siemens big data analysis group 3: mario massad, matthew toschi, tyler truong
TRANSCRIPT

Siemens Big Data AnalysisGROUP 3: MARIO MASSAD, MATTHEW TOSCHI, TYLER TRUONG

The Problem!We have lots of unstructured data in forms of news articles.
What do we do?
● Use Natural Language Processing (NLP) to evaluate unstructured data
● Use Latent Dirichlet Allocation to extract topics and relevance among words
● Allow users to query for relevant articles
● Recognize connections between entities
The Problem and Project Goals / Specification

● MongoDB / MongoDB GridFS
● Python 3
● Java 8
● NodeJS (Javascript)
● Stanford CoreNLP
Technologies and Tools

MongoDB
● Schema-less
● No strict rules on data-relations
● JSON becomes common interface to our data regardless of how we access it
Technologies

MongoDB GridFS
Used to store files (unstructured data)● Aggregation for stored files
● Sharding
● Emphasizes non-relational nature of files
Technologies

Node JS / Javascript
• Javascript is commonly used in web browsers
• Used to create web interface
• Node JS – Non-blocking I/O calls
• Allows applications to act as web servers without software such as Apache HTTP server/ IIS
Technologies

Java 8● Strictly object oriented
● Difficult to interpret and interact with MongoDB style objects
● MongoDB class underdeveloped
● However, Stanford CoreNLP is written in Java
Technologies
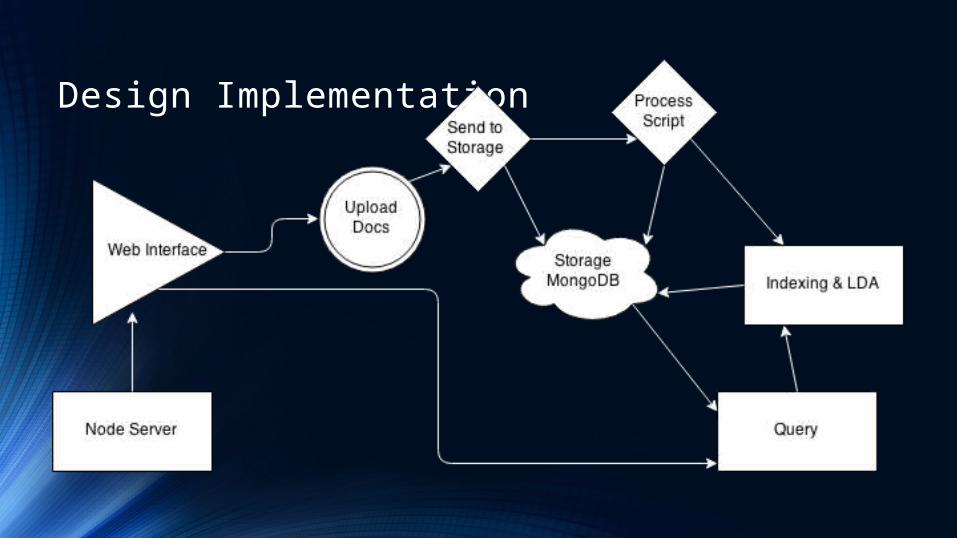
Design Implementation

● Science involving enabling computers to derive meaning from the human language
● NLP techniques to extract relevant information from articles
Several natural language processing techniques involve:- Parts-of-speech tagging-named entitiy recognition-dependency parsing-sentiment analysis
Natural Language Processing

Main tools are:● NLTK (Natural Language ToolKit) w/ Python
● Stanford CoreNLPo Entity Detectoro Parts-of-speech taggero Dependency Tree Parsingo Sentiment Analysis
NLP Tools

Parts-Of-Speech Tagging
● Breaks sentences into individual components and sub-phrases
● Useful for finding entities in addition to NER
(ROOT (S (NP (PRP They)) (VP (VBP include) (NP (NP (NN equipment)) (SBAR (WHNP (WDT that)) (S (VP (VBZ protects) (CC and) (VBZ controls) (NP (NP (DT the) (NN flow)) (PP (IN of) (NP (JJ electrical) (NN
power))))))))) (. .)))
They include equipment that protects and controls the flow of electrical power.

Part-of-speech tag list
Tag Description
NN/NNS/NNP Noun/Noun singular/Noun Plural
PRP Personal pronoun
RB Adverb
VB Verb
DT Determiner
JJ Adjective
POS Possessive

Dependency Parsing● Focuses relations between words● Relevance to other words● Resolves ambiguity
They include equipment that protects and controls the flow of electrical power.
nsub(include-2, They-1)root(ROOT-0, include-2)dobj(include-2, equipment-3)nsubj(protects-5, that-4)rcmod(equipment-3, protects-5)cc(protects-5, and-6)
conj(protects-5, controls-7)det(flow-9, the-8)dobj(protects-5, flow-9)prep(flow-9, of-10)amod(power-12, electrical-11)pobj(of-10, power-12)

Named Entity Recognition
Locating and Identifying entities in articles such as:
● Location● Organization● Name● Time● Quantities● Money● Percentages

Sentiment Analysis
Previous NLP techniques looks at facts
Sentiment Analysis extracts subjective information or opinions

Processing Extracted Information
Categorize
● Separate parts of sentences into categories - Who, What, Where, When
● Discard Junk
Processed 35,072 parsed filesIn 20.9 minutes (1,254 seconds)
Parsing approximately 35,000 documents on 40 cores took 2 hours

MongoDB Document
Group occurrences by base of word: “lemma”
•Named Entities, verbs, nouns, relations

Indexing
Term Weighting
eg.
• TF – frequency of a term in a document
• IDF – is the rarity of the term across all documents
• Logarithms prevent a document from being ranked high for spamming a single term

Indexing
Reverse Indexing An efficient way to search for documents by terms.
Note: MongoDB has array indexes

Indexing
Matrices• Latent Semantic Indexing• DecompositionTerm Document Matrix
• Used in building fuzzy sets
• ClusteringTerm-Term Matrix

Indexing Problem
•Too large to compute directly and cheaply
•Correlation is even worse • 3 weeks to compute
There needs to be heuristics and approximations

Latent Dirichlet Allocation (LDA)
A way of automatically discovering hidden topics
LDA can help group relevant articles together
Unsupervised and statistical approach for modeling text to discover latent semantic topics

Latent Dirichlet Allocation

User Interface/ Querying
• Users query against our indexed data
• System retrieves most relevant articles to query
• Custom or pre-defined ontology

Budget
•Hardware• Server machine up to client’s discretion• Demo- Intel® Core™i3-
3225 CPU @ 3.30 GHz 2 cores
• Internet connection for web service
•Software• All software used was free
• Licensing issues likely exist if sold. Siemens only required a private, in-house solutionTotal Budget: $0

Demo