software architecture for cloud infrastructure
TRANSCRIPT

Software ArchitectureSoftware Architecturefor Cloud Infrastructurefor Cloud Infrastructure

Tapio RautonenTapio Rautonen
@trautonengithub.com/trautonenfi.linkedin.com/in/trautonen
software architect
Enabling cloud superpowers in software development.

Cloud computing characteristicsCloud computing characteristics
On-demand self-serviceConsumer can provision computing capabilities without requiring human interaction
Broad network accessCapabilities are available over the network and accessible by heterogeneous clients
Resource poolingProvider's computing resources are pooled to serve multiple consumers dynamically
Rapid elasticityCapabilities can be elastically provisioned and appear unlimited for the consumer
Measured serviceAutomatically controlled and optimized resources by metering capabilities

Software architecture principlesSoftware architecture principles
● Intentional architecture with emergent design● High modularity
– high cohesion, loose coupling– low algorithmic complexity
● Well described elements– expressive and meaningful names and APIs– clean code
● Passes all defined tests or acceptance criteria● Lightweight documentation

Software architecture Software architecture cloud computing cloud computing
MicroservicesMicroservices

Distributed computing fallaciesDistributed computing fallacies
1. The network is reliable2. Latency is zero3. Bandwidth is infinite4. The network is secure5. Topology doesn't change6. There is one administrator7. Transport cost is zero8. The network is homogeneous
Peter Deutsch / Sun Microsystems

Design for failureDesign for failure

New era of design patternsNew era of design patterns
● Cache-Aside● Circuit Breaker● Compensating Transaction● Command and Query Responsibility Segregation (CQRS)● Event Sourcing● Queue-Based Load Leveling● Sharding● Throttling

Cache-Aside patternCache-Aside pattern
● Aggregated search combining multiple services– requires additional search cache (Solr, ElasticSearch, ...)
● Improve performance of frequentlyread data
● Local caching resultsinconsistent state betweeninstances
● Consistency of data storesand cache is really hard tomaintain
There are only two hard things
There are only two hard things
in Computer Science: cache
in Computer Science: cache
invalidation and naming things.
invalidation and naming things.
– – Phil KarltonPhil Karlton

Circuit Breaker patternCircuit Breaker pattern
● Cloud infrastructure and distributed systems allow remote services to fail in ways beyond imagination– prevent failures to cascade– allow system to operate in degraded mode
● Suitable for big microservices architecture– creates routing complexity and overhead– potential single point of failure must be highly available
● Enables central logging and metrics– dashboards and central state awareness

Circuit Breaker patternCircuit Breaker pattern
● During normal operation, breaker is in Closed state– failures will eventually trip breaker
● While in Open state– calls will fail fast and after some period attempts to reset
● In Half-Open state– on successful call resets breaker, otherwise trips breaker
http://doc.akka.io/docs/akka/snapshot/common/circuitbreaker.html

Netflix Hystrix dashboardNetflix Hystrix dashboard

Compensating Transaction patternCompensating Transaction pattern
● Irrecoverable failures in distributed systems are hard– eventual consistency, rollbacks are impossible
● Distributed transactions (XA)– difficult and complex to implement– still not bulletproof– not usable for generic REST services
● Undo the effects of the original operation– defines an eventually consistent steps for a reverse operation– compensation logic may be difficult to generate– operations should be idemponent to prevent further catastrophe

CQRS patternCQRS pattern
● Command and Query Responsibility Segregation– segregates read and write operations with separate interfaces– allows to maximize performance, scalability and security
● Introduces flexibility at the cost of complexity– traditionally same DTO is used for read and write operations– different data model for read (query) and write (command)– supports different read and write data stores– not suitable for simple business rules where CRUD is sufficient
● Often used together with event sourcing pattern

Event Sourcing patternEvent Sourcing pattern
● Append only store of events that describe actions for data– simplifies tasks in complex domains by avoiding synchronization– improves performance, scalability and consistency for
transactional data– can serve multiple different materialized views
● Maintains full audit trail and history– enables compensation actions– supports play back at any point in time
● Events are simple– the operation logic they describe might not be– updates and deletes must be implemented with compensation– “at least once” publication requires idemponent consumers
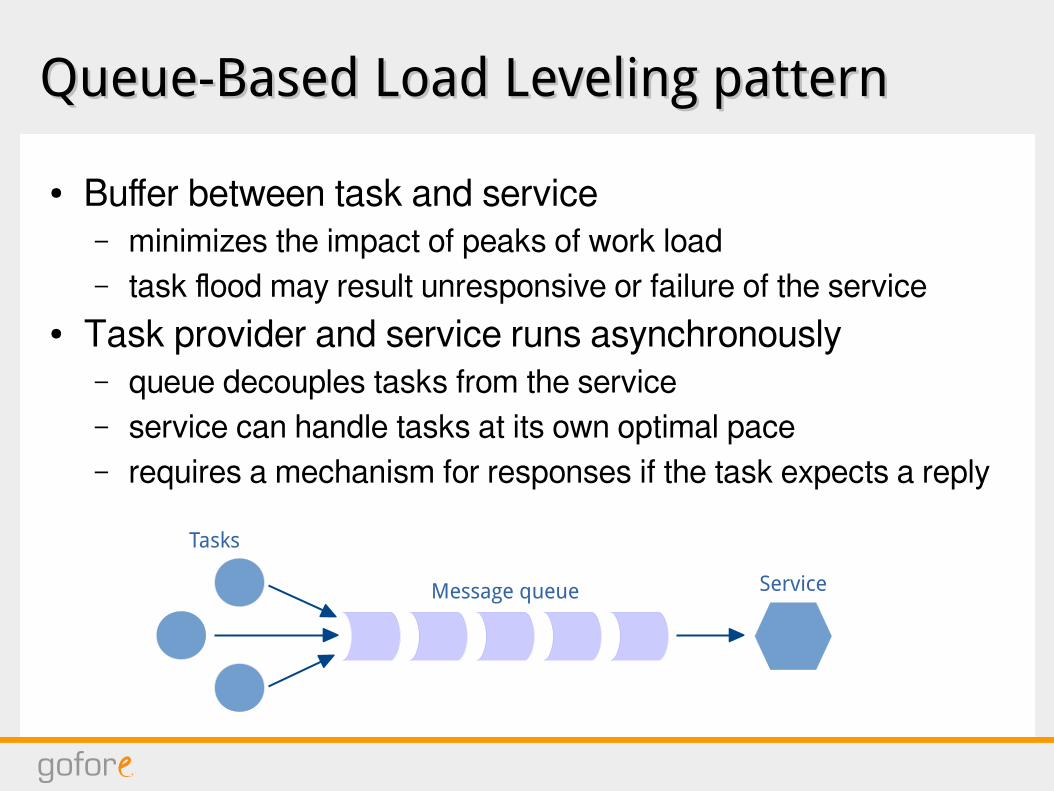
Queue-Based Load Leveling patternQueue-Based Load Leveling pattern
● Buffer between task and service– minimizes the impact of peaks of work load– task flood may result unresponsive or failure of the service
● Task provider and service runs asynchronously– queue decouples tasks from the service– service can handle tasks at its own optimal pace– requires a mechanism for responses if the task expects a reply
Service
Tasks
Message queue

Sharding patternSharding pattern
● Divide data store into multiple horizontal partitions– improves scalability when handling large volumes of data
● Overcomes limitations of single server data store– finite storage space– computing resources for large number of concurrent users– network bandwidth governed performance– geographically limited storage for legal or performance reasons
● Strategy defines the sharding key and data distribution– wrong sharding strategy results bad performance– balancing shards is not trivial, rebalancing is expensive– referential integrity and consistency is hard to maintain
● Configuring and managing big set of shards is a challenge

Throttling patternThrottling pattern
● Controls the consumption of resource used by a service– allows the system to function and meet SLA on extreme load
● Throttle after soft limit of resource usage is exceeded– reject requests for user that exceed the soft limits– disable or degrade functionality of nonessential services– queue-based load leveling with priority queues
● Throttling is an architectural decision– impacts the entire design of the system– must be detected and performed very quickly– services should return specific error code for clients– can be used as an interim measure while autoscaling

SaaS architecture methodologySaaS architecture methodology
● Declarative formats for setup and runtime automation● Clean contract with infrastructure for maximum portability● Cloud platform deployments, obviating the need for ops● Tooling, architecture and dev practices support scaling
Modern software is delivered from the cloud to heterogeneous clients on-demand

The Twelve-Factor AppThe Twelve-Factor App
I. Codebaseone codebase tracked in revision control, many deploys
II. Dependenciesexplicitly declare and isolate dependencies
III. Configstore config in the environment
IV. Backing Servicestreat backing services as attached resources
V. Build, release, runstrictly separate build and run stages
VI. Processesexecute the app as one or more stateless processes
http://12factor.net/

The Twelve-Factor AppThe Twelve-Factor App
VII. Port bindingexport services via port binding
VIII.Concurrencyscale out via the process model
IX. Disposabilitymaximize robustness with fast startup and graceful shutdown
X. Dev/prod paritykeep development, staging, and production as similar as possible
XI. Logstreat logs as event streams
XII. Admin processesrun admin/management tasks as one-off processes
http://12factor.net/

Break the monolith in piecesBreak the monolith in pieces
● Monoliths come with a burden– cognitive overload for developers– scaling and continuous deployment becomes difficult– long-term commitment to technology stack– allows taking shortcuts for architectural design
If you can't build a monolith, what makes you think microservices are the answer?

AWS reference architectureAWS reference architecture

Service discoveryService discovery
● Services need to know about each other– inexistence of centralized service bus– smart endpoints and client side load balancing
● Service registry is the new single point of failure?– value availability over consistency
● Provides a limited set of well defined features– services notify each other of their availability and status– cleaning of stale services– easy integration with standard protocols like HTTP or DNS– notifications on services starting and stopping

Ephemeral runtime environmentsEphemeral runtime environments
● Short lifetime of an application runtime environment– scaling, testing, materializing ideas– requires highly automatized infrastructure
● Nothing can be stored in the runtime environment– logs, file uploads, database storage files, configuration
● Results stateless services– optimal for horizontal scaling– integrates to State as a Service
● Must be repeatable and automatically provisioned

Metrics and loggingMetrics and logging
● Ephemeral and dynamic systems– requires central awareness of state– audit logging of changes in the system
● Gain understanding how the services are used– plan for future requirements– gather scaling metrics– bill customers for usage (pay-per-use)– detect faulty behavior
● Balance between value provided and cost of collecting– robustness of the metering system impacts on profitability– collect end-to-end scenarios rather than operational factors

AutoscalingAutoscaling
● Adapting to changing workloads– optimize capacity and operational cost– increase failure resilience
● Requires key performance metrics capturing– response times, queue sizes, CPU and memory utilization
● Decision logic based on scaling metrics– when to scale up and down– prevent scaling oscillation
● Application must be designed for scaling– stateless, immutable, automatically provisioned

Asynchronous messagingAsynchronous messaging
● Key strategy for services to communicate and coordinate– decouple consumer process from the implementing service– enables scalability and improves resilience
● Basic messaging patterns– sender posts a one-way message and receiver processes the
message at some point in time– sender posts a request message and expects a response
message from the receiver– sender posts a broadcast message which is copied and
delivered to multiple receivers● Numerous implementation concerns
– message ordering, grouping, repeating, poisoning, expiration, idempotency and scheduling

Reactive streamsReactive streams
● Originates from The Reactive Manifesto– Responsive system responds in a timely manner
– Resilient system stays responsive in the face of failure
– Elastic system stays response under varying workload
– Message Driven system relies on asynchronous messaging
● Initiative to provide standard for asynchronous stream processing with non-blocking back pressure– minimal set of interfaces and methods to achieve the goal
● Collaboration of people from high profile companies– Typesafe, Oracle, Pivotal, Netflix, Red Hat, Applied Duality, ...
● Akka Streams, Reactor Composable, RxJava, Ratpackhttps://www.coursera.org/course/reactive

Data consistencyData consistency
● All instances of application see the exact same data– strong consistency
● Application instance might see data of operation in flight– eventual consistency
● Distributed data stores are subjected to CAP theorem– consistency, availability, partition tolerance– only two of the features can be implemented
● Recovering from failures of eventually consistent data– retry with idemponent commands– compensating logic

Configuration managementConfiguration management
● Externalize configuration outof runtime environment– repeatable, versioned
● Local configuration pitfalls– limits to single application– hard for multiple instances
● Runtime reconfiguration– application can be reconfigured without redeployment or restart– minimize downtime, enable feature flags, help debugging– thread safety and performance is a concern– prepare for rollbacks and unavailability of configuration store

Software erosionSoftware erosion
● Slow deterioration of software leading to faulty behavior● Fighting erosion is more expensive than usually admitted● Erosion-resistance comes from separation of concerns
– application – infrastructure● Clear contract of services provided by infrastructure
– change in infrastructure does not break the contract– application can change within its respected realm
● Solutions against erosion– Platform as a Service– container virtualization

Cloud architecture pitfallsCloud architecture pitfalls
● Failures do cascade– even without a single point of failure
● Multi-service search is hard to get right– cache-aside issues
● Never rely on unreliable message delivery– use asynchronous persistent message stores
● Monolith has one big problem– microservices will generate a lot of small (and big) problems
● Do not ignore the platform's managed resources– but evaluate the lock-in risk

Reach for the skiesReach for the skies
● Distributed systems are hard to build– no silver bullet exists (sorry to disappoint again)
● Cloud infrastructure drives towards microservices– start with a monolith, expand to microservices– learn new design patterns during the journey– automated system requires less ops and offers more resilience
● Do you think Netflix did it right the first time?– learn from failure– design for failure
● Cloud native applications are the future

Thank youThank you