ofmultidimensional correlated data. This can be il-lustrated by a simple two-dimensional example:A hiker is to find the deepest valley in the SwissAlps starting from a high mountain. Once veryshallow valleys are rejected by a first glance, thehiker starts descending - however, without fur-ther tools he has no means to determine whetherthe next valley is deeper than this one. Prepro-cessing the input variables thus corresponds tofinding the optimal starting point for the subse-quent network training. Users can choose froma wide range of possible preprocessing options.Each preprocessing option is applied to either aspecific input variable or to all input variables. Afew options used in many applications from theextensive list of possible options are highlightedbelow. All variables can be normalised and (lin-early) decorrelated such that the covariance ma-trix of the thus obtained new set of input vari-ables is given by the unit matrix. Binary or dis-crete variables are automatically recognised andtreated accordingly in the further processing. IfNeuroBayes is used for shape-reconstruction, theinclusive shape can be fixed by introducing di-rect connections between the input and outputlayer of the network. Thus the network trainingcorresponds to learning deviations of the inclu-sive shape. Furthermore, the input variables canbe transformed such that the first new variablecontains all linear information about the mean,the second variable all linear information aboutthe width of the distribution to be learned, etc.The statistical significance of each input variableis computed automatically at the end of the pre-processing. A further option can be chosen toreject all (transformed) variables with a signifi-cance lower than n · σ (n = 1, . . . , 9). A veryimportant option from the extensive list of in-
dividual variable preprocessing is to handle vari-ables with a default value or δ-function. This cane.g. occur if not all parts of a detector can beread out for each candidate and the thus result-ing set of input variables is incomplete. Discrete
input variables can be interpreted as members ofordered classes (i.e. the value of the variable in-dicates a certain order, e.g. a lose, medium ortight cut) or unordered classes (i.e. class A isdifferent from class B but no further informationcan be obtained from the order the classes). ABayesian regularisation scheme is applied to ef-ficiently treat outliers far away from the bulk ofthe values. Instead of using the input variabledirectly, a new variable can be defined contain-ing the one-dimensional correlation to the train-ing target by performing a regularised spline-fit.The fit can either be done for a general continu-ous variable or can be forced to be monotonous.Furthermore, the influence on the correlation tothe training target of other input variables on agiven variable can be removed. All preprocess-ing options are very robust and work completelyautomatic without the need for further user in-teraction.
2.5. Regularisation
The use of regularisation techniques is of vitalimportance during network training. Employingtechniques based on Bayesian statistics the Neu-roBayes Teacher practically eliminates the risk ofovertraining and enhances the generalisation abil-ities of the network. Key aspects include the con-stant determination of the statistical relevance ofindividual connections and entire network nodes,separate regularisation constants for at least threegroups of weights, the automatic relevance deter-mination of the input variables and (in the case ofshape-reconstruction) the automated shape regu-larisation of the output nodes. Statistically in-significant network connections and even entirenodes are removed during the network training toensure that the network learns only real featuresof the data. The thus obtained trained networkrepresents the minimal topology needed to cor-rectly reproduce the characteristics of the datawhile being insensitive to statistical fluctuations.
3. Examples From High Energy Physics
NeuroBayes is successfully used in manyphysics analyses. Significant improvement hasbeen obtained in the identification of jets contain-

4 M.Feindt and U. Kerzel
efficiency0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
efficiency0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
pu
rity
0
0.2
0.4
0.6
0.8
1
CDF Run II Monte Carlo
bJetNet
IP jet prob
Figure 2. Improvement achieved by selecting jetscontaining B-hadrons with NeuroBayes comparedto the previously used method. The upper curve(in red) has been obtained using the NeuroBayesExpert, the lower curve (in blue) represents thebest result achieved with conventional methods.A significant improvement of up to 20% in thepurity of the selected jets at the same efficiencyis obtained.
ing B mesons, the determination of the b flavour(i.e. b or b) and the identification of the parti-cle type (e±, µ±) in the CDF experiment. Theseimprovements are of crucial importance in the ob-servation of the Bs mixing and the measurementof the mixing frequency ∆ms. Figure 2 illustratesthe improvement obtained using the NeuroBayesExpert to select events containing B mesons [3].The performance is evaluated by determining pu-rity and efficiency for multiple cuts on the pre-diction from the NeuroBayes Expert (or the finaldiscriminating variable in case of other methods).The efficiency is defined as the number of signalcandidates past a given network cut divided bythe number of all signal candidates, purity is de-fined as the number of signal candidates pas agiven network cut divided by the number of allparticles past the cut. This results in a charac-teristic curve in the purity-efficiency plane. The
ideal working point is the point with the small-est distance to the upper right corner represent-ing 100% purity at 100% efficiency, though anyother working point may be chosen dependingon the specific needs of the respective analysis.A further application is the automated cut opti-misation in case of resonance signals: Instead ofoptimising e.g. the ratio of signal yield dividedby background by successively optimising cuts onvarious variables, these variables can be used asinput to the NeuroBayes Teacher. The Teacheris then trained to distinguish between resonantand background events. This method can be ap-plied also on data only in case simulated eventsare not available by using the side-bands of theresonance as estimates for the background. Neu-roBayes can also be used to determine the quan-tum numbers JPC of an unknown particle as dis-cussed in [4]. Multiple networks are trained us-ing dedicated simulated events each generated ac-cording to a specific assumption of the quantumnumbers JPC . Applying the NeuroBayes Expertto the data, the resonance will be either enrichedor strongly suppressed depending on whether thecorrect JPC assignment is found.
The shape reconstruction mode of NeuroBayeshas been integrated into the BSAURUS [2] pack-age used in many DELPHI analyses to inclusivelydetermine the energy of a B hadron and providea measure of the error. Using this method thecore resolution of the pull (Erec − Etrue)/Etrue
has been improved from ≈ 40% to ≈ 10% as es-timated by simulation for events measured in theLEPII phase. A further example which has beenof crucial importance in the observation of B∗∗
s
at DELPHI [5] is the determination of the az-imuthal angle on the inclusively reconstructed Bhadron. Compared to the previously best clas-sical approach in BSAURUS [2], the resolutionimproved significantly. Using the measure of theuncertainty provided by NeuroBayes (e.g. thewidth of the predicted probability density distri-bution), only the high resolution candidates canbe selected for the subsequent analysis.

The NeuroBayes Neural Network package 5
4. Technology Transfer And Applications
In Industry
The technology provided by the NeuroBayesneural network package does not only play a vi-tal role in many physics analyses in the DEL-PHI and CDF collaboration but also have a widerange of applications in industry. The spin-offcompany phi-t (www.phi-t.de) has been foundedwith financial support by the exist-seed pro-gramme of the German Federal Ministry for Edu-cation and Research (BMBF) in 2002. The shapereconstruction feature has been successfully usedto optimise the buy-trade strategies in investmentbanking.
A successful project with the BadischeGemeinde Versicherungen has made it possibleto offer radically new policies for car insurancesto young drivers identifying low-risk customers.Identifying customers likely to cancel the con-tract in the near future enables the companyto get involved at an early stage of this deci-sion and thus helps to prevent losing the cus-tomer. Further applications in industry rangefrom the identification of (side-) effects of drugs inmedicine and pharmacy, to credit scoring (BaselII), financial time series prediction, risk minimi-sation in trading strategies to fraud detection ininsurance claims.
The power of the NeuroBayes technology hasbeen demonstrated recently at the Data MiningCup 2005 [6] with ≈ 500 participants from thewhole world. Using NeuroBayes, six studentsfrom the University of Karlsruhe were able to winthe positions 2, . . . , 7 in the final score.
5. Conclusion
The NeuroBayes neural network package pro-vides a sophisticated tool for the analysis ofhighly correlated data. NeuroBayes is based onBayesian statistics and the network output canbe directly interpreted as the Bayesian a poste-
riori probability. Taking a priori knowledge intoaccount, NeuroBayes will never return unphysicalresults. The use of advanced regularisation andpruning techniques practically eliminate the riskof overtraining and lead to an enhanced general-
isation ability of the trained network. An auto-mated and completely robust preprocessing pre-pares the input optimally for the network train-ing. The various preprocessing options act eitheron all input variables (e.g. linear decorrelation ofthe variables, expansion in orthogonal polynomi-als,. . . ) or individual variables (e.g. treatment ofvariables with δ-functions or default values, or-dered and unordered classes, . . . ) and cover awide range of cases. NeuroBayes can be usedboth for classification and for the prediction ofcomplete probability density distributions on aper candidate basis. Significant improvements inphysics analyses were obtained in the DELPHIand CDF collaborations using NeuroBayes. Thefoundation of the company phi-t transfers thistechnology to industry and has led to e.g. thedevelopment of new car insurance policies.
REFERENCES
1. M. Feindt, A Neural Bayesian Estima-tor for Conditional Probability Densities,arXiv:physics/0402093
2. M. Feindt et al., BSAURUS - A Package ForInclusive B-Reconstruction, hep-ex/0102001
3. C. Lecci, THESIS TITLE, PhD thesis (2005),Institut fur Exp. Kernphysik, University ofKarlsruhe
4. C. Marino, THESIS TITLE Diploma the-sis (2005, in preparation), Institut fur Exp.Kernphysik, University of Karlsruhe
5. Z. Albrecht, Analyse von orbital angeregtenB-Mesonen PhD thesis (2003), Institut furExp. Kernphysik, University of Karlsruhe
6. Data Mining Cup 2005,www.data-mining-cup.de