seminar speech recognition a short overview e.m. bakker liacs media lab leiden university
DESCRIPTION
Seminar Speech Recognition a Short Overview E.M. Bakker LIACS Media Lab Leiden University. Introduction What is Speech Recognition?. Words. Speech Recognition. “How are you?”. Speech Signal. Other interesting area’s: Who is talker (speaker recognition, identification) - PowerPoint PPT PresentationTRANSCRIPT

Speech Recognition LIACS Media Lab Leiden University
Seminar
Speech Recognition
a Short Overview
E.M. Bakker
LIACS Media Lab
Leiden University

Speech Recognition LIACS Media Lab Leiden University
Introduction What is Speech Recognition?
SpeechRecognition
Words“How are you?”
Speech Signal
Goal: Automatically extract the string of words spoken from the speech signal
• Other interesting area’s:– Who is talker (speaker recognition, identification)– Speech output (speech synthesis)– What the words mean (speech understanding, semantics)

Speech Recognition LIACS Media Lab Leiden University
MessageSource
LinguisticChannel
ArticulatoryChannel
AcousticChannel
Observable: Message Words Sounds Features
Bayesian formulation for speech recognition:
• P(W|A) = P(A|W) P(W) / P(A)
Recognition ArchitecturesA Communication Theoretic Approach
Objective: minimize the word error rate
Approach: maximize P(W|A) during training
Components:
• P(A|W) : acoustic model (hidden Markov models, mixtures)
• P(W) : language model (statistical, finite state networks, etc.)
The language model typically predicts a small set of next words based on knowledge of a finite number of previous words (N-grams).

Speech Recognition LIACS Media Lab Leiden University
Input Speech
Recognition ArchitecturesIncorporating Multiple Knowledge Sources
AcousticFront-end
AcousticFront-end
• The signal is converted to a sequence of feature vectors based on spectral and temporal measurements.
Acoustic ModelsP(A/W)
Acoustic ModelsP(A/W)
• Acoustic models represent sub-word units, such as phonemes, as a finite-state machine in which states model spectral structure and transitions model temporal structure.
RecognizedUtterance
SearchSearch
• Search is crucial to the system, since many combinations of words must be investigated to find the most probable word sequence.
• The language model predicts the next set of words, and controls which models
are hypothesized.Language Model
P(W)

Speech Recognition LIACS Media Lab Leiden University
FourierTransform
FourierTransform
CepstralAnalysis
CepstralAnalysis
PerceptualWeighting
PerceptualWeighting
TimeDerivative
TimeDerivative
Time Derivative
Time Derivative
Energy+
Mel-Spaced Cepstrum
Delta Energy+
Delta Cepstrum
Delta-Delta Energy+
Delta-Delta Cepstrum
Input Speech
• Incorporate knowledge of the nature of speech sounds in measurement of the features.
• Utilize rudimentary models of human perception.
Acoustic ModelingFeature Extraction
• Measure features 100 times per sec.
• Use a 25 msec window forfrequency domain analysis.
• Include absolute energy and 12 spectral measurements.
• Time derivatives to model spectral change.
Speech Recognition LIACS Media Lab Leiden University
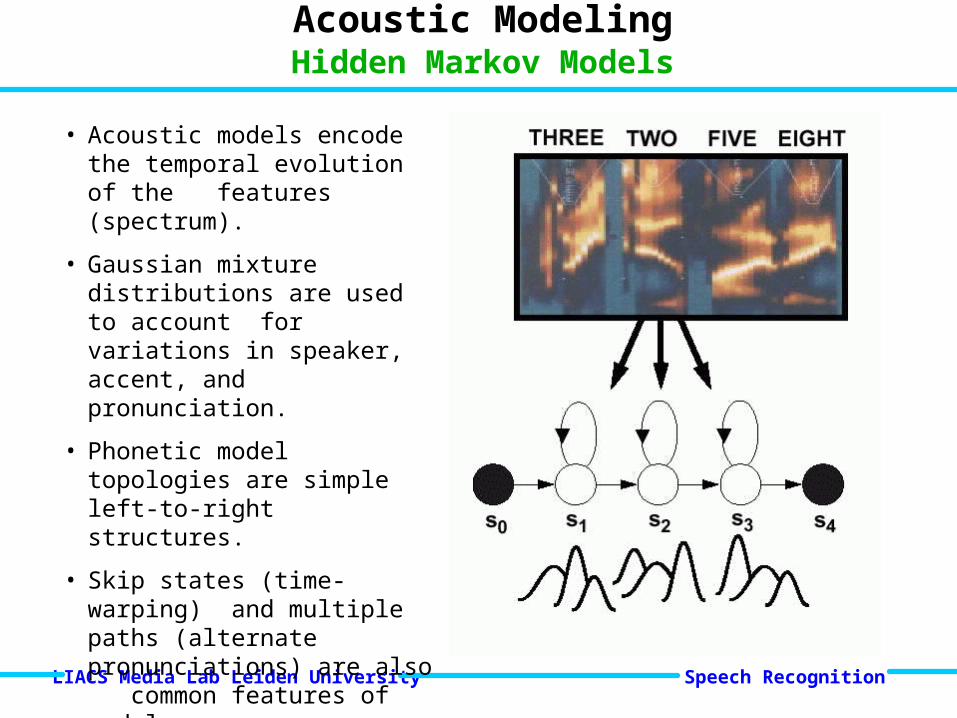
• Acoustic models encode the temporal evolution of the features (spectrum).
• Gaussian mixture distributions are used to account for variations in speaker, accent, and pronunciation.
• Phonetic model topologies are simple left-to-right structures.
• Skip states (time-warping) and multiple paths (alternate pronunciations) are also common features of models.
• Sharing model parameters is a common strategy to reduce complexity.
Acoustic ModelingHidden Markov Models

Speech Recognition LIACS Media Lab Leiden University
• Closed-loop data-driven modeling supervised only from a word-level transcription.
• The expectation/maximization (EM) algorithm is used to improve our parameter estimates.
• Computationally efficient training algorithms (Forward-Backward) have been crucial.
• Batch mode parameter updates are typically preferred.
• Decision trees are used to optimize parameter-sharing, system complexity, and the use of additional linguistic knowledge.
Acoustic ModelingParameter Estimation
• Initialization
• Single Gaussian Estimation
• 2-Way Split
• Mixture Distribution Reestimation
• 4-Way Split
• Reestimation
•••

Speech Recognition LIACS Media Lab Leiden University
Language ModelingIs A Lot Like Wheel of Fortune

Speech Recognition LIACS Media Lab Leiden University
Language ModelingN-Grams: The Good, The Bad, and The Ugly
Bigrams (SWB):
• Most Common: “you know”, “yeah SENT!”, “!SENT um-hum”, “I think”• Rank-100: “do it”, “that we”, “don’t think”• Least Common: “raw fish”, “moisture content”,
“Reagan Bush”
Trigrams (SWB):
• Most Common: “!SENT um-hum SENT!”, “a lot of”, “I don’t know”
• Rank-100: “it was a”, “you know that”• Least Common: “you have parents”,
“you seen Brooklyn”
Unigrams (SWB):
• Most Common: “I”, “and”, “the”, “you”, “a”• Rank-100: “she”, “an”, “going”• Least Common: “Abraham”, “Alastair”, “Acura”

Speech Recognition LIACS Media Lab Leiden University
Language ModelingIntegration of Natural Language
• Natural language constraints can be easily incorporated.
• Lack of punctuation and search space size pose problems.
• Speech recognition typically produces a word-level
time-aligned annotation.
• Time alignments for other levels of information also available.

Speech Recognition LIACS Media Lab Leiden University
• Typical LVCSR systems have about 10M free parameters, which makes training a challenge.
• Large speech databases are required (several hundred hours of speech).
• Tying, smoothing, and interpolation are required.
Implementation Issues Search Is Resource Intensive
Megabytes of Memory
FeatureExtraction
(1M)
Acoustic Modeling
(10M)
LanguageModeling (30M)
Search(150M)
Percentage of CPUFeature
Extraction1%
LanguageModeling
15%
Search 25% Acoustic
Modeling 59%

Speech Recognition LIACS Media Lab Leiden University
• Dynamic programming is used to find the most probable path through the network.
• Beam search is used to control resources.
Implementation IssuesDynamic Programming-Based Search
• Search is time synchronous and left-to-right.
• Arbitrary amounts of silence must be permitted between each word.
• Words are hypothesized many times with different start/stop times, which significantly increases search complexity.

Speech Recognition LIACS Media Lab Leiden University
• Cross-word Decoding: since word boundaries don’t occur in spontaneous speech, we must allow for sequences of sounds that span word boundaries.
• Cross-word decoding significantly increases memory requirements.
Implementation IssuesCross-Word Decoding Is Expensive

Speech Recognition LIACS Media Lab Leiden University
General Specification

Speech Recognition LIACS Media Lab Leiden University
Applications Conversational Speech
• Conversational speech collected over the telephone contains background noise, music, fluctuations in the speech rate, laughter, partial words, hesitations, mouth noises, etc.
• WER (Word Error Rate) has decreased from 100% to 30% in six years.
• Laughter
• Singing
• Unintelligible
• Spoonerism
• Background Speech
• No pauses
• Restarts
• Vocalized Noise
• Coinage

Speech Recognition LIACS Media Lab Leiden University
ApplicationsAudio Indexing of Broadcast News
Broadcast news offers some uniquechallenges:• Lexicon: important information in infrequently occurring words
• Acoustic Modeling: variations in channel, particularly within the same segment (“ in the studio” vs. “on location”)
• Language Model: must adapt (“ Bush,” “Clinton,” “Bush,” “McCain,” “???”)
• Language: multilingual systems? language-independent acoustic modeling?

Speech Recognition LIACS Media Lab Leiden University
• From President Clinton’s State of the Union address (January 27, 2000):
“These kinds of innovations are also propelling our remarkable prosperity...Soon researchers will bring us devices that can translate foreign languagesas fast as you can talk... molecular computers the size of a tear drop with thepower of today’s fastest supercomputers.”
Applications Real-Time Translation
• Imagine a world where:
• You book a travel reservation from your cellular phone while driving in your car without ever talking to a human (database query)
• You converse with someone in a foreign country and neither speakerspeaks a common language (universal translator)
• You place a call to your bank to inquire about your bank account and never have to remember a password (transparent telephony)
• You can ask questions by voice and your Internet browser returns answers to your questions (intelligent query)
• Human Language Engineering: a sophisticated integration of many speech and language related technologies... a science for the next millennium.

Speech Recognition LIACS Media Lab Leiden University
A Generic Solution

Speech Recognition LIACS Media Lab Leiden University
A Pattern Recognition Formulation

Speech Recognition LIACS Media Lab Leiden University
Solution:Signal Modeling

Speech Recognition LIACS Media Lab Leiden University
Speech Recognition
Erwin M. BakkerLeiden University

Speech Recognition LIACS Media Lab Leiden University
THE SPEECH RECOGNITION PROBLEM
• Boundaries between words or phonemes
• Large variations in speaking rates
• in fluent speech words and word-endings are less pronounced
• Great deal of inter- as well as intra-speaker variability
• Quality of speech signal
• Task-inherent syntactic-semantic constraints should be exploited

Speech Recognition LIACS Media Lab Leiden University
SEARCH ALGORITHMS

Speech Recognition LIACS Media Lab Leiden University
STATISTICAL METHODS IN SPEECH RECOGNITION
• The Bayesian Approach
• Acoustic Models
• Language Models

Speech Recognition LIACS Media Lab Leiden University
a statistical speech recognition system

Speech Recognition LIACS Media Lab Leiden University
Acoustic Models (HMM)
Some typical HMM topologies used for acoustic modeling in large vocabulary speech recognition:(a) typical triphone,(b) short pause(c)silence. The shaded states denote the start and stop states for each model.

Speech Recognition LIACS Media Lab Leiden University
Language Models

Speech Recognition LIACS Media Lab Leiden University
SEARCH ALGORITHMS
• The Complexity of Search.
• Typical Search Algorithms– Viterbi Search– Stack Decoders– Multi-Pass Search– Forward-Backward Search

Speech Recognition LIACS Media Lab Leiden University
Hierarchical representation of the search space.

Speech Recognition LIACS Media Lab Leiden University
An outline of the Viterbi search algorithm

Speech Recognition LIACS Media Lab Leiden University
Simple overview of the stack decoding algorithm.

Speech Recognition LIACS Media Lab Leiden University
Multi-Pass Search

Speech Recognition LIACS Media Lab Leiden University
Complexity of Search
•lexicon: contains all the words in the system’s vocabulary along with their pronunciations (often there are multiple pronunciations per word)•acoustic models: HMMs that represent the basic sound units the system is capable of recognizing•language model: determines the possible word sequences allowed by the system (encodes knowledge of the syntax and semantics of the language)

Speech Recognition LIACS Media Lab Leiden University

Speech Recognition LIACS Media Lab Leiden University

Speech Recognition LIACS Media Lab Leiden University
References
Neeraj Deshmukh, Aravind Ganapathiraju and Joseph Picone Hierarchical Search for Large Vocabulary Conversational Speech RecognitionIEEE Signal Processing Magazine, September 1999.
H. Ney and S. OrtmannsDynamic Programming Search for Continuous Speech RecognitionIEEE Signal Processing Magazine, September 1999.
V. ZueTalking with Your ComputerScientific American, August 1999

Speech Recognition LIACS Media Lab Leiden University
relative complexity of the search problem for large vocabulary
conversational
speech recognition

Speech Recognition LIACS Media Lab Leiden University
A TIME-SYNCHRONOUS VITERBI-BASED DECODER
• Complexity of Search– Network Decoding– N-Gram Decoding– Cross-Word Acoustic Models
• Search Space Organization– Lexical Trees– Language Model Lookahead– Acoustic Evaluation

Speech Recognition LIACS Media Lab Leiden University
Network decoding using word-internal context-dependent
models.
•The word network providing linguistic constraints •The pronunciation lexicon for the words involved •The network expanded using the corresponding word-internal triphones derived from the pronunciations of the words.

Speech Recognition LIACS Media Lab Leiden University

Speech Recognition LIACS Media Lab Leiden University
Search Space Organization

Speech Recognition LIACS Media Lab Leiden University
Lexical Tree

Speech Recognition LIACS Media Lab Leiden University
Generation of triphones

Speech Recognition LIACS Media Lab Leiden University
A TIME-SYNCHRONOUS VITERBI-BASED DECODER
• Search Space Reduction– Pruning
setting pruning beams based on the hypothesis score limiting the total number of model instances active at a given time setting an upper bound on the number of words allowed to end at
a given frame
– Path Merging– Word Graph Compaction

Speech Recognition LIACS Media Lab Leiden University

Speech Recognition LIACS Media Lab Leiden University
A TIME-SYNCHRONOUS VITERBI-BASED DECODER
• System Architecture
• PERFORMANCE ANALYSIS– a substitution error refers to the case where the decoder miss-recognizes a word in the
reference– sequence as another in the hypothesis.– a deletion error occurs when the there is no word recognized corresponding to a word in the– reference transcription.– an insertion error corresponds to the case where the hypothesis contains an extra word that
has no counterpart in the reference.

Speech Recognition LIACS Media Lab Leiden University
A TIME-SYNCHRONOUS VITERBI-BASED DECODER
• scalability: Can the algorithm scale gracefully from small constrained tasks to large unconstrained
• tasks?
• recognition accuracy: How accurate is the best word sequence found by the system?
• word graph accuracy: Can the system generate alternate choices that contain the correct word
• sequence? How large must this list of choices be?
• memory: What memory is required to achieve optimal performance? How does performance vary
• with the amount of memory required?
• run-time: How many seconds of CPU time per second of speech are required (xRT) to achieve
• optimal performance? How does run-time vary with performance (run-time should decrease
• significantly as error rates increase)?

Speech Recognition LIACS Media Lab Leiden University
A TIME-SYNCHRONOUS VITERBI-BASED DECODER
• Alphadigits
• Switchboard
• Beam Pruning
• MAPMI Pruning

Speech Recognition LIACS Media Lab Leiden University

Speech Recognition LIACS Media Lab Leiden University
Comparisons performed on a 333 MHz Pentium II processor
with 512MB RAM.

Speech Recognition LIACS Media Lab Leiden University
Forward-backward search

Speech Recognition LIACS Media Lab Leiden University
Introduction Speech in the Information Age
• Speech & text were revolutionary because of information access• New media and connectivity yield information overload• Can speech technology help?
Time
Source ofInformation Speech Text
Film, video, multimedia, voice mail,radio, television, conferences, web,on-line resources
Access toInformation
Listen,remember
Readbooks
Computertyping
Careful spoken,written input
Conversationallanguage

Speech Recognition LIACS Media Lab Leiden University
Conclusion and Future DirectionsTrends
We need new technology to help with information overload• Speech information sources are everywhere
– Voice mail messages– Professional talk– Lectures, broadcasts
• Speech sources of information will increase– As devices shrink– As mobility increases– New uses: annotation, documentation
Speech as Access Speech as Source Information as Partner
What are the words? What does it mean? Here’s what you need.

Speech Recognition LIACS Media Lab Leiden University
Conclusion and Future DirectionsApplications on the Horizon
Beginnings of speech as source of information
• ISLIP http://www.mediasite.net/info/frames.htm
• Virage http://www.virage.com Why
doesn’t belong inthe classroom• Beulah Arnott: also true of indoor plumbing
• BravoBrava: Co-evolving technology and people can– Dramatically reduce the cost of delivery of content– Increase its timeliness, quality and appropriateness– Target needs of individual and/or group – Reading Pal demo
Speech technology in education and training• Cliff Stoll, High Tech Heretic
–Good schools need no computers –Bad schools won’t be improved by them

Speech Recognition LIACS Media Lab Leiden University
OVERLAP IN THE CEPSTRAL SPACE (ALPHADIGITS)
The following plots demonstrate overlap of recognition features in the cepstral space. These plots consist of the vowels "aa" (as in "lock") and "iy" (as in "beat") excised from tokens in the OGI Alphadigit speech corpus.
In these plots, the first two cepstral coefficients are shown (c[1] and c[2]; energy, which is c[0], is not shown). Comparisons are provided as a function of the vowel spoken and the gender of the speaker:
Vowel Comparison: a comparison of male "aa" to male "iy"
Vowel Comparison: a comparison of female "aa" to female "iy"
Vowel Comparison: a combined plot of the above conditions
Gender Comparisons: a comparison of males and females for the vowels "aa" and "iy"
Combined Comparisons: a comparison of "aa" to "iy" for both genders
The Alphadigits vowel data used to generate these plots is available for classification experiments.

Speech Recognition LIACS Media Lab Leiden University
OVERLAP IN THE CEPSTRAL SPACE (SWB)
The following plots demonstrate overlap of recognition features in the cepstral space. These plots consist of the vowels "aa" (as in "lock") and "iy" (as in "beat") excised from tokens in the SWITCHBOARD conversational speech corpus.
In these plots, the first two cepstral coefficients are shown (c[1] and c[2]; energy, which is c[0], is not shown). Comparisons are provided as a function of the vowel spoken and the gender of the speaker:
•Vowel Comparison: a comparison of male "aa" to male "iy"
•Vowel Comparison: a comparison of female "aa" to female "iy"
•Vowel Comparison: a combined plot of the above conditions
•Gender Comparisons: a comparison of males and females for the vowels "aa" and "iy"
•Combined Comparisons: a comparison of "aa" to "iy" for both genders
The Switchboard vowel data used to generate these plots is available for classification experiments.

Speech Recognition LIACS Media Lab Leiden University
Implementation IssuesDecoding Example

Speech Recognition LIACS Media Lab Leiden University
Implementation IssuesInternet-Based Speech Recognition