schema mappings in pdms - hpi.de · 3 9. juni 2005 felix naumann, humboldt-universität zu berlin 5...
TRANSCRIPT

1
Schema Mappingsin PDMS
Rostock, 9. Juni 2005Prof. Felix Naumann
Humboldt-Universität zu Berlin
9. Juni 2005 Felix Naumann, Humboldt-Universität zu Berlin 2
Humboldt-Universität zu Berlin

2
9. Juni 2005 Felix Naumann, Humboldt-Universität zu Berlin 3
Humboldt-Universität zu Berlin
Wilhelm und Alexander von HumboldtEinheit von Lehre und ForschungFreiheit und Unabhängigkeit der Wissenschaft29 Nobelpreisträger
Mommsen, Hertz, Koch, Hahn, Planck, Einstein,...38,000 Studenten, (1100 Informatik)500 Professoren (21 Informatik)
9. Juni 2005 Felix Naumann, Humboldt-Universität zu Berlin 4
Forschungsgruppe Informationsintegration
Leitung: Felix Naumann ([email protected])Mitarbeiter
Jens Bleiholder ([email protected])Informationsfusion in relationalen Daten
Melanie Weis ([email protected])Objektidentifikation in XML Daten
AffiliatedArmin Roth ([email protected])
Datenqualität in Peer-Data-Management-SystemenAlexander Bilke ([email protected])
Schema MatchingForschungsthemen
ObjektidentifikationInformationsfusionOptimierungVisualisierung

3
9. Juni 2005 Felix Naumann, Humboldt-Universität zu Berlin 5
Überblick1. Informationsintegration und schematische
Heterogenität2. Schema Mapping3. Schema Matching4. Peer Data
Management (PDMS)5. Mappings und Anfrage-
bearbeitung in PDMS6. Weitere Themen der Arbeitsgruppe
9. Juni 2005 Felix Naumann, Humboldt-Universität zu Berlin 6
Integrierte Informationssysteme
Integriertes Informations-system
Oracle,DB2…
Web Service
Anwen-dung
HTML Form
IntegriertesInfo.-system
Datei-system
Anfrage

4
9. Juni 2005 Felix Naumann, Humboldt-Universität zu Berlin 7
Klassifikation von Informationssystemen [ÖV99]
Verteilung
Autonomie
Heterogenität
9. Juni 2005 Felix Naumann, Humboldt-Universität zu Berlin 8
Warum ist Informationsintegration so schwer? [Halevy04]
Alon Halevy: „It‘s plain hard!“System-bedingte Gründe
Verschiedene PlattformenAnfragebearbeitung über mehrere Systeme
Soziale GründeFinden relevanter Daten in UnternehmenBeschaffen relevanter Daten in UnternehmenMenschen zur Zusammenarbeit überreden
Logik-bedingte GründeSchema- und DatenheterogenitätDies ist unabhängig von der jeweiligen Integrationsarchitektur.

5
9. Juni 2005 Felix Naumann, Humboldt-Universität zu Berlin 9
Schematische Heterogenität -Beispiel
Person( Id, Vorname, Nachname, männlich, weiblich)
Männer( Id, Vorname, Nachname)Frauen( Id, Vorname, Nachname)
Person( Id, Vorname, Nachname, Geschlecht)
Attribut vs. Wert
Relation vs. Wert
Relation vs. Attribut
9. Juni 2005 Felix Naumann, Humboldt-Universität zu Berlin 10
Schematische Heterogenität -Beispiel
Normalisiert vs. DenormalisiertAssoziationen zwischen Werten wird unterschiedlich dargestellt
Durch Vorkommen im gleichen TupelDurch Schlüssel-Fremdschlüssel Beziehung
•ARTICLE•artPK•title•pages
•AUTHOR•artFK•name
•PUBLICATION•pubID•title•date•author
vs.

6
9. Juni 2005 Felix Naumann, Humboldt-Universität zu Berlin 11
Schematische Heterogenität -Beispiel
Geschachtelt vs. FlachAssoziationen werden unterschiedlich dargestellt
Als geschachtelte ElementeAls Schlüssel-Fremdschlüssel Beziehung
•ARTICLE•artPK•title•pages•AUTHOR
•name
•PUBLICATION•pubID•title•author
vs.
9. Juni 2005 Felix Naumann, Humboldt-Universität zu Berlin 12
Schematische Heterogenität -Lösungen
Zwei alternative Probleme1. Einheitlich auf beide Schemata zugreifen
Auf Schemaebene: Schema-Sprachen (SchemaSQL, MSQL, CPL)Schema Mapping (Clio, Rondo, Tools)
Auf Datenebene: Virtuelle Integration2. Beide Schemata in ein gemeinsames neues
Schema integrierenAuf Schemaebene: SchemaintegrationAuf Datenebene: Materialisierte Integration, ETL

7
9. Juni 2005 Felix Naumann, Humboldt-Universität zu Berlin 13
Schematische Heterogenität –Lösungen
SchemaSQL [LSS96] Erweiterung von SQLDaten und Metadaten werden gleich behandeltUmstrukturierungen innerhalb der AnfrageDynamische Sicht-DefinitionHorizontale Aggregation
SELECT RelAFROM uniA->RelA, uniA::RelA A, uniB::grundgehalt BWHERE RelA = B.institutAND A.Kategorie = „Student“ Join zwischen
Relationennameund Attributwert
9. Juni 2005 Felix Naumann, Humboldt-Universität zu Berlin 14
Schematische Heterogenität –Lösungen (Ausblick)
Schema Mapping•ARTICLE
•artPK•title•pages
•AUTHOR•artFK•name
•PUBLICATION•pubID•title•date•author
SELECT artPK AS pubIDtitle AS titlenull AS datename AS author
FROM ARTICLE, AUTHORWHERE ARTICLE.artPK = AUTHOR.artFK

8
9. Juni 2005 Felix Naumann, Humboldt-Universität zu Berlin 15
Überblick1. Informationsintegration und schematische
Heterogenität2. Schema Mapping3. Schema Matching4. Peer Data
Management (PDMS)5. Mappings und Anfrage-
bearbeitung in PDMS6. Weitere Themen der Arbeitsgruppe
9. Juni 2005 Felix Naumann, Humboldt-Universität zu Berlin 16
Quell-schema S
Ziel-schema T
• Möchte Daten aus S• Versteht/Kennt T• Versteht nicht immer S
Mapping
“entspricht”
Daten
Mapping Compiler
Logisches Mapping
“entspricht”
Schema Mapping im Kontext
Quelle: [FHP+02]
Korrespondenzen
Interpretation
Ergebnis der Trans-formationsanfrage

9
9. Juni 2005 Felix Naumann, Humboldt-Universität zu Berlin 17
Warum ist Schema Mapping nützlich?
Datentransformation zwischen heterogenen SchemataAltes aber immer wiederkehrendes ProblemÜblicherweise schreiben Experten komplexe Anfragen oder Programme
ZeitintensivExperte für die Domäne, für Schemata und für AnfrageXML macht alles noch schwieriger
XMLSchema, XQuery
Idee: AutomatisierungGegeben: Zwei Schemata und ein high-level Mapping dazwischenGesucht: Anfrage zur DatentransformationSpäter: Schema Matching = automatisches Finden des high-levelMapping
9. Juni 2005 Felix Naumann, Humboldt-Universität zu Berlin 18
Warum ist Schema Mapping schwierig?
Generierung der „richtigen“ Anfrage unter Berücksichtigung des Quell und Ziel-Schemas,des Mappingsund der Nutzer-Intention
Semantik der Daten erhaltenAssoziationen entdeckenSchemata und deren Integritätsbedingungen nutzenGgf. neue Datenwerte erzeugenKorrekte Gruppierungen erzeugen
Garantie, dass die transformierten Daten dem Zielschema entsprechenEffiziente Datentransformation
Für materialisierte IntegrationFür virtuelle Integration

10
9. Juni 2005 Felix Naumann, Humboldt-Universität zu Berlin 19
Schema Mapping Beispiel
•ARTICLE•artPK•title•pages
•AUTHOR•artFK•name
•PUBLICATION•pubID•title•date•author
SELECT artPK AS pubIDtitle AS titlenull AS datenull AS author
FROM ARTICLE
UNION SELECT null AS pubIDnull AS titlenull AS datename AS author
FROM AUTHOR
Normalisiert vs. Denormalisiert
1:1 Assoziationen zwischen Werten wird unterschiedlich dargestellt
Durch Vorkommen im gleichen TupelDurch Schlüssel-Fremdschlüssel Beziehung
9. Juni 2005 Felix Naumann, Humboldt-Universität zu Berlin 20
Schema Mapping Beispiel
•ARTICLE•artPK•title•pages
•AUTHOR•artFK•name
•PUBLICATION•pubID•title•date•author
SELECT artPK AS pubIDtitle AS titlenull AS datename AS author
FROM ARTICLE, AUTHORWHERE ARTICLE.artPK = AUTHOR.artFK
Dies ist nur eine von vier Inter-pretationen!

11
9. Juni 2005 Felix Naumann, Humboldt-Universität zu Berlin 21
Schema Mapping Beispiel
•ARTICLE•artPK•title•pages
•AUTHOR•artFK•name
•PUBLICATION•title•date•author
SELECT SK(title) AS artFKauthor AS name
FROM PUBLICATION
SELECT SK(title) AS artPKtitle AS titlenull AS pages
FROM PUBLICATION
9. Juni 2005 Felix Naumann, Humboldt-Universität zu Berlin 22
Schema Mapping BeispielGeschachtelt vs. Flach
1:n Assoziationen werden unterschiedlich dargestellt
Als geschachtelte ElementeAls Schlüssel-Fremdschlüssel Beziehung
•ARTICLE•artPK•title•pages•AUTHOR
•name
•PUBLICATION•pubID•title•author
LET $doc0 := document(“articls.xml") RETURN<dblp> { distinct-values (
FOR $x0 IN $doc0/authorDB/ARTICLE, $x1 IN $x0/AUTHORRETURN
<publication> <pubID> { $x0/artPK/text() } </pubID><title> { $x0/title/text() } </title><author> { $x1/name/text() } </author></publication> )
} </dblp>

12
9. Juni 2005 Felix Naumann, Humboldt-Universität zu Berlin 23
LET $doc0 := document(“publication.xml")RETURN<articles> { distinct-values (
FOR $x0 IN $doc0/dblp/publication RETURN<ARTICLE>
<title> { $x0/title/text() } </title>{ distinct-values (FOR $x0L1 IN $doc0/dblp/publicationsWHERE $x0/title/text() = $x0L1/title/text()RETURN
<AUTHOR> <name> { $x0L1/author/text() } </name>
</AUTHOR> )} </ARTICLE> ) } </articles>
Schema Mapping Beispiel•ARTICLE
•title•AUTHOR
•name
•PUBLICATION•title•date•author
9. Juni 2005 Felix Naumann, Humboldt-Universität zu Berlin 24
Schema Mapping mit Clio
SQL, XQuery, XSLT, SQL/X
Clio
TargetSchema
User mapping
Clio
XML repositoryXML repository
DBDB
WebServiceWebService
ApplicationApplication
XML repositoryXML repository
DBDB
WebServiceWebService
ApplicationApplication
SourceSchemas
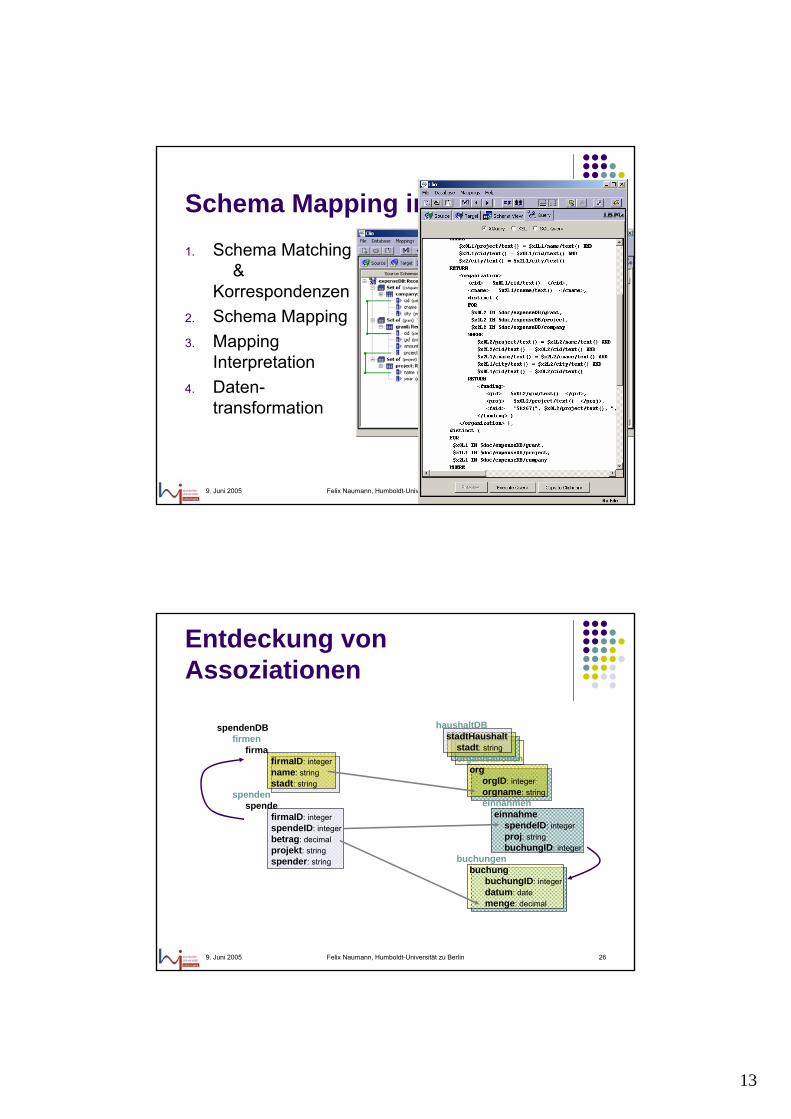
13
9. Juni 2005 Felix Naumann, Humboldt-Universität zu Berlin 25
Schema Mapping im Kontext1. Schema Matching
& Korrespondenzen
2. Schema Mapping3. Mapping
Interpretation4. Daten-
transformation
9. Juni 2005 Felix Naumann, Humboldt-Universität zu Berlin 26
Entdeckung von Assoziationen
haushaltDBstadtHaushalt
stadt: stringorganisationen
orgorgID: integerorgname: stringeinnahmen
einnahmespendeID: integerproj: stringbuchungID: integer
buchungenbuchung
buchungID: integerdatum: datemenge: decimal
spendenDBfirmen
firmafirmaID: integername: stringstadt: string
spendenspende
firmaID: integerspendeID: integerbetrag: decimalprojekt: stringspender: string
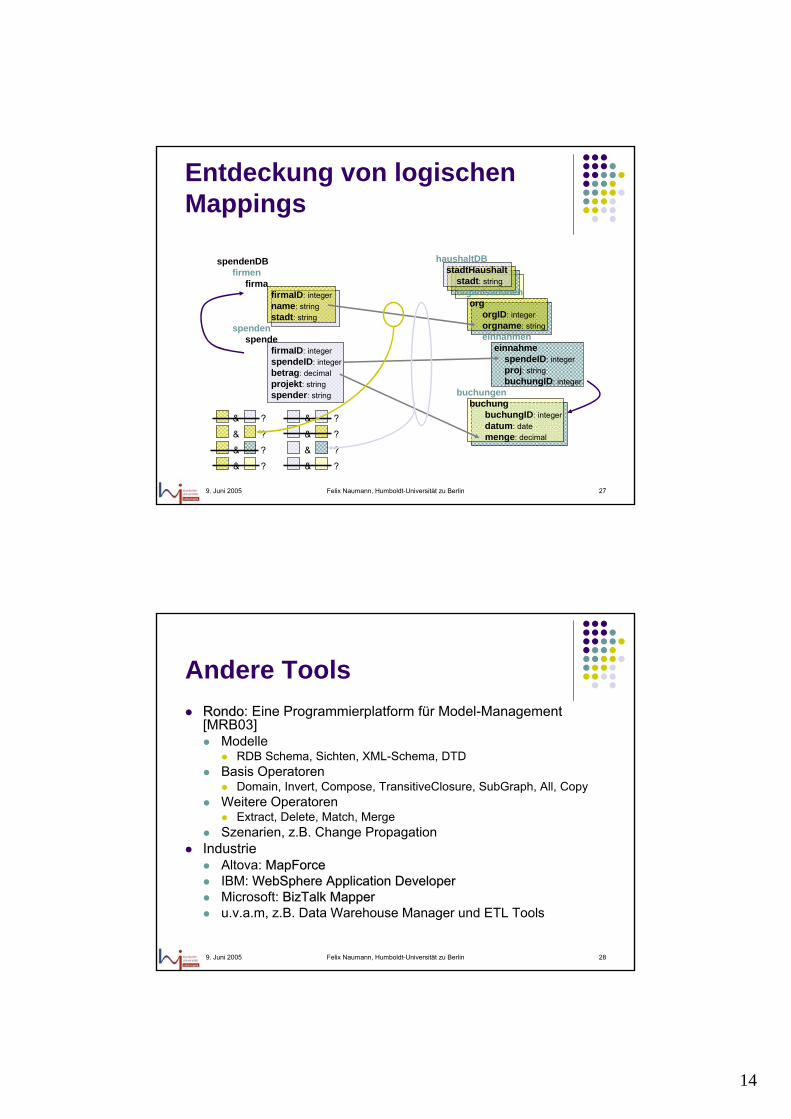
14
9. Juni 2005 Felix Naumann, Humboldt-Universität zu Berlin 27
Entdeckung von logischen Mappings
haushaltDBstadtHaushalt
stadt: stringorganisationen
orgorgID: integerorgname: stringeinnahmen
einnahmespendeID: integerproj: stringbuchungID: integer
buchungenbuchung
buchungID: integerdatum: datemenge: decimal
spendenDBfirmen
firmafirmaID: integername: stringstadt: string
spendenspende
firmaID: integerspendeID: integerbetrag: decimalprojekt: stringspender: string
& ?
& ?
& ?
& ? & ?
& ?
& ?
& ?
9. Juni 2005 Felix Naumann, Humboldt-Universität zu Berlin 28
Andere ToolsRondoRondo: Eine Programmierplatform für Model-Management [MRB03]
ModelleRDB Schema, Sichten, XML-Schema, DTD
Basis OperatorenDomain, Invert, Compose, TransitiveClosure, SubGraph, All, Copy
Weitere OperatorenExtract, Delete, Match, Merge
Szenarien, z.B. Change PropagationIndustrie
Altova: MapForceMapForceIBM: WebSphereWebSphere ApplicationApplication DeveloperDeveloperMicrosoft: BizTalk BizTalk MapperMapperu.v.a.m, z.B. Data Warehouse Manager und ETL Tools

15
9. Juni 2005 Felix Naumann, Humboldt-Universität zu Berlin 29
Modellmanagement als Vision [BLP00, Ber03]
Modelle als First-Class-CitizensRDB Schema, Sichten, XMLSchema, DTD, Anfragen, Java Classen, HTML Seiten, usw.Allgemein Graphen:
Objekte + Relationships+ Mappings
Basis AlgebraCreate, Update, DeleteSelect, Project, SetDifference, ApplyFunction, Copy, Enumerate
Weitere Operatoren der AlgebraExtract, Delete, Match, Merge, Compose
Teilweise implementiert in RONDOMuch to do!
9. Juni 2005 Felix Naumann, Humboldt-Universität zu Berlin 30
Überblick1. Informationsintegration und schematische
Heterogenität2. Schema Mapping3. Schema Matching4. Peer Data
Management (PDMS)5. Mappings und Anfrage-
bearbeitung in PDMS6. Weitere Themen der Arbeitsgruppe

16
9. Juni 2005 Felix Naumann, Humboldt-Universität zu Berlin 31
Schema Matching – MotivationGroße Schemata
> 100 Tabellen, viele AttributeBildschirm nicht lang genug
Unübersichtliche SchemataTiefe SchachtelungenFremdschlüsselBildschirm nicht breit genugXML Schema
Fremde SchemataUnbekannte Synonyme
Irreführende SchemataUnbekannte Homonyme
Fremdsprachliche SchemataKryptische Schemata
|Attributnamen| ≤ 8 Zeichen|Tabellennamen| ≤ 8 Zeichen
9. Juni 2005 Felix Naumann, Humboldt-Universität zu Berlin 32
Man beachte die Scrollbar!
Man beachte die Schachtelungstiefe (9)!
Die FolgenFalsche Mappings (false positives)Fehlende Mappings (falsenegatives)Frustration
User verlieren sich im SchemaUser verstehen Semantik der Schemata nicht

17
9. Juni 2005 Felix Naumann, Humboldt-Universität zu Berlin 33
Schema Matching –Der Kernalgorithmus
Gegeben zwei Schemata mit Attributmengen A und B.Für jedes Attributpaar: Vergleiche Ähnlichkeit
bezgl. Attributnamen,Bezgl. Daten, usw.Ähnlichste Paare sind Matches
Probleme:EffizienzÄhnlichkeitsmaßAuswahl der besten globalen Matches
Iterativ?Stable Marriage?
9. Juni 2005 Felix Naumann, Humboldt-Universität zu Berlin 34
Schema Matching Klassifikation [RB01]
Schema Matching basierend aufNamen der Schemaelemente (label-based)Darunterliegende Daten (instance-based)Struktur des Schemas (structure-based)Mischformen, Meta-Matcher

18
9. Juni 2005 Felix Naumann, Humboldt-Universität zu Berlin 35
Duplicate-driven Schema Matching [BN05a]
Instance-based Schema Matching:Correspondences based on similar data values or their properties
Conventional solution: VerticalComparison of columns= Attribute classification
Our solution: HorizontalComparison of rows= Duplicate detection (despite missing attribute correspondences)
9. Juni 2005 Felix Naumann, Humboldt-Universität zu Berlin 36
Duplicate-driven Schema Matching
...............
EDCBA
601- 4839204601- 4839204mMichelMax
............
GE‘FB‘
601- 4839204 UNIXmaxmMichel
TemporarymatchingA B‘ B FC E‘D GE
??

19
9. Juni 2005 Felix Naumann, Humboldt-Universität zu Berlin 37
Duplicate-driven Schema Matching
541- 8121164541- 8127100mAdamsSam
EDCBA
601- 4839204601- 4839204mMichelMax
WinXP541- 8127164beerAdams
GE‘FB‘
601- 4839204 UNIXmaxmMichel
Temporary matchingA B‘ B FC E‘D GE
??? ?
AssumptionsThere is data in both DBs.There are (at least a few) duplicates in both DBs.Equal or similar values reflect same semantics of attributes.
9. Juni 2005 Felix Naumann, Humboldt-Universität zu Berlin 38
Schema Matching –Erweiterungen
1:n, n:1 MatchesVorname, Nachname → Name
Viele KombinationsmöglichkeitenViele Funktionen denkbar: Mathematische Operatoren, Konkatenation, etc.
Name → Vorname, NachnameViele KombinationsmöglichkeitenViele Parsingregeln
Globales matchingMatche nicht nur einzelne Attribute (oder Attributmengen)Sondern komplette Tabellen oder komplette SchemataStable Marriage ProblemMaximum Weighted Matching Problem

20
9. Juni 2005 Felix Naumann, Humboldt-Universität zu Berlin 39
Überblick1. Informationsintegration und schematische
Heterogenität2. Schema Mapping3. Schema Matching4. Peer Data
Management (PDMS)5. Mappings und Anfrage-
bearbeitung in PDMS6. Weitere Themen der Arbeitsgruppe
9. Juni 2005 Felix Naumann, Humboldt-Universität zu Berlin 40
PDMS – IdeaIdea: Peer network (P2P)
[HIST03], [HIMT03], [BGK+02]
Each peer canExport data (= data source)Provide views on data (= wrapper)Accept and forward queries of other peers (= mediator)
Schema Mappings Not between local and global schemabut between peers schemas

21
9. Juni 2005 Felix Naumann, Humboldt-Universität zu Berlin 41
Peer-Data-Management Systems (PDMS)
Peer 1
Peer 2
Peer 4
Peer 3Peer 5
??
simple mapping
9. Juni 2005 Felix Naumann, Humboldt-Universität zu Berlin 42
PDMS vs. P2P file sharingP2P
Only complete files (low granularity)Simple queries
Filename
Incomplete query response
No schemaException: Napster for music files
Highly dynamic
PDMSObjects (high granularity)
Complex queriesQuery language (SQL, etc.)Possibly search queries
Complete quers response expectedSchema
Usual Assumption: Controlled dynamics

22
9. Juni 2005 Felix Naumann, Humboldt-Universität zu Berlin 43
PDMS ApplicationsHealth information system
Hospital data distributed on many systemsDoctors want to distribute only parts of their dataContent-management-like search is important.Complex and heterogeneous schemataAdded-values for patients through data sharing
Life sciences dataLabs have the will and the duty to freely publish data.Complex schemata and complex queriesKnown relationships among the data and schemataCreation of global schema difficult to impossible
Automobile industryCatastrophe management
9. Juni 2005 Felix Naumann, Humboldt-Universität zu Berlin 44
Piazza – Example [HIST03]

23
9. Juni 2005 Felix Naumann, Humboldt-Universität zu Berlin 45
PDMS vs. FDBMSAdvantages
Users need to know only their own schema.All data is reachable (transitive closure of mappings).Adding new schemata and peers is incremental and easy.Mapping only to most similar schema
Disadvantages / Problems
Finding mappings automatically (schema matching)Mapping compositionMany mapping steps
EfficiencyScalabilityData Quality
Efficient data placementRead-only or updates?
9. Juni 2005 Felix Naumann, Humboldt-Universität zu Berlin 46
Überblick1. Informationsintegration und schematische
Heterogenität2. Schema Mapping3. Schema Matching4. Peer Data
Management (PDMS)5. Mappings und Anfrage-
bearbeitung in PDMS6. Weitere Themen der Arbeitsgruppe

24
9. Juni 2005 Felix Naumann, Humboldt-Universität zu Berlin 47
Modeling Data Sources
Main ideaSchema Mapping: Model structurally heterogeneous source schemas to a global schema as views.Relational modelIn general: A view combines multiple relations and produces one relation.Here: A view on relations of one schema produces a relation of the other schema.
9. Juni 2005 Felix Naumann, Humboldt-Universität zu Berlin 48
Global as View / Local as View
Global as ViewRelations of the global schema are expressed as views on the local sources.
Local as ViewRelations of the local source schemas are expressed a s views on the global schema.

25
9. Juni 2005 Felix Naumann, Humboldt-Universität zu Berlin 49
Query Answering in PDMS“Syntactic & structural” challenges (certain answers)
No centralized controlLong mapping pathsMixed GaV/LaV query reformulationCyclesRouting query responsesScalability
“Semantic” challenges (best answers)Peer selection & Data LineageCompletenessInformation Quality
9. Juni 2005 Felix Naumann, Humboldt-Universität zu Berlin 50
Query Answering in PDMS –The rule-goal tree

26
9. Juni 2005 Felix Naumann, Humboldt-Universität zu Berlin 51
PDMS and Scalability
FlexibilityFlexible and rapid modeling
In particular LaVMapping to one or more similar peers
Schema matching helpsFull query language on all data!
Conceived for tens of sources, not moreFinding CERTAIN answers is complex.Finding ALL certain answers is complex.
9. Juni 2005 Felix Naumann, Humboldt-Universität zu Berlin 52
Improving Scalability1. Concessions towards completeness
Not all certain answers (coverage)Not all query attributes (density)Prune the rule-goal-tree
Using completeness and other IQ criteriaI.e.: Making it more P2P-y (GRID-y)
2. Take P2P idea furtherOn demand source discovery using P2P IndexOn the fly schema mapping using matching
Automatic data integration = autonomic data integration„Ontology shortcuts“
27
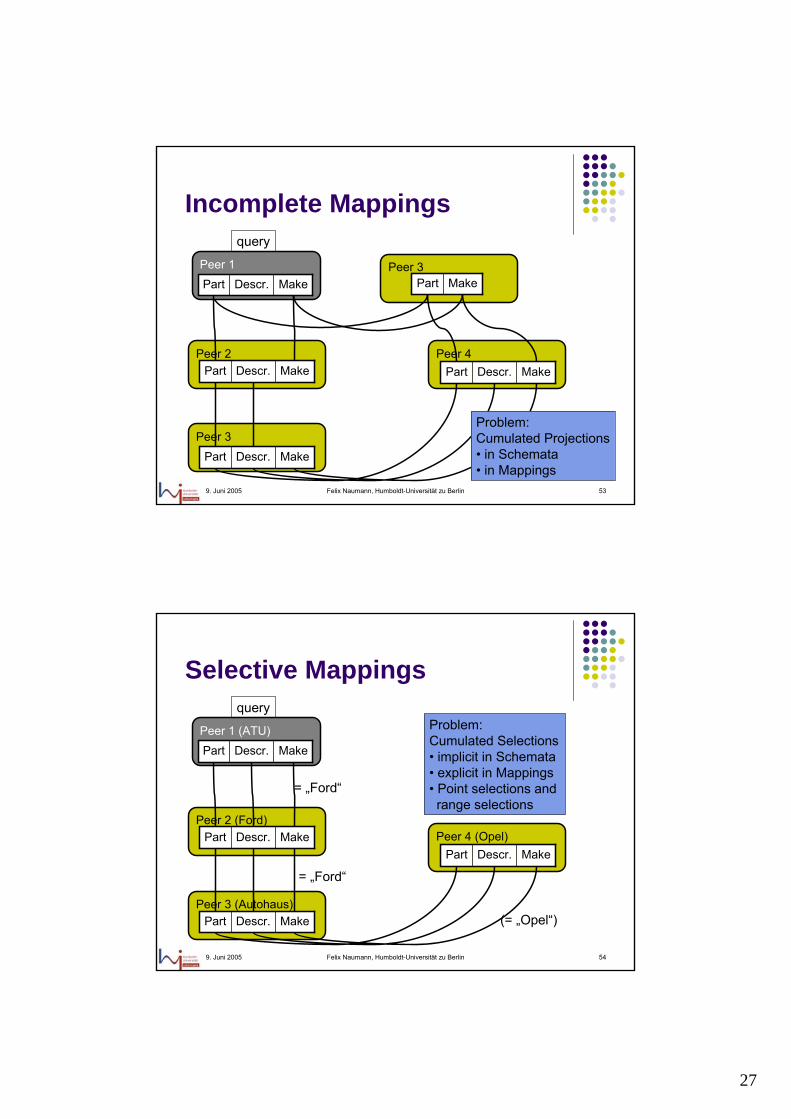
9. Juni 2005 Felix Naumann, Humboldt-Universität zu Berlin 53
Incomplete Mappings
Peer 3
Peer 2 Peer 4
Peer 3
Peer 1MakeDescr.Part
MakeDescr.Part
MakePart
query
MakeDescr.Part
MakeDescr.Part
Problem: Cumulated Projections• in Schemata• in Mappings
9. Juni 2005 Felix Naumann, Humboldt-Universität zu Berlin 54
Selective Mappings
Peer 2 (Ford)
Peer 1 (ATU)MakeDescr.Part
MakeDescr.Part
query
= „Ford“
Peer 3 (Autohaus)MakeDescr.Part
= „Ford“
Peer 4 (Opel)MakeDescr.Part
(= „Opel“)
Problem: Cumulated Selections• implicit in Schemata• explicit in Mappings• Point selections and range selections

28
9. Juni 2005 Felix Naumann, Humboldt-Universität zu Berlin 55
The effect of selections and projections
Completeness of data suffersExtensional completeness (= coverage)
Number of tuples reachedCompared to all certain answers
Intensional completeness (= density)Number of attributes reachedMeasured for each relation and sourceCompared to all attributes of the queryConventional PDMS and Query Answering usingviews: density = 1
9. Juni 2005 Felix Naumann, Humboldt-Universität zu Berlin 56
Optimization in PDMSIdea: Do not find all certain answers, just find some.Idea: Do not demand all attributes, just some.Optimization goal:
Maximize completeness given some cost constraintCost:
Response time / latencyNumber of peersNumber of bytes / network load$$$
Main problem: Strictly local optimization – no global knowledge!Opportunity for growth: Scalable PDMS

29
9. Juni 2005 Felix Naumann, Humboldt-Universität zu Berlin 57
Pruning the rule-goal-tree
Predict CompletenessSelectivity estimation on steroidsComplex formulasMany assumptions (independence)Many overlap variations
Different strategiesThreshold for completeness – direct pruningBudget-approach – direct budget along promisingmappings
OngoingOngoing workwork
9. Juni 2005 Felix Naumann, Humboldt-Universität zu Berlin 58
Überblick1. Informationsintegration und schematische
Heterogenität2. Schema Mapping3. Schema Matching4. Peer Data
Management (PDMS)5. Mappings und Anfrage-
bearbeitung in PDMS6. Weitere Themen der Arbeitsgruppe

30
9. Juni 2005 Felix Naumann, Humboldt-Universität zu Berlin 59
DBMS DBMS XML XML... ...
Schema conversion RDB2XML
RDB2XML
XML2RDB
XML2RDB
QueryOptimization
SQL XQuery
DataFusion
Que
ry E
xecu
tion
DuplicateDetection
GraphicalQuery Builder
SQL XQuery
Data Visualization
Tables XML
Metadata Services
MetadataRepository
SchemaMapping
SchemaMatching
DataLineage
DataStatistics
Samples
RDB XML
RDB XML
Data transformation
Hum
Mer
–H
umbo
ldt M
erge
rD
ata
Impo
rt U
ser
Inte
rface
9. Juni 2005 Felix Naumann, Humboldt-Universität zu Berlin 60
Algorithm [WN05]
1. Create data structureXQueries to extract relevant elements
Elements of one type at one levelplus descendants
2. Acceleration of similarity comparisonsEdit-distance filter
3. Avoidance of similarity comparisonsElement-similarity-filterConnected components
4. Similarity comparisonsAmong remaining elementssim(e1,e2) ≥ tdup
Supported by graph-based data structure:
Similarity of tokens are edges between token-nodes
Similarity of elements are edges between element-nodes

31
9. Juni 2005 Felix Naumann, Humboldt-Universität zu Berlin 61
Fuse By – Queries [BN05b]
SELECT *FROM Q1FUSE BY (Name)
Grouping withcoalesceaggregation
SELECT *FROM Q1FUSE BY ()
Subsumption
SELECT *FROM Q1, Q2FUSE BY ()
Minimum Union
SELECT Name, RESOLVE(Age, max), RESOLVE(Student, vote), RESOLVE(Place), RESOLVE(Phone)
FROM Q1, Q2FUSE BY (Name) ON ORDER Q2.Age DESC
9. Juni 2005 Felix Naumann, Humboldt-Universität zu Berlin 62
Visualisierung Integrierter Daten
Why Provenance & Where ProvenanceKonflikte en detail und im Überblick (zoom out)

32
9. Juni 2005 Felix Naumann, Humboldt-Universität zu Berlin 63
Research Group –Acknowledgments
PhD studentsJens Bleiholder ([email protected])
Information fusion for relational dataMelanie Weis ([email protected])
Object identification for XML dataArmin Roth ([email protected])
Data Quality in Peer-Data-Management-SystemsAlexander Bilke ([email protected])
Schema MatchingTopics of masters students (“Diplom”)
Classification of schema mapping toolsSchema integration using schema mappingsMeta Schema-matchingSorted neighborhood in XML dataMetasearching using DB2 II
HeterogenitätSchema MappingSchema Matching
Peer Data Management (PDMS)Anfragebearbeitung in PDMS
Weitere Themen der Arbeitsgruppe

33
9. Juni 2005 Felix Naumann, Humboldt-Universität zu Berlin 65
Literatur[BN05a] Alexander Bilke and Felix Naumann: Schema Matching using Duplicates, ICDE, 2005.[BN05b] Jens Bleiholder and Felix Naumann: Declarative Data Fusion - Syntax, Semantics, and Implementation, ADBIS, 2005.[WN05] Melanie Weis and Felix Naumann: DogmatiX Tracks down Duplicates in XML, SIGMOD, 2005.[BB+05] Alexander Bilke, Jens Bleiholder, Christoph Böhm, Karsten Draba, Felix Naumann and Melanie Weis: Automatic Data Fusion with HumMer, VLDB, 2005, Demonstration.
[Ber03] Philip A. Bernstein: Applying Model Management to Classical Meta Data Problems. CIDR 2003[BLP00] A Vision for Management of Complex Models. Philip A. Bernstein, Alon Y. Levy, Rachel A. Pottinger, MSR-TR-2000-53, 2000.[FHP+02] Ron Fagin, Mauricio Hernandez, Lucian Popa, Renee Miller, and Yannis Velegrakis, Translating Web Data, VLDB 2002, Hong Kong, China.[Halevy04] Alon Halevy: SSS, Invited talk at VLDB 2004, Toronto.[LSS96] Lakshaman, Sadri, Subramanian, SchemaSQL – A Language for Interoperability in Relational Mulitdatabase Systems, in VLDB 1996[MRB03] S. Melnik, E. Rahm, P. A. Bernstein: Rondo: A Programming Platform for Model Management, in Proc. ACM SIGMOD 2003, San Diego, June 2003 [ÖV99] Principles of Distributed Database Systems, M. Tamer Özsu, Patrick Valduriez, Prentice Hall, 1999.[RB01] Erhard Rahm and Philip Bernstein, A survey of approaches to automatic schema matching, VLDB Journal 10(4), 2001.