stk643 pemodelan non-parametrik - ipb university · dengan 𝜇 adalah median contoh. •pemulus...
TRANSCRIPT

STK643 PEMODELAN NON-PARAMETRIK
Pendugaan Fungsi Kepekatan Regresi Nonparametrik

KARAKERISTIK DASAR PENDUGA KEPEKATAN
• Penduga kepekatan;
𝑓 𝑥 =1
𝑛 𝑤
𝑥 − 𝑥𝑖
ℎ
𝑛
1
• Nilai tengah atau Rataan (mean)
𝐸{𝑓 𝑥 } = 𝑤𝑥 − 𝑧
ℎ𝑓 𝑧 𝑑𝑧
≈ 𝑓 𝑥 +ℎ2
2𝜎𝑤
2𝑓"(𝑥)
𝜎𝑤2 = 𝑧2𝑤 𝑧 𝑑𝑧 adalah ragam fungsi kernel

KARAKERISTIK DASAR PENDUGA KEPEKATAN
• Ragam
𝑣𝑎𝑟 𝑓 (𝑥) ≈1
𝑛ℎ𝑓(𝑥)𝛼(𝑤)
𝛼 𝑤 = 𝑤2 𝑧 𝑑𝑧
• Rataan dan ragam tergantung pada fungsi kepekatan sebenarnya, f(x), dan
turunan kedua fungsi, f ”(x) masalah bias
• Kuantifikasi variabilitas suatu penduga kepekatan tanpa memperhitungkan
adanya bias ragam didekai dengan
𝑣𝑎𝑟 𝑓 (𝑥) ≈1
4
1
𝑛ℎ𝛼(𝑤)

SELANG KEPERCAYAAN
• Selang kepercayaan untuk kepekatan sebenarnya pada berbagai nilai x
dapat dinyatakan dengan lebar dua salah baku
2𝛼(𝑤)
4𝑛ℎ=
𝛼(𝑤)
𝑛ℎ≈ 𝑓
y <- log (aircraft$Span) [aircraft$Period==3]
sm.density(y, xlab = "Log span", display = "se")

PEMULUSAN OPTIMAL
• Berdasarkan minimisasi MISE secara asimtotik diperoleh
ℎ𝑜𝑝𝑡 =𝛾(𝑤)
𝛽 𝑓 𝑛
1/5
dengan 𝛾 𝑤 =𝛼(𝑤)
𝜎𝑤4 dan 𝛽 𝑓 = 𝑓"(𝑥)2𝑑𝑥
• Pemulus optimal normal
ℎ = 𝜎4
3𝑛
1/5
dengan σ adalah simpangan baku sebaran.
• Penduga σ yang robust adalah

PEMULUSAN OPTIMAL
• Penduga σ yang robust , untuk mengatasi kemungkinan adanya pencilan,
adalah
𝜎 = 𝑚𝑒𝑑𝑖𝑎𝑛 𝑦𝑖 − 𝜇 /0.6745
dengan 𝜇 adalah median contoh.
• Pemulus optimal normal untuk kasus multidimensi
ℎ𝑖 = σi4
𝑝 + 2 𝑛
1/(𝑝+4)
dengan p adalah banyaknya peubah bebas (dimensi),
hi adalah pemulus optimal,
σi adalah simpangan baku dimensi ke-i
•
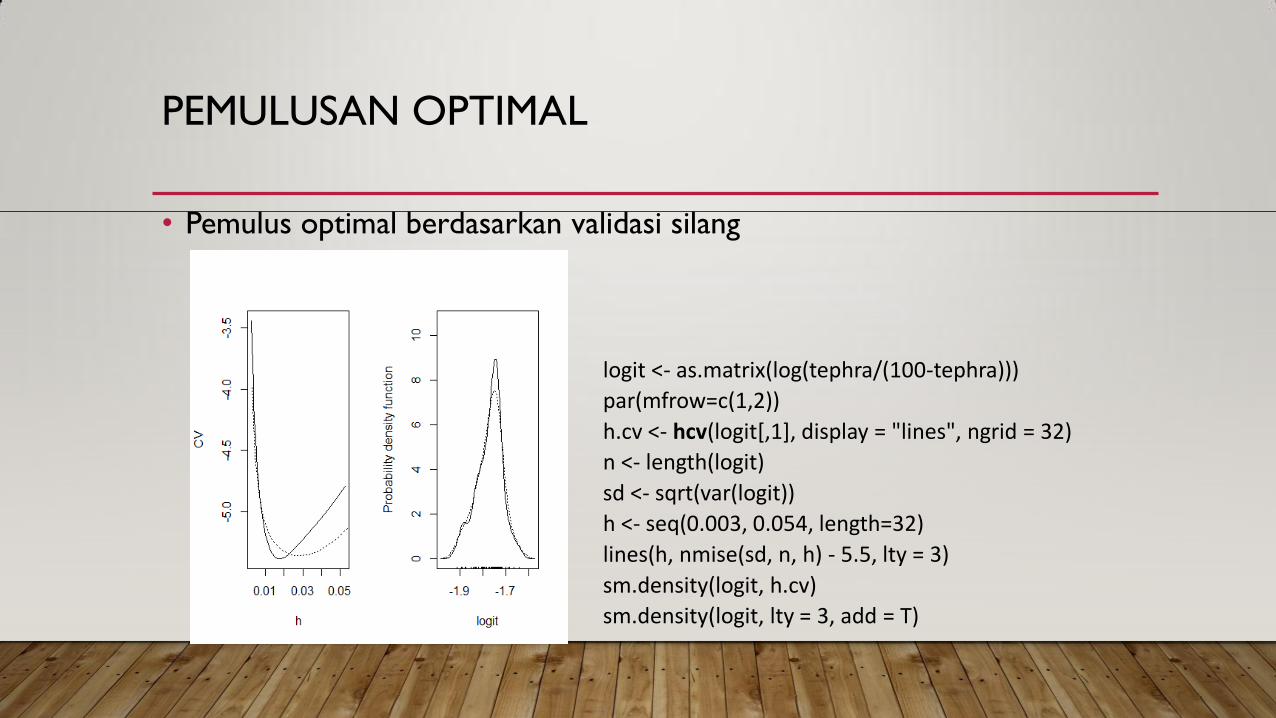
PEMULUSAN OPTIMAL
• Pemulus optimal berdasarkan validasi silang
logit <- as.matrix(log(tephra/(100-tephra)))
par(mfrow=c(1,2))
h.cv <- hcv(logit[,1], display = "lines", ngrid = 32)
n <- length(logit)
sd <- sqrt(var(logit))
h <- seq(0.003, 0.054, length=32)
lines(h, nmise(sd, n, h) - 5.5, lty = 3)
sm.density(logit, h.cv)
sm.density(logit, lty = 3, add = T)

KENORMALAN
logit <- as.matrix(log(tephra/(100-tephra)))
par(mfrow=c(1,2))
qqnorm(logit)
qqline(logit)
# cat("ISE statistic:", nise(logit),"\n")
sm <- sm.density(logit)
y <- sm$eval.points
sd <- sqrt(hnorm(logit[,1])^2 + var(logit[,1]))
lines(y, dnorm(y, mean(logit), sd), lty = 3)
par(mfrow=c(1,1))

KENORMALAN
logit <- as.matrix(log(tephra/(100-tephra)))
par(mfrow=c(1,2))
sm.density(logit, model="Normal")
sm.density(logit, h=hsj(logit[,1]), model="Normal")
par(mfrow=c(1,1))

BOOTSRAP PENDUGA KEPEKATAN
sm.density(y, xlab = "Log span")
for (i in 1:10) sm.density(sample (y, replace=T), col=5, add=T)
sm.density(y, xlab = "Log span", add=T)

REGRESI NONPARAMETRIK
• Ketidaklinearan dalam data
• Regresi nonparametrik bertujuan untuk memperoleh rata-rata pemodelan
data
• Teknik pemulusan masih berguna dengan cara plot tebaran data (scatter
plot) untuk menampilkan struktur data tanpa referensi suatu model
parametrik

REGRESI NONPARAMETRIK PLOT TEBARAN DATA

REGRESI NONPARAMETRIK MODEL
Model: 𝑦 = 𝑚 𝑥 + 𝜀
dengan 𝑦 = peubah respon
𝑥 = peubah bebas (covariate)
𝜀 = galat dengan rata2 0 dan ragam σ2
𝑚 𝑥 = 𝑤
𝑥𝑖 − 𝑥ℎ
𝑦𝑖𝑛𝑖=1
𝑤𝑥𝑖 − 𝑥
ℎ𝑛𝑖=1
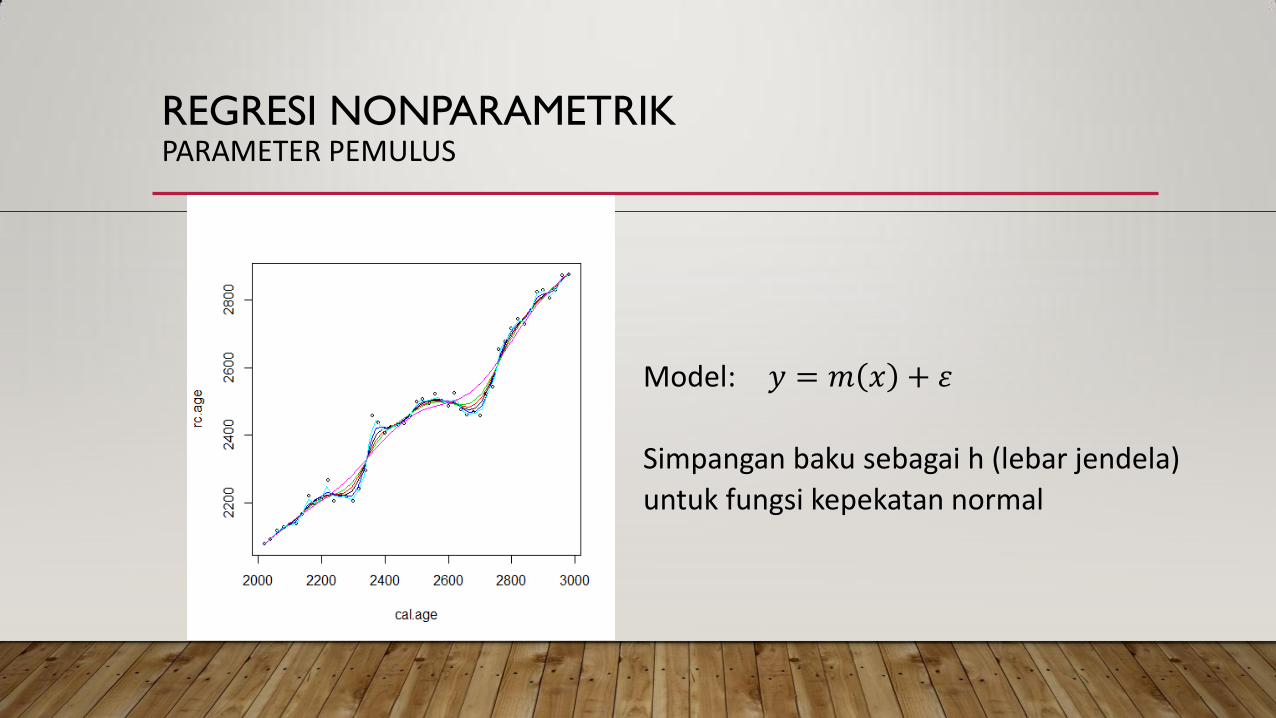
REGRESI NONPARAMETRIK PARAMETER PEMULUS
Model: 𝑦 = 𝑚 𝑥 + 𝜀
Simpangan baku sebagai h (lebar jendela)
untuk fungsi kepekatan normal

REGRESI NONPARAMETRIK PARAMETER PEMULUS
Parameter pemulus, h, mengendalikan lebar fungsi kernel dan juga derajat pemulusan terhadap data Parameter pemulus besar akan menghasilkan penduga dengan beberapa karakteristik kurva yang hilang; sebaliknya, parameter pemulus kecil akan menghasilkan penduga dengan banyak ‘patahan’ pada kurva; sehingga perlu dicari h yang tepat

REGRESI NONPARAMETRIK BOOTSTRAP
x <- radioc$Cal.age[radioc$Cal.age>2000 &
radioc$Cal.age<3000]
y <- radioc$Rc.age[radioc$Cal.age>2000 &
radioc$Cal.age<3000]
plot(x, y, xlab="Calendar.age", ylab="Radiocarbon.age",
type="n")
model <- sm.regression(x, y, h=30, eval.points=x,
display="none")
mhat <- model$estimate
r <- y - mhat
r <- r - mean(r)
for (i in 1:50) sm.regression(x, mhat + sample(r,
replace=T), h=30, add=T, col=2, lty=1)
sm.regression(x, y, h=30, add=T, col=”blue”)

REGRESI NONPARAMETRIK SELANG KEPERCAYAAN 95%
> x <- radioc$Cal.age[radioc$Cal.age>2000 &
radioc$Cal.age<3000]
> y <- radioc$Rc.age[radioc$Cal.age>2000 &
radioc$Cal.age<3000]
> plot(x, y, xlab="Calendar.age", ylab="Radiocarbon.age")
> model <- sm.regression(x, y, h=30, eval.points=x)
> w <- sqrt(2*qt(0.95,1)) #95% dari statistik t-student
> lo <- model$estimate-w*model$se
> hi <- model$estimate+w*model$se
> sm.regression(x, lo, h=30, add=T, col=2, lty=1, add=T)
> sm.regression(x, hi, h=30, add=T, col=2, lty=1, add=T)

KEPUSTAKAAN
1) Bowman AW, Azzalini A. 1997. Applied Smoothing Techniques for Data Analysis: the Kernel
Approach With S-Plus Illustrations. Oxford University Press. London.
2) Silverman BW. 1986. Density Estimation for Statistics and Data Analysis. Vol. 26 of
Monographs on Statistics and Applied Probability. Chapman & Hall/CRC. London.
3) Simonoff JS. 1996. Smoothing Methods in Statistics. Springer. New York.