stormとその周辺 2013.03.15
TRANSCRIPT

ウルシステムズ株式会社http://www.ulsystems.co.jp
mailto:[email protected]
Tel: 03-6220-1420 Fax: 03-6220-1402
ULS Copyright © 2013 UL Systems, Inc. All rights reserved.
Stormとその周辺
2013/3/15
講師役:近棟 稔

ULS Copyright © 2013 UL Systems, Inc. All rights reserved.
はじめに
2011年にTwitterのNathan Marz氏(元BackType社所属)らが開発した「Storm」がオープンソースとして公開されました。
Stormは、時々刻々と生み出されるストリームデータを並列分散処理するための基盤です。世の中的にはEDA(Event Driven Architecture)を実現するためのCEP基盤と位置づけられると思います。ただし、Stormは、かなりプリミティブな機能を提供します。CEPというよりも、やはり汎用の並列分散処理基盤だと考えたほうが正確だと思います。
Stormを一言で表現すると、「Javaのスレッドのようなものを複数台で走らせることが出来るようにしたもの」だと思います。JavaではひとつのJavaVMの中でconcurrentフレームワークを用いたマルチスレッド処理を記述しますが、 concurrentフレームワークは1プロセスのJavaVM内に閉じた計算しか出来ません。それをクラスター上で動かせるようにしたのがStormであると考えても良いかもしれません。
Stormの利用局面も、 concurrentフレームワークを利用したくなるシーンに似ています。例えば、可能な限り多くのCPUを使った大量の計算処理を高速に行いたい場合に向いています(例:科学計算や人工知能分野)。また、巨大なデータをある程度の大きさに分割して個別のCPUで処理したい場合にも向いています。もちろんストリーム処理にも向いていますが、CPU負荷が高くない(マルチスレッド処理でまかなえる)ストリーム処理にはオーバースペックだと思います。
1

ULS Copyright © 2013 UL Systems, Inc. All rights reserved.
パイプライン処理の振り返り
[お題] システムが単一フォルダーに出力する10個のログファイルから、ERRORログが何行書かれているかを取得したい状況を考えます。なお、問題を簡単にするために、ERRORログはgrep ERROR で抽出可能とします。
普段、なにげなく使っているパイプ「|」を使った上記の処理は、一般に「(ソフトウエア)パイプライン処理」といいます。このパイプライン処理は、以下の様な非常に優秀な特徴を備えています。
パイプラインで繋がれた各プロセスは、並列実行されます。上記の例では、cat と grep と wc が並列実行されます。grepはcatが行を吐き出すたびにそれに追随して行のフィルタリングを行いますし、wcはgrepがフィルタリングした行が出力されるたびにそれに追随して行をカウントします。
データを貯めこまず、逐次実行されるため、処理全体としてメモリーをあまり必要としません。
並列実行される各プロセスは処理速度に差がありますが、その速度差をパイプラインは自動調整ししてくれます。
各パイプは適切にバッファリングを行います。このバッファリングによって、処理に緩急がある場合でも、スループットを可能な限り上げることが可能になります。
2
$ cat *.log | grep ERROR | wc -l
答えの例 (UNIXもしくはそれに類する環境で)
• cat *.log によって、全ファイルをダンプします。• 標準出力で出てきたデータをパイプで受け取って、grepにかけます。• 絞られたログをwc (Word Count)にかけて、行数をカウントします。
cat grep wcバッファ速度調整
バッファ速度調整
並列実行 (処理全体として省メモリ)
read
10ファイル
ULS Copyright © 2013 UL Systems, Inc. All rights reserved.
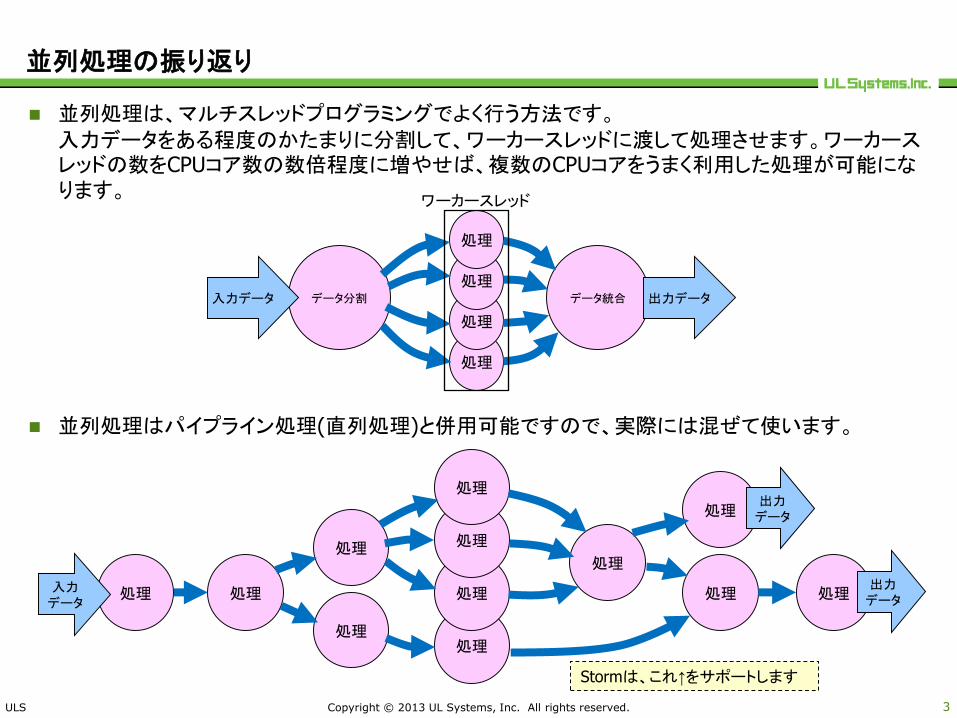
並列処理の振り返り
並列処理は、マルチスレッドプログラミングでよく行う方法です。入力データをある程度のかたまりに分割して、ワーカースレッドに渡して処理させます。ワーカースレッドの数をCPUコア数の数倍程度に増やせば、複数のCPUコアをうまく利用した処理が可能になります。
並列処理はパイプライン処理(直列処理)と併用可能ですので、実際には混ぜて使います。
3
データ分割
処理
処理
処理
処理
データ統合 出力データ入力データ
ワーカースレッド
処理
処理
処理
処理
処理
処理
処理
処理処理 処理
処理
入力データ
出力データ
処理出力データ
Stormは、これ↑をサポートします

ULS Copyright © 2013 UL Systems, Inc. All rights reserved.
Stormはパイプライン処理と並列処理の両方をサポートします
StormとUNIXのパイプライン処理の共通点
StormがUNIXのパイプライン処理と異なる所
4
共通点 説明
ストリーム処理であることStormの処理はストリームに対する処理です。パイプライン上のプロセスは、入力を受け取り次第、自分の受け持ち処理をして、後続処理に渡します。
自動速度調整ストリーム上にボトルネックとなるノードが存在する場合、そのノードに歩調を合わせて全体のストリームの処理速度が決まります。
バッファの存在Stormもプロセス間の速度差を調整するためのバッファーがあります。Stormのバッファーはキューで実現されています。
相違点 説明
プロセスの入出力ストリームは何本でも持てる
UNIXのパイプライン処理はコマンドラインベースの場合、標準入力や標準出力など限られたストリームを使います。しかし、Stormの場合は任意の本数の入力ストリームと出力ストリームを扱うことが可能です。(UNIXも名前付きパイプを使えば複数のストリームを扱えるのと似ている)
並列処理可能典型的なUNIXのパイプライン処理と異なり、Stormは並列処理も可能です。Stormでは直列にも並列にも処理を分散可能なので、処理の特性に応じた構成に調整することが可能です。この、処理(ストリーム)の繋がりをStormではトポロジーといいます。
メッセージの処理保証Stormはトポロジー上を流れるデータが完全に流れたか否かをトラッキングする事が可能です。このことにより、個々のメッセージが、少なくとも一度は処理がされた事を保証可能です。
スケールアウト可能Stormは複数台のマシンを用いてスケールアウトさせることを前提としています。UNIXのパイプでもnetcatなどを組み合わせれば可能ではあるものの、実運用には耐えられません。
耐障害性ノードが一部落ちた場合であっても、システム全体が落ちることのない、耐障害性を持っています。この性質は、後述するZooKeeper によって得ています。

ULS Copyright © 2013 UL Systems, Inc. All rights reserved.
Stormの構成要素
Stormは独特な要素で構成されています。
5
要素 英語的な意味 構成要素の説明
Spout 吹き出し口
Spoutは処理対象のデータストリームを生成するコンポーネントです。SpoutはデータストリームをDBやMQやRPCなどからデータを取得し、後続の処理に渡す役割をします。データストリームは何種類でも作成可能です。また、別の重要な役割として、後続の処理すべてでメッセージが処理し終えた際に、その通知を受け取るコンポーネントでもあります。
Bolt稲妻thunderbolt(雷電, 落雷)
重い処理を分散して行う、ワーカーとして振る舞うコンポーネントです。Boltは複数種類の入力ストリームを受け取り、複数種類の出力ストリームに吐き出します。Boltは別のBoltへ出力ストリームを渡すこともあります。また、DBの読み書きやRPC呼び出しをBolt内に記述することもあります。
TuplePythonなどの言語で扱う「タプル」と同義レコード。組。
SpoutやBoltが入出力する単位は「タプル」と呼ばれるレコード(組)になります。DBの1レコード相当のものをSpoutやBoltはストリーム上でやり取りします。なお、タプルの定義(スキーマ定義と類似)はストリーム毎に行います。
Topology
ネットワーク構成、繋がりの形
StormではSpoutとBoltがネットワーク状に接続された状態で動作します。この、SpoutとBoltの接続状態をStormではTopologyと呼びます。Topologyは、並列実行の指示、タプルのグルーピング方法などの情報も保持します。
ストリームには以下のものが付随します。・streamId(ストリームの名前)・流れるTupleの定義
Spout
Bolt
Bolt
Tuple
SpoutやBoltには以下のものが付随します。・ componentId・複数の出力ストリームの定義
Tuple
Tuple
ULS Copyright © 2013 UL Systems, Inc. All rights reserved.
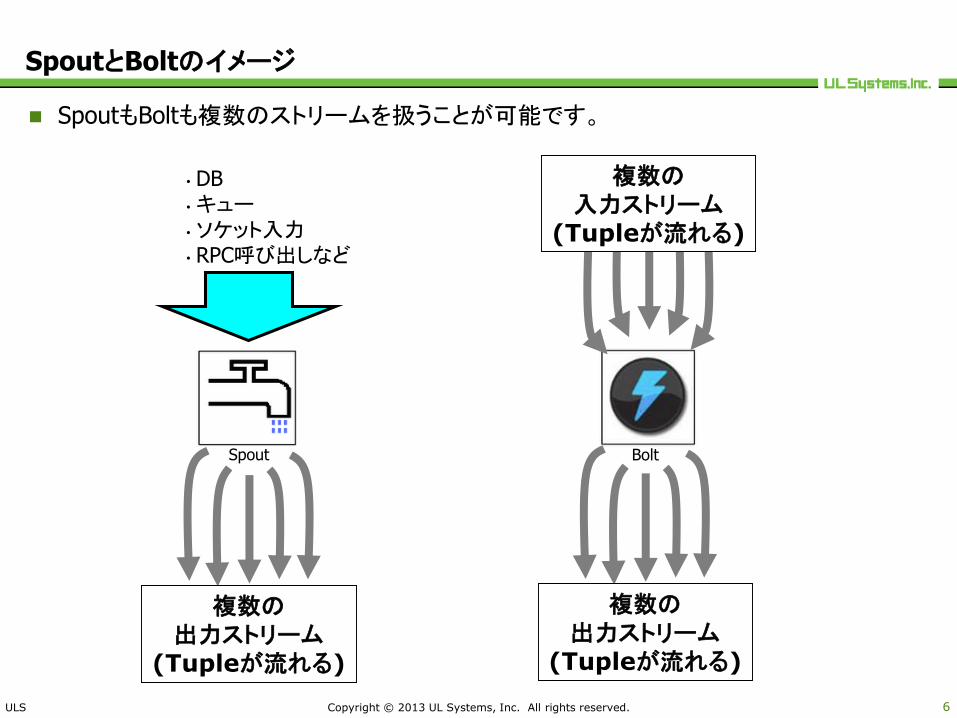
SpoutとBoltのイメージ
SpoutもBoltも複数のストリームを扱うことが可能です。
6
Spout Bolt
複数の出力ストリーム(Tupleが流れる)
複数の入力ストリーム(Tupleが流れる)
複数の出力ストリーム(Tupleが流れる)
• DB•キュー• ソケット入力• RPC呼び出しなど

ULS Copyright © 2013 UL Systems, Inc. All rights reserved.
Stormのプログラム例:数を数えさせてみる
Spoutから数値を機械的に振り出し、その数をBoltで数えるサンプルを作ってみます。
7
NumSpout CountBoltack / fail
... 5 4 3 2 1
Topologyの定義
componentID 並列数

ULS Copyright © 2013 UL Systems, Inc. All rights reserved.
NumSpoutの実装
数値を出力するNumSpoutの実装は以下の通りです。
8
初期化
Spoutの出力フォーマット
"default"の名前でストリームを1つ作成している。自分で名前を付けて複数のストリームを記述することも可能
数値を出力するロジック本体emitはこのメソッド内で何度やっても大丈夫。
トポロジーを正常に通り抜けてきた場合は、ここでそのメッセージIDが通知される
トポロジーを正常に通り抜ける事が出来なかった場合は、ここでそのメッセージIDが通知される
ackやfailで利用するメッセージIDは自分で指定する

ULS Copyright © 2013 UL Systems, Inc. All rights reserved.
CountBoltの実装
メッセージの数を数えるCountBoltの実装を以下に示します。このBoltは出力をしないためdeclareOutputFieldsが空実装になっています。
9
初期化
Boltの出力フォーマットの定義は無し
メッセージをカウントするロジック本体
Tupleの1項目目を取得
正常に処理したことを伝達

ULS Copyright © 2013 UL Systems, Inc. All rights reserved.
単一のJVM環境で実行 (デバッグ用)
Stormは単一のJVM環境でTopologyを実行可能です。主にデバッグ用に利用します。
起動すると、通常のmainから実行するJavaアプリケーションとして動作し、Stormのすべての内部モジュールを単一のJVM内で立ち上げた後、ここで作成したTopologyが実行されます。
実行すると、プログラムを止めるまでNumSpoutは数字を吐き出し続け、CountBoltはそれを数え続けます。
10
このモードで実行

ULS Copyright © 2013 UL Systems, Inc. All rights reserved.
Stormクラスターで実行
Stormクラスターで実行するには、以下の部分が実行されるようにします。
Stormクラスターで実行するには、Stormクラスターをセットアップする必要があるため、まずはセットアップ方法を説明します。
11
このモードで実行

ULS Copyright © 2013 UL Systems, Inc. All rights reserved.
Stormクラスターのセットアップ
Stormクラスターのセットアップには以下のステップを踏みます。
Linux環境を用意
ZooKeeperのインストール(Linuxのパッケージになっているものをそのまま使います)
ZMQライブラリのインストール(これもLinuxパッケージになっています)
JZMQのコンパイル(nathanmarz作成のZMQのJavaラッパーです。JNIでラッピングされているため、C++でのコンパイルが必要です)
Stormの配布パッケージをダウンロードし、好きな場所に展開。binフォルダーにPATHを通しておく。
少し大変なのは、JZMQのコンパイルでした。私が試した際にはビルドスクリプトがうまく動きませんでした。一旦コンパイル出来てしまえば作られるのは単なるシェアードライブラリですので、ビルドスクリプトがうまく動作すればここも問題なかったはずです。
重要な設定ファイルは以下の2つです。複数マシンでクラスター環境を作る場合は設定が必要になります。単一マシンにすべてのソフトウエアをセットアップする場合はデフォルトの設定で大丈夫です。
zookeeperの設定ファイル
Stormの設定ファイル(クラスター側とクライアント側)
私が試したのは、Ubuntu 12.10 Desktop版 の環境です。他のLinuxディストリビューションでも同様の作業となります。なお、Windows上でのセットアップはハードルが高いと思われます。
12

ULS Copyright © 2013 UL Systems, Inc. All rights reserved.
Stormクラスターの起動
Stormクラスターは以下の手順で実行します。
zookeeperをスタートします。Ubuntuの場合は、インストールすると自動起動しました。
「storm nimbus」でnimbusを起動します。
「storm supervisor」でsupervisorを起動します。
「storm ui」でStormのユーザーインターフェースを起動します。
すべて起動すると、以下のUIで起動状況を確認可能です。
13
zooinspector(zookeeperが管理している情報を閲覧)
Storm UI(Stormで動作しているTopologyの状態を表示可能。
TopologyをUI上から停止・再開する事も可能)

ULS Copyright © 2013 UL Systems, Inc. All rights reserved.
StormクラスターにTopologyを投入
StormクラスターにTopologyを投入するために、まずは自作のTopology実装をjarにまとめます。ここでは「numcount.jar」にまとめたとします。
以下のコマンドでStormクラスターにnumcount.jarを投入します。なお、argsは特に必要ありませんが、現在のNumCountTopologyが何らかの引数を与えられるとStormクラスターにデプロイするように記述してあるために与えています。> storm jar numcount.jar num.NumCountTopology args
jarを投入すると、Stormクラスターにjarが配布され、クラスター内で処理が始まります。このTopologyの場合、Topologyを止めるまでNumSpoutは数字を吐き出し続け、CountBoltはそれを数え続けます。
Storm UIを見ると、 EmittedやAckedの値が急上昇していく事が確認できます。
14
Storm UI(EmittedやAckedの値が急上昇)
htopの表示CPUは4コア張り付く

ULS Copyright © 2013 UL Systems, Inc. All rights reserved.
動作中のStorm
すべてのコンポーネントを1つのマシン上にデプロイして動かしている様子です。
15

ULS Copyright © 2013 UL Systems, Inc. All rights reserved.
この構成でどの程度のパフォーマンスが出るか
この非常に単純な処理で、1件あたり約0.03ミリ秒(30マイクロ秒)かかりました。この性能について少し考えてみます。JDBCのバッチinsertを用いると、Oracleでは最速で1件あたり0.007ミリ秒(7マイクロ秒)程度でinsert出来ます。それに比べると少し遅く感じます。ただし、7マイクロ秒はIOの限界に近い性能で、インメモリーベースのKVSであるRedisでさえ8マイクロ秒前後のput性能です。30マイクロ秒は頑張っている方だと思います。
なお、このパフォーマンステストではVirtualBoxを用いていますし、すべてのコンポーネントを1台のVMに入れているなど、条件が悪い所があります。Stormのマニュアルによると、通常は1ノードあたり1メッセージあたり平均で1マイクロ秒で処理可能であるとの記載があります。これは一般的に見てもかなり高速な処理になります。というのも、メインメモリーへの平均参照時間は0.1マイクロ秒ですので、1マイクロ秒は、そのたった10倍の時間でしかありません。光の速さで移動したとして、300m移動可能な時間でしかありません。
16
NumSpout CountBoltack / fail
... 5 4 3 2 1
行って帰るまでのターンアラウンドタイムが30マイクロ秒
来たメッセージの数を数える
(参考) https://gist.github.com/nahurst/3711264

ULS Copyright © 2013 UL Systems, Inc. All rights reserved.
Stormのアーキテクチャ
Nimbus, Supervisor, ZooKeeper, ØMQ, Thrift などの役割を以下に示します。
17
構成要素 英語の意味 説明
Nimbus後光オーラ
NimbusはStormにおけるマスターノードです。Nimbusはクラスター内にコードを配信し、タスクをアサインし、異常をモニタリングします。
Supervisor
管理人監督
SupervisorはStormにおけるワーカーノードです。Nimbusからの依頼に従い、ワーカープロセス(別のJVMプロセス)を起動します。トポロジーはStormクラスター内の複数のマシンにまたがったワーカープロセス内で実行されます。
ZooKeeper
飼育員
元々GoogleのChubbyを真似たHadoop実装で、分散システムを運用可能な状態にするためのキーテクノロジーとなります。Hadoop以外の分散システムでも利用例が多いです。ZooKeeperがあれば、クラスター全体の設定情報の共有に始まり、クラスター内のマシンの生死の管理やノードの動的な追加への対応など、管理可能な分散システムを構成するために不可欠な要素が入っています。
ØMQ -C++で書かれた非常に高速なソケットライブラリーです。StormではSpoutやBolt間で高速な通信を実現するために利用されています。
Kryo (軽量)Tupleを非常にコンパクトにシリアライズするために利用されています。Storm以外のプロダクトでもよく使われているようです。GoogleのProtocol Buffersよりも優秀という話もあります。
Thrift 節約 Facebookが作成したRPCの仕組みです。Stormのトポロジーの実態はThriftで定義されたものです。
Clojure - Stormのコア部分はClojure(Lisp方言)で書かれています。
NimbusZooKeeperZooKeeperZooKeeperZooKeeperZooKeeper
SupervisorSupervisorSupervisorSupervisorSupervisorSupervisorSupervisor
ステートレスステートレス
状態管理
最低5台で運用
(参考) https://github.com/nathanmarz/storm/wiki/Implementation-docs

ULS Copyright © 2013 UL Systems, Inc. All rights reserved.
ZooKeeperを理解するには、ZooKeeperが参考にしたGoogleのChubbyを理解するのが手っ取り早いです。
Chubbyは、Windowsのレジストリーのような細かな情報をツリー状のフォルダー階層に格納可能にしたものです。この中に、クラスター内で利用したい設定値などを入れて利用します。
Chubbyは運用時には最低5台以上のマシンを利用します。1つのノードをChubbyでは「Chubbyセル」と呼びます。Chubbyセルの中の1つはマスターとして機能し、このマシンが健在の間はすべてのリクエストをこのマスター1台で処理します。他の4台は、いつでもマスターに成り代わることのできるバックアップです。更に、5つのChubbyセルのうち1つは、別のデータセンターに置く運用をされています。
新たなマスターを選ぶ必要が生じた際には、Paxosというコンセンサスアルゴリズムを用います。初回起動時や障害発生時は、生きているマシン達は投票によって誰が次のマスターになるかを決定します。これらの挙動はChubbyのクローンであるZooKeeperでもほとんど同じです。
マスターがすべて対処
どれか1台は別のデータセンターに配置
18
ULS Copyright © 2013 UL Systems, Inc. All rights reserved.
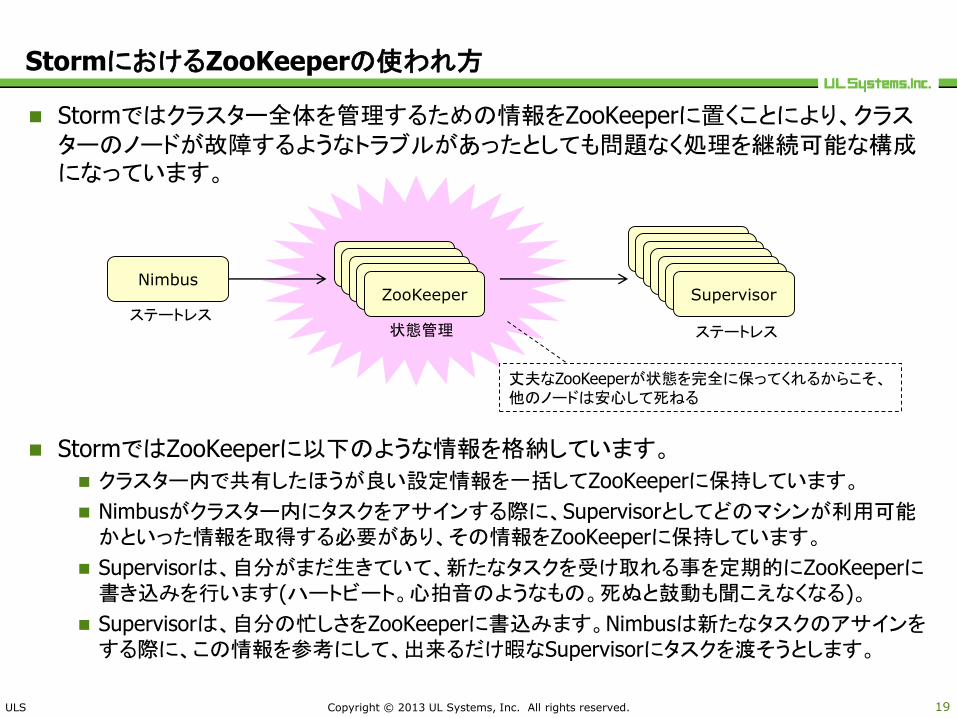
Stormではクラスター全体を管理するための情報をZooKeeperに置くことにより、クラスターのノードが故障するようなトラブルがあったとしても問題なく処理を継続可能な構成になっています。
StormではZooKeeperに以下のような情報を格納しています。
クラスター内で共有したほうが良い設定情報を一括してZooKeeperに保持しています。
Nimbusがクラスター内にタスクをアサインする際に、Supervisorとしてどのマシンが利用可能かといった情報を取得する必要があり、その情報をZooKeeperに保持しています。
Supervisorは、自分がまだ生きていて、新たなタスクを受け取れる事を定期的にZooKeeperに書き込みを行います(ハートビート。心拍音のようなもの。死ぬと鼓動も聞こえなくなる)。
Supervisorは、自分の忙しさをZooKeeperに書込みます。Nimbusは新たなタスクのアサインをする際に、この情報を参考にして、出来るだけ暇なSupervisorにタスクを渡そうとします。
StormにおけるZooKeeperの使われ方
19
NimbusZooKeeperZooKeeperZooKeeperZooKeeperZooKeeper
SupervisorSupervisorSupervisorSupervisorSupervisorSupervisorSupervisor
ステートレスステートレス状態管理
丈夫なZooKeeperが状態を完全に保ってくれるからこそ、他のノードは安心して死ねる

ULS Copyright © 2013 UL Systems, Inc. All rights reserved.
Stormにおけるデータの処理保証(トランザクション)
Stormの大きな特徴の1つはデータの処理保証です。以下の3つの方式から選択出来ます。
20
方式 説明
何も保証しないデータがすべて処理されたか否かを気にしなくても良い場合に使用する方式です。
各タプルを最低1回処理する
(more than once)
ack/failを使用し、各タプルが最低1回は処理されることを保証する方式です。StormはSpoutから投入したTupleがトポロジー全体を通して処理されたか否かをトラッキングします。もしもトポロジーの一部の処理で問題が発生した場合、もしくは時間が経ってもTupleのackが返ってこない場合、再度そのTupleを処理します。そのため、複数回処理される可能性はあるものの、すべてのTupleが最低1回処理されるように作ることが可能です。
各タプルをカッチリ1回処理する
(exactly once)
more than onceのセマンティクスでは、word countにて単語を数えすぎてしまうような挙動をしてしまいます。Stormではmore than onceを更に押し進めたexactly onceセマンティクスもサポートしています。このためにはTransactional TopologyもしくはTridentを用います。なお、TridentはStorm上で作られたDSLのような存在です。

ULS Copyright © 2013 UL Systems, Inc. All rights reserved.
Stormと組み合わせて使われるキューやDB
Stormは単体で動作させることはまず無く、外部と何らかの入出力を伴います。Stormと組み合わせて利用される典型的なソフトウエアを以下に示します。
21
タイプ 典型例 Stormでの使われ方
インメモリーDB
Redis
Redisはディスク書き出し機能と豊富なデータ構造サポートの付いたインメモリーDBです。格納可能なデータはメモリーの量に制限されてしまいますが、動作は非常に高速です。RedisはMySQLの代替えとして使われることさえあります。Stormと組み合わせて使う場合、RedisはStormクラスターで使えるグローバル変数の置き場のような位置づけとして使います。たとえば、トポロジーでの処理結果をBoltから書き込んでおくといった使い方が典型例です。
MQ Kafka
MQを用いて他システムとStorm間のデータを受け渡す事は、とても一般的です。nathanmarzによると、色々存在するキューの仕組みの中でもApache Kafkaが最もStormとの相性が良いようです。Kafkaはディスク書き込みを前提としたキューですが、インメモリーのキューと同程度に高速に動作します。
巨大なDB
MongoDB
MongoDBは巨大なデータを扱うことの出来るNoSQLデータベースです。テラバイト級のデータを扱えるため、Redisのような容量制限を気にすることなく大きなデータを蓄えることが出来ます。fluentdによって収集したログをMongoDBに書いておくといった用途にも利用可能なほど余裕があります。MongoDBには「tailable cursor」という機能があります。この機能は「tail -f」のように、他から書き込みがあった場合に即時変更分が通知されるような機能です。この機能はStormのSpoutによって未処理のデータを吸い出す方法として都合が良いです。
その他の外部API
DRPCREST
StormはStorm自身に内蔵されているDRPC機能によって外部からトポロジーをRPC呼び出しする事も可能です。また、RESTや単純なソケット通信によって、Spoutにデータを流し込む事も可能です。

ULS Copyright © 2013 UL Systems, Inc. All rights reserved.
Redisの紹介
RedisはメモリーベースのKVSですが、非常にユニークです。KVSというとキーにBLOBを保存するという形を思い浮かべますが、Redisではそのような使い方をしません。RedisでのkeyはRDBでのテーブル名や、プログラム中の変数名に近いです。
Redisでは、key(変数名相当)に対し、List,HashMap,Set,SortedSetなどを保持させます。トランザクション中では、これらのコレクションを操作し、状態を変更します。このような考え方をするため、keyの増減はあまりせず、keyの指し示すコレクション(データコンテナ)の中身が頻繁に変わるような動きをさせるのが標準的な使い方になります。
Redisは300KB程度しかない小さなプログラムですが、クラスター構成を取ることも可能な扱いやすいDBです。データを随時ディスクに書くことが出来るため、 MySQLの代替えとしてトランザクションデータの書き込み先として利用する事例も出てきています。Redisを何か他のDBのキャッシュとして見なすのではなく、単独のDBとして使うという事です。
22
key1 スカラー値key2 List key3 HashMapkey4 HashSet key5 SortedSet・ ・・ ・ disk
定期的もしくは即時書き出し
Redisでのキーはテーブル名や変数名みたいなものであまり増減しない
RedisではListを用いてFIFOを作ったり、HashSetを用いてテーブルのような物を扱ったりといった使い方をする。
Redisのクライアント
Redisは、DBを扱っているというよりも、(リモートにある)変数を扱っているような感覚で扱えます。パフォーマンスが非常に良いので、クエリー回数を減らすような努力もあまり必要ではありません。
Redisサーバー

ULS Copyright © 2013 UL Systems, Inc. All rights reserved.
Redisを使ってみる (Javaから使う場合はJedisライブラリーを使います)
Redisの起動コマンドラインから「redis-server redis.conf」 で起動出来ます。Ubuntuの場合、Redisをパッケージからインストールすると、自動的にデーモンとして動作し始めました。
RedisでMQを作ってみます。RedisのListを"queue1"というキーに入れることで実現しています。
23
$ redis-cli
> lpush queue1 a
> lpush queue1 b
セッション1(エンキュー側)
$ redis-cli> brpop queue1 100
1) "queue1"2) "a"
セッション2(デキュー側1つ目)
$ redis-cli
> brpop queue1 100
1) "queue1"2) "b"
セッション3(デキュー側2つ目)
"queue1"からpop要求をする。この時、blocking指定をすると、メッセージが到達するまで待ちに入る。
"queue1"からpop要求をする。こちらも待ちに入る。"queue1"へ文字列"a"を投入。
"l"は左(left)の意味。
瞬時に取得される
瞬時に取得される
"queue1"へ文字列"b"を投入
このようなRedisの性質をStormの
Spoutで利用すると都合が良いです。

ULS Copyright © 2013 UL Systems, Inc. All rights reserved.
Redis+StormをJavaの概念とマッピングしてみる
Redis+Stormの組み合わせは概念的にJavaのグローバル変数やスレッドの概念にマッピング可能です。ただし、JavaはJavaVMに閉じた話になりますが、Redis+Stormでは複数台のマシンで処理可能な事が違います。
24
Java Redis+Storm
グローバル変数
Redisのキーはグローバル変数名に相当すると考えられます。また、Redisのサポートする5つの型は、Javaのコレクションライブラリーにマッピング可能です。マルチスレッドプログラミングにてグローバル変数に触りすぎると性能が落ちてしまうのと同様に、Redisにアクセスし過ぎると全体のパフォーマンスは落ちてしまいます。このあたりの性質も似ています。
ロック Redisを用いればロックによるタイミングの制御(排他制御)は可能です。
スレッドStormはJavaのスレッドに相当すると考えられます。Javaでのマルチスレッドプログラミングでは、BlockingQueueなどを用いてデータの流れを構成しますが、Stormでのストリームの処理と非常に近いです。

ULS Copyright © 2013 UL Systems, Inc. All rights reserved.
Kafka
主なプロダクトとの連携例
システムのログ収集~ログ解析までのイメージを書いてみると以下のようになります。下の図は全くのイメージですが、Stormクラスターの役割はこのあたりになります。ただし、ログの解析処理がそれほど大きなCPU負荷にならない場合、Stormはオーバースペックになる可能性があります。
StormはTwitterではツイートのリアルタイム解析に用いているようです。ツイートの解析にはCPUパワーが必要なため、Stormを用いて分散処理しているそうです。
25
稼働サーバー群
fluentdで各サーバーのログを収集して
mongoDBへストア
Web表示
他システム
Stormクラスター
ログのリアルタイム解析
ログDB