roblema - universidad autónoma de madrid · como en la estimación de la media, seguimos 4 pasos:...
TRANSCRIPT

4-1
Introducción a la Regresión Lineal (SW Capítulo 4)
Problema: Nº de alumnos por clase y resultados escolares Política educativa: ¿Qué efecto tiene en dichos resultados reducir el nº de alumnos en 1 estudiante por clase? ¿y en 8? • ¿Cúal es la medida correcta de los resultados escolares? � Satisfacción de los padres � Desarrollo personal del estudiante � Bienestar futuro en la edad adulta � Ganancias futuras en la edad adulta � Resultados en varios tests estándar

4-2
¿Qué nos dicen los datos sobre el nº de alumnos por clase y las puntuaciones en los tests (Test Scores)?
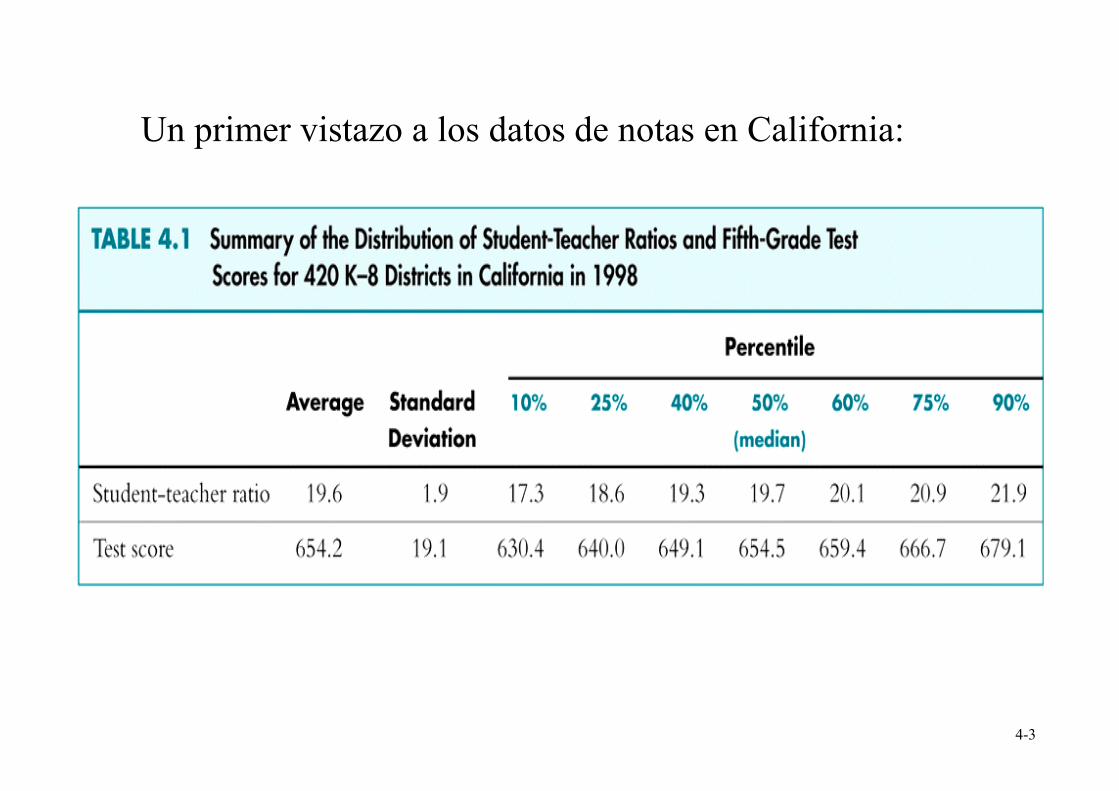
Datos de puntuaciones en California en 1998
Escuelas primarias en distintos distritos (n = 420) Variables:
•
Puntuaciones en un test de 5º curso que combina lectura y matemáticas: nota media en cada distrito
• Ratio estudiante-profesor (STR: Student-teacher ratio):
nº de estudiantes en el distrito dividido por el nº de profesores a tiempo completo
4-3
Un primer vistazo a los datos de notas en California:
4-4
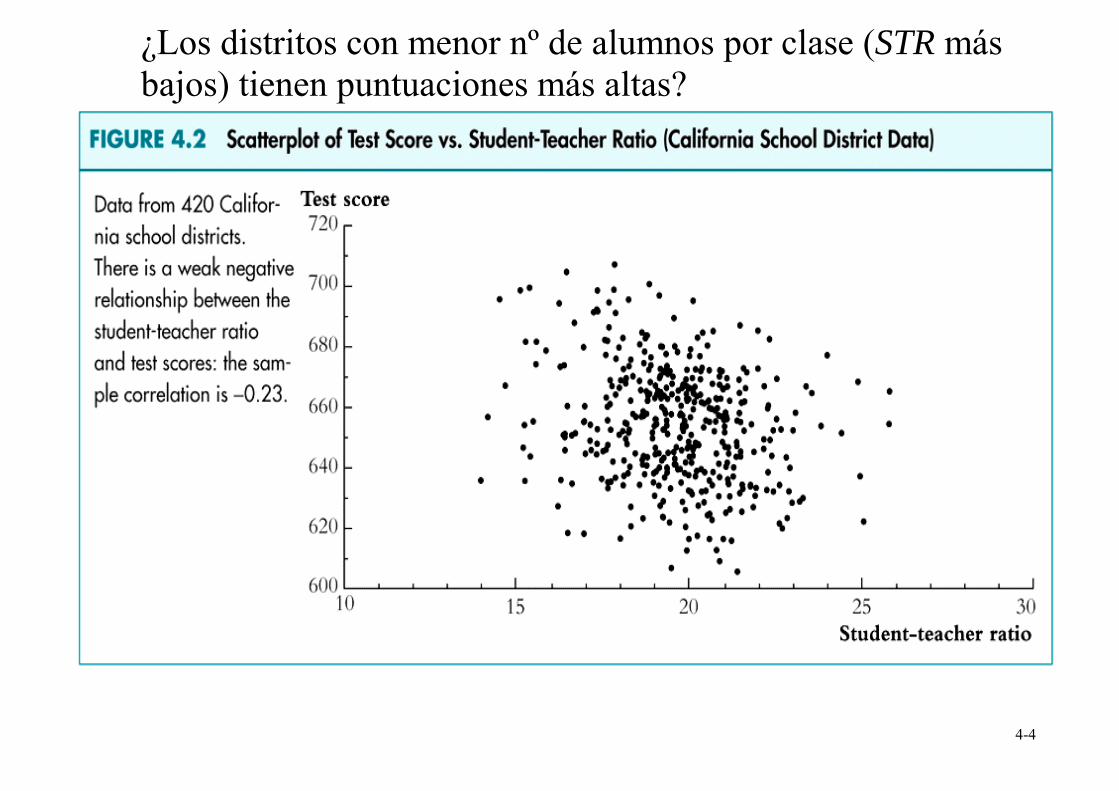
¿Los distritos con menor nº de alumnos por clase (STR más bajos) tienen puntuaciones más altas?

4-5
Pregunta de interés (policy question) sobre la relación entre el nº de alumnos por clase y las calificaciones:
•
¿Qué efecto tiene sobre las calificaciones reducir el ratio STR en un estudiante por clase?
• Objeto de interés:
• Esto es la pendiente de la recta que relaciona las notas con el ratio estudiante/profesor STR.
STRNotas
∆∆

4-6
Esto sugiere que nos gustaría trazar una recta sobre la nube de puntos de Notas vs. STR,... pero ¿cómo?

4-7
Un poco de notación y terminología
(Secciones 4.1 y 4.2) La recta de regresión poblacional:
Notas = β0 + β1 STR β1 = pendiente de la recta de regresión poblacional
STRNotas
∆∆=
= cambio en las notas ante un cambio unitario en STR
•
¿Por qué son β0 y β1 parámetros “poblacionales”? •
Nos gustaría conocer el valor poblacional de β1 •
No conocemos β1, debemos estimarlo utilizando datos

4-8
•
¿Cómo podemos estimar β0 y β1 a partir de los datos?
Recordemos: Y es el estimador de mínimos cuadrados de µY: Y es la solución del problema:
2
1
min ( )n
m ii
Y m=
−∑
Análogamente, nos centraremos en el estimador de mínimos cuadrados (MCO: mínimos cuadrados ordinarios) de los parámetros desconocidos ββββ0 y ββββ1.
Dicho estimador resuelve el siguiente problema:
0 1
2, 0 1
1
min [ ( )]n
b b i ii
Y b b X=
− +∑

4-9
El estimador MCO resuelve el problema:
0 1
2, 0 1
1
min [ ( )]n
b b i ii
Y b b X=
− +∑
•
El estimador MCO minimiza el promedio del cuadrado de la diferencia entre los valores observados Yi y la predicción (valor ajustado) basada en la recta estimada.
•
Este problema de minimización puede resolverse utilizando el cálculo elemental (ver Apéndice 4.2)
•
El resultado de este problema es el estimador MCO de ββββ0 y ββββ1.

4-10
¿Por qué utilizar MCO en lugar de algún otro estimador?
•
MCO es una generalización de la media muestral: si la “recta” que buscamos es un valor constante (sin variable X), el estimador MCO es simplemente la media muestral de Y1,…Yn (Y ).
•
Al igual que Y , el estimador MCO tiene algunas “buenas” propiedades: bajo ciertas condiciones, es insesgado (esto es, E( 1β ) = β1), y su distribución muestral tiene menor varianza que la de otros posibles estimadores de β1
•
Y no menos importante, este estimador es el que todo el mundo utiliza, el “lenguaje” común de la regresión lineal.

4-11

4-12
Aplicación a los datos de California: Puntuaciones – Nº de alumnos por clase
Pendiente estimada = 1β = – 2.28 Término constante estimado = 0β = 698.9 Regresión lineal estimada: Notas = 698.9 – 2.28×STR

4-13
Interpretación del término constante y la pendiente estimados
Notas = 698.9 – 2.28×STR • Los distritos con un estudiante más por clase tienen en media
puntuaciones 2.28 puntos más bajas.
• Esto es: 28.2−=∆
∆STR
Notas
• El término constante (tomado literalmente) significa que, de acuerdo a la recta estimada, los distritos con 0 estudiantes por profesor tendrían una puntuación (estimada) de 698.9.
• Esta interpretación del término constante no tiene sentido en esta aplicación - extrapola la recta fuera del rango de los datos - no tiene significado económico.

4-14
Valores ajustados (estimados) y residuos:
Uno de los distritos en los datos es Antelope, CA, para el cual STR = 19.33 y Notas = 657.8 valor estimado: ˆ
AntelopeY = 698.9 – 2.28×19.33 = 654.8
residuo: ˆAntelopeu = 657.8 – 654.8 = 3.0

4-15
Regresión MCO: STATA output
regress testscr str, robust
Regression with robust standard errors Number of obs = 420F( 1, 418) = 19.26Prob > F = 0.0000R-squared = 0.0512Root MSE = 18.581
-------------------------------------------------------------------------| Robust
testscr | Coef. Std. Err. t P>|t| [95% Conf. Interval]--------+----------------------------------------------------------------
str | -2.279808 .5194892 -4.39 0.000 -3.300945 -1.258671_cons | 698.933 10.36436 67.44 0.000 678.5602 719.3057
-------------------------------------------------------------------------
Notas = 698.9 – 2.28×STR (discutiremos más en detalle estos resultados)

4-16
La recta de regresión MCO es una estimación calculada usando nuestra muestra de datos; con otra muestra de datos habríamos obtenido un valor diferente de 1β . ¿Cómo podemos:
•
cuantificar la variabilidad muestral asociada a 1β ? •
utilizar 1β para contrastar hipótesis como β1 = 0? •
construir un intervalo de confianza para β1? Como en la estimación de la media, seguimos 4 pasos:
1. El marco probabilístico en la regresión lineal 2. Estimación 3. Contrastes de hipótesis 4. Intervalos de confianza

4-17
1. El marco probabilístico en la regresión lineal Población población de interés (ej: todos los distritos escolares) Variables aleatorias: Y, X Ej: (Notas, STR) Distribución conjunta de (Y,X) El punto clave es que suponemos que existe en la población una relación lineal que relaciona X e Y; esta relación lineal es la “regresión lineal poblacional”

4-18
El modelo de Regresión Lineal Poblacional (Sección 4.3)
Yi = β0 + β1Xi + ui, i = 1,…, n
•
X es la variable independiente ó regresor • Y es la variable dependiente • β0 = término independiente • β1 = pendiente •
ui = “término de error” • El término de error consiste en factores omitidos o
posibles errores de medida en Y. En general, estos factores omitidos son otros factores que afectan a Y, distintos de la variable X.

4-19
Ej.: La recta de regresión poblacional y el término de error
¿Cuáles son algunos de los factores omitidos en este ejemplo?

4-20
Datos y muestreo: Los objetos poblacionales (“parámetros”) β0 y β1 son desconocidos; por tanto, para hacer inferencia sobre estos parámetros debemos recoger datos relevantes.
Muestreo aleatorio simple: Elegir aleatoriamente n elementos de la población de interés y observar (registrar) X e Y para cada una de ellos.
El muestreo aleatorio simple implica que {(Xi, Yi)}, i = 1,…, n}, son independientes e idénticamente distribuidos (i.i.d.). (Nota: (Xi, Yi) se distribuyen independientemente de (Xj, Yj) para observaciones i y j diferentes).

4-21
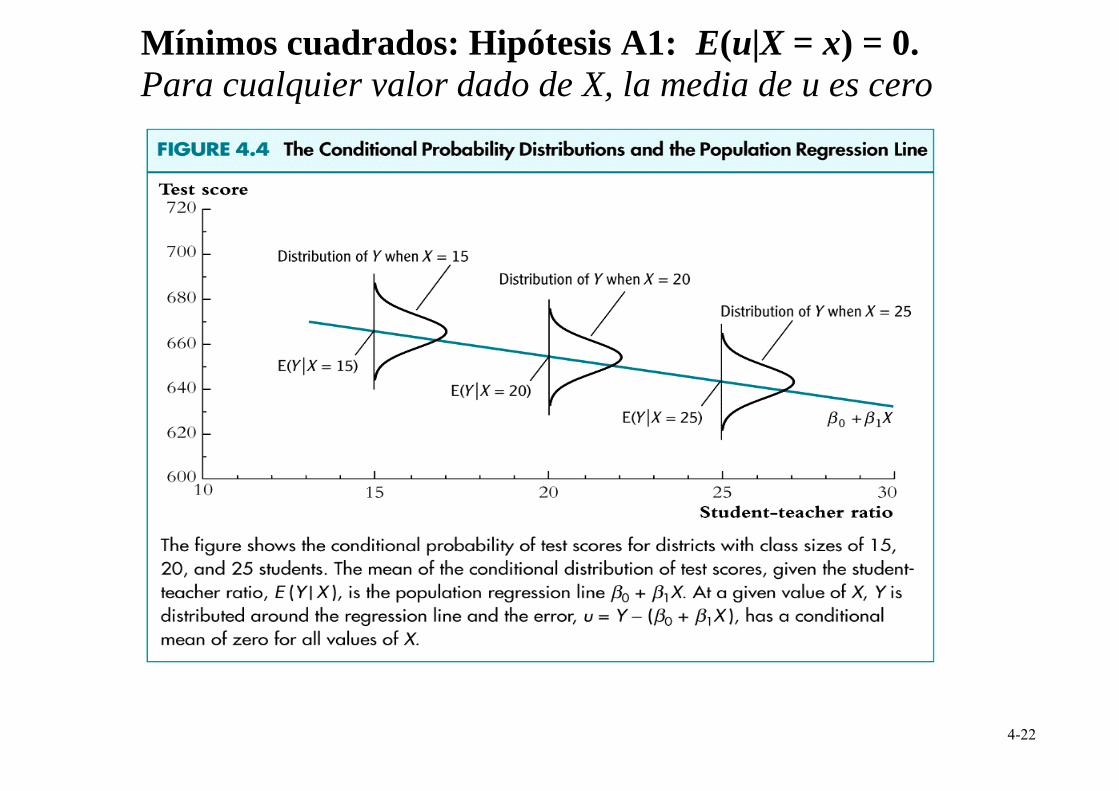
Nuestra tarea: caracterizar la distribución muestral del estimador MCO. Para hacer esto, necesitamos tres hipótesis:
Las hipótesis de Mínimos Cuadrados A1. La distribución condicional de u dado X tiene media 0,
esto es, E(u|X = x) = 0.
A2. (Xi,Yi), i =1,…,n, son i.i.d.
A3. X y u tienen cuartos momentos, esto es:
E(X4) < ∞ y E(u4) < ∞.
Discutiremos cada una de estas hipótesis.
4-22
Mínimos cuadrados: Hipótesis A1: E(u|X = x) = 0. Para cualquier valor dado de X, la media de u es cero

4-23
Ejemplo: Hipótesis A1 en el ejemplo del nº de alumnos Notasi = β0 + β1STRi + ui, ui = otros factores
“Otros factores:”
•
implicación de los padres • otras oportunidades de aprendizaje (clases extra,..) •
ambiente familiar que fomente la lectura •
renta familiar como proxy útil para muchos de estos factores
Por tanto, E(u|X=x) = 0 implica que E(Family Income|STR) = constante (lo que implica que la renta familiar y STR están incorrelados). Esta hipótesis no es inocua!. Volveremos a ella a menudo.

4-24
Mínimos cuadrados: Hipótesis A2:
(Xi,Yi), i = 1,…,n son i.i.d. Esto ocurre automáticamente si el elemento (individuo, distrito) proviene de un muestreo aleatorio simple: el elemento es seleccionado, y entonces X e Y son observados y registrados. Un caso en el que no encontraremos muestras i.i.d es cuando los datos son recogidos a lo largo del tiempo (“series temporales”); esto introduce complicaciones adicionales.

4-25
Mínimos cuadrados: Hipótesis A3:
E(X4) < ∞∞∞∞ y E(u4) < ∞∞∞∞ Dado que Yi = β0 + β1Xi + ui, A3 puede escribirse de forma equivalente como, E(X4) < ∞ y E(Y4) < ∞. En general, A3 es una hipótesis plausible. Un dominio finito de los datos implica cuartos momentos finitos. (Las puntuaciones estandarizadas satisfacen esta hipótesis; STR, renta familiar, etc. también).

4-26
1. El marco probabilístico en la regresión lineal 2. Estimación: la distribución muestral de 1β
(Sección 4.4) 3. Contrastes de hipótesis 4. Intervalos de confianza Como ocurre con Y , 1β tiene una distribución muestral.
•
¿Qué es E( 1β )? (es donde está centrada) •
¿Qué es var( 1β )? (medida de la variabilidad muestral) •
¿Qué es la distribución muestral en muestras finitas? •
¿Qué es la distribución muestral en muestras grandes?

4-27
La distribución muestral de 1β : un poco de álgebra: Yi = β0 + β1Xi + ui Y = β0 + β1 X + u
entonces: Yi – Y = β1(Xi – X ) + (ui – u ) Por tanto:
1β = 1
2
1
( )( )
( )
n
i ii
n
ii
X X Y Y
X X
=
=
− −
−
∑
∑
= 1
1
2
1
( )[ ( ) ( )]
( )
n
i i ii
n
ii
X X X X u u
X X
β=
=
− − + −
−
∑
∑

4-28
1β = 1
1
2
1
( )[ ( ) ( )]
( )
n
i i ii
n
ii
X X X X u u
X X
β=
=
− − + −
−
∑
∑
= 1 11
2 2
1 1
( )( ) ( )( )
( ) ( )
n n
i i i ii i
n n
i ii i
X X X X X X u u
X X X Xβ = =
= =
− − − −+
− −
∑ ∑
∑ ∑
por tanto,
1β – β1 = 1
2
1
( )( )
( )
n
i ii
n
ii
X X u u
X X
=
=
− −
−
∑
∑

4-29
Podemos simplificar la fórmula teniendo en cuenta que:
1
( )( )n
i ii
X X u u=
− −∑ = 1
( )n
i ii
X X u=
−∑ – 1
( )n
ii
X X u=
− ∑
= 1
( )n
i ii
X X u=
−∑ .
Por tanto:
1β – β1 = 1
2
1
( )
( )
n
i ii
n
ii
X X u
X X
=
=
−
−
∑
∑ = 1
2
1
1
n
ii
X
vnn s
n
=
−
∑
donde vi = (Xi – X )ui.

4-30
1β – β1 = 1
2
1
1
n
ii
X
vnn s
n
=
−
∑ , donde vi = (Xi – X )ui
Ahora calculamos la media y la varianza de 1β :
E( 1β – β1) = 2
1
1 1n
i Xi
nE v sn n=
−
∑
= 21
11
ni
i X
vn En n s=
−
∑
= 21
11
ni
i X
vn En n s=
−
∑

4-31
Ahora E(vi/ 2Xs ) = E[(Xi – X )ui/ 2
Xs ] = 0 porque E(ui|Xi=x) = 0 (ver detalles en Apéndice 4.3)
Por tanto, E( 1β – β1) = 21
11
ni
i X
vn En n s=
−
∑ = 0
con lo que: E( 1β ) = β1 Es decir, 1β es un estimador insesgado de ββββ1.

4-32
Cálculo de la varianza de 1β :
1β – β1 = 1
2
1
1
n
ii
X
vnn s
n
=
−
∑
Este cálculo se simplifica suponiendo que n es grande (por tanto, 2
Xs puede reemplazarse por 2Xσ ); el resultado es,
var( 1β ) = 2
var( )
X
vnσ
(Para más detalles, ver Apéndice. 4.3.)

4-33
La distribución muestral exacta es complicada, pero cuando el tamaño muestral es grande tenemos buenas aproximaciones, que además son bastante sencillas:
(1) Puesto que var( 1β ) ∝ 1/n y E( 1β ) = β1, 1β p
→ β1 (2) Cuando n es grande, la distribución muestral de 1β se
aproxima bien por una distribución normal (TCL: Teorema Central del Límite)

4-34
1β – β1 = 1
2
1
1
n
ii
X
vnn s
n
=
−
∑
Cuando n es grande: •
vi = (Xi – X )ui ≅ (Xi – µX)ui, que es i.i.d. (¿por qué?) y tiene dos momentos, esto es, var(vi) < ∞ (¿por qué?). Por
tanto, 1
1 n
ii
vn =∑ se distribuye N(0,var(v)/n) cuando n es
grande •
2Xs es aproximadamente igual a 2
Xσ cuando n es grande
•
1nn− = 1 – 1
n ≅ 1 cuando n es grande
Teniendo todo esto en cuenta:

4-35
Aproximación asintótica (n grande) de la distribución de 1β :
1β – β1 = 1
2
1
1
n
ii
X
vnn s
n
=
−
∑ ≅ 1
2
1 n
ii
X
vn
σ=∑
,
que se distribuye aproximadamente N(0,2
2 2( )v
Xnσσ
).
Puesto que vi = (Xi – X )ui, podemos escribir esto como:
1β se distribuye aproximadamente N(β1, 4
var[( ) ]i x i
X
X un
µσ− )

4-36
Recordemos brevemente la distribución muestral de Y : Para (Y1,…,Yn) i.i.d. con 0 < 2
Yσ < ∞, •
La distribución exacta (muestras finitas) de Y tiene media µY (“Y es un estimador insesgado de µY”) y varianza 2
Yσ /n •
Excepto su media y su varianza, la distribución exacta de Y es complicada y depende de la distribución de Y
• Y p
→ µY (ley de los grandes números)
•
( )var( )
Y E YY
− se distribuye aproximadamente N(0,1) (TCL)

4-37
Conclusiones paralelas para el estimador MCO de 1β : Bajo las tres hipótesis de Mínimos Cuadrados,
• La distribución muestral exacta (muestras finitas) de 1β tiene media β1 (“ 1β es un estimador insesgado de β1”), y var( 1β ) es inversamente proporcional a n.
•
Excepto su media y su varianza, la distribución exacta de
1β es complicada y depende de la distribución de (X,u)
• 1β p
→ β1 (ley de los grandes números)
• 1 1
1
ˆ ˆ( )ˆvar( )
Eβ ββ
− se distribuye aproximadamente N(0,1) (CLT)

4-38

4-39
1. El marco probabilístico en la regresión lineal 2. Estimación 3. Contrastes de hipótesis (Sección 4.5) 4. Intervalos de confianza
Suponga que alguien escéptico sugiere que reducir el número de estudiantes por clase no tiene efecto en el aprendizaje, o más específicamente, en las calificaciones. Esta persona escéptica, por tanto, defiende esta hipótesis:
H0: β1 = 0
Queremos contrastar esta hipótesis usando los datos, alcanzar algún tipo de conclusión acerca de si es correcta o incorrecta.

4-40
Hipótesis nula e hipótesis alternativa de doble cola:
H0: β1 = 0 vs. H1: β1 ≠ 0 o, de forma más general:
H0: β1 = β1,0 vs. H1: β1 ≠ β1,0 donde β1,0 es el valor del parámetro β1 bajo la hipótesis nula. Hipótesis nula y alternativa de una sola cola:
H0: β1 = β1,0 vs. H1: β1 < β1,0 En economía, casi siempre es posible encontrar problemas en los que el efecto de una variable podría ir en cualquier dirección, por lo que es habitual centrarse en alternativas bilaterales.

4-41
Recordemos que el contraste de la media poblacional basado en Y :
t = ,0
/Y
Y
Ys n
µ−
rechaza la hipótesis nula si |t| >1.96.
donde el denominador es la raíz cuadrada de un estimador de la varianza del estimador.

4-42
Si lo aplicamos a una hipótesis sobre β1:
t = estimador - valor hipotéticoerror estándar del estimador
es decir
t = 1 1,0
1
ˆˆ( )SE
β ββ
−
en donde β1,0 es el valor hipotético de β1 bajo la hipótesis nula (por ejemplo, si es cero, entonces, β1,0 = 0.) ¿Qué es SE( 1β )?
SE( 1β ) = la raíz cuadrada de un estimador de la varianza de la distribución muestral de 1β

4-43
Recordemos la expresión de la varianza de 1β (n grande):
var( 1β ) = 2 2
var[( ) ]( )
i x i
X
X un
µσ
− = 2
4v
Xnσσ
donde vi = (Xi – xµ )ui. El estimador de la varianza de 1β :
1
2ˆˆ
βσ = 2
2 2
1 estimador de (estimador de )
v
Xnσ
σ×
=
2 2
12
2
1
1 ˆ( )1 2
1 ( )
n
i ii
n
ii
X X un
nX X
n
=
=
−−× −
∑
∑
.

4-44
1
2ˆˆ
βσ =
2 2
12
2
1
1 ˆ( )1 2
1 ( )
n
i ii
n
ii
X X un
nX X
n
=
=
−−× −
∑
∑
.
De acuerdo, esta fórmula es desagradable, pero:
•
No es necesario memorizarla •
El ordenador la calcula automáticamente •
SE( 1β ) = 1
2ˆˆ
βσ es una salida típica del programa
•
Es menos complicada de lo que parece. El numerador estima var(v), el denominador estima var(X).

4-45
Regresemos al cálculo del estadístico t:
t = 1 1,0
1
ˆˆ( )SE
β ββ
− =
1
1 1,0
2ˆ
ˆ
ˆβ
β βσ−
• Rechazo al 5% de significación si |t| > 1.96 •
El valor-p es p = Pr[|t| > |tcalculado|] = probabilidad en las colas de la normal por encima de |tcal|
•
Las dos afirmaciones anteriores son aproximaciones para muestras grandes; típicamente n = 50 es lo suficientemente grande como para que la aproximación sea excelente.

4-46
Ejemplo: Notas y STR, datos de California Regresión Estimada: Notas = 698.9 – 2.28×STR Salidas del programa:
SE( 0β ) = 10.4 SE( 1β ) = 0.52
t que contrasta β1,0 = 0: 1 1,0
1
ˆˆ( )SE
β ββ
− = 2.28 0
0.52− − = –4.38
•
Al nivel del 1%, el valor crítico de dos colas es 2.58; por tanto, rechazamos la nula al 1% de significación.
•
Alternativamente, podemos calcular el valor-p…

4-47

4-48
El valor-p en la aproximación normal de muestras grandes al estadístico-t es 0.00001 (10–5) 1. El marco probabilístico en la regresión lineal 2. Estimación 3. Contrastes de hipótesis 4. Intervalos de confianza (Sección 4.6) En general, si la distribución muestral del estimador es normal para n grande, entonces podemos construir el intervalo de confianza al 95% como:
estimador ± 1.96×error estándar Es decir, el intervalo de confianza al 95% para β1 es,
{ 1β ± 1.96×SE( 1β )}

4-49
Ejemplo: Puntuaciones y STR, datos de California Regresión estimada: Notas = 698.9 – 2.28×STR
SE( 0β ) = 10.4 SE( 1β ) = 0.52
Intervalo de confianza al 95% para β1:
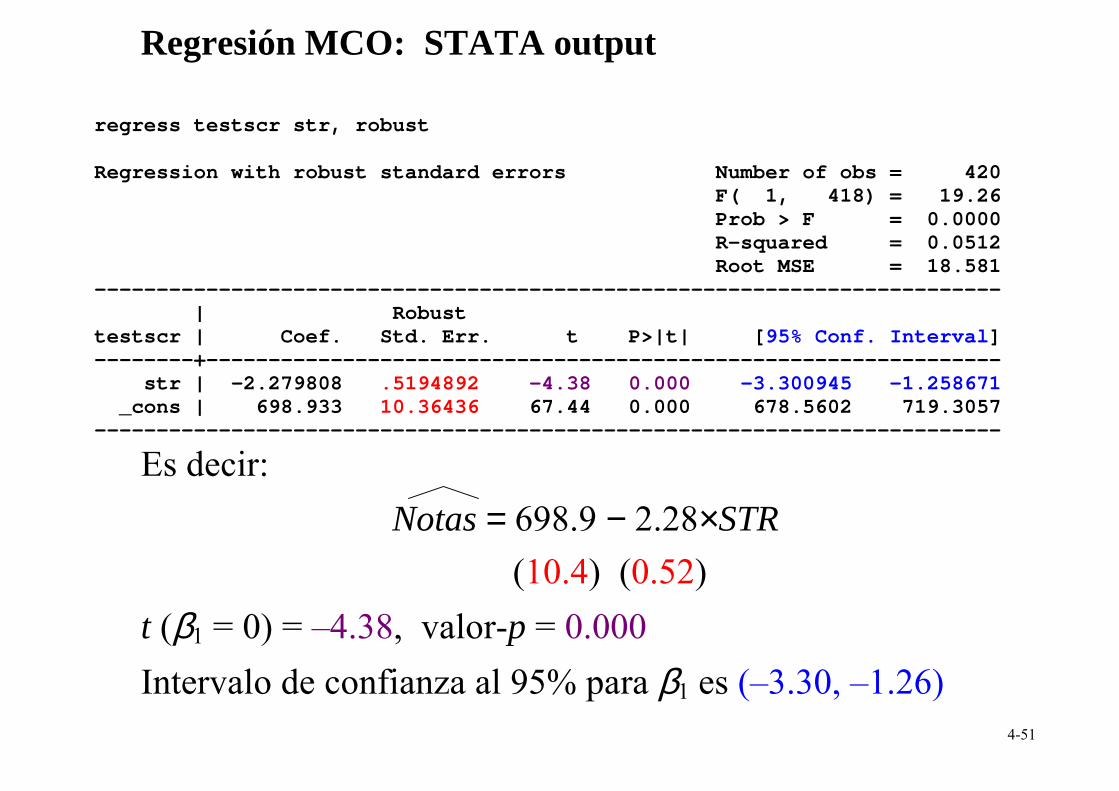
{ 1β ± 1.96×SE( 1β )} = {–2.28 ± 1.96×0.52} = (–3.30, –1.26) Afirmaciones equivalentes: •
El IC al 95% no incluye al cero; • La hipótesis β1 = 0 se rechaza al 5%

4-50
Información de la regresión estimada: Ponemos el error estándar en paréntesis debajo de la estimación
Notas = 698.9 − 2.28×STR (10.4) (0.52)
Esta expresión significa que:
• La regresión estimada es Notas = 698.9 − 2.28×STR
• El error estándar de 0β es 10.4 • El error estándar de 1β es 0.52
4-51
Regresión MCO: STATA output
regress testscr str, robust
Regression with robust standard errors Number of obs = 420F( 1, 418) = 19.26Prob > F = 0.0000R-squared = 0.0512Root MSE = 18.581
-------------------------------------------------------------------------| Robust
testscr | Coef. Std. Err. t P>|t| [95% Conf. Interval]--------+----------------------------------------------------------------
str | -2.279808 .5194892 -4.38 0.000 -3.300945 -1.258671_cons | 698.933 10.36436 67.44 0.000 678.5602 719.3057
-------------------------------------------------------------------------
Es decir: Notas = 698.9 − 2.28×STR
(10.4) (0.52) t (β1 = 0) = –4.38, valor-p = 0.000 Intervalo de confianza al 95% para β1 es (–3.30, –1.26)

4-52
Regresión cuando X es binaria (Sección 4.7) Algunas veces un regresor es binario:
• X = 1 si “mujer,” = 0 si “hombre” •
X = 1 si “en tratamiento médico,” = 0 si no •
X = 1 si “clase con pocos alumnos,” = 0 si no Hasta ahora, hemos denominado “pendiente” a β1, pero en este caso no tendría sentido. ¿Cómo interpretamos la regresión con un regresor binario?

4-53
Yi = β0 + β1Xi + ui, donde X es binaria (Xi = 0 ó 1):
•
Cuando Xi = 0: Yi = β0 + ui •
Cuando Xi = 1: Yi = β0 + β1 + ui Por tanto:
•
Cuando Xi = 0, la media de Yi es β0 •
Cuando Xi = 1, la media de Yi es β0 + β1 es decir:
•
E(Yi|Xi=0) = β0 •
E(Yi|Xi=1) = β0 + β1 consecuentemente:
β1 = E(Yi|Xi=1) – E(Yi|Xi=0) = diferencia en la media poblacional de ambos grupos

4-54
Ejemplo: Notas y STR, datos de California Sea
Di = 1 si 200 si 20
i
i
STRSTR
≤ >
La estimación por MCO de la regresión que relaciona Notas con D (con errores estándar en paréntesis) es:
Notas = 650.0 + 7.4×D (1.3) (1.8)
Diferencia de medias entre grupos = 7.4;
SE = 1.8 t = 7.4/1.8 = 4.0

4-55
Comparamos los resultados de la regresión con los de las medias de grupos calculadas directamente:
Tamaño de clase Nota media (Y ) Desv.Est.(sY) N Pequeño (STR < 20) 657.4 19.4 238 Grande (STR ≥ 20) 650.0 17.9 182 Estimación: pequeño grandeY Y− = 657.4 – 650.0 = 7.4
Test ∆∆∆∆=0: 7.4( ) 1.83p g
p g
Y Yt
SE Y Y−
= =−
= 4.05
Intervalo al 95% = {7.4 ± 1.96×1.83} = (3.8, 11.0) El mismo resultado que en la regresión!
Notas = 650.0 + 7.4×D (1.3) (1.8)

4-56
Resumen: regresión cuando Xi es binaria (0/1) Yi = β0 + β1Xi + ui
• β0 = media de Y dado X = 0 • β0 + β1 = media de Y dado X = 1 • β1 = diferencia de medias, X =1 menos X = 0 •
SE( 1β ) tiene la interpretación usual •
t e IC construidos de la forma habitual •
Ésta es otra forma de hacer análisis de diferencias de medias
• El análisis de regresión es especialmente útil cuando disponemos de regresores adicionales

4-57
Otros Estadísticos de la Regresión (Sección 4.8) Una pregunta natural es si la línea de regresión explica o se “ajusta” bien a los datos. Hay dos estadísticos de la regresión que proporcionan medidas complementarias sobre la calidad del ajuste:
• El R2 de la regresión mide la fracción de la varianza de Y que es explicada por X; no posee unidades de medida y su rango se encuentra entre cero (sin ajuste) y uno (ajuste perfecto)
• El error estándar de la regresión mide el ajuste – el tamaño típico de un residuo de la regresión – en unidades de Y.

4-58
El R2
Escribamos Yi como la suma de la predicción MCO + residuo MCO:
Yi = iY + ˆiu El R2 es la fracción de la varianza muestral de Yi “explicada” por la regresión, esto es, por iY :
SCTSCER =2
donde SCE = 2
1
ˆ ˆ( )n
ii
Y Y=
−∑ y SCT = 2
1
( )n
ii
Y Y=
−∑ .

4-59
El R2:
• R2 = 0 significa que SCE = 0, es decir X no explica nada de la variación de Y
•
R2 = 1 significa que SCE = SCT, o Y = Y , es decir X explica toda la variación de Y
•
0 ≤ R2 ≤ 1 •
En la regresión con un sólo regresor (el caso en el que estamos), R2 es el cuadrado del coeficiente de correlación entre X e Y

4-60
El Error Estándar de la Regresión (SER) El error estándar de la regresión es (casi) la desviación estándar muestral de los residuos MCO:
SER = 2
1
1 ˆ ˆ( )2
n
i ii
u un =
−− ∑
= 2
1
1 ˆ2
n
ii
un =− ∑
(la segunda igualdad viene de 1
1 ˆn
ii
un =∑ = 0).

4-61
SER = 2
1
1 ˆ2
n
ii
un =− ∑
El SER: • Se mide en unidades de u, que son unidades de Y •
Mide la dispersión de la distribución of u •
Mide el “tamaño” medio del residuo MCO (el “error” medio cometido por la regresión MCO)
• La raíz cuadrada del error cuadrático medio (RMSE) está muy relacionada con el SER:
RMSE = 2
1
1 ˆn
ii
un =∑
Que mide lo mismo – la única diferencia es la división por n en lugar de por (n–2).

4-62
Nota: ¿por qué se divide por (n–2) y no por (n–1)?
SER = 2
1
1 ˆ2
n
ii
un =− ∑
•
La división por (n–2) es una corrección de “grados de libertad” como lo es la división por (n–1) en 2
Ys ; la diferencia es que, en el SER, se han estimado dos parámetros (β0 y β1 mediante 0β y 1β ), mientras que en 2
Ys sólo se ha sido estimado uno (µY mediante Y ).
•
Cuando n es grande, es indiferente dividir por n, (n–1), ó (n–2) – aunque la fórmula convencional utiliza (n–2) cuando hay un único regresor.
•
Detalles en Sección 15.4

4-63
Ejemplo de R2 y SER
Notas = 698.9 − 2.28×STR, R2 = 0.05, SER = 18.6 (10.4) (0.52) El coeficiente de la pendiente es estadísticamente significativo y grande, aun cuando STR explica sólo una fracción pequeña de la variación en las notas.

4-64
Nota Práctica: Heteroscedasticidad, Homoscedasticidad, y Fórmula de los Errores Estándar de 0β y 1β
(Sección 4.9)
• ¿Qué significan estos dos términos? •
Consecuencias de la homoscedasticidad • Cálculo de los errores estándar
¿Qué significan estos dos términos? Si var(u|X=x) es constante – es decir, la varianza de la distribución condicional de u dado X no depende de X, entonces u es homoscedástica. En otro caso, u será heteroscedástica.

4-65
Homoscedasticidad en un gráfico:
• E(u|X=x) = 0 (u satisface la Hipótesis A1 de MCO) •
La varianza de u no cambia con (depende de) x
4-66
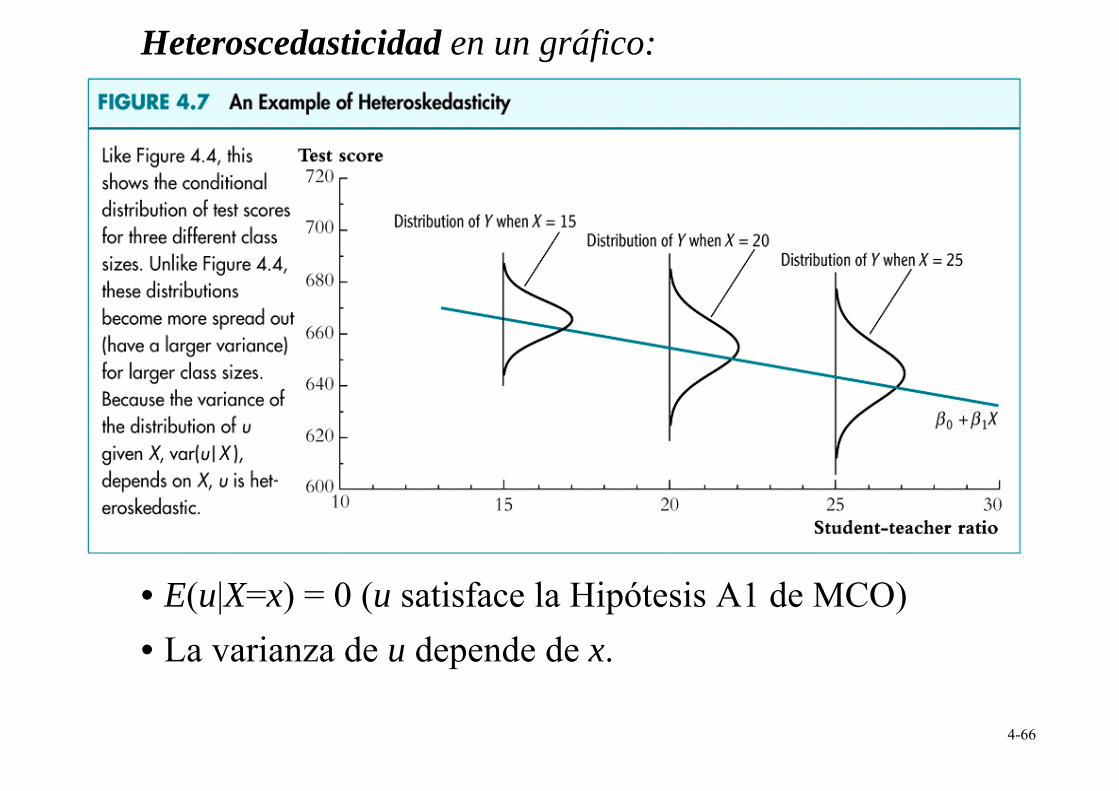
Heteroscedasticidad en un gráfico:
•
E(u|X=x) = 0 (u satisface la Hipótesis A1 de MCO) • La varianza de u depende de x.

4-67
Ejemplo real de heteroscedasticidad en Economía Laboral: ganancias medias por hora vs. años de educación (fuente: Current Population Survey 1999)
A
vera
ge h
ourly
ear
ning
s
Scatterplot and OLS Regression LineYears of Education
Average Hourly Earnings Fitted values
5 10 15 20
0
20
40
60

4-68
¿Son heteroscedásticos los datos del nº de alumnos por clase?
Difícil de decir…son casi homoscedásticos, aunque la dispersión parece menor para valores grandes de STR.

4-69
Hasta ahora, hemos supuesto (sin decirlo expresamente) que u es heteroscedástica: Recordemos las tres hipótesis de MCO:
1. La distribución condicional de u dado X tiene media cero, esto es, E(u|X = x) = 0.
2. (Xi,Yi), i =1,…,n, son i.i.d. 3. X y u poseen momentos finitos de cuarto orden.
Heteroscedasticidad y homoscedasticidad hacen referencia a var(u|X=x). Puesto que no hemos supuesto explícitamente homoscedasticidad, permitimos implícitamente heteroscedasticidad.

4-70
¿Y si los errores fuesen de hecho homoscedásticos?: • Podríamos probar algunos teoremas de MCO (en
particular, el teorema de Gauss-Markov, que dice que MCO es el estimador con menor varianza entre aquellos que son funciones lineales de (Y1,…,Yn); véase Sección 15.5).
•
Las fórmulas de la var( 1β ) y del error estándar se simplifican (Apéndice. 4.4): Si var(ui|Xi=x) = 2
uσ , entonces
var( 1β ) = 2 2
var[( ) ]( )
i x i
X
X un
µσ
− = … = 2
2u
Xnσσ
Nota: var( 1β ) es inversamente proporcional a var(X):
mayor dispersión en X significa mayor información sobre 1β .

4-71
Fórmula general del error estándar de 1β : es la de
1
2ˆˆ
βσ =
2 2
12
2
1
1 ˆ( )1 2
1 ( )
n
i ii
n
ii
X X un
nX X
n
=
=
−−× −
∑
∑
.
Caso especial con homoscedasticidad:
1
2ˆˆ
βσ =
2
1
2
1
1 ˆ1 2
1 ( )
n
ii
n
ii
un
n X Xn
=
=
−×−
∑
∑.
A veces se dice que la fórmula de abajo es más simple.

4-72
La fórmula “sólo válida con homoscedasticidad” del error estándar de 1β y la que es “robusta a la heteroscedasticidad” (la fórmula que es válida con heteroscedasticidad) difieren en general: obtenemos errores estándar distintos con ambas fórmulas.
La fórmula “sólo con homoscedasticidad” de los errores estándar es la que suelen utilizar por defecto los paquetes informáticos – a veces la única (e.g. Excel). Para obtener la general, “robusta a la heteroscedasticidad”, debemos anular la primera.
Si no lo hacemos y de hecho hay heteroscedasticidad, obtendremos errores estándar, así como t e IC, erróneos.

4-73
Puntos críticos: • No hay problema con utilizar la fórmula de
heteroscedasticidad cuando los errores son homoscedásticos.
•
Si utilizamos la fórmula de homoscedasticidad con errores heteroscedásticos, los errores estándar serán incorrectos.
•
Ambas fórmulas coinciden (cuando n es grande) en el caso especial de homoscedasticidad.
• Conclusión: deberíamos utilizar siempre la fórmula de heteroscedasticidad – convencionalmente, Errores estándar robustos a la heteroscedasticidad.

4-74
SE robustos a la heteroscedasticidad en STATA
regress testscr str, robust
Regression with robust standard errors Number of obs = 420F( 1, 418) = 19.26Prob > F = 0.0000R-squared = 0.0512Root MSE = 18.581
-------------------------------------------------------------------------| Robust
testscr | Coef. Std. Err. t P>|t| [95% Conf. Interval]--------+----------------------------------------------------------------
str | -2.279808 .5194892 -4.39 0.000 -3.300945 -1.258671_cons | 698.933 10.36436 67.44 0.000 678.5602 719.3057
-------------------------------------------------------------------------
¡¡¡Utiliza la opción “, robust” !!!

4-75
Resumen y Valoración (Sección 4.10) • Cuestión inicial de política educativa:
Suponga que se contratan nuevos profesores con la intención de disminuir el ratio estudiante-profesor en un estudiante por clase. ¿Qué efecto tendrá esta medida sobre las notas de los estudiantes?
•
¿Da nuestra regresión una respuesta convincente? Realmente no – Aquellos distritos con menor STR suelen ser los que tienen más recursos y renta familiar, proporcionándoles mayores oportunidades de aprendizaje fuera del colegio … lo que sugiere que corr(ui,STRi) > 0, y por tanto E(ui|Xi)≠0.

4-76
Digresión sobre Causalidad La pregunta original (¿cuál es el efecto cuantitativo de una intervención que reduzca el nº de alumnos por clase?) es una cuestión sobre un efecto causal: el efecto sobre Y que tiene la aplicación de una unidad de tratamiento es β1.
•
Pero ¿qué es, exactamente, un efecto causal? •
La definición de sentido común no es suficientemente precisa para nuestros propósitos.
• En este curso, lo definiremos como el efecto que se mide en un experimento aleatorio controlado ideal.

4-77
Experimento Aleatorio Controlado Ideal (EACI) •
Ideal: los sujetos siguen el protocolo del tratamiento – cumplimiento perfecto, información sin error, etc.!
•
Aleatorio: se asignan los sujetos de la población de interés aleatoriamente al grupo de control o tratamiento (sin factores de confusión)
•
Controlado: con un grupo de control se puede medir el efecto diferencial del tratamiento
• Experimento: el tratamiento es asignado como parte del experimento: los sujetos no tienen elección, con el fin de evitar que se dé una “causalidad inversa” cuando los sujetos eligen aquel tratamiento que piensan que les funcionará mejor.

4-78
De vuelta con el nº de alumnos por clase: • ¿Cómo sería un EACI que midiese el efecto sobre las notas de
una reducción de STR? • ¿En qué difiere el análisis de regresión basado en datos
observados del ideal? oEl tratamiento no está asignado aleatoriamente oEn USA – con nuestros datos observados – los distritos de
mayor renta suelen ser aquellos con menor nº de alumnos por clase y mejores notas.
oComo resultado es posible que E(ui|Xi=x) ≠ 0. oSi es así, no se cumpliría la hipótesis A1 de MCO. o 1β sesgado: la omisión de variables hace que, para explicar
las notas, el nº de alumnos por clase parezca parezca más importante de lo que realmente es.