scaling up coordinate descent algorithms for large regularization
TRANSCRIPT

Scaling Up Coordinate Descent Algorithmsfor Large `1 Regularization Problems
Chad Scherrer [email protected]
Pacific Northwest National Laboratory
Mahantesh Halappanavar [email protected]
Pacific Northwest National Laboratory
Ambuj Tewari [email protected]
University of Texas at Austin
David Haglin [email protected]
Pacific Northwest National Laboratory
Abstract
We present a generic framework for par-allel coordinate descent (CD) algorithmsthat includes, as special cases, the orig-inal sequential algorithms Cyclic CD andStochastic CD, as well as the recent paral-lel Shotgun algorithm. We introduce twonovel parallel algorithms that are also spe-cial cases—Thread-Greedy CD and Coloring-Based CD—and give performance measure-ments for an OpenMP implementation ofthese.
1. Introduction
Consider the `1-regularized loss minimization problem
minw
1n
n∑
i=1
`(yi, (Xw)i) + λ‖w‖1 , (1)
where X ∈ Rn×k is the design matrix, w ∈ Rk isa weight vector to be estimated, and the loss func-tion ` is such that `(y, ·) is a convex differentiablefunction for each y. This formulation includes Lasso(`(y, t) = 1
2 (y − t)2) and `1-regularized logistic regres-sion (`(y, t) = log(1 + exp(−yt))).In this context, we consider a coordinate descent (CD)algorithm to be one in which each iteration performs
Appearing in Proceedings of the 29 th International Confer-ence on Machine Learning, Edinburgh, Scotland, UK, 2012.Copyright 2012 by the author(s)/owner(s).
updates to some number of coordinates of w, and eachsuch update requires traversal of only one column ofX.
The goal of the current work is to identify and exploitthe available parallelism in this class of algorithms,and to provide an abstract framework that helps tostructure the design space.
Our approach focuses on shared-memory architec-tures, and in particular our experiments use theOpenMP programming model.
This paper makes several contributions to this field.First, we present GenCD, a Generic CoordinateDescent framework for expressing parallel coordinatedescent algorithms, and we explore how each stepshould be performed in order to maximize parallelism.
In addition, we introduce two novel special cases ofthis framework: Thread-Greedy Coordinate Descentand Coloring-Based coordinate descent, and comparetheir performance to that of a reimplementation of therecent Shotgun algorithm of Bradley et al. (2011), inthe context of logistic loss.
A word about notation: We use bold to indicate vec-tors, and uppercase bold to indicate matrices. We de-note the jth column of X by Xj and the ith row of Xby xTi . We use ej to denote the vector in Rk consist-ing of all zeros except for a one in coordinate j. Weassume the problem at hand consists of n samples andk features.

Scaling Up Coordinate Descent
Table 1. Arrays stored by GenCD
Name Dim Description Stepδ k proposed increment Proposeϕ k proxy Proposew k weight estimate Updatez n fitted value Update
2. GenCD: A Generic Framework forParallel Coordinate Descent
We now present GenCD, a generic coordinate descentframework. Each iteration computes proposed incre-ments to the weights for some subset of the coordi-nates, and then accepts a subset of these proposals,and modifies the weights accordingly. Algorithm 1gives a high-level description of GenCD.
Algorithm 1 GenCDwhile not converged do
Select a set of coordinates JPropose increment δj , j ∈ J // parallelAccept some subset J ′ ⊆ J of the proposalsUpdate weight wj for all j ∈ J ′ // parallel
In the description of GenCD, we refer to a numberof different arrays. These are summarized in Table 1.For some algorithms, there is no need to maintain aphysical array in memory for each of these. For ex-ample, it might be enough for each thread to have arepresentation of the proposed increment δj for thecolumn j it is currently considering. In such cases thearray-oriented presentation serves only to benefit theuniformity of the exposition.
2.1. Step One: Select
We begin by selecting J coordinates for considera-tion during this major step in an iteration of GenCD.The selection criteria differs for variations of CD tech-niques.
There are some special cases at the extremes of thisselection step. Sequential algorithms like cyclic CD(CCD) and stochastic CD (SCD) correspond to se-lection of a singleton, while parallel “full greedy” CDcorresponds to J = {1, · · · , k}.Between these extremes, Shotgun (Bradley et al.,2011) selects a random subset of a given size. Otherobvious choices include selection of a random block ofcoordinates from some predetermined set of blocks.
Though proposals can be computed in parallel, thenumber of features is typically far greater than the
number of available threads. Thus in general, wewould like to have a mechanism for scaling the numberof proposals according to the degree of available paral-lelism. As the first step of each iteration, we thereforeselect a subset J of the coordinates for which proposalswill be computed.
2.2. Step Two: Propose
Given the set J of selected coordinates, the secondstep computes a proposed increment δj for each j ∈J . Note that this step does not actually change theweights; δj is simply the increment to wj if it wereto be updated. This is critical, as it allows evaluationover all selected coordinates to be performed in parallelwithout concern for conflicts.
Some algorithms such as Greedy CD require a wayof choosing a strict subset of the proposals to accept.Such cases require computation of a value on whichto base this decision. Though it would be natural tocompute the objective function for each proposal, wepresent the more general case where we have a proxyfor the objective, on which we can base this decision.This allows for cases where the objective function isrelatively expensive but can be quickly approximated.
We therefore maintain a vector ϕ ∈ Rk, where ϕj is aproxy for the objective function evaluated at w+δjej ,and update ϕj whenever a new proposal is calculatedfor j.
Algorithm 2 shows a generic Propose step.
Algorithm 2 Propose stepfor each j ∈ J do // parallel
Update proposed increment δjUpdate proxy ϕj
2.3. Step Three: Accept
Ideally, we would like to accept as many proposals aspossible in order to avoid throwing away work donein the proposal step. Unfortunately, as Bradley et al.(2011) show, correlations among features can lead todivergence if too many coordinates are updated atonce. So in general, we must restrict to some sub-set J ′ ⊆ J . We have not yet explored conditions ofconvergence for our new Thread-Greedy algorithm (seeSection 7) but find robust convergence experimentally.
In some algorithms (CCD, SCD, and Shotgun), fea-tures are selected in a way that allows all proposalsto be accepted. In this case, an implementation cansimply bypass the Accept step.

Scaling Up Coordinate Descent
2.4. Step Four: Update
After determining which proposals have been ac-cepted, we must update according to the set J ′ ofproposed increments that have been accepted.
In some cases, the proposals might have been com-puted using an approximation, in which case we mightlike to perform a more precise calculation for thosethat are accepted.
As shown in Algorithm 3, this step updates theweights, the fitted values, and also the derivative ofthe loss.
Algorithm 3 Update stepfor each j ∈ J ′ do // parallel
Improve δjwj ← wj + δjz← z + δjXj // atomic
Note that each iteration of the for loop can be donein parallel. The wj updates depend only upon theimproved δj . While the updates to z have the po-tential for collisions if Xij1 = Xij2 for some distinctj1, j2 ∈ J ′, this is easily avoided by using atomic mem-ory updates available in OpenMP and other sharedmemory platforms.
3. Approximate Minimization
As described above, the Propose step calculates a pro-posed increment δj for each j ∈ J . For a given j, wewould ideally like to calculate
δ = argminδ
F (w + δej) + λ|wj + δ| , (2)
where F is the smooth part of the objective function,
F (w) =1n
n∑
i=1
`(yi, (Xw)i) . (3)
Unfortunately, for a general loss function, there isno closed-form solution for full minimization along agiven coordinate. Therefore, one often resorts to one-dimensional numerical optimization.
Alternatively, approximate minimization along a givencoordinate can avoid an expensive line search. Wepresent one such approach that follows Shalev-Shwartz& Tewari (2011).
First, note that the gradient and Hessian of F are
∇F (w) =1n
∑
i
`′(yi, (Xw)i)xi
H(w) =1n
∑
i
`′′(yi, (Xw)i)xixTi .
Here `′ and `′′ denote differentiation with respect tothe first variable.
3.1. Minimization for squared loss
For the special case of squared loss, the exact mini-mizer along a coordinate can be computed in closedfrom. In this case, `′′(y, t) ≡ 1, the Hessian H is con-stant, and we have the second-order expansion
F (w + δ) = F (w) + 〈∇F (w), δ〉+12δ>Hδ .
Along coordinate j, this reduces to
F (w + δej) = F (w) +∇jF (w)δ +Hjj
2δ2 .
As is well known (see, for example, (Yuan & Lin,2010)), the minimizer of (2) is then given by
δ = −ψ(wj ;∇jF (w)− λ
Hjj,∇jF (w) + λ
Hjj
), (4)
where ψ is the clipping function
ψ(x; a, b) =
a if x < ab if x > bx otherwise .
Note that this is equivalent to
δ = sλ/Hjj
(wj −
∇jF (w)Hjj
)−wj ,
where s is the “soft threshold” function
sτ (x) = sign(x) · (|x| − τ)+ ,
as described by Shalev-Shwartz & Tewari (2011).
3.2. Bounded-convexity loss
More generally, suppose there is some β such that∂2
∂z2 `(y, z) ≤ β for all y, z ∈ R. This condition holdsfor squared loss (β = 1) and logistic loss (β = 1/4).Then, let
Fw(w + δ) = F (w) + 〈∇F (w), δ〉+β
2δ>δ .

Scaling Up Coordinate Descent
In particular, along any given coordinate j, we have
Fw(w + δej) = F (w) +∇jF (w)δ +β
2δ2 (5)
≥ F (w + δej) . (6)
By (4), this upper bound is minimized at
δ = −ψ(wj ;∇jF (w)− λ
β,∇jF (w) + λ
β
). (7)
Because the quadratic approximation is an upperbound for the function, updating δj ← δ is guaran-teed to never increase the objective function.
3.3. A proxy for the objective
In cases where J ′ is a strict subset of J , there mustbe some basis for the choice of which proposals to ac-cept. The quadratic approximation provides a way ofquickly approximating the potential effect of updatinga single coordinate. For a given weight vector w andcoordinate j, we can approximate the decrease in theobjective function by
ϕjw = Fw(w + δej)− Fw(w) (8)
=β
2δ2 +∇jF (w)δ + λ(|wj + δ| − |wj |) . (9)
4. Experiments
4.1. Algorithms
At this point we discuss a number of algorithms thatare special cases of the GenCD framework. Our intentis to demonstrate some of the many possible instanti-ations of this approach. We perform convergence andscalability tests for these cases, but do not favor anyof these algorithms over the others.
For current purposes, we focus on the problem of clas-sification, and compare performance across algorithmsusing logistic loss. All of the algorithms we tested ben-efited from the addition of a line search to improve theweight increments in the Update step. Our approachto this was very simple: For each accepted proposalincrement, we perform an additional 500 steps usingthe quadratic approximation.
SHOTGUN is a simple approach to parallel CD intro-duced by Bradley et al. (2011). In terms of GenCD, theSelect step of Shotgun chooses a random subset of thecolumns, and the Accept step accepts every proposal.This makes implementation very simple, because iteliminates the need for computation of a proxy, andallows for fusion of the Propose and Update loops.
Algorithm 4 Proposal via approximationfor each j ∈ J do // parallelg ← 〈`′(yi, zi),Xj〉 /n // thread-localδj ← −ψ
(wj ; g−λβ , g+λβ
)
ϕj ← β2 δ
2j + gδj + λ(|wj + δj | − |wj |)
Bradley et al. (2011) show that convergence of Shot-gun is guaranteed only if the number of coordinatesselected is at most P ∗ = k
2ρ , where k is the numberof columns of X, and ρ is the spectral radius (≡ max-imal eigenvalue) of X>X. For our experiments, wetherefore use P ∗ columns for this algorithm.
Bradley et al. (2011) suggest beginning with a largeregularization parameter, and decreasing graduallythrough time. Since we do not implement this, ourresults do not apply to Shotgun variations that usethis approach.
In our novel THREAD-GREEDY algorithm, the Selectstep chooses a random set of coordinates. Propos-als are calculated in parallel using the approximationdescribed in Equation (7) of Section 3.2, with eachthread generating proposals for some subset of the co-ordinates. Each thread then accepts the best of theproposals it has generated.
We have not yet determined conditions under whichthis approach can be proven to converge, but our em-pirical results are encouraging.
Similarly, GREEDY selects all coordinates, and usesthe computed proxy values to find the best for eachthread. However, rather than accept one proposal foreach thread, proxy values are compared across threads,and only the single best is chosen in the Accept step.Dhillon et al. (2011) provide an analysis of convergencefor greedy coordinate descent.
COLORING is a novel algorithm introduced in this pa-per. The main idea here is to determine sets of struc-turally independent features, in order to allow safeconcurrent updates without requiring any synchro-nization between parallel processes (threads). Color-ing begins with the preprocessing step, where struc-turally independent features are identified via partialdistance-2 coloring of a bipartite graph representationof the feature matrix. In the Select step, a randomcolor (or a random feature) is selected. All the fea-tures that have been assigned this color are updatedconcurrently. Based on the colors, a different numberof features could get selected at each iteration.
In contrast to Shotgun, conflicting updates are notlost. However, we note that Coloring is suitable only

Scaling Up Coordinate Descent
Table 2. Specific cases of the GenCD framework.
Algorithm Select AcceptSHOTGUN Rand subset All
THREAD-GREEDY All Greedy/threadGREEDY All Greedy
COLORING Rand color All
for sparse matrices with sufficient independence in thestructure. Details of this algorithm are provided inAppendix A.
Since COLORING only allows parallel updates for fea-tures with disjoint support, updating a single color isequivalent to updating each feature of that color in se-quence. Thus convergence propoerties for COLORING
should be very similar to those of cyclic/stochastic co-ordinate descent.
Table 2 provides a summary of the algorithms we con-sider.
4.2. Implementation
We provide a brief overview of software implementa-tions in this section. All the four algorithms are im-plemented in C language using OpenMP as the par-allel programming model Chapman et al. (2007). Weuse GNU C/C++ compilers with -O3 -fopenmp flags.Work to be done in parallel is distributed among ateam of threads using OpenMP parallel for con-struct. We use static scheduling of threads whereeach thread gets a contiguous block of iterations ofthe for loop. Given n iterations and p threads, eachthread gets a block of n
p iterations.
Threads running in parallel need to synchronize forcertain operations. While all the algorithms need tosynchronize in the Update step, Algorithm GREEDY
also needs to synchronize during the Select step to de-termine the best update. We use different mechanismsto synchronize in our implementations. Concurrentupdates to vector z are made using atomic memoryoperations. We use OpenMP atomic directive for up-dating real numbers and use the x86 hardware opera-tor sync fetch and add for incrementing integers.We use OpenMP critical sections to synchronizethreads in the Propose step of GREEDY algorithm. Inorder to preserve all the updates, we synchronize in theUpdate step of SHOTGUN. Note that this is differentfrom the SHOTGUN algorithm as proposed in Bradleyet al. (2011). Since structurally independent featuresare updated at a given point of time in the COLORING
algorithm, there is no need for synchronization in theUpdate step.
4.3. Platform
Our experimental platform is an AMD Opteron(Magny-Cours) based system with 48 cores (4 socketswith 12 core processors) and 256 GB of globally ad-dressable memory. Each 12-core processor is a multi-chip module consisting of two 6-core dies with separatememory controllers. Each processor has three levels ofcaches: 64 KB of L1 (data), 512 KB of L2, and 12 MBof L3. While L1 and L2 are private to each core, L3is shared between the six cores of a die. Each sockethas 64 GB of memory that is globally addressable byall four sockets. The sockets are interconnected usingthe AMD HyperTransport-3 technology1.
We conduct scaling experiments on this system in pow-ers of two (1, 2, 4, . . ., 32). Convergence results pro-vided in Figure 1 are on 32 processors for each inputand algorithm.
4.4. Datasets
We performed tests on two sets of data. For each, wenormalized columns of the feature matrix in order tobe consistent with algorithmic assumptions.
DOROTHEA is the drug discovery data described byGuyon et al. (2004). Here, each example correspondsto a chemical compound, and each feature correspondsto a structural molecular feature.
The feature matrix is binary, indicating presence orabsence of a given molecular feature. There are 800examples and 100,000 features, with 7.3 nonzeros perfeature on average. We estimate P ∗ to be about 23.Our coloring resulted in a mean color size of 16.
As a response, we are given an indicator of whethera given compound binds to thrombin. There are 78examples for which this response is positive.
For the DOROTHEA data set, we used a regularizationparameter of λ = 10−4.
REUTERS is the RCV1-v2/LYRL2004 Reuters textdata described by Lewis et al. (2004). In this data,each example corresponds to a training document, andeach feature corresponds to a term. Values in thetraining data correspond to term frequencies, trans-formed using a standard tf-idf normalization.
The feature matrix consists of 23865 examples and47237 features. It has 1.7 million nonzeros, or 37.2nonzeros per feature on average. We estimate P ∗ tobe about 800. Our coloring resulted in a mean color
1Further details on Opteron can be found at http://www.amd.com/us/products/embedded/processors/opteron/Pages/opteron-6100-series.aspx.
Scaling Up Coordinate Descent
Table 3. A summary of data sets.
DOROTHEA REUTERS
Samples 800 23865Features 100000 47237
Nonzeros/feature 7.3 37.2P ∗ 23 800
Features/color 16 22Time to color 0.7 sec 1.6 secOur chosen λ 10−4 10−5
minF (w) + λ‖w‖1 0.279512 0.165044Best-fit NNZ 14182 1903
size of 22.
Each document in this data is labeled as belongingto some set of “topics”. The most common of these(matching 10786 documents) is CCAT, correspondingto “ALL Corporate-Industrial”. Based on this, weused membership in the CCAT topic as a response.
For the REUTERS data set, using a regularization pa-rameter of λ = 10−4 led to an optimal solution of 0,so we reduced it to λ = 10−5.
5. Results And Discussion
5.1. Convergence rates
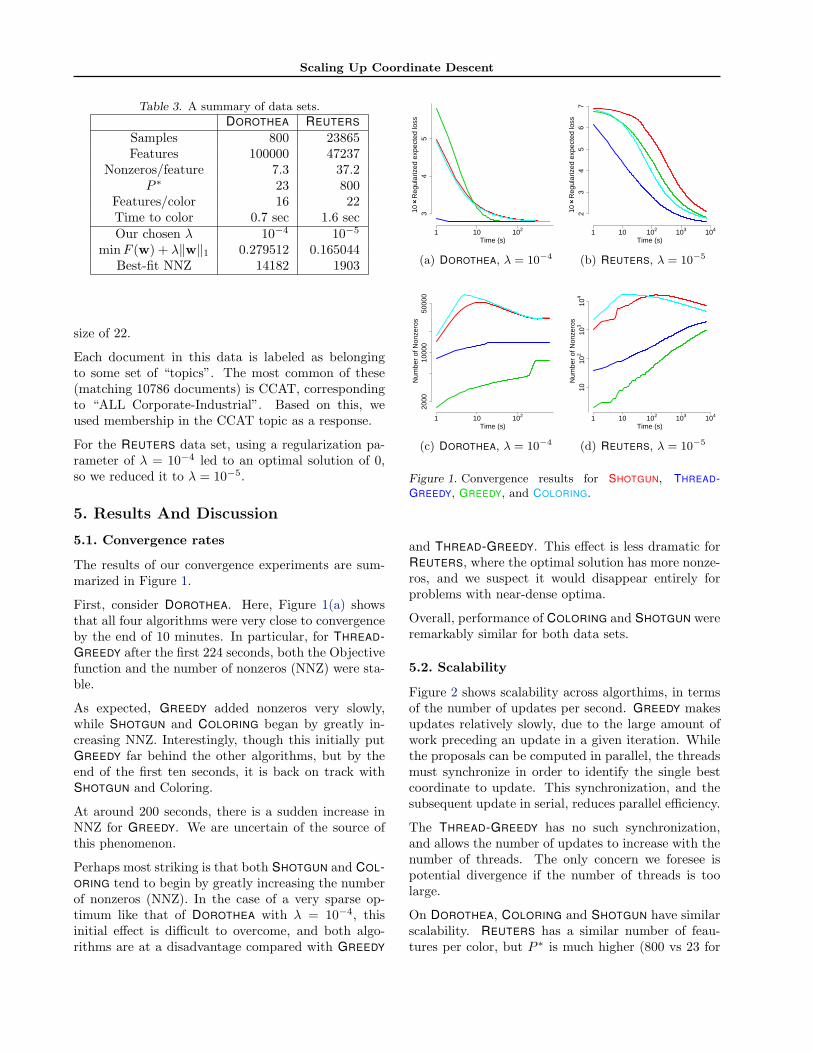
The results of our convergence experiments are sum-marized in Figure 1.
First, consider DOROTHEA. Here, Figure 1(a) showsthat all four algorithms were very close to convergenceby the end of 10 minutes. In particular, for THREAD-GREEDY after the first 224 seconds, both the Objectivefunction and the number of nonzeros (NNZ) were sta-ble.
As expected, GREEDY added nonzeros very slowly,while SHOTGUN and COLORING began by greatly in-creasing NNZ. Interestingly, though this initially putGREEDY far behind the other algorithms, but by theend of the first ten seconds, it is back on track withSHOTGUN and Coloring.
At around 200 seconds, there is a sudden increase inNNZ for GREEDY. We are uncertain of the source ofthis phenomenon.
Perhaps most striking is that both SHOTGUN and COL-ORING tend to begin by greatly increasing the numberof nonzeros (NNZ). In the case of a very sparse op-timum like that of DOROTHEA with λ = 10−4, thisinitial effect is difficult to overcome, and both algo-rithms are at a disadvantage compared with GREEDY
Time (s)
10××
Reg
ular
ized
exp
ecte
d lo
ss
1 10 102
34
5
(a) DOROTHEA, λ = 10−4
Time (s)
10××
Reg
ular
ized
exp
ecte
d lo
ss
1 10 102 103 104
23
45
67
(b) REUTERS, λ = 10−5
Time (s)
Num
ber
of N
onze
ros
1 10 102
2000
1000
050
000
(c) DOROTHEA, λ = 10−4
Time (s)
Num
ber
of N
onze
ros
1 10 102 103 104
1010
210
310
4
(d) REUTERS, λ = 10−5
Figure 1. Convergence results for SHOTGUN, THREAD-GREEDY, GREEDY, and COLORING.
and THREAD-GREEDY. This effect is less dramatic forREUTERS, where the optimal solution has more nonze-ros, and we suspect it would disappear entirely forproblems with near-dense optima.
Overall, performance of COLORING and SHOTGUN wereremarkably similar for both data sets.
5.2. Scalability
Figure 2 shows scalability across algorthims, in termsof the number of updates per second. GREEDY makesupdates relatively slowly, due to the large amount ofwork preceding an update in a given iteration. Whilethe proposals can be computed in parallel, the threadsmust synchronize in order to identify the single bestcoordinate to update. This synchronization, and thesubsequent update in serial, reduces parallel efficiency.
The THREAD-GREEDY has no such synchronization,and allows the number of updates to increase with thenumber of threads. The only concern we foresee ispotential divergence if the number of threads is toolarge.
On DOROTHEA, COLORING and SHOTGUN have similarscalability. REUTERS has a similar number of feau-tures per color, but P ∗ is much higher (800 vs 23 for

Scaling Up Coordinate Descent
Processors
Upd
ates
per
sec
ond
2 4 8 16 32
200
103
104
(a) DOROTHEA
ProcessorsU
pdat
es p
er s
econ
d2 4 8 16 32
2010
210
3
(b) REUTERS
Figure 2. Scalability for SHOTGUN, THREAD-GREEDY,GREEDY, and COLORING.
DOROTHEA). This leads to greater scalability for SHOT-GUN in this case, but not for COLORING.
6. Related work
The importance of coordinate descent methods for`1 regularized problems was highlighted by Friedmanet al. (2007) and Wu & Lange (2008). Their insightsled to a renewed interest in coordinate descent meth-ods for such problems. Convergence analysis of andnumerical experiments with randomized coordinate orblock coordinate descent methods can be found in thework of Shalev-Shwartz & Tewari (2011), Nesterov(2010) and Richtarik & Takac (2011a). Greedy coordi-nate descent is related to boosting, sparse approxima-tion, and computational geometry. Clarkson (2010)presents a fascinating overview of these connections.Li & Olsher (2009) and Dhillon et al. (2011) applygreedy coordinate descent to `1 regularized problems.Recently, a number of authors have looked at par-allel implementations of coordinate descent methods.Bradley et al. (2011) consider the approach of ignoringdependencies, and updating a randomly-chosen sub-set of coordinates at each iteration. They show thatconvergence is guaranteed up to a number of coordi-nates that depends on the spectral radius of X>X.Richtarik & Takac (2011b) present an approach us-ing GPU-accelerated parallel version of greedy andrandomized coordinate descent. Yuan & Lin (2010)present an empirical comparison of several methods,including coordinate descent, for solving large scale `1regularized problems. However, the focus is on serialalgorithms only. A corresponding empirical study forparallel methods does not exist yet partly because thelandscape is still actively being explored. Finally, wenote that the idea of using graph coloring to ensureconsistency of parallel updates has appeared before(see, for example, (Bertsekas & Tsitsiklis, 1997; Low
et al., 2010; Gonzalez et al., 2011)).
7. Conclusion
We presented GenCD, a generic framework for ex-pressing parallel coordinate descent algorithms, anddescribed four variations of algorithms that follow thisframework. This framework provides a unified ap-proach to parallel CD, and gives a convenient mech-anism for domain researchers to tailor parallel imple-mentations to the application or data at hand. Still,there are clearly many questions that need to be ad-dressed in future work.
Our THREAD-GREEDY approach can easily be extendedto one that accepts the best |J ′| proposals, indepen-dently of which thread proposed to update a givencoordinate. This would have additional synchroniza-tion overhead, and it is an open question whether thisoverhead could be overcome by the improved Acceptstep.
Another open question is conditions for convergence ofthe THREAD-GREEDY algorithm. A priori, one mightsuspect is would have the same convergence criteria asSHOTGUN. But for DOROTHEA, P ∗ = 23, yet updatinga coordinate for each of 32 threads results in excellentconvergence.
It is natural to consider extending SHOTGUN by parti-tioning the columns of the feature matrix into blocks,and then computing a P ∗b for each block b. Intuitively,this can be considered a kind of “soft” coloring. Itremains to be seen what further connections betweenthese approaches will bring.
Our COLORING algorithm relies on a preprocessingstep to color the bipartite graph corresponding to theadjacency matrix. Like most coloring heuristics, oursattempts to minimize the total number of colors. Butin the current context, fewer colors does not necessar-ily correspond with greater parallelism. Better wouldbe to have a more balanced color distribution, even ifthis would require a greater number of colors.
References
Bertsekas, D. P. and Tsitsiklis, J. N. Parallel and Dis-tributed Computation: Numerical Methods. AthenaScientific, 1997.
Bradley, J. K., Kyrola, A., Bickson, D., and Guestrin,C. Parallel Coordinate Descent for L1-RegularizedLoss Minimization. In International Conference onMachine Learning, 2011.
Catalyurek, U., Feo, J., Gebremedhin, A., Halap-

Scaling Up Coordinate Descent
panavar, M., and Pothen, A. Graph Coloring Algo-rithms for Multi-core and Massively MultithreadedArchitectures. Accepted for publication by Journalon Parallel Computing Systems and Applications,2011.
Chapman, Barbara, Jost, Gabriele, and Pas, Ruudvan der. Using OpenMP: Portable Shared Mem-ory Parallel Programming (Scientific and Engineer-ing Computation). The MIT Press, 2007. ISBN0262533022, 9780262533027.
Chung, F. R. K. Spectral Graph Theory. AmericanMathematical Society, 1997.
Clarkson, K. L. Coresets, sparse greedy approxima-tion, and the Frank-Wolfe algorithm. ACM Trans-actions on Algorithms, 6(4):1–30, August 2010.
Dhillon, I. S., Ravikumar, P., and Tewari, A. Near-est neighbor based greedy coordinate descent. InAdvances in Neural Information Processing Systems24, 2011.
Friedman, J., Hastie, T., Hofling, H., and Tibshirani,R. Pathwise coordinate optimization. Annals ofApplied Statistics, 1(2):302–332, 2007.
Gonzalez, J., Low, Y., Gretton, A., and Guestrin, C.Parallel gibbs sampling: From colored fields to thinjunction trees. Journal of Machine Learning Re-search - Proceedings Track, 15:324–332, 2011.
Guyon, I., Gunn, S., Ben-Hur, A., and Dror, G. Re-sult analysis of the NIPS 2003 feature selection chal-lenge. Advances in Neural Information ProcessingSystems, 17:545–552, 2004.
Lewis, D., Yang, Y., Rose, T., and Li, F. RCV1 : ANew Benchmark Collection for Text CategorizationResearch. Journal of Machine Learning Research, 5:361–397, 2004.
Li, Y. and Olsher, S. Coordinate Descent Optimizationfor `1 Minimization with Application to CompressedSensing ; a Greedy Algorithm Solving the Uncon-strained Problem. Inverse Problems and Imaging,3:487–503, 2009.
Low, Y., Gonzalez, J., Kyrola, A., Bickson, D.,Guestrin, C., and Hellerstein, J. M. Graphlab:A new framework for parallel machine learning.In Proceedings of the Twenty-Sixth Conference onUncertainty in Artificial Intelligence, pp. 340–349,2010.
Nesterov, Y. Efficiency of coordinate descent methodson huge-scale optimization problems. Technical Re-port CORE Discussion Paper #2010/2, UniversiteCatholique de Louvain, 2010.
Nikiforov, V. Chromatic number and spectral radius.Linear Algebra and its Applications, 426(2-3):810–814, October 2007.
Richtarik, P. and Takac, M. Iteration complexity ofrandomized block-coordinate descent methods forminimizing a composite function. Arxiv preprintarXiv:1107.2848, 2011a.
Richtarik, P. and Takac, M. Efficient Serial and Par-allel Coordinate Descent Methods for Huge-ScaleTruss Topology Design. In Operations Research Pro-ceedings, pp. 1–6, 2011b.
Shalev-Shwartz, S. and Tewari, A. Stochastic meth-ods for l1-regularized loss minimization. Journal ofMachine Learning Research, 12:1865–1892, 2011.
Wu, T. and Lange, K. Coordinate descent algorithmsfor lasso penalized regression. Annals of AppliedStatistics, 2:224–244, 2008.
Yuan, G. and Lin, C. A Comparison of Opti-mization Methods and Software for Large-scale L1-regularized Linear Classification. Journal of Ma-chine Learning Research, 11:3183–3234, 2010.
Zuckerman, D. Linear Degree Extractors and the Inap-proximability of Max Clique and Chromatic Num-ber. Theory of Computing, 3:103–128, 2007.

Scaling Up Coordinate Descent
A. Coloring-based CD
We now introduce the concept of graph coloring. LetG = (V,E) be a graph with a vertex set V and edge setE. A distance-k coloring of a graph is an assignment ofcolors (unique identities) to each vertex such that notwo vertices that are distance-k apart (connected bya path of length k edges) receive the same color. Theobjective of coloring is to minimize the total numberof colors used to color a graph.
Consider a sparse feature matrix M . In a bipartitegraph representation of this matrix, G = (X ∪ Y,E),each row of M is represented by a vertex in X, eachcolumn is represented by a vertex in Y . The nonzeroelements of M form an edge in E. The vertex setV = X ∪ Y is formed such that X ∩ Y = ∅, and anedge ex,y ∈ E is formed such that one of its endpointsis in X and the other is in Y . A partial distance-2coloring of G is an assignment of colors to every ver-tex in Y (columns of M) such that no two Y -verticesadjacent to the same X-vertex receive the same color.The vertices in X remain uncolored. The result ofsuch a coloring of Y is a partitioning of the featurematrix into structurally independent submatrices suchthat no two columns in a partition (a group of columnswith the same color) have a nonzero on the same row.Thus, a partial distance-2 coloring of a feature matrixreveals sets of features with disjoint support that canbe updated concurrently without a need to synchronizeamong different threads running in parallel.
Since the features of a given color have disjoint sup-port, there is no possibility of collision during the up-date of z as described in 3. This allows for an imple-mentation in which z is updated without any mecha-nism for locking. Therefore, coloring-based algorithmis suitable for implementation on platforms where lock-ing is expensive. On distributed-memory platforms,such an algorithm would avoid a need to pass mes-sages for synchronization.
The minimum number of colors needed to color agraph using a distance-1 coloring scheme is called thechromatic number of a graph. Computing (or evenclosely approximating) the chromatic number is knownto be an NP-hard problem (Zuckerman, 2007). How-ever, simple heuristics work well in practice. They arealso amenable to parallel implementation. In our im-plementation, we adapt the iterative distance-1 color-ing algorithm of Catalyurek et al. (2011) for comput-ing a partial distance-2 coloring of M as illustrated inAlgorithm 5. In order to find a minimal color for agiven vertex yi ∈ Y (a feature), we search all distance-2 paths from yi to other Y -vertices and track the colorsthat have already been used. These colors are marked
as Forbidden and are stored in a vector (Line 8 in Al-gorithm 5). The minimum color available is then as-signed to yi (Lines 9 and 10). In a parallel context,the algorithm assigns colors speculatively and couldlead to conflicts (vertices colored incorrectly). There-fore, after each phase of coloring (Phase-1), we detect(Phase-2) all the conflicts and speculatively color themagain (Lines 12–16). Given a pair of conflicting ver-tices, only one of them needs to be recolored. Thischoice (Line 15) can be made using vertex identitiesor can be determined using random numbers assignedto vertices. Conflicting vertices are added to a newqueue, R (Line 16), which is then assigned to Q (Line17). In a parallel context, threads need to synchronizefor adding vertices to R. We use atomic memory oper-ations to the tail of the queue so that each thread canreceive a unique position to add in the queue. Thealgorithm iterates until all the Y -vertices have beencolored correctly. The computational time of a (se-rial) partial distance-2 coloring heuristic is given byO(n · d2), where n = |Y | represents the number ofvertices in Y , and d2 is a generalization of the vertexdegree denoting the average number of distinct pathsof length 2 starting at a vertex in G. The scalabilityof this algorithm on several classes of inputs and dif-ferent architectures is documented in Catalyurek et al.(2011).
While we strive to exploit parallelism from structuralindependence through coloring, the approach in Shot-gun exploits parallelism that is implicitly provided inthe structural and numerical properties of a featurematrix through the computation of eigenvalues (spec-tral radius). While we do not attempt to derive a for-mal relationship between the two approaches, we notethat such a connection might be possible based on thepioneering work of Fiedler (algebraic connectivity of agraph (Chung, 1997)) and Nikiforov (2007) (relation-ship of the chromatic number of a graph to its spectralradius).

Scaling Up Coordinate Descent
Algorithm 5 Iterative parallel algorithms for partial distance-2 coloring.Input: A bipartite graph G = (X ∪ Y,E).Output: A vector color representing the color of each vertex in Y .Data structures: Two queue data structures, Q and R; a thread-private vector to store colors being used byneighbors, ForbiddenColors.1: Initialize data structures2: Q← Y // Color vertices only in Y3: while Q 6= ∅ do4: for each u ∈ Q in parallel do // Phase 1: tentative coloring5: for each v ∈ adj (u) do // Vertices in X6: for each w ∈ adj (v) do // Vertices in Y7: ForbiddenColors[color[w]] ← u8: c ← min{i > 0 : ForbiddenColors[i] 6= u}9: color[u] ← c
10: R← ∅ // Vertices that need to be recolored11: for each u ∈ Q in parallel do // Phase 2: conflict detection12: for each v ∈ adj (u) do // Vertices in X13: for each w ∈ adj (v) do // Vertices in Y14: if color[u] = color[w] and u > w then15: R← R ∪ {u} // Uses atomic memory operations16: Q← R // Swap the two queues