seasr applications and future work national center for supercomputing applications university of...
TRANSCRIPT

SEASR Applications and
Future Work
National Center for Supercomputing Applications
University of Illinois at Urbana-Champaign

Outline
• Audio Applications
• Future
• Hands-On

Defining Music Information Retrieval?• Music Information Retrieval (MIR) is the
process of searching for, and finding, music objects, or parts of music objects, via a query framed musically and/or in musical terms
• Music Objects: Scores, Parts, Recordings (WAV, MP3, etc.), etc.
• Musically framed query: Singing, Humming, Keyboard, Notation-based, MIDI file, Sound file, etc.
• Musical terms: Genre, Style, Tempo, etc.

NEMA
Networked Environment for Music Analysis
– UIUC, McGill (CA), Goldsmiths (UK), Queen Mary (UK), Southampton (UK), Waikato (NZ)
– Multiple geographically distributed locations with access to different audio collections
– Distributed computation to extract a set of features and/or build and apply models

SEASR @ Work – NEMA
Executes a SEASR flow for each run
– Loads audio data
– Extracts features from every 10 second moving window of audio
– Loads models
– Applies the models
– Sends results back to the WebUI

NEMA Flow – Blinkie

NEMA Vision
• researchers at Lab A to easily build a virtual collection from Library B and Lab C,
• acquire the necessary ground-truth from Lab D,
• incorporate a feature extractor from Lab E, combine with the extracted features with those provided by Lab F,
• build a set of models based on pair of classifiers from Labs G and H
• validate the results against another virtual collection taken from Lab I and Library J.
• Once completed, the results and newly created features sets would be, in turn, made available for others to build upon

Do It Yourself (DIY) 1

DIY Options
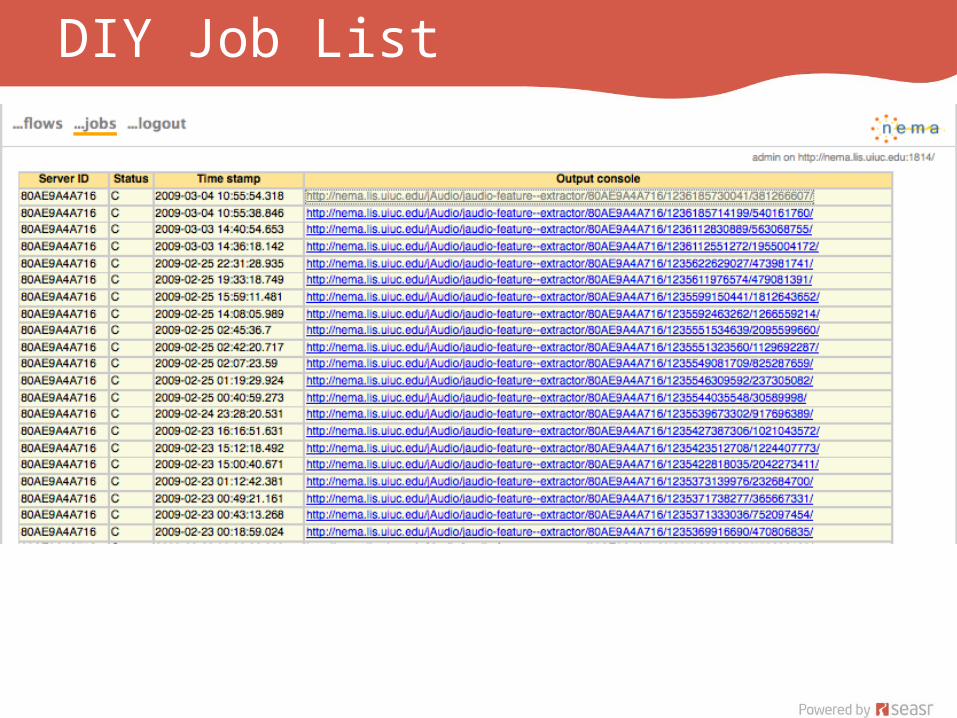
DIY Job List

DIY Job View

Nester: Cardinal Annotation
• Audio tagging environment
• Green boxes indicate a tag by a researcher
• Given tags, automated approaches to learn the pattern are applied to find untagged patterns

NESTER: Cardinal Audio Analysis

NESTER: Cardinal Audio Analysis

Examining Audio Collection
• Tagged a set of examples Male and Female

SEASR Central
feedback | login | searchcentral
Categories Recently Added Top 50 Submit About RSS
Featured Component [read more]
Word Counter by Jane Doe
Description Amazing component that given text stream, counts all the different words that appear on the text
Rights: NCSA/UofI open source license
Featured Flow [read more]FPGrowth by Joe Does
Browse
By Joe DoeRights: NCSA/UofIDescription:Webservices given a Zotero entry tries to retrieve the content and measure its
Type
Component
Flows
Categories
Image
JSTOR
Zotero
Name
Author Centrality
Readability
Upload Fedora

SEASR Central Use Cases
• register for an account• search for components / flows• browse components / flows / categories• upload component / flow• share component / flow with: everyone or group• unshare component / flow• create group / delete group• join group / leave group• create collection• generate location URL (permalink) for components,
flows, collection (the location URL can be used inside the Workbench to gain access to that component or flows)
• view latest activity in public space / my groups

Hot topics on 1.4.X
• Complex concurrency model based on traditional semaphores written in Java
• Server performance bounded by JENA’s persistent model implementation
• State caching on individual servers increase complexity of single-image clusters
• Cloud-deployable, but not cloud-friendly

How 1.5 efforts turned into 2.0?• Cloud-friendly infrastructure required
rethinking core functionalities
• Drastic redesign of backend state storage
• Revisited execution engine to support distributed flow execution
• Changes on the API that will render returned JSON documents incompatible with 1.4.X

What's New 2.0 Series?
• Rewritten from scratch in Scala
• RDBMS backend via Jena/JDBC has been dropped
• MongoDB for state management and scalability
• Meandre 2.0 server is stateless
• Meandre API revised– Revised response documents
– Simplified API (reduced the number of services)
– New Job API (Submit jobs for execution; Track them (monitor state, kill, etc.); Inspect console and logs in real time

What's New From 1.4.X Series?
• New HTML interaction interface
• Off-the-shelf full-fledged single-image cluster
• Revised flow execution lifecycle: Queued, Preparing, Running, Done, Failed, Killed, Aborted
• Flow execution as a separate spawned process. Multiple execution engines are available
• Running flows can be killed on demand
• Rewritten execution engine (Snowfield)
• Support for distributed flow fragment execution

Meandre 2.0
• Meandre 2.0 requires at least 2 separate services running
– A MongoDB for shared state storage and management
• holds all server state, job related information, and system information
– A Meandre server to provide services and facilitate execution (customizable execution engines)
• A single-image Meandre cluster scales horizontally by adding new Meandre servers and sharding the MongoDB store

Meandre and Cloud Computing
• Next generation data-intensive applications will:– Use cloud computing technologies and
conduits – Require adaptation of programming paradigms – Leverage a flexible architecture and a modular – Promote processing and resources at scale.
• Meandre – Data-intensive execution engine– Component-based programming architecture– Distributed data flow designs to allow
processing to be co-located with data sources and enable transparent scalability
– Orchestrate cloud deployments– Leverage cloud conduits

Meandre Workbench Futures
• Copy and paste (between and within flows)
• Add custom property editor for types (checkbox, lists, etc)
• Ability to specify parallel computation like in ZigZag
• Ability to use flows within flows (for grouping of functionality)

Projects
• SEASR Follow-On with Mellon Foundation
– Collaborators: Stanford, University of Maryland, George Mason University
• Hathi-Trust Research Center
– NCSA as a Computational Site
– Collaboration with Indiana University
– HTRC reception at Digital Humanities 2011
• 6:00pm - 7:30pm (PDT) on Monday, June 20
• Bamboo
– Deploy a set of analytical services

Demonstration

Discussion Questions
• How can SEASR benefit my research?
• What does SEASR need to look like for the future of humanities research?
• What scholarly questions do I have from my research for what to do with a million books?