scaling hybrid coarray/mpi miniapps on archer - cug.org · scaling hybrid coarray/mpi miniapps on...
TRANSCRIPT

Scaling hybrid coarray/MPI miniapps on Archer
L. Cebamanos1, A. Shterenlikht2, J.D. Arregui-Mena3,L. Margetts3
1Edinburgh Parallel Computing Centre (EPCC)The University of Edinburgh, King's Buildings, Edinburgh EH9 3FD, UK
Email: [email protected]
2Department of Mechanical EngineeringThe University of Bristol, Bristol BS8 1TR, UK, Email: [email protected]
3School of Mechanical, Aero and Civil EngineeringThe University of Manchester, Manchester M13 9PL, UK
Emails: [email protected], Lee.Margetts@manchester .ac.uk
CUG2016, London 8-12-MAY-2016

CGPACK - cellular automata microstructure simulationlibrary: https://sourceforge.net/projects/cgpack
I Solidi�cation,recrystallisation, andfracture ofpolycrystallinemicrostructures.
I Fortran 2008 coarrays+ TS 18508 [1]extensions.
I HECToR, ARCHER,Intel,OpenCoarrays/GCCsystems.
I BSD license f100g and f110g micro-cracks in individual
crystals merge into a macro-crack.

CGPACK design
I CA spacecoarray - 4Darray, 3Dcorank -structured grid[2, 3, 4].
I Integer cellstates
I Fixed orself-similarboundaries
I Traditionalhalo exchange

CGPACK space coarray:integer, allocatable :: space(:,:,:,:)[:,:,:]
I Discrete space,discrete time
I Meshindependentresults require� 105 CA cellsper crystal onaverage [5].
I Crystal (grain)is a cluster ofcells of thesame value.
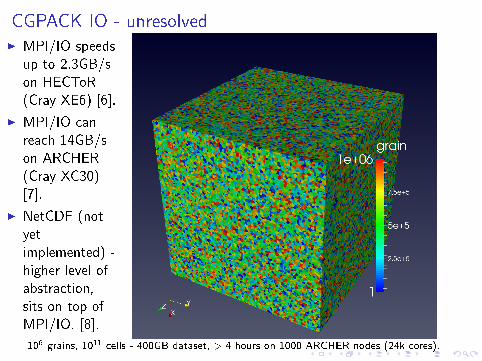
CGPACK IO - unresolvedI MPI/IO speeds
up to 2.3GB/son HECToR(Cray XE6) [6].
I MPI/IO canreach 14GB/son ARCHER(Cray XC30)[7].
I NetCDF (notyetimplemented) -higher level ofabstraction,sits on top ofMPI/IO. [8].
106 grains, 1011 cells - 400GB dataset, > 4 hours on 1000 ARCHER nodes (24k cores).

CGPACK scalingI Up to 32k
cores onHECToR andARCHER forsolidi�cationproblems.
I Scaling variesfor di�erentprograms builtwith CGPACK,depending onwhich routinesare called, inwhat order andrequirementsfor synchroni-sation.
1
10
100
1000
8 64 512 4096 32768
speed-u
p
Number of cores, Hector XE6
sync allsync images serial
sync images d&cco_sum
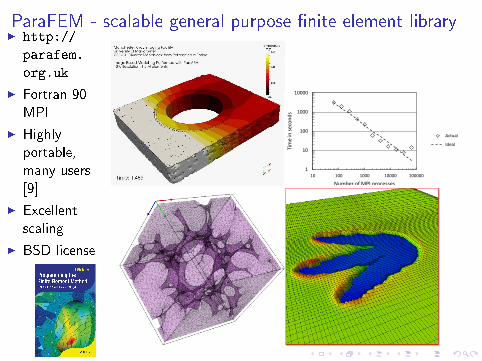
ParaFEM - scalable general purpose �nite element libraryI http://
parafem.
org.uk
I Fortran 90MPI
I Highlyportable,many users[9]
I Excellentscaling
I BSD license
1
10
100
1000
10000
10 100 1000 10000 100000
Tim
e in
sec
on
ds
Number of MPI processes
Actual
Ideal

Cellular Automata Finite Element (CAFE)
I Used for solidi�cation[10], recrystallisation[11] and fracture[12, 13].
I FE - continuummechanics - stress,strain, etc.
I CA - crystals, crystalboundaries, cleavage,grain boundaryfracture
I FE ! CA - stress,strain
I CA ! FE - damagevariables

CAFE design: structured CA grid + unstructured FE grid
body (domain)
material
multi−scale model
FE + CA = CAFE
MPI 1
MPI 4
MPI 2
multi−scale model
MPI 3
image 2
image 4
image 3
image 1
Example with 4 PE (4 MPI pro-cesses, 4 coarray images). Arrowsare FE $ CA comms.
PE 4
PE 2PE 1
PE 3

FE ! CA mapping via a private allocatable array ofderived type:
type mceni n t e g e r : : image , elnumr e a l : : c e n t r (3 )
end type mcentype ( mcen ) , a l l o c a t a b l e : : l c e n t r ( : )
based on coordinates of FE centroids calculated by each MPIprocess and stored in centroid tmp coarray:
type r car e a l , a l l o c a t a b l e : : r ( : , : )
end type r catype ( r ca ) : : c en t r o i d tmp [ � ]:
a l l o c a t e ( c en t r o i d tmp%r (3 , n e l s p p ) )
where nels pp is the number of FE stored on this PE.

lcentr arrays on images P and Q
PE, image, MPI process P
.
.
b.
.
.
.
a.
.
.
elements
image
elnum
centr
. . . Q . . . P . . .
CA
r
s
lcentr
. . . n . . . b . . .
. . . r . . . s . . .
PE, image, MPI process Q
.
.
m.
.
.
.
n.
.
.
elements
image
elnum
centr
. . . Q . . . P . . .
CA
lcentr
. . . m . . . a . . .
. . . u . . . t . . .
ut

All-to-all vs nearest neighbour for lcentr
I cgca pfem cenc - all-to-all routine.
I cgca pfem map - nearest neighbour - temporary arrays andcoarray collectives CO SUM and CO MAX, described in TS18508 [1] and will be included in the next revision of theFortran standard, Fortran 2015. At the time of writing coarraycollectives are available on Cray systems as extension to thestandard [14]. The two routines di�er in their use of remotecommunications.
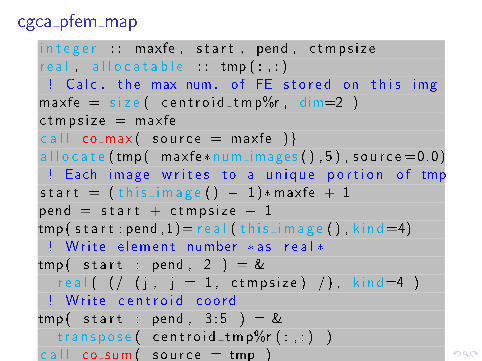
cgca pfem map
i n t e g e r : : maxfe , s t a r t , pend , c tmps i z er e a l , a l l o c a t a b l e : : tmp ( : , : )! Ca lc . the max num . o f FE s t o r e d on t h i s img
maxfe = s i z e ( c en t r o i d tmp%r , dim=2 )c tmps i z e = maxfec a l l co max ( s ou r c e = maxfe )ga l l o c a t e ( tmp( maxfe�num images ( ) , 5 ) , s ou r c e =0.0)! Each image w r i t e s to a un ique p o r t i o n o f tmp
s t a r t = ( t h i s ima g e ( ) � 1)�maxfe + 1pend = s t a r t + c tmps i z e � 1tmp( s t a r t : pend ,1)= r e a l ( t h i s ima g e ( ) , k i nd=4)! Wr i te e l ement number � as r e a l �
tmp( s t a r t : pend , 2 ) = &r e a l ( (/ ( j , j = 1 , c tmps i z e ) /) , k i nd=4 )
! Wr i te c e n t r o i d coordtmp( s t a r t : pend , 3 : 5 ) = &
t r a n s p o s e ( c en t r o i d tmp%r ( : , : ) )c a l l co sum ( sou r c e = tmp )

Initial CAFE scaling
100
1000
10000
100 1000 10000 100000
1
10
tim
e, s
scalin
g
runtimescaling
ParaFEM/CGPACK MPI/coarray miniapp scaling on ARCHERXC30 for a 3D problem with 1M FE and 800M CA cells.

Initial pro�ling
Pro�ling function distribution for ParaFEM/CGPACK MPI/coarrayminiapp with all-to-all routine cgca gcupda at 7200 cores.

Initial pro�ling
Raw pro�ling data for ParaFEM/CGPACK MPI/coarray miniappwith all-to-all routine cgca gcupda at 7200 cores.

cgca gcupda - all-to-all
i n t e g e r : : gcupd ( 1 0 0 , 3 ) [ � ] , r nd i n t , j , &img , g c u p d l o c a l (100 ,3 )
r e a l : : rnd:c a l l random number ( rnd )r n d i n t = i n t ( rnd �num images ( ) ) + 1do j = rnd i n t , r n d i n t + num images ( ) � 1img = ji f ( img . gt . num images ( ) ) &
img = img � num images ( )i f ( img . eq . t h i s ima g e ( ) ) c y c l e:g c u p d l o c a l ( : , : ) = gcupd ( : , : ) [ img ]:
end do

cgca gcupdn - nearest neighbour
do i = �1 , 1do j = �1 , 1do k = �1 , 1! Get the co i ndex s e t o f the ne i ghbou rncod = mycod + (/ i , j , k /):g c u p d l o c a l ( : , : ) = &
gcupd ( : , : ) [ ncod (1 ) , ncod (2 ) , ncod ( 3 ) ]:
end doend doend do
Note: the nearest neighbour must be called multiple times topropagate changes from every image to all other images.

Pro�ling cgca gcupdn
Pro�ling function distribution for ParaFEM/CGPACK MPI/coarrayminiapp with the neareast neighbour routine cgca gcupdn at 7200cores.

Pro�ling cgca gcupdn
Raw pro�ling data for ParaFEM/CGPACK MPI/coarray miniappwith the neareast neighbour routine cgca gcupdn at 7200 cores.

Scaling improvement with cgca gcupdn over cgca gcupda
10
100
1000
10000
100 1000 10000 100000
1
10
100ti
me, s
scalin
g
cgca_gcupda runtimecgca_gcupdn runtimecgca_gcupdn scaling
Runtimes and scaling for ParaFEM/CGPACK MPI/coarrayminiapp with the nearest neighbour, cgca gcupdn, and all-to-all,cgca gcupda, algorithms.Scaling limit increased from 2k to 7k cores.

Pro�ling with cgca pfem map
Pro�ling function distribution for ParaFEM/CGPACK MPI/coarrayminiapp with cgca gcupdn and cgca pfem map at 7200 cores.

Pro�ling with cgca pfem map
Raw pro�ling datafor ParaFEM/CG-PACK MPI/coarrayminiapp withcgca gcupdn andcgca pfem map at7200 cores.

Pro�ling with cgca pfem map
10
100
1000
10000
100 1000 10000 100000
1
10
100ti
me, s
scalin
g
_map runtime_cenc runtime_map scaling
Runtimes and scaling for ParaFEM/CGPACK MPI/coarrayminiapp with cgca pfem map and cgca pfem cenc.cgca pfem map or cgca pfem cenc are called only once during theexecution of the miniapp. Hence only a minor improvement isobtained, only from about 1000 cores.

Issues with CrayPAT
cgca gcupda is top in sampling results, but is absent from tracing.It is called the same number of times as cgca hxi.

Issues with CrayPAT
All pro�ling was done with single thread.
Incorrect number of threads indenti�ed by CrayPAT in a tracingexperiment of ParaFEM/CGPACK MPI/coarray miniapp withcgca gcupda.

Future work - optimisation of coarray synchronisation
! ===>>> i m p l i c i t sync a l l i n s i d e <<<===c a l l c g c a s l d ( cgca space , . f a l s e . , 0 , 10 , c g c a s o l i d )c a l l c g c a i g b ( cgca spac e )c a l l cgca gbs ( cg ca spac e )c a l l c g c a h x i ( cg ca spac e )sync a l lc a l l cgca gcu ( cgca spac e )sync a l l
I Some routines have sync inside.
I Other sync responsibility is left to the end user.
I Over-synchronisation?
I Enough sync is required by the standard. A standardconforming Fortran coarray program will not deadlock orsu�er races.

ISO/IEC JTC1/SC22/WG5 N2074, TS 18508 Additional Parallel Features in
Fortran, 2015.
A. Shterenlikht and L. Margetts, \Three-dimensional cellular automata modellingof cleavage propagation across crystal boundaries in polycrystallinemicrostructures," Proc. Roy. Soc. A, vol. 471, p. 20150039, 2015. [Online].Available: http://eis.bris.ac.uk/�mexas/pub/2015prsa.pdf
A. Shterenlikht, L. Margetts, L. Cebamanos, and D. Henty, \Fortran 2008coarrays," ACM Fortran Forum, vol. 34, pp. 10{30, 2015. [Online]. Available:http://eis.bris.ac.uk/�mexas/pub/2015acm�.pdf
A. Shterenlikht, \Fortran coarray library for 3D cellular automata microstructuresimulation," in Proc. 7th PGAS Conf., 3-4 October 2013, Edinburgh, Scotland,
UK, M. Weiland, A. Jackson, and N. Johnson, Eds. The University ofEdinburgh, 2014, pp. 16{24. [Online]. Available:http://www.pgas2013.org.uk/sites/default/�les/pgas2013proceedings.pdf
J. Phillips, A. Shterenlikht, and M. J. Pavier, \Cellular automata modelling ofnano-crystalline instability," in Proc. 20th UK ACME Conf. 27-28 March 2012,
The University of Manchester, UK, 2012. [Online]. Available:http://eis.bris.ac.uk/�mexas/pub/2012 ACME.pdf
A. Shterenlikht, \Fortran 2008 coarrays," Invited talk at Fortran specialist groupmeeting, BCS/IoP joint meeting, 2014. [Online]. Available:http://eis.bris.ac.uk/�mexas/pub/coar bcs.pdf
D. Henty, A. Jackson, C. Moulinec, and V. Szeremi, \ Performance of Parallel IOon ARCHER, version 1.1," ARCHER White Papers, 2015. [Online]. Available:

http://archer.ac.uk/documentation/white-papers/parallelIO/ARCHER wp parallelIO.pdf
T. Collins, \Using NETCDF with Fortran on ARCHER , version 1.1," ARCHERWhite Papers, 2016. [Online]. Available: http://archer.ac.uk/documentation/white-papers/fortanIO netCDF/fortranIO netCDF.pdf
I. M. Smith, D. V. Gri�ths, and L. Margetts, Programming the Finite Element
Method, 5th ed. Wiley, 2014.
C. A. Gandin and M. Rappaz, \A coupled �nite element-cellular automatonmodel for the prediction of dendritic grain structures in solidi�cation processes,"Acta Met. and Mat., vol. 42, no. 7, pp. 2233{2246, 1994.
C. Zheng and D. Raabe, \Interaction between recrystallization and phasetransformation during intercritical annealing in a cold-rolled dual-phase steel: Acellular automaton model," Acta Materialia, vol. 61, pp. 5504{5517, 2013.
A. Shterenlikht and I. C. Howard, \The CAFE model of fracture { application toa TMCR steel," Fatigue Fract. Eng. Mater. Struct., vol. 29, pp. 770{787, 2006.
S. Das, A. Shterenlikht, I. C. Howard, and E. J. Palmiere, \A general method forcoupling microstructural response with structural performance," Proc. Roy. Soc.
A, vol. 462, pp. 2085{2096, 2006.
ISO/IEC 1539-1:2010, Fortran { Part 1: Base language, International Standard,2010.