spss-i në praktikë - teknikat statistikore me shumë ndryshore
TRANSCRIPT

0
SPSS-i NË PRAKTIKË
TEKNIKAT STATISTIKORE ME SHUMË
NDRYSHORE
Prof. Dr. Sheref KALLAJXHË
2016

SPSS-i NË PRAKTIKË
TEKNIKAT STATISTIKORE ME SHUMË
NDRYSHORE
EDITOR: Prof. Dr. ŞEREF KALAYCI
PËRKTHYES: KUJTIM HAMELI
BOTIMI 6
2016

APLIKIMET ME SPSS
TEKNIKAT STATISTIKORE ME SHUMË NDRYSHORE
AUTORËT
Kapitulli: Kapitulli:
Prof. Dr. Şeref Kalaycı 12, 13
Ligj. Engin Küçüksille 9, 10
Ndih.Doç.Dr. Belma Ak 3, 4
Ndih.Doç.Dr. Meltem Karaatlı 1
Ndih.Doç.Dr. Hidayet Ü. Keskin 8
Ndih.Doç.Dr. Eda Ü. Çiçek 2
Ndih.Doç.Dr. Aliye Kayış 11, 15
Ndih.Doç.Dr. Ömer L. Antalyalı 7
Ligj. Nezihe Uçar 14
Ligj. Doç.Dr. Hakan Demirgil 5
Asis. Hul. Onur Sungur 6
EDITOR
Prof. Dr. Şeref Kalaycı
Botimi i gjashtë 2014
Përkthyer 2015
Edituar 2016



i
FJALA E PËRKTHYESIT
Falendërimet i takojnë Zotit të Madh që ma lehtësoi dhe më shtoi durimin gjatë
kryerjes së këtij punimi. Respektin tim ia shfaq dy më të dashurve të mi, prindërve, të cilët
janë motivimi im më i madh për çdo punë. Falenderoj të gjithë ata që kanë kontribuar në
kompletimin dhe dizajnimin e këtij libri.
Duke parë mungesën e literaturës rreth këtij programi dhe nevoja e përdorimit për
këtë program, mora vetëiniciativën për të dhënë një kontribut literaturës shqipe duke
përkthyer këtë libër, i cili përmban analizat statistikore më të përdorura për hulumtim në
shkencat shoqërore.
I nderuar hulumtues! Ky libër i mrekullueshëm rreth programit SPSS (Statistical
Package for the Social Sciences) i punuar nga një grup profesorësh të Turqisë, do të të
ndihmoj për të kryer analizat statistikore në program hap pas hapi përmes fotografive si
dhe bën interpretimin e rezultateve të përfituara nga analizat. Ky libër është dizajnuar në
mënyrë të tillë që çdo kush i cili nuk ka njohuri rreth SPSS-it, do të jetë në gjendje që të
kryej vetë një analizë në programin SPSS. Me shpresën se ky libër do t’iu shërbej gjatë
kryerjes së hulumtimeve tuaja, ju lë me prezencën e analizave në vazhdim dhe programit të
mirënjohur SPSS.
Për çdo vërejtje, koment apo sugjerim, mund të më shkruani në email adresën time.
Kujtim Hameli
25.07.2015, Stamboll

ii
PARATHËNIE
Në ditët e sotme mund të kryhen shumë lehtë shumë analiza statistikore përmes
kompjuterëve dhe programeve të sofistikuara që në të kaluarën ishte e pamundur për t’u
bërë. Në këtë kontekst, teknikat statistikore themelore dhe me shumë ndryshore përdoren
mjaft në universitetet tona nga studentët hulumtues, përmes paketave të ndryshme.
Dhe ne për këtë arsye kemi përgatitur punimin që keni në duar duke përdorur
programin e mirënjohur SPSS në shtetin tonë, për t’iu ndihmuar në aplikimin dhe
interpretimin e rezultateve të teknikave statistikore themelore dhe me shumë ndryshore.
Karakteristika më e rëndësishme e librit është aplikimi i metodës së mësimit aktiv. Pra,
edhe ai i cili nuk ka njohuri të mjaftueshme në nivelin e duhur rreth programit SPSS dhe
statistikës, me anë të librit tonë do të mund të mësojë se si mund t’i bëj analizat e
dëshiruara dhe si të i interpretojë rezultatet e përfituara.
Ideja e shkruarjes së librit filloi nga bisedat me kolegët e mi (nga autorët e librit
ligjëruesit dhe asistentët e hulumtimit) se përgatitja e një libri me aplikime në lidhje me
tema metodologjike do të ishte shumë i dobishëm për një audiencë të gjerë si për
akademikët, hulumtuesit dhe studentët dhe se edhe ata do të jepnin kontribut në
përgatitjen e këtij libri. Përveç kësaj, libri mori formën përfundimtare nga kontributet e
shokëve e mi të ndershëm të punës (Abdullah Eroğlu, Ali Sait Albayrak, Aliye Kayış) me
përgatitjen e kapitujve të tyre.
Kapitujt janë shkruar në mënyrë që mund të lexohen ndaras. Për këtë arsye, në libër
janë përsëritur disa gjëra. Një i cili ka njohuri themelore të statistikës, nuk ka nevojë që të
lexojë kapitujt e mëparshëm për leximin e çfarëdo kapitulli.
Mendimet dhe rekomandimet tuaja rreth këtij libri që menduam të jetë i dobishëm për
një audiencë të gjerë, i presim në email adresën tonë. Në bazë të rekomandimeve do të
provojmë që t’a bëjmë sa më të dobishëm për ju.
Prof. Dr. Sheref KALLAJXHË

iii

iv
PËRMBAJTJA
FJALA E PËRKTHYESIT i
PARATHËNIE ii
PËRMBAJTJA iv
1.RREGULLIMI DHE PARAQITJA E TË DHËNAVE .......................................................... 1
1. ORGANIZIMI I TË DHËNAVE ......................................................................................... 1
2. Shembull Aplikimi ............................................................................................................... 1
3. KOMENTIMI I TABELAVE TË KRIJUARA NË LIDHJE ME RREGULLIMIN E TË
DHËNAVE DHE PARAQITJEN E TYRE ................................................................................ 4
4. ANALIZA E VLERAVE EKSTREME (OUTLIERS)...................................................... 11
4.1. Shembull Aplikimi ..................................................................................................... 12
5. SHQYRTIMI I TË DHËNAVE QË MUNGOJNË ........................................................... 17
5.1. Shembull Aplikimi ..................................................................................................... 17
6. PLOTËSIMI I MUNGESËS SË TË DHËNAVE .............................................................. 32
2. STATISTIKAT PËRSHKRUESE ......................................................................................... 37
1. MATËSIT E TENDECËS QENDRORE .............................................................................. 37
1.1. Mesatarja Aritmetike ...................................................................................................... 37
1.2. Mediana (Mesorja) ......................................................................................................... 38
1.3. Moda............................................................................................................................... 38
2. MATËSIT E DEVIJIMIT NGA MESATARJA ................................................................... 39
2.1. Varianca ......................................................................................................................... 39
2.2. Devijimi Standart ........................................................................................................... 40
3. MATËSIT E DEVIJIMEVE NGA NORMALJA ................................................................. 40
3.1. Shpërndarja Normale Për Një Ndryshore....................................................................... 40
3.1.1. Shembull Aplikimi .................................................................................................. 41
3.2. Ngushtësia ...................................................................................................................... 46
3.3. Pjerrësia .......................................................................................................................... 46
4. Shembull Aplikimi ............................................................................................................. 47

v
3. TESTIMI I HIPOTEZAVE ................................................................................................... 52
1. PËRCAKTIMI I HIPOTEZAVE........................................................................................... 52
1.1. Hipoteza Zero (Null Hypothesis) ................................................................................... 52
1.2. Hipoteza Alternative (Alternative Hypothesis) .............................................................. 52
2. TESTET STATISTIKORE.................................................................................................... 53
3. TESTET NJË DHE DY ANËSORE ..................................................................................... 53
4. GABIMI I LLOJIT TË PARË DHE TË DYTË .................................................................... 55
5. NIVELI I RËNDËSISË (α) DHE INTERVALI I BESIMIT (1-α) ....................................... 55
6. MADHËSIA E MOSTRËS ................................................................................................... 57
6.1. Shembull Aplikimi ......................................................................................................... 57
4. TESTET PARAMETRIKE ................................................................................................... 60
1. SUPOZIMET E TESTEVE PARAMETRIKE...................................................................... 60
2. Testi T .................................................................................................................................... 61
2.1. Test T i dy Mostrave të Pavarura (Indepedent-Samplest t-Test) ................................... 62
2.1.1. Shembull Aplikimi .................................................................................................. 62
2.2. Testi T i dy Mostrave të Varura (Paired Samples t-Test) .............................................. 65
2.2.1. Shembull Aplikimi .................................................................................................. 65
2.3. Testi T i një Mostre(One-Sample t-Test) ....................................................................... 68
2.3.1. SHEMBULL APLIKIMI ........................................................................................ 68
3. TESTI-Z................................................................................................................................. 70
3.1. Testi Z një Mostërsh ....................................................................................................... 70
3.1.1. Shembull Aplikimi .................................................................................................. 71
3.2. Testi Z dy Mostrash........................................................................................................ 71
3.2.1. Shembull Aplikimi .................................................................................................. 72
4. ANALIZA E VARIANCËS (ANOVA) ................................................................................ 72
5. TESTET JO PARAMETRIKE (NON – PARAMETRIC) TË TESTIMIT TË
HIPOTEZAVE ............................................................................................................................ 74
1. TESTI KATRORI-KI ............................................................................................................ 75
1.1. Testi i Përshtatshmërisë i Katrorit-Ki dhe Shembull Aplikimi ...................................... 75

vi
1.2. Testi i Pavarësisë i Katrorit-Ki dhe Shembull Aplikimi ................................................ 80
1.3. Testi i Homogjenitetit i Katrorit-Kit dhe Shembull Aplikimi ........................................ 86
2. TESTI RUNS DHE SHEMBULL APLIKIMI ...................................................................... 89
3. TESTI MAN-WHITNEY U DHE SHEMBULL APLIKIMI ............................................... 93
4. TESTI WALD-WOLFOWITZ DHE SHEMBULL APLIKIMI ........................................... 95
5. TESTI WILCOXON SIGNED RANK DHE SHEMBULL APLIKIMI ............................... 98
6. TESTI KRUSKAL-WALLIS DHE SHEMBULL APLIKIMI ........................................... 102
7. TESTI FRIEDMAN DHE SHEMBULL APLIKIMI .......................................................... 104
8. KORRELACIONI SPEARMAN’S RANK ORDER DHE SHEMBULL APLIKIMI ....... 107
6. ANALIZA E KORRELACIONIT....................................................................................... 111
1. KOEFICIENTI I KORRELACIONIT TË PEARSONIT .................................................... 112
2. KOEFICIENTI I KORRELACIONIT TË PJESSHËM ...................................................... 113
3. MATËSIT E TJERË TË LIDHJES ..................................................................................... 113
3.1. PHI ............................................................................................................................... 113
3.2. Korrelacioni Rendor i Spearmanit................................................................................ 113
3.3. Koeficienti i Normalitetit ............................................................................................. 114
3.4. ETA .............................................................................................................................. 114
4. Shembull Aplikimi .............................................................................................................. 114
5. Shembull Aplikimi 2 ........................................................................................................... 118
5.1. Metoda Bivariate .......................................................................................................... 119
5.2. Metoda e Pjesshme (Partial) ......................................................................................... 122
5.3. Metoda Distances ......................................................................................................... 124
7. ANALIZA E VARIANCËS (ANOVA – MANOVA) ......................................................... 128
1. HYRJE ................................................................................................................................. 128
2. ANOVA NJË DREJTIMSHE ............................................................................................. 131
2.1. Shembull Aplikimi ....................................................................................................... 131
2.2. Daljet e SPSS-it dhe Interpretimi ................................................................................. 135
3. ANOVA DY DREJTIMSHE............................................................................................... 140

vii
3.1. Shembull Aplikimi ....................................................................................................... 140
3.2. Daljet e SPSS-it dhe Interpretimi ................................................................................. 148
4. MANOVA NJË DREJTIMSHE .......................................................................................... 157
4.1. Shembull Aplikimi ....................................................................................................... 157
4.2. Daljet e SPSS-it dhe Interpretimi ................................................................................. 161
5. MANOVA DY DREJTIMSHE ........................................................................................... 170
5.1. Shembull Aplikimi ....................................................................................................... 170
5.2. Daljet e SPSS-it dhe Interpretimi ................................................................................. 174
8. ANALIZA E KOVARIANCËS ........................................................................................... 198
1. AVANTAZHET E APLIKIMIT TË ANALIZËS SË KOVARIANCËS ........................... 199
2. FUSHAT E PËRDORIMIT TË ANALIZËS SË KOVARIANCËS ................................... 199
3. SUPOZIMET E ANALIZËS SË KOVARIANCËS ........................................................... 200
4. Shembull Aplikimi .............................................................................................................. 201
4.1. Hyrja e të Dhënave dhe Testimi i Supozimeve ............................................................ 201
4.2. Aplikimi i Analizës së Kovariancës ............................................................................. 207
9. REGRESIONI I THJESHTË LINEAR .............................................................................. 214
1. MODELI I REGRESIONIT TË THJESHTË LINEAR ...................................................... 214
2. PARAMETRAT E PARASHIKUARA (VLERËSUARA) ................................................ 214
3. Shembull Aplikimi .............................................................................................................. 215
3.1. Formimi i Modelit dhe Parashikimi i Parametrave ...................................................... 216
3.2. Interpretimi i Parametrave ............................................................................................ 216
4. PARASHIKIMI ME MODELIN E REGRESIONIT .......................................................... 216
4.1. Shembull Aplikimi ....................................................................................................... 217
4.2. Të Dalurat nga SPSS dhe Interpretimi ......................................................................... 219

viii
10. MODELI I REGRESIONIT TË SHUMËFISHTË LINEAR ......................................... 222
1. MODELI .............................................................................................................................. 222
2. TESTIMI I HIPOTEZAVE NË MODELIN E REGRESIONIT TË SHUMËFISHTË
LINEAR ...................................................................................................................................... 222
3. KOEFICIENTI I PËRCAKTIMIT ...................................................................................... 223
4. ZGJEDHJA E NDRYSHOREVE TË MODELIT ............................................................... 223
4.1. Metoda Enter ................................................................................................................ 223
4.2. Metoda e Shtimit të Ndryshoreve (Forward Selection) ............................................... 223
4.3. Funksioni i Elemnimit të Ndryshoreve (Backward Selection) ..................................... 224
4.4. Metoda e Shtimit dhe Largimit të Ndryshoreve (Stepwise Selection) ......................... 224
5. Shembull Aplikimi .............................................................................................................. 224
6. Daljet e SPSS-it dhe Interpretimi ........................................................................................ 232
11. MODELI I REGRESIONIT PROBIT (PROBIT REGRESSION MODELS) ............. 237
1. HYRJE ............................................................................................................................. 237
2. ANALIZA PROBIT NË SPSS ........................................................................................ 238
3. KOEFICIENTËT PROBIT .............................................................................................. 241
4. Shembull Aplikimi ........................................................................................................... 242
12. ANALIZA FAKTORIALE ................................................................................................ 258
1. FAZAT E ANALIZËS FAKTORIALE .............................................................................. 258
1.1. Vlerësimi i Përshtatshmërisë së Setit të të Dhënave për Analizën Faktoriale ............. 258
1.2. Përfitimi i Faktorëve..................................................................................................... 259
1.3. Rotacioni i Faktorëve ................................................................................................... 260
1.4. Emërimi i Faktorëve ..................................................................................................... 260
2. Shembull Aplikimi .............................................................................................................. 260
3. Të Dalurat nga SPSS-i dhe Interpretimi Për Analizën Faktoriale ....................................... 266
3.1. Vlerësimi i Përshtatshmërisë së Setit të të Dhënave Për Analizën Faktoriale ............. 266
3.2. Përcaktimi i Numrit të Faktorëve ................................................................................. 267
3.3. Variancat e Përbashkëta të Ndryshoreve ...................................................................... 268
3.4. Faza e Rotacionit .......................................................................................................... 269

ix
3.5. Emërimi i Faktorëve ..................................................................................................... 270
3.6. Rezultatet Faktoriale .................................................................................................... 271
13. ANALIZA DISKRIMINUESE (DISCRIMINANT ANALYSIS) ................................... 273
1. QËLLIMET E PËRDORIMIT TË ANALIZËS DISKRIMINUESE .................................. 273
2. SUPOZIMET E ANALIZËS DISKRIMINUESE ............................................................... 273
3. MADHËSIA E DUHUR E SETIT TË TË DHËNAVE PËR ANALIZËN
DISKRIMINUESE ..................................................................................................................... 274
4. SHEMBULL APLIKIMI ..................................................................................................... 274
5. DALJET E SPSS-it DHE INTERPRETIMI PËR ANALIZËN DISKRIMINUESE .......... 282
5.1. VLERËSIMI I SUPOZIMEVE TË ANALIZËS DISKRIMINUESE ......................... 282
5.2. VLERËSIMI I RËNDËSISË SË FUNKSIONEVE TË NDARJES (DISRCRIMINANT)
283
5.3. VLERËSIMI I RËNDËSISË SË NDRYSHOREVE TË PAVARURA NË ANALIZËN
E DISKRIMINIMIT ................................................................................................................ 284
5.4. FUNKSIONI I DISKRIMINIMIT DHE INTERPRETIMI ......................................... 285
5.5. VLERËSIMI I RËNDËSISË SË ANALIZËS SË DISKRIMINIMIT ......................... 286
14. ANALIZA E GRUPIMIT (CLUSTER ANALYSIS) ....................................................... 290
1. PROCESI I VENDIMMARRJES PËR ANALİZËN E GRUPIMIT .................................. 291
1.1. Qëllimet e Analizës së Grupimit .................................................................................. 294
1.2. Plani i Hulumtimit në Analizën e Grupimit ................................................................. 294
1.3. Matjet e Ngjashmërive ................................................................................................. 294
1.4. Matjet e Korrelacionit .................................................................................................. 297
1.5. Matjet e Distancës ........................................................................................................ 298
1.6. Matja e Partneriteteve................................................................................................... 301
1.7. Standardizimi i të Dhënave .......................................................................................... 301
1.8. Supozimet e Analizës së Grupimit ............................................................................... 302
1.9. Zgjedhja e një Algoritmi të Grupimit ........................................................................... 302
1.10. Grupimi Hierarkik .................................................................................................... 303
1.11. Përcaktimi i Numrit të Grupeve ................................................................................ 303

x
1.12. Koeficientët e Distancës ........................................................................................... 304
1.13. Grafiku i Pemës ........................................................................................................ 304
1.14. Grupimi Johiearkik ................................................................................................... 305
1.15. Rregullimi i Analizës së Grupimit ............................................................................ 306
1.16. Interpretimi i Grupeve .............................................................................................. 307
1.17. Vlefshmëria dhe Profili i Grupeve ............................................................................ 307
2. Shembull Aplikimi .............................................................................................................. 308
2.1. Analiza e Grupimit Hiearkik ........................................................................................ 308
2.2. Analiza e Grupimit Johiearkik ..................................................................................... 318
15. ANALIZA E BESUESHMËRISË (RELIABILITY ANALYSIS) .................................. 327
1. SUPOZIMET E ANALIZËS SË BESUESHMËRISË ........................................................ 328
2. ANALIZAT DHE TESTET NË LIDHJE ME MATËSIT .................................................. 328
3. MODELET E PËRDORURA NË ANALIZËN E BESUESHMËRISË ............................. 329
3.1. Modeli Alfa (α) (Cronbach Alpha Coefficient) ........................................................... 329
3.2. Modeli Ndarës Mëdysh (Split Half) ............................................................................. 330
3.3. Modeli Guttman ........................................................................................................... 330
3.4. Modeli Paralel .............................................................................................................. 330
3.5. Modeli Strikt Paralel .................................................................................................... 330
4. Shembull Aplikimi .............................................................................................................. 331
5. Shembull Aplikimi .............................................................................................................. 334


1. RREGULLIMI DHE PARAQITJA E TË
DHËNAVE

1
RREGULLIMI DHE PARAQITJA E TË DHËNAVE
1. ORGANIZIMI I TË DHËNAVE Përpara se të fillohet me analizat statistikore, gjëja e parë që duhet të bëj një hulumtues
është rregullimi i të dhënave të punimit. Në qoftë se punohet me numër të madh të të dhënave
është e dobishme që të shikohet forma e të dhënave dhe pikat e lakimit përmes tabelave të
shpërndarjes së frekuenacave dhe grafiqeve të ndryshme. Më tej, ky stil është një shfaqje dhe
siguron paraqitjen e të dhënave në një mënyrë më të qartë në qoftë se punohet me shumë
ndryshore.
Në punimet statistikore në mënyrë për zbatimin e shumë analizave, shpërndarja e të
dhënave duhet të jetë normale apo afër normales. Për të parë shpërndarjen e të dhënave, përdoren
grafiqe të ndryshme si histogrami, grafiku handle box, grafiku detrended normal, leaves branches
etj. Po ashtu përdoren edhe testet Kolmogrov Smirnov dhe Shapiro Wilks.
2. Shembull Aplikimi Duke përdorur vlerat mujore të indeksit të IMKB-100 si ndryshore të varur dhe vlerat
mujore të interesit të thesarit si ndryshore e pavarur, do të bëhet shpjegimi i shpërndarjes dhe
paraqitjes së të dhënave.
Tabela 1: Të Dhënat Mujore Për Indeksin IMKB-100 dhe Normave të Interesit Për Bonot e
Thesarit
Indeksi i të
dhënave për
IMKB-100
Indeksi i të dhënave
për IMKB-
100Normat e
interesit për bonot e
thesarit
Indeksi i të
dhënave për
IMKB-100
Indeksi i të dhënave
për IMKB-
100Normat e
interesit për bonot e
thesarit
2635,14 92,26 19206,00 34,36
2265,94 137,29 16206,00 40,47
2196,38 141,34 14466,00 44,82
2577,54 145,20 13870,00 35,59
2597,91 145,19 13132,06 33,44
2568,16 130,21 11350,30 36,04
3890,83 124,80 13538,44 38,00
4544,07 103,82 8747,68 41,00
5354,03 100,57 9437,21 41,01
5069,22 100,46 10685,07 64,93
4950,21 11,50 8791,60 124,21
5805,45 102,88 8022,72 193,71

2
5018,28 115,17 12367,36 130,42
6071,12 112,09 10879,83 82,19
6509,92 109,21 11204,24 88,38
8459,48 94,63 9914,61 95,02
15208,78 94,64 9878,88 92,63
16715,00 38,20 7625,87 87,39
15946,00 42,09 9848,76 86,39
15920,00 39,21 11633,93 79,32
Në hapin 1, përmes Analyze zgjedhet Descriptive Statistics dhe pastaj Explore.
Hapi 1: Dritarja Për Rregullimin e të Dhënave
Në kutinë Dependent vendoset ndryshorja IMKB dhe në Label Cases By ndryshorja bonot
e thesarit.
Pas kësaj klikohet në tabin Statistics. Në këtë pjesë përzgjedhen Descriptives dhe Outliers
dhe pastaj klikoket në butonin Continue.

3
Hapi 2: Dritarja e Statistikave Përshkruese
Pastaj klikohet butoni Plots. Te pjesa Boxplots përzgjedhet Factors levels together, te
pjesa Descriptive përzgjedhen Stem-and-leaf dhe Histogram. Së fundi, përzgjedhet dhe
Normality Plots with tests dhe klikohet në butonin Continue.
Hapi 3: Dritarja e Grafiqeve

4
3. KOMENTIMI I TABELAVE TË KRIJUARA NË LIDHJE ME RREGULLIMIN E
TË DHËNAVE DHE PARAQITJEN E TYRE
Tabela 2: Numri i të Dhënave Totale të Futura në Aplikim
Cases
Valid Missing Total
N Percent N Percent N Percent
imkb 40 100.0% 0 0.0% 40 100.0%
Tabela 2 tregon se nga të dhënat e IMKB-së 40 të dhëna janë përdorur plotësisht. Në
setin e të dhënave nuk ka aspak të dhëna mangu (missing value).
Tabela 3: Statistikat Përshkruese
Statistic Std. Error
imkb Mean 9128.4505 746.38833
95% Confidence Interval for
Mean
Lower Bound 7618.7376
Upper Bound 10638.1634
5% Trimmed Mean 9020.9639
Median 9114.4050
Variance 22283821.307
Std. Deviation 4720.57426
Minimum 2196.38
Maximum 19206.00
Range 17009.62
Interquartile Range 7909.87
Skewness .205 .374
Kurtosis -.941 .733

5
Një vrojtim numerik paraqet mesataren aritmetike të grupit pjesëtuar me numrin total të
vrojtimeve në grup. Nëse shuma e devijimeve nga vlera mesatare e çdo vrojtimi pjestohet me
numrin e vrojtimeve dhe duke marrë rrënjën katrore gjendet devijimi standard. Katrori i devijimit
standart jep variancën. Në këtë tabelë shihen statistikat përshkruese në bazë të ndryshores së
varur (IMKB). Sipas tabelës, mesatarja aritmetike e 40 të dhënave (IMKB) është gjetur si
9128,4505 dhe devijimi standart për 4720,57426. Po ashtu, me 95% besueshmëri, janë dhënë
vlerat me limitet më të ulëta dhe më të larta (intervali i besueshmërisë), 7618,7376 dhe
10638,1634. Llogaritja e hapësirës që mbetet në mes të madhësisë së vlerësuar quhet “interval
besueshmërie”.
Mesatarja e këtyre të dhënave është 9020,9639. Mesatarja është vlerë e cila e ndan serinë e
të dhënave në dy pjesë të barabarta. Vlerat minimale dhe maksimale të serisë së të dhënave janë
2196,38 dhe 19206,00.
Në punimet statistikore shpërndarja më e përdorur është shpërndarja normale. Zakonisht,
shumë ndodhi tregojnë shpërndarje normale. Për shembull, gjatësia e një grupi të studentëve
tregon një shpërndarje normale. Shpërndarja normale është një shpërndarje e vazhdueshme dhe
mesatarja e popullsisë µ, devijimi standart σ janë shpërndarje. Shpërndarja normale është
simetrike. Forma e saj është lakore. Vlera më e lartë e shpërndarjes simetrike është e barabartë
me mesataren dhe mesataren aritmetike të saj.
Në këtë tabelë statistikat përshkruese më të rëndësishme janë matësit e kurtozës (kurtosis)
dhe pjerrësisë (skewness). Këto vlera tregojnë se a janë shpërndarë të dhënat në mënyrë normale.
Në rastet simetrike (lakore e drejtë), mesatarja aritmetike, teksa moda dhe mediana duke qenë të
barabarta koeficienti i lakueshmërisë (skewness) do të jetë zero. Në qoftë se ky barazim prishet,
shpërndarja do të deformohet. Me rritjen e deformimit moda dhe mesatarja atirmetike do të
largohen nga njëra tjetra. Në qoftë se është më e madhe se mediana mesatare, shpërndarja e
vlerave për njësi do të lëviz në të djathtë (devijim pozitiv). Në qoftë se është më e vogël se
mediana mesatare, shpërndarja e të dhënave lëviz në të majtë (devijim negativ). Koeficienti i
devijimit merr vlerat ndërmjet – ∞ dhe + ∞. Por kur në raste matësi i devijimit merr vlera prej ±3
(sipas disa gjykimeve ±2) pranohet si normale.
Vlera në tabelë prej 0,204 është koeficienti i devijimit të Fisherit. Duke e pjestuar me
gabimin standart të devijimit, nxirret vlera e devijimit. Koeficienti i devijimit standardizohet
duke u pjestuar me gabimin e vet standart. Më vonë këto vlera kritike standarde krahasohen me
vlerat në tabelë. Ky përfundim, mund të komentohet për nga aspekti i lakimit të shpërndarjes
normale. Kjo vlerë e devijimit është e pranueshme në nivelin e rëndësisë (5% sipas nivelit të
rëndësisë) ndërmjet vlerave 1,96 ose nën vlerat -1,96.
Sepse, vlerat në shpërndarjen normale marrin pjesë në mes të devijimit standart mesatarisht
ndërmjet +1,96 dhe -1,96. Në këtë rast kur koeficienti i devijimit 0,205 me gabim të devijimit
standart 0 pjestohet me 374 (0,205/0,374) fitohet vlera prej 0,548. Kjo vlerë tregon që të dhënat

6
janë të shpërndara afër normales sepse gjendet ndërmjet -1,96 dhe +1,96. Kur kjo vlerë është
pozitive lakimi bëhet në të djathtë, kurse në rastin kur është negative lakohet në të majtë. Në
rastin tonë për arsye se vlera e dalur është pozitive mund të thuhet se shpërndarja lakohet në të
djathtë. Përveç kësaj, kjo gjë kuptohet edhe ngase grupi i të dhënave është më i madh se
mesatarja aritmetike, gjë që shpërndarja ka prirje në të djathtë.
Kurtoza tregon sa kurba e shpërndarjes normale. është e drejtë apo e shtypur Për një lakore
të plotë, koeficienti i shtypjes është zero. Kur lakorja sipas normales është më e drejtuar,
koeficienti i shtypjes është pozitiv. Kurse kur është negativ, lakorja është më e shtypur. Në
tabelën 3, koeficienti i Fisherit është -0.941. Kur gabimi standart i lakimit të pjestohet me 0,733
(-0.941/0,733) gjendet vlera prej 1,284. Kjo vlerë për arsye se gjendet ndërmjet -1,96 dhe +1,96
mund të themi se lakorja nuk është e drejtë.
Grafiqet janë paraqitje e të dhënave statistikore në mënyrë që të shihen me sy. Të dhënat
statistikore nuk paraqiten vetëm me tabela apo numra. Për më tepër, grafiqet sigurojnë një
paraqitje më të bukur të të dhënave për shqyrtuesin. Grafiqet më të përdorura janë histogrami dhe
stem and leaf.
Figura 1: Paraqitja e Histogramit Për Të Dhënat e Indeksit Të IMKB 100
Vijat e histogramit tregojnë se sa herë të dhënat nominale (klasifikuese) apo ordinale
(rendore) përsëriten. Teksa boshti horizontal bën klasifikimet në mënyrë sistematike, vijat
vertikale tregojnë frekuencat për secilën kategori dhe përqindjen që përfaqësojnë. Në qoftë se e
shohim histogramin e të dhënave për IMKB, lakorja nuk është plotësisht simetrike dhe është e

7
kthyer në të djathtë. Të qenurit plotësisht simetrike nënkupton që të dhënat janë plotësisht të
shpërndara normal.
Gjatë shqyrimit të të dhënave, një grafik tjetër i përdorur është edhe grafiku steam and
leaf. Grafiku steam and leaf, i klasifikon të dhënat në të majtë, përbrenda një klase çdo vrojtim
klasifikohet në të djahtë. Grafiku steam and leaf i përngjan histogramit, mirëpo histogrami për
intervale të caktuara teksa paraqet numrin e rasteve përmes vijave në grafik, nuk mund të
specifikojë detajet e vlerave në interval.
Tabela 4: Tabela Stem and Leaf Për Indeksin e Të Dhënave Për IMKB 100
Frequency
(Frekuencat)
Stem & Leaf
7,00 0,222223
6,00 0,445555
3,00 0,667
8,00 0,88889999
5,00 1,0011
4,00 1,2333
4,00 1,4555
2,00 1,66
1,00 1,9
Stem width: 10000,00
Each leaf: 1 case (s)
Për shembull, në tabelën e 4, rreshti i parë tregon që ekzistojnë 7 të dhëna të cilat fillojnë
me 2000 dhe 3000.

8
Figura 2: Grafiku i Shpërndarjes Normale Për Të Dhënat e IMKB
Kur të bëhet analiza e normalitetit për të dhënat, përdoret grafiku i probabilitetit i cili
paraqet të dhënat e vlerave të vrojtuara me atyre të pritura mbi një grafik. Në qoftë se popullimi i
cili tregon një shpërndarje normale është marrë nga një pjesë, vlerat duhet të mblidhen në këtë
drejtim apo përrreth. Po të shohim normalitetin e të dhënave për IMKB 100, për arsye se të
dhënat janë të shpërndara në këtë drejtim, mund të themi se grupi i të dhënave është afër
normales.
Një grafik tjetër i normalitetit është grafiku me prirje më pak të normalitetit. Në figurën 3
shihet grafiku Detrended Normal Plot për të indeksin e të dhënave të IMKB 100.

9
Figura 3: Grafiku Me Pak Prirje Normaliteti Për Indeksin e Të Dhënave Për IMKB 100
Në qoftë se një grup i të dhënave tregon shpërndarje normale dhe vlerat e shfaqura mbi zero
tregojnë devijimin në grafikun (detrend) e probabilitetit, shpërndarja e pikave vertikalisht mbi
boshtin “0” pa formuar ndonjë funksion me pikat përrreth është e rastësishme. Siç shihet në
figurën 3 seti i të dhënave për IMKB është i shpërndarë afër normales.
Metodë tjetër për kryerjen e analizës së normalitetit është edhe grafiku handle box. Në
figurën 4 është paraqitur grafiku handle box për indeksin e të dhënave të IMKB.

10
Figura 4: Diagrami Handle Box Për Të Dhënat e IMKB-së
Diagrami Handle Box, është një prej llojeve të grafiqeve të statistikave përshkruese që
bazohet në përqindje. Gjatësia e formës, paraqet hapësirën ndërmjet çerekëve. Pra, fillon me
përqindjen e 25-të dhe mbaron me përqindjen e 75-të. Këto përqindje quhen Tugey’s Hings.
Kutia jep informata rreth prirjes qendrore dhe përhapjes në 50% të shpërndarjes. Përmes
mesatares është e mundur që të përcaktohet tendenca qendrore, kurse përmes gjatësisë së kutisë
shpërndarja e vrojtimeve. Në qoftë se mesatarja gjendet nën vijën e qendrës, shpërndarja ka një
lakim pozitiv, në qoftë se gjendet mbi lakim është negativ. Kurse nëse gjendet në mes tregon
shpërndarjen normale të vendit të të dhënave. Siç shihet në figurën 4, në grafikun e handle box së
indeksit së të dhënave të IMKB 100, të dhënat të cilat gjenden nën kuti janë të lakuara në të
djathtë. Si dhe për shkak që nuk gjendet ndonjë e dhënë jashtë kutisë nuk ka vlera ekstreme
(outliers).
Tabela 5: Testi i Normalitetit Për Të Dhënat e IMKB
Tests of Normality
Kolmogorov-Smirnova Shapiro-Wilk
Statistic df Sig. Statistic df Sig.
imkb .091 40 .200* .958 40 .141
Grafiqet e normalitetit dhe grafiqet e tjera (histogrami, diagrami i kutisë dhe grafiku steam
and leaf) na ndihmojnë për të i kuptuar disa pika. Por testi i normalitetit kuptohet duke i përdorur
testin Kolmogrov-Smirnov dhe Shapiro Wilk. Kur numri i vrojtimeve është më i vogël se 29

11
përdoret Shapiro-Wilk, kurse kur numri i vrojtimeve është më i madh se 29 përdoret Kolmogrov-
Smirnov. Për shkak se numri i të dhënave tona është 40, do të përdoret testi Kolmogrov-
Smirnov. Hipotezën null H0 dhe hipotezën alternative HA të këtij testi mund t’i shkruajmë si më
poshtë:
H0: Shpërndarja e të dhënave ndjek shpërndarjen normale.
HA: Shpërndarja e të dhënave nuk ndjek shpërndarjen normale.
Sipas nivelit të rëndësisë 5%, për shkak që vlera e të dy testeve (0,2 dhe 0,141) e indeksit të
të dhënave të IMKB 100, janë më të mëdha se 5%, hipoteza H0 pranohet. Pra, mund të thuhet se
të dhënat janë të shpërndara në mënyrë normale.
4. ANALIZA E VLERAVE EKSTREME (OUTLIERS) Gjatë analizës të setit së të dhënave, faza tjetër është hulumtimi për vlera ekstreme.
Ekzistojnë dy arsye të rëndësishme për hulumtimin e vlerave ekstreme në setin e të dhënave:
1. Duke i zbuluar vlerat ekstreme, mund të bëhet nxjerrja e tyre nga seti i të dhënave për
arsye se do të pengojnë përfitimin e rezultateve normale.
2. Vlerat ekstreme në të njëjtën kohë mund të jenë një burim informacioni. Pasi të zbulohen
vlerat ekstreme, kërkohen arsyet e tyre.
Vlerat ekstreme ndahen në dy lloje; vlera shumë ekstreme (extreme value) dhe vlera të
veçanta (outlier value). Arsyet ekstreme mund të jenë këto:
1. Hyrja gabuese e të dhënave apo kodim i gabuar
2. Vrojtimi i rrallë i një rasti.
Mund të ndërhyhet në dy mënyra me vlerat ekstreme:
Vlerat ekstreme mund të korrigjohen në fazën e pastrimit të të dhënave
Hulumtuesi mund të vendos për nxjerrjen e vlerave esktreme në bazë të rëndësisë së
hulumtimit.
Në qoftë se ka ndonjë vlerë ekstreme e cila është paraqitur për ndonjë arsye të panjohur,
atëherë mund të nxirret nga seti i të dhënave.

12
4.1. Shembull Aplikimi Më poshtë janë paraqitur orët shtesë të punës së bërë nga 20 punonjës.
Tabela 6: Orët Shtesë të Punës të Punonjësve
Punonjësi Ora
1 2
2 4
3 3
4 6
5 2
6 6
7 3
8 4
9 12
10 3
Punonjësi Ora
11 6
12 1
13 3
14 5
15 15
16 3
17 5
18 6
19 5
20 14
Për këto të dhëna mund të shohim se cilat vlera janë vlera ekstreme, pra cilët punonjës
kanë punuar më shumë orë për nga punonjësit e tjerë. Për ta bërë këtë, siç u tregua në shembullin
e mëparshëm, zgjedhet Analyze Descriptive Statistics Explore. Këtu, në pjesën
Dependent bartet “ora”, kurse në pjesën Label Cases by “punonjësi”. Pastaj nga pjesa Statistics
përzgjedhet Outliers. Në figurën e mëposhtme, në grafikun e kutisë mund të shihen vlerat shumë
extreme (extreme values) dhe vlerat e veçanta (outlier values). Në këtë rast, mund të shihet se 15
punonjës kanë vlera shumë të larta ekstreme, pra punojnë më shumë orë për nga të tjerët. Mund
të shihet se punonjësi i njëzet dhe nëntë kanë vlera ekstreme. Në të njëjtën kohë, mund të shihet
se shpërndarja në kutinë e mëposhtme ka prirje në të djathtë.
Figura 5: Diagrami i Kutisë për Orët Shtesë

13
Tani të shohim histogramin dhe grafikun e normalitetit të këtyre vlerave.
Figura 6: Histogrami i Orëve Shtesë të Punës
Në grafikun e histogramit, po të shpërndaheshin të dhënat në mënyrë normale, do të duhej
që pjerrësia të ishte simetrike, por nga grafiku shihet se është e lakuar pak në të djathtë.
Figura 7: Grafiku i Normalitetit për Orët Shtesë të Punës

14
Në figurën 7, mund të shihet se devijimet në drejtim të regresionit janë të shumta. Pra,
shpërndarja nuk është plotësisht normale.
Tabela 7: Testi i Normalitetit për Orët Shtesë të Punës
Tests of Normality
Kolmogorov-Smirnova Shapiro-Ëilk
Statistic df Sig. Statistic df Sig.
ora .289 20 .000 .793 20 .001
a. Lilliefors Significance Correction
Në analizën e normalitetit të të dhënave, H0 refuzohet ngaqë të dy testet janë më të vegjël
se 5%. Pra, të dhënat nuk janë të shpërndara në mënyrë normale.
Tani, të e kryejmë analizën përsëri duke i nxjerrur vlerat shumë ekstreme dhe vlerat e
veçanta si dhe duke i ndryshuar disa vlera të tjera.
Tabela 6: Orët Shtesë të Punës të Punonjësve pas Nxjerrjes së Vlerave Ekstreme
Punonjësi Ora
1 1
2 3
3 4
4 2
5 5
6 3
7 4
8 2
10 1
Punonjësi Ora
11 5
12 3
13 4
14 3
16 1
17 1
18 4
19 3

15
Figura 8: Histogrami për Orët e Punës Shtesë pas Nxjerrjes së Vlerave Ekstreme dhe
Shumë Ekstreme
Histogrami është plotësisht simetrik. Pra, të dhënat tani kanë formën plotësisht normale.
Paraqitja e kutisë grafike plotësisht në mes, tregon që të dhënat ndjekin shpërndarjen normale.
Figura 9: Diagrami i Kutisë Për Orët Shtesë të Punës pas Nxjerrjes së Vlerave Ekstreme
dhe Shumë Ekstreme

16
Përveç diagramit të kutisë, kur shikojmë grafikun e normalitetit (figura 9), mund të
vërejmë se devijimet janë më të vogla nga vija e regresionit dhe se janë shumë afër shpërndarjes
normale.
Figura 9: Grafiku i Normalitetit për Orët Shtesë të Punës pas Nxjerrjes së Vlerave
Ekstreme dhe Shumë Ekstreme
Tabela 10: Testi i Normalitetit Për Orët Shtesë të Punës pas Nxjerrjes së Vlerave Ekstreme
dhe Shumë Ekstreme
Tests of Normality
Kolmogorov-Smirnova Shapiro-Ëilk
Statistic df Sig. Statistic df Sig.
ora .181 17 .140 .902 17 .073
a. Lilliefors Significance Correction
Kur shikojmë testet e normalitetit, ngaqë që të dy janë më të mëdha se 5%, H0 pranohet.
Pra, shpërndarja e të dhënave është normale.

17
5. SHQYRTIMI I TË DHËNAVE QË MUNGOJNË Mungesa e të dhënave (missing values), me të vërtet është një situatë me të cilën mund të
përballemi gjatë bërjes së çfarëdo analize. Për shembull, gjatë bërjes së një ankete, përgjegjësi
mund t’a lë të zbrazët pyetjen në lidhje me të ardhurat. Përsëri, mund të që të mos i siguroni disa
vlera të vrojtimeve në lidhje me disa ndryshore. Çfarë duhet bërë në të këtilla raste?
Procesi i cili buron nga përgjegjësi apo jashtë tij dhe që i hap rrugën humbjes së të
dhënave, quhet proces i mungesës së të dhënave. Parashikimi i procesit të mungesës së të
dhënave që buron nga përgjegjësi është i pamundur. Në këtë situatë, hulumtuesi duhet të kërkojë
se a ekziston ndonjë strukturë e cila e zbulon procesin e mungesës së të dhënave. Gjatë
shqyrtimit të kësaj, hulumtuesi duhet të marrë në konsideratë dy pika të rëndësishme:
Të dhënat mangu a janë shpërndarë në mënyrë të rastësishme ndërmjet vrojtimeve apo
është krijuar ndonjë strukturë e veçantë?
Duhet të hulumtohet se sa shpesh ndeshemi me të dhëna mangu.
Disa hulumtues i largojnë nga grupi i të dhënave vrojtimet të cilat i hapin rrugë mungesës
së të dhënave. Në këtë rast, ndonjëherë përveç që zvogëlohet në mënyrë të konsiderueshme
numri i vrojtimeve, mund të ndikojë në mënyrë negative madhësinë e mjaftueshme të mostrës.
Po ashtu, kjo do të ndikojë në mënyrë te konsiderueshme edhe besueshmërinë dhe rezultatet e
hulumtimit. Prandaj, kur te përballemi me mungesë të të dhënave, mund të bëhen këto gjëra:
Mund të shtohen vlera të reja të vrojtimeve.
Përmes çasjeve të ndryshme statistikore provohet të gjendet zgjidhje për vlerat që
mungojnë.
Qëllimi i shqyrtimit të mungesës së të dhënave, është që kuptohet se në cilën ndryshore
dhe në çfarë mase ekziston mungesë e të dhënave, të dhënat a mungojnë vetëm për një
ndryshore apo edhe për tjetrën, në çfarë niveli do të ulet numri i vrojtimeve në qoftë se fshihet
ndryshorja me mungesë të të dhënave.
5.1. Shembull Aplikimi Në tabelën e mëposhtë janë dhënë vlerat mujore të indeksit të IMKB-100 si ndryshore e
varur dhe vlerat mujore të çmimit të arit të shtetit, indeksit të industrisë së prodhimit, normave të
interesit të depozitave dhe të indeksit të çmimit të konsumatorëve si ndryshore të pavarura. Nga
vlerat e 60 vrojtimeve, ekziston mungesë e disa vlerave.

18
Tabela 10: Të Dhënat Përkatëse Të Shembullit
IMKB-100 ARI SHTET. NOR.
DEPOZ.
INDUS.
PRODH.
IÇK
36,41 208333 37,26 68,5 3,8
, 212833 , 70 4,4
32,94 211503 35,96 79,6 5,2
33,08 208666 35,99 65 ,
, 206500 36,02 71,7 3,1
41,33 203500 36,21 71,5 1,4
53,84 , 36,24 62,5 -0,9
49,39 228250 36,27 67,9 2,5
50,85 , 36,37 79,5 8,7
45,7 232000 36,93 84,3 6,8
, 230000 37,77 , 5
32,56 236500 38,69 72,6 1,7
42,13 254750 40,01 63,6 ,
51,03 272000 42,06 72,5 5,4
, 281000 45,97 81,9 4,4
35,54 , 48,35 66,5 6,6
36,26 311500 51,96 81,3 3,3
35,87 309750 52,13 , 3
30,41 355333 52,75 74,4 ,
33,01 353333 53,82 72,8 4
, 356000 , 80,9 6,1
27,47 378000 57,9 85,1 6,6
40,58 390250 58,14 82,8 5,2
43,69 , , , 4,4
49,26 412200 57,38 76,8 9,4
36,64 440000 56,87 76,8 5
40,77 463750 , 82,1 4,9
36,86 476000 58,01 71,7 3,8
32,97 495600 58,43 80,6 0,9
44,07 , 58,42 72,3 0,5
42,64 531100 57,94 78,9 1,3
41,58 531666 57,06 74,8 ,
39,76 , 57,12 85,4 7,4
36,43 566500 57,07 86,8 7,6
37,86 594000 57,54 83 4,9
40,04 614600 57,6 80,9 2,7
43,83 635250 57,66 79,4 5,3
59,24 659000 54,95 80,1 4
58,64 683000 52,74 79,5 4,8
, 718000 52,81 , 4,4

19
IMKB-100 ARI SHTET. NOR.
DEPOZ.
INDUS.
PRODH.
IÇK
83,76 821250 52,83 83,2 4,7
107,79 876666 52,82 78,1 1,8
100,78 996666 52,82 85,8 4,9
123,57 1003750 52,83 77 2,7
150,8 964500 52,86 90,4 5,6
145,01 1022000 , 90,3 ,
189,77 1126670 52,9 87,1 6,4
206,83 1197500 52,88 92,5 3,6
, 1366250 56,35 86,2 4,4
150,04 1543750 68,67 77,2 6
140,87 1930000 71,42 81 5,2
150,97 2476000 , 73,8 24,7
147,49 , 118,71 69,6 10
197,66 2555000 114,53 71,5 0,9
217,52 2551000 64,46 , 1,7
252,82 2610000 54,46 76,7 2
, 2870000 54,37 83,9 7,2
248,9 2982500 49,74 84,6 9,5
281,81 3030000 59,79 84,7 ,
272,57 3064000 61,79 81,9 6,3
Duke shkuar tek Analyze, Missing Value Analyze në SPSS, mund të bëhet shqyrtimi i të
dhënave që mungojnë.

20
Hapi 1: Menyja e Missing Value Analyze
Në pjesën Estimation, siç shihet më poshtë do të ndeshemi me 4 metoda. Më poshtë janë
dhënë informata të përgjithshme rreth këtyre metodave.

21
Hapi 2: Dritarja e Missing Value Analysis
1. Metoda Listwise (Metoda e Përdorjes së Vrojtimeve të Plota): Në këtë metodë,
merren në konsideratë vetëm vrojtimet e plota. Vrojtimet mangu nuk merren në
konsideratë. Kjo metodë për arsye se merr në konsideratë vrojtimet e plota sugjerohet të
përdoret në rastet kur numri i të dhënave mangu është i vogël. Është një metodë e cila
përdoret shumë. Përveç kësaj, struktura e të dhënave mangu, duhet të jetë plotësisht e
rastësishme.
2. Metoda Pairwise: Kjo analizë përfshin ndryshoret të dhënat e të cilave janë të plota.
3. Metoda e Regresionit: Qëllimi i metodës së regresionit është që me ndihmën e një apo
më shume ndryshoreve të pavarura të testohen vlerat e ndryshores së varur. Në metodën e
regresionit, ndryshorja e varur është ndryshorja mangu e vëzhguar, kurse ndryshoret tjera
janë të pavarura. Kjo metodë sugjerohet të përdoret veçanërisht në rastet kur numri i të
dhënave mangu nuk është i madh. Për ta përdorur këtë metodë, lidhja ndërmjet
ndryshores së varur dhe ndryshores së pavarur duhet të jetë shumë e fuqishme.
4. Metoda EM (Expectation-Maximization): Metoda EM, është një metodë dy fazash dhe
e cila përsëritet. Faza E jep vlerësimet më të mira të mundshme për të dhënat që
mungojnë, kurse faza M jep vlerësime në lidhje me mesataren, devijimin standart apo

22
korrelacionin për të dhënat që mungojnë. Ky proces vazhdon deri në shkallën e zvogëlimt
të papërfillshëm të ndryshimit në vlerat e parashikuara.
Hapi 3: Dritarja e Missing Value Analysis
Të gjitha ndryshoret barten në pjesën Quantitative Variables. Nga pjesa Estimation
zgjedhet metoda Listwise sepse numri i plotë i vrojtimeve është më i madh se numri mangu i
vrojtimeve. Pas kësaj, shkohet te përzgjedhjet Patterns dhe Descriptives.
Pasi të jetë hyrë në përzgjedhjen Patterns etiketohen të gjitha zgjedhjet në pjesën
Display. Në të njëjtën kohë, në pjesën Variables, të gjitha ndryshoret transferohen në pjesën
Additional Information For. Pastaj klikohet në butonin Continue.

23
Hapi 4: Dritarja Patterns
Pas kësaj, shkojmë te përzgjedhja Descriptives. Edhe këtu etiketohen të gjitha
alternativat dhe klikohet në butonin Continue.

24
Hapi 5: Dritarja Descriptives
Më poshtë do të shqyrtohen me radhë të gjitha të dalurat, mirëpo në fillim duhet të bëhet
testi i rastësisë për mungesën e të dhënave. Në të dalurat statistikore, sa është e rëndësishme
tërheqja e një mostre nga popullimi, po aq është e rëndësishme rastësia e të dhënave mangu në
një mostër.
Për të dhënë një numër konkluzionesh rreth popullimit, duhet që mostra të mirret në një
madhësi të caktuar nga popullimi. Mundësia e zgjedhjes së njësive nga popullimi që do të
përdoren në mostër duhet të jetë e njëjtë dhe zgjedhja e një njësie nuk duhet të ndikojë zgjedhjen
e një njësie tjetër. Pra, secila njësi duhet të ketë probabilitet të barabartë për t’u zgjedhur nga
popullimi. Kjo situatë quhet rastësi. Në strukturën e të dhënave, vrojtimet e një ndryshoreje
mund të i ndajmë në dy grupe; në vrojtime të cilat kanë mungesë të të dhënave dhe të atyreve që
nuk kanë mungesë. Për të hulumtuar se a ekziston një dallim i rëndësishëm për nga aspekti i
vlerave të ndryshoreve tjera (të dy grupeve) bëhet testi T, ose ndryshoret reduktohen në dy
forma; në ato që kanë mungesë të të dhënave dhe ato që nuk kanë mungesë të të dhënave. Për
shembull, të supozojmë se jemi duke punuar në një mostër e cila ka dy ndryshore. Njëra
ndryshore le të jetë shuma e qerasë (ndryshorja e varur) dhe ndryshorja tjetër le të jenë të
ardhurat (ndryshorja e pavarur). Në ndryshoren e të ardhurave le të gjendet mungesë e
vrojtimeve. Le të e ndajmë ndryshoren e të ardhurave në dy grupe; në vrojtime mangu dhe në
vrojtime të plota dhe në secilin grup të hulumtojmë se a ka dallim ndërmjet mesatareve të qerasë.
Në qoftë se në këto dy grupe ekziston një dallim jo i rëndësishëm në mesataret e qerasë, atëherë
mund të thuhet se mungesa e të dhënave është e rastësishme. Në këtë situatë, shikohet koeficienti
i korrelacionit të Pearsonit ndërmjet ndryshoreve. Në qoftë se korrelacioni është i ulët, mund të

25
thuhet se ekziston rastësia në mungesën e të dhënave. Për këtë arsye, në fillim do të shqyrtohen
testet T dhe matrica e korrelacionit.
Hipotezat e rastësisë:
H0: Ekziston rastësi në mungesën e të dhënave.
HA: Nuk ekziston rastësi në mungesën e të dhënave.
Në qoftë se pranohet hipoteza H0, mund të thuhet se ekziston rastësi në strukturën e të
dhënave. Për t’a pranuar hipotezën H0, vlera e P-së (Sig.) duhet të jetë më e madhe se 5%. Sipas
kësaj, për arsye vlerat e ndryshoreve të IÇK-së, indeksit të industrisë së prodhimit, çmimit të arit
shtetëror, normat e interesit të depozitave dhe ndryshores së varur IMKB janë më të mëdha
(vlerat e treguara me ngjyrë të zezë në tabelën e testit T të situatës së rastësisë) se vlera e P-së
(sipas nivelit të rëndësisë 5%), hipoteza H0 refuzohet. Pra, mund të themi se ekziston rastësi në
mungesën e të dhënave.
Tabela 11: Tabela e Testit T të Situatës së Rastësisë
Separate Variance t Testsa
IMKB100 ari_shtetëror normat_depozitore industria_prodhimit IÇK
IMKB100 t . .4 1.7 -.4 .1
df . 9.3 9.8 6.5 34.9
P(2-tail) . .675 .114 .731 .954
# Present 52 45 48 49 46
# Missing 0 8 6 6 8
Mean(Present) 87.7238 933501.9111 54.5696 78.0592 4.9174
Mean(Missing) . 780072.8750 47.2150 79.1000 4.8750
ari_shtetëror t 1.7 . -.5 1.7 -.2
df 14.6 . 5.2 5.8 7.4
P(2-tail) .102 . .648 .136 .823
# Present 45 53 48 49 47
# Missing 7 0 6 6 7
Mean(Present) 92.1422 910342.8113 53.0712 78.8510 4.8617
Mean(Missing) 59.3200 . 59.2017 72.6333 5.2429
normat_depozitore t -.2 .0 . -.4 -1.1
df 3.8 4.8 . 4.7 4.1
P(2-tail) .818 .992 . .724 .330
# Present 48 48 54 50 49
# Missing 4 5 0 5 5
Mean(Present) 87.1083 910783.0417 53.7524 78.0480 4.5041
Mean(Missing) 95.1100 906116.6000 . 79.4200 8.9000

26
industria_prodhimit t -.2 -.1 .4 . 1.7
df 2.1 3.3 4.1 . 12.3
P(2-tail) .860 .940 .738 . .122
# Present 49 49 50 55 49
# Missing 3 4 4 0 5
Mean(Present) 87.0318 906926.9184 53.9092 78.1727 5.0347
Mean(Missing) 99.0267 952187.5000 51.7925 . 3.7000
IÇK t -.2 .0 1.0 .7 .
df 5.7 5.8 6.0 5.5 .
P(2-tail) .840 .981 .367 .519 .
# Present 46 47 49 49 54
# Missing 6 6 5 6 0
Mean(Present) 86.6874 911611.7872 54.2251 78.5041 4.9111
Mean(Missing) 95.6700 900402.5000 49.1200 75.4667 .
For each quantitative variable, pairs of groups are formed by indicator variables (present, missing).
a. Indicator variables ëith less than 5% missing are not displayed.
Ekzistencën e rastësisë mund ta shikojmë edhe përmes matricës së korrelacionit ndërmjet
ndryshoreve.
Tabela 12: Tabela e Matricës së Korrelacionit të Pearsonit Për Situatën e Rastësisë
Listwise Correlations
IMKB100
ari_shtetër
or
normat_de
pozitore
industria_p
rodhimit IÇK
IMKB100 1
ari_shtetëror .924 1
normat_depozitore .361 .531 1
industria_prodhimit .295 .188 .046 1
IÇK .130 .136 -.098 .440 1
Në këtë tabelë mund të shohim koeficientët e korrelacionit të Pearsonit. Korrelacionet e
ulëta tregojnë rastësinë në strukturën e të dhënave mangu për secilën ndryshore. Në këtë tabelë,
jashtë korrelacionit të krijuar ndërmjet ndryshores së varur IMKB dhe ndryshores së pavarur arit
shtetëror (0,924), nuk mund të shihet ndonjë korrelacion i lartë. Kjo vlerë e lartë është normale
sepse IMKB-100 është ndryshore e varur, kurse çmimi i arit shtetëror është ndryshore e pavarur.
Për të ekzistuar rastësia, nuk duhet të ketë korrelacion të lartë ndërmjet dy ndryshoreve. Në këtë
rast, mund të thuhet se procesi i të dhënave është i rastësishëm në shembullin tonë.

27
Në tabelën 13, në pjesën Listwise janë llogaritur mesataret aritmetike duke i marrë në
konsideratë vetëm vrojtimet e plota për të gjitha ndryshoret, kurse në pjesën All Values, janë
llogaritur mesataret aritmetike duke i marrë në konsideratë të gjitha vlerat. Në qoftë se shikohen
me kujdes mesataret, mund të vërejmë se nuk ekziston ndonjë dallim i rëndësishëm ndërmjet dy
grupeve. Ndryshimet janë shumë të vogla. Edhe nga këtu mund të themi se struktura e mungesës
së të dhënave është e rastësishme. Zaten, kjo qe përcaktuar nga testi T dhe matrica e korrelacionit
se struktura e të dhënave mangu është e rastësishme në procesin e rastësisë.
Tabela 13: Mesataret e Parashikuara
Summary of Estimated Means
IMKB100 ari_shtetëror
normat_de
pozitore
industria_
prodhimit IÇK
Listwise 89.3500 880133.4571 54.3411 79.4400 4.4343
All Values 87.7238 910342.8113 53.7524 78.1727 4.9111
Në tabelën e mëposhtme e cila përfshin numrin e plotë dhe mangu të vrojtimeve, janë
dhënë numrat e të dhënave mangu dhe përqindjet për secilin vrojtim (në total 60 vrojtime). Teksa
për vrojtimet e plota tregohen me hapësirë (bosh), mungesa e të dhënave është shfaqur me “S”.
Vendet e shfaqura me “+”, tregojnë vlerat e mëdha ekstreme. Për shembull, në vrojtimin e parë
nuk gjendet asnjë vlerë mangu, kurse në vrojtimin e dytë gjenden mangu 2 vrojtime dhe
përqindja e tyre është 40.

28
Tabela 14: Numrat e Vrojtimeve të Plota dhe Mangu
Data Patterns (all cases)
Case # Missing % Missing
Missing and Extreme Value Patterns
IMKB100
ari_shtetëro
r
normat_dep
ozitore
industria_pr
odhimit IÇK
1 0 .0
2 2 40.0 S S
3 0 .0
4 1 20.0 S
5 1 20.0 S
6 0 .0
7 1 20.0 S
8 0 .0
9 1 20.0 S
10 0 .0
11 2 40.0 S S
12 0 .0
13 1 20.0 S
14 0 .0
15 1 20.0 S
16 1 20.0 S
17 0 .0
18 1 20.0 S
19 1 20.0 S
20 0 .0
21 2 40.0 S S
22 0 .0
23 0 .0
24 3 60.0 S S S
25 0 .0
26 0 .0
27 1 20.0 S
28 0 .0
29 0 .0
30 1 20.0 S
31 0 .0
32 1 20.0 S
33 1 20.0 S

29
34 0 .0
35 0 .0
36 0 .0
37 0 .0
38 0 .0
39 0 .0
40 2 40.0 S S
41 0 .0
42 0 .0
43 0 .0
44 0 .0
45 0 .0
46 2 40.0 S S
47 0 .0
48 0 .0
49 1 20.0 S
50 0 .0
51 0 .0
52 1 20.0 + S +
53 1 20.0 S +
54 0 .0 + +
55 1 20.0 + S
56 0 .0 +
57 1 20.0 S +
58 0 .0 +
59 1 20.0 + S
60 0 .0 +

30
Tabela 15: Struktura e Mungesës së të Dhënave
Missing Patterns (cases with missing values)
Case # Missing % Missing
Missing and Extreme Value Patternsa
industria_pr
odhimit
normat_dep
ozitore IÇK ari_shtetëror IMKB100
4 1 20.0 S
13 1 20.0 S
19 1 20.0 S
32 1 20.0 S
59 1 20.0 S +
46 2 40.0 S S
27 1 20.0 S
52 1 20.0 S + +
21 2 40.0 S S
2 2 40.0 S S
5 1 20.0 S
49 1 20.0 S
15 1 20.0 S
57 1 20.0 + S
40 2 40.0 S S
11 2 40.0 S S
55 1 20.0 S +
18 1 20.0 S
7 1 20.0 S
16 1 20.0 S
53 1 20.0 + S
33 1 20.0 S
30 1 20.0 S
9 1 20.0 S
24 3 60.0 S S S
Në tabelën e më sipërme, në rreshtin dhe në kolonën e fundit janë paraqitur vrojtimet dhe
ndryshoret të cilat kanë më shumë mungesë të të dhënave. Vrojtimet e plota nuk janë paraqitur
për të gjitha ndryshoret. Për shembull, në vrojtimin e pesëdhjetë e nëntë ka një mungesë të
dhënash (IÇK), ka tri vrojtime të plota (indeksi i industrisë së prodhimit, normat e interesit të
depozitave, ari shtetëror dhe IMKB100) dhe një nga këto vlera është ekstreme (ari shtetëror).
Kurse në vrojtimin e njëzet e katër, ekzistojnë 3 të dhëna mangu (indeksi i industrisë së
prodhimit, normat e interesit të depozitave dhe ari shtetëror) dhe ky vrojtim ka më së shumti

31
mungesë të të dhënave. Vrojtimet mangu janë çmimi i arit shtetëror, normat e interesit të
depozitave dhe indeksi i industrisë së prodhimit.
Tabela 16: Struktura Tabelore e Mungesës së të Dhënave
Tabulated Patterns
Number
of Cases
Missing Patternsa
Co
mp
lete
if
...b
IMK
B1
00
c
ari
_sh
tetë
rorc
no
rmat_
dep
ozito
rec
ind
ustr
ia_
pro
dh
imit
c
IÇK
c
ind
ustr
ia_
pro
d
him
it
no
rmat_
dep
ozi
tore
IÇK
ari
_sh
tetë
ror
IMK
B1
00
35 35 89.3500 880133.4571 54.3411 79.4400 4.4343
5 X 40 85.8020 876083.0000 49.1200 72.5000 .
1 X X 43 145.0100 1022000.0000 . 90.3000 .
2 X 37 95.8700 1469875.0000 . 77.9500 14.8000
2 X X 43 . 284416.5000 . 75.4500 5.2500
4 X 39 . 1180937.5000 48.1775 80.9250 4.7750
2 X X 43 . 474000.0000 45.2900 . 4.7000
2 X 37 126.6950 1430375.0000 58.2950 . 2.3500
6 X 41 61.9250 . 59.2017 72.6333 5.3833
1 X X X 46 43.6900 . . . 4.4000
a. Variables are sorted on missing patterns.
b. Number of complete cases if variables missing in that pattern (marked with X) are not used.
c. Means at each unique pattern
Në tabelën më lartë shihet struktura e mungesës së të dhënave. Për shembull, nga tabela
shihet se ekzistojnë 35 vrojtime të plota. Përderisa vrojtimet e tjera janë të plota, vrojtimet
mangu të IÇK-së janë 5. Kur të largohet ndryshorja e IÇK-së nga të dhënat, numri i vrojtimeve
mbetet 40. Në të njëjtën mënyrë, ekziston mungesë e 1 vrojtimi për normat e interesit të
depozitave dhe për IÇK-në. Në qoftë se ky vrojtim largohet nga këto dy ndryshore, atëherë
numri i vrojtimeve të plota do të jetë 43.
Më poshtë është dhënë tabela e fundit. Në këtë tabelë janë paraqitur përqindjet e
mospajtimeve.

32
Tabela 17: Përqindjet e Mospajtimeve
Percent Mismatch of Indicator Variables.a,b
industria_prodhimit normat_depozitore IÇK ari_shtetëror IMKB100
industria_prodhimit 8.33
normat_depozitore 15.00 10.00
IÇK 18.33 16.67 10.00
ari_shtetëror 16.67 18.33 21.67 11.67
IMKB100 15.00 16.67 23.33 25.00 13.33
The diagonal elements are the percentages missing, and the off-diagonal elements are the mismatch percentages
of indicator variables.
a. Variables are sorted on missing patterns.
b. Indicator variables with less than 5% missing values are not displayed.
Tabela e përqindjeve të mospajtimeve paraqet përqindjet e numrit të përgjithshëm të
vrojtimeve për secilën ndryshore çift ku njëra nga ndryshoret ka vlera mangu kurse tjetra jo. Për
shembull, numri i vrojtimeve mangu për ndonjërin nga IÇK apo industria e prodhimit është 11.
Numri total i vrojtimeve është 60. Përqindja e mospajtimit të këtyre ndryshoreve është 18,33
(11/60). IMKB dhe ari shtetëror kanë përqindjen më të lartë të mospajtimit prej 25%.
Veçanërisht në hulumtimet me shumë ndryshore mund të jetë e pamundur ndonjëherë që
të sigurohen të dhëna të plota. Gjatë kryerjes së këtyre hulumtimeve, është shumë e rëndësishme
që paraprakisht të përcaktohet shkalla e mungesës së të dhënave. Ndonjëherë mund të jetë e
nevojshme që të nxirret nga analiza ndryshorja e cila ka mungesë të të dhënave. Mirëpo, kjo
mund të ketë edhe një sërë rreziqesh. Numri i ndryshoreve do të ulet. Përpos kësaj, në qoftë se
është një ndryshore me rëndësi dhe patjetër duhet të mbahet në hulumtim, atëherë rezultatet e
aplikimit mund të jenë shumë të ndryshme. Në fillim, duhet të shqyrtohet rastësia e procesit të
mungesës së të dhënave. Ky proces bëhet për të gjetur një çasje të problemit me mungesën e të
dhënave.
6. PLOTËSIMI I MUNGESËS SË TË DHËNAVE Këtu do të bëjmë fjalë se si të i përfshijmë të dhënat mangu në analizë pa i larguar nga
grupi i të dhënave në rastin kur të ndeshemi me këto të dhëna. Për t’a bërë këtë, në SPSS
shkojmë te menyja Transform, Replace Missing Values. Më pas, do të hapet dritarja e më
poshtme.

33
Hapi 1: Menyja e Plotësimit të Mungesës së të Dhënave

34
Hapi 2: Dritarja e Plotësimit për të Dhënat Mangu
Në pjesën e metodave përzgjidhet sipas dëshirës.
Series mean: Duke marrë mesataren e serive, zëvendësohen vendet e të dhënave mangu.
Mean of nearby points: Në vendin e vrojtimit mangu vendoset vlera e mesatares
aritmetike e marrë nga vlerat para dhe pas vrojtimit mungesë.
Median of nearby points: Në vendin e vrojtimit mangu vendoset vlera e medianës e
llogaritur nga vlerat nën dhe mbi vrojtimin mangu.
Linear interpolation: Vlera e vrojtimit të plotë të fundit përpara vlerës mangu dhe vlera e
vrojtimit të plotë të parë pas vlerës mangu vendosen në vendet ku ka mungesë. Në qoftë se vlerat
e vrojtimit të parë dhe të fundit të serisë janë mangu, vlerat e humbura nuk mund të vendosen.
Linear trend at point: Mungesa e të dhënave zëvendësohet nga vlera të parashikuara nga
seria aktuale prej 1 deri në N.
Për shembull, duke marrë në konsideratë mesataren e serive, në qoftë se u jepen vlera të reja
të dhënave mangu, bëhen përzgjedhjet e mëposhtme.

35
Hapi 3: Dritarja e Plotësimit të të Dhënave Mangu
Nga pjesa Method zgjedhet Series Mean dhe barten të gjitha ndryshoret në pjesën New
Variable(s). Klikohet në butonin OK. Vendet e zbrazëta tashmë do të plotësohen dhe është e
mundur që të bëhen analizat e dëshiruara më të dhënat.

36
2. STATISTIKAT PËRSHKRUESE

37
STATISTIKAT PËRSHKRUESE
Gjatë kryerjes së një punimi, interpretimi i të dhënave vetëm duke i shikuar ato dhe
nxjerrja e një rezultati kuptimplotë është i pamundshëm. Është e nevojshme që të prezantohen
një sërë karakteristikash të këtyre të dhënave. Veçanërisht duhet të vlerësohet mesatarja e të
dhënave dhe shpërndarja e të dhënave rreth kësaj mesatareje si dhe në çfarë mase është devijuar
nga mesatarja.
Në kategorinë e statistikave përshkruese marrin pjesë matësit e tendencës qendrore si
mesatarja, mediana dhe moda, matësit e devijimeve nga mesatarja si devijimi standart dhe
varianca si dhe matësit e devijimeve nga normalja si pjerrësia dhe kurtoza.
Me ndihmën e statistikave përshkruese gjatë vlerësimit të rezultateve të përfituara në fund
të një analize të kryer, gjëja e parë që duhet të kihet kujdes është kontrollimi i rëndësisë
statistikore. Rëndësia; rëndësia statistikore, shpreh konceptet si niveli i rëndësisë apo mundësisë
dhe këto koncepte tregohen me shkronjën P (apo me Sig. në SPSS).
Mendimi i pranuar përgjithësisht është kur vlera p është më e vogël se 0,05 rezultatet do
të jenë të rëndësishme në mënyrë statistikore. Me fjalë të tjera, në qoftë se gjasat e rastësisë së
një gjetjeje janë më pak se 5%, atëherë ky rezultat konsiderohet i rëndësishëm statistikisht.
1. MATËSIT E TENDECËS QENDRORE Në statistikë, një shifër e cila në mënyrë të mjaftueshme shpreh dhe përfaqëson një numër
të termeve quhet mesatare. Mesatarja në të njëjtën kohë identifikon karakteristikat e serisë.
Mesatarja, tregon se vlerat e një seti të dhënash nga cilat mjedise të vlerave janë mbledhur, për
këtë arsye në të njëjtën kohë quhet edhe “matësit e tendencës qendrore”. Matjet me tendencë
qendore përbëhen nga mesatarja aritmetike, mediana dhe moda.
1.1. Mesatarja Aritmetike Mesatarja aritmetike është matësi më i shpeshtë i tendencës qendrore. Mesatarja aritmetike
gjendet me pjesëtimin e totalit e të gjitha vlerave të një seti të dhënash me numrin e të dhënave të
setit. Për shembull, mesatarja artimetike e një seti që përbëhet nga 7 të dhëna (3,5,7,5,6,7,9)
gjendet në këtë mënyrë:

38
Mesatarja aritmetike ngaqë ndikohet nga të gjitha vlerat në setin e të dhënave nuk është një
statistikë e përshtatshme përshkruese në rastet kur nuk dihen të gjitha vlerat e setit të të dhënave.
Përfitimi i mesatares aritmetike, në mënyrë matematikore shprehet në këtë mënyrë:
∑x në formulë tregon totatin e të dhënave në seri, kurse N numrin e të dhënave.
1.2. Mediana (Mesorja) Mediana është vlera e cila merr pjesë plotësisht në mes të setit të të dhënave. Pra, medianë
quhet vlera e cila përkon mu në mes të një serie të renditur dhe që e ndan këtë seri në dy pjesë të
barabarta.
Në qoftë se numri të dhënave në setin e të dhënave është numër tek, mediana e serive është
(n+1) /2. Në qoftë se numri i të dhënave është çift, mediana e serive është mesatarja aritmetike e
2 të dhënave të mesit.
Për shembull, një set i të dhënave (3,5,7,5,6,8,9) në qoftë se bëhet renditja e të dhënave nga
e vogla te e madhja (3,5,5,6,7,8,9), mediana e kësaj serie do të jetë (7+1)/2 = 4. Pra, numri që
përkon me pozitën e katërt është 6.
Kurse për një seri të renditur në formën (6,7,8,9,10,11), (6+1) /2 = 3,5. Kjo vlerë nënkupton
që mesatarja e serive gjendet nga mesatarja aritmetike e numrit të tretë dhe të katërt, pra (8+9) /2
= 8,5.
Ngaqë mediana nuk është e ndjeshme ndaj vlerave ekstreme veçanërisht ne rastet kur vlerat
janë të pjerrëta mund të përdoret në shpërndarjet simetike dhe josimetrike dhe në të dhënat
ekstreme për të cilat nuk dihet seti i plotë i të dhënave.
1.3. Moda Modë quhet vlera e cila paraqitet më së shpeshti në nje set të të dhënave (me fjalë të tjera
frekuanca më e lartë). Moda mund të përdoret si një matës i tendencës qendrore për ndryshoret
intervalore, proporcionale dhe rendore.
Në seritë e thjeshta (kur nuk ka vlera që përsëriten) nuk mund të llogaritet moda ngaqë të
gjitha frekuancat që përkojnë me X përsëriten 1 herë. Për përcaktimin e modës në të dhënat e
klasifikuara, gjendet vlera X e cila jep vlerën më të lartë të frekuencës në kolonën e frekuencës.
Për shembull, në serinë e mëposhtme të shpërndarë, vlera më e lartë e frekuencës është 6 dhe
këtë vlerë të frekuencës e jep X e cila jep modën e 2 serive.

39
X N
1
2
3
4
6
2
6
2
1
3
Kurse gjetja e modës në të dhënat e grupuara është pak më ndryshe. Në fillim duhet të
përcaktohet intervali i modës. Intervali i modës në të dhënat e grupuara është intervali me
frekuencën më të lartë. Pasi të gjendet intervali i modës, pastaj llogaritet moda. Llogaritja e
modës bëhet në këtë mënyrë:
(
)
Nga formula, l tregon kufirin më të ulët të modës, s tregon gjerësinë e intervalit, ∆1 tregon
dallim ndërmjet frekuencës së intervalit modal dhe frekuencës paraprake, ∆2 dallimin ndërmjet
frekeuncës së intervalit modal dhe frekeuncës pasuese.
Për shembull;
Intervali N
0-4 2
4-8 5
8-12 7
12-16 6
(
)
Matësit e tendencës qendrore janë të dobishëm për gjetjen e pikës mesatare të të dhënave,
mirëpo gjetja vetëm e pikës mesatare së të dhënave nuk është e mjaftueshme për një analizë të
mirë. Në të njëjtën kohë duhet të analizohet edhe shpërndarja e të dhënave dhe devijimi i tyre
nga mesatarja.
2. MATËSIT E DEVIJIMIT NGA MESATARJA
2.1. Varianca
Vlera e variancës gjendet nga pjestimi i totalit të katrorëve të devijimeve nga mesatarja me
totalin e numrit të vlerave. Për shembull, në qoftë se mesatarja aritmetike e serisë (3,5,7,5,6,7,9)
është 6, varianca llogaritet në këtë mënyrë:

40
2.2. Devijimi Standart Devijimi standart tregon largësinë e vrojtimeve nga mesatarja dhe është e barabartë me
rrënjën katrore të variancës. Për shembull, varianca e serisë (3,5,7,5,6,7,9) është 3,14 (nga
llogaritja e mësipërme), kurse devijimi standart do të jetë √ = 1,77.
3. MATËSIT E DEVIJIMEVE NGA NORMALJA
3.1. Shpërndarja Normale Për Një Ndryshore Shpërndarja e të dhënave është shumë me rëndësi në punimet statistikore sepse në
hulumtimet statistikore për aplikimin e shumë testeve shpërndarja duhet që të jetë normale apo
afër normales.
Shpërndarja normale është një shpërndarje e vazhdueshme. Për shembull, një pjesë e madhe
e notave të financave të një pjese të madhe të studentëve do të mblidhen me anë të mesatares,
kurse disa nota, do të shpërndahen anash të reduktuara brenda një intervali të gjerë konstant. Në
qoftë se mesatarja e këtij provimi është 70, numri i studentëve të cilët kanë marrë notë ndërmjet
intervalit 65-70 pritet të jetë më i madh se ai i intervalit 85-95. Ky është funksioni i densitetit të
probabilitetit që i ngjan ziles i cili zvogëlohet përgjatë vlerave ekstreme të cilat kalojnë mbi
limitet e mesaters. Shpërndarja normale është një shpërndarje simetrike. Mesatarja aritmetike,
moda dhe mediana janë të barabarta.
Figura 1: Kurba e Shpërndarjes Normale
Shpërndarja standarte normale e cila me një mesatare 0 dhe devijim standart 1, ka një
frekuencë në formë të ziles. Shpërndarjet normale të cilat kanë një mesatare të ndryshme nga 0
dhe devijim standart të ndryshëm nga 1, nuk janë shpërndarje normale standarte. Zakonisht gjatë
aplikimeve bëhen krahasime me të këtilla lloje të shpërndarjeve.
Në mostrat me një ndryshore për kërkimin e normalitetit përdoren metodat grafike si
grafiku pa tendecë, diagrami i kutisë, Q-Q, grafiku i histogramit dhe në të njëjtën kohë testet si
Shapiro-Wilks, Kolmogorov-Smirnov.

41
Në punimet statistikore u përmend më parë se për kryerjen e shumë testeve shpërndarja
duhet të jetë normale apo afër normales sepse largësia e të dhënave nga normalja shkakton
rezultate të gabueshme të analizës dhe rrjedhimisht interpretimet e bëra do të jenë gabim. Për
këtë arsye, të dhënat të cilat nuk tregojnë shpërndarje normale duhet të konvertohen në atë
mënyrë që të tregojnë shpërndarje normale. Shkalla e pjerrësisë së të dhënave dhe metoda e
konvertimit janë paraqitur më poshtë në tabelën 1.
Tabela 1: Konvertimet Sipas Lakimit
Lakueshmëri e
Moderuar Pozitive
Lakueshmëri
Ekstreme
Pozitive
Lakueshmëri
Negative
(përzgjedhja 1)
Lakueshmëri
Negative
(përzgjedhja 2)
Lakueshmëri
Ekstreme
Negative
Konvertimi në
rrënjë katore (është
e përshtatshme për
të dhënat e
grumbulluara)
Konvertim
logaritmik
Kthimi në një
shpërndarje
pozitive anësore
dhe përdor
metodën e
përdorur këtu
Kovertimi i X2
apo X3, apo
konvertimi (x/
(1-x))
Mirret vlera e
kundërt e
vrojtimit (1/x),
kurse norma
logit(p) =loge (p/
(1-p))
3.1.1. Shembull Aplikimi Shumat e prodhimit ditor të 10 punëtorëve të një firme janë si më poshtë.
Tabela 2: Të Dhënat Përkatesë të Shembullit
Nr. Punëtorëve Shume e Prodhimit
1 50,00
2 200,00
3 80,00
4 92,00
5 25,00
6 18,00
7 42,00
8 82,00
9 22,00
10 40,00
Për të parë në fillim se shumat e prodhimit a ndjekin shpërndarjen normale, të paraqesim
histogramin dhe grafikun e normalitetit. Për t’a bërë këtë në SPSS, shkohet tek menyja Graphs
Legacy Dialogs Histogram. Në dritaren e hapur, ndryshorja “shuma e prodhimit”
transferohet në pjesën Variables. Më vonë, etiketohet përzgjedhja “Display Normal Curve”
dhe klikohet butoni OK. Në fund të këtij funksioni do të përfitohet histogrami i mëposhtëm.

42
Figura 2: Rezultatet e Histogramit
Sipas grafikut të përfituar të histogramit dhe kurbës së shpërndarjes normale, mund të
shihet se ndryshorja nuk ndjek shpërndarjen normale dhe se është e lakuar në të djathtë në
mënyrë të konsiderueshme.
Teksa seti i të dhënave në këtë mënyrë nuk ndjek shpërndarjen normale, nuk është e
drejtë që të bëhet ndonjë analizë. Për këtë arsye ndryshoret të konvertohen në mënyrë që ndjekin
shpërndarjen normale. Për këtë, të shikojmë dallimin duke e bërë konvertimin në rrënjën katrore
në SPSS. Në fillim, në SPSS, shkohet te menyja Transform Compute Variable.
Hapi 1: Menyja Filluese e Funksionit të Konvertimit

43
Më vonë, në pjesën Target Variable shkruhet emri i të dhënave që do të përfitohen në
fund të konvertimit. Duke e përzgjedhur ndryshoren e shumës së prodhimit, bëhet bartja në
pjesën Numeric Expression. Nga butonat e makinës llogaritëse duke shtypur butonin e shenjës
së yllave shkruhet 0,5 dhe klikohet butoni OK.
Hapi 2: Dritarja e Konvertimit të Rrënjës Katrore
Tabela 3: Konvertimi i Rrënjës Katrore
Nr. Punëtorëve Shume e Prodhimit Rrënja Katrore
1 50,00 7,07
2 200,00 14,14
3 80,00 8,94
4 92,00 9,59
5 25,00 5,00
6 18,00 4,24
7 42,00 6,48
8 82,00 9,06
9 22,00 4,69
10 40,00 6,32

44
Në fund të konvertimit në rrënjë katrore, për të parë se të dhënat e reja të përfituara a
ndjekin shpërndarjen normale, bëhet përsëri vizatimi i histogramit.
Figura 3: Rezultatet e Histogramit e Konvertimit në Rrënjë Katrore
Siç mund të shihet, të dhënat tani jam pak më afër normales. Tani duke bërë konvertimin
logaritmik mund të shohim shpërndarjen e të dhënave.
Për këtë, në SPSS, shkohet tek menyja Transforom Compute Variable. Në pjesën
Target Variable shkruhet emri i të dhënave që do të përfitohen në fund të konvertimit të bërë.
Në pjesën Function Group përzgjedhet Arithmetic dhe nga pjesa Functions and Special
Variables përzgjedhet lg10. Pas kësaj në pjesën e makinës llogaritëse klikohet shigjeta që tregon
drejtimin lartë dhe funksioni bartet në pjesën Numeric Expression. Në vend të ? në pjesën
Numeric Expression bartet ndryshorja shuma e prodhimit dhe klikohet butoni OK.

45
Hapi 3: Dritarja e Konvertimit Logaritmik
Tabela 4: Konvertimi Logaritmik
Nr. Punëtorëve Shume e Prodhimit Konvertimi Logaritmik
1 50,00 1,70
2 200,00 2,30
3 80,00 1,90
4 92,00 1,96
5 25,00 1,40
6 18,00 1,26
7 42,00 1,62
8 82,00 1,91
9 22,00 1,34
10 40,00 1,60

46
Në fund të konvertimit logaritmik, për të parë se të dhënat e reja të përfituara a ndjekin
shpërndarjen normale, bëhet përsëri vizatimi i histogramit. Siç mund të shihet më poshtë në
figurën 4, në fund të konvertimit logaritmik të dhënat e përfituara ndjekin shpërndarjen normale.
Figura 4: Rezultate e Histogramit të Konvertimit Logaritmik
3.2. Ngushtësia
Shpërndarja kurtozës (kurtosis) është një matës që jep informata rreth situatës së pikave
më të larta të të dhënave, pra drejtimit dhe vertikales. Një lakim afër zeros krijon një formë afër
shpërndarjes normale. Një vlerë pozitive e lakueshmërisë është shenjë e një shpërndarjeje më të
vertikale nga normalja. Një vlerë negative e lakueshmërisë është një shenjë e një shpërndarjeje
më të drejtë nga normalja.
3.3. Pjerrësia Shpërndarja e pjerrësisë (Skewness) është një matës që përcakton se sa ka devijuar
shpërndarja në rrethin e mesatares nga simetria, pra përcakton simetrinë e të dhënave. Vlera zero
është shenjë e një shpërndarjeje simetrike, pra një ekulibrimi mesatar. Pjerrësia pozitive tregon
që ekzistojnë shumë vlera të vogla, kurse pjerrësia negative tregon që ekzistojnë shumë vlera të
mëdha. Në rastin kur mesatarja e çfarëdo seti të të dhënave është më e madhe se mediana, vihet
në pah një shpërndarje e pjerrët në të djathtë, në rastin e mesatares më të vogël se mediana vihet
në pah një shpërndarje e pjerrët në të majtë.

47
4. Shembull Aplikimi Shpërndarja e moshave të studentëve të një klase le të jetë si më poshtë në tabelën 5.
Sipas kësaj, me këtë set të të dhënave mund të analizojmë matësit e tendencës qendrore
(mesataren aritmetike, medianën, modën), matësit e devijimit nga mesatarja (variancën,
devijimin standart) dhe matësit e devijimit nga normalja (ngushtësinë, pjerrësinë).
Tabela 5: Të Dhënat Përkatëse të Shembullit
NO MOSHA
1 21
2 19
3 20
4 21
5 19
6 22
7 23
8 17
9 18
10 20
NO MOSHA
11 26
12 21
13 25
14 18
15 20
16 27
17 22
18 24
19 23
20 26
Për të grupuar të dhënat që posedojmë dhe për të gjetur frekuncat e këtyre grupeve,
përdoren këto përzgjedhje.
Për të aplikuar metodën Frequencies në SPSS, ndiqen këto faza:
Ananlyze Descriptive Statistics Frequencies.
Hapi 1: Menyja Filluese e Metodës Frequencies
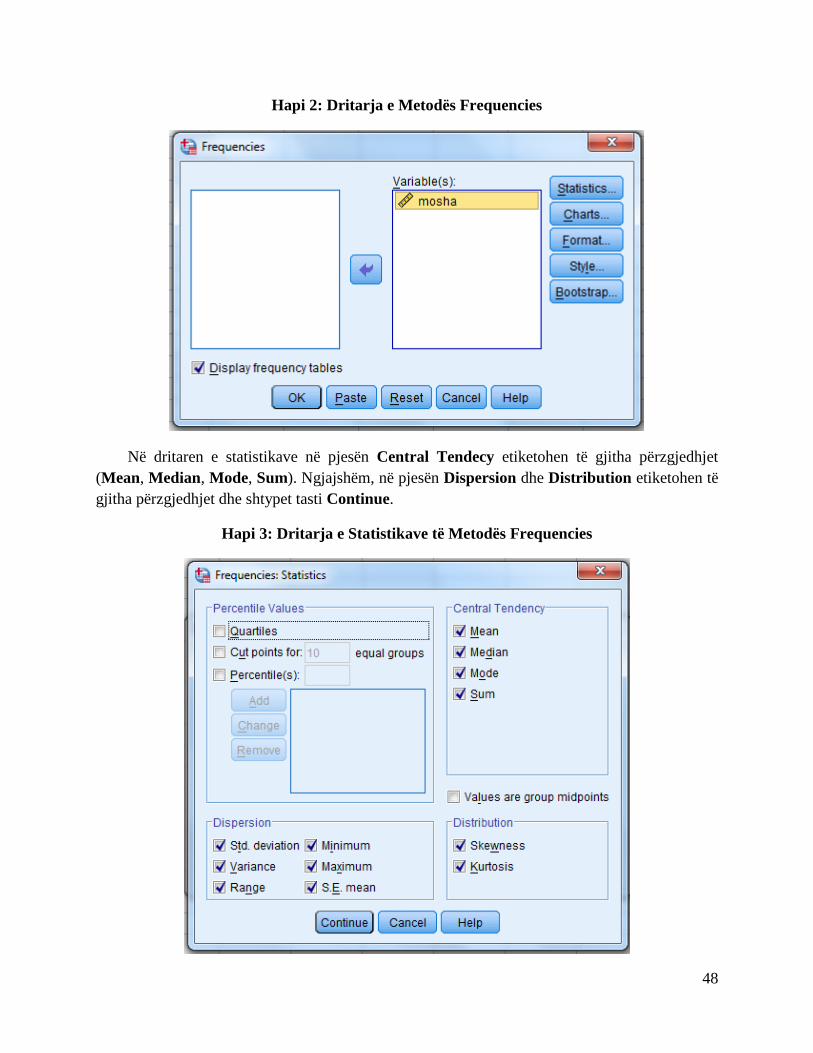
48
Hapi 2: Dritarja e Metodës Frequencies
Në dritaren e statistikave në pjesën Central Tendecy etiketohen të gjitha përzgjedhjet
(Mean, Median, Mode, Sum). Ngjajshëm, në pjesën Dispersion dhe Distribution etiketohen të
gjitha përzgjedhjet dhe shtypet tasti Continue.
Hapi 3: Dritarja e Statistikave të Metodës Frequencies

49
Pasi të kthehet në dritaren Frequencies, shtypet tasti OK dhe do të realizohet analiza.
Rezultatet e analizës janë dhënë më poshtë.
Tabela 6: Rezultatet e Testit të Metodës Frequencies
Statistics
mosha
N Valid 20
Missing 0
Mean 21.6000
Std. Error of Mean .64645
Median 21.0000
Mode 20.00a
Std. Deviation 2.89100
Variance 8.358
Skewness .358
Std. Error of Skewness .512
Kurtosis -.778
Std. Error of Kurtosis .992
Range 10.00
Minimum 17.00
Maximum 27.00
Sum 432.00
a. Multiple modes exist. The smallest
value is shoën
Në fund të analizës janë përcaktuar statistikat përshkruese për të dhënat e moshës dhe
sipas kësaj mesatarja e serive është 21,16, mediana 21 dhe moda 20. Jashtë këtyre, vlera
minimale e serisë është 17, kurse vlera maksimale është 27. Koeficienti skewness i serisë është
0,358 dhe vlera kurtosis është -0,778.

50
Tabela 7: Rezultatet e Testit të Metodës Frequencies
mosha
Frequency Percent Valid Percent
Cumulative
Percent
Valid 17.00 1 5.0 5.0 5.0
18.00 2 10.0 10.0 15.0
19.00 2 10.0 10.0 25.0
20.00 3 15.0 15.0 40.0
21.00 3 15.0 15.0 55.0
22.00 2 10.0 10.0 65.0
23.00 2 10.0 10.0 75.0
24.00 1 5.0 5.0 80.0
25.00 1 5.0 5.0 85.0
26.00 2 10.0 10.0 95.0
27.00 1 5.0 5.0 100.0
Total 20 100.0 100.0
Në këtë tabelë, në kolonën Frequency në lidhje me të dhënat e moshës është treguar se sa
herë janë përsëritur vlerat dhe në kolonën Percent janë dhënë përqindjet e këtyre vlerave.
Të njëjtat rezultate mund t’i përfitojmë edhe përmes AnalyzeDescriptive Statistics,
me ndihmën e menyve Descriptive, Explore dhe Crosstabs.

51
3. TESTIMI I HIPOTEZAVE

52
TESTIMI I HIPOTEZAVE
1. PËRCAKTIMI I HIPOTEZAVE Testimi i hipotezave paraqet krahasimin e parametrave të një popullimi të definuar më
parë (p.sh. mesatarja e popullimit) me parametrat e përfituara nga masa e mostrës (p.sh.
mesatarja e mostrës). Në qoftë se vlera e mostrës është e afërt me vlerën parametrike të testuar,
hipoteza nuk refuzohet, pranohet drejtëpërsëdrejti. Por në qoftë se vlera e mostrës është shumë e
ndryshme nga vlera parametrike e testuar, hipoteza drejtëpërsëdrejti refuzohet, nuk pranohet. Për
të aplikuar testin e hipotezave, në fillim duhet definuar hipotezën zero (null hypothesis) dhe
hipotezën alternative (alternative hypothesis).
1.1. Hipoteza Zero (Null Hypothesis) Hipoteza zero zakonisht shënohet në formën H0 dhe shpreh vlerën parametrike e cila do
të testohet (µ0). Hipoteza zero bazohet në parimin se “nuk ekziston dallim” ndërmjet vlerës së
përcaktuar parametrike me vlerën e realizuar. Hipoteza zero supozohet të jetë e saktë përderisa të
vërtetohet e kundërta. Për këtë aryse, gjatë krijimit të hipotezës zero duhet të kihet kujdes që të
jetë e plotë dhe e qartë në mënyrë statistikore. Për shembull, në qoftë se dëshirohet të krijohet një
hipotezë në lidhje me të ardhurat për kokë banori në një nga krahinat e Kosovës, duhet të
shprehet një numër i caktuar në hipotezën zero. Në këtë rast, hipoteza zero mund të krijohet në
këtë mënyrë.
H0: Të ardhurat për kokë banori të krahinës X janë 1,000€.
1.2. Hipoteza Alternative (Alternative Hypothesis) Hipoteza alternative zakonisht shënohet në formën HA dhe shpreh vlerën e cila pranohet
në rastet kur refuzohet hipoteza zero. Hipoteza alternative pranohet vetëm në rastet kur hipoteza
zero refuzohet. Në shembullin e më lartë, hipoteza alternative e hipotezës zero duhet të shpreh se
të ardhurat për kokë banori të krahinës X nuk janë 1,000€. Në qoftë se do t’a shkruanim në formë
statistikore, do të ishte:
H0: µ = µ0 H0: µ = 1,000 €
HA: µ ≠ µ0 HA: µ ≠ 1,000 €
Siç shihet edhe nga shembulli, hipoteza alternative përfshin vlera të cilat nuk marrin pjesë
në hipotezën zero. Pra, në shembull, në qoftë se duke e refuzuar hipotezën zero pranohet
hipoteza alternative, nënkuptohet se vlera e të ardhurave për kokë banori në krahinën X është e
ndryshme nga 1,000€.

53
2. TESTET STATISTIKORE
Rezultatet e një hipotezeje mund të jenë vetëm dy: hipoteza zero pranohet ose refuzohet.
Siç dihet nga statistika, vlerat e shpërndarjes normale mund të konvertohen në rezultatet e Z-së
dhe probabilitetet tregohen në tabelën e z-së. Prandaj, vlera e z-së është një shembull i
statistikave të testit. Për të i testuar hipotezat, duhet të zbulohet një numër për të përcaktuar se në
çfarë vlera hipoteza zero do të pranohet apo do të refuzohet. Kjo vlerë zakonisht njihet si vlera
kritike (critical value) apo vlera e tabelës ngaqë shikohet nga tabela. Në qoftë se vlera e
llogaritur, është më e vogël se kjo vlerë kritike, hipoteza zero refuzohet.
3. TESTET NJË DHE DY ANËSORE Emërimi i testeve të hipotezave të krijuara si një dhe dy anësor lidhet me krijimin e
hipotezës alternative. Në qoftë se hipoteza alternative është si më poshtë, kemi të bëjmë me
testin një anësor të majtë.
H0: µ = k
HA: µ < k
Në hipotezën zero, mesatarja e popullimit është e barabartë me k (k paraqet çfarëdo
numri), kurse në hipotezën alternative është më e vogël se k.
Figura 1: Testi Një Anësor i Majtë
Në qoftë se në hipotezën alternative, mesatarja e popullimit specifikohet se është me e
madhe se k, këtë radhë kemi të bëjmë me testin një anësor të djathtë.
H0: µ = µ0 HA: µ > µ0

54
Figura 2: Testi Një Anësor i Djathtë
Në qoftë se hapësira e refuzimit është e ndarë në dy pjesë të barabarta në hipotezë, kemi të
bëjme me testin dyanësor. Në testin dyanësor, kemi të bëjmë me jo barazi në hipotezën
alternative.
Figura 3: Testi Dyanësor

55
4. GABIMI I LLOJIT TË PARË DHE TË DYTË
Lloji i Parë i Gabimit: Refuzimi i hipotezës zero kur ajo është saktë. Mundësia e gabimit të
llojit të parë tregohet me α.
Lloji i Dytë i Gabimit: Pranimi i hipotezës zero kur ajo është jo e saktë. Lloji i gabimit
tregohet me β.
Lloji i Parë dhe i Dytë i Gabimit: Për të i kuptuar koncepetet e gabimit të llojit të parë dhe të
dytë, në fillim duhet të kuptohet niveli i rëndësisë (significance level).
5. NIVELI I RËNDËSISË (α) DHE INTERVALI I BESIMIT (1-α)
Niveli i rëndësisë është një standart bazë statistikor për të refuzuar hipotezën zero. Në
testimin e hipotezave, në të njëjtën kohë α tregon nivelin e rëndësisë. Qëllimi i nivelit të
rëndësisë, është që të jap një bazë rreth dallimeve të krijuara ndërmjet vlerës së mostrës dhe
parametrave të popullimit që marrin pjesë në hipotezë dhe për të vendosur se dallimet a janë
krijuar rastësisht apo janë të rëndësishme në mënyrë statistikore.
Niveli i përzgjedhur i rëndësisë (α) siguron përcaktimin e zonave të pranimit dhe të
refuzimit në shpërndarjen e mostrës. Në departamentet e inxhinierisë, shëndetësisë etj, zakonisht
përdoret niveli i rëndësisë prej 0,05 ose mund të jetë edhe në vlera më të vogla 0,01, po ashtu
mund të përdoren edhe vlera më të mëdha si 0.10 apo edhe më lartë. Ajo çfarë duhet të kihet
kujdes gjatë përzgjedhjes, janë çëshjtet apo kostot që mund të lindin me rastin e refuzimit të një
hipoteze të saktë zero. Pra, është i rëndësishëm Lloji i Parë i Gabimit. Po ashtu, edhe rasti me
pranimin e një hipoteze jo të saktë zero mund të shkaktojë rezultate jo të sakta apo kosto shtesë.
Këtu pra, kemi të bëjmë me Llojin e Dytë të Gabimit. Për të shmangur situata të tilla, duhet të
përzgjedhet një vlerë e lartë e α-së (p.sh. 0,25 apo më shumë).
Niveli i rëndësisë mund të shpjegohet edhe përmes konceptit të intervalit të
besueshmërisë. Niveli i rëndësisë prej 5% shpreh intervalin e besueshmërisë prej 95%. Pra, në
qoftë se vlera e testuar është 95% brenda intervalit të besueshmërisë, hipoteza zero nuk
refuzohet. Mirëpo, në qoftë se bie në zonën e mbetur prej 5%, hipoteza zero refuzohet. Kjo
situatë, mund të shihet në figurën e mëposhtme.

56
Figura 4: Zonat e Pranimit dhe Refuzimit të Hopotezës (α = 0,05)
Në bazë të dy llojeve të gabimeve, ekzistojnë edhe dy lloje të vendimeve të sakta: pranimi
i hipotezës së saktë zero dhe refuzimi i hipotezës së gabuar zero. Mundësia e saktë e pranimit
është sa pjesa që e përmbush Lloji i Parë i Gabimit (niveli i rëndësisë). Në qoftë se niveli i
rëndësisë është 0,05, probabiliteti i pranimit të një hipoteze të saktë zeroje është 1,00-α=1,00-
0,05=0,95. Në të njëjtën mënyrë, mundësia e refuzimit të një hipoteze të gabuar zeroje është sa
pjesa që e përmbush Lloji i Dytë i Gabimit (1-β). Këto mund të i përmbledhim në këtë mënyrë:
Vendimi Hipoteza zero e saktë Hipoteza zero jo e saktë
Hipoteza zero pranohet Pranim i saktë (1-α) Lloji i dytë i gabimit (β)
Hipoteza zero refuzohet Lloji i parë i gabimit (α) Refuzim i saktë (1-β)
Shmangia e gabimeve të llojit të parë dhe të llojit të dytë shpesh është e mundur. Për
arsye se mund t’a përcaktojmë vetë nivelin e rëndësisë, mund t’a kontrollojmë mundësinë e
bërjes së gabimit të llojit të parë. Mënyra për t’a kontrolluar llojin e dytë të gabimit është
zgjedhja e përshtatshme e madhësisë së mostrës. Në qoftë se madhësia e mostrës është konstante,
mundësia e paraqitjes së llojit të parë të gabimit ulet dhe rritet mundësia e paraqitjes së llojit të
dytë të gabimit. Në qoftë se tersi të cilin e sjell krijimi i llojit të parë të gabimit është relativisht
më i madh se tersi të cilin e sjell lloji i gabimit të dytë, niveli i rëndësisë duhet të përcaktohet i
ulët.

57
6. MADHËSIA E MOSTRËS
Gjatë shqyrtimit të hulumtimit numri i njësive që marrin pjesë në zonën e hulumtimit
quhet madhësi e mostrës. Madhësia e mostrës është e rëndësishme si për nga aspekti i
besueshmërisë së hulumtimit ashtu edhe për kryerjen me lehtësi të hulumtimit. Në qoftë se
madhësia e mostrës është më e madhe se sa që duhet të jetë, rriten kostot e hulumtimit. Zbulimi i
madhësisë së mostrës së hulumtimit lidhet me qëllimin e hulumtuesit. Karakteristikat e
hulumtimit, numri i ndryshoreve të përdorur në hulumtim, karakteristikat e analizave që do të
përdoren në hulumtim etj, ndikojnë përzgjedhjen e madhësisë së mostrës. Përveç kësaj, së
bashku me këta faktorë madhësia e mostrës mund të zbulohet edhe në mënyrë kuantitative.
Hulumtuesi, mund të përzgjedh një madhësi të mostrës pasi më parë të përcaktojë gjerësinë e
intervalit të besueshmërisë. Për t’a llogaritur madhësinë e mostrës, përdoret formula e
mëposhtme.
n = (Z2σ
2) / (X-µ)
2
n: madhësia e mostrës
σ2: katrori i devijimit standard
Z2: katrori i vlerës Z e cila lexohet nga tabela z në lidhje me vlerën e α-së sipas intervalit të
përcaktuar të besueshmërisë.
(X-µ)2: vlera e mesatares X nga një distancë e caktuar nga µ.
Në rastet e aplikimeve kur nuk dihet varianca e popullimit (σ2), përdoret varianca e mostrës
(S2).
6.1. Shembull Aplikimi Të parashikohet paga mesatare për orë e punëtorëve të një firme të tekstilit që do të ketë
devijim standart për 10€ nga mesatarja e vërtetë e popullimit brenda 95% intervalit të
besueshmërisë. Duke u mbështetur në të dhënat e kaluara, devijimi standart i llogaritur për
bizneset është i njohur të jetë 50€. Në këtë rast, sa duhet të jetë madhësia e mostrës?
Në fillim duhet të dihet se sa është vlera e z-së brenda intervalit të besueshmërisë 95%.
Sipas kushteve të shpërndarjes normale, siç shihet edhe më poshtë, hapësira e cila do të ndahet
në tabelën z është 0,475. Vlera e dhënë e z-së në këtë zonë është 1,96.

58
n = (Z2σ
2) / (X-µ)
2
n = (1,96)2(50)
2 / (10)
2
n = (3,8416) (2500) / 100
n = 96,04 96

59
4. TESTET E HIPOTEZAVE
PARAMETRIKE

60
TESTET PARAMETRIKE
Teoria e mostrës, përveç parashikimit të parametrave të popullimit, mundëson edhe
testimin e hipotezave statistikore. Testimi i hipotezave përfshin çështjet për të hulumtuar
supozimet rreth të dhënave të një popullimi në një nivel të caktuar të kuptueshmërisë (niveli i
gabimit). Këto teste përcaktojnë nëse statistikisht është e rëndësishme informacioni i prodhuar
me vlerën e njohur më parë duke përdorur vlerën e njësisë së mostrës. Në qoftë se ka dallim,
rëndësia e këtij dallimi përcakton se a është e mjaftueshme për të refuzuar hipotezën zero. Në
rastin kur dallimi është i rëndësishëm, hipoteza zero refuzohet dhe në rastin e kundërt pranohet.
Në testet e hipotezave, gjithmonë hipoteza e cila testohet është hipoteza zero. Zakonisht,
për të vendosur në lidhje me hipotezën zero parametrat e së cilës janë të përcaktuara më parë dhe
që tregon se vlera e njohur nuk ka ndryshuar, duhet bërë përgjithësimi duke u bazuar në
mundësinë e informacionit të mostrës.1 Në këtë rast, është e nevojshme që të dihet shpërndarja
statistikore e mostrës e cila prodhon informacionin rreth parametrës së caktuar. Me fjalë të tjera,
informacioni në lidhje me parametrat e popullimit, nuk prodhohet nga statistikat e përfituara nga
të dhënat e mostrës, por nga shpërndarja teorike në përputhje më këto statistika. Për shembull,
sipas Teoremës së Qendrës Kufitare (Central Limit Theorem), pavarësisht shpërndarjes së
popullimit, në qoftë se vëllimi i mostrës është i madh sa duhet (n ≥ 30), mesataret e popullimit do
të ndjekin shpërndarjen normale. Nga testet parametrike, do të shqyrtohet testi T, testi z dhe testi
ANOVA.
1. SUPOZIMET E TESTEVE PARAMETRIKE Të dhënat duhet të jenë intervalore ose proporcionale.
Të dhënat duhet të ndjekin shpërndarjen normale (vlerat e kurtosës dhe lakueshmërisë
duhet të jenë ndërmjet -1 dhe +1).
Grupi i variancave duhet të jetë i barabartë (variancat mund të jenë të ndryshme deri
në katër, por jo më shumë).
Gjatë kryerjes së hulumtimit për të vendosur se cilat analiza të përdoren, duhet përgjigjur
tri pyetjeve të mëposhtme:
Sa grupe të të dhënave kemi në duar?
Si është lidhja ndërmjet grupeve (e varur – e pavarur)?
Cilat supozime i plotësojnë?
Sipas përgjigjeve alternative, tabela e mëposhtme shpjegon se cilat teste në cilat raste
duhet përdorur.
1Mund të jenë hipotezat (sugjerimet) rreth popullimit, vlerat e parametrave, një nivel i njohur më parë, një vlerë
standarte apo një vlerë e supozuar.

61
NUMRI I
GRUPEVE
GJENDJA E
GRUPEVE
SUPOZIMET
TESTI I
NEVOJSHËM
2 Grupet e pavarura Ne qoftë se plotësohen të tri kushtet Testi T i pavarur
2 Grupet e pavarura Në qoftë se një nga kushtet nuk
është plotësuar
Testi Mann-Whitney U
(test jo parametrik)
2 Grupet e varura Në qoftë se së paku supozimi 1 dhe
2 përmbushen
Testi T i varur
2 Grupet e varura Në qoftë se supozimi 1 dhe 2 nuk
plotësohen
Testi Wilcoxon
(test jo parametrik)
2 Në qoftë se përdoren të dhëna
nominale
Testi Katrori-Ki
3 dhe mbi Grupet e pavarura Në qoftë se përmbushen të tri
supozimet
Testi ANOVA
3 dhe mbi Grupet e pavarura Në qoftë se një nga supozimet nuk
përmbushet
Testi Kruskal-Wallis
(test jo parametrik)
2. Testi T
Testi T përdoret për të hulumtuar dallimin ndërmjet dy grupeve të mostrave për nga
mesataret. Testi T përcakton se a ka dallim të konsiderueshëm mesatarja e një grupi me
mesataren e grupit tjetër. Në testin T pika kritike është ‘dy’. Testi T gjithmonë krahason dy
mesatare apo dy vlera të ndryshme. Veçanërisht, në rastet kur madhësia e mostrës nuk është e
madhe, kur nuk dihet devijimi standart i popullimit të marrë nga mostra dhe kur parametrat e
popullimit nuk përdoren në testin e hipotezave preferohet testi T.
Teksa shqyrtohen dallimet e grupeve në nivelin e rëndësisë në testin T, është e
rëndësishme të kihen parasysh testet njëanësor (one-tailed) dhe dy anësor (two-tailed). Në testin
dy anësor, nuk është me rëndësi drejtimi pozitiv apo negativ i dallimit të mesatares së një grupi
për nga grupi tjetër. Por në testin një anësor, në një drejtim të caktuar (pozitiv apo negativ) pritet
që mesatarja e grupit të parë te jetë e ndryshme prej mesatares së grupit të dytë. Për shembull,
suksesi i një kampanjeje të reklamës, mund të shoqërohet me rritjen në shitje. Kështu që këtu
duhet të aplikohet testi t një anësor. Në raport me hulumtimin mund të përdoret edhe testi t dy
anësor. Për shembull, gjatë vlerësimit të suksesit të provimit, rritja e notës (pozitive) apo ulja
(negative) ngaqë do të jetë e rëndësishme për analistin, do të ishte më e saktë që në vend të testit
t një anësor, të zgjedhet testi t dy anësorësh. Gjatë aplikimeve, duke e ndarë vlerën Sig 2-tailed të
cilën e përcakton SPSS-i, mund të kalkulohet vlera e një testit një anësor. Me pak fjalë, vlera e
testit dy anësor, është sa dy herë vlera e tesit një anësor.
Në programin SPSS paraqiten tri alternativa të testit : Independent-Samples T Test (testi t
i dy mostrave të pavarura), Paired Samples T Test (testi t i dy mostrave të varura) dhe One
Sample T Test (test t një mostre). Testi i përdor më shumë gjatë aplikimeve është testi i dy
mostrave të pavarura.

62
2.1. Test T i dy Mostrave të Pavarura (Indepedent-Samplest t-Test) Testi T i dy mostrave të pavarura bën krahasiminn e dy grupeve të ndryshme të mostrave.
Anëtarët e dy grupeve janë të ndarë nga njëri-tjetri. Në mes të dy grupeve nuk duhet të ketë
anëtarë të përbashkët. (P.sh.: mashkull-femër, studentët e vitit të parë-studentët e vitit të dytë,
njohës i gjuhëve të huaja-njohës jo i gjuhëve të huaja etj.).
2.1.1. Shembull Aplikimi Duke përdor matësin e Likertit 5 shkallësh në një anketë të realizuar kërkohet të
përcaktohet se a është burim prestigji institucioni në të cilin punojnë të anketuarit (5=plotësisht
pajtohem, 4=pajtohem, 3=pjesërisht pajtohem, 2=nuk pajtohem, 1=plotësisht nuk pajtohem).
Duke i ndarë pjesëmarrësit në dy grupe meshkuj dhe femra, është bërë krahasimi i komenteve në
lidhje me pyetjen. Në këtë rast, duke e përdorur Testin T të dy mostrave të pavarura, mund të
krahasohen mesataret e dy grupeve (meshkuj-femra).
Tabela 1: Të Dhënat Përkatëse të Rastit
(Numri 1 përfaqëson Meshkujt, Numri 2 përfaqëson Femrat)
Gjinia Komenti Gjinia Komenti
1 3 2 4
2 4 2 4
1 3 2 5
2 4 1 2
1 3 1 3
1 4 1 2
2 4 2 3
1 1 1 3
2 4 2 4
2 4 2 5
1 3 2 4
1 3 2 5
2 5 2 4
1 4 1 3
1 3 2 4
Pasi të jenë futur të dhënat në SPSS, zgjidhen me radhë: Analyze, Compare Means,
Independent-Samples T Test. (Hapi 1)

63
Hapi 1: Zgjedhja e Independent-Samples T Testit nga Menyja
Pasi të jetë përzgjedhur, në vazhdim do të paraqitet ekrani i mëposhtëm. (Hapi 2) Në këtë
dritare në pjesën Test Variables vendoset kolona “komenti” e cila përfaqëson përgjigjet e
pjesëmarrësve dhe në pjesën Grouping Variables vendoset “gjinia”. Për të vazhduar më tutje,
bëhen rregullimet e nevojshme në pjesën Define Groups. (Hapi 3)
Hapi 2: Dritarja e Dialogut të Testit T

64
Hapi 3: Dritarja Për Përcaktimin e Grupeve, Independent Samples t-T
Pasi të shkruhen 1 dhe 2 në kutizat Group 1 dhe Group 2 për dy grupet në shembullin
tonë (mashkull:1, femër:2), vazhdohet tutje me Continue. Pasi të klikojmë OK do të fitojmë
rezultatet e analizës si më poshtë.
Tabela 2: Rezultatet e Independent-Samples t-Testit
Group Statistics
Gjinia N Mean Std. Deviation Std. Error Mean
Komenti 1.00 14 2.8571 .77033 .20588
2.00 16 4.1875 .54391 .13598
Sipas rezultateve të analizës, mesatarja e 14 meshkujve pjesëmarrës është 2,8571 dhe
mesatarja e 14 femrave pjesëmarrëse është 4,1875. Pra, femrat pajtohen me mendimin se
institucioni në të cilin punojnë është burim prestigji, kurse meshkujt nuk pajtohen me këtë
mendim, mirëpo ata shihet të pajtohen pjesërisht (në anketë qenë përcaktuar vlerat 2=pajtohem,
3=pjesërisht pajtohem. Mesatarja për meshkujt është 2,85). Shihet se ekziston një dallim i
rëndësishëm ndërmjet grupeve. Edhe rezultati i Sig (2-tailed) (p=0,000) tregon që ekziston një

65
dallim i rëndësishëm ndërmjet mesatareve të grupeve (Vlera e Sig. është më e vogël se 0.05
brenda intervalit të besueshmërisë 95%). Në këtë mënyrë, refuzohet hipoteza zero (null) dhe
pranohet hipoteza alternative.
H0: Nuk ekziston dallim ndërmjet mesatareve të dy grupeve.
HA: Ekziston dallim ndërmjet mesatareve të dy grupeve.
Në këtë rast mund të komentojmë se meshkujt dhe femrat mendojnë ndryshe në çështjen
se a e shohin si burim prestigji institucionin në të cilin punojnë dhe se femrat e shohin si burim
prestigji institucionin në të cilin punojnë.
Në fund të analizës komenti për pjesën Levene’s Test for Equality of Variances duhet
të bëhet sipas Equal variances assumed dhe Equal variances not assumed. Në qoftë se
shpërndarjet nuk tregojnë dallim në masë të rëndësishme, do të ishte më e saktë që në vend të
supozimit të equal variance (shpërndarje e barabartë) të përdoret supozimi unequal variance
(shpërndarje jo të barabarata). Në këtë fushë, vlera e Sig (0,540) tregon se shpërndarja kërkon
dallim dhe në mënyrë statistikore është më e përshtatshme që të përdoret supozimi unequal
variance. Në shembullin tonë, për arsye se vlera e Sig (2-tailed) është e rëndësishme (p=0,000) si
për equal variance assumed ashtu dhe për variances not assumed, nuk do të ketë ndonjë ndryshim
në komentimin e analizës.
2.2. Testi T i dy Mostrave të Varura (Paired Samples t-Test) Në testin T të dy mostrave të pavarura përsëri bëjmë krahasimin e mesatareve. Por këtu,
nuk janë dy grupe të ndara. Analizat bëhen mbi grupin e njëjtë të mostrës (p.sh.: masim pritjet e
grupit brenda periudhave të ndryshme kohore, sukseset, shpejtësitë etj.).
2.2.1. Shembull Aplikimi Supozoni se një mësimdhënës dëshiron të mas suksesin ndërmjet notave të kollokfiumit
dhe provimit final të studentëve. Pasi të futen notat e kollokfiumit dhe të provimit final të një
grupi prej 20 vetash në SPSS duke përdorur Paired Sampes T Test, mund të shihet dallimi në
rastin e suksesit.

66
Tabela 3: Të Dhënat Përkatëse Për Rastin
Kollokfium Final
45 75
67 73
60 85
55 72
48 56
62 73
48 76
63 80
72 95
50 82
Pasi të jenë futur të dhënat në SPSS, zgjidhen me radhë: Analyze, Compare Means,
Paired-Samples T Test. (Hapi 1)
Hapi 1: Zgjedhja e Paired Samples T Testit nga Menyja
Kollokfium Final
77 92
81 90
56 70
45 60
68 87
75 95
49 90
88 96
67 80
87 90

67
Hapi 2: Dritarja e Dialogut Të Paired Samples T Test
Siç shihet nga dritarja, ndryshoret tona kollokfiumi dhe final barten në pjesën Paired
Variables. Pasi të klikoket OK fitojmë rezultatet e mëposhtme.
Tabela 4: Rezultatet e Paired-Samples T Test
Paired Samples Correlations
N Correlation Sig.
Pair 1 Kollokfium & Final 20 .715 .000
Paired Samples Test
Paired Differences
t df
Sig.
(2-
tailed) Mean
Std.
Deviation
Std.
Error
Mean
95% Confidence Interval
of the Difference
Lower Upper
Pair 1 Kollokfium - Final -17.70000 9.75003 2.18017 -22.26316 -13.13684 -8.119 19 .000
Paired Samples Statistics
Mean N Std. Deviation Std. Error Mean
Pair 1 Kollokfium 63.1500 20 13.74304 3.07304
Final 80.8500 20 11.45368 2.56112

68
Sipas rezultateve të analizës, mesatarja e notave të kollokfiumit të 20 studentëve është
63,15 dhe mesatarja e notave finale është 80,85. Vlera Sig (2-tailed) në intervalin 95% të
besueshmërisë është më e vogël se 0,05 (p=0,000). Pra, ekziston një dallim i rëndësishëm
ndërmjet mesatareve të notave të kollokfiumit dhe finalit. Në këtë rast, ashtu si në rastin e parë
duke e refuzuar hipotezën zero (nuk ekziston dallim ndërmjet mesatareve), do të pranohet
hipoteza alternative (ekziston dallim ndërmjet mesatareve).
Korrelacioni ndërmjet notave të kollokfiumit dhe finalit është 0,715. Në këtë rast, mund
të thuhet se ekziston një lidhje ndërmjet notës së kollokfiumit dhe finalit për arsye se lidhja e tyre
është e lartë (korrelacioni), në qoftë se nota e kollokfiumit është e lartë edhe nota e finalit është e
lartë, në qoftë se nota e kollokfiumit është e ulët edhe nota e kollokfiumit është e ulët.
2.3. Testi T i një Mostre(One-Sample t-Test) Testi T i një mostre përdoret për të përcaktuar ekzistimin e dallimit në masë të
rëndësishme të çfarëdo mesatareje që i përket një grupi me një vlerë të parapërcaktuar. Personi i
cili do të bëj analizën, krahason mesataren e grupit me vlerën e përcaktuar apo të dëshiruar
(p.sh.: vlerësimi i performancës, përcaktimi i nivelit të suksesit të një grupi, pritjet e sportistëve
nën apo mbi përpjekjet e treguara etj.).
2.3.1. SHEMBULL APLIKIMI Në lidhje me të dhënat e më larta në shembullin e dytë, mësimdhënësi pret që mesatarja e
finalit të studentëve të jetë 90. Duke përdorur one sample t-test, mund të shqyrtohet se a është
ndryshme mesatarja e klasës nga vlera e pritur 90.
Për të filluar me analizën, zgjidhen me radhë në SPSS: Analyze, Compare Means, One-
Sample T Test. (Hapi 1)

69
Hapi 1: Zgjedhja e One Sample T Testit nga Menyja
Hapi 2: Dritarja e Dialogut të One-Sample T Test
Në ekranin e mësipërm, në pjesën Test Variable(s) mirret vlera mesataren e së cilës
dëshirojmë ta vlerësojmë. Në pjesën Test Value shënohet vlera e dëshiruar e mesatares. Në
shembullin tonë, për arsye se mësimdhënësi pret që notat finale të jenë 90, është përshkruar kjo
vlerë. Pasi të klikohet OK do të fitohen të dhënat e mëposhtme.
Tabela 5: Rezultatet e One-Sample T Test
One-Sample Statistics
N Mean Std. Deviation Std. Error Mean
Final 20 80.8500 11.45368 2.56112

70
One-Sample Test
Test Value = 90
t df Sig. (2-tailed) Mean Difference
95% Confidence Interval of the
Difference
Lower Upper
Final -3.573 19 .002 -9.15000 -14.5105 -3.7895
Në fund shihet se mesatarja e notës finale është 80,85, ndërkaq vlera e dëshiruar ishte
90 (Test Value = 90). Kështu që ekziston një dallim i rëndësishëm ndërmjet mesatares së
realizuar dhe asaj të pritur. Vlera e Sig. (2-tailed) me 95% interval besueshmërie është më e
vogël se 0,05 (p=0,002). Në pjesën Mean Difference është dhënë dallimi (-9,15) ndërmjet dy
mesatareve. Mesatarja e finales është 9,15 më e vogël se ajo e pritur.
3. TESTI-Z Testi z, ka për qëllim hulumtimin në një nivel të caktuar të rëndësisë rreth çdo pretendimi
në lidhje me parametrat e popullimit duke përfituar nga të dhënat e mostrës. Për aplikimin e testit
z, popullimi duhet të ndjek shpërndarjen normale dhe duhet të dihen parametrat.
3.1. Testi Z një Mostërsh Hipotezat e popullimit të cilat do të krijohen në lidhje me masën kryesore se parametrat X
ku µ është e barabartë me një vlerë teorike si µ0 janë si më poshtë:
H0: µ = µ0
HA: µ ≠ µ0
HA: µ < µ0
HA: µ > µ0
Formula e testit z e cila do të përdoret për testimin e këtyre hipotezave është kështu:
Z = (X - ) / σ / √ )
X = mesatarja e mostrës
µ0 = parametri i supozuar i popullimit
σ = devijimi standart i popullimit, n = numri i njësive të mostrës

71
3.1.1. Shembull Aplikimi Një grup prej 1500 vetave ka aplikuar një dietë të veçantë një mujore për humbjen e
peshës. Nga 29 veta të zgjedhur rastësisht nga ky grup është vrojtuar që në fund të muajit të kenë
humbur peshë mesatarisht 6,7 kg (kilogram). Sipas devijimit standart të këtij grupi që është 7,1
kg, cila është mundësia që secili nga këta persona përgjatë një muaji të kenë dhënë së paku 5 kg?
H0: µ < 5
HA: µ > 5
Z = (6,7 – 5) / 7,1 / √
Z = 1,289
Për t’a interpretuar vlerën e llogaritur, duhet të dijmë rregullën e mëposhtme.
Zllogaritur < Ztabelës => H0 pranohet, HA refuzohet.
Vlera Z e tabelës në nivelin e rëndësisë α = 0,05 është 1,64. (Vlera e Z-së e cila
korrespondon me zonën 0,4495 në tabelë është 1,64)
Vlera e llogaritur e z-së (1,289), ngaqë është më e vogël se vlera e z-së nga tabela (1,64) H0
pranohet. Pra, shuma e humbur mujore e kilogramëve është më pak se 5 kg.
3.2. Testi Z dy Mostrash Hipotezat të cilat do të krijohen me rastin e supozimit kur në popullimin e parë parametri µ1
është e barabartë me një vlerë teorike si µ0 dhe në popullimin e dytë kur një parametër si µ2 është
e barabartë më një vlerë teorike si µ0 janë si më poshtë. Për aplikimin e testit z dy mostrash,
përsëri popullimet duhet të ndjekin shpërndarjen normale, por popullimet duhet të jenë të
pavarura nga njëra-tjetra.
H0: µ1 = µ2
HA: µ1 ≠ µ2
HA: µ1 < µ2
HA: µ1 > µ2
Për testimin se H0: µ1 = µ2 është HA: µ1 ≠ µ2 përdoret formula e mëposhtme.
√

72
3.2.1. Shembull Aplikimi Devijimi standart i një përbërje të gjetur në gjak për donatorët e gjakut meshkujt (dhënësit e
gjakut) është 14,1 ppm (parts per million) dhe 9,5 ppm për donatorët femra. Mesatarja e 75
meshkujve të zgjedhur rastësisht është 28 ppm dhe 50 femrave të zgjedhur rastësisht është 33
ppm. Çfarë është mundësia që kjo përbërje e gjakut të jetë e njëjtë (barbartë) me mesataren e
popullimit, për meshkuj dhe femra?
H0: µ1 = µ2 ose H0: µ1 - µ2 = 0
HA: µ1 ≠ µ2 ose HA: µ1 - µ2 ≠ 0
Z = (28-33) / √
Z = -2,37
Z = 2,37 (Interpretimi i vlerës z bëhet duke marrë vlerën absolute).
Në nivelin α = 0,05 vlera e z-së nga tabela është 1,96. (Vlera e Z-së e cila korrespondon me
zonën 0,4750 në tabelë është 1,96)
Zllogaritur < Ztabelës => H0 pranohet, HA refuzohet.
Për shkak që 2,37 > 1,96 H0 refuzohet. Pra, mesatarja e popullimit për meshkuj dhe femra
nuk është e barabartë.
4. ANALIZA E VARIANCËS (ANOVA)
Kjo temë është shpjeguar në detaje në kapitullin e Analizës së Variancës (Kapitulli 7).

73
5. TESTET JO PARAMETRIKE (NON –
PARAMETRIC) TË TESTIMIT TË
HIPOTEZAVE

74
TESTET JO PARAMETRIKE (NON – PARAMETRIC) TË TESTIMIT
TË HIPOTEZAVE
Para se të bëhet ndonjë analizë statistikore, në fillim duhet të shikohet se të dhënat a janë
kategorike (nominale, ordinale) apo të vazhdueshme (intervalore, propocionale). Teksa në të
dhënat kategorike aplikohen statistikat jo parametrike, në të dhënat e vazhdueshme aplikohen
statistikat parametrike. Në burimet statistikore, në përgjithësi ekzistojnë dy lloje të ndryshme të
teknikave statistikore: parametrike dhe jo parametrike. Cili është dallimi ndërmjet këtyre dy
grupeve? Përse është i rëndësishëm dallimi? Testet parametrike (p.sh. testet T, analiza e
variancës) prodhojnë supozime në lidhje me mostrën e nxjerrë nga modeli. Këto supozime
shpesh herë janë të lidhura me formën e shpërndarjes së mostrës (p.sh. shpërndarjes normale).
Kurse teknikat jo parametrike, nuk kërkojnë kërkesa të këtilla të rrepta dhe supozime në lidhje
me shpërndarjen e mostrës. Përkundër që janë më pak të paqarta, statistikat jo parametrike kanë
edhe disavantazhe. Testet jo parametrike, janë më të ndjeshme nga testet efektive parametrike
dhe për këtë arsye mund të jenë të pamjaftueshme për të gjetur dallimin ndërmjet grupeve. Për të
dhëna të përshtatshme dhe të fuqishme është më e saktë që të përdoren teknikat parametrike.
Kurse teknikat jo parametrike janë më të përshtatshme për të dhënat nominale (kategorike) dhe
ordinale (rendore). Teknikat jo parametrike janë më të përdorshme për mostra të vogla dhe për
ato të dhëna të cilat nuk ndjekin supozimet e testeve parametrike.
Testet jo parametrike janë teste që mund të aplikohen në raste kur ka më pak kushte. Për të
mund të aplikuar pothuajse të gjitha testet parametrike, së paku të dhënat duhet të ndjekin
shpërndarjen normale, variancat duhet të jene homogjene dhe varësisht në secilin test duhet të
sigurohen kushte të ndryshme. Testet parametrike, janë më të fuqishme dhe elastike për nga
testet jo parametrike. Përveç që ndihmojnë për të shqyrtuar efektin e shumë ndryshoreve të
pavarura mbi ndryshoren e varur, ato po ashtu ndihmojnë për të vlerësuar edhe bashkëveprimet
ndërmjet tyre.
Në përgjithësi, teksa me testet jo parametrike mund të analizohen të dhënat numerike
nominale, ordinale apo të dhënat me shpërndarje jashtë normales, me testet parametrike mund të
bëhet analiza e të dhënave numerike të cilat tregojnë shpërndarje normale. Në anën tjetër, teksa
aplikimi i testeve jo parametrike mbi të dhënat të cilat ndjekin shpërndarje normale nuk njihet
gabim, aplikimi i testeve parametrike mbi të dhënat të cilat tregojnë shpërndarje ordinale apo
jashtë normales është i papërshtatshëm. Për të aplikuar secilin test, sigurisht duhet ditur mirë se
cilat janë kushtet e nevojshme dhe si të dhënat do të i përshtaten këtyre kushteve. Në qoftë se
nuk dihet se a janë plotësuar kushtet, përdorimi i testeve jo parametrike në analizën e të dhënave
është me i sigurt. Por, në qoftë se aplikohen testet joparametrike pavarësisht së janë plotësuar
kushtet e nevojshme për testet parametrike, atëherë nuk do të jetë përfituar nga avantazhet e
veçanta të testeve parametrike.

75
1. TESTI KATRORI-KI
Testi Katrori-Ki është një test që përdoret dhe që zgjedhet shpesh për shkak të lehtësisë së
aplikimit në hulumtimet statistikore. Varësisht qëllimi dhe situatës, testi Katrori-Ki përbëhet nga
tri lloje: testi i përshtatshmërisë, testi i pavarësisë dhe testi i homogjenitetit.
1.1. Testi i Përshtatshmërisë i Katrorit-Ki dhe Shembull Aplikimi Testi Katrori-Ki i cili është një ndër testet që përdoret më së shumti brenda testeve jo
parametrike, mat përshtatshmërinë e shpërndarjes së vlerave të grupit të mostrës (shpërndarje
normale etj.) me shpërndarjen e popullimit për të cilat janë krijuar hipotezat. Quhet “test i
përshtatshmërisë” për arsye se kërkohet përshtatshmëria apo pajtueshmëria ndërmjet vlerës së
pritur dhe vlerës së përfituar. Teksa përcaktohet hipoteza zero përcaktohet edhe se çfarë
shpërndarje kanë të dhënat. Bëhet krahasimi i vlerës së frekuencës së pritur me vlerën e
frekuencës së vrojtuar. Në qoftë se ekziston pajtueshmëri ndërmjet vlerës së pritur me vlerën e
vrojtuar, hipoteza zero pranohet dhe në qoftë se nuk ka pajtueshmëri, duke e refuzuar hipotezën
zero pranohet hipoteza alternative.
SHEMBULL: Një firmë e automobilave dëshiron të mësoj se a ka dallim sasia e
porosisë të marrë nga tregtarët sipas muajve. Shuma e porosive të tregtarëve sipas muajve (vlerat
e vrojtuara) është dhënë më poshtë.
Tabela 1: Të Dhënat Përkatëse Për Shembullin
MUAJT SASIA E POROSISË
1 60
2 68
3 63
4 70
5 80
6 95
7 98
8 46
9 75
10 51
11 120
12 125
Pasi të jenë futur të dhënat në SPSS, në mënyrë që SPSS të mund të i përceptojë të dhënat
si frekuencë, duhet të bëhet ponderimi i të dhënave duke shkuar tek menyja Data, Weight
Cases. Në qoftë se aplikohet analiza e Katrorit-Ki pa u realizuar kjo fazë, nuk do të arrihen
rezultate të sakta.

76
Hapi 1: Përgatitja e të Dhënave Për Testin e Katrorit-Ki
Në ekranin e mëposhtëm zgjidhet butoni Weight cases by. Pas këtij veprimi në kutizën e
aktivizuar Frequency Variable vendoset “sasia e porosisë” e cila përfaqëson sasinë e porosive
të marrura sipas muajve. Pasi të klikohet OK funksioni do të përmbushet. Pas kësaj, me lehtësi
mund të aplikohet testi i Katrorit-Ki, pasi SPSS “sasinë e porosisë” do ta vlerësojë si frekuencë.

77
Hapi 2: Përcaktimi i të Dhënave si Frekuenca
Në këtë fazë, për ta bërë testin e Katrorit-Ki, në ekranin e SPPS zgjidhen me radhë
Analyze, Nonparametric Tests, Legacy Dialogs, Chi-Square.
Hapi 3: Menyja e Katrorit-Ki

78
Hapi 4: Dritarja e Testit Katrori-Ki
Në ekranin e mësipërm (Hapi 4), në fillim “sasia e porosisë” bartet në pjesën Test
Variable List. Në pjesën Expected Range duhet të jetë e përzgjedhur Get from data. Në pjesën
Expected Values në qoftë nuk do të përcaktohet ndonjë kufi i ulët apo i lartë, atëherë duhet të
jetë e përzgjedhur All categories equal. Pjesa Values përdoret për të kryer testin e
përshtatshmërisë që ndjekin shpërndarjen binomale. Në një rast të tillë, përzgjedhet butoni
Values dhe futen vlerat e pritura në qelizë përmes butonit Add dhe mund të futen të gjitha vlerat
teorike. Për arsye se shembulli ynë paraqet një mostër që ndjek shpërndarjen normale, të gjitha
grupet pranohen të barabarta. Pra, analiza jonë do të bëhet sipas përzgjedhjes All categories
equal.
Në hapin 4, në qoftë se përzgjedhet butoni Options do të përfitohet ekrani i mëposhtëm.
Pasi të përzgjidhen butonat e duhura në këtë ekran, do të përfitohen informacione përshkruese
(mean, median, standart deviation etj.) rreth të dhënave. Më poshtë do të shpejgohen në më
detaje të dhënat e përfituara nga kjo arenë.

79
Hapi 5: Dritarja e Përzgjedhjeve
Në këtë ekran (Hapi 5) pasi të klikohet Continue dhe më pas OK analiza do të jetë
përmbushur dhe rezultatet do të përfitohen si më poshtë.
Tabela 2: Rezultatet e Testit të Përshatshmërisë të Katrorit-Ki
Descriptive Statistics
N Mean
Std.
Deviation Minimum Maximum
Percentiles
25th 50th (Median) 75th
Sasia_e_porosisë 951 86.7392 25.38133 46.00 125.00 68.0000 80.0000 120.0000
Sasia_e_porosisë
Observed N Expected N Residual
46.00 46 79.3 -33.3
51.00 51 79.3 -28.3
60.00 60 79.3 -19.3
63.00 63 79.3 -16.3
68.00 68 79.3 -11.3
70.00 70 79.3 -9.3
75.00 75 79.3 -4.3
80.00 80 79.3 .8
95.00 95 79.3 15.8
98.00 98 79.3 18.8
120.00 120 79.3 40.8
125.00 125 79.3 45.8
Total 951

80
Test Statistics
Sasia_e_porosisë
Chi-Square 89.871a
df 11
Asymp. Sig. .000
a. 0 cells (0.0%) have expected
frequencies less than 5. The minimum
expected cell frequency is 79.3.
Në pjesën e parë të rezutateve janë të paraqitura rezultatet e nxjerra nga butoni Options.
Sipas kësaj, sasia totale e porosive është N=951 dhe mesatarja (mean) 86,73. Në mes të porosive,
sasia më e vogël e porosive (minimum) është 46 dhe sasia më e lartë e porosive është 125.
Sipas analizës, janë nxjerrë vlerat e pritura dhe të vrojtuara të porosive (Observed N dhe
Expected N) si dhe Residual e cila tregon dallimin pozitiv apo negativ të vlerave të vrojtuara dhe
të pritura. Në total janë 951 porosi dhe sipas 12 muajve vlera e pritur për çdo muaj është
llogaritur si 79,3. Qëllimi në testin e Katrorit-Ki është përcaktimi i dallimit ndërmjet vlerave të
realizuara të sasisë së porosive me vlerën e pritur (79,3). Pra, do të testohet përshtatshmëria
ndërmjet vlerës së vrojtuar dhe vlerës së pritur. Në këtë rast, hipoteza zero dhe alternative mund
të shkruhen si më poshtë:
H0: Nuk ekziston dallim ndërmjet sasisë së porosive sipas muajve.
HA: Ekziston dallim ndërmjet sasisë së porosive sipas muajve.
Në shembullin tonë, për arsye se vlera Sig. 0,000 (P<0,05), hipoteza zero refuzohet.
Ekziston një dallim i rëndësishëm ndërmjet sasisë së porosive sipas muajve. Kurse vlera e
Katrorit-Ki (Chi-Square) është përcaktuar si 89.871.
1.2. Testi i Pavarësisë i Katrorit-Ki dhe Shembull Aplikimi Testi i pavarësisë i Katrorit-Ki përdoret për të shqyrtuar se a ekziston lidhje ndërmjet dy apo
më shumë grupeve të ndryshoreve. Pra, hulumtohet se a janë të pavarura ndryshoret nga njëra-
tjetra. Hipotezat tona:
H0: Ndryshoret janë të pavarura nga njëra-tjetra.
HA: Ndryshoret nuk janë të pavarura nga njëra-tjetra.
Për të aplikuar testin e pavarësisë së Katrorit-Ki, rezultatet e vrojtimeve duhet të
klasifikohen apo grupohen në formë të serive. Ky lloj klasifikimi quhet tabela e paparashikuar.
Kjo tabelë përbëhet nga rreshtat dhe shtyllat në të cilat vendosen ndryshoret. Në qoftë se në

81
tabelë numri i rreshtave (row) shfaqet me (r) dhe numri i shtyllave (column) me (c) do të
përfitohet një tabelë kontigjente (rXc). Në këtë mënyrë, klasifikimi kryq bëhet për të shqyrtuar
lidhjen (varësinë apo jovarësinë) ndërmjet çfarëdo elementi të rreshtit me elementin e shtyllës.
Për këtë arsye, duhet të krahasohen frekuencat e pritura (expected) me frekuencat e vrojtuara
(observed) të çfarëdo elementi të rreshtit apo shtyllës.
Për të llogaritur testin e Katrorit-Ki përdoret kjo formulë:
Në qoftë se X2 > X
2α; (r-1) (c-1), hipoteza H0 refuzohet, hipoteza HA pranohet.
Në qoftë se X2 < X
2α; (r-1) (c-1), hipoteza H0 pranohet, hipoteza HA refuzohet.
SHEMBULL: Njerëzit e dy regjioneve të ndryshme janë klasifikuar sipas grupeve të gjakut
dhe janë përfituar rezultatet e mëposhtme. Sipas kësaj, testoni lidhjen në nivelin e rëndësisë
α=0,01 ndërmjet regjioneve dhe grupeve të gjakut. (Notë: Të dhënat e këtij shembulli janë marrë
nga libri i Dr. Bülbül Ergün, “Çözümsel İstatistik”).
H0: Regjionet dhe grupet e gjakut janë të pavarura nga njëra-tjetra. (Nuk ekziston lidhje
ndërmjet regjioneve dhe grupeve të gjakut)
HA: Regjionet dhe grupet e gjakut nuk janë të pavarura nga njëra-tjetra. (Ekziston lidhje
ndërmjet regjioneve dhe grupeve të gjakut)
Tabela 2: Të Dhënat Përkatëse Për Shembullin
REGJIONET GRUPET E GJAKUT TOTAL
0 A B AB
Perëndim 30 145 68 37 280
Lindje 60 115 32 13 220
Total 90 260 100 50 500
Në fillim duhet të gjejmë vlerën e testit të Katrorit-Ki (X2). Për të bërë këtë, duhet ditur
shkalla e lirisë.
Shkalla e lirisë: v = (r-1) (c-1), r = numri i rreshtave, c = numri i kolonave
Në shembullin tonë shkalla e lirisë është v = (2-1) (4-1)
Në shembull vlera e α ishte përcaktuar për 0,01. Në kërë rast, nga tabela e shpërndarjes së
X2, për vlerat v=3 dhe α=0,01, X
2=11,34. Në qoftë se vlera të cilën do ta llogarisim X
2 është më
e madhe se nga vlera në tabelë, hipoteza H0 do të refuzohet (X2>11,34 => H0REF).

82
Për të llogaritur vlerën e X2 nga formula, së pari duhet të llogaritet frekuenca e pritur (Eij).
Në tabelën e mëposhtë janë të përmbledhura llogaritjet e vlerave të vrojtuara (Oij) dhe vlerave të
pritura (Eij).
Tabela 4: Llogaritja e Frekuancave të Pritura
REGJIONET GRUPET E GJAKUT TOTAL
0 A B AB
Perëndim 30 (O11) E11 =
(280x90)/500
E11=50,4
145 (O12) E12=
(280x260)/500
E12=145,6
68 (O13) E13 =
(280x100)/500
E13=56
37 (O14) E14 =
(280x50)/500
E14=28
280
Lindje 60 (O21) E21 =
(220x90)/500
E21=39,6
115(O22) E22 =
(220x260)/500
E22=114,4
32 (O23) E23 =
(220x100)/500
E23=44
13 (O24) E24 =
(220x50)/500
E13=22
220
Total 90 260 100 50 500
= (30-50,4)2/50,4 + (145-145,6)
2/145,6 + (68-56)
2/56 + (37-28)
2/28 + (60-39,6)
2/39,6 + (115-
114,4)2/114,4 + (32-44)
2/44 + (13-22)
2/22 = 31,19
Për arsye se 31,19 > 11,34 hipoteza H0 refuzohet. Pra, ekziston lidhje ndërmjet regjioneve
dhe grupeve të gjakut.
Për ta zgjedhur këtë shembull përmes SPSS-it, bëhen aplikimet e poshtme me radhë.
Hapi 1: Futja e të Dhënave në SPSS
Pasi të futen të dhënat siç tregohet më lartë, njëjtë sikurse te testi i përshtatshmërisë i
Katrorit-Ki, përmes menysë Data duke zgjedhur “Weight Cases” bëhet njohja e vlerave të
frekuencës.

83
Hapi 2: Përgatitja e të Dhënave Për Testin e Katrorit-Ki

84
Hapi 3: Përcaktimi i të Dhënave si Frekuencë
Pas kësaj faze, për të bërë testin e pavarësisë së Katrorit-Ki, bëhen këto udhëzime me radhë
në ekranin e SPSS-it, Analyze, Descriptive Statistics, Crosstabs.
Hapi 4: Menya e Crosstabs

85
Hapi 5: Dritarja e Crosstabs
Në ekranin e mësipërm, pasi të përzgjidhet butoni “Statistics” zgjidhet “Chi-Square” nga
ekrani i ardhshëm.
Hapi 6: Dritarja e Testeve

86
Pasi të përfundohet ky funksion, do të përfitohen rezultatet e mëposhtme.
radha * kolona Crosstabulation
Count
kolona
Total 1.00 2.00 3.00 4.00
radha 1.00 30 145 68 37 280
2.00 60 115 32 13 220
Total 90 260 100 50 500
Chi-Square Tests
Value df
Asymp. Sig. (2-
sided)
Pearson Chi-Square 31.191a 3 .000
Likelihood Ratio 31.710 3 .000
Linear-by-Linear Association 28.126 1 .000
N of Valid Cases 500
Siç shihet më lartë, vlera e llogaritur e X2 nga SPSS (Pearson Chi-Square) është e njëjtë me
vlerën tonë të cilën e llogaritëm me anë të formulës më parë (X2=31,19). Për arsye se kjo vlerë
ëshë më e madhe nga vlera X2 e tabelës ishte specifikuar se hipoteza H0 do të refuzohej. Të
njëjtin interpretim mund ta bëjmë edhe për rezultatet e SPSS-it. Përveç kësaj, për shkak se edhe
vlera e Asym. Sig. (2-sided) është kuptimplotë (0,001<0,01), mund të interpretojmë se ekziston
një lidhje ndërmjet regjioneve dhe grupeve të gjakut.
1.3. Testi i Homogjenitetit i Katrorit-Kit dhe Shembull Aplikimi Testi i homogjentitetit i Katrorit-Ki përdoret për të përcaktuar se a janë marrë nga i njëjti
popullim dy mostra apo më shumë të cilat janë të pavarura ndërmjet vete. Hipotezat tona:
H0: Mostrat janë përzgjedhur nga popullimi i njëjtë.
HA: Mostrat nuk janë përzgjedhur nga popullimi i njëjtë.
SHEMBULL: Një bankë dëshiron të shqyrtoj rastin e suksesit se a ka dallim ndërmjet
departamenteve të Fakultetit të Ekonomisë (departamentet a janë homogjene për nga aspekti i
suksesit) për studentët të cilët do të futen në provimin e saj. Nga pjesëmarësit në provim, në
mënyrë të rastësishme rastet e suksesit dhe departamentet e studentëve janë dhënë në tabelën e
mëposhtme. Sipas kësaj, në nivelin e rëndësisë 5%, testoni se a janë homogjene departamentet
për nga aspekti i suksesit.

87
H0: Departamentet janë homogjene për nga aspekti i suksesit.
HA: Departamentet nuk janë homogjene për nga aspekti i suksesit.
Tabela 6: Të Dhënat Përkatëse Për Shembullin
Situata e suksesit Departamentet
Total Administrim
Biznesi
Ekonomiks Financa Administratë
Publike
Të suksesshëm 30 36 24 20 110
Të pa suksëshëm 24 20 18 28 90
Total 54 56 42 48 200
Ky shembull zgjidhet në të njëjtën mënyrë edhe me forumlat e dhëna në testin e pavarësisë
së Katrorit-Ki, po ashtu edhe me ndihmën e SPSS-it.
Në fillim bëhet njohja e frekuencave nga menyja Data, “Weight Cases”. Më tutje, për të
bërë testin e homogjenitetit të Katrorit-Ki, ndiqen veprimet e mëposhtme në ekranin e SPSS-it,
Analyze, Descriptive Statistics, Crosstabs.
Hapi 1: Nisja e Testit Katrorit-Ki

88
Hapi 2: Dritarja Funksionale Crosstabs Për Testin Katrori-Ki
Në ekranin e mësipërm, pasi të përzgjidhet butoni “Statistics” zgjidhet “Chi-Square” nga
ekrani i ardhshëm.

89
Pasi të përfundohet ky funksion, do të përfitohen rezultatet e mëposhtme.
Tabela 7: Rezultatet e Testit të Homogjentetit të Katrorit-Ki
radha * kolona Crosstabulation
Count
kolona
Total 1.00 2.00 3.00 4.00
radha 1.00 30 36 24 20 110
2.00 24 20 18 28 90
Total 54 56 42 48 200
Chi-Square Tests
Value df
Asymp. Sig. (2-
sided)
Pearson Chi-Square 5.483a 3 .140
Likelihood Ratio 5.500 3 .139
Linear-by-Linear Association 2.368 1 .124
N of Valid Cases 200
a. 0 cells (0.0%) have expected count less than 5. The minimum
expected count is 18.90.
Siç shihet më lartë, vlera e llogaritur nga SPSS-i e Pearson Chi-Square është X2=5,48. Vlera
e X2, për shkallën e lirisë (v=3) dhe nivelin e rëndësisë (α=0,05) gjendet nga tabela dhe vlera e tij
është 7,82. Për arsye se 5,48<7,82, hipoteza H0 pranohet. I njëjti rezultat arrihet edhe nga vlera e
Sig. në tabelën e mësipërme. Për arsye se vlera e Asym. Sig. (2-sided) p=0,140>0,05, hipoteza
H0 pranohet. Pra, departamentet janë homogjene për nga aspekti i suksesit (mostrat janë
përzgjedhur nga popullimi i njëjtë).
2. TESTI RUNS DHE SHEMBULL APLIKIMI Testi Runs përdoret zakonisht për të testuar rastësinë e një mostre. Megjithatë është me
rëndësi të specifikohet një pikë se testi Runs është i nevojshëm për të testuar rastësinë, por është i
pamjaftueshëm. Testi Runs bazohet në serinë e grupeve. Për shembull, seria AAABBCCC
paraqet një seri prej tre grupeve që përbëhet nga 3 shkronja A, 2 B dhe 3C. AAAABBB është një
seri prej dy grupeve dhe ABBBBA një seri prej tre grupeve.
SHEMBULL: Supozojmë se dëshirojmë të testojmë rastësinë e serive të indeksit së
industrisë së prodhimit të metalit bazë për të dhënat 2000Q1 – 2005Q1.

90
Tabela 8: Të Dhënat Përkatëse Të Shembullit
Për t’a aplikuar testin Runs në SPSS, ndiqen këto faza: Analyze, Nonparametrics Tests,
Legacy Dialogs, Runs.
Vitet Indeksi i industrisë së
prodhimit të metalit bazë
2000Q1 93,5
2000Q2 107,2
2000Q3 105,8
2000Q4 102,9
2001Q1 97,1
2001Q2 100,4
2001Q3 94,5
2001Q4 97,3
2002Q1 92,2
2002Q2 109,3
2002Q3 111,4
2002Q4 115,3
2003Q1 112,3
2003Q2 121,4
2003Q3 122,4
2003Q4 122,9
2004Q1 126,4
2004Q2 135,8
2004Q3 137,7
2004Q4 134,7
2005Q1 135,1

91
Hapi 1: Menyja e Testit Runs
Në dritaren e testit Runs, indeksi i industrisë së prodhimit vendoset në pjesën Test Variable
List. Në zgjedhjen e Cut Point-it përcaktohet se cila vlerë do të mirret për bazë për pikën e
prerjes së serisë. Sipas kësaj, testi i rastësisë Runs bëhet sipas medianës, modës, mesatares apo
një pikë prerjeje të veçantë të përcaktuar.

92
Hapi 2: Dritarja e Testit Runs
Tabela 9: Rezultatet e Testit Runs
Runs Test
indeksi_i_prodhi
mit
Test Valuea 1114.00
Cases < Test Value 10
Cases >= Test Value 11
Total Cases 21
Number of Runs 2
Z -4.029
Asymp. Sig. (2-tailed) .000
a. Median
Sipas të të dhënave të përfituara vlera e Z-së është -4,029 dhe vlera e Sig. është 0,000. Për
arsye se –Z < –Z α/2 hipoteza zero refuzohet (H0: Të dhënat janë të rastësishme). Pra, të dhënat
nuk janë të rastësishme.

93
3. TESTI MAN-WHITNEY U DHE SHEMBULL APLIKIMI
Kjo teknikë përdoret për të testuar dallimin ndërmjet dy grupeve të pavaruara të matura me
të dhëna jo intervalore. Ky test i cili aplikohet për mostrat e pavarura është një test jo parametrik
si alternativë e testit T. Në vend të krahasimit të mesatareve të grupeve si në testin T, testi Man-
Whitney U krahason medianat e grupeve. Vlerat e ndryshoreve të vazhdueshme i kthen në formë
rendore brenda dy grupeve. Në këtë mënyrë, vlerësohet se a ka dallim ndërmjet rendimit të dy
grupeve. Për arsye se të dhënat kthehen në formë rendore, nuk është me rëndësi shpërndarja e
saktë e vlerave.
SHEMBULL: Një firmë e ka ndarë personelin e saj në dy grupe në mënyrë të rastësishme
10 (A) dhe 11 (B) për të krahasuar dy tastiera të ndryshme të makinës llogaritëse të prodhimit.
Secilit grup i është dhënë makina me standarte të njëjta dhe grupi A përdor llojin e parë të
tastierës, kurse grupi B përdor llojin e dytë të tastierës. Koha (sekondat) e përfundimit të një
funksioni për secilin individ është si më poshtë:
Tabela 10: Të Dhënat Përkatëse Të Shembullit
Sipas kësaj, përmes ndihmës së testit Mann-Whitney U, do të shikohet se a ka dallim
ndërmjet përdorimit të tastierës së parë dhe asaj të dytë.
Bëhet hyrja e të dhënave në SPSS për dy grupet e ndryshoreve. Në fillim, bëhet hyrja e
kohës së përfundimit të funksionit në makinën llogaritëse të individëve si një ndryshore e
vazhdueshme në SPSS. Më vonë për të i njohur grupet, bëhet hyrja e një ndryshoreje kategorike
(grupi A=1, grupi B=2). Për të aplikuar testin Mann-Whitney U përmes SPSS, ndiqet kjo
procedurë: Analyze, Nonparametric Test, Legacy Dialogs, 2 Independent Samples.
Në dritaren e hapur, ndryshorja përkatëse e kohës së përfundimit të funksionit A vendoset
në pjesën Test Variable List, kurse ndryshorja B e cila strehon vlerat kategorike transferohet në
pjesën Grouping Variable.
GRUPI A GRUPI B
23 24
18 28
17 32
25 28
22 41
19 27
31 35
24 34
28 27
32 35
33

94
Hapi 1: Menyja e Testit Man-Whitney U
Hapi 2: Dritarja e Testit Man-Whitney U
Për arsye se për
vlerat e ekipit të
tastierës së parë
kemi përdorur 1
dhe ekipit të dytë
2, në kutizën
Define Groups
njihen me numrat
1 dhe 2.

95
Të dhënat të cilat duhet të shqyrtohen në rezultatet e prodhuara, janë nivelet e rëndësisë;
vlera Z dhe Asymp. Sig (2-tailed). Në qoftë se madhësia e mostrës është më e madhe se 30,
SPSS do të jap vlerën e z-approximation për të dhënat.
Tabela 11: Rezultatet e Testit Man-Whitney U
Test Statisticsa
A
Mann-Whitney U 16.000
Wilcoxon W 71.000
Z -2.753
Asymp. Sig. (2-tailed) .006
Exact Sig. [2*(1-tailed Sig.)] .005b
a. Grouping Variable: B
b. Not corrected for ties.
Në shembullin tonë, janë përfituar vlera e Z për -2,753 dhe vlera e nivelit të rëndësisë p për
0,006. Vlera e probabilitetit është sa vlera e (p) 0,05 ose më e vogël. Për këtë arsye, rezultati
është i rëndësishëm për nga ana e statistikës dhe në mënyrë statistikore ekziston një dallim
ndërmjet dy grupeve në pikën e lehtësisë së përdorimit të tastierave.
4. TESTI WALD-WOLFOWITZ DHE SHEMBULL APLIKIMI Testi Wald-Wolfowitz përdoret për të testuar se dy mostra a vijnë nga universet me
shpërndarje të njëjtë në dy grupe. Për ta zbatuar këtë test, bëhet renditja duke i bashkuar vlerat e
dy mostrave. Numri i vogël i serive tregon se dy universet i takojnë shpërndarjeve të ndryshme.
H0: Dy mostrat janë marrë nga universet me shpërndarje të njëjtë.
HA: Dy mostrat janë marrë nga universet me shpërndarje të ndryshme.
SHEMBULL: Në shembullin e mëposhtëm për testin Wald-Wolfowitz, do të testojmë se
indeksi i pagave reale a vjen nga universet të cilat i përkasin të njëjtës shpërndarje për sektorin e
Tekstilit dhe Veshjeve të periudhës 1998Q1 – 2004Q2. Një pikë e rëndësishme që duhet të
theksohet në këtë metodë është se për mostrat e vogla (n1,n2<20) duhet të ndahen në rend zbritës
dy mostrat e pavarura.
Tabela 12: Të Dhënat Përkatëse Të Shembullit
Sektori i Tekstilit Paga Sektori i Veshjeve Paga
1 151,9 2 142,5
1 171,1 2 148,9
1 184,6 2 171,7

96
Për të i njohur sektoret, bëhet hyrja e një ndryshoreje kategorike (1=Sektori i Tekstilit,
2=Sektori i Veshjeve). Për të aplikuar testin Wald-Wolfowitz në SPSS, ndiqen këto faza:
Analyze, Nonparametric Test, Legacy Dialogs, 2 Independent Samples.
Në dritaren e Two Independent Samples të dhënat e pagave sipas sektoreve transferohen
në pjesën Test Variable List dhe ndryshorja kategorike e sektoreve e cila bën njohjen e tyre
transferohet në pjesën Grouping Variable. Në seksionin e Define Groups për sektorin e tekstilit
shkruhet numri 1 dhe për sektorin e veshjeve shkruhet numri 2 në kutizat përkatëse. Kurse në
pjesën Test Type përzgjet testi Wald-Wolfowitz runs dhe pastaj klikohet OK.
1 201,3 2 185,2
1 282,3 2 256,3
1 309,7 2 272,9
1 357,7 2 310,3
1 384,6 2 328,7
1 450,2 2 388,2
1 482,5 2 401,2
1 496 2 454,7
1 513,2 2 478
1 543,9 2 521,7
1 600,1 2 550,8
1 654,7 2 590,6
1 706,4 2 631,9
1 823,8 2 725,4
1 894,9 2 725,6
1 924,7 2 808,6
1 955,7 2 872,4
1 1065,7 2 1008,4
1 1066,9 2 995,8
1 1100,6 2 1022,7
1 1148,9 2 1058,7
1 1279,6 2 1205,7
1 1253,3 2 1232,5

97
Hapi 1: Menyja e Testit Wald-Wolfowitz
Hapi 2: Dritarja e Testit Wald-Wolfowitz

98
Frequencies
sektor N
paga 1.00 26
2.00 26
Total 52
Test Statisticsa,b
Number of Runs Z
Asymp. Sig. (1-
tailed)
paga Exact Number of Runs 28c .280 .610
a. Wald-Wolfowitz Test
b. Grouping Variable: sektor
c. No inter-group ties encountered.
Sipas të dhënave të përfituara nga tabela, vlera e p (Sig.) është 0.610 dhe në nivelin e
rëndësisë 0,05 hipoteza H0 pranohet, pra dy mostrat janë marrë nga universet me shpërndarje të
njëjta.
5. TESTI WILCOXON SIGNED RANK DHE SHEMBULL APLIKIMI
Testi Wilcoxon Signed Rank përdoret për vlerat të cilat përsëriten. Testi Wilcoxon Signed
Rank përdoret në qoftë se mostrat e hulumtimit maten në dy raste apo dy kushte të ndryshme. Ky
test është test joparametrik si alternativë e testit T. Por, në vend të krahasimit të mesatareve, testi
Wilcoxon për t’i renditur dhe krahasuar të dhënat i konverton në korniza të ndryshme kohore (në
formën e Koha 1 dhe Koha 2) dhe teston se a ka dallim në vlera ndërmjet këtyre dy periudhave
kohore.
SHEMBULL: Dëshirohet të llogaritet se a ka dallim nga përgjigjet e sakta të provimit të
bërë përpara marrjes së kursit të statistikës me përgjigjet e sakta pas marrjes së kursit të
statistikës pas një muaji, të studentëve që studiojnë statistikë.

99
Tabela 14: Të Dhënat Përkatëse Të Shembullit
Për t’a aplikuar testin Wilcoxon Signed Rank në SPSS, nga dritarja e menysë ndiqen këto
hapa: Analyze, Nonparametric Tests, Legacy Dialogs, 2 Related Samples. Fazat e aplikimit
bëhen si më poshtë.
P1 P2
0 1
0 1
3 3
-7 4
9 5
9 5
-11 8
11 8
11 8
14 10
16 11
17 12
17 12
18 14

100
Hapi 1: Menyja e Testit Wilcoxon Signed Rank
Në dritaren e hapur duke i zgjedhur të dy ndryshoret (Provimi1 dhe Provimi2) barten në
kutizën e Test Pair(s) List. Në kutizën Test Type përzgjidhet testi Wilcoxon.

101
Hapi 2: Dritarja e Testit Wilcoxon Signed Rank
Në rezultatet e prodhuara duhet të kihen parasysh dy vlera: vlera e Z dhe vlera e cila e
tregon nivelin e rëndësisë Asymp. Sig. (2-tailed). Në qoftë se niveli i rëndësisë është më i vogël
se 0,05 apo është e barabartë, kjo na tregon se ekziston një dallim i rëndësishëm statistikor
ndërmjet dy vlerave.
Tabela 15: Rezultatet e Testit Wilcoxon Signed Rank
Test Statisticsa
provimi2 -
provimi1
Z -1.229b
Asymp. Sig. (2-tailed) .219
a. Wilcoxon Signed Ranks Test
b. Based on positive ranks.
Në shembullin tonë, është përfituar vlera significant prej 0,219 dhe kjo është më e madhe se
0,05. Sipas kësaj, nuk ka ndonjë ndryshim në numrin e përgjigjeve të sakta të studentëve në
krahasim para kursit dhe pas.

102
6. TESTI KRUSKAL-WALLIS DHE SHEMBULL APLIKIMI
Testi Kruskal-Wallis (ndonjëherë njihet edhe si testi testi Kruskal-Wallis H), është
alternativa joparametrike e analizës së variancës një drejtimshe (One-way ANOVA). Kjo analizë
mundëson krahasimin ndërmjet tre apo më shumë grupe ndryshoret e të cilave janë të
vazhdueshme. Vlerat konvertohen në formë rendore dhe krahasohen mesataret rendore për
secilin grup. Kjo është një analizë ndërmjet grupeve, kështu që njerëz të ndryshëm duhet të jenë
në secilin prej grupeve të ndryshme.
SHEMBULL: Në tabelën e mëposhtme është dhënë numri i fjalive të marra nga faqet e
zgjedhura në mënyrë të rastësishme nga tre romanet rreth dedektivëve të tre shkrimtarëve të
ndryshëm.
Tabela 16: Të Dhënat Përkatëse Të Shembullit
Sipas kësaj, duke përdorur testin Kruskal-Wallis të përcaktohet se a ekziston dallim
ndërmjet shkrimtarëve për nga aspekti i gjatësisë mesatare të fjalive. Për t’a aplikuar testin
Kruskal-Wallis në SPSS, nga menyja Analyze, zgjedhet Nonparametric Tests, Legacy Dialogs,
K Independent Samples.
Ndryshorja e vazhdueshme numri i fjalive (ndryshore e varur) merret dhe bartet në kutizën
Test Variable List, kurse ndryshorja kategorike shkrimtarët (ndryshore e pavarur) bartet në
kutizën Grouping Variable. Duke klikuar në butonin Define Range bëhet njohja e radhës së
vlerave kategorike minimum 1 dhe maksimum 3. Në pjesën Test Type përzgjidhet testi
Kruskal-Wallis H dhe pastaj klikohet OK.
Shkrimtari 1 Shkrimtari 2 Shkrimtari 3
13 43 33
27 35 37
26 47 33
22 32 26
26 31 44
37 33
54

103
Hapi 1: Menyja e Testit Kruskal-Wallis
Hapi 2: Dritarja e Testit Kruskal-Wallis

104
Nga rezultatet e përfituara, kemi nevojë për vlerat themelore, vlerën e Chi-Square, shkallën
e lirisë (df) dhe nivelin e rëndësisë (Asymp. Sig).
Tabela 17: Rezultatet e Testit Kruskal-Wallis
Ranks
shkrimtarët N Mean Rank
fjalitë 1.00 5 3.40
2.00 6 12.08
3.00 7 11.64
Total 18
Test Statisticsa,b
fjalitë
Chi-Square 9.146
df 2
Asymp. Sig. .010
a. Kruskal Wallis Test
b. Grouping Variable:
shkrimtarët
Në qoftë se niveli i rëndësisë është më i vogël se 0,05, mund të thuhet se ekziston një dallim
statistikor në mënyrë të rëndësishme ndërmjet tre grupeve të ndryshores së ndryshueshme.
Renditja mesatare e tre shkrimtarëve mund të kontrollohet në kolonën e Mean Ranks në tabelën
Ranks. Vlerat Mean Ranks tregojnë se cili shkrimtar ka shkallën më të lartë të përgjithshme.
Niveli i rëndësisë është 0,010 dhe është i vogël se vlera e alfas 0,05. Kështu që, mund të themi se
ekziston dallim ndërmjet këtyre shkrimtarëve të romaneve të ndryshme rreth dedektivëve për nga
aspekti i gjatësisë mesatare të fjalive. Sipas vlerave të Mean Ranks, shkrimtari i dytë ka numrin
më të madh të gjatësisë së fjalive dhe shkrimtari i parë ka numrin më të vogël të gjatësisë së
fjalive.
7. TESTI FRIEDMAN DHE SHEMBULL APLIKIMI
Testi Friedman është alternativa jo parametrike e analizës së variancës një drejtimshe për
vlerat të cilat përsëriten. Testi Friedman përdoret kur mostrat mirren nga e njëjta çështje dhe kur
këto mostra maten në tri apo më shumë pika apo nën tri kushte të ndryshme.

105
SHEMBULL: Një listë e cila përbëhet nga 12 emra, u lexohet me zë 10 studentëve të cilët
sapo kishin filluar trajnimin. Nga 12 emrat, katër emra u përkasin personave sportistë (grupi A),
katër të tjerë politikanëve kombëtar dhe ndërkombëtar (grupi B) dhe katër emrat e fundit janë
persona të njohur në nivelin kombëtar. Në fund të leximit, kërkohet nga studentët që të përsërisin
emrat me aq sa ata kishin mbajtur në mend. Përgjigjet e dhëna janë si më poshtë.
Tabela 18: Të Dhënat Përkatëse Të Shembullit
Për të provuar se a ka dallim ndërmjet niveleve të kujtesës të tre grupeve me testin
Friedman, zgjedhim Analyze, Nonparametric Tests, Legacy Dialogs, K Related Samples nga
programi SPSS.
Hapi 1: Menyja e Testit Friedman
ANËTARËT A B C D E F G H I J
GRUPI A 3 1 2 4 3 1 3 3 2 4
GRUPI B 2 1 3 3 2 0 2 2 2 3
GRUPI C 0 0 1 2 2 0 4 1 0 2

106
Ndryshoret grupi A, grupi B, dhe grupi C të cilat paraqesin emrat e tre grupeve të të
famshëve barten në kutizën Test Variables. Në pjesën Test Type përzgidhet testi Friedman.
Hapi 2: Dritarja e Testit Friedman
Tabela 19: Rezultatet e Testit Friedman
Ranks
Mean Rank
Grupi_A 2.70
Grupi_B 2.00
Grupi_C 1.30
Test Statisticsa
N 10
Chi-Square 10.889
df 2
Asymp. Sig. .004
a. Friedman Test
Rezultatet e përfituara tregojnë se ekziston një dallim i rëndësishëm ndërmjet kujtesës së
emrave të tre grupeve të ndryshme (Asymp. Sig.: 0,004<0,05). Përveç kësaj, nga tabela Ranks
kuptohet se grupi i emrave i të cilave është mbajtur në mend më së shumti është grupi i
sportistëve.

107
8. KORRELACIONI SPEARMAN’S RANK ORDER DHE SHEMBULL APLIKIMI
Korrelacioni Spearman’s Rank Order (rho) përdoret për të llogaritur nivelin e lidhjes
ndërmjet dy ndryshoreve të vazhdueshme. Ky test është alternativa jo parametrike e koeficientit
të korrelacionit të Pearsonit.
SHEMBULL: Që prej fillimit të përmirësimit të standarteve të shërbimeve të higjienës dhe
shëndetit vërehet një rritje e përgjithshme në jetëgjatësinë gjatë shekullit 19 dhe 20. Rritja e
jetëgjatësisë mesatare tregon dallim nga shteti në shtet, nga shoqëria në shoqëri dhe madje nga
familja në familje. Më poshtë të dhënat i përkasin një familjeje të madhe rreth viteve të vdekjes
dhe viteve të jetesës së personave. Të shqyrtohet se a ka rritje në jetëgjatësinë mesatare për këtë
familje.
Tabela 20: Të Dhënat Përkatëse Të Shembullit
Në qoftë se vitet e vdekjes i shkruajme si x dhe moshën e vdekjes si y dhe bëjmë renditjen e
tyre, koeficienti pozitiv rho do të tregojë rritjen mesatare të jetëgjatësisë. Për të parë lidhjen
ndërmjet viteve të vdekjes dhe moshës së vdekjes përmes testit të koeficientit të Spearmanit, në
programin SPSS ndjekim këtë procedurë: Analyze, Correlate, Bivariate.
Viti Mosha
1827 13
1884 83
1895 34
1908 1
1914 11
1918 16
1924 68
1928 13
1936 77
1941 74
1964 87
1965 65
1977 83

108
Hapi 1: Menyja e Korrelacionit të Spearman’s Rank Order
Të dy ndryshoret barten në pjesën Variables. Në pjesën Correlation Coeficients përzgjihet
Spearman.
Hapi 2: Dritarja e Korrelacionit Spearman’s Rank Order

109
Tabela 21: Rezultatet e Korrelacionit Spearman’s Rank Order
Correlations
viti_i_vdekjes
mosha_e_vdekj
es
Spearman's rho viti_i_vdekjes Correlation Coefficient 1.000 .507
Sig. (2-tailed) . .077
N 13 13
mosha_e_vdekjes Correlation Coefficient .507 1.000
Sig. (2-tailed) .077 .
N 13 13
Niveli i rëndësisë i koeficientit të korrelacionit (rho) mund të ndikohet nga madhësia e
mostrës. Në një mostër të vogël (si p.sh. N=30), mund të përfitohet një vlerë e korrelacionit jo
shumë e fuqishme e cila nuk është më e vogël se vlera e alfas 0,05 në nivelin e rëndësisë. Në të
njëjtën kohë, në mostrat e mëdha (si p.sh. N=100) vlera shumë të vogla të korrelacionit mund të
jenë të rëndësishme. Në këtë pikë, shumë autorë kanë specifikuar se duhet përcaktuar niveli i
rëndësisë, por nuk duhet theksuar. Në shembullin tonë, vlera e përfituar e rho-së është 0,507 dhe
shenja e koeficientit është pozitive. Kjo na tregon se me kalimin e viteve është rritur edhe
jetëgjatësia mesatare. Kur koeficienti i korrelacionit është prej 0,50 – 1,00 konsiderohet të jetë
një lidhje e lartë, prandaj kjo na tregon se ekziston një lidhje e fuqishme ndërmjet këtyre dy
ndryshoreve.

110
6. ANALIZA E KORRELACIONIT

111
ANALIZA E KORRELACIONIT
Analiza e korrelacionit është një metodë statistikore e cila përdoret për të testuar
marrëdhënien lineare ndërmjet dy ndryshoreve apo mardhënien e një ndryshoreje me dy apo
shumë ndryshore si dhe për matjen e shkallës të kësaj marrëdhënie në qoftë se ekziston.
Qëllimi në analizën e korrelacionit është që të shikohet se çfarë drejtimi do të marrë
ndryshorja e varur (y) kur të ndryshojë ndryshorja e pavarur (x).
Për t’a bërë analizën e korrelacionit, dy ndryshoret duhet të jenë të vazhdueshme dhe duhet
të ndjekin shpërndarjen normale.
Në fund të analizës së korrelacionit, koeficienti i korrelacionit llogarit se a ekziston një
marrëdhënie lineare dhe në çfarë niveli. Koefcienti i korrelacionit shënohet me “r” dhe merr
vlerat prej -1 deri +1.
Më poshtë, në Figurën 1-a është paraqitur rasti kur ekziston një korrelacion pozitiv ndërmjet
dy ndryshoreve. Marrëdhënia është pozitive, në rastin kur me rritjen e vlerave të ndryshores X
kanë tendencë rritjeje edhe vlerat e ndryshores Y ose në rastin kur vlerat e ndryshores X
zvogëlohen, edhe vlerat e ndryshores Y kanë tendencë zvogëlimi.
Në Figurën 1-b është paraqitur rasti kur ekziston një korrelacion negativ. Marrëdhënia është
negative, në rastin kur me rritjen e vlerave të njërës ndryshore, vlerat e ndryshores tjetër
zvogëlohen.
Në Figurën 1-c është paraqitur rasti kur nuk ekziston korrelacion ndërmjet dy ndryshoreve.
a. Korrelacion pozitiv b. Korrelacion negativ c. Nuk ekziston korrelacion
Figura 1: Rastet e Ndryshme të Korrelacionit
Korrelacioni nuk nënkupton marrëdhënien shkak-pasojë. Pra, kur ekziston korrelacion
ndërmjet ndryshoreve A dhe B në model, nuk nënkupton që A do të shkaktojë B apo B do të
shkaktojë A.

112
1. KOEFICIENTI I KORRELACIONIT TË PEARSONIT
Koeficienti i korrelacionit të Pearsonit përdoret për të matur shkallën e marrëdhënies së
drejpërdrejtë të dy ndryshoreve të vazhdueshme. Me fjalë të tjera, kërkohet përgjigja e pyetjes se
a ekziston një marrëdhënie e rëndësishme ndërmjet dy ndryshoreve.
Përpara se të llogaritet koeficienti i korrelacionit, përmes grafikut të shpërndarjes duhet të
kontrollohet se a ekziston marrëdhënie e drejtpërdrejtë, sepse koeficienti i korrelacionit duhet të
llogaritet vetëm nëse ekziston marrëdhënie e drejtëpërdrejtë.
Koefcienti i korrelacionit shënohet me “r” dhe merr vlerat prej -1 deri +1. Në qoftë se,
r = -1; ekziston një marrëdhënie e plotë negative lineare. Pra, kur njëra ndryshore rritet,
tjetra zvogëlohet dhe anasjelltas, kur njëra zvogëlohet, tjetra rritet. Në këtë rast, edhe
trendi i grafikut do të ketë prirje negative.
r = 1; ekziston një marrëdhënie e plotë pozitive lineare. Pra, kur njëra ndryshore rritet,
edhe tjera rritet dhe anasjelltas, kur njëra zvogëlohet, edhe tjetra zvogëlohet. Në këtë rast,
edhe trendi i grafikut do të ketë prirje pozitive.
r = 0; nuk ekziston marrëdhënie ndërmjet dy ndryshoreve.
Koeficienti i korrelacionit të Pearsonit llogaritet në këtë mënyrë:
√
Nga formula;
SSxy = ) (yi - )
SSxx = )2
SSyy = )2
Interpretimi për koeficientin e korrelacionit ndërmjet dy ndryshoreve mund të bëhet si
më poshtë:
r Lidhja
0,00 – 0,25 Shumë e dobët
0,26 – 0,49 E dobët
0,50 – 0,69 E mesme
0,70 – 0,89 E lartë
0,90 – 1,00 Shumë e lartë

113
2. KOEFICIENTI I KORRELACIONIT TË PJESSHËM
Në disa raste, gjatë kërkimit të lidhjes ndërmjet ndryshoreve teksa mirren nën kontroll
ndikimi i një sërë ndryshoreve, duhet shikuar edhe në lidhjet e tjera ndërmjet ndryshoreve. Kjo
metodë quhet korrelacioni i pjesërishëm. Me këtë metodë, kur të merret nën kontroll ndryshorja e
tretë, mundësohet shpjegimi i korrelacionit të dy ndryshoreve tjera të mbetura. Arsyeja e
përdorimit të kësaj metode është se shpjegon plotësisht marrëdhënien ndërmjet dy ndryshoreve.
Numri i ndryshoreve të marrura nën kontroll përcakton shkallën e korrelacionit të pjesshëm.
Për ta aplikuar korrelacionin e pjesërishëm, ndryshoret duhet që të kenë lidhje lineare.
Korrelacioni i pjesërishëm përdoret për të zbuluar lidhjen e fshehur ndërmjet ndryshoreve.
3. MATËSIT E TJERË TË LIDHJES Në analizën e korrelacionit përdoren edhe matës të tjerë për të matur marrëdhënien ndërmjet
ndryshoreve përveq koeficientit të korrelacionit të Pearsonit. Këto janë phi, korrelacioni rendor i
Spearmanit, Kendall’s Tau, koeficienti i normalitetit dhe eta.
3.1. PHI Koeficienti i phi-së përdoret për të kërkuar lidhjen ndërmjet dy ndryshoreve e cila rezulton
më përgjigjen po ose jo. Vlera r e përfituar në fund të analizës, paraqet korrelacionin ndërmjet
ndryshoreve, vëzhgimet e të cilave mund të jenë bipolare dhe ky koeficient i korrelacionit quhet
koeficienti i phi-së.
3.2. Korrelacioni Rendor i Spearmanit Në rastet kur shpërndarja e ndryshoreve është normale apo është afër normales, përdoret
koeficienti i korrelacionit të Pearsonit, por në rastet kur shpërndarja e ndryshoreve është larg
normales përdoret korrelacioni rendor i Spearmanit. Në rastet kur nuk përdoren të dhënat e plota
të ndryshoreve ose në mungesë të vlerave absolute, është e mundur renditja e të dhënave të
disponueshme me numra sipas kualifikimeve të tyre. Në qoftë se ndryshoret renditen në këtë
mënyrë, në këtë rast përdoret korrelacioni rendor i Spearmanit. Pra, korrelacioni rendor i
Spearmanit është një verzion parametrik i korrrelacionit të Pearsonit i cili përdor të dhënat
rendore.
Korrelacioni rendor i Spearmanit, njëjtë si koeficienti i korrelacionit të Pearsonit merr vlerat
nga -1 deri në +1. Në qoftë se koeficienti i korrelacionit është +1, ekziston një lidhje e përkryer
pozitive lineare ndërmjet ndryshoreve, në qoftë se koeficienti i korrelacionit është -1, ekziston
një lidhje e përkryer negative lineare ndërmjet ndryshoreve. Në rastin kur koeficienti i
korrelacionit të Spearmanit është 0, kjo nënkupton se nuk ekziston ndonjë lidhje lineare ndërmjet
ndryshoreve.

114
3.3. Koeficienti i Normalitetit Koeficienti i normalitetit përdoret për të matur lidhjen ndërmjet dy ndryshoreve nominale.
Për llogaritjen e këtij koeficienti përdoret testi i Katrorit-Ki.
3.4. ETA Teknika matëse ETA, përdoret për të matur lidhjen jolineare. Vlerat të cilat i merr
koeficienti janë ndërmjet 0 dhe +1. Mund të përdoret për secilin lloj të ndryshoreve.
4. Shembull Aplikimi Një kompani dëshiron të mat lidhjen ndërmjet shumës së shitjeve dhe të ardhurave nga
shitja. Shumat e shitjes dhe të ardhurat nga shitja janë dhënë më poshtë sipas viteve.
Hapi 1: Hyrja e Të Dhënave në SPSS
Pasi të futen të dhënat në SPSS, shkohet të menyja Analyze, Correlate. Këtu ndeshemi me
3 alternativa. Nga këto zgjedhet menyja Bivariate. (Alternativat tjera do të shpjegohen në detaje
pas këtij shembulli, në këtë shembull do të elaborohet vetëm metoda Bivariate).

115
Hapi 2: Menyja e Korrelacionit Bivariate
Nga dritarja e hapur, ndryshoret e shumës së shitjeve dhe të ardhurave nga shitja barten në
pjesën Variables. Më vonë, bëhen përzgjedhjet e bëra më poshtë.
Fare në fund, duke klikuar në butonin Options do të hapet dritarja e përzgjedhjeve. Në
dritaren e hapur, në pjesën Missing Values përzgjidhet Exclude Cases Listwise dhe pastaj me
radhë klikohet Continue, OK dhe do të kryhet analiza.

116
Hapi 3: Dritarja e Korrelacionit Bivariate
Hapi 4: Dritarja e Përzgjedhjeve
Në fund të analizës, SPSS do të jep rezultatet e mëposhtme.

117
Tabela 1: Rezultatet e Analizës së Korrelacionit
Correlationsb
shuma_e_shitje
ve
të_hyrat_nga_s
hitja
shuma_e_shitjeve Pearson Correlation 1 .987**
Sig. (2-tailed) .000
të_hyrat_nga_shitja Pearson Correlation .987**
1
Sig. (2-tailed) .000
**. Correlation is significant at the 0.01 level (2-tailed).
b. Listwise N=10
Sipas kësaj, ekziston një lidhje e fuqishme, pozitive dhe e rëndësishme ndërmjet shumës
vjetore së shitjeve dhe të ardhurave vjetore nga shitjet. Koeficienti i korrelacionit është llogaritur
të jetë r = 0,987. Nga kjo, mund të themi se me rritjen e shumës së shitjeve janë rritur edhe të
hyrat nga shitja.
Kjo lidhje, mund të shikohet edhe përmes së diagramit të shpërndarjes. Në Figurën 2, mund
të shihet diagrami i shpërndarjes i cili tregon lidhjen ndërmjet shumës vjetore të shitjeve dhe të
hyrave vjetore nga shitja. (Për ta bërë diagramin e shpërndarjes nga menyja e SPSS-it, shkohet te
Graphs, Legacy Dialogs, Scatter/Dot. Më pas zgjedhet Simple Scatter, Define. Në boshtin Y
vendoset ndryshorja e varur, në boshtin X vendoset ndryshorja e pavarur dhe shtypet butoni
OK.).
Figura 2: Diagrami i Shpërndarjes

118
Vlera e r2 është llogaritur për 0,9742. (Kjo në të njëjtën koha është vlera në katror e
koeficientit të korrelacionit 0,987). Pra, 97,42% e ndryshimeve në të ardhurat vjetore nga shitja,
arsyetohet nga shuma vjetore e shitjeve. Mund të themi edhe të kundërtën e kësaj për nga ana e
teorisë, pra 97.42% e ndryshimit në shumën e shitjeve mund të spjegohet nga ndryshimi në të
ardhurat nga shitja. Më fjalë të tjera, një analizë e këtillë, nuk tregon marrëdhnien shkak-pasojë,
mirëpo jep idenë se në çfarë niveli dhe në çfarë drejtimi do të ndryshojnë ndryshoret.
5. Shembull Aplikimi 2 Të shqyrtohet lidhja ndërmjet të ardhurave vjetore, kohës së trajnimit, përvojës së punës dhe
moshës së 20 punëtorëve të një kompanie. Të dhënat përkatëse të punëtorëve janë dhënë më
poshtë.
Tabela 2: Të Dhënat Përkatëse Të Shembullit
Ndryshoret: të ardhurat vjetore, trajnimi, mosha dhe përvoja.
Në SPSS, shkohet te Analyze, Bivariate. Këtu kemi 3 metoda të ndryshme.
Të ardhurat
vjetore
(10,000 €)
Vite trajnimi Vitet e
përvojës
Mosha
5,0 2 9 29
9,7 4 18 50
28,4 8 21 41
8,8 8 12 55
21,0 8 14 34
26,6 10 16 36
25,4 12 16 61
23,7 12 9 29
22,5 12 18 64
19,5 12 5 30
21,7 12 7 28
24,8 13 9 29
30,1 14 12 35
24,8 14 17 59
28,5 15 19 65
26,0 15 6 30
38,9 16 17 40
22,1 16 1 23
33,1 17 10 58
48,3 21 17 44

119
5.1. Metoda Bivariate Metoda Bivariate, përveç shkallës së rëndësisë bën llogaritjen edhe të koeficientit të
korrelacionit të Perasonit, koeficientit të Spearmanit si dhe llogarit Kendall’s tau-b.
Hapi 1: Menyja e Korrelacionit Bivariate
Hapi 2: Dritarja e Korrelacionit

120
Në hapin 2, në pjesën Test of Significance ndeshemi me dy zgjedhje: two tailed dhe one
tailed.
Two-tailed: Kjo hipotezë përdoret në qoftë se hipotezat e krijuara kanë orientim të dyfishtë,
pra H0 (null) në formën hipoteza ëshë e barabartë, HA (alternative) në formën hipoteza nuk është
e barabartë. Për shembull, në qoftë se kërkohet përgjigjja se studentët e departamentit të
Administrim Biznesit a i kanë notat e Financës të njëjta me studentët e departamentit të
Ekonomiksit, hipotezat të cilat do të krijohen duhet të jenë në këtë mënyrë:
H0: µadministrimbiznesi = µekonomiks ose µadministrimbiznesi - µekonomiks = 0
HA: µadministrimbiznesi ≠ µekonomiks ose µadministrimbiznesi - µekonomiks ≠ 0
One-tailed: Kjo hipotezë përdoret në qoftë se hipotezat e krijuara kanë orientim një
drejtimësh, pra H0 (null) në formën hipoteza është më e madhe ose e barabartë, ose është më e
vogël ose e barabartë, HA (alternative) hipoteza është më e vogël ose më e madhe. Për shembull,
në qoftë se kërkohet përgjigjja se studentët e departamentit të Administrim Biznesit a i kanë
notat e Financës më të mëdha për nga studentët e departamentit të Ekonomiksit, hipotezat të cilat
do të krijohen duhet të jenë në këtë mënyrë:
H0: µadministrimbiznesi ≤ µekonomiks ose µadministrimbiznesi - µekonomiks ≤ 0
HA: µadministrimbiznesi > µekonomiks ose µadministrimbiznesi - µekonomiks > 0
Gjatë përcaktimi të fuqisë së lidhjes ndërmjet ndryshoreve, zakonisht përdoret Two-tailed.
Më vonë duke klikuar në butonin Options, hapet dritjarja e përzgjedhjeve.
Hapi 3: Dritarja e Përzgjedhjeve
Në pjesën Missing Values përballemi me dy alternativa.

121
Exclude cases pairwise: I konsideron ndryshoret të cilat nuk kanë mungesë të dhënash.
Exclude cases listwise: I konsideron të dhënat e disponueshme. (Preferohet përdorimi i
kësaj).
Tabela 3: Rezultatet e Korrelacionit Bivariate
Correlationsb
të_ardhurat trajnimi përvoja mosha
të_ardhurat Pearson Correlation 1 .846**
.266 .102
Sig. (2-tailed) .000 .258 .669
trajnimi Pearson Correlation .846**
1 -.107 .098
Sig. (2-tailed) .000 .654 .680
përvoja Pearson Correlation .266 -.107 1 .676**
Sig. (2-tailed) .258 .654 .001
mosha Pearson Correlation .102 .098 .676**
1
Sig. (2-tailed) .669 .680 .001
**. Correlation is significant at the 0.01 level (2-tailed).
b. Listwise N=20
Në fillim, në qoftë se i formojmë hipotezat:
H0: Nuk ekziston lidhje ndërmjet ndryshoreve.
HA: Ekziston lidhje ndërmjet ndryshoreve.
Në fund të analizës së korrelacionit janë dhënë koeficientët e korrelacionit ndërmjet
ndryshoreve. Sipas kësaj, në nivelin e rëndësisë 5%, vlerat më të vogla se 0,05 teksa tregojnë se
nuk ekzsiton lidhje ndërmjet ndryshoreve, pra hipoteza H0 teksa refuzohet, vlerat më të mëdha se
0,05 tregojnë se ekziston lidhje ndërmjet ndryshoreve, pra hipoteza HA pranohet. Në tabelën 3,
numrat e shënuar me asteriks (**) tregojnë se ekziston korrelacion ndërmjet ndryshoreve në
nivelin e rëndësisë 1%. Sipas kësaj, shihet se ekziston një korrelacion i lartë dhe pozitiv prej
0,846 ndërmjet të ardhurave vjetore dhe trajnimit, një korrelacion i dobët dhe pozitiv prej 0,266
ndërmjet të ardhurave vjetore dhe përvojës dhe një korrelacion shumë i dobët por pozitiv prej
0,105 ndërmjet të ardhurave vjetore dhe përvojës. Sipas këtij rezultati, korrelacioni më i lartë
është ndërmjet ndryshoreve të të ardhurave vjetore dhe trajnimit. Përndryshe, koeficientët e
korrelacioneve ndërmjet ndryshoreve të trajnimit, moshës dhe përvojës shihet të jenë të ulët
(trajnim – përvojë -0,107, trajnim – moshë 0,098). Kurse koeficienti i korrelacionit ndërmjet
përvojës dhe moshës me një vlerë të lartë prej 0,676, është i përshtatshëm sipas pritjeve tona.

122
5.2. Metoda e Pjesshme (Partial) Metoda e pjesshme e korrelacionit mundëson llogaritjen e lidhjes lineare ndërmjet dy
ndryshoreve duke marrë nën kontroll ndikimin e një apo shumë ndryshoreve. Me fjalë të tjera,
gjendet një marrëdhnie e qartë ndërmjet dy ndryshoreve.
Hapi 1: Menyja e Korrelacionit të Pjesërishëm (Partial)
Hapi 2: Dritarja e Korrelacionit të Pjesërishëm (Partial)

123
Hapi 3: Dritarja e Përzgjedhjeve
Tabela 4: Rezultatet e Korrelacionit të Pjesshëm (Partial)
Correlations
Control Variables të_ardhurat trajnimi përvoja
mosha të_ardhurat Correlation 1.000 .844 .268
Significance (2-tailed) . .000 .267
df 0 17 17
trajnimi Correlation .844 1.000 -.236
Significance (2-tailed) .000 . .331
df 17 0 17
përvoja Correlation .268 -.236 1.000
Significance (2-tailed) .267 .331 .
df 17 17 0
Në tabelën 4, nga ndryshorevet e pavarura, ndryshorja e moshës është marrë nën kontroll.
Sipas kësaj metode të pjesshme, ekziston një korrelacion i fuqishëm pozitiv ndërmjet trajnimit
dhe të ardhurave (0,844).
Lidhja ndërmjet trajnimit dhe të ardhurave ishte më e lartë (r = 0,846) përpara se të merrej
ndryshorja e moshës nën kontroll (Tabela 3). Kur ndryshorja e moshës të mirret nën kontroll kjo
marrëdhënie do të zvogëlohet (r = 0,844).

124
5.3. Metoda Distances Kjo metodë ka për qëllim që të mas distancën ndërmjet ndryshoreve. Në metodën Distances
dëshirohet që koeficienti i korrelacionit ndërmjet ndryshoreve të jetë i ulët.
Hapi 1: Menyja e Korrelacionit Distances
Pasi të hapet dritarja e Distances, të gjitha ndryshoret barten në pjesën Variables.
Hapi 2: Dritarja e Distances

125
Më pas klikohet në butonin Measures.
Hapi 3: Dritarja e Measures
Në dritaren Measure, përzgjedhet Interval nga tri alternativat dhe nga këtu përzgjedhet
Euclidean distances. Më poshtë tek Transform Values, tek pjesa Standardize duhet të jetë e
përzgjedhur None dhe pastaj klikohet butoni Continue.
Tabela 5: Rezultatet e Metodës Distance
Case Processing Summary
Cases
Valid Missing Total
N Percent N Percent N Percent
20 100.0% 0 0.0% 20 100.0%

126
Proximity Matrix
Euclidean Distance
të_ardhurat trajnimi përvoja mosha
të_ardhurat .000 62.164 68.035 105.444
trajnimi 62.164 .000 32.465 147.482
përvoja 68.035 32.465 .000 139.682
mosha 105.444 147.482 139.682 .000
This is a dissimilarity matrix
Sipas të dalurave në fund të analizës, teksa distancat ndërmjet të ardhurave vjetore me
trajnimin dhe përvojën janë pothuajse të njëjta (62,164 dhe 68,035), është një distancë më e
largët me moshën (105,444). Teksa ekziston një distancë e afërt ndërmjet trajnimit dhe përvojës
(32,465), ndryshorja e moshës është e largët nga trajnimi (147,482) dhe nga përvoja (139,862).
Ekzistimi i distancave të largëta të ndryshoreve të pavarura zvogëlon nivelet e shpjegimit të
ndryshores së varur. Siç e kemi parë edhe në analizat e tjera të mëparshme, ndryshorja e moshës
është ndryshorja e cila e ndikon më së paku ndryshoren e varur (të ardhurat vjetore).

127
7. ANALIZA E VARIANCËS (ANOVA –
MANOVA)

128
ANALIZA E VARIANCËS (ANOVA – MANOVA)
1. HYRJE Analiza e variancës përdoret për të testuar hipotezat në lidhje me atë se a ekziston dallim
ndërmjet dy apo më shumë mesatareve. Për të testuar se a ekziston një dallim i rëndësishëm
ndërmjet dy mesatareve përdoret edhe testi t, por në rastet e krahasimit të më shumë se dy
mesatereve testi t mund të krijoj probleme. Sado që të jetë e mundur që me testin t të krahasohen
më shumë se dy mesatare në formën dy nga dy ndaras, kjo mënyrë do të dërgoj në rritje më të
madhe të gabimit të llojit të parë. Sa më shumë që të testohet, lloji i parë i gabimit aq më shumë
rritet. Analiza e variancës është një test që përdoret për të krahasuar më shumë se dy mesatare pa
u rritur niveli i gabimit të llojit të parë. Në analizën e variancës, hipoteza H0 është në formën se
të gjitha mesataret e popullimit janë të njëjta,
H0 = µ1 = µ2 = µ3 = ... µn Pra nuk ekziston dallim ndërmjet mesatareve
HA: Ekziston dallim se paku ndërmjet dy mesatareve.
Hipoteza H0 testohet me anë të krahasimit të dy vlerave të variancave. E para nga këto është
varianca brenda grupeve (Mean square error MSE). MSE paraqet vlerësimin e variancës (σ2)
qoftë apo jo e saktë hipoteza H0. Vlerësimi i dytë bazohet në variancat e mestareve të grupeve
(Mean Square Between MSB). MSB është vlerësim i variancës (σ2) vetëm nëse hipoteza H0
është e saktë. Në qoftë se hipoteza H0 është gabim, MSB vlerëson një numër që është më i madh
se σ2. Përfundimisht, testi i hipotezave në analizën e variancës mund të shkruhet në këtë formë:
Në qoftë se MSE dhe MSB janë përafërsisht të sakta Hipoteza H0 e saktë
Në qoftë se MSB është më e madhe se MSE Hipoteza H0 e pasaktë
Siç shihet edhe nga këtu, qëllimi themelor në analizën e variancës është që të kuptohet se a
ekziston dallim ndërmjet mesatareve. Për arsye se për të arritur në përfundim përdoren dy lloje të
krahasimeve të variancave është quajtur analiza e variancës. Testimi i hipotezës bëhet sipas
ekzistimit të dallimit ndërmjet variancës të marrë ndërmjet grupeve dhe variancës të marrë
brenda grupeve.
Në analizën e variancës, përdoret vlera F për të testuar hipotezat.
Në qoftë se vlera e F-së është më e vogël se vlera nivelit të dëshiruar të rëndësisë (vlera e
tabelës), hipoteza H0 nuk refuzohet. Pra, arrihet në përfundim se nuk ekziston një dallim i
rëndësishëm ndërmjet mesatareve. Në qoftë se vlera e F-së, është më e madhe se vlera e tabelës,

129
hipoteza H0 refuzohet. Në këtë rast, gjykohet se ekziston një dallim i rëndësishëm ndërmjet
mesatareve.
Në analizën e variancës bëhet fjalë për ndryshoren e varur dhe të pavarur. Ndryshoreve të
pavarura u jepet emri faktorë. Kërkohet ndikimi i faktorëve mbi ndryshoret e varura. Ndryshorja
e pavarur duhet të jetë kategorike, kurse ndryshorja e varur duhet të jetë metrike. Në qoftë se do
ta shpjegonim këtë përmes një shembulli:
Ndryshorja e Pavarur: Gjinia (Mashkull, Femër)
Ndryshorja e Varur: Niveli i Përdorimit të Kompjuterit
Ndryshorja e pavarur këtu gjinia ka karakterstikë kategorike si dhe kjo ndryshore ka dy
grupe: mashkull dhe femër. Ndryshorja e varur është një ndryshore e cila mat nivelin e
përdorimit të kompjuterit të personave. Në këtë shembull, analiza e variancës përdoret për të
hulumtuar se a ekziston ndonjë dallim në nivelin e përdorimit të kompjuterit ndërmjet meshkujve
dhe femrave. Në qoftë se e vëreni, ndryshorja e pavarur përbëhet nga dy grupe. Në këtë rast
mund të përdoret edhe testi t i cili hulumton dallimin ndërmjet mesatareve të dy grupeve. Në
raste të këtilla, analiza e variancës dhe testi t do të japin rezultate të njëjta.
Në qoftë se jepet një shembull tjetër në rastet kur ndryshorja e pavarur përbëhet më shumë
se dy grupe:
Ndryshorja e Pavarur: pozicioni i punës në firmë
Ndryshorja e Pavarur: dashuria ndaj punës që e bën
Në këtë shembull, ndryshorja e pavarur përbëhet nga 3 grupe: punëtor, mbikëqyrës,
menaxher. Analiza e variancës përdoret për të hulumtuar ndryshimin ndërmjet pasionit për
punën sipas pozicionit që kanë secili. Një shembull i këtillë, është plotësisht një shembull i
Analizës së Variancës Një Drejtimshe (ANOVA).
ANOVA Një Drejtimshe është analiza më e thjeshtë e variancës. Përbëhet nga dy
ndryshore. Njëra nga këto është ndryshorja e pavarur e cila ka karakteristikë kategorike dhe
ndryshorja tjetër ndryshorja e varur e cila ka karakteristikë metrike. Brenda ndryshores së
pavarur mund të ekzistojnë dy apo më shumë grupe. ANOVA Një Drejtimshe teston ekzistimin
e dallimit ndërmjet mesatareve të ndryshores së varur sipas grupeve.
Lloji i analizës së variancës ndryshon sipas numrit të ndryshoreve të varura dhe të pavarura.
Më poshtë janë përmbledhur llojet e analizës së variancës sipas numrit të ndryshoreve të varura
dhe të pavarura.

130
Numri i Ndryshoreve të Pavarura
Një Dy
Numri i
ndryshoreve
të varura
Një ANOVA Një Drejtimshe ANOVA Dy Drejtimshe
Më shumë se një MANOVA Një
Drejtimshe
MANOVA Dy
Drejtimshe
Të mendojmë një shembull të këtillë;
1. Ndryshorja e pavarur: koha e kaluar në vendin e punës të një personi (java e parë, pas
3 muajve, pas 6 muajve, pas 1 viti)
2. Ndryshorja e pavarur: pozicioni i personit në firmë (punëtor, mbikëqyrës, menaxher)
1. Ndryshorja e varur: Niveli i pasionit për punën
2. Ndryshorja e varur: Niveli i kënaqësisë nga politikat e firmës
3. Ndryshorja e varur: Niveli i mjaftueshëm i pagës
Për të hulumtuar se koha e personit që ka punuar në pozitën aktuale në firmë a ka ndikuar
në personin që ta dojë punën që e ka bërë, përdoret ANOVA Dy Drejtimshe. ANOVA Dy
Drejtimshe bën testimin e ndryshoreve të varura si një e vetme mbi ndryshoren e pavarur.
Për të hulumtuar se a ka ndikim pozicioni i personit në firmë në pasionin për punën, në
kënaqësinë nga politikat e firmës dhe në mjaftueshmërinë e pagës përdoret MANOVA Një
Drejtimshe. MANOVA Një Drejtimshe bën testimin e dallimit ndërmjet grupeve të ndryshores
së varur të përmbledhura në një ndryshore dhe ndryshores së pavarur.
Kurse për të hulumtuar se të gjitha ndryshoret e pavarura a kanë ndonjë ndikim mbi të gjitha
ndryshoret e varura përdoret MANOVA Dy Drejtimshe. MANOVA Dy Drejtimshe vlerëson
dallimin duke i krahasuar në total grupet e më shumë se një ndryshoreje të pavarur sipas më
shumë se një ndryshoreje të varur.
Një pikë tjetër me rëndësi në analizën e variancës është numri i mostrave të grupeve. Sado
që numri i mostrave të grupeve të jetë i bararabartë, numri i dallimeve ndërmjet numrit të
mostrave nuk duhet të jetë tepër edhe në qoftë se kjo nuk është një parakusht për analizën e
variancës. Numri i mostrave sado që të jetë i përafërt me njëra-tjetrën, analiza e variancës po aq
do të jap rezultate të shëndetshme. Po ashtu, numri i mostrave të grupeve preferohet të jetë mbi
10.
Pas kësaj hyrjeje të shkurtër, në faqet e ardhshme do të jepen detaje gjatë zgjidhjes së
shembujve.

131
2. ANOVA NJË DREJTIMSHE
Ekzistojnë dy supozime themelore në ANOVA Një Drejtimshe. Sipas këtyre supozimeve
çdo grup ndjek shpërndarjen normale dhe variancat e grupeve janë homogjene.
Përpara se të shqyrtohen rezultatet e shembullit të ANOVA Një Drejtimshe, duhet të
testohen supozimet. Në përgjithësi, studimet nisen nga testi i homogjentitet të variancave. Në
qoftë se variancat janë homogjene, pranohet se janë siguruar të gjitha supozimet. Për ta bërë
testin e homogjentitet të variancave në SPSS, zgjihet Options nga menyja e analizës së ANOVA
Një Drejtimshe.
Testimi i supozimeve do të shihet më mirë gjatë prezantimit të shembullit. Në lidhje me
ANOVA Një Drejtimshe, janë dhënë të dhënat në Shtojcën-1. Në këtë shembull kërkohet se a
ndikon pozicioni i personit në firmë në pranimin e politikave të firmës.
2.1. Shembull Aplikimi Në progamin SPSS shkojmë tek menyja Analyze, Compare Means, One Way ANOVA.
Duke e marrë ndryshoren e pavarur pozita e bartim në pjesën Factor, kurse ndryshorja e
varur pranimi bartet në pjesën Dependent List. Përpara se të përfundojmë me analizën, duhet të
bëhen edhe disa përzgjedhje të tjera. Në menynë e One-Way ANOVA gjenden përzgjedhjet
Contrasts, Post Hoc dhe Options.
Hapi 1: Drtiarja e ANOVA Një Drejtimshe
Gjatë analizës është e rëndësishme Post Hoc dhe pasi të përzgjedhim atë, do të hapet
dritarja e mëposhtme.

132
Hapi 2: Dritarja e Post Hoc
Testi Post Hoc është i rëndësishëm për të parë se nga cili grup buron dallimi, në qoftë se në
fund të analizës së variancës është gjetur dallim ndërmjet grupeve. Tabela ANOVA tregon në
përgjithësi se a ka dallim ndërmjet mestareve të grupeve. Ajo teston se mesataret e të gjitha
grupeve a janë të njëjta, qoftë 3 grupe apo qoftë 10 grupe. Në qoftë se ekziston dallim vetëm
ndërmjet dy grupeve dhe ndërmjet grupeve tjera jo, ANOVA do të jap rezultatin se “ekziston
dallim ndërmjet grupeve”. Mirëpo, me testet Post Hoc mund të mësojmë se nga buron dallimi
dhe ndërmjet cilat grupeve ekziston ky dallim.
Në testin Post Hoc ekzistojnë shumë alternativa. Funksioni themelor i të gjithave është i
njëjtë. Përdoret për të kuptuar se ndërmjet cilat grupeve ekziston dallim. Sipas algoritmeve të
përdorura, niveleve të ndjeshmërisë etj., në përgjithësi japin rezultate të njëjta edhe në qoftë se
ekzistojnë disa dallime të vogla ndërmjet tyre. Përbrenda këtyre më të përdorura gjatë studimeve
janë Tukey dhe Bonferroni. Përzgjedhja e vetëm njërës nga këto është e mjaftueshme, kurse ne
kemi përzgjedhur të dyja për të parë dallimin ndërmjet tyre në shembullin tonë.
Pasi të përfundohen përzgjedhjet duke klikuar në butonin Continue kthehemi te menyja
kryesore. Përzgjedhja Contrasts përdoret në analizat e niveleve më të larta të statistikave. Teksa
në përzgjedhjen Post Hoc krahasohen dy nga dy mesataret e ndryshores së varur sipas
nëngrupeve të ndryshores së pavarur, me anë të përzgjedhjes Contrasts mund të bëhen
krahasime në nivele më të larta. Për shembull, krahasimi i një grupi me mesataren e përgjithshme
të grupeve tjera apo krahasimi i mesatares së përgjithshme të grupit të dytë dhe të tretë me

133
mesataren e përgjithshme të grupit të parë dhe të pestë bëhet përmes Contrasts duke i futur
koeficientët e nevojshëm të tyre.
Po ashtu në rastet kur është e rëndësishme forma e funksionit në lidhje me nivelet e lidhjes
së ndryshores së varur dhe ndryshores së pavarur, është e rëndësishme analiza e trendit. Për
shembull, shuma e çmimit (shpërblimit) dhënë një subjekti le të jetë ndryshore e pavarur dhe
shuma e vrapimit në lidhje me këtë le të jetë ndryshore e varur. Në një shembull të këtillë, për
testimin e formës së funksionit të ndryshores së varur dhe ndryshores së pavarur sipas
pikëpamjeve të ndryshme, mund të përdoret analiza e trendit. Në raste të këtilla, në përzgjedhjen
Contrasts mund të përdoren komponentet e disponueshëm të trendit. Për arsye se menyja
Contrasts përdoret për analiza të niveleve të larta, nuk do të futemi më shumë në detajet e kësaj
menyje.
Në menynë kryesore, në pjesën Options gjenden gjithashtu alternativa të rëndësishme. Kur
të klikojmë në butonin Options, do të hapet dritarja e mëposhtme:
Hapi 3: Dritarja e Përzgjedhjeve
Jep statistikat themelore, si mesataren,
devijimin standart, vlerat e minimumit,
maksimumit për secilin grup.
Jep devijimin standart, gabimin e devijimit
dhe intervalin e besueshmërisë për
modelet fikse dhe intervalin e
besueshmërisë të gabimit standart dhe
variancën ndërmjet komponentëve për
modelet e probabilitetit.
Teston supozimin e homogjentitetit të
variancave të grupeve.
Jep paraqitjen grafike të mesatareve të
nën grupeve.
Përdoren për krahasimin e mesatereve të
grupeve në rastet kur supozimi i
homogjentitetit të variancave të grupeve
është i pavlefshëm.
Në qoftë se ekziston mungesë në
ndryshoren e varur apo të pavarur në
analizë, nuk e përdor atë rresht në të cilën
mungojnë të dhënat.
Në qoftë se ekziston mungesë në
ndryshoren e varur apo të pavarur në
analizë, nuk e përdor asnjë rresht në të
cilën mungojnë të dhënat. Është e
rëndësishme në rastet kur janë përcaktuar
më shumë se një ndryshore e varur.

134
Më lartë janë dhënë kuptimet për secilën përzgjedhje të menysë Options. Për një ANOVA
standarte, homogjeniteti i variancave është përzgjedhja e cila duhet të testohet patjetër. Nga
rezultatet e testit të supozimit të homogjenetitet të variancës do të kuptohet vlefshmëria e
zbatimit të ANOVA Një Drejtimshe. Për këtë arsye, më lartë është përzgjedhur Homogeneity of
variance test. Descriptive është përzgjedhur për të i parë rezultatet në kuptim të përgjithshëm.
Kjo përzgjedhje jep numrin e mostrave të përdorura sipas grupeve, mesataret, devijimin standart,
gabimin standart të mesatareve, vlerat e minimumit dhe maksimumit dhe nivelin e
besueshmërisë 95%. Alternativa Means plot mund të përzgjedhet për të parë ndryshimin në
mënyrë grafike të ndryshores së varur sipas grupeve të ndryshores së pavarur.
Alternativa Fixed and random effects ka të bëjë me mbledhjen e të dhënave nga kategoritë
e ndryshores së pavarur. Në qoftë se të dhënat janë mbledhur nga të gjitha kategoritë e
ndryshores së pavarur, quhen modele fikse, kurse në qoftë se të dhënat janë mbledhur nga një
pjesë e kategorive quhen modelet e probabilitetit. Llogaritjet në ANOVA Një Drejtimshe janë të
njëjta për secilin model. Në qoftë se rritet numri i ndryshoreve të pavarura do të ketë dallime
ndërmjet modeleve. Alternativa Fixed and random effects jep vlerat e përshkruara më lartë në
tabelë për ndikimet fikse dhe të rastësishme. Kjo alternativë përdoret në analizat statistikore të
niveleve të larta dhe në të njëjtën kohë do të jipen më shumë detaje në pjesën ANOVA Dy
Drejtimshe. Alternativat Brown-Forsythe dhe Welch, përdoren për të bërë krahasime ndërmjet
mesatareve në rastet kur nuk është siguruar supozimi i Anovës të homogjentitetit të variancave.
Në aplikimin e ANOVA Një Drejtimshe, tek pjesa e ndryshores së varur mund të vendosen
më shumë se një ndryshore. Në rastin e vendosjes së më shumë se një ndryshoreje të pavarur,
nuk duhet të konsiderohet se të gjitha ndryshoret janë subjekt i të njëjtës analizë. Në ANOVA
Një Drejtimshe, secila ndryshore e pavarur është është subjekt i ndryshores së varur ndaras dhe
rezultatet jepen ndaras. Alternativa e më lartë Missing Values merr kuptim në raste të tilla. Në
qoftë se është zgjedhur vetëm një ndryshore e varur dhe vetëm një ndryshore e pavarur,
alternativa Exclude cases listwise nuk ka kuptim. Por në qoftë se janë zgjedhur më shumë se një
ndryshore e varur, kjo metodë përzgjedhet që të mos përdoren vlerat mangu gjatë gjithë analizës.
Ngaqë në shembullin tonë kemi vetëm një ndryshore të varur dhe vetëm një ndryshore të
pavarur, cilën do që ta përzgjedhim, rezultatet nuk do të ndryshojnë.
Pasi të bëhen përzgjedhjet mësipër, klikohet butoni Continue dhe pastaj duke klikuar OK
në menynë kryesore të One-Way ANOVA, do të përfitohen rezultatet.

135
2.2. Daljet e SPSS-it dhe Interpretimi
Tabela 1: Statistikat Përshkruese
Descriptives
përvetësimi
N Mean
Std.
Deviation Std. Error
95% Confidence Interval for
Mean
Minimum Maximum Lower Bound Upper Bound
punëtor 15 2.3333 .81650 .21082 1.8812 2.7855 1.00 4.00
mbikëqyrës 14 3.7857 .80178 .21429 3.3228 4.2487 2.00 5.00
menaxher 11 4.2727 1.00905 .30424 3.5948 4.9506 2.00 5.00
Total 40 3.3750 1.19158 .18841 2.9939 3.7561 1.00 5.00
Gjëja e parë e cila tërheq vëmendjen në tabelën Descriptives është numri i mostrës së
grupeve. Përderisa do të duhej të ishin 17 punëtorë janë vrojtuar 15, do të duhej të ishin 15
mbikëqyrësa jane vrojtuar vetëm 14. Arsyeja e kësaj është mungesa e vlerave në të dhëna. Në të
dhënat tona kishte 3 vlera mangu dhe në këtë mënyrë në total 3 vlera janë lënë jashtë analizës.
Në tabelë janë dhënë të dhënat statistikore themelore si mesatarja, devijimi standart etj, për
secilin grup.
Tabela 2: Testi i Homogjentitetit të Variancës
Test of Homogeneity of Variances
përvetësimi
Levene Statistic df1 df2 Sig.
.497 2 37 .612
Në tabelën 2, mund të shihet rezultati i testit të supozimit themelor të ANOVA Një
Drejtimshe, homogjentitetit të variancës. Për arsye se këtu vlera e p (Sig. 0,612) është më e
madhe se 0,05, mund të thuhet se variancat janë homogjene. Ngaqë është siguruar supozimi
themelor i analizës së variancës, mund të themi se në fund rezultatet e përfituara nga analiza e
variancës janë të shëndetshme.

136
Tabela 3: Tabela e Analizës së Variancës
ANOVA
përvetësimi
Sum of Squares df Mean Square F Sig.
Between Groups 27.503 2 13.751 18.255 .000
Within Groups 27.872 37 .753
Total 55.375 39
Tabela ANOVA teston dallimin ndërmjet grupeve në përvetësimin e politikave të firmës.
Në qoftë se këtu vlera e F-së është më e madhe se vlera e tabelës në nivelin e rëndësisë 95%,
hipoteza H0 do te refuzohet. Natyrisht, këtu nuk nuk është e nevojshme që të shikojmë nga tabela
vlerën e F-së. SPSS jep vlerën e p-së (Sig.) dhe në qoftë se kjo vlerë është më e vogël se 0,05
hipoteza H0 do te refuzohet. Vlera e p-së (0,000) në tabelën e mësipërme është më e vogël se
0,005. Prandaj mund të themi se ekziston një dallim ndërmjet grupeve në përvetësimin e
politikave të firmës. Dhe pikërisht, në këtë pikë vijnë në shprehje testet Post Hoc. Ekziston një
dallim ndërmjet grupeve, në rregull, por midis cilave grupe? Testet Post Hoc japin përgjigjjen e
kësaj pyetjeje.
Tabela 4: Tabela e Krahasimeve të Shumëta
Multiple Comparisons
Dependent Variable: përvetësimi
(I) pozita (J) pozita
Mean
Difference (I-J) Std. Error Sig.
95% Confidence Interval
Lower Bound Upper Bound
Tukey HSD punëtor mbikëqyrës -1.45238* .32253 .000 -2.2398 -.6649
menaxher -1.93939* .34453 .000 -2.7806 -1.0982
mbikëqyrës punëtor 1.45238* .32253 .000 .6649 2.2398
menaxher -.48701 .34970 .355 -1.3408 .3668
menaxher punëtor 1.93939* .34453 .000 1.0982 2.7806
mbikëqyrës .48701 .34970 .355 -.3668 1.3408
Bonferroni punëtor mbikëqyrës -1.45238* .32253 .000 -2.2612 -.6436
menaxher -1.93939* .34453 .000 -2.8034 -1.0754
mbikëqyrës punëtor 1.45238* .32253 .000 .6436 2.2612
menaxher -.48701 .34970 .516 -1.3640 .3899
menaxher punëtor 1.93939* .34453 .000 1.0754 2.8034
mbikëqyrës .48701 .34970 .516 -.3899 1.3640
*. The mean difference is significant at the 0.05 level.

137
Në tabelën e mësipërme janë dhënë rezultatet e testit Tukey dhe Bonferroni. Nga tabela e
mësipërme janë bërë këto krahasime me renditjet e testit Tukey.
Figura 1: Përmbledhja e Tabelës së Krahasimeve të Shumëfishta
Figura 1 është përgatitur për të kuptuar më mirë tabelën e krahasimeve të shumëfishta.
Mesataret në lidhje me ndryshoren e varur përvetësimi janë marrë nga tabela 1 në kolonën Mean.
Dallimet mesatare janë marrë nga tabela 4 në kolonën Mean Difference. Kurse niveli i rëndësisë
është marrë nga kolona Sig. në tabelën 4. Mund të thuhet se ekziston një dallim i rëndësishëm
për grupet të cilat gjenden nën nivelin e rëndësisë 0,05.
Pa shikuar në nivelin e rëndësisë, përmes lehtësisë të cilën e ofron SPSS-i mund të zbulohet
se midis cila grupeve ekziston dallim. Me anë të shenjës së asteriksit (*) në kolonën e mesatareve
të dallimeve (Mean Difference) në tabelën 4, mund të kuptohet se midis cilat grupeve ekziston
dallim për nga mesataret. Mesataret të cilat kanë shenjën * tregojnë që ndërmjet atyre grupeve
ekziston një dallim në nivelin e rëndësisë 0,05.
EKZISTON
DALLIM
PUNËTOR
Mesatarja:
2,333
MBIKËQYRËS
Mesatarja:
3,7857
MENAXHER
Mesatarja:
4,2727
EKZISTON
DALLIM
NUK KA DALLIM

138
Sipas këtyre rezultateve;
Mbikëqyrësit i kanë përvetësuar më shumë politikat e firmës në krahasim me punëtorët.
Dallimi ndërmjet tyre është 1,452 dhe kjo gjendet nën nivelin e rëndësisë 0,05.
Menaxherët i kanë përvetësuar më shumë politikat e firmës në krahasim me punëtorët.
Dallimi ndërmjet tyre është 1,939 dhe kjo gjendet nën nivelin e rëndësisë 0,05.
Nuk ekziston ndonjë dallim i rëndësishëm ndërmjet menaxherëve dhe mbikëqyrësve në
përvetësimin e politikave të firmës. Dallimi ndërmjet tyre është 0,487 dhe kjo është më e
madhe se niveli i rëndësisë 0,05 (0,355).
Përsëri ajo çfarë tërheq vëmendjen në tabelë është se Tukey dhe Benferroni kanë dhënë
rezultate të njëjta. Në analiza, zakonisht përzgjedhet njëra nga këto. Kurse siç e cekëm edhe më
parë, testi Tukey përdoret më shumë.
Tabela 5: Tabela e Nëngrupeve
përvetësimi
pozita N
Subset for alpha = 0.05
1 2
Tukey HSDa,b
punëtor 15 2.3333
mbikëqyrës 14 3.7857
menaxher 11 4.2727
Sig. 1.000 .333
Means for groups in homogeneous subsets are displayed.
a. Uses Harmonic Mean Sample Size = 13.100.
b. The group sizes are unequal. The harmonic mean of the group sizes is
used. Type I error levels are not guaranteed.
SPSS-i ka krijuar nëngrupet sipas përvetësimit të politikave të firmës. Nga këto, grupi i
punëtorëve ka formuar një grup të vetëm, kurse mbikëqyrësit dhe menaxherët janë përfshirë në
një grup së bashku. Përfshirja e mbikëqyrësve dhe menaxherëve në një grup, përsëri tregon se
këto dy grupe nuk kanë karakteristika të dy grupeve të ndara, pra mbikëqyrësit dhe menaxherët
tregojnë karakteristika të njëjta në përvetësimin e politikave të firmës. Kurse punëtorët janë
përcaktuar në një grup të veçantë për arsye se tregojnë karakteristika të ndryshme edhe nga
mbikëqyrësit edhe nga menaxherët.
Grafiku i përfituar nga alternativa Means Plot në menynë Options paraqet në mënyrë
vizuale dallimet e mesatareve të përvetësimit të punëtorëve, mbikëqyrësve dhe menaxherëve
sipas pozitave. Boshti vertikal tregon nivelin e përvetësimit (Mean Difference), kurse boshti
horizontal tregon grupet e pozitave. Ky grafik i cili rezultatet i paraqet në mënyrë vizuale, nuk

139
është i mjaftueshëm për të kuptuar se a ekziston një dallim i rëndësishëm ndërmjet grupeve.
Interpretimi vetëm përmes grafikut pa ndihmën e testeve tjera, jep rezultate të gabueshme.
Figura 2: Grafiku Tregues i Lidhjes Ndërmjet Faktorit të Pozitës dhe Ndryshores së
Përvetësimit
Në qoftë se do të bënim një përmbledhje të shembullit të analizuar në lidhje me ANOVA
Një Drejtimshe;
Pozita aktuale e punëtorëve ndikon ndjenjën e përvetësimit të politikave të firmës.
Punëtorët janë përvetësuesit më të paktë të politikave të firmës.
Menaxherët dhe mbikëqyrësit i përvetësojnë më shumë politikat e firmës.
Sado që menaxherët i përvetësojnë politikat e firmës më shumë se mbikëqyrësit, përsëri
nuk ekziston ndonjë dallim i rëndësishëm ndërmjet tyre.

140
3. ANOVA DY DREJTIMSHE Gjatë hulumtimit të ndikimit të dy ndryshoreve të pavarura mbi një ndryshore të varur, në
vend të hulumtimit të ndikimit të ndryshoreve të pavarura mbi ndryshoren e varur veç e veç,
vendosja e tyre në një funksion të vetëm shpesh është më produktive. Kjo çasje e cila bën
llogaritjen e ndikimit të ndryshoreve të pavarura veç e veç mbi ndryshoren e varur, llogarit edhe
bashkëveprimin ndërmjet ndryshoreve të pavarura. Kjo situatë do të kuptohet më mirë përmes
shembullit.
3.1. Shembull Aplikimi Në Shtojcën-2 gjenden dy ndryshore të pavarura. Këto janë pozita e personave në firmë dhe
koha e gjendjes në punë. Kurse ndryshorja e varur është niveli i kënaqësisë së personave nga
puna e bërë. Në këtë shembull, kërkohet të hulumtohet ndikimi i pozitës së punonjësve (punëtor,
mbikëqyrës, menaxher) në kënaqësinë e marrë nga puna që bëjnë. Në të njëjtën kohë, kërkohet të
matet se a ka ndryshuar kënaqësia nga pozita në të cilën gjenden në fund të javës së parë, në fund
të tre muajve, në fund të gjashtë muajve dhe në fund të një viti. Për shembull, është pyetur një
punonjës në lidhje me nivelin e kënaqësisë në punë në fund të javës së parë pasi ka filluar punën,
në fund të tre muajve, në fund të gjashtë muajve dhe në fund të një viti. Në këtë mënyrë janë
pyetur 4 punonjës. Po ashtu, në të njëjtën mënyrë janë pyetur 4 mbikëqyrësa dhe 4 menaxherë në
peridhuat e lartëpërmendura. Në fund, është përfituar tabela në Shtojcën-2. Në tabelë gjenden 48
të dhëna në total.
Hulumtimi veç e veç i nivelit të kënaqësisë me pozitën e punës dhe kohën e kaluar në atë
punë, do të ishte një gabim sepse mund të ketë një bashkëveprim ndërmjet këtyre dy ndryshoreve
të pavarura. Për shembull, teksa niveli i kënaqësisë së një punëtori mund të zvogëlohet me
kalimin e kohës, e kundërta mund të jetë për një menaxher. Një menaxher, me kalimin e kohës
do të i përcaktojë vetë politikat dhe do të i përvetësojë më shumë se të tjerët. Në situata të tilla,
në vend që ndryshoret e pavarura të analizohen veç e veç me ANOVA Një Drejtimshe, është më
e kuptimtë që të analizohen përmes një funksioni me ANOVA Dy Drejtimshe.
Për ta kryer Anovën Dy Drejtimshe në SPSS, shkohet tek Analyze, General Linear
Model¸ Univariate dhe do të paraqitet ekrani i mëposhtëm.

141
Hapi 1: Dritarja e ANOVA Dy Drejtimshe
Ndryshorja e pavarur kënaqësia bartet në pjesën Dependent Variable. Kemi dy lloje të
ndryshoreve të pavarura dhe këto kanë karakteristika të ndryshme. Ndryshorja e pavarur pozita
strehon të gjitha grupet që na interesojnë. Ndryshoret e këtilla, siç shihet më lartë, barten në
pjesën Fixed Factor(s). Kurse ndryshorja e kohës është më e ndryshme. Kjo ndryshore përfshin
4 grupe. Këto janë java e parë, 3 muajtë e parë, 6 muajtë e parë dhe 1 vit. Qëllimi këtu është që të
hulumtohet se me kalimin e këtyre periudhave a ka ndryshuar niveli i kënaqësisë. Në qoftë se
konsiderohet se këto grupe përfshijnë të gjitha grupet brenda zonës sonë së interesit, atëherë këto
mund të transferohen në pjesën Fix Factor(s). Në shembullin tonë nuk konsiderohet se këto
grupe përfshinë të gjitha grupet e tjera sepse mund të qenë bërë matje p.sh. në fund të një muaji,
Në qoftë se të gjitha grupet janë përfshirë në kuadër të ndryshores së pavarur, ndryshoret e tilla të pavarura shtohen në pjesën Fixed Factor(s). Në kuadër të faktorit të pozitës janë shqyrtuar 3 grupe.
Në qoftë se nuk janë përfshirë të gjitha grupet në kuadër të ndryshores së pavarur, ndryshoret e tilla shtohen në pjesën Random Factor(s). Në ndryshoren koha janë shqyrtuar 4 periudha. Qëllimi këtu është që të kuptohet se me kalimin e kohës a ka ndryshuar kënaqësia. Përveç 4 periudhave të përmendura këtu, mund të ketë edhe më shumë periudha të tjera.
Në analizën e ponderuar të katrorëve më te vegjël (Weighted Least
Squares Analyses), një ndryshore mund të shtohet si e ponderuar
(Weighting Variable). Nuk është një karakteristikë e cila përdoret
shpesh.
Këtu shtohet ndryshorja e pavarur në kombinim me nivelet e faktorit të
cilat mund të lidhen me covariate (ndryshore kolektive). Ngaqë kjo
është një temë e analizës së kovariancës, këtu nuk do të futemi në
detaje.

142
në fund të 9 muajve apo në fund të 2 viteve dhe në këtë mënyrë do të ishin krijuar më shumë se 4
grupe. Po të kishin qenë më shumë se 4 grupe edhe rezultatet do të ndryshonin. Për këtë arsye,
ndryshorja koha është bartur në pjesën Random Factor(s).
Në aplikimin e ANOVA Dy Drejtimshe pjesa me rëndësi kritike është pjesa Model. Kur të
klikohet në butonin Model do të hapet dritarja e mëposhtme. Në shembull qe përcaktuar se
ndërmjet pozitës dhe kohës mund të ketë bashkëveprim. Prandaj, përveç shikimit të ndikimit
kryesor të pozitës mbi kënaqësinë, ndikimit kryesor të kohës mbi kënaqësinë, në të njëjtën kohë
duhet të shikohet edhe ndikimi i bashkëveprimit të pozitës dhe kohës mbi kënaqësinë. Përcaktimi
i këtyre përzgjedhjeve bëhet në pjesën Model. Në ekranin Model përzgjedhja Full Factorial
është e vetëpërzgjedhur. Nga kjo, SPSS do të jep rezultatin e të gjitha ndërveprimeve të
dëshiruara.
Hapi 2: Dritarja e Modelit
Alternativat Full Factorial dhe Custom ofrojnë mundësinë për të hulumtuar llojet e ndikimeve të
faktorëve mbi ndryshoren e varur. Përzgjedhja Full Factorial llogaritë të gjitha mundësitë. Pra,
llogarit ndikimin kryesor të pozitës, ndikimin kryesor të kohës dhe ndërveprimin e pozitës dhe
kohës si dhe hulumton ndikimin e secilës nga 3 përzgjedhjet mbi ndryshoren e varur.

143
Në qoftë se përzgjedhet Custom, SPSS jep mundësinë për të zgjedhur se çfarë ndikimi faktorial po
kërkohet mbi ndryshoren e varur. Ndryshoret në pjesën Factors & Covariates barten në pjesën
Model duke pasur kujdes përzgjedhjet në Build Term(s). Për shembull, për të mësuar ndikimin
kryesor të pozitës mbi kënaqësinë zgjedhet Main Effects nga kutiza Build Term(s) dhe pastaj barten
në pjesën Model. Për të mësuar ndikimin e ndërveprimit të pozitës dhe kohës mbi kënaqësinë, duke
i selektuar të dyjat barten në pjesën Model duke përzgjedhur Interaction nga pjesa Build Term(s).
Në ekranin e mësipërm duke zgjedhur secilën mundësi janë bartur në pjesën Model. Në këtë
mënyrë edhe Full Factorial do të jap rezultatet e njëjta nga dritarja e mësipërme ku është e
vetëpërzgjedhur. Në rastet kur ekzistojnë më shumë se një ndryshore e pavarur, për të hulumtuar
ndërveprimet treshe, katërshe apo pesëshe, nga kutiza Build Term(s) përdoren përzgjedhjet All 3-
way, All 4-way, All 5-way. Në shembullin tonë është e pakuptimtë të përdoren këto sepse kemi
vetëm dy ndryshore të pavarura.
Këtu është e përzgjedhur Type III në mënyrë standarte. Për të llogaritur totalin e katrorëve këtu
gjenden 4 alternativa. Për modele të ndryshme zgjedhen alternativa të ndryshme. Për shembull, për
modelet e dizajneve të ekuilibruara ose modelin e regresionit polinom është e përshtatshme
alternativa Type I. Këtu zakonisht alternativa Type III dhe Type IV përdoren më shumë. Në Type III
është më e lehtë që të interpretohet rezultatet dhe përdoret në të gjitha modelet, si të ekuilibruara
ashtu edhe jo të ekuilibruara. Në qoftë se në shembull nuk ekziston grup i zbrazët është e
përshtatshme Type III, në qoftë se po Type IV.

144
Duke klikuar butonin Continue vazhdohet tutje. Univariate e cila realizon aplikimin e
ANOVA Dy Drejtimshe, ofron edhe përzgjedhjen e grafikut. Përmes grafikut mund të shohim se
si ndryshon ndryshorja e varur me ndikimin e faktorëve. Për t’a përfituar grafikun, në ekranin
Univariate klikohet butoni Plots. Përmes ekranit të hapur më poshtë, mund të përcaktohet
vizatimi i grafikut. Boshti vertikal i grafikut është ndryshore e varur në mënyrë automatike. Në
shembullin tonë, vlera e pritur marxhinale e ndryshores sonë të varur kënaqësia do të paraqitet në
boshtin vertikal të grafikut. Ndryshoret e pavarura shfaqen në 3 mënyra në grafik. Detajet e
këtyre 3 përzgjedhjeve janë dhënë afër ekranit të mëposhtëm. Në shembullin tonë, ndryshorja e
kohës teksa tregohet në boshtin horizontal, ndryshorja e pozitës është përcaktuar që të shfaqet me
vija të ndara. Ajo çfarë nuk duhet të harrohet këtu është që pasi të bëhen përzgjedhjet e
nevojshme duhet të shtypet tasti Add. Përndryshe nuk do të shfaqet grafiku. Pasi të klikojmë në
tastin Add kutizat e përzgjedhura do të zbrazen. Në këtë mënyrë, në qoftë se dëshirohen grafiqe
të formave tjera, pas ripërzgjedhjes klikohet butoni Add dhe bëhet shtimi i tyre. Pasi të
përfundohet funksioni klikohet Continue dhe do të kthehemi në menynë kryesore Univariate.
Hapi 3: Dritarja e Grafikut
Testet Post Hoc të cilët qenë përmendur në ANOVA Një Drejtimshe, ekzistojnë edhe në
ANOVA Dy Drejtimshe. Tabela ANOVA tregon dallimin e ndryshores së varur në lidhje me një
faktor dhe në të njëjtën kohë ndërmjet cilave grupeve të faktorit ekziston dallimi. Testet Post
Hoc ofrojnë mundësinë për të parë detajet e këtilla. Nga menyja kryesore Univariate hyhet në
përzgjedhjen Post Hoc. Në ekranin e mëposhtëm, ndryshoret të cilat dëshirohet të jenë subjekte
të testit Post Hoc, duke i përzgjedhur nga pjesa Factor(s) barten në pjesën Post Hoc Tests for.
Ndryshorja e shtuar në këtë
pjesë do të shfaqet në
boshtin horizontal në grafik.
Ndryshorja e shtuar në këtë
pjesë do të shfaqet me pika
të ndryshme ngjyrash në
grafik.
Ndryshorja e shtuar në këtë
pjesë do të shfaqet me vija të
ndryshme ngjyrash në grafik.

145
Ajo çfarë tërheq vëmendjen këtu është mungesa e ndryshores së kohës e cila qe përcaktuar si
Random Factor. Për arsye se ndryshoret e rastësishme nuk i përfshijnë të gjitha kategoritë, nuk
mund të jenë subjekte të testeve Post Hoc. Në qoftë se testi Post Hoc është i rëndësishëm për
këta faktorë, atëherë këta faktorë do të duhej përcaktuar si Fixed Factor në menynë kryesore
Univariate. Siç qe specifikuar në fillim të shembullit, për ne është me rëndësi të kuptohet
dallimi i kënaqësisë në 4 peridhuat e përcaktuara kohore në mënyrë të rastësishme dhe në çfarë
drejtimi do të ndryshojë. Niveli i kënaqësisë veç e veç në këto katër periudha nuk tërheq
vëmendjen tonë. Po të ishte ashtu, kjo do të përcaktohej në Fixed Factor. Për të parë se në çfarë
drejtimi ekziston ndryshimi, këtë do të mund t’a vështrojmë përmes përmes grafikut të cilin e
përcaktuam nga përzgjedhja Plots. Ekrani i Post Hoc është si më poshtë.
Hapi 4: Dritarja Post Hoc e Krahasimeve të Shumëfishta për Mesataret e Vrojtuara
Nga rezultatet që do
të përfitohen nga
alternativat e pjesës
Equal Variances
Assumed do të
shikohet se a arrihet
supozimi themelor i
Anovës,
homogjentiteti i
variancave. Arritja e
homogjentitet të
variancave tregohet
nga rezultatet e
Homogeniety Test.
Testi më i përdorur
prej këtyre është
testi Tukey. Dallimi
ndërmjet këtyre
testeve qe treguar
në mënyrë të
thjeshtë në ANOVA
Një Drejtimshe.
Kjo pjesë përdoret për të parë ndryshimet në ndryshoren e varur sipas grupeve të faktorit në rastet kur
nuk sigurohet homogjentiteti i variancave. Në qoftë se është e nevojshmë që sipas rezultatit të
Homogeniety Test, atëherë përdoret rezultati që e jep kjo pjesë. Në rastet kur nuk ekziston
homogjentiteti i variancave, testi më i përdorur këtu është Tamhane’s T2.

146
Duke përzgjedhur Tukey nga testet Post Hoc dhe Tamhane’s T2 klikohet në butonin
Continue. Në fund të Homogeneity test, në qoftë se arrihet në përfundim se variancat janë
homogjene, përdoren rezultatet e testit Tukey, kurse në qoftë se arrihet në përfundim se
variancat nuk janë homogjene, përdoren rezultatet e testit Tamhane’s T2.
Në menynë kryesore Univariate, butoni Options ofron kontribute të mëdha për të
interpretuar rezultatet e ANOVA Dy Drejtimshe. Duke klikuar në butonin Options do të hapet
menyja e saj. Në këtë meny, ndryshoret e gjendura në pjesën Factor(s) and Factor Interactions
barten plotësisht në pjesën Display Means For. Në këtë mënyrë, do të mund të shohim
mesataret dhe intervalet e besueshmërisë të cilat gjenden nën çfarëdo lloje të ndikimit të
ndryshoreve të pavarura mbi ndryshoren e varur. Përmes komentimit të tabelave që do të shfaqen
si rezultat i kësaj alternative, do të mund të shikojmë se nga cilat ndryshore të pavarura ndryshon
ndryshorja e varur, në cilat grupe të ndryshoreve të pavarura dhe në çfare drejtime. Në të njëjtën
kohë, në dritaren e më poshtë Options në qoftë se përzgjedhet Compare Main Effects do të
bëhet përsëri testi Post Hoc për ndryshoret veç e veç. Këtu ekzistojnë dy pika me rëndësi. E
para, në menynë normale të Post Hoc, teksa ndryshoret e identifikuara nuk janë subjekt i
Random Variables, me rastin e alternativës Compare Main Effects të gjitha ndryshoret do të
jenë subjekt i kësaj. Në qoftë se përzgjedhjet ky opsion, do të bëhen krahasime ndërmjet 4
grupeve të ndryshores së shembullit tonë kohës. Mirëpo, siç është specifikuar edhe më parë, në
shembullin tonë nuk kemi nevojë për një analizë të këtij lloji. Pika e dytë me rëndësi është se me
rastin e përzgjedhjes së Compare Main Effects krahasohen vetëm ndikimet kryesore të
ndryshoreve dhe nuk bëhet ndonjë analizë në lidhje me ndërveprimin ndërmjet dy ndryshoreve.
Në ekranin Options, alternativa Homogeneity test përdoret për të testuar supozimin
themelor të analizës së variancës, barazinë e variancave. Më etiketimin e kësaj alternative, në
qoftë se vlera e përfituar në tabelë p (vlera e Sig.) është më e madhe se 0,05, atëherë pranohet se
variancat janë homogjene. Mirëpo në disa studime, testi Homogeneity është i pamjaftueshëm për
testimin e supozimit. Për këtë arsye me etiketimin e Spread vs. level plot mund të kontrollohet
barazia e variancave përmes grafikut që do të përfitohet. Madje në disa raste, në qoftë se testi i
homogjenitetit sjell interpretimin për mosbarazinë e variancave, përzgjedhja Spread vs. level
plot përmes grafikut mund të sjell interpretimin e kundërt.
Në menynë Options në qoftë se etiketohet Descriptives statistics do të përfitohen
mesataret, devijimet standarte dhe madhësitë e mostrave për të gjitha grupet. Përzgjedhja
Estimates of effect size shpreh nivelin e ndikimit të ndryshoreve të pavarura në ndryshoret e
varura. Estimates of effect size e cila llogarit variancën e shpërndarë për ndryshoret dhe nivelin
total të variancës së mbetur gabim, përveç që tregon ndikimin e ndryshores së pavarur në
ndryshoren e varur, tregon se edhe në çfarë niveli gjendet ky ndikim. Gjatë shqyrtimit të
rezultateve të SPSS-it, kjo pjesë do të kuptohet më mirë.

147
Hapi 5: Dritarja e Përzgjedhjeve
Pas përzgjedhjes së preferencave në menynë Options klikohet Continue dhe bëhet kthimi
në menynë kryesore Univariate.
Butoni Save që gjendet në menynë kryesore Univariate, shërben për të shtuar ndryshore të
reja në setin e të dhënave. Për shembull, në qoftë se etiketohet Unstandardized Predicted
Values, pasi të përfundojmë analizën Univariate në setin e të dhënave do të jetë shtuar një
kolonë e re. Në këtë meny, do të gjenden vlerat e parashikuara për secilin rresht. Këto vlera nuk
janë tjetër gjë përveçse mesatare. Për shembull, duke e marrë mesataren e përgjigjjeve të
mbikëqyrësit të dhënë në fund të tre muajve, në setin e të dhënave në rreshtin e pozitës do të
Për të mbajtur në
mend, në pjesën LSD
gjenden testet Post
Hoc Bonferroni dhe
Sidak. Ndryshorja e
pavarur edhe në
qoftë se është
përcaktuar në
Random Factor(s)
madje, këtu në qoftë
se bëhet përzgjedhje
ofrohet mundësia e
krahasimit ndërmjet
grupeve. Në qoftë se
ju kujtohet në
menynë Post Hoc
nuk i zgjedhnim
ndryshoret e
përcaktuara si
Random Factor.
Përzgjedhjet më të përdorura këtu gjenden të etiketuara në figurë.
Veçanërisht përzgjedhja Homogeneity test duhet të etiketohet patjetër. Ky
test përdoret provuar qëndrueshmërinë e bazave të analizës së variancës.
Supozimi bazë barazia e variancave analizohet përmes këtij testi.
Intervali i
besueshmërisë që do
të përdoret në
analiza mund të
ndërrohet nga këtu.
Forma e përzgjedhur
standarte është 0,05.

148
shkruhet mbikëqyrës dhe në vendin e kohës tre muaj. SPSS, në këtë mënyrë do të plotësojë të
gjithë setin e të dhënave. Edhe pse në përzgjedhjen Save mund të gjenden etiketime të ndryshme
për shtimin e ndryshoreve të reja, nuk është një meny e cila përdoret shpesh. Mirëpo, është e
rëndësishme në rastet kur të dhënat e reja të krijuara janë të nevojshme për të bërë analiza të reja.
Kjo është një situatë e cila aplikohet në nivelet e larta të statistikës.
Gjithashtu ngaqë edhe përzgjedhja Contrast përdoret në aplikimet e niveleve të larta të
statistikës, këtu nuk do të ndalemi në detajet e kësaj menyje. Mirëpo, duhet të tregojmë një
dallim me rëndësi prej menysë Contrast të menysë Univariate dhe menysë Contrast të menysë
së One-Way ANOVA. Përderisa në One-Way ANOVA ekziston seksioni për përcaktimin e
koeficientëve për të bërë krahasime të kombinimeve ndërmjet grupeve të ndryshme, nuk ekziston
një seksion i tillë në Univariate. Për të bërë krahasime të tilla në Univariate mund të bëhet vetëm
duke e shkruar syntax (Nuk bëhet përmes menyve të SPSS-it, por me kod të programimit përmes
gjuhës programore të SPSS-it, ashtu siç ndodh në gjuhët programore).
Klikohet butoni OK në menynë Univariate dhe do të përfitohen rezultatet.
3.2. Daljet e SPSS-it dhe Interpretimi Në tabelën 6, është e mundur që të shikohet ndërveprimi ndërmjet pozitës dhe kohës. Me
kalimin e kohës zvogëlohet mesatarja e kënaqësisë së punëtorëve. Mesataret e mbikqyrësve në
lidhje me kohën nuk kanë ndonjë ndryshim serioz. Kurse me kalimin e kohës, mesatarja e
kënaqësisë për menaxherët rritet. Ajo çfarë nuk duhet të harrohet këtu është se me rezultatet e
marra nga Descriptive Statistics mund të bëhet interpretim vetëm në nivel të përgjithshëm. Pa
shikuar në nivelin e rëndësisë, testimi i hipotezave është një gabim shkencor.
Në fillim të ANOVA Dy Drejtimshe duhet të kontrollohet supozimi themelor, homogjeniteti
i variancave. Për t’a bërë këtë, shikohet tabela Leven’s Test of Equality of Variances.

149
Tabela 6: Statistikat Përshkruese
Descriptive Statistics
Dependent Variable: kënaqësia
pozita koha Mean Std. Deviation N
punëtor java e parë 5.2500 1.25831 4
3 muaj 4.5000 .57735 4
6 muaj 2.7500 .95743 4
1 vit 1.7500 .50000 4
Total 3.5625 1.63172 16
mbikëqyrës java e parë 6.7500 1.25831 4
3 muaj 6.5000 .57735 4
6 muaj 6.0000 .81650 4
1 vit 6.0000 .81650 4
Total 6.3125 .87321 16
menaxher java e parë 6.0000 .81650 4
3 muaj 8.0000 1.15470 4
6 muaj 9.2500 .50000 4
1 vit 9.7500 .50000 4
Total 8.2500 1.65328 16
Total java e parë 6.0000 1.20605 12
3 muaj 6.3333 1.66969 12
6 muaj 6.0000 2.86039 12
1 vit 5.8333 3.45972 12
Total 6.0417 2.39644 48
Tabela 7: Testi i Homogjentitetit të Variancave
Levene's Test of Equality of Error Variancesa
Dependent Variable: kënaqësia
F df1 df2 Sig.
.942 11 36 .513
Tests the null hypothesis that the error variance of
the dependent variable is equal across groups.
a. Design: Intercept + pozita * koha + pozita +
koha
Për arsye se vlera e tabelës p (Sig.) është më e madhe se 0,05 arrihet në përfundim se është
siguruar supozimi i homogjenitetit të variancave.
Nga rezultatet e Descriptive
Statistics, tërheq vëmendjen
dallimi i mesatareve të
përgjithshme të punëtorve,
mbikëqyrësve dhe
menaxherëve në lidhje me
kënaqësinë. Për të kuptuar sa
është i rëndësishëm ky dallim
do të shikohet tabela e
ANOVA-së dhe testet Post
Hoc.
Sipas ndryshores së kohës
nuk bie në sy ndonjë dallim i
rëndësishëm i mesatareve të
përgjithshme të kënaqësisë
së punës.

150
Figura 3: Devijimet Standarte Sipas Mesatareve të Kënaqësisë
Supozimi i homogjenitetit të variancave mund të kontrollohet edhe nga tabela e Spread vs.
Level Plot of kënaqësia. Me fjalë të tjera, ky grafik është një test vizual i homogjenitetit të
variancave. Dobia shtesë e këtij grafiku është se na ndihmon të kuptojmë nëse shkelja e
supozimit të barazimit të variancave buron nga lidhja ndërmjet mesatareve të grupeve dhe
devijimeve standarte. Boshti vertikal në grafik jep devijimet standarte, kurse boshti horizontal
jep mesataret e grupeve. Në ndryshoren e pozitës gjenden 3 grupe, kurse në ndryshoren e kohës
gjenden 4 grupe. Nëse këto grupe konsiderohen të mbivendosura në njëra-tjetrën, në total
formohen 12 grupe. Kurse në grafikun e mësipërm gjenden 10 pika. Arsyeja e kësaj është se
mesataret e disa nga grupeve janë të barabarta dhe pikat gjenden njëra mbi tjetrën. Në qoftë se
shikojmë intervalet e variancës dhe shpërndarjet e pikave, do të testohet edhe në mënyrë vizuale
se është siguruar supozimi i homogjenitetit të variancave.

151
Tabela 8: Testi i Ndërveprimeve
Tests of Between-Subjects Effects
Dependent Variable: kënaqësia
Source
Type III Sum of
Squares df Mean Square F Sig.
Partial Eta
Squared
Intercept Hypothesis 1752.083 1 1752.083 3319.737 .000 .999
Error 1.583 3 .528a
pozita Hypothesis 177.542 2 88.771 8.285 .019 .734
Error 64.292 6 10.715b
koha Hypothesis 1.583 3 .528 .049 .984 .024
Error 64.292 6 10.715b
pozita * koha Hypothesis 64.292 6 10.715 14.557 .000 .708
Error 26.500 36 .736c
a. MS(koha)
b. MS(pozita * koha)
c. MS(Error)
Përpara se të interpretojmë tabelën 8, të kemi parasysh një pikë të rëndësishme. Variancat e
llogaritura (totali i katrorëve (sum of squares)) të ndryshoreve dhe ndërveprimit të ndryshoreve,
si dhe gabimet e llogaritura të variancave (error) janë ndikuar nga formimet e faktorëve të
rastësishëm (random) apo fiksë (fixed) të ndryshoreve. Në shembullin tonë, ndryshorja koha
ishtë përcaktuar si random factor. Në qoftë se kjo ndryshore do të përcaktohej si fixed factor,
gabimet e variancave do të rriteshin. Vlerat në kolonën e rëndësisë (Sig.) do të zvogëloheshin si
dhe do të zvogëloheshin vlerat ne kolonën e ndikimeve (Partial Eta Squared). Në fund do të
konsideronim se është më e rëndësishme, mirëpo do të arrinim në rezultate të vlerave më të ulëta
të ndikimeve dhe vlerave më të larta të gabimeve të variancës. Me fjalë të tjera, me përcaktimin e
një faktori si random factor vështirësohet arritja e rezultateve të larta të nivelit të rëndësisë dhe
në të njëjtën kohë arrihen rezultate më të besueshme. Siç e kemi specifikuar më parë, në qoftë se
grupet brenda një ndryshoreje nuk shihen të mjaftueshme, atëherë përcaktimi i kësaj ndryshore si
random factor është shumë më i përshtatshëm statistikisht. Arritja e rezultateve të dëshiruara
është më e vështirë, por rezultatet do të jenë më të besueshme.
Rreshti i pozitës hulumton
ndikimin kryesor mbi
kënaqësinë, rreshti i kohës
ndikimin e kohës mbi
kënaqësinë dhe rreshti
pozita*koha ndikimin e
pozitës-kohës mbi
kënaqësinë.
Me të dhënat nga kjo
kolonë kuptohet shkalla e
ndikimit të ndryshores së
pavarur mbi ndryshoren e
varur. Kjo kolonë është
përfituar nga përzgjedhja
Estimates of Effect Size.
Duke shikuar në këtë kolonë
vendoset rëndësia e ndikimit
të ndryshores së pavarur mbi
ndryshoren e varur.

152
Në tabelën e mësipërme, në fillim duhet të shikojmë kolonën Sig. Vlerat të cilat janë më të
vogla se 0,05 tregojnë se ndryshoret kanë një ndikim të rëndësishëm mbi ndryshoren e varur.
Sipas tabelës së mësipërme, kuptohet se ekziston një ndikim i rëndësishëm i pozitës dhe
ndërveprimit të pozitës-kohës mbi kënaqësinë. Kurse koha si e vetme nuk ka ndonjë ndikim të
rëndësishëm. Me fjalë të tjera, nuk ka ndonjë dallim të rëndësishëm të nëngrupeve të kohës mbi
nivelin e kënaqësisë. Vlerat në kolonën Partial Eta Squared përcaktojnë madhësinë e ndikimit
të faktorëve. Informatat në lidhje se si janë llogaritur këto vlera qenë dhënë gjatë shpjegimit të
alternativës Estimates of Effect Size e cila e siguron këtë kolonë. Siç kuptohet nga llogaritjet,
me zvogëlimin e gabimit të variancave këto vlera rriten. Këto vlera mund të marrin vlera më së
shumti deri në 1. Sado më afër që të jenë ndyshoret afër 1-shit, po aq është ndikimi i tyre. Kjo
është mjaft e rëndësishme në praktikë. Për të arritur në përfundim se ekziston një ndikim i
rëndësishëm i ndryshores së pavarur mbi ndryshoren e varur, është e pamjaftueshme që të thuhet
gjithmonë se ekziston një ndikim i madh i këtij ndikimi. Duke shikuar në tabelë, arrihet në
përfundim se ndikimet e pozitës dhe ndërveprimit të pozitës-kohës janë të larta.
Në qoftë se shikojmë rezultatet e përfituara nga përzgjedhja Estimated Marginal Means,
veçse do të përforcohen rezultatet e arritura më larta.
Tabela 9: Tabela e Mesatareve Sipas Ndryshores së Pavarur Pozicionit
2. pozita
Dependent Variable: kënaqësia
pozita Mean Std. Error
95% Confidence Interval
Lower Bound Upper Bound
punëtor 3.563 .214 3.127 3.998
mbikëqyrës 6.313 .214 5.877 6.748
menaxher 8.250 .214 7.815 8.685
Në tabelën e mësipërme janë dhënë mesataret, gabimet standarte dhe intervali i
besueshmërisë për punëtorët, mbikëqyrësit dhe menaxherët në lidhje me kënaqësinë. Pika e parë
që duhet të kihet parasysh këtu është mospërputhja e intervaleve të besueshmërisë të nivelit të
kënaqësisë ndërmjet grupeve. Intervali i besueshmërisë për nivelin e kënaqësisë së punëtorëve
është prej 3,127 deri në 3,998. Ai i mbikëqyrësve fillon prej 5,877 deri në 6,748. Nga këtu mund
të kuptohet se kënaqësitë e punëtorëve dhe mbikëqyrësve janë të ndryshme dhe se kënaqësia e
punëtorëve është më e ulët. Intervali i besueshmërisë në lidhje me kënaqësinë e menaxherëve
fillon prej 7,815 deri në 8,685. Kjo tregon që kënaqësia e menaxherëve është e ndryshme dhe më
e lartë në krahasim me mbikëqyrësit. Pra edhe njëherë u vërtetua se ekzistojnë dallime të këtilla
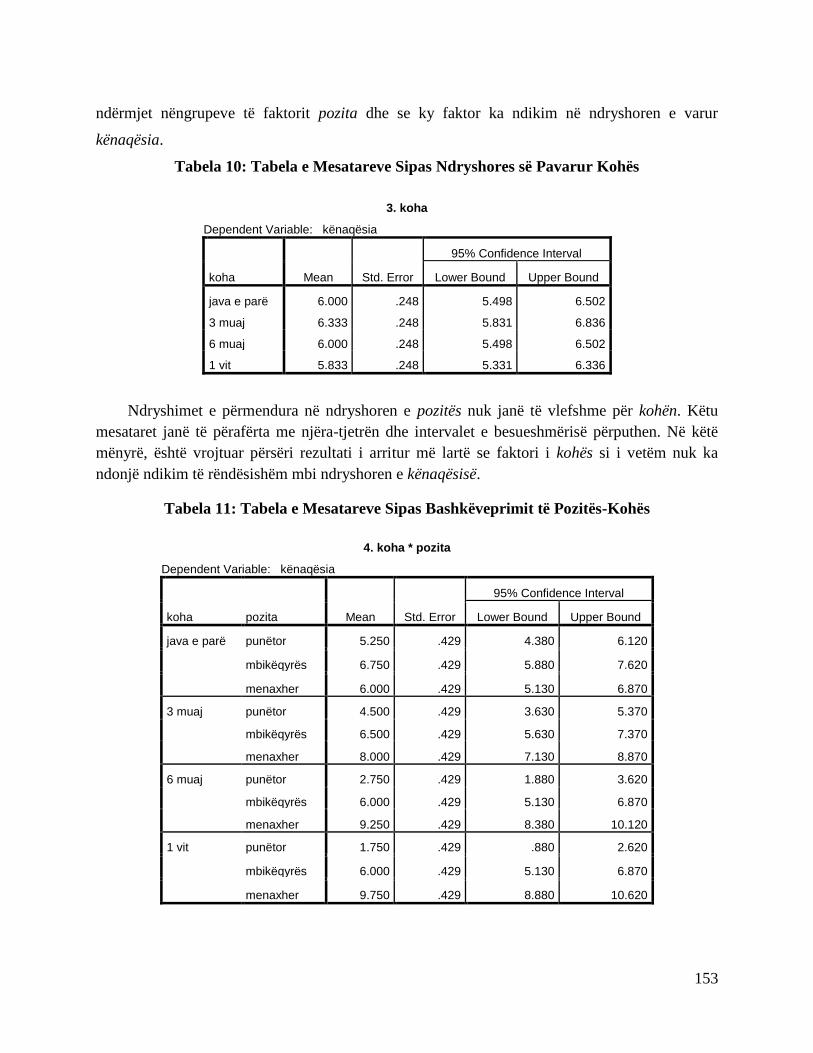
153
ndërmjet nëngrupeve të faktorit pozita dhe se ky faktor ka ndikim në ndryshoren e varur
kënaqësia.
Tabela 10: Tabela e Mesatareve Sipas Ndryshores së Pavarur Kohës
3. koha
Dependent Variable: kënaqësia
koha Mean Std. Error
95% Confidence Interval
Lower Bound Upper Bound
java e parë 6.000 .248 5.498 6.502
3 muaj 6.333 .248 5.831 6.836
6 muaj 6.000 .248 5.498 6.502
1 vit 5.833 .248 5.331 6.336
Ndryshimet e përmendura në ndryshoren e pozitës nuk janë të vlefshme për kohën. Këtu
mesataret janë të përafërta me njëra-tjetrën dhe intervalet e besueshmërisë përputhen. Në këtë
mënyrë, është vrojtuar përsëri rezultati i arritur më lartë se faktori i kohës si i vetëm nuk ka
ndonjë ndikim të rëndësishëm mbi ndryshoren e kënaqësisë.
Tabela 11: Tabela e Mesatareve Sipas Bashkëveprimit të Pozitës-Kohës
4. koha * pozita
Dependent Variable: kënaqësia
koha pozita Mean Std. Error
95% Confidence Interval
Lower Bound Upper Bound
java e parë punëtor 5.250 .429 4.380 6.120
mbikëqyrës 6.750 .429 5.880 7.620
menaxher 6.000 .429 5.130 6.870
3 muaj punëtor 4.500 .429 3.630 5.370
mbikëqyrës 6.500 .429 5.630 7.370
menaxher 8.000 .429 7.130 8.870
6 muaj punëtor 2.750 .429 1.880 3.620
mbikëqyrës 6.000 .429 5.130 6.870
menaxher 9.250 .429 8.380 10.120
1 vit punëtor 1.750 .429 .880 2.620
mbikëqyrës 6.000 .429 5.130 6.870
menaxher 9.750 .429 8.880 10.620

154
Edhe të dhënat nga kjo tabelë në lidhje me ndërveprimin pozita-koha mbështesin rezultatet
e mësipërme. Për shembull, intervalet e besueshmërisë së një punëtori nuk përputhen në lidhje
me nivelin e kënaqësisë në javën e parë, nivelin e kënaqësisë në fund të gjashtë muajve dhe
nivelin e kënaqësisë në fund të një viti. Pra ekziston dalllim. Përsëri ky dallim në fund të javës së
parë, në fund të tre muajve dhe në fund të një viti, është vrojtuar plotësisht në mënyrë të kundërt
për menaxherët. Me kalimin e kohës rritet kënaqësia në punë për menaxherët. Kjo tregon që
ndryshorja e kohës edhe në qoftë se nuk ka ndonjë ndikim të rëndësishëm mbi kënaqësinë, ky
ndryshim bëhet i rëndësishëm kur është në bashkëveprim me ndryshoren e pozitës.
Tabelat e diskutuara të Estimated Marginal Means japin një kontribut të rëndësishëm për
ndryshoret e rastësishme. Këtu vrojtuam dallimet ndërmjet nëngrupeve të faktorit të kohës të
përcaktuar si random factor. Ashtu siç është specifikuar më parë, testet Post Hoc të cilat bëjnë
krahasime ndërmjet grupeve nuk aplikohen për faktorët e rastësishëm. Në kushtet normale,
krahasimet ndërmjet grupeve të faktorëve të rastësishëm nuk tërheqin shumë vëmendjen, por në
rastet kur tërheqin vëmendjen përdoren tabelat Estimated Marginal Means të cilat u shpjeguan
më lartë. Përsëri me testet Post Hoc nuk mund të bëjmë interpretim mbi bashkëveprimet. Me
tabelat Estimated Marginal Means qe ofruar mundësia për të interpretuar bashkëveprimin e
pozitës-kohës.
Testet Post Hoc zbulojnë vetëm dallimet ndërmjet grupeve të faktorëve fiks (fixed) për
ndryshoren e varur. Me testet Post Hoc mund të shohim ndryshimin ndërmjet nëngrupeve të
ndryshores pozita si faktor fiks në shembullin tonë.
Tabela 12: Tabela e Krahasimeve të Shumëfishta
Multiple Comparisons
Dependent Variable: kënaqësia
Tukey HSD
(I) pozita (J) pozita
Mean
Difference (I-J) Std. Error Sig.
95% Confidence Interval
Lower Bound Upper Bound
punëtor mbikëqyrës -2.7500* .30334 .000 -3.4914 -2.0086
menaxher -4.6875* .30334 .000 -5.4289 -3.9461
mbikëqyrës punëtor 2.7500* .30334 .000 2.0086 3.4914
menaxher -1.9375* .30334 .000 -2.6789 -1.1961
menaxher punëtor 4.6875* .30334 .000 3.9461 5.4289
mbikëqyrës 1.9375* .30334 .000 1.1961 2.6789

155
Për sigurimin e supozimit të homogjenitetit të variancave shikojmë rezultatet e testit Tukey
HSD. Vlerat të cilat pranë tyre kanë asteriks (*) në kolonën Mean Difference, tregojnë se
ekziston dallim ndërmjet atyre grupeve. Shenja e asteriksit (*) është vendosur pranë atyreve të
cilat gjenden nën 0,05 nga kolona Sig. Ndërmjes mesatares së kënaqësisë së punëtorit dhe
mesatares së kënaqësisë së mbikëqyrësit ekziston një dallim prej 2,75 dhe ky dallim është i
rëndësishëm. Shfaqja e dallimit me -2,75 tregon se mesatarja e punëtorëve është më e ulët.
Mesatarja e kënaqësisë së punëtorëve është për 4,6875 më e vogël se mesatarja e kënaqësisë së
menaxherëve. Kurse mesatarja e mbikëqyrësve është më e vogël për 1,9375 nga menaxherët.
Përfundimisht, ekziston një dallim i rëndësishëm në nivelin e kënaqësisë ndërmjet të gjitha
grupeve të ndryshores së pozitës. Sipas këtyre kushteve, në qoftë se dëshirohet të krijohen
nëngrupe të reja në ndryshoren e pozitës sipas nivelit të kënaqësisë, do të krijohen 3 grupe të
ndara sepse grupet janë plotësisht të ndryshme nga njëra-tjetra. Tabela e mëposhtme e shpjegon
këtë.
Tabela 13: Nëngrupet e Krijuara Sipas Ndryshorës së Pavarur Kënaqësisë
kënaqësia
Tukey HSDa,b
pozita N
Subset
1 2 3
punëtor 16 3.5625
mbikëqyrës 16 6.3125
menaxher 16 8.2500
Sig. 1.000 1.000 1.000
Në grupin e parë gjenden punëtorët. Në grupin e dytë gjenden mbikëqyrësit dhe në grupin e
tretë menaxherët. Kurse vlerat në tabelë janë mesataret e nivelit të kënaqësisë për secilin grup.
Figura 3: Grafiku tregues i ndryshimit të kënaqësisë sipas grupeve në ndryshoren e pavarur
Vija e cila tregon rritje u përket menaxherëve
Vija e cila është përafërsisht konstante u përket mbikëqyrësve
Vija e cila ka rënie u përket punëtorëve.

156
Grafiku Estimated Marginal Means of kënaqësia tregon se si ndryshon niveli i kënaqësive
të punonjësve me pozita të ndryshme me kalimin e kohës. Boshti vertikal në grafik tregon nivelin
e kënaqësisë, kurse boshti horizontal tregon kohën. Vija në rritje e nivelit të kënaqësisë i përket
menaxherëve, vija e cila është përafërsisht konstante u përket mbikëqyrësve dhe vija në rënie
punëtorëve.
Rezultatet e përfituara të ANOVA Dy Drejtimshe, mund të i përmbledhim në këtë mënyrë:
Kënaqësia në punë e menaxherëve është më e lartë se e mbikëqyrësve dhe kënaqësia në
punë e mbikëqyrësve është më e lartë se e punëtorëve.
Ndikimi i pozitës së punës është i fuqishëm mbi kënaqësinë e punës.
Ndikimi i pozitës dhe bashkëveprimit të kohës së kaluar në atë pozitë është i fuqishëm.
Nuk mund të bëhet një gjykim i veçantë apo i përgjithshëm për punëtorët, mbikëqyrësit
dhe menaxherët në lidhje me ndryshimin e kënaqësisë me kalimin e kohës.
Me kalimin e kohës zvogëlohet kënaqësia në punë e punëtorëve.
Me kalimin e kohës nuk ndodh ndonjë ndryshim i rëndësishëm në kënaqësinë e punës për
mbikëqyrësit.
Me kalimin e kohës rritet kënaqësia në punë e menaxherëve.

157
4. MANOVA NJË DREJTIMSHE
Në rastet kur një ndryshore e pavarur ndikon më shumë se një ndryshore të varur përdoret
MANOVA Një Drejtimshe. Hipoza H0 në MANOVA Një Drejtimshe është se nuk ekziston asnjë
ndryshim mesatar në asnjë prej ndryshoreve të varura sipas grupeve të faktorit. Kurse hipoteza
alternative është se ekziston një dallim mesatar së paku në një ndryshore të varur dhe së paku
sipas dy grupeve të faktorit. Me fjalë të tjera, në qoftë se vrojtohet një dallim ndërmjet
mesatereve të ndryshores së varur vetëm nga dy grupe të ndryshores së pavarur, hipoteza H0
refuzohet. Por nëse nuk gjendet asnjë ndryshim në mesataret e asnjërës ndryshore të varur sipas
grupeve të ndryshores së pavarur, hipoteza H0 nuk refuzohet.
Supozimet themelore të MANOVA Një Drejtimshe janë të njëjta me të Anovës, por në të
njëjtën kohë supozim shtesë këtu është se kërkohet barazia e kovariancave për shkak që
ekzistojnë më shumë se një ndryshore e varur. Përderisa në ANOVA kërkohej kushti i
homogjentitetit të variancave të grupeve të brendshme të ndryshores së varur sipas grupeve të
ndryshores së pavarur, në MANOVA ekziston supozimi që përgjatë grupeve korrelacionet
ndërmjet ndryshoreve të varura janë të njëjta. Dhe testimi i këtij supozimi është i mundur përmes
SPSS-it.
4.1. Shembull Aplikimi MANOVA Një Drejtimshe, do të shpjegohet më mirë përmes shembullit në Shtojcën-3.
Mirëpo, duhet të dihet se do të ndeshemi me shumicën e detajeve të dhëna në ANOVA. Në fund
të aplikimit të Manovës, një pjesë e të dhënave nga SPSS-i janë të njëjta me rezultatet e Anovës.
Mirëpo, këtu janë unike tabela themelore e Manovës dhe disa tabela tjera shtesë. Për këtë arsye,
këtu nuk do të jepen detaje për temat të cilat qenë shpjeguar gjatë aplikimit të Anovës.
Në shembullin e Shtojcës-3, një firmë kërkon të hulumtoj ndikimin e pozitës së personelit
punues femra dhe meshkuj në nivelin e kënaqësisë së punës. Pozita është përcaktuar si ndryshore
e pavarur dhe kënaqësia e femrave dhe kënaqësia e meshkujve janë përcaktuar si ndryshore të
varura. Rreth ndryshores së pozitës qenë përmendur 3 grupe. Këto janë punëtorët, mbikëqyrësit
dhe menaxherët.
Për analizën e MANOVA Një Drejtimshe, në SPSS shkohet tek menyja Analize, General
Lineal Model dhe nga këtu zgjedhet Multivariate. Në ekranin e hapur, ndryshoret femrat dhe
meshkujt për shkak që janë ndryshore të varura vendosen në pjesën Dependent Variables, kurse
ndryshorja pozita vendoset në pjesën Fixed Factor(s).

158
Hapi 1: Dritarja e MANOVA Një Drejtimshe
Ekrani i Multivariate ka shumë pak dallime prej ekranit Univariate. Ajo çfarë bie në sy e
para është se këtu nuk ekziston seksioni i Randon Factor(s). Në opsionin Multiavariate
faktorët do të trajtohen plotësit si faktorë fiks. Një dallim tjetër i Multivariate prej Univariate
gjendet në menynë Options. Menyja e Options duket si më poshtë.

159
Hapi 2: Dritarja e Përzgjedhjeve
Në menynë Options, gjenden disa përzgjedhje të ndryshme për nga menyja Options e
Univariate. Këtu më së shumti përdoren Descriptive Statistics, Estimates of Effect Size,
Homogeneity Tests, Spread vs. Level Plot dhe SSCP Matrices. Këto përzgjedhje përveç SSCP
Matrices qenë shpjeguar në ANOVA Dy Drejtimshe. SSCP (Sum-of-squares and cross-
products) matrices përdoret për testimin e ndikimit të modelit nga tabelat e përfituara me
etiketimin e kësaj përzgjedhjeje. Përmes tabelës së totalit të katrorëve, mund të shihen totali i
katrorëve dhe totali i gabimit të katrorëve në lidhje me faktorët. Vlerat e Estimates of Effect
Size llogariten me vlerat e përfituara nga matrica SSCP. Kryerja e kësaj llogaritje qe shpjeguar
në menynë Univariate. Në fund, mund të kuptohet ndikimi i faktorëve mbi ndryshoret e varura.
Në menynë Options për të parë mesataret sipas ndryshores së pavarur dhe intervalet e
besueshmërisë, OVERALL dhe pozita barten në pjesën e djathtë, ashtu siç shihet në ekranin e
mësipërm. Përmes tabelave që do të përfitohen nga këtu, do të jetë e mundur që të bëhen

160
krahasime ndërmjet grupeve të ndryshores së pavarur. Pasi të bëhen përzgjedhjet e duhura nga
menyja Options klikohet Continue dhe kthehemi në menynë kryesore të Multivariate.
Në menynë Post Hoc, pozita bartet në pjesën Post Hoc Tests for dhe bëhet etiketimi i
përzgjedhjes Tukey për rastet kur sigurohet homogjeniteti i variancave dhe përzgjedhjes
Tamhane’s T2 për rastet kur nuk sigurohet homogjentiteti i variancave. Përzgjedhja Post Hoc
duket si më poshtë.
Hapi 3: Dritjara Post Hoc e Krahasimeve të Shumëfishta për Mestaret e Vrojtuara
Pasi të bëhen përzgjedhjet e duhura në menynë Post Hoc, duke klikuar butonin Continue
kthehemi tek menyja kryesore Univariate.
Në MANOVA Një Drejtimshe, për shkak që ekziston vetëm një ndryshore e pavarur, bëhet
fjalë vetëm për ndikimet kryesore të kësaj ndryshore të pavarur mbi ndryshoren e varur. Po të
kishte pasur edhe një ndryshore tjetër të pavarur, do të duhej të shqyrtohej edhe ndërveprimi i
ndryshoreve të pavarura mbi ndryshoret e varura. Në rastet kur ekziston vetëm një ndryshore e
varur, nuk ka ndonjë kuptim përdorimi i alternativës Model në menynë kryesore Multivariate.
Vetëm se në menynë Model mund të zgjedhim me cilën metodë të bëhet llogaritja e totalit të
katrorëve dhe tashmë aty është e përzgjedhur në mënyrë standarte Type III.

161
Përsëri në menynë kryesore Multivariate për të parë lidhjen ndërmjet ndryshores së
pavarur dhe ndryshoreve të varura në mënyrë grafikore mund të përdoret përzgjedhja Plots,
mirëpo kjo nuk është shumë e nevojshme sepse kemi vetëm një ndryshore të pavarur. Për
shembull, në qoftë se vendoset ndryshorja e pavarur pozita në boshtin horizontal dhe njëra nga
ndryshoret e varura në boshtin vertikal do të fitohen dy grafiqe të ndara. Por siç e cekëm, në
qoftë se ka vetëm një ndryshore të varur, kjo përzgjedhje nuk është e nevojshme.
Në mënynë kryesore Multivariate duke klikuar butonin OK, përfitohen rezultatet e
analizës.
4.2. Daljet e SPSS-it dhe Interpretimi
Tabela 14: Rezultatet e Tesit të Barazisë së Kovariancave
Box's Test of Equality
of Covariance Matricesa
Box's M 5.315
F .831
df1 6
df2 46791.805
Sig. .546
Për të testuar supozimin e barazisë së kovariancave të ndryshoreve të varura përgjatë
grupeve në MANOVA përdoret testi Box’s M. Në qoftë se këtu vlera p (Sig.) është më e vogël
se 0,05 hipoteza refuzohet dhe nuk është siguruar supozimi themelor i barazisë së kovariancave.
Në qoftë se nuk sigurohet barazia e kovariancave rezultatet e Multivariate shihen me dyshim.
Vlera p (Sig.) në tabelën e mësipërme është më e madhe se 0,05. Me këtë rast është siguruar
supozimi themelor i barazisë së kovariancave.
Tabela 15: Rezultatet e Testit Levene
Levene's Test of Equality of Error Variancesa
F df1 df2 Sig.
meshkujt 1.482 2 47 .237
femrat .723 2 47 .491
Levene’s Test of Equality of Error Variances bën testimin e supozimit tjetër, barazinë e
variancave ndërmjet grupeve të ndryshoreve të pavarura. Ky test jep rezultate të ndryshme për

162
secilën ndryshore të varur dhe kontrollon se a është siguruar barazia e variancave ndërmjet
grupeve të asaj ndryshoreje të varur sipas grupeve të ndryshores së pavarur. Në qoftë se vlera p
(Sig.) është më e madhe se 0,05, arrihet në përfundim se është sigurar kushti i barazisë së
variancave për atë ndryshore të varur. Sipas tabelës së mësipërme, mund të konkludojmë se është
arritur barazia e variancave për secilin grup të ndryshoreve të varura meshkuj dhe femra. Vlera p
e femrave është 0,491, e meshkujve 0,237 dhe që të dyja janë më të mëdha se 0,05.
Figura 5: Devijimet Standarte dhe Mesataret për Meshkujt

163
Figura 6: Devijimet Standarte dhe Mesataret për Femrat
Me grafikun e përfituar Spread vs. Level Plot mund të shohim në mënyrë vizuale barazinë
e variancave sipas ndryshoreve të varura meshkujt dhe femrat e cila u testua me testin Levene’s
Test of Equality of Error Variances. Në tabelën Levene’s Test of Equality of Error
Variances vlera p për ndryshoren e meshkujve ishte 0,237 dhe 0,49 për ndryshoren e femrave.
Pra, homogjeniteti i ndryshores së femrave është më kuptimplotë për nga ndryshorja e
meshkujve. Ky dallim mund të vërehet qartë po ashtu në grafiqet Spread vs. Level Plot. Teksa
devijimi standart i shfaqur përmes pikave në grafik ndryshon ndërmjet 0,77 dhe 0,60 për
meshkujt në figurën 5, pikat e krijuara në figurën 6 për femrat ndryshojnë ndërmjet 0,59 dhe
0,64. Hapësirat ndërmjet femrave janë më të vogla. Në fund, sado që është arritur kushti i
barazisë së variancave për të dyja ndryshoret e varura dhe rezultatet e përfituara nga të dyjat

164
sado të jenë të besueshme, rezultatet e përfituara në lidhje me ndryshoren e varur femrat janë më
të shëndetshme sesa rezultatet e përfituara nga ndryshorja e varur meshkujt.
Tabela 16: Rezultatet e MANOVA Një Drejtimshe për Testimin e Hipotezës H0
Multivariate Testsa
Effect Value F
Hypothesis
df Error df Sig.
Partial Eta
Squared
Intercept Pillai's Trace .990 2277.262b 2.000 46.000 .000 .990
Wilks' Lambda .010 2277.262b 2.000 46.000 .000 .990
Hotelling's Trace 99.011 2277.262b 2.000 46.000 .000 .990
Roy's Largest Root 99.011 2277.262b 2.000 46.000 .000 .990
pozita Pillai's Trace 1.148 31.653 4.000 94.000 .000 .574
Wilks' Lambda .051 79.004b 4.000 92.000 .000 .775
Hotelling's Trace 14.761 166.064 4.000 90.000 .000 .881
Roy's Largest Root 14.492 340.552c 2.000 47.000 .000 .935
a. Design: Intercept + pozita
b. Exact statistic
c. The statistic is an upper bound on F that yields a lower bound on the significance level.
Kjo pjesë është e rëndësishme për të kuptuar ndikimin
e ndryshores së pavarur pozita mbi ndryshoret e
varura. Testet Pillai’s Test, Hotelling’s Trace dhe Roy’s
Largest Root janë teste me vlera pozitive dhe në
kolonën Value me rritjen e vlerave konsiderohet se
rritet kontributi i ndikimit të faktorëve në model. Kurse
Wilks’ Lambda është nje test i vlerave negative dhe në
kolonën Value me uljen e vlerave konsiderohet se ulet
edhe kontributi i ndikimit të faktorëve në model. Vlera
e Hotelling’s Trace është gjithmonë më e madhe se
vlera e Pillai’s Trace. Me zvogëlimin e tyre, këto vlera
afrohen më shumë njëra-tjetrës. Përseri vlera e
Hotelling’s Trace është më e madhe apo e barabartë se
vlera e Roy’s Largest Root. Por, në qoftë se ekziston
një korrelacion i fortë ndërmjet ndryshoreve të varura
apo në qoftë se ndikimi i faktorëve është i dobët mbi
ndryshoret e varura, këto vlera përafrohen me njëra-
tjetrën. Testi më i besueshëm prej këtyre 4 testeve
është Pillai’s Trace. Kurse më i përdoruri është Wilk’s
Lambda.
Këto kolona janë pjesa më e
rëndësishme për të kuptuar rezultatet
e analizës Multivariate. Veçanërisht
kolona Sig. e cila teston hipotezën
themelore të Manovës. Këtu në qoftë
se vlerat janë më të vogla se 0,05,
arrihet në përfundim se ekziston një
dallim i rëndësishëm së paku
ndërmjet dy grupeve të faktorëve dhe
së paku një ndryshoreje të varur.
Kurse kolona Partial Eta Squared
është e rëndësishme për të kuptuar
nivelin e ndikimit të faktorëve. Kjo
kolonë është përfituar nga etiketimi i
Estimates of effects size në menynë
Options. Vlerat të cilat i afrohen 1-
shit, tregojnë rritjen e ndikimit. Në
shembullin tonë, ndikimi i faktorit të
pozitës së femrave apo meshkujve në
kënaqësinë e punës është i qartë.

165
Tabela 16, është tabela MANOVA e cila përdoret për të testuar hipotezën H0. Në një aplikim
standart të MANOVA-së, zakonisht shikohet vetëm kolona Sig. dhe nga kjo kolonë preferohet
vlera e Wilk’s Lambda. Në tabelën e mësipërme, sipas vlerës së kolonës Sig. (e cila është më e
vogël se 0,05) hiptoeza H0 refuzohet. Pra, ekziston një dallim ndërmjet grupeve të femrave dhe
meshkujve sipas grupeve të punëtorëve, mbikëqyrësve dhe menaxherëve.
Në qoftë se është e nevojshme që të interpretohet në më detaje, vlerat tjera në tabelë ofrojnë
shpjegime të rëndësishme. Për shembull, sipas të dhënave të kolonës Partial Eta Squared
faktori pozita ka një ndikim të fuqishëm mbi kënaqësinë. Përafërsia e vlerave të testeve
Hotelling’s Trace dhe Roy’s Largest Root tregon që ndryshoret e varura (kënaqësia në punë e
femrave dhe kënaqësia në punë e meshkujve) kanë një korrelacion të lartë ndërmjet veti. Siç e
shpjeguam edhe nga tabela, ky nuk është rezultati i vetëm që mund të dal prej përafërsisë së
këtyre vlerave. Mirëpo, mundësia tjetër është mundësia e ndikimit të dobët të faktorëve dhe për
arsye se të dhënat në kolonën Partial Eta Squared nuk merren parasysh mbetet vetëm një
mundësi dhe ajo është korrelacioni i lartë ndërmjet ndryshoreve të varura.
Tabela 17: Matrica SSCP
Matrica SSCP edhe pse nuk përdoret shumë për të shqyrtuar rezultatet e analizës është e
rëndësishme për përfitimin e tabelës Multivariate. Arsyeja përse e kemi vendosur këtë tabelë
këtu nuk është për të nxjerrë ndonjë konkluzion nga kjo, mirëpo që t’a kemi më konkrete në
mendje përgatitjen e tabelës Multivariate. Në të njëjtën kohë, nga kjo tabelë mund të nxirren
konkluzione të cilat përdoren në nivelet e larta të statistikës.
Between-Subjects SSCP Matrix
meshkujt femrat
Hypothesis Intercept meshkujt 646.130 825.389
femrat 825.389 1054.381
pozita meshkujt 111.115 120.905
femrat 120.905 146.213
Error meshkujt 23.365 -2.945
femrat -2.945 18.207
Based on Type III Sum of Squares
Kjo matricë përdoret për të
testuar rëndësinë e ndikimit të
faktorit të pozitës. Këto vlera janë
vlerat e totalit të katrorëve dhe
rezultateve të kryqëzuara.
Kjo matricë përdoret për të
kuptuar ndikimin e gabimit. Këto
vlera, përdoren për të kuptuar
shkallën e ndikimit të faktorit. Për
llogaritjen e vlerave të kolonës
Partial Eta Squared në tabelën e
mëparshme, mund të
shfrytëzohen vlerat e matricës së
pozitës dhe matrica e gabimit.

166
Tabela 18: Tabela e Analizës së Variancës
Tests of Between-Subjects Effects
Source Dependent Variable
Type III Sum
of Squares df
Mean
Square F Sig.
Partial Eta
Squared
Corrected Model meshkujt 111.115a 2 55.558 111.759 .000 .826
femrat 146.213b 2 73.106 188.717 .000 .889
Intercept meshkujt 646.130 1 646.130 1299.743 .000 .965
femrat 1054.381 1 1054.381 2721.778 .000 .983
pozita meshkujt 111.115 2 55.558 111.759 .000 .826
femrat 146.213 2 73.106 188.717 .000 .889
Error meshkujt 23.365 47 .497
femrat 18.207 47 .387
Total meshkujt 754.000 50
femrat 1195.000 50
Corrected Total meshkujt 134.480 49
femrat 164.420 49
a. R Squared = .826 (Adjusted R Squared = .819)
b. R Squared = .889 (Adjusted R Squared = .885)
Tabela e mësipërme dhe të tjerat pas janë tabelat nga aplikimi i Anovës me të cilat jemi
mësuar tashmë. Në tabelën e mësipërme për të shqyrtuar ndikimin e faktorit pozita, duhet të
shikohet rreshti i pozitës. Janë dhënë rezultatet veç e veç për ndryshoren e varur meshkujt dhe
ndryshoren e varur femrat. Duke shikuar kolonën Sig. mund të arrihet në përfundim se ekziston
një dallim i rëndësishëm ndërmjet mesatareve të kënaqësisë së punës së femrave sipas
nëngrupeve të faktorit pozita. E njëjta gjë është e vlefshme edhe për meshkujt. Me fjalë të tjera,
faktori pozita ndikon në kënaqësinë e punës së femrave dhe meshkujve sepse për të dytë vlera p
(Sig.) është më e vogël se 0,05. Në qoftë se shikohet kolona Partial Eta Squared, ndikimi i
faktorit pozita është mjaft i fuqishëm. Përderisa vlera për femra është 0,889, ajo për meshkuj
është 0,826. Ndikimi i pozitës është i madh në kënaqësinë e punës si për femrat ashtu edhe për
meshkujt dhe njëkohësisht ndikimi i pozitës është pak më shumë për femrat.
Tabela 19: Mesataret e Përgjithshme të Ndryshores së Pavarur
1. Grand Mean
Dependent Variable Mean Std. Error
95% Confidence Interval
Lower Bound Upper Bound
meshkujt 3.605 .100 3.404 3.806
femrat 4.605 .088 4.428 4.783

167
Nga tabela 19, mund të shikojmë se kënaqësia e punës a është më e lartë për femrat apo për
meshkujt. (Femrat: 4,605, Meshkujt: 3,605). Kufinjtë e ulët dhe të lartë të intervalit të
besueshmërisë nuk përputhen me njëri-tjetrin.
Tabela 20: Mesataret e Ndryshoreve të Pavarura Sipas Grupeve të Pozitës
2. pozita
Dependent Variable pozita Mean Std. Error
95% Confidence Interval
Lower Bound Upper Bound
meshkujt punëtor 1.882 .171 1.538 2.226
mbikëqyrës 3.333 .166 2.999 3.668
menaxher 5.600 .182 5.234 5.966
femrat punëtor 2.294 .151 1.990 2.598
mbikëqyrës 5.056 .147 4.760 5.351
menaxher 6.467 .161 6.143 6.790
Shumica e rezultateve të përfituara nga tabela Pozita (Tabela 20), mund të nxirren edhe
nga tabela Multiple Comparasions (Post Hoc). Ngaqë tabela Post Hoc është më e lehtë për t’u
lexuar, konkuzionet e tilla do të i bëjmë në tabelën Multiple Comparasions. Rezultatet që mund
të i nxjerrim nga kjo tabelë e që nuk mund të i nxjerrim nga tabela Multiple Comparasions kanë
të bëjnë me dallimet ndërmjet ndryshoreve të varura.
Ajo çfarë bie në sy e para në tabelën e mësipërme është mosekzistimi i ndonjë dallimi të
rëndësishëm ndërmjet nivelit të kënaqësisë së femrave punëtore dhe nivelit të kënaqësisë së
meshkujve punëtorë. Teksa intervali i besueshmërisë së meshkujve punëtorë fillon prej 1,538
deri në 2,226, ai i femrave punëtore fillon prej 1,990 deri në 2,598. Këto dy intervale përputhen
me njëra-tjetrën. Prandaj, nuk ekziston ndonjë dallim i rëndësishëm ndërmjet tyre. Rasti i
mbikëqyrësve dhe menaxherëve është i ndryshëm. Sipas mesatareve dhe intervaleve të
besueshmërisë në tabelë, femrat mbikëqyrëse për nga meshkujt mbikëqyrës dhe femrat
menaxhere për nga meshkujt menaxherë janë më të kënaqura nga puna që bëjnë. Konkluzione të
këtilla nuk mund të bëhen me testet Post Hoc të cilat krahasojnë ndryshoret e varura.
Nga tabela Multiple Comparasions (Post Hoc) mund të mësohet se ndërmjet cilave grupe
të ndryshores së pavarur ekziston dallim për secilën ndryshore të varur. Në kolonën Mean
Difference, mund të thuhet se ekziston një dallim ndërmjet atyre grupeve të cilat pranë kanë
asteriks (*). Në të njëjtën mënyrë nga kolona Sig. vlerat të cilat gjenden nën 0,05 tregojnë që
ekziston një dallim ndërmjet grupeve.

168
Tabela 21: Tabela e Krahasimeve të Shumëfishta
Multiple Comparisons
Dependent Variable (I) pozita (J) pozita
Mean
Difference
(I-J)
Std.
Error Sig.
95% Confidence
Interval
Lower
Bound
Upper
Bound
meshkujt Tukey HSD punëtor mbikëqyrës -1.4510* .23845 .000 -2.0281 -.8739
menaxher -3.7176* .24977 .000 -4.3221 -3.1132
mbikëqyrës punëtor 1.4510* .23845 .000 .8739 2.0281
menaxher -2.2667* .24649 .000 -2.8632 -1.6701
menaxher punëtor 3.7176* .24977 .000 3.1132 4.3221
mbikëqyrës 2.2667* .24649 .000 1.6701 2.8632
Tamhane punëtor mbikëqyrës -1.4510* .23211 .000 -2.0358 -.8662
menaxher -3.7176* .23955 .000 -4.3272 -3.1081
mbikëqyrës punëtor 1.4510* .23211 .000 .8662 2.0358
menaxher -2.2667* .26243 .000 -2.9298 -1.6035
menaxher punëtor 3.7176* .23955 .000 3.1081 4.3272
mbikëqyrës 2.2667* .26243 .000 1.6035 2.9298
femrat Tukey HSD punëtor mbikëqyrës -2.7614* .21050 .000 -3.2709 -2.2520
menaxher -4.1725* .22048 .000 -4.7061 -3.6390
mbikëqyrës punëtor 2.7614* .21050 .000 2.2520 3.2709
menaxher -1.4111* .21759 .000 -1.9377 -.8845
menaxher punëtor 4.1725* .22048 .000 3.6390 4.7061
mbikëqyrës 1.4111* .21759 .000 .8845 1.9377
Tamhane punëtor mbikëqyrës -2.7614* .20742 .000 -3.2831 -2.2398
menaxher -4.1725* .21824 .000 -4.7259 -3.6192
mbikëqyrës punëtor 2.7614* .20742 .000 2.2398 3.2831
menaxher -1.4111* .22360 .000 -1.9766 -.8457
menaxher punëtor 4.1725* .21824 .000 3.6192 4.7259
mbikëqyrës 1.4111* .22360 .000 .8457 1.9766
Based on observed means.
The error term is Mean Square(Error) = .387.
*. The mean difference is significant at the .05 level.
Në tabelën e mësipërme, janë dhënë rezultatet e testeve Tukey dhe Tamhane veç e veç për
secilën ndryshore të varur meshkuj dhe femra. Ngaqë është siguruar kushti i barazisë së
variancave, është e mjaftueshme që të shikohen vetëm rezultatet e Tukey. Ndryshimi i mesatares
së kënaqësisë ndërmjet punëtorëve dhe mbikëqyrësve të ndryshores së varur meshkujt është

169
1,4510 dhe kjo është më e ulët për punëtorët. Dallimi ndërmjet punëtorëve dhe menaxherëve
është 3,7176 dhe kjo është më e ulët për punëtorët. Dallimi ndërmjet mbikëqyrësve dhe
menaxherëve është 2,2667 dhe kjo është më e ulët për mbikëqyrësit. Për arsye se vlerat p janë
më të vogla se 0,05, këto ndryshime janë plotësisht të rëndësishme. Kurse për femrat, dallimi
ndërmjet punëtorëve dhe mbikëqyrësve është 2,7614 dhe kjo është më e vogël për punëtorët.
Dallimi ndërmjet punëtorëve dhe menaxherëve është 4,1725 dhe kjo është më e vogël për
punëtorët. Dallimi ndërmjet mbikëqyrësve dhe menaxherëve është 1,4111 dhe kjo është më e
vogël për mbikëqyrësit. Për arsye se vlerat p janë më të vogla se 0,05, këto ndryshime janë
plotësisht të rëndësishme.
Tabela 22: Nëngrupet e Formuara Sipas Ndryshoreve të Pavarura Meshkuj dhe Femra
meshkujt
pozita N
Subset
1 2 3
Tukey HSDa,b,c
punëtor 17 1.8824
mbikëqyrës 18 3.3333
menaxher 15 5.6000
Sig. 1.000 1.000 1.000
femrat
pozita N
Subset
1 2 3
Tukey HSDa,b,c
punëtor 17 2.2941
mbikëqyrës 18 5.0556
menaxher 15 6.4667
Sig. 1.000 1.000 1.000
Në përfundim, përfitimi i tabelave të mësipërme nuk është surprizë. Për arsye të dallimeve
të mesatareve sipas të gjitha grupeve të faktorit të pozitës në çdo ndryshore të varur, numri i
nëngrupeve të formuara në ndryshoret e varura është sa numri i grupeve të ndryshores së
pavarur. Këto tabela paraqesin mesataret e secilit grup veç e veç për ndryshoret e varura meshkuj
dhe femra. Dallimet ndërmjet grupeve mund të kuptohen në mënyrë të qartë nga tabela 22.
Nga aplikimi i shembullit, sipas rezultateve të analizës MANOVA Një Drejtimshe, mund të
nxjerrim këto konkluzione:
Faktori i pozitës ndikon në kënaqësinë e punës qoftë për meshkujt apo femrat
Me rritjen e pozitës në punë, rritet kënaqësia e punës për femrat.

170
Me rritjen e pozitës në punë, rritet kënaqësia e punës për meshkujt.
Nuk ekziston dallim i kënaqësisë në punë ndërmjet punëtorëve femra dhe meshkuj
Femrat të cilat punojnë si mbikëqyrëse dhe menaxhere janë më të kënaqura për nga
meshkujt të cilat punojnë në këto pozita.
Përpara se të kalojmë në analizën MANOVA Dy Drejtimshe, është me dobi që të mbahet në
mend kjo. Ekzistojnë përngjasime të rëndësishme ndërmjet alternativave dhe tabelave të
rezultateve të MANOVA Një Drejtimshe dhe alternativave dhe tabelave të rezultateve të
ANOVA-së gjatë përdorimit të SPSS-it. Për këtë arsye, për t’a kuptuar më lehtë aplikimin e
MANOVA-së Një Drejtimshe ju sugjerojmë që të lexoni pjesën e ANOVA-së në këtë libër.
5. MANOVA DY DREJTIMSHE
MANOVA Dy Drejtimshe është si një përzierje e ANOVA Një Drejtimshe dhe MANOVA
Dy Drejtimshe. Hulumtohet ndikimi i dy ndryshoreve të pavarura në më shumë se një ndryshore
të varur. Hipoteza H0 këtu supozon se nuk ekziston asnjë dallim i mesatareve në asnjë ndryshore
të varur sipas grupeve të faktorëve. Në qoftë se vrojtohet një dallim vetëm në një ndryshore të
varur, hipoteza refuzohet.
Gjatë shqyrtimit të temës së MANOVA Dy Drejtimshe, nuk kemi për qëllim të japim
informata shtesë. Duke përdorur përsëri menynë Multivariate për këtë aplikim në SPSS, menytë
e përzgjedhjeve dhe tabelat të cilat do të përfitohen në fund të analizës janë shpjeguar në mënyrë
të detajuar në ANOVA Dy Drejtimshe dhe në MANOVA Një Drejtimshe. Me një shembull
shtesë këtu synohet që të bëhet konsolidimi i temave tjera si dhe dhënia e një shembulli në lidhje
me MANOVA Dy Drejtimshe. Gjatë sqarimit të shembullit, lexuesi do të udhëzohet për
shpjegimin e detajeve në lidhje me menytë që do të paraqiten dhe tabelat.
5.1. Shembull Aplikimi Shembulli është shpjeguar në Shtojcën-4. Bëhet hulumtimi i ndikimit të pozitës së
punonjësve dhe departamentit në të cilin punojnë mbi kënaqësinë e punës që punojnë,
përvetësimin e politikave të firmës dhe dëshirës për të qëndruar në firmë (përherë).
Në SPSS, në pjesën Analyze, General Linear Model, përzgjedhet Multivariate. Në
menynë kryesore Multivariate ndryshoret pozita dhe departamenti barten në pjesën Fixed
Factor(s), kurse ndryshoret kënaqësia, përvetësimi dhe qëndrueshmëria barten në pjesën
Dependent Variables. Ekrani i menysë kryesore të Multivariate duket si më poshtë.

171
Hapi 1: Dritarja e MANOVA Dy Drejtimshe
Nga këtu, detajet e përzgjedhjeve Model, Plots dhe Save janë shpjeguar në ANOVA Një
Drejtimshe, detajet e përzgjedhjes Post Hoc janë shpjeguar në ANOVA Një Drejtimshe dhe
ANOVA Dy Drejtimshe dhe detajet e Options janë shpjeguar në MANOVA Një Drejtimshe.
Përsëri për pjesët Covariate(s) dhe WLS Weight janë dhënë shkurtimisht informata në ANOVA
Dy Drejtimshe. Këtu do të tregohen dritaret për etiketimin e përzgjedhjeve të duhura dhe nuk do
të futemi në detaje.
Në pjesën Model përzgjedhjet e duhura janë të vetëpërcaktuara. Për këtë arsye këtu nuk
mund të kryhet ndonjë funksion. Klikohet në butonin Plots. Nga ekrani i hapur, ndryshorja
departamenti vendoset në pjesën Horizontal Axis, kurse ndryshorja pozita vendoset në pjesën
Separate Lines dhe ekrani do të duket si më poshtë.
Në ekranin Plot pasi të përcaktohen boshti horizontal dhe vijat e ndara, duhet të klikohet
butoni Add. Në qoftë se nuk klikohet ky buton, SPSS-i nuk do të i vizatoj grafiqet. Pastaj duke
klikuar në butonin Continue, bëhet kthimi në menynë kryesore Multivariate.

172
Hapi 2: Dritarja e Grafiqeve
Hapi 2: Dritarja e Krahasimeve të Shumëfishta Post Hoc për Mesataret e Vrojtuara

173
Pastaj klikohet në butonin Post Hoc dhe bëhet transferimi i faktorëve (ndryshoreve të
pavarura) në pjesën Post Hoc Tests for. Përzgjedhen testet Tukey dhe Tamhane’s T2 dhe duke
klikuar në butonin Continue bëhet kthimi në menynë kryesore Multivariate.
Hapi 4: Dritarja e Përzgjedhjeve
Nga menyja kryesore Multivariate klikohet butoni Options dhe bëhet hyrja në menynë
Options. Në këtë meny, pozita, departamenti dhe pozita*departamenti (bashkëveprimi i pozitës
me departamentin) barten në pjesën Display Means for. Duke etiketuar opsinet Homogeneity
tests dhe Estimates of effect size klikohet butoni Continue. Nga menyja Multivariate klikohet
butoni OK dhe përfitohen rezultatet e MANOVA Dy Drejtimshe.

174
5.2. Daljet e SPSS-it dhe Interpretimi Në tabelën 23 është dhënë numri i mostrave të secilit nëngrup të ndryshores së pavarur.
Numri i përafërt i mostrave është i rëndësishëm për shëndetin e rezultateve.
Tabela 23: Madhësitë e Mostrave të Grupeve
Between-Subjects Factors
Value Label N
pozita 1.00 Punëtor 39
2.00 Mbikëqyrës 44
3.00 Menaxher 42
departamenti 1.00 Prodhim 25
2.00 Aksione 26
3.00 Kontabilitet 24
4.00 Marketing 26
5.00 H&Zh 24
Tabela 24: Rezultatet e Testit të Supozimit të Barazisë së Kovariancave
Box's Test of Equality
of Covariance
Matricesa
Box's M 122.279
F 1.212
df1 84
df2 9862.734
Sig. .091
Tabela Box’s M bën testimin e barazimit të matricave të kovariancave. Ngaqë vlera p (Sig.)
është më e madhe se 0,05 arrijmë në përfundim se matricat e kovariancave janë të barabarta.
Mirëpo, përafërsia e vlerave 0,05 dhe 0,091 do të ulë vlerën e rezultateve në një masë.
Tabela 25: Rezultatet e Testit të Supozimit të Variancave
Levene's Test of Equality of Error Variancesa
F df1 df2 Sig.
kënaqësia .887 14 110 .574
përvetësimi .562 14 110 .889
qëndrueshmëria .717 14 110 .754

175
Sipas tabelës Levene’s Test of Equality of Error Variances është siguruar barazia e
variancave për secilën ndryshore të varur sipas grupeve të ndryshoreve të pavarura.
Tabela 26: Krahasimet e Shumëfishta
Multivariate Testsa
Effect Value F
Hypothesis
df Error df Sig.
Partial Eta
Squared
Intercept Pillai's Trace .988 2871.129b 3.000 108.000 .000 .988
Wilks' Lambda .012 2871.129b 3.000 108.000 .000 .988
Hotelling's Trace 79.754 2871.129b 3.000 108.000 .000 .988
Roy's Largest Root 79.754 2871.129b 3.000 108.000 .000 .988
pozita Pillai's Trace .915 30.645 6.000 218.000 .000 .458
Wilks' Lambda .135 61.845b 6.000 216.000 .000 .632
Hotelling's Trace 6.014 107.258 6.000 214.000 .000 .750
Roy's Largest Root 5.952 216.251c 3.000 109.000 .000 .856
departamenti Pillai's Trace 1.100 15.918 12.000 330.000 .000 .367
Wilks' Lambda .104 32.243 12.000 286.033 .000 .530
Hotelling's Trace 6.696 59.522 12.000 320.000 .000 .691
Roy's Largest Root 6.403 176.086c 4.000 110.000 .000 .865
pozita * departamenti Pillai's Trace .662 3.893 24.000 330.000 .000 .221
Wilks' Lambda .449 4.159 24.000 313.834 .000 .234
Hotelling's Trace .994 4.419 24.000 320.000 .000 .249
Roy's Largest Root .711 9.775c 8.000 110.000 .000 .416
a. Design: Intercept + pozita + departamenti + pozita * departamenti
b. Exact statistic
c. The statistic is an upper bound on F that yields a lower bound on the significance level.
Nga tabela Multivariate Tests testi Pillai’s Trace sado që të jetë testi më i besueshëm, në
përgjithësi përdoren rezutlatet e Wilk’s Lambda. Në tabelën Multivariate Tests janë dhënë
rezultatet e ndikimeve kryesore të ndryshoreve pozita dhe departamenti mbi ndryshoret e varura
si dhe në të njëjtën kohë ndikimi i bashkëveprimit pozita*departamenti mbi ndryshoret e varura.
Në kolonën Sig. të gjitha vlerat janë më të vogla se 0,05. Sipas vlerave të kolonës Sig. ndikimet e
ndryshores së pozitës, ndryshores së departamentit dhe bashkëveprimit të pozitës*departamentit
mbi ndryshoret e varura janë të rëndësishme. Në qoftë se shikohet kolona Partial Eta Squared,
sipas testit Wilks’ Lambda, vlera e pozitës është 0,632, vlera e departamentit është 0,530 dhe
vlera e pozitës*departamentit është 0,234. Duke shikuar këto vlera, ndikimet e ndryshoreve

176
pozita dhe departamenti janë të fuqishme ndaras dhe në të njëjtën kohë ndikimi i bashkëveprimit
pozita*departamenti është mi i dobët për nga këto dyja.
Tabela 27: Tabela e Ananlizës së Variancës
Tests of Between-Subjects Effects
Source Dependent Variable
Type III Sum of
Squares df
Mean
Square F Sig.
Partial Eta
Squared
Corrected Model kënaqësia 432.484a 14 30.892 38.708 .000 .831
përvetësimi 517.512b 14 36.965 48.821 .000 .861
qëndrueshmëria 502.061c 14 35.862 30.254 .000 .794
Intercept kënaqësia 4082.927 1 4082.927 5116.001 .000 .979
përvetësimi 4775.021 1 4775.021 6306.481 .000 .983
qëndrueshmëria 3960.952 1 3960.952 3341.629 .000 .968
pozita kënaqësia 344.348 2 172.174 215.738 .000 .797
përvetësimi 328.696 2 164.348 217.058 .000 .798
qëndrueshmëria 279.909 2 139.954 118.072 .000 .682
departamenti kënaqësia 58.735 4 14.684 18.399 .000 .401
përvetësimi 133.688 4 33.422 44.141 .000 .616
qëndrueshmëria 203.978 4 50.995 43.021 .000 .610
pozita * departamenti kënaqësia 23.079 8 2.885 3.615 .001 .208
përvetësimi 47.152 8 5.894 7.784 .000 .361
qëndrueshmëria 22.995 8 2.874 2.425 .019 .150
Error kënaqësia 87.788 110 .798
përvetësimi 83.288 110 .757
qëndrueshmëria 130.387 110 1.185
Total kënaqësia 4679.000 125
përvetësimi 5468.000 125
qëndrueshmëria 4688.000 125
Corrected Total kënaqësia 520.272 124
përvetësimi 600.800 124
qëndrueshmëria 632.448 124
a. R Squared = .831 (Adjusted R Squared = .810)
b. R Squared = .861 (Adjusted R Squared = .844)
c. R Squared = .794 (Adjusted R Squared = .768)

177
Në qoftë se shikojmë tabelën Test of Between-Subjects, do të vërehet se secila ndryshore e
pavarur ka një ndikim kuptimplotë mbi ndryshoret e varura. Po të vështrojmë kolonën Sig. për
pozitën, departamentin dhe pozita*departamenti do të vërejmë se secila ka një ndikim
kuptimplotë mbi kënaqësinë, përvetësimin dhe qëndrueshmërinë. Të gjitha vlerat janë më të
vogla se 0,05. Po të vështrojmë kolonën Partial Eta Squared, do të vërejmë se pozita ka
ndikimin më të lartë mbi kënaqësinë dhe përvetësimin dhe se bashkëvepimi pozita*departamenti
ka ndikimin më të ulët mbi kënaqësinë dhe përvetësimin. Ndryshorja departamenti teksa ka një
ndikim më të madh mbi ndryshoret përvetësimi dhe qëndrueshmëria, ka një ndikim relativisht
më të ulët mbi ndryshoren kënaqësia.
Tabela Multiple Comparisons nuk është vendosur këtu për shkak të madhësisë së faqes.
Në ANOVA Një Drejtimshe, ANOVA Dy Drejtimshe dhe MANOVA Një Drejtimshe është
shpjeguar se si bëhet leximi i kësaj tabele. Në qoftë se shikojmë ndryshoren e pavarur pozita në
tabelën Post Hoc (Multiple Comparisons) do të vërehet se të gjitha pozitat kanë pikëpamje të
ndryshme në lidhje me kënaqësinë në punë, përvetësimin e politikave të firmës dhe dëshirës për
të qëndruar në firmë. Menaxherët janë më të kënaqur në punë, i përvetësojnë më shumë politikat
dhe kanë më shumë dëshirë që të jenë të përhershëm në punë në krahasim me mbikëqyrësit.
Kurse mbikëqyrësit janë më të kënaqur në punë, i përvetësojnë më shumë politikat dhe kanë më
shumë dëshirë që të jenë të përhershëm në punë në krahasim me punëtorët.
Tabela 28: Nëngrupet e Formuara për Ndryshoren e Varur Kënaqësia Sipas Ndryshores së
Pavarur Pozita
kënaqësia
Tukey HSDa,b,c
pozita N
Subset
1 2 3
Punëtor 39 3.7179
Mbikëqyrës 44 5.5909
Menaxher 42 7.8571
Sig. 1.000 1.000 1.000
Në tabelën Kënaqësia këto ndryshime mund të vërehen shumë qartë. Vlerat e paraqitura në
tabelë tregojnë mesataret e kënaqësisë për punëtorët, mbikëqyrësit dhe menaxherët. Ngaqë
ekzistojnë dallime të rëndësishme ndërmjet tyre janë krijuar nëngrupe të ndryshme. Në qoftë se
do të shikonim tabelat e përvetësimit dhe qëndrueshmërisë, do të vërehen rezultate të
ngjashme. Përmes këtyre tabelave mund të shohim përmbledhjen e rezultateve të arritura nga
tabela Multiple Comparisons.
Në qoftë se do të shikonim tabelën Multiple Comparison të përgatitur sipas ndryshores
departamenti (përsëri për shkak të madhësisë tabelës nuk i është dhënë vend këtu), do të vërejmë

178
se kënaqësia e punës është më e lartë në departamentin H&Zh dhe se kënaqësia më e ulët e punës
është në departamentin e aksioneve. Kënaqësia e punës në departamentin e marketingut sado që
për një shumë është më e vogël, nuk ka ndonjë dallim të rëndësishëm ndërmjet departamentit
H&Zh dhe të marketingut në kënaqësinë e punës.
Përsëri sipas tabelës Multiple Comparisons departamenti H&Zh dhe departamenti i
marketingut përvetësojnë më shume biznesin dhe departamenti i aksioneve, kontabilitetit dhe
prodhimit përvetësojnë më pak politikat e biznesit. Në lidhje me qëndrueshmërinë në firmë janë
arritur pothuajse rezultate plotësisht të kundërta. Përderisa ata të departamentit të stoqeve
dëshirojnë që të qëndrojnë më shumë në firmë, këta të departamentit H&Zh dhe të marketingut
dëshirojnë më pak që të jenë të përhershëm në firmë. Në tabelat e mëposhtme këto rezultate
mund të vrojtohen në mënyrë më të qartë.
Tabela 29: Nëngrupet e Formuara të Ndryshores së Varur Kënaqësia Sipas Ndryshores së
Pavarur Departamenti
kënaqësia
Tukey HSDa,b,c
departamenti N
Subset
1 2 3 4
Aksione 26 4.7308
Prodhim 25 5.4800
Kontabilitet 24 5.6667 5.6667
Marketing 26 6.1923 6.1923
H & Zh 24 6.8333
Sig. 1.000 .947 .237 .090
Tabela Kënaqësia e cila jep mesataret e kënaqësisë sipas departamenteve tregon se si mund
të klasifikohen nivelet e kënaqësive sipas departamenteve. Niveli i kënaqësisë është më i lartë
për punonjësit në departamentin e Marketingut dhe H&Zh. Kurse departamenti i stoqeve është
departmenti i cili ofron kënaqësinë më të ulët.

179
Tabela 30: Nëngrupet e Formuara të Ndryshores së Varur Përvetësimi Sipas Ndryshores së
Pavarur Departamenti
përvetësimi
Tukey HSDa,b,c
departamenti N
Subset
1 2
Aksione 26 5.1538
Kontabilitet 24 5.2500
Prodhim 25 5.8000
Marketing 26 7.4615
H & Zh 24 7.5417
Sig. .073 .998
Sipas tabelës Përvetësimi departamentet të cilat kanë përvetësuar më shumë biznesin
janë departamenti i marketingut dhe H&Zh. Kurse departamentet që kanë përvetësuar më pak
janë ai i stoqeve, kontabilitetit dhe prodhimit. Në qoftë se shikojmë vlerat p (Sig.) në lidhje me
përvetësimin e biznesit, punonjësit e departamentit të marketingut dhe H&Zh kanë formuar një
grup kuptimplotë. Sado që këto vlera të i afrohen 1-shit, grupi do të jetë po aq më kuptimplotë.
Tabela 31: Nëngrupet e Formuara të Ndryshores së Varur Qëndrueshmëria sipas
Ndryshore së Varur Departamentit
qëndrueshmëria
Tukey HSDa,b,c
departamenti N
Subset
1 2 3 4
H & Zh 24 4.1667
Marketing 26 4.4615
Kontabilitet 24 5.6667
Prodhim 25 6.6000
Aksione 26 7.5000
Sig. .874 1.000 1.000 1.000
Tabela Qëndrueshmëria paraqet rezultate interesante. Po të shikojmë tabelën, punonjësit
sado që të mund të jenë të kënaqur nga puna dhe sado që të e përvetësojnë punën, mund që të
mos dëshirojnë të jenë të përhershëm në firmë. Punonjësit e departamentit të aksioneve përderisa
e përvetësojnë më së paku punën, dëshirojnë që të jenë të përhershëm në firmë më shumë se të
tjerët. Kurse punonjësit e departamentit të marketingut dhe H&Zh të cilët e pëvetësojnë më
shumë punën, janë ata që mendojnë më pak të jenë të përhershëm në firmë. Në të vërtet ky
rezultat nuk është edhe shumë interesant. Punonjësit e H&Zh janë njerëz të kualifikuar. Kurse

180
punonjësit e marketingut janë në një pozitë më shoqërore. Këta punonjës të këtyre
departamenteve kanë mundësinë që të marrin propozime më tërheqëse në çdo moment. Kurse
nuk mund të thuhet e njëjta gjë për departamentin e aksioneve. Sado që të mos jenë të kënaqur
nga puna, sado që të mos e përvetësojnë punën, ata nuk kanë alternativa tjera para tyre. Për këtë
arsye ata dëshirojnë që të jenë të përhershëm në firmë. Gjatë përcaktimit të politikave të firmës,
duhet të kihen parasysh këta faktorë.
Tani përsëri në qoftë se do konsideronim ndikimet e faktorit pozita dhe ndikimet e faktorit
departamenti mbi ndryshoret e varura, do të kuptohej fare qartë se ekziston një bashkëveprim
ndërmjet këtyre dy faktorëve. Përderisa mesataret e të gjitha ndryshoreve të varura rriten me
kalimin nëpër grupet (punëtor, mbikëqyrës dhe menaxher) e faktorit pozita, një lidhje e tillë nuk
ekziston ndërmjet departamenteve. Veçanërisht sipas departamenteve dallimet në ndryshoren e
varur qëndrueshmëria janë të ndryshme për nga dallimet në ndryshoret e varura kënaqësia dhe
përvetësimi. Prandaj, duke i marrë parasysh pozitat në këto departamente, do të arrihen rezultate
më të shëndetshme.
Këto që thamë do të kuptohen më mirë në qoftë se shikojmë tabelën pozita*departamenti
e cila gjendet nën titullin Estimated Marginal Means nga rezultatet e SPSS-it.
Tabela 32: Intervalet e Besueshmërisë
3. pozita * departamenti
Dependent
Variable pozita departamenti Mean Std. Error
95% Confidence Interval
Lower Bound Upper Bound
kënaqësia Punëtor Prodhim 2.750 .316 2.124 3.376
Aksione 3.125 .316 2.499 3.751
Kontabilitet 3.875 .316 3.249 4.501
Marketing 4.125 .316 3.499 4.751
H & Zh 4.857 .338 4.188 5.526
Mbikëqyrës Prodhim 5.889 .298 5.299 6.479
Aksione 4.000 .298 3.410 4.590
Kontabilitet 5.125 .316 4.499 5.751
Marketing 5.667 .298 5.077 6.257
H & Zh 7.222 .298 6.632 7.812
Menaxher Prodhim 7.750 .316 7.124 8.376
Aksione 6.889 .298 6.299 7.479
Kontabilitet 8.000 .316 7.374 8.626
Marketing 8.556 .298 7.965 9.146
H & Zh 8.125 .316 7.499 8.751

181
përvetësimi Punëtor Prodhim 2.875 .308 2.265 3.485
Aksione 3.125 .308 2.515 3.735
Kontabilitet 4.625 .308 4.015 5.235
Marketing 5.750 .308 5.140 6.360
H & Zh 5.857 .329 5.205 6.509
Mbikëqyrës Prodhim 6.000 .290 5.425 6.575
Aksione 4.222 .290 3.647 4.797
Kontabilitet 4.000 .308 3.390 4.610
Marketing 6.889 .290 6.314 7.464
H & Zh 7.667 .290 7.092 8.241
Menaxher Prodhim 8.500 .308 7.890 9.110
Aksione 7.889 .290 7.314 8.464
Kontabilitet 7.125 .308 6.515 7.735
Marketing 9.556 .290 8.981 10.130
H & Zh 8.875 .308 8.265 9.485
qëndrueshmëria Punëtor Prodhim 3.875 .385 3.112 4.638
Aksione 6.500 .385 5.737 7.263
Kontabilitet 3.500 .385 2.737 4.263
Marketing 3.000 .385 2.237 3.763
H & Zh 2.286 .412 1.470 3.101
Mbikëqyrës Prodhim 7.000 .363 6.281 7.719
Aksione 6.889 .363 6.170 7.608
Kontabilitet 5.750 .385 4.987 6.513
Marketing 4.222 .363 3.503 4.941
H & Zh 3.889 .363 3.170 4.608
Menaxher Prodhim 8.875 .385 8.112 9.638
Aksione 9.000 .363 8.281 9.719
Kontabilitet 7.750 .385 6.987 8.513
Marketing 6.000 .363 5.281 6.719
H & Zh 6.125 .385 5.362 6.888
Sipas kësaj tabele, përderisa punëtorët e marketingut dhe H&Zh kanë kënaqësinë më të lartë
në punë dhe kanë përvetësimin më të madh të punës, janë që kanë dëshirë më së paku të jenë të
përhershëm në firmë. Sipas tabelës e njëjta situatë është e vlefshme edhe për mbikëqyrësit dhe
menaxherët.

182
Punëtorët e departamentit të prodhimit dhe aksioneve përderisa kanë kënaqësinë më të ulët
të punës dhe përvetësim më të vogël të punës, dëshirojnë që të jenë të përhershëm në firmë
sidomos punëtorët e departamentit të aksioneve. Niveli më i ulët i kënaqësisë dhe përvetësimi më
i vogël i mbikëqyrësve është në departamentet e aksioneve dhe kontabilitetit, kurse dëshira më e
madhe për të qëndruar në firmë është në departamentet e prodhimit dhe aksioneve. Niveli më i
ulët i kënaqësisë së menaxherëve është në departamentin e aksioneve, përvetësimi më i ulët i
biznesit është në departamentin e kontabilitetit dhe dëshira më e madhe për të qëndruar në firmë
është në departamentet e prodhimit dhe aksioneve.
Nga tabela pozita*departamenti është e mundur që të nxirren më shumë konkluzione, por
ky interpretim është i mjaftueshëm për të kuptuar ndërveprimin ndërmjet pozitës dhe
departamentit.
Figura 7: Grafiku tregues i ndryshimit të kënaqësisë sipas grupeve të ndryshoreve të
pavarura
Vija më e lartë u përket menaxherëve
Vija e mesme u përket mbikëqyrësve
Vija e poshtme u përket punëtorëve

183
Grafiku Estimated Marginal Means of kënaqësia përdoret për të shikuar në mënyrë
vizuale ndryshimin e kënaqësisë sipas departamenteve dhe pozitave. Boshti horizontal paraqet
departamentet kurse boshti vertikal paraqet nivelin e kënaqësisë. Vija më e lartë paraqet
menaxherët, vija e mesme mbikëqyrësit dhe vija e poshtme punëtorët. Përmes këtij grafiku mund
të kuptohet ndërveprimi pozita*departamenti. Për shembull, një punëtor i cili punon në
departamentin H&Zh mund më të ketë një nivel më të lartë të kënaqësisë në punë për nga një
shef i departamentit të aksioneve.
Figura 8: Grafiku tregues i ndryshimit të përvetësimit sipas grupeve të ndryshoreve të
pavarura
Vija më e lartë u përket menaxherëve
Vija e mesme u përket mbikëqyrësve
Vija e poshtme u përket punëtorëve
Grafiku Estimated Marginal Means of përvetësimi përdoret për të shikuar në mënyrë
vizuale ndryshimin e përvetësimit sipas departamenteve dhe pozitave. Në këtë grafik boshti
vertikal paraqet nivelin e përvetësimit të politikave të firmës. Vija më e lartë paraqet menaxherët,
vija e mesme mbikëqyrësit dhe vija e poshtme punëtorët. Ndryshimi në përvetësimin e politikave
të firmës sipas departamenteve dhe pozitave mund të shihet shumë qartë.

184
Figura 9: Grafiku tregues i ndryshimit të qëndrueshmërisë sopas grupeve të ndryshoreve të
pavarura
Vija më e lartë u përket menaxherëve
Vija e mesme u përket mbikëqyrësit
Vija e poshtme u përket punëtorëve
Grafiku Estimated Marginal Means of qëndrueshmëria në lidhje me dëshirën për të
qëndruar në firmë, ashtu si grafiqet tjera paraqet në mënyrë vizuale dallimin e dëshirës për të
qëndruar në firmë sipas departamenteve dhe pozitave. Përsëri vija më e lartë paraqet menaxherët,
vija e mesme mbikëqyrësit dhe vija e poshtme punëtorët. Boshti vertikal këtu përcakton nivelin e
qëndrueshmërisë në firmë.
Gjatë leximit të grafiqeve një gjë e cila duhet të kihet parasysh është se nuk mund të bëhet
në mënyrë të qartë interpretimi për dallimet ndërmjet grupeve vetëm përmes grafiqeve. Për të
thënë se ekziston një dallim i rëndësishëm ndërmjet dy grupeve, nuk është e mjaftueshme që të
shohim se ekziston një dallim numëror ndërmjet mesatareve. Ekziston nevoja për testet të cilat
tregojnë se sa është kuptimplotë ky dallim. Për këtë arsye, sado që këto grafiqe janë të dobishme
për nga aspekti i paraqitjes vizuale të mesatareve sipas grupeve, nuk janë të mjaftueshme si të
vetme. Interpretimet duhet të bëhen duke përdorur tabelat e përmendura gjatë shpjegimit, të cilat
mundësojnë të kuptojmë dallimet ndërmjet grupeve.

185
Në fund, rezultatet që mund të i nxjerrim nga ky shembull janë:
Menaxherët janë më të kënaqur se mbikëqyrësit dhe mbikyqrësit më të kënaqur se
punëtorët
Menaxherët përvetësojnë më shumë punën se mbikëqyrësit dhe mbikëqyrësit më shumë
se punëtorët
Menaxherët dëshirojnë që të jenë të përhershëm në firmë më shumë se mbikëqyrësit dhe
mbikëqyrësit më shumë se punëtorët
Punonjësit e marketingut dhe H&Zh kanë nivelin më të lartë të kënaqësisë së punës dhe
përvetësimin më të lartë të politikave të firmës dhe në të njëjtën kohë më së paku
dëshirojnë të jenë të përhershëm në firmë
Ekziston një ndërveprim kuptimplotë ndërmjet departamenteve dhe pozitave. Për
shembull, përderisa punëtorët e departamentit të prodhimit dhe stoqeve kanë nivelin më
të ulët të kënaqësisë në punë dhe përvetësim më të ulët të punës, dëshirojnë që të jenë të
përhershëm në firmë, sidomos punonjësit në departamentin e stoqeve.
Prandaj, gjatë bërjes së analizës, departamentet dhe pozitat duhet të vlerësohen së bashku.
Një gjest i tillë është më i shendetshëm në krahasim me interpretime të përgjithshme në
lidhje me pozitën apo me interpretime të përgjithshme në lidhje me departamentin.
Siç qe cekur edhe në fillim nuk ishte synim që të jepen informata të reja në lidhje me
MANOVA Dy Drejtimshe në SPPS për lexuesin. Qëllimi këtu ishte që të bëhej një konsolidim
me të dhënat e analizës së variancës dhe që të sillet në një formë më konkrete për t’u mbajtur në
mend MANOVA Dy Drejtimshe. Kuptimi më i mirë i kësaj teme lidhet me kuptimin e mirë të
temave të shpjeguara më lartë në këtë kapitull.

186
SHTOJCA 1
Një firmë dëshiron që të mat ndikimin e pozitës së punëtorëve në pranimin e politikave të
firmës. Në mostër marrin pjesë 17 punëtorë, 15 mbikëqyrës dhe 11 menaxherë dhe janë pyetur se
a pajtohen me gjykimin “Politikat e firmës janë si duhet dhe duhet të përvetësohen”. Është
përdorur pesëmatësi i Likertit.
Plotësisht pajtohem :5
Pajtohem :4
Neutral :3
Nuk pajtohem :2
Plotësisht nuk pajtohem :1
Në vlerësimin e përgjigjeve janë përdorur të dhëna numerike. Të dhënat në SPSS janë futur
në këtë mënyrë
Përvetësimi Pozita
1 2 1
2 3 1
3 2 1
4 3 1
5 3 1
6 1
7 1 1
8 1 1
9 2 1
10 2 1
11 3 1
12 2 1
13 4 1
14 2 1
15 2 1
16 3 1
17 3
18 3 2
19 4 2
20 4 2
21 5 2
22 4 2
23 4 2
24 3 2
25 3 2

187
26 4 2
27 4 2
28 2 2
29 2
30 4 2
31 5 2
32 4 2
33 5 3
34 5 3
35 4 3
36 5 3
37 5 3
38 4 3
39 4 3
40 2 3
41 3 3
42 5 3
43 5 3

188
SHTOJCA 2
Të hulumtohet ndikimi i pozitës së punonjësve në firmë dhe kohës së kaluar në atë pozitë në
kënaqësinë e punës. Pozitat e punonjësve dhe koha e kaluar në atë pozitë janë dhënë më poshtë
në formën e numrave.
Punëtor :1 Fundi i javës së parë: :1
Mbikëqyrës :2 Fundit 3 muajve: :2
Menaxher :3 Fundi i 6 muajv :3
Fundi i 1 viti :4
Punonjësit janë pyetur në lidhje me kënaqësine e punës në periudhat e cekura. Për shembull,
një mbikëqyrës është pyetur se a është i kënaqur nga puna në fund të javës së parë pasi ka filluar
punën, në fund të 3 muajve, në fund të 6 muajve dhe pas 1 viti. Është kërkuar që të përzgjedh
numrat prej 1 deri në 10 ashtu siç e sheh ai më të përshtatshëm për të. Këtu këta numri shprehin:
10: Shumë i kënaqur
1: Aspak i kënaqur.
Të dhënat e mëposhtme janë futur në SPSS.
Ndryshorja e parë pavarur: Pozita
Ndryshorja e dytë e pavarur: Koha
Ndryshorja e Varur: Kënaqësia
Kënaqësia Pozita Koha
1 7 1 1
2 5 1 2
3 4 1 3
4 2 1 4
5 5 1 1
6 5 1 2
7 3 1 3
8 1 1 4
9 5 1 1
10 4 1 2
11 2 1 3
12 2 1 4
13 4 1 1
14 4 1 2
15 2 1 3

189
16 2 1 4
17 5 2 1
18 6 2 2
19 5 2 3
20 5 2 4
21 7 2 1
22 6 2 2
23 6 2 3
24 7 2 4
25 8 2 1
26 7 2 2
27 6 2 3
28 6 2 4
29 7 2 1
30 7 2 2
31 7 2 3
32 6 2 4
33 5 3 1
34 7 3 2
35 9 3 3
36 10 3 4
37 6 3 1
38 9 3 2
39 10 3 3
40 10 3 4
41 7 3 1
42 9 3 2
43 9 3 3
44 10 3 4
45 6 3 1
46 7 3 2
47 9 3 3
48 9 3 4

190
SHTOJCA 3
Kërkohet të analizohet se a ndikon pozita e punonjësve sipas gjinisë në kënaqësinë e punës.
Me fjalë të tjera, ndikimi i pozitës së punës a ndryshon sipas femrave apo sipas meshkujve në
kënaqësinë e punës. Në analizë janë mbledhur të dhëna nga 15 femra dhe 15 meshkuj
menaxherë, 18 femra dhe 18 meshkuj mbikëqyrës si dhe 17 femra dhe 17 meshkuj punëtorë.
Niveli i kënaqësisë është matur me këtë numër të personelit. Për matjen e kënaqësisë është
përdorur pesëmatësi i Likerit. Këtu;
1 – Nuk jam aspak i kënaqur
7 – Jam shumë i kënaqur.
Ndryshorja e varur: Pozita
Ndryshorja e parë e pavarur: Femrat
Ndryshorja e dytë e pavarur: Meshkujt
Pozita 1: Punëtor
Pozita 2: Mbikëqyrës
Pozita 3: Menaxher
Femra Meshkuj Pozita
1 2 2 1
2 3 1 1
3 2 2 1
4 2 2 1
5 1 2 1
6 2 3 1
7 3 2 1
8 2 2 1
9 3 1 1
10 2 1 1
11 2 2 1
12 2 2 1
13 3 3 1
14 2 2 1
15 2 2 1
16 3 1 1
17 3 2 1
18 5 3 2
19 5 3 2

191
20 4 4 2
21 5 3 2
22 6 2 2
23 5 3 2
24 5 3 2
25 6 4 2
26 5 4 2
27 4 5 2
28 5 4 2
29 5 4 2
30 6 3 2
31 5 3 2
32 5 2 2
33 4 3 2
34 5 4 2
35 6 3 2
36 7 6 3
37 7 5 3
38 6 6 3
39 7 6 3
40 6 4 3
41 6 5 3
42 5 5 3
43 7 6 3
44 7 6 3
45 7 5 3
46 6 6 3
47 7 7 3
48 6 6 3
49 6 6 3
50 7 5 3

192
SHTOJCA 4
Dëshirohet të hulumtohet ndikimi i pozitës së punonjësve dhe departamentit në të cilin
punojnë në kënaqësinë e punës që punojnë, përvetësimin e politikave të firmës dhe dëshirës për
të qëndruar në firmë (përherë). Janë përcaktuar 3 grupe për ndryshoren e parë të pavarur:
punëtor, mbikëqyrës dhe menaxher i nivelit të lartë. Janë përcaktuar 5 grupe për ndryshoren e
dytë të pavarur: prodhim, stoqe, kontabilitet, marketing dhe H&Zh (Hulumtim dhe Zhvillim).
Janë mbledhur të dhëna në total prej 125 vetëve nga pozita dhe departamente të ndryshme në
lidhje me kënaqësinë e punës, përvetësimit të politikave të firmës dhe dëshirës për të qëndruar në
firmë.
Përgigjjet e dhëna në lidhje me kënaqësinë e punës;
1 – Nuk jam aspak i kënaqur
10 – Jam shumë i kënaqur
Përgjigjet e dhëna në lidhje me përvetësimin e politikave të firmës;
1 – Nuk i përvetëson aspak
10 – I përvetëson plotësisht
Përgjigjjet e dhëna në lidhje me dëshirën për të qëndruar në firmë;
1 – Nuk dëshiron aspak
10 – Dëshiron shumë.
Të dhënat janë futur si më poshtë në SPSS.
Ndryshorja e parë e pavarur: Pozita
Ndryshorja e dytë e pavarur: Departamenti
Ndryshorja e parë e varur: Kënaqësia
Ndryshorja e dytë e varur: Përvetësimi
Ndryshorja e tretë e varur: Qëndrueshmëria
Pozita 1: Punëtor
Pozita 2: Mbikëqyrës
Pozita 3: Menaxher
Departamenti 1: Prodhim

193
Departamenti 2: Aksionet
Departamenti 3: Kontabilitet
Departamenti 4: Marketing
Departamenti 5: H-Zh.
Pozita Departamenti Kënaqësia Përvetësimi Qëndrueshmëria
1 1 3 4 3 4
2 2 1 6 6 7
3 3 4 9 10 7
4 1 2 3 2 6
5 3 4 7 10 5
6 2 2 4 4 7
7 1 4 5 5 4
8 2 1 5 6 6
9 2 1 5 5 6
10 3 4 9 10 6
11 1 4 4 6 2
12 2 1 7 7 8
13 3 4 8 9 5
14 2 3 5 4 6
15 2 2 4 4 6
16 1 3 4 5 2
17 2 2 5 5 8
18 3 4 10 10 8
19 2 3 6 5 7
20 1 2 4 2 7
21 2 1 7 5 8
22 3 4 8 9 5
23 2 3 5 3 5
24 1 3 4 4 3
25 2 5 5 8 6
26 2 2 3 4 6
27 2 1 5 7 7
28 2 5 8 8 4
29 1 2 3 4 8
30 3 4 9 10 6
31 2 5 6 9 2
32 1 5 5 5 2
33 3 5 8 9 6
34 2 3 6 5 7
194
35 1 3 4 5 5
36 3 5 9 9 7
37 2 5 7 7 5
38 3 5 7 10 5
39 1 5 5 6 2
40 3 5 8 8 7
41 2 2 4 5 8
42 3 5 7 8 6
43 2 5 8 6 3
44 2 1 7 7 8
45 3 5 8 8 5
46 1 3 3 5 4
47 3 5 9 9 6
48 2 5 8 8 4
49 2 3 4 3 5
50 1 2 3 4 8
51 2 5 7 7 3
52 2 1 5 5 6
53 1 5 6 7 3
54 1 3 3 4 2
55 2 4 6 7 5
56 2 4 5 6 3
57 2 1 6 6 7
58 2 5 9 9 5
59 2 5 7 7 3
60 2 2 4 4 6
61 3 1 9 10 10
62 3 1 7 8 8
63 1 5 4 5 1
64 3 2 8 9 10
65 1 1 3 4 6
66 3 2 6 7 8
67 2 3 5 4 6
68 3 3 9 8 9
69 2 2 3 5 7
70 1 2 3 3 5
71 3 3 7 6 7
72 1 4 4 6 3
73 3 4 9 9 7
74 1 5 5 6 4
75 3 3 8 7 8
76 2 2 5 3 6
77 1 1 4 4 5

195
78 3 3 7 8 7
79 2 3 3 3 3
80 3 3 8 8 6
81 2 2 4 4 8
82 3 1 8 9 9
83 3 4 8 9 5
84 3 3 7 7 7
85 1 5 4 6 1
86 1 2 4 5 6
87 3 5 9 10 7
88 3 3 9 6 9
89 1 4 5 7 4
90 3 1 7 8 8
91 1 3 4 5 3
92 2 3 7 5 7
93 1 3 5 6 5
94 2 4 6 7 4
95 1 2 3 3 7
96 1 1 4 3 3
97 3 1 8 7 10
98 2 4 7 6 5
99 1 2 2 2 5
100 3 3 9 7 9
101 1 4 4 5 2
102 1 1 3 3 3
103 1 1 1 2 4
104 3 2 7 8 9
105 3 1 7 9 7
106 2 4 5 8 3
107 1 1 2 2 2
108 3 1 8 8 10
109 2 4 4 6 5
110 3 2 8 7 8
111 3 1 8 9 9
112 3 2 6 9 10
113 1 1 3 2 5
114 1 4 5 7 4
115 3 2 7 8 10
116 2 4 5 6 4
117 1 4 3 5 2
118 3 2 6 8 9
119 2 4 6 7 4
120 3 2 7 8 9

196
121 1 4 3 5 3
122 1 5 5 6 3
123 3 2 7 7 8
124 2 4 7 9 5
125 1 1 2 3 3

197
8. ANALIZA E KOVARIANCËS

198
ANALIZA E KOVARIANCËS
Analiza e kovariancës është një zgjatje e analizës së variancës. Analiza e variancës
(ANOVA) përdoret për të gjetur dallimet ndërmjet mesatareve të grupit. Në analizë tentohet të
zbulohet ndikimi i disa ndryshoreve të pavarura (kategorike) mbi një ndryshore të varur
(vazhdueshme). Kurse në analizën e kovariancës tema kryesore është hulumtimi apo eleminimi i
ndryshores së varur e cila ndikon një ndryshore tjetër të varur gjatë krahasimit të mesatareve të
një ndryshoreje të varur të një apo më shumë grupi.
Analiza e kovariancës është një metodë statistikore shumë e dobishme dhe e fuqishme në
rastet kur përmbushen supozimet.
Në analizën e kovariancës gjatë matjes së dallimit ndërmjet mesatereve grupore, përdoren
analiza e regresionit dhe analiza e variancës së bashku. Pra analiza e kovariancës, është një
kombinim i analizës së variancës dhe analizës së regresionit. Në fillim, zbatohet procedura e
regresionit, pastaj metoda e analizës së variancës normale mbi vlerat e korrigjuara. Në këtë
mënyrë, bëhet një korrigjim për lidhjen lineare ndërmjet ndryshores së varur dhe kondryshores
(covariate-ndryshore e përbashkët). Në fund të kësaj, reduktohet gabimi variancor dhe mund të
zbulohen dallimet ndërmjet grupeve duke pasur parasysh dallimet e tjera ndërmjet të dhënave.
Analiza e kovariancës, ul gabimin e variancës përderisa arrin të marr nën kontroll
ndryshimin në ndryshoren e varur e cila ndikon të gjithë grupin.
Ashtu si në analizën e variancës, edhe në analizën e kovariancës gjenden ndryshoret e
varura dhe të pavarura por si shtim i këtyre ndryshoreve u bashkangjiten edhe një apo më shumë
ndryshore tjera. Këto ndryshore të cilat bashkangjiten quhen “kondryshore (covariate)”.
Shkurtimisht, në analizën e kovariancës gjendet vetëm një ndryshore e varur dhe disa ndryshore
të pavarura dhe kondryshore.
Analiza e kovariancës përdoret si një pjesë përbërëse e teknikave të analizës së variancës
“Një Drejtimshe” (one-way), “Dy Drejtimshe” (two-way) dhe “Shumë Ndryshoresh”
(multivariate). Numri i ndryshoreve të përdorura në analizën e kovariancës një dhe dy drejtimshe
është në këtë mënyrë:
ANCOVA Një Drejtimshe: një ndryshore e pavarur, një ndryshore e varur, një apo më
shumë kondryshore
ANCOVA Dy Drejtimshe: dy ndryshore të pavarura, një ndryshore e varur, një apo më
shumë kondryshore.

199
1. AVANTAZHET E APLIKIMIT TË ANALIZËS SË KOVARIANCËS
Aplikimi i analizës së kovariancës ka shumë dobi. Këto mund t’i rendisim në këtë mënyrë:
Analiza e kovariancës redukton gabimin variancor, në këtë mënyrë rritet vlera F dhe rritet
fuqia e modelit.
Regresionet ndërmjet grupeve të ndryshme janë të barabarta.
Po ashtu, analiza e kovariancës është shumë e dobishme në rastet kur madhësia e mostrës
është e vogël apo ndikimi i madhësisë është i vogël.
2. FUSHAT E PËRDORIMIT TË ANALIZËS SË KOVARIANCËS Analiza e kovariancës, në përgjithësi, mund të përdoret në të gjitha fushat dhe problemet ku
përdoret analiza e variancës. ANCOVA, në mënyrë bazike, hulumton se a ekziston ndonjë dallim
i rëndësishëm statstikor ndërmjet grupeve. Dallimi i ANCOVA prej ANOVA është përfshirja e
llojit të tretë të ndryshores në setin e ndryshoreve të pavarura dhe të varura, pra kondryshores.
Për shembull, duke i ndarë në 3 grupe punonjësit e një firme, dëshirohet të shqyrtohet se a
ekziston ndonjë dallim për nga aspekti i shumës së prodhimit të produkteve të punonjësve
ndërmjet grupeve. Mirëpo, shuma e prodhimit për punonjësit ndryshon në lidhje me përvojën
dhe specializimin e tij. Prandaj, për të bërë një analizë sa më të saktë, përvoja (p.sh. numri i
viteve të punimit) duhet të futet si kondryshore në model. Në këtë mënyrë, pasi të eleminohen
dallimet që burojnë nga përvoja dhe specializimi, mund të bëhet një parashikim më i saktë.
Apo, në qoftë se 3 grupe përbëhen nga kuajt garues, dëshirohet të shqyrtohet se a ekziston
dallim për nga aspekti i shpejtësisë së vrapimit ndërmjet grupeve. Mirëpo, shpejtësia e një kali
garues ndryshon në lidhje me moshën e tij. Prandaj, mosha e kuajve garues duhet të përfshihet në
model si një kondryshore, në këtë mënyrë eleminohet dallimi që buron nga mosha, zvogëlohet
gabimi i modelit dhe do të jetë bërë një analizë më e saktë.
ANCOVA përdoret edhe për të barazuar grupet, në qoftë se grupet për çfarëdo arsye nuk
janë të barabarta. Për shembull, gjatë krahasimit të metodave të ndryshme të arsimit të përdorura
si të dhënat për studentët e zgjedhur jorastësisht, ekziston një dallim i njohur që në fillim
ndërmjet grupeve, si p.sh. zgjuarsia. Në këtë rast, gjatë krahasimit të klasëve, IQ duhet të futet në
model si kondryshore dhe përpara se të krahasohen mesateret e grupeve, duhet të eleminohet
ndikimi i intelegjencës.
ANCOVA mund të përdoret edhe në rastet kur mostra e rastësishme nuk është e
suksesshme. Për shembull, në mostrat e vogla grupet mund të mos jenë të barabarta edhe në
qoftë se është bërë mostër e rastësishme. Në këtë rast, duke përdorur ANCOVA ky problem
mund të eleminohet.

200
3. SUPOZIMET E ANALIZËS SË KOVARIANCËS
Që analiza ANCOVA të jetë e vlefshme dhe të mund të interpretohet, duhet që të
përmbushen disa supozime. Këto supozime janë:
Grupet:
Grupet duhet të jenë të pavarura prej njëra-tjetrës.
Variancat e grupeve duhet të jenë të barabarta, pra konstante. Me fjalë të tjera, duhet të
sigurohet homogjeniteti i variancave, pra, nuk duhet të jetë variancë e cila ndryshon.
Koeficientët e regresionit brenda grupeve duhet të jenë të barabartë.
Ndryshorja e varur:
Ndryshorja e varur duhet të jetë intervalore apo proporcionale. Përsëri, ndryshorja e varur
duhet të ndjek shpërndarjen normale apo duhet të jetë afër normales.
Kondryshorja:
Kondryshorja duhet të jetë në formën intervalore apo propocionale. Ndryshoret nominale
nuk mund të përdoren si kondryshore. Po ashtu, kondryshorja duhet të përzgjidhet me
shumë kujdes. Sidomos, duhet kuptuar mirë teoria në lidhje me atë çështje dhe duhet
siguruar se është e nevojshme përfshirja e asaj kondryshoreje në model. (Në këtë pikë,
është e dobishme që të shikohen punimet e bëra në lidhje me këtë çështje.)
Ndryshorja(et) e zgjedhur(a) duhet të jetë(në) e(të) besueshme, pra duhet të jetë e matur
në një mënyrë të pagabuar sepse ANCOVA supozon se kondryshorja është matur
pagabime dhe në mënyrë plotësisht të saktë.
Në qoftë se do të përdoren më shumë se një kondryshore, nuk duhet të ekzistojë
korrelacion i fortë ndërmjet kondryshoreve të zgjedhura. Në qoftë se ekziston një
korrelacion në shkallë të lartë (r=0,8 dhe më lartë), duhet që të nxirret një apo më shumë
kondryshore.
Kondryshorja dhe ndryshorja e pavarur duhet të jenë brenda një marrëdhënie të drejtë
lineare. Në qoftë se nuk ekziston marrëdhënie lineare ndërmjet kondryshores dhe
ndryshores së varur, nuk mund të mirret rendimenti i dëshiruar nga analiza. Me fjalë të
tjera, mospërfillja e këtij supozimi, zvogëlon fuqinë e testit sepse në një rast të këtillë
gabimi i variancës mund të ulet shumë pak. Ky test është efektiv në rastet kur
korrelacioni ndërmjet kondryshores dhe ndryshores së varur është më i lartë se 0,30. Një
marrëdhënie sa më e fortë lineare mundëson rezultate më të fuqishme të ANCOVA. Në
qoftë se marrëdhënia ndërmjet kondryshores dhe ndryshores së varur nuk është lineare,
mund aplikohet testi ANOVA i ndryshores së pavarur. Një zgjedhje tjetër për sigurimin e
marrëdhënies lineare është konvertimi matematikor i ndryshoreve. Për testimin e
linearitetit të marrëdhënies ndërmjet ndryshores së varur dhe kondryshores, mund të
përdoret diagrami i shpërndarjes (scatterplot). (Për t’a bërë këtë në SPSS, zgjedhet
menyja Graphs Scatter. Pastaj zgjedhet Simple Define. Në pjesën e boshtit Y

201
vendoset ndryshorja e varur, në boshtin X kondryshorja, në pjesën Set markers by
ndryshorja e pavarur dhe shtypet butoni OK.)
Fuqia dhe drejtimi i lidhjes ndërmjet kondryshores dhe ndryshores së varur duhet të jetë e
ngjashme në çdo grup. Kjo situatë njihet si “homogjeniteti i regresionit të grupeve”. Me
fjalë të tjera, nuk duhet të kete ndikim të ndryshores së pavarur mbi lidhjen ndërmjet
kondryshores dhe ndryshores së varur. Pra, kondryshorja duhet të ketë të njëjtin ndikim mbi
ndryshoren e varur të grupeve. Në figurën 1, është paraqitur regresioni në rastet e kur është
homogjen dhe në rastin e kundërt, kur nuk është.
Figura 1: Homogjeniteti i Regresionit
4. Shembull Aplikimi
4.1. Hyrja e të Dhënave dhe Testimi i Supozimeve
Në lidhje me lëndën e matematikës, ekzistojnë 3 metoda të ndryshme të shpjegimit,
kërkohet të testohet a ekziston ndonjë dallim ndërmjet këtyre metodave për nga aspekti i suksesit
të studentëve. Për këtë qëllim, me ndihmën e 9 studentëve janë formuar 3 grupe dhe janë
aplikuar metoda të ndryshme në secilin grup. Mirëpo, zgjuarsia (shkathtësitë) e studentëve në
matematikë ndikon në suksesin e mësimit. Prandaj, parimisht për të matur intelegjencën
matematikore të studentëve përpara se të fillohet me analizën, është aplikuar një test i
intelegjencës. Ndryshoret e modelit janë në këtë mënyrë:
Ndryshorja e varur: Notat e realizuara të studentëve nga provimi i matematikës
Ndryshorja e pavarur: Grupet
Kondryshorja: Shkalla e intelegjencës së studentëve (Rezultatet e testit të aplikuar të
intelegjencës).

202
Hapi 1: Hyrja e të Dhënave në SPSS
Pasi të futen të dhënat në SPSS, përpara se të bëhet analiza e kovariancës duhet të
testohet siguria e supozimeve të nevojshme në mënyrë që analiza e kovariancës të jetë e
vlefshme. Këto supozime janë supozimet e homogjenitetit të regresionit dhe homogjenitetit të
variancave. Për t’a bërë këtë, realizohen këto funksione me radhë:
Analyze General Linear Model Univariate.
Hapi 2: Menyja Filluese e Analizës së Kovariancës
Në dritaren e hapur duhet të bëhet njohja e ndryshoreve. Këtu; në pjesën Dependent
Variable bartet ndryshorja e varur (nota_provimit), në pjesën Fixed Factor(s) baret
ndryshorja e pavarur (grupi) dhe në pjesën Covariate(s) bartet kondryshorja (aftësia).

203
Hapi 3: Dritarja e Analizës së Kovariancës
Më vonë në këtë dritare klikohet në butonin “Model”. Në dritaren e hapur të Modelit në
fillim, nga pjesa Specify Model përzgjedhet Custom. Pastaj, nga ndryshoret në anën e majtë
zgjedhet grupi dhe në pjesën Build Terms klikohet shenja ok, më vonë, duke përzgjedhur aftësia
përsëritet funksioni dhe në fund përzgjedhen së bashku grupi dhe aftësia dhe duke klikuar në
butonin Continue mbyllet dritarja.

204
Hapi 4: Dritarja e Modelit
Më vonë duke klikuar në butonin “Options” hapet Dritarja e Përzgjedhjeve. Në këtë sektor,
nën pjesën Factor(s) and Factor Interactions e cila gjendet nën Estimates Marginal Means,
duke përzgjedhur ndryshoren e pavarur (grupi) klikohet shenja ok dhe transferohet në pjesën
Display Means for. Etiketohet përzgjedhja Compare main effects dhe nga pjesa Confidence
interval adjustment përzgjedhet Bonferroni. Së fundi, në pjesën Display bëhen etiketimet e
treguara më poshtë dhe duke klikuar me radhë Continue dhe OK bëhet realizimi i analizës.

205
Hapi 5: Dritarja e Përzgjedhjeve
Rezultatet e përfituara dhe daljet e SPSS-it pas analizës së bërë janë dhënë më poshtë.
Tabela 1: Statistikat Përshkruese
Descriptive Statistics
Dependent Variable: Nota_provimit
Grupi Mean Std. Deviation N
1.00 4.3333 1.52753 3
2.00 8.3333 1.52753 3
3.00 11.3333 1.15470 3
Total 8.0000 3.27872 9

206
Tabela 2: Testi Levene
Levene's Test of Equality of Error Variancesa
Dependent Variable: Nota_provimit
F df1 df2 Sig.
1.330 2 6 .333
Tests the null hypothesis that the error variance of
the dependent variable is equal across groups.
a. Design: Intercept + Grupi + Aftësia + Grupi *
Aftësia
Tabela 3: Testi i Bashkëveprimit Ndërmjet Subjekteve
Tests of Between-Subjects Effects
Dependent Variable: Nota_provimit
Source
Type III Sum of
Squares df Mean Square F Sig.
Corrected Model 84.905a 5 16.981 46.513 .005
Intercept 1.629 1 1.629 4.461 .125
Grupi 1.415 2 .708 1.938 .288
Aftësia 10.343 1 10.343 28.332 .013
Grupi * Aftësia .129 2 .065 .177 .846
Error 1.095 3 .365
Total 662.000 9
Corrected Total 86.000 8
a. R Squared = .987 (Adjusted R Squared = .966)
Në tabelën e statistikave përshkruese (Descriptive Statistics) janë dhënë mesataret dhe
devijimet standarte të grupeve. Sipas kësaj, devijimet standarte janë të përafërta me njëra-tjetrën,
kurse ekzistojnë dallime të mëdha ndërmjet mesatareve të grupeve.
Përpara se të bëhet analiza e kovariancës, me ndihmën e rezultateve të përfituara, duhet të
testohen supozimet, homogjeniteti i variancave dhe nëse pjerrësia e kondryshores është e njëjtë
në mënyrë të arsyeshme me ndryshoren e varur. Nga këto supozime, për testimin e supozimit
“homogjeniteti i variancave” siç mund të përdoren grafiqet “varianca vs. mesatarja” apo
“devijimi standart vs. mesatarja”, po ashtu mund të përdoren edhe testet e hipotezave. Këtu është
përdorur testi Levene. Sipas rezultatit të Levene’s Test, vlera Sig. është 0,333 dhe për shkak që
kjo vlerë është më e madhe se 0,05, mund të thuhet se është siguruar supozimi i homogjenitetit të
variancave.

207
Sipas supozimit të dytë, duhet të përcaktohet nëse ndryshorja e varur (nota_provimit) është
e njëjtë në mënyrë të arsyeshme me pjerrësinë e kondryshores (aftësia). Për këtë, duhet të
shikojmë rreshtin Grupi*Aftësia në tabelën Test of Between-Subjects Effects. Në qoftë se ky
bashkëveprim është i rëndësishëm statistikisht, hipoteza “pjerrësia është e njëjtë për të dy grupet”
refuzohet. Sipas rezultateve në tabelë, vlera e përfituar Sig. është 0,846 dhe kjo vlerë ngaqë është
më e madhe se vlera 0,05 nuk është e rëndësishme statistikisht dhe pranohet hipoteza “pjerrësia
është e njëjtë për të dy grupet”. Me fjalë të tjera, pjerrësitë e regresionit janë të barabarta.
Për shpërndarjet tjera normale dhe supozimin e linearitetit, shikonin pjesën e supozimeve të
teknikave statistikore shumë ndryshoresh.
Në fund të analizës, pasi të kuptohet që supozimet janë të vlefshme, mund të kalohet në
analizën e kovariancës.
4.2. Aplikimi i Analizës së Kovariancës Për realizimin e analizës së kovariancës, ndiqen me radhë këta hapa:
Analyze General Linear Model Univariate.
Hapi 1: Menyja Filluese e Analizës së Kovariancës
Në dritaren e hapur duhet të bëhet njohja e ndryshoreve. Këtu; në pjesën Dependent
Variable baret ndryshorja e varur (nota_provimit), në pjesën Fixed Factor(s) baret
ndryshorja e pavarur (grupi) dhe në pjesën Covariate(s) bartet kondryshorja (aftësia).

208
Hapi 2: Dritarja e Analizës së Kovariancës
Më vonë në këtë dritare klikohet në butonin “Model”. Në dritaren e hapur të Modelit, nga
pjesa Specify Model përzgjedhet Full Factorial dhe shtypet butoni Continue.

209
Hapi 3: Dritarja e Modelit
Më vonë duke klikuar në butonin “Options” hapet Dritarja e Përzgjedhjeve. Në këtë sektor,
nën pjesën Factor(s) and Factor Interacions e cila gjendet nën Estimates Marginal Means,
duke përzgjedhur ndryshoren e pavarur (grupi) klikohet shenja ok dhe transferohet në pjesën
Display Means for. Etiketohet përzgjedhja Compare main effects dhe nga pjesa Confidence
interval adjustment përzgjedhet Bonferroni. Së fundi, në pjesën Display bëhen etiketimet e
treguara më poshtë dhe duke klikuar me radhë Continue dhe OK bëhet realizimi i analizës.

210
Hapi 4: Dritarja e Përzgjedhjeve
Rezultatet e përfituara dhe daljet e SPSS-it pas analizës së bërë janë dhënë më poshtë.
Tabela 4: Statistikat Përshkruese
Descriptive Statistics
Dependent Variable: Nota_provimit
Grupi Mean Std. Deviation N
1.00 4.3333 1.52753 3
2.00 8.3333 1.52753 3
3.00 11.3333 1.15470 3
Total 8.0000 3.27872 9

211
Tabela 5: Testi i Bashkëveprimit Ndërmjet Subjekteve
Tests of Between-Subjects Effects
Dependent Variable: Nota_provimit
Source
Type III Sum of
Squares df Mean Square F Sig.
Partial Eta
Squared
Corrected Model 84.776a 3 28.259 115.401 .000 .986
Intercept 1.891 1 1.891 7.723 .039 .607
Aftësia 10.776 1 10.776 44.005 .001 .898
Grupi 26.587 2 13.294 54.288 .000 .956
Error 1.224 5 .245
Total 662.000 9
Corrected Total 86.000 8
a. R Squared = .986 (Adjusted R Squared = .977)
Tabela 7: Vlerësimet e Parametrave
Parameter Estimates
Dependent Variable: Nota_provimit
Parameter B
Std.
Error t Sig.
95% Confidence Interval Partial Eta
Squared Lower Bound Upper Bound
Intercept 4.500 1.069 4.210 .008 1.752 7.248 .780
Aftësia .788 .119 6.634 .001 .483 1.094 .898
[Grupi=1.00] -4.897 .514 -9.537 .000 -6.217 -3.577 .948
[Grupi=2.00] -1.423 .469 -3.036 .029 -2.628 -.218 .648
[Grupi=3.00] 0a . . . . . .
a. This parameter is set to zero because it is redundant.
Tabela 7: Mesataret e Vlerësuara Margjinale
Estimates
Dependent Variable: Nota_provimit
Grupi Mean Std. Error
95% Confidence Interval
Lower Bound Upper Bound
1.00 5.209a .315 4.400 6.018
2.00 8.684a .291 7.937 9.431
3.00 10.107a .340 9.232 10.982

212
a. Covariates appearing in the model are evaluated at the following
values: Aftësia = 7.1111.
Në tabelën 5, sipas nivelit të aftësisë së studentëve në matematikë, ekziston një dallim i
rëndësishëm ndërmjet mesatareve të notave të marra në provimin e korrigjuar të matematikës.
(Sepse vlerat Sig. të grupit dhe aftësisë janë 0,001 dhe 0,000) Me fjalë të tjera, ekziston një
marrëdhënie ndërmjet notave të marra në matematikë dhe aftësisë së studentëve në mësim.
Duke përdorur tabelën 4 dhe tabelën 7, në tabelën e re të përfituar (tabela 8) mesatarja e
notave të grupit të tretë duket e lartë, por kur niveli i aftësisë së grupeve në matematikë merret
nën kontroll, vërehet se ndodhin ndryshim në mesataret e grupeve. Kështuqë, mesatarja e notave
e korrigjuar e grupit të tretë lëviz në 10,1. Përkundër kësaj, mesataret e korrigjuara të grupit të
parë dhe të dytë rriten për 5,2 dhe 8,6 dhe si përfundim dallimet ndërmjet grupeve janë
zvogëluar.
Tabela 8: Mesataret e Grupeve dhe Mesataret e Korrigjuara
GRUPI N MESATARJA MESATARJA E KORRIGJUAR
1 3 4,3 5,2
2 3 8,3 8,6
3 3 11,3 10,1
A thua, dallimet ndërmjet mesatareve të korrigjuara ndërmjet grupeve a janë të
rëndësishme? Për këtë, kur shikojmë tabelën 9 (tabela e krijuar duke përdorur tabelat e
mësipërme), kuptohet se dallimi ndërmjet grupeve është i rëndësishëm. (Sepse vlera F është
kuptimplotë).
Tabela 9: Rëndësia e Dallimeve të Grupeve
BURIMI I
VARIANCËS
TOTALI I
KATRORËVE
MESATARJA E
KATRORËVE
F NIVELI I
RËNDËSISË
Aftësia 10,776 10,776 44,005 0,001
Grupi 26,587 13,294 54,288 0,000

213
9. REGRESIONI I THJESHTË LINEAR

214
REGRESIONI I THJESHTË LINEAR
Analiza e regresionit paraqet procesin e spjegimit të lidhjes ndërmjet një ndryshoreje të
varur dhe një të pavarur (regresioni i thjeshtë) apo lidhjen ndërmjet një ndryshoreje të varur dhe
më shumë se një ndryshoreje të pavarur (regresioni i ponderuar) me një barazim matematikor.
Në analizën e regresionit, në qoftë se lidhja ndërmjet ndryshoreve është lineare quhet
regresion linear dhe e kundërta quhet regresion jo linear. Në këtë libër, do të spjegohet vetëm
regresioni linear.
1. MODELI I REGRESIONIT TË THJESHTË LINEAR
y = β0 + β1x + ε
β0: ndërprerja në boshtin y në popullsi
β1: pjerrësia e popullsisë
ε: gabimi i rastësishëm
Këtu β0 dhe β1 janë parametrat e llogaritur të popullsisë. Mirëpo, për arsye se mund që të
mos merren në konsideratë ndryshoret e pavarura, është shtuar në model termi i gabimit ε që
tregon ndryshimin e rastësishëm të të dhënave.
Në qoftë se nuk dihet vlerat e β0 dhe β1 në praktikë, duke marrë një mostër nga popullsia
mund të prodhohen informatat e dëshiruara rreth parametrave të popullsisë. Në këtë rast
përdoren vijat e parashikuara b0 dhe b1.
ŷ = b0 + b1x
ŷ: vlera e parashikuar (vlerësuar)
2. PARAMETRAT E PARASHIKUARA (VLERËSUARA)
Në analizën e regresionit për gjetjen e parametrave përdoret teknika e katrorëve më të vegjël
(Least Squares Method). Qëllimi i kësaj është që të gjendet distanca e pikave të paraqitura në
diagramin e shpërndarjes (scatter diagram) dhe minimizimi total i tyre. Mirëpo, në analizën e
regresionit ngaqë ky funksion do të jetë gjithmonë zero, nuk përdoret për të gjetur vlerat e b0 dhe
b1.
∑(yi – ŷi) = 0
Në këtë rast, duke gjetur totalin e katrorit të gabimit (devijimi nga ekuacioni i regresionit),
krijojmë një funksion të ri.

215
min∑(yi – ŷi)2 = min∑(yi – b0 – b1xi)
2
Vlerat optimale b0 dhe b1 të cilat minimizojnë këtë funksion, do të jenë vlerat e parashikuara
të β0 dhe β1. Për të gjetur vlerat optimale të cilat e minimizojnë funksionin, sipas funksionit b0
dhe b1 është e mjaftueshme që të merren vlerat të cilat e bëjnë zero derivatin parcial.
⇒
(1)
⇒ (2)
xi: vlera e vrojtuar e ndryshores së pavarur, i = 1,2,...,n.
yi: vlera e vrojtuar e ndryshores së varur, i = 1,2,...,n.
x : mesatarja e ndryshores së pavarur
y : mesatarja e ndryshores së varur
n: numri total i vrojtimeve
3. Shembull Aplikimi Për të gjetur lidhjen ndërmjet shpenzimeve mujore të ushqimit dhe të ardhurave mujore për
person, janë pyetur 30 vetë në lidhje me të ardhurat e tyre mujore dhe shpenzimet që bëjnë për
ushqim dhe janë realizuar të dhënat e mëposhtme.
Tabela 1: Të Dhënat Përkatëse Për Shembullin
Nr. Shpenzimet për
ushqim (100 €)
Të ardhurat
(100 €)
Nr. Shpenzimet për
ushqim (100 €)
Të ardhurat
(100 €)
1 9 35 16 16 50
2 15 49 17 13 45
3 7 21 18 13 46
4 11 39 19 10 37
5 5 15 20 10 38
6 8 28 21 7 20
7 9 25 22 7 23
8 7 24 23 9 32
9 8 29 24 8 31
10 9 34 25 8 30
11 12 40 26 7 26
12 3 10 27 14 47
13 5 14 28 12 41
14 4 13 29 4 14
15 8 27 30 13 42

216
3.1. Formimi i Modelit dhe Parashikimi i Parametrave Modeli: y = β0 + β1x + ε
Barazimi i regresionit do të jetë kështu.
y = b0 + b1x
y = shpenzimet për ushqim
x = të ardhurat.
Duke përdorur formulat (1) dhe (2) b0 = 0,314 dhe b1 = 0,283 dhe modeli i regresionit linear
gjendet në këtë mënyrë ŷ = 0,314 + 0,283x.
3.2. Interpretimi i Parametrave Parametrat e regresionit b0 dhe b1 mund të komentohen në këtë mënyrë:
b0, është vlera mesatare e vlerësuar e ndryshores së varur kur x = 0. Në shembullin e më
lartë, kur b0 = 0,314 ka këtë kuptim: Shpenzimet e ushqimit të një personi do të jenë 31,4 € edhe
në qoftë se nuk realizon aspak të ardhura. (Notë: vlera b0 jo mund të shpreh një kuptim).
b1, është koeficienti i regresionit dhe paraqet ndryshimin e vlerësuar të vlerës y si rezultat i
ndryshimit të një njësie të x. Kur b1 është pozitive nënkupton që me rastin e rritjes së ndryshores
së pavarur x do të rrite edhe y (lidhje pozitive lineare). Në të njëjtën mënyrë në kur b1 është
negative, me rastin e rritjes së ndryshores së pavarur x, do të zvogëlohet y (lidhje negative
lineare). Sipas kësaj, në shembullin tonë, kur të ardhurat do të rriten për 1 €, shpenzimet e
ushqimit do të rriten për 28,3 cent.
4. PARASHIKIMI ME MODELIN E REGRESIONIT Duke përdorur ekuacionin e regresionit, për një vlerë të dhënë të x mund të gjendet vlera e
parashikuar e y, mirëpo madhësia e x mund të bëjë vlerësime më të mira ndërmjet vlerave
minimale dhe maksimale në setin e të dhënave. Në fakt, për gjetur vlerësime më të sakta duhet
që të krijohet modeli i regresionit (b1, b0) sa herë që të gjendet një e dhënë e re.
PYETJE: Në lidhje me shembullin e më lartë, sa do të jenë shpenzimet e parashikuara të
ushqimit të një personi i cili ka të ardhura prej 3500 €?
ŷ = 0,314 + 0,283x. = 0,314 + 0,283 (3500) => shpenzimet e parashikuara mujore të
ushqimit do të jenë = 990,814 €.

217
4.1. Shembull Aplikimi Përpara se të kalohet në analizën e regresionit të thjeshtë linear duhet të testohen supozimet
e shpërndarjes normale dhe lidhjes lineare (në analizën e regresionit të shumëfishtë shpërndarja
normale e shumë ndryshoreve). Ekzistimi i lidhjes lineare ndërmjet ndryshoreve mund të
shqyrohet përmes diagramit të shpërndarjes. (Për t’a bërë diagramin e shpërndarjes në SPSS
shkohet te menyja Graphs, Scatter. Më vonë zgjedhet Simpe, Define. Në boshtin y vendoset
ndryshorja e varur, në boshtin x vendoset ndryshorja e pavarur dhe klikohet OK. Pastaj mund të
vrojtohet se a ekziston lidhje lineare).
Rreth shpërndarjes normale shikoni kapitullin përkatës në libër.
Për t’a bërë analizën e regresioni të thjeshtë linear përzgjedhen me radhë Analyze,
Regression, Linear. Pasi të vendosen ndryshorja e varur dhe e pavarur dhe të jetë zgjedhur
metoda e dëshiruar klikohet OK dhe do të përfitohen rezultatet e mëposhtme.
Hapi 1: Menyja e Regresionit të Thjeshtë Linear

218
Hapi 2: Dritarja e Regresionit të Thjeshtë Linear
Hapi 3: Dritarja e Statistikave

219
4.2. Të Dalurat nga SPSS dhe Interpretimi
Tabela 2: Përmbledhje e Modelit
Model Summaryb
Model R R Square
Adjusted R
Square
Std. Error of the
Estimate Durbin-Watson
1 .975a .950 .949 .75869 1.863
a. Predictors: (Constant), të_ardhurat
b. Dependent Variable: ushqimet
Në tabelë është dhënë vlera e R2. Vlera e gjetur këtu është 0,950. Sipas këtij rezultati, 95% e
ndryshimit në ndryshoren e varur shpjegohet nga ndryshorja e pavarur e përfshirë në model. Me
fjalë të tjera, pjesa e ndryshimit prej 95% në shpenzime shpjegohet nga ndryshimi në të ardhura.
Në tabelën 3, vlerë me rëndësi e cila duhet të interpretohet është vlera F e cila tregon
rëndësinë e modelit dhe vlera Sig. e cila tregon nivelin e rëndësisë. Në qoftë se vlera e F-së është
e rëndësishme, mund të vijmë në përfundim se modeli statistikisht është plotësisht i rëndësishëm.
Modeli jonë i cili shpejgon shpenzimet me të ardhurat është një model i rëndësishëm.
Tabela 3: Tabela e Analizës së Variancës
ANOVAa
Model Sum of Squares df Mean Square F Sig.
1 Regression 308.849 1 308.849 536.555 .000b
Residual 16.117 28 .576
Total 324.967 29
a. Dependent Variable: ushqimet
b. Predictors: (Constant), të_ardhurat
Dhe në tabela e fundit të cilën do t’a interpretojmë janë vlerat e parashikuara të
koeficientëve të modelit dhe vlerat e t-së në lidhje me këto. Sipas tabelës 4, një rritje e 1 njësie
në të ardhura, do të rrit shpenzimet totale të konsumit për 0,283 njësi. Vlerat e t-së në lidhje me
këtë koeficient janë të rëndësishme në çdo nivel (Sig. = 0,000) dhe prandaj koeficienti i
ndryshores së të ardhurave është i rëndësishëm statistikisht.

220
Tabela 4: Parashikimet e Parametrave
Coefficientsa
Model
Unstandardized Coefficients
Standardized
Coefficients
t Sig. B Std. Error Beta
1 (Constant) .314 .401 .783 .440
të_ardhurat .283 .012 .975 23.164 .000
a. Dependent Variable: ushqimet
Për t’a përmbledhur, rezultati i parashikimit të modelit është si më poshtë:
ŷ = 0,314 + 0,283x
Këtu y paraqet shpenzimet e konsumimit dhe x të ardhurat.

221
10.MODELI I REGRESIONIT TË
SHUMËFISHTË LINEAR

222
MODELI I REGRESIONIT TË SHUMËFISHTË LINEAR
Modeli i regresionit të thjeshtë linear mund të jetë i përshtatshëm për shumë situata, por në
jetën reale për të spjeguar shumë modele mund të ketë nevojë për dy apo më shumë ndryshore
shpjeguese. Modelet me më shumë se një ndryshore shpjeguese quhen modeli i regresionit të
shumëfishtë linear.
1. MODELI
ε shpreh se modeli është stokastik dhe përfshin vlerat të cilat nuk janë të përfshira në model.
Në të njëjtë kohë, pasqyron gabimin e rastësishëm gjatë spercifikimit të ndikimit në model.
Supozimet e modelit të regresionit të shumëfishtë linear janë si më poshtë:
1. Shpërndarja normale.
2. Lineariteti.
3. Mesatarja e gabimit të rastësishëm ëshët zero.
4. Variancë konstante.
5. Jo autokorrelacion.
6. Mos ekzistimi i lidhjeve të shumta ndërmjet ndryshoreve të pavarura.
2. TESTIMI I HIPOTEZAVE NË MODELIN E REGRESIONIT TË SHUMËFISHTË
LINEAR Teksa hipoteza H0 në modelin e regresionit të shumëfishtë linear krijohet në formën se të
gjithë koeficientët e regresionit janë të barabartë me zero (H0: β1 = β2 = ... = βp = 0), hipoteza HA
krijohet në formën se së paku një βi është e ndryshme nga zero. Për të testuar statistikisht
rëndësinë e parametrave veç e veç përdoret testi t dhe për të testuar modelin se a është i
rëndësishëm si i tërë përdoret testi F.
Modeli i Regresionit të Thjeshtë Linear: y = β0 + β1x + ε,
Modeli i Regresionit të Shumëfishtë Linear: y = β0 + β1x1 + ... + β1x1 + ε
Y ndryshorja e varur
Xi ndryshorja e pavarur
βi parametra e vlerësuar
ε gabimi i rastësishëm

223
3. KOEFICIENTI I PËRCAKTIMIT
Koeficienti i determinimit (R2) tregon se sa përqind e ndryshores së varur shpjegohet nga
ndryshorja e pavarur e përfshirë në model. Vetëm se ajo çfarë duhet të kihet kujdes në modelin e
regresionit të shumëfishtë është se koeficienti i përcaktimit rritet me rritjen e numrit të
ndryshoreve të përfshira në model. Në raste të këtilla, duhet të kontrollohet koeficienti i
rregulluar i përcaktimit (Adjusted R2).
4. ZGJEDHJA E NDRYSHOREVE TË MODELIT Lidhja ndërmjet ndryshores së pavarur dhe ndryshores së varur mund të shpjegohet më mirë
me rritjen e numrit të ndryshoreve. Mirëpo, për arsye se rritja e numrit të ndryshoreve kërkon
matje shtesë, është një punë e vështirë dhe e kushtueshme. Prandaj, qëllimi duhet të jetë që me sa
më pak ndryshore të shpjegohet varianca totale.
Me rastin e shtimit në model, ekzistojnë rrugë të ndryshme për të përcaktuar apo zgjedhur
ndryshoret të cilat sigurojnë rritje të rëndësishme në shpjegimin e variancës të ndryshores së
varur. Rëndësia e zgjedhjes së ndryshoreve rritet në rastet kur ekzistojnë dy apo më shumë
ndryshore të pavarura. Metodat të cilat përdoren më së shpeshti në zgjedhjen e ndryshoreve janë:
1. Metoda Enter
2. Funksioni i Shtimit të Ndryshoreve (Forward Selection)
3. Funksioni i Eliminimit të Ndryshoreve (Backward Selection)
4. Funksioni i Shtimit dhe Eleminimit të Ndryshoreve (Stepwise Selection)
4.1. Metoda Enter Në metodën Enter, hulumtuesi i përcakton ndryshoret e pavarura të cilat e përbëjnë
modelin. Pas kësaj, vlerësohet suksesi i parashikimit të ndryshoreve të varura të modelit. Në
qoftë se një ndryshore e pavarur nuk mendohet të jetë më e rëndësishme se një tjetër, atëherë
përdoret ky model. Ashtu siç shtohet çdo ndryshore në model ashtu vlerësohet edhe kontributi i
secilës ndryshore. Në qoftë se ndryshorja e shtuar nuk e rrit fuqinë e parashikimit të modelit,
atëherë nuk ka problem në qoftë se nxirret nga modeli.
4.2. Metoda e Shtimit të Ndryshoreve (Forward Selection) SPSS në metodën e përzgjedhjes Forward, i vendos me radh ndryshoret sipas fuqisë së
korrelacionit me ndryshoren e varur. Matet ndikimi i secilës ndryshore të futur në model dhe
ndryshoret të cilat nuk ndikojnë në mënyrë të konsiderueshme nxirren nga modeli.

224
4.3. Funksioni i Elemnimit të Ndryshoreve (Backward Selection) Me metodën Backward Selection, SPSS i përfshin të gjitha ndryshoret në model.
Ndryshorja e pavarur më e dobëta nxirret nga modeli dhe llogaritet përsëri regresioni. Në qoftë
se në kërë rast modeli dobësohet në mënyrë të konsiderueshme, ndryshorja e pavarur shtohet
prap në model, në qoftë se dobësia nuk është në masë të konsiduerueshme, ndryshorja e varur
largohet nga modeli. Ky proces përsëritet deri sa në model të mbesin vetëm ndryshoret e
dobishme të pavarura.
4.4. Metoda e Shtimit dhe Largimit të Ndryshoreve (Stepwise
Selection) Me metodën Stepwise, çdo ndryshore futet me radhë në model dhe pastaj modeli vlerësohet.
Në qoftë se ndryshorja e shtuar ofron kontribut, kjo ndryshore qëndron në model. Mirëpo, për të
vlerësuar se të gjitha ndryshoret e tjera a japin kontribut në model, bëhet testimi përsëri. Në qoftë
se nuk japin kontribut në masë të konsiderueshme, nxirren nga modeli. Në këtë mënyrë, me
ndihmën e sa më pak ndryshoreve bëhet shpjegimi i modelit.
5. Shembull Aplikimi Të supozojmë se një firmë dëshiron të zbulojë se çfarë ndikimi kanë shpenzimet e reklamës
dhe ndryshimi i çmimit të produktit në të ardhurat totale. Për këtë qëllim, më poshtë në tabelën 1
është dhënë seti i të dhënave në lidhje me të dhënat totale javore, shpenzimet e reklamës dhe
çmimet e produktit. Me rritjen e shpenzimeve të reklamës në çfarë masen rriten të ardhurat totale
apo të ardhurat totale në çfarë niveli janë të ndjeshme ndaj ndryshimit të çmimeve.
Në këtë situatë, modeli mund të shprehet si më poshtë.
Të ardhurat = α0 + β1 (reklama) + β2 (çmimi) + e
Tabela 1: Të Dhënat e Shembullit
NO TË ARDHURAT ÇMIMI REKLAMA
1 123,10 1,92 12,40
2 124,30 2,15 9,90
3 89,30 1,67 2,40
4 141,30 1,68 13,80
5 112,80 1,75 3,50
6 108,10 1,55 1,80
7 143,90 1,54 17,80
8 124,20 2,10 9,80
9 110,10 2,44 8,30

225
10 111,70 2,47 9,80
11 123,80 1,86 12,60
12 123,50 1,93 11,50
13 110,20 2,47 7,40
14 100,90 2,11 6,10
15 123,30 2,10 9,50
16 115,70 1,73 8,80
17 116,60 1,86 4,90
18 153,50 2,19 18,80
19 149,20 1,90 18,90
20 89,00 1,67 2,30
21 132,60 2,43 14,10
22 97,50 2,13 2,90
23 106,10 2,33 5,90
24 115,30 1,75 7,60
25 98,50 2,05 5,30
26 135,10 2,35 16,8
27 124,20 2,12 8,80
28 98,40 2,13 3,20
29 114,80 1,89 5,40
30 142,50 1,50 17,30
31 122,60 1,93 11,20
32 127,70 2,27 11,20
33 113,00 1,66 7,90
34 144,20 1,73 17,00
35 109,20 1,59 3,30
36 106,80 2,29 7,10
37 145,00 1,86 15,30
38 124,00 1,91 12,70
39 106,70 2,34 6,10
40 153,20 2,13 19,60
41 120,10 2,05 6,30
42 119,30 1,89 9,00
43 150,60 2,12 18,70
44 92,20 1,87 2,20
45 130,50 2,09 16,00
46 112,50 1,76 4,50
47 111,80 1,77 4,30
48 120,10 1,94 9,30
49 107,40 2,37 8,30
50 128,60 2,10 15,40
51 124,60 2,29 9,20
52 127,20 2,36 10,20

226
NOTË: Të dhënat janë marrë nga Griffiths dhe Judge “Undergraduate Econometrics”, John
Wiley & Sons Inc., 1997.
Pasi të futen të dhënat në SPSS, ndiqen këto faza: Analyze, Regression, Linear.
Hapi 1: Menyja e Regresionit të Shumëfishtë Linear

227
Hapi 2: Dritarja e Regresionit Linear
Për arsye se ndryshoret tona janë në numër të vogël, zgjedhja e metodës “Enter” do të jetë e
saktë.
Hapi 3: Pas kësaj klikohet në butonin Statistics dhe në vazhdim do të ndeshemi me ekranin
e mëposhtëm. Në këtë ekran përzgjedhen të dhënat që dëshirohet të sigurohen duke klikuar pranë
kutizave dhe pastaj klikohet butoni Continue. Për shembull, Estimates, tregon parametrat e
modelit, gabimin standart në lidhje me parametrat, vlerën e standardizuar të parametrave, vlerat e
t-së dhe nivelin e rëndësisë së t-së.
Collinearity diagnostics supozon se nuk ekziston lidhje lineare ndërmjet ndryshoreve të
pavarura të modelit të regresionit të shumëfishtë. Në situatat kur ekziston një lidhje e plotë
lineare është e pamundur që të parashikohen parametrat e modelit. Në lidhjet lineare afër të
plotës, parametrat teknikisht mund të parashikohen, por rezultatet nuk janë te besueshme. Për të
hulumtuar se a ekziston një problem i këtillë, përzgjedhjet kjo kutizë.
Confidence intervals paraqet intervalin e besueshmërisë 95% për çdo koeficient të
regresionit apo matricë të kovariancës.

228
Hapi 3: Dritarja e Statistikave
Me ndihmën e Model fit listohen ndryshoret e shtuara dhe të nxjerra nga modeli dhe
analizohen R e shumëfishtë, R square, adjusted R square, devijimi i parashikuar standart dhe
tabela e variancës.
Përzgjedhja e R squared change njëjtë si përzgjedhja stepwise, është e dobishme atëherë
kur të zgjedhet ndonjë metodë statistikore. Tregon se si ndryshon fuqia e modelit kur një
ndryshore e pavarur të shtohet apo të largohet nga modeli.
Descriptives jep mesataren, devijimin standart dhe numri e vlefshëm të rasteve në analizë.
Part and partial correlations jep korrelacionet.
Koeficienti i Durbin Watson përdoret për të testuar autokorrelacionin. Vlerat ndryshojnë
prej 0 deri në 4. Vlera afër 0, tregojnë një korrelacion ekstrem pozitiv, vlerat afër 4 tregojnë një
korrelacion ekstrem negativ, vlerat afër dy-shit tregojnë se nuk ka autokorrelacion. Vlerat e
Durbin Watsonit preferohet të jenë prej 1,5 deri në 2,5. Autokorrelacioni pozitiv nënkupton se
gabimi standart i koeficientit b është shumë i vogël, kurse autokorrelacioni negativ nënkupton se
gabimi standart është shumë i madh.
Pasi të klikojmë në butonin Continue do të kthehemi te dritarja e Linear Regression. Duke
klikuar në butonin Plots, etiketohen grafiqet e dëshiruara. Përsëri në fund klikohet Continue.

229
Hapi 4: Dritarja e Grafiqeve
Në dritaren Plots kuptimi i vlerave të cilat mund të vendosen në boshtet x dhe y është si më
poshtë:
ZPRED: Vlerat e parashikuara të standardizuara
ZRESID: Mbetjet e standardizuara (residual)
DRESID: Vlerat e fshira (residual)
ADJPRED: Vlerat e parashikuara të rregulluara
STRESID: Vlerat Studentized
SDRESID: Vlerat e fshira Studentized
Duke etiketuar pjesën e Histogram dhe Normal probability plot, mund të testojmë dy
supozimet e modelit të regresionit të shumëfishtë linear (supozimet e shpërndarjes së shumtë
normale dhe linearitetit).
Në dritaren e Linear Regression klikojmë në kutinë SAVE dhe do të hapet dritarja e
mëposhtme.

230
Hapi 5: Dritarja e Ruajtjes
Në pjesën Predicted Values mund të etiketohet një nga cilado zgjedhjet apo mund të
etiketohet zgjedhja e dëshiruar.
Unstandardized paraqet vlerën e parashikuar të modelit për ndryshoren e varur.
Standardized paraqet ndryshimin e vlerës së parashikuar nga vlera e mesatares.
Adjusted paraqet vlerën e parashikuar të rregulluar
S.E of mean predicitions paraqet gabimin standart të vlerës së parashikuar.

231
Distances
Përdoret për tri pika të analizave.
Mahalanobis paraqet distancën e Mahalanobisit. Vlerat e larta të kësaj distance tregojnë se
ndryshoret e pavarura kanë një apo më shumë vlera të veçanta (outliers).
Cook’s paraqet distancën e Cookit. Tregon se vlerat e koeficientëve do të ndryshojnë në
masë të konsiderueshme në fund të rezultateve të regresionit.
Leverage Values paraqet vlerat e qendrës leverage. Mat ndikimin e përshtatshmërisë së
regresionit mbi një pikë.
Prediction Intervals
Mean llogarit kufinjtë më të ulët dhe më të lartë të mesatares së parashikuar për intervalin e
parashikuar.
Individual paraqet kufinjtë më të ulët dhe më të lartë të intervalit të parashikuar të një
vrojtimit të vetëm.
Confidence Interval (Intervali i Besueshmërisë). Vlera e vlefshme për intervalin e
mesatares dhe individual është 95%. Për t’a bërë të pa vlefshme këtë vlerë, jepet një vlerë më e
madhe se 0 dhe më e vogël se 100. Për shembull, 99%.
Residual (Vlerat e mbetura)
Unstandardized paraqet dallimin ndërmjet vlerës së vrojtuar dhe asaj të parashikuar.
Standardized paraqet hersin e vlerës së parashikuar me devijimin standart. Këto vlera
njihen si Pearson residuals, mesatarja e tyre është 0 dhe devijimi standart është 1.
Studentized mbetjet studentized
Deleted paraqet dallimin ndërmjet vlerës së ndryshores së varur dhe vlerës së parashikuar
të rregulluar.
Studentized Deleted paraqet hersin ndërmjet mbetjes së fshirë dhe devijimit standart.
Influece Statistics (Statistikat e Ndikuara)
DfBeta (s) paraqet ndryshimin e krijuar në koeficientin e regresionit si rezultat i nxjerrjes së
një ndryshoreje të caktuar.
Standardized DfBeta (s) paraqet ndryshimin në vlerën e Betas, pra ndryshimin në
koeficientin e regresionit si rezultat i nxjerrjes së çfarëdo ndryshoreje.

232
DfFit paraqet ndryshimin në vlerën e parashikuar si rezultat i nxjerrjes së një ndryshoreje të
caktuar.
Standardized DfFit paraqet ndryshimin e vlerës së parashikuar si rezultat i nxjerrjes së
çfarëdo ndryshoreje.
6. Daljet e SPSS-it dhe Interpretimi Tabela 2: Statistikat Përshkruese
Descriptive Statistics
Mean Std. Deviation N
të_ardhurat 120.3231 16.31873 52
çmimi 2.0017 .26771 52
reklama 9.6615 5.11764 52
Tabela e parë është tabela të cilën e kemi përzgjedhur në pjesën e statistikave descriptives.
Kjo tabelë paraqet mesataren aritmetike dhe devijimin standart të ndryshoreve që i kemi
përfshirë në model.
Kurse tabela e dytë paraqet korrelacionet ndërmjet ndryshoreve. Në këtë pikë nuk dëshirohet
që të ketë korrelacion të fortë ndërmjet ndryshoreve të pavarura sepse në këtë rast kontributet e
ndryshoreve të pavarura në model janë shumë të përafërta njëra me tjetrën dhe qenia apo
mosqenia e ndryshoreve në model nuk e ndikon fuqinë e modelit. Në qoftë se korrelacioni
ndërmjet ndryshoreve të pavarura është 0,80 apo më lartë, ky rast tregon që ekziston problemi i
lidhjeve të shumëfishta. Në këtë rast, hulumtuesi duhet që të i nxjerr nga modeli disa ndryshore.
Tabela 3: Rezultatet e Korrelacionit
Correlations
të_ardhurat çmimi reklama
Pearson Correlation të_ardhurat 1.000 -.014 .925
çmimi -.014 1.000 .101
reklama .925 .101 1.000
Sig. (1-tailed) të_ardhurat . .461 .000
çmimi .461 . .237
reklama .000 .237 .
N të_ardhurat 52 52 52
çmimi 52 52 52
reklama 52 52 52

233
Tabela 4: Përmbledhje e Modelit
Model Summaryb
Model R
R
Square
Adjusted R
Square
Std. Error of the
Estimate
Change Statistics
Durbin-
Watson
R Square
Change
F
Change df1 df2
Sig. F
Change
1 .931a .867 .862 6.06961 .867 159.828 2 49 .000 2.041
a. Predictors: (Constant), reklama, çmimi
b. Dependent Variable: të_ardhurat
Tabela e përmbledhjes së modelit (Tabela 4) është një tabelë me rëndësi. R Square na
tregon sa % e ndryshores së varur shpjegohet nga ndryshoret e pavarura. Në shembullin tonë,
86,7% e ndryshimit në ndryshoren e varur shpjegohet nga ndryshoret e çmimit dhe të
shpenzimeve të reklamës. Kurse pjesa e mbetur prej 13,3% shpjegohet nga ndryshoret të cilat
nuk janë përfshirë në model me anë të gabimit të rastësishëm. Kur të rritet numri i ndryshoreve të
pavarura në model (ndryshoret e shtuara le të jenë çfarëdo) rritet edhe R2. Për këtë arsye duhet të
shikojmë Adjusted R2 sepse Adjusted R
2 rritet vetëm nëse ndryshore janë në lidhje me modelin.
Përsëri nga tabela një test me rëndësi është testi Durbin-Ëatson i cili tregon se a ekziston
autokorrelacion në modelin tonë. Zakonisht, vlerat e testit të Durbin Ëatson rreth 1,5 – 2,5
tregojnë se nuk ekziston autokorrelacion.
Tabela 5: Tabela e Analizës së Variancës
ANOVAa
Model Sum of Squares df Mean Square F Sig.
1 Regression 11776.184 2 5888.092 159.828 .000b
Residual 1805.168 49 36.840
Total 13581.352 51
a. Dependent Variable: të_ardhurat
b. Predictors: (Constant), reklama, çmimi
Tabela e ANOVA-së është e dobishme për të testuar rëndësinë e modelit si të tërë. Vlera e
F-së në tabelë prej 159,828, tregon se modeli jonë është i rëndësishëm në çdo nivel si i tërë (Sig.
= ,000).

234
Tabela 6: Tabela e Koeficientëve
Në tabelën 6, janë të shfaqura vlerat e parametrave të rezultateve të parashikuara të modelit
dhe vlerat e t-së në lidhje me këto. Vlerat statistikore të parametrave mund të i shohim për
secilën ndryshore veç e veç se janë të rëndësishmë (në nivelin e rëndësisë 5%). Më lartë teksa
bëmë fjalë për vlerën e F-së e cila përdorej për të testuar rëndësinë e modelit si të tërë, statistika e
t-së përdoret për të testuar rëndësinë e ndryshoreve veç e veç.
Siç shihet nga tabela, vlera konstante është gjetur për 104,786. Kuptimi i kësaj është se edhe
në qoftë se shpenzimet e çmimit dhe të reklamës do të jenë zero, firma do të përfitojë një të
ardhur prej 104,79 njësish. Parametri i çmimit është -6,642. Rritja e një njësie në çmim do të
zgoëlojë të ardhurat totale për 6,642 njësi. Ndryshe nga kjo, rritja e një njësie në shpenzimet e
reklamës do të rrisë të ardhurat totale për 2,98 njësi.
Nga tabela statistika tjera me rëndësi të etiketuara nga pjesa collinearity diagnostics nga
dritarja “STATISTICS” janë vlerat e tolerancës dhe VIF-it të cilat tregojnë se a ekziston
problemi i lidhjeve të shumëfishta. Vlerat e ulëta të tolerancës dhe vlerat e larta të VIF tregojnë
se ekzistojnë lidhje të shumëfishta ndërmjet ndryshoreve të pavarura.
Nga tabela në pjesën standardized coeffiecients Beta tregon rendin e rëndësisë së
ndryshoreve të pavarura. (Mos e merrni në konsideratë shenjën e Beta-së.) Ndryshorja me vlerën
më të lartë të Beta-së është ndryshorja më e rëndësishme e pavarur.
Pasi të jenë parashikuar parametrat e modelit, vlerat e parashikuara të ndryshores së varur
dhe vlerat e gabimit të rastësishëm mund të i llogarisim edhe në SPSS. Në figurën e mëposhtme,
në fund të analizës janë shtuar vlerat e parashikuara të ndryshores së varur, vlerat e
standardizuara dhe vlerat e rregulluara në setin e të dhënave. Në këtë mënyrë ofrohet mundësia
për të i krahasuar vlerat e vrojtuara dhe vlerat e realizuara. Për shembull, teksa vlera e vrojtuar e
të ardhurave totale në javën e parë është 123,10, vlera e parashikuar e të ardhurave totale është
gjetur për 129,03. Kurse dallimin ndërmjet vlerës së vrojtuar dhe vlerës së realizuar e jep gabimi
i rastësishëm.

235
Figura 1: Vlerat e Parashikuara, Standardizuara dhe Rregulluara
Ndryshorja e varur Vlerat e parashikuara e rregulluar Vlerat e parashikuara
të standardizuara

236
11.MODELI REGRESIONIT PROBIT
(PROBIT REGRESSION MODELS)

237
MODELI I REGRESIONIT PROBIT (PROBIT REGRESSION
MODELS)
1. HYRJE Modelet kategorike të varura apo të cilat përbëhen prej përgjigjjeve si po-jo, i suksesshëm-
pasuksesshëm dhe që kodohen (dichotomous) me 0 dhe 1, quhen modele ndryshoresh të varura
bipolare. Për vlerësimin e këtyre modeleve përdoren çasje të ndryshme si Probabiliteti Linear,
Logit (logjistik) dhe Probit.
Analiza Probit është një model që përdoret si alternativë e regresionit logjistik (logistic
regression). Këto analiza janë të përngjashme me njëra-tjetrën dhe vlerësimet e probabilitetit të
secilës metodë janë të përafërta. Përderisa në analizën e regresionit logjistik përdoren log odd
(bastet), në analizën probit përdoret shpërndarja normale kumulative (cumulative normal
distribution).
Supozimi i analizës probit gjendet nga funksioni response Yi* = α + βXi + ui. Këtu, Xi ësntë
ndryshore e cila mund të vrojtohet, por Yi* ndryshore e cila nuk mund të vrojtohet. Kurse në
aplikim, vlera e vrojtuar është Yi. Në qoftë se Yi>0, Yi=1, përndryshe merr vlerën Yi=0. Këtë
mund t’a shprehim si më poshtë:
Në qoftë se Yi=1, α + βXi + ui > 0
Në qoftë se Yi=0, α + βXi + ui ≤ 0.
Në qoftë se për ndryshoren e standardizuar normale z, (z) e njohim si funksion të
shpërndarjes normale kumulative, pra, në qoftë se (z) = P(Z ≤ z), atëherë
P(Yi = 1) = P (ui > –α – βXi) = 1 - (
)
P(Yi = 0) = P (ui ≤ –α – βXi) = (
)
(Burimi: Ramanathan, Ramu, Introductory Econometrics ëith applications 4th edition)
Në rastin kur në modelin probit gjenden më shumë se një ndryshore e pavarur:
Pr (Y = 1 / X) = (Xβ).
Kjo vlerë shpreh mundësinë e ndryshores së varur (response) Y të jetë 1, kur jepet vektori i
ndryshores së pavarur X.
Këtu, është shpërndarja normale standarde e probabilitetit. Xβ quhet rezultati apo
indeksi probit dhe ndjek shpërndarjen normale. Koeficienti probit β shpreh rritjen e devijimit

238
standart β (standard deviation) të një njësie të vlerësuar në rezultatin probit (në vlerën standarte
z).
Funksioni log-mundësisë (log-likelihood) i modelit probit:
ln L = ln (xjb) + ln(1 (xjv)).
Këtu ëj është vlera vlera peshuese e cila do të largoj ndryshueshmërinë e variancës gabim në
model.
Ekzistojnë dy arsye pse modeli logjistik është më i njohur se modeli probit; interpretimi i
normave të probabilitetit (odds rations) të koeficientëve logjistik eksponencial dhe përdorimi i
regresionit logjistik më shumë si mjet diagonstik i modelit.
Analiza probit në SPSS edhe pse është rregulluar kryesisht për përgjigjjet e shumës së
dozave (dose-response) të njësive të aplikuara në eksperimentet e bëra në fushën e mjekësisë,
ajo mund të përdoret edhe për qëllime më të gjera. Analiza probit siguron mundësi për
vlerësimin e ndikimit të ndryshores së pavarur të nevojshme për të arritur në një nivel të caktuar
të ndryshores së varur (response), për shembull, mund të kërkohet vlerësimi i shumës së dozës së
ndikimit të mediave në një hulumtim. Të shqyrtojmë shembullin e mëposhtëm në lidhje me këtë.
SHEMBULL: Me analizën probit mund të hulumtohet se një helm i prodhuar për insekte sa
do të ndikojë në milingona dhe sa duhet të jetë shuma (doza) e nevojshme e ilaçit për t’u
përdorur. Për një studim të këtillë duhet të përgatitet një eksperiment. Në këtë eksperiment
krijohen grupet e mostrave (milingonat) mbi të cilat do të aplikohen doza të ndryshme të
përzierjes së ilaçit dhe pasi të jetë aplikuar doza mbi secilin grup ruhet numri i secilës milingonë
të ngordhur nga ndikimi i ilaçit. Me aplikimin e analizës mbi setin e përfituar të të dhënave,
ashtu siç mund të përcaktojmë fuqinë e lidhjes ndërmjet nivelit të ngordhjes së milingonave nga
doza e ilaçit, mund të përcaktojmë edhe shumën e dozës së nevojshme për vdekjen e
milingonave në një nivel të caktuar (p.sh., 95% e milingonave janë ndikuar nga ky ilaç).
2. ANALIZA PROBIT NË SPSS Për të aplikuar analizën probit në SPSS zgjedhet Analyze Regression Probit. Pasi të
hapet dritarja Probit Analysis bëhet njohja e ndryshoreve. Klikohet butoni OK dhe kryhet analiza
probit.
Fazat e aplikimit të analizës probit në programin SPSS janë si më poshtë:

239
Hapi 1: Menyja Filluese e Analizës Probit

240
Hapi 2: Dritarja e Analizës Probit
Response Frequency: Është ndryshorja e varur e koduar me 0 apo 1, ndryshe quhet edhe
‘reponse count’.
Total Observed: Kjo ndryshore është ndryshore e cila i ka të gjitha vlerat 1. Përmes
komandës Compute e cila gjendet në alternativën Transform mund të krijohet një ndryshore e re
e cila i ka të gjitha vlerat 1 (e barabartë me numrin e vrojtimeve). Probit përdoret për të
llogaritur nivelet e kësaj ndryshore të pavarur të vlerave 0 dhe 1.
Factor: Është ndryshore e pavarur kategorike. Mund të përzgjedhet sipas dëshirës. Në qoftë
se është përcaktuar një faktor, probit nivelet faktoriale të kësaj ndryshore i merr si të rreme
(dummy) në model. Në qoftë se është njohur çfarëdo ndryshore kategorike, përmes komandës
Degine range bëhet njohja e niveleve minimale dhe maksimale të ndryshores.
Covariate(s): Është alternativa e cila njeh ndryshoren e pavarur të vazhdueshme
(continues) e cila gjendet së paku një ndryshore e këtillë që shpjegon ndryshoren e varur në
model.

241
Transform: Mund të bëhen analiza me dryshoret e pavarura në SPSS përderisa nuk janë të
përcaktuara dhe pa u bërë ndonjë konvertim. Në qoftë se duhet të konvertohen ndryshoret e
pavarura zgjihet njëra natural log apo ln.
Hapi 3: Dritarja e Përzgjedhjeve
3. KOEFICIENTËT PROBIT Koeficientët probit, vektori β, në regresion përkojnë me koeficientët e regresionit, kurse në
regresionin logit apo logjistik përkojnë me koeficientët logit. Të gjithë paraqesin ndikimin e
koeficientëve. Zakonisht në logit dhe në probit për të dhënat e njëjta arrihen rezultatet e njëjta,
mirëpo koeficientët logit dhe probit janë të ndryshëm për nga rëndësia dhe madhësia.
Koeficientët logit për ndryshoren e njëjtë përkojnë përafërsisht sa 1.8 herë koeficientët probit.
Koeficientët probit shpreshin se ndryshimi i një njësie (unit) që do të bëhet në ndryshoren e
pavarur sa do të krijoj ndryshim nga shpërndarja normale kumulative në ndryshoren e varur. Pra,
Jep frekuencat e vrojtuara dhe të
pritura për secilën situatë.
Jep nivelin potencial të medianës
për secilin nivel faktorial dhe limitet
e besueshmërisë 95%. Kjo
alternativë mund të përdoret nëse
është njohur çfarëdo faktori dhe
ekziston vetëm një ndryshore e
pavarur e vazhdueshme në model.
Nëse është njohur çfarëdo faktori
teston hipotezën se nivelet
faktoriale a kanë pjerrësinë (slope)
e përbashkët.
Shpreh numrin e nevojshëm maksimal të iteracioneve për përfitimin e vlerësimit në
metodën e përdorur për vlerësimin e parametrave.

242
koeficienti probit mat ndikimin që do të krijojë ndryshorja e pavarur në vlerën standarte Z të
ndryshores së varur.
Madhësia numerike e koeficientëve të vlerësuar probit nuk ka ndonjë rëndësi dhe ndonjë
interpretim të veçantë, koeficientët probit japin vetëm drejtimin dhe shkallën e marrëdhënies.
Vlerat e larta me shenjë pozitive shprehin ndikimin pozitiv të funksionit të probabilitetit, kurse
vlerat me shenjë negative shprehin ndikimin negativ të funksionit të probabilitetit. Me fjalë të
tjera, këta koeficientë japin fuqinë e ndikimit të marrëdhënies që do të krijohet gjatë
probabilitetit të vrojtuar të ndryshores së varur.
SHEMBULL: Në një studim është hulumtuar se a i ndikojnë ndryshoret e pavarura Arsimi
(Vitet) dhe Mosha (Vitet) mendimet e personave rreth politikës (identiteti politik a është liberal
apo jo). Për të vlerësuar mundësinë normale kumulative të të qenurit liberal është aplikuar
analiza Probit mbi setin e të dhënave dhe është përfituar modeli i vlerësuar më poshtë. (Vlerat e
vlerësuara Y, janë vlerat standarte z)
Y = -0,3349 – 0,0829 (Mosha) – 0,0216 (Arsimi)
Koeficienti i prerjes këtu -0,3349 shpreh vlerën standarte z të një personi i cili ka
ndryshoren e arsimit dhe moshës 0 (Ky koeficient jep vlerën e ndryshores së varur Y në rastet
kur ndryshorja e pavarur është 0 (zero) edhe në qoftë se nuk është kuptimplotë për këtë pyetje).
Përderisa vlera z rritet 0,00826 për një rritje të një njësie në moshë, kjo vlerë zvogëlohet 0,0216
për çdo vit të arsimit.
Vlerat e vlerësuara probit të modelit, pra vlerat-z mund të shprehen duke përdorur kushtet e
probabilitetit. Për shembull, mundësia e të qenurit liberal e një personi arsimi dhe mosha e të cilit
janë zero është vlera 0,3707 e cila korrespondon me shpërndarjen normale standarte z = -0,3349.
Pra, në qoftë se një person ka një karakteristikë të këtillë, mundësia e mendimit liberal është
përafërsisht 37,1%.
4. Shembull Aplikimi Më poshtë në setin e të dhënave janë paraqitur ndryshorja e pranimit të 60 studentëve të
huaj në një universitet dhe ndryshorja e disa karakteristikave të studentëve. (Burimi:
Ramanathan, Ramu, Introductory Econometrics ëith Applications, 4th edition)
{
}
GPA: Mesatarja kumulative gjatë studimeve
BIO: Pikët nga testi i pranimit në fakultetin e mjekësisë nga seksioni i biologjisë (MCAT –
Medical College Admissions Test)

243
CHEM: Pikët e MCAT nga seksioni i kimisë
PHY: Pikët e MCAT nga seksioni i fizikës
RED: Pikët e MCAT nga seksioni i leximit
PRB: Pikët e MCAT nga seksioni i problem-zgjidhje
QNT: Pikët e MCAT nga seksioni numerik
AGE: Mosha e kandidatit
GJINIA: Gjinia e kandidatit ( 1 nëse mashkull, 2 nëse femër)
Duke marrë në konsideratë ndryshoret e mësipërme dhe duke aplikuar procedurën e analizës
probit, të vlerësojmë lidhjen ndërmjet ndryshores ACCEPT (pranoj) dhe ndryshoreve të tjera për
të dhënat e dhëna më poshtë.
Tabela 1: Të Dhënat e Shembullit
AC
CE
PT
GP
A
BIO
CH
EM
PH
Y
RE
D
PR
B
QN
T
AG
E
GE
ND
ER
0 3,47 10 10 10 9 10 11 22 1
1 3,80 12 10 9 6 5 6 22 0
0 3,96 10 10 9 10 8 9 22 1
1 3,02 13 10 10 8 7 7 22 0
0 2,90 10 9 8 8 7 7 21 1
1 2,78 10 10 9 6 6 7 21 0
1 3,00 13 13 11 9 9 9 23 1
0 3,00 10 9 8 8 9 7 24 0
... ... ... ... ... ... ... ... ... ...
... ... ... ... ... ... ... ... ... ...
... ... ... ... ... ... ... ... ... ...
... ... ... ... ... ... ... ... ... ...
1 4,00 10 14 13 13 14 12 26 0
0 2,40 9 7 8 6 6 5 24 1
0 3,88 12 11 9 8 7 7 23 0
0 2,66 9 8 11 6 5 4 23 1
1 3,67 13 12 14 13 13 13 23 0
1 2,08 7 7 6 8 6 7 22 1
0 2,78 7 10 9 7 7 6 22 0
0 2,77 5 2 3 5 4 4 22 1
0 3,91 7 5 8 5 4 4 22 0

244
Përpara se të fillohet me analizën duhet të krijohet kolona e vrojtimeve totale të cilat kanë
vlerat 1. Kjo kolonë krijohet si më poshtë.
Hapi 1: Dritarja e Përfitimit të Kolonës së Vrojtimeve me Vlerë 1
Numeric Expression: Për kolonën total observed (vrojtimeve totale) nga menyja
Transform-Compute hapet dritarja Compute Variable. Duke e emëruar ndryshoren bëhet
barazimi me 1 dhe duke klikuar butonin OK përfitohet kolona e cila i ka të gjitha vlerat 1.

245
Hapi 2: Dritarja e Analizës Probit
Më vonë, ndryshoret përkatëse barten në pjesën Covariate(s). Në hapin 3 mund të shihet
forma e bartjes së ndryshoreve.

246
Hapi 3: Dritarja e Analizës Probit

247
Hapi 4: Dritarja e Define Range
Rezultatet e Analizës Probit për shembullin tonë janë si më poshtë:
Tabela 2: Rezultatet e Analizës Probit
Data Information
N of Cases
Valid 60
Rejected Out of Rangea 0
Missing 0
Number of Responses >
Number of Subjects 0
Control Group 0
GENDER 0 33
1 27
a. Cases rejected because of out of range group values.
Bëhet njohja e nivelit të ndryshorëve faktorialë. Në shembullin tonë ndryshorja
gjinia (gender) është koduar si 0 për femrat dhe 1 për meshkujt.

248
**********PROBIT ANALYSIS**********
Parameter estimates converged after 30 iterations.
Optimal solution found.
Paramter Estimates (PROBIT model: (PROBIT (p)) = Intercept + BX)
Parameter Estimates
Parameter
Regression
Coeff. Std. Error Coeff./S.E.
PROBITa age -,00051 ,08866 -,00571
bio ,16145 ,13929 1,15910
chem ,18408 ,14949 1,23141
gpa -,12147 ,48795 -,24893
phy ,24907 ,14390 1,73091
prb -,00943 ,18683 -,05048
qnt -,00651 ,17715 -,03675
red ,07642 ,21173 ,36095
Interceptb 0 -5,78737 2,68521 -2,15528
1 -5,14635 2,60340 -1,97678
a. PROBIT model: PROBIT(p) = Intercept + BX
b. Corresponds to the grouping variable GENDER.
Chi-Square Tests
Chi-Square dfa Sig.
PROBIT Pearson Goodness-of-Fit
Test 50.332 50 .461
a. Since Goodness-of-Fit Chi square is NOT significant, no heterogeneity factor
is used in the calculation of confidence limits.
-------------------------------------------
Covariance (below) and Correlation (above) Matrices of Parameters Estimates.
Japin vlerën e
llogaritur standarde Z.
Koeficientët e regresionit
nuk janë të rëndësishëm
statistikisht sipas vlerës z.
Janë të rëndësishëm në 1%.

249
age bio chem gpa phy prb qnt red
age bio
chem gpa phy prb qnt red
0786 00177 00133 ,00655 ,00207 ,00004 ,00087 00278
14311
01940 ,00700 ,01136 00095 ,00078 ,00410 00318
10060 ,33603
02235 ,01352 ,00617 00176 00042 ,00788
,15152 ,16712 ,18537
23810 ,00512 01315 ,02105 ,01312
,16235 04728 ,28659 ,07291
02071 00064 ,00307 ,00477
-,00225 -,02995 ,06311 ,14426 ,02363
,03491 -,01637 -,02127
,05561 ,16612 01600 ,24353 ,12046
,49465 03138 ,00340
14834 10781 ,24892 ,12696 ,15669 ,53777
,09054 004483
**********PROBIT ANALYSIS**********
Observed and Expected Frequencies
gender age Number of subjects
Observed responses
Expected responses
Residual Prob
0 22,00 1,0 1,0 ,553 ,447 ,55258
0 22,00 1,0 1,0 ,778 ,222 ,77784
0 21,00 1,0 1,0 ,467 ,533 ,46722
0 24,00 1,0 ,0 ,338 -,338 ,33756
0 27,00 1,0 ,0 ,034 -,034 ,03366
0 28,00 1,0 ,0 ,000 ,000 ,00002
0 24,00 1,0 1,0 ,657 ,343 ,65747
0 25,00 1,0 ,0 ,154 -,154 ,15374
0 22,00 1,0 ,0 ,290 -,290 ,28992
0 22,00 1,0 1,0 ,603 ,397 ,60272
0 22,00 1,0 ,0 ,069 -,069 ,06945
0 22,00 1,0 1,0 ,648 ,352 ,64834
0 22,00 1,0 ,0 ,917 -,917 ,91673
0 26,00 1,0 1,0 ,973 ,027 ,97299
0 23,00 1,0 ,0 ,668 -,668 ,66768
0 23,00 1,0 1,0 ,990 ,010 ,99026
0 22,00 1,0 ,0 ,311 -,311 ,31078
0 22,00 1,0 ,0 ,112 -,112 ,11210
0 28,00 1,0 1,0 ,970 ,030 ,97020
0 33,00 1,0 ,0 ,326 -,326 ,32627
0 27,00 1,0 1,0 ,543 ,457 ,54326
0 24,00 1,0 1,0 ,268 ,732 ,26804
0 22,00 1,0 1,0 ,682 ,318 ,68151
0 22,00 1,0 1,0 ,751 ,249 ,75123
0 24,00 1,0 1,0 ,677 ,323 ,67672
0 21,00 1,0 ,0 ,023 -,023 ,02307
0 26,00 1,0 ,0 ,163 -,163 ,16272
0 23,00 1,0 1,0 ,906 ,094 ,90591
0 23,00 1,0 ,0 ,007 -,007 ,00651
0 22,00 1,0 ,0 ,188 -,188 ,18795
Shpreh variancën-kovariancën dhe matricat e korrelacionit ndërmjet ndryshoreve
të vazhdueshme të pavarura (Vlerat me të zeza janë vlerat e korrelacionit).

250
0 22,00 1,0 ,0 ,086 -,086 ,08584
0 22,00 1,0 ,0 ,522 -,522 ,52245
1 22,00 1,0 ,0 ,813 -,813 ,81300
1 22,00 1,0 ,0 ,755 -,755 ,75450
1 21,00 1,0 ,0 ,600 -,600 ,60042
1 23,00 1,0 1,0 ,988 ,012 ,98789
1 26,00 1,0 1,0 ,719 ,281 ,71939
1 22,00 1,0 1,0 ,908 ,092 ,90820
1 22,00 1,0 1,0 ,868 ,132 ,86804
1 22,00 1,0 1,0 ,893 ,107 ,89338
1 23,00 1,0 ,0 ,021 -,021 ,02095
1 21,00 1,0 1,0 ,931 ,069 ,93110
1 23,00 1,0 1,0 ,768 ,232 ,76759
1 23,00 1,0 ,0 ,012 -,012 ,01233
1 24,00 1,0 ,0 ,365 -,365 ,36453
1 23,00 1,0 ,0 ,716 -,716 ,71559
1 22,00 1,0 1,0 ,162 ,838 ,16165
1 22,00 1,0 ,0 ,001 -,001 ,00057
1 23,00 1,0 1,0 ,563 ,437 ,56346
1 25,00 1,0 ,0 ,333 -,333 ,33296
1 33,00 1,0 1,0 ,858 ,142 ,85827
1 31,00 1,0 ,0 ,011 -,011 ,01138
1 24,00 1,0 ,0 ,186 -,186 ,18624
1 22,00 1,0 ,0 ,128 -,127 ,12726
1 22,00 1,0 1,0 ,663 ,337 ,66328
1 23,00 1,0 1,0 ,927 ,073 ,92703
1 21,00 1,0 1,0 ,651 ,349 ,65107
1 23,00 1,0 1,0 ,247 ,753 ,24698
1 30,00 1,0 1,0 ,999 ,001 ,99947
Siç shihet nga rezultatet e mësipërme, është bërë vlerësimi i pikave të përputhjes për femrat
(0) dhe për meshkujt (1) dhe janë përfituar vlerësimet e modelit për secilin grup. Vlerat standarde
z të parametrave të vlerësuara në model janë dhënë nga kolona Coeff./S.E. Në vazhdim, duke
shikuar cilëndo tabelë të shpërndarjes standarde normale mund të llogariten vlerat p dhe bëhet
krahasimi me vlerën kritike të përcaktuar α. Zakonisht vlera kritike e α-së është 1% apo 5%.
Vlera e z-së e cila korrespondon me këto vlera (në testimin e hipotezave dy drejtimshe) merr
vlerat përafërsisht 2,58 dhe 1,96. Vlerësimet e parametrave përjashtim prej pikave të prerjes
(intercept) nuk janë gjetur të rëndësishme në nivelin 1% dhe 5% për asnjërin grup.
Për të njëjtin shembull, pa bërë ndonjë ndarje gjinore është shqyrtuar analiza probit për
marrëdhënien ndërmjet pikëve të biologjisë dhe pranimit në fakultetin e mjekësisë dhe është
vlerësuar modeli i mëposhtëm:
Y = -3,06647 + 0,33273 (bio)

251
Vlerësimet parametrike të modelit, siç është dhënë më poshtë, janë gjetur statistikisht të
rëndësishme. Koeficienti i përputhjes -3,06447 jep vlerën standarde z për secilin kandidat i cili
ka ndryshoren bio 0. Një rritje në ndryshoren bio shkakton rritjen e një njësie për 0,33273 në
vlerën-z.
Vlerat e përfituara të analizës probit, pra vlerat z, mund të shprehen duke përdorur tabelën e
shpërndarjes normale. Këto vlera janë dhënë në pjesën Observed and Expected Frequencies,
gjegjësisht në kolonën observed responses (ose prob). Për shembull, përderisa mundësia për t’u
pranuar në fakultetin e mjekësisë për një kandidat me pikë të biologjisë bio=12 është 0,823 ose
82,3%, mundësia e një kandidati me pikë të biologjisë bio=13 është 89,6%.
Tabela 3: Rezultatet e Analizws Probit
**********PROBIT ANALYSIS**********
Parameter estimates converged after 11 iterations.
Optimal solution found.
Parameter Estimates (PROBIT model (PROBIT (p)) = Intercept + BX):
Regression Coeff. Standard Error Coeff./S.E
Bio ,33273 ,09270 3,58912
Intercept Standard Error Intercept/S.E.
-3,06647 ,87510 -3,50414
Pearson Goodness-of-Fit Chi Square = 56,190 DF = 58 P = ,543
Since Goodness-of-Fit Chi Square is NOT significant, no heterogeneity factor is used in the calculation of confidence
limits.
------------------------------------------------------------------
**********PROBIT ANALYSIS**********
Observed and Expected Frequencies
bio Number of subjects
Observed responses
Expected responses
Residual Prob
10,00 1,0 ,0 ,603 -,603 ,60288
12,00 1,0 1,0 ,823 ,177 ,82285
10,00 1,0 ,0 ,603 -,603 ,60288
13,00 1,0 1,0 ,896 ,104 ,89595
10,00 1,0 ,0 ,603 -,603 ,60288
Janë të rëndësishme
statistikisht.

252
10,00 1,0 1,0 ,603 ,397 ,60288
13,00 1,0 1,0 ,896 ,104 ,89595
10,00 1,0 ,0 ,603 -,603 ,60288
8,00 1,0 1,0 ,343 ,657 ,34287
7,00 1,0 ,0 ,230 -,230 ,23045
2,00 1,0 ,0 ,008 -,008 ,00817
12,00 1,0 1,0 ,823 ,177 ,82285
9,00 1,0 ,0 ,471 -,471 ,47133
11,00 1,0 1,0 ,724 ,276 ,72359
9,00 1,0 ,0 ,471 -471 ,47133
12,00 1,0 1,0 ,823 177 ,82285
13,00 1,0 1,0 ,896 104 ,89598
7,00 1,0 1,0 ,230 770 ,23045
6,00 1,0 ,0 ,142 -,142 ,14229
7,00 1,0 ,0 ,230 -,230 ,23045
9,00 1,0 1,0 ,471 ,529 ,47133
9,00 1,0 1,0 ,471 ,529 ,47133
12,00 1,0 ,0 ,823 -,823 ,82285
11,00 1,0 1,0 ,724 ,276 ,72359
6,00 1,0 ,0 ,142 -,142 ,14229
10,00 1,0 1,0 ,603 ,397 ,60288
9,00 1,0 ,0 ,471 -,471 ,47133
12,00 1,0 ,0 ,823 -,823 ,82285
9,00 1,0 ,0 ,471 -,471 ,47133
13,00 1,0 1,0 ,896 ,104 ,89598
7,00 1,0 1,0 ,230 ,770 ,23045
7,00 1,0 ,0 ,230 -,230 ,23045
5,00 1,0 ,0 ,080 -,080 ,08033
7,00 1,0 ,0 ,230 -,230 ,23045
9,00 1,0 1,0 ,471 ,529 ,47133
7,00 1,0 ,0 ,230 -,230 ,23045
8,00 1,0 ,0 ,343 -,343 ,34287
10,00 1,0 1,0 ,603 ,397 ,60288
9,00 1,0 1,0 ,471 ,529 ,47133
10,00 1,0 ,0 ,603 -,603 ,60288
6,00 1,0 ,0 ,142 -,142 ,14229
8,00 1,0 1,0 ,343 ,657 ,34287
7,00 1,0 ,0 ,230 -,230 ,23045
9,00 1,0 1,0 ,471 529 ,47133
6,00 1,0 ,0 ,142 -142, ,14229
9,00 1,0 1,0 ,471 ,529 ,47133
7,00 1,0 1,0 ,230 ,770 ,23045
11,00 1,0 1,0 ,724 ,276 ,72359
10,00 1,0 1,0 ,603 ,397 ,60288
10,00 1,0 1,0 ,603 ,397 ,60288
11,00 1,0 1,0 ,724 ,276 ,72359
7,00 1,0 ,0 ,230 -,230 ,23045
10,00 1,0 1,0 ,603 ,397 ,60288

253
10,00 1,0 ,0 ,603 -,603 ,60288
14,00 1,0 1,0 ,944 ,056 ,94428
13,00 1,0 1,0 ,896 ,104 ,89598
7,00 1,0 ,0 ,230 -,230 ,23045
10,00 1,0 ,0 ,603 -,603 ,60288
6,00 1,0 ,0 ,142 -,142 ,14229
10,00 1,0 ,0 ,603 -,603 ,60288
E njëjta analizë është shqyrtuar edhe sipas grupeve të gjinisë dhe janë përfituar rezultatet e
mëposhtme:
Modeli i vlerësuar për gjininë 0, pra femrat është në formën
Y = -3,66997 + 0,36967 (bio) dhe
modeli i vlerësuar për meshkujt
Y = -3,09905 + 0,36967 (bio).
Vlerat z të cilat korrespondojnë me vlerësimet e parametrave të mësipërme janë të
rëndësishme statistikisht në nivelin e gabimit 1%. Në këtë rast, mundësitë e pjesëmarrjes do të
jenë të ndryshme në lidhje me dy grupet.
Përderisa koeficienti i përputhjes -3,66997 jep vlerën standarde z për kandidatët femra të
cilat kanë ndryshore BIO zero, koeficienti -3,09905 shpreh vlerën standarde z për kandidatët
meshkuj ndryshorja BIO e të cilëve është zero. Një rritje e një njësie në ndryshoren bio për
secilin grup, shkakton një rritje njësie prej 0,36967 në vlerën z.
Vlerat e përfituara të modelit, pra vlerat z në qoftë se shprehen nga kushtet e probabilitetit
duke përdorur tabelën e shpërndarjes normale standarde (siç janë dhënë në kolonën observed
responses (ose prob) nga pjesa Observed and Expected Frequencies), mundësitë e pranimit në
fakultetin e mjekësisë, për shembull për një kandidat femër me 12 pikë nga biologjia janë 0,778
ose 77,8% dhe për të njëjtat pikë, mundësitë e pranimit për një kandidat mashkull janë 0,090 ose
90,9%. (Rezultatet e gjetura janë përfituar nga përkufizimet e barabarta të cilat korrespondojnë
me ndryshoren e biologjisë në model për meshkujt dhe femrat. Për të bërë krahasime ndërmjet
niveleve të pranimit ndërmjet meshkujve dhe femrave duhet të përfitohet një model i ri pa bërë
kufizime dhe interpretimet duhet të bëhen sipas këtyre rezultateve.)

254
Tabela 4: Rezultatet e Analizës Probit
**********PROBIT ANALYSIS**********
DATA Information
60 unweighted cases accepted.
0 cases rejected because of out-of-range group values.
0 cases rejected because of missing data.
0 cases are in the control group.
Group information.
Gender Level N of Cases Label
0 33 0
1 27 1
MODEL Information
ONLY Normal Sigmoid is requested.
---------------------------------------------------
>Warning # 13520
>All the ratios (respose count over observation count) adjusted for the specified natural response rate are out of
range. The plot is skipped.
**********PROBIT ANALYSIS**********
Parameter estimates converged after 15 iterations.
Optimal solution found.
Parameter Estimates (PROBIT model (PROBIT (p)) = Intercept + BX):
Regression Coeff. Standard Error Coeff./S.E
Bio ,3697 ,10073 3,66976
Intercept Standard Error Intercept/S.E. gender
-3,66997 1,01510 -3,61537 0
-3,09905 ,91046 -3,40383 1
Janë të rëndësishme
statistikisht.

255
Pearson Goodness-of-Fit Chi Square = 53,432 DF = 57 P = ,610
Parallelism Test Chi Square = 1,000E-08 DF = 1 P = 1,000
Since Goodness-of-Fit Chi Square is NOT significant, no heterogeneity factor is used in the calculation of confidence
limits.
**********PROBIT ANALYSIS**********
Observed and Expected Frequencies
gender bio Number of subjects
Observed responses
Expected responses
Residual Prob
0 12,00 1,0 1,0 ,778 ,222 ,77817
0 13,00 1,0 1,0 ,872 ,128 ,87196
0 10,00 1,0 1,0 ,511 ,489 ,51065
0 10,00 1,0 ,0 ,511 -,511 ,51065
0 7,00 1,0 ,0 ,140 -,140 ,13956
0 2,00 1,0 ,0 ,002 -,002 ,00169
0 12,00 1,0 1,0 ,778 ,222 ,77817
0 9,00 1,0 ,0 ,366 -,366 ,36581
0 9,00 1,0 ,0 ,366 -,366 ,36581
0 13,00 1,0 1,0 ,872 ,128 ,87196
0 6,00 1,0 ,0 ,073 -,073 ,07325
0 9,00 1,0 1,0 ,366 ,634 ,36581
0 12,00 1,0 ,0 ,778 -,778 ,77817
0 10,00 1,0 1,0 ,511 ,489 ,51065
0 12,00 1,0 ,0 ,778 -,778 ,77817
0 13,00 1,0 1,0 ,872 ,128 ,87196
0 7,00 1,0 ,0 ,140 -,140 ,13956
0 7,00 1,0 ,0 ,140 -,140 ,13956
0 7,00 1,0 ,0 ,140 -,140 ,13956
0 10,00 1,0 1,0 ,511 ,489 ,51065
0 10,00 1,0 ,0 ,511 -,511 ,51065
0 8,00 1,0 1,0 ,238 ,762 ,23804
0 9,00 1,0 1,0 ,366 ,634 ,36581
0 9,00 1,0 1,0 ,366 ,634 ,36581
0 11,00 1,0 1,0 ,654 ,346 ,65408
0 10,00 1,0 1,0 ,511 ,489 ,51065
0 7,00 1,0 ,0 ,140 -,140 ,13956
0 10,00 1,0 ,0 ,511 -,511 ,51065
0 13,00 1,0 1,0 ,872 ,128 ,87196
0 7,00 1,0 ,0 ,140 -,140 ,13956
0 10,00 1,0 ,0 ,511 -,511 ,51065
0 6,00 1,0 ,0 ,073 -,073 ,07325
0 10,00 1,0 ,0 ,511 -,511 ,51065
1 10,00 1,0 ,0 ,725 -,725 ,72496
1 10,00 1,0 ,0 ,725 -,725 ,72496
1 10,00 1,0 ,0 ,725 -,725 ,72496

256
1 13,00 1,0 1,0 ,956 ,044 ,95605
1 8,00 1,0 1,0 ,444 ,556 ,44365
1 11,00 1,0 1,0 ,833 ,167 ,83330
1 12,00 1,0 1,0 ,909 ,091 ,90938
1 7,00 1,0 1,0 ,305 ,695 ,30454
1 7,00 1,0 ,0 ,305 -,305 ,30454
1 9,00 1,0 1,0 ,590 ,410 ,59016
1 11,00 1,0 1,0 ,833 ,167 ,83330
1 6,00 1,0 ,0 ,189 -,189 ,18915
1 9,00 1,0 ,0 ,590 -,590 ,59016
1 9,00 1,0 ,0 ,590 -,590 ,59016
1 7,00 1,0 1,0 ,305 ,695 ,30454
1 5,00 1,0 ,0 ,106 -,106 ,10552
1 9,00 1,0 1,0 ,590 ,410 ,59016
1 8,00 1,0 ,0 ,444 -,444 ,44365
1 9,00 1,0 1,0 ,590 ,410 ,59016
1 6,00 1,0 ,0 ,189 -,189 ,18915
1 7,00 1,0 ,0 ,305 -,305 ,30454
1 6,00 1,0 ,0 ,189 -,189 ,18915
1 7,00 1,0 1,0 ,305 ,695 ,30454
1 10,00 1,0 1,0 ,725 ,275 ,72496
1 11,00 1,0 1,0 ,833 ,167 ,83330
1 10,00 1,0 1,0 ,725 ,275 ,72496
1 14,00 1,0 1,0 ,981 ,019 ,98107

257
12.ANALIZA FAKTORIALE

258
ANALIZA FAKTORIALE
Analiza faktoriale është një teknikë statistikore e ndryshoreve të shumta, e cila përdoret
mjaft për të reduktuar numrin e ndryshoreve të cilat gjenden në raport me njëra tjetrën në numër
më të vogël të rëndësishëm të ndryshoreve dhe të pavarura nga njëra-tjetra (Kleinbaum, Miller
1998: 601). Analiza faktoriale përfshin teknika të ndryshme por që në të njëjtën kohë janë të
lidhura ndërmjet vete. Këto teknika janë Principal Component Analysis, Principal Factor
Analysis, Image Factoring, Maximum Likelihood Factoring, Alpha Factoring, Unweighted Least
Squares Factoring, Generalized ose Wieghted Least Squares Factoring. Metoda më e përdorur
prej këtyre analizave është analiza e komponenteve themelore (Principal Component Analysis
– PCA). Në këtë metodë, llogaritet faktori i parë i cili e shpejgon variancën maksimale ndërmjet
ndryshoreve. Për të shpjeguar në shumë maksimale variancën e mbetur përdoret faktori i dytë.
Kjo situatë vazhdon në këtë mënyrë (Rreth numrit të faktorëve do të jepen shpjegime në faqet e
ardhshme). Pika me rëndësi këtu është që në fund të analizës të mos ketë korrelacion ndërmjet
faktorëve, me fjalë të tjerë faktorët duhet të jenë ortogonalë.
Në analizën faktoriale nuk është i disponueshëm seti i ndryshores së varur dhe ndryshores
së pavarur, kjo e fundit e cila tenton të shpjegojë ndryshoren e varur ashtu si në analizën e
regresionit. Në analizën faktoriale duke i grumbulluar ndryshoret të cilat kanë korrelacione të
larta ndërmjet vete kemi të bëjmë me krijimin e ndryshoreve të përgjithshme (faktorë). Qëllimi
këtu është që:
- Të zvogëlohet numri i ndryshoreve,
- Të zbulohet struktura lidhëse e ndryshoreve, me fjalë të tjera të bëhet klasifikimi i
ndryshoreve.
1. FAZAT E ANALIZËS FAKTORIALE Në analizën faktoriale ekzistojnë katër faza themelore. Këto janë: vlerësimi i
përshtatshmërisë së setit së të dhënave për analizën faktoriale, përfitimi i faktorëve, rotacioni i
faktorëve dhe emërimi i faktorëve.
1.1. Vlerësimi i Përshtatshmërisë së Setit të të Dhënave për Analizën
Faktoriale Për të vlerësuar përshtatshmërinë e setit së të dhënave për analizën faktoriale përdoren 3
metoda. Këto janë krijimi i matricës së korrelacioneve, testi Barlett dhe testi Kaiser-Meyer-Olkin
(KMO).
1. Krijimi i matricës së korrelacioneve për të gjitha ndryshoret e përdorura në analizë:
Hapi i parë për të zbuluar përshtatshmërinë e setit së të dhënave për analizën faktoriale

259
është shqyrtimi i koeficientëve të korrelacioneve ndërmjet ndryshoreve. Këtu dëshirohet
që të ekzistojnë korrelacione të larta ndërmjet ndryshoreve sepse sado të larta që të janë
korrelacionet ndërmjet ndryshoreve, aq është e lartë mundësia për krijimin e faktorëve të
përbashkët të ndryshoreve. Me fjalë të tjera, ekzistimi i korrelacioneve të larta ndërmjet
ndryshoreve tregon se faktorët e përbashkët të ndryshoreve janë matur në forma të
ndryshme. Ekzistimi i korrelacioneve të dobëta ndërmjet ndryshoreve është shenjë se
ndryshoret nuk do të formojnë faktorë të përbashkët.
2. Testi Barlett (Barlett test of Spherricity): Teston mundësinë e ekzistimit të
korrelacioneve të larta së paku ndërmjet një pjese të ndryshoreve në matricën e
korrelacionit. Për të vazhduar me analizën, duhet që të refuzohet hipoteza zero “Matrica e
korrelacioneve është një matricë njësie”. Refuzimi i hipotezës zero tregon se ekzistojnë
korrelacione të larta ndërmjet ndryshoreve, me fjalë të tjera tregon se seti i të dhënave
është i përshtatshëm për analizën faktoriale (Hair dhe të tjerët, 1998: 374).
3. Matësi i madhësisë së mostrës Kaiser-Meyer-Olkin (KMO): Është një indeks i cili
krahason madhësinë e koeficientit të korrelacionit të vrojtuar me madhësinë e koeficientit
të korrelacionit të pjesërishëm. Niveli i KMO-së duhet të jetë mbi 0,5. Sado i lartë të jetë
niveli, aq është i mirë seti i të dhënave për të bërë analizën faktoriale. Vlerat e KMO-së
dhe interpretimet janë si më poshtë (Sharma 1996: 116)
Vlerat e KMO-së Interpretimi
0,90 Përkryer
0,80 Shumë mirë
0,70 Mirë
0,60 Mesatare
0,50 Dobët
nën 50 Nuk pranohet
1.2. Përfitimi i Faktorëve Qëllimi në këtë fazë është që të përfitohen sa më pak faktorë të cilët do të përfaqësojnë
lidhjen ndërmjet ndryshoreve në shkallë të lartë. Në lidhje se sa faktorë do të përfitohen,
ekzistojnë kritere të ndryshme (Dunteman 1989: 16):
1. Vlera Eigen (Eigenvalues): Vlera Eigen i pranon si të rëndësishëm faktorët të cilat janë
më të mëdhenj se 1.
2. Testi Scree: Grafiku i testit Scree (vija e grafikut) tregon variancën totale në lidhje me
secilin faktor. Faktorët e gjendur deri te pika e cila merrë formë horizontale në grafik
pranohen si faktorët maksimal që do të përfitohen.
3. Metoda e përqindjes së variancës totale: Nëse kontributi në shpjegimin e variancës
totale të cilitdo faktor të shtuar bie nën 5%, nënkupton që është arritur numri maksimal i
faktorëve.
4. Kriteri Joliffe: Të gjithë faktorët nën 0,7 nxirren nga modeli.

260
5. Kriteri i shpjegimit të variancës: Numri i cili shpjegon 90% të variancës pranohet si i
mjaftueshëm.
6. Përcaktimi i numrit të faktorëve nga ana e hulumtuesit: Vendimi i vetë hulumtuesit
rreth numrit të faktorëve.
1.3. Rotacioni i Faktorëve Qëllimi i rotacionit të faktorëve është që të përfitohen faktorë të cilët mund të emërohen dhe
të interpretohen. Metoda më e përdorur e rotacionit është Rotacioni Ortogonal. Në rotacionin
ortogonal, faktorët e përfituar nuk kanë korrelacione ndërmjet vete. Kurse në korrelacion jo
ortogonal (oblique) faktorët kanë korrelacione ndërmjet vete. Me fjalë të tjera, nuk janë të
pavarur nga njëri-tjetri. Në rotacionin ortogonal përdoren tri metoda. Këto janë varimax (metoda
më e përdorur), equamax dhe quartimax. Kurse metodat Promax dhe Direct Oblimin përdoren
gjatë kryerjes së rotacionit oblique. Në qoftë se seti i të dhënave ëshë shumë i madh preferohet
rotacioni Promax.
1.4. Emërimi i Faktorëve Në lidhje me emrimin e faktorëve janë dhënë informata gjatë interpretimit të të dalurave të
SPSS-it.
2. Shembull Aplikimi
Më poshtë janë dhënë 14 norma të cilat tregojnë gjendjen financiare të 96 firmave të
industrisë së prodhimit. Qëllimi ynë është që këto 14 ndryshore të i reduktojmë në sa më pak
faktorë. Simbolet e 14 ndryshoreve dhe emërimi i tyre është në këtë formë:
ROA: Fitimi Neto / Totali i Aktivës
GM: Fitimi Bruto / Shitjet Neto
PM: Fitimi Përpara Tatimit / Kapitali
OM: Fitimi EBIT
NPM: Fitimi Neto / Shitjet Neto
NSTA: Shitjet Neto / Pasuria Totale
ATR: Norma e Testit Acid
FL: Borxhet Totale / Pasuria Totale
DE: Borxhet Totale / Kapitali
STFDTA: Borxh. Af.Shkurt. / Pas. Tot.
NSE: Shitjet Neto / Totali i Kapitalit
NSFA: Shitjet Neto / Pasuria Fikse
CR: Raporti Aktual
CR2: Raporti i Keshit
Në programin SPSS, futen ndryshoret në data editor si më poshtë. Kolona e parë tregon
ndryshoren e parë, kolonat tjera tregojnë ndryshoret tjera me radhë.

261
Hapi 1: Futja e të Dhënave në SPSS2
Për ta kryer analizën faktoriale, shkohet te Analyze, Dimension Reduction, Factor.
2 Seti i plotë i të dhënave mungon në libër

262
Hapi 2: Menyja e Analizës Faktoriale
Më vonë, siç shihet në dritaren e hapit 3, të gjitha ndryshoret barten në pjesën Variables.
Hapi 3: Dritarja e Analizës Faktoriale

263
Hapi 4: Përzgjedhja e Ndryshoreve në Analizën Faktoriale
Siç shihet më lartë, në menynë e Analizës Faktoriale gjenden disa zgjedhje si
Descriptives, Extraction, Rotation, Scores dhe Options. Për ta kryer analizën duhet që të
etiketohen disa pjesë nga këto përzgjedhje. Kur të klikojmë në butonin Descriptives do të hapet
dritarja e mëposhtme dhe nga këto përzgjidhen Initial solution, KMO and Barlett’s test of
sphericity dhe pastaj klikojmë butonin Continue.
Hapi 5: Dritarja e Statistikave Përshkruese

264
Kur të klikojmë në butonin Extraction, do të hapet dritarja e mëposhtme në hapin 6. Siç
është specifikuar në fillim të kapitullit, zgjedhim metodën e përfitimit të faktorëve Principal
componets. Pas kësaj zgjedhen me radhë Correlation matrix, Eigenvalues over 1 (shikoni
metodat e përfitimit të faktorëve), në qoftë se hulumtuesi dëshiron përzgjedh vet numrin e
faktorëve përzgjedh Number of factors (por kjo nuk preferohet), Unrotated factor solution dhe
Scree plot.
Hapi 6: Dritarja e Metodës së Përfitimit të Faktorëve
Kur të klikojmë në butonin Rotation, siç shihet në hapin 7, përzgjedhen Varimax dhe
Rotated solution.

265
Hapi 7: Dritarja e Rotacionit
Duke klikuar në butonin Scores zgjedhet një nga metodat Regression, Bartlett dhe
Anderson-Rubin, e cila do ta ruaj ndryshoren si rezultat të faktorit. Kur të përzgjedhet një nga
këto metoda, mund të përfitojmë rezultate të faktorëve (factor scores) të cilat mund të përdoren si
ndryshore në analizat tjera (p.sh. Regresion i Shumëfishtë Linear apo Analiza e Ndarjes).
Rezultatet e faktorëve do të shihen si fac1_1, fac2_1, fac3_1 në faqen filluese të të dhënave.
Hapi 8: Dritarja e Rezultateve Faktoriale
Kur të shtypet butoni Options, në qoftë se përzgjedhet Exclude cases listwise, nuk do të
mirren në konsideratë vlerat e humbura të ndryshoreve (missing values). Përzgjedhja Exclude
cases pairwise merr në konsideratë ndryshoret të dhënat e të cilave janë të plota. Kurse

266
përzgjedhja Replace with mean, në vend të vlerave të humbura, përdor mesataren aritmetike në
lidhje me ndryshoret përkatëse. Përzgjedhja Sort by size bën klasifikimin e ndryshoreve sipas
peshës së faktorëve në matricën e rrotulluar faktoriale.
Hapi 9: Dritarja e Përzgjedhjeve
3. Të Dalurat nga SPSS-i dhe Interpretimi Për Analizën Faktoriale Më poshtë janë paraqitur rezultatet dhe interpretimet më të rëndësishme të analizës
faktoriale.
3.1. Vlerësimi i Përshtatshmërisë së Setit të të Dhënave Për Analizën
Faktoriale Siç shihet në tabelën e mëposhtme, testi KMO është 71,3% (,713). Për arsye se 71,3>0,50
mund të themi se seti i të dhënave është i përshtatshmëm për analizën faktoriale. Testi i dytë të
cilën do ta shikojmë është testi Barlett. Siç shihet nga tabela, testi Barlett është i rëndësishëm
(Sig.). Kjo do të thotë që ekzistojnë korrelacione të larta ndërmjet ndryshoreve, me fjalë të tjera
seti i të dhënave tona është i përshtatshmëm për analizën faktoriale.

267
Tabela 1: Rezultatet e KMO-së dhe Testit Barlett
KMO and Bartlett's Test
Kaiser-Meyer-Olkin Measure of Sampling Adequacy. .713
Bartlett's Test of
Sphericity
Approx. Chi-Square 631.722
df 91
Sig. .000
Për vlerësimin e përshtatshmërisë së setit së të dhënave për analizën faktoriale mund të
shikohet edhe matrica e korrelacionit. Në qoftë se koeficientët e korrelacionit ndërmjet
ndryshoreve janë 0,30 dhe më sipër, kjo tregon që do të krijohen faktorë me probabilitet të lartë.
Në qoftë se numri i ndryshoreve është i madh, atëherë interpretimi i matricës së korrelacionit
është i vështirë.
3.2. Përcaktimi i Numrit të Faktorëve
Ekzistojnë faktorë të ndryshëm për përcaktimin e numrit të faktorëve. Në shembullin tonë
ne patëm përzgjedhur vlerën Eigen e cila merr në konsideratë faktorët më të mëdhenj se 1.
Në tabelën 2, janë 4 faktorë më të mëdhenj se vlera 1 (Eigenvalues). Faktori i parë e
shpjegon 21,050% variancën totale (në kolonën e djathtë të fundit). Faktori i parë dhe faktori i
dytë së bashku e shpjegojnë variancën 39,482%. Kurse katër faktorët së bashku e shpejgojnë
variancën 70,757%.
Tabela 2: Numri i Faktorëve në Lidhje me Vlerën Eigen dhe Përqindja Shpjeguese e
Variancës
Component
Initial Eigenvalues Rotation Sums of Squared Loadings
Total
% of
Variance
Cumulative
% Total
% of
Variance
Cumulative
%
1 2 3 4 5 6 7 8 9 10 11 12 13 14
4.136 2.942 2.042 1.235
.827
.681
.636
.453
.397
.337
.283
.219
.200 .62
29.541 17.803 14.588 8.824 5.908 4.863 4.543 3.238 2.832 2.405 2.022 1.567 1.425
.440
29.541 47.345 61.933 70.757 76.666 81.528 86.071 89.309 92.141 94.545 96.567 98.135 99.560
100.000
2.947 2.580 2.469 1.910
21.050 18.432 17.634 13.642
21.050 39.482 57.115 70.757

268
Gjatë përcaktimit të numrit të faktorëve që do të futen në rotacion, mund të përdoren edhe
metoda të tjera përveq vlerës Eigen. Për shembull, më poshtë në Figurën 1, numri i faktorëve
përcaktohet deri në pikën kur vija e pjerrësisë fillon të humb në grafik. Sipas kësaj, pas faktorit të
4 vija e grafikut do të fillojë të humb pjerrësinë në masë të konsiderueshme. Nga kjo, numrin e
faktorëve mund t’a klasifikojmë në 4 apo 5 faktorë.
Figura 1: Vija Grafike e Analizës Faktoriale
3.3. Variancat e Përbashkëta të Ndryshoreve Communality (variancat e përbashkëta) paraqet shumën e variancës që një ndryshore e ndan
bashkë me ndryshoret e tjera që marrin pjesë në analizë (Hair dhe të tjerët, 1998: 365). Në
analizën faktoriale, duke i nxjerrur nga analiza ndryshoret të cilat kanë varianca të ulëta (p.sh.
nën 0,50) mund të bëhet përsëri analiza faktoriale. Në këtë rast do të rriten edhe KMO edhe
vlera statistike e cila e shpjegon variancën.
Në qoftë se vlera e communality del mbi 1, në këtë situatë ose seti i të dhënave është i vogël
ose janë përcaktuar numër i madh apo numër i vogël i faktorëve në hulumtim. Në tabelën e
mëposhtme, ndryshoret të cilat kanë variancën e përbashkët më të lartë janë ROA dhe NSE.

269
Tabela 3: Tabela e Variancës së Përbashkët
Communalities
Initial Extraction
roa 1.000 .771
nse 1.000 .771
nsfa 1.000 .704
nsta 1.000 .705
gm 1.000 .525
om 1.000 .624
pm
npm
cr
atr
cr2
fl
de
stfdta
1.000
1.000
1.000
1.000
1.000
1.000
1.000
1.000
.852
.822
.610
.813
.746
.690
.580
.692
Extraction Method: Principal
Component Analysis.
3.4. Faza e Rotacionit Qëllimi i rotacionit është që të përfitohen faktorë të kuptimshëm që mund të interpretohen.
Më poshtë në Tabelën 4 shihet matrica e faktorëve të rrotulluar (Rotated Component Matrix).
Kjo matricë është rezulati përfundimtar i analizës faktoriale. Në matricë mund të shihen
korrelacionet ndërmjet ndryshores origjinale dhe faktorit të saj. Ndryshorja e cila ka peshën më
të madhë nën një faktor të caktuar nënkupton që ajo ndryshore ka një lidhje të përafërt me atë
faktor. Në qoftë se numri i të dhënave (vrojtimeve) është 350 dhe më lartë, pesha e faktorit duhet
të jetë 0,30 dhe më shumë. Kurse peshat 0,50 dhe më lartë pranohen si vlera shumë të mira (Hair
dhe të tjerët 1998: 385).
Në shembullin tonë, në tabelën 4 janë dhënë 4 faktorë (kolona) dhe peshat e secilës
ndryshore nën faktorë (factor loadings – koeficienti i korrelacioneve ndërmjet ndryshoreve dhe
faktorëve). Nga tabela, ndryshorja ROA ka peshën më të madhe nën faktorin 1 (,807), ndryshorja
OM përsëri edhe kjo ka peshën më të madhe nën faktorin e parë (,757). Ndryshorja FL ka peshën
më të madhe nën faktorin 2 (,807), ndryshorja ATR nën faktorin 3 (,878) dhe ndryshorja NSFA
nën faktorin 4 (,806).

270
Tabela 4: Matrica e Faktorëve të Rrotulluar
Rotated Component Matrixa
Component
1 2 3 4
roa .807 -.067 .095 .327
om .757 .052 -.213 -.062
pm .730 -.542 .159 .008
npm .710 -.551 .116 -.015
gm .674 .127 .160 -.173
fl -.046 .807 -.189 .037
de
atr
cr2
cr
stfdta
nsfa
nsta
nse
-.083
-.012
.346
-.017
.221
.146
-.167
-.068
.737
-.189
-.059
-.180
.537
.074
-.369
.514
-.156
.878
.783
.753
-.543
.167
.086
-.090
-.079
.070
.102
.101
.246
.806
.730
.702
Extraction Method: Principal Component
Analysis.
Rotation Method: Varimax with Kaiser
Normalization.
a. Rotation converged in 6 iterations.
3.5. Emërimi i Faktorëve Për të bërë emërimin e faktorëve, duhet të bëhet grupimi i ndryshoreve të cilat kanë peshë
më të madhe nën një faktor. Për shembull, në tabelën 4, ndryshoret ROA (,807), OM (,757), PM
(,730), NPM (,710) dhe GM (,674) kanë peshën më të madhe nën faktorin 1 (ndryshoret të cilat
kanë pesha të vogla nën faktorin 1 nuk merren parasysh). Këto ndryshore kanë të bëjnë plotësisht
me fitimin e firmës, kështuqë faktorin e parë mund ta emërojmë si faktori i fitimit. Në të njëjtën
mënyrë, ndryshoret FL (,807), DE (,737) dhe STFDTA (,537) kanë peshën më të madhe nën
faktorin 2. Këto tri ndryshore kanë të bëjnë me strukturën financiale të firmës, kështu që faktorin
e dytë mund ta emërojmë si faktori i strukturës financiare. Nën faktorin e tretë, ndryshoret
ATR (,878), CR2 (,783), CR (,753) kanë peshën më të madhe. Këto tri ndryshore kanë të bëjnë
me likuiditetin e firmës, kështu që faktorin e tretë mund ta emërojmë si faktori i likuiditetit.
Nën faktorin e katërt, ndryshoret NSFA (,806), NSTA (,730) dhe NSE (,702) kanë peshën më të
madhe. Karakteristika e përbashkët e këtyre ndryshoreve është produktiviteti, kështu që këtë
faktor mund ta emërojmë si faktori i produktivitetit.

271
3.6. Rezultatet Faktoriale Qëllimi i analizës faktoriale ishte që setin e të dhënave ta reduktonte në numër sa më të
vogël dhe më të rëndësishëm të faktorëve. Para se të fillonim me analizën faktoriale kishim 14
ndryshore. Pas analizës faktoriale, 14 ndryshoret u reduktuan në 4 faktorë. Në të njëjtën kohë,
kemi përfituar edhe rezultatet e faktorëve ashtu sa numri i faktorëve. Me fjalë të tjera, është
përfituar kolona e rezultateve të faktorëve (factor scores) për secilën ndryshore. Rezultatet e
përfituara të faktorëve duhet të plotësojnë kushtin e shpërndarjes normale dhe nuk duhet të kenë
probleme me lidhje të shumëfishta. Rezultatet e faktorëve të përfituara mund të përdoren në
analiza të tjera duke qenë ndryshore në vete. Pasi të përfundojmë analizën e rezultateve të
faktorëve, mund të i shohim këto në faqen e parë aty ku kemi bërë hyrjen e të dhënave (Shikoni
hapin 10: Dritarja e rezultateve të faktorëve).
Hapi 10: Rezultatet e Faktorëve
Për më shumë detaje rreth analizës faktoriale, shikoni Bryant dhe Yarnold (1995),
Dunteman (1989), Gorsuch (1983), Hutcheson dhe Sofroniou (1999), Kim dhe Muller (1978a,
1978b), Morrison (1990).

272
13.ANALIZA DISKRIMINUESE
(DISCRIMINANT)

273
ANALIZA DISKRIMINUESE (DISCRIMINANT ANALYSIS)
Analiza diskriminuese është një nga teknikat statistikore me shumë ndryshore e cila ka për
qëllim të vlerësoj marrëdhënien ndërmjet ndryshores(ve) së varur(a) kategorike dhe ndryshoreve
të pavarura metrike.
1. QËLLIMET E PËRDORIMIT TË ANALIZËS DISKRIMINUESE Mund të përdoret për të vlerësuar anëtarësinë e grupit, me fjalë të tjera, për të vendosur se
një e dhënë (vrojtim, subjekt, ndodhi) në cilin grup të ndryshores do të marrë pjesë.
Duke përdorur barazinë e funksionit të diskriminimit, ndihmon ndarjen e të dhënave në
grupe.
Mund të përdoret për të zbuluar si ndryshojnë mesataret aritmetike të ndryshoreve të
pavarura ndërmjet grupeve.
Mund të përdoret për të identifikuar se ndryshoret e pavarura sa mund të shpjegojnë
variancën e ndryshores së varur.
Mund të përdoret për të identifikuar ndryshoret të cilat janë efektive dhe ato që nuk janë
janë gjatë ndarjes së grupeve.
Mund të përdoret për të testuar klasifikimin e të dhënave të vlerësuara.
2. SUPOZIMET E ANALIZËS DISKRIMINUESE Për të shmangur mundësinë e klasifikimit gabim në analizën diskriminuese;
shumica e ndryshoreve duhet të ndjekin shpërndarjen normale,
matricat e kovariancave duhet të jenë të barabarta për të gjitha grupet dhe
duhet të mos ekzistojë problemi i lidhjeve të shumëfishta lineare ndërmjet ndryshoreve të
pavarura.
(Për detajet e supozimeve të analizës diskriminuese, shikoni kapitullin e supozimeve të
teknikave me shumë ndryshore).
Lachenbruch (1975) ka realizuar se një mospërfillje e lehtë e supozimeve të shpërndarjes së
shumëfishta normale dhe kovariancave të barabarta (dy supozimet shumë të rëndësishme të
analizës diskriminuese) nuk ndikon në masë të konsiderueshme rezultatet e analizës. Klecka
(1980), ka realizuar se shpesh ndryshoret dikotomike (rezultatet dyshe si po, jo) të cilat shkelin
rregullin e shpërndarjes normale, nuk do të ndikojnë rezultatet e analizës diskriminuese. Po
ashtu, në qoftë se shpërndarja e të dhënave nuk është normale dhe në masë të konsiderueshme ka
pabarazi në madhësitë e grupeve, mund të përdoret analiza e regresionit Logjistik në vend të
analizës diskriminuese. Në analizën e regresionit logjistik nuk është kusht karakteristika e
shpërndarjes së ndryshoreve të pavarura. Mirëpo, në rastet kur regresioni logjistik nuk mund të

274
përdoret për tri apo më shumë kategori të ndryshoreve të varura, duhet patjetër të përdoret
analiza diskriminuese.
3. MADHËSIA E DUHUR E SETIT TË TË DHËNAVE PËR ANALIZËN
DISKRIMINUESE Madhësia e duhur e setit të të dhënave për analizën diskriminuese, duhet të jetë së paku prej
100 ku për çdo ndryshore duhet të jenë minimum 20 të dhëna.
Detajet e analizës diskriminuese do të shpjegohen përmes aplikimit të shembullit të
mëposhtëm.
4. SHEMBULL APLIKIMI Të supozojmë se dëshirojmë të bëjmë një hulumtim mbi studentët të cilët e përfundojnë me
sukses programin e masterit në një universitet dhe mbi ata të pasuksesshëm. Çështjet të cilat jemi
kureshtarë të indentifikojmë janë karakteristikat ndarëse të studentëve të suksesesshëm dhe atyre
të pasuksesshëm, një student me potencial a do të jetë i suksesshëm apo i pasukesshëm, si
ndryshojnë mesataret aritmetike të ndryshoreve të pavarura ndërmjet grupeve, ndryshoret e
pavarura sa e shpjegojnë variancën në ndryshoren e varur, ndryshoret efektive në ndarjen e
grupeve të suksesshme dhe të pasuksesshme. Për këtë qëllim, do të përdoren rezultatet e provimit
pranues të masterit (PPM), mesataret e notave të studentëve (MN) dhe provimi i gjuhës për
nënpunës civil (PGNC)3. Për këtë arsye, është siguruar lista e studentëve të sukseshëm
(diplomuar) dhe atyre të pasukesshëm si dhe rezultatet e provimit pranues (PPM), mesataret e
notave (MN) dhe rezultatet e provimit të gjuhës për nënpunësit civil (PGNC) nga Instituti i
Shkencave Shoqërore të një universiteti tonë.4 Këtu kemi dy grupe të ndryshores së varur (1:
grupi i studentëve të suksesshëm, 2: grupi i studentëve të pasukesshëm). Në analizën
diskriminuese mund të jenë më shumë se dy grupe (kategori) në ndryshoren e varur. Kurse
ndryshoret tona të pavarura janë ndryshorja PPM, MN dhe PGNC (në fakt, është ideale që
analiza diskriminuese të bëhet me numër më të madh të ndryshoreve të pavarura).
Ndryshoret tona të pavarura dhe të varura, futen në programin e SPSS-it ashtu siç shihet më
poshtë. Kolona e parë paraqet ndryshoren e varur (30 rreshtat e parë me numrin 1 paraqesin
studentët e suksesshëm, kurse prej rreshtit 31 deri te 60 me numrin 2 janë vendosur studentët e
pasuksesshëm). Në rreshtin e parë mund të shihen pikët e PP, mesatares së notës MN dhe
rezultatet e provimit PGNC për një student që e ka përfunduar me sukses programin e masterit.
Duke zbritur tutje, mund të shihen rastet e studentëve të tjerë.
3 KDPS (Kamu Personeli Dil Sınavı) është një provim shtetëror për turqit për të zbuluar nivelin e njohurive të
gjuhëve të huaja për punonjësit e sektorit publik. 4 D.m.th. Turqisë

275
Hapi 1: Hyrja e të Dhënave në SPSS
Pasi të bëhet hyrja e të dhënave si më sipër, për bërjen e analizës diskriminuesi, përzgjedhet
Analyze Classify Discriminant.

276
Hapi 2: Menyja e Analizës Diskriminuese
Pas kësaj, duhet të bëhet pozicionimi i ndryshoreve të pavarura dhe të varura në dritaren e
analizës diskriminuese.

277
Hapi 3: Dritarja e Analizës Diskriminuese
Në fillim, siç shihet në Hapin 4, duke e selektuar ndryshoren e varur grupin e bartim në
pjesën Grouping Variable dhe klikojmë në butonin Define Range e cila gjendet menjëherë
përfundi. Në dritaren e hapur, në pjesën minimum shkruajmë 1 dhe në pjesën maksimun 2
(studentët e suksesshëm qenë cilësuar me 1, të pasuksesshëm 2) dhe pastaj klikojmë Continue.
(Po të kishin qenë më shume se dy grupe, p.sh. katër grupe, në pjesën minimum do të duhej të
shkruanim 1 dhe në pjesën maksimum 4).

278
Hapi 4: Dritarja e Ndryshores së Varur
Më vonë, siç shihet në Hapin 5, ndryshoret tona të pavarura, PPM, MN, PGNC barten në
pjesën Independents.
Hapi 5: Dritarja e Ndryshoreve të Pavarura

279
Në menynë e analizës diskriminuese gjenden alternativat Statistics, Method, Classify dhe
Save. Klikojmë në butonin Statistics dhe etiketohen alternativat Box’s, Unstandardized dhe
Within-group correlations. Gjatë selektimit të ndryshoreve, mund të zgjedhim metodën e
ndarjes hap pas hapi (stepwise).
Hapi 6: Dritarja e Statistikave
Kur të klikojmë në butonin Method, hapet dritarja e stepwise method. (Hapi 7) Këtu,
përzgjedhim alternativën Wilks’ lambda për krjimin e barazisë së ndarjes (discriminant). Kjo
metodë, synon të minimizojë vlerën e secilës ndryshore të re e cila hyn në barazinë e ndarjes.
Kurse vlera F në pjesën Criteria paraqet vlerat të cilat duhet të përdoren me rastin e
përfshirjes së një ndryshoreje në model apo për nxjerrjen e saj nga modeli. Këto vlera janë 3,84
dhe 2,71 dhe pranohen në nivelin e rëndësisë prej 0,5 dhe 0,10. Në pjesën Display përzgjedhim
alternativën summary of steps. Po të zgjedhnim si metodë Mahalanobis distance në vend të
Wilks’s Lambda, do të duhej të përzgjedhnim F for pairwise distances. Më vonë, duke klikuar
Continue, vazhdohet me analizën.

280
Hapi 7: Dritarja e Ndarjes Hap pas Hapi
Kur të klikojmë në butonin Classify, (Hapi 8), zgjedhim alternativën All groups equal në
qoftë se numri i grupeve të krahasuara të ndryshores së varur është i njëjtë (në shembullin tonë
kemi 30 studentë të suksesshëm dhe 30 studentë të pasuksesshëm). Po të mos ishte numri i
grupeve i barabartë do të duhej të përzgjedhnim alternativën Compute from group sizes. Kurse
nga pjesa Display, në qoftë se numri i vrojtimeve nuk është shumë i madh, duhet të përzgjedhet
patjetër alternativa Casewise result. Kjo alternativë tregon rezultatet diskriminuese për secilin
subjekt, grupin përkatës, mundësinë e të qenurit në një grup etj. Një alternativë tjetër që duhet të
selektojmë dhe e cila ofron informata të dobishme është Summary table. Përmes përzgjedhjes
së kësaj alternative, mund të shoshim rezultatet e klasifikimit të saktë dhe të pasaktë si përqindje
si dhe si me numra për secilin grup. Alternativa Within-groups bën klasifikim e ndryshoreve në
lidhje me matricat e kovariancave për të gjitha grupet. Kurse nën Plot marrin pjesë alternativat e
grafikut.
Në qoftë se dëshirojmë të marrim grafiqet e grupeve të gjitha së bashku me një vend apo
ndaras, përzgjedhim alternativat Combined-groups apo Separate-groups. Për përfitimin e grafikut
të alternativës combined-groups numri i grupeve duhet të jetë më shumë se dy. Territorial map
paraqet formatin e grafikut të mesatareve të grupeve kur numri i grupeve në ndryshoren e varur
është më shumë se dy. Kurse alternativa e cila gjendet në fund të dritares Replace missing
values with mean përdoret kur në setin e të dhënave ekziston mungesë e të dhënave (Shikoni
pjesën e shqyrtimit të mungesës së të dhënave në libër).

281
Hapi 8: Dritarja e Klasifikimit
Hapi 9: Dritarja e Ruajtjes
Në dritaren Save e cila merr pjesë në analizën diskriminuese, i selektojmë të gjitha
alternativat dhe së fundi duke klikuar OK në dritaren filluese do të përfitohen rezultatet e
analizës diskriminuese.

282
5. DALJET E SPSS-it DHE INTERPRETIMI PËR ANALIZËN
DISKRIMINUESE Më poshtë janë prezantuar rezultatet dhe interpretimet të cilat i konsideruam si më të
rëndësishme për nga aspekti i analizës ndarëse.
5.1. VLERËSIMI I SUPOZIMEVE TË ANALIZËS DISKRIMINUESE Për një analizë diskriminuese optimale dhe për të minimizuar klasifikimin e gabueshëm,
duhet të sigurohen disa supozime. Supozimet më të rëndësishme të analizës diskriminuese ishin
kovariancat e barabarta, lidhjet e shumëfishta dhe shpërndarja normale. Për testimin e supozimit
të barazisë së kovariancave përdoret testi Box’s M. Këtu, hipoteza zero është në formën
“matricat e kovariancave të grupeve janë të barabarta”. Siç shihet më poshtë në tabelën 1,
hiptoeza zero nuk refuzohet në nivelin e rëndësisë (,05). Pra, grupet janë të barabarta për nga
aspekti i matricave të kovariancave. Kështu që në këtë mënyrë është realizuar supozimi i
barazimit të kovariancave në shembullin tonë. Në qoftë se numri i vrojtimeve do të ishte shumë i
madh, devijimet e vogla nga homogjeniteti do të shkaktonin një rezultat të rëndësishëm (sig.).
Supozimi jonë i dytë ishte që të mos ekzistonte problemi i lidhjeve të shumta ndërmjet
ndryshoreve. Për këtë, mund të shikojmë korrelacionet ndërmjet ndryshoreve të varura. Në qoftë
se korrelacioni ndërmjet dy ndryshoreve është më i madh se 70, atëherë njëra nga ndryshoret
duhet të lihet jashtë analizës ose ndryshoret duhet të bashkohen. Siç mund të shihet më poshtë në
tabelën 2, nuk ekzistojnë korrelacione të cilat mund të konsiderohen shumë të larta ndërmjet
ndryshoreve. (Për supozimin e shpërndarjes së shumëfishtë normale, shikoni kapitullin e
supozimeve të teknikave statistikore me shumë ndryshore).
Tabela 1: Test Box’s M
Test Results
Box's M 8.375
F Approx. 2.687
df1 3
df2 605520
Sig. .055
Tests null hypothesis of equal
population covariance matrices.

283
Tabela 2: Matrica e Korrelacionit
Pooled Within-Groups Matrices
PPM MN PGNC
Correlation PPM 1.000 .484 .630
MN .484 1.000 .514
PGNC .630 .514 1.000
5.2. VLERËSIMI I RËNDËSISË SË FUNKSIONEVE TË NDARJES
(DISRCRIMINANT) Për të përcaktuar se sa i rëndësishëm është funksioni (funksionet) e diskriminimit shikohen
statistikat Canonical Correlation, Eigenvalue dhe Wilks’s Lambda.
Canonical Correlation mat lidhjen ndërmjet rezultateve të diskriminimit dhe grupeve si dhe
tregon totalin e variancës të shpjeguar. Më poshtë në tabelën 3, vlera Canonical Correlation është
,855. Për interpretimin e kësaj vlerë marrim katrorin e saj (,8552 = ,73). Pra, modeli mund të
shpjegojë 73% të variancës në ndryshoren e varur (studentët të cilët e kanë përfunduar me sukses
programin e masterit dhe ata që nuk kanë mundur t’a përfundojnë).
Tabela 3: Statistika e Vlerës Eigen
Eigenvalues
Function Eigenvalue % of Variance Cumulative %
Canonical
Correlation
1 2.719a 100.0 100.0 .855
a. First 1 canonical discriminant functions were used in the analysis.
Sado qe vlera Eigen të jetë më e madhe, nënkupton që pjesa më e madhe e variancës së
ndryshores së varur do të shpjegohet nga ai funksion. Vlera Eigen edhe pse nuk është një vlerë e
prerë, pranohet si e mirë mbi 0,40. Në rezultatet e shembullit tonë statistika e vlerës Eigen është
2,719 dhe mund të themi se se funksioni ynë siguron një ndarje (diskriminim) të mirë. Ngaqë
ndryshorja e varur përbëhet nga dy kategori do të jetë vetëm një funksion i diskriminimit.
Më poshtë në tabelën 4, statistika Wilks’ Lambda tregon pjesën (normën) e pashpjeguar të
totalit të variancës në rezultatet e ndarjes nga dallimet ndërmjet grupeve. Në shembullin tonë, siç
shihet më poshtë, përafërsisht 27% (,269) e totalit të variancës të rezultateve të ndarjes nuk është
shpjeguar nga dallimet ndërmjet grupeve.

284
Tabela 4: Statistika Wilks’ Lambda (U)
Wilks' Lambda
Test of Function(s) Wilks' Lambda Chi-square df Sig.
1 .269 74.870 2 .000
Dallimi i shpjeguar më lartë nga Wilks’ Lambda shërben për një qëllim. Këtu Wilks’
Lambda teston rëndësinë e statistikës së Eigenvalue për secilin funksion diskriminues. Në
shembullin tonë është vetëm një funksion dhe është kuptimplotë.
5.3. VLERËSIMI I RËNDËSISË SË NDRYSHOREVE TË PAVARURA NË
ANALIZËN E DISKRIMINIMIT Për vlerësimin e rëndësisë së ndryshoreve të pavarura duhet të shikohen koeficientët e
funksionit të diskriminit dhe pesha (loadings) e secilës ndryshore të pavarur në matricën
structure. Në tabelën 5 janë dhënë koeficientët e funksionit të standardizuar të diskriminimit.
Siç shihet në tabelë, në ndarjen e grupeve të studentëve të suksesshëm dhe të pasuksesshëm,
ndryshoret e pavarura, rezultatet e provimit pranues (PPM) dhe mesatarja e notave të studentëve
(MN) janë dallues të rëndësishëm. Koeficientët e tyre janë ,503 dhe ,654. Këta koeficientë,
pranojnë koeficientin beta në analizën e regresionit. Pra, tregojnë rëndësinë relative të
ndryshoreve të pavarura në vlerësimin e ndryshores së varur. Kurse Provimi i Gjuhës për
Nënpunësit Civil (PGNC) shihet të mos jetë një ndryshore efektive në ndarjen e studentëve në të
suksesshëm dhe të pasuksesshëm (Nuk merr pjesë ne tabelën 5).
Tabela 5: Koeficientët e Funksionit të Ndarjes
Standardized
Canonical
Discriminant
Function
Coefficients
Function
1
MN
PPM
.503
.654
Matrica Structure është një matricë e cila mund të përdoret për të vlerësuar rëndësinë e
ndryshoreve të pavarura. Matrica Structure paraqet korrelacionet ndërmjet funksionit të
diskriminimit me secilën ndryshore. Ngaqë në shembullin tonë kemi një funksion, ekziston
vetëm një kolonë. Kur numri i kategorive në ndryshoren e varur të jetë më i madh edhe numri i

285
funksioneve të ndarjes do të jetë më i madh. Secila kolonë tregon një funksion. Korrelacionet
këtu janë të ngjashme me peshët (Loadings) e faktorëve në analizën faktoriale.
Tabela 6: Matrica e Strukturës (Structure)
Structure Matrix
Function
1
PPM .898
MN .820
PGNC .671
Sipas matricës së strukturës funksionet e diskriminimit me korrelacionet më të larta janë me
rend ndryshorja PPM, NM dhe PGNC. Ndryshorja e pavarur PGNC nuk është një vlerësues i
rëndësishëm.
5.4. FUNKSIONI I DISKRIMINIMIT DHE INTERPRETIMI Funksioni i diskriminimit (Discriminant Function) i quajtur edhe canonical root është një
kombinim linear i ndryshoreve të pavarura. Kështu pra:
Z = α + b1X1 + b2X2 + bnXn
Këtu, rezultati i diskriminimit Z ( njihet edhe si rezultati Z), α constant dhe b-të janë
koeficientët e diskriminimit, kurse X-at janë ndryshoret e e pavarura. Ky barazim i ngjan
regresionit të shumëfishtë. Mirëpo, këtu b-të maksimizojnë distancën ndërmjet mesatareve të
ndryshoreve të pavarura.
Tabela 7: Koeficientët e Diskriminimit Kanonik
Canonical Discriminant
Function Coefficients
Function
1
MN
PPM
.088
.144
(Constant) -15.213
Unstandardized
coefficients
Tabela 7 paraqet koeficientët e pastandardizuar të diskriminimit. I referohet betave të
pastandardizuara në regresionin e shumëfishtë. Pra, përdoren për të krijuar modelin e vlerësuar

286
saktë që mund të përdoret në klasfikimin e vrojtimeve të reja. Në qoftë se do të shkruanim
funksionin e diskriminimit:
Z = -15,213 + ,088 (MN) + ,144 (PPM)
Në qoftë se do të llogarisnim rezultatin Z të kandidatit të parë që ka përfunduar programin e
masterit:
Z = -15,213 + ,088 (83) + ,144 (76)
Z = 3,075
Rezultatet Z të kandidatëve do të marrin pjesë në rezultatet e SPSS-it në qoftë se nga
dritarja Classify selektohet Casewise results. Shenjat plus apo minus të koeficientëve nuk janë
me rëndësi. Ato tregojnë vetëm lidhjen pozitive apo negative të ndryshoreve të pavarura me
ndryshoren e varur.
Më poshtë në tabelën 8, janë paraqitur rezultatet e mesatareve të funksionit të diskriminimit
(grupi 1 që ka përfunduar me sukses programin e masterit dhe grupi 2 të pasuksesshmit).
Mesatarja e grupit të parë është 1,621, kurse e grupit të dytë -1,621.
Tabela 8: Mesataret e Funksionit të Diskriminimit të Grupeve
Functions at
Group Centroids
grupi
Function
1
1.00 1.621
2.00 -1.621
Unstandardized
canonical
discriminant
functions evaluated
at group means
5.5. VLERËSIMI I RËNDËSISË SË ANALIZËS SË DISKRIMINIMIT
Në analizën diskriminuese, suksesi i analizës është përqindja e klasifikimit të saktë. Pra,
sado që përqindja e klasifikimit të saktë është e lartë, analiza është aq e suksesshme. Më poshtë
në tabelën 9, personat e përfshirë në mostër janë klasifikuar në mënyrë të saktë 93%. Në
shembullin tonë, nga 30 personat të cilët kanë kryer me sukses programin e masterit janë
vlerësuar 29 në mënyrë të saktë dhe 1 person është klasifikuar gabim. Nga 30 personat të cilët
nuk kanë mundur t’a kryejnë me sukses programin e masterit janë klasifikuar 27 saktë dhe 3 prej

287
tyre janë klasifikuar gabim. Në qoftë se do t’i shprehnim me përqindje, 96,7% e atyreve që e
kanë kryer me sukses programin e masterit janë klasifikuar drejtë dhe 3,3% gabim. Kurse 90% e
atyreve që nuk kanë mundur t’a kryejnë me sukses programin e masterit janë klasifikuar drejtë
dhe 10% gabim.
Për të vlerësuar saktësinë e këtij klasifikimi, duhet të llogarisimim kriteret e mundësisë
relative dhe kriteret e mundësive maksimale. Madhësia e mostrës sonë përbëhej nga 60 vetë. 30
vetë përbënin grupin e parë, kurse 30 të tjerët grupin e dytë. Me fjalë të tjera, 50% përbënte
grupin e parë, 50% grupin e dytë. Kështu që, vlera e llogaritur e mundësisë është 50%. Kurse në
shembullin tonë (në pjesën e poshtme të tabelës 9), vlera e klasifikimit të saktë është 93,3% dhe
kjo është më e madhe se 50%. Pra, saktësia e klasifikimit të analizës sonë është më e madhe se
kriteri i mundësisë.
Të supozojmë se madhësia e mostrës sonë nuk është e barabartë 30-30, por grupi i parë
përbëhet nga 10 vetë, kurse grupi i dytë nga 50 vetë, në këtë rast, a do të mund të thonim se nuk
ekziston mundësia e normës 93% të klasifikimit të saktë? Gjëja e parë që duhet të bëjmë për këtë
është llogaritja e përqindjeve të grupit të parë dhe të dytë. Përqindja e grupit të parë brenda totalit
është = 0,17 (10 / 60) dhe përqindja e grupit të dytë brenda totalit është = 0,83 (50 60). Në qoftë
se do të llogaritnim kriterin e mundësisë relative duke përdorur këto vlera: Kriteri i mundësisë
relative = 0,26 (0,102 + 0,50
2). Niveli i klasifikimit të saktë (93,3%) është më i lartë se vlerat e
kriterit të mundësisë relative (26%). Po ashtu, niveli i klasifikimit të saktë (93%) është më i lartë
se kriteri i mundësisë maksimale (83%). Në këtë mënyrë, përqindja e lartë e klasifikimit të saktë
tregon që analiza është bërë me sukses.
Tabela 9: Rezultatet e Klasifikimit
Classification Resultsa,c
grupi
Predicted Group Membership
Total
1.00 2.00
Original Count 1.00 29 1 30
2.00 3 27 30
% 1.00 96.7 3.3 100.0
2.00 10.0 90.0 100.0
Cross-validatedb Count 1.00 29 1 30
2.00 3 27 30
% 1.00 96.7 3.3 100.0
2.00 10.0 90.0 100.0
a. 93.3% of original grouped cases correctly classified.

288
Gjatë aplikimit të shembullit patëm pyetur se cilat janë karakteristikat ndarëse të studentëve
të suksesshëm dhe atyre të pasuksesshëm. Në fund të analizës diskriminuese mësuam se këto
janë ndryshoret PPM dhe MN. Ndryshorja PGNC nuk kishte ndonjë rëndësi ndërmjet grupeve.
Një përgjigjje tjetër që dëshironim të mësonim ishte si ndryshojnë mesataret aritmetike të
ndryshoreve të pavarura ndërmjet grupeve. Kjo përgjigjje mund të merret nga tabela “Group
Statistics” (nuk e pamë të nevojshme të e vendosim tabelën e saj). Një përgjigjje tjetër që ishim
kureshtarë të dinim ishte e pyetjes se sa ndryshoret e pavarura e shpjegonin variancën në
ndryshoren e varur. Përgjigjja e kësaj pyetjeje që shpjeguar gjatë interpretimit të tabelës 3.

289
14.ANALIZA E GRUPIMIT (CLUSTER
ANALYSIS)

290
ANALIZA E GRUPIMIT (CLUSTER ANALYSIS)
Analiza e grupimit është një metodë statistikore e shumë ndryshoreve e cila përdoret shpesh
për të bërë klasifikimin e të dhënave sipas ngjashmërive.
Qëllimi parësor i analizës së ndryshoreve të shumta, analizës së grupimit, është që të bëj
grupimin e individëve apo objekteve duke marrë si bazë karakteristikat e tyre të ngjashme. Me
fjalë të tjera, analiza e grupimit ofron informata përmbledhëse për hulumtuesin duke bërë
grupimin e të dhënave të pagrupuara sipas ngjashmërive të tyre. Analiza e grupimit, në të njëjtën
kohë përdoret për qëllime të ndryshme, si për përcaktimin e llojeve të grupeve, parashikimin e
grupeve, testimin e hipotezave, vlerësimin e grupeve në vend të të dhënave dhe gjetjen e vlerave
të veçanta.
Analiza e grupimit fokusohet në grupet të cilat formohen nga llogaritja e vlerave të të gjitha
ndryshoreve të individëve apo objekteve të vrojtuara në hulumtim. Për të gjetur ngjashmëritë
ndërmjet individëve apo objekteve përdoren matjet e distancës, matjet e korrelacionit apo matjet
e përngjasimeve të të dhënave cilësore.
Analiza e grupimit bën grupimin e individëve apo objekteve në të njëjtin grup, të cilët
përngjajnë me njëri-tjetrin sipas kritereve të përzgjedhjes të përcaktuara më parë (p.sh.,
përgjegjësit e anketës, produktet, sëmundjet dhe/ose inputet tjera të pavarura). Në fund të
analizës, homogjeniteti brenda grupeve të formuara dhe heterogjeniteti ndërmjet tyre është
shumë i lartë. Pra, individët/objektet e një grupi të cilët ngjajnë në mes vete, nuk do të ngjajnë
me individët/objektet e një grupi tjetër. Në fund, në qoftë se klasifikimi është i suksesshëm,
objektet brenda grupit do të jenë shumë të përafërta me njëra-tjetrën gjeometrikisht, kurse grupet
e ndryshme do të jenë shume larg nga njëra-tjetra.
Në analizën e grupimit, koncepti ndryshore është shumë me rëndësi dhe është shumë i
ndryshëm nga analizat tjera me shumë ndryshore. Në analizën e grupimit, bëhet krahasimi i
ndryshoreve duke përdorur karakteristikat e tyre sepse ndryshorja e analizës së grupimit nuk
përfshin vetëm karakteristikat të cilat përcaktojnë objektet. Dallimi i analizës së grupimit prej
analizës ndarëse (diskriminuese) është se përcaktimi i grupeve përfitohet në fund të analizës
teksa në analizën diskriminuese përcaktimi bëhet më parë. Pra, në analizën e grupimit, matrica e
të dhënave nuk mund të ndahet në analizën e parashikuar dhe nëngrupe të kritereve.
Analiza e grupimit i ngjan analizës faktoriale për nga disa mënyra. Ashtu si në analizën
faktoriale, edhe në analizën e grupimit ndryshoret, e pavarur dhe e varur, nuk i ndajmë në dy
grupe. Një mënyrë tjetër e cila i ngjan analizës faktoriale është edhe grumbullimi i individëve
apo objekteve të hulumtimit të cilët kanë ngjashmëri ndërmjet vete, pra kriteri i klasifikimit.
Po ashtu dallimi themelor ndërmjet matësit shumëdimensional i cili siguron matricat e
afërsisë dhe paraqitjen e saj vizuale dhe analizës së grupimit e cila i ka këto karakteristika është

291
se matja shumëdimensionale ofron paraqitjen hapësinore të afërsisë kurse analiza e grupimit
ofron paraqitjen e afërsive në formë të pemës. Veçanërisht gjatë vlerësimit të metodave të
grupimit hierarkik, teksa grupet e vogla vrojtohet të përshtaten ndërmjet vete dhe të formojnë
grupe kuptimplota, është e mundur që përmes grafikut të pemës grupet e mëdha ekstreme të mos
jenë kuptimplota. Për këtë arsye, në analizën e grupimit mund të nxirret ndonjë kuptim nga
mospërngjasime e voglat, por është e vështirë të interpretohen mospërngjasimet e mëdha. Por
analiza e matësit shumëdimensional përkundër analizës së grupimit ka karakteristikën e
vlerësimit të mospërngjasimeve të mëdha apo nxjerrjes së kuptimeve nga këto mospërngjasime.
Analiza e grupimit është një teknikë mjaft e dobishme për të analizuar të dhënat e situatave
të ndryshme. Për shembull, një hulumtues ka mbledhur të dhënat me anë të anketës por numri i
madh i vrojtimeve i vështirson grupimin e të dhënave dhe nxjerrjen e kuptimit të tyre. Në këtë
situatë, analiza e grupimit do të bëj grupimin e të gjitha vrojtimeve sipas kritereve të cilat i
përcakton hulumtuesi dhe të dhënat do të reduktohen ose do të formohen grupe të cilat japin
informata të përgjithshme.
Po ashtu, hulumtuesit mund të kenë dobi nga analiza e grupimit në rastet kur dëshirojnë që
të zhvillojnë supozime në lidhje me karakteristikat e të dhënave apo kur dëshirojnë të testojnë
supozimet më parë. Për shembull, një hulumtues supozon se shprehitë e tregtisë në një hapësirë
në të cilën pihet vazhdimisht alkooli janë të ndryshme nga ajo në të cilën pihet ndonjëherë
alkooli. Në këtë rast, me analizën e grupimit përcaktohen ngjashmëritë dhe dallimet ndërmjet
hapësirës në të cilën pihet vazhdimisht alkooli dhe asaj në të cilën pihet ndonjëherë alkooli dhe
sipas këtij rezultati zhvillohen supozimet.
1. PROCESI I VENDIMMARRJES PËR ANALİZËN E GRUPIMIT
Ashtu si në analizat e tjera me shumë ndryshore, edhe aplikimi i analizës së grupimit bëhet
duke kaluar nëpër disa faza të caktuara.

292
Figura 1: Procesi i Marrjes së Vendimi Për Analizën e grupimit

293

294
1.1. Qëllimet e Analizës së Grupimit Qëllimi parësor i analizës së grupimit është ndarja e vrojtimeve të përfituara në fund të
hulumtimit në dy apo më shumë grupe duke marrë për bazë ngjashmëritë e tyre. Përdorimi më i
përgjithshëm i analizës së grupimit është më qëllim hulumtimi. Analiza e grupimit përdoret
shpesh për të zhvilluar një klasifikim objektiv. Ndarjet e përfituara në fund të analizës mund të
ndihmojnë në krijimin e supozimeve në lidhje me strukturën e objekteve. Përsëri analiza e
grupimit e cila shihet si një teknikë hulumtimi, në të njëjtën kohë përdoret edhe për qëllime
testimi.
1.2. Plani i Hulumtimit në Analizën e Grupimit Pas përcaktimit të qëllimeve dhe përzgjedhjes së ndryshoreve, hulumtuesi përpara se të
fillojë hulumtimin duhet të u përgjigjet këtyre tri pyetjeve: (1) A janë identifikuar linjat kryesore
të hulumtimit apo këto kufizime duhet të fshihen? (2) Çfarë duhet të jetë matja e ngjashmërive të
vrojtimeve? (3) A duhet të ketë standarte të të dhënave? Për t’iu përgjigjur këtyre pyetjeve
ekzistojnë çasje të ndryshme. Në të njëjtën kohë, asnjëra nga këto çasje nuk janë të mjaftueshme
për të dhënë një përgjigje të qartë dhe saktë dhe për fat të keq shumica e çasjeve japin rezultate të
ndryshme për të dhënat e njëjta.
1.3. Matjet e Ngjashmërive Qëllimi themelor në analizën e grupimit është që të zbulohen ngjashmëritë apo
largësitë/afërsitë ndërmjet individëve apo objekteve të vrojtuara. Ngjashmëria, e kundërta e
konceptit të largësisë, tregon afërsinë e dy objekteve me njëra-tjetrën kur ekziston numër i madh
i ngjashmërive dhe largësinë ndërmjet dy objekteve kur ekziston numër i vogël i ngjashmërive.
Zgjedhja e matjes së ngjashmërive ndryshon sipas të dhënave kategorike dhe metrike. Të
Dhënat Kategorike: Mënyra më e thjeshtë për të zbuluar ngjashmëritë e dy objekteve është
zbulimi i karakteristikave të cilat shfaqin më shumë ngjashmëri ndërmjet dy objekteve. Kjo
matje bëhet me të dhëna kategorike. Për shembull, gjatë bërjes së një hulumtimi në lidhje me
blerësit e automobilave, mund të identifikohen tri karakteristika të cilave blerësit i kushtojnë
vëmendje. Këto janë:
Modeli (klasik, sportiv, tipit familjar) (1, 2, 3)
Le të jetë vlera (1) për zgjedhësit e modeleve klasike, (2) për zgjedhësit e modeleve sportive
dhe (3) për zgjedhësit e modeleve familjare
Shteti (Japonia, Franca)
Le të jetë vlera (1) për zgjedhësit e automobilave të prodhimit japonez, (2) për zgjedhësit e
automobilave të prodhimit francez.
295
Ngjyra (kaltër, bardhë, kuqe, zezë) le të jenë (1, 2, 3, 4)
Le të jetë vlera (1) për zgjedhësit e ngjyrës së kaltër, (2) për zgjedhësit e ngjyrës së bardhë,
(3) për zgjedhësit e ngjyrës së kuqe dhe (4) për zgjedhësit e ngjyrës së zezë.
Le të jenë përzgjedhjet e automobilave të 5 klientëve të takuar si më poshtë.
Tabela 1: Preferencat e Klientëve të Automobilave
Klientët
Karakteristikat e përzgjedhjes së automobilave
Modeli Shteti Ngjyra
1 2 2 3
2 2 1 4
3 1 1 2
4 3 1 1
5 3 2 3
Siç kuptohet nga tabela, vrojtimet përbëhen nga 5 klientë. Në total gjenden 10 lidhje
dyfishe. Këto janë (1,2), (1,3), (1,4), (1,5), (2,3), (2,4), (2,5), (3,4), (3,5), (4,5). Për të identifikuar
ngjashmëritë ndërmjet cila do dy vrojtimeve, duhet të bëhen vlerësime sipas secilës ndryshore.
Në qoftë se vlerësimi i dy klientëve është i njëjtë për një ndryshore, dallimi është 0. Ato të cilat
kanë totalin më të lartë të këtyre vlerave, nënkupton që janë më të afërta me njëra-tjetrën
(përngjajnë më shumë).
Në qoftë se do t’a shpjegonim shembullin; bëhet krahasimi i Rr12 me klientin e parë dhe
të dytë. Që të dy, klienti i parë dhe i dytë kanë përzgjedhur modelin sportiv të makinës dhe për
secilin klient përzgjedhjet e modelit janë dhënë me (2). Në këtë situatë, ngaqë vlerësimet e të dy
klientëve janë të njëjta gjatë krahasimit, shënohet (1) në barazimin Rr12 për ndryshoren e
modelit. Përsëri vazhdojmë me krahasime dhe shikojmë vlerat e dhëna të klientëve për nga
aspketi i shtetit. Meqë klienti i parë ka përzgjedhur makinat e prodhimit francez, shkruajmë (2).
Kurse meqë klienti i dytë ka përzgjedhur makinat e prodhimit japonez, shkruajmë (1). Në këtë
rast, ngaqë përzgjedhjet e tyre janë të ndryshme nga njëra-tjetra, për ndryshoren e shtetit,
shënohet (0) në barazimin Rr12 për ndryshoren e shtetit. Përsëri në të njëjtën mënyrë, klienti i
parë ka përzgjedhur ngjyrën e kuqe (3), kurse klienti i dytë ka përzgjedhur ngjyrën e zezë (4).
Ngaqë përzgjedhjet e ngjyrave të klientëve janë të ndryshme, shënohet (0) për Rr12 për
ndryshoren e ngjyrës. Pastaj bëhet mbledhja e këtyre shënimeve. Klientët të cilët kanë totalin më
të lartë të këtyre vlerave, janë ata që përngjajnë më shumë me njëri-tjetrin.

296
Tabela 2: Përzgjedhjet e Automobliave të Klientëve
Klientët
Karakteristikat e përzgjedhjes së automobilave
Modeli Shteti Ngjyra
1 2 2 3
2 2 1 4
Rr12 = 1+0+0= 1 Rr13 = 0+0+0= 0 Rr14 = 0+0+0= 0 Rr15 = 0+1+1= 2
Rr23 = 0+1+0= 1 Rr24 = 0+1+0= 1 Rr25 = 0+0+0= 0 Rr34 = 0+1+0= 1
Rr35 = 0+0+0= 0 Rr45 = 1+0+0= 1
Në këtë rast mund të thuhet se klientët të cilët përngjajnë më shumë ndërmjet veti janë
klientët me numër 1 dhe 5 (Rr15). Kurse është e vështirë që të bëhet interpretim për ngjashmëritë
tjera. Për të shpëtuar nga kjo situatë dhe për të shprehur ngjashmëritë me matje më të qarta,
duhet që të vlerësohet pesha e secilit vrojtim. Meqë ndryshorja e modelit është 3-matëse,
ndryshorja e shtetit 2-matëse dhe ndryshorja e ngjyrës 4-matëse, këto vlera kanë pesha pranuese
dhe shumëzohen me vlerat e dhëna.
Rr12 = (3) 1+(2) 0+(4) 0= 3 Rr13 = (3) 0+(2) 0+(4) 0= 0 Rr14 = (3) 0+(2) 0+(4) 0= 0
Rr15 = (3) 0+(2) 1+(4) 1= 6 Rr23 = (3) 0+(2) 1+(4) 0= 2 Rr24 = (3) 0+(2) 1+(4) 0= 2
Rr25 = (3) 0+(2) 0+(4) 0= 0 Rr34 = (3) 0+(2) 1+(4) 0= 2 Rr35 = (3) 0+(2) 0+(4) 0= 0
Rr45 = (3) 1+(2) 0+(4) 0= 3
Gjatë shqyrtimit të vlerave të gjetura, përsërit klientët të cilët ngjajnë më shumë janë Rr15,
pra klienti i parë dhe i pestë. Klienti i parë dhe i dytë, mund të thuhet se përngjajnë më shumë me
njëri-tjetrin por ngjashmëritë nuk mund t’i shprehin në mënyrë të qartë (me shumëzimin e
peshave është gjetur vlera “3”) kurse në rastin e parë kanë vlerat “1”, si dhe klienti i katërt dhe i
pestë (përsëri me shumëzimin e peshave është gjetur vlera “3”) në krahasim me të tjerët sepse me
pranimin e vlerave matëse si pesha, vlerat më të larta të arritura tregojnë klientët të cilët ngjajnë
më së shumti.
Në një matje të ngjashmërive, në qoftë se të gjitha ndryshoret janë kategorike, përdoret
metoda e krahasimit të koeficientëve. Por, në rastet kur njëra ndryshore ka pasur një matje të
ndryshme, nuk përdoret metoda e krahasimit të koeficientëve. Për këtë arsye janë zhvilluar
metoda e devijimeve absolute dhe metoda e shumës së ndryshimit të katrorit. Metoda e
devijimeve absolute llogarit dallimet ndërmjet vrojtimeve sipas vlerave absolute, kurse metoda e
shumës së ndryshimit të katrorit llogarit këto dallime sipas sipas katrorëve. Për shembull, në
qoftë se tri ndryshore janë matur me Matjen e Likertit, një ndryshore është matur me matje

297
proporcionale, ngjashmëritë ndërmjet vrojtimeve nuk përcaktohen me metodën e krahasimit të
koeficientëve por me metodën e shumës së ndryshimit të katrorit.
Në analizën e grupimit, këto tri metoda veçanërisht kanë një rol të rëndësishëm në matjen e
ngjashmërive: matjet e korrelacionit, matjet e largësisë dhe matjet e partneriteve
(përbashkimeve). Secila nga këto metoda tregon një rrugë të veçantë të ngjashmërisë në lidhje
me qëllimin e llojit të të dhënave. Për matjet e ngjashmërive/largësive përdoren të dhënat
kategorike ose metrike. Për matjet e korrelacionit dhe largësisë përderisa janë të nevojshme të
dhënat metrike, për matjen e parterneriteve janë të nevojshme të dhënat kategorike (jo metrike).
1.4. Matjet e Korrelacionit Në matjen e ngjashmërive, parimisht mirret në konsideratë korrelacioni ndërmjet vrojtimeve
çifte. Rrjedhimisht, koeficienti i korrelacionit paraqet korrelacionin (ngjashmërinë) ndërmjet dy
vrojtimeve. Korrelacioni i lartë tregon për ekzistimin e ngjashmërive, kurse korrelacioni i ulët
tregon për mungesën e ngjashmërive.
Tabela 3: Matja e Ngjashmërive: Korrelacioni
Vrojtimi
Vrojtimi 1 2 3 4 5 6 7
1 1.00
2 -.147 1.00
3 .000 .000 1.00
4 .087 .516* -.824 1.00
5 .963* -.408 .000 -.060 1.00
6 -.466 .791* -.354 .699* -.645 1.00
7 .891* -.516 .165 -.239 .963* -.699 1.00
Vlerat me (-) janë korrelacione me drejtim negativ dhe shprehin mosngjashmëritë ndërmjet
vrojtimeve.
Vlerat me (*) janë korrelacione të larta me drejtim pozitiv dhe shprehin ngjashmëritë
ndërmjet vrojtimeve.
Kurse të tjerat janë koeficientë me korrelacion të ulët.
Siç kuptohet nga tabela e mësipërme, me korrelacionet ndërmjet vrojtimeve mund të
krahasohen dy grupe të ndryshme. Parimisht, në qoftë se vlerësojmë ngjashmëritë e vrojtimit të
parë me vrojtimet e tjera, koeficientët e korrelacionit të vrojtimit të parë, të pestë dhe të shtatë
janë të larta (0,963*, 0,891) dhe mund të themi se këto kanë mostra të ngjashme në mes vete. Në
të njëjtën mënyrë, mund të shihet se koeficientët e korrelacionit të vrojtimit të dytë, katërt dhe
gjashtë janë të larta (0,516*, 0,791*), por të ulëta me vrojtimet e tjera (0,000) apo edhe negative

298
(-0,408, -0,516). Kjo do të thotë që vrojtimi i dytë ka ngjashmëri të larta me vrojtimin e katërt
dhe të gjashtë por ngjashmëritë me të tjerat janë të vogla ose në drejtim të kundërt. Vrojtimi i
tretë ka një korrelacion negativ (-0,824, -0,354) ose të ulët (0,000, 0,165) me të gjitha vrojtimet
tjera dhe mund të parashikohet që do të formojë një grup të vetëm. Gjatë shqyrtimit të kolonës së
katërt, mund të shihet se vrojtimi i katërt ka një ngjashmëri të lartë me vrojtimin e gjashtë
(0,699) dhe përsërimi vrojtimi i katërt me vrojtimet e tjera ka një ngjashmëri me drejtim negativ
(-0,060, -0,239). Në kolonën e pestë mund të vëzhgohet që vrojtimi i pestë ka një ngjashmëri të
lartë me vrojtimin e shtatë (0,963) dhe një lidhje me drejtim negativ me vrojtimin e gjashtë. Në
kolonën e gjashtë, vrojtimi i gjashtë ka një koeficient negativ të korrelacionit me ndryshoren e
shtatë, pra, mund të kuptohet që këto vrojtime nuk kanë ngjashmëri ndërmjet vete. Korrelacionet
tregojnë madhësitë e mostrave në njërën anë dhe krahasimet ndërmjet vetë vrojtimeve në anën
tjetër në lidhje me ndryshoret. Mirëpo, matjet e korrelacionit përdoren rrallë sepse në analizën e
grupimit nuk u jepet rëndësi vrojtimeve, por madhësisë së vrojtimeve në lidhje me ndryshoret.
1.5. Matjet e Distancës Matjet e korrelacionit, si aplikime intuitive të cilat përdoren në shumicën e teknikave me
ndryshore të shumëfishta, zakonisht nuk përdoren në analizën e grupimit për matjen e
ngjashmërive. Matësi (matja) e distancës së ngjashmërive mat afërsinë e vrojtimeve në lidhje me
ndryshoret brenda grupeve të ndryshoreve dhe përdoret shpesh për matjen e ngjashmërive.
Tabela 4: Matësi i Ngjashmërive: Distanca e Euklidit (Euclidean)
Vrojtimi
Vrojtimi 1 2 3 4 5 6 7
1 nc
2 3.32 nc
3 6.86 6.63 nc
4 10.24 10.20 6.00 nc
5 15.78 16.19 10.10 7.07 nc
6 13.11 13.00 7.28 3.87 3.87 nc
7 11.27 12.16 6.32 5.10 4.90 4.36 nc
nc: nuk janë llogaritur distancat.
Në tabelën e mësipërme janë matjet e distancave të ngjashmërive të shtatë vrojtimeve dhe
janë zbuluar rezultate të ndryshme nga matjet e korrelacionit. Teksa vrojtimi i parë, krijon një
grup me vrojtimin e dytë dhe të tretë (3,32, 6,86), vrojtimi i katër, vrojtimi i pestë, vrojtimi i
gjashtë dhe vrojtimi i shtatë krijojnë një grup tjetër (10,24, 15,75, 13,11, 11,27). Këto grupe,
përkundër vlerave të ulëta korrespondojnë me vlera të mëdha dhe gjenden dallime të vogla dhe
ngjashmëri të mëdha brenda grupeve. Në vend të zgjedhjes së matjeve të korrelacionit, një

299
hulumtues i cili përdor matjet e përgjithshme të distancave, do të bëj interpretime shumë të
ndryshme të rezultateve. Grupet të cilat marrin për bazë matjet e korrelacionit formohen sipas
mostrave të ngjashme dhe jo sipas ndryshoreve të ngjashme. Grupet e formuara sipas matjeve të
distancës bëjnë krahasimin e ngjashmërive brenda ndryshoreve por mostrat mund të jenë shumë
të ndryshme nga njëra-tjetra. Matja më e përdorur e distancës është distanca e Euklidit. Distanca
e Euklidit supozon se ekzistojnë dy pika, respektivisht koordinatat dy dimensionale (X1, Y1) dhe
(X2, Y2). Distanca e Euklidit ndërmjet pikave është gjatësia e vërtetë e një hipotenuze
trekëndëshe. Ky koncept, mund t’i përgjithësoj në mënyrë të lehtë ndryshoret e shtuara.
Në disa situata përdoren matjet alternative të shprehura si shuma e ndryshimeve absolute të
vrojtimeve ose shuma e ndryshimeve të katrorit. Kjo metodë quhet edhe funksioni i distancës
absolute apo city-block. Çasja city-block mund t’i ndaj dallimet e llogaritura nën kushte të
caktuara, por edhe mund të shkaktojë disa probleme. Në rastin kur nuk ekziston lidhje ndërmjet
ndryshoreve dhe pranohet sikur ekziston një lidhje e tillë, grupet e formuara nuk do të jenë të
vlefshme.
Një problem tjetër është edhe matja e ndryshoreve me matje të ndryshme. Për shembull,
supozojmë se kemi tri vrojtime A, B dhe C dhë bëhet një matje dy ndryshoresh. Nga këto dy
ndryshore, njëra le të jetë koha e hargjuar për të parë reklamën e një produkti (minuta/sekonda)
dhe mundësia e blerjes (përqindja).
Tabela 5: Kohët e Shikimit të Reklamës Sipas Vrojtimeve
Vrojtimi Mundësia e Blerjes (%) Minuta Sekonda
A 60 3.0 180
B 65 3.5 210
C 63 4.0 240
Llogaritjet me këto vlera të distancës së thjeshtë të Euklidit, distancës absolute të Euklidit,
shuma e ndryshimit të katrorëve dhe distanca city-block paraqitur në tabelën e mëposhtme. Sado
që vlerat e distancave të jenë më të vogla, nënkupton që ngjashmëritë/afërsitë janë po aq të
mëdha.
Në qoftë se do të llogaritnim distancën e Euklidit, katrorëve të Euklidit dhe city-block për
çiftin e vrojtimeve A-B;
Distanca e Thjeshtë e Euklidit: (60-65)2 + (3,0-3,5)
2 = √ = 5,025
Distanca e Katrorëve të Euklidit: (60-65)2 + (3,0-3,5)
2 = 25,25
Distanca City-Block: (60-65) + (3,0-3,5) = 5,5

300
Distancat e Kohës së Shikimit me Bazë Minutat
Çiftimi i
Vrojtimit
Distanca e
Thjeshtë e Euklidit
Distanca e
Katrorëve të
Euklidit
Distanca
City-Block
A-B 5.025 25.25 5.5
A-C 3.162 10.00 4.0
B-C 2.062 4.25 2.5
Të njëjtat llogaritje janë bërë edhe për çiftin e vojtimeve A-C dhe B-C dhe janë arritur vlerat
e mësipërme në tabelë. Siç mund të kuptohet nga tabela, vrojtimet të cilat përngjajnë më shumë
njëra-tjetrës janë B dhe C (2,062, 4,25, 2,5) dhe vrojtimet A dhe C. Kurse vrojtimet të cilat
përngjajnë më pak njëra-tjetrës jane vrojtimet A dhe B (5,025, 25,25, 5,5). Të gjitha matjet e
distancave japin rezultate në të njëjtën mënyrë, por distanca e Euklidit e cila tregon katrorët e
ndryshimeve absolute tregon rezultate të ndryshme.
Ndryshimet në matjet e njërës nga ndryshoret shkakton ndryshime në rezultatet e
ngjashmërisë. Kur në vend të kohës së shikimit minutave të merren sekondat, rezultatet e
paraqitura do të ndryshojnë si në tabelën e mëposhtme.
Tabela 6: Dallimet e Distancave Ndërmjet Vrojtimeve
Çiftimi i
Vrojtimit
Distanca e
Thjeshtë e Euklidit
Distanca e
Katrorëve të
Euklidit
Distanca
City-Block
A-B 30.41 925 35
A-C 60.07 3609 63
B-C 30.06 904 32
Në tabelën e mësipërme, mund të shihet se vrojtimet të cilat ngjajnë më shumë janë B dhe
C. Në këtë tabelë, vrojtimet të cilat ngjajnë më pak janë vrojtimet A dhe C. Përderisa vrojtimet A
dhe B përngjanin më pak kur koha e shikimit ishte marrë për minutat, gjatë vlerësimit të
sekondave vlera e ngjashmërisë është rritur ndërmjet tyre. Matja e ndryshores së kohës së
shikimit ka një vend me rëndësi në llogaritje, kurse ndryshorja e mundësisë së blerjes është më
pak e rëndësishme. Gjatë llogaritjeve kur koha e shikimit merret për minuta edhe mundësitë e
blerjes shihet të kenë një peshë më të madhe. Për këtë arsye, hulumtuesit duhet të specifikojnë
patjetër në qoftë se kanë përdorur një matje të ndryshores e cila është e mjaftueshme për të
ndryshuar zgjidhjen e rezultateve. Prandaj, rekomandohet qe hulumtuesit të i shmangin matjet e
ndryshoreve të cilat në masë të mjaftueshme do të ndryshrojnë rezultatet ashtu si në këtë
shembull.

301
Një metodë tjetër standarte e përdorur në pëgjithësi është edhe metoda e Distancës
Mahalanobis e cila bën kombinim drejtëpërdrejtë. Metoda e distancës Mahalanobis llogaritet në
atë mënyrë që distancat ndërmjet vrojtimeve mund të krahasohen me R2 e analizës së regresionit.
Një hulumtues gjatë përdorimit të një matjeje të distancës duhet të kujtoj problemet e
specifikuara të saj. Rasti më i zakonshëm është kur matjet e ndryshme të distancës dërgojnë në
rezultate të ndryshme të grupeve. Hulumtuesit rekomandohen që të përdorin metoda të
ndryshme, të krahasojnë rezultatet me informata teorike dhe me shembuj të punuar më parë.
1.6. Matja e Partneriteteve Matja e partneriteteve të ngjashmërive (association measures of similarity) përdoret vetëm
në krahasimet e të dhënave jometrike. Për shembull, përgjigjjet në formën “po” apo “jo” janë të
dhëna jometrike. Matja e partneriteteve të ngjashmërive bën krahasime ndërmjet çdo dy
përgjegjësve apo vlerëson shkallën e pajtimit. Forma më e thjeshtë e matjes së parteriteteve të
ngjashmërive është dhënia e përqindjes së formës së përshtatjes të përgjigjjedhënësve të cilët i
janë përgjegjur pyetjes me “po” apo “jo”.
1.7. Standardizimi i të Dhënave Përpara se hulumtuesit të zgjedhin matjen e ngjashmërive, duhet të i përgjigjen kësaj
pyetjeje: A është bërë standardizimi i të dhënave përpara llogaritjes së ngjashmërive? Përgjigjja e
kësaj pyetje shpjegon disa pika të rëndësishme. Veçanërisht shumica e matjeve të distancave janë
mjaft të ndjeshme ndaj matësve të ndryshëm apo madhësive ndërmjet ndryshoreve. Ashtu si në
shembullin e mësipërm, ku rezultatet qenë ndryshuar me rastin e ndryshimit të minutave në
sekonda për kohën e shikimit. Zakonisht ndryshoret të cilat tregojnë shpërndarje të madhe
(devijim të madh standart), ndikojnë më shumë rezultatet e ngjashmërisë.
Me shtimin e ndryshoreve edhe matjet e ndryshoreve mund të tregojnë dallim nga njëra-
tjetra. Për këtë arsye, të dhënat duhet të standardizohen përpara se të futen në analizë. Për
shembull, në qoftë se një pjesë e ndryshoreve është matur me matjen e Likertit, pjesa tjetër mund
të jetë matur me para, metra, litër, vit etj. Marrja e këtyre ndryshoreve së bashku në analizë është
gabim dhe do të shkaktojë rezultate të gabueshme. Prandaj, të gjitha ndryshoret e analizës duhet
të shprehen me të njëjtën vlerë.
Forma më e zakonshme e standardizimit është “rezultati Z” që bën konvertimin e çdo
ndryshoreje në vlera standarte. Për këtë përdoret formula “z = (xi-µ) / σ”. Sipas kësaj formule, të
gjitha vlerat konvertohen në një formë që mesatarja aritmetike ëshët “0” dhe devijimi standart
“1”. Në këtë mënyrë, bëhet standardizimi i të dhënave duke i sjellur të dhënat e matjeve të
ndryshme në një bazë të njëjtë. Në ditët e sotme, këto funksione bëhen përmes programeve

302
kompjuterike. Me programet e avancuara kompjuterike mund të bëhen analizat e grupeve duke
bërë procesimin e shumë ndryshoreve dhe vrojtimeve të cilat nuk janë të standardizuara.
1.8. Supozimet e Analizës së Grupimit Analiza e grupimit është një metodë e avancuar objektive për vlerësimin e karakteristikave
të strukturës së vrojtimeve. Në analizën e grupimit, hulumtuesit duhet të përzgjedhin një mostër
të besueshme e cila do të përfaqësojë në mënyrë të saktë strukturën e popullimit. Hulumtuesit
duhet t’a kuptojnë se suksesi i analizës së grupimit është i lidhur me zgjedhjen e një mostreje të
mirë. Prandaj duhet të bëhen përpjekje për të zgjedhur një mostër të besueshme dhe rezultatet
duhet të jenë në atë mënyrë që mund të përgjithësojnë popullimin.
Me rritjen e numrit të ndryshoreve duhet të rritet edhe numri i vrojtimeve. Përforcimi i
sistemeve kompjuterike dhe rritja e vazhdueshme e përdorimit të programeve të avancuara
statistikore, ka ndikuar në rritjen e dëshirës së hulumtuesve për të zvogëluar numrin e
ndryshoreve dhe vrojtimeve. Por sipas një mendimi të përgjithshëm, numri i vrojtimeve duhet të
jetë sa 3-4 herë numri i ndryshoreve.
1.9. Zgjedhja e një Algoritmi të Grupimit Funksioni i grupimit bëhet në dy mënyra: grupimi hierarkik dhe grupimi johierarkik.
Metoda më e përdorur është metoda e grupimit hiearkik. Kjo metodë ndahet në në dy pjesë,
grupimi hierarkik kumulativ (agglomerative hierarchical clustering) dhe grupimi hierarkik
diviziv (divisive hierarchical clustering). Metoda më e përdorur dhe aktive e grupimit hierarkik
është metoda e hierarkisë kumulative. Kjo metodë, në fillim bën grumbullimin e të gjitha
vrojtimeve në një grup, pastaj ato vrojtime të cilat janë më shumë kundër këtij grupi i ndan nga
ky grup dhe mundëson krijimin e një grupi tjetër. Metoda vendos vetë se sa grupe duhet të
krijohen. Pjesa më superiore e metodës hierakike kumulative është se mund të lexohet dhe
interpretohet lehtë. Kurse pjesa më problematike është mosqenia fikse dhe besueshmëria e ulët.
Ndryshe nga kjo, metoda më e përdorur në grupimin johierarkik është metoda e k-
mesatareve (k-means clustering). Grupimi johierarkik ndahet në tri teknika. Këto janë pragu
vijues (sequential threshold), pragu paralel (paralel threshold) dhe ndarja optimale (optimizing
partitioning). Rezultatet e secilës nga tri teknikat janë të përafërta me njëra-tjetrën dhe përdorimi
i vetëm njërës është i mjaftueshëm. Përdorimi i të dyjave, si metodës hierarkike dhe johierarkike
është i dobishëm sepse ofrohet mundësia për të krahasuar se rezultatet e cilës metodës janë më të
përshtatshme.

303
1.10. Grupimi Hierarkik
Metoda më e përdorur brenda metodës hierarkike kumulative është metoda e lidhjeve
(linkage methods). Po ashtu përdoren edhe metoda e variancës dhe metoda centrale. Metodat e
lidhjes ndahen në tri pjesë, lidhja e vetme (single linkage), lidhja e plotë (complete linkage) dhe
lidhja mesatare (average linkage). Kurse funksionet e tyre;
Metoda e lidhjes së vetme: Kryesisht bazohet në distancën më të shkurtër. Bën gjetjen e dy
vrojtimeve të cilat janë më të përafërta me njëra-tjetrën dhe krijohet faza e parë e bërthamës së
grupit. Pas kësaj, gjen dy vrojtore të tjera të përafërta me njëra tjetrën ose një vrojtore tjetër e cila
gjendet afër kësaj selie të grupit dhe bën zgjerimin e grupit. Në këtë mënyrë, mund të krijohet më
shumë se një grup.
Metoda e lidhjes së plotë: I përngjan metodës së lidhjes së vetme. Dallimi i vetëm është
fillimi nga dy ndryshore të largëta.
Metoda e lidhjes mesatare: Nuk fillon nga vrojtimet ekstreme. Merr për bazë vrojtimin i
cili gjendet në mes të grupit.
Metoda e Variancës (Metoda Ward’s): Merr për bazë distancën mesatare të vrojtimit që
gjendët në mes të grupit nga vrojtimet e tjera që gjenden në grup. Ka dobi nga devijimi total i
katrorëve.
Metoda e Qendrës: Merr për bazë mesataret e vrojtimeve të cilat përbëjnë një grup. Në
qoftë se në një grup ka vetëm një vrojtim, vlera e këtij vrojtimi pranohet si qendër.
1.11. Përcaktimi i Numrit të Grupeve
Një çështje tjetër kritike në metodën e grupimit hierarkik është përcaktimi i numrit të
grupeve. Problemi i përcaktimit të numrit të grupeve nuk ekziston në grupimin johiearkik sepse
në grupimin johierarkik numri i grupeve mund të përcaktohet më parë. Por në grupimin hiearkik,
përcaktimi i numrit të grupeve varet nga vendimi i rezultateve të analizës. Ky përcaktim mund të
bëhet në tri mënyra.

304
1.12. Koeficientët e Distancës
Koeficientët e distancës mund të merren si matje për përcaktimin e numrit të grupeve. Në
këtë rast koeficientët e tabelës kumulative apo grafiku i pemës mund të jenë përcaktues. Në fund
të temës, gjatë shqyrtimit të shembullit, do të vërehet një rritje e madhe e koeficientëve në fazën
e shtatëmbëdhjetë, tetëmbëdhjetë dhe nëntëmbëdhjetë (79.667,172.667, 328.600).
1.13. Grafiku i Pemës Gjatë shqyrtimit edhe të grafikut të pemës nëpër aplikimet e shembujve, mund të arrihen
rezultatet e njëjta. Vrojtimet e shembullit në vazhdim, shihet të grupohen më shumë tri grupe
(14- - - 18), (2- - - 20) dhe (3- - - 15). Në grupin e parë dhe të dytë gjenden 6 vrojtime dhe në
grupin e tretë 8 vrojtime. Këto vrojtime janë përcaktuar pranë grafikut të pemës.
Programi SPSS, do të shfaq dritaren e mëposhtme për grumbullimin hierarkik.
Figura 2: Dritarja e Grupimit Hierarkik
Këtu në qoftë se dëshirojmë që programi të bëj vetë grupimin etikohet përzgjedhja “None”,
në qoftë se dëshirohet një grupim fiks etikohet përzgjedhja “Sing solution”, në qoftë se
dëshirohet një interval i caktuar i grupeve (p.sh. më së paku 2 dhe më së shumti 4), etiketohet
përzgjedhja “Range of solutions”.

305
1.14. Grupimi Johiearkik Metoda e përdorur në grupimin johierarkik është metoda e grupimit të k-mesatareve. Këtu
mund të përcaktohet më parë numri i grupeve. Kjo bëhet duke u bazuar në njohuritë dhe përvojat
e hulumtuesit. Pastaj bëhet zgjedhja e vojtimeve tipike për secilin grup. Vrojtimet e ngjashme,
grupohen një nga një përrreth vrojtimit tipik. Këtu duke përdorur llojet e testit ANOVA shikohen
mesataret e secilit vrojtim që përbëjnë grupin sipas ndryshoreve. Avantazhi më i lartë është
besueshmëria. Përkundër kësaj problemi i vetëm është interpretimi i vështirë.
Edhe grupimi johierarkik ndahet në tri pjesë përbrenda vetes. Këto janë pragu vijues
(sequential threshold), pragu paralel (paralel threshold) dhe ndarja optimale (optimizing
partitioning). Rezultatet e secilës nga tri teknikat janë të përafërta me njëra-tjetrën dhe përdorimi
i vetëm njërës është i mjaftueshëm.
Ngaqë në grupimin e k-mesatareve numri i grupeve përcaktohet nga hulumtuesi, është e
nevojshme që të sqarohen disa çështje. E para është numri i përsëritjeve të funksioneve (iteration
numbers) dhe kriteri i konvergjencës (convergence criterion). Burimet sugjerojnë që funksionet
duhet të përsëriten më së shumti deri në dhjetë herë dhe kriteri i konvergjencës të jetë një numër i
vogël sipas mundësive ndërmjet 0 dhe 1. Me zvogëlimin e kësaj norme, hudhja e vrojtimeve
nëpër grupe është më e besueshme.
Një çështje tjetër kritike në grupimin e mesatareve k është edhe distanca e anëtarësisë së
grupit të vrojtimeve nga qendra e grupit të vrojtimeve. Këto dy të dhëna tregojnë edhe
homogjenitetin e vrojtimeve që bëjnë pjesë në grup edhe afërsinë ndërmjet tyre. Po ashtu,
qendrat fillestare të grupit dhe mesataret e ndryshoreve të çdo grupi gjenden me ANOVA.
Qendrat e Para të Grupeve: Është e nevojshme që të dihen qendrat e grupeve të
përcaktuara më parë sipas ndryshoreve. Qendrat e para grupore nuk janë mesatare aritmetike, ato
tregojnë vetëm qendrën e çdo grupi sipas asaj ndryshoreje.
Informatat e Përsëritjes: Tregojnë numrin e pësëritjeve të funksionit. Sugjerohen deri në
10 përsëritje (iteracione). Por në qoftë se grupimi ndodh me më pak funksione, atëherë përsëritja
nuk ka nevojë që të vazhdohet deri në 10.
Anëtarësia e Grupeve: Është një nga daljet me të rëndësishme në grupimin johierarkik.
Këtu përcaktohet se cili vrojtim është anëtar i cilit grup. Nga kjo tabelë është e mundshme që të
gjendet distanca e anëtarit të secilit vrojtim nga grupi në të cilin gjendet. Në këtë mënyrë ëshë e
mundur që të identifikohen vrojtimet më të rëndësishme brenda grupit. Hulumtuesit mund të
nxjerrin rezultate të rëndësishme nga kjo tabelë. Për shembull, duke i sjellur së bashku anëtarët e
një grupi dhe duke vrojtuar karakteristikat e përbashkëta, mund të bëhet emërimi i vrojtimeve në
këtë grup. Ky funksion edhe pse i përngjan emërimit në analizën faktoriale, në analizën
faktoriale përderisa emërohen ndryshoret, në analizën e grupimeve emërohen vrojtimet.

306
Qendrat e Fundit të Grupeve: Është një tjetër dalje me rëndësi në analizën e grupimit
johierarkik. Tregojnë mesataret e ndryshoreve sipas grupeve. Përfshin rezultate shumë të
rëndësishme rreth ndryshoreve dhe grupeve.
Distancat Ndërmjet Qendrave të Fundit të Grupeve: Ky rezultat tregon largësinë e një
grupi nga një grup tjetër. Vlerat e distancës ndërmjet dy grupeve sado që të jenë të vogla në
krahasim me të tjerat, mund të thuhet se këto dy grupe janë po aq të afërta njëra me tjetrën në
krahasim me grupet tjera. Me rritjen e vlerave të distancës, ngjashmëria zvogëlohet. Këto
rezultaten bëhen më të kuptimta dhe më të rëndësishme pas emrimit të grupeve.
Rezultatet ANOVA: Rezultatet ANOVA në analizën e grupimit përdoren për të mësuar
dallimet e ndryshoreve sipas grupeve. Dallimet e ndryshoreve sipas grupeve janë normale sepse
me analizën e grupimit dallimi ndërmjet grupeve është përcaktuar në nivelin më të lartë. Të
dhënat nga ANOVA përdoren vetëm për qëllime përshkruese.
Numri i Njësive në Grupe: Është e rëndësishme se sa anëtar gjenden në secilin grup. Nuk
është kusht që numri i anëtarëve të jetë i njëjtë në çdo grup por as nuk preferohet situata kur
ekzistojnë dallime të mëdha ndërmjet numrit të anëtarëve të grupeve.
1.15. Rregullimi i Analizës së Grupimit
Që të jetë e pranueshme një zgjidhje e analizës së grupimit duhet që hulumtuesi të shqyrtojë
strukturat themelore që prezantojnë grupet. Mirëpo duhet të kihet kujdes në rastet e
jashtëzakonshme kur grupet përbëhen vetëm nga një apo dy vrojtime apo kur madhësitë e
grupeve janë plotësisht të ndryshme nga njëra-tjetra. Një hulumtues gjatë shqyrtimit të
rezultateve i cili ndeshet me grupe të cilat kanë madhësi shumë të ndryshme nga njëra-tjetra, në
fillim duhet që të shqyrtojë literaturën, të krahasojë rezultatet e arritura me studimet e bëra më
parë dhe të krahasojë rezultatet e arritura me qëllimet dhe pritjet e hulumtimit.
Një problem tjetër janë grupet një vrojtimshe. Në qoftë se ekzistojnë vrojtime të tilla të
veçanta, këto vrojtime mund të nxirren nga analiza qysh në fillim. Në qoftë se ka grupe një
anëtarësh (një vrojtim apo në krahasim me grupet e tjera shumë i vogël), hulumtuesi duhet të
vendos këtë: Ky grup a tregon një strukturë të vlefshme brenda mostrës? Në qoftë se jo, ky
vrojtim mund të nxirret. Në qoftë se nxirret një vrojtim, sidomos kur punohet me zgjidhje
hierarkike, hulumtuesit duhet që t’a përsërisin analizën e grupimit dhe duhet të bëhet njohja e
grupeve përsëri.

307
1.16. Interpretimi i Grupeve Rreshti i parë në analizën e grupimit hierarkik, tregon fazën e parë të analizës së grupimit
dhe kolona e fazës tregon se nga sa grupe përbëhet zgjidhja. Nën titullin “Grupet e Kombinuara”
në Grupin 1 mund të shihen dy vrojtimet me të përafërta me njëra-tjetrën. Kështu, pas kësaj,
kolona “Koeficientët” mat distancën ndërmjet grupeve. Ky koeficient njihet si distanca e
katrorëve euklidian (sqaured euclidean distance) dhe sado që të jetë i vogël ky numër, tregon që
vrojtimet po aq (ngjajnë) janë më afër njëra-tjetrës. Kolona “Faza e Parë e Paraqitjes së
Grupeve” tregon se në cilën fazë formohet një grup. Kurse kolona “Faza e Ardhshme” tregon se
dy vrojtimet e atij rreshti në cilën fazën do të formojnë një grup duke u bashkuar me një vrojtim
tjetër. Në fazën e dytë dy vrojtimet e dyta shihet të jenë më të përafërta me njëra-tjetrën. Lidhjet
ndërmjet vrojtimeve gjatë fazave dhe interpretimet do të tregohen në më detaje gjatë shqyrtimit
të shembullit. Të gjitha fazat vazhdojnë derisa të arrihet në fazën e fundit. Në fazën e fundit,
tashmë distancat ndërmjet vrojtimeve do të jenë rritur. Në fund, të gjitha vrojtimet janë futur nën
një grup. Ky shpjegim është i mundur të bëhet edhe përmes grafikut të pemës duke e lexuar nga
e majta në të djathtë.
1.17. Vlefshmëria dhe Profili i Grupeve Vlefshmëria e cila garanton besueshmërinë e punimit të hulumtuesit shpreh se zgjidhja e
grupimit përfaqëson popullimin e përgjithshëm dhe në këtë mënyrë mund të bëhet përgjithësimi
për objektet/individët e tjerë dhe se kjo është e pandryshueshme. Për të krahasuar rezultatet e
analizës së grupimit dhe për të vlerësuar qëndrueshmërinë e rezultateve ekzistojnë metoda të
ndryshme nga analiza e grupimit. Në të njëjtën kohë, për shkak të kufizimeve të kohës dhe
kostove apo mosarritja me lehtësi tek klientët prej të cilëve janë mbledhur të dhënat, nuk është
edhe aq e mundur që të aplikohen këto çasje. Një çasje e përgjithshme e pranuar në vlerësimin e
vlefshmërisë është ndarja e mostrave në dy grupe. Bëhet analiza e grupimit për secilin grup të
ndarë dhe rezultatet krahasohen. Në një formë tjetër, mirren qendrat e grupeve nga njëri grup dhe
këto qendra përdoren për të njohur grupet e tjera të grupit të dytë. Pastaj kontrollohet vlefshmëria
duke i krahasuar rezultatet ndërmjet dy grupeve.
Pasi të krahasohen rezultatet e analizës së grupimit hiearkik dhe grupit johierarkik të
vrojtimeve të ndryshoreve të përcaktuara, mund të përcaktohet profili i grupeve. Tabela më e
rëndësishme e cila do të përdoret në përcaktimin e profilit është “qendrat finale të grupeve”.
Gjatë shqyrtimit të grupeve, mund të bëhet interpretim rreth karakteristikave të këtyre grupeve
dhe duke i identifikuar profilet e tyre mund t’u jipen emra grupeve.

308
2. Shembull Aplikimi
Një pronar galerie duke shqyrtuar profilet e klientëve dëshiron të identifikojë se a ekziston
ndonjë dallim ndërmjet profesionit të klientëve, rrjedhimisht statustit të të ardhurave dhe
pikëpamjeve ndaj automobilave. Në fund të hulumtimit, pronari i galerisë do t’i ndryshojë
shërbimet në lidhje me grupin shënjestër të cilët interesohen më shumë me makina dhe për të
siguruar kënaqësinë konsumatore. Duke përdorur teknikën e anketës është kërkuar vlerësimi i
deklaratave më poshtë nga një grup i mostrës i përbërë nga 20 vetë të cilët janë zgjedhur në
mënyrë të rastësishme gjatë ardhjes në galeri. Anketa është përgatitur me 7 Matjet e Likertit dhe
është kërkuar nga pjesëmarrësit që të identifikojnë edhe profesionin e tyre.
X1: Më pëlqen që të merrem (interesohem) me makina.
X2: Blerja e makinës e vështirëson buxhetin tim.
X3: Në ditët e sotme është e domosdoshme që të kesh një makinë.
X4: Gjatë blerjes së makinës në fillim i kushtoj kujdes çmimit.
X5: Nuk i di karakteristikat e makinave.
X6: Nuk më pëlqen që t’a ndërroj makinën time.
Shembulli në fillim është zgjidhur me metodën e analizës së grupimit hierarkik dhe pastaj
me metodën e analizës së grupimit johiearkik.
2.1. Analiza e Grupimit Hiearkik Hapi 1: Gjashtë deklaratat e 20 vrojtimeve janë ngarkuar si më poshtë në “Data Editor”.
Këtu gjatë njohjes së ndryshoreve, llojet e ndryshoreve X1....X6 duhet të jenë “numeric” dhe
ndryshorja e profesionit duhet të jetë “string”.

309
Hapi 1: Hyrja e të Dhënave në SPSS
Hapi 2: Nga komanda “Analyze” përzgjedhjet “Classify” dhe pas kësaj përzgjedhet
komanda “Hierarchical Cluster”.
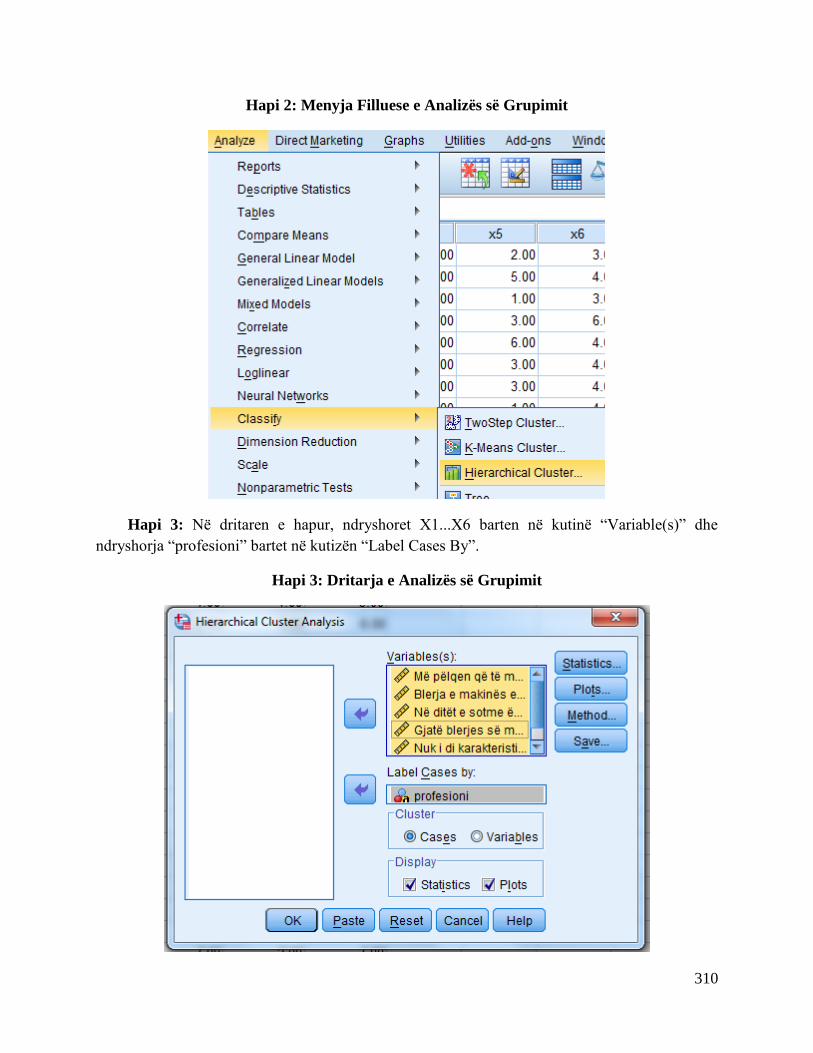
310
Hapi 2: Menyja Filluese e Analizës së Grupimit
Hapi 3: Në dritaren e hapur, ndryshoret X1...X6 barten në kutinë “Variable(s)” dhe
ndryshorja “profesioni” bartet në kutizën “Label Cases By”.
Hapi 3: Dritarja e Analizës së Grupimit

311
Hapi 4: Në fillim klikohet në komandën “Statistics” dhe bëhet etiket e nevojshme të
treguara më poshtë.
Hapi 4: Dritarja e Statistikave

312
Hapi 5: Duke klikuar “Continue” bëhet kthimi në dritaren kryesore dhe pastaj klikojmë
komandën “Plots” ku bëhen etiketimet e mëposhtme.
Hapi 5: Dritarja e Grafiqeve
Hapi 6: Përsëri duke klikuar butonin “Continue” bëhet kthimi në dritaren kryesore. Këtë
radhë duke klikuar komandën “Methods” hapet dritarja e më poshtme dhë bëhen përzgjedhjet e
nevojshme.

313
Hapi 6: Dritarja e Metodave
Në fund duke klikuar “Continue” bëhet kthimi në dritaren kryesore dhe për fitimin e
rezultateve klikohet “OK” dhe përfitohen rezultate e mëposhtme.
Tabela 7: Rezultatet e Analizës së Grupimit
Case Processing Summarya,b
Cases
Valid Missing Total
N Percent N Percent N Percent
20 100.0 0 .0 20 100.0
a. Squared Euclidean Distance used
b. Ëard Linkage
Tabela e mësipërme tregon se analiza është kryer nga 20 vetë dhe tregon përdorimin e
distancës së katrorëve euklidian dhe metodës Ward.

314
Agglomeration Schedule
Stage
Cluster Combined
Coefficients
Stage Cluster First Appears
Next Stage Cluster 1 Cluster 2 Cluster 1 Cluster 2
1 14 16 1.000 0 0 6
2 6 7 2.000 0 0 7
3 2 13 3.500 0 0 15
4 5 11 5.000 0 0 11
5 3 8 6.500 0 0 16
6 10 14 8.167 0 1 9
7 6 12 10.500 2 0 10
8 9 20 13.000 0 0 11
9 4 10 15.583 0 6 12
10 1 6 18.500 0 7 13
11 5 9 23.000 4 8 15
12 4 19 27.750 9 0 17
13 1 17 33.100 10 0 14
14 1 15 41.333 13 0 16
15 2 5 51.833 3 11 18
16 1 3 64.500 14 5 19
17 4 18 79.667 12 0 18
18 2 4 172.667 15 17 19
19 1 2 328.600 16 18 0
Rreshti i parë tregon fazën e parë të analizës së grupimit dhe përbëhet nga 19 grupe. Nën
titullin “Grupet e Kombinuara” (Cluster Combined), në Grupin 1 vrojtimi i katërmbëdhjetë (pra
student) me vrojtimin e gjashtëmbëdhjetë (pra punëtor) në Grupin 2 shihet të jenë vrojtimet më
të përafërta me njëra-tjetrën. Kështu, kolona e ardhshme “Koeficientët” mat distancën ndërmjet
vrojtimeve dhe distanca ndërmjet këtyre dy vrojtimeve shihet të jetë 1. Ky koeficienti njihet si
distanca e katrorëve euklidian (squared euclidean distance) dhe tregon se këto dy vrojtime janë
më të përafërta me njëri-tjetrin. Kolona “Faza e Parë e Paraqitjes së Grupeve” (Stage Cluster
First Appears) tregon se në cilën fazë formohet një grup. Kurse kolona “Faza e Ardhshme”
tregon se dy vrojtimet e atij rreshti në cilën fazë formojnë një grup duke u bashkuar me një
vrojtim tjetër. Për shembull, në rreshtin e parë, faza e ardhshme shihet të jetë faza e gjashtë. Pra
vrojtimi i katërmbëdhjetë dhe gjashtëmbëdhjetë të cilët marrin pjesë në këtë rresht, do të
formojnë grupin e parë në fazën e gjashtë duke marrë edhe një tjetër në mesin e tyre. Kur të
shkohet në fazën e gjashtë, shihet se vrojtimi i dhjetë (polic) u bashkangjitet vrojtimit të
katërmbëdhjetë dhe të gjashtëmbëdhjetë dhe se në kolonën “Faza e Parë e Paraqitjes së Grupeve”
në fazën e gjashtë në “Grupi 2” është formuar një grup.

315
Në fazën e dytë, vrojtimet më të përafërta janë vrojtimi i gjashtë dhe i shtatë (inxhinier dhe
student). Distanca ndërmjet tyre është 2. Në fazën e shtatë, duke iu bashkangjitur një vrojtim
tjetër këtyre dyve, formohet një grup. Po të shikojmë fazën e shtatë, mund të vërejmë se vrojtimi
i dymbëdhjetë (tregtar) u bashkohet vrojtimit të gjashtë dhe të shtatë dhe në kolonën “Grupi 1” të
“Fazës së Parë të Paraqitjes së Grupeve” është formuar grupi i dytë.
Kur të shikojmë fazën e tretë, mund të vërejmë bashkimin e vrojtimit të dytë dhe të
trembëdhjetë (pensioner dhe kontabilist). Distanca ndërmjet tyre është 3,5. Këta do të grupohen.
në fazën e pesëmbëdhjetë duke marrë një të ngjashëm Kur të shikohet faza e pesëmbëdhjetë,
shihet se këtyre u është shtuar vrojtimi i pestë (shërbyes civil). Në këtë grup formohet selia e
tretë e një grupi. Por këtu shfaqet një situatë e ndryshme. Nga “Faza e Parë e Paraqitjes së
Grupeve” në “Grupin 2” shihet grupi i tretë dhe në të njëjtën kohë në “Grupin 2” shihet numri
11. Kjo tregon që vrojtimi i pestë është element i grupit të tretë dhe në të njëjtën kohë në fazën e
ardhshme do të jetë element i grupit të njëmbëdhjetë.
Të gjitha fazat vazhdojnë në këtë mënyrë derisa të arrihet në fazën e nëntëmbëdhjetë.
Tashmë në fazën e nëntëmbëdhjetë distancat ndërmjet vrojtimeve janë rritur dukshëm. Në fund,
të gjitha vrojtimet janë mbledhur nën një grup të vetëm. Ky shpjegim është i mundur të bëhet
edhe përmes grafikut të pemës duke e lexuar nga e majta në të djathtë.

316
Tabela 8: Grafiku i Pemës
Gjatë shqyrtimit të shembullit, vërehet një rritje e madhe e koeficientëve në fazën e
shtatëmbëdhjetë, tetëmbëdhjetë dhe nëntëmbëdhjetë (79.667,172.667, 328.600). Kurse në
grafikun e pemës, vrojtimet shihet të jenë ndarë më shumë në tri grupe (14- - - 18), (2- - - 20)
dhe (3- - - 15). Në grupin e parë dhe të dytë gjenden 6 vrojtime dhe në grupin e tretë 8 vrojtime.
Këto vrojtime janë përcaktuar pranë grafikut të pemës. Gjatë shqyrtimit të koeficientëvë të
distancës dhe grafikut të pemës, mund të shihet qartë që do të jenë tri grupe. Por në rastin kur
janë 2 grupe apo 4 grupe, për të parë se në cilin grup do të jenë vrojtimet dhe sa vrojtime do të
jenë në secilin grup, etiketohet përzgjedhja “Range of solutions”.

317
Hapi 7: Përcaktimi i Numrit të Dëshiruar të Vrojtimeve në Grupet e Përfituara
Pasi të bëhen përzgjedhjet e duhura klikohet butoni Continue dhe do të paraqiten rezultatet
e mëposhtme në “Data Editor”.

318
Në qoftë se dëshirohet që numri i grupeve të jetë katër, në grupin e katërt paraqitet vetëm
vrojtimi i tetëmbëdhjetë (profesor). Kjo nuk është një zgjidhje logjike. Në qoftë se dëshirohet që
të jenë 2 grupe, në grupin e parë paraqiten 8 vrojtime dhe në grupin e dytë 12 vrojtime. Prirja e
vrojtimit të katërt (profesor), dhjetë (polic), katërmbëdhjetë (student), gjashtëmbëdhjetë
(profesor) dhe nëntëmbëdhjetë (shërbyes civil) të grupit të dytë për të formuar një grup
përbrenda vetes mund të shihet edhe nga grafiku i pemës. Në këtë rast, grupi duhet të ndahet në
dy pjesë për vrojtimet e tjera të mbetura në grup, gjë që kjo tregon se numri ideal i grupeve është
tre.
2.2. Analiza e Grupimit Johiearkik Hapi 1: Gjashtë deklaratat e 20 vrojtimeve janë ngarkuar si më poshtë në “Data Editor”.
Hapi 1: Hyrja e të Dhënave në SPSS

319
Hapi 2: Nga komanda “Analyze” përzgjedhjet “Classify” dhe komanda “K-Means
Cluster”.
Hapi 2: Menyja Filluese e Analizës së Grupimit Johierarkik
Hapi 3: Në dritaren e hapur ndryshoret X1...X6 barten në kutinë “Variables dhe ndryshorja
“profesioni” në kutizën “Label Cases by”. Numri i grupeve përcaktohet 3. Klikohet në komandën
“Iterate” dhe hapet dritarja përkatëse.

320
Hapi 3: Dritarja e Analizës së Grupimit Johierarkik
Hapi 4: Pasi të hapet dritarja “Iterate”, përcaktohet 10 “Maximum Iterations” dhe 0,2
“Convergence Criterions”.
Hapi 4: Dritarja e Iteracionit

321
Hapi 5: Përzgjedhja e radhës është komanda “Save”. Kur të klikohet në komandën “Save”
do të hapet dritarja përkatëse dhe bëhen etiketimet e nevojshme si më poshtë. Rezultati i këtyre
etiketime nuk është në dalje, por do të renditen afër vrojtimeve në “Data Editor”.
Hapi 5: Dritarja e Ruajtjes së Ndryshoreve të Reja
Hapi 6: “QCL_1” e cila do të shfaqet në Data Editor tregon për secilën ndryshore në cilin
grup ndodhet dhe “QCL_2” tregon distancën e secilit vrojtim nga qendra e grupit.
Hapi 6: Paraqitja e Vrojtimeve të Përfituara në Ekranin e të Dhënave në SPSS
Hapi 7: Në fund, duke klikuar komandën “Options” bëhen etiketimet e mëposhtme.

322
Hapi 7: Dritarja e Përzgjedhjeve
Dhe krejt në fund, klikohet butoni Continue dhe OK dhe përfitohen rezultatet e
mëposhtme.
Tabela 9: Qendrat e Para të Grupeve
Initial Cluster Centers
Cluster
1 2 3
Më pëlqen që të merrem me
makina. 4.00 2.00 7.00
Blerja e makinës e
vështirëson buxhetin tim. 6.00 3.00 2.00
Në ditët e sotme është e
domosdoshme që të kesh
një makinë.
3.00 2.00 6.00
Gjatë blerjes së makinës në
fillim i kushtoj kujdes çmimit. 7.00 4.00 4.00
Nuk i di karakteristikat e
makinave. 2.00 7.00 1.00
Nuk më pëlqen që t’a
ndërroj makinën time. 7.00 2.00 3.00
Qendrat e para të grupeve (Initial Cluster Centers): Siç u përcaktua më parë që do të
jenë tri grupe, është e dobishme që të gjenden qendrat e këtyre grupeve të ndryshoreve. Vlerat e
qendrave të grupeve, tregojnë qendrat e secilit grup në lidhje me atë ndryshore.

323
Tabela 10: Tabela e Përsëritjeve (Iteration History)
Iteration Historya
Iteration
Change in Cluster Centers
1 2 3
1 2.154 2.102 2.550
2 .000 .000 .000
a. Convergence achieved due to no or small
change in cluster centers. The maximum
absolute coordinate change for any center is
.000. The current iteration is 2. The minimum
distance between initial centers is 7.746.
Tabela e Përsëritjeve (Iteration History): Tabela e përsëritjeve jep numrin e
përsëritjeve. Në shembull, qenë sugjeruar më shumë 10 përsëritje. Mirëpo programi tregon se në
2 përsëritje janë formuar 3 grupe. Prandaj, nuk ka qenë e nevojshme të bëhen 10 përsëritje.
Tabela 11: Anëtarësia e Grupeve (Cluster Membership)
Cluster Membership
Case Number profesioni Cluster Distance
1 Doktor 3 1.414
2 Pensioner 2 1.323
3 Investues 3 2.550
4 Profesor 1 1.404
5 Shërbyes civil 2 1.848
6 Inxhinier 3 1.225
7 Student 3 1.500
8 Doktor 3 2.121
9 Amvise 2 1.756
10 Polic 1 1.143
11 Punëtor 2 1.041
12 Tregtar 3 1.581
13 Kontabilist 2 2.598
14 Student 1 1.404
15 Avokat 3 2.828
16 Punëtor 1 1.624
17 Arkitekt 3 2.598
18 Profesor 1 3.555
19 Shërbyes civil 1 2.154
20 Infermiere 2 2.102

324
Tabela e Anëtarësisë së Grupeve (Cluster Membership): Nga kjo tabelë mund të nxirren
rezultate me rëndësi. Për shembull, duke i vlerësuar së bashku vrojtimet e secilit grup (kolona
cluster) dhe duke i shqyrtuar karakteristikat e përbashkëta këtyre grupeve mund të u jipet një
emër i përbashkët.
Tabela 19: Qendrat e Fundit të Grupeve (Final Cluster Centers)
Final Cluster Centers
Cluster
1 2 3
Më pëlqen që të merrem me
makina. 3.50 1.67 5.75
Blerja e makinës e
vështirëson buxhetin tim. 5.83 3.00 3.63
Në ditët e sotme është e
domosdoshme që të kesh
një makinë.
3.33 1.83 6.00
Gjatë blerjes së makinës në
fillim i kushtoj kujdes çmimit. 6.00 3.50 3.13
Nuk i di karakteristikat e
makinave. 3.50 5.50 1.88
Nuk më pëlqen që t’a
ndërroj makinën time. 6.00 3.33 3.88
Kjo tabelë jep mesataret e gjashtë ndryshoreve në 3 grupe. Për shembull, grupit të tretë i
pëlqen më shumë që të merret me makina (5,75), kurse grupit të parë (3,50) i pëlqen më së paku.
Tabela 13: Distancat Ndërmjet Qendrave të Fundit të Grupeve
Distances between Final Cluster Centers
Cluster 1 2 3
1 5.568 5.698
2 5.568 6.928
3 5.698 6.928
Nga kjo tabelë mund të themi se grupi i parë dhe grupi i dytë janë më të përafërt me njëri-
tjetrin dhe se grupi i dytë dhe grupi i tretë janë më larg njëri-tjetrit. Kjo do të thotë që grupi i parë
merr pjesë në mes të grupit të dytë dhe grupit të tretë.

325
Tabela 14: Numri i Vrojtimeve Përkatëse Për Secilin Grup
Number of Cases in each
Cluster
Cluster 1 6.000
2 6.000
3 8.000
Valid 20.000
Missing .000
Në tabelën e mësipërme janë dhënë numrat e vrojtimeve përkatëse për secilin grup.
Tabela 15: Rezultatet e ANOVA-së të Analizës së Grupimit
ANOVA
Cluster Error
F Sig. Mean Square df Mean Square df
Më pëlqen që të merrem me
makina. 29.108 2 .608 17 47.888 .000
Blerja e makinës e
vështirëson buxhetin tim. 13.546 2 .630 17 21.505 .000
Në ditët e sotme është e
domosdoshme që të kesh
një makinë.
31.392 2 .833 17 37.670 .000
Gjatë blerjes së makinës në
fillim i kushtoj kujdes çmimit. 15.713 2 .728 17 21.585 .000
Nuk i di karakteristikat e
makinave. 22.537 2 .816 17 27.614 .000
Nuk më pëlqen që t’a
ndërroj makinën time. 12.171 2 1.071 17 11.363 .001
Rezultatet e ANOVA-së brenda analizës së grupimit duhet të përdoren për të mësuar
dallimet e ndryshoreve sipas grupeve. Dallimet e ndryshoreve sipas grupeve janë normale sepse
analiza e grupimit e ka krijuar vetë këtë ndryshim dhe e ka bërë maksimal dallimin ndërmjet
grupeve. Kështu që, shpërndarja e vrojtimeve nëpër grupe nuk është e rastësishme.

326
15. ANALIZA E BESUESHMËRISË
(RELIABILITY ANALYSIS)

327
ANALIZA E BESUESHMËRISË (RELIABILITY ANALYSIS)
Në matjen e karakteristikave të ndryshme si sjelljeve, qëndrimeve dhe të dhënave të
popullimit apo të zgjedhur rastësisht njësive të mostrës në lidhje me çështjen e hulumtimit, janë
zhvilluar matës të ndryshëm të tilla si anketat, të njohura si mjete matëse që përbëhen nga një
numër i caktuar pyetjesh. Gjatë krijimit të një mjeti të besueshëm matjetje (matësi) duhet të
kihen parasysh shumë pika. Disa nga këto pika janë aftësia e pyetjeve të cilat e përbëjnë matësin
për të zbuluar saktësinë e hulumtimit, ekzistimi i lidhjes ndërmjet tyre, qëndrueshmëria, të qenit
të kuptueshme dhe në numër të mjaftueshëm etj.
Për të përcaktuar besueshmërinë e një matjeje të bërë mbi një ndryshore, analiza e
korrelacionit është një nga aplikimet më të rëndësishme. Në qoftë se matjet mbi një set të
objekteve (njësi-objects) nuk mund të përfitohen përsëri nënkupton që ekzistojnë ndryshore
ekstreme të rezultateve (pikëve) të fituara ose rezultatet e perfituara nga secili objekt (njësi) janë
të rastësishme. Sidoqoftë në secilin rast, në qoftë se matja e njësisë nuk reflekton karakteristikat
e veta, nuk njihet si një matje e mirë.
Koncepti i besueshmërisë është i nevojshëm për secilën matje të bërë sepse besueshmëria
shpreh qëndrueshmërinë ndërmjet pyetjeve të cilat marrin pjesë në një test apo anketë dhe në
çfarë mase matësi i përdorur pasqyron pyetjen. Besueshmëria përbën një bazë për interpretimin e
matjeve të përfituara dhe analizave të cilat mund të zbulohen më vonë.
Gjatë vrojtimit të një seti të njësive për një ndryshore, pyetja e parë e cila do na vij në
mendje është se shpërndarja e rezultateve të përfituara a është e rastësishme apo njësitë burojnë
nga karakteristikat e tyre të vërteta. Në rastin e dytë, në matjet e bëra në kohë të ndryshme secila
njësi do të ketë vlera të njëjta apo të ngjashme të rezultateve. Në këtë rast mund të themi se
matësit janë të besueshëm, në të kundërtën matësit nuk janë të besueshëm.
Shembull: Le të supozojmë se një firmë dëshiron të aplikoj një test me qëllim për të matur
diturinë e kandidatëvë që kanë aplikuar për punë. Ky test le të jepet ndaras në dy ditë. Në qoftë
se rezultatet e dy ditëve nuk tregojnë ndonjë lidhje ndërmjet vete atëherë ky rast shpreh se
ekziston një problem në testin e aplikuar apo në kandidatët që kanë aplikuar për punë sepse në
qoftë se testi të cilin e kemi aplikuar është i qëndrueshëm, pritjet tona nga rezultatet janë që ata të
cilët kanë marrë rezultate të larta apo të ulëta në ditën e parë, do të shfaqin një situatë të njëjtë
apo të ngjashme brenda dy ditëve. (Këto lloje të testeve quhen testimi-ritestimi i besueshmërisë
(test-retest reliability)). (Burimi: Kachigan. Sam K. “Multivariate Statistical Analysis: a
conceptual introduction”, 2nd ed.. Radius Press. Neë York)
Analiza e Besueshmërisë (Reliability Analysis) është metodë e zhvilluar për vlerësimin e
karakteristikave dhe besueshmërisë së testeve, anketave apo matësve të përdorur gjatë matjes.
Me procedurën e Analizës së Besueshmërisë bëhet llogaritja e koeficientëve të cilët

328
përcaktojnë besueshmërinë e rezultateve (pikëve) totale të matësve si Likertit, tipi Q dhe
përfitohen informata në lidhje me marrëdhënien ndërmjet pyetjeve të matësit.
Në qoftë se do t’a përmbledhnim me një shembull: për hulumtimin e kënaqësisë
konsumatore, për anketën apo testin e përgatitur, duke e bërë analizën e besueshmërisë mund të
hulumtojnë pyetjen “Kënaqësia konsumatore a është duke u matur në një mënyrë të mirë?”. Po
ashtu, me ndihmën e kësaj analize, mund të grupohen pyetjet përkatëse dhe mund të zbulohen
pyetjet problematike të matësit.
1. SUPOZIMET E ANALIZËS SË BESUESHMËRISË Njësitë e vrojtuara duhet të jenë të pavarura nga njëra-tjetra dhe nuk duhet të ketë
marrëdhënie ndërmjet gabimeve dhe pyetjeve të cilat e përbëjnë matësin.
Çdo pyetje çifte dy-ndryshoresh duhet të ndjek shpërndarjen normale.
Matësi duhet të ketë karakteristikën e shtimit (additivity). Në këtë mënyrë çdo pyetje e
matësit do të ketë lidhje lineare me rezultatet totale.
Si shtesë e supozimeve të mësipërme, për t’a bërë analizën e besueshmërisë duhet të
kihen parasysh dy kushte në lidhje me numrin e nevojshëm të k pyetjeve të cilat e
përbëjnë matësin dhe n njësive ndaj të cilave aplikohet matësi.
Këto janë:
Numri i pyetjeve të cilat e përbëjnë matësin (me përjashtim të çështjeve të cilat
hulumtojnë karakteristikat individuale) duhet të jetë k > 30
Numri i njësive të pavarura ndaj të cilave do të aplikohet matësi duhet të jetë n > 50.
2. ANALIZAT DHE TESTET NË LIDHJE ME MATËSIT Në qoftë se do t’i përmbledhnim shkurtë analizat dhe testet në lidhje me besueshmërinë e
matësit të cilat do të na i jep SPSS në vazhdim:
Njësitë (individët) përgjegjës të pyetjeve të një matësi dhe rëndësia e tyre sipas pyetjeve
bëhet me analizën e variancës dy drejtimshe (two-way analysis of variance). Kurse
analiza e ngjashmërisë ndërmjet pyetjeve që e përbëjnë matësin përfitohet me testin F.
Në qoftë se përgjigjjet e pyetjeve të matësit janë dhënë me rezultate (pika) renditëse,
analiza e dallimeve ndërmjet individëve dhe pyetjeve bëhet me testin Friedman
Katrori-Ki (Friedman Chi-square test).
Në qoftë se përgjigjjet e pyetjeve të matësit janë dhënë dy vlerash në formën 0 apo 1,
atëherë analiza e rëndësisë sipas individëve dhe pyetjeve bëhet me testin Cochran
Katrori-Ki (Cochran Chi-square).
Përshtatshmëria e një matësi me llojin shtues (additivity) të matësit bëhet me testin
mbledhës Tukey (Tukey’s additivity test).

329
Për të parë se pyetjet e një matësi a përceptohen me të njëjtën çasje nga individët dhe
secila pyetje e cila merr pjesë në matës a është e barabartë me shkallën e vështirësë
përdoret statistika Hotelling T2 (Hotelling’s T
2 statistic).
Në disa hulumtime matës themelorë janë sjelljet e përfituara nga testet e shkruara apo
gojore ose vrojtimet e koduara mbi njësitë. Në të këtilla situata, veçanërisht, ekzistojnë dy
apo më shumë vlerësues (rater) vrojtues të sjelljeve së njësive të testuara. Në këtë rast,
është ngjashmëria e vlerësimeve të bëra ndërmjet vlerësuesve të besueshmërisë dhe quhet
besueshmëria ndërmjet vlerësuesve (interrater reliability). Koeficientët e
korrelacionit ndërmjet klasëve (interclass correlation coefficients) përdoren për të
vlerësuar këtë besueshmëri.
3. MODELET E PËRDORURA NË ANALIZËN E BESUESHMËRISË
3.1. Modeli Alfa (α) (Cronbach Alpha Coefficient) Kjo metodë hulumton se k pyetjet të cilat marrin pjesë në matës a tregojnë një strukturë
homogjene në përgjithësi. Është mesatarja e ndryshimit standart të ponderuar dhe përfitohet me
ndarjen e totalit të variancave të k pyetjeve të një matësi me variancën e përgjithshme. Ky
koeficient, i cili merr vlerat ndërmjet 0 dhe 1 quhet koeficienti Alfa (Cronbach).
Koeficienti i llogaritur Alfa është një koeficient i cili zbulon ngjashmërinë apo afërsinë e
pyetjeve në matjet e përfituara nga rezultatet totale të njësive dhe mbledhjen e pikave të çdo
pyetjeje të matësit. Në qoftë se është bërë standardizimi i pyetjeve, ky koeficient përfitohet nga
korrelacioni mesatar i pyetjeve.
Në qoftë se korrelacioni ndërmjet pyetjeve është negativ edhe koeficienti Cronbach Alfa i
llogaritur me metodën Alfa do të jetë negativ. Kur ky koeficient është negativ shkakton prishjen
e modelit të besueshmërisë. Me fjalë të tjera, shpreh prishjen e karakteristikës shtuese të matësit
të përdorur.
Interpretimet e besueshmërisë së matësit në lidhje me koeficientin Alfa (α) mund të bëhen si
më poshtë:
nëse 0.00 ≤ α ≤ 0.40 matësi nuk është i besueshëm,
nëse 0.40 ≤ α ≤ 0.60 besueshmëria e matësit është e ulët,
nëse 0.60 ≤ α ≤ 0.80 matësi është shumë i besueshëm dhe
nëse 0.80 ≤ α ≤ 1.00 matësi është një matës me shkallë të lartë të besueshmërisë.

330
3.2. Modeli Ndarës Mëdysh (Split Half) Ky model pyetjet e matësit i ndan në dy pjesë dhe llogarit korrelacionin ndërmjet pjesëve.
Në të njëjtën kohë llogarit koeficientët Alfa α për secilën pjesë. Në qoftë se numri i pyetjeve të
matësit është çift, secila pjesë merr k/2 pyetje. Në rastet kur numri i pyetjeve është tek, numri i
pyetjeve në pjesën e parë është (k+1)/2 dhe pyetjet e mbetura e formojnë pjesën tjetër.
3.3. Modeli Guttman Në modelet në të cilat llogaritet besueshmëria me çasjen e kovariancës apo variancës, për
një besueshmëri të vërtetë llogariten kufinjët minimal të Gutmmanit dhe gjashtë koeficientët e
besueshmërisë, prej 1 lambda deri ne 6 lambda.
3.4. Modeli Paralel Ky model supozon barazinë e variancave për të gjitha pyetjet e matësit dhe barazinë e
gabimit të variancave brenda pyetjeve përsëritëse. Me këtë model bëhet vlerësimi më i lartë i
ngjashmërisë dhe përshtatshmëria e vlerësimit ndaj vlerave bëhet me testin Katrori-Ki (chi-
square).
3.5. Modeli Strikt Paralel Në këtë model supozimi i barazisë së variancave dhe në të njëjtën kohë barazia e
mesatareve ndërmjet pyetjeve janë tema kryesore.
Duke shikuar statistikat përshkruese të secilës pyetjeje që e formon matësin mund të
vendosim se cilin nga modelet e mësipërme do t’a përdorim për analizën e besueshmërisë. Për
shembull, në qoftë se ekziston barazi (homogjeniteti) e variancave ndërmjet pyetjeve, duke
përdorur modelet Alfa dhe Paralel, koeficientët e përfituar të besueshmërisë vlerësohen si
koeficienti i besueshmërisë së matësit. Në qoftë se mesataret ndërmjet pyetjeve janë homogjene,
përdoret koeficienti i besueshmërisë i Modelit Strikt.

331
4. Shembull Aplikimi
Për t’a aplikuar analizën e besueshmërisë në SPSS, shkohet te Analysis Scale
Reliability Analysis.
Hapi 1: Menyja e Analizës Reliability
Më vonë në këtë dritare, në pjesën Items (Pyetjet) (për matësin shtesë / additive scale)
transferohen dy apo më shumë pyetje (ndryshore / item).

332
Hapi 2: Dritarja e Analizës Reliability
Items: Është pjesa e cila bën njohjen e pyetjeve (items) të përdorura në matës.
Model Alpha (cronbach): Është modeli në lidhje me korrelacionin ndërmjet pyetjeve. Jep
koeficientin Alpha (Alfa). Ky koeficienti i cil merr dy vlera 0 apo 1 (Dichotomous) është i
barabartë me Kuder-Richardson 20 (KR20). Split Half Models: E ndan matësin mëdysh dhe
shqyrton korrelacionin ndërmjet pjesëve. Llogarit koeficientin Alfa për secilën pjesë. Po ashtu
jep edhe koeficientin e gjysëm-besueshmërisë Gutman Split dhe për gjatësinë e të dhënave të
barabarta dhe jo të barabarta jep koeficientin e besueshmërisë Spearman-Brown. Guttman
Models: Jep koeficientin e besueshmërisë nga lambda 1 deri në lambda 6 për besueshmërinë e
vërtetë. Parallel ve Strict Parallel Models: Llogarit testin e përshtatshmërisë së modelit (test for
Goodness-of-fit of model), vlerën e gabimit të variancës, vlerat e përbashkëta dhe të vërteta të
variancës, vlerat e korrelacionit të përbashkët ndërmjet pyetjeve, besueshmërinë e parashikuar ve
vlerën e paanshme të besueshmërisë.
Nga lista Model (drop-down) etiketohet përzgjedhjat e modelit përkatës.
Duke klikuar në butonin Statistics etiketohen përkufizimet ose testet për matësin apo për
çfarëdo pyetje dhe shtypet butoni Continue. Duke shtypur butonin OK bëhet procesimi dhe
përfitohen të dalurat e programit.

333
Hapi 3: Dritarja e Statistikave
Descriptive for: Në dritaren Reliability Analysis: Statistics ekzistojnë tri përzgjedhje për
bërjen e statistikave përshkruese, analizave apo testeve të dëshiruara: matës (scale), pyetje
(item) dhe matësi në qoftë se pyetjet janë fshirë (scale if item deleted).
Inter-Item: Është pjesa prej të cilës përfitohet korrelacioni ndërmjet pyetjeve
(correlations) dhe matricat e kovariancave (covariances).
Summaries: Llogarit statistikat përshkruese, mesataren, variancën, kovariancën dhe vlerat e
korrelacionit për shpërndarjen e të gjitha pyetjeve të matësit.
ANOVA table: Tabela ANOVA jep testet të cilët matin barazinë e mesatareve. Zgjedhjet
janë asnjëra (none), testi F (F test), testet Friedman dhe Cochran Katrori-Ki (chi-square).
Hotelling’s T-square: Hotelling T2 është nje test shumëndryshoresh që analizon barazinë e
mesatareve të të gjitha pyetjeve të matësit.
Tukey’s test of additivity: Është test që hulumton karakteristikën e shtimit (additivity) të
matësit.

334
Intraclass correlation coefficient: Llogarit koeficientët të cilët masin qëndrueshmërinë e
vlerave dhe pajtueshmërinë absolute brenda njësive. Model: Përcakton modelin përmes të cilit
dëshirojmë të llogarisim koeficientin e korrelacionit ndërmjet klasave. Modelet të cilat mund të
përdoren janë: Përzierja Dy Drejtimshe (Two-Way Mixed), Rastësia Dy Drejtimshe (Two-Way
Random) dhe Rastësia Një Drejtimshe (One-Way Random). Type: Paraqet llojin e treguesit.
Gjenden treguesit e qëndrueshmërisë dhe përshatjes absolute. Confidence Interval: Përcakton
nivelin e intervalit të interesuar të besueshmërisë (1-alfa). Në rastet kur nuk jepet ndonjë vlerë,
në mënyrë automatike merret vlera 95%. Test value: Është vlera e koeficientit të llogaritur e cila
do të krahasohet apo testohet në testimin e hipotezave. Në rastet kur nuk përcaktohet, vlera e
testit është 0.
5. Shembull Aplikimi Në një firmë të pijeve u është dhënë 91 punëtorëve një test i përbërë nga 32 pyetje në lidhje
me përvojat e punës i quajtur “matësi i kënaqësisë së punës” (Burimi: Batıgün, D.A., Şahin,
H.N. (2005) “Dy Matësit për Hulumtimin e Stresit të Punës dhe Shëndetit Psikologjik:
Personaliteti i Llojit-A dhe Kënaqësia e Punës”, Revista Turke e Psikiatrisë (gjatë fazës së
vlerësimit)).
Me Matësin e Kënaqësisë së Punës me 32 pyetjet është është pyetur se në ç’shkallë janë të
kënaqur (kënaqësia e punës) dhe është kërkuar të bëhet një vlerësim prej 0% deri në 100%.
Pikësimi i llojit të matësit të Likertit është në këtë mënyrë: 0%=1, 25%=2, 50%=3, 75%=4 dhe
100%=5. Renditja e pikëve është prej 1 deri në 160 dhe pikët e larta të marrura nga matësi
shprehin kënaqësinë e lartë të punës. Nga faktorët e përfituar (nën-matësit) në fund të analizës
faktoriale të aplikuar mbi këtë matës njëri nga këta Faktorë Individual është nën-matësi në
lidhje me kënaqësinë e punës i pëbërë nga 5 pyetje.
Përgjigjet e dhëna në lidhje me këtë nën-matës të pyetjeve 12, 21, 30, 31, 32 të 91
punëtorëve janë koduar si më poshtë në SPSS.
Tabela 1: Përgjigjet e Marra nga Anketa
PYETJA NR.
VETA P12 P21 P30 P31 P32
1 3 3 3 3 3
2 4 4 4 4 4
3 2 2 2 3 3
4 3 3 3 3 3
5 3 3 2 1 2
6 4 4 4 4 4
7 3 4 3 1 1
8 2 2 4 4 4
9 2 1 2 2 2

335
10 2 0 3 2 2
11 3 2 1 1 2
12 1 2 1 1 1
13 4 4 4 4 4
14 3 4 4 2 3
15 3 3 2 2 3
16 3 4 3 4 4
17 3 3 3 4 2
18 4 4 3 1 4
19 2 3 2 2 2
20 3 3 2 3 3
21 4 3 4 4 4
22 2 3 4 4 4
23 3 4 3 3 3
24 3 4 4 3 4
25 3 2 3 3 3
26 3 2 3 2 3
27 3 3 3 2 2
28 4 4 4 3 4
29 2 3 2 2 3
30 3 4 4 4 4
31 4 4 4 4 3
32 4 1 0 0 0
33 3 3 2 0 2
34 4 4 4 4 4
35 1 2 3 3 3
36 2 2 2 2 2
37 3 4 4 0 3
38 2 1 2 2 2
39 3 4 4 3 3
40 2 1 1 1 1
41 3 3 2 3 3
42 4 4 4 4 4
43 3 9 3 3 3
44 3 3 4 2 4
45 4 2 4 4 4
46 0 0 0 0 1
47 2 2 3 2 2
48 3 3 3 2 3
49 3 2 4 4 4
50 3 3 3 3 3
51 3 2 3 3 3
52 3 4 3 4 3
53 4 3 4 4 4
54 4 4 4 4 4

336
55 3 4 4 4 4
56 3 4 2 2 3
57 0 0 3 0 1
58 3 3 4 4 4
59 3 3 3 3 3
60 4 4 4 4 4
61 3 3 3 3 3
62 4 3 4 4 4
63 4 4 2 1 1
64 2 3 3 3 3
65 2 3 3 3 3
66 4 4 4 3 4
67 4 4 4 4 4
68 4 4 4 3 4
69 4 4 4 4 4
70 2 2 3 1 4
71 4 3 4 4 4
72 2 2 3 3 4
73 2 3 4 2 2
74 3 4 4 2 4
75 2 2 3 0 3
76 3 3 3 4 3
77 3 3 4 3 4
78 3 3 3 3 3
79 3 4 3 2 2
80 3 3 4 3 3
81 3 3 3 3 3
82 2 2 1 1 0
83 3 3 3 2 2
84 4 4 4 4 4
85 3 3 3 4 4
86 3 4 4 2 4
87 3 1 2 1 3
88 4 4 4 3 3
89 3 3 4 3 3
90 3 1 2 3 3
91 4 3 3 4 3

337
Hapi 1: Hyrja e të Dhënave në SPSS

338
Hapi 2: Dritarja e Analizës Reliability
Hapi 3: Dritarja e Statistikave

339
Rezultatet e përfituara të Analizës së Besueshmërisë duke aplikuar modelin Alfa për setin e
të dhënave të nënmatësit të Faktorëve Individual janë si më poshtë.
Tabela 2: Rezultatet e Analizës së Besueshmërisë Sipas Modelit Alfa5
Item Statistics
Mean Std. Deviation N
p12 2.9560 .86810 91
p21 3.0000 1.22020 91
p30 3.0879 .97352 91
p31 2.6813 1.20995 91
p32 3.0220 .99976 91
Inter-Item Covariance Matrix
p12 p21 p30 p31 p32
p12 .754 .589 .404 .508 .423
p21 .589 1.489 .589 .567 .522
p30 .404 .589 .948 .739 .742
p31 .508 .567 .739 1.464 .840
p32 .423 .522 .742 .840 1.000
Inter-Item Correlation Matrix
p12 p21 p30 p31 p32
p12 1.000 .556 .478 .484 .488
p21 .556 1.000 .496 .384 .428
p30 .478 .496 1.000 .628 .763
p31 .484 .384 .628 1.000 .695
p32 .488 .428 .763 .695 1.000
Case Processing Summary
N %
Cases Valid 91 100.0
Excludeda 0 .0
Total 91 100.0
a. Listwise deletion based on all variables in the
procedure.
5 Tabelat janë të renditura sipas librit për shkak të interpretimit, kurse renditja sipas rezultateve të SPSS-it është e
ndryshme.

340
Scale Statistics
Mean Variance Std. Deviation N of Items
14.7473 17.502 4.18355 5
Summary Item Statistics
Mean Minimum Maximum Range
Maximum /
Minimum Variance
N of
Items
Item Means 2.949 2.681 3.088 .407 1.152 .025 5
Item Variances 1.131 .754 1.489 .735 1.976 .108 5
Inter-Item Covariances .592 .404 .840 .437 2.081 .019 5
Inter-Item Correlations .540 .384 .763 .379 1.988 .014 5
Item-Total Statistics
Scale Mean if
Item Deleted
Scale Variance
if Item Deleted
Corrected Item-
Total
Correlation
Squared
Multiple
Correlation
Cronbach's
Alpha if Item
Deleted
p12 11.7912 12.900 .617 .409 .827
p21 11.7473 11.480 .548 .378 .850
p30 11.6593 11.605 .746 .630 .793
p31 12.0659 10.729 .670 .525 .813
p32 11.7253 11.446 .748 .664 .791
ANOVA with Tukey's Test for Nonadditivity
Sum of Squares df Mean Square F Sig
Between People 315.037 90 3.500
Within People Between Items 9.002 4 2.251 4.181 .003
Residual Nonadditivity 1.451a 1 1.451 2.708 .101
Balance 192.347 359 .536
Total 193.798 360 .538
Total 202.800 364 .557
Total 517.837 454 1.141
Grand Mean = 2.9495
a. Tukey's estimate of power to which observations must be raised to achieve additivity = 2.423.
Hotelling's T-Squared Test
Hotelling's T-
Squared F df1 df2 Sig
17.326 4.187 4 87 .004

341
Reliability Statistics
Cronbach's
Alpha
Cronbach's
Alpha Based on
Standardized
Items N of Items
.846 .854 5
Në pjesën e parë të rezultateve të analizës së besueshmërisë nga SPSS janë dhënë statistikat
përshkruese përkatëse të 5 pyetjeve të cilat e përbëjnë nënmatësin e faktorit individual:
mesataret, variancat dhe matricat e variancës-kovariancës të cilat tregojnë lidhjen ndërmjet
variancave dhe pyetjeve. Mesatarja e matësit të përbërë nga 5 pyetje është 14,7472 dhe
devijimi standart 5,27153. Mesatarja e përgjithshme (grand mean) e pyetjeve është 2,949
dhe varianca mesatare 1,131. Intervali i mesatareve të 5 pyetjeve është 0,407 dhe intervali i
ndryshimit të variancave është 0,735. Në mënyrë të ngjashme, mesatarja e përgjithshme e
korrelacioneve ndërmjet pyetjeve (inter-item correlations) është 0,540, kurse korrelacioni
minimal është 0,384 dhe korrelacioni maksimal 0,763.
Në pjesën Item-total Statistics, me rastin e nxjerrjes së një pyetjeje nga matësi është
llogaritur mesatarja e matësit dhe variancës nga pyetjet e mbetura (scale mean if item deleted
dhe scale variance if item deleted) si dhe korrelacioni ndërmjet pyetjes së nxjerrë nga matësi
dhe totalit të pyetjeve tjera të matësit (corrected Item-Total correlation). Po ashtu, pas
nxjerrjes së pyetjes përkatëse nga matësi, në këtë pjesë raportohen edhe koeficientët e
korrelacionit të shumëfishtë (Squared Multiple correlation, R2) dhe vlera e besueshmërisë Alfa
(Alpha if item deleted) në lidhje me pyetjet e mbetura.
Në këtë pjesë me ndihmën e rezultateve të përfituara hulumtohet se secila pyetje e adresuar
(e nxjerrur nga matësi – item deleted) a bart karakteristikën e shtimit përsëri në matës. Në
qoftë se kontributi i korrelacionit total të pyetjes së rregulluar (corrected item – total
correlation) është i ulët, kontributi i pyetjes përkatëse do të jetë i ulët në gjithë matësin. Pyetjet
të cilat kanë vlera shumë të ulëta, duhet të nxirren nga matësi.
Në punimin tonë, korrelacionet Pyetje-Total (Item-Total) janë ndërmjet 0,548 dhe 0,748
dhe si të tilla paraqesin vlera të larta. Për mos-prishjen e karakteristikës së shtimit të matësit,
pritet që koeficientët e korrelacionit ndërmjet pyetjeve dhe totalit të jenë negative dhe më të
mëdha se vlera 0,25. Sipas këtij koeficienti për të vendosur nëse një pyetje duhet nxjerrë nga
matësi duhet të vlerësohet rëndësia e pyetjes përkatëse duke shikuar ndryshimin në koeficientin e
besueshmërisë Alfa (Alpha if item deleted) dhe ndryshimin në mesataren dhe variancën (scale
mean and scale variance if item deleted) pasi të jetë nxjerrë pyetja.
Në shembullin tonë, mund të themi se këto vlera nuk tregojnë ndonjë ndryshim të madh
ndërmjet veti.

342
Koeficienti i përgjithshëm Alfa i besueshmërisë së matësit i llogaritur në tabelën e fundit
është 0,846. Kjo është një vlerë e lartë dhe tregon se matësi i përdorur është shumë i besueshëm.
Me nxjerrjen e pyetjes përkatëse nga matësi, me rastin e krahasimit të koeficientit Alfa me
koeficientin e përgjithshëm Alfa të besueshmërisë mund të shohim se vlerat e llogaritura janë
shumë afër vlerës së përgjitshme Alfa 0,846 apo më të ulëta. Ky rast tregon se të gjitha pyetjet
duhet të marrin pjesë në matës. Nëse me rastin e nxjerrjes së një pyetjeje nga matësi vlera e
përfituar Alfa është më e madhe se Alfa e përgjithshme, ajo është një pyetje e cila e zvogëlon
besueshmërinë dhe që duhet të nxirret nga matësi. Në rastin e kundërt, pra, në qoftë se Alfa e
llogaritur është nën vlerën e përgjithshme Alfa, ajo pyetje duhet të marrë pjesë në matës. Në
shembullin tonë, sipas vlerës së përfituar Alfa (Alpha if item deleted) pas nxjerrjes së pyetjes,
mund të bëjmë renditjen e pyetjeve në formën nga më e vogla te më e madhja, P32, P30, P31,
P12, P21. Sipas kësaj renditjeje tri pyetjet e fundit nuk e ndryshojnë besueshmërinë e matësit por
janë pyetje që e mbështesin matësin. P32 dhe P31 janë pyetje që e rrisin besueshmërinë, qoftë
edhe pak.
Siç u cek më parë, më qëllim për të testuar përshtatshmërinë e modelit në llogaritjet e
besueshmërisë në lidhje me matësit, përdoren testet Hotelling T2, F, Friedman Katrori-Ki apo
Cochran Katrori-Ki. Rezultatet përkatëse të këtyre testeve janë dhënë në tabelën e analizës së
variancës (analysis of variance) dhe në tabelat e fundit.
Kur shikojmë tabelën e analizës së variancës për shembullin tonë, mund të themi se dallimi
ndërmjet matjeve (between measures) P=0,003 është i rëndësishëm statistikisht si dhe vlera e
karakteristikës së mosmbledhjes (nonadditivity) P=1,01 nuk është e rëndësishme statistikisht. Me
fjalë të tjera, nënmatësi pesë-pyetjesh ka karakteristikën e mbledhjes mirëpo ekzistojnë dallime
ndërmjet matjeve.
Testi Hotelling’s T2 i cili teston barazinë e mesatareve të pyetjeve është llogaritur P=0,004.
Ky rezultat shpreh se ekziston një dallim i rëndësishëm statistikor ndërmjet mesatareve të
pyetjeve. Me fjalë të tjera, ekziston dallim së paku ndërmjet dy mesatareve. Duhet të hulumtohet
se nga cilat pyetje buron ky dallim. Duke shikuar pyetjet të cilat shkaktojnë dallimin apo sipas
kritereve tjera të pyetjeve duhet të vendoset në lidhje më nxjerrjen e tyre nga matësi.
Në qoftë se dëshirojmë të bëjmë analizën e besueshmërisë për nënmatësin e Faktorëve
Individual sipas modelit Split Half në dritaren Reliability Analysis nga pjesa Model
përzgjedhet Split Half.

343
Hapi 4: Aplikimi i Modelit Split-Half
Rezultatet e SPSS-it janë si më poshtë. (Notë: Statistikat përshkruese nuk janë paraqitur
përsëri ngaqë janë të njëjtat me tabelat e mëparshme.)
Tabela 3: Rezultatet e Analizës së Besueshmërisë sipas Modelit Split-Half6
Case Processing Summary
N %
Cases Valid 91 100.0
Excludeda 0 .0
Total 91 100.0
Scale Statistics
Mean Variance Std. Deviation N of Items
Part 1 9.0440 6.354 2.52064 3a
Part 2 5.7033 4.144 2.03576 2b
Both Parts 14.7473 17.502 4.18355 5
a. The items are: p12, p21, p30.
b. The items are: p31, p32.
6 Tabelat janë të renditura sipas librit për shkak të interpretimit, kurse renditja sipas rezultateve të SPSS-it është e
ndryshme.

344
Summary Item Statistics
Mean Minimum Maximum Range
Maximum
/ Minimum Variance
N of
Items
Item Means Part 1 3.015 2.956 3.088 .132 1.045 .005 3a
Part 2 2.852 2.681 3.022 .341 1.127 .058 2b
Both Parts 2.949 2.681 3.088 .407 1.152 .025 5
Item Variances Part 1 1.063 .754 1.489 .735 1.976 .145 3a
Part 2 1.232 1.000 1.464 .464 1.465 .108 2b
Both Parts 1.131 .754 1.489 .735 1.976 .108 5
Inter-Item Covariances Part 1 .527 .404 .589 .185 1.458 .009 3a
Part 2 .840 .840 .840 .000 1.000 .000 2b
Both Parts .592 .404 .840 .437 2.081 .019 5
Inter-Item Correlations Part 1 .510 .478 .556 .078 1.163 .001 3a
Part 2 .695 .695 .695 .000 1.000 .000 2b
Both Parts .540 .384 .763 .379 1.988 .014 5
a. The items are: p12, p21, p30.
b. The items are: p31, p32.
ANOVA with Tukey's Test for Nonadditivity
Sum of Squares df Mean Square F Sig
Between People 315.037 90 3.500
Within People Between Items 9.002 4 2.251 4.181 .003
Residual Nonadditivity 1.451a 1 1.451 2.708 .101
Balance 192.347 359 .536
Total 193.798 360 .538
Total 202.800 364 .557
Total 517.837 454 1.141
Grand Mean = 2.9495
a. Tukey's estimate of power to which observations must be raised to achieve additivity = 2.423.
Hotelling's T-Squared Test
Hotelling's T-
Squared F df1 df2 Sig
17.326 4.187 4 87 .004

345
Reliability Statistics
Cronbach's Alpha Part 1 Value .747
N of Items 3a
Part 2 Value .811
N of Items 2b
Total N of Items 5
Correlation Between Forms .682
Spearman-Brown Coefficient Equal Length .811
Unequal Length .816
Guttman Split-Half Coefficient .800
a. The items are: p12, p21, p30.
b. The items are: p31, p32.
Në rezultatet e modelit Split-Half vërehet një situatë më ndryshe nga modeli Alfa ku janë të
paraqitura vlerat e statistikave përshkruese të dy pjesëve të shprehura si part1 dhe part2.
Rezultatet e analizës së variancës janë të njëjta për të dy modelet. Në fund të tabelës janë dhënë
koeficientët e llogaritur Alfa të besueshmërisë të 5 pyetjeve (Reliability Statistics) të ndarë në dy
vlera. Sipas rezultateve të mësipërme, vlera e përgjithshme Alfa për pjesën e parë (part 1) është
0,747 dhe për pjesën e dytë (part 2) 0,811. Besueshmëria në të dy pjesët është e përafërt dhe
shumë e lartë. Këto vlera shprehin atributet e pyetjeve të mbajtura në matës.
Në modelin Split-Half, besueshmëria e matësit përcaktohet me koeficientin e korrelacionit
ndërmjet formave, pjesëve (correlation between forms). Në të njëjtën kohë, edhe koeficientët
Guttman Split Half, gjatësia e barabartë apo jo e barabartë e Spearman-Brown marrin pjesë në
rezultate si matës të busueshmërisë. Sipas tabelës, me radhë koeficientët e besueshmërisë 0,682,
0,811, 0,816 dhe 0,800 shprehin se besueshmëria e matësit është e lartë.
Kur dëshirojmë t’a bëjmë Analizën Reliability sipas modelit Guttman, nga komanda
Model, përzgjedhet Guttman.

346
Hapi 5: Aplikimi i Modelit Guttman
Rezultatet e SPSS-it janë si më poshtë. (Notë: Rezultatet e njëjta që marrin pjesë në tabelat
e tjera si statistikat përshkruese, analiza e variancës etj., nuk janë paraqitur në tabelën e
mëposhtme.)
Tabela 4: Rezultatet e Analizës së Besueshmërisë Sipas Modelit Guttman
Reliability Statistics
Lambda 1 .677
2 .851
3 .846
4 .800
5 .832
6 .843
N of Items 5
Sipas modelit Guttman, koeficienti më i ulët i besueshmërisë nga gjashtë koeficientët e
llogaritur është me 0,677 lambda dhe vlerat e tjera janë shumë të larta. Sipas këtyre vlerave,
matësi është shumë i besueshëm.
Kur dëshirojmë t’a bëjmë Analizën Reliability sipas modelit Parallel, nga komanda Model,
përzgjedhet Parallel.

347
Hapi 6: Aplikimi i Modelit Parallel
Rezultatet e SPSS-it janë si më poshtë. (Notë: Rezultatet e njëjta që marrin pjesë në tabelat
e tjera si statistikat përshkruese, analiza e variancës etj., nuk janë paraqitur në tabelën e
mëposhtme.)
Tabela 5: Rezultatet e Analizës së Besueshmërisë sipas Modelit Paralel
Test for Model Goodness of Fit
Chi-Square Value 64.426
df 13
Sig .000
Log of Determinant of Unconstrained Matrix -1.957
Constrained Matrix -1.224
Reliability Statistics
Common Variance 1.131
True Variance .592
Error Variance .538
Common Inter-Item
Correlation .524
Reliability of Scale .846
Reliability of Scale
(Unbiased) .850

348
Sipas metodës Paralel, koeficienti i besueshmërisë është koeficienti i vlerësuar i
besueshmërisë së matësit (estimated reliability of scale). Kjo vlerë për shembullin tonë është
llogaritur të jetë 0,846 dhe shpreh besueshmëri të lartë. Kurse vlera e parashikuar e koeficientit të
besueshmërisë së paanshme është 0,850. Këto dy vlera janë të përafërta me njëra-tjetrën.
Së fundi, nëse dëshirojmë t’a bëjmë Analizën Reliability sipas modelit Strict, nga komanda
Model, përzgjedhet Strict parallel.
Hapi 7: Aplikimi i Modelit Strikt Paralel
Rezultatet e SPSS-it janë si më poshtë. (Notë: Rezultatet e njëjta që marrin pjesë në tabelat
e tjera si statistikat përshkruese, analiza e variancës etj., nuk janë paraqitur në tabelën e
mëposhtme.)
Tabela 6: Rezultatet e Analizës së Besueshmërisë Sipas Modelit Strikt-Paralel
Test for Model Goodness of Fit
Chi-Square Value 80.667
df 17
Sig .000
Log of Determinant of Unconstrained Matrix -1.957
Constrained Matrix -1.045
Under the strictly parallel model assumption
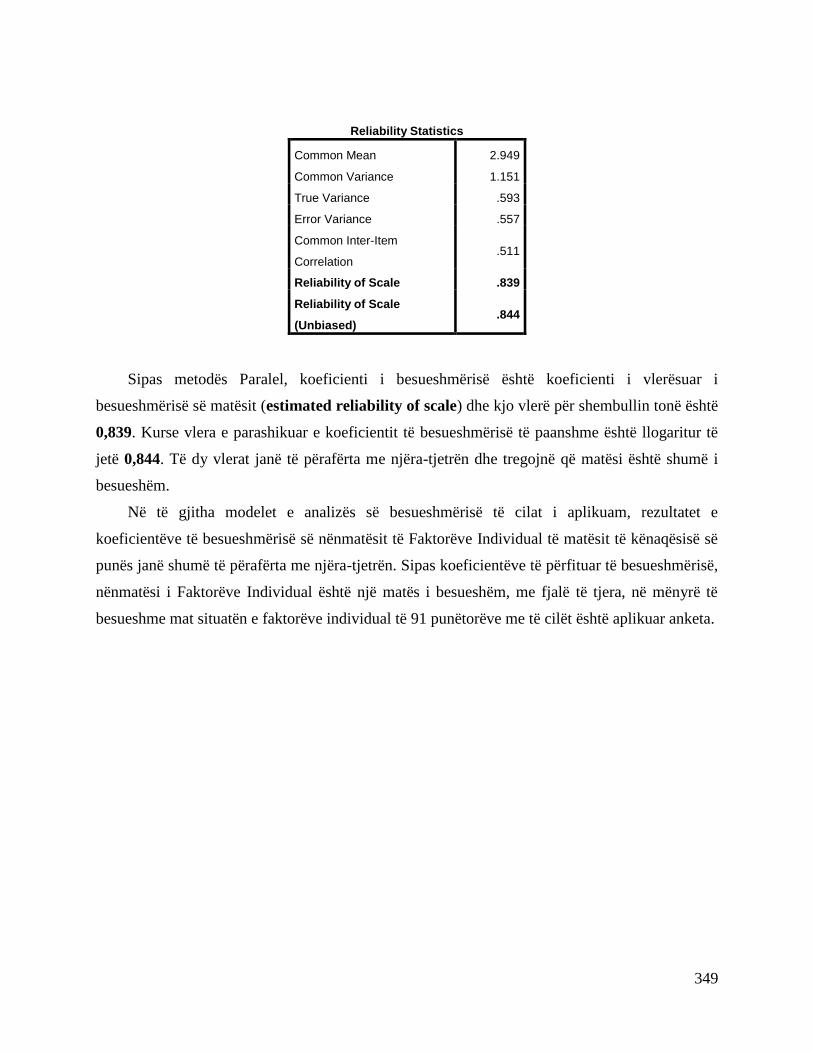
349
Reliability Statistics
Common Mean 2.949
Common Variance 1.151
True Variance .593
Error Variance .557
Common Inter-Item
Correlation .511
Reliability of Scale .839
Reliability of Scale
(Unbiased) .844
Sipas metodës Paralel, koeficienti i besueshmërisë është koeficienti i vlerësuar i
besueshmërisë së matësit (estimated reliability of scale) dhe kjo vlerë për shembullin tonë është
0,839. Kurse vlera e parashikuar e koeficientit të besueshmërisë të paanshme është llogaritur të
jetë 0,844. Të dy vlerat janë të përafërta me njëra-tjetrën dhe tregojnë që matësi është shumë i
besueshëm.
Në të gjitha modelet e analizës së besueshmërisë të cilat i aplikuam, rezultatet e
koeficientëve të besueshmërisë së nënmatësit të Faktorëve Individual të matësit të kënaqësisë së
punës janë shumë të përafërta me njëra-tjetrën. Sipas koeficientëve të përfituar të besueshmërisë,
nënmatësi i Faktorëve Individual është një matës i besueshëm, me fjalë të tjera, në mënyrë të
besueshme mat situatën e faktorëve individual të 91 punëtorëve me të cilët është aplikuar anketa.

350

351
BURIMET
1. Agresti, A. (1990), Categorical Data Analysis, Wiley, New York.
2. Akgül, A. Çevik, O., “İstatistiksel Analiz Teknikleri, SPSS’te İşletme Yönetimi
Uygulamaları”, Yeni Mustafa Kitabevi, Ankara 2003.
3. Allison, Paul D. (1999), Comparing Logit and Probit Coefficients Across Groups,
Sociological Methods and Research, 28, 2, fq. 186-208
4. Anderson, D. A., E. S. Carney (1974), Ridge Regression Estimation Procedures Applied
to Canonical Correlation Analysis, Unpublished Manuscript, Cornell University, Ithaca,
NY.
5. Armitage, P. (1971), Statistical Methods in Medical Research, Oxford, Blackwell
Scientific Publications.
6. Barcikowski, R. J. P. Stevens (1975), “A Monte Carlo Study of the Stability of the
Canonical Correlations, Canonical Weights and Canonical Variate-Variable
Correlations”, Multivariate Behavioral Research, 10, fq. 353-364.
7. Box, G. E. P., D. R. Cox (1984), “An Analysis of Transformations Revisited, Rebuttal”,
Journal of American Statistical Association, fq. 209-210.
8. Box, G. E. P., D. R. Cox (1984), “An Analysis of Transformations”, Journal of the Royal
Statistical Society, B (26), fq. 211-43.
9. Bryant dhe Yarnold (1995), Principal Components Analysis and Exploratory and
Confirmatory Factor Analysis. In Grimm and Yarnold, Reading and Understanding
Multivariate Analysis, American Psychological Books.
10. Büyüköztürk, Şenol, Sosyal Bilimler İçin Veri Analizi El Kitabı, İstatistik, Araştırma
Deseni SPSS Uygulamaları ve Yorum, 2. Baskı, Pegema Yayıncılık
11. Carroll, R. J., D. Ruppert (1984), “Power Transformation When Fitting Theoretical
Models to Data”, Journal of American Statistical Association, 79, fq. 321-328
12. Cliff, N., D. J. Krus (1976), Interpretation of Canonical Analysis: Rotated vs. Unrotated
Solutions, Psychometrika, 41, fq. 35-42.
13. Cochrane, D., G. H. Orcutt (1949), “Application of Least Squares Regressions to
Relationships Containing Autocorrelation Error Term”, Journal of American Statistical
Association, Vol. 44, fq. 32-61
14. Cox, D. R. and E. J. Snell (1989), The Analysis of Binary Data, 2nd
Ed., Chapman &
Hall, London.
15. Çakıcı M., Oğuzhan A., Özdil., Temel İstatistik 1, Özal Matbaası, 4. Baskı, İstanbul,
2003
16. DeMaris, Alfred (1992), Logit modeling: Practical Applications., Thousands Oaks, CA,
Sage Publications Series, Quantitative Applications in the Social Sciences, No. 106.
17. Dillon, William, R., and Goldstein, Mathew (1984), Multivariate Analysis Methods and
Applications, John Wiley & Sons Inc., New York.
18. Draper, N. R., and H. Smith (1981), Applied Regression Analysis, New York, Willey.

352
19. Dunteman, George H. (1989), Principal Components Analysis. Thousands Oaks, CA:
Sage Publications, Quantitative Applications in the Social Sciences Series, No. 69.
20. Durbin, J. (1960), “Estimating of Parameters in Time Series Regression Models”, Journal
of the Royal Statistics Society, Ser. B, Vol. 22, fq. 139-153.
21. Edwards, A. L. (1995), Doğrusal Regresyon ve Korelasyona Giriş (Pwrkth. S.
Hovardaoğlu), Ankara, Hatipoğlu Yayınları.
22. Estrella, A. (1998), “A New Measure of Fit for Equations With Dichotomous Dependent
Variables”, Journal of Business and Economic Statistics, 16, 2, 198-205.
23. Everitt, B. S. (1979), “A Monte Carlo Investigation of the Robustness of Hotelling’s One
and Two Sample T2 Tests”, Journal of the American Statistical Association, 74, fq. 48-
51.
24. Freeman, D. H. (1987) Applied Categorical Data Analysis, Dekker, New York.
25. George D., Mallery P., SPSS For Windows Step by Step, 4th
Edition, Allyn and Bacon
Publishing House, ShBA, 2003.
26. Glass, G. V., K. Hopkins (1984), Statistical Methods in Education and Psychology,
Prentice-Hal, NJ.
27. Glass, G. V., P. D. Peckham, and J. R. Sanders (1972), “Consequences of Failure to Meet
Assumptions Underlying the Fixed Effects Analyses of Variance and Covariance”,
Review of Educational Research, 42, fq. 237-288.
28. Gnandesikan, R. (1990), Methods for Statistical Analysis of Multivariate Observations,
Wiley, NY.
29. Gorsuch, Richard L. (1983), Factor Analysis, Hillsdale, NJ: Erlbaum.
30. Gujarati, D. N. (1995), Basic Econometrics, 3rd Ed., McGraw-Hill, New York.
31. Hair, J. F., R. E. Anderson, R. L. Tatham, W. C. Black (1998), Multivariate Data
Analysis, Prentice Hall, New Jersey.
32. Heiman, G. W. (1996), Basic Statistics for the Behavioral Sciences (Second Edition),
Boston, Houghton Mifflin Comp.
33. Helberg, Clay “Pitfalls of Data Analysis”: http://www.execpc.com/~helberg/pitfalls, 05
Maj 2003.
34. Holloway, L. N., O. J. Dunn (1967), “The Robustness of Hotelling’s T2”, Journal of the
American Statistical Association, 62, fq. 124-136.
35. Hosmer, David and Stanley Lemeshow (1989), Applied Logistic Regression, NY, Wiley
& Sons. Disa nga statistikat e treguara në këtë libër në lidhje me regresion logjistik, janë
të përfshira në versionet e fundit të SPSS-it.
36. Hutcheson, Graeme dhe Nick Sofroniou (199), The multivariate social scientist:
Introductory statistics using generalized linear models. Thousand Oaks, CA: Sage
Publications.
37. Jacques, Tacg (1997), Multivariate Techniques in Social Sciences, Sage Pub. Ltd.,
London.

353
38. Johnson, R. A., D. W. Wichern (1992), Applied Multivariate Statistical Analysis,
Prentice Hall, NJ.
39. Johnson, Richard A. (1992), Applied Multivariate Data Analysis, Prentice Hall, New
Jersey.
40. Johnston, J., (1984), Econometric Methods, 3rd ed., McGraw-Hill, New York.
41. Kazım Özdamar, Paket Programlar ile İstatistik Veri Analizi – 2 (Çok Değişkenli
Analizler), Yenilenmiş 5. Baskı, Kaan Kitabevi, 2004.
42. Kenny, D., C. Judd (1986), “Consequences of Violating the Independence Assumption in
the Analysis of Variance”, Psychological Bulletin, 99, fq. 421-431.
43. Kim, Jae- On dhe Charles W. Muller (1978a), Introduction to Factor Analysis: What it is
and how to do it. Thousands Oaks, CA: Sage Publications, Quantitative Applications in
the Social Sciences Series, No. 13.
44. Klecka, W. R. (1980) Discriminant Analysis, London, Sage Publications.
45. Kleimbaum, D. G. Lawrence L. Kupper and Keith E. Muller (1988), Applied Regression
Analysis and Other Multivariable Methods, Duxbury Press.
46. Kleinbaum, D. G. (1994), Logistic Regression: A Self-Learning Text, New York,
Springer-Verlag.
47. Kramer, J. S. (1991), The Logit Model for Economist, Edward Arnold Publishers,
London.
48. Mardia, K. V. (1971), “The Effect of Non-Nationality on Some Multivariate Tests and
Robustness to Non-Normality in the Linear Model”, Biometrika, 58, fq. 105-212.
49. McKelvey, Richard and Willian Zavoina (1994), “A Statistical Model for the Analysis of
Ordinal Levent Dependent Variables”, Journal of Mathematical Sociology, 4, fq. 103-
120. Në këtë artikull argumentohen Modelet e Logitit të shumë grupeve (Polytomous)
dhe rendore (Klasifikuese).
50. Menard, Scott (1995), Applied Logistic Regression Analysis., Thousands Oaks, CA, Sage
Publications Series, Quantitative Applications in the Social Sciences, No. 106.
51. Morrison, Donald F. (1990), Multivariate Statistical Methods, New York: McGraw-Hill.
52. Nagelkerke, N. J. D. (1991), “A Note on a General Definition of the Coefficient of
Determination”, Biometrika, Vol. 78, 3, fq. 691-692.
53. Netter, J., W. Wasserman, M. H. Kunter (1983), Applied Linear Regression Models,
Illinois.
54. Newbold P., İşletme ve İktisat İçin İstatistik, Ümit Şenesen (Përkthyes), Literatür
Yayıncılık, 4. Baskı, İstanbul, 2002.
55. Norusis, M. J., and SPSS Inc. (1993), SPSS for Windows, Base System User’s Guide,
Rel. 6.0.
56. Norusis, Marija and SPSS Inc. (1999), SPSS Regression Models, 10.0, SPSS Inc.,
Chicago.
57. Olson, C. L. (1974), “Comparative Robustness of Six Tests in Multivariate Analysis of
Variance”, Journal of American Statistical Association, 69 (348), fq. 894-907.

354
58. Orhunbilge, N. (1996), Uygulamalı Regresyon ve Korelasyon Analizi, Avcıol-Basım,
İstanbul.
59. Orhunbilge, N. (2000), Tanımsal İstatistik Olasılık ve Olasılık Dağımları, Avcıol Basım,
İstanbul.
60. Pallant, J., “SPSS Survival Manual”, Open University Press, McGraw-Hill, 2003.
61. Pedhazur, E. K. (1992), Multiple Regression in Behavioral Research: Explanation and
Prediction (Second Edition), USA, Rinehart and Winston.
62. Reha Alpar, Uygulamalı Çok Değişkenli İstatistiksel Yöntemlere Giriş 1, Değiştirilmiş ve
Genişletilmiş 2. Baskı, Nobel Yayın Dağıtım, Ankara, Janar 2003.
63. Scariano, S. J. Davenport (1986), “The Effect of the Independece Assumption in the One
Way ANOVA”, The American Statistician, 41, fq. 123-129.
64. Sharma, Subhash (1996), Applied Multivariate Techniques, John Wiley & Sons Inc.,
New York.
65. SPSS, Inc. (1996), SPSS® 10 Syntax Reference Guide for SPSS Advanced Models,
Chicago.
66. Stevens, James (1996), Applied Multivariate Statistics for Social Sciences, Lawrence
Erlbaum Associates, Publishers, Mahwah, New Jersey.
67. Tabachnick, Barbara, G., and Fidel, Linda S. (1996), Using Multivariate Statistics, 3rd
Ed., Harper Collings College Publisher, California State University, North Bridge.
68. Tadlıdil, H., (1996), Uygulamalı Çok Değişkenli İstatistiksel Analiz, Cem Ofset Ltd. Şti.,
Ankara.
69. Ünver, Ö., Gamgam H., Uygulamalı İstatistik Yöntemler, Siyasal Kitapevi, 3. Baskı,
Ankara, 1999.
70. Webster, A. (1995), Applied Statistics for Business and Economics, 3rd
ed., 1995.

355

356