spatial role labeling task for semeval 2012
DESCRIPTION
Spatial Role Labeling Task for SemEval 2012. Natural Language Processing for Massive Textual Data Management Group Presentation. 1. Outline. Introduction Identification of Spatial Indicators Identification of Trajectors and Landmarks Jointly identification Experiments Conclusion. 2. - PowerPoint PPT PresentationTRANSCRIPT

Spatial Role LabelingSpatial Role LabelingTask for SemEval 2012Task for SemEval 2012
Natural Language Processing for Massive Textual Data Management
Group Presentation
1

1.Introduction
2.Identification of Spatial Indicators
3.Identification of Trajectors and Landmarks
4.Jointly identification
5.Experiments
6.Conclusion
OutlineOutline
2

1.Introduction
2.Identification of Spatial Indicators
3.Identification of Trajectors and Landmarks
4.Jointly identification
5.Experiments
6.Conclusion
OutlineOutline
3

Deal with the novel task of spatial role
labeling in natural language text.
Extracting spatial roles and their relations:
A. Find spatial prepositions and then the related trajectors
and landmarks.
B. Joint learning approach, where a spatial relation and its
composing indicator, trajector and landmark are classified
collectively.
C. Create triplets of <indicator, trajector, landmark>.
IntroductionIntroduction
4

Task A has to be treated sequentially into several sub-problems:
1) Identifying the pivot of the spatial relations learning to predict prepositions (Spatial Indicator).
2) Identify possible arguments of the spatial relations learning to predict trajectors and landmarks.
In task B we investigate another setting in which we classify all roles jointly (without separating classifications for spatial indicators and trajectors/landmarks.
IntroductionIntroduction
5
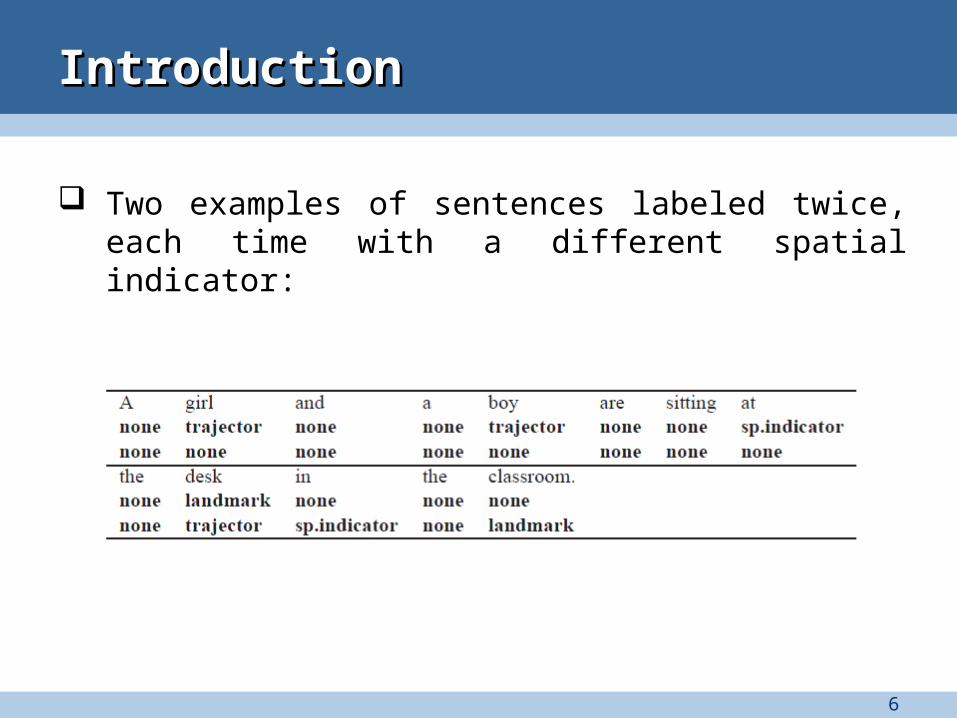
Two examples of sentences labeled twice, each time with a different spatial indicator:
IntroductionIntroduction
6

1.Introduction
2.Identification of Spatial Indicators
3.Identification of Trajectors and Landmarks
4.Jointly identification
5.Experiments
6.Conclusion
OutlineOutline
7

Spatial information can be expressed primarily by using prepositions.
Task: classify prepositions on “SI” or “not SI” from these Features:o PREPOSITIONo PREPOSITION_POS
(from dependency tree (Stanford Parser))o HEAD1: word directly dependent on the prepositiono HEAD2: word on which the preposition is directly dependento HEAD1_LEMMA (WordNet)o HEAD1_POS (Stanford Parser)o HEAD2_LEMMA (WordNet)o HEAD2_POS (Stanford Parser)
(from TPP dictionary)o PREP_SPATIAL: % of acceptions where preposition is spatial.
Identification of Spatial IndicatorsIdentification of Spatial Indicators
8

1.Introduction
2.Identification of Spatial Indicators
3.Identification of Trajectors and Landmarks
4.Jointly identification
5.Experiments
6.Conclusion
OutlineOutline
9

We aim to classify : Features of a word:
• Form, POS tag, dependency to the syntactic head in the dependency tree, semantic role, subcategorization.
Features of the spatial indicator:• Form, subcategorization.
Relational Features of the word with respect to the SI:• Path, linear position.
We tried to use Hidden Markov Models and Averaged perceptron and in order to see the probability of each word (with except to the SI) of being trajector, landmark or none.
Identification of trajectors and Identification of trajectors and landmarkslandmarks
10

The features obtained:
PREPOSITION
WORD: The word form
WORD_POS: word's part of speech
WORD_DPRL: syntactic relation with the head
WORD_BINARY: if is at left or at right of the preposition
WORD_PATH: describe the path from the word to the preposition.
Transformed into numeric features for the perceptron Using a hash Function
Identification of trajectors and Identification of trajectors and landmarkslandmarks
11

1.Introduction
2.Identification of Spatial Indicators
3.Identification of Trajectors and Landmarks
4.Jointly identification
5.Experiments
6.Conclusion
OutlineOutline
12

Predict each triplet of segments indicator-trajector-landmark jointly.
Omitting the first task of predicting the spatial indicator.
Tagging words with trajector, landmark, SI or none. Allows multiple words to be classified as SI.
We wanted to use HMM and Averaged Perceptron with another class “SI” added.
Jointly IdentificationJointly Identification
13

1.Introduction
2.Identification of Spatial Indicators
3.Identification of Trajectors and Landmarks
4.Jointly identification
5.Experiments
6.Conclusion
OutlineOutline
14

We use K-Fold Cross Validation with K=5
• Training Data chosen: 90% of the original data set.• Accuracy with Naïve Bayes: 85% (on the 10% of test Data)
(not considering multi-word prepositions. "in" is not "in front of")
• Problem: "You are in my dreams and they are in my nightmares". Two repeated prepositions, two marked up SI. Which is each one?
• Solution: considering word positions
Experiments for SI identificationExperiments for SI identification
15

Averaged perceptron [4,5]:
The inference step must be efficient:
Φ = A representation, mapping each (x, y) to a feature vector Φ(x, y) - defined as local feature vectors.
Possible approaches for Trajectors Possible approaches for Trajectors and Landmarks Identificationand Landmarks Identification
16

Possible approaches for Trajectors Possible approaches for Trajectors and Landmarks Identificationand Landmarks Identification
17

Trying to use HMM of [5]
Difficulty was in adapting from the training data with the features extracted to the HMM network.
Then, we wanted to use Viterbi Algorithm to predict the probabilities of belonging to each label (T/L/None).
Use K-Fold Cross Validation with K=5 with the same training set and test set.
Possible approaches for Trajectors Possible approaches for Trajectors and Landmarks Identificationand Landmarks Identification
18

We wanted to use the same criteria as in the previous task by adding one new 4th observation for the classification “SI” (T/L/SI/None).
Use K-Fold Cross Validation with K=5 with the same training set and test set.
Possible approaches for Jointly Possible approaches for Jointly IdentificationIdentification
19

1.Introduction
2.Identification of Spatial Indicators
3.Identification of Trajectors and Landmarks
4.Jointly identification
5.Experiments
6.Conclusion
OutlineOutline
20

We achieved results for SI identification by using slightly different features.
Try to add new features.
Grateful to offer the possibility of working the whole group together, dealing with the added problems of organization, communication and coordination.
Future Work is for the following tasks with the multi-classification problem.
ConclusionConclusion
21

ReferencesReferences
[1] P. Kordjamshidi, M van Otterlo, and M. F. Moens. Spatial role labeling: task definition and annotation scheme. In LREC, 2010.
[2] P. Kordjamshidi, M van Otterlo, and M. F. Moens. From language towards formal spatial calculi.In Workshop on Computational Models of Spatial Language Interpretation (CoSLI 2010, at SpatialCognition 2010), 2010.
[3] Parisa Kordjamshidi, Martijn van Otterlo, and Marie-Francie Moens. Spatial role labeling: Towards extraction of spatial relations from natural language. ACM Transactions on Speech and Language Processing, Nov. 2011. to appear.
[4] Michael Collins. Discriminative Training Methods for Hidden Markov Models: Theory and Experiments with Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP), Philadelphia, July 2002, pp. 1-8. Association for Computational Linguistics.
[5] LingPipe Carpenter, Bob and Breck Baldwin. 2011. Text Analysis with LingPipe 4.
[6] Rabiner. A tutorial on hidden Markov models and selected applications in speech recognition. Proceedings of the IEEE, 1989.
22

Thank you!Thank you!
Spatial Role LabelingSpatial Role LabelingTask for SemEval 2012Task for SemEval 2012
23