thapliyal 1mapld 2005/1011 a high speed and efficient method of elliptic curve encryption using...
TRANSCRIPT

Thapliyal 1 MAPLD 2005/1011
A High Speed and Efficient Method of Elliptic Curve
Encryption Using Ancient Indian Vedic Mathematics
Himanshu Thapliyal and M.B Srinivas ([email protected], [email protected])
Center for VLSI and Embedded System Technologies
International Institute of Information Technology Hyderabad-500019, India

Thapliyal 2 MAPLD 2005/1011
Abstract• This paper presents efficient hardware circuitry for point addition and
doubling using multiplication and square algorithms of Ancient Indian Vedic Mathematics.
• The multiplier architecture is based on the vertical and crosswise algorithm of ancient Indian Vedic Mathematics.
• In the proposed architecture 4 bits of the multiplicand and multiplier are grouped together and the partial product is made available within a single clock cycle.
• In order to calculate the square of a number, “Duplex” D property of binary numbers is proposed.
• A technique for computation of fourth power of a number is also being proposed.
• In the Duplex, twice the product of the outermost pair is taken, and add twice the product of the next outermost pair, and so on till no pairs are left.
• A considerable improvement in the point additions and doubling has been observed when implemented using proposed techniques for exponentiation.

Thapliyal 3 MAPLD 2005/1011
Introduction of ECC
• An Elliptic curve is defined by an equation in two variables, with coefficients. The variables and coefficients are restricted to elements in finite field, which results in a finite Abelian group.
• Weierstrass equation in GF(2m) y2+xy=x3+ax2+b
• Weierstrass equation in GF(p) y2=x3+ax+b

Thapliyal 4 MAPLD 2005/1011
Elliptic Curve Cryptography
• Emerging as a new generation of cryptosystems based on public key cryptography
• No sub-exponential algorithm to solve the discrete logarithm problem
• Smallest key size & highest strength per bit compared to other public key cryptosystems
• Smaller key sizes suitable for hardware implementation

Thapliyal 5 MAPLD 2005/1011
Elliptic Curve Arithmetic
Arithmetic Operation Hierarchy
A d d it ion , S u b trac tion , M u lt ip lica tion an d L e ft-S h ift (a ll m od u lo a la rg e in teg er p rim e)
E llip t ic C u rve P o in t A d d it ion s an d D ou b lin g s
M u lt ip lica tion o f a p o in t P = (x,y,z ) on th e e llip t ic cu rve b y a sca la r M
Thapliyal 6 MAPLD 2005/1011
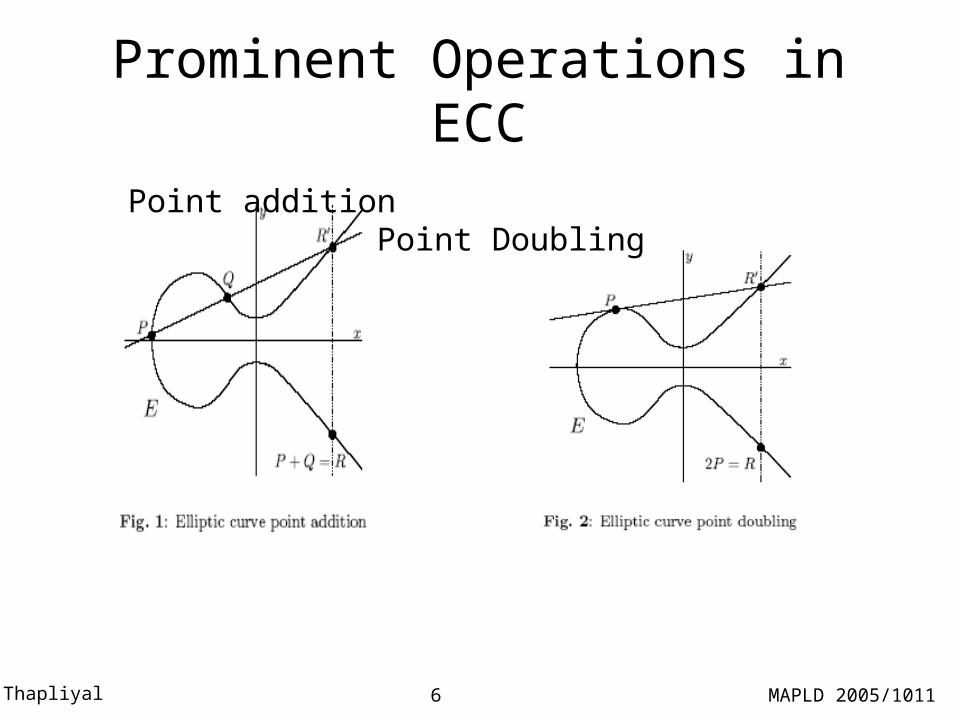
Prominent Operations in ECC
Point addition Point Doubling

Thapliyal 7 MAPLD 2005/1011
Point Doubling (Using Projective
Co-Ordinate System)• In GF(p) field

Thapliyal 8 MAPLD 2005/1011
Prominent Bottleneck Operations in Point Doubling
• Multiplier efficiency can be one of the bottlenecks in efficiency of point doubling
• Exponentiation operations like square, cube and computation of fourth power are the major bottlenecks in the efficiency of the point additions and doubling.

Thapliyal 9 MAPLD 2005/1011
Proposed Multiplication
Multiplier Architecturea. The multiplier deals with N x N bit numbers and
takes less time as the number of bits increases. b. It takes n bits of multiplicand and multiplier and
produces 2n bit of product Implemented Algorithm Urdhva Tiryakbhyam (Vertical & Crosswise) -Urdhva means vertically up-down, Tiryakbhyam
means left to right or vice versa
Thapliyal 10 MAPLD 2005/1011
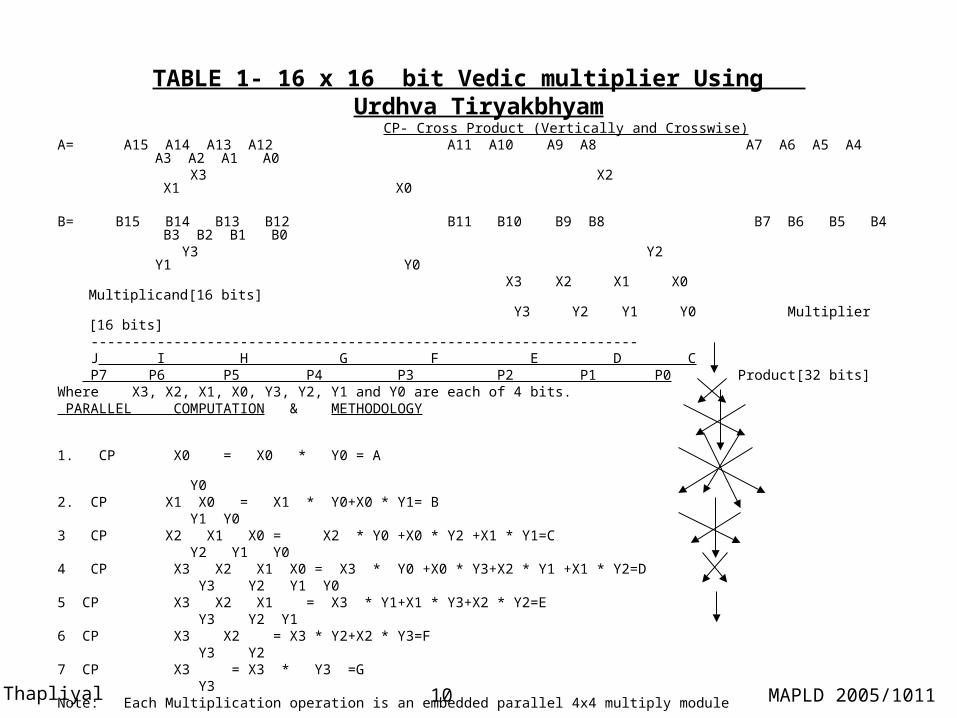
TABLE 1- 16 x 16 bit Vedic multiplier Using Urdhva Tiryakbhyam
CP- Cross Product (Vertically and Crosswise)A= A15 A14 A13 A12 A11 A10 A9 A8 A7 A6 A5 A4 A3 A2 A1 A0
X3 X2 X1 X0 B= B15 B14 B13 B12 B11 B10 B9 B8 B7 B6 B5 B4 B3 B2 B1 B0 Y3 Y2 Y1 Y0
X3 X2 X1 X0 Multiplicand[16 bits] Y3 Y2 Y1 Y0 Multiplier [16 bits] ------------------------------------------------------------------ J I H G F E D C P7 P6 P5 P4 P3 P2 P1 P0 Product[32 bits]Where X3, X2, X1, X0, Y3, Y2, Y1 and Y0 are each of 4 bits. PARALLEL COMPUTATION & METHODOLOGY
1. CP X0 = X0 * Y0 = A Y02. CP X1 X0 = X1 * Y0+X0 * Y1= B Y1 Y03 CP X2 X1 X0 = X2 * Y0 +X0 * Y2 +X1 * Y1=C Y2 Y1 Y04 CP X3 X2 X1 X0 = X3 * Y0 +X0 * Y3+X2 * Y1 +X1 * Y2=D Y3 Y2 Y1 Y05 CP X3 X2 X1 = X3 * Y1+X1 * Y3+X2 * Y2=E Y3 Y2 Y1 6 CP X3 X2 = X3 * Y2+X2 * Y3=F Y3 Y2 7 CP X3 = X3 * Y3 =G Y3 Note: Each Multiplication operation is an embedded parallel 4x4 multiply module

Thapliyal 11 MAPLD 2005/1011
Existing Efficient Square proposed by Flynn et. al

Thapliyal 12 MAPLD 2005/1011
Proposed Duplex Property of Binary Numbers For Square
Computation• In the Duplex, we take twice the product of the outermost pair, and then
add twice the product of the next outermost pair, and so on till no pairs are left.
• When there are odd number of bits in the original sequence there is one bit left by itself in the middle, and this enters as such. Thus,
1. For a 1 bit number, D is the same number i.e D(X0)=X0.
2. For a 2 bit number D is twice their product i.e D(X1X0)=2 * X1 * X0.
3. For a 3 bit number D is twice the product of the outer pair + the e middle bit i.e D(X2X1X0)=2 * X2 * X0+X1.
4. For a 4 bit number D is twice the product of the outer pair + twice the product of the inner pair i.e D(X3X2X1X0) =2 * X3 * X0+2 * X2 * X1
• The pairing of the bits 4 at a time is done for number to be squared.

Thapliyal 13 MAPLD 2005/1011
Proposed Vedic Square Using Duplex

Thapliyal 14 MAPLD 2005/1011
Proposed Technique for Calculating Fourth Power of a
Number• This Paper also proposes an algorithm for calculating the fourth
power of a number.• The technique is developed as an extension of the duplex and
Anurupya Sutra of Vedic Mathematics. • If a and b are two digits, then according to proposed technique,
the number M of N bits whose 4th power is to be calculated can be decomposed into two number a & b of N/2 bits.
• Now, the 4th power of M can be calculated as follows.
• The number can again be further decomposed until the we can get the product through the smallest 4x4 or 8x8 multiplier available.

Thapliyal 15 MAPLD 2005/1011
Verification and Implementation
• The algorithms and architecture have been implemented using Verilog HDL and the simulation has been done using Modelsim Simulator.
• The codes are synthesized in Xilinx ISE foundation 6.3. The designs are optimized for speed using Xilinx , Device Family : VirtexE, Device : XCV300e, Package: bg432, Speed grade: -8.
• The designs are completely technology independent and can be easily converted from one technology to another.

Thapliyal 16 MAPLD 2005/1011
Comparison Results of Square
Name ofMultiplier
Vendor DeviceFamily &Device
Package
SpeedGrade
CellUse
Estimated Delay (ns)
Square Proposed by Flynn et.al
8 x 8 bit
Xilinx
VirtexEXcv300e
Bg432 -8 177 30.370
16 x 16 bit
Xilinx VirtexEXcv300e
Bg432 -8 727 60.646
Proposed Square
8 x 8 bit Xilinx VirtexEXcv300e
Bg432 -8 190 15.193
16 x 16 bit
Xilinx VirtexEXcv300e
Bg432 -8 751 23.600

Thapliyal 17 MAPLD 2005/1011
Comparison Results of Point Doubling
Point Doubling Using Square
Vendor DeviceFamily &Device
Package
SpeedGrade
CellUse
Estimated Delay (ns)
UsingSquare Proposed by Flynn et.al
8 x 8 bit
Xilinx
VirtexEXcv300e
Bg432 -8 25599 604.861
16 x 16 bit
Xilinx VirtexEXcv300e
Bg432 -8 96663 1327.809
UsingProposed Square
8 x 8 bit Xilinx VirtexEXcv300e
Bg432 -8 26290 542.325
16 x 16 bit
Xilinx VirtexEXcv300e
Bg432 -8 96805 1207.677

Thapliyal 18 MAPLD 2005/1011
Results of Point Doubling When Using Proposed Technique for
computation of 4th PowerPoint Doubling Vendor Device
Family &Device
Package
SpeedGrade
CellUse
Estimated Delay (ns)
UsingProposed Square
8 x 8 bit Xilinx VirtexEXcv300e
Bg432 -8 26290 542.325
16 x 16 bit
Xilinx VirtexEXcv300e
Bg432 -8 96805 1207.677
UsingProposed Fourth Power Technique
8 x 8 bit Xilinx VirtexEXcv300e
Bg432 -8 33828 537.885
16 x 16 bit
Xilinx VirtexEXcv300e
Bg432 -8 139059 1348.971

Thapliyal 19 MAPLD 2005/1011
Conclusions
• The results shows there is a significant improvement in speed/area using the proposed square.
• In FPGA, the proposed technique for computation of fourth power should be used for small bit sizes only.
• For higher bit sizes, it is better to perform the fourth power operation by recursively using the proposed square rather than directly calculating using the proposed technique.
• The proposed techniques of square and fourth power computation will be highly beneficial for low power operation as the sub-modules can be switched on and off based on the requirement.

Thapliyal 20 MAPLD 2005/1011
References
• Sangook Moon,"Elliptic Curve Scalar Point Multiplication Using Radix-4 Booth's Algorithm", International Symposium on Communications and Information Technologies 2004(ISCIT 2004),pp. 80-83, Japan, October 26-29,2004.
• Siddaveerasharan Devarkal and Duncan A. Buell," Elliptic Curve Arithmetic", Proceedings, MAPLD 2003.
• Duncan A. Buell, James P. Davis, and Gang Quan, “Reconfigurable computing applied to problems in communication security,” Proceedings, MAPLD 2002.
• Energy Scalable Reconfigurable Cryptographic Hardware for Portable Applications. James Ross Goodman, PhD Dissertation, MIT .
• Albert A. Liddicoat and Michael J. Flynn, "Parallel Square and Cube Computations", 34th Asilomar Conference on Signals, Systems, and Computers, California, October 2000.
• Albert Liddicoat and Michael J. Flynn," Parallel Square and Cube Computations", Technical report CSL-TR-00-808 , Stanford University, August 2000.

Thapliyal 21 MAPLD 2005/1011
References Continued • Karatsuba A.; Ofman Y. Multiplication of multidigit numbers by automata, Soviet Physics-
Doklady 7, p. 595-596, 1963
• Bailey, D. V. and Paar, C.,” Efficient Arithmetic in Finite Field Extensions with Application in Elliptic Curve Cryptography”, Journal of Cryptology, vol. 14, no. 3, 153–176. 2001
• A.Weimerskirch, C.Paar and S.C.Shantz (2001), “Elliptic Curve Cryptography on a Palm OS Device”, Proceeding of 6th Australasian Conference on Information Security and Privacy (ACISP 2001), 11-13 July 2001, Macquarie University, Sydney, Australia.
• M. Rosner, Elliptic Curve Cryptosystems on reconfigurable hardware. Master’s Thesis, Worcester Polytechnic Institute, Worcester, USA, 1998.