system structuring: levels, modules, and cooperation models
TRANSCRIPT

Master Degree Program (Laurea Magistrale) in Computer Science and Networking
High Performance Computing
Computer Architecture Fundamentals
System Structuring:
Levels, Modules, and Cooperation Models

Introductory statement
• These slides contain a reminder on prerequisites: it must be used to test your background knowledges (Book Appendix).
• HIGHLY RECOMMENDED.
• Proposed Exercises (these slides): HOMEWORK-0 – Exercise 1
– Exercise 2
– Exercise 3
– Exercise 4
– Exercise 5
– Exercise 6
– Exercise 7
– Exercise 8
• Discuss your doubts, if any, with the teachers. • No official submission; deadline is up to you.
MCSN - M. Vanneschi: High Performance Computing 2
MCSN - M. Vanneschi: High Performance Computing 3
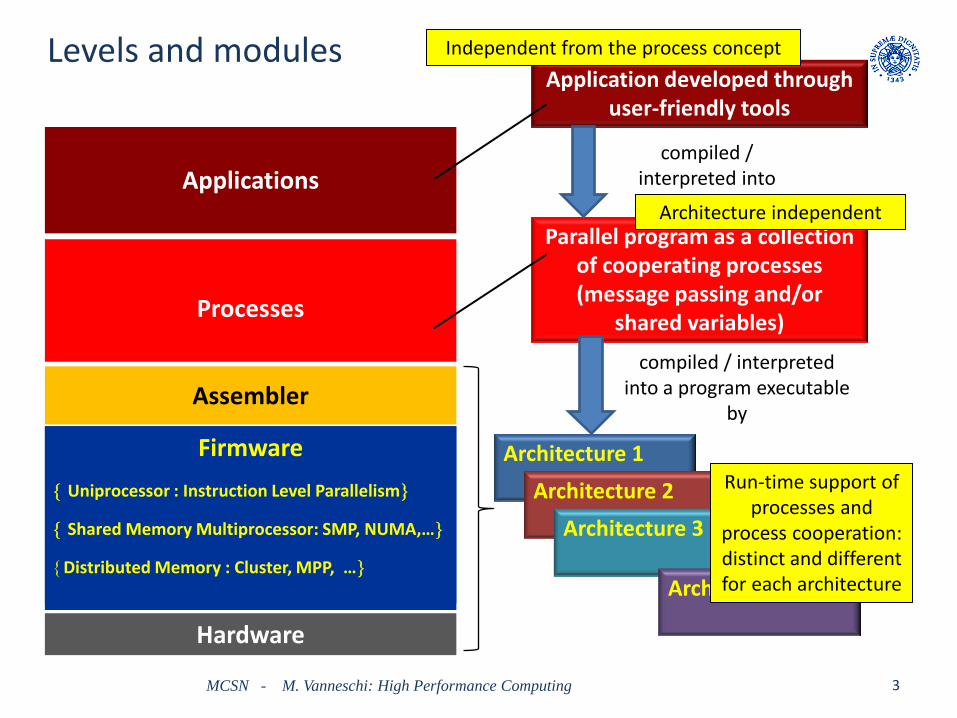
Firmware
Hardware
Applications
Processes
Assembler
Application developed through user-friendly tools
Parallel program as a collection of cooperating processes (message passing and/or
shared variables)
compiled / interpreted into
compiled / interpreted into a program executable
by
Firmware
Uniprocessor : Instruction Level Parallelism
Shared Memory Multiprocessor: SMP, NUMA,…
Distributed Memory : Cluster, MPP, …
Architecture 1 Architecture 2
Architecture 3
Architecture m
Independent from the process concept
Architecture independent
Run-time support of processes and
process cooperation: distinct and different for each architecture
Levels and modules

Structured view of computing architectures
• System structuring: – by Levels:
• vertical structure, hierarchy of interpreters
– by Modules:
• horizontal structure, for each level (e.g. processes, processing units)
– Cooperation between modules and Cooperation Models
• message passing, shared object, or both
• Each level (even the lowest ones) is associated a proper programming language
• At each level, the organization of a system is derived by, and/or is strongly related to, the semantics of the primitives (commands) of the associated language – “the hardware – software interface”
MCSN - M. Vanneschi: High Performance Computing 4

System structuring by hierarchical levels
MCSN - M. Vanneschi: High Performance Computing 5
• “Onion like” structure
• Hierarchy of Virtual Machines (MV)
• Hierarchy of Interpreters or Run-Time Supports: commands of MVi language are
interpreted by programs at level MVj, where j < i (often: j = i – 1)
Abstraction or
Virtualization
Concretization or
Interpretation
Object types (Ri) and Language (Li) of level MVi

Interpretation or Run-time support
MCSN - M. Vanneschi: High Performance Computing 6
Implementation of commands of language Li (mechanisms) by means of programs written in Li-k (policies)
interpretation
Primitive command (mechanism) COM Level MVi , Li
Run-time support of mechanism COM (policy for COM implementation):
RTS (COM)
Level MVi-k , Li-k
In the executable code, COM is represented (encoded) in Li-k. At run-time a mechanism of Li-k causes the execution of RTS (COM). Example: a procedure call, a method call, a message, …

Exercise 1 (Homework-0)
• OSI-like protocol stack layers are not interpretation levels: explain this sentence.
• Would it be convenient to implement network protocols according to a true interpretation level approach? (found a new start-up company …)
MCSN - M. Vanneschi: High Performance Computing 7

Compilation and interpretation
The implementation of some levels can exploit optimizations through a static analysis and compilation process
MCSN - M. Vanneschi: High Performance Computing 8
Level MVi, Language Li
Li commands: Ca … Cb …. Cc
Level MVi-k, Language Li-k
Run-time support of Li
RTS(Li)
implemented by
programs written
in Li-k
------ ------ ------
------ ------ ------
One version of Ca implementation: pure interpretation
------ ------ ------
------ ------ ------
------ ------ ------
Alternative versions of Cb implementation, selected according to the whole computation in which Cb is present: partial or full compilation
------ ------ ------

Very simple example of optimizations at compile time
MCSN - M. Vanneschi: High Performance Computing 9
int A[N], B[N], X[N]; for (i = 0; i < N; i++) X[i] = A[i] B[i] + X[i]
int A[N], B[N]; int x = 0; for (i = 0; i < N; i++) x = A[i] B[i] + x
• Apparently similar program structures
• A static analysis of the programs (data types manipulated inside the for loop) allows the compiler to understand important differences and to introduce optimizations
• First example: at i-th iteration of for command, three memory-read operations (A[i], B[i], X[i]) and one memory-write operation (X[i]) must be executed
• Second example: a temporary variable for x is initialized and allocated in a CPU Register (General Register), and only at the exit of for commmand the x value is written into memory
• 2N memory accesses are saved
• is such minimization of memory accesses important ?

Exercise 2
• Evaluate the completion time of the previous two programs, at least approximately, in terms of – processor clock cycle and memory access time,
• for a computer architecture without cache memories.
– Give approximate values of processor clock cycle and memory access time for
a current technology computer.
– (‘is such minimization of memory accesses important ?’)
• Study the same problem for a system with a memory hierarchy: main memory – (primary) cache memory.
MCSN - M. Vanneschi: High Performance Computing 10
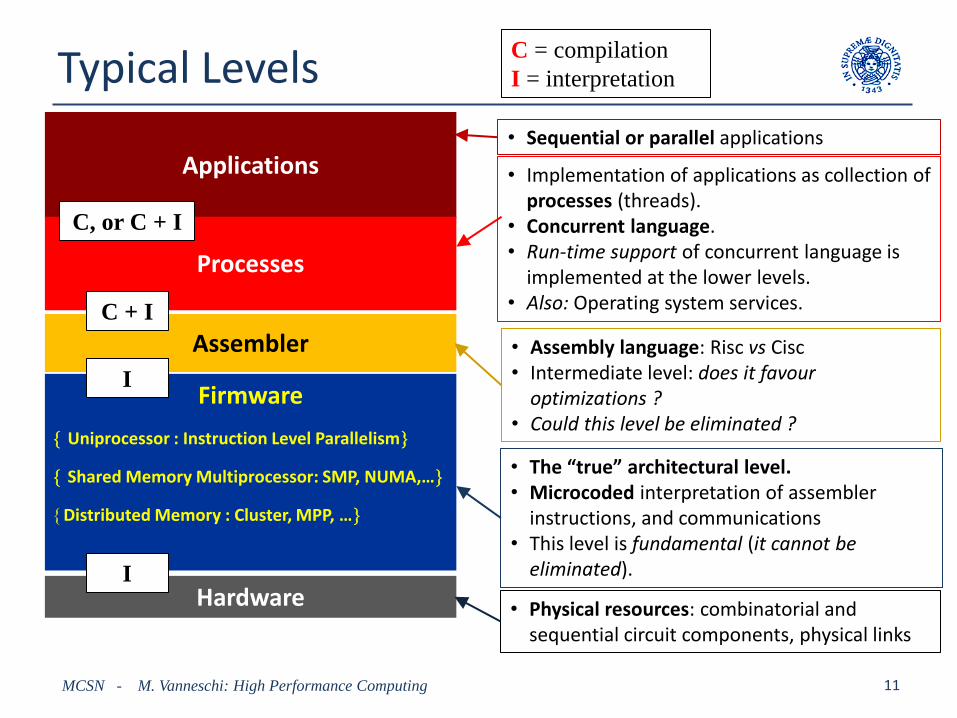
Typical Levels
MCSN - M. Vanneschi: High Performance Computing 11
Hardware
Applications
Processes
Assembler
Firmware
Uniprocessor : Instruction Level Parallelism
Shared Memory Multiprocessor: SMP, NUMA,…
Distributed Memory : Cluster, MPP, …
• Sequential or parallel applications
• Implementation of applications as collection of processes (threads).
• Concurrent language. • Run-time support of concurrent language is
implemented at the lower levels. • Also: Operating system services.
• Assembly language: Risc vs Cisc • Intermediate level: does it favour
optimizations ? • Could this level be eliminated ?
• The “true” architectural level. • Microcoded interpretation of assembler
instructions, and communications • This level is fundamental (it cannot be
eliminated).
• Physical resources: combinatorial and sequential circuit components, physical links
C = compilation
I = interpretation
C, or C + I
C + I
I
I

Exercise 3
• Explain and discuss
– the Assembly level box
– the Firmware level box
of previous slide: study Sections 2, 3, 4 of Book Appendix.
MCSN - M. Vanneschi: High Performance Computing 12

Example
C-like application language
• Compilation of the majority of sequential code and data structures
– Intensive optimizations according to the assembler – firmware
architecture
• Memory hierarchies, Instruction Level Parallelism, co-processors
• Interpretation of dynamic memory allocation and related data structures
• Interpretation of interprocess communication primitives
• Interpretation of invocations to linked services (OS, networking protocols, and so on)
MCSN - M. Vanneschi: High Performance Computing 13

Example
MCSN - M. Vanneschi: High Performance Computing 14
----------------- ----------------- ----------------- Call dynamic memory allocation procedure M ----------------- ----------------- ----------------- Call send-message to I/O Driver process ----------------- ----------------- ----------------- ----------------- Procedures: page-fault handler, send implementation, …
Executable assembler-level compiled version of an application program
Procedure call assembler instruction to invoke the run-time support of a memory page-fault exception (invisible to the source program). As always, the called procedure (page-fault handler) is contained in the same addressing space of the calling program. Pure interpretation: the same piece of code is executed each time a page-fault exception is raised. Possible optimizations could be provided inside the procedure.
The source program contains a high-level command T for I/O transfer. Let’s assume that 1) the corresponding I/O Driver is implemented as a process, 2) the language at the process level is a message-passing one. The compiler insert a proper send primitive: a message has to be sent to the Driver process in order to request the needed service. The send is implemented as a procedure, thus the interface to RTS(T) is just a send procedure call. In this case, the interpreter of the I/O service is encapsulated in the I/O Driver process: it is invisible to the application (possible optimizations could exist inside the process). In turn, the send primitive has its run-time support: RTS(send), which is a procedure, thus in the same addressing space of the application.

Exercize 4
• Verify your understanding of, and explain more in-depth, the sentences in the previous slide boxes.
MCSN - M. Vanneschi: High Performance Computing 15

Levels and executable code
• The hierarchy of interpreters disappears in the executable compiled version of an application
• That is, in the executable version all levels are flatten onto the binary assembler representation of the application
– The assembler interpretation at the firmware level casues the execution of the
application process.
MCSN - M. Vanneschi: High Performance Computing 16
Application level: I/O transfer command T
Process level: RTS(T) = send message to I/O Driver process
Assembler level: RTS (send) = send procedure

Firmware level
MCSN - M. Vanneschi: High Performance Computing 17
Control Part j
Operating Part j
U1
Uj
Un
U2
. . . . . .
. . .
• Each Processing Unit is
• autonomous: it has its own control, i.e. it has self-control capability, i.e. it is an active computational entity
• described by a sequential program, called microprogram.
• Cooperation is realized through COMMUNICATIONS
Communication channels implemented by physical links and a firmware protocol.
• Parallelism between units.

Example
MCSN - M. Vanneschi: High Performance Computing 18
Cache Memory
.
.
.
Main Memory
Memory Management
Unit
Processor
Interrupt Arbiter
I/O1 I/Ok . . .
. . .
CPU
A uniprocessor architecture
In turn, CPU is a collection of
communicating units (on the
same chip)
Cache
Memory
In turn, the Cache Memory can be
implemented as a collection of
parallel units: instruction and data
cache, primary – secondary –
tertiary… cache
In turn, the Main Memory can be implemented as a
collection of parallel units: modular memory,
interleaved memory, buffer memory, or …
In turn, the Processor can be
implemented as a (large)
collection of parallel, pipelined
units
In turn, an advanced
I/O unit can be
a parallel architecture
(vector / SIMD
coprocessor / GPU /
…),
or a powerful
multiprocessor-based
network interface,
or ….

Microprograms and clock cycle
MCSN - M. Vanneschi: High Performance Computing 19
when clock do R_output = R_input
R_input
R_output = R_present_state
Register_writing
Register output and state remain STABLE during a clock cycle
R R_output = R_present_state
clock (pulse signal)
R_input
A clocked register:
The processing unit behavior is described by a microprogram. Every microinstruction is executed exactly in one clock cycle. Several elementary operations can be executed in parallel in a microinstruction.
Typical current values of clock cycle: 0.25 nsec – 1 nsec
(clock frequency 1 GHz – 4 GHz) Many multicore chips : 1 GHz

Exercise 5
• Give examples of microinstructions containing more than one elementary operations.
• Justify typical values of the clock cycle, of a processor and of a RAM memory component, according the current hardware technology.
MCSN - M. Vanneschi: High Performance Computing 20

System structuring by modules
• Horizontal structuring, i.e. inside each level
• At each level: set of cooperating active entities, expressing the computation at that level, called PROCESSING MODULES (simply: MODULES).
MCSN - M. Vanneschi: High Performance Computing 21
Level i
Level i-1

Modules at different levels
• The same definition of Processing Unit extends to Modules at any level:
• Each Module is
– autonomous
• has its own control, i.e. it has self-control capability, i.e. it is an active computational entity
– described by a sequential program, e.g. a process or a thread at the Process Level.
• Cooperation is realized through COMMUNICATIONS and/or SHARED OBJECTS
– depending on the level: at some levels both cooperation model are feasible (Processes), in
other cases only communication is a feasible module in a primitive manner (Firmware).
• Parallelism among Modules.
MCSN - M. Vanneschi: High Performance Computing 22
M1
Mj
Mn
M2
. . . . . .
. . .

Exercise 6
• Class instances of an object-oriented language are not modules: explain this sentence.
MCSN - M. Vanneschi: High Performance Computing 23

Cooperation models
• Cooperation of modules at each level is expressed by proper mechanisms
• These mechanisms have a double valence: – They express how the modules interact
– Their semantics include parallelism handling: synchronization, communication, atomicity, …
Two basic approaches:
• Local environment, or message-passing, model – Each module operates on private variables / objects only (i.e., no sharing)
– Distinct modules cooperate by explicit exchange of values
• Global environment, or shared-variables (shared-objects), model – Modules operate on private and on shared variables / objects
– The cooperation mechanisms are expressed by proper operations on shared data
MCSN - M. Vanneschi: High Performance Computing 24

Cooperation through message-passing
MCSN - M. Vanneschi: High Performance Computing 25
Variables (Objects)
Source process
Destination process
Communication channel
send (channel_identifier, message_value)
receive (channel_identifier, target_variable)
Each process works on private variables (objects) only, i.e. no sharing.
The only possibity for interaction among processes is the communication by value.

MCSN - M. Vanneschi: High Performance Computing 26
A B C
D
Symmetric channel
Asymmetric channel
Symmetric and asymmetric channels can be synchronous or aynchronous
Message-passing is feasible at the firmware level and at the process level.
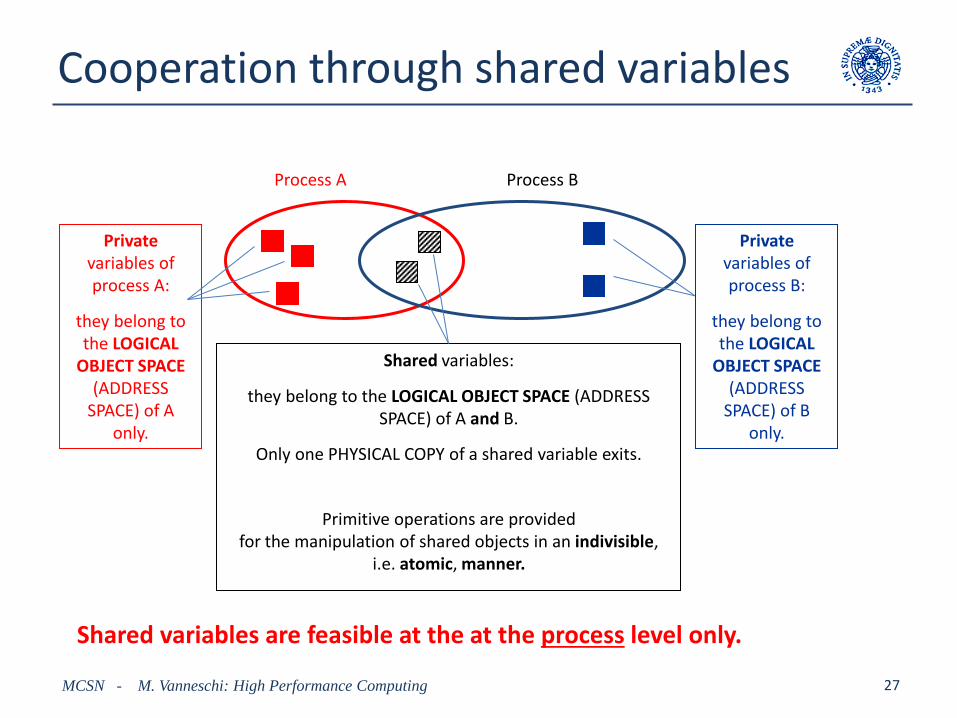
Cooperation through shared variables
MCSN - M. Vanneschi: High Performance Computing 27
Process A Process B
Private variables of process A:
they belong to the LOGICAL
OBJECT SPACE (ADDRESS
SPACE) of A only.
Shared variables:
they belong to the LOGICAL OBJECT SPACE (ADDRESS SPACE) of A and B.
Only one PHYSICAL COPY of a shared variable exits.
Primitive operations are provided for the manipulation of shared objects in an indivisible,
i.e. atomic, manner.
Private variables of process B:
they belong to the LOGICAL
OBJECT SPACE (ADDRESS
SPACE) of B only.
Shared variables are feasible at the at the process level only.

Examples of shared variable mechanisms
• Semaphores
• Locking
• Critical sections
• Monitors
• …
MCSN - M. Vanneschi: High Performance Computing 28
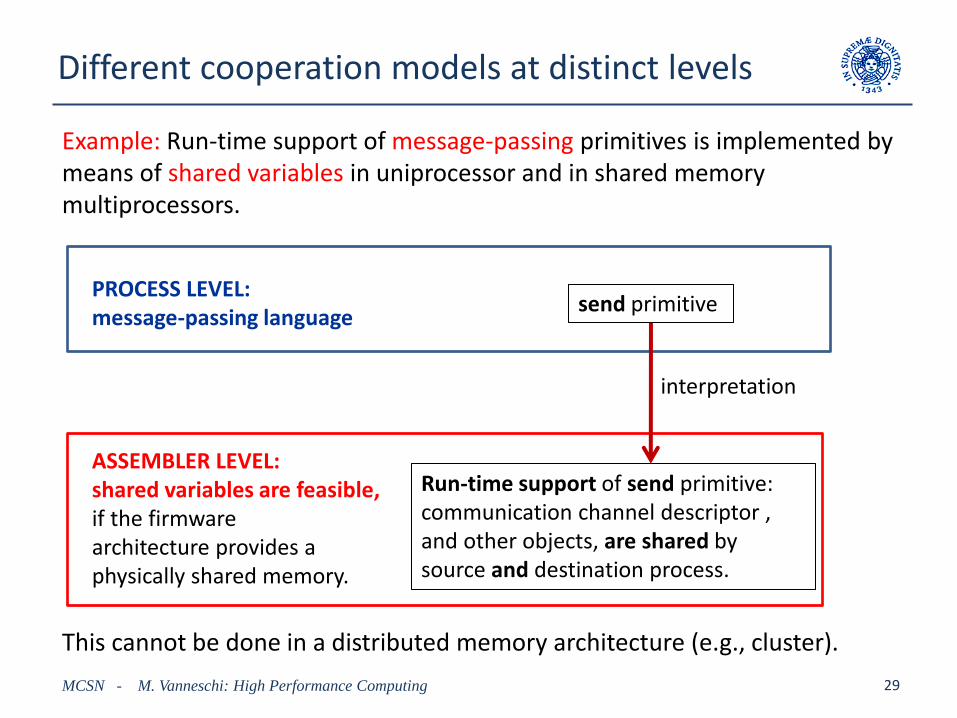
Different cooperation models at distinct levels
MCSN - M. Vanneschi: High Performance Computing 29
Example: Run-time support of message-passing primitives is implemented by means of shared variables in uniprocessor and in shared memory multiprocessors.
send primitive
Run-time support of send primitive: communication channel descriptor , and other objects, are shared by source and destination process.
interpretation
PROCESS LEVEL: message-passing language
ASSEMBLER LEVEL: shared variables are feasible, if the firmware architecture provides a physically shared memory.
This cannot be done in a distributed memory architecture (e.g., cluster).

Exercise 7
• Assume that the send primitive run-time support of previous slide is used in a distributed memory machine (with the same processors): what is the final outcome of a send execution?
MCSN - M. Vanneschi: High Performance Computing 30

preempted
Basic support to process low-level scheduling
MCSN - M. Vanneschi: High Performance Computing 31
Progress states of a process, and progress state transitions
suspended wake-up
without
preemption
terminated created
resumed into
execution
wake-up with
preemption
Pronto
Ready Running
Wait
Context-switching: running process is suspended (passes into Wait state) and the first Ready process passes into execution (Running state) Wake-up: the waiting condition of a Waiting process are verified: such process passes into the Ready state, or directly into the Running state by preempting the currently running process.

Data structures
• Process Control Block (PCB), containing – the internal state (images of General Registers and Program Counter)
– pointer to the Ready List (Linked List of PCBs of Ready processes)
– pointers to other PCBs in the Ready List
– pointer to the process Relocation Table
– pointers to other run-time support data structures
– process identifier and priority (if any)
– utility information (e.g. stack)
• Relocation Table of every process
• Channel Descriptors
• Channel Table: – maps channel identifiers onto channel descriptor addresses
MCSN - M. Vanneschi: High Performance Computing 32
Basic support to process low-level scheduling

Shared objects for run-time support
MCSN - M. Vanneschi: High Performance Computing 33
PCBA PCBB PCBC
Ready List
PCB… PCB… PCB…
Channel Descriptor 1
(CH1)
. . .
Channel Descriptor 2
(CH2)
Channel Descriptor 3
(CH3) . . .
SHARED OBJECTS
TAB_CHA
Local variables of A Process A
TAB_CHB
Local variables of B Process B

Exercise 8
Select the correct sentence, and explain the choice:
1. The logical address space of process A consists of the local variables of A and TAB_CHA.
2. The logical address space of process A includes the shared objects too.
MCSN - M. Vanneschi: High Performance Computing 34