story compression joseph w. barker dr. james w. davis
TRANSCRIPT

Story Compression
Joseph W. Barker
Dr. James W. Davis

Dataset: National News Video
• Recordings of 3 national news programs on January 9th, 2013– ABC World News with Diane Sawyer
(WSYX 6)– CBS Evening News with Scott Pelley
(WBNS 10)– NBC Nightly News with Brian
Williams (WCMH 4)
• 4 stories common across all 3 broadcasts
• 7 stories common across 2 broadcasts
Name ABC CBS NBCBASEBALLHOF X X XFERRYCRASH X X XFLU X X XTREASSEC X X XARMSTRONGDOPING X XAURORA X XAUSFIRES X X
BINGEDRINKING X X
GUNCONTROL X X
HILARY X XMONOPOLY X XAIGSUE XASTEROID XCANCERTEST XCSCAM XHOSTAGE XLABALION XOLYMPIAN XPOLICEPOWERS X
SANDYCHARITY XSPORTSINTERV XTMOBILEBULLPEN X

Common Stories
• Content overlap– General covered across all (or several) broadcasts– Specific covered in only one broadcast
• Information Gathering– Waste time if all broadcasts viewed (general content →
redundancy)– Miss information if only one broadcast viewed
• Story Compression– Detect general vs. specific content and create single story
from all broadcasts with no redundancy

Story Compression
• Divide story into content segments (i.e., single idea)– Video shot (continuous scene) detection
• Compare segments– Speech/text contains most of the informational content– Word similarity → Segment Similarity
• Detect specific vs. general segments• Create combined sequence– Select (single) representative for each topic covered by
general segments– Insert all specific segments

Story Compression
General Content Specific Content
• For example:ABC
CBS
NBC

Story Compression
General Content Specific Content
Compressed (General + Specific):
• For example:ABC
CBS
NBC

Comparing Content Segments
• How to determine general vs. specific content?• Speech/text similarity– Contains most of the informational content in a broadcast– Inexact due to phrasing, speech-to-text errors, etc.
• Video comparison– Good positive results– Many false negatives
• E.g., different hosts talking about same topic
• Focus on speech/text and incorporate video later
ABC NBCCBS
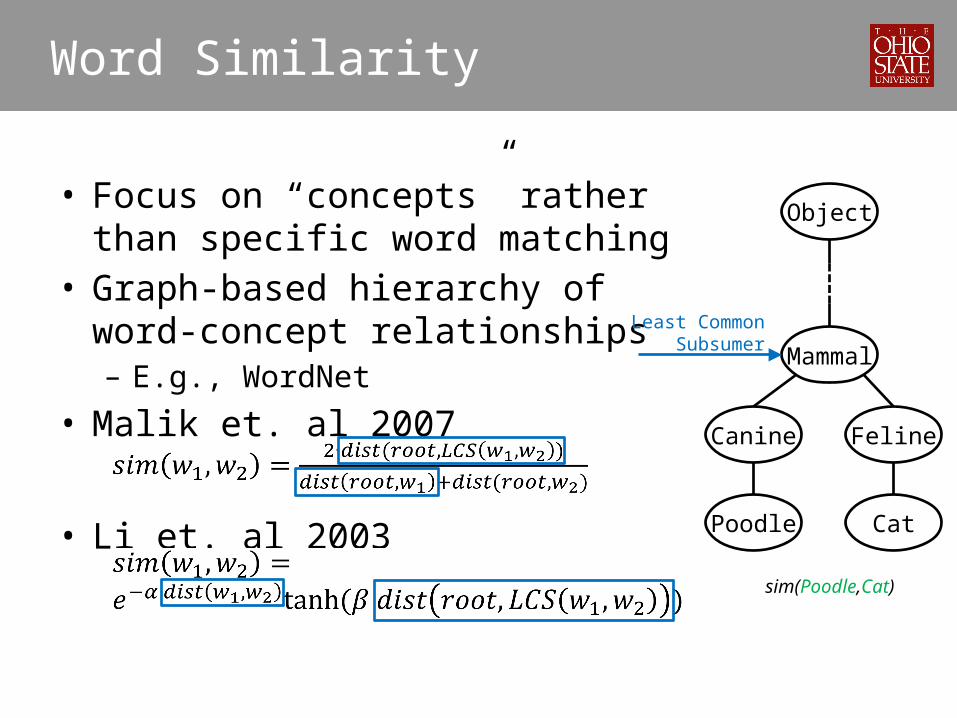
• Focus on “concepts” rather than specific word matching
• Graph-based hierarchy of word-concept relationships– E.g., WordNet
• Malik et. al 2007
• Li et. al 2003
Word Similarity
Feline
Mammal
Canine
Poodle
Object
Cat
sim(Poodle,Cat)
Least Common Subsumer

Word Similarity
ABC CBS NBC
ABC
CBS
NBC
Li similarityStory: FLU
Wor
ds

Segment Similarity
• Given (temporal) segment → Ordered list of words– Goal: Determine which segments are unique and which are
related/similar– Segments range from sub-sentence to multiple sentences– How to compare segments using multiple words’ similarity?
• Sentence similarity?– Li and Malik both suggest measures for sentence similarity– Provided speech-to-text does not offer strong sentence
boundaries• Word gap length (as boundary) tested, but not reliable
– Treat segment as one “sentence” ?• Measures emphasize grammar/word order• Does not make sense to mix multiple sentences together (sentence order
unimportant)
– Even given sentences, doesn’t solve problem• How to compare segments using multiple words’ sentences’ similarity?

Segment Similarity
• N-grams?– How to compare segments using multiple words’ N-grams’
similarity?
• Bag-of-words?– Solves ordering problem by ignoring it (context insensitive)– Plethora of measures for comparison– But also assumes each word type independent– i.e., common methods ignore similarity between different
words with similar concepts (e.g., Chi-squared,…)
• Graph Collapsing– Also ignores ordering– Utilizes similarity between different words– Similarity value between segments is direct result (no extra
measures needed)

Graph Collapsing
• Consider word similarity matrix in graph form• Random walks on graphs– From current vertex, step to new vertex with probability
proportional to the weight connecting them
• Random walk from a vertex tends to concentrate on “similar” vertices
• Random walks between groups?
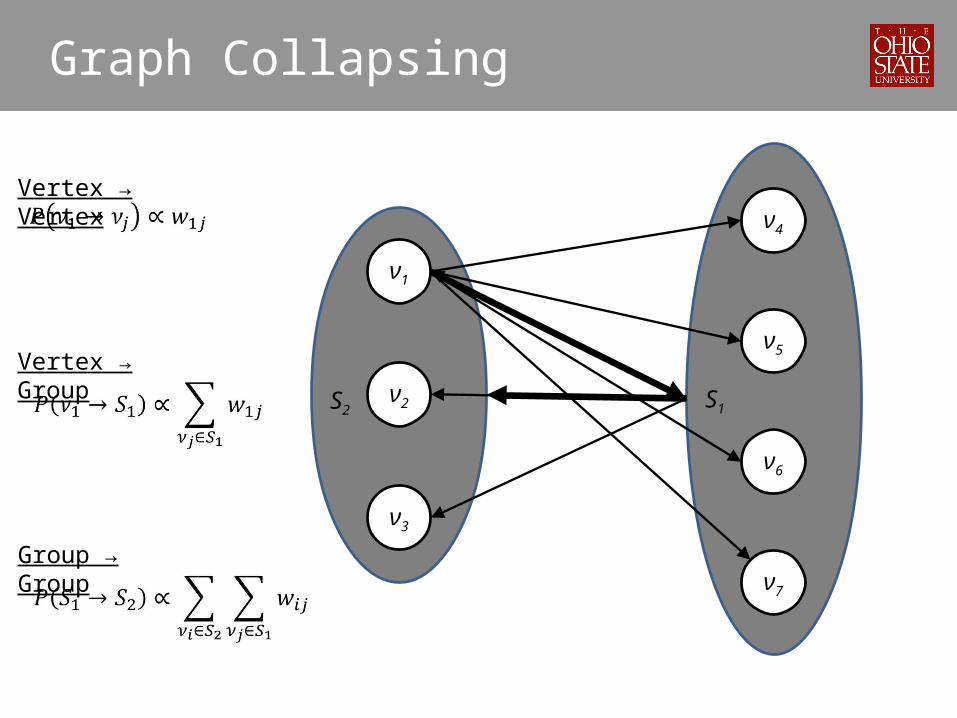
S2 S1
Graph Collapsing
ν1
ν2
ν3
ν4
ν5
ν6
ν7
Vertex → Vertex
Vertex → Group
Group → Group

Graph Collapsing
• Sum of weights → Group of vertices collapsed to single vertex
• Random walks between groups equivalent to random walks between collapsed vertices
• In our case, leads to sum of blocks (segments) of weights in word similarity matrix:
ABC
CBS
NBC
Words
Word Similarity Segment Similarity
Segments

Graph Collapsing
• Further justification: Spectral Clustering• Recall Normalized Cuts
– V ← Eigenvector of 2nd smallest eigenvalue of normalized Laplacianℒ=I-D -1/2·A·D -1/2• Equivalent [1]:
– V ← Eigenvector of largest eigenvalue of random walk normalized Laplacian: P=D -1·A
• Spectral clustering ↔ “Random walk from a vertex tends to concentrate on similar vertices”
• Spectral clustering on collapsed graph is equivalent to clustering forced groups
[1] Marina Meilă & Jianbo Shi, "Learning Segmentation by Random Walks", Neural Information Processing Systems 13 (NIPS 2000), 2001, pp. 873–879.

Segment Generality/Specificity
• Uniqueness measures– Specific content– Perfect uniqueness → Perfect
dissimilarity– i.e., sum of rows/columns (except
diagonal) should approach zero
• Relatedness measures– General content– Related → Group self-similar– Perfect self-similarity → Similarity
matrix for group all one– Thus, sum of elements should approach n2 (n=number in group)
• Both can also be defined in terms of graph collapsing
Perfect dissimilarity
Perfect similarity
Somewhat similar
Seg. 1
Seg. 2
Seg. 3
Seg. 1
Seg. 2
Seg. 3
Seg. 1
Seg. 2
Seg. 3
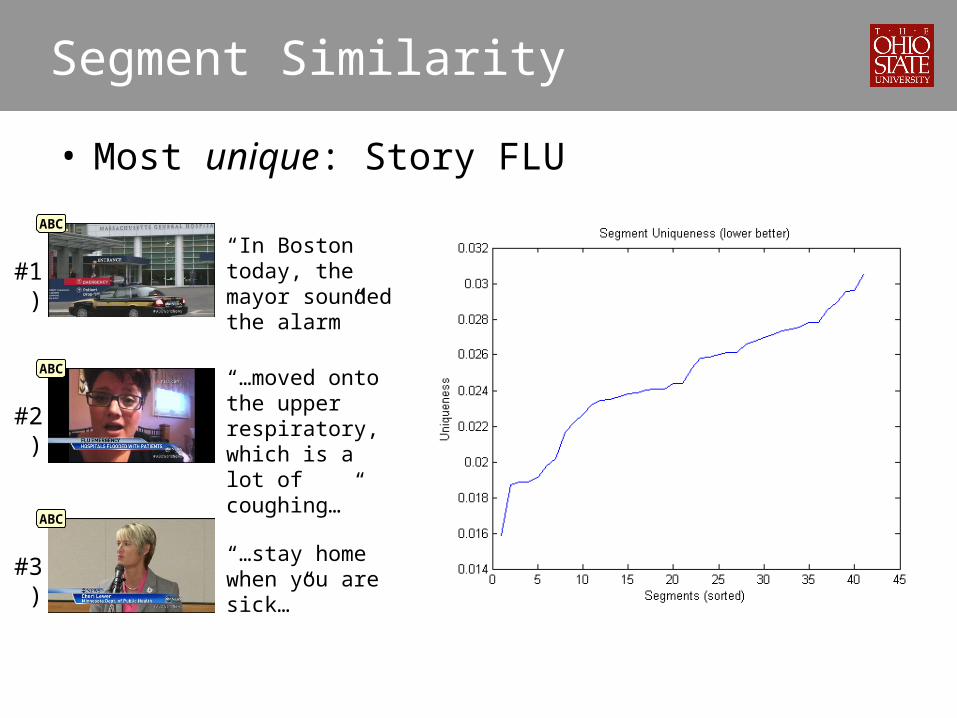
Segment Similarity
• Most unique: Story FLU
“In Boston today, the mayor sounded the alarm”
“…moved onto the upper respiratory, which is a lot of coughing…”
“…stay home when you are sick…”
#1)
ABC
ABC
ABC
#2)
#3)

Segment Similarity
• Most related: Story FLU
“…declaring a public health emergency….”
“…declaring a public health emergency….”
“Good evening. This national flu epidemic….”
“Good evening. We begin tonight with this flu outbreak….”
“…declaring a public health emergency….”
“…to repeat, declared a public health emergency….”
ABC
ABC
NBC
NBC
NBC
CBS
#1)
#2)
#3)

Segment Detection
• How to decide the boundaries of segments?– Without sentences, text not strong indicator
• Video shots– Shot: continuous scene (typically no or slow movement of
camera)– News videos tend to change shots as the anchor moves
from one (sub-)topic to the next• E.g., supporting video clips
– Shots good indicator of content topic change
Shot change

Segment Detection
• Detect change from one scene to another: shot detection• Temporal extent
– Consecutive: compare consecutive pairs of frames– Key frame: compare to “key” frame of previous segment
• Distance measures– Pixel-based
• SAD: Sum of Absolute Differences• SSD: Sum of Squared Differences• NCC: Normalized Cross-Correlation
– Color-based (color histograms)• Chi-squared• Bhattacharyya
– Texture-based• SIFT: Scale Invariant Feature Transform

Segment Detection
Shot Detection on Story FLU
• Compared to manual segmentation (ground truth)

Segment Detection
Method F TP FP FN
SAD 0.747 0.596 0.081 0.322
SSD 0.746 0.595 0.044 0.362
NCC 0.770 0.626 0.009 0.365
BATTA-H16 0.779 0.638 0.125 0.237
CHI2-H16 0.210 0.117 0.005 0.878
Shot Detection on Other Stories

Improving Segment Detection
• Shown methods examine single temporal extent
• Use graph collapsing to examine all extents
• All frames between segment start and segment end should be related
• Sum of blocks on diagonal approaches n2 if members in segment– Normalize by 1/n2
• Efficient calculation via summed area table
Video Similarity
Sum of Diagonal Blocks
Star
t Fr
ame
End Frame
Fram
es
Frames

Improving Segment Detection
• Conversely, frames before and after a segment boundary should be unique
• Strong condition if confined to preceding and following segment
• Without segments, use entire video– Start → Boundary– Boundary → End
• Sum of block anti-diagonal should approach zero at segment boundaries
• Clear boundaries• Problem: Peak/valley scale varies with
segment size• Combine with previous to eliminate
false positives
Video Similarity
Fram
es
Frames

Next?
• Finalize and evaluate graph-collapsing shot detection• Compare graph-collapsing specific/general
categorization to more typical clustering techniques– Develop quantitative measure for comparison of
specific/general categorization
• Expand word similarity to include multi-lingual support• Investigate sub-image feature extraction/matching
– E.g., Boston Mayor Thomas Menino
• Extend results to include other sources– E.g., collections of YouTube videos