review of triplet learning
TRANSCRIPT

Triplet LearningAdwin Jahn

FaceNet

Task1. Face Verification
• is this the same person
2. Face recognition
• who is this person
3. Clustering
• find similar people among these faces

Key idea
An embedding f(x), from an image x into a feature space Rd, such that the squared distance between all faces, independent of imaging conditions, of the same identity is small, whereas the squared distance be- tween a pair of face images from different identities is large.

Key idea
The triplet loss tries to enforce a margin between each pair of faces from one person to all other faces. This allows the faces for one identity to live on a manifold, while still enforcing the distance and thus discriminability to other identities.
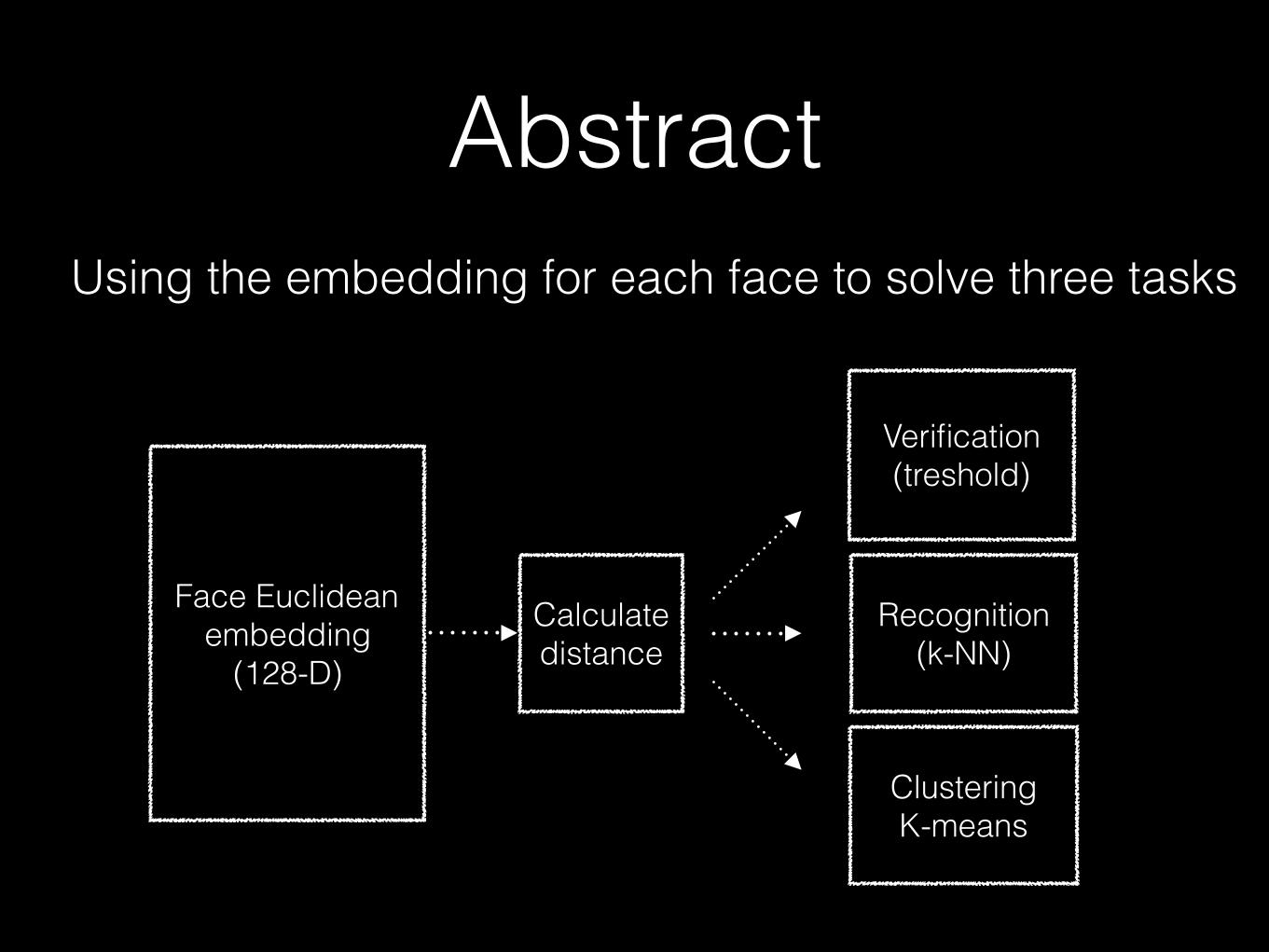
Abstract
Face Euclidean embedding
(128-D)
Recognition (k-NN)
Verification (treshold)
Clustering K-means
Calculate distance
Using the embedding for each face to solve three tasks

Face Verification
• With threshold 1.1, if the distance is lover than threshold, we verify both face are the same ID

Triplet Loss• Minimize the distance between same ID faces and maximize the distance with
different ID faces, with a margin alpha

Prepare data• Correct triplet selection is crucial for fast convergence
• Triplet constraint: The distance of negative samples should have larger distance with the anchor image (compared to positive image)
• Triplet is formed by (anchor, positive, negative )

Hard data
• In order to ensure fast convgerence, it is crucial to select triplets that violate the triplet constraint
• It is infeasible to compute the hard positive and hard negative across the whole training set.

Visualize of hard data
Embedding location of anchor Embedding location
of anchor
Green area is the distribution of positive faces over embedding space. Red is distribution of negative faces over the same space.
Hard positive means the furtherest sample (to the anchor location) in the positive space, and hard negative is the closest sample (to the anchor location) among the negative faces. Hard sample should help training converges faster.

Triplet generation• Generate triplets online.• This can be done by select- ing the hard positive/negative exemplars from
within a mini-batch.• Mini batch: few thousand exemplars• 40 faces are selected per ID per mini batch, and randomly add negative
faces• Only consider argmin and argmax within a mini-batch• Mis labeled and poorly image might lead to poor training

Semi-hard sample • Selecting the hardest negatives can win
practice lead to bad local minima early on in training
• For negative data, this is semi-hard because its lower bound positive data. In other words, the negative data cannot look more similar than all the positive data.
• Compared with triplet constraint, this is more hard because semi-hard cancel the margin alpha

Setting• Batch size: around 1800 samplers
• Optimize: SGD or AdaGrad
• Hardware: CPU cluster for 1000~2000 hours
• Train rate start: 0.05, will decrease
• Activation: Relu
• Data set: Labelled Faces in the Wild, YouTube Faces
• Training amount: 100M~200M with 8M different ID

Performance on different CNN model
NNS2 is smallest model the paper test on. Capable to run on the mobile phone, and the NNS2 performance is not too bad

Performance on different CNN model

Size to represent a face• Optimally, a face is presented as 128 dimension byte vector.
• Bigger dims not promises better performance

Tensor flow for face embedding

Concern• Sampling the sample might be hard
• Huge batch size
• Sensitive to mislabeled and bad image (need good quality image data)
• Might need 100M data
• Need multiple experiment to decide embedding size
• Long time to train

Opportunity
• Possible to use train small CNN to achieve good embedding
• Could be applied for other datasets
• One embedding can be used for multiple different tasks