the design of the borealis stream processing engine cidr 2005 brandeis university, brown university,...
TRANSCRIPT

The Design of the Borealis Stream Processing Engine
CIDR 2005
Brandeis University, Brown University, MIT
Kang, Seungwoo
2005.3.15
Ref. http://www-db.cs.wisc.edu/cidr/presentations/26 Borealis.ppt

Outline Motivation and Goal Requirements Technical issues
Dynamic revision of query resultsDynamic query modificationFlexible and scalable optimizationFault tolerance
Conclusion

Motivation and Goal Envision the second-generation SPE
Fundamental requirements of many streaming applications not supported by first-generation SPE
Three fundamental requirements Dynamic revision of query results Dynamic query modification Flexible and scalable optimization
Present the functionality and preliminary design of Borealis

Requirements
Dynamic revision of query results Dynamic query modification Flexible and highly scalable optimization

Changes in the models Data model
Revision support Three types of messages
Query model Support modification of Op box semantic
Control lines
QoS model Introduce QoS metrics in tuple basis
Each tuple (message) holds VM (Vector of Metrics) Score function
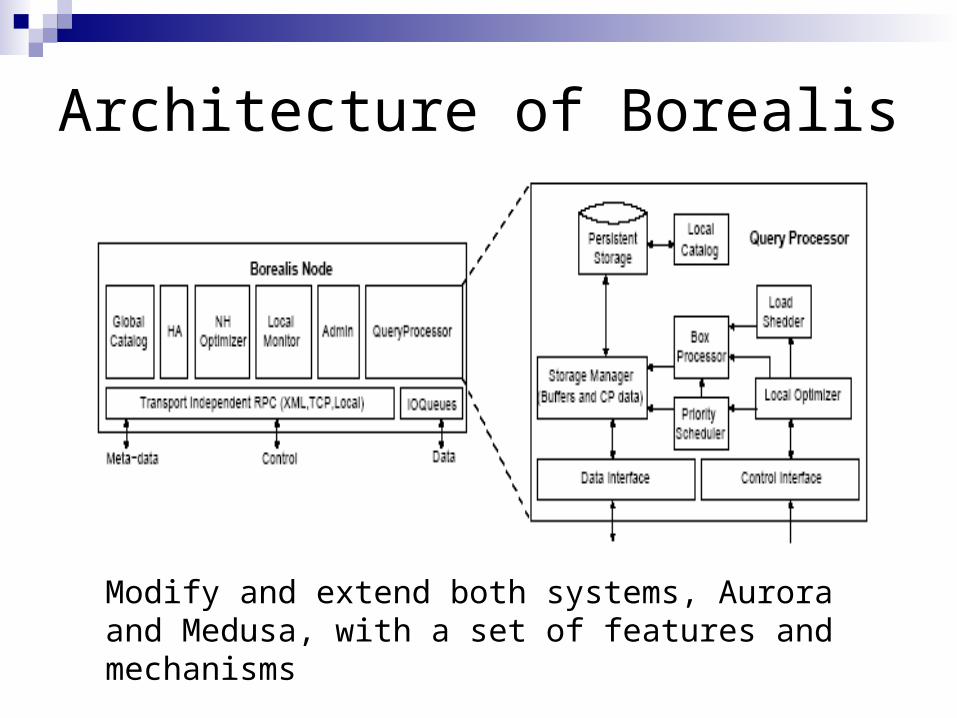
Architecture of Borealis
Modify and extend both systems, Aurora and Medusa, with a set of features and mechanisms

1.Dynamic revision of query results
Problem Corrections of previously reported data from data
source Highly volatile and unpredictable characteristics of
data sources like sensors Late arrival, out-of-order data
Just accept approximate or imperfect results Goal
Support to process revisions and correct the previous output result

Causes for Tuple Revisions Data sources revise input streams:
“On occasion, data feeds put out a faulty price [...] and send a correction within a few hours” [MarketBrowser]
Temporary overloads cause tuple drops Data arrives late, and miss its processing wnd
Averageprice
1 hour
(1pm,$10)(2pm,$12)(3pm,$11)(4:05,$11)(4:15,$10)(2:25,$9)

New Data Model for Revisions
time: tuple timestamp type: tuple type
insertion, deletion, replacement id: unique identifier of tuple on stream
header data
(time,type,id,a1,...,an)
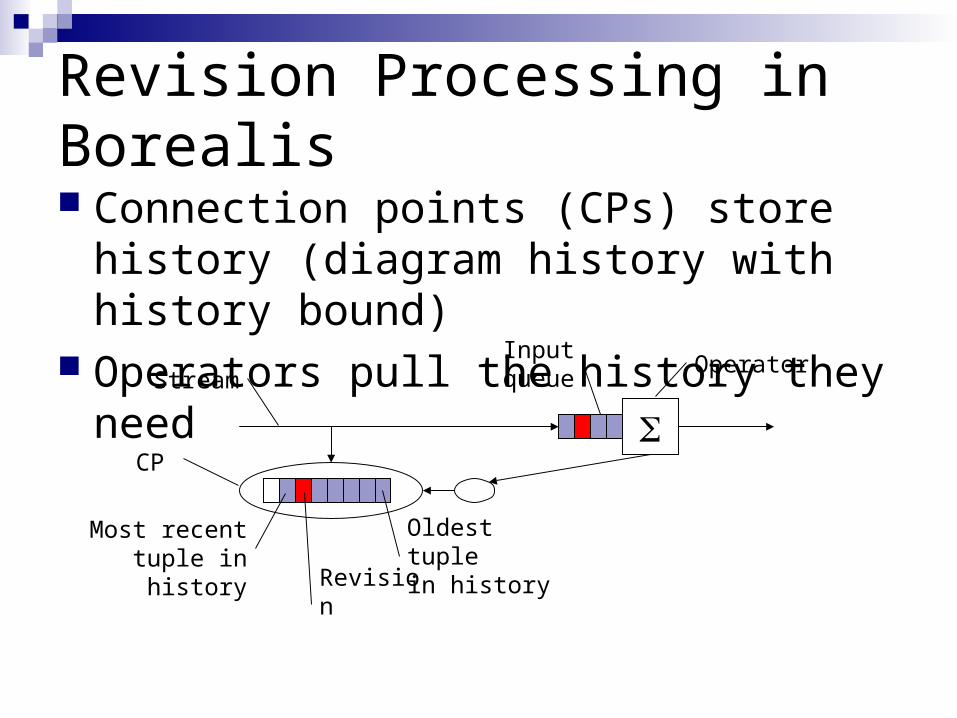
Revision Processing in Borealis
Connection points (CPs) store history (diagram history with history bound)
Operators pull the history they need
Operator
CP
Oldest tuplein history
Most recent tuple in history
Revision
Input queueStream

Discussion Runtime overhead
Assumption Input revision msg < 1% Revision msg processing can be deferred
Processing cost Storage cost
Application’s needs / requirements Whether it is interested in revision msg or not What to do with revision msg
Rollback, compensation ?? Application’s QoS requirement Delay bound

2. Dynamic query modification Problem
Change certain attributes of the query at runtime Manual query substitutions – high overhead, slow to take effect
Goal Low overhead, fast, and automatic modifications
Dynamic query modification Control lines
Provided to each operator box Carry messages with revised box parameters and new box functions
Timing problem Specify precisely what data is to be processed according to what control
parameters Data is ready for processing too late or too early
old data vs. new parameter -> buffered old parameters new data vs. old parameter -> revision message and time travel

Time travel Motivation
Rewind history and then repeat it Move forward into the future
Connection Point (CP) CP View
Independent view of CP View range
Start_time Max_time
Operations Undo: deletion message to rollback the state to time t Replay
Prediction function for future travel
1 2 3 4 5 6
2 3 4
3 4 5 6

3.Optimization in a Distributed SPE Goal: Optimized resource allocation Challenges:
Wide variation in resources High-end servers vs. tiny sensors
Multiple resources involved CPU, memory, I/O, bandwidth, power
Dynamic environment Changing input load and resource availability
Scalability Query network size, number of nodes

Quality of Service A mechanism to drive resource allocation Aurora model
QoS functions at query end-points Problem: need to infer QoS at upstream nodes
An alternative model Vector of Metrics (VM) carried in tuples
Content: tuple’s importance, or its age Performance: arrival time, total resource consumed, ..
Operators can change VM A Score Function to rank tuples based on VM Optimizers can keep and use statistics on VM

Example Application: Warfighter Physiologic Status Monitoring (WPSM)
Area State Confidence
ThermalHydrationCognitiveLife SignsWound Detection
90%60%100%90%80%
Physiologic Models
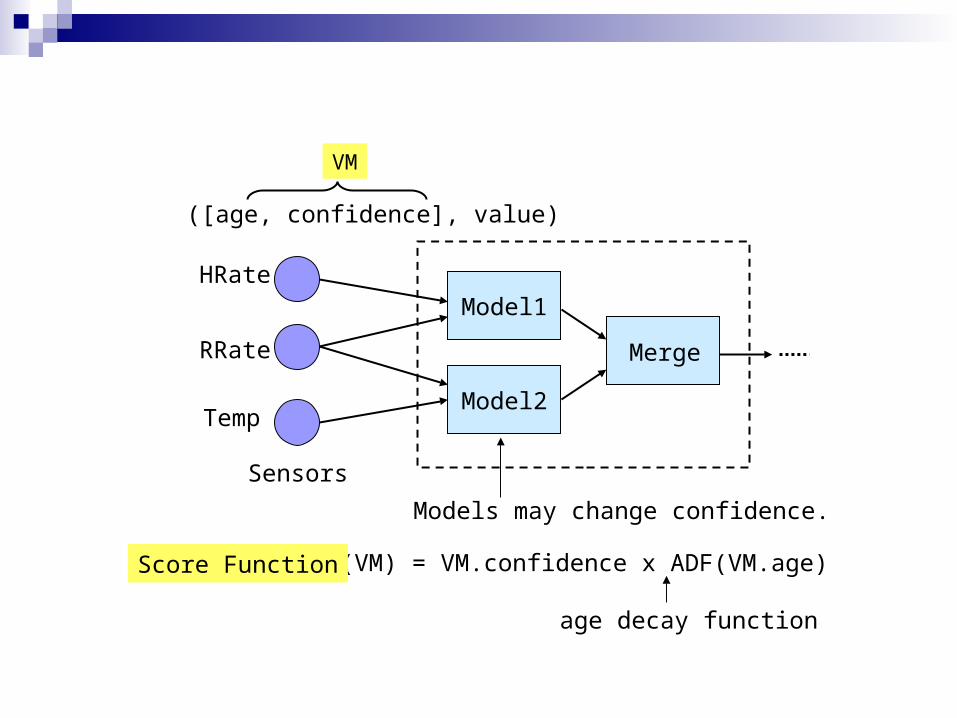
SF(VM) = VM.confidence x ADF(VM.age)
age decay function
Score Function
Sensors
Model1
Model2
([age, confidence], value)
VM
Merge
Models may change confidence.
HRate
RRate
Temp

Borealis Optimizer Hierarchy
End-point Monitor(s) Global Optimizer
Local Monitor
Local Optimizer
Neighborhood Optimizer
Borealis Node
statistics trigger decision

Optimization Tactics
Priority scheduling - Local Modification of query plans - Local
Changing order of commuting operators Using alternate operator implementations
Allocation of query fragments to nodes - Neighborhood, Global
Load shedding - Local, Neighborhood, Global

Priority scheduling Highest QoS Gradient box
Evaluate the predicted-QoS score function on each message with values in VM
average QoS Gradient for each box By comparing average QoS-impact scores between the
inputs and outputs of each box
Highest QoS-impact message from the input queue Out-of-order processing Inherent load shedding behavior
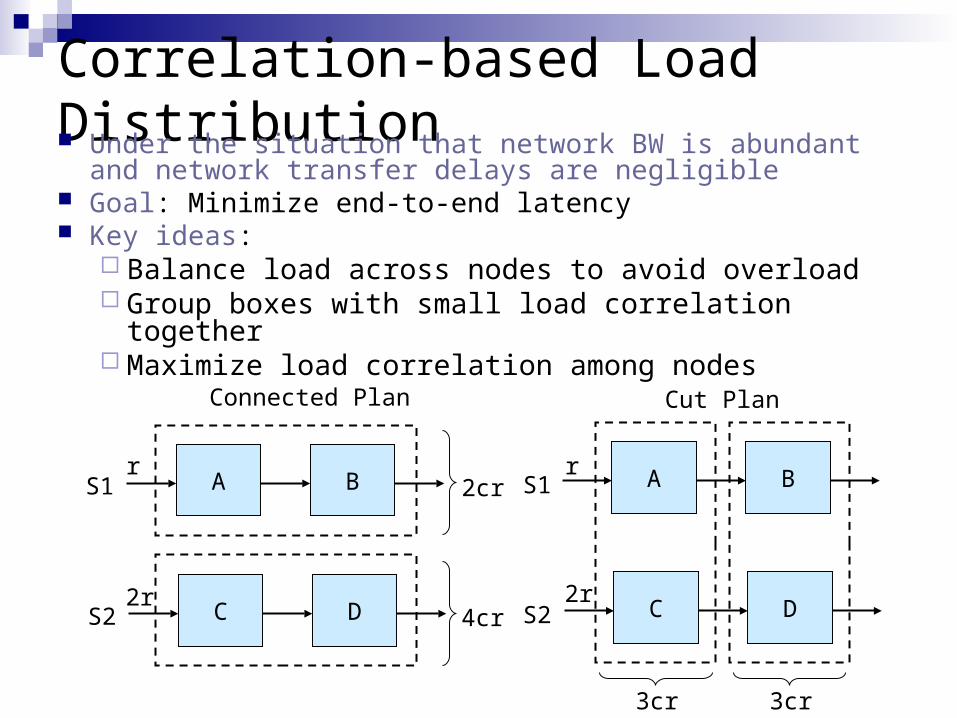
Correlation-based Load Distribution Under the situation that network BW is abundant and
network transfer delays are negligible Goal: Minimize end-to-end latency Key ideas:
Balance load across nodes to avoid overload Group boxes with small load correlation together Maximize load correlation among nodes
Connected Plan
A BS1
C DS2
r
2r
2cr
4cr
Cut Plan
S1
S2
A B
C D
r
2r
3cr 3cr

Load Shedding
Goal: Remove excess load at all nodes and links Shedding at node A relieves its descendants Distributed load shedding
Neighbors exchange load statistics Parent nodes shed load on behalf of children Uniform treatment of CPU and bandwidth problem
Load balancing or Load shedding?
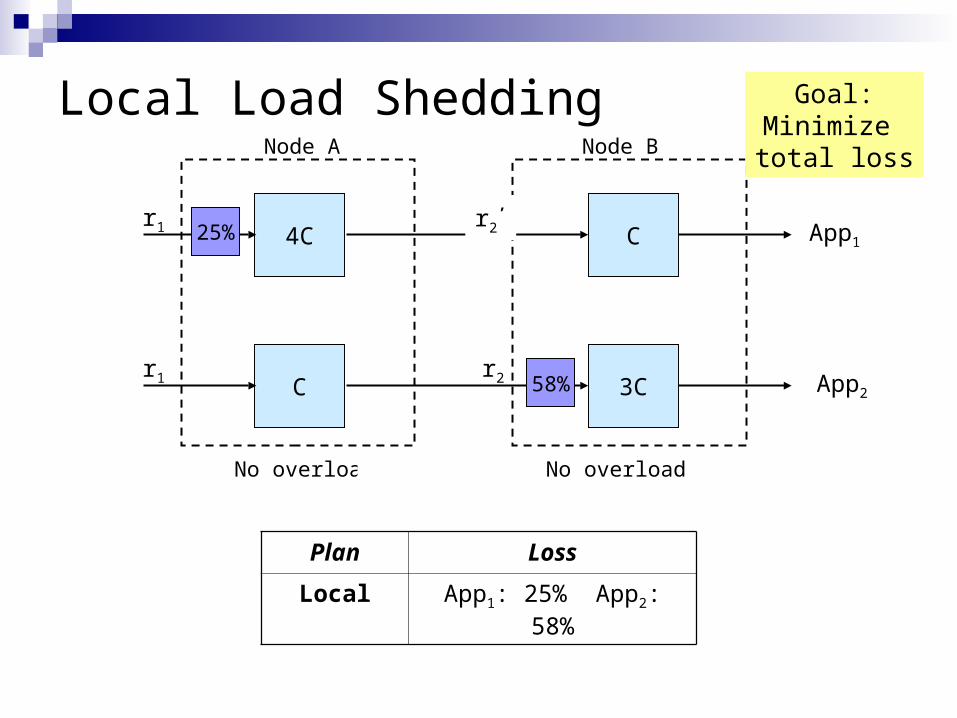
Local Load Shedding
Plan Loss
Local App1: 25% App2: 58%
CPU Load = 5Cr1, Cap = 4Cr1 CPU Load = 4Cr2, Cap = 2Cr2
A must shed 20% B must shed 50%
4C C
C 3C
r1
r1
r2
r2
App1
App2
Node A Node B
Goal:Minimize total loss
25%
58%
CPU Load = 3.75Cr2, Cap = 2Cr2
B must shed 47% No overload No overload
A must shed 20% A must shed 20%
r2’

Distributed Load Shedding
CPU Load = 5Cr1, Cap = 4Cr1 CPU Load = 4Cr2, Cap = 2Cr2
A must shed 20% B must shed 50%
4C C
C 3C
r1
r1
r2
r2
App1
App2
Node A Node B
9%
64%
Plan Loss
Local App1: 25% App2: 58%
Distributed App1: 9% App2: 64%smaller
total loss!
No overload No overload
A must shed 20% A must shed 20%
r2’
r2’’
Goal:Minimize total loss

Fault-Tolerance through Replication Goal: Tolerate node and network failures
U
Node 1’
Node 2’
Node 3’
U
s1
s2
Node 1
U
Node 3
U Node 2
s3
s4
s3’

Fault-Tolerance Approach If an input stream fails, find another replica No replica available, produce tentative tuples Correct tentative results after failures
STABLEUPSTREAM
FAILURE
STABILIZING
Missing or tentative inputs
Failu
re h
eals
Anoth
er u
pstre
am
failu
re in
pro
gres
sReconcile state
Corrected output

Conclusions Next generation streaming applications require a
flexible processing model Distributed operation Dynamic result and query modification Dynamic and scalable optimization Server and sensor network integration Tolerance to node and network failures
http://nms.lcs.mit.edu/projects/borealis