scalable vaccine distribution in large graphs given uncertain data
DESCRIPTION
Scalable Vaccine Distribution in Large Graphs given Uncertain Data. Yao Zhang, B . Aditya Prakash Department of Computer Science Virginia Tech. CIKM, Shanghai, November 6, 2014. Outline. Motivation Problem Definition Our Proposed Methods Experiments Conclusion. - PowerPoint PPT PresentationTRANSCRIPT

Scalable Vaccine Distribution in Large Graphs given Uncertain
Data
Scalable Vaccine Distribution in Large Graphs given Uncertain
Data
Yao Zhang, B. Aditya Prakash
Department of Computer Science
Virginia Tech
CIKM, Shanghai, November 6, 2014

2
OutlineOutline• Motivation• Problem Definition• Our Proposed Methods• Experiments• Conclusion
Zhang and Prakash, CIKM2014

3
Propagation on networksPropagation on networks
[from leverage.com]
[from the Economist]
Information spreads over social networksE.g., Millions of photos/messages sharing
Virus outbreaks over population networkE.g., WHO estimates 5,000 to 10,000 new Ebola cases weekly in West Africa by the first week of December
Zhang and Prakash, CIKM2014
4
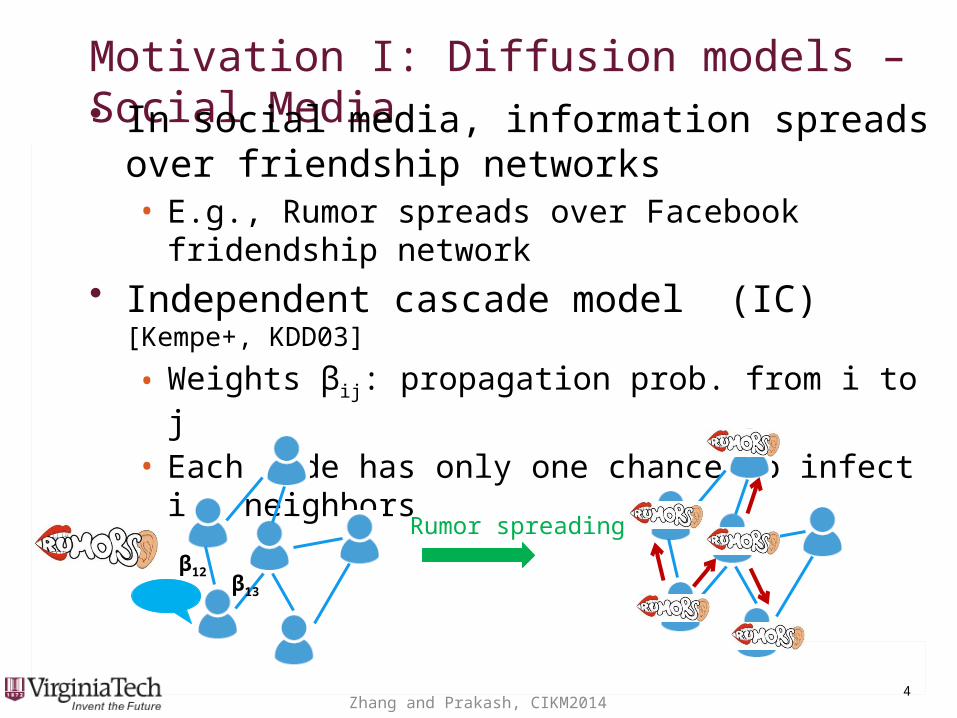
Motivation I: Diffusion models – Social MediaMotivation I: Diffusion models – Social Media• In social media, information spreads over
friendship networks• E.g., Rumor spreads over Facebook fridendship
network
• Independent cascade model (IC) [Kempe+, KDD03]
• Weights βij: propagation prob. from i to j
• Each node has only one chance to infect its neighbors
Rumor spreading
Zhang and Prakash, CIKM2014
β12β13

5
Motivation I: Diffusion models – EpidemiologyMotivation I: Diffusion models – Epidemiology• In epidemiology, virus spreads over population
contact networks• E.g., ebola, chickenpox, etc. may spread if people are
coming to contact
• SIR model [Anderson+ 1991]
• Susceptible-Infectious-Recovered
• Weights βij: propagation prob. from i to j
• Recovered prob. δ for each infected node
Ebola spreading
Zhang and Prakash, CIKM2014
β12 β13
δ

6
Motivation II: ImmunizationMotivation II: Immunization
• Epidemiology• Centers for Disease Control
(CDC)• Which people to vaccinate to
control spread of Ebola?
• Social Media• Twitter• Which people to warn to stop
rumors like “wall street crashing”
Common abstract goal: “find best nodes to remove”
Zhang and Prakash, CIKM2014

7
Immunization StrategiesImmunization Strategies• Pre-emptive Strategy• choose nodes before the
epidemic starts• Netshield [Tong+ 2010]
• Minimize the epidemic threshold (which is focusing on the largest eigenvalue[Prakash+ 2011]), above which a lot of people get infected
Which nodes to vaccinate
Zhang and Prakash, CIKM2014

8
Immunization StrategiesImmunization Strategies• Pre-emptive Strategy• choose nodes before the
epidemic starts• Netshield [Tong+ 2010]
• Data-aware Strategy• choose nodes knowing current
infections (which nodes are infected)
• DAVA-fast algorithm [Zhang and Prakash 2014]
Which nodes to vaccinate
However…Zhang and Prakash, CIKM2014

9
Motivation III: Real Data is UncertainMotivation III: Real Data is Uncertain
• Epidemiology• Public-health surveillance
We don’t know who exactly are infected
??
Each level have a certain probability to miss some truly infected people
CNN headlines
Not sure
Not sure
Surveillance Pyramid [Nishiura+, PLoS ONE 2011]
CDC
Lab
Hospital
Zhang and Prakash, CIKM2014

10
• Social Media• Twitter: due to the uniform samples [Morstatter+,
ICWSM 2013], the relevant ‘infected’ tweets may be missed
?
?
Missing
Missing
Motivation III: Real Data is UncertainMotivation III: Real Data is Uncertain
We don’t know who exactly are infected
Tweets
Sampled Tweets
Sampling
Zhang and Prakash, CIKM2014
11
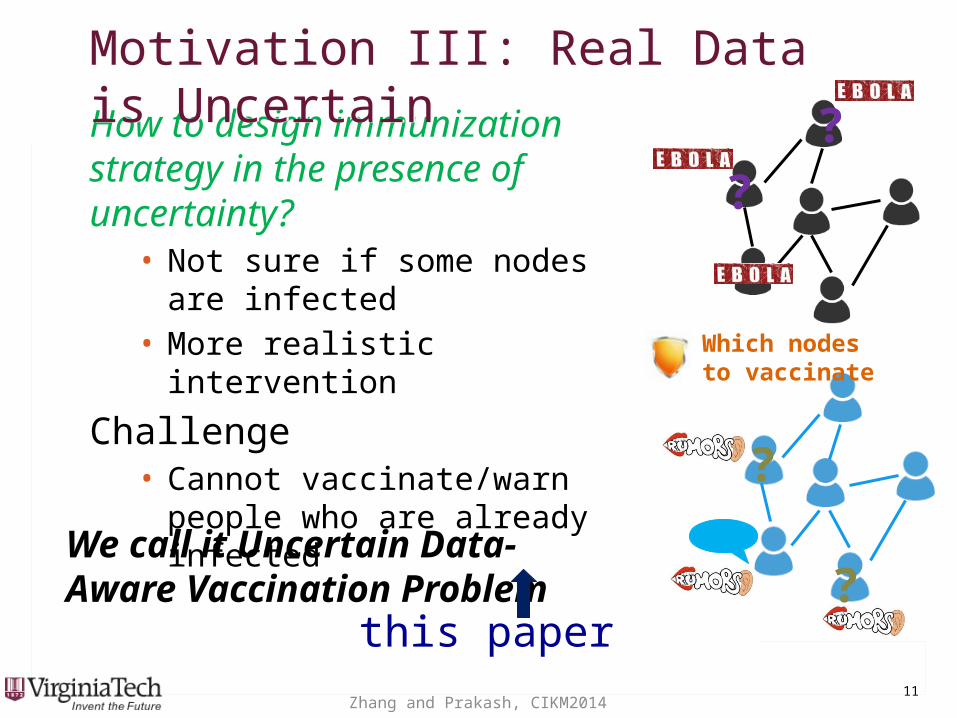
How to design immunization strategy in the presence of uncertainty?• Not sure if some nodes are
infected• More realistic intervention
Challenge• Cannot vaccinate/warn people
who are already infected
Which nodes to vaccinate
??
?
?We call it Uncertain Data-Aware Vaccination Problem
this paper
Motivation III: Real Data is UncertainMotivation III: Real Data is Uncertain
Zhang and Prakash, CIKM2014

12
OutlineOutline• Motivation• Problem Definition• Uncertainty Models• Problem Formulation
• Our Proposed Methods• Experiments• Conclusion
Zhang and Prakash, CIKM2014
13
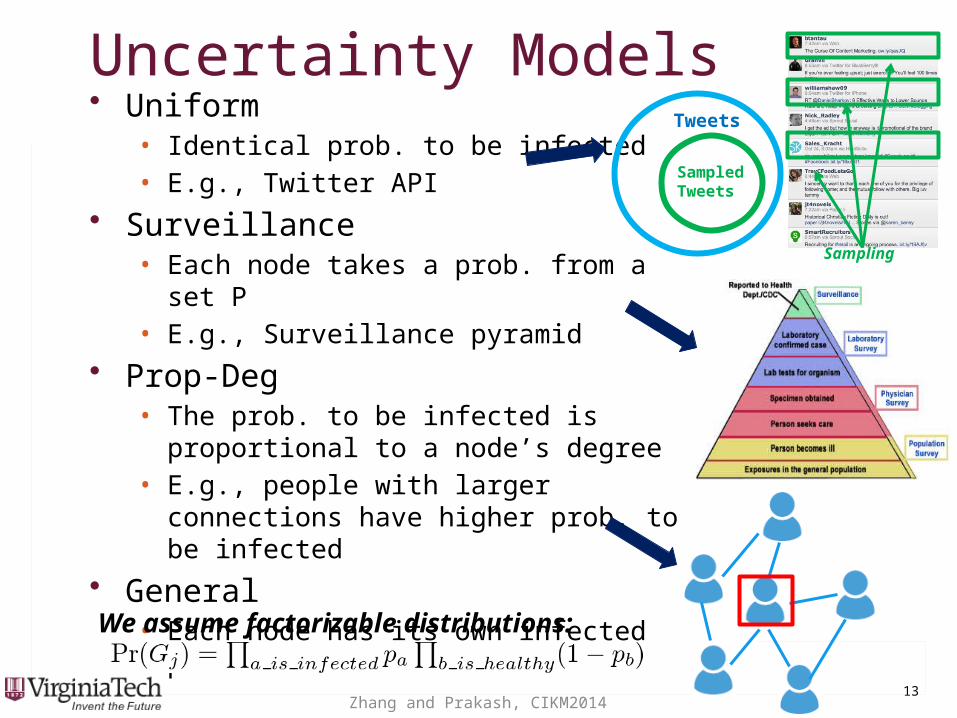
Uncertainty ModelsUncertainty Models• Uniform
• Identical prob. to be infected• E.g., Twitter API
• Surveillance• Each node takes a prob. from a set P• E.g., Surveillance pyramid
• Prop-Deg• The prob. to be infected is proportional to a
node’s degree• E.g., people with larger connections have
higher prob. to be infected
• General• Each node has its own infected prob.
Tweets
Sampled Tweets
Sampling
We assume factorizable distributions:
Zhang and Prakash, CIKM2014
14
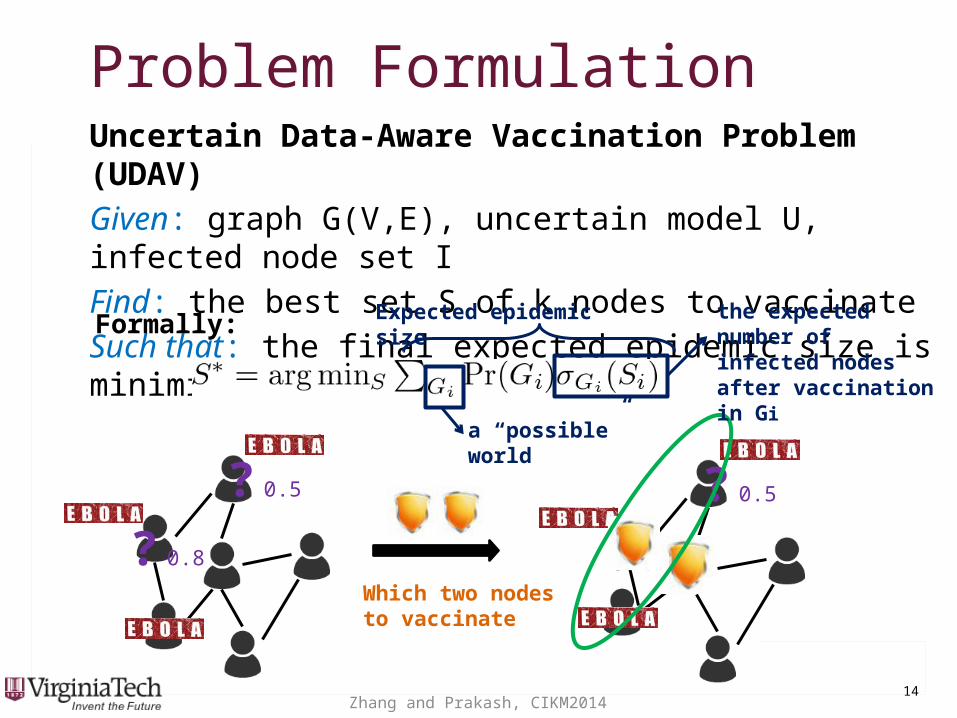
Problem FormulationProblem FormulationUncertain Data-Aware Vaccination Problem (UDAV)
Given: graph G(V,E), uncertain model U, infected node set I
Find: the best set S of k nodes to vaccinate
Such that: the final expected epidemic size is minimized
Which two nodes to vaccinate
? 0.5
? 0.8
? 0.5
? 0.8
Formally: the expected number of infected nodes after vaccination in Gi
Expected epidemic size
a “possible” world
Zhang and Prakash, CIKM2014

15
Complexity of UDAVComplexity of UDAV• NP-hard, and cannot be approximated within
an absolute error• A special case of UDAV (equal to the deterministic
case) is NP-hard [Zhang+ 2014]
Zhang and Prakash, CIKM2014

16
OutlineOutline• Motivation• Problem Definition• Our Proposed Methods• Experiments• Conclusion
Zhang and Prakash, CIKM2014
17
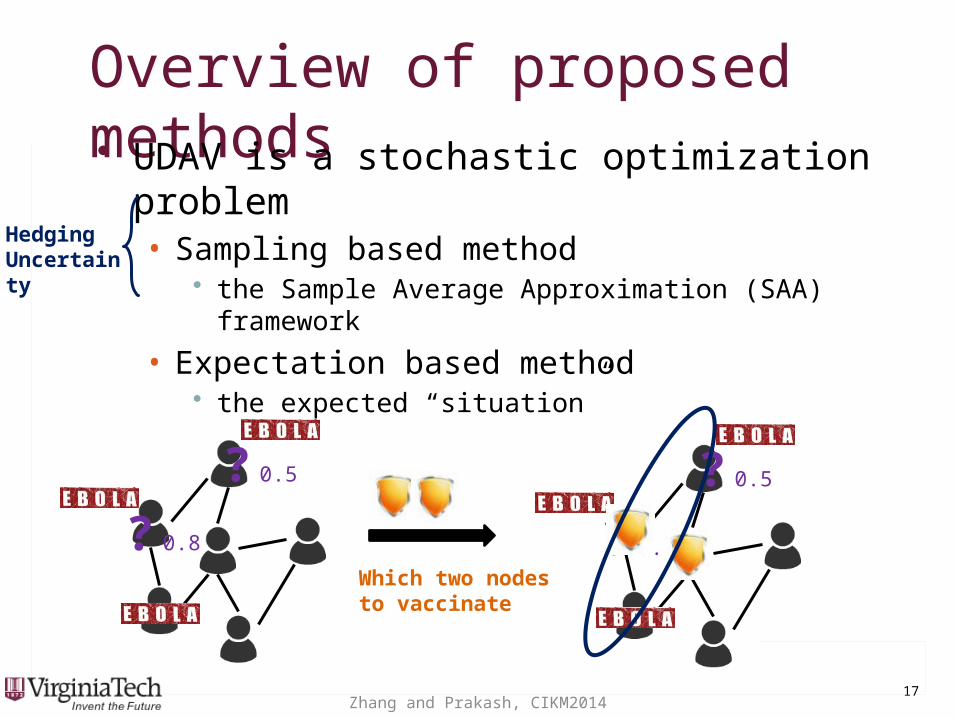
Overview of proposed methodsOverview of proposed methods• UDAV is a stochastic optimization problem• Sampling based method
• the Sample Average Approximation (SAA) framework
• Expectation based method• the expected “situation”
Which two nodes to vaccinate
? 0.5
? 0.8
? 0.5
? 0.8
Hedging Uncertainty
Zhang and Prakash, CIKM2014

18
OutlineOutline• Motivation• Problem Definition• Our Proposed Methods• Sample-Cascade• Expect-Max
• Experiments• Conclusion
Zhang and Prakash, CIKM2014
19
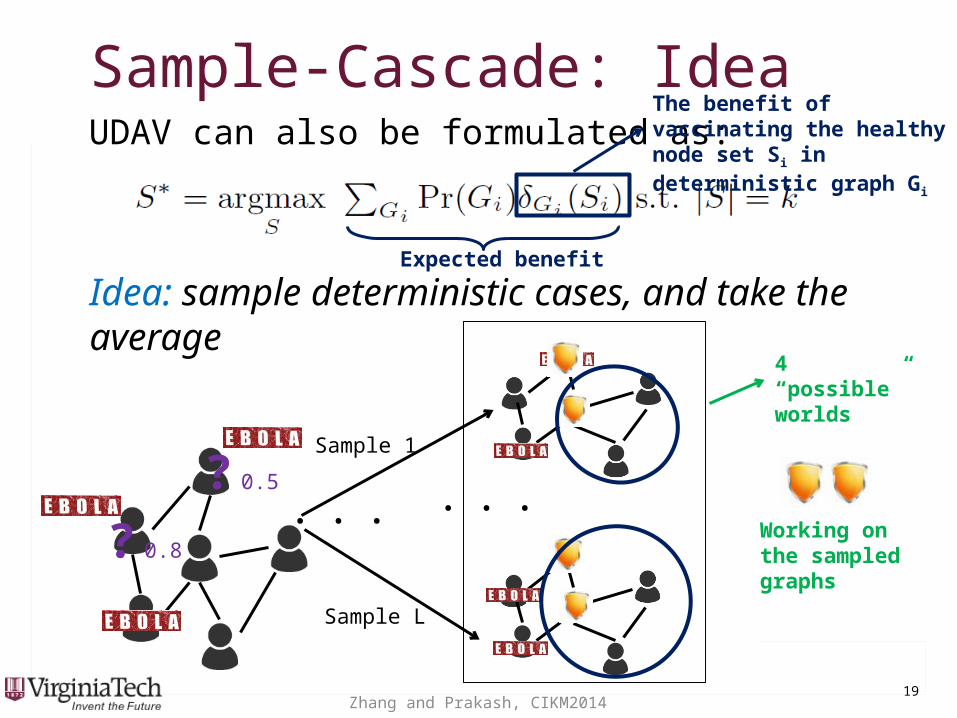
Sample-Cascade: IdeaSample-Cascade: Idea
Idea: sample deterministic cases, and take the average
? 0.5
? 0.8
UDAV can also be formulated as: The benefit of vaccinating the healthy node set Si in deterministic graph Gi
Working on the sampled graphs
...Sample L
Sample 1...
Expected benefit
4 “possible” worlds
Zhang and Prakash, CIKM2014
20
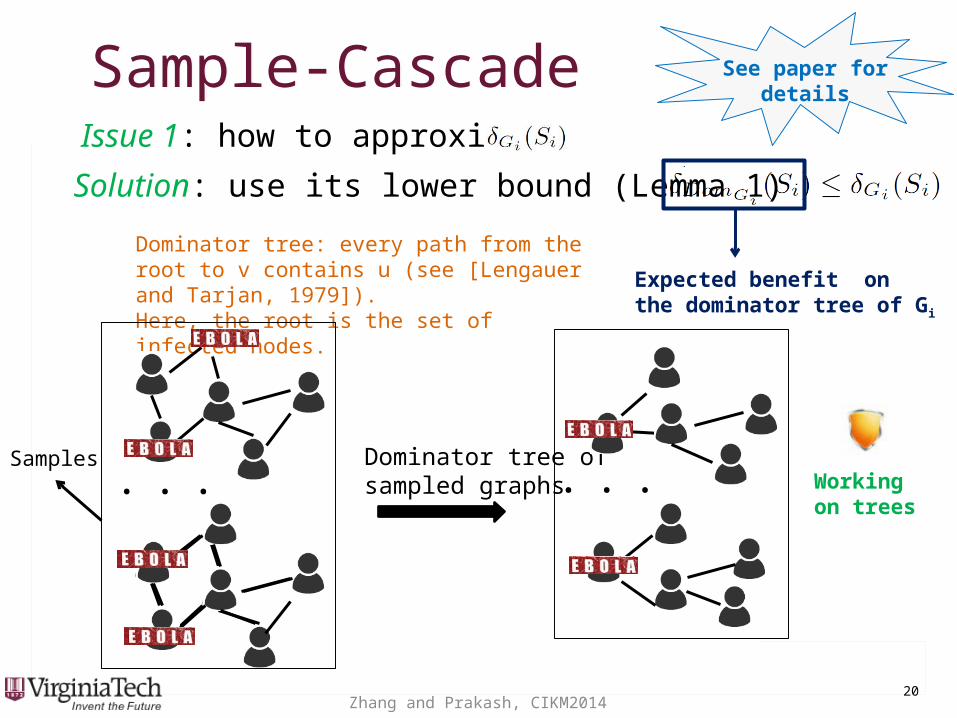
Sample-CascadeSample-CascadeIssue 1: how to approximate
See paper for details
Solution: use its lower bound (Lemma 1)
Expected benefit on the dominator tree of Gi
Dominator tree: every path from the root to v contains u (see [Lengauer and Tarjan, 1979]).Here, the root is the set of infected nodes.
Working on trees
... Dominator tree of sampled graphs
...Samples
Zhang and Prakash, CIKM2014
21
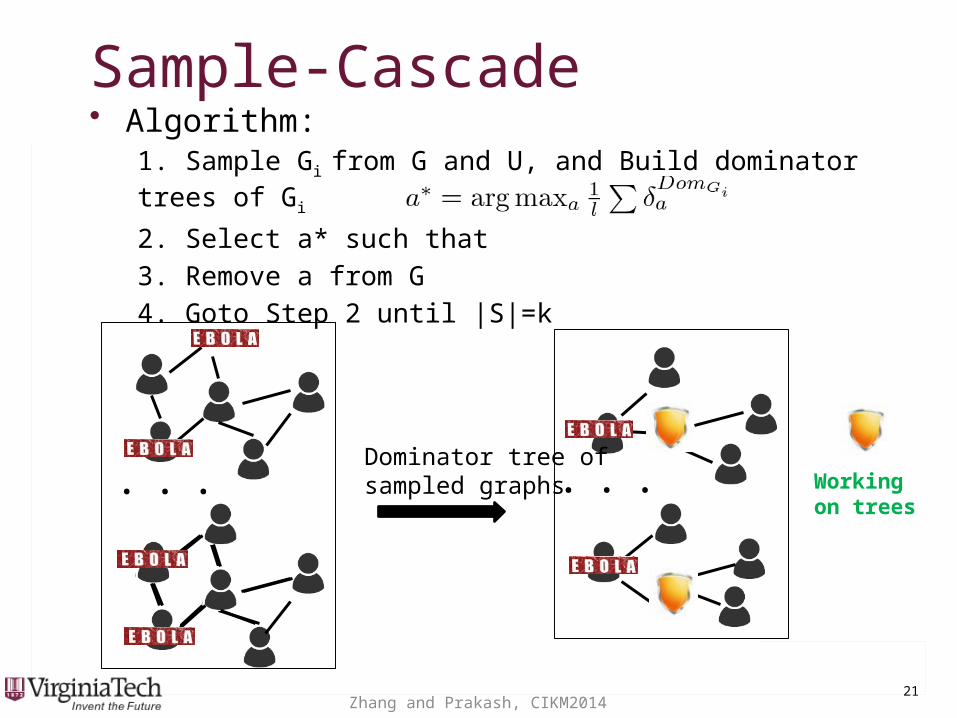
• Algorithm: 1. Sample Gi from G and U, and Build dominator trees of Gi
2. Select a* such that
3. Remove a from G
4. Goto Step 2 until |S|=k
Sample-CascadeSample-Cascade
Working on trees
...Dominator tree of sampled graphs
Zhang and Prakash, CIKM2014
...

22
Sample-CascadeSample-CascadeIssue 2: number of samples l
Running time: O(l*(k|E|+k|V|+ |V|log|V|))
Accurate, but too slow for large networks!
Solution: (Hoeffding's Inequality) Worse case l=O(|V|2)
Working on trees
...Dominator tree of sampled graphs
Zhang and Prakash, CIKM2014
...

23
OutlineOutline• Motivation• Problem Definition• Our Proposed Methods• Sample-Cascade• Expect-Max
• Experiments• Conclusion
Zhang and Prakash, CIKM2014
24
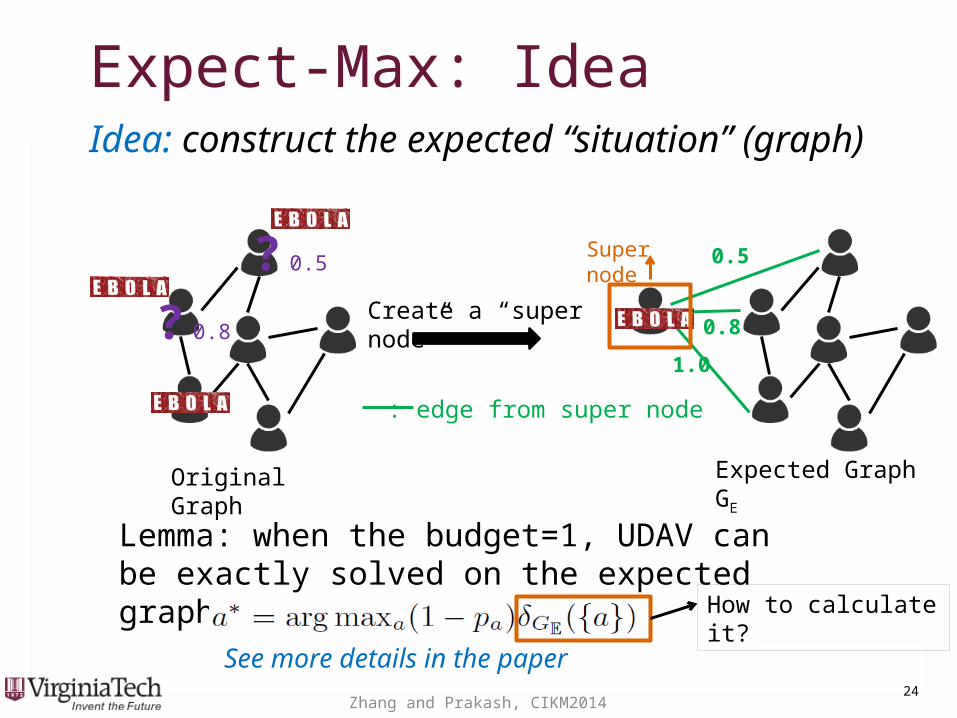
Expect-Max: IdeaExpect-Max: IdeaIdea: construct the expected “situation” (graph)
? 0.5
? 0.8
Original Graph
: edge from super node
Create a “super node”
0.5
0.8
1.0
See more details in the paper
Lemma: when the budget=1, UDAV can be exactly solved on the expected graph
Expected Graph GE
How to calculate it?
Super node
Zhang and Prakash, CIKM2014

25
Calculating Benefit on the Expected GraphCalculating Benefit on the Expected Graph
• We propose two methods to calculate• Using dominator tree
• Expect-Dom
• Using the drop of the first eigenvalue• Expect-Eig
Zhang and Prakash, CIKM2014
26
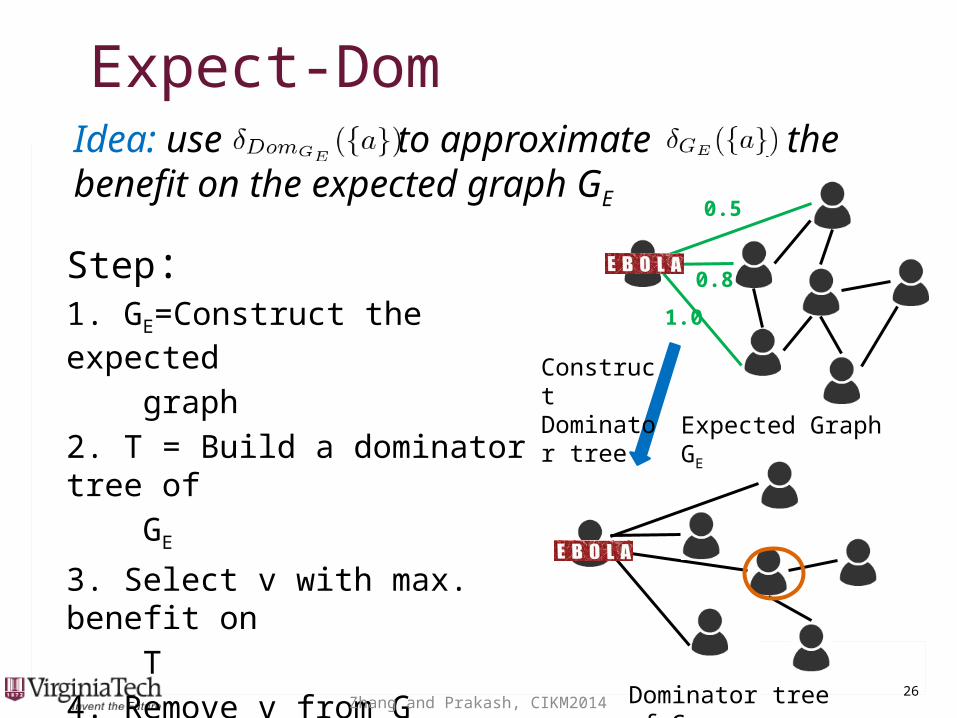
Expect-DomExpect-DomIdea: use to approximate , the benefit on the expected graph GE 0.5
0.8
1.0
Expected Graph GE
Dominator tree of GE
Construct Dominator tree
Step: 1. GE=Construct the expected
graph
2. T = Build a dominator tree of
GE
3. Select v with max. benefit on
T
4. Remove v from G
5. Goto Step 3 until |S|=k
Zhang and Prakash, CIKM2014

27
Expect-EigExpect-EigIdea: use to approximate , the benefit on the expected graph GE
0.5
0.8
1.0
Expected Graph GE
0.5
0.8
1.0
Expected Graph GE
: the drop of the first eigenvalue(Measuring the threshold of the epidemic).
Lemma : The number of newly infected nodes is bounded by the first eigenvalue (details in the paper)
(Can be computed fast [Tong+, ICDM 2010])
Calculate
Zhang and Prakash, CIKM2014

28
Expect-EigExpect-EigIdea: use to approximate , the benefit on the expected graph GE 0.5
0.8
1.0
Expected Graph GE
0.5
0.8
1.0
Calculate
Step: 1. GE=Construct the expected
graph
2. Select v with max.
3. Remove v from G
4. Goto Step 2 until |S|=k
Zhang and Prakash, CIKM2014

29
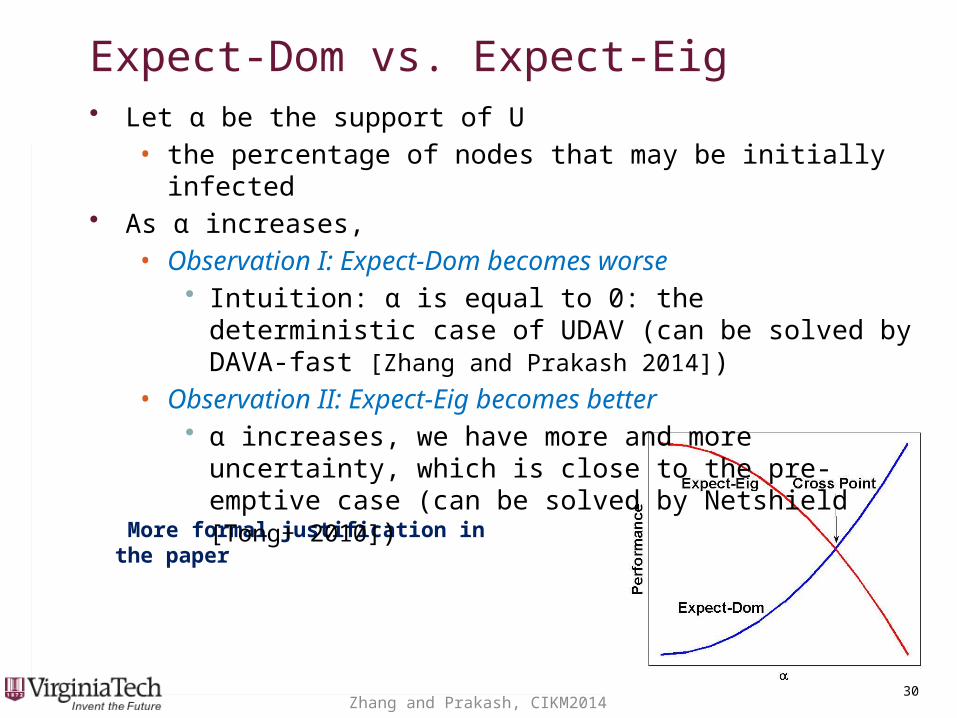
Expect-Dom vs. Expect-EigExpect-Dom vs. Expect-Eig• Let α be the support of U
• the percentage of nodes that may be initially infected
Zhang and Prakash, CIKM2014
? 0.5
? 0.8
α=0.5
30
Expect-Dom vs. Expect-EigExpect-Dom vs. Expect-Eig
More formal justification in the paper
• Let α be the support of U • the percentage of nodes that may be initially infected
• As α increases, • Observation I: Expect-Dom becomes worse
• Intuition: α is equal to 0: the deterministic case of UDAV (can be solved by DAVA-fast [Zhang and Prakash 2014])
• Observation II: Expect-Eig becomes better• α increases, we have more and more uncertainty, which is
close to the pre-emptive case (can be solved by Netshield [Tong+ 2010])
Zhang and Prakash, CIKM2014

31
Expect-Max: a hybrid algorithmExpect-Max: a hybrid algorithm
As they are complementary for different distributions and different networks (we don’t know where the crosspoint is)
• pick the better one between Expect-Dom and Expect-Eig
Idea: put Expect-Dom and Expect-Eig together
Running time (subquadratic): O(k(|V|+|E|)+|V|log|V|+T)
Zhang and Prakash, CIKM2014

32
Extending to SIRExtending to SIR• Our methods can be extended to SIR
model• Idea: using an equivalent IC model with the
propagation probability
See paper for details
Zhang and Prakash, CIKM2014

33
OutlineOutline• Motivation• Problem Definition• Our Proposed Methods• Experiments• Conclusion
Zhang and Prakash, CIKM2014
34
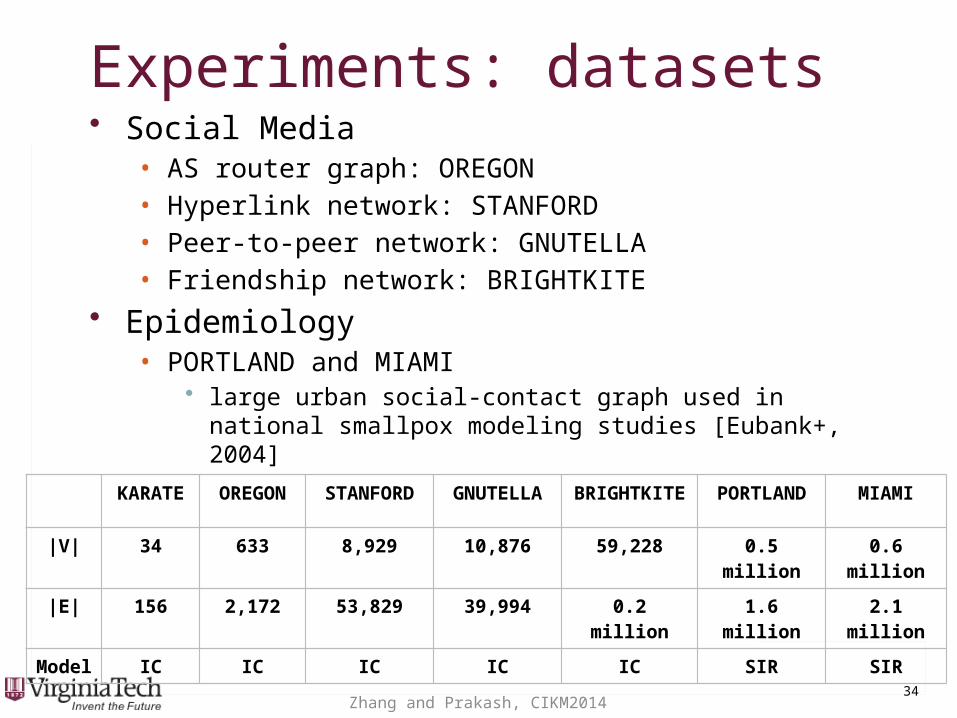
Experiments: datasetsExperiments: datasets• Social Media
• AS router graph: OREGON• Hyperlink network: STANFORD• Peer-to-peer network: GNUTELLA• Friendship network: BRIGHTKITE
• Epidemiology• PORTLAND and MIAMI
• large urban social-contact graph used in national smallpox modeling studies [Eubank+, 2004]
KARATE OREGON STANFORD GNUTELLA BRIGHTKITE PORTLAND MIAMI
|V| 34 633 8,929 10,876 59,228 0.5 million 0.6 million
|E| 156 2,172 53,829 39,994 0.2 million 1.6 million 2.1 million
Model IC IC IC IC IC SIR SIR
Zhang and Prakash, CIKM2014

35
Experiments: setupExperiments: setup• Uncertainty models• Uniform: p=0.6• Surveillance: p is chosen from {0.1, 0.5}
• Prop-Deg: pi=di/dmax
• Settings• Uniformly randomly pick 5% of nodes as infected• Number of samples: 500
See more details in the paper
Tweets
Sampled Tweets
Sampling
Zhang and Prakash, CIKM2014

36
Experiments: baselinesExperiments: baselines• OPTIMAL: brute-force algorithm which tries all possible cases
(optimal, and only run it on KARATE)
• RANDOM: randomly uniformly choose nodes from W
• DEGREE: choose top-k nodes from W according to weighted degrees
• PAGERANK: choose top-k nodes from W with top pageranks
• PER-PRANK: choose top-k nodes from W with top personalized pageranks with respect to infected nodes
• DAVA-fast• A fast data-aware immunization method in presence of already
infected nodes [Zhang+, SDM 14]
W: a set of nodes that are not definitely infected (0<=p<1)
Zhang and Prakash, CIKM2014
37
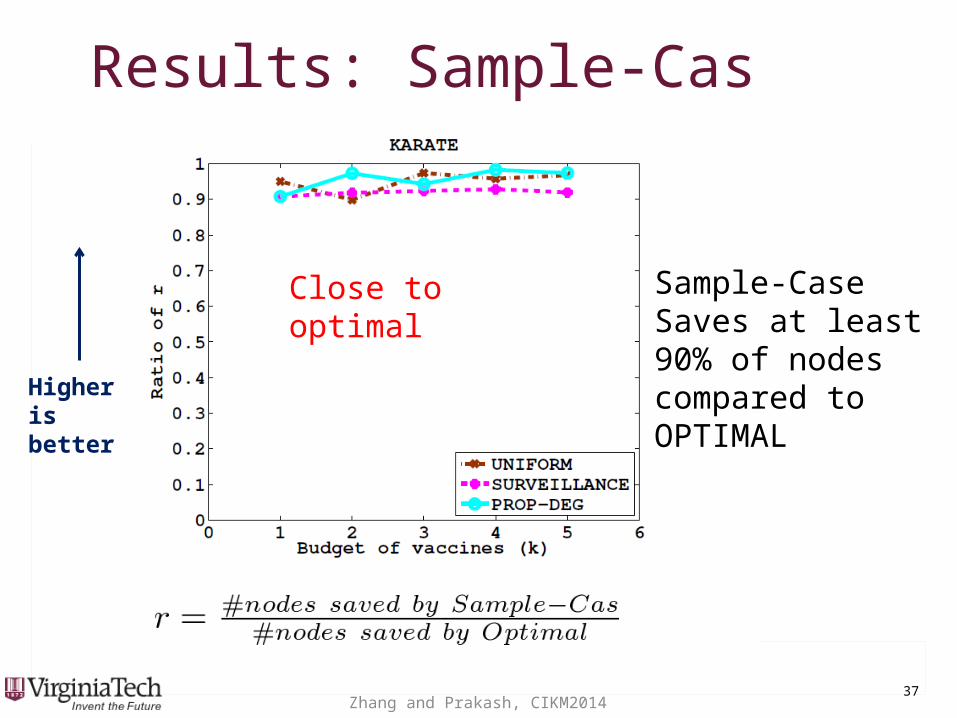
Results: Sample-CasResults: Sample-Cas
Sample-Case Saves at least 90% of nodes compared to OPTIMALHigher
is better
Close to optimal
Zhang and Prakash, CIKM2014

38
Results: Expect-Max: α mattersResults: Expect-Max: α mattersSTANFORD BRIGHTKITE
R>1: Expect-Dom is betterR<1: Expect-Eig is better
R=1: cross point (different for different networks and different distributions)
This is why we use Expect-Max
Zhang and Prakash, CIKM2014
39
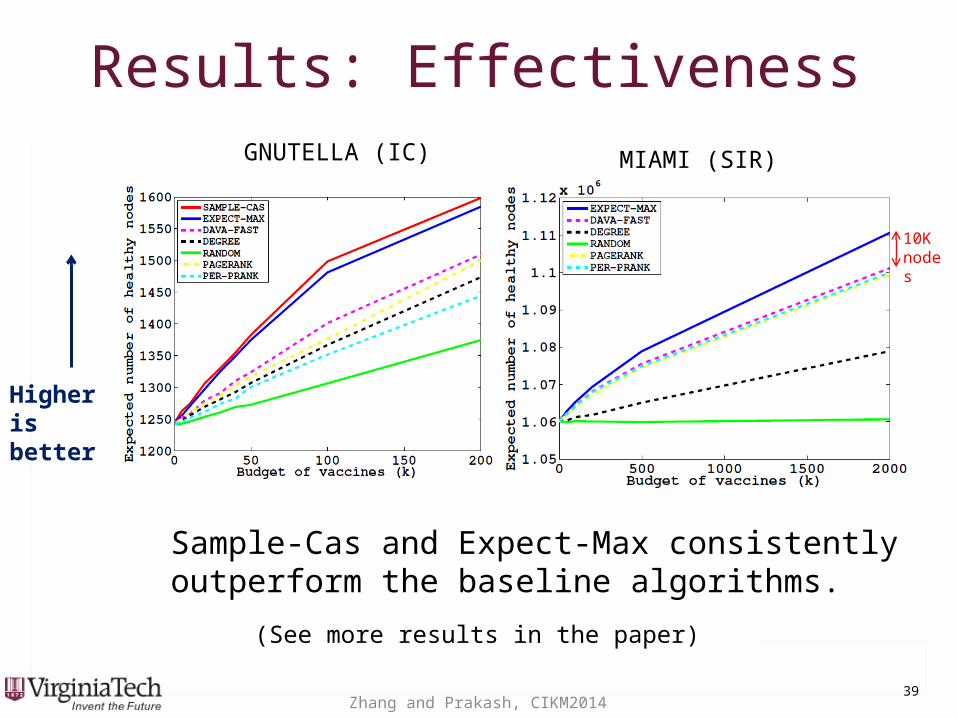
Results: EffectivenessResults: Effectiveness
(See more results in the paper)
GNUTELLA (IC) MIAMI (SIR)
Higher is better
Sample-Cas and Expect-Max consistently outperform the baseline algorithms.
10K nodes
Zhang and Prakash, CIKM2014
40
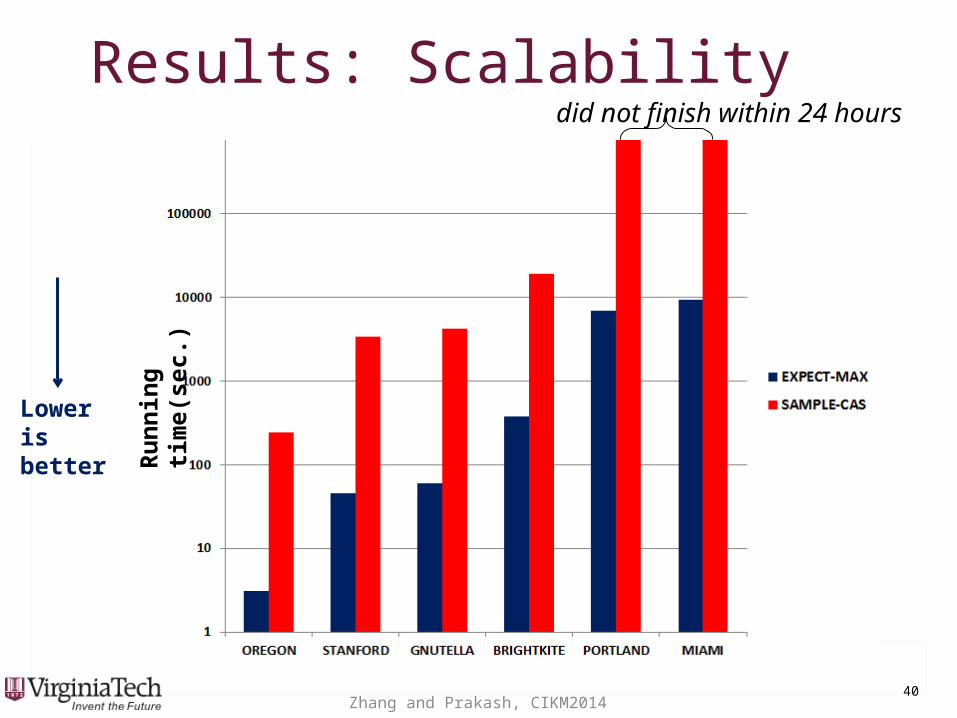
Results: ScalabilityResults: Scalability
Lower is better
did not finish within 24 hours R
un
nin
g t
ime(
sec.
)
Zhang and Prakash, CIKM2014

41
OutlineOutline• Motivation• Problem Definition• Our Proposed Methods• Experiments• Conclusion
Zhang and Prakash, CIKM2014

42
ConclusionConclusionUncertain Data-Aware Vaccination
Given: Graph and Uncertain model
Find: ‘best’ k nodes for vaccination• Uncertainty models
• Uniform, Surveillance, Prop-Deg, General
• Proposed Methods• Sample-Cas: sampling graphs (slow,
accurate)• Expect-Max: constructing expected
graph (fast, subquadratic)
0.5
0.8
1.0
? 0.5
? 0.8
...
Expected Graph
Sampling
Zhang and Prakash, CIKM2014

43
Any questions?Any questions?Code at:http://people.cs.vt.edu/~yaozhang Funding:
Yao Zhang B. Aditya Prakash
Zhang and Prakash, CIKM2014