textil & design - cs-geiger.de reulingen/formelsammlung/formelsammlung ttb.pdf · textil &...
TRANSCRIPT

STATISTIK
Dipl. Mathematiker (FH) Roland Geiger Rosenstr. 23
72631 Aichtal [email protected]
www.cs-geiger.de
Formelsammlung Statistik
Textil & Design

STATISTIK
2-31
Grundlagen
Bezeichnungen
𝑥𝑖 einzelnen Messergebnisse einer Stichprobe
𝑛𝑖 absolute Häufigkeit
ℎ𝑖 relative Häufigkeit
𝑁𝑖 absolute Summenhäufigkeit oder absolute kumulierte Häufigkeit
𝐻𝑖 relative Summenhäufigkeit oder relative kumulierte Häufigkeit
Ω Menge aller Merkmalsausprägungen
∅ Leere Menge
Relative Häufigkeit
ℎ𝑖 =𝑛𝑖
𝑛
𝑛𝑖: absolute Häufigkeit
𝑛: Anzahl aller Möglichkeiten

STATISTIK
3-31
Lage- und Streumaße
Arithmetisches Mittel
�� =1
𝑛∙ ∑ 𝑥𝑖
𝑛
𝑖=1
n: Gesamtanzahl der Werte in der Stichprobe
Median
Die Merkmalsausprägung des genau in der Mitte liegenden Einzelwertes. Dabei müssen die Messergebnisse der Größe nach sortiert werden.
n: Anzahl der Messergebnisse
n ist gerade
xMedian =1
2∙ (x
(n2
)+ x
(n2
+1))
n ist ungerade
xMedian = x(
n+12
)
Modus oder Modalwert
Derjenige Wert der am häufigsten in einer Stichprobe vorkommt.
Schiefe
𝑣 =1
𝑛∙ ∑ (
𝑥𝑖 − ��
𝑠)
3𝑛
𝑖=1
n: Anzahl der Messergebnisse
s: Standardabweichung
Wölbung
𝑤 =1
𝑛∙ ∑ (
𝑥𝑖 − ��
𝑠)
4𝑛
𝑖=1
Gewogenes(gewichtetes arithmetisches Mittel
�� =1
𝑛∙ ∑ 𝑥�� ∙ 𝑛𝑖
𝑘
𝑖=1
𝑥𝑖: unterschiedliche Mittelwerte der Teilmengen
𝑛𝑖: absolute Häufigkeit in den einzelnen Teilmengen

STATISTIK
4-31
Geometrisches Mittel
��𝑔𝑒𝑜 = √𝑥1 ∙ 𝑥2 ∙ … ∙ 𝑥𝑛𝑛
Harmonisches Mittel
��ℎ =𝑎1 + 𝑎2 + 𝑎3 + ⋯ + 𝑎𝑛
𝑎1
𝑥1+
𝑎2
𝑥2+
𝑎3
𝑥3+∙∙∙∙∙∙∙∙ +
𝑎𝑛
𝑥𝑛
=𝑛
1𝑥1
+1𝑥2
+1𝑥3
+∙∙∙∙∙∙∙∙ +1
𝑥𝑛
=𝑛
∑1𝑥𝑖
𝑛1
Spannweite
𝑅 = 𝑥𝑚𝑎𝑥 − 𝑥𝑚𝑖𝑛
Quartil
Einteilung in 25%-ige Intervalle (n: Anzahl der Werte der Stichprobe)
Q0: Der kleinste Wert
Q1 = Qunten: x = 0,25 ∙ (n + 1)
Q2 = xMed: Median
Q3 = Qoben: x = 0,75 ∙ (n + 1)
Q4: Der größte Wert
Quartilsabstand
𝑄𝐴 = 𝑄3 − 𝑄1
Durchschnittliche Abweichung
𝑥𝐷 =1
𝑛∙ ∑|(𝑥𝑖 − ��)|
𝑛
𝑖=1
Varianz
𝑠2 =1
𝑛∙ ∑(𝑥𝑖 −
𝑛
𝑖=1
��)²
Standardabweichung
𝑠 = √1
𝑛∙ ∑(𝑥𝑖 −
𝑛
𝑖=1
��)²
Variationskoeffizient
𝑉 =𝑠
��∙ 100%

STATISTIK
5-31
Graphische Darstellung von Lage- und Streumaßen
Box-Plot oder Whiskers-Diagramm

STATISTIK
6-31
Wahrscheinlichkeitsrechnung
Kombinatorik-Modelle
Anzahl der Möglichkeiten, n Elemente anzuordnen
𝑛!
Geordnete Stichprobe mit zurücklegen
𝑛𝑘
𝑛: Anzahl der zur Verfügung stehenden Elemente
𝑘: Anzahl der Ziehvorgänge
Geordnete Stichprobe ohne zurücklegen
𝑛!
(𝑛 − 𝑘)!
Taschenrechner: nPr
𝑛: Anzahl der zur Verfügung stehenden Elemente
𝑘: Anzahl der Ziehvorgänge
Ungeordnete Stichprobe ohne zurücklegen
(𝑛𝑘
) =𝑛!
𝑘! ∙ (𝑛 − 𝑘)!
Taschenrechner: nCr
𝑛: Anzahl der zur Verfügung stehenden Elemente
𝑘: Anzahl der Ziehvorgänge
Ungeordnete Stichprobe mit zurücklegen
(𝑛 + 𝑘 − 1
𝑘)
Taschenrechner: nCr
𝑛: Anzahl der zur Verfügung stehenden Elemente
𝑘: Anzahl der Ziehvorgänge
Anzahl der Kombinationen n-ter Ordnung aus N Elementen:
mit Zurücklegen ohne Zurücklegen
mit Reihenfolge 𝑛𝑘
𝑛!
(𝑛 − 𝑘)!
ohne Reihenfolge (
𝑛 + 𝑘 − 1𝑘
) (𝑛𝑘
) =𝑛!
𝑘! ∙ (𝑛 − 𝑘)!

STATISTIK
7-31
Berechnung der Wahrscheinlichkeit
𝑃(𝐴) =𝑛𝑖
𝑛
𝑛𝑖: Anzahl der günstigen Möglichkeiten
𝑛: Anzahl aller Möglichkeiten
Rechenregeln für Wahrscheinlichkeiten
Sicheres Ereignis
A ∪ A = Ω
P(Ω) = 1
Unmögliches Ereignis
𝐴 ∩ 𝐴 = ∅
𝑃(∅) = 0
Unvereinbarkeit
A ∩ B = ∅ → unvereinbarkeit
Negierte Wahrscheinlichkeit
𝑃(A) = 1 − 𝑃(𝐴)
𝑃(A|𝐵) = 1 − 𝑃(𝐴|𝐵)

STATISTIK
8-31
Pfadregel
Produktregel
Die Wahrscheinlichkeit eines Pfades in einem Baumdiagramm ist gleich dem Produkt der Wahrscheinlichkeiten entlang dieses Pfades im Baumdiagramm.
Summenregel
Gibt es mehrere Pfade als mögliche Lösungen, so werden die Wahrscheinlichkeiten die-ser einzelnen Pfade addiert.
Additionsgesetz
Additionsgesetz für unvereinbare Ereignisse (ODER-Verknüpfung)
𝑃(𝐴 ∪ 𝐵) = 𝑃(𝐴) + 𝑃(𝐵)
Additionsgesetz für vereinbare Ereignisse (ODER-Verknüpfung)
𝑃(𝐴 ∪ 𝐵) = 𝑃(𝐴) + 𝑃(𝐵) − 𝑃(𝐴 ∩ 𝐵)
Multiplikationsgesetz
Multiplikationsgesetz für unvereinbare Ereignisse (UND-Verknüpfung)
𝑃(𝐴 ∩ 𝐵) = 0
Multiplikationsgesetz für vereinbare Ereignisse (UND-Verknüpfung)
𝑃(𝐴 ∩ 𝐵) = 𝑃(𝐴) ∙ 𝑃(𝐵)
Bedingte Wahrscheinlichkeit
𝑃(𝐴|𝐵) =𝑃(𝐴 ∩ 𝐵)
𝑃(𝐵)

STATISTIK
9-31
Binomialverteilung
Formel der Binomialverteilung
𝑏(𝑘; 𝑛; 𝑝) = 𝑃(𝑋 = 𝑘) = (𝑛𝑘
) ∙ 𝑝𝑘 ∙ (1 − 𝑝)𝑛−𝑘 = (𝑛𝑘
) ∙ 𝑝𝑘 ∙ 𝑞𝑛−𝑘
𝑛: Anzahl der Ziehversuche
𝑘: Anzahl der "Treffer" die erzielt werden sollen
𝑝: Wahrscheinlichkeit für einen "Treffer"
𝑞: Wahrscheinlichkeit für eine "Niete" oder keinen "Treffer
Erwartungswert einer binomialverteilten Zufallsvariable
𝐸(𝑥) = 𝑛 ∙ 𝑝
Varianz einer binomialverteilten Zufallsvariable
𝑉(𝑥) = 𝑛 ∙ 𝑝 ∙ 𝑞
Standardabweichung einer binomialverteilten Zufallsvariable
𝑆(𝑥) = √𝑛 ∙ 𝑝 ∙ 𝑞

STATISTIK
10-31
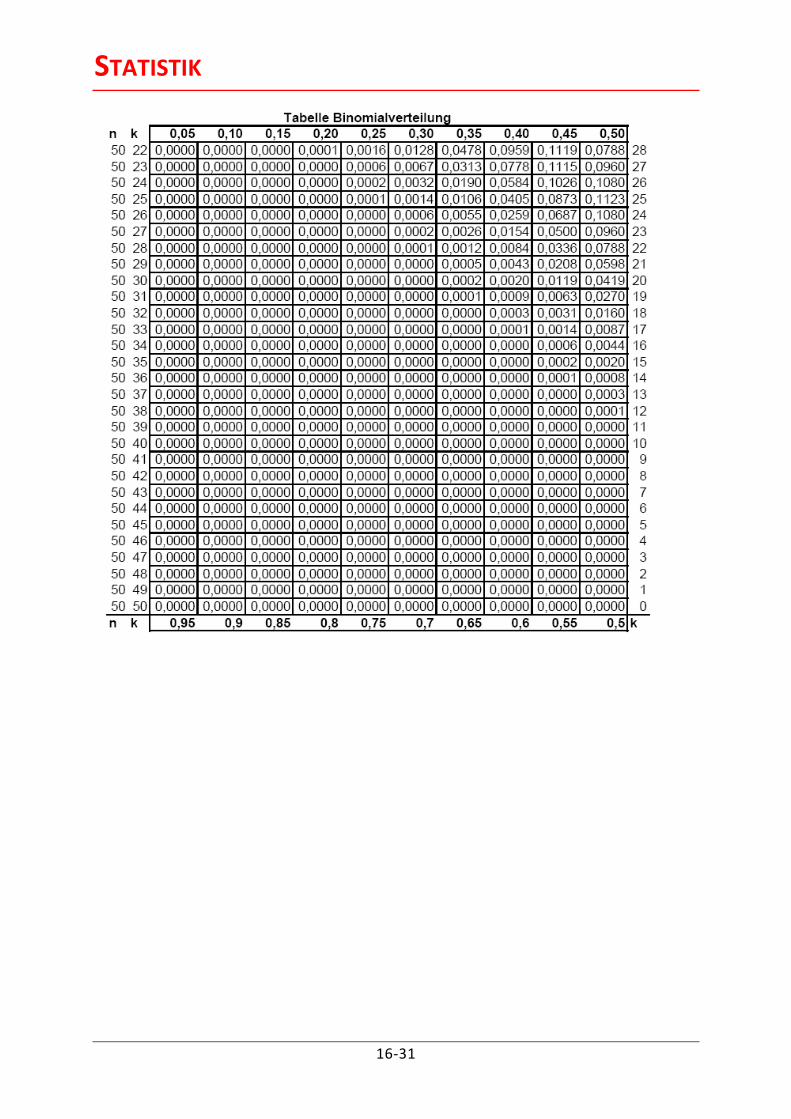
Tabellen zur Binomialverteilung

STATISTIK
11-31

STATISTIK
12-31

STATISTIK
13-31

STATISTIK
14-31

STATISTIK
15-31
STATISTIK
16-31

STATISTIK
17-31
Hypergeometrische Verteilung
Zufallsgröße
h(x|N; M; n) =(
Mx
) ∙ (N − Mn − x
)
(Nn
)
N: Die Elementanzahl der Grundgesamtheit
M: Die Zahl der Elemente mit einer bestimmten Eigenschaft
n: Die Zahl der Elemente in einer Stichprobe die gezogen werden
x: Die Anzahl der Elemente mit der bestimmten Eigenschaft, die sich in der gezogenen Stichprobe befinden
Erwartungswert
E(x) = n ∙M
N
Varianz
V(x) = n ∙M
N∙ (1 −
M
N) ∙ (
N − n
N − 1)
Standardabweichung
S(x) = √V(x)

STATISTIK
18-31
Poisson-Verteilung
Zufallsgröße
P(X = k) =μk
k!∙ e−μ
μ: durchschnittlicher zu erwartender Wert
k: Anzahl der gesuchten Treffer
Erwartungswert
E(x) = μ
Varianz
V(x) = μ
Standardabweichung
S(x) = √V(x)

STATISTIK
19-31
Tabellen zur Poisson-Verteilung

STATISTIK
20-31

STATISTIK
21-31

STATISTIK
22-31
Normal-/Standardnormalverteilung
Dichtefunktion der Normalverteilung
𝑓(𝑥) =1
𝑠 ∙ √2𝜋∙ 𝑒
(−12
∙(𝑥−��
𝑠)
2)
𝑠: Standardabweichung
��: arithmetische Mittel
Verteilungsfunktion der Normalverteilung
𝑓(𝑥; ��; 𝑠) =1
𝑠 ∙ √2𝜋∙ ∫ 𝑒
(−12
∙(𝑥−��
𝑠)
2)
𝑑𝑥
z-Transformation zur Bildung einer Standardnormalverteilung
𝑧 =𝑥 − ��
𝑠
Erwartungswert einer normalverteilten Zufallsvariable
𝐸(𝑥) = ��
Varianz einer normalverteilten Zufallsvariable
𝑉(𝑥) = 𝑠2
Standardabweichung einer normalverteilten Zufallsvariable
𝑆(𝑥) = √𝑠2

STATISTIK
23-31

STATISTIK
24-31

STATISTIK
25-31

STATISTIK
26-31
Indexberechnung
Preisindex nach Laspeyres
n
i
ii
n
i
ii
tL
t
mp
mp
P
1
00
1
0
,0
𝑚0𝑖 : Menge das Basisjahres
𝑝0𝑖 : Preis das Basisjahres
𝑝𝑡𝑖: Preis das Berichtsjahres
Preisindex nach Paasche
n
i
i
t
i
n
i
i
t
i
tP
t
mp
mp
P
1
0
1,0
𝑚𝑡𝑖 : Menge das Berichtsjahres
𝑝0𝑖 : Preis das Basisjahres
𝑝𝑡𝑖: Preis das Berichtsjahres
Mengenindex nach Laspeyres
n
i
ii
n
i
i
t
i
L
t
mp
mp
M
1
00
1
0
,0
𝑚0𝑖 : Menge das Basisjahres
𝑚𝑡𝑖 : Menge das Berichtsjahres
𝑝0𝑖 : Preis das Basisjahres

STATISTIK
27-31
Mengenindex nach Paasche
n
i
ii
t
n
i
i
t
i
tP
t
mp
mp
M
1
0
1,0
𝑝𝑡𝑖: Preis das Berichtsjahres
𝑚0𝑖 : Menge das Basisjahres
𝑚𝑡𝑖 : Menge das Berichtsjahres
Umsatzindex
n
1i
i
0
i
0
n
1i
i
t
i
t
t,0
mp
mp
U
𝑝0𝑖 : Preis das Basisjahres
𝑝𝑡𝑖: Preis das Berichtsjahres
𝑚0𝑖 : Menge das Basisjahres
𝑚𝑡𝑖 : Menge das Berichtsjahres
Fisher-Preisindex
𝑃𝐹(𝑡) = √𝑃𝐿(𝑡) ∙ 𝑃𝑃(𝑡)

STATISTIK
28-31
Regressions- und Korrelationsrechnung
Regressionsgleichung
iii bxay
xbya
)xx(
)yy()xx(
bn
1i
2
i
n
1i
ii
Korrelationskoeffizient nach Bravais-Pearson
1r1-
)yy()xx(
)yy)(xx(
rn
1i
n
11
2
i
2
i
n
1i
ii

STATISTIK
29-31
Lorenzkurve
Mit der Lorenzkurve lassen sich Konzentrationsphänomene in Beobachtungen grafisch darstellen.
Ausgangspunkt für die Lorenzkurve ist eine geordnete und nicht negative statistische Reihe mit positiver Summen der Beobachtungswerten.
Die Lorenzkurve ergibt sich, in dem man nach und nach Punkte in einem Koordinaten-system verbindet, wobei der Ausgangspunkt der Ursprung (0|0) ist. Auf der x -Achse berechnet man den Anteil an der statistischen Masse (u k), während auf der y-Achse der Anteil an der Merkmalssumme vk entscheidend ist.
Statistische Masse
uk =k
n
n: Anzahl der Elemente
k: Nummer des entsprechenden Elements
Merkmalssumme
𝑣𝑘 =∑ 𝑥𝑖
𝑘𝑖=1
∑ 𝑥𝑖𝑛𝑖=1
=𝑥1 + ⋯ + 𝑥𝑘
𝑥1 + ⋯ + 𝑥𝑛
Bezeichnungen
Eigenschaften der Lorenzkurve
Sie beginnt immer im Ursprung(0|0) und endet immer im Punkt (1|1) Steigung ist monoton Kurve ist Konvex Lorenzkurve verläuft nirgendwo oberhalb der Diagonalen

STATISTIK
30-31
Gini-Koeffizient
Der Ginikoeffizient oder auch Gini-Index ist ein statistisches Maß für Verteilungsgleich-heit. Als Ginikoeffizient G wird bezeichnet der Anteil der Fläche, die durch die Winkel-halbierende und die Lorenzkurve gebildet wird, an der Gesamtfläche unter der Winkel-halbierenden.
Gini-Ungleichverteilungskoeffizient (GUK)
GUK =A − B
A=
0,5 − 𝐵
0,5
Normierter G-Koeffizient
G∗ =G
Gmax=
n
n − 1∙ G

STATISTIK
31-31
Testverfahren
Ein statistischer Test dient in der mathematischen Statistik dazu, anhand vorliegender Beobachtungen eine begründete Entscheidung über die Gültigkeit oder Ungültigkeit einer Hypothese zu treffen.
Vorgehensweise
Formulierung einer Nullhypothese H0 und ihrer Alternativhypothese H1
Wahl des geeigneten Tests (Testgröße oder Teststatistik T)
Bestimmung des kritischen Bereiches K zum Signifikanzniveau α, das vor Realisa-tion der Stichprobe feststehen muss. Der kritische Bereich wird aus den unter der Nullhypothese nur mit geringer Wahrscheinlichkeit auftretenden Werten der Test-statistik gebildet.
Berechnung des Werts der Beobachtung tobs der Testgröße T aus der Stichprobe (je nach Testverfahren etwa den t-Wert oder U oder H oder χ2…).
Treffen der Testentscheidung:
Liegt tobs nicht in K, so wird H0 beibehalten.
Liegt tobs in K, so lehnt man H0 zugunsten von H1 ab.