survey of speech-to-speech translation systems: who are the players joy (ying zhang) language...
Post on 22-Dec-2015
216 views
TRANSCRIPT

Survey of Speech-to-speech Translation Systems: Who are the
players
Joy (Ying Zhang)
Language Technologies Institute
Carnegie Mellon University

Major Players
And many others ….

Major Speech Translations Systems
US Europe Japan China
Research Janus, DIPLOMAT, Tongues, Nespole! Maxtor
Verbmobil, Nespole! LC-Star, TC-Star
MATRIX LodeStar,
Digital Olympics
Commercial AT&T NEC
Military Phraselator, Babylon, LASER

Who is doing what in the co-op projects?ATR
RWTH
UKA
IBM
CMU
NSC
Nokia Siemense ITC-irst
UPC Etri SRI
UPV
CAS
CLIPS
Nespole!
Babylon
EuTrans
LC-Star
PF-Star
TC-Star
“C-Star”
Digital-Olympic
Verbmobil

AT&T “How May I Help You”
• Spanish-to-English• MT: transnizer
– A transnizer is a stochastic finite-state transducer that integrates the language model of a speech recognizer and the translation model into one single finite-state transducer
– Directly maps source language phones into target language word sequences
– One step instead of two
• Demo

MIT Lincoln Lab
• Two way Korean/English speech translation
• Translation system: interlingua (Common Coalition Language)

MIT Lincoln Lab

NEC
C/S version as in [Yamabana ACL03]Stand-alone version [ISOTANI03]

NEC
• Special issues in ASR:– To reduce memory requirment
• Gaussian reduction based on MDL [Shinoda, ICASSP2002]• Global tying of the diagonal covariance matrices of Gaussian
mixtures
– To reduce calculation time• Construct a hierarchical tree of gaussians • Leaf node correspond to gaussians in the HMM states• Parent node gaussians cover gaussians of the child nodes• Prob calculation of an input feature vector does not always
need to reach the leaf• 10 times faster with minimum loss of accuracy
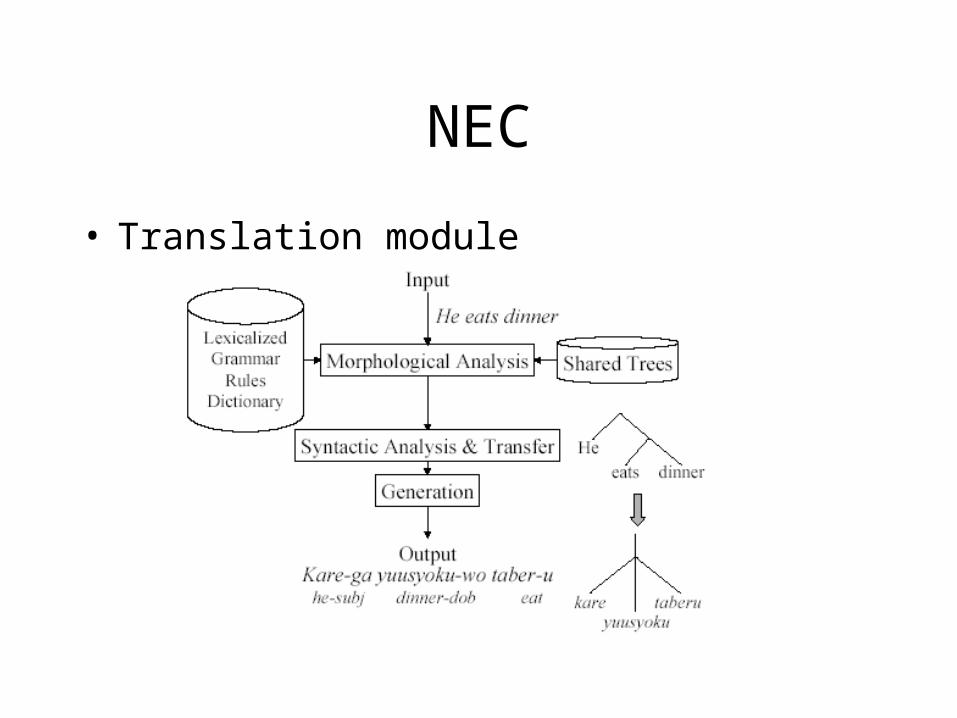
NEC
• Translation module
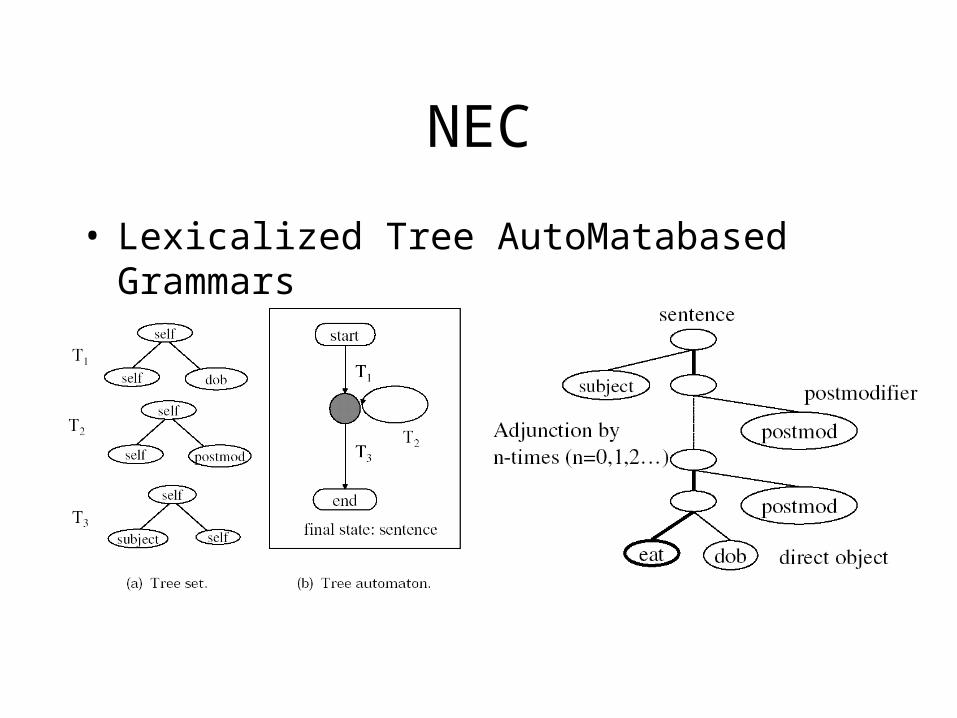
NEC
• Lexicalized Tree AutoMatabased Grammars

NEC
• Translation procedure– Morphological analysis to build initial word lattice– Load feature structure and the tree automata– The parser performs left-to-right bottom-up chart
parsing (breadth-first)– Chose the best path– Top-down generate
• Pack trees for compact translation engine– 8MB for loading the translation model– 1~4MB working memory

NEC
Translation Example [Watanabe, ICSLP00]

NEC• Implementation issues
– 27MB to load the system– 1~4MB working memory– OS (PocketPC) limites mem to 32MB– Runs on PDAs with StrongARM 206 MHz CPU– Delay of several seconds in ASR
• Accuracy– ASR: 95% for Japanese, 87% for English– Translation
• J->E: 66% Good, 88% Good+OK• E->J: 74% Good, 90% Good+OK


Phraselator
• Major challenges are not from ASR– Tough environment– Power needs to last for hours– Batteries can be charged from 12VDC, 24VDC;
110/220VAC– Critical human engineering criteria – Audio system allows full range freq. Response
from mic through CODEC and back out to the speaker

PF-STAR
• Preparing Future Multisensorial Interaction Research
• Crucial areas:– Speech-to-speech translation
– Detection and expressions of emotional states
– Core speech technologies for children
• Participant: ITC-irst, RWTH, UERLN, KTH, UB, CNR ISTC-SPFD

TC-STAR_P• To prepare a future integrated project named
"Technology and Corpora for Speech to Speech Translation" (TC-STAR)
• Objectives:– Elaborating roadmaps on SST
– Strengthening the R&D community• Industrial; Academics; Infrastructure entities
– Buildup the future TC-STAR management structure
• Participants: – ELDA, IBM, ITC-irst, KUN, LIMSI-CNRS, Nokia,
NSC, RWTH, Siemens, Sony, TNO, UKA, UPC

LC-STAR
• Launched: Feb 2002• Focus: creating language resources for speech
translation components– Flexible vocabulary speech recognition– High quality text-to-speech synthesis– Speech centered translation
• Objective:• To make large lexica available for many languages that cover
a wide range of domains along with the development of standards relating to content and quality

LC-STAR
• Drawbacks of existing LR– Lack of coverage for application domains
– Lack of suitability for synthesis and recognition
– Lack of quality control
– Lack of standards
– Lack of coverage in languages
– Mostly limited to research purposes
(lc-star, eurospeech 93)

LC-STAR
• For speech-to-speech translation– Focus: statistical approaches using suitable LR– “Suitable” LR
• Aligned bilingual text corpora
• Monolingual lexica with morpho-syntactic information
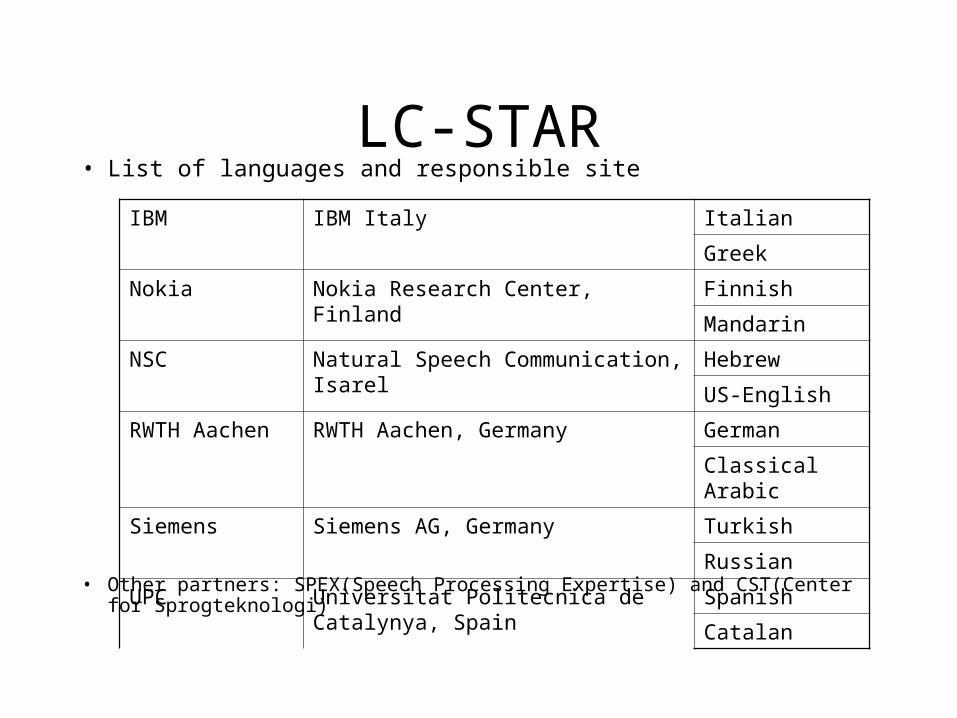
LC-STAR• List of languages and responsible site
• Other partners: SPEX(Speech Processing Expertise) and CST(Center for Sprogteknologi)
IBM IBM Italy Italian
Greek
Nokia Nokia Research Center, Finland Finnish
Mandarin
NSC Natural Speech Communication, Isarel Hebrew
US-English
RWTH Aachen RWTH Aachen, Germany German
Classical Arabic
Siemens Siemens AG, Germany Turkish
Russian
UPC Universitat Politecnica de Catalynya, Spain Spanish
Catalan

LC-STAR
• Progress and Schedule1. Design of Specifications2. Corpora collections3. Phase I: build large lexica for ASR and TTS4. Phase II:
– Can MT benefit from linguistic features in bilingual lexica (RWTH)
– Define specification for bilingual lexica– Create special speech-to-speech translation lexica

EuTrans
• Sponsor: European Commission program ESPRIT
• Participants:– University of Aachen(RWTH), Germany
– Research center of the Foundazione Ugo Bordoni, Italy
– ZERES GmbH, German company
– The Universitat Politecnica of Valencia, Spain
• Project stages:– First stage (1996, six month): to demonstrate the viability
– Second stage (1997-2000, three years): developed methodologies to address everyday tasks

EuTrans
• Features– Acoustic model is part of the translation model
(tight integration)– Generate acoustic, lexical and translation
knowledge from examples (example-based)– Limited domain– Later work used categories (come word classes)
to reduce the corpus size

EuTrans
• ATROS (Automatically Traninabl Recognition of Speech) is a continuous-speech recognition/translation system – based on stochastic finite state acoustic/lexical/syntactic/translation models

EuTrans
• FST
• A set of algorithms to learn the transducers– Make_TST (tree subsequential transducer); Make_OTST (onward TST);
Push_back; Merge_states; OSTIA (OST Inference Alg.); OSTIA-DR

DARPA Babylon • Objective: two-way, multilingual speech translation interfaces for
combat and other field environment• Performance goals:
– 1-1.5x real time– ASR accuracy 90%– MT accuracy 90%– Task computation 80-85%
• Qualitative goals:– User satisfaction/acceptance– Ergonomic compliance to the uniform ensemeble– Error recovery procedures– User tools for field modification and repair
• Scalability– Hardware: to PDA and workstations– Software: non-language expert can configure a new language or add to an
existing language

Speechlator (Babylon)
• Part of the Babylon project• Specific aspects:
– Working with Arabic– Using interlingua approach to
translation• Pure knowledge-based approach,
or• Statistical approach to translate IF
to text in target language
– Host entire two-way system on a portable PDA-class device
Waible [NAACL03]

ATR
• Spoken Language Translation Research Lab– Department1: robust multi-lingual ASR;
– Department2: integrating ASR and NLP to make SST usable in real situations
– Department3: corpus-based spoken language translation technology, constructing large-scale bilingual database
– Department4: J-E translation for monologue, e.g. simultaneous interpretation in international conference
– Department5: TTS

ATR MATRIX
• MATRIX: Multilingual Automatic Translation System [Takezawa98]
• Cooperative integrated language translation method
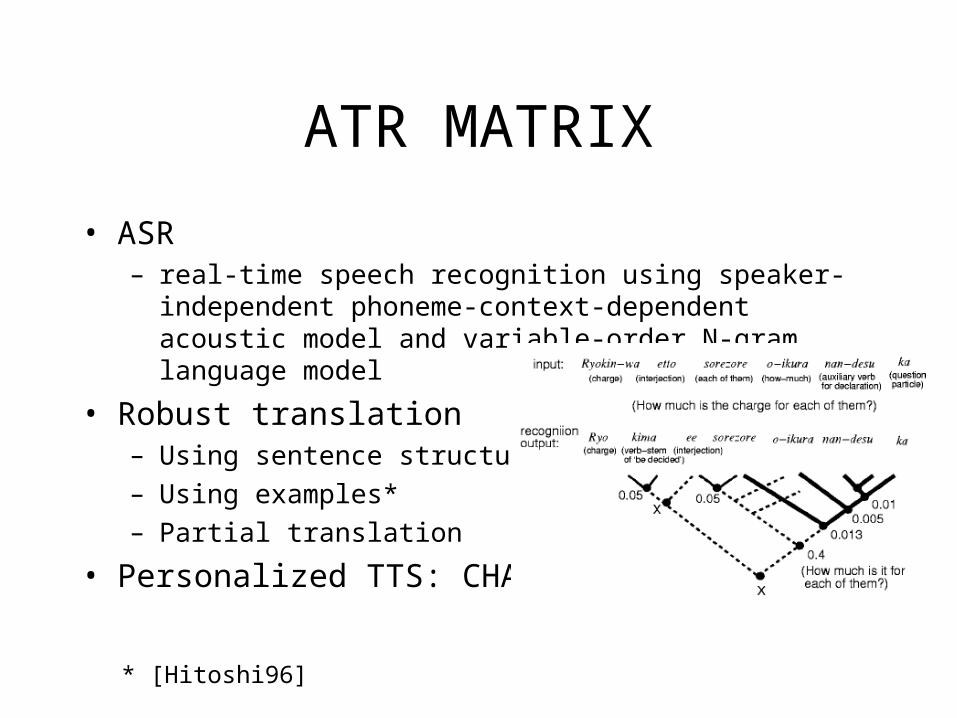
ATR MATRIX
• ASR– real-time speech recognition using speaker-independent phoneme-
context-dependent acoustic model and variable-order N-gram language model
• Robust translation– Using sentence structure
– Using examples*
– Partial translation
• Personalized TTS: CHATR
* [Hitoshi96]

IBM MASTOR
• Statistical parser• Interlingua-like
semantic and syntactic feature representation
• Sentence-level NLG based on Maximum Entropy, including:– Previous symbols– Local sentence type
in the semantic tree– Concept list remains
to be generated [Liu, IBM Tech Report RC22874 ]

Janus I
• Acoustic modeling - LVQ• MT: a new module that
can run several alternate processing strategies in parallel – LR-parser based
syntactic approach– Semantic pattern based
approach (as backup)– Neural network, a
connectionist approach (as backup): PARSEC
• Speech Synthesizer: DECtalk
Woszczyna [HLT93]

Janus II/III• Acoustic model
– 3-state Triphones modeled via continuous density HMMs
• MT: Robust GLR + Phoenix translation (as backup); GenKit for generation
• MT uses the N-best list from ASR (resulted in 3% improvement)
1. Cleaning the lattice by mapping all non-human noises and pauses into a generic pause
2. Breaking the lattice into a set of sub-lattices at points where the speech signal contains long pauses
3. Prune the lattice to a size the the parser can process
Lavie [ICSLP96]

DIPLOMAT / Tongues
• Toshiba Libretto: 200MHz, 192MB RAM– Andrea handset, custom touchscreen, new GUI
• Speech recognizer: Sphinx II (open source)– Semi-continuous HMMs, real-time
• Speech synthesizer: Festival (open source)– Unit selection, FestVox tools
• MT: CMU’s EBMT/MEMT system– Collected data via chaplains role-playing in
• English; translated and read by Croatians– Not enough data, Croatian too heavily female
[Robert Frederking]

Nespole!
• Negotiating through SPOken language in E-commerce
• Funded by EU and NSF
• Participant: ISL, ITC-irst
• Demo

Nespole!
[Lavie02]
•Translation via interlingua
• Translation servers for each language exchange interlingua (IF) to perform translation
Speech recognition: (Speech -> Text)
Analysis: (Text -> IF)
Generation: (IF-> Text)
Synthesis: (Text -> Speech)

Verbmobil
• Funded by German Federal Ministry of Education and Research (1993-2000) with 116 million DM
• Demo ; See Bing’s talk for more details

Digital Olympics
• Multi-Linguistic Intellectual Information Service
• Plan:– Plan I: voice-driven phrasebook translation
(low risk). Similar to phraselator– Plan II: robust speech translation within
very narrow domains. Similar to Nespole! (medium risk)
– Plan III: Highly interactive speech translation with broad linguistic and topic coverage (Olympic 2080?)
[Zong03]

Conclusions
• Major sponsor: government (DARPA,EU)• ASR: mainly HMM • MT:
– Interlingua (Janus, Babylon)– FST (AT&T, UPV)– EBMT(ATR, CMU)/SMT(RWTH,CMU)
• Coupling: between ASR and MT– See “
Coupling of Speech Recognition and Machine Translation in S2SMT” by Szu-Chen (Stan) Jou for more discussions

Reference and Fact-sheet
• http://projectile.is.cs.cmu.edu/research/public/talks/speechTranslation/facts.htm