scalable fault tolerance: xen virtualization for pgas models on high-performance networks
DESCRIPTION
Daniele Scarpazza, Oreste Villa, Fabrizio Petrini, Jarek Nieplocha, Vinod Tipparaju, Manoj Krishnan Pacific Northwest National Laboratory Radu Teodoresci, Jun Nakanom Josep Torrellas University of Illinois Duncan Roweth Quadrics In collaboration with Patrick Mullaney, Novell - PowerPoint PPT PresentationTRANSCRIPT

FastOS, Santa Clara CA, June 18 2007
Scalable Fault Tolerance: Scalable Fault Tolerance: Xen Virtualization for PGAs Models Xen Virtualization for PGAs Models
on High-Performance Networkson High-Performance Networks
Daniele Scarpazza, Oreste Villa, Fabrizio Petrini, Jarek Nieplocha, Vinod Tipparaju, Manoj Krishnan
Pacific Northwest National Laboratory
Radu Teodoresci, Jun Nakanom Josep Torrellas
University of Illinois
Duncan Roweth
Quadrics
In collaboration with
Patrick Mullaney, Novell
Wayne Augsburger, Mellanox

FastOS, Santa Clara CA, June 18 2007
Project MotivationProject Motivation
• Component count in high-end systems has been growing
• How do we utilize large (103-5 processor) systems for solving complex science problems?
• Fundamental problems– Scalability to massive processor
counts– Application performance on single
processor given the increasingly complex memory hierarchy
– Hardware and software failures1000 10000 100000
System Size (number of nodes)
0
20
40
60
80
100
120
140
160
MT
BF
(h
ours
)
10,000100,0001,000,000
TeraFLOPS
PetaFLOPS
MTBF as a function of system size

FastOS, Santa Clara CA, June 18 2007
Multiple FT TechniquesMultiple FT Techniques
Application drivers Multidisciplinary, multiresolution, and multiscale nature of scientific problems drive the demand
for high end systems
Applications place increasingly differing demands on the system resources: disk, network, memory, and CPU
Some of them have natural fault resiliency and require very little support
System drivers Different I/O configurations, programmable or simple/commodity NICs,
proprietary/custom/commodity operating systems
Tradeoffs between acceptable rates of failure and cost Cost effectiveness is the main constraint in HPC
Therefore, it is not cost-effective or practical to rely on a single fault tolerance approach for all applications and systems

FastOS, Santa Clara CA, June 18 2007
Key Elements of SFTKey Elements of SFT
Virtualization of High Performance Network Interfaces and Protocols
Virtualization of High Performance Network Interfaces and Protocols
ReVive and ReVive I/O provide efficient CR capability for shared memory servers (cluster node):
ReVive and ReVive I/O provide efficient CR capability for shared memory servers (cluster node):
IBA/QsNET
ReVive (I/O)
Buffered Coscheduling provides global coordinationof system activities, communication, CR
Buffered Coscheduling provides global coordinationof system activities, communication, CR
BCS
Fault-Tolerance module for ARMCI runtime system Fault-Tolerance module for ARMCI runtime system
FT ARMCI
Hypervisor to enable virtualization of compute nodeenvironment including OS (external dependency)
Hypervisor to enable virtualization of compute nodeenvironment including OS (external dependency)
XEN
Fo
cus
of
the
talk

FastOS, Santa Clara CA, June 18 2007
Transparent System-level CR of PGA Transparent System-level CR of PGA Applications on Infiniband and QsNETApplications on Infiniband and QsNET
We explored a new approach to cluster fault-tolerance by integrating Xen with the latest generations of Infiniband and Quadrics high-performance networks
Focus on Partitioned Global Address Space (PGAs) programming models Most of existing work focused on MPI
Design Goals low-overhead and transparent migration

FastOS, Santa Clara CA, June 18 2007
Main ContributionsMain Contributions
Integration of Xen and Infiniband Enhanced Xen’s kernel modules to fully support user-
level Infiniband protocols and IP over IB with minimal overhead
Support for Partitioned Global Address space programming models (PGAs) Emphasis on ARMCI
Automatic Detection of a Global Recovery Line and Coordinated Migration Perform a live migration without any change to user
applications
Experimental evaluation

FastOS, Santa Clara CA, June 18 2007
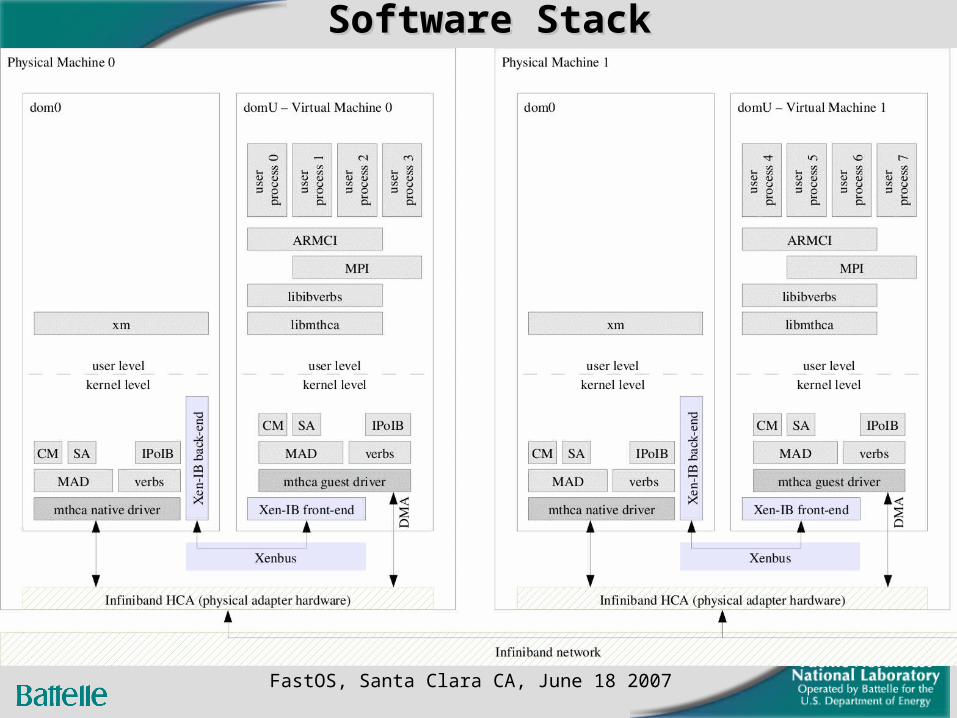
Xen HypervisorXen Hypervisor
On each machine Xen allows the creation of a privileged virtual machine (Dom0) and and one or more non-privileged VMs (DomUs)
Xen provides the ability to pause, un-pause, checkpoint and resume DomUs
Xen employs para-virtualization Non-privileged domains run a modified operating
system featuring guest device drivers Their requests are forwarded to the native device driver
in Dom0 using a split driver model

FastOS, Santa Clara CA, June 18 2007
Infiniband Device DriverInfiniband Device Driver
The driver is implemented in two sections A paravirtualized section for slow path control operations (e.g., q-
pair creation) and A direct access section for fast path data operations
(transmit/receive)
Based on Ohio State/IBM implementationDriver was extended to support additional CPU architectures and Infiniband adapters Added proxy layer to allow Subnet and Connection management
from guest VMs Propagate suspend/resume to the applications not only kernel
modules Several stability improvements
FastOS, Santa Clara CA, June 18 2007
Software StackSoftware Stack
FastOS, Santa Clara CA, June 18 2007
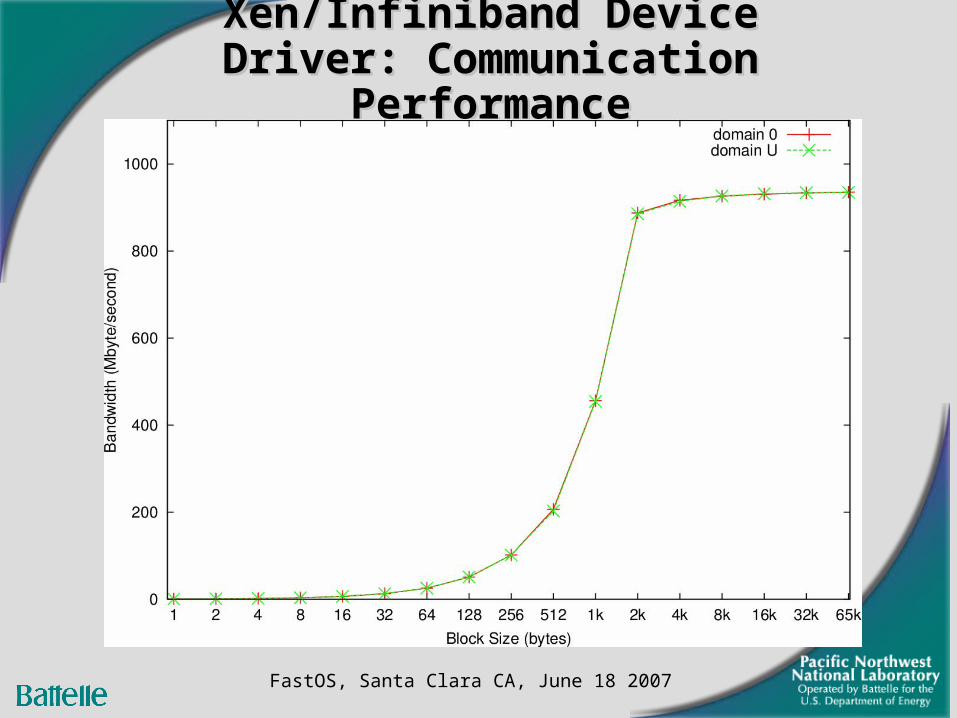
Xen/Infiniband Device Driver: Xen/Infiniband Device Driver: Communication PerformanceCommunication Performance

FastOS, Santa Clara CA, June 18 2007
Xen/Infiniband Device Driver: Xen/Infiniband Device Driver: Communication PerformanceCommunication Performance

FastOS, Santa Clara CA, June 18 2007
Parallel Programming ModelsParallel Programming Models
Single Threaded Data Parallel, e.g. HPF
Multiple Processes Partitioned-Local Data Access
MPI
Uniform-Global-Shared Data Access OpenMP
Partitioned-Global-Shared Data Access Co-Array Fortran
Uniform-Global-Shared + Partitioned Data Access UPC, Global Arrays, X10

FastOS, Santa Clara CA, June 18 2007
Fault Tolerance In PGAs ModelsFault Tolerance In PGAs Models
Implementation considerations 1-sided communication, perhaps some 2-sided and collectives Special considerations in implementation of global recovery line Memory operations need to be synchronized for
checkpoint/restart
Memory is a combination of local and global (globally visible) Global memory could be shared from OS view Pinned and registered with network adapter
P
G
Network
SMP node 0
SMP node nP
L
G
L
P
G
P
L
G
L

FastOS, Santa Clara CA, June 18 2007
Xen-enabled ARMCIXen-enabled ARMCI
Runtime system - one-sided communication Global Arrays, Rice Co-Array Fortran, GPSHEM, IBM X10 port
under way
Portable high performance remote memory copy interface
Asynchronous remote memory access (RMA)
Fast Collective Operations
Zero-copy protocols, explicit NIC support
“Pure” non-blocking communication - 99.9% overlap
Data Locality Shared-memory within SMP node and RMA across
nodes
High performance delivered on wide range of platforms
Multi-protocol and multi-method implementation
message passing2-sided model
P1P0receive send
BA
P1P0
put
remote memory access (RMA)1-sided model
A B
P1P0
A=B
shared memory load/stores0-sided model
A B
Examples of data transfers optimized in ARMCI
Fundamental CommunicationModels in HPC

FastOS, Santa Clara CA, June 18 2007
Global Recovery Lines (GRLs)Global Recovery Lines (GRLs)
A GRL is required before each checkpoint / migration
A GRL is required for Infiniband networks because IBA does not allow location-independent layer 2 and 3 addresses IBA hardware maintains stateful connections not accessible by
software
The protocol that enforces a GRL has A drain phase, which completes any ongoing communication Followed by a global silence, where it is possible to perform node
migration And a resume phase, where the processing nodes acquire
knowledge of the new network topology

FastOS, Santa Clara CA, June 18 2007
GRL and Resource ManagementGRL and Resource Management

FastOS, Santa Clara CA, June 18 2007
Experimental EvaluationExperimental Evaluation
Our experimental testbed is a cluster of 8 Dell PowerEdge 1950
Each node has two dual-core Intel Xeon Woodcrest running @ 3.0 GHz, with 8 Gbytes of memory
The cluster is interconnected by a Mellanox Infinihost III 4X HCA adapters
Suse Linux Enterprise Server 10.0
Xen 3.02

FastOS, Santa Clara CA, June 18 2007
Timing of a GRLTiming of a GRL
FastOS, Santa Clara CA, June 18 2007
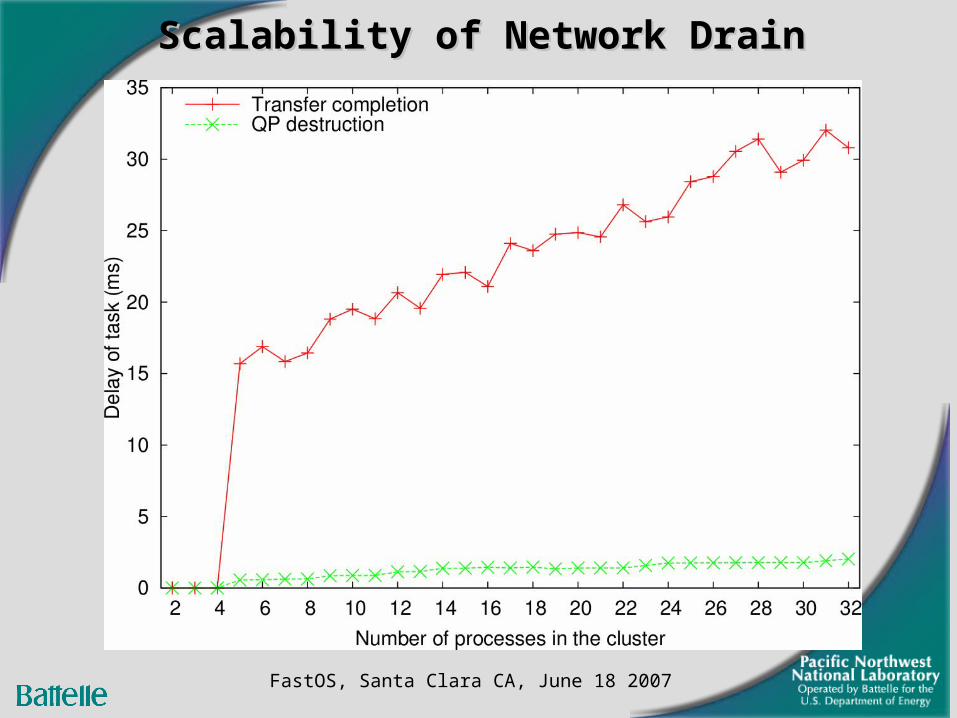
Scalability of Network DrainScalability of Network Drain

FastOS, Santa Clara CA, June 18 2007
Scalability of Network ResumeScalability of Network Resume
FastOS, Santa Clara CA, June 18 2007
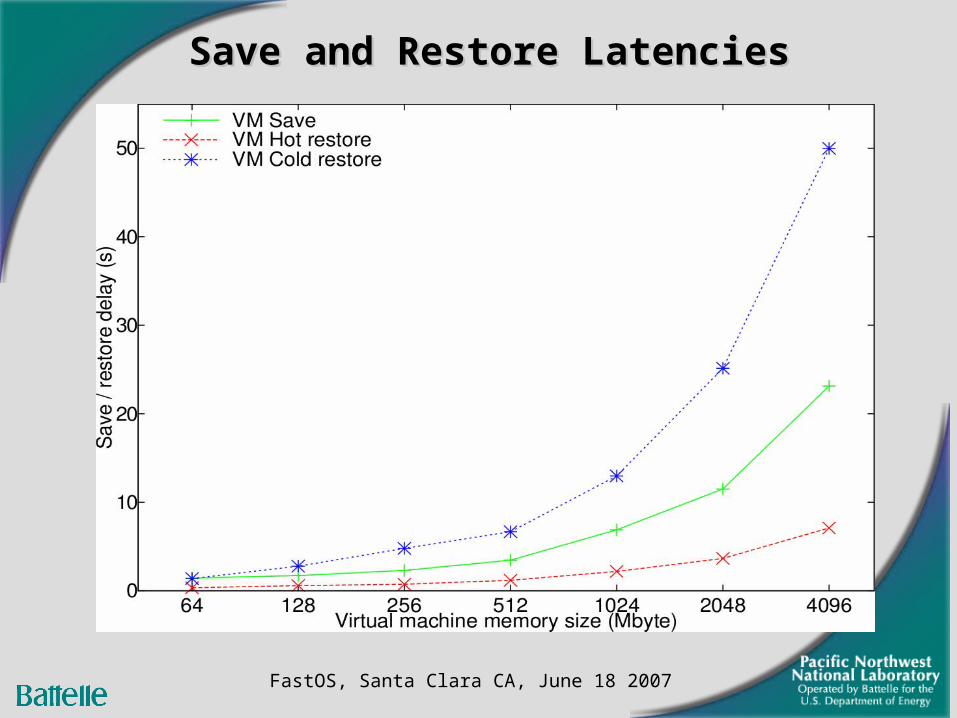
Save and Restore LatenciesSave and Restore Latencies
FastOS, Santa Clara CA, June 18 2007
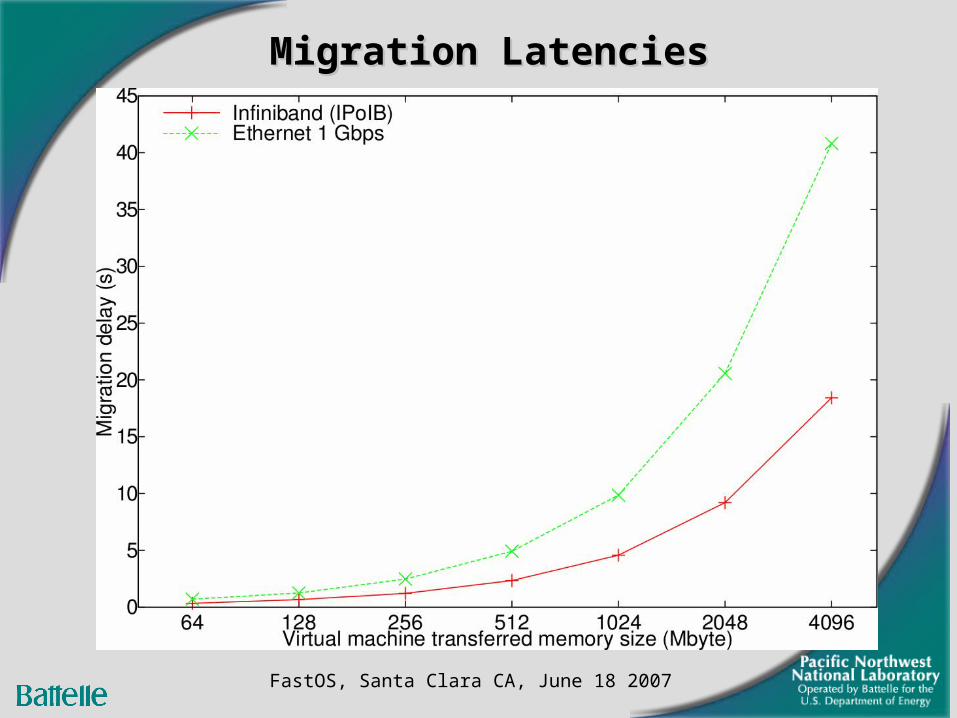
Migration LatenciesMigration Latencies

FastOS, Santa Clara CA, June 18 2007
ConclusionConclusion
We have presented a novel software infrastructure that allows completely transparent checkpoint/restart
We have implemented a device driver that enhances the existing Xen/Infiniband drivers
Support for PGAs programming models
Minimal overhead, 10s of milliseconds Most of the time is spent saving/restoring the node
image