seminar in advanced machine learning rong jin. course description introduction to the...
Post on 22-Dec-2015
219 views
TRANSCRIPT

Seminar in Advanced Machine LearningRong Jin

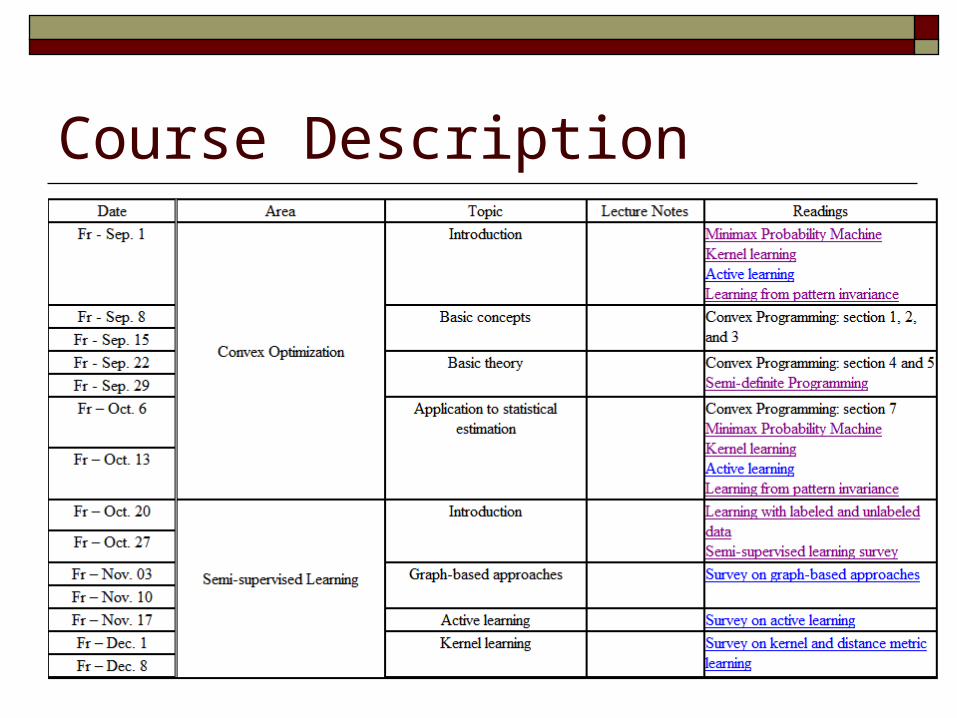
Course Description Introduction to the state-of-the-art techniques
in machine learning Focus of this semester
Convex optimization Semi-supervised learning
Course Description

Course Organization Each group has 1 to 3 students Each group covers one or two topics
Usually each topic will take two lectures Please send me the information about each
group and interesting topics to cover by the end of this week
May take 1~2 credits as enrolling in independent study (CSE890)
Course Organization Course website:
http://www.cse.msu.edu/~rongjin/adv_ml The best way to learn is discussion,
discussion and discussion Never hesitate to raise questions Never ignore any details
Let’s have fun!

Convex Programming and Classification Problems
Rong Jin

Outline Connection between classification and linear
programming (LP), convex quadratic programming (QP) has a long history
Recent progresses in convex optimization: conic and semi-definite programming; robust optimization
The purpose of this lecture is to outline some connections between convex optimization and classification problems

Support Vector Machine (SVM)
Training examples
Can be solved efficiently by quadratic programming
D = f(x1;y1);(x2;y2);: : : ;(xn ;yn)g
wherexi 2 Rd; yi 2 f¡ 1;+1g
min kwk22
s. t. yi (w>xi ¡ b) ¸ 1; i = 1;2;: : : ;n

SVM: Robust Optimization
SVMs are a way to handle noise in data points assume each data point is unknown-but-bounded in a
sphere of radius and center xi
find the largest such that separation is still possible between the two classes of perturbed points
½

SVM: Robust Optimization
How to solve it?
max ½
s. t. 8i = 1;2;::: ;n
jx ¡ xi j2 · ½! yi (w>x ¡ b) ¸ 1

SVM: Robust Optimizationjx ¡ xi j2 · ½! yi (w>x ¡ b) ¸ 1
yi (w>xi ¡ b) ¡ ½kwk2 ¸ 1
max ½
s. t. 8i = 1;2;:: : ;n
yi (w>xi ¡ b) ¡ ½kwk2 ¸ 1

Robust Optimization Linear programming (LP)
Assume ai's are unknown-but-bounded in ellipsoids
Robust LP
minc>x; : a>i x · bi ; i = 1;2;: : : ;n
minc>x; : 8ai 2 Ei ; a>i x · bi ; i = 1;2;: : : ;n
Ei = fai j(ai ¡ ai )>§ ¡ 1i (ai ¡ ai ) · 1g

Minimax Probability Machine (MPM)
How to decide the decision boundary ?
x>a · b
Negative class: x¡ » N (¹x¡ ;§ ¡ )
x>a ¸ bNegative Class
Positive Class
Positiveclass: x+ » N (¹x+;§ +)
x>a = b

Minimax Probability Machine (MPM)
wherex¡ » N (¹x¡ ;§ ¡ ) and x+ » N (¹x+;§ +)
x>a· b
x>a¸ bNegative Class
Positive Class
min max(²+;²¡ )
s. t. Pr(x>+a · b) = 1¡ ²+
Pr(x>¡ a ¸ b) = 1¡ ²¡

Minimax Probability Machine (MPM)
wherex¡ » N (¹x¡ ;§ ¡ ) and x+ » N (¹x+;§ +)
x>a· b
x>a¸ bNegative Class
Positive Class
min ²
s. t. Pr(x>+a · b) ¸ 1¡ ²
Pr(x>¡ a ¸ b) ¸ 1¡ ²

Minimax Probability Machine (MPM)
Assume x follows the Gaussian distribution N (¹x;§ )
Pr(x>a · b) · 1¡ ²
¹x>a + · k§ ak2 · bwhere · = ©¡ 1(1¡ ²) x>a · b
x>a ¸ bNegative Class
Positive Class

Minimax Probability Machine (MPM)max ·
s. t. x>+a + · k§ +ak2
2 · b
x>¡ a ¡ · k§ ¡ ak2 ¸ b
Second order cone constraints
min ®+ ¯
s. t. a>(x¡ ¡ x+) = 1
®¸ k§ +ak22; ¯ ¸ k§ ¡ ak2
2
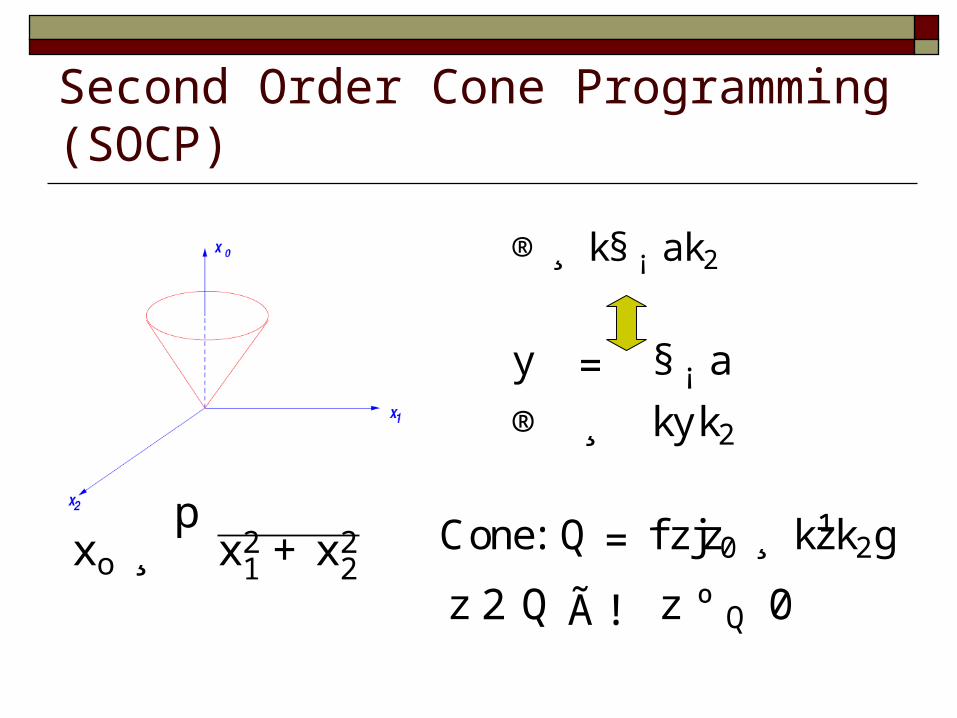
Second Order Cone Programming (SOCP)
xo ¸p
x21 +x2
2
®¸ k§ ¡ ak2
y = § ¡ a
® ¸ kyk2
z 2 Q Ã ! z º Q 0
Cone: Q = fzjz0 ¸ k¹zk2g

Second Order Cone Programming (SOCP)
SOCP LP
Generalize the inequality definition

Minimax Probability Machine (MPM)min ²
s. t. Pr(x>+a · b) ¸ 1¡ ²
Pr(x>¡ a ¸ b) ¸ 1¡ ²
wherex¡ » N (¹x¡ ;§ ¡ ) and x+ » N (¹x+;§ +)
min ²
s. t. infx+ » (¹x+ ;§ + )
Pr(x>+a · b) ¸ 1¡ ²
infx ¡ » (¹x¡ ;§ ¡ )
Pr(x>¡ a ¸ b) ¸ 1¡ ²

MPM Chebychev inequality
infx» (¹x;§ )
Pr(x>a · b) =(b¡ ¹x>a)2
+
(b¡ ¹x>a)2+ +a>§ a
where [x]+ outputs 0 when x < 0 and x when x ¸ 0.
min ®+¯
s. t. a>(x¡ ¡ x+) = 1
®¸ k§ +ak22; ¯ ¸ k§ ¡ ak2
2

Pattern Invariance In Images
Translation
Rotation
Shear

Learning from Invariance Trans.
Á1
Á2

Incorporating Invariance Trans. Invariance transformation
SVM incorporating invariance trans.Infinite number of examples
T (x;µ= 0) = xx(µ) = T (x;µ) : Rd £ R ! Rd
min kwk22
s. t. 8 µ2 R; i = 1;2;: : : ;n
yi (w>xi (µ) ¡ b) ¸ 1

Taylor Approximation of Invariance
Taylor Expansion about 0=0 gives

Polynomial Approximation
What is the necessary and sufficient condition for a polynomial to always be non-negative?
8µ2 R : yw>x(µ) ¡ 1¸ 0

Non-Negative Polynomials (I) Theorem (Nesterov,2000): If r=2l , the necessary
and sufficient condition for polynomial p(µ) to be non-negative everywhere is
Example:
9P º 0; s. t. p(µ) = µ>P µ

Semidefinite Programming Machines
Aj:=
g1,j
gi,j
gm,j
B:= 1
1
1
1
G1,j
Gi,j
Gm,j
1 0
0 0
1 0
0 0
1 0
0 0
Semi-definite programming

Semidefinite Programming (SDP)LPSDP
Generalize the inequality definition

Beyond Convex Programming In most cases, problems are non-convex
optimization Approximation
Linear programming approximation LMI relaxation (drop rank constraints) Submodular function approximation Difference of two convex functions (DC)
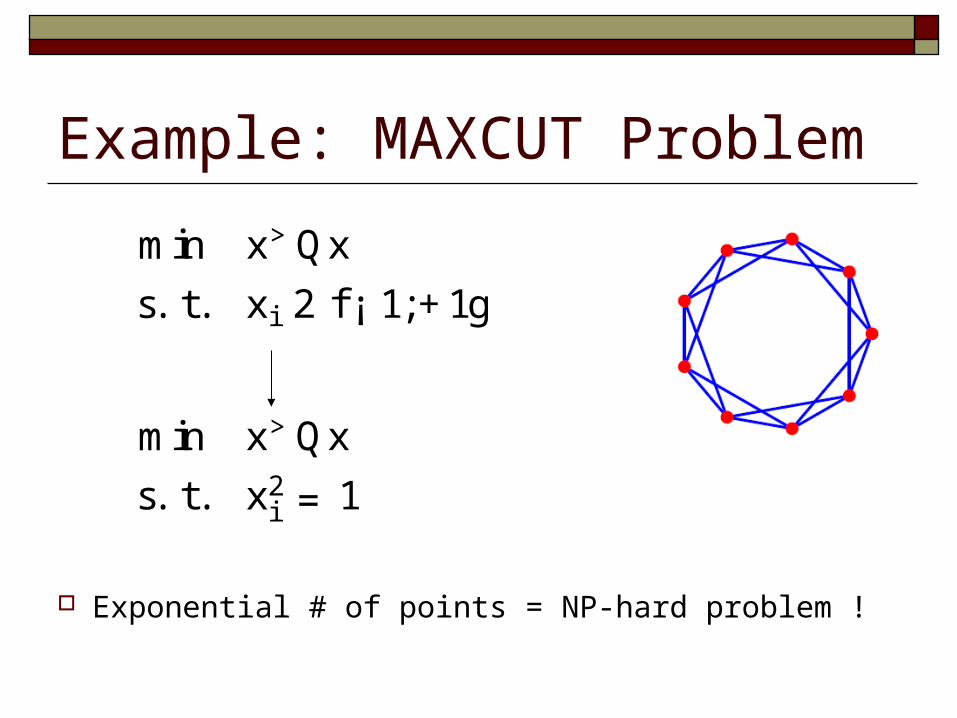
Example: MAXCUT Problem
Exponential # of points = NP-hard problem !
min x>Qx
s. t. xi 2 f ¡ 1;+1g
min x>Qx
s. t. x2i = 1

LMI Relaxation
x2i = 1 X = xx>
X i ;i = 1
min x>Qx
s. t. xi 2 f ¡ 1;+1gmin
X
i ;j
Qi ;j X i ;j
s. t. X i ;i = 1
X º 0; rank(X ) = 1min
X
i ;j
Qi ;j X i ;j
s. t. X i ;i = 1; X º 0

How Good is the Approximation? Nesterov prove recently
d¤ = min x>Qx
s. t. xi 2 f ¡ 1;+1g
g¤ = minX
i ;j
Qi ;j X i ;j
s. t. X i ;i = 1; X º 0
1¸g¤
d¤¸
2¼= 0:6366

What you should learn ? Basic concepts of convex sets and functions Basic theory of convex optimization How to formulate a problem into the standard
convex optimization? How to efficiently approximate the solution given
large datasets? (optional) How to approximate the non-convex
programming problems into a convex one?