scalable reliable multicast in wide area networks sneha kumar kasera department of computer science...
TRANSCRIPT

Scalable Reliable Multicast in Wide Area Networks
Sneha Kumar Kasera
Department of Computer Science
University of Massachusetts, Amherst

Why Multicast ?
multiple unicast broadcast multicast
one sender three receivers

Why Reliable Multicast ?
applications one-to-many file transfer information updates
(e.g., stock quote, web cache updates)
shared whiteboardmulticast
lossy network

Goal
design, evaluate multicast loss recovery approaches that
make efficient use of end-host, network resources scale to several thousand receivers spanning wide
area networks

Feedback Implosion
NAK implosion ? NAK suppression (using timers) NAK aggregation (by building hierarchy)
pkt ACK
sender sender sender
receiver receivers receivers
pkt
ACK
pkt
NAK
loss
problem: ACK implosion solution: use NAKs

sender
loss
original transmission
loss
pktlost
retransmission
unicast
multicast

Problem of Retransmission Scoping
if same channel for retransmissions, retransmissions go everywhere
how to shield receiver from loss recovery due to other receivers ?
sender
loss
original transmission
loss
retransmission

Loss Recovery Burden
when #receivers large, each pkt lost at some rcvr with high probability
sender retransmits almost all pkts several times
how to share burden of loss recovery ?
sender
loss losspkt 1 pkt 4
pkt 2pkt 3
loss
loss
retransmitspkts 1, 2, 3, 4

scoping retransmissions using multiple multicast channels
server-based local recovery performance benefits resource requirements
“active” repair services signaling for locating, invoking, revoking services
router support
Thesis Contributions

scoping retransmissions using multiple multicast channels
server-based local recovery performance benefits resource requirements
“active” repair services signaling for locating, invoking, revoking services
router support
summary and future directions
Overview

one channel for original transmissions, Aorig
additional channels for retransmissions, pkt k sent on Ak
on detecting loss of pkt k, receiver
joins Ak
recovers packet k leaves Ak
Scalable Reliable Multicast Using Multiple Multicast Channels
sender
loss
Aorig
loss
Ak
Kasera, Kurose, Towsley, ACM SIGMETRICS Conference ‘97

Issues
how much is performance improved ? receiver, sender processing network bandwidth
if (multicast channel IP multicast group), realistically only finite channels available !
overhead of join, leave operations ?
router support for multiple multicast channels ?

Analysis
rcvrs unicast NAKs to sender
infinite channels available
system model one sender, R receivers independent loss, probability p NAKs not lost
E[Y] = E[Yp] + pE[Yj] + pE[Yn]/(1-p) + p2E[Yt]/(1-p)
determined various proc times by instrumenting Linux kernel
Y = total per pkt rcv proc time
Yp = rcvd pkt proc time
Yj = join, leave proc time
Yn = NAK proc time
Yt = timer proc time
NAK processing timer processing join, leave processing
rcvd pkt processing

considerable reduction in rcvr processing costs by using infinite channels
example: when R = 1000, p = 0.05, processing cost reduces by approx. 65%
similar behavior observed for protocols that multicast NAKs for NAK suppression
Receiver Processing Cost Reduction
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0 200 400 600 800 1000Receivers
p = 0.01
p = 0.05
p = 0.10
p = 0.20
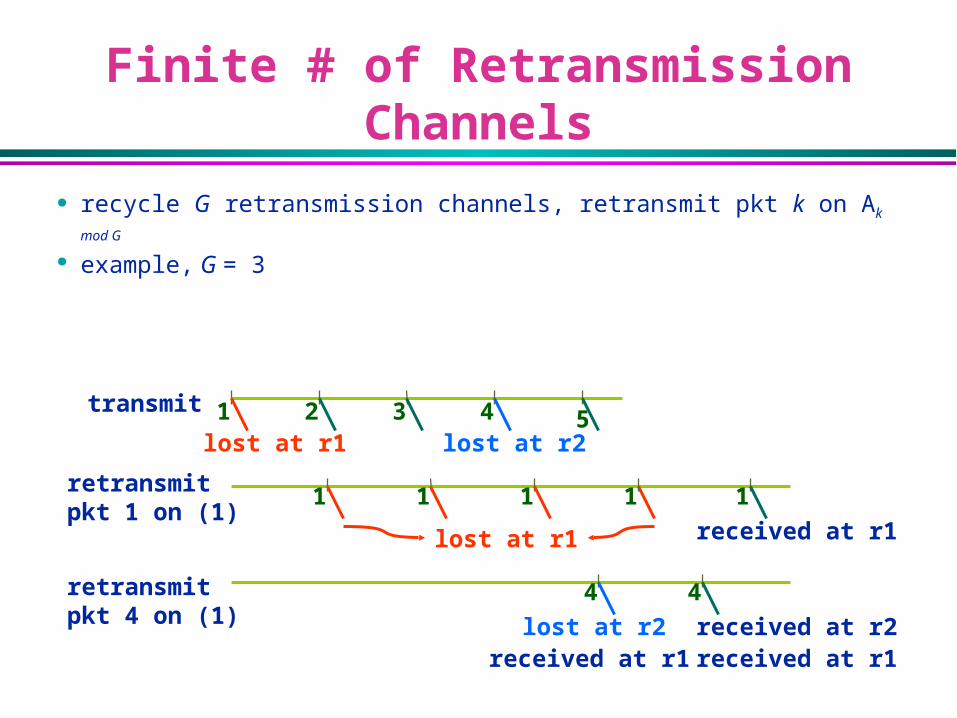
recycle G retransmission channels, retransmit pkt k on Ak mod G
example, G = 3
Finite # of Retransmission Channels
transmit
retransmitpkt 1 on (1)
1 2 3 4 5
retransmitpkt 4 on (1)
lost at r1 lost at r2
lost at r1
lost at r2
received at r1
received at r2received at r1 received at r1
1 1 1 1 1
4 4

find #unwanted pkts, U, at receiver due to using G channels only
model same as before transmit with interval retransmit with interval ’ (if pending NAK)
U depends upon G, p, R, /’ receiver processing cost, E[Y’] = E[Y] + E[U]E[Yp]
Finite # of Retransmission Channels
unwanted pkt processing

How many channels do we need ?
find minimum #channels s.t. increase in cost within 1%
small #channels for wide range of p, /’, R
#channels <= 10 when/’ >= 0.5
sensitive to low /’ /’
0
5
10
15
20
25
30
35
40
45
50
0 0.5 1 1.5 2 2.5 3
p=0.01
p=0.05
p=0.10
p=0.20
#Receivers = 1000

Summary (part 1)
use of multiple multicast channels reduces receiver processing
small to moderate #channels achieve almost perfect retransmission scoping
implementation using router support also saves network bandwidth
sender still bottleneck, no improvement in protocol performance

Local Recovery
server and/or other receivers aid in loss recovery
distribution of loss recovery burden
possible reduction in network bandwidth recovery latency
retransmission scoping
sender
loss
transmission
loss
local domains
server

scoping retransmissions using multiple multicast channels
server-based local recovery performance benefits resource requirements
“active” repair services signaling for locating, invoking, revoking services
router support
summary and future directions
Overview

repair servers co-located with routers at strategic locations
placement of application level repair service in routers
repair servers cache recent pkts
receivers, repair servers, recover lost pkts from upper level repair servers, sender
repairserver
Repair Server Based Local Recovery
sender
receivers
Kasera, Kurose, Towsley, IEEE INFOCOM ‘98

Issues
how much is performance improved over traditional local recovery approaches ?
SRM: dynamically elect receiver for every loss RMTP, LBRM: designated receiver, logger for
supplying repairs
where to place repair servers ?
what are repair server resource requirements ?

based on [YKT ‘97]
loss free backbone, sites
loss at source link, tails
temporally independent loss, probability p
sender
receivers
backbone
tail
site local domain
source link
System Model

based on [YKT ‘97]
loss free backbone, sites
loss at source link, tails
temporally independent loss, probability p
sender
receivers
backbone
tail
site local domain
source link
System Model
designated receiver

based on [YKT ‘97]
loss free backbone, sites
loss at source link, tails
temporally independent loss, probability p
sender
receivers
backbone
tail
site local domain
source link
System Model
repair server

metrics throughput = 1/max(sender-processing time, receiver-
processing time) bandwidth usage = total bytes transmitted over all links
per correct transmission
analysis: similar approach as in previous problem (optimistic bounds for SRM)
Performance Evaluation

repair server-based (RSB) compared to SRM: throughput upto 2.5 times, bandwidth reduction 60% DR-based (DRB): throughput upto 4 times, bandwidth reduction 35%
Performance Comparison
0
0.5
1
1.5
2
2.5
3
3.5
4
100 1000 10000 100000Tails
p = 0.05
p = 0.25
p = 0.05
p = 0.25
RSB/DRB
RSB/SRM
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
100 1000 10000 100000Tails
p = 0.05
p = 0.25
p = 0.05
p = 0.25
RSB/DRB
RSB/SRM

additional sender retransmission required if some domains without repair servers
place repair servers in high loss domains first
homogeneous loss: high % domains require repair server
Insufficient Repair Servers
20% tail loss in 20% domains, 1% tail loss in 80% domains
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
0 10 20 30 40 50 60 70 80 90 100% Domains with Repair Servers
#Domains = 100
#Domains = 1000

theoretically: infinite
realistically: allot finite buffers replace pkts when buffers full
if required, replaced pkts recovered upstream
size depends upon amount of upstream recovery pkt arrival process, buffer
holding time replacement policy
Repair Server Buffer Requirements (per session)
example: when p = 0.05, 15 buffers ensure almost perfect local recovery
0
0.5
1
1.5
2
2.5
3
3.5
4
4.5
0 5 10 15 20 25 30 35 40Buffer Size
p = 0.01
p = 0.05
p = 0.10
p = 0.20
Mean Arrival Rate = 128pkts/sec
Retransmission Interval = 40ms
Replacement Policy - FIFO
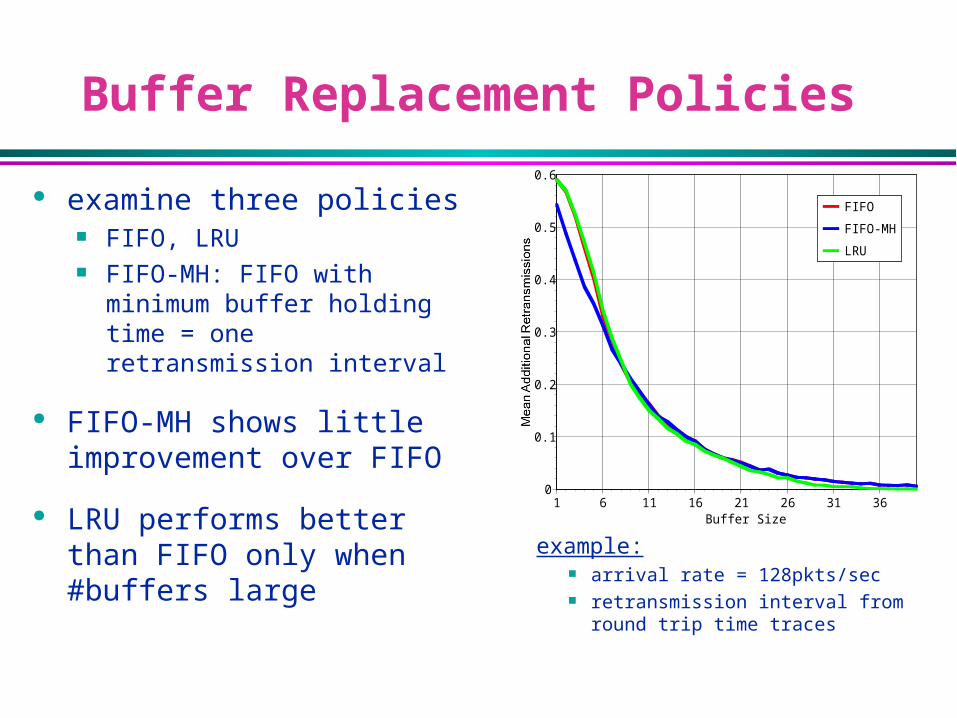
examine three policies FIFO, LRU FIFO-MH: FIFO with
minimum buffer holding time = one retransmission interval
FIFO-MH shows little improvement over FIFO
LRU performs better than FIFO only when #buffers large
Buffer Replacement Policies
example: arrival rate = 128pkts/sec retransmission interval from
round trip time traces
0
0.1
0.2
0.3
0.4
0.5
0.6
1 6 11 16 21 26 31 36Buffer Size
FIFO
FIFO-MH
LRU

repair server-based approach exhibits superior performance over traditional approaches
repair server placement - above loss, higher loss domains first
buffer requirement several 10s of buffers (per session) simple FIFO replacement policy sufficient
how to make repair server approach dynamic ?
Summary (part 2)

scoping retransmissions using multiple multicast channels
server-based local recovery performance benefits resource requirements
“active” repair services signaling for locating, invoking, revoking services
router support
summary and future directions
Overview
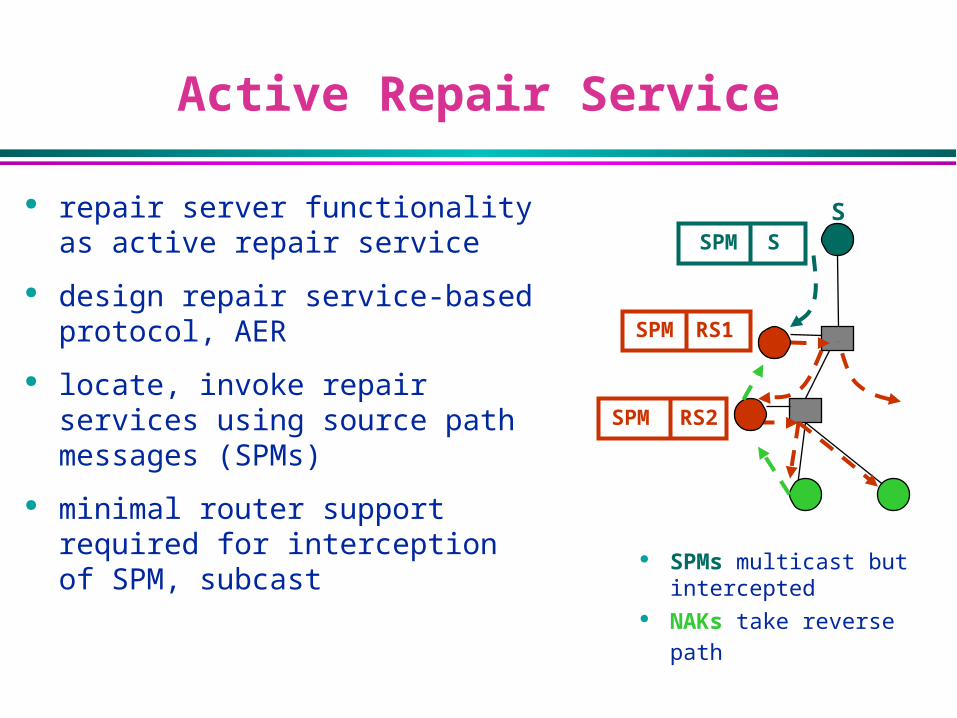
Active Repair Service
repair server functionality as active repair service
design repair service-based protocol, AER
locate, invoke repair services using source path messages (SPMs)
minimal router support required for interception of SPM, subcast
S
SPM RS1
SPM RS2
SPM S
SPMs multicast but intercepted
NAKs take reverse path

scoping retransmissions using multiple multicast channels
server-based local recovery performance benefits resource requirements
“active” repair services signaling for locating, invoking, revoking services
router support
Thesis Contributions

model cost of additional network resources
buffer requirements multiple sessions other applications (e.g., web caching)
composable multicast services
other multicast research revisit IP multicast service model congestion control pricing
Future Directions

identify performance enhancing services, examples
feedback aggregation selective forwarding repair, rate conversion,
log services
invoke/revoke services based on
application requirements network conditions
Composable Multicast Services(Work in Progress)
senderprotocol
feedbackaggregation
rcvrprotocol
rcvrprotocol
rcvrprotocol
rcvrprotocol
issues: implementing composability signaling mechanism (SPM++) measurement-based infrastructure
rate conversion