supplementary information for: the yak genome …...supplementary information for: the yak genome...
TRANSCRIPT

Supplementary information for:
The yak genome and adaptation to life at high-altitude
Qiang Qiu1,17
, Guojie Zhang2,17
, Tao Ma1,17
, Wubin Qian2,3,17
, Junyi Wang2,3,17
, Zhiqiang Ye4,5,17
,
Changchang Cao2,3
, Quanjun Hu1, Jaebum Kim
6,7, Denis M. Larkin
8, Loretta Auvil
9, Boris
Capitanu9, Jian Ma
6,10, Harris A. Lewin
11, Xiaoju Qian
2,3, Yongshan Lang
2,3, Ran Zhou
1, Lizhong
Wang1, Kun Wang
1, Jinquan Xia
2, Shengguang Liao
2,3, Shengkai Pan
2,3, Xu Lu
1, Haolong Hou
2,3,
Yan Wang2, Xuetao Zang
2, Ye Yin
2, Hui Ma
1, Jian Zhang
1, Zhaofeng Wang
1, Yingmei Zhang
1,
Dawei Zhang1, Takahiro Yonezawa
12, Masami Hasegawa
12, Yang Zhong
12, Wenbin Liu
2, Yan
Zhang2, Zhiyong Huang
2, Shengxiang Zhang
1, Ruijun Long
1, Johannes A.Lenstra
13, David N.
Cooper14
, Yi Wu1, Peng Shi
4, Jun Wang
2,15, Jianquan Liu
1,16
1State Key Laboratory of Grassland Agro-Ecosystem, College of Life Science, Lanzhou University, Lanzhou 730000,
China. 2BGI-Shenzhen, Shenzhen 518083, China. 3Key Laboratory of Genomics, BGI-Shenzhen, Shenzhen 518083,
China. 4State Key Laboratory of Genetic Resources and Evolution, Institute of Kunming Zoology, Chinese Academy
of Sciences, Kunming 650223, China. 5Graduate School of Chinese Academy of Sciences, Beijing 100039, China. 6
Institute for Genomic Biology, University of Illinois at Urbana-Champaign, Urbana IL 61801, USA. 7Department of
Animal Biotechnology, Konkuk University, Seoul 143-701, Korea. 8 Institute of Biological, Environmental and Rural
Sciences, Aberystwyth University, Aberystwyth, Ceredigion SY23 3DA, UK. 9 National Center for Supercomputing
Applications, University of Illinois at Urbana-Champaign, Urbana IL 61801, USA. 10 Department of Bioengineering,
University of Illinois at Urbana-Champaign, Urbana IL 61801, USA. 11 Department of Evolution and Ecology,
University of California, Davis CA 95616, USA. 12School of Life Sciences, Fudan University, Shanghai 200433,
China. 13Faculty of Veterinary Medicine, Utrecht University, Utrecht 3584 CM, Netherlands. 14Institute of Medical
Genetics, School of Medicine, Cardiff University, Cardiff CF14 4XN, UK. 15 Department of Biology, University of
Copenhagen, Copenhagen DK-2200, Denmark. 16Key laboratory for Bio-resources and Eco-environment, College of
Life Science, Sichuan University, Chengdu 610061, China. 17These authors contributed equally to this work.
Correspondence and requests for materials should be addressed to J.Q.L ([email protected]), J.W.
([email protected]) or P.S. ([email protected])
Nature Genetics: doi:10.1038/ng.2343

Supplementary Figures
Supplementary Figure 1: Distribution of sequencing depth of the assembled yak
genome.
Nature Genetics: doi:10.1038/ng.2343

Nature Genetics: doi:10.1038/ng.2343

Supplementary Figure 2: Comparison of scaffolds with sequence of fosmids (A)
Yakbx, (B) Yakfx, (C) Yakgx, (D) Yakhx, (E) Yakjx and (F) Yakkx, to evaluate the
completeness and accuracy of the yak assembly. Read depth on the fosmid was
calculated by mapping the short reads onto the fosmid sequences. The predicted genes
and annotated transposable elements (TEs) are shown in green and red, respectively.
The remaining unclosed gaps on the scaffolds are marked as white blocks; most of
these correspond to repetitive sequences.
Nature Genetics: doi:10.1038/ng.2343

Supplementary Figure 3: The GC content of the yak genome. (A) Distribution of
GC content in Yak (red), Cattle (purple) and Human (blue) genomes. The proportion
of 500 bp non-overlapping sliding windows with a given GC content is shown. (B)
Local GC content versus sequencing depth. We used 500-bp non-overlapping sliding
windows along the assembled sequence to calculate GC content and average
sequencing depth using short reads. The box plot was performed using the R package.
Nature Genetics: doi:10.1038/ng.2343
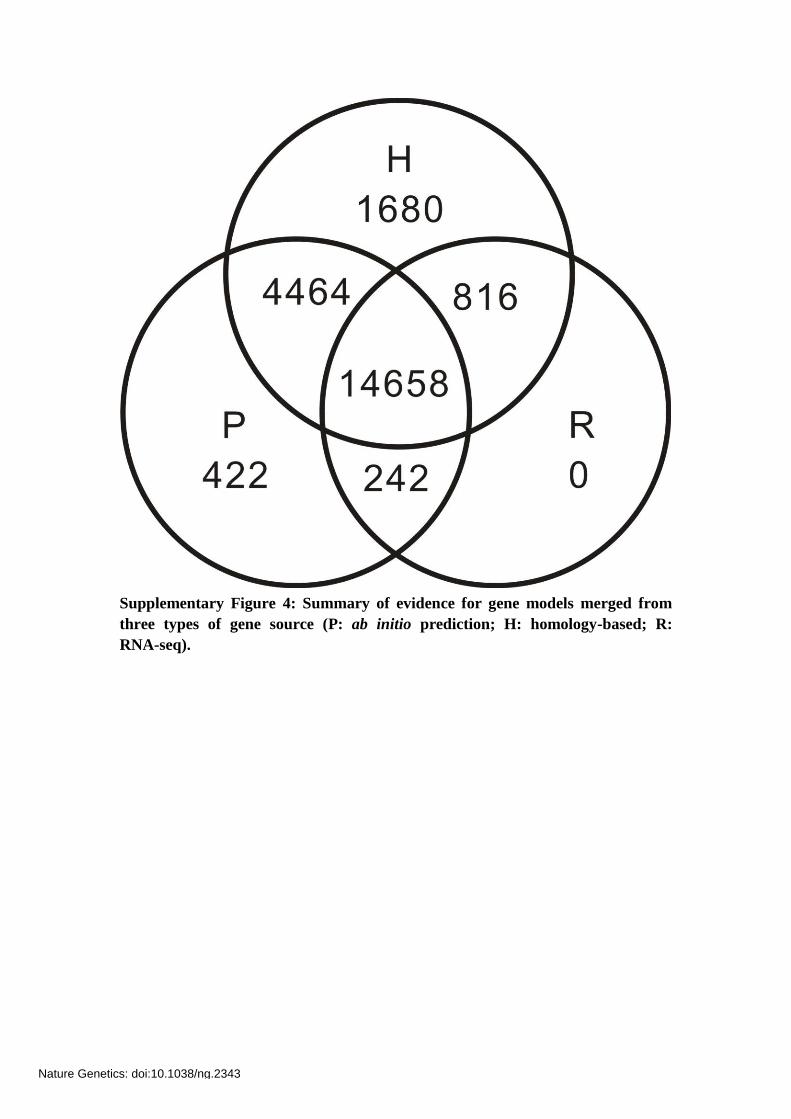
Supplementary Figure 4: Summary of evidence for gene models merged from
three types of gene source (P: ab initio prediction; H: homology-based; R:
RNA-seq).
Nature Genetics: doi:10.1038/ng.2343

Supplementary Figure 5: Distribution of heterozygosity density in the yak
genome. Non-overlapping 50-kb windows were chosen and the heterozygosity
density in each window was calculated.
Nature Genetics: doi:10.1038/ng.2343

Supplementary Figure 6: Five examples of Sanger trace files showing
heterozygous SNVs.
Nature Genetics: doi:10.1038/ng.2343
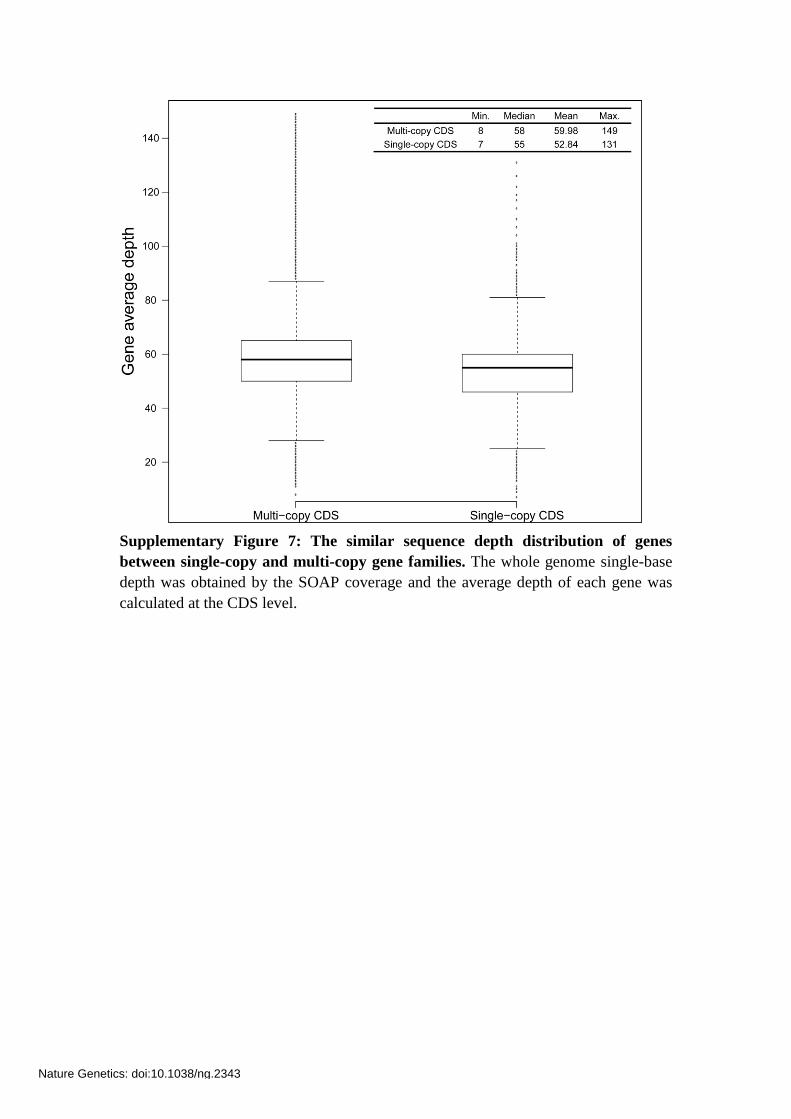
Supplementary Figure 7: The similar sequence depth distribution of genes
between single-copy and multi-copy gene families. The whole genome single-base
depth was obtained by the SOAP coverage and the average depth of each gene was
calculated at the CDS level.
Nature Genetics: doi:10.1038/ng.2343

Supplementary Figure 8: Numbers of orthologous gene sets of yak-cattle-human
and the shared orthologous sets with the indicated species. Genes were required to
fall into regions of large scale synteny between genomes, and to have completely
aligned coding regions of human annotation, not to have frame-shift indels or altered
gene structures, and not to show signs of recent duplication.
Nature Genetics: doi:10.1038/ng.2343

Supplementary Figure 9: Distribution of amino acid identity of orthologs
between yak and the other mammalian species (cattle, horse, dog, mouse,
chimpanzee and human).
Nature Genetics: doi:10.1038/ng.2343

Supplementary Figure 10: Distribution of orthologous protein similarity between
yak and cattle (A) and between human and chimpanzee (B). To calculate the
percent protein similarity between two sequences, the number of identical residues
was divided by the total number of alignment positions.
Nature Genetics: doi:10.1038/ng.2343
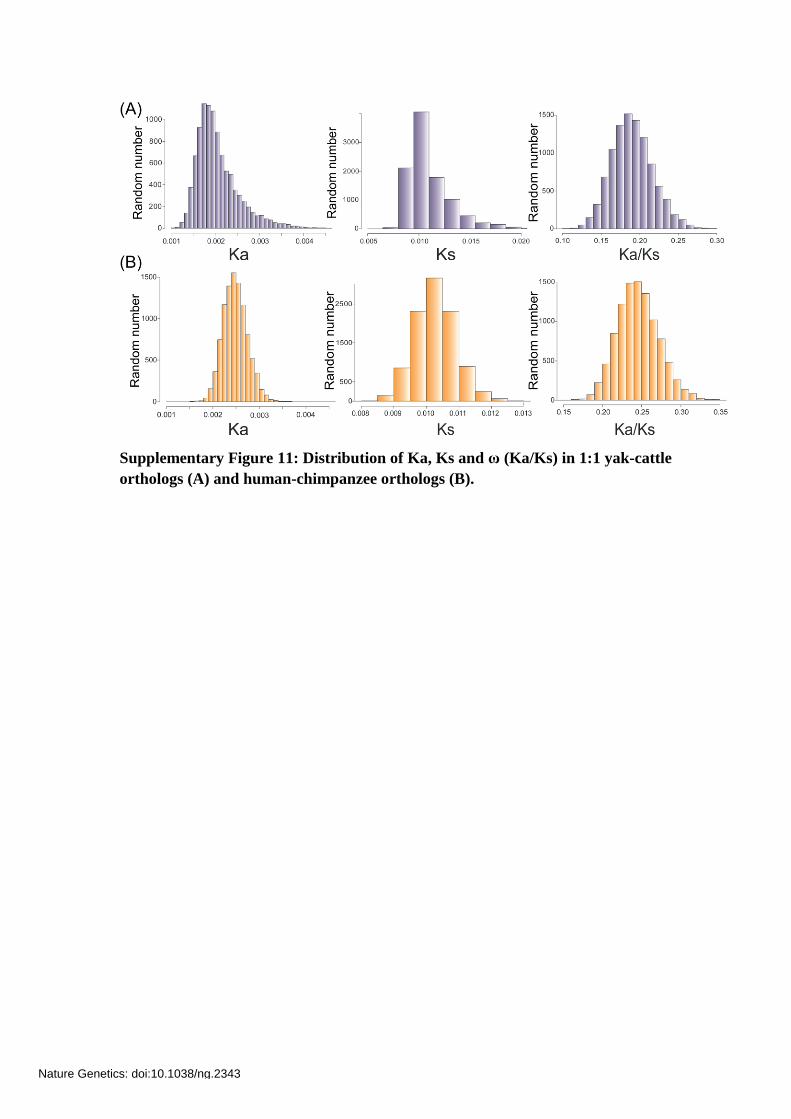
Supplementary Figure 11: Distribution of Ka, Ks and ω (Ka/Ks) in 1:1 yak-cattle
orthologs (A) and human-chimpanzee orthologs (B).
Nature Genetics: doi:10.1038/ng.2343
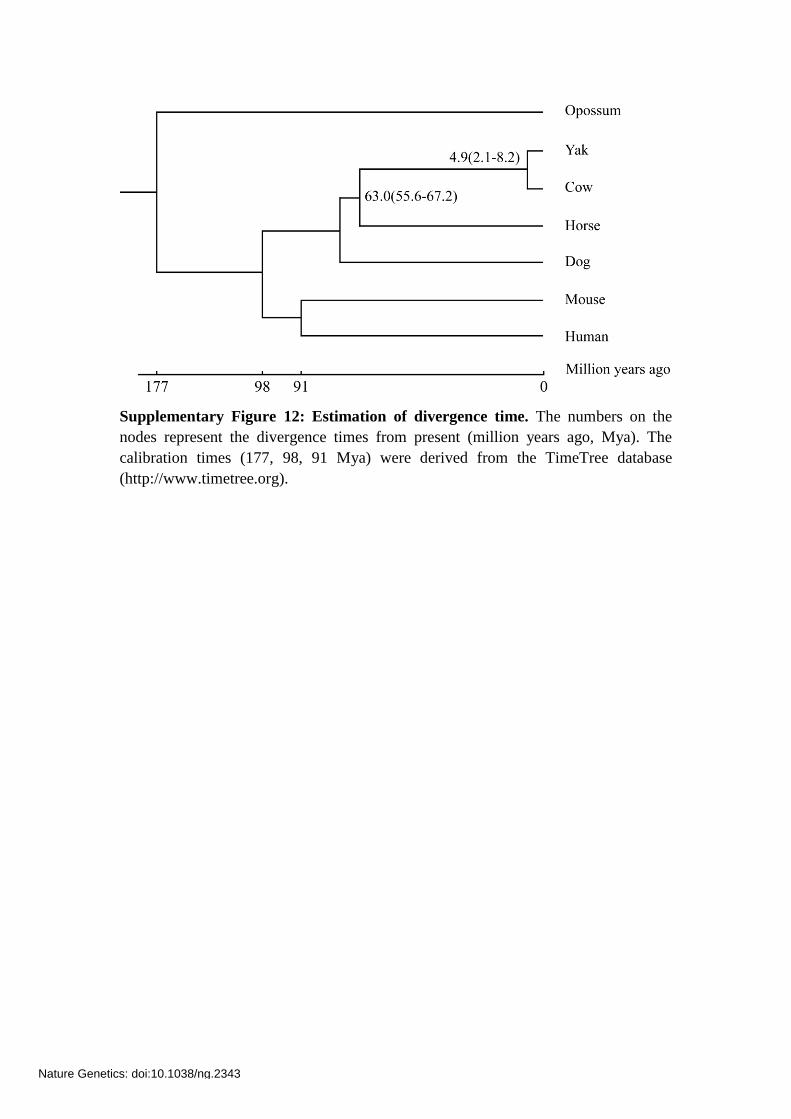
Supplementary Figure 12: Estimation of divergence time. The numbers on the
nodes represent the divergence times from present (million years ago, Mya). The
calibration times (177, 98, 91 Mya) were derived from the TimeTree database
(http://www.timetree.org).
Nature Genetics: doi:10.1038/ng.2343

Supplementary Tables
Supplementary Table 1: Clones and reads used in the sequencing of the yak
genome.
Paired-end
insert size
Raw reads Qualified reads1
Total
data
(Gb)
Read
length
(bp)
Sequence
coverage2
(X)
Physical
coverage2
(X)
Total
data
(Gb)
Read
length
(bp)
Sequence
coverage2
(X)
Physical
coverage2
(X)
200 bp 60.37 100 20.12 20.12 49.68 91 16.56 18.14
500 bp 70.83 104 23.61 56.46 48.62 88 16.21 45.8
800 bp 72.48 100 24.16 96.64 38.92 76 12.97 67.88
2 kb 46.86 68 15.62 229.4 29.82 52 9.94 191.15
5 kb 42.92 63 14.31 560.88 24.99 51 8.33 402.63
10 kb 31.04 57 10.35 897.5 17.24 50 5.75 565.54
20 kb 32.11 66 10.7 1618.41 3.49 47 1.16 243.91
Total 356.63 81 118.87 3479.41 212.77 69 70.92 1533.58
1Qualified reads were generated by filtering the low quality reads, base-calling
duplicate and adapter contamination from the raw reads. 2Coverage was calculated under the assumption of a genome size of 3 Gb. Sequence
coverage refers to the total length of generated reads, and physical coverage refers to
the total cloned DNA used for the paired reads.
Nature Genetics: doi:10.1038/ng.2343
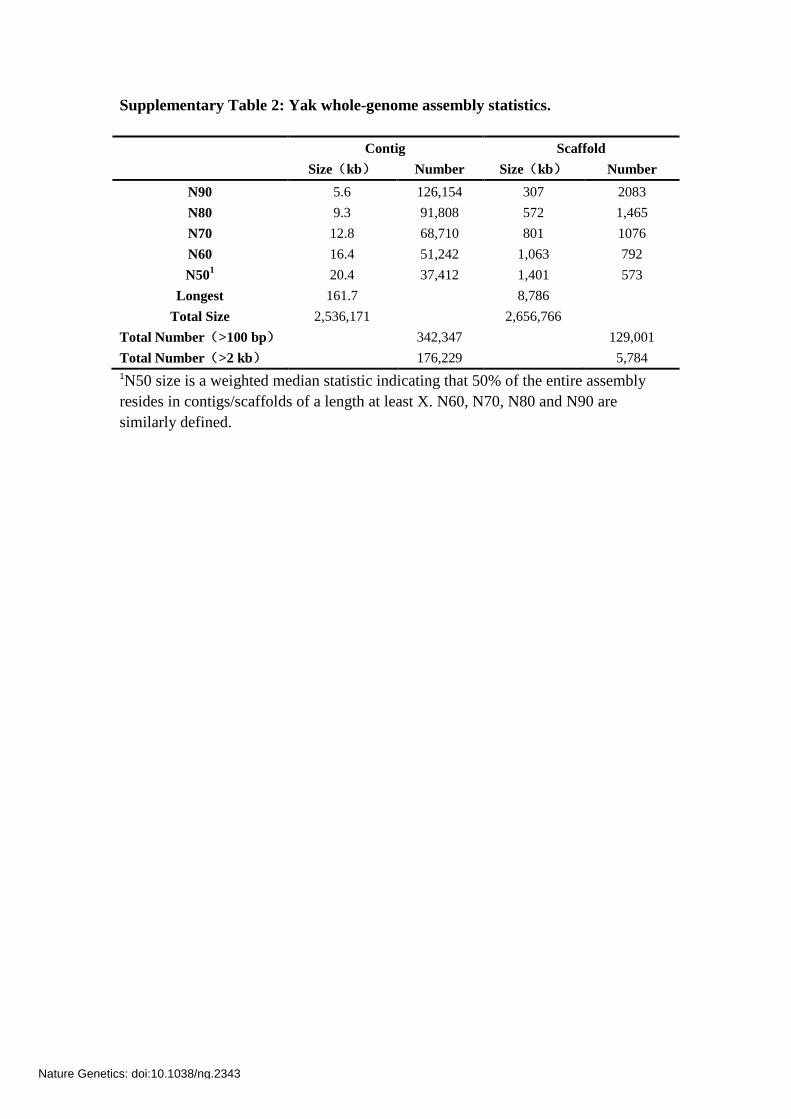
Supplementary Table 2: Yak whole-genome assembly statistics.
Contig Scaffold
Size(kb) Number Size(kb) Number
N90 5.6 126,154 307 2083
N80 9.3 91,808 572 1,465
N70 12.8 68,710 801 1076
N60 16.4 51,242 1,063 792
N501 20.4 37,412 1,401 573
Longest 161.7 8,786
Total Size 2,536,171 2,656,766
Total Number(>100 bp) 342,347 129,001
Total Number(>2 kb) 176,229 5,784
1N50 size is a weighted median statistic indicating that 50% of the entire assembly
resides in contigs/scaffolds of a length at least X. N60, N70, N80 and N90 are
similarly defined.
Nature Genetics: doi:10.1038/ng.2343

Supplementary Table 3: Assembly statistics from published animal genomes
generated by next-generation sequencing (NGS) technology.
Blank entries indicate that data are not available. Note that NGS assemblies may not be as
contiguous as the Sanger-sequenced genomes with lower coverage.
Genome name Sequencing
platform
Assembled
genome size Scaffold Contig
Total
Number
N50 Size
(kb)
N50
number
Largest
(kb)
Total
Number
N50 Size
(kb)
N50
number
Largest
(kb)
Yak (Bos grunniens) Illumina 2.66 Gb 129,001 1,401 573 8,786 342,347 20.4 37,412 161.7
Panda (Ailuropoda melanoleura)1 Illumina 2.30 Gb 81,469 1,282 521 6,048 198,274 39.9 16,102 434.6
Naked mole rat (Heterocephalus glaber)2 Illumina 2.66 Gb 181,133 1,586 508 7,787 447,279 19.3 38,321 179
Macaque (Macaca mulatta lasiota)3 Illumina 2.84 Gb 92,997 891 959 - 584,482 12 61,486 -
Macaque (Macaca fascicularis)3 Illumina 2.85 Gb 104,664 652 1,303 - 555,029 12.5 60,974 -
Chinese hamster (Cricetulus griseus)4 Illumina 2.45 Gb 14,122 1,116 567 - - 38.3 - -
Kangaroo (Macropus eugenii)5 Sanger & 454 2.9 Gb 582,687 19 38,335 543 - 2.91 - -
Atlantic cod (Gadus morhua)6 454 753 Mb 157,887 459 344 4,999 284,239 2.8 50,237 77
Schistosome (Schistosoma haematobium)7 Illumina 385 Mb 99,953 307 365 1,826 129,284 21.7 3,215 181
Monarch Butterfly (Danaus plexippus)8 Illumina & 454 273 Mb 7,780 207 331 5,575 14,019 50.7 1,202 2527
Ant (Camponotus floridanus)9 Illumina 238 Mb 24,026 442 147 2,672 - 24.1 2,523 432.8
Ant (Harpegnathos saltator)9 Illumina 297 Mb 21,347 598 145 2,277 - 38 2,055 477.3
Ant (Linepithema humile)10
Illumina & 454 220 Mb 3,030 1,429 40 7,334 18,227 35.9 - -
Ant (Pogonomyrmex barbatus)11
454 235 Mb 4,646 817 81 3,905 - 11.6 - -
Ant (Solenopsis invicta)12
Illumina & 454 353 Mb 10,543 721 104 6,355 90,231 14.7 - 192
Ant (Atta cephalotes)13
Illumina & 454 318 Mb 2,835 5,155 21 15,679 42,754 14.2 - -
Ant (Acromyrmex echinatior)14
Illumina 313 Mb - 1,094 75 5,247 - 62.7 1,340 464
Lemur (Daubentonia madagascariensis)15
Illumina 2.97 Gb 2,564,533 14 55,001 252 3,237,204 3.7 - 86.4
Hydra (Hydra magnipapillata) 16
Sanger & 454 1.05 Gb 132,902 63.4 - 236,282 12.8 - -
Coral (Acropora digitifera)17
Illumina & 454 419 Mb 4,765 191.5 642 1,590 53,725 10.7 - 98.2
Python (Python molurus bivittatus)18
Illumina & 454 1.18 Gb 324,418 2.2 - - 1.4 - -
Turkey (Meleagris gallopavo)19
Illumina & 454 1.04 Gb 27,007 1,500 - 9,000 145,663 12.6 - 90
Tasmanian devil ( Sarcophilus harrisii )20
Illumina 3.17 Gb 35,974 1,847 5,315 237,291 20.1 189.9
Nature Genetics: doi:10.1038/ng.2343

Supplementary Table 4: Assessment of sequence coverage of the yak genome
assembly using finished fosmid sequences. Each fosmid sequence was well aligned
to a single scaffold, and up to 97% of the total fosmid regions were covered by the
assembled scaffolds. Fosmids Yakbx and Yakkx have the relatively low coverage due
to a high abundance of repetitive elements, corresponding to the unclosed gaps in
Supplementary Figure 2 with high read depth.
Fosmid Total length (bp) Coverage by the draft genome1
Yakbx 37,403 94.8%
Yakfx 36,272 97.9%
Yakgx 34,266 99.7%
Yakhx 36,241 98.1%
Yakjx 40,410 97.7%
Yakkx 39,671 94.6%
Total 224,263 97.1% 1After aligning the scaffolds with the fosmids via Blast, the coverage of the fosmid
sequences by our assembled scaffolds was calculated.
Nature Genetics: doi:10.1038/ng.2343

Supplementary Table 5: Assessment of sequence coverage of the yak genome
assembly using RNA-seq.
Length of
Unigene Number
Total
length (bp)
Covered by
the draft
genome
with >90% sequence
in one scaffold
with >50% sequence
in one scaffold
Number Percent Number Percent
All 81,020 70,519,797 98.4% 78,627 97.05 79,947 98.68
>1000 bp 19,183 28,806,788 98.8% 18,684 97.40 19,000 99.05
>1500 bp 6,592 13,756,050 99.1% 6,432 97.57 6,546 99.30
>2000 bp 2,683 7,080,922 99.1% 2,608 97.20 2,665 99.33
Nature Genetics: doi:10.1038/ng.2343

Supplementary Table 6: Summary of predicted protein-coding genes and their characteristics.
Gene set Number
Average
gene
length (bp)
Average
CDS
length (bp)
Average
exons
per gene
Average
exon
length (bp)
Average
intron
length (bp)
De novo Augustus 26,419 18,654 1,073 6 179 3,512
Genscan 40,967 39,440 1,233 8 163 5,826
Homolog Cattle
1 19,458 26,780 1,472 9 169 3,277
Human1 19,148 30,957 1,535 9 173 3,731
Final 22,282 29,107 1,475 8 174 3,704
1Ensembl release 56.
Nature Genetics: doi:10.1038/ng.2343
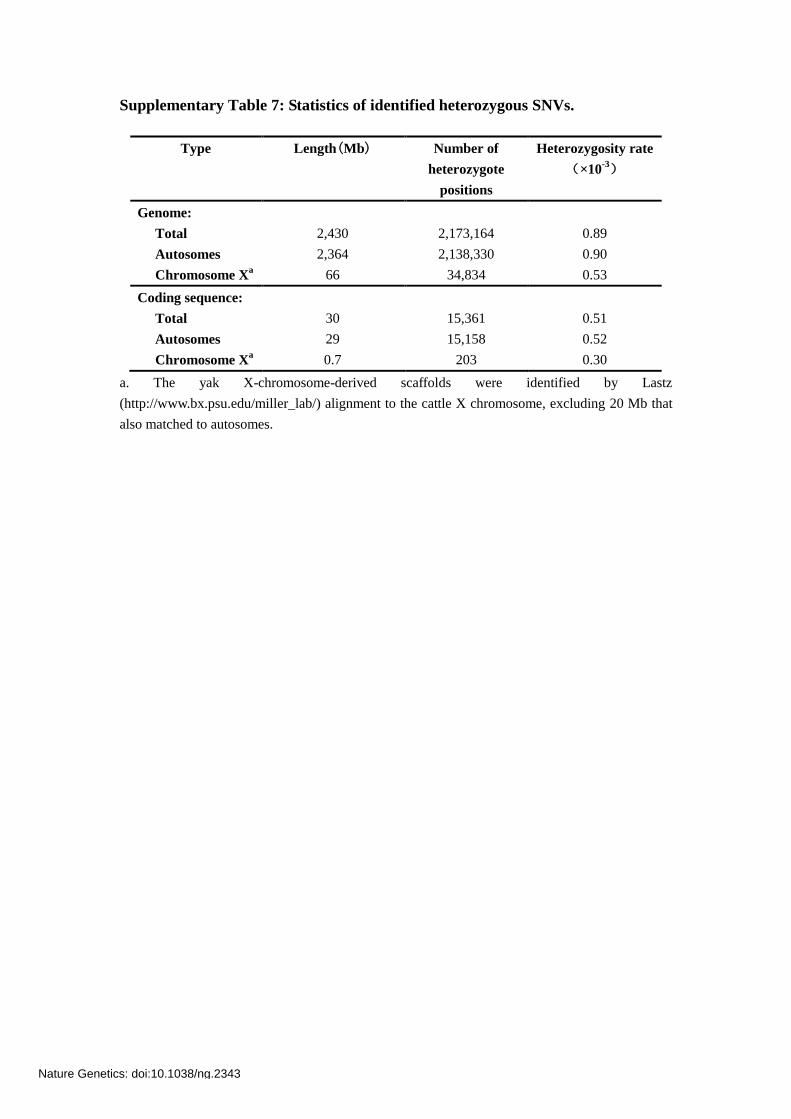
Supplementary Table 7: Statistics of identified heterozygous SNVs.
Type Length(Mb) Number of
heterozygote
positions
Heterozygosity rate
(×10-3)
Genome:
Total 2,430 2,173,164 0.89
Autosomes 2,364 2,138,330 0.90
Chromosome Xa 66 34,834 0.53
Coding sequence:
Total 30 15,361 0.51
Autosomes 29 15,158 0.52
Chromosome Xa 0.7 203 0.30
a. The yak X-chromosome-derived scaffolds were identified by Lastz
(http://www.bx.psu.edu/miller_lab/) alignment to the cattle X chromosome, excluding 20 Mb that
also matched to autosomes.
Nature Genetics: doi:10.1038/ng.2343

Supplementary Table 8: Heterozygous single nucleotide variants (SNVs) selected
for validation by Sanger sequencing.
Scaffold ID Coordinate Reference
Allele
Heterozygous
Allele
Forward Primer Reverse Primer SNV
Status
scaffold590_1 591292 C T CAGCTCTCTGGGACAAGACC GAAGACAGGGCAGTGAGGAG VALID
scaffold1596_1 75737 G A GAGCTCTGTCCCCTCACATC GGACCTGAACTTGGGTCTCA VALID
scaffold1617_1 8134 C G CTCCACAGGAAGGACTCAGC GGCCTTTCAGCTCTGTGAAC VALID
scaffold1537_2 1076924 C T CCTGCACTCTCCTCTGCTCT CTAGCTTCATCCCAACCCAA VALID
scaffold1954_1 70399 G C GTCCTCTGCTCACACTTCCC TTCTCCCAAAAGTGGTGGAC VALID
scaffold1745_1 443881 T G GTTCCAGTCTCTGGCTCTGC TTCTCAGGCATATCATCCCC VALID
scaffold4140_1 1001 A G GTGTGAGACTGGCAGACACG GGAGAGGCATATTTTGGGTG VALID
scaffold785_1 1837197 C T TAGTCACTCAGCCAGGTCCC GAGCCAAAATGGACCAAAGA VALID
scaffold1461_1 1374133 A G CCAGTGGACACACCAGTGAC CGCATTTTACATGATGGTTCA VALID
scaffold1638_1 1247612 G C TGGGGACTTGGACAAGTAGG GGGTACTAGGACCTCTGGGC VALID
scaffold679_1 192904 C G TGAGCAGAGCAAGTCACCAG GTGGCTGAGAGTGAAGAGGG VALID
scaffold2048_2 192734 A G AGGTATCATGGCCTCACTGG CCCATCTCTCTCAGTGGCTC VALID
scaffold1375_1 4321165 C G CAGGGTATTCTCCTCTGCCA GAGACCTCATCCAACAAGCC VALID
scaffold1681_1 216048 A G GGCAGTTTCTGCTTCTCCAC TGGTATCCCTGTTGGCTAGG VALID
scaffold797_1 1703618 C T AAGGGATGTGTGACAGGGTC AGTCCCTGCTGTCCTTCTGA VALID
scaffold864_1 2246281 T C ACTTTCCTGGTGGTCCAGTG TCCAGAGATGTCTTGGGGTC VALID
scaffold931_1 2265546 T C CGTACCATGCACTACGATGC GAGCATGGCTCTAAGTTGCC VALID
scaffold1282_1 1695921 C T CTCCTGCAAACTCAGAGCCT ATCTTCAGGCCTTCTCCCTC VALID
scaffold6_1 193969 C T GTGCTGCTTCTGAGGAGCTT GGCACTTCACAGGGCTTTAG VALID
scaffold2863_1 179629 C A TCTCAGGCCTGGTCTCTTGT CCAATGTCCTCCTTTTGTGG VALID
scaffold1556_1 91424 C T AGGATGCCCACACATCTAGG TCTGGCAGTTTTGGTAAGGC VALID
scaffold1731_1 725151 C T GCCAGTGTGTTACAGGGACA ATCCCCATGGGAGCAAGTAT VALID
scaffold1041_1 65426 T C GACCATTGTGGGTGCTACCT TTGCCTGATTCCCTGTCTTC VALID
scaffold1471_1 861439 A G TGGGCTAGAGGCAGTCTGAT CTCAGTGATAGCATTGCCGA VALID
scaffold511_1 28639 C G CACGTGACCAGCAGAACTGT CTGGATCCCTTTGTGGTTGT VALID
scaffold1176_1 765298 C T TGGCAGCTGTGTGTAAGCTC ACTCTGAAACTTGGCGCTGT VALID
scaffold1534_1 185891 A G GACTCGCTTACACAGCGACA CATGCTGTAAGCAGGGGAAT VALID
scaffold3621_1 37416 T C ACCTGGATACCACAGGGTCA ATGGGAGGGGAGAATGGATA VALID
scaffold1491_1 1196294 T C AGAGCTGAAGGTGTGGGCTA GCTCCACATGCTAATTGGGT VALID
scaffold2201_1 513634 C G GGACAAAAGGAGAAGAGGGC CGAACCAGAGGAAGGAAGAA VALID
scaffold2112_1 264661 T C ACCTTCCTCCTGCAGAGCTT AGCCTGCCCTCCATTAGTTT VALID
scaffold3396_1 53502 T C AAGGGGGTCATAGCTGTCCT GATTCACCAAGGAAGTGGGA VALID
scaffold557_1 1522242 C G TTTAGAGGTGGAGGACACCC AACTGGCAAGGCACTCTTACA VALID
scaffold2559_1 326858 T C TGTCTCCCCTGGGAATACTG AACTCTTTGCAACCCCATTG VALID
scaffold478_1 113708 T G ACTGAGGCCAGTCAATCACC TCACTTCTGCCCATTGAACA VALID
scaffold1823_1 52330 C G GTGGGTGGTGCTTATCAGGT AACAAAAACCCAAGACCGTG VALID
scaffold419_1 291259 C T GCACTGACCTCCTTGTGTCA TTAAAGGCTGTCGGCTGATT VALID
scaffold432_1 2057126 G A GTTAAGTGGCAGGGTCAGGA TGGGGACAGGTTTTCTTTGA VALID
Nature Genetics: doi:10.1038/ng.2343

scaffold2105_1 200646 T C GGCCTGTCCATCTGTGATCT TGTTTGAAGTGCACATCCGT VALID
scaffold188_2 501012 G A GCAGTGCTCCAACATGTCTC TTCCATTCACACATTCGCTC VALID
scaffold794_1 2074038 A T GTCTGTAGGGGCTGGGATTT TGTCTTCCATCCCATAATCCA VALID
scaffold290_1 588702 T C AGGTGAGGTTCTCCAAGGGT AGAGGGCAAAATTTGTTTGG VALID
scaffold182_1 287717 A T CAGGTCCCCCTTTAGACCAT AACCAGTGATTGAAAAATGCC VALID
scaffold323_1 100205 A T CATCAGTGGCAGATTTGGG TCCTAAGCCTGATTGCATGA VALID
scaffold1233_1 92533 A G TCCCAGAGTATGTTGGGTAGG CAGAACACATATGCCCACCA VALID
scaffold1199_1 601285 G C GTGGCAAACAGCATCTCTCA CCTCCCACTCTTCTGCTCTG VALID
scaffold1628_1 1082030 T C AGAATTCAGCCAAGGGAGGT GACCCAGAGCAGCCAGTAAG VALID
scaffold1052_1 283416 T C TAAAGCTGTTCCCACATGCC GCTTCCCTCCTTCAGGACTC VALID
scaffold104_1 613637 C T GGGGTAAATCCAGCATTCCT CTGGAAACTTGCTCTCCCAG VALID
scaffold2054_1 2132328 A G CGCAGCCAGAAACTGACTTA AAGACTTGGGTCACCACACC VALID
scaffold2612_1 31612 A G AGGTGGGACAATGAGGAATG GACGAGATACTGGCCATGCT VALID
scaffold313_1 2171938 A C GGGAGTGACCGAAATGCTAA ACAGTTCCTGCCCTCAGAGA VALID
scaffold1548_1 684630 T C GGACAACCCACTTTTGTGCT ATGTAGGAAGGGGCTAGGGA VALID
scaffold1180_1 3801833 T C GGGGCTCACACTTGTCATTT GGCTGTAATCCCTTGTGCTG VALID
scaffold172_1 877425 T C ACCCAGCCTATGCTCAAACA GGTGGACAGGCAAAAGTCTC VALID
scaffold923_1 1106969 C T AATGCTCCTAGAACCGGGAT TGCTGGGAGAAGACCTCTGT VALID
scaffold2127_1 268010 A G GAACTACGGGCAGCCAATTA CCAACCATCTCACCCTCTGT VALID
scaffold2954_1 57496 A G GGCAATCAAGACCATCAGGT TATCCTCAACACCCTAGCCG VALID
scaffold3551_1 420322 G A ATGGCAAACTAAGCAGCAGG TCTGCAGAAGACAGGTCACG VALID
scaffold484_1 761439 A C GTTCCCTGACCAAACCCTTT CTTAGCTTCTGGCTAGGGCA VALID
scaffold142_1 983810 A T CAACGGGAGGCCAATAGTTA CAAGATGCATCATCTCCCCT VALID
scaffold1483_1 472220 A T CTGATGCCGTGTTCTGCTAA TGTCTGCTCTCAGCTTTCCA VALID
scaffold3824_1 505719 A G GTGGTCCTTGCAAAACAGGT TCTTCTTTGGCTGTGGTTCC INVALID
scaffold1703_1 384635 A T GGTGTCCTTGCCACCTTAAA GTAACTTTCCGTGACCCGAA VALID
scaffold1222_1 372089 A G CCATCAGAATGCTGTGGATG CCATTGCTGTGGACTCAAGA VALID
scaffold2990_1 498983 G A TACCCTGGCGATCTTCAATC ATGTCCACATGGCTTTCCTC VALID
scaffold1959_1 148549 C A TGTCATTGCCTTCTCTGTGG GGCAAGGGATCTGCTACAAA VALID
scaffold1681_1 323958 A C TTGACTTTAAGACCCCACCG ACTATCAGGGAAGCCCCAAAAG VALID
scaffold36_1 166823 T C TGGGAAACTCTAAACCCTGG GCTCGCCATATCAAGGACAT INVALID
scaffold2747_1 306609 T C ATCCAATGTTGCTCGGAGAC GAACCTGTTCACTCCCCAAA VALID
scaffold1537_2 1215436 G A CACTGACTGCCAGGGAATTT GTCAAAGGCCAAGATGGTGT VALID
scaffold157_1 825855 T C TTATGGAGGCAGCCATTAGG AGCCACACATACATGCAGGA VALID
scaffold4084_1 94396 G T GATGCAGCCCCATCATAAGT GAAAATTCACCTTCGGGGAT VALID
scaffold849_1 227910 A G GAGTGAAACCCTTGTTCCCA TCCCCATCTATTTCCCATGA VALID
scaffold923_1 81574 G C CACCTGCTTTGGCAGTTCTT TTCCAATGTACCCATGTCCA VALID
scaffold2023_1 520664 A G TATAAATCCAGCAGCCAGGG TTGGGATTAGCTGCTTTTGG VALID
scaffold1180_1 2407773 T C ACAAAACCCAGCTCTCTGGA TATTTCTTTGGCTGCCTTGG VALID
scaffold556_1 908792 T G CATGTATCAATCCTGTGGCG CGGCAACCCTATGAATGAAT VALID
scaffold1073_1 2262005 T C TACTGCCCGTGTTTTGACTG TTGATGCCATGGTAGTGCAT VALID
scaffold550_1 729513 A G TAATCCAGCACCACCAGGAT TCCCCATCTATTTCCCATGA VALID
scaffold891_1 1412879 T C AGAAATGCTGGAGTTCGAGG TTCTTTGCTTCTGGCATCAG VALID
Nature Genetics: doi:10.1038/ng.2343
scaffold1427_1 5136 A G GGCATCTTCAGGCTCCAATA CTGCAAAGAGACTTGCCAAA VALID
scaffold1474_1 167669 C T GAGCAATTGTGAGTCCCCTT GAAAAACTTTGGCGTGCTTG VALID
scaffold3563_1 302316 A G TCACAATGGTCCACTTCCAG TGGTCCAAGAAAAAGGCACT VALID
scaffold2689_1 28974 C T GGGTTTTGCTGGTATCGTTC CACACTTCCCGCACAAATTA VALID
scaffold1654_1 18690 T C TCCACTGCAGAAGCTGAAGA TCCGGTTATTGATCCCATGT VALID
scaffold1420_1 49648 G T TTACGGAGCACTGCATTCTG AGGCAGCGCTTTAAAACATC VALID
scaffold461_1 1206057 G A GCCACCAGTTTCACACACAT TCTGGCTTTTGCATCATCTG VALID
scaffold1570_1 66754 G A GAAGCGCTGCTTATCTGTCA TGAGCACCACTTTTGCTGTT VALID
scaffold607_1 2831374 A G CTTCTGATGGGCTGCTGAAT CAAGGAATGTTTGCTTTAGAGAGA VALID
scaffold1623_1 400466 C T ACTCTAACATGGCCCCAAAG TAATCGCCCCAATCATTTTT VALID
scaffold946_1 49881 G C TGGCTCTTGTGAGTTTCCCT CAAAAGTCAATTTCAGGTTGATTG VALID
scaffold497_1 1957457 C A CCAAGTGCCTTTTCCCATAG GCAATTGAAAAATTCCTTTCCA VALID
scaffold185_1 533999 A T TGCCACAAAGCAGTCTCTTG GCAAATCCTGAGATGAAATT VALID
scaffold1214_1 1580050 A G CATCCAAAAGAACAGACAGGC TGCTAGTTTGTGAAGAGCAAGG VALID
scaffold530_1 1326298 C T TTTGTCTCCCTGACGTCTGTT CCCCCTTTAAAAACAAGGAAA VALID
scaffold512_1 1416325 T C TCAAACAGTACTTGCTTGCACC GTGCATGACCAATTGCATCT VALID
scaffold325_1 544006 T C CAAGACTCTGGACATCAAACCA TCAAACCAGAAAACTGCCAA VALID
scaffold1196_1 3479675 C G AGCCCCAAATAATGGAAAGG CCTCTTAACTCCTCTGGGGG VALID
scaffold229_1 1206197 C T TTCATAGGGTTTGGGCTCAT TTGGCTGTTACCACCTCTCC VALID
scaffold199_1 51621 A C CATTTCCATGGGGATGAAAG AGTCCAGCAGCCTCCAGATA VALID
scaffold2774_1 1791611 G A GCAAGCTGTGCTTTGCTTTT GAGATGAGTTTGAGCTGGGC VALID
scaffold1470_1 1815478 T C TATCATCACGTTGGGAAGCA CTGCACCATGGGTTATCAGA VALID
scaffold1091_1 110033 T C CCACCTTGTCAAAAAGCCAT CGATGGAGATGGAAAGCAGT VALID
scaffold294_1 372224 C T GGTTTCCGATCTGCATGAAT ACCTGCATGAACTGGTTGCT VALID
scaffold1093_1 697270 T C TCAGATGGGAATTGTCAGCA TGAGTTCAGAGTGGGGAACA VALID
scaffold1289_1 614554 A G AAATCCTTCCATGCCTTTCC CCTGGAGGAAGAAACATCCA VALID
scaffold1826_3 1215735 T G CAATTTGGTCATGGAAGCCT TGGTCCATCTGATGACAAGC VALID
scaffold995_1 475532 G A ATGCGGCTATTTGCAGTCTT TGTCTCATCACACAGGCACA VALID
scaffold218_1 681898 T C TGAGATTATGCTCCCTGCAA TCCATGAAAGCTAGGGCTGT VALID
scaffold309_1 2278472 C T CACTCGGTTTGCTTTTGACA AAGGCCTTTTAGAAGCCGAG INVALID
scaffold399_2 2587914 T C TCTGAGGTTTAATTTGCGGC GGCAAGTTGTGGTCCAGTTT VALID
scaffold1121_1 1920337 A G CGGTGGTCATTTCTCCATTT CCCTTTCAAACTCATGTGGG VALID
scaffold3775_1 111422 C T TCCATGACCCTCCTTTGATT TCCCATCTAAAGCATCCTGG VALID
scaffold1292_1 640175 A G TTGCATGGGTTGGTAGTTCA GGAAAACTTTCTGATGGCCC VALID
scaffold437_2 3486521 A G GACATGCGAAAAGAAGCACA TGGTGTAGCTGAAACATGGG VALID
scaffold1843_1 147005 A T TCGGTTCTCCCAAGTTTGAA TTGCCAAATAGCTTTCCCTG VALID
scaffold1568_1 356707 A T AAGCAACAATCCTTTGTGCC AAATGAAAGTCCATTCCCCC VALID
scaffold234_1 1910276 C T GTTTTGCAACATGTTCCCCT TTGCTGAAGCTACGAGAAAGTT VALID
scaffold495_1 31860 C G GCAAAGACACTGTGGCAAAT TTCTGTTACCAGGATTGCTT VALID
scaffold1913_1 880469 G A CAGTCCTTGATAACTGAGAAGCA GTCGGTTGCTCTGATCCAGT VALID
scaffold2059_1 1066281 A G GGTGGAGCAGAATAAAAACCA CCATCCTACCATGGTGATCC VALID
scaffold1438_1 316595 A G CTTTCCTGGTCATTCAACCAA TTCCAGCTATGTCATGCAGC VALID
scaffold1399_1 1687829 G A TGATTGGCCAAGTGATCTAAG TGTTTGCCCATGTGTCTTTT VALID
Nature Genetics: doi:10.1038/ng.2343

scaffold2383_1 273248 G A ATGTGCTCATGCACACACATA AATGGAAGAAATGACAAGCCA VALID
scaffold444_2 1007945 G C TCCTTATGATCATGGAAGACGA AGGAGTGAGCTGTCCCCTCT VALID
scaffold3594_1 99002 C A GCAACATGGTAGCATTCTTTTG CCTTACCTCTTTCATGAGCCT VALID
scaffold3637_1 10138 G T ACAACATTAAAAGCTGGAGGGA GTTTTGGGCTCACAAAATGG VALID
scaffold1018_1 1464590 A G AGCAGCAAAACAGGCAAAAT GAGGCTGGTCACATACCTTCA VALID
scaffold608_1 976369 A G AATGGAACCATGCACATCAT TATGCAGGCACACACCTTGT VALID
scaffold125_1 1017917 T C TTGCAGAATATTTAGCGGCA CCAAGACACCTGTGCAAGAA VALID
scaffold1497_1 8744 T C GATGGGCTTTTCATTTTCCA TCAATGTCAGCGTTTTCTGC INVALID
scaffold708_1 1178466 G C AGCACAATAATGTTCCATAGCTG AGCATGTAGTATGTGCAGGGTG VALID
scaffold1581_1 567856 C T TCATGAGAGGCTTTCAATATTCTG GGGCAGGGAGAAAGAGGTTA VALID
scaffold305_1 1904752 T C GGAAATTCAGAGAAATTTGCAG TGGTCTTTTGAAGTCACTGCT VALID
scaffold1093_1 927940 G C TCTTTTCCCCAAAAAGCAAAC AGGGAAGGGAAATCCAGAAAC VALID
scaffold879_1 42676 G C GGTGGAATTAGTTGATTAAAATGC TCAGCTCTTGCTTGGCAGTA VALID
scaffold2111_1 71406 G T TGATGAAACATTAAGAGAGGCTTT TGATGCAAGTTCAAGAACCG VALID
scaffold2134_1 149545 T C CTTTGATTGTTTTGCTTCTTG GCAAGTTAGGGCTGAAACAGA VALID
scaffold1677_1 301842 C T GCGTAGAGATGGGAGACTGC GACCCCTGTAATTGGAAGCA VALID
scaffold322_1 745287 T C CAGAGCCTGAGGAGTCAACC GGAAATTGGGGGTGATTTTT VALID
scaffold2004_1 282669 A C CCACCTCCAACCATGAGACT TCTCATCCTCTGTCATCCCC VALID
scaffold1111_1 379048 T A AAGAAGAGCCCCTGGAGAAG ATCAATTTCATTCCCCCACA VALID
scaffold423_1 1018019 C T TCCAATTTCTCCCTGAGGTG GCGCTCCTACTATCACCCTG VALID
scaffold345_1 1353757 C T CAGTTGTTCCAGGAGAAGCA TATTTGCCTTCGTCAGACCC VALID
scaffold1951_1 1107665 T G ACTGGTGAAGGTTCCGTTTG TGATCTCATCCCCTTTCACC VALID
scaffold137_1 738613 A T GAAGCACAGCTGGTTCAACA TGGGCATCATTCTTAGCCTC VALID
scaffold1305_1 43386 G A AAGCAGTGCAACACACAAGC GCGCCAGTATGTGAAACAGA VALID
scaffold5_1 561895 G A AAAGCCACAGAGAAGAGGCA GCGTCCTGTCCACTTTGTTT VALID
scaffold2475_1 34051 C A GCATAATGCATGCCAGAGTG CCATATCAATAATTTGGCCTCA VALID
Nature Genetics: doi:10.1038/ng.2343

Supplementary Table 9: Statistics of reconstructed ancestral homologous synteny blocks (aHSBs) and evolutionary breakpoint regions (ERBs).
Number of HSBs 2,558
Total length of HSBs in cattle 2.531 Gb (95%)
Total length of HSBs in yak 2.505 Gb (94%)
Number of reconstructed aHSBs 207
Number of aHSBs that correspond to complete cattle chromosomes1 1
Number of aHSBs without outgroup (human) matches2 24
Total length3 of aHSBs 2.505 Gb
Max. length3 of aHSBs 117 Mb
Min. length3 of aHSBs 150 kb
Median length3 of aHSBs 3.684 Mb
Max. number of yak scaffolds in aHSBs 107
Min. number of yak scaffolds in aHSBs 1
Number of primate or ruminant breakpoint regions 317
Number of cattle breakpoint regions 41
Number of yak scaffolds that have more than one HSB 70 (3%4)
Mapped to the same aHSB 33
Mapped to different aHSBs5 37
1The ruminant aHSB 118 corresponds to entire cattle chromosome BTA 20.
2 There were no mapped human genome fragments to these ruminant aHSBs.
3The length of each aHSB was computed by adding the lengths of all HSBs in yak that belong to
that aHSB. 4Percentage of the total number of aligned yak scaffolds (2475).
5One yak scaffold out of 37 was mapped to three different aHSBs. The remaining 36 yak scaffolds
were mapped to two different aHSBs.
Nature Genetics: doi:10.1038/ng.2343

Supplementary Table 10: Annotated domains of the yak lineage-specific gene families.
InterProScan ID Number Description
Sensory perception
IPR000725 14 Olfactory receptor
IPR001190 1 Speract/scavenger receptor
IPR004072 1 Vomeronasal receptor, type 1
Immunity and host defense
IPR013106 6 Immunoglobulin V-set
IPR007110 3 Immunoglobulin-like
IPR007775 1 Leukocyte-specific transcript 1, LST-1
IPR020329 1 Beta defensin 126
Oxidation-reduction
IPR001128 4 Cytochrome P450
IPR000889 2 Glutathione peroxidase
IPR002198 1 Short-chain dehydrogenase/reductase SDR
ATP binding
IPR001140 1 ABC transporter, transmembrane domain
IPR001404 1 Heat shock protein Hsp90
GTP binding
IPR002452 2 Alpha tubulin
IPR000038 1 Cell division/GTP binding protein
IPR001401 1 Dynamin, GTPase domain
IPR006689 1 ARF/SAR superfamily
Others
IPR007087 5 Zinc finger
IPR000232 3 Heat shock factor (HSF)-type, DNA-binding
IPR000509 3 Ribosomal
IPR002213 3 UDP-glucuronosyl/UDP-glucosyltransferase
IPR022423 2 Neurohypophysial hormone, conserved site
IPR000721 2 Retroviral nucleocapsid protein Gag
IPR020683 2 Ankyrin repeat-containing domain
IPR001254 1 Peptidase S1/S6, chymotrypsin/Hap
IPR002404 1 Insulin receptor substrate-1, PTB
IPR003590 1 Leucine-rich repeat, ribonuclease inhibitor subtype
IPR004000 1 Actin-like
IPR005024 1 Snf7
IPR006623 1 Testicular haploid expressed repeat
IPR007204 1 ARP2/3 complex, p21-Arc subunit
IPR008197 1 Whey acidic protein, 4-disulphide core
IPR009602 1 Protein of unknown function DUF1208
IPR015706 1 RNA-directed DNA polymerase (reverse transcriptase)
Nature Genetics: doi:10.1038/ng.2343

IPR020864 1 Membrane attack complex component/perforin (MACPF) domain
IPR021930 1 Heparan sulphate-N-deacetylase
IPR001452 1 Src homology-3 domain
IPR001849 1 Pleckstrin homology domain
Nature Genetics: doi:10.1038/ng.2343

Supplementary Table 11: GO enrichment analysis for expansions and
contractions of specific genes in the yak genome. For each GO subcategory, a 2 × 2
contingency table was constructed by recording the numbers of genes included or not
included in a category of ‘genome background’ genes and expanded or contracted
genes. Two-tailed χ2 tests were used to calculate statistical significance.
GO ID Description Taxonomy Number of
genes
P-value
Expansions
GO:0015171 amino acid transmembrane transporter activity MF 23 1.85E-09
GO:0042773 ATP synthesis coupled electron transport BP 5 1.56E-02
GO:0015986 ATP synthesis coupled proton transport BP 14 4.29E-03
GO:0006879 cellular iron ion homeostasis BP 31 2.20E-16
GO:0004129 cytochrome-c oxidase activity MF 12 2.52E-03
GO:0046080 dUTP metabolic process BP 14 2.97E-08
GO:0008199 ferric iron binding MF 31 2.20E-16
GO:0004364 glutathione transferase activity MF 6 1.98E-02
GO:0006546 glycine catabolic process BP 6 2.69E-03
GO:0007156 homophilic cell adhesion BP 21 3.85E-03
GO:0046933 hydrogen ion transporting ATP synthase
activity, rotational mechanism MF 6 3.42E-02
GO:0006826 iron ion transport BP 31 2.20E-16
GO:0015934 large ribosomal subunit CC 25 2.20E-16
GO:0006869 lipid transport BP 11 8.86E-04
GO:0042157 lipoprotein metabolic process BP 13 1.27E-03
GO:0004984 olfactory receptor activity MF 467 2.20E-16
GO:0004522 pancreatic ribonuclease activity MF 9 3.78E-04
GO:0003755 peptidyl-prolyl cis-trans isomerase activity MF 12 1.33E-04
GO:0016503 pheromone receptor activity MF 29 2.20E-16
GO:0006508 proteolysis BP 96 3.87E-02
GO:0046961 proton-transporting ATPase activity, rotational
mechanism MF 10 4.23E-04
GO:0050909 sensory perception of taste BP 17 7.64E-09
GO:0015935 small ribosomal subunit CC 8 5.13E-04
GO:0006352 transcription initiation BP 17 2.00E-05
GO:0016986 transcription initiation factor activity MF 17 5.48E-12
GO:0006414 translational elongation BP 11 1.38E-05
Contraction
GO:0042612 MHC class I protein complex CC 16 2.20E-16
GO:0019028 viral capsid CC 9 4.49E-09
GO:0005044 scavenger receptor activity MF 8 3.82E-04
GO:0005507 copper ion binding MF 5 2.90E-03
GO:0009607 response to biotic stimulus BP 5 2.13E-04
Nature Genetics: doi:10.1038/ng.2343

GO:0042613 MHC class II protein complex CC 5 4.96E-05
GO:0016032 viral reproduction BP 9 3.51E-08
GO:0008131 primary amine oxidase activity MF 5 2.49E-06
GO:0048038 quinone binding MF 5 3.14E-05
GO:0005254 chloride channel activity MF 9 1.78E-07
GO:0019882 antigen processing and presentation BP 21 2.20E-16
MF: molecular function; BP: biological process; CC: cellular component
Nature Genetics: doi:10.1038/ng.2343

Supplementary Table 12: Over-represented PFAM domains in the genome of yak.
Pfam domains were retrieved from seven mammals and examples where their
abundance differed between yak and all other mammals were identified by applying
Fisher’s Exact test (P < 0.05).
PfamID Description Yak Cattle Chimp Dog Horse Human Mouse P-value
PF00001 7 transmembrane receptor (rhodopsin family) 1558 1358 604 1007 1199 760 1421 2.20E-16
PF00078 Reverse transcriptase (RNA-dependent DNA polymerase) 98 47 1 1 213 2 3 4.29E-09
PF09072 Translation machinery associated TMA7 8 2 0 0 1 1 1 1.66E-04
PF04548 AIG1 family 24 13 7 7 10 7 9 2.75E-04
PF03372 Endonuclease/Exonuclease/phosphatase family 100 52 25 26 216 26 35 4.12E-04
PF01221 Dynein light chain type 1 12 6 4 3 3 4 5 6.27E-03
PF04588 Hypoxia induced protein conserved region 13 9 5 4 4 5 4 1.07E-02
PF00014 Kunitz/Bovine pancreatic trypsin inhibitor domain 33 26 17 16 18 20 20 1.47E-02
PF00252 Ribosomal protein 150 87 33 62 28 27 82 2.02E-02
PF00324 Amino acid permease 43 35 21 33 37 22 25 3.20E-02
PF02935 Cytochrome c oxidase subunit VIIc 6 4 2 2 0 1 2 3.23E-02
PF09006 Lung surfactant protein D coiled-coil trimerisation 5 3 1 1 1 1 1 3.46E-02
PF10630 Protein of unknown function (DUF2476) 6 0 2 1 0 5 4 4.25E-02
PF01597 Glycine cleavage H-protein 7 6 2 2 2 2 2 4.70E-02
PF00201 UDP-glucoronosyl and UDP-glucosyl transferase 27 18 13 17 13 21 21 4.88E-02
Nature Genetics: doi:10.1038/ng.2343
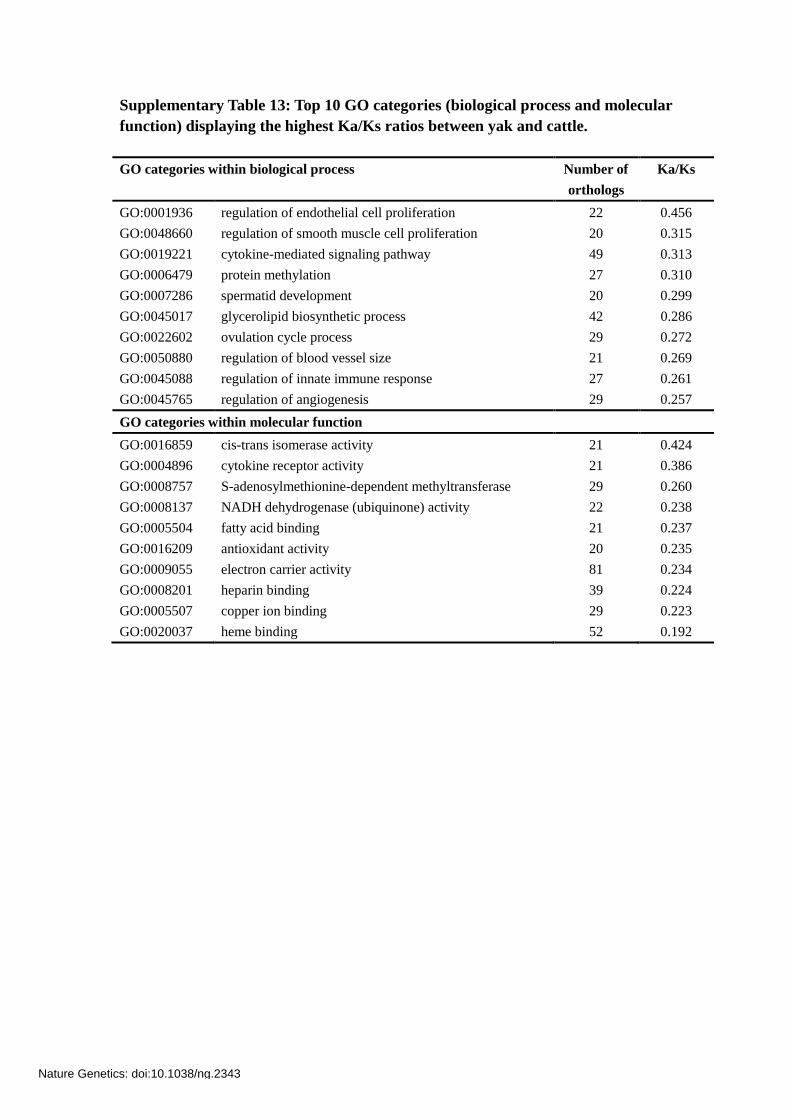
Supplementary Table 13: Top 10 GO categories (biological process and molecular
function) displaying the highest Ka/Ks ratios between yak and cattle.
GO categories within biological process Number of
orthologs
Ka/Ks
GO:0001936 regulation of endothelial cell proliferation 22 0.456
GO:0048660 regulation of smooth muscle cell proliferation 20 0.315
GO:0019221 cytokine-mediated signaling pathway 49 0.313
GO:0006479 protein methylation 27 0.310
GO:0007286 spermatid development 20 0.299
GO:0045017 glycerolipid biosynthetic process 42 0.286
GO:0022602 ovulation cycle process 29 0.272
GO:0050880 regulation of blood vessel size 21 0.269
GO:0045088 regulation of innate immune response 27 0.261
GO:0045765 regulation of angiogenesis 29 0.257
GO categories within molecular function
GO:0016859 cis-trans isomerase activity 21 0.424
GO:0004896 cytokine receptor activity 21 0.386
GO:0008757 S-adenosylmethionine-dependent methyltransferase 29 0.260
GO:0008137 NADH dehydrogenase (ubiquinone) activity 22 0.238
GO:0005504 fatty acid binding 21 0.237
GO:0016209 antioxidant activity 20 0.235
GO:0009055 electron carrier activity 81 0.234
GO:0008201 heparin binding 39 0.224
GO:0005507 copper ion binding 29 0.223
GO:0020037 heme binding 52 0.192
Nature Genetics: doi:10.1038/ng.2343

Supplementary Table 14: Positively selected genes identified in the yak and cattle
genomes.
Gene Symbol Gene description P-value
Yak
PPIP5K1 diphosphoinositol pentakisphosphate kinase 1 0.00E+00
ZNF202 zinc finger protein 202 0.00E+00
ZNF782 zinc finger protein 782 5.00E-09
ZNF215 zinc finger protein 215 6.50E-09
ZSCAN29 zinc finger and SCAN domain containing 29 5.80E-08
SRSF9 serine/arginine-rich splicing factor 9 1.56E-07
ATRN attractin 4.54E-06
ZNF436 zinc finger protein 436 2.27E-05
ADCY2 adenylate cyclase 2 (brain) 3.14E-05
IPO5 importin 5 7.73E-05
PCDHGA8 protocadherin gamma subfamily A, 8 1.42E-04
TEC tec protein tyrosine kinase 1.44E-04
NUDT9 nudix (nucleoside diphosphate linked moiety X)-type motif 9 1.65E-04
ZNF45 zinc finger protein 45 1.86E-04
PSMA7 proteasome (prosome, macropain) subunit, alpha type, 7 1.90E-04
C6orf146 chromosome 6 open reading frame 146 1.97E-04
KLRD1 killer cell lectin-like receptor subfamily D, member 1 2.75E-04
PIRT phosphoinositide-interacting regulator of transient receptor potential
channels 3.15E-04
ZNF619 zinc finger protein 619 3.87E-04
PHIP pleckstrin homology domain interacting protein 4.39E-04
CRTAM cytotoxic and regulatory T cell molecule 5.58E-04
EPHA1 EPH receptor A1 5.65E-04
TBC1D17 TBC1 domain family, member 17 5.79E-04
BECN1 beclin 1, autophagy related 5.92E-04
CAMK2B calcium/calmodulin-dependent protein kinase II beta 5.93E-04
NWD1 NACHT and WD repeat domain containing 1 6.67E-04
ADAM17 ADAM metallopeptidase domain 17 6.78E-04
ARHGAP20 Rho GTPase activating protein 20 7.39E-04
GCNT3 glucosaminyl (N-acetyl) transferase 3, mucin type 7.58E-04
C14orf109 chromosome 14 open reading frame 109 8.53E-04
CD300LF CD300 molecule-like family member f 8.72E-04
MAP3K4 mitogen-activated protein kinase kinase kinase 4 9.29E-04
TXNDC9 thioredoxin domain containing 9 1.09E-03
KIAA1328 KIAA1328 1.55E-03
ZKSCAN1 zinc finger with KRAB and SCAN domains 1 1.70E-03
TMCO7 transmembrane and coiled-coil domains 7 1.86E-03
SRD5A1 steroid-5-alpha-reductase, alpha polypeptide 1 (3-oxo-5 alpha-steroid delta
4-dehydrogenase alpha 1) 2.09E-03
Nature Genetics: doi:10.1038/ng.2343

MPP7 membrane protein, palmitoylated 7 (MAGUK p55 subfamily member 7) 2.42E-03
IL4R interleukin 4 receptor 2.65E-03
ADAM12 ADAM metallopeptidase domain 12 3.00E-03
MZT1 mitotic spindle organizing protein 1 3.10E-03
ATP1A2 ATPase, Na+/K+ transporting, alpha 2 polypeptide 3.12E-03
DNTT deoxynucleotidyltransferase, terminal 3.85E-03
KIR3DX1 killer cell immunoglobulin-like receptor, three domains, X1 4.50E-03
MAPK12 mitogen-activated protein kinase 12 5.18E-03
CABP1 calcium binding protein 1 5.36E-03
PAAF1 proteasomal ATPase-associated factor 1 5.84E-03
TUBAL3 tubulin, alpha-like 3 5.87E-03
BCO2 beta-carotene oxygenase 2 5.93E-03
SCOC short coiled-coil protein 6.31E-03
ILDR1 immunoglobulin-like domain containing receptor 1 6.39E-03
HPS3 Hermansky-Pudlak syndrome 3 6.48E-03
TOM1L2 target of myb1-like 2 (chicken) 6.72E-03
GABRG3 gamma-aminobutyric acid (GABA) A receptor, gamma 3 6.80E-03
RPS20 ribosomal protein S20 6.90E-03
MMP3 matrix metallopeptidase 3 (stromelysin 1, progelatinase) 7.76E-03
NPC1L1 NPC1 (Niemann-Pick disease, type C1, gene)-like 1 8.59E-03
C3orf16 chromosome 3 open reading frame 16 8.85E-03
GLUL glutamate-ammonia ligase 1.05E-02
ZNF696 zinc finger protein 696 1.09E-02
HIPK4 homeodomain interacting protein kinase 4 1.23E-02
PUF60 poly-U binding splicing factor 60KDa 1.27E-02
WHSC1 Wolf-Hirschhorn syndrome candidate 1 1.34E-02
C8orf34 chromosome 8 open reading frame 34 1.40E-02
HLA-DQB1 major histocompatibility complex, class II, DQ beta 1 1.44E-02
ADAMTSL4 ADAMTS-like 4 1.47E-02
HSD17B12 hydroxysteroid (17-beta) dehydrogenase 12 1.58E-02
C16orf5 chromosome 16 open reading frame 5 1.58E-02
GIF gastric intrinsic factor (vitamin B synthesis) 1.58E-02
PITPNB phosphatidylinositol transfer protein, beta 2.05E-02
SART3 squamous cell carcinoma antigen recognized by T cells 3 2.30E-02
ARG2 arginase, type II 2.42E-02
ANKRD1 ankyrin repeat domain 1 (cardiac muscle) 2.47E-02
ENSP00000358766 none 2.69E-02
TMC5 transmembrane channel-like 5 2.84E-02
HAS2 hyaluronan synthase 2 2.90E-02
SIRT5 sirtuin 5 3.00E-02
EFHB EF-hand domain family, member B 3.05E-02
NHEJ1 nonhomologous end-joining factor 1 3.22E-02
ZFP90 zinc finger protein 90 homolog (mouse) 3.22E-02
TMCC3 transmembrane and coiled-coil domain family 3 3.96E-02
Nature Genetics: doi:10.1038/ng.2343

RAD9B RAD9 homolog B (S. pombe) 4.33E-02
CBR1 carbonyl reductase 1 4.64E-02
PEF1 penta-EF-hand domain containing 1 4.66E-02
CEACAM1 carcinoembryonic antigen-related cell adhesion molecule 1 (biliary
glycoprotein) 4.85E-02
Cattle
PDE6A phosphodiesterase 6A, cGMP-specific, rod, alpha 0.00E+00
MTMR7 myotubularin related protein 7 0.00E+00
BIN2 bridging integrator 2 0.00E+00
LTBP1 latent transforming growth factor beta binding protein 1 0.00E+00
TP53BP2 tumor protein p53 binding protein, 2 0.00E+00
MMP27 matrix metallopeptidase 27 0.00E+00
GNAS GNAS complex locus 0.00E+00
ATRN attractin 0.00E+00
ATR ataxia telangiectasia and Rad3 related 3.00E-08
STOML3 stomatin (EPB72)-like 3 4.15E-08
GFPT1 glutamine--fructose-6-phosphate transaminase 1 1.19E-07
SLC4A10 solute carrier family 4, sodium bicarbonate transporter, member 10 2.14E-07
PDS5A PDS5, regulator of cohesion maintenance, homolog A 2.32E-07
ATP8A1 ATPase, aminophospholipid transporter (APLT), class I, type 8A 2.74E-07
FSTL4 follistatin-like 4 4.80E-07
ATF2 activating transcription factor 2 5.51E-06
GSTM3 glutathione S-transferase mu 3 (brain) 1.07E-05
ITIH3 inter-alpha (globulin) inhibitor H3 1.37E-05
GABARAPL1 GABA(A) receptor-associated protein like 1 1.85E-05
CNDP2 CNDP dipeptidase 2 5.11E-05
LYPD6 LY6/PLAUR domain containing 6 5.78E-05
DAPK2 death-associated protein kinase 2 9.13E-05
SDK2 sidekick homolog 2 (chicken) 1.35E-04
TBC1D17 TBC1 domain family, member 17 1.64E-04
TPST2 tyrosylprotein sulfotransferase 2 1.90E-04
CROT carnitine O-octanoyltransferase 2.31E-04
RNASEH1 ribonuclease H1 2.33E-04
FAM151A family with sequence similarity 151, member A 2.41E-04
CDC14A CDC14 cell division cycle 14 homolog A 2.67E-04
CA13 carbonic anhydrase XIII 3.05E-04
GSK3B glycogen synthase kinase 3 beta 3.12E-04
INTS6 integrator complex subunit 6 3.41E-04
DSC2 desmocollin 2 3.58E-04
PRLHR prolactin releasing hormone receptor 3.61E-04
SH3GLB1 SH3-domain GRB2-like endophilin B1 4.37E-04
LSM12 LSM12 homolog (S. cerevisiae) 4.64E-04
ANG angiogenin, ribonuclease, RNase A family, 5 4.99E-04
PSMB8 proteasome (prosome, macropain) subunit, beta type, 8 5.36E-04
Nature Genetics: doi:10.1038/ng.2343
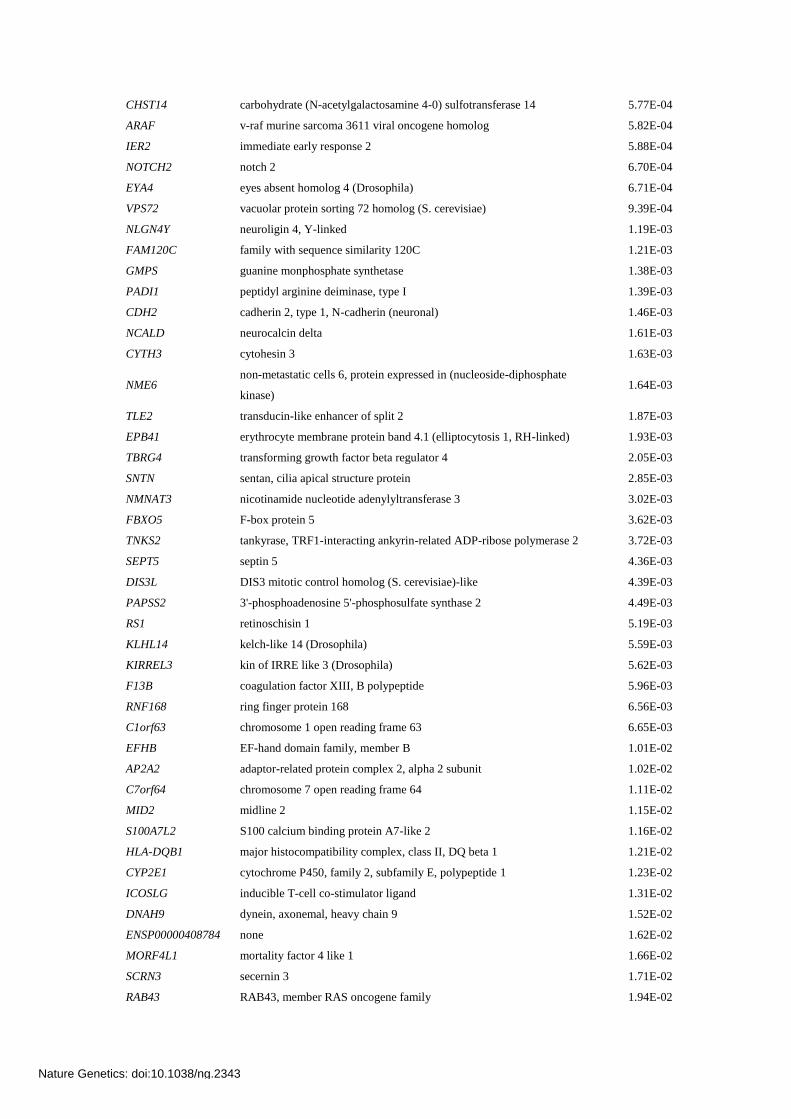
CHST14 carbohydrate (N-acetylgalactosamine 4-0) sulfotransferase 14 5.77E-04
ARAF v-raf murine sarcoma 3611 viral oncogene homolog 5.82E-04
IER2 immediate early response 2 5.88E-04
NOTCH2 notch 2 6.70E-04
EYA4 eyes absent homolog 4 (Drosophila) 6.71E-04
VPS72 vacuolar protein sorting 72 homolog (S. cerevisiae) 9.39E-04
NLGN4Y neuroligin 4, Y-linked 1.19E-03
FAM120C family with sequence similarity 120C 1.21E-03
GMPS guanine monphosphate synthetase 1.38E-03
PADI1 peptidyl arginine deiminase, type I 1.39E-03
CDH2 cadherin 2, type 1, N-cadherin (neuronal) 1.46E-03
NCALD neurocalcin delta 1.61E-03
CYTH3 cytohesin 3 1.63E-03
NME6 non-metastatic cells 6, protein expressed in (nucleoside-diphosphate
kinase) 1.64E-03
TLE2 transducin-like enhancer of split 2 1.87E-03
EPB41 erythrocyte membrane protein band 4.1 (elliptocytosis 1, RH-linked) 1.93E-03
TBRG4 transforming growth factor beta regulator 4 2.05E-03
SNTN sentan, cilia apical structure protein 2.85E-03
NMNAT3 nicotinamide nucleotide adenylyltransferase 3 3.02E-03
FBXO5 F-box protein 5 3.62E-03
TNKS2 tankyrase, TRF1-interacting ankyrin-related ADP-ribose polymerase 2 3.72E-03
SEPT5 septin 5 4.36E-03
DIS3L DIS3 mitotic control homolog (S. cerevisiae)-like 4.39E-03
PAPSS2 3'-phosphoadenosine 5'-phosphosulfate synthase 2 4.49E-03
RS1 retinoschisin 1 5.19E-03
KLHL14 kelch-like 14 (Drosophila) 5.59E-03
KIRREL3 kin of IRRE like 3 (Drosophila) 5.62E-03
F13B coagulation factor XIII, B polypeptide 5.96E-03
RNF168 ring finger protein 168 6.56E-03
C1orf63 chromosome 1 open reading frame 63 6.65E-03
EFHB EF-hand domain family, member B 1.01E-02
AP2A2 adaptor-related protein complex 2, alpha 2 subunit 1.02E-02
C7orf64 chromosome 7 open reading frame 64 1.11E-02
MID2 midline 2 1.15E-02
S100A7L2 S100 calcium binding protein A7-like 2 1.16E-02
HLA-DQB1 major histocompatibility complex, class II, DQ beta 1 1.21E-02
CYP2E1 cytochrome P450, family 2, subfamily E, polypeptide 1 1.23E-02
ICOSLG inducible T-cell co-stimulator ligand 1.31E-02
DNAH9 dynein, axonemal, heavy chain 9 1.52E-02
ENSP00000408784 none 1.62E-02
MORF4L1 mortality factor 4 like 1 1.66E-02
SCRN3 secernin 3 1.71E-02
RAB43 RAB43, member RAS oncogene family 1.94E-02
Nature Genetics: doi:10.1038/ng.2343

NSUN6 NOP2/Sun domain family, member 6 2.03E-02
KDM4C lysine (K)-specific demethylase 4C 2.12E-02
PKD2L1 polycystic kidney disease 2-like 1 2.26E-02
CBR1 carbonyl reductase 1 2.32E-02
FAM118A family with sequence similarity 118, member A 2.53E-02
AC110814.1 Neuron-specific protein family member 1 2.55E-02
ENSP00000396640 none 2.71E-02
PGLYRP1 peptidoglycan recognition protein 1 2.73E-02
GZMA granzyme A 2.95E-02
PLUNC palate, lung and nasal epithelium associated 3.10E-02
REEP1 receptor accessory protein 1 3.59E-02
AC008021.1 Uncharacterized protein DKFZp781G0119 3.92E-02
CLN3 ceroid-lipofuscinosis, neuronal 3 4.33E-02
ECT2L epithelial cell transforming sequence 2 oncogene-like 4.90E-02
Nature Genetics: doi:10.1038/ng.2343

Supplementary Table 15: GO categories over-represented among genes predicted
to be under positive selection in yak (P-values from Fisher’s Exact test).
GO categories Description Taxonomy Gene number P-value
All PSGs
GO:0004222 metalloendopeptidase activity MF 39 4 4.89E-04
GO:0032496 response to lipopolysaccharide BP 51 3 1.25E-02
GO:0000082 G1/S transition of mitotic cell cycle BP 21 2 1.68E-02
GO:0004674 protein serine/threonine kinase activity MF 224 6 1.98E-02
GO:0002699 positive regulation of immune effector process BP 23 2 1.99E-02
GO:0001101 response to acid BP 23 2 1.99E-02
GO:0009064 glutamine family amino acid metabolic process BP 27 2 2.70E-02
GO:0042113 B cell activation BP 27 2 2.70E-02
GO:0014075 response to amine stimulus BP 29 2 3.08E-02
GO:0017124 SH3 domain binding MF 30 2 3.28E-02
GO:0030198 extracellular matrix organization BP 33 2 3.91E-02
GO:0001666 response to hypoxia BP 81 3 4.19E-02
GO:0030098 lymphocyte differentiation BP 35 2 4.36E-02
GO:0000502 proteasome complex CC 36 2 4.58E-02
MF: molecular function; BP: biological process; CC: cellular component
Nature Genetics: doi:10.1038/ng.2343
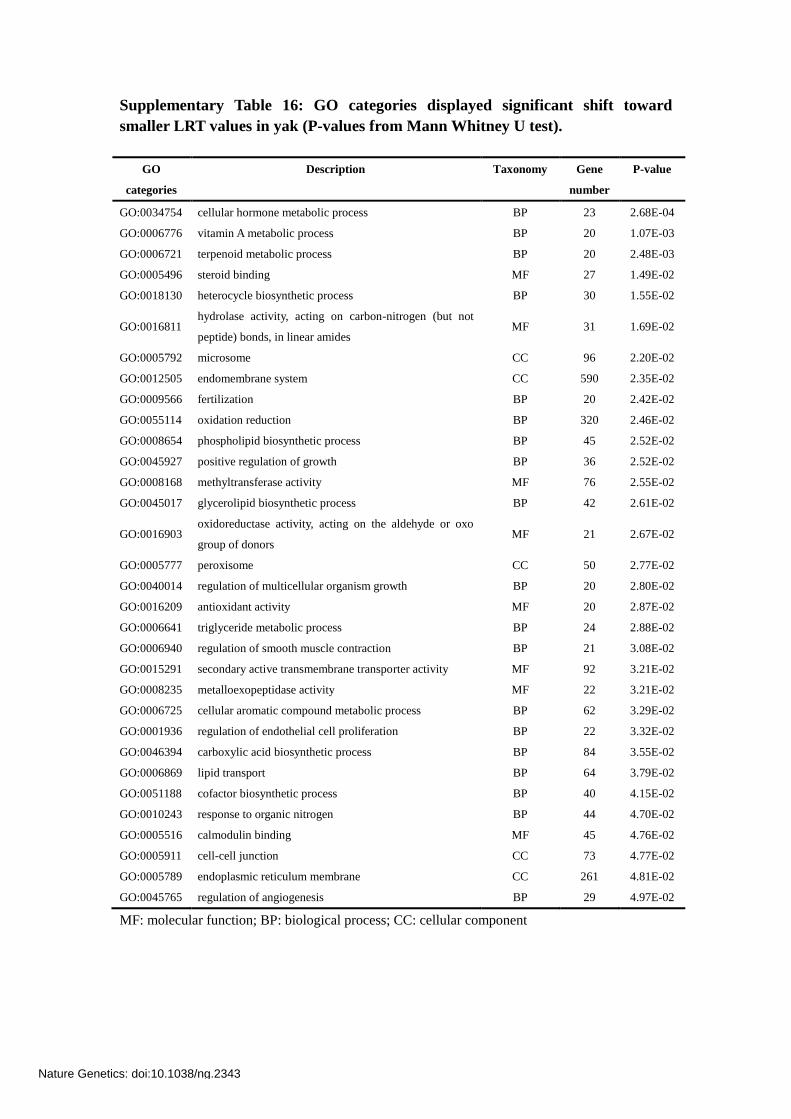
Supplementary Table 16: GO categories displayed significant shift toward
smaller LRT values in yak (P-values from Mann Whitney U test).
GO
categories
Description Taxonomy Gene
number
P-value
GO:0034754 cellular hormone metabolic process BP 23 2.68E-04
GO:0006776 vitamin A metabolic process BP 20 1.07E-03
GO:0006721 terpenoid metabolic process BP 20 2.48E-03
GO:0005496 steroid binding MF 27 1.49E-02
GO:0018130 heterocycle biosynthetic process BP 30 1.55E-02
GO:0016811 hydrolase activity, acting on carbon-nitrogen (but not
peptide) bonds, in linear amides MF 31 1.69E-02
GO:0005792 microsome CC 96 2.20E-02
GO:0012505 endomembrane system CC 590 2.35E-02
GO:0009566 fertilization BP 20 2.42E-02
GO:0055114 oxidation reduction BP 320 2.46E-02
GO:0008654 phospholipid biosynthetic process BP 45 2.52E-02
GO:0045927 positive regulation of growth BP 36 2.52E-02
GO:0008168 methyltransferase activity MF 76 2.55E-02
GO:0045017 glycerolipid biosynthetic process BP 42 2.61E-02
GO:0016903 oxidoreductase activity, acting on the aldehyde or oxo
group of donors MF 21 2.67E-02
GO:0005777 peroxisome CC 50 2.77E-02
GO:0040014 regulation of multicellular organism growth BP 20 2.80E-02
GO:0016209 antioxidant activity MF 20 2.87E-02
GO:0006641 triglyceride metabolic process BP 24 2.88E-02
GO:0006940 regulation of smooth muscle contraction BP 21 3.08E-02
GO:0015291 secondary active transmembrane transporter activity MF 92 3.21E-02
GO:0008235 metalloexopeptidase activity MF 22 3.21E-02
GO:0006725 cellular aromatic compound metabolic process BP 62 3.29E-02
GO:0001936 regulation of endothelial cell proliferation BP 22 3.32E-02
GO:0046394 carboxylic acid biosynthetic process BP 84 3.55E-02
GO:0006869 lipid transport BP 64 3.79E-02
GO:0051188 cofactor biosynthetic process BP 40 4.15E-02
GO:0010243 response to organic nitrogen BP 44 4.70E-02
GO:0005516 calmodulin binding MF 45 4.76E-02
GO:0005911 cell-cell junction CC 73 4.77E-02
GO:0005789 endoplasmic reticulum membrane CC 261 4.81E-02
GO:0045765 regulation of angiogenesis BP 29 4.97E-02
MF: molecular function; BP: biological process; CC: cellular component
Nature Genetics: doi:10.1038/ng.2343

Supplementary Table 17: Identification of lineage-specific accelerated GO
categories (provided in a separate file).
Nature Genetics: doi:10.1038/ng.2343

Supplementary Note
Sequence strategy and data output
We used a whole genome shotgun strategy and the Illumina HiSeq 2000 to
sequence the yak genome. Library preparation and sequencing followed the
manufacturer's instructions. Sequence reads were collected from the output of the
Illumina data processing pipeline using default parameters. To decrease the risk of
non-randomness and optimize the de novo assembly quality, 30 paired-end sequencing
libraries were constructed with various insert sizes (200 bp to 20 kb). In total, we
generated about 356.63 Gb sequence.
Quality checking and read filtering
The raw reads generated from the Illumina-Pipeline included artificial reads, which
were caused by base-calling duplicates and adapter contamination. In order to
facilitate the assembling works, we have undertaken a series of checking and filtering
measures. Low quality reads were filtered and potential sequencing errors were
removed or corrected by the k-mer frequency based methodology1. We filtered the
following type of reads:
(1) Reads with ≥10% unidentified nucleotides.
(2) Reads from short insert-size libraries having more than 65% bases with Q20 ≤
7, and reads from large insert-size libraries that contained more than 80% bases with
Q20 ≤7.
(3) Reads with more than 10 bp aligned to the adapter sequence, allowing ≤2 bp
Nature Genetics: doi:10.1038/ng.2343

mismatches.
(4) Small insert size paired-end reads that overlapped ≥ 10 bp with the
corresponding paired end.
(5) Read1 and read2 of two paired-end reads that were completely identical, (and
thus considered to be the products of PCR duplication).
(6) Reads having a k-mer frequency <4 (to minimize the influence of sequencing
errors).
After these quality control and filtering steps, a total of 212.77 Gb data were
retained for assembly.
Genome assembly
The yak genome was assembled by SOAP de novo software1
(http://soap.genomics.org.cn), which employs the de Bruijn graph algorithm in order
to simplify the assembly and reduce computational complexity. SOAP de novo mainly
follows three steps:
(1) To construct contigs, SOAP de novo firstly constructed the de Bruijn graph by
splitting the reads from short insert size libraries (200 bp - 800 bp) into 31-mers (30
bp overlaps with 1 bp overhangs) and merging the 31-mers, then clipping tips,
merging bubbles and removing low coverage links. After that, contig sequences
without unambiguous connections in de Bruijn graphs were collected. The total contig
size and N50 were 2.54 Gb and 20.4 kb, respectively.
Nature Genetics: doi:10.1038/ng.2343

(2) To construct scaffolds, usable reads were realigned onto the contig sequences.
Subsequently, paired-end information was used to construct scaffolds by linking
contigs. We calculated the amount of shared paired-end relationships between each
pair of contigs, weighted the rate of consistent and conflicting paired-ends, and
constructed the scaffolds step by step, from short insert-sized paired ends to long
paired ends. At least 3 supporting read pairs from libraries of short insert size (200 to
800 bp) or at least 5 supporting read pairs from libraries of long insert size (2 to 20 kb)
were required to link two contig/scaffold together. The total scaffold size and N50
were 2.66 Gb and 1.4 Mb, respectively.
(3) To close the gaps inside the constructed scaffolds, which were mainly composed
of repeat sequences that were masked before the scaffold construction, we used the
paired-end information to retrieve read pairs with one end uniquely aligned to a contig
and the other end in the gap region, and then performed a local assembly for these
collected reads.
GC content assessment
GC content is known to be an unavoidable bias in NGS library amplification, and it
is positively correlated with the sequencing depth1,21
. Using 500-bp non-overlapping
sliding windows along the yak genome, we found that both very low and very high
GC regions had a relatively lower sequencing depth. However, the distribution of GC
content across the yak genome was normally distributed, with an average GC content
of 41.7%, being comparable with the genome sequence data for cattle (41.8%)
Nature Genetics: doi:10.1038/ng.2343

(Supplementary Fig. 3a). In addition, all regions with GC content between 15% and
70% had more than 10× coverage, which is sufficient for de novo assembly
(Supplementary Fig. 3b). Finally, we calculated the fraction of yak and cattle
genome with extreme GC content (lower than 20% or higher than 80%) and found
that only a small fraction of the yak (0.011%) and cattle (0.019%) genome displayed
an extreme GC content (Supplementary Fig. 3a). Assuming similar GC content in
the two genomes, only 0.2 Mb sequence with extreme GC content may have missed in
the yak genome.
This bias could further lead to under-represent the promoter regions of genes in our
assembly. To evaluate how this affects our assembly, we also calculated the number of
yak genes in our assembly with gaps at 5’ flanking regions. Only 599 genes,
representing less than 2.7% of the entire gene set, contain gaps in their 1kb upstream
regions. This small under-representation of high GC regions in the beginning of genes
regions seems to have little impact on our further analyses based on the open reading
frames.
Nature Genetics: doi:10.1038/ng.2343

Supplementary References
1. Li, R. et al. The sequence and de novo assembly of the giant panda genome.
Nature 463, 311-317 (2010).
2. Kim, E. B. et al. Genome sequencing reveals insights into physiology and
longevity of the naked mole rat. Nature 479, 223-227 (2011).
3. Yan, G. et al. Genome sequencing and comparison of two nonhuman primate
animal models, the cynomolgus and Chinese rhesus macaques. Nature
Biotechnology 29, 1019-1023 (2011).
4. Xu, X. et al. The genomic sequence of the Chinese hamster ovary (CHO)-K1 cell
line. Nature Biotechnology 29, 735-741 (2011).
5. Renfree, M. B. et al. Genome sequence of an Australian kangaroo, Macropus
eugenii, provides insight into the evolution of mammalian reproduction and
development. Genome Biol 12(8), R81 (2011).
6. Star, B. et al. The genome sequence of Atlantic cod reveals a unique immune
system. Nature 477, 207-210 (2011).
7. Young, N. D. et al. Whole-genome sequence of Schistosoma haematobium. Nat
Genet 44, 221-225 (2012).
8. Zhan, S. et al. The monarch butterfly genome yields insights into long-distance
migration. Cell 147, 1171-1185 (2011).
9. Bonasio, R. et al. Genomic comparison of the ants Camponotus floridanus and
Harpegnathos saltator. Science 329, 1068-1071(2010).
10. Smith, C. D. et al. Draft genome of the globally widespread and invasive
Argentine ant (Linepithema humile). Proc Natl Acad Sci U S A 108, 5673-5678
(2011).
11. Smith, C. R. et al. Draft genome of the red harvester ant Pogonomyrmex barbatus.
Proc Natl Acad Sci U S A 108, 5667-5672 (2011).
12. Wurm, Y. et al. The genome of the fire ant Solenopsis invicta. Proc Natl Acad Sci
U S A 108, 5679-5684 (2011).
13. Copenhaver, G. et al. The Genome Sequence of the Leaf-Cutter Ant Atta
cephalotes Reveals Insights into Its Obligate Symbiotic Lifestyle. PLoS Genet 7,
e1002007 (2011).
14. Nygaard, S. et al. The genome of the leaf-cutting ant Acromyrmex echinatior
suggests key adaptations to advanced social life and fungus farming. Genome Res
21, 1339-1348 (2011).
15. Perry, G. H. et al. A Genome Sequence Resource for the Aye-Aye (Daubentonia
madagascariensis), a Nocturnal Lemur from Madagascar. Genome Biol Evol 4,
126-135 (2012).
16. Chapman, J. A. et al. The dynamic genome of Hydra. Nature 464, 592-596
(2010).
17. Shinzato, C. et al. Using the Acropora digitifera genome to understand coral
responses to environmental change. Nature 476, 320-323 (2011).
18. Todd, A. C. et al. Sequencing the genome of the Burmese python (Python molurus
bivittatus) as a model for studying extreme adaptations in snakes. Genome
Nature Genetics: doi:10.1038/ng.2343

Biology 12, 406 (2011).
19. Dalloul, R. A. et al. Multi-platform next-generation sequencing of the domestic
turkey (Meleagris gallopavo): genome assembly and analysis. PLoS Biol 8
(2010).
20. Elizabeth, P. M. et al. Genome Sequencing and Analysis of the Tasmanian Devil
and Its Transmissible Cancer. Cell 148, 780-791 (2012).
21. Bentley, D. R. et al. Accurate whole human genome sequencing using reversible
terminator chemistry. Nature 456, 53–59 (2008).
Nature Genetics: doi:10.1038/ng.2343