takács györgy 16. előadás 2014. 05. 15
DESCRIPTION
Beszédfelismerés és beszédszintézis Beszédfelismerés neurális hálózatokkal Beszélő személy felismerés. Takács György 16. előadás 2014. 05. 15. A Markov modell előnyei. Kezelhetővé teszi a folyamatos beszédfelismerés problémáját, - PowerPoint PPT PresentationTRANSCRIPT

Beszedf 2014. 05. 15. 1
Beszédfelismerés és beszédszintézis
Beszédfelismerés neurális hálózatokkal
Beszélő személy felismerés
Takács György
16. előadás
2014. 05. 15.

Beszedf 2014. 05. 15. 2
A Markov modell előnyei
• Kezelhetővé teszi a folyamatos beszédfelismerés problémáját,
• Szétválasztható az állapot rákövetkezések gyakoriságának és állapotok jellegvektorokkal kapcsolatos tulajdonságainak tanítása,
• Szétválasztható a személyfüggő és személyfüggetlen elemek tanítása,
• Kifinomult programrendszerek forráskódú formái rendelkezésre állnak,
• A rendszerek értékelésére gazdag tanító- és teszt-adatbázisok rendelkezésre állnak a világnyelveken

Beszedf 2014. 05. 15. 3
A Markov modell problémái
• Diszkrét állapotok sorozatával modellez
• Az állapotban maradás esélye dominál
• Ha egy állapotsorozat = fonémasorozat, akkor milyen hosszú legyen a fonémasorozat
• Nehezen kezelhetők a bizonytalan állapotok
Beszedf 2014. 05. 15. 4
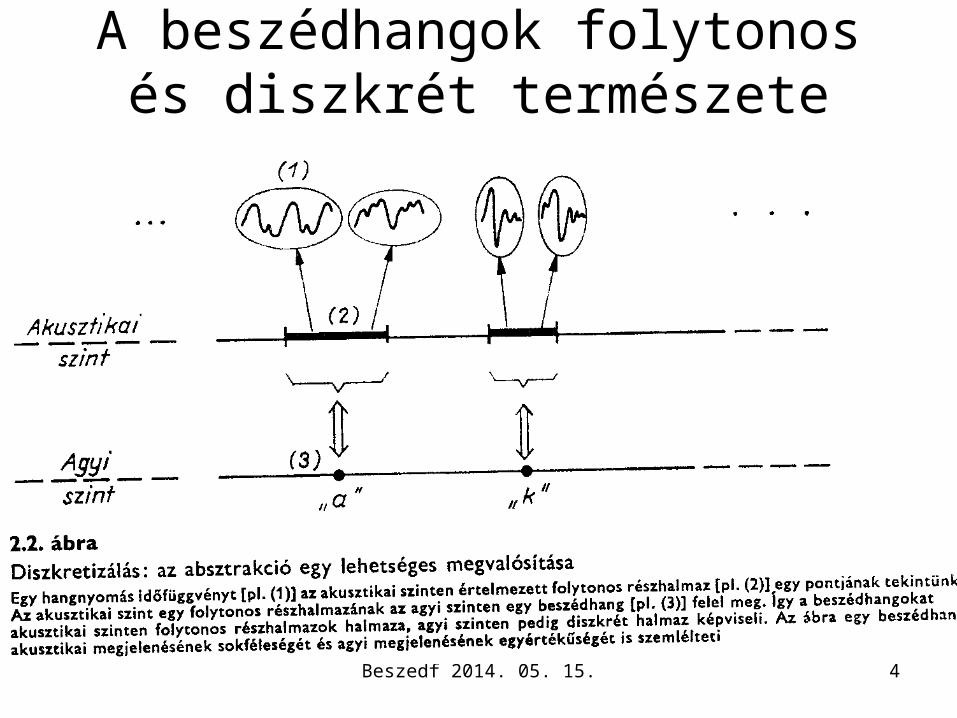
A beszédhangok folytonos és diszkrét természete

Beszedf 2014. 05. 15. 5
A feladat: beszédjel bemenet – írott szöveg kimenet

Beszedf 2014. 05. 15. 6
• Az időben folytonos bemenő jel jön (néha szünet)• A kimenet diszkrét halmaz elemeinek egymás utáni
(térbeli) füzére (néha szóközi szünet).• Az egyes halmazelemekre a megfigyelés alapján egy
vagy több jelöltet állíthatunk.• A jelöltállítás történhet szabályos időközönként, vagy ha
új jelölt bukkan fel.• A jelöltek akusztikai-fonetikai szinten leggyakrabban
fonémák.• A feldolgozás több rétegben célszerű (akusztikai-
fonetikai réteg, szintaktikai réteg, szemantikai réteg …)

Beszedf 2014. 05. 15. 7
Modellek a folyamatos beszéd felismerési folyamatához
• Kezelni legyenek képesek a folytonos folyamat diszkrét állapotokba átrendezését
• Minél több összefüggés megtanítása a diszkrét reprezentáció alapján lehetséges legyen
• Alkalmas modell egy olyan neurális háló, amely bemenetén fogadja a folyamatos beszédjelet előfeldolgozás után és kimenetén adja a diszkrét szimbólumokat
• Alkalmas modell egy rejtett Markov folyamat, amely az állapotsorozatok kezelését lehetővé teszi.

Beszedf 2014. 05. 15. 8
Ha nagyon sokat tudunk a beszédfolyamatról – mire lehet építeni a
beszédfelismerőket?
• A -- az agy beszédfelfogási folyamatait utánzó modellekre?
• B -- beszédkeltési folyamatokat leíró modellekre?

Beszedf 2014. 05. 15. 9
A mai bemutatott neurális hálózatos megoldás jellegzetességei
• Nem pontos mása az agyban lejátszódó folyamatoknak, bár A típusú megoldásra tör!
• Sok ötletet próbál átvenni azokból amit tudunk az emberi beszédérzékelési folyamatokról
• Empirikus megoldásokat keres arra is, amire nincs átvehető és megvalósítható racionális módszer
• A vázolt módszer csak az akusztikai-fonetikai szintet tartalmazza, a magasabb nyelvi szintek Prószéky Professzor Úr tárgyához kapcsolódnak…..

Beszedf 2014. 05. 15. 10
Általános alapproblémák, amelyekre az NN alapú megközelítéstől megoldást remélünk
• A beszéd folyamatos (nincsenek szóközönként szünetek) igazi szünetek csak nagyobb prozódiai egységek között vannak – folyamatosan adjon a kimenet fonéma jelölteket. Adjon egy hálózat kimenet akkor aktivitást, amikor fonéma váltás van, pedig a fonémaváltás folytonos!
• Ugyanannak a diszkrét beszédhangnak gyakorlatilag végtelen sok reprezentációja elképzelhető (bemondó, tempó, hangerő, hanglejtés, hangkörnyezet, hasonulás….., érzelem függvényében) -- Mégis tanítsuk a hálózatot arra, hogy fonémajelölteket adjon, a jelöltek közül válogasson a rendszer magasabb nyelvi szinteket alapul véve
• Elnagyolt ejtés, pontatlanság, ejtési hiba, beszédhiba, gyakran előfordul – kisebb hálózati aktivitás jelezze az elnagyolt jelöltet is.
• „érteni” kell a mondandót ahhoz, hogy jól felismerhessük! Ez természetesen marad a nyelvi feldolgozó szintnek.

Beszedf 2014. 05. 15. 11
A feladat: beszédjel bemenet – írott szöveg kimenet

Beszedf 2014. 05. 15. 12
A rendszer elemei

Beszedf 2014. 05. 15. 13
Beszedf 2014. 05. 15. 14

Beszedf 2014. 05. 15. 15

Beszedf 2014. 05. 15. 16
Beszedf 2014. 05. 15. 17

Beszedf 2014. 05. 15. 18

Beszedf 2014. 05. 15. 19
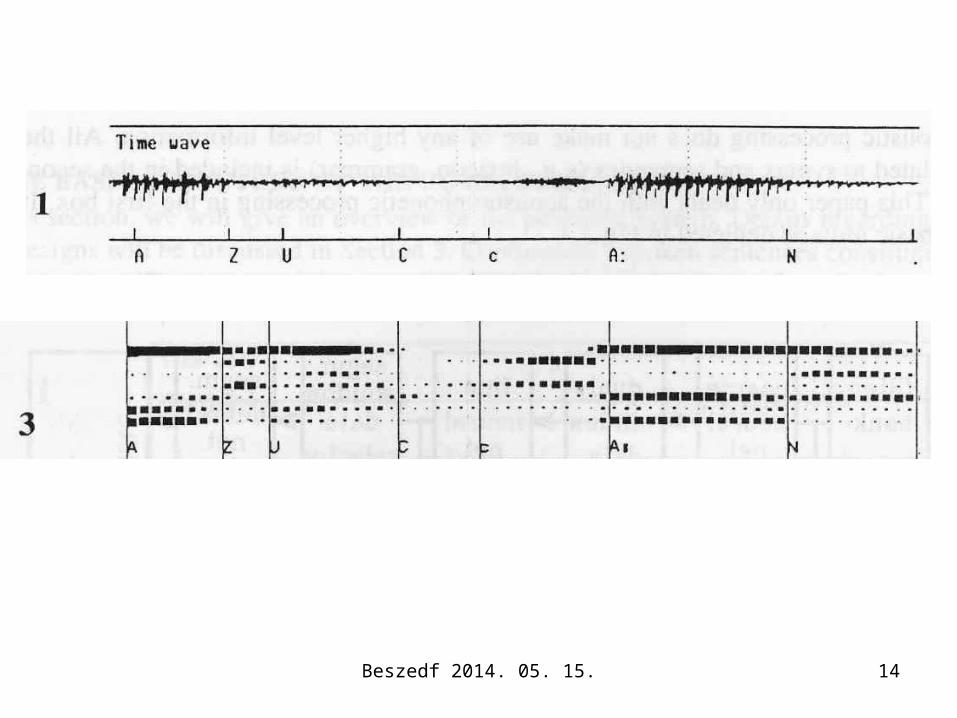
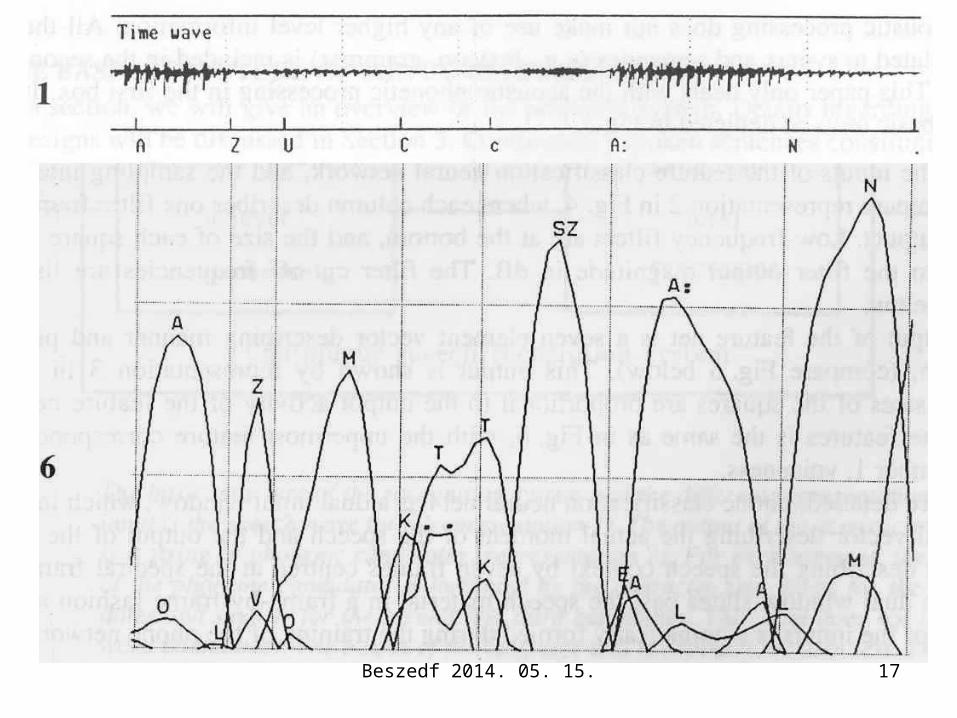
A kettős ablak elve: a szűrőkimenetek aktuális állapotát és a durva hálózat megelőző és rákövetkező állapotait egyszerre veszi figyelembe a fonémajelöltek számolásakor

Beszedf 2014. 05. 15. 20
Az előfeldolgozó szűrő jellemzői

Beszedf 2014. 05. 15. 21
A magyarfonémakészletés azegyes fonémákdurva(főbb)képzésijellemzői

Beszedf 2014. 05. 15. 22

Beszedf 2014. 05. 15. 23

Beszedf 2014. 05. 15. 24

Beszedf 2014. 05. 15. 25
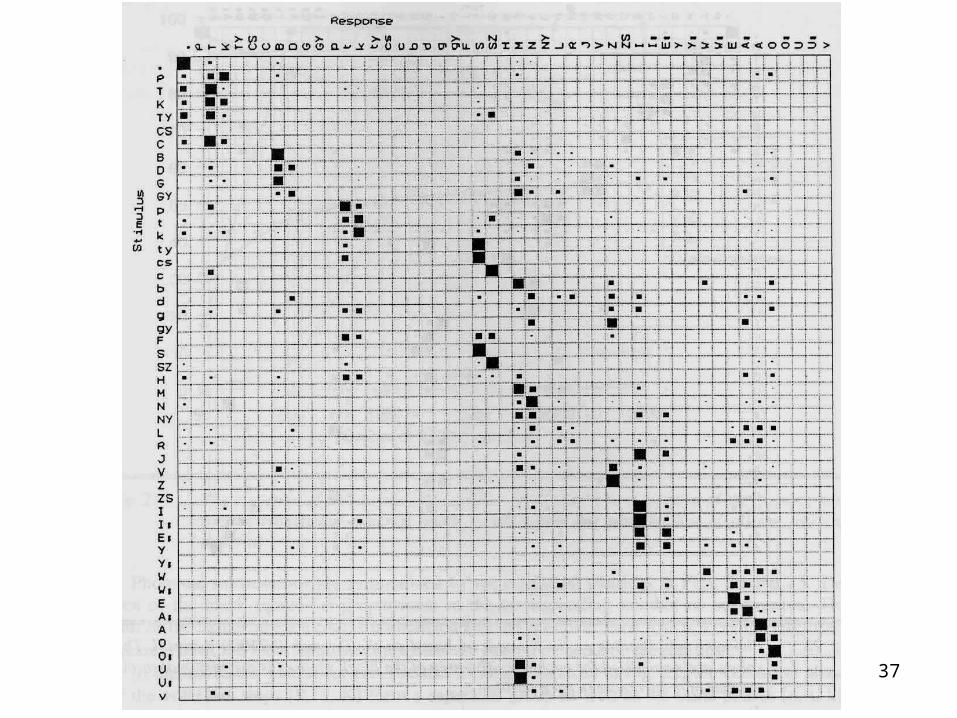
A fonémajelölteketszámolóhálózatasvéd ésa magyarfonéma készletre

Beszedf 2014. 05. 15. 26

Beszedf 2014. 05. 15. 27

Beszedf 2014. 05. 15. 28

Beszedf 2014. 05. 15. 29

Beszedf 2014. 05. 15. 30

Beszedf 2014. 05. 15. 31

Beszedf 2014. 05. 15. 32

Beszedf 2014. 05. 15. 33

Beszedf 2014. 05. 15. 34

Beszedf 2014. 05. 15. 35

Beszedf 2014. 05. 15. 36
Beszedf 2014. 05. 15. 37
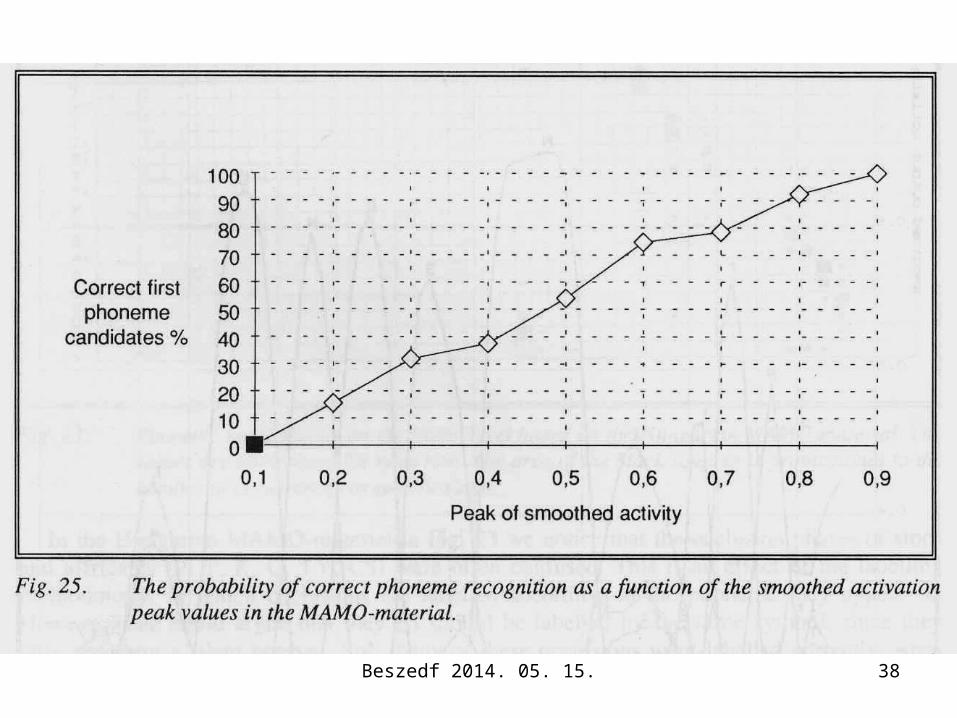
Beszedf 2014. 05. 15. 38

Beszedf 2014. 05. 15. 39

Beszedf 2014. 05. 15. 40
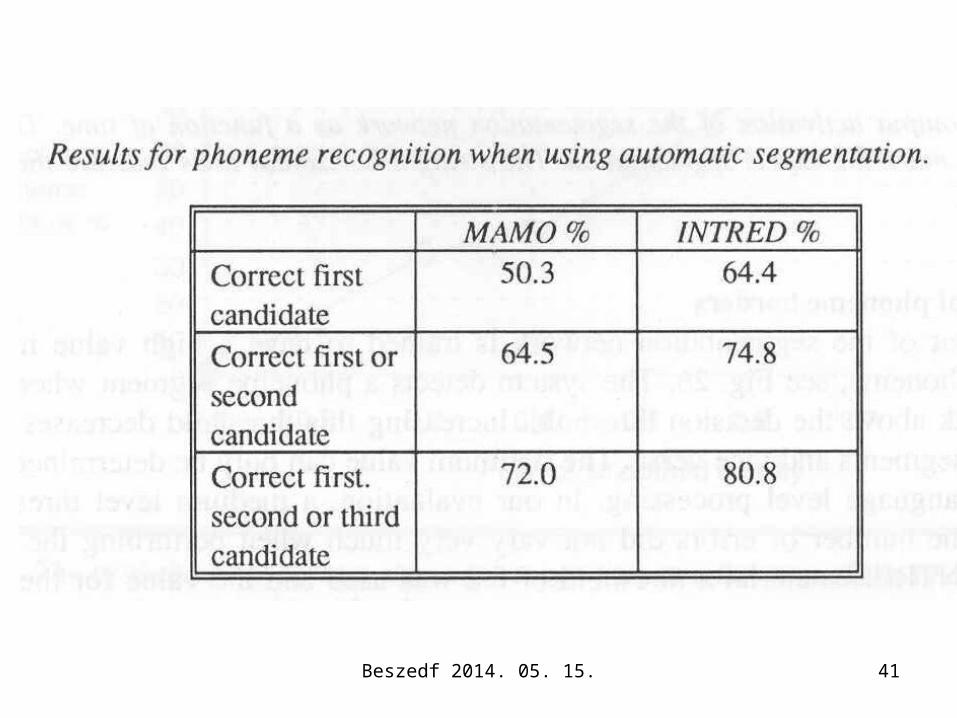
Beszedf 2014. 05. 15. 41

Beszedf 2014. 05. 15. 42
Beszélő személy felismerésbeszélő személy azonosításbeszélő személy verifikálás

Beszedf 2014. 05. 15. 43
• Speaker recognition: who is speaking• Speaker verification (voice authentication) : the
speaker claims to be of a certain identity and the voice is used to verify this claim . Speaker verification is a 1:1 match where one speaker's voice is matched to one template
• Speaker identification is the task of determining an unknown speaker's identity. Speaker identification is a 1:N match where the voice is matched to N templates. Speaker identification problems generally fall into two categories:– Differentiating multiple speakers when a conversation is taking
place. – Identifying an individual's voice based upon previously supplied
data regarding that individual's voice.

Beszedf 2014. 05. 15. 44
Személy azonosítás alapjai
• Alapulhat az azonosítás olyan tárgyon, amit az adott személy birtokol (kulcs, kártya, igazolvány)
• Alapulhat azon, amit az érintett személy tud (PIN, jelszó)
• Alapulhat a személy statikus testi jellemzőin (magasság, testsúly, ujjlenyomat, kéz alakja, retina jellemzők, arc, egyes beszédjellemzők)
• Alapulhat a személy tevékenységi, viselkedési jellemzőin (kézírás, gesztusok, arckifejezések, egyes beszédjellemzők)

Beszedf 2014. 05. 15. 45
Személy azonosítás gyakorlati megvalósításai
• A feladattól függően a birtokolt, a tudott, a statikus testi jellemzők és a viselkedési jellemzők együttese.
• Tényleges letagadhatatlanok és utánozhatatlanok a bevett jellemzők? – Ujjlenyomat, aláírás, fényképes igazolvány, PIN …
– Kellenek az újak?– Szem felvétel– DNS vizsgálat– Hanglenyomat– mozgásminták

Beszedf 2014. 05. 15. 46
Mennyire megbízható a „hanglenyomat”?
• Összemérhető az aláírással – biztonsági szempontból?– gépesítés szempontjából?– költség szempontjából?
• Összemérhető az ujjlenyomattal – biztonsági szempontból?– gépesítés szempontjából?– költség szempontjából?

Beszedf 2014. 05. 15. 47

Beszedf 2014. 05. 15. 48
2006.10.31
This credit card might be too secure for you
I've been checking out a new high-tech credit card that
reminds me of a security lesson I learned years ago.Soon after I started a tech reporting job at the San Jose Mercury News in 1999, I was lucky enough to land a cubicle next to a guy named David L. Wilson. Dave, who covered the Microsoft anti-trust trial, was a geek's geek and a treasure trove of information. One of the things he explained to me early on was a basic concept in security — something called three-factor authentication.If you want to make it hard to break into something — I mean, really lock it down — demand three unique pieces of information from people before they're allowed in.1.Something they carry, like a key. 2.Something they know, like a password. 3.Something they are — a piece of biometric data like a fingerprint, a voice print or a retinal scan.

Beszedf 2014. 05. 15. 49
Beszedf 2014. 05. 15. 50

Beszedf 2014. 05. 15. 51

Beszedf 2014. 05. 15. 52

Beszedf 2014. 05. 15. 53
Beszedf 2014. 05. 15. 54

Beszedf 2014. 05. 15. 55

Beszedf 2014. 05. 15. 56
Automatic speaker recognitionis the use of a machine to recognize a person from a spokenphrase. These systems can operate in two modes: to identifya particular person or to verify a person’s claimed identity.

Beszedf 2014. 05. 15. 57
Alapkérdések a beszélő személy felismerésben
• Milyen jellemzőket mérjünk?• Hogyan normalizáljunk?• Szövegfüggő vagy szöveg-független legyen?• Hogyan ítélhető meg a döntés biztonsága?• Mennyire utánozható?• Mennyire változtatható el tudatosan (esetleg
náthától magától is)?• Menyire eredeti vagy manipulált a
bemondás/felvétel?

Beszedf 2014. 05. 15. 58
Mért jellemzők
• Anatómiai meghatározottságúak (magasabb formánsok, zárfelpattanási idő, toldalékcső hossza, arcüreg, homloküreg rezonanciái, akusztikus csőmodell paraméterei – LPC paraméterek)
• Tanult vonások (egyes hangok ejtése, intonáció, ritmus, tempó, szófordulatok…)

Beszedf 2014. 05. 15. 59
Normalizálás
• Kétszer nem tudunk pontosan ugyanúgy elmondani még egy szót sem.
• A hangerő, környezeti zaj, tempó viszonylag széles skálán változhat.
• Normalizálás lehetséges az időben, szintben (mint izolált szavas felismerésnél)
• Normalizálás lehetséges a szövegfüggetlen beszélő felismerésnél hosszabb időre vett átlagok alapján a paraméter térben.

Beszedf 2014. 05. 15. 60
Szövegfüggő vagy szövegfüggetlen legyen?

Beszedf 2014. 05. 15. 61
1) Fixed password system, where all users share the same password sentence. This kind of system is not likely to be used in a real application, instead, every user would have a unique password to improve security. However, it is a good way to test speaker discriminability in a text-dependent system 2) User-specific text-dependent system, where every user has his own password3) Vocabulary-dependent system, where a password sequence is composed from a fixed vocabulary to make up new password sequences. Note that the password may or may not be prompted by the system. Examples: randomised digit sequences.4) Speech-event-dependent system, where the system spots, and depends on specific speech events. Phonetic events, such as the occurrence of vowels, fricatives or nasals, are candidates for the characteristic speech events5) Machine-driven text-independent system, where the system prompts for an unpredictable text to be spoken. In this case, speaker recognition is combined with speech recognition techniques to verify that the right text was uttered6) User-driven text-independent system, where the user can say any text he wants

Beszedf 2014. 05. 15. 62
Szövegfüggőség és rendszerjellemzők kategóriákba rendezve:1 – gyenge, 2 – közepes, -- jó

Beszedf 2014. 05. 15. 63
Hogyan ítélhető meg a döntés biztonsága egy rendszerben?

Beszedf 2014. 05. 15. 64

Beszedf 2014. 05. 15. 65
A beszélő azonosítás állatkertje
• „birkák” – gondnélküli felhasználók alacsony hibaértékekkel
• „kecskék” – megbízhatatlan felhasználók, változatos hanglenyomatok, nagy hibaértékekkel
• „bárányok” – sebezhető felhasználók, könnyen utánozhatók
• „farkasok” – a potenciálisan sikeres imposztorok

Beszedf 2014. 05. 15. 66
Az imposztorok ügyei
• Nehéz ezekről statisztikailag értékes anyagot gyűjteni,
• Lehetnek alapos ismereteik a támadott személy hangjáról,
• A hangfelvétel gyűjtést akadályozni kell!• Lehetnek technikailag igen képzett imposztorok
(felvételek készítése, lejátszása, manipulálása, személyfüggő szintézis)
• Gyanús lehet, ha a referencia és azonosítandó felvétel túl hasonló (felvétel visszajátszása)

Beszedf 2014. 05. 15. 67

Beszedf 2014. 05. 15. 68

Beszedf 2014. 05. 15. 69
Mennyire utánozható?Mennyire változtatható el tudatosan (esetleg náthától magától is)?Menyire eredeti vagy manipulált a bemondás/felvétel?

Beszedf 2014. 05. 15. 70
VoiceID99,5% biztonság

Beszedf 2014. 05. 15. 71
Azonosítási vagy verifikálási hibákhoz vezető tényezők:

Beszedf 2014. 05. 15. 72

Beszedf 2014. 05. 15. 73

Beszedf 2014. 05. 15. 74
Azonos személyek mért beszédjellemzőinek változásai a felvételek közötti idő függvényében

Beszedf 2014. 05. 15. 75

Beszedf 2014. 05. 15. 76

Beszedf 2014. 05. 15. 77
Beszedf 2014. 05. 15. 78
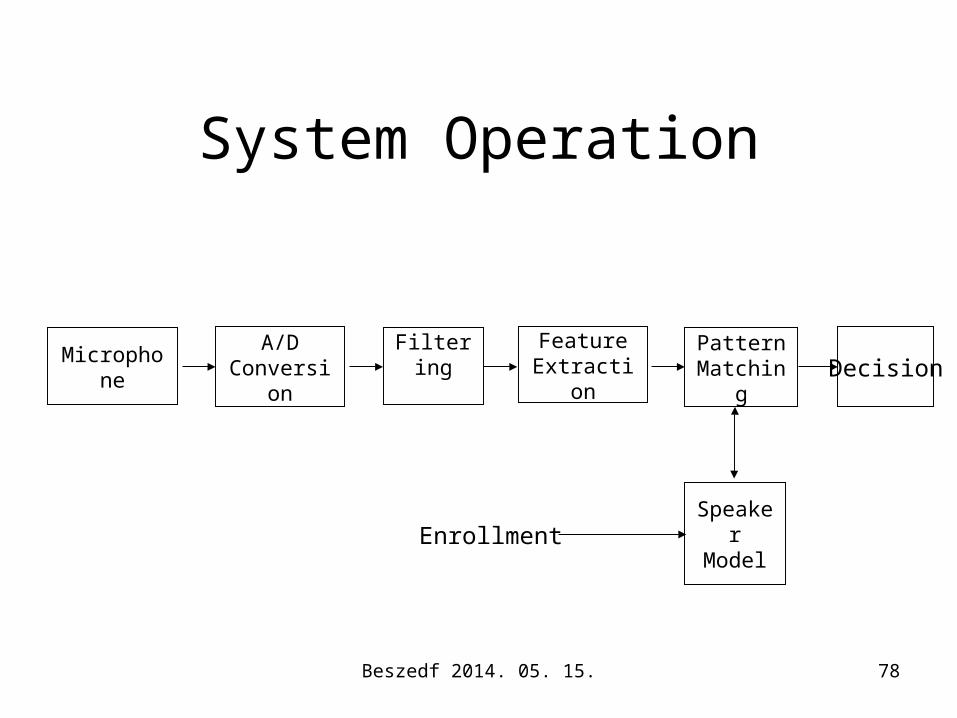
System Operation
MicrophoneA/D
ConversionFiltering Feature
ExtractionPattern
Matching
Speaker Model
Decision
Enrollment

Beszedf 2014. 05. 15. 79
Technical Overview
Feature Extraction Preprocessing
Sample Utterence
End Point Detection
Silence Removal
Emphasis Filtering
Segmentation
Cepstrum Coefficient
CepstralNormalization
Expansion by Polynomial Function
Feature Selection
Speaker Model
Dynamic Time Warping
Reference Template
Weight
Pattern Matching
DistanceComputation
Comparison
Accept/Reject
A/D Conversion

Beszedf 2014. 05. 15. 80

Beszedf 2014. 05. 15. 81

Beszedf 2014. 05. 15. 82

Beszedf 2014. 05. 15. 83
Termék példa: Nuance Voice Biometric

Beszedf 2014. 05. 15. 84

Beszedf 2014. 05. 15. 85

Beszedf 2014. 05. 15. 86

Beszedf 2014. 05. 15. 87

Beszedf 2014. 05. 15. 88