taming the data science monster with a new ‘sword’ – u-sql
TRANSCRIPT

Microsoft Data Science SummitSept 26 – 27 | Atlanta, GA

Taming the Data Science Monster with A New ‘Sword’ – U-SQL
Michael RysPrincipal Program Manager Big Data@[email protected]://aka.ms/azuredatalake

Agenda Today (BR014): Introduction to Azure Data Lake and U-SQL What is Azure Data Lake? Why U-SQL? Core concepts
Schema on read on file and file sets C# extensibility SQL with U-SQL Script level execution and optimization
Tool usage
Tomorrow (BR013): Killer extensibility in Azure Data Lake with U-SQL Custom rowset aggregation How to do JSON processing Image processing How to call R from U-SQL

The Data Lake approach
Ingest all data regardless of requirements
Store all data in native format without schema definition
Do analysisUsing analytic engines like Hadoop
Interactive queriesBatch queries
Machine LearningData warehouse
Real-time analytics
Devices

Introducing Azure Data LakeBig Data Made Easy
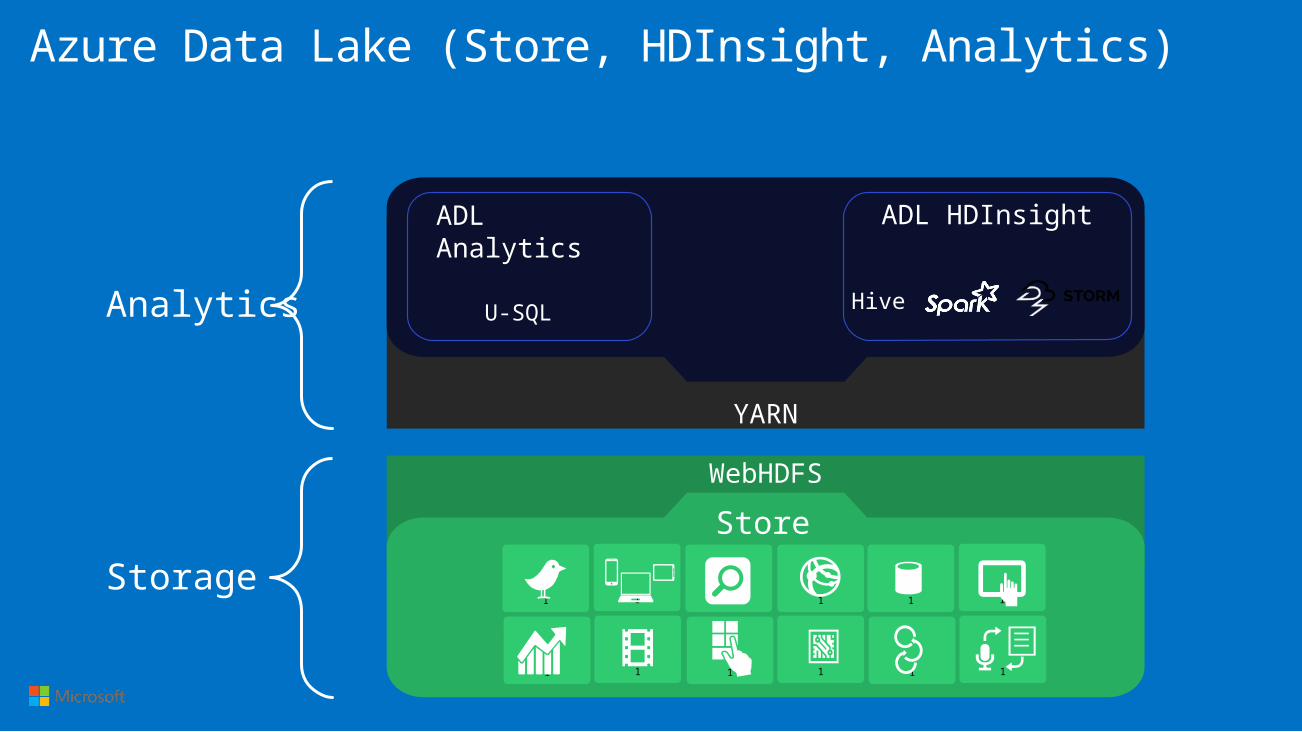
WebHDFS
YARN
U-SQL
ADL Analytics
ADL HDInsight
1
1
1
1
1
1 1
1
1
1
1
1
Store
HiveAnalytics
Storage
Azure Data Lake (Store, HDInsight, Analytics)

Azure Data Lake & U-SQL

Why U-SQL?

Some sample use casesDigital Crime Unit – Analyze complex attack patterns to understand BotNets and to predict and mitigate future attacks by analyzing log records with complex custom algorithmsImage Processing – Large-scale image feature extraction and classification using custom codeShopping Recommendation – Complex pattern analysis and prediction over shopping records
using proprietary algorithms
Characteristics of Big Data Analytics• Requires processing
of any type of data • Allow use of custom
algorithms• Scale to any size and
be efficient

Status Quo:SQL for Big Data
Declarativity does scaling and parallelization for you
Extensibility is bolted on and not “native” hard to work with anything other
than structured data difficult to extend with custom
code

Status Quo:Programming Languages for Big Data
Extensibility through custom code is “native”
Declarativity is bolted on and not “native” User often has to
care about scale and performance
SQL is 2nd class within string Often no code reuse/
sharing across queries

Why U-SQL? Declarativity and Extensibility are equally native to the language!
Get benefits of both!Makes it easy for you by unifying:• Unstructured and structured data
processing• Declarative SQL and custom imperative
Code (C#)• Local and remote Queries• Increase productivity and agility from Day
1 and at Day 100 for YOU!

The origins of U-SQL
U-SQLSCOPE
Hive
T-SQL/ ANSI SQL
SCOPE – Microsoft’s internal Big Data language• SQL and C# integration model• Optimization and Scaling model• Runs 100’000s of jobs daily
Hive• Complex data types (Maps, Arrays)• Data format alignment for text files
T-SQL/ANSI SQL• Many of the SQL capabilities (windowing functions,
meta data model etc.)

Query data where it livesEasily query data in multiple Azure data stores without moving it to a single store
Benefits• Avoid moving large amounts of data across the
network between stores• Single view of data irrespective of physical
location • Minimize data proliferation issues caused by
maintaining multiple copies• Single query language for all data• Each data store maintains its own sovereignty• Design choices based on the need• Push SQL expressions to remote SQL sources
• Projections• Filters• Joins
U-SQL Query
Query
Query
Query
WriteAzure Storage Blobs
Azure SQL in VMs
Azure SQL DB
Azure Data Lake Analytics
Query
Azure SQL Data Warehouse
Que r
y
Writ
e
Azure Data Lake Storage

Show me U-SQL!https://github.com/Azure/usql/tree/master/Examples/TweetAnalysis

• Schema on Read• Write to File• Built-in and custom
Extractors and Outputters• ADL Storage and Azure Blob
Storage
“Unstructured” Files EXTRACT Expression@s = EXTRACT a string, b int FROM "filepath/file.csv"USING Extractors.Csv(encoding: Encoding.Unicode);
• Built-in Extractors: Csv, Tsv, Text with lots of options• Custom Extractors: e.g., JSON, XML, etc.
OUTPUT ExpressionOUTPUT @sTO "filepath/file.csv"USING Outputters.Csv();
• Built-in Outputters: Csv, Tsv, Text• Custom Outputters: e.g., JSON, XML, etc. (see http://usql.io)
Filepath URIs• Relative URI to default ADL Storage account: "filepath/file.csv"
• Absolute URIs:• ADLS:
"adl://account.azuredatalakestore.net/filepath/file.csv"• WASB: "wasb://container@account/filepath/file.csv"
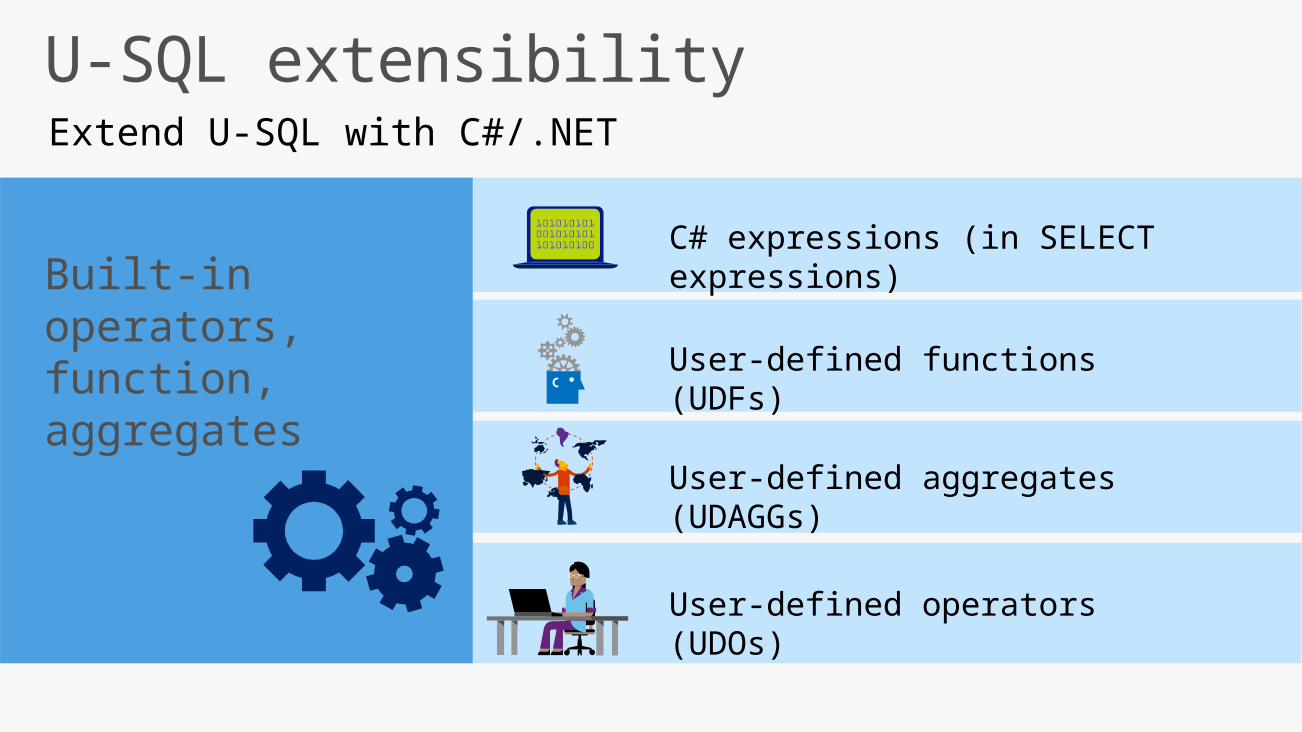
U-SQL extensibilityExtend U-SQL with C#/.NET
Built-in operators, function, aggregates
C# expressions (in SELECT expressions)
User-defined aggregates (UDAGGs)
User-defined functions (UDFs)
User-defined operators (UDOs)

Extending U-SQL!https://github.com/Azure/usql/tree/master/Examples/TweetAnalysis

Managing Assemblies
• CREATE ASSEMBLY db.assembly FROM @path;• CREATE ASSEMBLY db.assembly FROM byte[];
• Can also include additional resource files
• REFERENCE ASSEMBLY db.assembly;
• Referencing .Net Framework Assemblies• Always accessible system namespaces:
• U-SQL specific (e.g., for SQL.MAP)• All provided by system.dll system.core.dll
system.data.dll, System.Runtime.Serialization.dll, mscorelib.dll (e.g., System.Text, System.Text.RegularExpressions, System.Linq)
• Add all other .Net Framework Assemblies with:REFERENCE SYSTEM ASSEMBLY [System.XML];
• Enumerating Assemblies• Powershell command• U-SQL Studio Server Explorer
• DROP ASSEMBLY db.assembly;
Create assemblies Reference assemblies Enumerate assemblies Drop assemblies
VisualStudio makes registration easy!

USING clause 'USING' csharp_namespace | Alias '=' csharp_namespace_or_class.
Examples: DECLARE @ input string = "somejsonfile.json";
REFERENCE ASSEMBLY [Newtonsoft.Json];REFERENCE ASSEMBLY [Microsoft.Analytics.Samples.Formats];
USING Microsoft.Analytics.Samples.Formats.Json;
@data0 = EXTRACT IPAddresses string FROM @input USING new JsonExtractor("Devices[*]");
USING json = [Microsoft.Analytics.Samples.Formats.Json.JsonExtractor];
@data1 = EXTRACT IPAddresses string FROM @input USING new json("Devices[*]");
Allows shortening and disambiguating C# namespace and class names

Show me File Sets!https://github.com/Azure/usql/tree/master/Examples/TweetAnalysis

• Simple Patterns• Virtual Columns• Only on EXTRACT for now
(On OUTPUT being worked on)
File Sets Simple pattern language on filename and path@pattern string = "/input/{date:yyyy}/{date:MM}/{date:dd}/{*}.{suffix}";
• Binds two columns date and suffix• Wildcards the filename• Limits on number of files
(Current limit 800 and 3000 being increased in next refresh)
Virtual columnsEXTRACT
name string, suffix string // virtual column, date DateTime // virtual column
FROM @patternUSING Extractors.Csv();
• Refer to virtual columns in query predicates to get partition elimination(otherwise you will get a warning)

Create shareable data and codehttps://github.com/Azure/usql/tree/master/Examples/TweetAnalysis

Meta Data Object ModelADLA Account/Catalog
Database
Schema
[1,n]
[1,n]
[0,n]
tables views TVFs
C# Fns C# UDAgg
ClusteredIndex
partitions
C# Assemblies
C# Extractors
Data Source
C# ReducersC# Processors
C# CombinersC# Outputters
Ext. tables
Abstract objects
User objects
Refers toContains Implemented and named by
Procedures
Creden-tials
MD Name C# Name
C# Applier
Table Types
Legend
Statistics
C# UDTs

• Naming• Discovery• Sharing• Securing
U-SQL Catalog Naming• Default Database and Schema context: master.dbo• Quote identifiers with []: [my table]• Stores data in ADL Storage /catalog folder
Discovery• Visual Studio Server Explorer• Azure Data Lake Analytics Portal• SDKs and Azure Powershell commands
Sharing• Within an Azure Data Lake Analytics account
Securing• Secured with AAD principals at catalog level (inherited
from ADL Storage)• At General Availability: Database level access control

• CREATE TABLE• CREATE TABLE AS SELECT
Tables CREATE TABLE T (col1 int , col2 string , col3 SQL.MAP<string,string> , INDEX idx CLUSTERED (col1 ASC) DISTRIBUTED BY HASH (driver_id) );
• Structured Data• Built-in Data types only (no UDTs)• Clustered Index (needs to be specified): row-oriented• Fine-grained distribution (needs to be specified):
• HASH, DIRECT HASH, RANGE, ROUND ROBIN
CREATE TABLE T (INDEX idx CLUSTERED …) AS SELECT …;CREATE TABLE T (INDEX idx CLUSTERED …) AS EXTRACT…;CREATE TABLE T (INDEX idx CLUSTERED …) AS myTVF(DEFAULT);
• Infer the schema from the query• Still requires index and partitioning

Let’s do some SQL with U-SQL!https://github.com/Azure/usql/tree/master/Examples/TweetAnalysis

U-SQLJoins
Join operators
• INNER JOIN• LEFT or RIGHT or FULL OUTER JOIN• CROSS JOIN• SEMIJOIN
• equivalent to IN subquery• ANTISEMIJOIN
• Equivalent to NOT IN subqueryNotes
• ON clause comparisons need to be of the simple form: rowset.column == rowset.columnor AND conjunctions of the simple equality comparison
• If a comparand is not a column, wrap it into a column in a previous SELECT
• If the comparison operation is not ==, put it into the WHERE clause
• turn the join into a CROSS JOIN if no equality comparison
Reason: Syntax calls out which joins are efficient

U-SQLAnalytics
Windowing Expression
Window_Function_Call 'OVER' '(' [ Over_Partition_By_Clause ]
[ Order_By_Clause ] [ Row _Clause ]')'.
Window_Function_Call :=Aggregate_Function_Call
| Analytic_Function_Call| Ranking_Function_Call.
Windowing Aggregate Functions
ANY_VALUE, AVG, COUNT, MAX, MIN, SUM, STDEV, STDEVP, VAR, VARP
Analytics Functions
CUME_DIST, FIRST_VALUE, LAST_VALUE, PERCENTILE_CONT, PERCENTILE_DISC, PERCENT_RANK; soon: LEAD/LAG
Ranking Functions
DENSE_RANK, NTILE, RANK, ROW_NUMBER

“Top 5”sSurprises for SQL Users
• AS is not as• C# keywords and SQL keywords overlap• Costly to make case-insensitive -> Better
build capabilities than tinker with syntax• = != ==
• Remember: C# expression language• null IS NOT NULL
• C# nulls are two-valued• PROCEDURES but no WHILE• No UPDATE nor MERGE

Summary of U-SQL

U-SQL Language Philosophy
Declarative Query and Transformation Language:• Uses SQL’s SELECT FROM WHERE with GROUP
BY/Aggregation, Joins, SQL Analytics functions• Optimizable, ScalableExpression-flow programming style:• Easy to use functional lambda composition • Composable, globally optimizableOperates on Unstructured & Structured Data• Schema on read over files• Relational metadata objects (e.g. database, table)Extensible from ground up:• Type system is based on C#• Expression language IS C#• User-defined functions (U-SQL and C#)• User-defined Aggregators (C#)• User-defined Operators (UDO) (C#)
U-SQL provides the Parallelization and Scale-out Framework for Usercode• EXTRACTOR, OUTPUTTER, PROCESSOR, REDUCER,
COMBINER, APPLIERFederated query across distributed data sources
REFERENCE MyDB.MyAssembly;
CREATE TABLE T( cid int, first_order DateTime , last_order DateTime, order_count int , order_amount float );
@o = EXTRACT oid int, cid int, odate DateTime, amount float FROM "/input/orders.txt" USING Extractors.Csv();
@c = EXTRACT cid int, name string, city string FROM "/input/customers.txt" USING Extractors.Csv();
@j = SELECT c.cid, MIN(o.odate) AS firstorder , MAX(o.date) AS lastorder, COUNT(o.oid) AS ordercnt , AGG<MyAgg.MySum>(c.amount) AS totalamount FROM @c AS c LEFT OUTER JOIN @o AS o ON c.cid == o.cid WHERE c.city.StartsWith("New") && MyNamespace.MyFunction(o.odate) > 10 GROUP BY c.cid;
OUTPUT @j TO "/output/result.txt"USING new MyData.Write();
INSERT INTO T SELECT * FROM @j;

Unifies natively SQL’s declarativity and C#’s extensibilityUnifies querying structured and unstructuredUnifies local and remote queriesIncrease productivity and agility from Day 1 forward for YOU!Sign up for an Azure Data Lake account and join the Public Preview http://www.azure.com/datalake and give us your feedback via http://aka.ms/adlfeedback or at http://aka.ms/u-sql-survey!
This is why U-SQL!
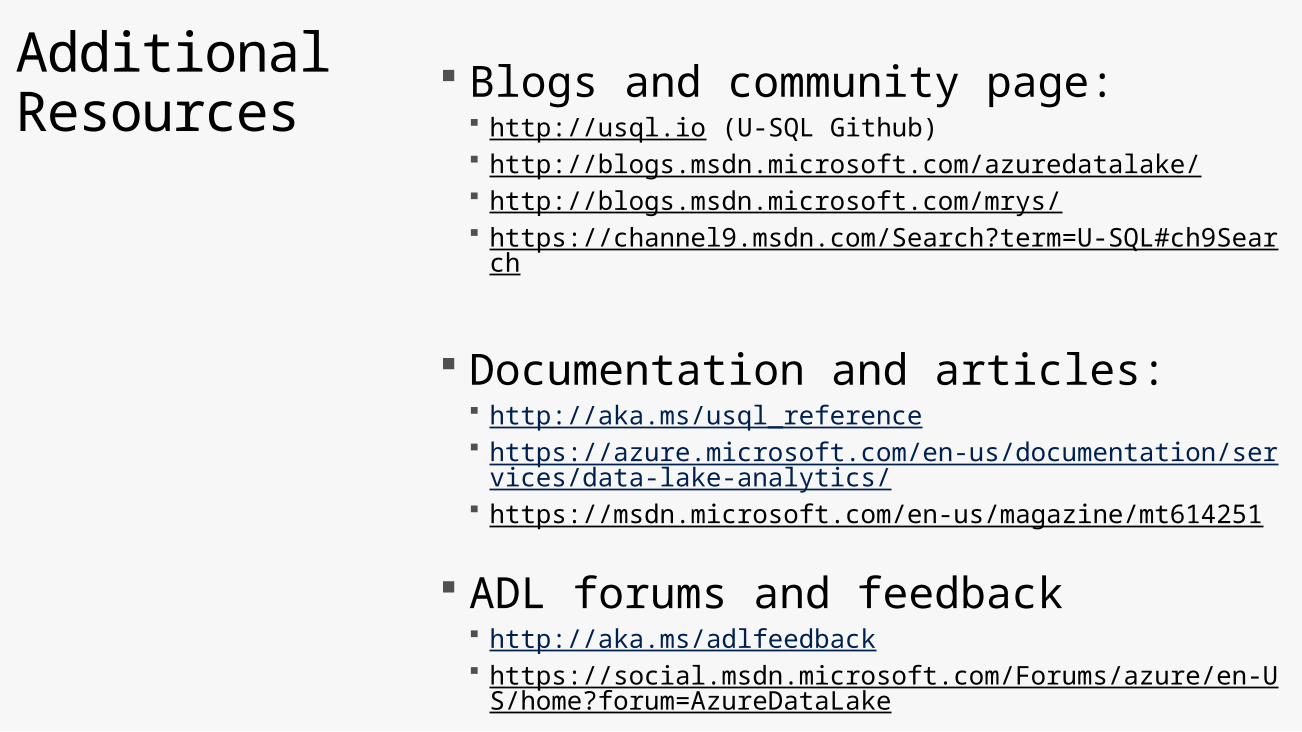
Additional Resources Blogs and community page:
http://usql.io (U-SQL Github) http://blogs.msdn.microsoft.com/azuredatalake/ http://blogs.msdn.microsoft.com/mrys/ https://channel9.msdn.com/Search?term=U-SQL#ch9Se
arch
Documentation and articles: http://aka.ms/usql_reference https://azure.microsoft.com/en-us/documentation/servic
es/data-lake-analytics/ https://msdn.microsoft.com/en-us/magazine/mt614251
ADL forums and feedback http://aka.ms/adlfeedback https://social.msdn.microsoft.com/Forums/azure/en-US/h
ome?forum=AzureDataLake
http://stackoverflow.com/questions/tagged/u-sql

© 2016 Microsoft Corporation. All rights reserved.