survivable grids: resource management through …gsw2c/research/sc07_wasson.pdfsurvivable grids:...
TRANSCRIPT

1
Survivable Grids: Resource Management through Dynamic Authorization Control
Abstract Grids are rapidly becoming part of our nation’s critical infrastructure. As the importance of grids in our everyday
lives increases, so does the need to make grids survivable - that is, to allow them to be easily reconfigured to
support new priorities or changes in the underlying resource fabric. Few exposed mechanisms exist for such
reconfiguration in today’s grid software. We propose the use of authorization, through control of authorization
policy as a means to achieve this goal. This paper describes our use of a system based on multiple, independent
control loops that manipulate authorizations to manage a grid’s resources and dynamically make them more
available to different classes of users or applications. This reconfiguration is done using rights specifically delegated
to management authorities using the logic-based Security Policy Authorization Language (SecPAL).
1. Introduction
Grids are rapidly becoming part of the nation’s critical infrastructure. Soon grids will not only serve the scientific
community, which largely tolerates their idiosyncratic failures and lack of dependability, but will also be asked to
perform tasks needed in people’s everyday lives. As grids become more vital in application areas such as finance,
public medicine, response to natural disasters, and homeland defense, it becomes more and more important that
they be rapidly reconfigurable to support new national priorities or to withstand significant disruptions in the grid’s
underlying resource fabric.
A survivable information system [7] is said to continue to provide critical functionality to some or all users via one
or more different or degraded services if the primary service cannot be provided. For a computing grid to be called
a survivable grid, the grid must attempt to gracefully degrade its overall service (possibly through a set of
alternative services) rather than cease to function as conditions worsen. For example, if a large-scale power outage
occurs, the overall grid should continue to provide dynamically-reprioritized access to resources for specific groups

2
of users and/or applications. If grid capacity diminishes further, the remaining grid resources should be
reconfigured to be more available to these groups (with an obvious decrease in availability to others). While we
believe that no survivable grids exist today for general e-Science, we assert that dynamic control of authorization
policy is a natural enabler for such a grid.
In today’s grids, control of authorization rests with individual resources or more likely the sites which own those
resources. This is because resource (or site) autonomy is a primary goal. Although cross-domain sources of
authorization information, such as CAS [10] or VOMS [1], are sometimes used, these are typically for asserting
group membership, leaving the actual permissions of that group up to the sites. We believe that tomorrow’s large-
scale critical infrastructure grids will require authorization systems that are partly controlled by sites, partly
controlled by authorities running the grid itself, and partly controlled by the virtual organizations (VOs) to which a
site belongs. Control from the VO or grid level could be the result of online sensor and control logic, i.e.
authorization control could be the actuation of an automated control loop. It could also be triggered by human-in-
the-loop control, i.e. it could be the mechanism by which VO or grid administrators enact new VO or grid-wide
policy. In either case, it is likely that the automated system or the system administrator enacts these
configurations because they have a “wider view” of the VO or grid based on information that is not generally
available to the individual sites. For example, a VO may detect that one of its important users is not receiving the
throughput they require for their jobs and so it might reconfigures the authorization on several member sites to
make them more available to that user. Although the VO wishes to provide a higher quality of service to this user,
it does not want to unnecessarily disrupt other VO operations. Therefore, simply having each site enact the same
policy is inappropriate because it will remove too many resources from the pool available for other users. Instead
the VO can, at a fine-grained level, alter the authorization policy at different sites in different ways such that the
overall goal is achieved.
Controlling authorization means that resources (or sites) allow the controlling entities to dynamically issue claims
about users and/or resources in the system. Claims refer to statements about the privileges that a user (or group
of users) has with respect to a resource (or group of resources). In order to preserve site autonomy, the controlled
resources should have a mechanism for limiting the extent of the privileges that the controllers can manipulate

3
with these claims. In other words, the controlled resources should explicitly delegate the rights to be managed to
the managing controller. Such delegation allows different controllers to manage different rights and therefore
affect different aspects of the grid/VO’s overall operation.
This paper proposes a control system for survivable grids that uses multiple, independent controllers to configure
authorization policy to support desired grid-wide (or VO-wide) behavior. Experimental results show that
manipulation of authorization policy is both flexible, in the types of actions that are possible, and effective, in
terms of achieving and maintaining the desired goals, as a means of controlling the operations of a VO or grid.
Specifically, the contributions of this paper are:
A set of requirements for authorization systems to be used in survivable grids
An examination of authorization as an “actuator” in several scenarios
An example set of policies and claims that allow manipulation of grid/VO-wide availability of resources
The remainder of this paper is organized as follows. Section 2 discusses the current state of the art in grid
authorization and how it does not meet the needs of survivable grids. Section 3 described our problem domain and
how authorization configuration can be used to perform appropriate resource management. Section 4 discusses
our implementation of such a system using SecPAL, an experimental authorization language/engine from
Microsoft. Section 5 provides an evaluation of this system and Section 6 concludes.
2. Related Work
There are several authorization systems in use in grids today. The most common is the simple “gridmap” file. This
file maps a user’s grid-wide identity (often defined by an X509 certificate) to a local system identity. The operating
system then makes authorization decisions based on this local identity. While modern OSs have sophisticated
authorization systems, these systems are neither exposed for manipulation by external authorities nor uniform in
the capabilities they provide (the latter being an issue for management in heterogeneous grids). Queuing systems,
in use at many high-end computing facilities, provide another resource-level mechanism that could potentially be
manipulated to reconfigure the operations of a grid. However, modifying queue priorities/authorizations is

4
insufficient in many cases because numerous grid resources are not controlled by queues (e.g. storage, network
and even some compute resources).
Another authorization scenario in use in grids is one in which a user’s identity is mapped to a group (or set of
groups) through a proxy certificate issued by a “membership service” such as VOMS [1] or CAS [10]. Permissions
for the group are then defined by individual resources. This setup can be superior to the gridmap approach in that
changes in membership do not require changes at each site. Although manipulating the groupings assigned by
these services is another potential mechanism for reconfiguration, it suffers from two principle shortcomings. First,
these services are user-centric in that no authorization changes can be made without the user requesting a new
certificate (nor can they be made for entities other than users, e.g. for applications). Second, these certificates are
typically acquired when the user begins a grid session, i.e. when no information about the user’s intended actions
is known. This means that such information cannot be used to determine the user’s authorization – making it
difficult to, for example, give the user different rights on different resources just by manipulating group
membership.
Another authorization scenario is one in which resources make call-outs to external policy decision points (PDPs)
when clients request service. These PDPs then represent locations where authorization policy can be changed to
affect all resources using the PDP. However, this external PDP is typically allowed to manage all access privileges
for the resource. The system presented here allows each resource (or site) to explicitly delegate privileges to be
managed by an external authority while retaining control of other privileges locally.
Several advanced privilege management systems have been developed for grids as well. PERMIS [3] is a privilege
management system that consists of a policy language, engine and policy management infrastructure (e.g. a policy
repository) which integrates with many grid systems such as GT4 [5]. While the PERMIS system is not, in and of
itself, a system for creating survivable grids, it does have similar capabilities to the authorization system we
ultimately chose to build on for this work, SecPAL [4]. The decision to use SecPAL is partly because of the ease of
policy expression and partly to evaluate the utility of SecPAL in grids should it become widely deployed (and thus
highly leveragable) by Microsoft. We note however that, in principle, our system for survivable grids could be built

5
using PERMIS. PRIMA [9] is a privilege management system that leverages the security infrastructure of the host
operating system. Essentially, PRIMA enforces policy by dynamically configuring a local account to have the
privileges associated with a particular user. It is up to the user to present the privileges they want to be considered
by the resource when requesting service. While this provides certain flexibility (and privacy) for users, in the
survivable grid scenario a VO or grid controller may need to be sure that a resource knows a particular attribute of
a user and not leave it up to that user to present that information.
The Open Grid Forum (OGF) Authorization Frameworks and Mechanisms working group (AUTHZ-WG) has released
an informational document detailing different types of authorization architectures for grid computing [8]. These
frameworks typically involve a subject, who asks for service, a resource, from which service is requested and an
authorization authority which determines if the subject can receive the requested service from the resource. Our
proposed system is in keeping with these architectures.
An important system that reconfigures authorization to allow prioritized access to grid resources on the TeraGrid is
the SPRUCE [2] system. SPRUCE issues tokens to users that effectively provide them greater priority in job queues.
SPRUCE is user-request oriented, that is it changes the authorization for a user on a request by request basis.
While this is appropriate when small numbers of requests need increased priority in a well-functioning grid, it does
require the users to perform extra actions (request tokens, etc.). We believe that in the critical infrastructure
domain, demand will always be high and therefore when survivability is called for (i.e. when resources fail) there
will be a large number of requests that need additional priority. This makes our approach of configuring resources
advantageous because clients do not need to take addition actions. The resources themselves recognize a normal
request (from the client’s perspective) as one which should be prioritized. It is also not clear how SPRUCE would
handle resource types that are not controlled by queues.
Other systems which recognize the need for VO and/or grid level control of resources include [11] and [6]. While
this work shares a common motivation, it differs in its goals ([11] and [6] were designed to implement specific
policies) and mechanisms (the manipulation of authorization policy). We believe that authorization is an important

6
actuator for the grid because it is fundamentally part of access to all resources and, as such, should be available as
a point of control for every grid resource.
3. VO and Grid-wide Authorization
To more fully understand survivable grids, consider the following problem domain. Suppose there is a grid which
consists of multiple VOs. While each VO has a certain percentage of the grid’s total resources are member
resources, for each VO there exist some resources which are in the Grid, but not in the VO. Each VO allows its users
to run a set of applications on member resources. However, different applications have different importance to
the VO and thus, at times, the VO may need to shift resources to a particular application to improve its
performance (by adding resources) or to maintain its performance (by replacing resources which are not willing or
able to perform as needed). Such prioritization may come from the VO’s own board (the people in charge of VO-
wide operations), or from an external source, e.g. the CDC asks the Virology VO to predict the spread of a disease
recently detected in the US. This prediction is performed using a complex distributed application that runs at many
sites. While computing possible spreads of disease is just one of the activities in the VO’s normal workload, this
new priority elevates this work over other work. The Virology VO reconfigures its member resources to make them
available solely to the disease spread prediction application. However, scientists are still not able to meet the
deadline urgently requested by the CDC. So, the Virology VO asks the Grid control software for more resources.
The Grid controller then reconfigures certain sites which were in the grid, but not the VO to make them members
of the VO for a limited time, thereby allowing the application to run in more locations.
In order to achieve this vision of survivable grids, we propose a system with multiple, independent controllers that
can effect authorization policy at the resource level. Each controller would operate on behalf of a VO or the entire
grid, prioritizing the availability of its constituent resources based on its own control strategy. The actual
reconfigurations that can be performed on the sites are determined by the rights which the sites delegate to the
controllers.
The survivable grid system then has the following requirements.

7
An easy way to delegate the rights to be managed by the controllers
A mechanism to securely transmit authorization configuration commands from controller to site
A means of integrating authorization commands received over time into the site’s authorization engine
A mechanism for the controller to revoke previous configurations, either to reconfigure the site or
because the old configuration is no longer required.
In addition, it would be useful to follow the practice of many authorization systems in which some entities are in
charge of asserting the properties of principals (system entities with cryptographic identities) while other entities
are in charge of assigning permissions based on those properties. In our system, the Grid controller provides
attributes of VOs and the VO controllers provide the attributes of applications. The sites then map those attributes
to a set of rights.
Figure 1 shows an example of this survivable grid infrastructure.
The sites represent groups of resources controlled by the same authorization policy. The lines between sites and
controllers represent the ability of that controller to effect that site’s authorization. It is important to highlight two
properties of this architecture. First, sites can receive authorization configuration from multiple controllers,
meaning that conflict between configurations can occur. In general, resolving such conflicts is difficult or
impossible in a resource/domain independent way. It is anticipated that in many architectures with multiple
VO 1
Controller
Grid
Controller
VO 2
Controller
Site Site Site Site Site Site
Figure 1. Grid / VO Authz Control Architecture

8
controllers, each controller will have been delegated different rights by the controlled resource, thus inherently
preventing conflicts. The sites in the system described in Section 4 prevent conflict between VO and grid
controllers in this way. For other situations, conflict must be resolved through a priority scheme, typically under
the control of the site receiving the configuration commands. This is both powerful and problematic. It is powerful
because of its flexibility – each site has the autonomy to decide which configurations to allow. It is problematic
because this flexibility makes it difficult for a controller to determine what will happen as the result of a command
it issues. This problem can be mitigated to a degree by employing a control loop which senses the dynamic state of
the grid and uses this to make control decisions. In such a system, controllers can presumably adjust their behavior
based on the observed outcome of their commands, either trying different configurations on the same site, or the
same configuration on different sites.
It should be noted that the controllers need not be fully autonomous, i.e. automatically sensing and reconfiguring
resources. Instead, they could provide possible operations to administrators, allowing a human to select the final
action taken, or they could be the mechanism by which an administrator configures the grid, allowing that
administrator to determine the state of the grid (and hence the necessary configuration) by their own
methodology.
The second property of this architecture is that it is not strictly hierarchical. That is, the grid controller does not
control the VO controllers (which then control the sites), but rather “speaks” directly to the sites. While this may
seem to present a scalability problem, it need not. In other words, the grid and VO controllers should not be
thought of as part of the same control tree, but rather as roots of independent control trees – each of which must
separately address the problem of message delivery to the entities it controls based on the size of its controlled
pool.

9
4. A VO Authorization System using SecPAL
In this section we present a system that meets the requirements for the survivable grid domain described in
section 3. At the heart of this system is the Security Policy Authorization Language (SecPAL) system [4] and so we
briefly discuss the SecPAL language and authorization engine.
SecPAL is a declarative, logic-based security language. It was designed to be a complete solution for trust,
authorization and delegation policies as well as supporting auditing and PKI-based identity management. An
important aspect of the SecPAL language for this work is that SecPAL makes it easy to express authorization
concepts because policy statements are made using a syntax that allows them to be read as English sentences. This
facilitates an intuitive understanding of SecPAL policies. The SecPAL authorization engine runs queries against
collections of authorization statements. The engine uses a ProLog-like database of authorization claims (who can
do what to which resource under what conditions) and facts (statements about the current conditions) which can
be queried (“can user X perform action Y on resource Z?”). The grammar of the SecPAL language means that
queries in the SecPAL engine are guaranteed to terminate. Although space does not permit a complete discussion
of SecPAL’s features, we will highlight those used in the policies of our survivability scenario below.
Our survivable grid system consists of 3 types of components, the sites which each run a SecPAL engine, the VO
controllers which make assertions about the applications run by VO users, and a Grid controller which makes
assertions about VO membership. Authorization configuration by the controllers is performed by adding or
removing SecPAL statements (called claims) from the authorization engines running at the sites. Different
statements can be in use at different sites to create the desired overall effect on the VO/grid. At this point, it may
be helpful to examine an actual SecPAL site policy. The simplicity and power of SecPAL can be seen in the policy
shown in Figure 2.

10
In the above policy, the phrase “K-*” (e.g. K-Grid) indicates a cryptographic principal in the system, in other words,
an entity with a cryptographic ID. K-Grid is the principal associated with the grid controller. K-User is the principal
associated with a VO member. The items shown in bold text (p, t1, t2 and *.exe) are variables that will be bound to
values based on tokens issued by the controllers.
The first statement can be interpreted as “the grid controller (K-Grid) is allowed to assert (can say) that a principal
of the controller’s choosing (p) can operate with the rights of (can act as) the principal K-AppAuthorizer as long as
the current time is in a window specified by the grid controller (*t1, t2+ if t1 ≤ currentTime ≤ t2). In other words,
the site implementing this policy has delegated the right to determine who can act as K-AppAuthorizer to the grid
controller. The second policy statement details what a principal acting as K-AppAuthorizer can do. This statement
says that “a principal acting as K-AppAuthorizer (K-AppAuthorizer) can assert (can say) that a given principal (p) has
the attribute that it possesses an application name (possesses appName) and that that name matches the regular
expression “*.exe” (=“*.exe”) if the current time is within the specified time window (*t1, t2+ if t1 ≤ currentTime ≤
t2). The keyword “appName” is one of the attributes that SecPAL allows to be assigned to a principal. Here, K-
AppAuthorizer is allowed to bind a name to a principal, in this case a principal associated with an executable piece
of code. This binding is useful because users will want to refer to applications by human-readable names, while the
authorization system authorizes cryptographically secure principals. In effect, the site has delegated the right to
bind application names to (application) principals to whomever the grid controller has determined can be K-
AppAuthorizer. The final statement in the policy of Figure 2 describes the rights the site gives to a principal bound
Figure 2. SecPAL Policy for Survivable Grid Scenario
K-Grid can say that p can act as
K-AppAuthorizer [t1, t2] if t1 ≤
currentTime ≤ t2
K-AppAuthorizer can say that p
possesses appName=”*.exe” [t1,
t2] if t1 ≤ currentTime ≤ t2
K-User can execute p if p
possesses appName=”*.exe”

11
to an appName. A user (K-User)1 has the right to execute (can execute) a principal (p) if that principal has an
associated appName (if p possesses appName=“*.exe”).
The policy of Figure 2 runs in the SecPAL engine at each site. Along with those claims are claims made by the VO
and grid controllers in accordance with the rights delegated to them. For example:
The first statement says that K-Grid authorizes the principal associated with VO #1 (K-VO1) to act as K-
AppAuthorizer. This is how K-Grid to controls the VO membership of sites. Each principal (in this case, a VO) that
can act as K-AppAuthorizer can authorize its applications to run on that site making that site a member of that VO.
The time quantifier [now, maxTime] says that this claim is good starting now and continuing forever (though it can
later be revoked). The second statement shows how a VO authorizes its applications to run on a site. In this
statement K-VO1 binds K-ViroApp to the name outbreakPredictor.exe for the next 1 hour. Since sites allow
applications with associated appName attributes to execute (as per the policy of Figure 2), a user can run
outbreakPredictor.exe, for the next hour,on any site that receives this SecPAL statement from the VO1 controller.
It should now be apparent that the system makes two assumptions. First, it is assumed that all applications for all
VOs of which a site might ever be a member are deployed on that site or installable by a mechanism outside of this
system. We assume modern application provisioning systems are sufficient for this. Second, the time quantifiers
on claims assume (somewhat) synchronous clocks. The degree to which clocks must be synchronized depends on
allowable lag between claims being issued and being adhered to for the grid. We find synchronization such as
available with NTP acceptable.
1 Note that for compactness, the policy is shown authorizing a single user (K-User). An actual policy would use
another principal variable (with constraints) to authorize, for example, all users in a VO or all users who possess a given attribute.
Figure 3. Example Claims Made by Grid and VO Controllers
K-Grid says that K-VO1 can act as
K-AppAuthorizer [now, maxTime]
K-VO1 says that K-ViroApp has
appName=”outbreakPredictor.exe”
[now, now+1 hour]

12
The system works by having VO controllers authorize apps on sites which are members of the given VO (recall that
different statements can be sent to different sites). The VO controller can determine the percentage of the VO’s
resources that are potentially available to an application by the hosts on which it chooses to authorize that
application. The VO controller can make resources even more available to an application by de-authorizing other
applications that could run at a site. The grid controller in turn is responsible for allocating the resources of the grid
amongst the member VOs. This is done by configuring sites to allow different VO principals to act as K-
AppAuthorizer. By changing VO memberships, the grid controller can prioritize the grid’s resources to be more
available to particular VOs (and therefore less available to others).
Our implementation is built on .NET 3.0 using Windows Communication Foundation (WCF) web services running
the SecPAL engine. Each site is implemented as a web service that can receive job execution requests from users or
SecPAL statements from controllers. SecPAL does not define a protocol by which claims such as those shown in
Figure 3 are transmitted. We use a straightforward one in which statements signed by trusted controller principals
are sent to the sites’ web services. These messages are translated into programmatic claims that can be inserted
into the SecPAL engine. The site web services store the SecPAL claims currently in effect in a database.
One issue unaddressed in the above formulation is that of conflict between different principals operating as K-
AppAuthorizer. It is possible for a site to be a member of multiple VOs by virtue of multiple claims being issued by
the grid controller to a single site for different VO principals (it should also be noted that the delegation of control
over VO membership to the grid controller is not exclusive, i.e. a site can also make statements about the VOs that
it is in). This leaves open the possibility that, for example, VO1 could authorize an application and VO2 could later
de-authorize it. The current “can act as” formulation of site policy does not easily prevent different principals from
conflicting. However, in our system, the applications associated with each VO are disjoint and each VO controller
knows only about its own VO’s applications. Therefore, one controller will never authorize or de-authorize
another’s applications. If the current state of the grid does not permit a given site to be available to multiple VOs,
i.e. if the site must be reserved for a single VO’s work, it is expected that the grid controller will issues appropriate
statements such that only one VO principal is authorized (recall that previous statements can be revoked).

13
An interesting issue with any survivable system is how to determine when a particular system configuration is no
longer needed, i.e. when it is ok to “return to normal”. In general, it is easier to determine when a crisis is
occurring (and thus when the grid/VO must transmission out of its normal state), but it can be less obvious when a
crisis is over and normal operation can resume. For this reason, our system uses explicit time quantifiers on the
controller’s statements. This causes them to automatically expire unless they are periodically refreshed. This is
similar to the soft-state cleanup pattern used in many grid systems. While this mechanism does not definitely
answer the “when to return to normal” question, it does prevent the system from staying in a “crisis mode”. If the
authorization controllers are being used as the actuators of a control loop, when the system returns to its normal
state, the sensing portion of that loop can detect if the crisis conditions still exist and transition the sites back.
5. Implemented Use Case Scenario
We have created a testbed for this system to illustrate some important scenarios. This testbed consists of a
collection of web services based on Windows Communication Foundation (WCF) and .NET 3.0. There are 10 “site
services”, i.e. web services which can execute jobs based on user requests, which are used to simulate compute
sites. Each site is running the SecPAL engine using the policy shown in Figure 2. The sites are equally divided among
2 virtual organizations (VO1 and VO2). Authorization configuration for the sites in VO1 is controlled by a
VOManager process and the configuration of the entire grid (i.e. all sites) is handled by the GridManager (a
manager for VO2 is not used in this scenario). The VOManager issues tokens to appropriate sites authorizing (or
de-authorizing) applications. The GridManager issues tokens to sites placing them in particular VOs (VO1, VO2 or
VO1 and VO2). VO1 runs applications AppA and AppB. VO2 runs application AppC. The current throughput of any
application (how many jobs of that type completed in a given time window) is measured by each site. Jobs are
submitted by a client that simulates the kind of workload we expect to be present in critical infrastructure. That is,
there is an almost constant demand for almost all the available capacity. The client process queries the
GridManager to determine which sites are in which VOs, submits an AppA job to a random site in VO1, submits an
AppB job to a random site in VO1 and submits an AppC job to a random site in VO2. Jobs have exclusive access to a
host, i.e. if a host is running a job and another submission occurs, the second submission fails. Clients do not know

14
about the authorization status of different applications on the different sites so some submissions may result in a
“permission denied” error because of the site’s current authorization configuration.
In the first scenario, the VOManager’s goal is to keep the throughput of AppA at an acceptable rate (in this case 15
jobs per measurement window). How this rate is determined is orthogonal, but could be based on the VO’s own
priorities or priorities received from an external authority. At a specific time, we simulate the loss of sites in VO1.
Figure 4 shows some possible responses by the system and their effects on the overall throughput of the three
applications. The three lines in Figure 4 represent the sum of the throughput for a particular application across all
sites within a 30 second measurement window.
Figure 4. System Reaction and Relaxation when Prioritizing AppA
At the start (t=1), we can see that AppC is getting roughly twice the throughput of AppA or AppB. This is because
AppC has all the sites in VO2 available to it, while AppA and AppB must share the sites in VO1. The variance
between the throughput of AppA + throughput of AppB and the throughput of AppC is due to the fact that
execution sites are chosen randomly by the client and so some requests in any given time period will “collide” with
each other.
0
5
10
15
20
25
30
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29
Job
Th
rou
ghp
ut
Time (30s increments)
Grid-Wide Throughput
AppA
AppB
AppC

15
At time t=5, we simulate the loss of 3 hosts from VO1. This can be seen by the drop in throughput for both AppA
and AppB. This drop is detected by the VOManager which reconfigures the remaining 2 hosts to only accept AppA
jobs at t=10. This is done by revoking the “possesses appName” claim (such as the one shown at the bottom of
Figure 3) for AppB. At this point, we can see AppA’s throughput rises, while AppB’s throughput goes to 0 since it
cannot run on any sites. At time t=15, AppA’s throughput has still not reached the VOManager’s desired level and
so it asks the GridManager for additional resources. The GridManager then adds 3 sites from VO2 to VO1, by
sending those sites tokens indicating that VO1 can act as the AppAuthorizer (such as the token shown in the top of
Figure 3). We can see that this increases AppA’s throughput while decreasing AppC’s since AppC jobs now must
contend with AppA jobs for the same resources. Finally, at t=20, the VOManager decides that AppA’s throughput is
acceptable and so it reconfigures the new sites (those recently added by the GridManager) to accept AppB jobs as
well. This can be seen by the drop in AppA throughput and the rise in AppB throughput. Of course, at a later time
the GridManager may revoke its granting of the extra sites to VO1 and so the grid-wide throughput of AppA and
AppB would return to the approximate levels shown at t=1. This scenario shows how authorization configuration
can be used to configure resources to allow prioritized access by different applications. The ability of the sites to
integrate claims from multiple controllers allows a step-wise response, at the VO level first, and then at the
GridManager level.
Next we consider a second scenario which is similar to the first except that it includes the simultaneous loss of
hosts and the raising of the throughput requirement for AppA. In other words, more AppA jobs must be completed
despite the shrinking resource pool. Figure 5 shows an example system response and its effect on grid-wide
throughput.
16
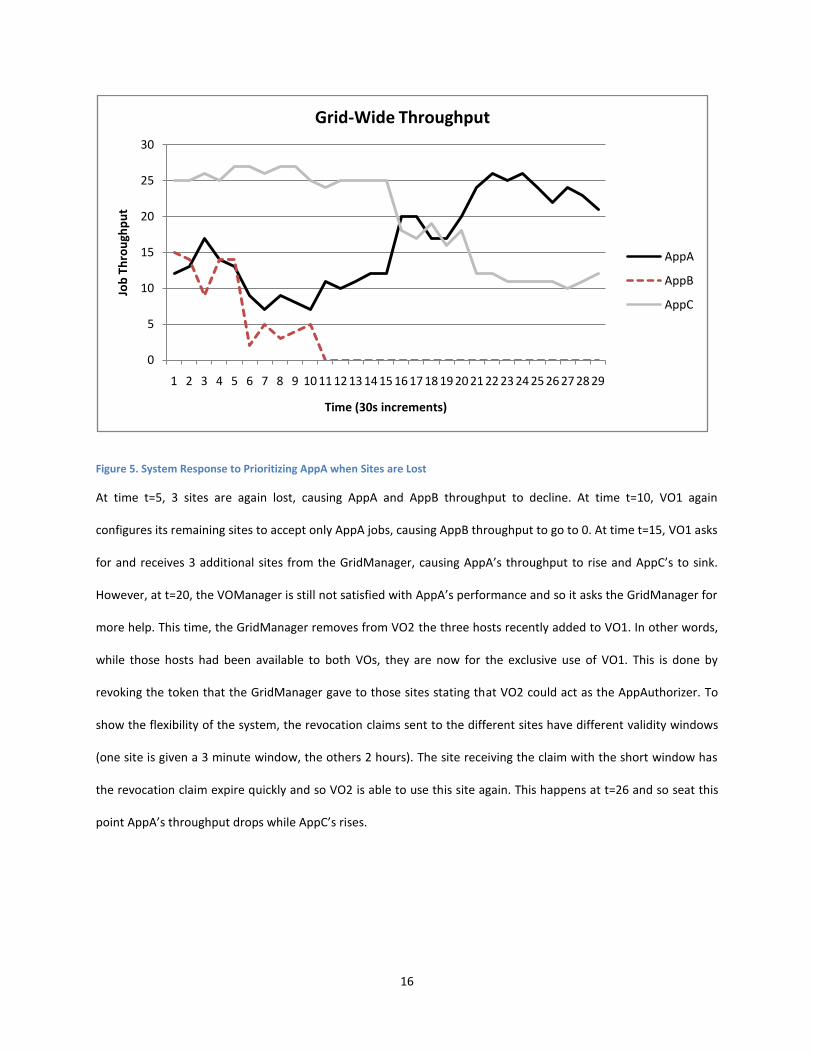
Figure 5. System Response to Prioritizing AppA when Sites are Lost
At time t=5, 3 sites are again lost, causing AppA and AppB throughput to decline. At time t=10, VO1 again
configures its remaining sites to accept only AppA jobs, causing AppB throughput to go to 0. At time t=15, VO1 asks
for and receives 3 additional sites from the GridManager, causing AppA’s throughput to rise and AppC’s to sink.
However, at t=20, the VOManager is still not satisfied with AppA’s performance and so it asks the GridManager for
more help. This time, the GridManager removes from VO2 the three hosts recently added to VO1. In other words,
while those hosts had been available to both VOs, they are now for the exclusive use of VO1. This is done by
revoking the token that the GridManager gave to those sites stating that VO2 could act as the AppAuthorizer. To
show the flexibility of the system, the revocation claims sent to the different sites have different validity windows
(one site is given a 3 minute window, the others 2 hours). The site receiving the claim with the short window has
the revocation claim expire quickly and so VO2 is able to use this site again. This happens at t=26 and so seat this
point AppA’s throughput drops while AppC’s rises.
0
5
10
15
20
25
30
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29
Job
Th
rou
ghp
ut
Time (30s increments)
Grid-Wide Throughput
AppA
AppB
AppC

17
6. Conclusion
In order for grids to be used as critical infrastructure, they must be made survivable. This means that they must be
able to reconfigure themselves to continue operation in the face of new organizational priorities or changes in the
underlying resource fabric. In addition, this reconfiguration must be under the control of authorities with a
broader view than that of individual sites, in other words, authorities representing an entire VO or grid.
Today’s grids provide few actuation points, that is, exposed mechanisms by which the internal configuration of a
resource (or service) can be manipulated. We have demonstrated one interesting actuation mechanism,
authorization policy. We have shown how authorization policy can be manipulated to manage the availability of
system resources.
We have implemented our authorization control system using SecPAL, an authorization policy language and
engine. While SecPAL is not the only technology that could be used for this problem, it does have several appealing
features. First, it provides an easy mechanism for sites to delegate a (small) subset of rights to external authorities
to be managed. Second, it provides straightforward options for revoking control decisions. Third SecPAL is easy to
use because SecPAL statements can be intuitively translated into English language sentences and vice versa.
Finally, SecPAL’s logic engine makes it simple to combine claims made by different entities over time to determine
current policy.
While this paper represents an important step toward survivable grids, much work remains. Here, we have
managed compute resources through control of the “execute” right. In the future, we will investigate management
of other resource types, such as data (via SecPAL’s “read” and “write” rights) and services (via the “call” right).
Also, we will further investigate how conflicts between the configurations of different controllers can be managed
and how to determine the minimal right-set that must be delegated by a site in order to achieve VO or grid
reconfigurability. For example, can a grid meet its resource availability goals if sites allow the grid to add VO
memberships, but not remove memberships asserted by the site?

18
References
[1] R. Alfieri, R. Cecchini, V. Ciaschini, L. dell'Agnello, A. Frohner, A. Gianoli, K. Lorentey, and F. Spataro, "VOMS, an
Authorization System for Virtual Organizations", European Across Grids Conference, 2003, pp. 33-40.
[2] P. Beckman, S. Nadella, N. Trebon, and I. Beschastnikh. “SPRUCE: A System for Supporting Urgent High-
Performance Computing”, IFIP WoCo 9, 2006.
[3] D.W. Chadwick and A. Otenko, “The PERMIS X.509 Role Based Privilege Management Infrastructure”. Future
Generation Computer Systems, 19(2): 277-289, February 2003.
[4] B. Dillaway, “A Unified Approach to Trust, Delegation, and Authorization in Large-Scale Grids”. Microsoft
Corporation. Sept. 2006.
[5] Globus Project. Globus Toolkit v. 4. http://www.globus.org
[6] A. Grimshaw, M. Humphrey, J.C. Knight, A. Nguyen-Tuong, J. Rowanhill, G. Wasson, and J. Basney. The
Development of Dependable and Survivable Grids. 2005 Workshop on Dynamic Data Driven Applications
(associated with the 2005 International Conference on Computational Science). Emory University, Atlanta, GA.
May 22-25, 2005.
[7] J.C. Knight, E. Strunk and K. J. Sullivan. “Towards a Rigorous Definition of Information System Survivability”.
DISCEX 2003, Washington DC (April 2003).
[8] M. Lorch, B. Cowles, R. Baker, L. Gommans, P. Madsen, A. McNab, L. Ramakrishnan, K. Sankar, D. Skow, and M.
Thompson. “Conceptual Grid Authorization Framework and Classification”. GFD-I.038. Authorization
Frameworks and Mechanisms WG. Open Grid Forum. Feb. 2003.
[9] M. Lorch and D. Kafura. The PRIMA Grid Authorization System. International Journal of Grid Computing, vol. 2
(3): 279-298, Sept. 2004.
[10] L. Pearlman, V. Welch, I. Foster, C. Kesselman, S. Tuecke. “A Community Authorization Service for Group
Collaboration”. Proceedings of the IEEE 3rd International Workshop on Policies for Distributed Systems and
Networks, 2002.
[11] G. Wasson, and M. Humphrey, “Policy and Enforcement in Virtual Organizations”, 4th International Workshop
on Grid Computing (GRID 03), 2003.