simulating the sensitivity of pooled-sample herd tests for fecal salmonella in cattle
TRANSCRIPT

Simulating the sensitivity of pooled-sample herd
tests for fecal Salmonella in cattle
David Jordan *
New South Wales Department of Primary Industries, Wollongbar Agricultural Institute,
1243 Bruxner Highway, Wollongbar, New South Wales 2477, Australia
Received 6 July 2004; received in revised form 8 February 2005; accepted 24 February 2005
Abstract
Samples from livestock or food items are often submitted to microbiological analysis to determine
whether or not the group (herd, flock or consignment) is shedding or is contaminated with a bacterial
pathogen. This process is known as ‘herd testing’ and has traditionally involved subjecting each
sample to a test on an individual basis. Alternatively one or more pools can be formed by combining
and mixing samples from individuals (animals or items) and then each pool is subjected to a test for
the pathogen. I constructed a model to simulate herd-level sensitivity of the individual-sample
approach (HSe) and the herd-level sensitivity of the pooled-sample approach (HPSe) of tests for
detecting pathogen. The two approaches are compared by calculating the relative sensitivity
(RelHSe = HPSe/HSe). An assumption is that microbiological procedures had 100% specificity.
The new model accounts for the potential for HPSe and RelHSe to be reduced by the dilution of
pathogen that occurs when contaminated samples are blended with pathogen-free samples. Key
inputs include a probability distribution describing the concentration of the pathogen of interest in
samples, characteristics of the pooled-test protocol, and a ‘test–dose–response curve’ that quantifies
the relationship between concentration of pathogen in the pool and the probability of detecting the
target organism. The model also compares the per-herd cost of the pooled-sample and individual-
sample approaches to herd testing. When applied to the example of Salmonella spp. in cattle feces it
was shown that a reduction in the assumed prevalence of shedding can cause a substantial fall in HPSe
and RelHSe. However, these outputs are much less sensitive to changes in prevalence when the
number of samples per pool is high, or when the number of pools per herd-test is high, or both. By
manipulating the number of pools per herd and the number of samples per pool HPSe can be
www.elsevier.com/locate/prevetmed
Preventive Veterinary Medicine 70 (2005) 59–73
* Tel.: +61 2 66261240; fax: +61 2 66281744.
E-mail address: [email protected].
0167-5877/$ – see front matter # 2005 Elsevier B.V. All rights reserved.
doi:10.1016/j.prevetmed.2005.02.013

optimized to suit the range of values of true prevalence of shedding of Salmonella that are likely to be
encountered in the field.
# 2005 Elsevier B.V. All rights reserved.
Keywords: Herd-test; Sensitivity; Pooled testing; Pooled fecal culture; Salmonella; Cattle
1. Introduction
Affordable methods are needed for classifying groups of animals or food products with
respect to the presence or absence of bacteria harmful to humans or animals. The pooled
(i.e. composite) sample approach is attractive because it delivers substantial savings in
laboratory costs (Wells et al., 2003). Savings are achieved by testing only a single sub-
sample from a pool that has been formed by physically combining and mixing a number of
individual samples (e.g. feces) (Whittington et al., 2000). The number of pools formed per
herd (or consignment in the case of food) is typically much smaller than the number of
individual samples that would otherwise each require testing. In veterinary epidemiology
this latter form of group classification, achieved by testing all individual samples separately
but interpreting them together, is referred to as ‘herd testing’ and has been discussed in
detail elsewhere (Christensen and Gardner, 2000; Donald et al., 1994; Jordan, 1996). In
many scenarios where the laboratory evaluation of samples consists of the detection of
bacterial pathogens by culture, some or all ‘presumptively positive’ isolates that are
recovered have their identity confirmed in assays for attributes such as virulence
determinants or surface antigens that provide conclusive identification. In these instances
test specificity at the level of the isolate, pool and herd can often be assumed to be 100%
(excluding errors arising from cross contamination and transcription of incorrect data).
However, when individual samples are combined the concentration of pathogen in the pool
can be diluted to a level that cannot be detected (van Schaik et al., 2003). Thus, the
sensitivity of the pooled-sample approach for detecting bacterial pathogens in herds
(HPSe) may not have the same sensitivity as the approach based on the evaluation of the
identical set of individual samples (HSe). Therefore, I developed a simple model for
estimating HPSe which allows for the dilution of pathogen during pooling and for
comparison with HSe. The case of detecting cattle herds that are shedding Salmonella spp.
is examined.
2. Methods
2.1. Model rationale
A simulation model for estimating HPSe was created as follows. An investigator
wishing to know whether a herd is excreting a particular enteric pathogen collects a fecal
sample from n individual animals randomly selected from the herd. A number of pools (r
where r � 1) of samples are constructed by physically combining and homogeneously
mixing s samples per pool (where s � 2 and rs = n; Appendix A). The weight of feces from
D. Jordan / Preventive Veterinary Medicine 70 (2005) 59–7360

the ith sample (wi) that is added to the pool could be a precise amount (minimal variance) or
could be described by a normal probability distribution to reflect the case of rapid
processing of samples (e.g. measurement by volume) as a further cost-saving measure (i.e.
wi � normal(uw, s2w). In an infected herd the probability that an animal chosen at random is
shedding the pathogen of interest (Shed = 1, i.e. ‘true’) is u (where u is an estimate of the
true prevalence within the herd). The number of samples containing pathogen (y) entering
a given pool is then binomially distributed, i.e. y � binomial(s, u), and the remaining
samples from individuals not shedding pathogen (Shed = 0, i.e. ‘false’) are not
contaminated. Again, it is assumed that follow-up investigation of presumptive-positive
isolates is such that pools yielding ‘cross-reacting organisms’ but not the pathogen of
interest are not misclassified as positive. If an estimate of the distribution of the
concentration of pathogen in feces is available (e.g. a probability distribution derived from
a fit to empirical data) it is possible to simulate the concentration of organisms in the ith
individual sample entering the pool (ci, being a random number from this distribution). The
concentration in the pooled sample (C) is then merely the sum of the weight multiplied by
concentration of pathogen for each individual sample all divided by the total weight of the
pooled sample, i.e. C =P
ðwiciÞ/P
wi. The number of individual pathogen cells (I) within
a sub-sample taken from the pool for microbiological analysis can then be derived as a
random variate from the Poisson probability distribution with mean equal to CQ where Q is
the weight of the sub-sample, i.e. I � Poisson(CQ) (Haas et al., 1999). The concentration of
organisms in each test sample (Z) is now calculated (Z = I/Q). The final test result for each
of the r pools is then simulated as a Bernoulli trial after consulting the ‘test–dose–response
curve’—a mathematical function that predicts the probability of a positive test result given
Z. The herd-test result is positive when one or more of the r pools yields the evidence that is
necessary to declare that the target organism is present. The logical basis of the model is
described in further detail in Appendix A.
The test–dose–response curve referred to above might consist of a logistic growth
function where the parameters are defined by fitting experimental data to a logistic
regression model. This particular logistic function can be expressed as:
p ¼ 1
1 þ exp ½�ðb0 þ b1 log10 concÞ (1)
In (1) p is the probability of a positive test, b0 and b1 are the intercept and concentration
coefficients, respectively and are defined from a logistic-regression model, and log10 conc
is the concentration of pathogen transformed to the log10 scale. An alternative model that
can be fit to similar data using non-linear regression is that of a modified Gompertz
function:
p ¼ A þ D exp �exp ½�Bðlog10 conc � MÞf g (2)
The double-exponential nature of the Gompertz function make it very flexible such that
it can accommodate asymmetry in the sigmoidal form of the test–dose–response
relationship and the four parameters (A, D, B and M) have utility in describing key features
of the function (McMeekin et al., 1993). In the pooled-testing model both the above logistic
and modified Gompertz function are available for predicting ‘test–dose–response’ with the
choice between these made according to goodness-of-fit criteria. An example of how both
curves are estimated from experimental data is given by Jordan et al. (2004). More
D. Jordan / Preventive Veterinary Medicine 70 (2005) 59–73 61

elaborate relationships such as that defined by a family of curves might be justified in future
versions of this model if more complex data were available.
The decision of whether or not to adopt a pooled-sample approach to herd testing
requires information on the sensitivity of the alternative approach to herd classification.
Hence the model performs an in-parallel assessment of HSe using the approach based on
individual tests applied to a sample of animals. This is achieved with a simplification of
the algorithm for the pooled approach whereby the model keeps track of the
concentration of pathogen in individual samples that enter each pool, then for each
individual sample the test result is simulated as for the sub-sample taken from the pool
(the pathogen concentration determines the probability of a positive test by reference to
the test–dose–response function). In the herd-test based on individual samples if any
individual is allocated a positive result then the herd-test result is positive. The logic
behind this process is described in the Appendix A. Under the assumptions inherent in
the pooled model the herd-test based on individuals will always be more sensitive than
the pooled approach when assessed across a large number of herds. However, because of
the assumed chance element in test performance it is possible to obtain a positive pooled-
sample test and a negative herd-test based on individuals for a minority of herds. As well,
this model allocates a shedding status to each individual within each pool based on
random sampling from the binomial probability distribution. A limitation occurs when
the number of animals sampled approaches the herd size and when herd size is very
small. At this high intensity of sampling and at low prevalence of infection it is possible
for the model to predict that there are no individuals shedding pathogen in the herd and
this is contradictory to the assumption that all herds being evaluated for HPSe do contain
at least one animal that is shedding the pathogen. Thus applying the model under these
circumstances should be avoided because HPSe and HSe will be underestimated. A
quantitative rule can be applied by calculating the probability (from the cumulative
binomial distribution) of having at least one animal shedding given a herd of certain size.
If the probability exceeds an arbitrary value (say 0.95 or 0.99) the limitation can be
overlooked. For example, in a herd of 100 animals, with u = 0.05, the probability of
having one or more shedders in the herd is:
Pðnumber of shedders� 1Þ ¼ 1 � Pðnumber of shedders ¼ 0Þ ¼ 1 � ð1 � 0:05Þ100
¼ 0:9941
which meets an arbitrary standard by exceeding a probability of 0.99. However, if the herd
size were 10 and u = 0.05 then the probability of at least one shedding animal being present
in a simulated ‘shedding’ herd is 0.401. Consequently, many of the simulated results for
pooled and individual herd tests for this smaller herd size would be negative because the
model inappropriately generates (contrary to assumptions) too many herds with a negative-
shedding status.
Each iteration of the model produces a herd status based on the pooled test and one from
testing of individual samples for a hypothetical herd that is shedding pathogen in feces at
the concentration and prevalence defined by input assumptions. By performing multiple
iterations (e.g. 1000 or more) for each combination of input variables herd-level sensitivity
for pooled-sample testing (HPSe) and that from individual tests (HSe) are derived as the
D. Jordan / Preventive Veterinary Medicine 70 (2005) 59–7362

proportion of herds within each simulation yielding a positive herd-test to the respective
method. As well, the model compares the sensitivity of each method of herd testing by
calculating the RelHse as HPSe divided by HSe. The RelHse measure of comparison is
based on identical samples being submitted to a pooled test and to a traditional herd-test
based on individual tests.
2.2. Cost of herd tests based on pooled and individual samples
Pooled and individual herd-test protocols are often compared on the basis of their cost.
The model therefore estimates the cost of both methods of herd testing so users can judge if
the compromise in sensitivity obtained from adopting a pooled-sample approach over an
individual test approach is justified. The calculations for the cost of performing one herd-
test based on the pooled and individual-test methods are based on simple arithmetic
relationships and are modeled deterministically as follows:
cost of pooled test ¼ a þ ðbrsÞ þ ðcrsÞ þ ðdrÞ þ ðerÞ (3)
cost of individual test ¼ a þ ðbnÞ þ ðcnÞ þ ðenÞ (4)
In these equations recall that n is the total number of individual samples obtained from a
herd, r is the number of pools per herd-test and s is the number of samples contributed to
each pool. Here also a is equal to the value of fixed expenses for each herd visit (these
include the monetary cost of having a technician visit a farm to collect samples, plus the
cost of packing and freighting samples to the laboratory); b is equal to the cost of obtaining
a sample from an individual animal (includes the money value of technician time and of
disposables consumed for each sample collected); c is the cost of preparing individual
samples (includes the cost of time taken to weigh each individual sample for an individual
test or as a component of a pool test, and the cost of disposable items so consumed), d is the
cost of preparing each pool (includes the cost of mixing and blending the weighed portions
of component samples); and e is the cost of the laboratory component of testing which is
the same for both pooled and individual samples (includes all costs associated with
technician time, disposable costs, reagents, operation of equipment and so forth). This cost
sub-model is a general approach that suits the example detailed in Section 2.4 below and
could be modified if necessary to suit other circumstances.
2.3. Model implementation
Conceptual development of the above model occurred in a spreadsheet environment
(Microsoft1 Excel 2002, Microsoft Corporation, Redmond, WA, USA) with the added
capacity for Monte-Carlo simulation provided by the installation of @Risk (Palisade
Corporation, NY, USA) as an add-in. Eventually the model was transferred to a
programming environment (Borland1 DelphiTM 7 for Windows1, Borland Software
Corporation, Scotts Valley, CA, USA) to produce a compiled version that is faster, less
prone to user-induced errors, and which can be readily distributed without requiring the
user to purchase any additional software. A complimentary copy of the compiled model is
available from the author on request.
D. Jordan / Preventive Veterinary Medicine 70 (2005) 59–73 63

2.4. Example: sensitivity of detecting cattle herds shedding Salmonella
The model described above was used to investigate the sensitivity of detecting cattle
herds shedding Salmonella using both pooled fecal culture and testing of an equivalent
number of individual fecal samples. Several scenarios were simulated (described below)
requiring the following assumptions to be made about the concentration of viable
Salmonella in cattle feces (Section 2.4.1), the form of the test–dose–response curve
(Section 2.4.2), and the cost of performing pooled and individual testing (Section 2.4.3).
2.4.1. Distribution of the concentration of Salmonella in bovine feces
A probability distribution describing the concentration of Salmonella in cattle feces was
derived from data collected during a national survey of Australian cattle at slaughter
(Fegan et al., 2004) and unpublished data gathered by the same authors from samples
obtained from cattle presented for slaughter in south-east Queensland. In both studies the
data on concentration of Salmonella spp. were obtained using the ‘most probable number’
(MPN) technique combined with immunomagnetic separation (IMS) and growth in
selective media as described by Fegan et al. (2004). Incorporation of IMS in the test
protocol is considered to be one of the best techniques for detecting small concentrations of
pathogen against a dense background of flora (Benoit and Donahue, 2003). In the published
data, the study population consisted of equal proportions of lot-fed and grass-fed cattle
(both steers and heifers), from 1–2 years of age presented for slaughter at abattoirs in all
Australian states. The unpublished data were generated from a similar mixture of grass-fed
and grain-fed cattle presented for slaughter in south-eastern Queensland. The 45 samples
subjected to enumeration were a subset from the group of 103 samples found to contain
Salmonella by IMS and enrichment culture out of a total of 450 samples that were
examined. The results (expressed as colony-forming units per gram of feces or cfu g�1) for
two different types of samples (21 caecal contents from the published survey and 24 fecal
pats in the unpublished survey) were combined prior to the analysis because of the small
number of available observations. A censoring limit of 3 cfu g�1 was applied by the
laboratory in their reporting of results and this is derived from standard ‘MPN’ tables which
are in turn derived from maximum-likelihood and Poisson probability theory (Haas, 1989).
Thus, the 14 samples from which Salmonella were isolated but which could not be
enumerated were assumed to each have a concentration in the range 0–3 cfu g�1. The left-
censored nature of the data prevents standard distribution-fitting techniques from being
used to estimate a probability distribution. To deal with this, it was assumed that when
transformed to the log10 scale the underlying distribution was normal. This assumption was
made because bacterial-concentration data often approximate a log-normal density
function and because the log-normal distribution is theoretically appropriate for quantities
resulting from the multiplicative combination of many factors (Law and Kelton, 2000).
Further, expressing results on a log10 scale (rather than as untransformed or on a natural-log
scale) is desirable for convenient interpretation of concentration data in microbiology.
Analysis of the data was then performed using censored regression (also known as Tobit
estimation), a maximum-likelihood technique that in this case accounts for the left-
censoring of observations below the specified limit of detection (Fan and Gijbels, 1994).
The regression model that was fitted to data included only the intercept term so that in the
D. Jordan / Preventive Veterinary Medicine 70 (2005) 59–7364

regression output the estimate for the intercept becomes the mean of the required normal
distribution and the estimate of the error becomes the variance. A censored regression
routine implemented within S-Plus (version 6.2, Insightful Corporation, Seattle, WA,
USA) was used to fit the observed data and the result assessed by forming a quantile-
quantile plot and a chi-squared test for goodness-of-fit of censored data (Hollander and
Proschan, 1979).
2.4.2. Test–dose–response curve for detecting Salmonella in bovine feces
In all simulation scenarios the testing of samples for Salmonella was assumed to be
carried out by IMS followed by recovery on selective media. The relationship between the
concentration of Salmonella and probability of a positive test (test–dose–response curve)
was defined as a modified Gompertz function Eq. (2). The parameters were estimated in a
separate study also based on the use of IMS and selective enrichment (Jordan et al., 2004).
Briefly, in this latter work known amounts of a fluorescent and kanamycin-resistant marker
strain of Salmonella were inoculated into bovine feces at various concentrations, with
multiple replicates (from 14 to 18) at each concentration. Attempts were made to recover
the introduced organism using an IMS-based protocol followed by differentiation of
presumptively positive isolates from wild-strains of Salmonella using the marker traits.
The data, representing log10 transformed concentrations of the marker strain of Salmonella
(11 different concentrations) and the observed proportion of detections at each
concentration were fitted to a modified Gompertz function using non-linear regression
(Myers, 1990). The estimated coefficients were A = 0.0857, D = 0.8323, B = 73.68 and
M = 0.3034 and these were used in a modified Gompertz function within the model to
define the test–dose–response relationship for detecting Salmonella in cattle herds.
2.4.3. Cost input assumptions for detecting Salmonella in cattle herds
A comparison between the cost per herd for the pooled-sample approach and the
individual-test approach to herd-level diagnosis of shedding of Salmonella in cattle were
performed using the relationships defined earlier Eqs. (3) and (4). Input assumptions
(expressed in Australian dollars) were $200 for herd visit overheads (transportation costs,
technician time, sample handling costs), $3.50 for per animal sampling costs (time to
obtain each sample and consumable items), $2.50 per individual sample preparation costs
(time and consumables), $3.00 per preparation of each pool (time and consumables), and
$50.00 for the laboratory component of testing (each pool or each individual sample).
These estimates are indicative of the cost of labor and materials at the time of writing and
mainly serve to provide a fair basis for comparing the expense incurred under the pooled
and individual-sample approaches to herd testing for Salmonella in cattle.
2.4.4. Simulation scenarios
In all simulations each individual sample contributed 5 g of feces to a pool and the entire
pool became the sub-sample submitted for isolation of Salmonella. When tested as
individual samples each weighed 5 g. In scenario SpecPrev the number of samples
(‘‘specimens’’) entering each pool was varied (5–15 samples per pool), as was the assumed
prevalence of shedding within herds (2–20% in steps of 2%), while the number of pools
was held constant at five per herd test. In scenario PoolPrev the number of pools per herd-
D. Jordan / Preventive Veterinary Medicine 70 (2005) 59–73 65

test was varied from one to ten in steps of one, assumed prevalence of shedding within
herds was varied from 2% to 20% in steps of 2%, while the number of samples per pool was
fixed at 10. In scenario PoolSpec it was assumed that prevalence of shedding within herds
was constant at 10% while the number of pools per herd-test varied from one to ten in steps
of one and the number of samples per pool varied from 5 to 25 in steps of one. In each
simulation scenario 10,000 iterations of the model were performed for each combination of
the levels of the varying inputs (thus in all of the SpecPrev scenario a total of 1.1 million
iterations were performed). The number of individual samples submitted to the pooled test
was the same as that for the individual tests. The resulting output values of HPSe, HSe and
RelHSe were summarized as contour plots using the algorithm provided in S-Plus 6.2. The
algorithm provides an approximation of the shape of the three-dimensional surface that
describes the output of each sensitivity analysis. Interpretation of the contour plots relies on
noticing the shape of contours and the distances between contours. When contours are
located close together the slope of the three dimensional surface is steep indicating a large
change in HPSe or RelHSe for a small change in input assumptions. Conversely when
contours are further apart the slope of the surface is gentle and the output is less sensitive to
inputs. Where the contours are parallel to a particular axis, changes in the input variable
described by that axis are having no effect on the output (HPSe or RelHSe). Conversely,
when the contours are oblique to an axis then changes in the input variable described by
that axis do have an effect on the output.
The comparison of the cost of pooled and individual sample tests was performed for all
levels of the number of pools and number of samples per pool which was conveniently
calculated in the PoolPrev scenario.
3. Results
Analysis of the data describing the concentration of Salmonella in bovine feces by
censored regression provided estimates of the mean and standard deviation for the log10
transformed cfu g�1 of 0.993 and 1.315 respectively. These findings allow the log10
concentration of Salmonella in bovine feces to be stochastically modeled as a normal
distribution with a mean 0.993 cfu g�1 and standard deviation of 1.315 cfu g�1.
The response surfaces displaying the relationship between differing levels of model
inputs (assumed prevalence of shedding within herds, number of pools per herd-test and
number of samples per herd test) and outputs (HPSe and RelHSe) for the detection of
Salmonella in cattle herds appear sufficiently complex (Figs. 1–3) to warrant only a few
general remarks. In all simulations the value of RelHSe was always less than unity
regardless of the number of samples collected or the pooling protocol (Figs. 1–3). In the
SpecPrev scenario (number of pools fixed at five per herd) HPSe declined noticeably as the
assumed prevalence of shedding of Salmonella within herds declined (Fig. 1a, the contours
are closer together at low assumed prevalence). At higher levels of assumed prevalence of
shedding a somewhat larger gain in HPSe and RelHSe (Fig. 1a and b, respectively) is
obtained for each increment in the number of samples per pool than what occurs at lower
assumed values of prevalence (i.e. the contours are more oblique to the x-axis at higher
prevalence). At low assumed prevalence of shedding (e.g. less than 5%) neither pooled or
D. Jordan / Preventive Veterinary Medicine 70 (2005) 59–7366
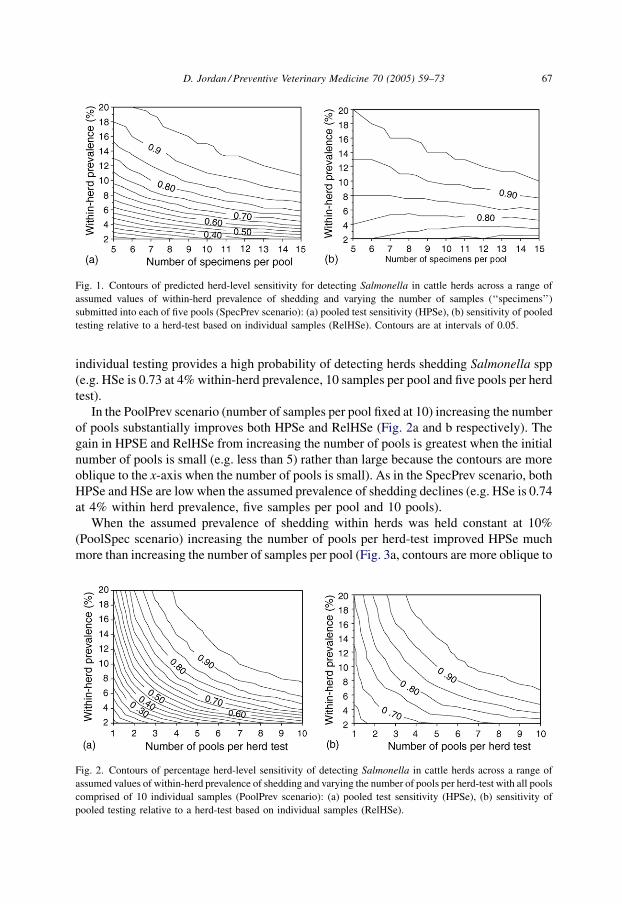
individual testing provides a high probability of detecting herds shedding Salmonella spp
(e.g. HSe is 0.73 at 4% within-herd prevalence, 10 samples per pool and five pools per herd
test).
In the PoolPrev scenario (number of samples per pool fixed at 10) increasing the number
of pools substantially improves both HPSe and RelHSe (Fig. 2a and b respectively). The
gain in HPSE and RelHSe from increasing the number of pools is greatest when the initial
number of pools is small (e.g. less than 5) rather than large because the contours are more
oblique to the x-axis when the number of pools is small). As in the SpecPrev scenario, both
HPSe and HSe are low when the assumed prevalence of shedding declines (e.g. HSe is 0.74
at 4% within herd prevalence, five samples per pool and 10 pools).
When the assumed prevalence of shedding within herds was held constant at 10%
(PoolSpec scenario) increasing the number of pools per herd-test improved HPSe much
more than increasing the number of samples per pool (Fig. 3a, contours are more oblique to
D. Jordan / Preventive Veterinary Medicine 70 (2005) 59–73 67
Fig. 1. Contours of predicted herd-level sensitivity for detecting Salmonella in cattle herds across a range of
assumed values of within-herd prevalence of shedding and varying the number of samples (‘‘specimens’’)
submitted into each of five pools (SpecPrev scenario): (a) pooled test sensitivity (HPSe), (b) sensitivity of pooled
testing relative to a herd-test based on individual samples (RelHSe). Contours are at intervals of 0.05.
Fig. 2. Contours of percentage herd-level sensitivity of detecting Salmonella in cattle herds across a range of
assumed values of within-herd prevalence of shedding and varying the number of pools per herd-test with all pools
comprised of 10 individual samples (PoolPrev scenario): (a) pooled test sensitivity (HPSe), (b) sensitivity of
pooled testing relative to a herd-test based on individual samples (RelHSe).

the x-axis which describes the number of pools). The advantage of increasing the number
pools per herd-test at 10% assumed prevalence of shedding is very evident in Fig. 3b where
contours of RelHSe are for the most very oblique to the x-axis.
The per-herd cost of classifying the Salmonella shedding status of cattle by the pooled-
sample approach and by the individual-sample approach is compared for all protocols
simulated in the PoolSpec scenario (Fig. 4). Regardless of the number of individual
samples collected, processing them as pooled samples is consistently and markedly less
costly irrespective of the pooling protocol used. The differences between the cost of the
various pooled-test protocols that handle an identical number of individual samples is
trivial compared to the difference between the cost of a pooled protocol and the
D. Jordan / Preventive Veterinary Medicine 70 (2005) 59–7368
Fig. 3. Contours of percentage herd-level sensitivity of detecting Salmonella in cattle herds across a range of
number of samples (‘‘specimens’’) per pool and number of pools per herd test, and assuming a constant within herd
prevalence of 10% (PoolSpec scenario): (a) pooled test sensitivity (HPSe), (b) sensitivity of pooled testing relative
a herd-test based on individual samples (RelHSe).
Fig. 4. Cost comparison in Australian dollars for herd tests performed by testing individual samples (H) and by the
pooled-sample approach (P) for the PoolSpec scenario (i.e. all combinations of pool size and number of samples
per pool). The comparison is on the basis of the number of individual samples collected which are then either
tested individually or in a varying number of pools (1–10) with a varying number of samples per pool (5–25).

corresponding herd-test based on individual samples (same number of individual samples
collected in each test). The cost advantage of herd tests based on pooled samples versus
testing of individual samples increases substantially as the number of individual samples
collected increases. This is largely explained by the rapid increase in the cost of individual-
test protocols as number of samples increases whereas the expense of pooled test protocols
rises at a much slower rate.
4. Discussion
Although approaches have been described for appraising the performance of assays for
antibody in pooled serum samples (e.g. Sacks et al., 1989; Brookmeyer, 1999; Tu et al.,
1994) these methods are not necessarily suited to the isolation of pathogens because they
do not account for the effect of dilution during pooling (this phenomenon is not regarded as
important when pooled sera are assayed). Because the present model does allow for the
effect of dilution the opportunity now exists to identify the optimum pooling protocol from
a myriad of possible candidate protocols (each arising from the possible combinations of r,
s, wi and Q) when an investigator wishes to detect enteric pathogens in herds or groupings
of food products. Model-based solutions such as this are attractive because of the cost and
practical constraints that apply to obtaining empirical estimates of HPSe and RelHSe. One
obvious role for this model is as a technique for screening a range of pooled-test protocols
to select those that should undergo more rigorous evaluation either in empirically based
studies (like that described by Wells et al. (2003)) or by Bayesian analysis (like that
described by Sergeant et al. (2002)) once sufficient data for providing informed prior
distributions are available. Such an evaluation could be incorporated into any major effort
on control of enteric pathogens where samples are already planned to be collected and
resources for the additional laboratory effort can be secured.
An essential requirement for use of this model is access to data describing two key input
variables. The first of these is the test–dose–response relationship. Importantly, there are
few published examples of test–dose–response curves for sensitive tests that are suited to
detecting enteric pathogens in pooled samples. Consequently, the test–dose–response
curve used here was purposefully derived in a companion study to facilitate the creation
and demonstration of the present model (Jordan et al., 2004). It appears that the available
methodology only allows such curves to be obtained from experimental studies which by
their nature exclude many of the factors that account for variation in the performance of
tests when they are used in a practical setting. The second key requirement for use of this
model is data describing the concentration of enteric pathogens in livestock or food
specimens of interest. There appears to be a great deficiency in the amount and quality of
such data in the literature. The Salmonella-concentration data used in this study are likely
to be accurate because of the analytical sensitivity of IMS-based test used. Although the
data set is small (necessitated by the cost of combining IMS detection with an MPN
procedure) it is derived from designed surveys with the samples collected under conditions
of commercial beef production. In contrast, opportunities for application of the model to
additional pathogens, livestock or food production systems are presently limited because of
the aforementioned lack of data. However, the availability of a new model for appraising
D. Jordan / Preventive Veterinary Medicine 70 (2005) 59–73 69

the performance of culture of pooled samples might provoke greater interest in the study of
these key variables as they pertain to other enteric pathogens, microbiological tests and
production systems. Any such new data would expand the range of applications of the
present model and also deliver a basis for refining the model to suite particular
circumstances. A final constraint on use of the model is that when values of within-herd
prevalence are assumed to be low or when herd sizes are small the estimates of HSe and
HPSe might be biased downwards because of the difficulty of correctly simulating the
shedding status of herds in these circumstances (Section 2.1 describes the method for
assessing if this applies for a particular herd size and within-herd prevalence).
Some limitations apply to extrapolating the predictions of HPSe and RelHSe reported
here to other populations of cattle, small herds and to circumstances where a procedure
other than IMS and enrichment has been used for detecting Salmonella. However, there are
several benefits in presenting these predictions here despite the fact that they might only be
specific for Australian cattle and the IMS test. Firstly, published estimates of HSpe for
fecal-borne pathogens are scarce despite the apparent widespread use of pooled testing for
many decades and the economic and public health importance of many of the organisms
involved. Secondly, the predictions reveal hitherto un-described relationships between the
attributes of pooled-test protocols that are under the control of an investigator (r and s),
prevalence and the probability of detecting herds shedding Salmonella spp. Thirdly, the
predictions display the type of output that another investigator could generate for another
pathogen within another population of livestock provided the investigator has access to
appropriate data on test–dose–response and concentration of pathogen. To demonstrate the
scope of use for the model I have illustrated the output in a form that represents a sensitivity
analysis of the impact of within-herd prevalence, the number of pools and number of
samples per pools on HPSe. The latter two are key features of a pooled test protocol that are
also under the control the investigator. The true prevalence of shedding of pathogen within
a herd is clearly uncontrolled so the range of assumed prevalence of shedding used in these
sensitivity analyses is arbitrary and demonstrates how a user of the model would
manipulate the range to investigate a particular scenario of interest. Although the
predictions of HPSe reported here do have some general interest each user of the model
should judge how much reliance can be placed on them given that empirical data providing
validation may or may not be available. The primary use of the model should be for
identifying the pooled-test protocol that most likely provides the best performance and
value for money when traditional herd testing based on individual samples is prohibited
due to cost. Investigators considering ongoing reliance on a pooled protocol identified by
the model should plan to undertake an empirical validation study particularly if decisions
dependent on the accuracy of data have an important social or economic impact.
In conclusion, the model demonstrated here estimates HPSe by allowing for the dilution
of pathogens in pools and the impact this has on probability of detecting the organism by
IMS then culture. Predictions from the model indicate that pooled-test protocols become
useful for detecting cattle herds shedding Salmonella when the true prevalence of
individual animals shedding the organism increases and as the number of pools per herd-
test increases provided the number of samples per pool is not small. Predictions from the
model also indicate that pooled-sample protocols for detecting cattle herds shedding
Salmonella need to be defined on a case-by-case basis for each population of herds
D. Jordan / Preventive Veterinary Medicine 70 (2005) 59–7370

according to the particular objective, economic constraints, and range of values of true
prevalence of shedding that may be encountered.
Acknowledgements
I thank Meat and Livestock Australia for funding this work, Dr. Narelle Fegan of Food
Science Australia for providing data on Salmonella in bovine feces, and Mr. Stephen
Morris of NSW Department of Primary Industries for his advice on censored regression.
Appendix A
The logic of the model for estimating HPSe, HSe and RelHSe can be represented as
shown below. Input and output variables are indicated, the remaining are derived variables
created in the process of producing the outputs.
D. Jordan / Preventive Veterinary Medicine 70 (2005) 59–73 71
Variables
n Number of individual samples obtained from a herd (input)
r Number of pools constructed for each herd-test (input)
s Number of samples entering each of the r pools (input)
u Within-herd prevalence of shedding the pathogen
of interest (input)
mw, s2w
Mean and variance of wi (input)
TDRFunction Test–dose–response function that predicts the probability of a
positive test given the concentration of pathogen in either the
sub-sample from the pool or individual sample (input)
X Probability distribution describing the concentration of pathogen
in samples from animals shedding pathogen (input)
Q The weight of a sub-sample taken from a pool of specimens
for testing (input)
y Number of samples in a pool that are from animals
shedding pathogen
Shedi Shedding status of the animal providing the ith sample to a pool
(0, false, not shedding; 1, true, shedding)
wi Weight of the ith specimen entering a pool
ci Concentration of pathogen in the ith specimen
C Concentration of pathogen in the pool
I The number of pathogen cells present in a sub-sample of
weight Q from a pool
Z The concentration of pathogen in the sub-sample from a pool
that is then tested
Tpool Test result for any pool (0 or 1 as above)
Tindividual Test result for any individual sample (0 or 1 as above)
HTpool Herd-test result from analysis of pooled specimens
(0 or 1 as above)
HTindividual Herd-test result from analysis of individual specimens
(0 or 1 as above)

References
Benoit, P.W., Donahue, D.W., 2003. Methods for rapid separation and concentration of bacteria in food that bypass
time consuming cultural enrichment. J. Food Protect. 66, 1935–1948.
Brookmeyer, R., 1999. Analysis of multistage pooling studies of biological specimens estimating disease
incidence and prevalence. Biometrics 55, 608–612.
Christensen, J., Gardner, I.A., 2000. Herd-level interpretation of test results for epidemiologic studies of animal
diseases. Prev. Vet. Med. 45, 83–106.
Donald, A.W., Gardner, I.A., Wiggins, A.D., 1994. Cut-off points for aggregate herd testing in the presence of
disease clustering and correlation of test errors. Prev. Vet. Med. 19, 167–187.
Fan, J., Gijbels, I., 1994. Censored regression: local linear approximations and their applications. J. Am. Stat.
Assoc. 89, 560–570.
Fegan, N., Vanderlinde, P., Higgs, G., Desmarchelier, P., 2004. Quantitation and prevalence of Salmonella in beef
cattle presenting at slaughter. J. Appl. Microbiol. 97, 892–898.
Haas, C.N., 1989. Estimation of microbial densities from dilution count experiments. Appl. Environ. Microbiol.
55, 1934–1942.
Haas, C.N., Rose, J.B., Gerba, C.P., 1999. Quantitative Microbial Risk Assessment. John Wiley and Sons, New
York.
Hollander, M., Proschan, M.A., 1979. Testing to determine the underlying distribution using randomly censored
data. Biometrics 35, 393–401.
D. Jordan / Preventive Veterinary Medicine 70 (2005) 59–7372
HPSe Sensitivity of detecting infected herds using
the pooled test (output)
HSe Sensitivity of detecting infected herds by testing individual
samples (output)
RelHSe HPSe relative to HSe (HPSe as a fraction of HSe) (output)
Assumptions
u > 0 Sensitivity can only be assessed for infected herds
Sp = 1 Specificity of tests on individual samples or pools is unity
HPSp = HSp = 1 Specificity of herd testing by individual and
pooled samples is unity
n = rs The number of individual samples is the product of the
number of pools and number of specimens per pool
Model
If Shedi = 1 then ci � X, else ci = 0
wi � normal(mw, s2w)
y � binomial(s, u)
C =P
ðwiciÞ/P
wi
I � Poisson(CQ)
Z = I/Q
if Z > 0 then Tpool � Bernoulli
(TDRFunction (Z)), else Tpool = 0
Pooled tests
If ci > 0 then Tindividual � Bernoulli
(TDRFunction (ci)), else Tindividual = 0
Individual tests
If any Tpool from the r pools = 1
then HTpool = 1, else HTpool = 0
Pooled tests
If any Tindividual for the n individuals = 1
then HTindividual = 1, else HT = 0
Individual tests
HPSe = # iterations (PT = 1)/# iterations
HSe = # iterations (HT = 1)/# iterations
RelHSe = HPSe/HSe

Jordan, D., 1996. Aggregate testing for the evaluation of Johne’s disease herd status. Aust. Vet. J. 73, 16–19.
Jordan, D., Vancov, T., Chowdhury, M.A., Andersen, L.M., Jury, K., Stevenson, A.E., Morris, S.G., 2004. The
relationship between concentration of a dual marker strain of Salmonella Typhimurium in bovine faeces and
its probability of detection by immunomagnetic separation and culture. J. Appl. Microbiol. 97, 1054–1062.
Law, A.M., Kelton, W.D., 2000. Simulation Modelling and Analysis. McGraw-Hill, New York.
McMeekin, T., Olley, J.N., Ross, T., Ratkowsky, D.A., McMeekin, T., Olley, J.N., Ross, T., Ratkowsky, D.A.,
1993. Predictive Microbiology Theory and Application Predictive Microbiology Theory and Application.
Research Studies Press, Taunton, UK.
Myers, R.H., 1990. Classical and Modern Regression with Applications Classical and Modern Regression with
Applications. Duxbury, Belmont.
Sacks, J.M., Bolin, S., Crowder, S.V., 1989. Prevalence estimation from pooled samples. Am. J. Vet. Res. 50, 205–
206.
Sergeant, E.S., Whittington, R.J., More, S.J., 2002. Sensitivity and specificity of pooled faecal culture and
serology as flock-screening tests for detection of ovine paratuberculosis in Australia. Prev. Vet. Med. 52, 199–
211.
Tu, X.M., Litvak, E., Pagano, M., 1905-1919. Studies of AIDS and HIV surveillance screening tests: can we get
more by doing less. Stat. Med. 13 .
van Schaik, G., Stehman, S.M., Schukken, Y.H., Rossiter, C.R., Shin, S.J., 2003. Pooled fecal culture sampling for
Mycobacterium avium subsp. paratuberculosis at different herd sizes and prevalence. J. Vet. Diagnost. Invest.
15, 233–241.
Wells, S.J., Godden, S.M., Lindeman, C.J., Collins, J.E., 2003. Evaluation of bacteriologic culture of individual
and pooled fecal samples for detection of Mycobacterium paratuberculosis in dairy cattle herds. J. Am. Vet.
Med. Assoc. 223, 1022–1025.
Whittington, R.J., Fell, S., Walker, D., McAllister, S., Marsh, I., Sergeant, E., Taragel, C.A., Marshall, D.J., Links,
I.J., 2000. Use of pooled fecal culture for sensitive and economic detection of Mycobacterium avium subsp.
paratuberculosis infection in flocks of sheep. J. Clin. Microbiol. 38, 2550–2556.
D. Jordan / Preventive Veterinary Medicine 70 (2005) 59–73 73